Embed Size (px)
DESCRIPTION
A Tutorial on Pronunciation Modeling for Large Vocabulary Speech Recognition. Dr. Eric Fosler-Lussier Presentation for CiS 788. Overview. Our task: moving from “read speech recognition” to recognizing spontaneous conversational speech - PowerPoint PPT Presentation
Citation preview

A Tutorial on Pronunciation Modeling
for Large Vocabulary Speech Recognition
Dr. Eric Fosler-Lussier
Presentation for CiS 788

Overview
• Our task: moving from “read speech recognition” to recognizing spontaneous conversational speech
• Two basic approaches for modeling pronunciationvariation – Encoding linguistic knowledge to pre-specify possible
alternative pronunciations of words– Deriving alternatives directly from a pronunciation corpus.
• Purposes of this tutorial – Explain basic linguistic concepts in phonetics and phonology– Outline several pronunciation modeling strategies – Summarize promising recent research directions.

Pronunciations & Pronunciation Modeling

Pronunciations & Pronunciation Modeling
• Why sub-word units? – Data sparseness at word level
– Intermediate level allows extensible vocabulary
• Why phone(me)s?– Available dictionaries/orthographies assume this unit
– Research suggests humans use this unit
– Phone inventory more manageable than syllables, etc. (in e.g., English)

Statistical Underpinnings for Pronunciation Modeling
• In the whole-word approach, we could find the most likely utterance (word-string) M* given the perceived signal:
M* =

Statistical Underpinnings for Pronunciation Modeling
• With independence assumptions, we can use the following approximation:
• Argmax P(M|X)

Statistical Underpinnings for Pronunciation Modeling
• PA(X|Q): the acoustic model– continuous sound (vector)s to discrete phone (state)s – Analogous to “categorical perception” in human hearing
• PQ(Q|M): the pronunciation model – Probability of phone states given words– Also includes context-dependence & duration models
• PL(M): the language model – The prior probability of word sequences

Statistical Underpinnings for Pronunciation Modeling
The three models working in sequence:

Linguistic Formalisms & Pronunciation Variation
• Phones & Phonemes
• (Articulatory) Features
• Phonological Rules
• Finite State Transducers

Linguistic Formalisms & Pronunciation Variation
• Phones & Phonemes– Phones: Types of (uttered) segments
• E.g., [p] unaspirated voiceless labial stop [spik]
• Vs. [ph] aspirated voiceless labial stop [phik]
– Phonemes: Mental abstractions of phones• /p/ in speak = /p/ in peak to naïve speakers
– ARPABET: between phones & phonemes– SAMPAbet: closer to phones, but not perfect…

SAMPA for American English
Selected Consonants (arpa)
• tS chin tSIn (ch)
• dZ gin dZIn (jh)
• T thin TIn (th)
• D this DIs (dh)
• Z measure "mEZ@` (zh)
• N thing TIN (ng)
• j yacht jAt (y)
• 4 butter bV4@` (dx)
Selected Vowels (arpa)
• { pat p{t (ae)
• A pot pAt (aa)
• V cut kVt (uh) !
• U put pUt (uh) !
• aI rise raIz (ay)
• 3` furs f3`z (er)
• @ allow @laU (ax)
• @` corner kOrn@` (axr)

Linguistic Formalisms & Pronunciation Variation
• (Articulatory) Features– Describe where (place) and how (manner) a
sound is made, and whether it is voiced.– Typical features (dimensions) for vowels
include height, backness, & roundness
• (Acoustic) Features– Vowel features actually correlate better with
formants than with actual tongue position

From Hume-O’Haire & Winters (2001)

Linguistic Formalisms & Pronunciation Variation
• Phonological Rules– Used to classify, explain, and predict phonetic
alternations in related words: write (t) vs. writer (dx)
– May also be useful for capturing differences in speech mode (e.g., dialect, register, rate)
– Example: flapping in American English

Linguistic Formalisms & Pronunciation Variation
• Finite State Transducers– (Same example transducer as on Tuesday)

Linguistic Formalisms & Pronunciation Variation
• Useful properties of FSTs– Invertible
(thus usable in both production & recognition)– Learnable (Oncina, Garcia, & Vidal 1993,
Gildea & Jurafsky 1996)– Composable– Compatible with HMMs

ASR Models: Predicting Variation in Pronunciations
• Knowledge-Based Approaches– Hand-Crafted Dictionaries– Letter to Sound Rules– Phonological Rules
• Data-Driven Approaches– Baseform Learning– Learning Pronunciation Rules

ASR Models: Predicting Variation in Pronunciations
• Hand-Crafted Dictionaries– E.g., CMUdict, Pronlex for American English– The most readily available starting point– Limitations:
• Generally only one or two pronunciations per word
• Does not reflect fast speech, multi-word context
• May not contain e.g., proper names, acronyms
• Time-consuming to build for new languages

ASR Models: Predicting Variation in Pronunciations
• Letter to Sound Rules– In English, used to supplement dictionaries– In e.g., Spanish, may be enough by themselves– Can be learned (e.g. by DTs, ANNs)– Hard-to-catch Exceptions:
• Compound-words, acronyms, etc.
• Loan words, foreign words
• Proper names (Brands, people, places)

ASR Models: Predicting Variation in Pronunciations
• Phonological Rules– Useful for modeling e.g., fast speech, likely
non-canonical pronunciations– Can provide basis for speaker-adaptation– Limitations:
• Requires labeled corpus to learn rule probabilities
• May over-generalize, creating spurious homophones
• (Pruning minimizes this)

Examples of Fast-Speech Rules

ASR Models: Predicting Variation in Pronunciations
• Automatic Baseform Learning1) Use ASR with “dummy” dictionary to find
“surface” phone sequences of an utterance
2) Find canonical pronunciation of utterance (e.g., by forced-Viterbi)
3) Align these two (w/ dynamic programming)
4) Record “surface pronunciations” of words

ASR Models: Predicting Variation in Pronunciations
• Limitations of Baseform Learning– Limited to single-word learning– Ignores multi-word phrases, cross word-
boundary effects (e.g., Did you “didja”)– Misses generalizations across words (e.g.,
learns flapping separately for each word)

ASR Models: Predicting Variation in Pronunciations
• Learning Pronunciation Rules– Each word has a canonical pronunciation c1 c2 …cj… cn.
– Each phone cj in a word can be pronounced by some sj.
– Set of surface pronunciations S: {Si = si1, …, si
n}
– Taking canonical tri-phone and last surface phone into account, the probability of a given Si can be estimated:

ASR Models: Predicting Variation in Pronunciations
• (Machine) Learning Pronunciation Rules– Typical ML techniques apply: CART, ANNs, etc.
– Using features (pre-specified or learned) helps
– Brill-type rules (e.g., Yang & Martens 2000):• A B // C __ D with P(B|A,C,D) positive rule
• A not B // C __ D with 1 - P(B|A,C,D) neg. rule
(Note: equivalent to Two-level rule types 1 & 4)

ASR Models: Predicting Variation in Pronunciations
• Pruning Learned Rules & Pronunciations – Vary # of allowed pronunciations by word-frequency
E.g., f (count(w)) = k log(count(w))
– Use probability threshold for candidate pronunciations
• Absolute cutoff
• “Relmax” (relative to maximum) cutoff
– Use acoustic confidence C(pj,wi) as measure

Online Transformation-Based Pronunciation Modeling
• In theory, a dynamic dictionary could halve error-rates– Using an “oracle dictionary” for each utterance
in switchboard reduces error by 43%– Using e.g., multi-word context, hidden
speaking-mode states may capture some of this.– Actual results less dramatic, of course!
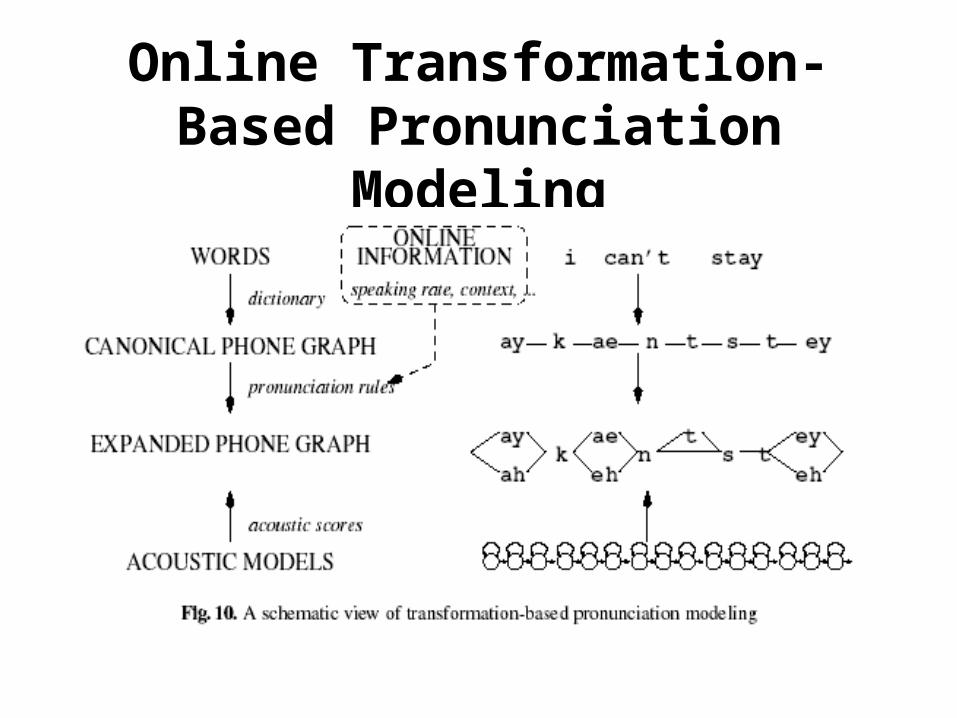
Online Transformation-Based Pronunciation Modeling

Five Problems Yet to Be Solved
• Confusability and Discriminability
• Hard Decisions
• Consistency
• Information Structure
• Moving Beyond Phones as Basic Units

Five Problems Yet to Be Solved
• Confusability and Discriminability– New pronunciations can create homophones not
only with other words, but with parts of words.– Few exact metrics exist to measure confusion

Five Problems Yet to Be Solved
• Hard Decisions– Forced-Viterbi throws away good, but “second-
best” representations.– N-best would avoid this (Mokbel and Jouvet),
but problematic for large-vocabulary – DTs also introduce hard decisions and data-
splitting

Five Problems Yet to Be Solved
• Consistency– Current ASR works word-by-word w/o picking
up on long-term patterns (e.g., stretches of fast speech, consistent patterns like dialect, speaker)
– Hidden speech-mode variable helps, but data is perhaps too sparse for dialect-dependent states.

Five Problems Yet to Be Solved
• Information Structure– Language is about the message!– Hence, not all words are pronounced equal– Confounding variables:
• Prosody & intonation (emphasis, de-accenting)
• Position of word in utterance (beginning or end)
• Given vs. new information; Topic/focus, etc.
• First-time use vs. repetitions of a word

Five Problems Yet to Be Solved
• Moving Beyond Phones as Basic Units– Other types of units
• “Fenones”
• Hybrid phones [x+y] for //x///y/ rules
– Detecting (changes in) distinctive features• E.g., [ax] {[+voicing,+nasality], [+voicing,
+nasality,+back], [+voicing,+back], …}
• (cf. Autosegmental & Non-linear phonology?)

Conclusions
• An ideal model would:– Be dynamic and adaptive in dictionary use– Integrate knowledge of previously heard
pronunciation patterns from that speaker– Incorporate higher-level factors (e.g., speaking
rate, semantics of the message) to predict changes from the canonical pronunciation
– (Perhaps) operate on a sub-phonetic level, too.





























