Embed Size (px)
Citation preview


2ACCU Oxford Lightning Talks June 2011

3ACCU Oxford Lightning Talks June 2011

4ACCU Oxford Lightning Talks June 2011

5ACCU Oxford Lightning Talks June 2011

SQLite: A SQL Server programmer’s perspective – Geraint Lloyd
Thoughts on Estimation – Jonathan Morris
Cache Efficient Collections – Robin Williams
Meta-template programming 101 with Boost MPL – Malcolm Noyes
Phil Nash’s CATCH C++/Objective C unit test framework – Malcolm Noyes
Learnings from Code Coverage – Nigel Lester
6ACCU Oxford Lightning Talks June 2011
ACCU Oxford Lightning TalksJune 2011

SQLite: A SQL Server
programmer‟s
perspective
Geraint Lloyd
Schlumberger

8
© 2011 Schlumberger. All rights reserved.
An asterisk is used throughout this presentation to denote a mark of Schlumberger.
Other company, product, and service names are the properties of their respective
owners.

The Problem
INTERSECT* – an oil and gas reservoir simulator.
Writes lots of „messages‟ (information) to a text file.
This file can get very big.
Want to search / extract selection of messages from file.
We have metadata to tag each message with.
DATABASE

The Problem - environment
Multiple platforms (Windows & Linux).
Varied deployment environments.
Want straightforward installation.
Want simple results copy.

Our solution: SQLite (www.sqlite.org)
Public domain.
Widely respected and widely used.
Library – no separate installation.
Cross platform (have C source)
Compact.

A SQL Server (or Oracle, or MySql ...) programmer‟s
perspective
„Embedded‟
no server process.
each application reads / writes directly to database.
Database – a file.
Access – mediated by file system.
DB app DB server
Files

A SQL Server (or Oracle, or MySql ...) programmer‟s
perspective (2)
Main differences in:
Concurrent access / Locking
Performance

Concurrent access and locks
SQLite acquires „lock‟ (SHARED or
EXCLUSIVE) before reading / writing.
Multiple concurrent reads.
No write while read in progress.
No read while write in progress.
DB File
App 1 App 2

Concurrent access - implications
SQLite calls (SELECT, UPDATE, INSERT ...) may:
Fail (return „busy‟).
Take time (depends on SQLite settings).
→ Store and retry queries if necessary.
Long-running query will impact other applications

Performance
SQLite:
data integrity first, performance second.
No slouch, however:
No server process caching in memory.
Disk access provides performance limit.

Performance - writing
Data is committed to disk at end of transaction.
Block multiple writes into one transaction.
Choice of:
Synchronous – good data integrity but slow.
Asynchronous – integrity risks, but faster.

Performance – reading
First time access important – file not cached.
Limit returned records for faster response.
SQLite will only use one index to optimise a query.
Careful query and index design to optimise performance

What did I do
Cached all writes (up to a limit) within time frame.
Asynchronous writes, and handle „corrupt‟ reads.
Writing to database in separate thread.
Retries if busy.
Ultimate timeout – give up if database locked for too long.
„Trial and error‟ to optimise queries.

Conclusion
SQLite – a great database.
Not SQL Server (or Oracle, MySQL ...).
Be aware of inherent limitations.
Has some great advantages too.

Lightning Talk
Thoughts on Estimation
Jonathan Morris

The problem:
It‟s too early in the development phase
No one has really thought about the technical issues
The only description of the task is a three word bullet point
Yet your manager comes to you and asks ...
How long is it going to take?

So how can I get an estimate out of you?
You have to be prepared to give an estimate at any time
At three month‟s notice
At a week‟s notice
At a minute‟s notice
What about trust? It‟s up to you to be strong ... you have to
make clear that a quick “guess” is only that
Otherwise you‟re in the sandbox

Capture your uncertainty
Give a lower and an upper bound.
Shows your level of uncertainty
But how to aggregate the all the optimistic and pessimistic
estimates?
We have to have an order of magnitude to play with

Aggregating uncertainty
Various possible ways of combining the optimistic and
pessimistic estimates
Take the average
Weighted average
Geometric mean
cPessimistiOptimisticeanGeometricM

“Justification”
Optimistic estimate: if everything goes right
Pessimistic estimate: if everything goes wrong
Neither seems likely
Δ = δx1 + ... + δxn
Pseudo-maths (use Central Limit Theorem)
Apply a Gaussian distribution to give an estimate on the
upper bound of the error

Practical application
Used effectively to manage widely varying estimates:
Optimistic 5 weeks, pessimistic 10 weeks
– Geometric mean = 7 weeks
Optimistic 5 weeks, pessimistic 30 weeks
– Geometric mean = 12 weeks
It doesn‟t matter that much:
“They‟re only estimates”

Further reading
“averaging of several adapted cases using a geometric mean provide the best estimates for software development effort”
Case-based reasoning Research and Development – David B. Leake and Enric Plaza, 1997
Simple Mean, Weighted Mean, or Geometric Mean?– Shu-Ping Hu, 2010 ISPA/SCEA Professional Development and
Training Workshop
Guesstimation: A New Justification of the Geometric Mean Heuristic– Olga Kosheleva and Vladik Kreinovich, App. Math. Sci, Vol 3 2009
No 47, 2335 - 2342

©Scott Adams, Inc. / Dist. By UFS, Inc.

Cache-efficient collections
Robin Williams
Orion Nebula: C.R. O’Dell, S.K. Wong & NASA/ESA, with permission
1

Context: Cloudy
• Photoionization Simulations for the Discriminating Astrophysicistsince 1978, www.nublado.org
• Models the spectra of astronomical nebulae
• Open-source C++, ∼ 215 kloc (was Fortran until 1999)
• Requirements: wide range of coupled physics, high portability,efficiency, ease of use by non-specialists
2

Model for a compute-intensive loop
for (int nt=0; nt<ntrans; ++nt)
{
transition &t = trans[nt];
t.popopc = t.lo->pop - t.hi->pop*t.lo->g/t.hi->g;
}
with e.g.
class transition {
public:
float popopc;
state *lo, *hi;
// and lots of physics relevant somewhere else...
float padding[NPAD];
};
3

Cache efficient implementation
Use standalone vectors of fundamental type for everything:
float * __restrict staterat = new float[nstate];
for (int i=0; i<nstate; ++i)
{
staterat[i] = statepop[i]/stateg[i];
}
for (int nt=0; nt<ntrans; ++nt)
{
int lo = los[nt];
int hi = his[nt];
popopc[nt] = statepop[lo]-staterat[hi]*stateg[lo];
}
delete [] staterat;
4

Speed results
Times for roughly constant work (with cache dirtying between iterations):
List size Object Object padded Packed vector100 18.7211 80.6850 21.4093200 23.8895 81.5731 21.2053500 18.7491 91.0177 20.96931000 18.9692 84.4693 20.58532000 18.3932 83.9852 20.00935000 18.4051 85.9534 20.425310000 19.2812 84.4573 18.9652
• Real-world padding slows Object implementation
• (Also have data for other variants, other systems, OpenMP, OpenCL...)
5

Challenges
Object implementation:
• Easy to pass around as an argument, etc.
• Simple to apply STL-style algorithms
• Cache misses slow performance dramatically as classes grow (seealso e.g. Albrecht 2009, ‘Pitfalls of Object Oriented Programming’)
Packed vector implementation:
• Cache efficient (and can also exploit SSE) but clumsy
• Naive implementations:
Integer indexing failure of encapsulation
Multiple iterators verbose, failure of DRY
• Both make function calls and STL more awkward
Can we do better?
6

Prototype proxied collection
// Class of packed vectors
class qList {
vector<double> m_ConBoltz; // and lots more...
friend class qStateProxy;
};
// Proxy object
class qStateProxy {
list_type *m_list;
int m_index;
public: double &ConBoltz()
{ return m_List->m_ConBoltz[m_index]; } // etc ...
};
// Iterator ‘Has-A’ proxy
template<class P, class C> class ProxyIterator {
P proxy;
public: P operator*(); // or P&? or const P&?
};
7

Performance
Application to a few core classes gives up to 50% speed up for the fullcode (10% is more typical)
8

Proxied collection properties
Implementation challenges:
• Access – lots of extra (), or non-portable ‘property’ implementation
• operator-> must decay to raw pointer – can create a temporaryobject (Alexandrescu), or more simply just a pointer to the internalproxy object
• Proxy has reference-like semantics: Deep vs. shallow const? Deepvs. shallow copy? Assignment vs. association at construction?
• To use overloaded swap for sort, g++ requires a real reference
__are_same<_ValueType1, _ValueType2>::__value
&& __are_same<_ValueType1&, _ReferenceType1>::__value
&& __are_same<_ValueType2&, _ReferenceType2>::__value
9

Summary
• vector<Class> hurts performance
• Class-of-vector can be awkward to work with
• Prototype proxy object implementation gains performance, retainsclass-like usage
• Still issues to address with STL compatibility– suggestions welcome!
Thanks due to Gary Ferland, Ryan Porter & Peter van Hoof for theirinput
10






































Learnings from Code Coverage
Nigel LesterSchlumberger

43
Mandatory Attribution Slide
(this title should not display)
© 2011 Schlumberger. All rights reserved.
An asterisk is used throughout this presentation to denote a mark of Schlumberger.
Other company, product, and service names are the properties of their respective
owners.

Aim: Increase code coverage
Why?
• Increase regression test coverage in a focused way
• Identify & remove dead code

Configuration
• Principally C++ Code base
• Multi-platform – MSVC & Linux (RedHat)
• Lcov & gcov running once a day run on Linux
• results presented on web.

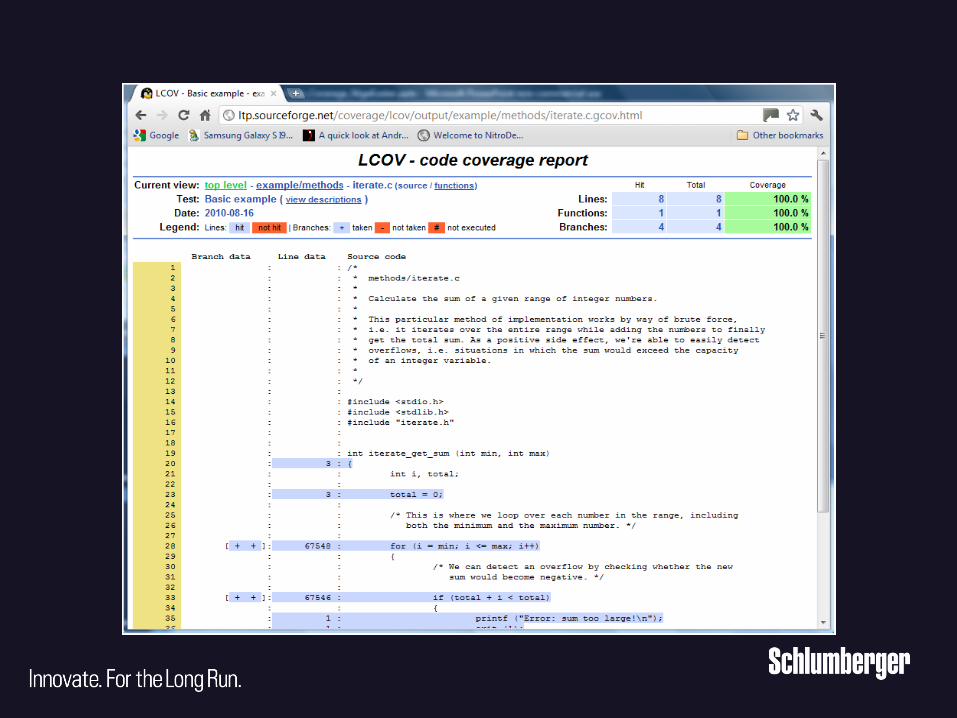

Started – How?
• Not all code is covered, just the higher level layers in system.
• Conducted a review to determine baseline and to establish
code coverage target
• System level tests only covered
• Results: ~65%

Our code coverage?

Code Coverage Target
• Set Target: 75% - line coverage
• Strategy: Maximum increase for minimum effort
• High level code only
• Tracking
• Formally reviewed at end of iterations
• Function coverage tracked
• Impact on downstream app tracked
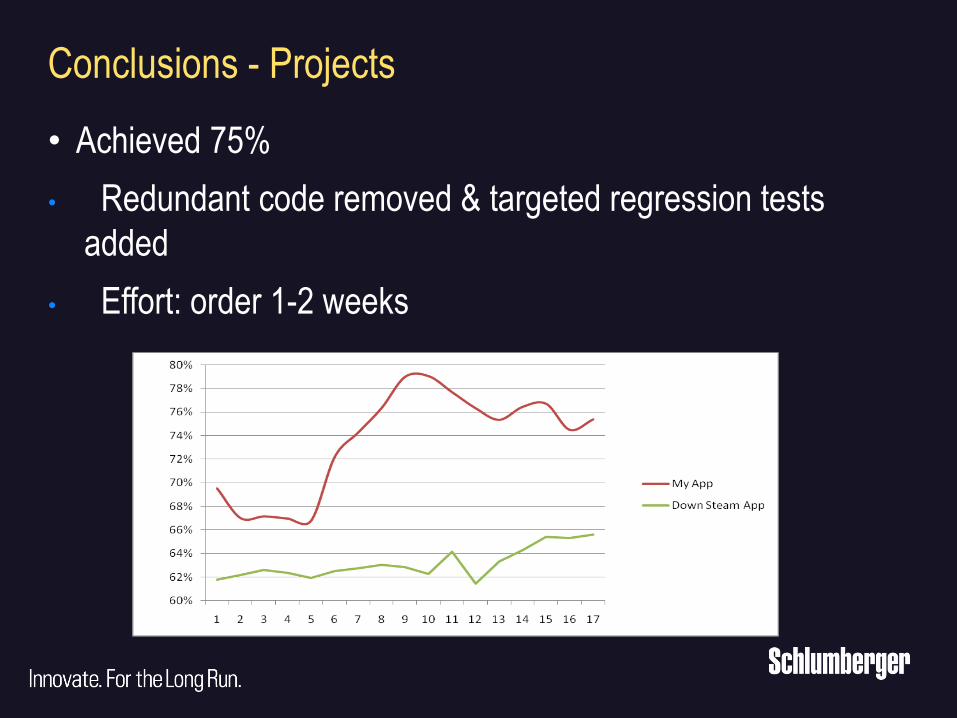
Conclusions - Projects
• Achieved 75%
• Redundant code removed & targeted regression tests
added
• Effort: order 1-2 weeks

Conclusions - Projects
Other projects using code coverage?
• Not tracked, 40% to 91%
• 91% achieved by TDD project.

Conclusions – Error Logic
• Generally it was thought that 20%-40% of code is error
handling.
• Increasing code coverage via system test for error handling
tests not practical:
• Complicated to setup
• Many tests needed
• Slow (many seconds per test)
• Error handling code needs to covered by unit tests.

Conclusions – Tooling & Team Issues
• lcov results seemed to be trustable
• Trend data needed – done by hand
• Created an Excel based gcov screen scraper.
• Helps determining whether a dev is “done done”
• Used in conjunction with functional coverage tracking system
• Coverage tracked on one platform seems ok
• Once a day build coverage build ok?
• Team haven’t adopted code coverage – tooling wrong?

Conclusions – Tooling
Image: JOSHUA CRANMER: http://quetzalcoatal.blogspot.com/2010/03/visualizing-code-coverage.html
Would be great to have graphical high-level drillable view

Conclusions – Tooling – Built in

100% needed for a happy ending?

Lightning Talkers!
Hosts: Oxford Computer Consultants
QRs : http://mojiq.kazina.com/
Timer – courtesy of:
58ACCU Oxford Lightning Talks June
2011
Acknowledgements





























