Embed Size (px)
Citation preview

A Unified Approach for Computing Top-k Pairs in Multidimensional Space
Presented By: Muhammad Aamir Cheema1
Joint work withXuemin Lin1, Haixun Wang2, Jianmin Wang3, Wenjie Zhang1
1 University of New South Wales, Australia2 Microsoft Research Asia3 Tsinghua University, China

Introduction
Top-k Pairs Query: Given a scoring function f() that computes the score of
a pair of objects, return k pairs of objects with smallest scores.
o2
o1
o3
o4
o5
x-axis
y-ax
is
Examples:
k-closest pairs
f(ou,ov) = dist(ou,ov)
Answer (k=1) = (o1,o2)
k-furthest pairs
f(ou,ov) = - dist(ou,ov)
Answer (k=1) = (o2,o4)
f(ou,ov) = (ou.x +ov.x) + (ou.y +ov.y)
Answer (k=1) = (o4,o5)

Related Work
• Computational geometry [M Smid, Handbook on Comp. Geometry]• Database community
[Hjaltason et. al, SIGMOD 1998][Corral et. al, SIGMOD 2000][Yang et. al, IDEAS 2002] [Shan et. al, SSTD 2003]
K-Closest Pairs Queries
[Supowit , SODA 1990][Katoh et. al, IJCGA 1995] [Corral et. al, DKE 2004]
K-Furthest Pairs Queries
Top-k Queries• Fagin’s Algorithm [Fagin, PODS 1996]•Threshold Algorithm [Fagin, JCSS 1999], [Nepal et. al, ICDE 1999] , [Gȕntzer et. al, VLDB 2000] • No Random Access Algoritm [Fagin, JCSS 1999], [Mamoulis et. al, TODS 2007]

Motivation
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id ORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;
• Other Lp distances (e.g., Manhattan distance) ?• More general scoring functions• Chromatic queries
• No existing work for more general queries
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id AND a.manager <> b.managerORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;
• No existing unified algorithm • One framework that answers a broad class of top-k pairs queries

Problem Definition (Preliminaries)
• Monotonic function
f() is monotonic if f(x1,…,xN) ≤ f(y1,…,yN) whenever xi ≤ yi for every 1 ≤ I ≤ N
Examples:f(x1,…,xN) = x1 + x2 + … + xN (summation) f(x1,…,xN) = (x1 + x2 + … + xN) / N (average)

Problem Definition (Preliminaries)
• Loose monotonic function
0 ∞-∞
s() takes two parameters and is loose monotonic if both of following hold for every fixed value x1. for every y > x, s(x,y) either monotonically increases or monotonically
decreases as y increases2. for every y < x, s(x,y) either monotonically increases or montonically
decreases as y decreases
x
1
y
2 5
s1(x,y) = |x – y| 1 4 = s2(x,y) = (x + y) 3 6 =
y
-3
1 -2
Loose monotonic functions are more general than the monotonic functions

Problem Definition
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id ORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;
• Return k pairs of objects with smallest scores. SCORE (a,b) = f ( s1(a,b),…,sd(a,b) )si( ) is called local scoring function and can be any loose monotonic function of user’s choice. f( ) is called global scoring function and can be any monotonic function that involves an arbitrary set of attributes.
s1(a,b) = | a.sold – b.sold | s2(a,b) = -| a.salary – b.salary |f( ) = s1(a,b) + s2(a,b)

Problem Definition
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id ORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;
• Return k pairs of objects with smallest scores among the valid pairs.
Let each object be assigned a color.Chromatic Queries: Homochromatic Queries: pairs containing objects of same color Heterochromatic Queries: pairs containing objects of different colors
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id AND a.manager ≠ b.managerORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id AND a.manager = b.managerORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;

Contributions
• k-closest pairs, k-furthest pairs and variants (any Lp distance)• queries involving any arbitrary subset of attributes• chromatic and non-chromatic queries• skyline pairs queries and rank based top-k pairs queries
Unified algorithm (internal and external)
• efficiently builds a simple data structure on-the-fly• can answer queries involving filtering conditions on objects
No pre-built indexes required
SELECT a.id , b.id FROM AGENT a, AGENT bWHERE a.id < b.id AND a.age > 40 AND b.age > 40ORDER BY |a.sold – b.sold| - |a.salary – b.salary|LIMIT k;
• existing R-tree based approaches may require arbitrarily large heaps
• our algorithm requires O(k) space + 2d buffer pages
Known memory requirement
• Theoretically Optimal for d ≤ 2 • Experimentally
Efficient

Framework
(o1,o2) 3
(o2,o5) 4
(o1,o3) 9
… …
(o2,o3) 5
(o1,o5) 6
(o1,o2) 6
… …
(o1,o2) 1
(o3,o4) 2
(o1,o4) 5
… …
s1(a,b) s2(a,b) sd(a,b)
…
Top-K algorithms (e.g., FA, TA, NRA etc.)
How to efficiently create and maintain these sources???
f ( s1(a,b), s2(a,b), …,sd(a,b) )

Creating/maintaining sources
Naïve approach
• Create all possible pairs O(N2)• Sort them according to their local scores O(N2 log N)
space requirement: O(N2)
Features of our approach
• Optimal internal memory algorithm• requires O(N) space• returns first pair in O(N log N)• each next best pair is returned in O( log N)
• Optimal external memory algorithm• B = number of elements that can be stored in one disk page• M = used internal memory minimum M = 2B• returns first pair in O(N/B logM/B N/B) • each next best pair is returned in O(logM/B N/B)

Creating/maintaining sources
6 12 14 15 20 302 1 5 106
o1 o2 o3 o4 o5 o6
(o3,o4) 1
(o2,o3) 2
(o4,o5) 5
(o1,o2) 6
(o5,o6) 10
63
(o2,o3) 2
(o4,o5) 5
(o3,o5) 6
(o1,o2) 6
(o5,o6) 10
(o2,o4) 3
(o4,o5) 5
(o3,o5) 6
(o1,o2) 6
(o5,o6) 10
Initialize• sort the objects• for each object ou
• create its best pair (ou,ov)• insert (ou,ov) in heap
getNextPair()• report the top pair (ou,ov) of heap• create next best pair of ou
• enheap the new pair and delete (ou,ov)s(x,y) = |x – y|

Homochromatic Queries
6 12 14 15 20 30
o1o2 o3 o4
o6o5
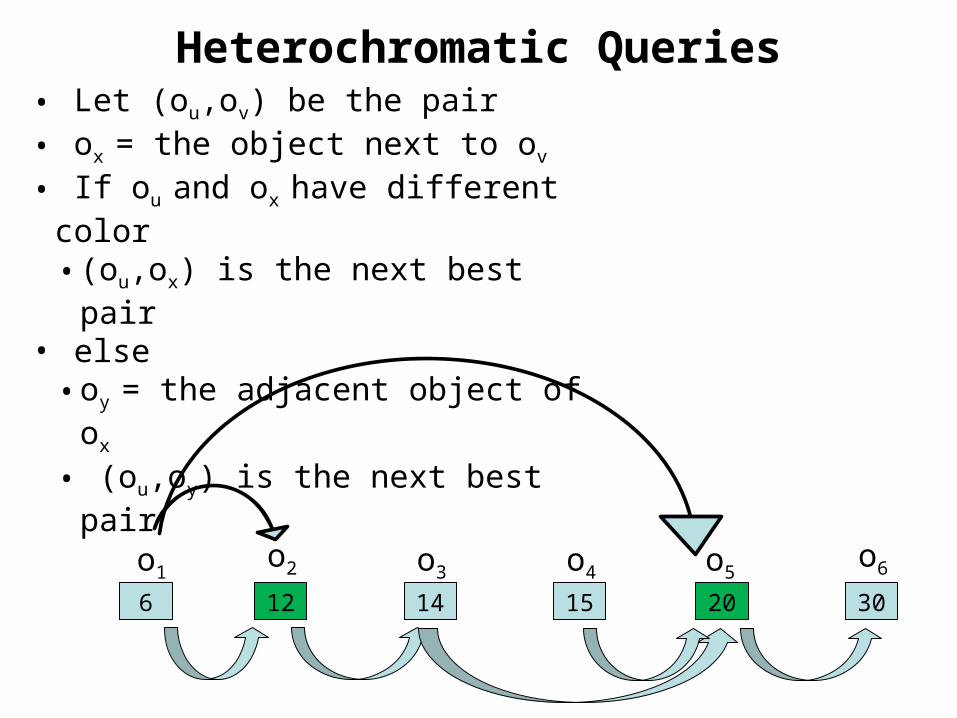
Heterochromatic Queries
6 12 14 15 20 30
o1o2 o3 o4
o6o5
• Let (ou,ov) be the pair• ox = the object next to ov
• If ou and ox have different color• (ou,ox) is the next best pair
• else• oy = the adjacent object of ox • (ou,oy) is the next best pair
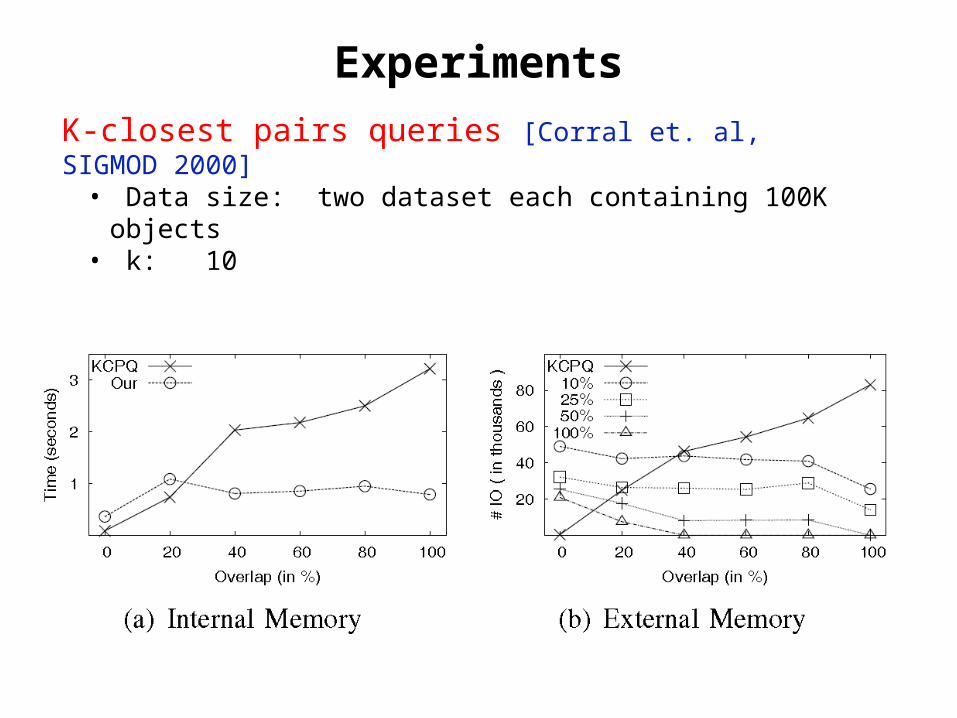
Experiments
K-closest pairs queries [Corral et. al, SIGMOD 2000]• Data size: two dataset each containing 100K objects• k: 10

Experiments
• Naive: join the dataset with itself using nested loop (block nested loop for external memory algorithm)
• Scoring function:• Local scoring function is either sum or absolute difference (chosen
randomly)• Global scoring function is weighted aggregate (weights are chosen
randomly and negative weights are allowed)

Number of Objects

Number of attributes (d)

Value of k

Number of colors

Thanks

Complexity
Internal memory algorithm =
External memory algorithm =
d = number of local scoring functions involvedN = total number of objectsV = total number of valid pairs (N2 at most)M = internal memory used by the algorithmB = the number of entries one disk page can store



![A Practical Framework for Constructing Structured Drawings Salman Cheema Sarah BuchananSumit Gulwani Joseph J. LaViola Jr. References [ 1] Cheema, S.,](https://img.dokumen.tips/doc/110x75/56649f455503460f94c66dac/a-practical-framework-for-constructing-structured-drawings-salman-cheema-sarah.jpg)

























