Embed Size (px)
Citation preview

Agenda:
Block Watch: Random Assignment, Outcomes, and indicators
Issues in Impact and Random Assignment: Youth Transition Demonstration
–Who is randomized?
–Sample size, power, and effect size
–Who’s in the average?

Block Watch: Random Assignment, Outcomes, and Indicators
What random assignment protocol would you use to assess the impacts of Block Watch?
What are the strengths and weaknesses of your approach?
What are the key outcomes you want to assess? What are indicators for those?

Youth Transition Demonstration Evaluation Plan: Background on YTD evaluation plan
The basics of Impact size and significance
Power and sample size
No Shows/ Intent to Treat vs. Treatment on the Treated
Multiple Comparisons
Regression adjusted comparisons

Youth Transition Demonstration:
Targets Youth receiving disability payments to help in transition to adult life and employment
Goals: increase earnings, decrease costs, facilitate transition to self-sufficiency
Six program sites with variation in programs
Services:
– Waiver of benefit decrease with earnings
– Education, Job training, work placements
– Case management, counseling, referral to services
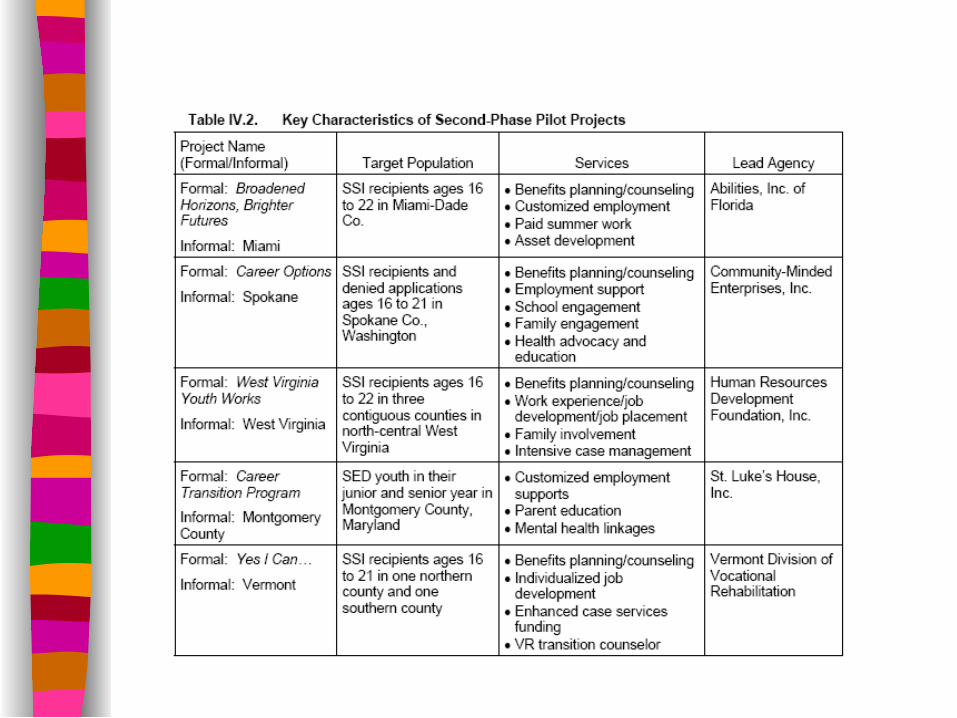


YTD Evaluation:
Selected 6 sites for demonstration and evaluation
Intervention built on research from past programs and evaluations
Randomly assigned youth to treatment or control
Large sample sizes to allow identification of smaller effects and sub-group effects
Process and Impact Evaluation
Data collected from administrative files, surveys before and after program
Advisory group of experts


Sampling:
Why did they divide the list of potential participants (sampling frame) into groups of 10 for contact?
Why did they randomize 55 percent to the treatment?
Why get pre-intervention characteristics if they are randomly assigning groups?

Comparisons may be: -over time -across intervention groups
with and without program;levels of intervention (“dosage”)
Impact here!

Statistical significance: When can we rule out having an impact IF there is no impact?
Compare 2 means from independent samples:
Means: Proportions:
Pooled sample variance:
2 22 1 1
2t t c c
pt c
n s n ss
n n
ˆ t c
t c
x xp
n n
2
0
1 1
t c
pt c
x xt
sn n
ˆ ˆ 0
1 1ˆ ˆ1
t c
t c
p pz
p pn n

2
0
1 1
t c
pt c
x xt
sn n
2 22 1 1
2t t c c
pt c
n s n ss
n n
Compare 2 means from independent samples:
Means: Proportions:
Pooled sample variance:
ˆ ˆ 0
1 1ˆ ˆ1
t c
t c
p pz
p pn n
ˆ t c
t c
x xp
n n

Compare 2 means from independent samples:
Means: Proportions:
Pooled sample variance:
ˆ ˆ 0
1 1ˆ ˆ1
t c
t c
p pz
p pn n
ˆ t c
t c
x xp
n n
2 2
2 1 1
2t t c c
pt c
n s n ss
n n
2
0
1 1
t c
pt c
x xt
sn n

2
0
1 1
t c
pt c
x xt
sn n
2 22 1 1
2t t c c
pt c
n s n ss
n n
Compare 2 means from independent samples:
Means: Proportions:
Pooled sample variance:
ˆ ˆ 0
1 1ˆ ˆ1
t c
t c
p pz
p pn n
ˆ t c
t c
x xp
n n

So, it’s easier to say impact is “real” (not just randomness) if:
– Size of impact is larger
– Variation in outcomes is small (S)
– Sample sizes are larger
Same factors figure into deciding how big a sample we need to find the effect if it’s there! [Power, sample size, minimally detectable effects]

Power and sample size:
Given randomness, what % of time will you be able to rule out the null, IF it is NOT true (there IS an impact)?
How big a sample size do you need to rule out NO effect if the program DOES have an impact? (Rossi et al p.312)

Online Calculators for Sample size and Power:
Sample size: – http://www.dssresearch.com/toolkit/sscalc/size_a2.asp – http://www.dssresearch.com/toolkit/sscalc/size_p2.asp
Power:– http://www.dssresearch.com/toolkit/spcalc/power_a2.asp – http://statpages.org/proppowr.html

Minimum Detectable Impacts:
What are the smallest effects you will be able to detect given n and predicted S?

Adjustments to impact assessment:
Regression adjusted impacts decrease S and increase power by controlling for “noise” using baseline characteristics
Multiple Comparisons are a problem because randomness happens if you look long enough!
– MDRC picked “primary outcomes”
– Use adjustments to account for multiple comparisons
*
ˆ ˆˆ
ˆˆ
baseline treatment
treatment all treatment
control all
Y X Treatment
Y X
Y X

Showing estimated impacts over time in program

Who’s in the average? “No shows” in treatment group didn’t get any services
– Unlikely to be similar to “shows”
– If drop, then may overstate potential impacts
“Intent to Treat” outcomes include outcomes for no-shows
“Treatment on the Treated” outcomes do not include no-shows
Non-response to follow-up surveys could bias impact
assessments– Use administrative data available for all for key outcomes– Put resources into follow up to minimize non-response– Construct weights to make survey sample estimates comparable to
baseline sample

Lessons from Summary: Randomization is hard
Need to use power analysis to choose target sample sizes
Even randomization may not give comparable baseline characteristics
Regression may increase comparability and precision
Worry about who we have outcome information for (both control and treatment)





























