Embed Size (px)
Citation preview

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
1!1!
Accelerating HPC I/O with DDN Infinite Memory Engine Jason Cope, PhD Principal Architect, IME Development July 25th, 2017

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
2!2! What is DDN’s Infinite Memory Engine (IME)? ▶ New Cache Layer using NVMe SSDs
inserted between compute cluster and Parallel File System (PFS)
• IME is configured as a CLUSTER with multiple SSD servers
• All compute nodes can access cache data on IME
▶ Accelerates "bad" IO on PFS ▶ Accelerates high IOPS, small or random IO
due to efficient SSD and IO management • PFS is pretty good at large sequential IO
▶ Can be configured as cache layer having huge IO bandwidth
• eg. over 1TB/sec BW on JCAHPC Oakforest-PACS
IME’s Active I/O Tier, is inserted right between Compute and the parallel file system
IME software intelligently virtualizes disparate NVMe SSDs into a single pool of shared memory that accelerates I/O, PFS & Applications

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
3!3! IME1.1 – IME240 Release
• IME240 NVMe Platform support with options for EDR, OPA or 40/100 GbE
Performance Density ~500GB/s in 1 rack Adaptive IO routes IO around heavily loaded IO servers Rebuild Speeds devices rebuild in minutes Flexible Erasure Coding N+M levels on a per file basis Flash-Native minimise write amplification. maximise SSD lifetime

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
4!4! IME1.1 | Blistering Performance
▶ IME240 Sequential performance for Single Shared File over 22GB/s per server (POSIX IO)
▶ 15GB/s with 4K IOs (MPIIO) ▶ consistent read and write
performance across IO sizes ▶ POSIX IO performance hits
max values at ~32K IO sizes

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
5!5! IME Motivation – Applying Flash-Cache Economics
▶ General downward trend in NAND Flash capacity ($/GB) favorable to building NAND Flash centric storage systems
▶ Applying Flash-Cache Economics to acceleration application I/O (Edge Caches, Burst Buffers) • High-bandwidth, High-IOPs Flash-Cache tier • High-capacity global storage tier (Lustre, …)
▶ Strong demand for new storage system architectures and approaches that harness existing and emerging non-volatile memory technologies
NAND Flash pricing 2010- 2015
Figure adapted from P. Carns, K. Harms et al., Understanding and Improving Computational Science Storage Access through Continuous Characterization
Parallel File System
Scale-Out Flash Cache
Flash-Cache Use Case

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
6!6! IME Motivation – Transparently Addressing I/O Challenges
Application Developer approach IO Characterization IO Challenge
Multi-physics Non-trivial mix of IO behaviors Filesystem must be optimized for all IO types, not just a small subset
Workflows and Ensembles Coordination of files/objects across many jobs. Different IO access patterns from different elements of the workflow
Requires a global namespace with strong consistency
Adaptive mesh refinement Very difficult to manage and maintain logical application “block” sizes with underlying filesystem
Non-optimal access to files, incurs RMW, fs lock contention
Metadata-orientation Small, random IOs, Shared file formats Limited by filesystem locking
Machine learning High read activity Tough for HDD: disk thrashing
Higher Concurrency and heterogeneous CPUs
Large thread counts make sequential IO look like random IO Avoids all assistance from Filesystem and Storage caches
ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
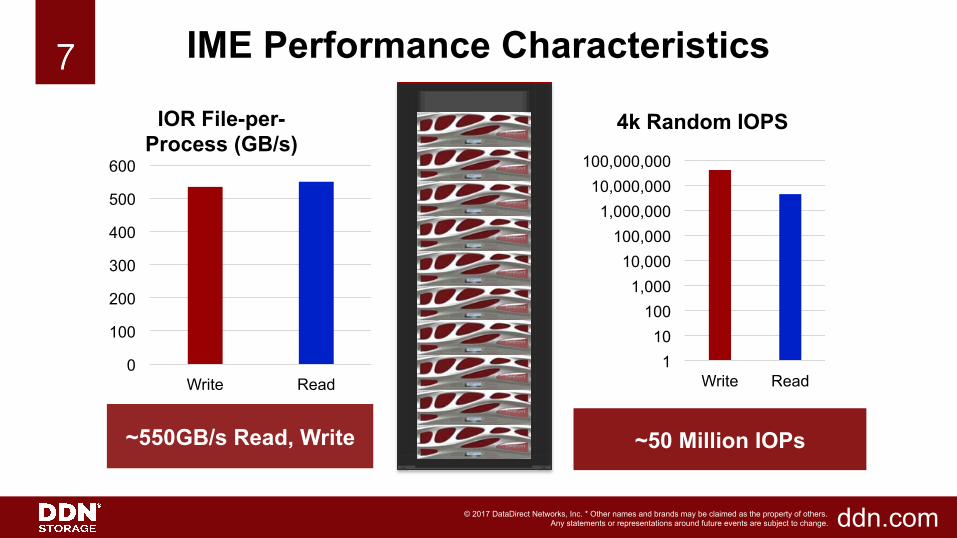
7!7! IME Performance Characteristics
~550GB/s Read, Write ~50 Million IOPs
0
100
200
300
400
500
600
Write Read
IOR File-per-Process (GB/s)
1 10
100 1,000
10,000 100,000
1,000,000 10,000,000
100,000,000
Write Read
4k Random IOPS

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
8!8! OakForest PACS | JCAHPC Universities of Tokyo and Tsukuba
▶ #7 in Top500, Japan's Fastest Supercomputer
▶ 8,208 Intel Xeon Phi processors with Knights Landing architecture
▶ Peak Performance: 25 PF ▶ 25 IME14K
• 940TB NVME SSD (with Erasure Coding) • measured 1.2 TB/s FPP and SFF
0.0
200.0
400.0
600.0
800.0
1000.0
1200.0
1400.0
JOB-J1(POSIX Write, FPP)
JOB-J2(POSIX Read, FPP)
JOB-J3(POSIX Write, SSF)
JOB-J4(MPIIO Write, FPP)
JOB-J5(MPIIO Write, SSF)
Thro
uhpu
t (G
B/s
ec)
IOR Performance at OakForest PACS
ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
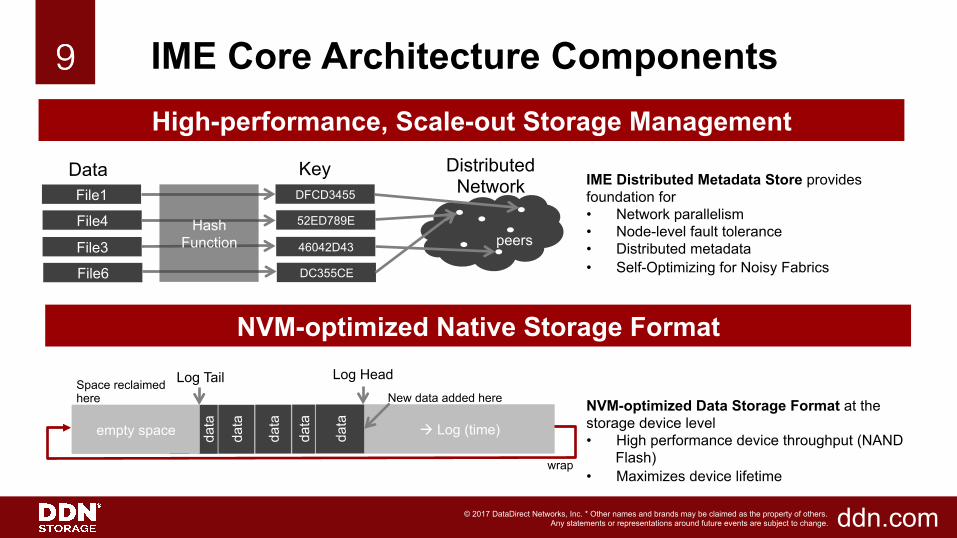
9!9!
File1 DFCD3455
File4 52ED789E
File3 46042D43
File6 DC355CE
Data Key Distributed Network
Hash Function peers
data
da
ta
data
data
da
ta
data
empty space à Log (time)
Log Tail Log Head New data added here
Space reclaimed here
wrap
IME Distributed Metadata Store provides foundation for • Network parallelism • Node-level fault tolerance • Distributed metadata • Self-Optimizing for Noisy Fabrics NVM-optimized Data Storage Format at the storage device level • High performance device throughput (NAND
Flash) • Maximizes device lifetime
High-performance, Scale-out Storage Management
NVM-optimized Native Storage Format
IME Core Architecture Components

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
10!10! DDN | IME I/O dataflow
Fast Data NVM & SSD
Persistent Data (Disk)
SFA7700TM
Diverse, high concurrency applications
Compute
Application issues IO to IME client.
Erasure Coding applied
IME client sends fragments to IME
servers
IME servers write buffers to NVM and manage
internal metadata
IME servers write aligned sequential I/O to SFA backend
Parallel File system operates at
maximum efficiency

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
11!11!
IME01 IME02 IME03 IME04 IME05
DDN | IME Data Flow to Servers
IME
BACKING FILE SYSTEM
COMPUTE
Clients send IO (network Buffers containing fragments and fragment
descriptors) to IME server layer
2 IME servers write to NVM devices and register writes with peers
3 Prior to synchronizing dirty data to the BFS, IO fragments which belong to the same BFS stripe are coalesced
4 IO sent to the BFS is optimized as aligned, sequential IO
1

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
12!12! DDN | IME DataFlow in the Client: Flexible Erasure Coding
APPLICATION
IME
LUSTRE
data buffers parity
file
open
, file
clo
se, s
tat
data and parity buffers sent to IME servers
3
COMPUTE NODE
POSIX or MPIIO I/O is issued by the application
IME places data fragments into buffers
and builds corresponding parity
buffers
metadata requests passed through to the PFS client
1
2
Erasure coding options:
1+1 1+2 1+32+1 2+2 2+32+3 3+2 3+3... ... ...15+1 15+2 15+3
ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
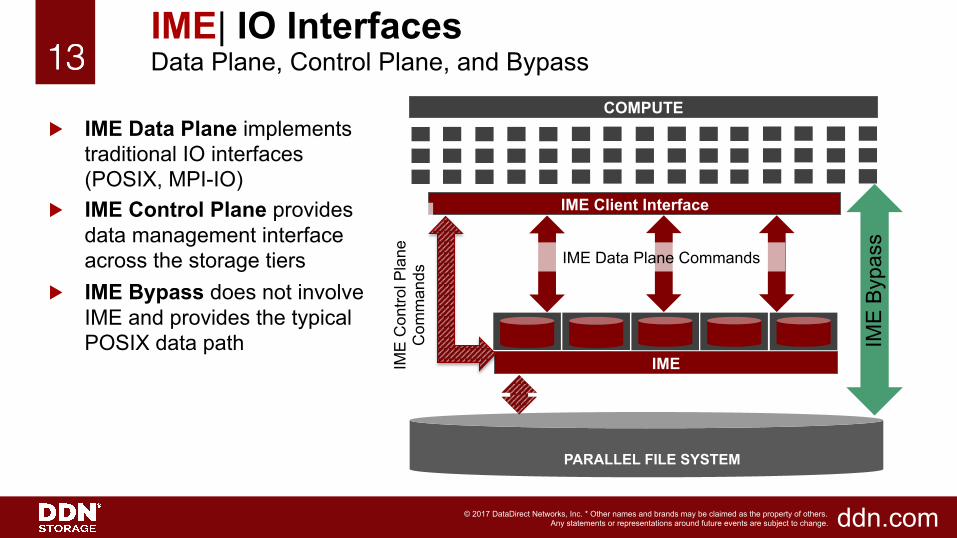
13!13!
PARALLEL FILE SYSTEM
COMPUTE
IME
Byp
ass
IME
IME Client Interface
IME Data Plane Commands
IME
Con
trol P
lane
C
omm
ands
IME| IO Interfaces Data Plane, Control Plane, and Bypass
▶ IME Data Plane implements traditional IO interfaces (POSIX, MPI-IO)
▶ IME Control Plane provides data management interface across the storage tiers
▶ IME Bypass does not involve IME and provides the typical POSIX data path

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
14!14! IME| Data Plane IO Interfaces POSIX, MPIIO, and IME Native APIs
PARALLEL FILE SYSTEM
COMPUTE ▶ Recommended IO interface is
POSIX ▶ Using the POSIX IO interface
requires NO application modifications
▶ For codes that use MPI-IO, the application should be recompiled / relinked against IME-capable MPI libraries (that use the IME ROMIO driver):
• MVAPICH (IME 1.0) • OpenMPI (IME 1.1)
PO
SIX
IO
POSIX IME ROMIO IME API
no application
modifications
IME
recompile or relink
recompile or relink

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
15!15!▶ While control plane are invoked
on IME, commands may start interacting with other storage tiers (e.g. the parallel file system)
▶ When using the POSIX IO interface • ime-ctl command line tool • ioctls()
▶ Additional command line tools available when not using the IME POSIX IO interface
▶ IME Native API available for development of custom data management and monitoring tools
PARALLEL FILE SYSTEM
COMPUTE
IME
Byp
ass
IME
POSIX (ioctls)
ime-XXXX CLI IME API
IME Control Plane Commands
IME| Control Plane IO Interfaces POSIX, ime-XXXX CLI, and IME Native APIs

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
16!16!Data Migration Policy Ingest from Backend File Systems (e.g. Lustre)
▶ Fully parallel • All IME servers participate in ingress
procedures
▶ Explicit only in IME 1.0 • Shell command interface • Issued by administrator or scheduler
▶ Reads of non-cached data are transparently ‘passed through’ to PFS
IME
BFS
ingest of files to IME from PFS

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
17!17!Data Migration Policy Egress from IME to Backend File System (e.g. Lustre)
▶ Data written onto IME will be cached ▶ Syncing cached data on IME to PFS
• 2 ways to sync ① IME syncing data to PFS automatically
• Determine timing of sync by free space threshold of IME
② Explicitly syncing data to PFS by command ▶ Cannot access the data on PFS until syncing
the data on IME to PFS • File exists on PFS, but data only exists on IME
IME
BFS
egress of files to PFS to IME

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
18!18!DDN | IME Data Residency Control
▶ Maximum percentage of dirty data resident in IME before the data is automatically synchronized to the PFS:
flush_threshold_ratio [0% .. 100%]
▶ Once Synchronised, the data is marked clean ▶ The clean data is kept in IME until the
min_free_space_ratio is reached. min_free_space_ratio [0% .. 100%]
COMPUTE
CLEAN
DIRTY
IME
PFS
purge clean data until min_free_space_ratio
sync dirty data until flush_threshold_ratio

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
19!19!▶ Data staging in PBSPro implemented via
PBSPro “hooks” • User specifies Stage-In and Stage-Out files
#PBS -W stagein=<stagein file list> #PBS -W stageout=<stageout file list>
▶ PBS Pro Scheduler executes Stage-In for job data ime-ctl -i $INPUT_FILE and then sets the job as “ready to run”
▶ Job Executes: All reads/writes to IME ▶ Temporary data that is not required can be
purged from IME ime-ctl -p $TMP_FILE
▶ Completion of the User Job initiates sync of output data to PFS ime-ctl -r $OUTPUT_FILE
IME
PFS
COMPUTE
1
Scheduler executes file Stage-In and sets Job status to "ready-to-run"
3 User Job is scheduled and executes
2
4 purge unwanted data
5 sync output file to PFS
IME| Control Plane IO Interfaces Example Usage in the Altair PBSPro

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
20!20! Shared File IO Optimization Process 0
File
Process 1 Process 2
Filesystem lock management when IO's cross page boundaries
▶ Parallel File systems can exhibit extremely poor performance for shared file IO due to internal lock management as a result of managing files in large lock units
▶ IME eliminates contention by managing IO fragments directly, and coalescing IO's prior to flushing to the parallel file system

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
21!21! Fabric-Aware Self-Optimizing IO
▶ IME clients “learn” and observe the load of IME servers and route write requests to avoid highly-loaded servers
IME
COMPUTE
Pending Request Queue Lengths
IO redirected in real-time to avoid bottlenecks

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
22!22! Extreme Rebuild Speeds
▶ Distributed Rebuild over all SSDs in Parity Group
▶ Each SSD performing rebuild at ~250MB/s
▶ 256GB SSD rebuilt in under 1 minute
0% 10% 20% 30% 40% 50% 60% 70% 80% 90%
100%
0 10 20 30 40 50 60
Perc
enta
ge R
ebui
lt
Time in Seconds
Rebuild Rate for a 256GB SSD (86% full)
SSD offlined
data fully rebuilt

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
23!23!
PFS
Flash-Native Maximize Flash performance and Lifetime
valid sectors with user data
Random writes incoming with LBA offsets corresponding to existing data
Log Structured Filesystem: SSDs sees writes to new block ranges
free, unused blocks
If IME reaches threshold then data is flushed or purged in large chunks
• Standard Storage Systems cannot manage Flash without incurring costly garbage collection, reducing performance and SSD Lifetime
• IME's Flash-Native approach maximises Flash lifetime by issuing IO in 128K chunks and unmapping in large chunks
IME PFS new writes invalidate
corresponding sectors
blocks with large invalid sector count undergo
garbage collection
ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
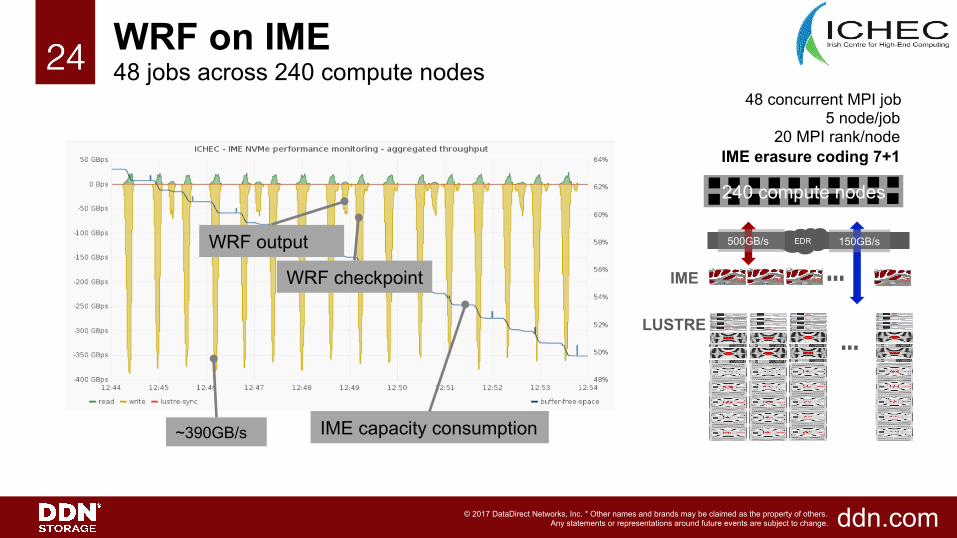
24!24!
EDR 500GB/s 150GB/s
IME
LUSTRE
IME capacity consumption
WRF output
WRF checkpoint
~390GB/s
WRF on IME 48 jobs across 240 compute nodes
48 concurrent MPI job 5 node/job
20 MPI rank/node IME erasure coding 7+1 240 compute nodes

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
25!25! WRF at Scale Summary Results
IME Parallel File system
# Throughput per
Metric (GB/s/<x>)
# Throughput per
Metric (GB/s/<x>)
IME Improvement
Application Throughput (GB/s) 380 100 x 3.8
Rack Units 36 10.5 224 0.45 x 23
# IO Nodes 18 21 42 2.4 x 8.7
# Drives 432 0.9 2800 0.04 x 22
Power Consumption (KW) 27 14 70 1.4 x 10
ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
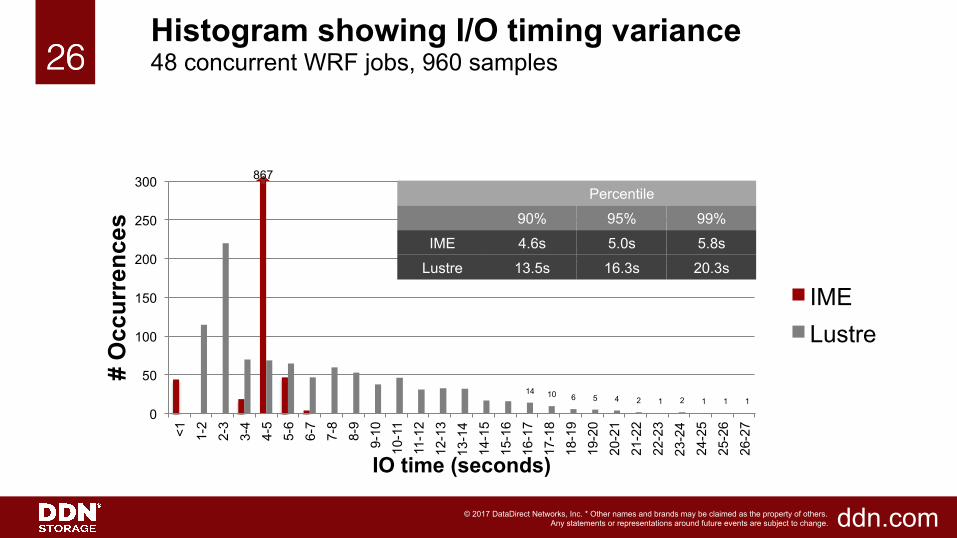
26!26!Histogram showing I/O timing variance 48 concurrent WRF jobs, 960 samples
14 10 6 5 4 2 1 2 1 1 1
0
50
100
150
200
250
300 <1
1-
2 2-
3 3-
4 4-
5 5-
6 6-
7 7-
8 8-
9 9-
10
10-1
1 11
-12
12-1
3 13
-14
14-1
5 15
-16
16-1
7 17
-18
18-1
9 19
-20
20-2
1 21
-22
22-2
3 23
-24
24-2
5 25
-26
26-2
7
# O
ccur
renc
es
IO time (seconds)
IME Lustre
867 Percentile
90% 95% 99%
IME 4.6s 5.0s 5.8s
Lustre 13.5s 16.3s 20.3s

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
27!27!IME | WRF with I/O quilting one I/O process per node
Measurement Speed Up
IO Wallclock 17.2x Total Execution Wallclock 3.5x
▶ Application wall time reduced by 3.5 using IME
▶ I/O time reduces by x17.2 ▶ Move from I/O bound to
compute bound

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
28!28! NEural Simulation Tool (NEST)
Slide 21Evaluation of IME · 23.06.2016 · WOPSSS 2016
Wolfram Schenck, Salem El Sayed, Maciej Foszczynski, Wilhelm Homberg, Dirk Pleiter
Brain Simulation (1)
Dendriten
Soma
Axon
Neuron
� Simulation software:
NEST (NEural Simulation Tool)
� Open source: www.nest-simulator.org / www.nest-initiative.org
� Purpose: Large-scale simulations of biologically realistic
neuronal networks (focus on large networks, use of simple point
neurons)
Spike
Slide 32Evaluation of IME · 23.06.2016 · WOPSSS 2016Wolfram Schenck, Salem El Sayed, Maciej Foszczynski, Wilhelm Homberg, Dirk Pleiter
Simulation Cycle(revisited)
Process-internal routing of spike events to their target neurons (incl. synapse update)
Updating of neuronal states (incl. spike generation)
Exchange of spike events between MPI processes
Communication interval
Update ofrecordingdevicesÎ I/O
BURST
Slide 44Evaluation of IME · 23.06.2016 · WOPSSS 2016Wolfram Schenck, Salem El Sayed, Maciej Foszczynski, Wilhelm Homberg, Dirk Pleiter
NEST: Data Retention Times
� Data retention time analysis: Classification of data depending on how long it will be retained
• NEST simulates large-scale neuronal networks
• Collaborative project with FZ Jülich • Please refer to
http://www.ddn.com/download/presentations/wolfram_schenck_ISC16_wopsss.pdf
NEST Simulation Cycle
NEST Workflow

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
29!29! NEST analysis
l Synchronization stage very costly
→ MPI ranks need to meet a barrier, thus sensitive to late arrival
→ GPFS scaling is killed by load imbalance

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
30!30! NEST analysis
Acceleration of data-intensive NEST workload by overlapping computation with I/O phases

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
31!31!Mini-apps for Brain Simulation: Neuromapp
• Collaboration with EPFL
• Captures the I/O behavior of large Neroun simulation
• Neuromapp is a set of mini-app which can be assembled together – Form the skeleton of the initial scientific application – Experiment work-flow optimization opportunities – 1 KLOC per mini-app (refer to github.com/BlueBrain/neuromapp)

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
32!32! Neuromapp experimental results
IME bandwidth scales with additional nodes Lustre bandwidth remains unchanged

ddn.com © 2017 DataDirect Networks, Inc. * Other names and brands may be claimed as the property of others. Any statements or representations around future events are subject to change.
33!33!
9351 Deering Avenue, Chatsworth, CA 91311
1.800.837.2298 1.818.700.4000
company/datadirect-networks
@ddn_limitless
Thank You! Keep in touch with us




![HPC Clusters as code in the [almost]* Infinite cloud · HPC Clusters as code in the [almost]* Infinite cloud ... Front-end Functions Identity ... 39 years of computational chemistry](https://img.dokumen.tips/doc/110x75/5acc6dc87f8b9ab10a8c7a7f/hpc-clusters-as-code-in-the-almost-infinite-cloud-clusters-as-code-in-the-almost.jpg)
























