Embed Size (px)
Citation preview

http://adb.sagepub.com/Adaptive Behavior
http://adb.sagepub.com/content/early/2012/08/31/1059712312455439The online version of this article can be found at:
DOI: 10.1177/1059712312455439
published online 31 August 2012Adaptive BehaviorLluis Barceló-Coblijn, Bernat Coromias-Murtra and Antoni Gomila
Syntactic trees and small-world networks: syntactic development as a dynamical process
Published by:
http://www.sagepublications.com
On behalf of:
International Society of Adaptive Behavior
can be found at:Adaptive BehaviorAdditional services and information for
http://adb.sagepub.com/cgi/alertsEmail Alerts:
http://adb.sagepub.com/subscriptionsSubscriptions:
http://www.sagepub.com/journalsReprints.navReprints:
http://www.sagepub.com/journalsPermissions.navPermissions:
What is This?
- Aug 31, 2012OnlineFirst Version of Record >>
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

Original Paper
Adaptive Behavior0(0) 1–16! The Author(s) 2012Reprints and permissions:sagepub.co.uk/journalsPermissions.navDOI: 10.1177/1059712312455439adb.sagepub.com
Syntactic trees and small-worldnetworks: syntactic development asa dynamical process
Lluıs Barcelo-Coblijn1, Bernat Corominas-Murtra2 and Antoni Gomila1
AbstractLanguage has been argued to exhibit a complex system behavior. In our approach, the syntactic relations of dependencybetween words have been represented as networks. In a previous study, two English infants’ corpora of utterances wereanalyzed longitudinally, offering a view of the ontogeny of syntax. Abrupt changes were detected in the growth patternof the Giant Connected Component – the largest connected set of nodes in a graph. In the present study, we have fur-ther analyzed and compared three more infants, from the CHILDES database, learning three different languages: Dutch,German and Spanish. Our results show, along with previous work with English-speaking infants, that all three infants’ syn-tactic networks change their topology in a similar way, from tree-like networks to small-world networks. This changehappens at a similar period in all three infants (between ~700 and ~800 days), regardless of the language they acquire.Our study also shows that the hubs – the most connected nodes in these small-world networks – are always theso-called functional words, which, according to linguistic theory, just contribute to the syntactic structure of human lan-guage. The emergence of these hubs happens abruptly, following a logarithmic growth pattern. This developmental pat-tern challenges usage-based theories of language acquisition and suggests that syntactic development is driven by thegrowth of the lexicon.
KeywordsLanguage acquisition, small-world networks, complex systems, syntactic development
1 Introduction
First language acquisition is perhaps one of the mostimportant achievements of human babies. Scientificstudy from many fields has paid attention to it fordecades. Despite controversies, scholars generally agreeon the high complexity involved in this process.Particularly, scientists are fascinated by the rapidacquisition of words, grammatical categories and lin-guistic structures, more or less at the same time. Thus,in their second year, infants undergo a two-word stageover a few months and suddenly they begin to con-struct more and more complex linguistic structures.This means that infants, at some point, become able tocombine words in a complex, productive, fashion. It isastonishing that they achieve linguistic completenesswithout explicit instruction from their parents.
Theories of language acquisition disagree mostly onwhether infants come to this process equipped withsome language-specific innate predisposition, or whethergeneral learning abilities can account for it. Within thislatter group, usage-based theories (Tomasello, 2003) arethe most sophisticated. According to them, infants are
thought to grasp the statistical regularities and transi-tional probabilities present in the input they receive,with the help of a critical social learning ability; the out-come of this process of abstraction is semantically speci-fied schemas, related to each kind of meaningfulsituation. The nativist approach, on the contrary, insistson the innovative linguistic forms and utterances pro-duced by infants, their rule-like patterns of errors andthe lack of negative feedback in the input they get(Chomsky, 1956; Chomsky & Miller, 1963; Pinker,1989). The novelty and creativity involved in this beha-vior is thought to be beyond the scope of general learn-ing mechanisms, and calls instead for some kind of
1Systematics laboratory, Human Cognition and Evolution group,Department of Philosophy and Social Work, Universitat de les IllesBalears, Palma, Illes Balears, Spain2ICREA-Complex Systems Lab, Parc de Recerca Biomedica de Barcelona,Universitat Pompeu Fabra (GRIB), Barcelona, Barcelona, Spain
Corresponding author:Antoni Gomila, University of the Balearic Islands, Campus Valldemossa,Palma, 07100, SpainEmail: [email protected]
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

biological predisposition, species-specific to make possi-ble the development of language. Recently, syntacticrecursivity has been single out as the critical innate com-ponent required for language acquisition, thought tohave evolved in our species only (Hauser et al., 2002).The debate, though, has reached a sort of stalemate.
Given this background, the application of complexsystems theory to language offers hope of progress onthis classical controversy (Corominas-Murtra, 2011),along with the dynamicist approach in cognitive science(Gomila & Calvo Garzon, 2008). While some complexlinguistic phenomena have been known for a long time,such as Zipf’s law (Zipf, 1936), recent developmentsbroaden the range of complex phenomena in languageto which attention is paid attention: De Jong (1998)proposed a model of lexicon emergence as a self-organized process, and Steels (2000) surveys recentwork on modeling the origins of communication sys-tems and shows that there seem to be biologicallyinspired principles behind the emergence of these sys-tems, self-organization being one of them. A differentline of research applies complex systems theory to syn-tactic relations: Ferrer-i-Cancho & Sole (2001), Steels(2000) and Sole, Corominas-Murtra, Valverde andSteels (2010), among others, view language organiza-tion in terms of a graph of word interactions. The latterapproach reaches two main conclusions regarding thestructure of massive corpora of public language: first, asmall-world effect, related to the shortest path betweenwords in the graph; and second, a scale-free distribu-tion of degrees. However, this approach assumes anexternal perspective on language as a network of wordcombinations, so that it is difficult to draw conclusionsfrom these results on how language, as a cognitivefaculty, is organized.
Complex systems have attracted the attention of lin-guists too. Thus, focusing on frequency of words in thecorpora of infants acquiring their first language, Niniohas shown in a series of studies (2003, 2006) that theacquisition of syntactic patterns undergoes an accelera-tion process that can be described by a power law, chal-lenging in this way usage-based theories (Tomasello,2003), which cannot account for this acceleration andnovelty effect. For example, Tomasello (1992) positedthe Verb–Island hypothesis, according to which infantsstart producing multi-word speech without knowledgeof syntactic categories, such as noun and verb, thuscombining pairs of words independently of any otheravailable combinations; words are supposed to belearned in context, but one by one. However, the longi-tudinal study by Ninio (2003) on the development ofSubject–Verb–Object patterns (SVO) and Subject–Verb–Indirect Object–Direct Object (SVIO) in Hebrew,showed that:
. 40% of the verbs in novel SVO constructions had noantecedent uses in the corpus, and none of the VIO
patterns had. Regardless of the presence or absence ofantecedent paradigms, the development of the SVO pat-tern for new verbs was facilitated by other verbs previ-ously learned in the same syntactic construction. (p. 3)
Clearly, Ninio’s work supports the view that infantslearn language in a special way; they seem sensitive tosyntactic categories/syntactic dependencies from veryearly on.
However, it is also clear that they are not sensitiveto syntax in their performance right from the momentthey begin to use language, in their second year of life.It is also equally clear that languages differ in their syn-tactic structuring. Therefore, it is interesting to studyin more detail both the pattern of syntactic develop-ment – which takes places mostly during the third yearof life – and consider whether this pattern is universalor language dependent. To know in more detail thedevelopmental pattern may provide further constraintson any plausible account of the process. Discoveringthat the pattern is language independent, despite thesyntactic variability of different languages, suggeststhat it is carried out in a way that it is not just inputdriven. If syntax governs linguistic structure, andinfants learn it effortlessly, an emergence effect is to beexpected in the timing of syntactic development. Thisraises the question of whether the same small-worldand scale-free structure is also present in the produc-tion corpora of infants learning a language. The goal,though, like Ninio’s, is to find the patterns of syntacticdevelopment, rather than just the patterns of lexicalassociation in the utterances. Thus, in this paper, weput forward a new approach, which combines a metho-dological application of complex networks along thelines of Ferrer-i-Cancho and Sole, with the gist of long-itudinal studies like Ninio’s.
2 The approach
The proposed approach consists of codifying the lin-guistic production of a child, collected at differentmoments during her third year of life, as a series ofgraphs, of networks, in order to visualize their respec-tive patterns of growth and change, to be able to com-pare them in the three cases we have selected. How thegraphs are to be interpreted in linguistic terms is there-fore an important aspect. In a graph, there are a num-ber of nodes connected by means of links. Linguists,regardless their theoretical framework, consider thathuman words relate to each other in specific ways.How words relate, and how these relationships affectthe structure of utterances, is the object matter of syn-tax. Although a syntactic structure is more than a set ofrelations between lexical items, we abstract it, therebyobtaining a graph of dependencies of lexical items (seeFigure 1 for details). Under this framework, a lexicalitem can establish a direct relationship with another
2 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

lexical item directly or indirectly through another item.For example, ‘‘the’’ and ‘‘apple’’ establish a direct linkin the phrase ‘‘the apple’’. However, these two wordscan be indirectly related to the word ‘‘big’’ in the utter-ance ‘‘The apple is big’’. This is possible because thephrase ‘‘the apple’’ is related to the verb ‘‘is’’, and thisverb is in turn related to the word ‘‘big’’. Now, we haveto imagine these words as represented by nodes on aplane, and their syntactical relationships by means oflinks among them. In linguistic theory, it is said thatwhen two lexical items check their compatibility, andthe result of this checking is the union of the two lexicalitems in a phrase, the operation Merge has taken place.This operation, along with the operation Move, is con-sidered crucial in modern syntax theory (Chomsky,2000). Thus, it is possible to represent and analyze
utterances by means of networks, taking into accountthe crucial aspects of syntactic theory.
A particular type of network is a scale-free network.An interesting aspect of these networks, relevant froma linguistic perspective, is that it is possible to detectthe so-called hubs easily – the nodes with the largestnumber of connections. A hub in a syntactic networkrepresents a very important node for syntactic struc-ture, because it is connected with so many words. Ifhubs are considered the core of a complex system –whose deletion would be critical for the whole system –then the hubs in a ‘‘syntactic’’ network should reflectthe syntactic role of those words. Put differently, thereshould be a correlation between the importance of hubsin a network, and the importance of the correspondingword in the syntactic structure.
Figure 1. Building syntactic networks. The infant (CHI) utters two sentences (A and B), which correspond to two syntacticstructures. These analyses can be represented in Dependency Grammar terms, here represented by boxes and links. Given thatboth A and B share part of the vocabulary, the integration of both sentences into a network (C) avoids the duplication of words likeappeltje. This kind of network does not capture how many times a word appears, but how many syntactic relationships a word has,and with which.
Barcelo-Coblijn et al. 3
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

Therefore, the project of representing linguisticknowledge through a network suggests itself, just as theproject of keeping track of the longitudinal develop-ment of such knowledge through infancy, by a succes-sion of such networks, and the identification of whichwords play this structuring role of a ‘‘hub’’ in the net-work, if this is the case. Of course, we cannot com-pletely reach this ambitious goal at the moment.However, it is possible to aim at it and to show that thisis a promising line of research. The first step requiresbuilding bridges between network theory and linguistictheory. How can we capture the essence of the opera-tions behind ‘‘the apple is big’’, so that it can be inter-preted in terms of nodes and links, without losing itslinguistic specificity? To this end, we have followedNinio (1996) in adopting a Dependency Grammar(Hudson, 1990; Mel’cuk, 1989). The dependency relationis identical to Merge. Thus, we have built syntactic net-works that capture dependency relations betweenwords, and we have captured the growth and develop-ment of merged structures. An important property of amerged structure is that it is a binary pyramid hierarchi-cally organized, considered one of the informativelyrichest types of hierarchical structure (Corominas-Murtra et al., 2011). This procedure fits well with mod-ern linguistic theory and moreover seems suitable forthe creation of networks, given that in essence, languagealways deals with binary combinations, rather than justconcatenation of elements – as the approach of Ke andYao (2008) assumes, who studied individual variabilityin co-occurrences of words.
Corominas-Murtra, Valverde, & Sole (2009), then, isthe first study exemplifying our approach. In thatstudy, two English corpora from the internationalCHILDES database were analyzed. Each corpus cov-ered roughly from 18 to 30 months of age for eachinfant. The infants’ utterances from each corpus wereextracted, syntactically analyzed and then transferredto network-building software. The software succeededat getting the syntactic relations between words, andproducing the corresponding networks. Interestingly,the analysis of the networks revealed a sharp transitionaround two and a half years of age: from a (pre-syntac-tic) tree-like structure to a scale-free, small-worldsyntactic network. The most connected nodes, theso-called hubs, were functional words like determiners(e.g., ‘‘the’’, ‘‘a’’, ‘‘that’’). In linguistic theory, functionalwords are those lexical items that play a nuclear role insyntax, with important structural information, thoughthey are in general considered semantically poorer thanother items like verbs, names or adjectives (e.g.,‘‘paint’’, ‘‘big’’, ‘‘shoe’’).
In the present work, we aim to develop this approachfurther. Since only one language was analyzed –English – no general conclusion could be establishedregarding whether the developmental path found islanguage-specific or universal. Case studies of speakers
of different languages are required. Therefore, we ana-lyzed corpora from other three infants learning threedifferent languages – Dutch, German and Spanish. Theresults are quite similar to those learning English: allthree infants acquired their respective first language fol-lowing a similar pattern. In each case and at similarages (between 700 and 800 days), syntactic networksundergo a sharp transition that changes the topology ofthe networks, from tree-like networks to small-worldnetworks. As in the English case, the same kinds ofhubs were detected in all three languages: determinersbecome the hubs of the transformed networks, laterand abruptly, around two and a half years of age. Thus,this new study confirms the previous one with English,supports the idea that there are universal patterns inlanguage acquisition, and suggests an ‘‘emergenceeffect’’, related to syntactic productivity, that may bedue to an innate predisposition for developing languagein H. sapiens, but that it is driven by the growth of thelexicon.
3 Procedure
The gist of our study is to keep track of the largest net-work that joins the lexical items in each infant’s speech.The largest network is called the Giant ConnectedComponent or GCC: a connected component of agiven random graph that contains a constant fractionof the nodes of the entire graph. The rest of smallernetworks are also taken into account in order to see theevolution of the connectivity: as the GCC growths insize and complexity, the smaller networks disappearprogressively. Thus, the present study aims to explorethe evolution of the GCC through time, as an abstractrepresentation of the syntactic capacity of the infant(Figure 2). Of course, it will always be a conservativerepresentation of the child’s real capacity (productionis an under-estimation of understanding).
In this study, we have reproduced the procedure car-ried out by Corominas-Murtra et al. (2009), and hencewe have kept the original criteria and parameters ofinterest (Corominas-Murtra, 2007). Three corporafrom the international database CHILDES have beenanalyzed. All corpora contain at least 10 transcribedconversations in which an infant talks with their par-ents in a natural environment (usually, at home). Thelanguages of these corpora are Dutch, German andSpanish. Three criteria guided the choice of the cor-pora: (1) a corpus had to contain at least 10 transcrip-tions as in the previous study on English – in this studythe three sets contain 17 corpora. (2) The corpus had tocover at least 300 days of the infant’s life, particularlyin the transition from 20 to 30 months of age. (3)Transcriptions must be regularly punctuated (for exam-ple, every 10 days or two weeks). The corpora are origi-nally dubbed ‘‘Daan’’ for Dutch, ‘‘Simone’’ for German
4 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

and ‘‘Aguirre’’ for Spanish, and can be found at theCHILDES component of the TalkBank system website(http://childes.psy.cmu.edu/). Each corpus has beenlabeled making reference to the temporal frame. Thus‘‘Daan: 2;05.25’’ means that the transcription belongsto the Daan corpus and that the transcription wasmade when the infant was 2 years, 5 months and 25days old. However, we are well aware that the proce-dure is not fully satisfactory, given that for the momentour networks do not capture morphological variationof words, or word order, for instance, which may besyntactically relevant properties, depending of the lan-guage in question.
The criteria followed in order to analyze each corpuscan be found in Corominas-Murtra (2007). The threemost important aspects are the following:
! Firstly, we identified the structures in child’s pro-ductions using the lexico-thematic nature of earlygrammars (Radford, 1990).
! Second, a basic analysis of constituency is per-formed, assuming that the semantically most rele-vant item is the head of the phrase and that the verbin finite form (if any) is the head of the sentence.Finally, a projection of the constituent structure ina dependency graph is obtained. An example of thiskind of pre-syntactic network is in Figure 1.
! Imitations are discarded.
Linguistic specificity has been attended – for example,the role of particles in Dutch or German – but alwaysfollowing an agreement and keeping coherence throughthe analyses of the corpora. Since the theoretical dis-cussion on some issues runs the risk of becomingnever-ending, and at some point one has to take a deci-sion, we have also tried to avoid ambiguities; linguisticdiscussions about the status of an element are not con-sidered for the moment. When an element, like for
instance the particles of Dutch verbs, has been chosenas head, this criterion has been coherently appliedthrough the whole set of corpora and convenientlyexplained in the section on lexical hubs.
After analyzing babies’ utterances from each tran-scription ‘‘by hand’’ in this way, and coding these struc-tures, the analyses were processed by the networksoftware Cytoscape (Shannon et al., 2003). To makethis possible we had to convert the original ‘‘.cha’’ filesfrom CHILDES into something legible for the networksoftware. Four steps were needed:
(1) Each file was converted from .cha to .xml files apply-ing to them the script ToXml.pl, in order to removeall the characters that did not belong to the infant’sexpression. We have checked that no piece of speechinformation was lost during the process. This scriptwas developed by Carlos Rodrıguez-Caro and BernatCorominas-Murtra. The change of format is requiredby the syntactical analysis programDGAanotator.
(2) Syntactic analyses were carried out by linguists,which used the DGAanotator program (Popescu,2003), always taking into account the original tran-scription in order to check the context of theconversation. This program analyzes sentences syn-tactically, by means of a Dependency Grammar.
(3) In order to make readable the analyses for the net-work program Cytoscape, the binary combinationsof the analyses must be ordered in two columns. Todo that, a specific script was created and applied toall syntactic analyses (XML2pairs.py) renderingnew files where all the information was ordered incolumns, while at the same time capturing the mergeoperation. This script was developed by HaroldFellermann and Bernat Comorminas-Murtra. Nopiece of information was lost during this process.
(4) Cytoscape was able to read the information fromall files without exception and produced the
Figure 2. Three snapshots of the Giant Connected Component (GCC). It represents a qualitative view of the transitions fromtree-like graphs to scale-free graphs.
Barcelo-Coblijn et al. 5
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

corresponding networks. Cytoscape producedalways several networks from each graph, reflectingthat not all the nodes were interconnected in aunique network. The organic and circular represen-tation was chosen in order to detect the hubs andsee better the connections (Figures 2 and 8).
The following parameters were longitudinally examinedfor each of the graphical representations obtained:
! Growth of the number of edges of the GCC: eachedge represents a syntactic link, so that this para-meter reflects how many connections there are inthe GCC.
! Growth of the size of the GCC: each node repre-sents a lexical item. This parameter reflects howmany lexical items there are the GCC.
! Average degree of the GCC: An interesting mea-sure is the average degree \k. of a network. Itrefers to the average number of connections pernode. In the context of syntactic analyses, degreerefers to the number of syntactic relationships aparticular node (i.e., a word) has. The value of thesize of the networks E (i.e., the number of edges)can be calculated from the definition of averagedegree. By definition, the average degree is twicethe number of edges E divided by the number ofnodes (the same edge is counted twice: in the degreeof the origin node and in that of the destinationnode): E=N\k./2.
! Relative size of the GCC: this measure reflects avalue of the GCC in relation to the whole network.As said, the GCC is the largest among the existentsub-networks. Its relative size is obtained fromdividing the number of nodes of the GCC by thetotal number of nodes of the network.
! Average clustering coefficient: It is a measure of theconnectivity; it is the ratio of nodes vs. edges. Forexample, the same number of edges than nodes indi-cates a low connectivity, whereas a higher numberof edges than nodes indicates that the connectivityof the network is more stressed. The question thatdescribes this measure is ‘‘What is the probabilitythat two of my friends are also friends?’’
! The characteristic path length, L, defined as thenumber of arcs in the shortest path between twonodes averaged over all pairs of nodes.
From each analyzed corpus, the GCC has been selectedapart and its statistical information recovered. Thehubs or ‘‘most connected nodes’’ were identified andtheir statistical information gathered. We have repre-sented this information trough graphics (see Results).The results from the three corpora have been comparedwith the published ones from the two English corpora(Corominas-Murtra et al., 2009).
4 Results
Before reporting the results, it is important to keep inmind that they will be affected by the nature and qual-ity of the original data. The CHILDES database wascollected quite independently, and without consider-ation of our purposes, which is a good indicator of theneutrality of the used data that are available in internetand can be checked. The weak point is that these cor-pora were not collected following the same guidelines,and there are clear differences between them. For exam-ple, the Dutch corpora has been gathered following aquite consistent temporal pattern, leaving 10–12 daysbetween each sampling. The German corpora, though,has been gathered in a different fashion. Sometimes theresearcher visited the infant three consecutive days in aweek. Hence, great differences should not be expectedin the corresponding graphical representation. Othereventual problems relate to whether the infant was col-laborative that day, or whether she was a little sick orsleepy.
In spite of these difficulties, we have been able todetect commonalities embedded or hidden in the tran-scription. A look at the networks created on thebasis of the three corpora clearly reveals that in thethree cases the linguistic development has followedtwo regimes at two different periods. During thefirst period, the number of both nodes (lexical units),and edges (syntactic relationships) has a linear quasi-parallel growth. In the second period, the numberof edges exceeds the number of edges at length(Table 1).
About 700 days of age, or shortly after this thresh-old, a change can be detected (see Table 1, underlinednumbers) consisting in a higher number of edges (E)than nodes (N). After this point, the distance betweenedges and nodes will be larger and larger until the num-ber of edges almost doubles the number of nodes(Figure 3A–C). For example, in the Dutch corpora, thegrowth pattern threshold is at 761 days (N=65,E=72). More or less 100 days later, at 854, the new pat-tern is clearly present (N=134, E=223). In German,milestones can be detected at 731 days (N=121,E=162), and more or less 100 days later, at 812(N=160, E=227). In the Spanish corpus, the transitiongoes from 667 days (N=79, E=101), to almost 100days later, at 747 (N=179, E=256).
The relative size of the GCC has been calculated foreach GCC of the 17 graphs of each language. In Figure3(D–F) we have depicted the development of the rela-tive size. The growth pattern followed by the GCC inthe three cases seems to be practically linear.
The clustering coefficient or C is viewed as the prob-ability that a pair of nodes a and b are connected, sinceeach one is also connected to a mutual friend j (form-ing a triangle). Metaphorically speaking, C somehowreflects the probability that friends of a are also friends
6 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

of each other. So defined, it seems clear that C is a mea-sure of the local structure of the network.
Typically, the largest value for C is 1 for a com-plete graph (in other words, all nodes are connectedwith each other) and the smallest is 0, when there areno connections among the nodes (an empty graph).Large values of C are indicators of the robustness ofthe connectivity: if a node is removed and this pro-vokes a disconnection of two portions of the system,this would easily be overcome by simply accessing the
adjacent working nodes through short-range neigh-boring nodes.
The graphics in Figure 4(G–I) show the growth ofthe average clustering coefficient C through time.Interestingly, after several corpora where this value iszero or near to zero, it shows a sudden increase. In theDutch corpora, this happens when the infant was2;00.04 (i.e., 736 days), increasing the clustering coeffi-cient from 0 to 0.039; in the German corpora, this hasbeen detected at the age of 2;01.21 (781 days), and the
Table 1. Number of nodes and edges for each corpus of each language
Age, days Nodes GCCDutch
Edges GCCDutch
Age, days Nodes GCCGerman
Edges GCCGerman
Age, days Nodes GCCSpanish
Edges GCCSpanish
631 2 1 650 5 4 579 1 0661 2 1 690 70 94 611 31 34687 2 1 714 29 32 625 10 9722 15 15 723 43 47 641 11 10736 29 29 731 121 162 655 49 54754 31 31 733 81 99 667 79 101761 65 72 753 67 76 671 136 160783 82 101 756 133 202 687 37 39795 138 188 776 69 94 691 76 86809 109 129 779 94 128 698 105 131827 107 139 781 98 136 701 120 168854 134 223 794 101 133 720 115 139868 120 175 795 119 172 732 115 140882 135 225 811 208 350 747 179 256895 145 282 869 159 233 762 67 78909 299 569 873 139 206 777 109 145926 223 368 895 161 248 825 237 393
Time is represented in days. GCC, Giant Connected Component.
Figure 3. A, B and C reflect the longitudinal growth of the number of nodes (words) and edges (syntactic relationships) in eachlanguage. D, E and F reflect the longitudinal growth of the relative size of the Giant Connected Component in each language.
Barcelo-Coblijn et al. 7
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

value growths from 0.002 to 0.031; in Spanish, this hasbeen detected when the infant is 1;09.27 (667 days), and
the value growths from 0 to 0.018. All values are foundin Table 2.
Figure 4. Longitudinal growth of the characteristic path length (A, B and C). Longitudinal growth of the average degree < k> ofthe Giant Connected Component (GCC; E, D and F). Longitudinal growth of the average clustering of the GCC (G, H and I).
Table 2. Average clustering coefficient (C) of the three languages through time
Age, days Av. clustering Dutch Age, days Av. clustering German Age, days Av. clustering Spanish
631 0 650 0 579 0661 0 690 0.002 611 0687 0 714 0 625 0722 0 723 0.003 641 0736 0.039 731 0.009 655 0754 0.043 733 0.008 667 0.018761 0.003 753 0.007 671 0783 0.034 756 0.011 687 0795 0.042 776 0.006 691 0.016809 0.037 779 0.003 698 0.009827 0.041 781 0.031 701 0.007854 0.087 794 0.011 720 0.022868 0.056 795 0.035 732 0.012882 0.035 811 0.008 747 0.027895 0.068 869 0.022 762 0909 0.053 873 0.035 777 0.053926 0.063 895 0.023 825 0.02
8 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

A rapid increase in the number of edges is inter-preted as a qualitative change in the properties of thenetwork. Interestingly, this increase of edges correlateswith a reduction of the path length.
The shortest path length distribution is also calledthe ‘‘characteristic path length’’ or L. It represents theaverage of the shortest distances between all pairs ofnodes. It is the average distance to be covered in orderto reach the majority of nodes in the graph. Thus, L isrelated to the global structure of the system. It providesthe ‘‘average minimum distance’’ between any pair ofnodes, hence measuring the typical separation betweentwo nodes in the graph. It can be seen as the averagenumber of friends in the shortest chain connecting twopeople (Watts and Strogatz, 1998). In the networks ofour study, after a spurt, there is a tendency to decreasein the vicinity of a value (4 points), suggesting stabiliza-tion (Figures 4A–C).
In scale-free networks, the majority of nodes havejust a few edges or links, while a small number of nodesexhibit many links. It is due to this inhomogeneouscharacteristic that a scale-free network becomes able totolerate some errors (in other words, it is quite robustagainst random failures like for instance deletion ofnodes). Paradoxically, a scale-free network is also quitefragile to attacks like the deletion of the most highlyconnected nodes. On the other hand, whereas in expo-nential networks the probability that a node has a verylarge number of edges is not very relevant, highly con-nected nodes become statistically significant in scale-free networks.
We have measured the degree distribution P(k),defined as the probability that a node as k edges. Theresults are in Table 3. Figure 4(D–F) shows the evolu-tion of the average degree of the GCC through time foreach language.
As mentioned above, it is characteristic of scale-freenetworks to include few elements (the hubs) with a verylarge number of connections. In this particular case,the hub represents a word that exceeds in connectivityregarding the rest of words. This connectvity has to beunderstood as syntactic connectvity. Put it differently,the presence of lexical hubs reveals the presence of cru-cial syntactical elements.
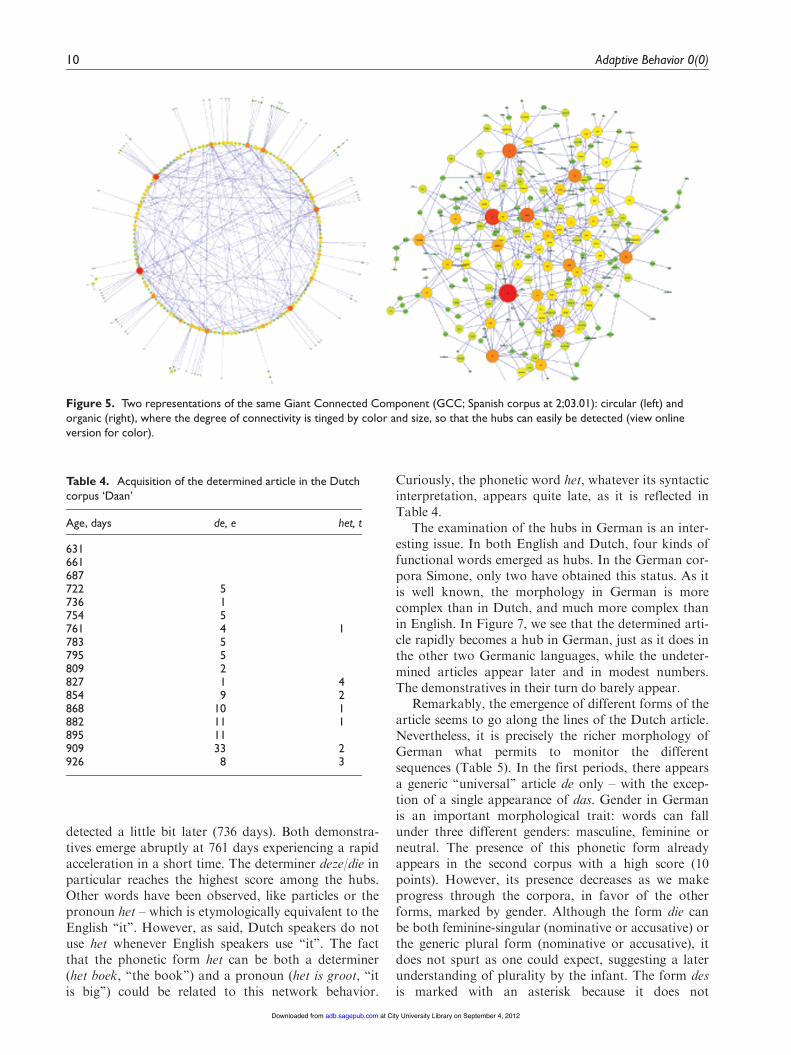
The degree of connectivity of the graph highlightsthe hubs of the scale-free network (Figure 5). This hasbeen done for each GCC and it reveals similar resultsto those found in the previous study on English cor-pora. In that study, functional elements like ‘‘the’’, ‘‘a’’or ‘‘it’’, which are semantically poorer than ‘‘house’’ or‘‘dog’’, emerged within the network late and abruptly.In these three corpora similar results point to an abruptemergence of functional words which suddenly becomethe hubs of the network. Admittedly, some differencesare expected due to typological differences among thestudied languages, but the take-home message is thatthe four analyzed languages show similar patterns ofacquisition.
In Figure 6, the emergence of functional words ashubs in Dutch is represented: the determined article(with two forms, de and het equivalent to the Englishthe) and the demonstrative (with two forms deze anddit equivalent to the English ‘‘this’’; deze is also theplural form equivalent to ‘‘these’’) are clearly the mostprominent. These hubs are followed by the undeter-mined article (een or ‘n, equivalent to the English ‘‘a’’),and the second demonstrative (die and dat, equivalentto the English ‘‘that’’; die can also be equivalent to theplural form ‘‘those’’). The determined article de/hetgrew in connectivity earlier (at 722 days) and remainedquite constant until 827 days, when it spurted again.The spurt of the undetermined article een/’n have been
Table 3. Average degree < k> of the Giant Connected Components (GCCs)
Age, days < k> Dutch Age, days < k> German Age, days < k> Spanish
631 1 650 1.6 579 0661 1 690 2.686 611 2.194687 1 714 2.186 625 1.8722 2 723 2.678 641 1.818736 2 731 2.42 655 2.163754 2 733 2.42 667 2.532761 2.21538462 753 2.269 671 2.338783 2.46341463 756 3.038 687 2.108795 2.72463768 776 2.725 691 2.237809 2.36697248 779 2.725 698 2.438827 2.59813084 781 2.702 701 2.767854 3.32835821 794 2.776 720 2.417868 2.91666667 795 2.634 732 2.417882 3.33333333 811 2.874 747 2.816895 3.88965517 869 2.931 762 2.328909 3.80602007 873 2.95 777 2.661926 3.30044843 895 3.081 825 3.28
Barcelo-Coblijn et al. 9
at City University Library on September 4, 2012adb.sagepub.comDownloaded from
detected a little bit later (736 days). Both demonstra-tives emerge abruptly at 761 days experiencing a rapidacceleration in a short time. The determiner deze/die inparticular reaches the highest score among the hubs.Other words have been observed, like particles or thepronoun het – which is etymologically equivalent to theEnglish ‘‘it’’. However, as said, Dutch speakers do notuse het whenever English speakers use ‘‘it’’. The factthat the phonetic form het can be both a determiner(het boek, ‘‘the book’’) and a pronoun (het is groot, ‘‘itis big’’) could be related to this network behavior.
Curiously, the phonetic word het, whatever its syntacticinterpretation, appears quite late, as it is reflected inTable 4.
The examination of the hubs in German is an inter-esting issue. In both English and Dutch, four kinds offunctional words emerged as hubs. In the German cor-pora Simone, only two have obtained this status. As itis well known, the morphology in German is morecomplex than in Dutch, and much more complex thanin English. In Figure 7, we see that the determined arti-cle rapidly becomes a hub in German, just as it does inthe other two Germanic languages, while the undeter-mined articles appear later and in modest numbers.The demonstratives in their turn do barely appear.
Remarkably, the emergence of different forms of thearticle seems to go along the lines of the Dutch article.Nevertheless, it is precisely the richer morphology ofGerman what permits to monitor the differentsequences (Table 5). In the first periods, there appearsa generic ‘‘universal’’ article de only – with the excep-tion of a single appearance of das. Gender in Germanis an important morphological trait: words can fallunder three different genders: masculine, feminine orneutral. The presence of this phonetic form alreadyappears in the second corpus with a high score (10points). However, its presence decreases as we makeprogress through the corpora, in favor of the otherforms, marked by gender. Although the form die canbe both feminine-singular (nominative or accusative) orthe generic plural form (nominative or accusative), itdoes not spurt as one could expect, suggesting a laterunderstanding of plurality by the infant. The form desis marked with an asterisk because it does not
Figure 5. Two representations of the same Giant Connected Component (GCC; Spanish corpus at 2;03.01): circular (left) andorganic (right), where the degree of connectivity is tinged by color and size, so that the hubs can easily be detected (view onlineversion for color).
Table 4. Acquisition of the determined article in the Dutchcorpus ‘Daan’
Age, days de, e het, t
631661687722 5736 1754 5761 4 1783 5795 5809 2827 1 4854 9 2868 10 1882 11 1895 11909 33 2926 8 3
10 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

correspond to the standard genitive form of the gendersmasculine and neutral. As it is well known, this genitiveform is not used orally. The genitive displays the formder for feminine and plural (this form was also absentin the corpora). In these corpora, it corresponds to aform between the universal de and the neutral das.Finally, the form den appears just three times, but whenthe accusative feminine form has already been detected.It must be noted that, although the relative pronounsin German mostly have the same form of determinedarticles, at that time the infant did not uttered any rela-tive sentence, so that these forms cannot be confusedwith relative pronouns.
In Spanish, the picture is just apparently differentfor several reasons. Spanish is a Romance languagethat has two genders (masculine and feminine) anddisplays marks for plurality. As for the learners of theGermanic languages, the hubs are again functionalwords, also the determined article, the undeterminedarticle and two of the three demonstratives. Thedetermined article is no doubt the most importantnode in the network, reaching really high scores(almost 50). This article presents four different forms,exhausting all the combinations of gender and
plurality. Additionally, there is a neutral form lo, apronoun roughly equivalent to the English ‘‘it’’ whenused as a verbal complement (Ella lo vio, ‘‘She sawit’’). The feminine pronoun is la, therefore we had tocheck one by one the nodes linked to these two formsin order to discriminate their syntactic nature.Additionally, there is considerable homophonybetween the forms when the uttered form is somehowdegraded, mostly due to a non uttered coda by theinfant: a – instead of la – can be article singular, arti-cle plural (a nina ‘‘the girl’’, a ninas ‘‘the girls’’). Theform ‘‘a’’ can also be a preposition, and the links ofsuch nature must not be taken into account. The samecan happen in the case of the masculine form el,uttered as e, which sometimes can be the verb ‘‘to be’’(e nino ‘‘the boy’’ vs. e bueno ‘‘it is good’’). No pluralpronoun has been detected – in either possible pho-netic form (‘‘los, las’’, for example: I saw them . (Yo)los/las vi). All these possible sources of artifacts havebeen checked one by one in the networks and accord-ingly reflected in Table 6 and Figures 8 and 9.
Typically, the Spanish demonstratives cover threedistances regarding the speaker and the object, andhence there are three sets of morphological forms:
Figure 6. Longitudinal growth of the connectivity of the hubs in Dutch, identified with the definite articles de and het; the indefinitearticle een; the demonstratives deze, dit (equivalent to the English this); and die and dat (equivalents to the English that).
Barcelo-Coblijn et al. 11
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

(1) Este, estos, esta, estas: for a neighboring object,equivalent to the English this.
(2) Ese, esos, esa, esas: for a distant object, equivalentto the English that.
(3) Aquel, aquellos, aquella, aquellas: for an evenmore distant object, also equivalent to the Englishthat.
Figure 8 shows how children acquire this element. Thedemonstrative este (and related forms) appears close tothe 600 days, following a rapid growth. Instead, ese isalmost absent until a sudden spurt close to 700 days.No single case of aquel (or related forms) has beenfound in the corpora.
5 Discussion
The pattern in the developmental sequence for the threelanguages examined here is quite similar to the previous
study on English. The three infants acquire their firstlanguage in similar ways, regardless the different typol-ogy – Germanic vs. Romance, two Indo-Europeanfamilies. A parallel, sudden and abrupt, emergence offunctional words, around 700 days of age, seems toindicate the mastering of syntactic categories for wordcombination. As expected, some differences are alsoevident due to the peculiarities of each language: in thecase of the acquisition of the articles, an English kidhas to learn just two (i.e., ‘‘the’’ and ‘‘a’’); a Dutchinfant has to deal with two determined articles and oneundetermined (i.e., ‘‘de/het’’ and ‘‘een’’), whereas theSpanish one differentiates between the forms for mas-culine/feminine and plural/singular (‘‘el/la’’ and ‘‘los/las’’) in addition to a neutral form ‘‘lo’’, which is a pro-noun but that at the beginning is confused with a deter-miner. In the case of German, the cognitive effort iseven greater since there are three genders (called mas-culine, feminine and neutral) and four cases in the
Figure 7. Longitudinal monitoring of the emergence of some functional words in German. Clearly, the determined article (in thecenter) is the most relevant showing a late and sudden growth. The undetermined article (on the left) experiences even later thisabrupt emergence. However, the demonstrative (on the right) has not emerged as hub, and although acquired and used, it clearlydoes not play the same role of, for example, the English or Dutch demonstratives.
Table 5. Acquisition of the determined article in the Germancorpus ‘Simone’
Age, days de die der den des* das
650 1690 10714 2723 1 1 2731 4 3 1 1733 3 1753 2 3 8756 4 6776 5 3 4 1779 3 4 1 1781 1 1 6 14794 3 4 3 3 6795 2 1 6 3 7811 3 2 6 4 17869 1 10 6 2 15873 1 5 8 2895 2 14 5 1 13
Table 6. Acquisition of the determined article and thepronouns la and lo in the Spanish corpus ‘Aguirre’
Age la, a lapronoun
el, e las / la los / lo loarticle
lopronoun
579
611 8 6625 4641 2655 12 6667 18 9671 28 16687 11 6691 13 8698 22 6 3701 16 7720 5 1 9 2 3 3732 21 13 3 8 1747 21 15 5 5 9762 8 5 2 1777 8 9 1 5825 20 16 3 5 15
12 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

spoken language (Nominative, Accusative, Genitive –for feminine and plural forms – and Dative), so thatthe number of forms to store in the mental lexicon hasto be taken into account for comparisons. On the otherhand, whereas German has one demonstrative, Englishand Dutch have two and Spanish three.
Functional words basically encode syntactic infor-mation and the semantics they may exhibit has to beunderstood in quite formal, relational terms.Interestingly, they appear late in comparison to otherwords and occupy the place of hubs in the scale-freenetworks that represent the syntactical knowledge ofthe infant. This later aspect has to be tinged: let usstress that a graph from a transcription just provides aquite conservative snapshot of the potential of theinfant. The graph comes from the available informa-tion we find in a transcription. Probably, the linguisticknowledge of the infant is greater and richer. However,the same conservative view is consistently applied to allcases studied. Consequently, the properties of the
Figure 8. Longitudinal monitoring of the emergence of the hubs in the networks of the Spanish corpora. The emergence of thedetermined article (top left) is clearly the most prominent. The undetermined article (top right) accelerates in a short time, thoughwith more modest scores. This spurt happens close to 700 days, when two of the demonstratives (bottom left and right) alsoaccelerate.
Figure 9. Longitudinal monitoring of the emergence of thepronoun lo in the networks of the Spanish corpora. Its firstappearances have been detected at 698 (three edges), and itspurts tripling the edges (nine) at 747 days and reaching 15edges at 825 days.
Barcelo-Coblijn et al. 13
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

graphs are an interesting source of information, regard-ing the ontogeny of syntax in infants. Our most impor-tant finding, then, is the change in the topology ofnetwork that happens around 700 days of age. The firstnetworks are quite simple, and their nodes exhibitscarce connectivity. This kind of network grow inquantity of nodes and edges in the first period, withoutrelevant qualitative changes; then at some point, a newregime is created, where words are combined produc-tively, and scale-free networks emerge.
The change to scale-free networks is favored by twoimportant characteristics of these networks: most nodeshave few edges, but some nodes gain quickly in connec-tivity, becoming the hubs of the networks. This kind ofnetworks, as it has been mentioned above, are veryrobust against random attacks – like the deletion of somenodes – but very fragile if the deleted nodes are hubs.The reason is simple: to delete a hub implies the discon-nection of a lot of nodes. The hubs we have detected arepractically the same in all these languages: functionalwords like determiners (articles and demonstratives) butalso pronouns that appear as direct complement or sub-ject in these languages: it in English, het in Dutch, la,loin Spanish. Interestingly, our scale-free networks exhibitthe small-world effect, through a process that implies anincrease of the clustering coefficient C (Figure 5), and adecrease and stabilization of the characteristic pathlength L. Particularly the latter measure has reached sim-ilar scores in all three languages. After an initial spurt ofL, we see a tendency of this parameter to decrease pro-gressively in all three languages, each time with shorterdifferences between scores, and the graphic shows a ten-dency to a stabilization of L around four points: inDutch (926 days, L=3,686), in German (895 days,L=4,074) and in Spanish (825 days, L=4,125). Thepresent work thus provides further support to the pio-neer work on English (Corominas-Murtra et al., 2009),given the similar behavior of these three children acquir-ing three different languages.
In summary, we have found evidence for a universalpattern in language development, and for syntactic pro-ductivity appearing around two and a half years of age,driven by the increase of the lexicon. Up until now, fivechildren acquiring four different first languages show asimilar patterning in the development of syntax. Inaddition, the abrupt change of topology of the initialnetworks to small-world networks and the emergenceof functional words as hubs is similar in all five cases.It is true that the evidence is not conclusive, because,from the linguistic point of view, the historical distancebetween Germanic languages and Romance languagesis not huge, and the syntactical distance is not enor-mous either (e.g., Longobardi & Guardiano, 2011).Evidence from infants acquiring non Indo-Europeanlanguages is also required. These results, then, by them-selves, are not enough to settle the question of thenature of language acquisition, although they
undermine usage-based theories and learning-basedtheories in general. These results rather suggest thatusage- and learning-based theories contend that syntac-tic structures are abstracted from the examples at asteady pace (e.g., Vogt & Lieven, 2010). Our resultsrather suggest that syntactic competence is the outcomeof a self-organization process that connects words intobasic syntactic structures, when the lexical repertoireexpands, leaving the basic ‘‘merge’’ operation intact.
Acknowledgements
We would like to thank Mireia Oliva for the analysis ofGerman corpora, and Carlos Rodrıguez-Caso and HaroldFellermann for their help with data analysis.
Funding
This study has been supported by the grant BES2007-64086,the projects FFI2010-20759 and FFI2009-13416-C02 fromthe Ministerio de Ciencia e Innovacion (Spain) and IST-FETECAGENTS EU 011940.
References
Corominas-Murtra, B. (2011). An unified approach to theemergence of complex communication. Unpublished PhD.dissertation, Universitat Pompeu, Fabra/Parc de RecercaBiomedica de Barcelona. http://repositori.upf.edu/handle/10230/12833
Corominas-Murtra, B. (2007). Network statistics on earlyEnglish syntax: Structural criteria. ArXiv:0704.3708v2.
Corominas-Murtra, B., Fortuny, J., & Sole, R. V. (2011).Emergence of Zipf’s law in the evolution of communica-tion. Physical Review E, 83, 32767.
Corominas-Murtra, B., Valverde, S., & Sole, R. V. (2009).The ontogeny of scale-free syntax networks: Phase transi-tions in early language acquisition. Advances in ComplexSystems (ACS) 12, 371–392.
Chomsky, N. (1956). Three models for the description of lan-guage. IRE Transactions on Information Theory, 2, 113–124.
Chomsky, N. (2000). Minimalist inquiries: The framework. InR. Martin, D. Michaels, & J. Uriagereka (Eds.), Step bystep: Essays on minimalist syntax in honor of Howard Las-nik. Cambridge, MA: MIT Press.
Chomsky, N., & Miller, G. A. (1963). Introduction to the for-mal analysis of natural languages. In D. Luce, R. R. Bush,& E. Galanter (Eds.), Handbook of mathematical psychol-ogy (pp. 269–321). New York: Wiley.
Ferrer-i-Cancho, R., & Sole, R. V. (2001). The small world ofhuman language. Proceedings of the Royal Society B: Bio-logical Sciences, 268, 2261–2265.
Gomila, A. & Calvo Garzon, F. (2008) Directions for anembodied cognitive science: Towards an integratedapproach. In F. J. Calvo Garzon & A. Gomila (Eds.),Handbook of cognitive science: An embodied approach (pp.1–25). Amsterdam: Elsevier Publishers Limited.
Hauser, M. D., Chomsky, N., & Fitch, W. T. (2002). Thefaculty of language: What is it, who has it, and how did itevolve? Science, 298, 1569–1579.
14 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

Hudson, R. A. (1990). English word grammar. Oxford:Blackwell.
de Jong, E. D. (1998). The development of a lexicon based onbehavior. In H. La Poutre and J. van den Herik (Eds.),Proceedings of the Tenth Netherlands/Belgium Conferenceon Artificial Intelligence NAIC’98 (pp. 27–36). Amsterdam:CWI.
Ke, J., & Yao, Y. (2008). Analyzing language developmentfrom a network approach. Journal of Quantitative Linguis-tics, 15, 70–99.
Longobardi, G., & Guardiano C. (2011). The biolinguisticprogram and historical reconstruction. In A. M. DiSciullo, & C. Boeckx (Eds.), The biolinguistic enterprise.Oxford: Oxford University Press.
Mel’cuk, I. A. (1988). Dependency syntax: Theory and prac-tice. Albany, NY: State University of New York Press.
Ninio, A. (1996). A proposal for the adoption of dependencygrammar as the framework for the study of languageacquisition. In G. Ben Shakhar & A. Lieblich (Eds.), Vol-ume in honor of Shlomo Kugelmass (pp. 85–103). Jerusa-lem: Magnes.
Ninio, A. (2003). No verb is an island: Negative evidence onthe Verb Island hypothesis. Psychology of Language andCommunication, 7, 3–21.
Ninio, A. (2006). Language and the leaning curve: A new the-ory of syntactic development. Oxford: Oxford UniversityPress.
Pinker, S. (1989). Learnability and cognition: The acquisitionof the argument structure. Cambridge, MA: MIT Press.
Popescu, M. (2003). Dependency grammar anotator. In F.Hristea and M. Popescu (Eds.), Building awareness in lan-
guage technology (pp. 17–34). Bucharest: Editura Universi-tatxii din Bucuresxti.
Radford, A. (1990). Syntactic theory and the acquisition ofEnglish syntax: The nature of early child grammars of Eng-lish. Oxford: Blackwell.
Shannon, P., Markiel, A., Ozier, O., Baliga, N. S., Wang, J.T., Ramage, D., Amin, N., Schwikowski, B., & Ideker, T.(2003). Cytoscape: A software environment for integratedmodels of biomolecular interaction networks. Genome Res,13, 2498–2504.
Sole, R. V., Corominas-Murtra, B., Valverde, S., & Steels, L.(2010). Language networks: Their structure, function, andevolution. Complexity, 15, 20–26.
Steels, L. (2000). Language as a complex adaptive system. InM. Schoenauer (Ed.), Proceedings of PPSN VI LectureNotes in Computer Science. Berlin: Springer-Verlag). Avail-able at: http://www.isrl.uiuc.edu /~amag/langev/paper/steels00languageAs.html.
Tomasello, M. (1992). First verbs: A case study of early gram-matical development. Cambridge: Cambridge UniversityPress.
Tomasello, M. (2003). Constructing a language: A usage-basedtheory of language acquisition. Cambridge, MA: HarvardUniversity Press.
Vogt, P., & Lieven, E. (2010). Verifying theories of languageacquisition using computer models of language evolution.Adaptive Behavior, 18, 21–35.
Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of"small-world" networks. Nature, 396, 440–442.
Zipf, G. K. (1936). The psycho-biology of language: An intro-duction to dynamic philology. London: Routledge.
About the Authors
Lluıs Barcelo-Coblijn is a member of the research group on human cognition and evo-lution at the University of the Balearic Islands (UIB), where he got his Ph.D. with thedissertation ‘‘Recursion, duality of patterning and vocal systems: assessing the marks oflanguage as a Homo sapiens’ specific faculty’’, under the supervision of Antoni Gomila.Lluıs holds degrees in Catalan philology and German languages (UIB and UniversittPaderborn) and in linguistics (University of Barcelona and Vrije UniversiteitAmsterdam). He has Master’s degrees in cognitive science and language (University ofBarcelona) and human cognition and evolution (UIB). He is currently working on anevo-devo-inspired approach to the evolution of the language faculty, giving to complexsystems a central role.
Bernat Corominas-Murtra obtained a degree in physics at the Universitat Autonomade Barcelona, in a graduate program centered in theoretical physics. He followed byobtaining a degree in linguistics at the University of Barcelona, focusing on logics andtheoretical syntax. Finally, he obtained a Master’s degree in mathematics in the sameuniversity, in a program centered in dynamical systems and stochastic processes, pre-senting as his Master’s thesis the results of research on nested subgraphs. He began hisresearch activity working within the ‘‘ECAgents’’ project, which ended in 2008. His cur-rent research is funded by the James McDonnell foundation through project‘‘Emergence of complexity in tinkered networks’’. He has also actively contributed tothe ‘‘Mesomorph’’ project, the ‘‘ComplexDys’’ project and the NWO project‘‘Dependency in universal grammar’’. His Ph.D. thesis, entitled ‘‘An unified approachto the emergence of complex communication’’, was advised by Ricard Sole, within thedoctorate program of the Parc de Recerca Biomedica de Barcelona.
Barcelo-Coblijn et al. 15
at City University Library on September 4, 2012adb.sagepub.comDownloaded from

Antoni Gomila is full professor of psychology at the psychology department of theUniversity of the Balearic Islands. His background is in philosophy (Ph.D. in 1990,‘‘After the computational mind’’), and his interests have centered on issues at the ‘‘noman’s land’’ of the frontiers between philosophy of mind, psychology and cognitive sci-ence: representation and meaning, expression and intersubjectivity, intentional explana-tion and rationality, always taking an evolutionary perspective into account. He is aresearcher of the human evolution and cognition research group. His last book is‘‘Verbal Minds: Language and the Architecture of the Mind’’ (Elsevier, 2011).
16 Adaptive Behavior 0(0)
at City University Library on September 4, 2012adb.sagepub.comDownloaded from





























