Embed Size (px)
Citation preview

A Small IP Forwarding Table Using Hashing
Yeim-Kuan Chang and Wen-Hsin ChengDept. of Computer Science and Information Engineering
National Cheng Kung UniversityTainan, Taiwan R.O.C.

Outline Introduction Existing Schemes Designed for
Compaction Techniques used Performance Evaluation
Proposed Data Structure using Hashing Optimizations Performance
Conclusions

Introduction Increasing demand for high bandwidth on
Internet next generation routers: forward multiple
millions of packets per second Required fast routing table lookup

Introduction Routing table lookup problem
The most important operation in the critical path Find the longest prefix that matches the input IP
(from more than one matches)
Solutions: Reduces number of memory references Reduce memory required the forwarding table
fit in the application specific integrated circuit (ASIC) fit in the L1/L2 caches

Introduction: Binary TrieNG E H O A DMI CK BFL J
00010*
0001*
001100*
01001100
0100110*
01011001
01011*
01*
10*
10110001
1011001*
10110011
1011010*
1011*
110*
Routing table
F is the Longest prefix match for IP = 0101-1000
GE
HK
O N
AB
FI
M
J
DC
L

Existing Schemes Designed for Compaction
Small Forwarding Table (Degermark et.al.) Classified as 12-4-8-8
The compressed 16-x scheme (Huang et.al.) Classified as 16-x, x = 0 to 16
The Level Compressed Trie (Nilsson et.al.) Variable stride
Technique summary Run length encoding Local index of pre-allocation array

Memory Sizes
# of segments (avg # of prefixes per segment)Sparse: 2,765 (2.9)Dense: 4,300 (25.5)
Very dense: 586 (91.7)Maptable: 5.3KBase rray: 2K
Code Word array: 8K
# of nodes: 259,371 (4 bytes each)Base vector: 110,679 (16 bytes each)Prefix vector: 9,927 (12 bytes each)Next Hop vector: 255 (4 bytes each)
Base array: 427 KBCompressed Bit-map: 427 KB
CNHA: 37.9 KB
# of nodes: 320,478 (7 bytes each)# of nodes: 222,334 (8 bytes each)
# of prefixes: 112,286 (4 bytes each)# of blocks: 71,034 (64 bytes each)
5792 nodes of 256 entries (4 bytes each)# of prefixes: 120,635 (45 bits each)
Statistics
649.9 KB
2,859 KB
1,147 KB
2,446.8 KB1,993 KB1,104 KB4,695 KB
5,792 KB662.7 KB
Memory size
# of level-1 pointers:13,317
# of level-2 pointers:461
(4 bytes each)
Branch factor: 16Fill factor: 0.5
16-bit segmentation table:
65535 entries(4 byte each)
8-bit segmentation table
N/A
Segmentation
SFT
LC trie
Compressed16-x
Binary trieBSD trie
Binary rangeMultiway range
Original 8888Original table
Scheme
Routing table: 120,635 prefixes.

Lookup latency
1/12
1/5
1/3
8/32
8/26
1/18
1/6
# of memory access
(min/max)
SFT
LC trie
Compressed 16-x
Binary trie
BSD trie
Binary range
Multiway range
Scheme
378
455
230
432
490
264
226
10th percentile(cycles)
657
777
434
1065
1006
680
541
50th percentile(cycles)
892
1070
830
1548
1452
1022
861
90th percentile(cycles)
503
757
409
1140
1077
648
568
Average lookup
time(cycles)
0.207
0.312
0.169
0.470
0.444
0.267
0.234
Average lookup
time(s)

Other results for compressed 16-x
Memory sizes of compressed 16-x is not proportional to the number of prefixes in the routing table Number of prefixes with length longer than 24
Therefore, difficult to predict the required amount of memory for compressed 16-x
Therefore, we will only compare our proposed scheme with SFT in this paper
Oix-80k Oix-120k Oix-150k
89,088 120,635 151,511
1,838 Kbytes 1,147 KB 3,182 Kbytes

Proposed Data Structure The binary trie is the simplest data structure Reason for high memory usage in binary trie
space for the left and right pointers. 8 bytes for left and right pointers 1 byte for next port number, a total of 9 bytes
Example routing table: 120,635 entries ~370K trie nodes in a binary trie.
370K x 9 bytes = 3,330K = 3.3 Mbytes

Pre-allocated array of trie nodes If all the trie nodes are organized in an array, we
can use node indices of the array as pointers. the trie nodes are physically stored in a sequential
array but are logically structured in the binary trie. Assuming no more than one million trie nodes,
20 bits are sufficient for a pointer. 40 bits are required for two pointers plus 8 bits for the next
port number. A total of 6 bytes is required for a trie node.
370K nodes needs around 2.2 Mbytes. Note: LC trie implementation used this idea.

Proposed Data Structure (clustering) Simple technique to reduce memory size:
Clustering Nodes in a cluster are layout in an array Node size can be reduced by using only one
global pointer and other pointers are local indices to the array corresponding to the cluster.

Proposed Data Structure (clustering) a cluster consists of only one trie node: Node size can be reduced by using only one global
pointer. If both left and right children exist, two additional bits are
sufficient to indicate whether left and right children exist. The node size is thus reduced from 48 (20*2+8) bits to
30 (20+2+8) bits. (Notice that the number of trie nodes remains the same.)
Thus, for the binary trie of 370K trie nodes, the total memory requirement is now 1.4 Mbytes.

Proposed Data Structure (clustering) Generalization:
The nodes in a subtree of k levels are grouped into a cluster such that accessing any node inside the cluster is based on the local indices of the node inside the cluster.
Figure I shows the generic data structure for global and local nodes (GNode and LNode).
Gnode and Lnode take 31+4k bits and 12+2k bits, respectively.
The number N is of size one bit more than M because every node in the cluster can be local node and only the nodes in the bottom of k levels can be global node.

Proposed Data Structure (clustering) The number of local nodes increases when k
increases. What is the good choice for k in order to have minimum
memory requirement for building the binary trie? The following table shows the memory requirements
with different k using a large routing table. We can see that the best value for k is 3. In fact, k = 2 or 4 are also very good.
The table also shows the number of internal nodes that are not prefixes, called non-prefix nodes.
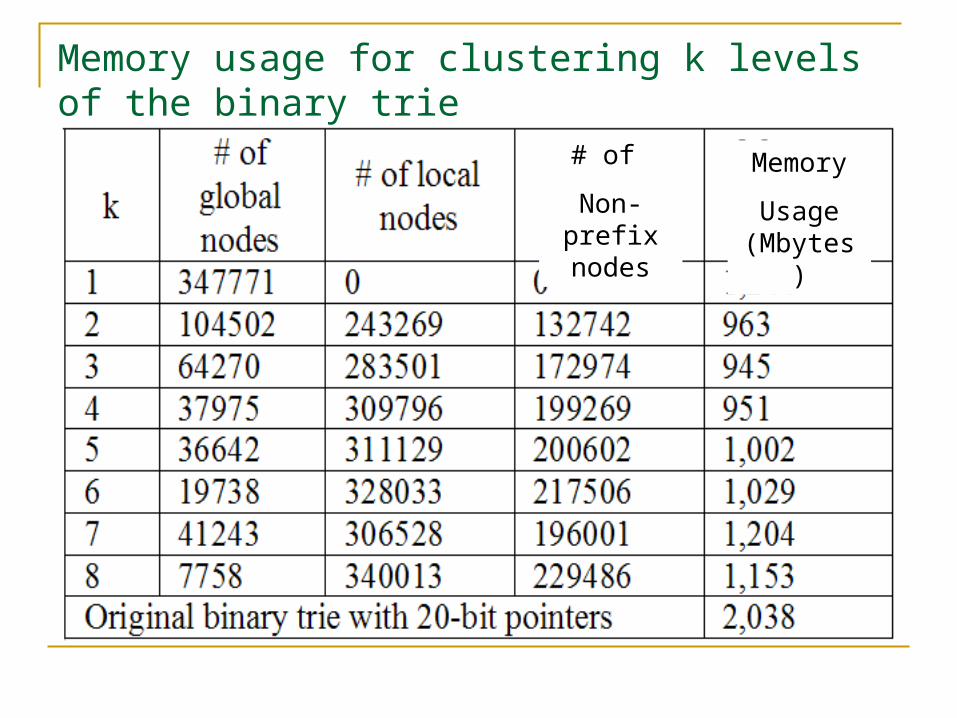
Memory usage for clustering k levels of the binary trie
# of
Non-prefix nodes
Memory
Usage (Mbytes)

Multi-bit trie and Hashing Multi-bit trie: improve lookup performance but
increasing required memory Overhead: unused pointers
Consider a list of eight 4-bit numbers, 0000, 0001, 0010, 0011, 0100, 1000, 1001, and 1011.
A traditional hash function: H(bn-1… b0) = ∑bi*2i a perfect hash, not minimal
0 … 0 0
2n-1 … 2 1
bi=0
bi=1

We can construct arrays V0 = [3,0,0,1] and V1 = [0,3,2,0].
We have H(0000) = 4, H(0001) = 3, H(0010) = 6, H(0011) = 5, H(0100) = 7, H(1000) = 1, H(1001) = 0, H(1011) = 2.

A near-minimal perfect hash function The form of the proposed hash function, H,
for an n-bit number (bn-1… b0) is defined as
H(bn-1… b0) = |∑Vbi[i]| , where bi = 0 or 1 and V0[n-1 … 0] and V1[n-1 … 0] are two precomputed arrays at least one of V0[i] and V1[i] is zero and the values of the non-zero elements are in the
range of -MinSize to MinSize ,where MinSize = min(H_Size - 1, 2n-1).

A near-minimal perfect hash function Computing V0[n-1 … 0] and V1[n-1 … 0]:
The construction algorithm for arrays V0 and V1 is based on exhaustive search.
Briefly, for each cell in arrays V0 and V1, a number in range -MinSize to MinSize is tried one at a time until the hash values of keys are unique.

A near-minimal perfect hash functionStep 1: sort the keys based on the frequencies of the
occurrences of 0 or 1 starting from dimension 0 to n – 1.
Now assume the keys are in the order of k0, … , km-1 after sorting.
In the next two steps the keys are processed in this order.

A near-minimal perfect hash functionStep 2: compute the cells in arrays V0 and V1 that the
current key controls. The key, bn-1… b0, has the control on Vbi[i] if Vbi[i] is not yet controlled by one of preceding keys for i = n-1 to 0.

A near-minimal perfect hash functionStep 3: Use the following rules to assign a number in
range (-MinSize) to MinSize to each cell controlled by the current key. If the hash value, H(bn-1… b0), of the key is
taken by preceding keys or larger than MinSize or smaller than -MinSize, every cell must be re-assigned a new number.
If no number can be found after exhausting all the possible numbers for the cells controlled by the key, we will backtrack to the previous key by reassigning it a new number and continues the same procedure

Analysis of the 4-bit hash table Since the building a hash uses the
exhaustive search, it is not feasible for a large n.
Therefore, we select the hash table of size n = 4 as the building block for creating a large routing table.
We use the exhaustive search to check whether finding a minimal perfect hash function is possible for a set of N 4-bit numbers, where N = 1 to 16.

Analysis of the hash table We find out that the minimal perfect hash
function exists for all cases except some rare cases when N = 10 or 11.
The perfect hash function with the minimal hash size increased by one exists for these rare cases when N = 10 or 11.
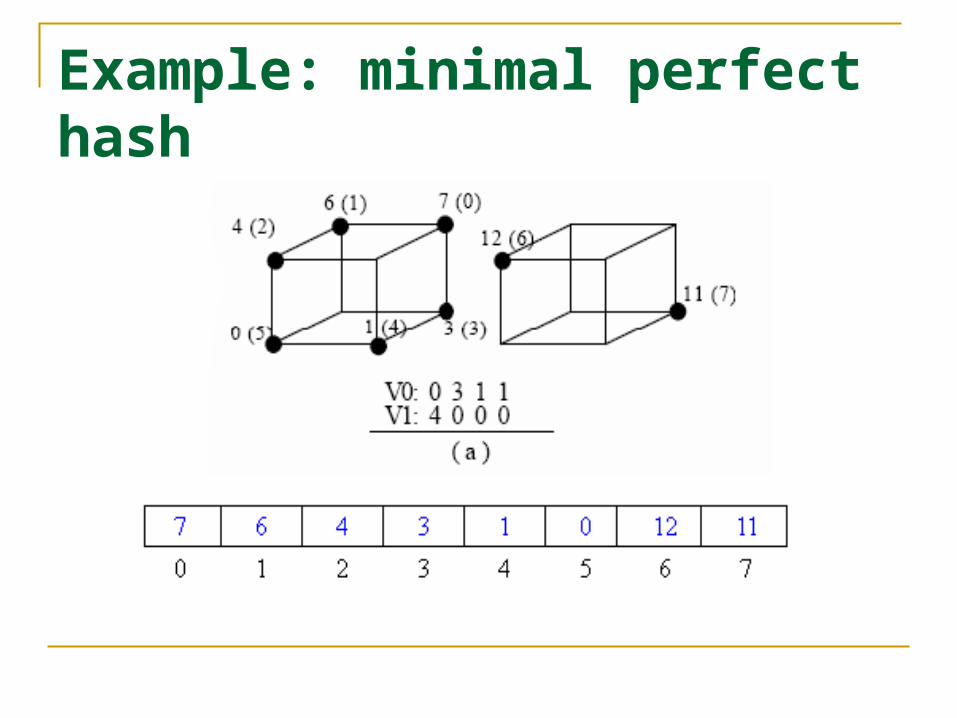
Example: minimal perfect hash
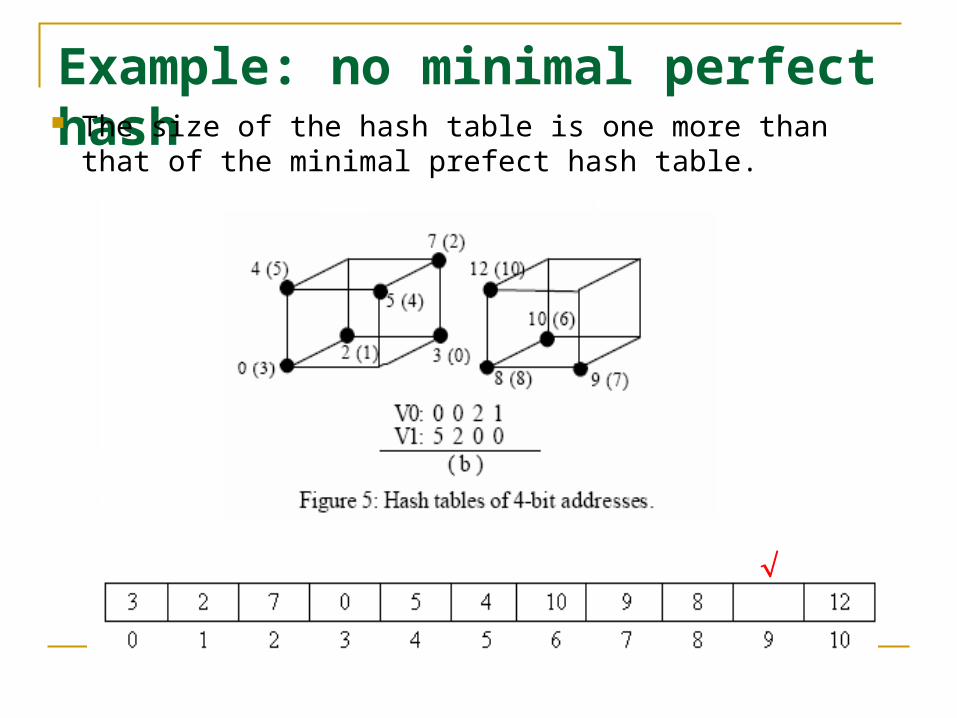
Example: no minimal perfect hash The size of the hash table is one more than that of
the minimal prefect hash table.
Lager n The advantage is as follows. The size of the hash
table of 8-bit addresses is 10 bytes (8x8+8+8 bits) and thus can fit in a cache block of 16 bytes or larger.
However, the obvious drawback is the time-consuming computation of the hash table. the existence of the minimal perfect hash can not be known
in advance, exponential compute time

4-bit building blocks Additional Data Structure for IP Lookup Store Count and prefix
15(4)
8(9)
Numerical representation(1000, 4311)=20bits
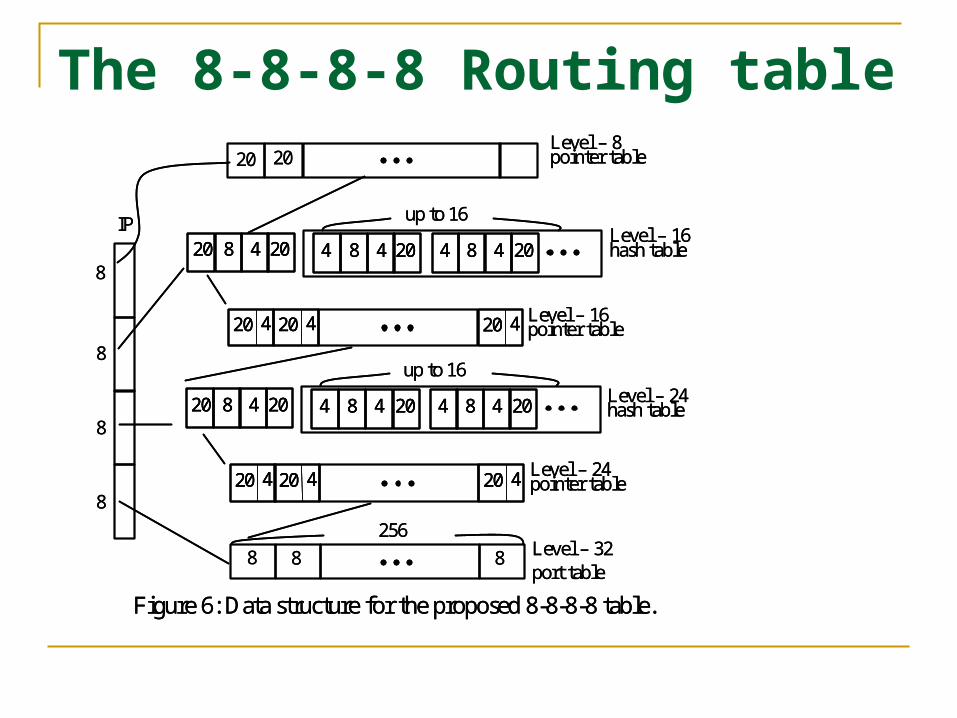
The 8-8-8-8 Routing table
8
8
8
8
IP
Level – 24hash table
Level – 24pointer table
Level – 16pointer table
Level – 8pointer table
Level – 32port table
256
up to 16Level – 16hash table
Figure 6: Data structure for the proposed 8-8-8-8 table.
20
8 8 8
20
20 8 20 4 4 8 20 4 4 8 20 4
up to 16
20 8 20 4 4 8 20 4 4 8 20 4
20 4 20 4 20 4
20 4 20 4 20 4
8
8
8
8
IP
Level – 24hash table
Level – 24pointer table
Level – 16pointer table
Level – 8pointer table
Level – 32port table
256
up to 16Level – 16hash table
Figure 6: Data structure for the proposed 8-8-8-8 table.
20
8 8 8
20
20 20 8 8 20 20 4 4 4 4 8 8 20 20 4 4 4 4 8 8 20 20 4 4
up to 16
20 20 8 8 20 20 4 4 4 4 8 8 20 20 4 4 4 4 8 8 20 20 4 4
20 420 4 20 420 4 20 420 4
20 420 4 20 420 4 20 420 4

Building and updating Similar to the 4-bit trie except the some internal nodes in
each 4-bit subtrie are replaced by the recursive hash tables of 4-bit addresses.
Maintain the 4-bit trie and then compute the corresponding hash tables and the associated pointer tables.
When a prefix is deleted from or added in the routing table, the 4-bit trie is then updated and thus the corresponding part of the proposed 8-8-8-8 routing table can be changed accordingly.

IP lookup performance Based on the distribution of prefix lengths, 99.9% of the
routing entries have the prefix length less than or equal to 24. Thus, the number of the memory references is from 1 to 8.
The hash tables on level-16 are used to compute the index of level-16 pointer array for accessing the level-24 hashing tables if needed. The operations are similar for level-24 hash tables and pointer table.
Notice that we have counted twice of the memory references in accessing the level-16 and level-24 hash tables because accessing two hash tables of 4-bit addresses is needed.

Optimizations: Level compression Level compression
The level-8 pointer array can be combined with the left-most hash table of the level-16 hash table, as marked as ‘*a’ in Figure II.
Similarly, the level-16 pointer table can be combined with the left-most hash table of level-24 hash table, as marked as ‘*b’.
Additionally, the level-24 pointer table can be combined with level-32 port table, marked as ‘*c’, but with a possible waste of memory space. With these optimizations, the total number of memory accesses becomes 1 to 5.

Optimizations: Maptable Pre-computed hash tables by exhaustive search
217 different hash tables for all possible combinations of N=1..16 4-bit values
(1111, index to the array of pre-computed hash tables): 12 bits (1111, index to array of 16 pre-computed hashed values):
avoid computing the hashed values One more memory access to maptable
V0: 0 0 0 0V1: 4 3 1 1
(1111, 4, 3, 1, 1)
Graphical representation
Numerical representation
Hashed
values
Keys
(a)
(b)
0 1 2 3 4 5 6 7
0 1 1 2 3 4 4 5
8 9 10 11 12 13 14 15
4 5 5 6 7 8 8 9
Figure 7: Illustrations of lists containing various numbers of keys hashed to a 4-bit hash table.
V0: 0 0 0 0V1: 4 3 1 1
(1111, 4, 3, 1, 1)
Graphical representation
Numerical representation
V0: 0 0 0 0V1: 4 3 1 1
(1111, 4, 3, 1, 1)
Graphical representation
Numerical representation
Hashed
values
Keys
(a)
(b)
0 1 2 3 4 5 6 7
0 1 1 2 3 4 4 5
8 9 10 11 12 13 14 15
4 5 5 6 7 8 8 9
Figure 7: Illustrations of lists containing various numbers of keys hashed to a 4-bit hash table.

Performance Evaluation Simulation methodology
Input traffic: randomly permutated IP parts of the prefixes in the routing table
Measure the lookup latency one IP at a time Use the Pentium Instruction rdtsc to get the time
in clock cycles
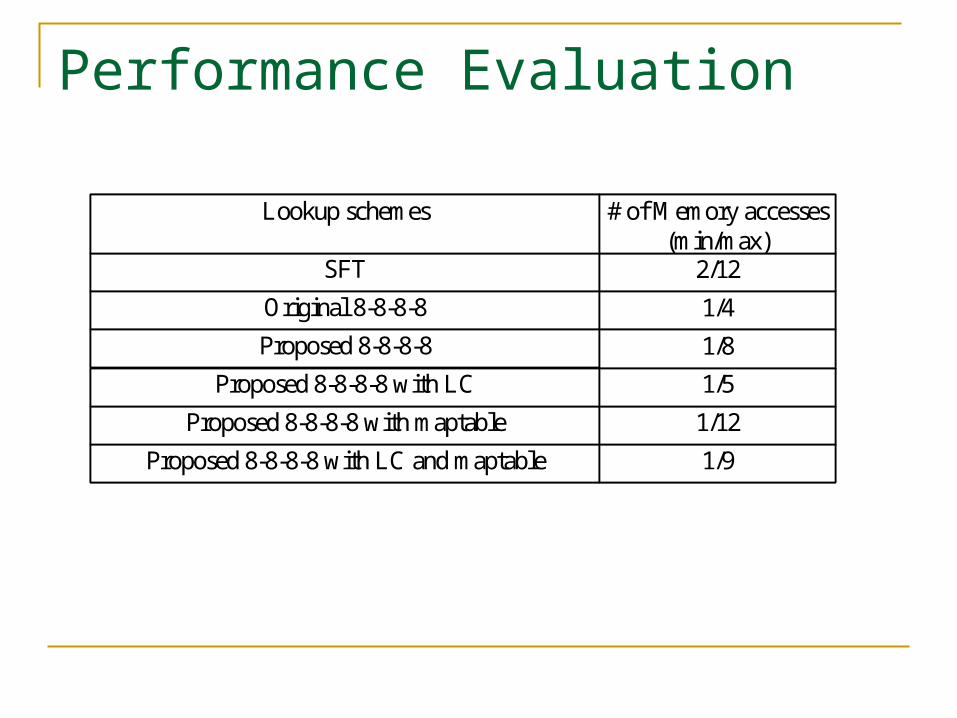
Performance Evaluation
Proposed 8-8-8-8 with LC and maptable
Proposed 8-8-8-8 with maptable
SFT
Original 8-8-8-8
Proposed 8-8-8-8
Proposed 8-8-8-8 with LC
Lookup schemes
1/9
1/12
2/12
1/4
1/8
1/5
# of Memory accesses (min/max)
Proposed 8-8-8-8 with LC and maptable
Proposed 8-8-8-8 with maptable
SFT
Original 8-8-8-8
Proposed 8-8-8-8
Proposed 8-8-8-8 with LC
Lookup schemes
1/9
1/12
2/12
1/4
1/8
1/5
# of Memory accesses (min/max)

Performance Evaluation
41,709
8-30-32
1997-10-30
Funet-40k
89,088
8-32
2003-12-28
Oix-80k
120,635
8-32
2002-12-01
Oix-120k
151,511
8-32
2004-2-1
Oix-150k
# of prefixes
Length distribution
Date
General information of the routing tables considered in the paper.
184.7
274.5
174.7
195.4
164.2
Funet-40k
417.7
538.2
415.9
441.5
392.1
Oix-80k
541.7
722.5
533.5
572.8
503.4
Oix-120k
688.2
880.6
707.1
726.3
666.9
Oix-150k
Proposed 8-8-8-8 with LC and maptable
SFT
Proposed 8-8-8-8
Proposed 8-8-8-8 with LC
Proposed 8-8-8-8 with maptable
Routing tables
Memory in Kbytes required for the proposed data structures.
41,709
8-30-32
1997-10-30
Funet-40k
89,088
8-32
2003-12-28
Oix-80k
120,635
8-32
2002-12-01
Oix-120k
151,511
8-32
2004-2-1
Oix-150k
# of prefixes
Length distribution
Date
41,709
8-30-32
1997-10-30
Funet-40k
89,088
8-32
2003-12-28
Oix-80k
120,635
8-32
2002-12-01
Oix-120k
151,511
8-32
2004-2-1
Oix-150k
# of prefixes
Length distribution
Date
General information of the routing tables considered in the paper.
184.7
274.5
174.7
195.4
164.2
Funet-40k
417.7
538.2
415.9
441.5
392.1
Oix-80k
541.7
722.5
533.5
572.8
503.4
Oix-120k
688.2
880.6
707.1
726.3
666.9
Oix-150k
Proposed 8-8-8-8 with LC and maptable
SFT
Proposed 8-8-8-8
Proposed 8-8-8-8 with LC
Proposed 8-8-8-8 with maptable
Routing tables
184.7
274.5
174.7
195.4
164.2
Funet-40k
417.7
538.2
415.9
441.5
392.1
Oix-80k
541.7
722.5
533.5
572.8
503.4
Oix-120k
688.2
880.6
707.1
726.3
666.9
Oix-150k
Proposed 8-8-8-8 with LC and maptable
SFT
Proposed 8-8-8-8
Proposed 8-8-8-8 with LC
Proposed 8-8-8-8 with maptable
Routing tables
Memory in Kbytes required for the proposed data structures.

Performance Evaluation
292
300
286
Funet-40k
452
350
348
Oix-80k
507
401
392
Oix-120k
546
423
411
Oix-150k
SFT
Proposed 8-8-8-8 with LC
Proposed 8-8-8-8 with LC and maptable
Routing tables
average lookup latencies in clock cycles.
292
300
286
Funet-40k
452
350
348
Oix-80k
507
401
392
Oix-120k
546
423
411
Oix-150k
SFT
Proposed 8-8-8-8 with LC
Proposed 8-8-8-8 with LC and maptable
Routing tables
average lookup latencies in clock cycles.Average lookup latencies in clock cycles

Performance Evaluation
Funet-40k
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600 700 800 900CPU clock cycles
freq
uenc
y
8-8-8-8
Hash
SFT
Proposed + LCProposed + LC+maptable
Figure 9: IP lookup latency for Oix-120k routing table.
Funet-40k
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600 700 800 900CPU clock cycles
freq
uenc
y
8-8-8-8
Hash
SFT
Proposed + LCProposed + LC+maptable
Figure 9: IP lookup latency for Oix-120k routing table.
Funet-40k
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600 700 800 900CPU clock cycles
freq
uenc
y
8-8-8-8
Hash
SFT
Proposed + LCProposed + LC+maptable
Figure 9: IP lookup latency for Oix-120k routing table.
Proposed + LC
Proposed + LC + Maptable
SFT

Performance Evaluation
Funet-40k
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 100 200 300 400 500 600 700 800 900CPU clock cycles
freq
uenc
y
8-8-8-8
Hash
SFT
Figure 8: IP lookup latency for Oix-120k routing table.
Proposed + LC
Proposed + LC+maptable
Oix-120K

Conclusions and future work a new hash table to compact the routing table Hash tables of 4-bit addresses are used as
the building blocks to construct 8-8-8-8 hierarchical routing table.
Simulations showed Smaller than any existing schemes Faster than most schemes except the
compressed 16-x scheme Future work: hashing without 4-bit expansion
and fast algorithm for n larger than 4

The End
Thank you






















![Hsin Hsin Ming[1]](https://img.dokumen.tips/doc/110x75/55cf9a0d550346d033a04059/hsin-hsin-ming1.jpg)






