Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 16, NO. 7, JULY 2008 781
A Scalable Packet Sorting Circuit for High-SpeedWFQ Packet Scheduling
K. McLaughlin, S. Sezer, H. Blume, X. Yang, F. Kupzog, and T. Noll
Abstract—A novel implementation of a tag sorting circuit fora weighted fair queueing (WFQ) enabled Internet Protocol (IP)packet scheduler is presented. The design consists of a search tree,matching circuitry, and a custom memory layout. It is implementedusing 130-nm silicon technology and supports quality of service(QoS) on networks at line speeds of 40 Gb/s, enabling next gen-eration IP services to be deployed.
Index Terms—Internet packet scheduling, lookup, quality of ser-vice (QoS), time-stamp sorting, traffic management, weighted fairqueueing (WFQ).
I. INTRODUCTION
T HE INTERNET was the defining technology at the be-ginning of the 21st century. It has become the dominant
medium for global communications, information, business, andentertainment. In the near future streaming services, such asvideo on demand, high definition television, voice over InternetProtocol (VoIP), and 3-D multimedia, etc., will rapidly take off.To deliver this next generation of applications requires a newgeneration of Internet routers that allow quality of service (QoS)to be delivered via the Internet.
Most current solutions aimed at providing QoS are based onsoftware implemented on a network processor with multipleprocessor cores, but despite these configurations, software solu-tions are unable to keep up with the increasing bandwidth of theInternet, which doubles approximately every 12 months. In ad-dition, streaming and real-time content associated with VoIP andIPTV introduces further constraints by reducing the packet sizeand setting rigid delay requirements. Despite the shortcomingsof software, a comprehensive study investigating a full hardwareimplementation of fair queueing for IP traffic management hasnot yet been carried out—this research targets this specific appli-cation in order to overcome the processing limitations for nextgeneration QoS supporting Internet routers.
This paper presents a novel tag sort/retrieve circuit, designedfor an IP packet scheduler that deploys a weighted fair queueing(WFQ) scheduling policy, which is fully implemented in hard-ware. WFQ is one of a family of fair queueing algorithms thecircuit can support in hardware [1]. WFQ can be described as a
Manuscript received April 1, 2007; revised July 3, 2007. This work was sup-ported by Invest Northern Ireland and the Department for Employment andLearning. It is protected by Patent No. 0524845.
K. McLaughlin, S. Sezer, and X. Yang are with The Institute of Electronics,Communications and Information Technology, Queen’s University Belfast,Belfast BT3 9DT, Northern Ireland, U.K.
H. Blume, F. Kupzog, and T. Noll are with The Institute of Electrical En-gineering and Computer Systems, RWTH Aachen University, Aachen 52056,Germany.
Digital Object Identifier 10.1109/TVLSI.2008.2000323
rate-based flow control strategy, where a traffic source is statis-tically characterized by rate, burstiness, etc. There may also bea QoS requirement such that worst case or average delays arespecified, with the aim of providing guarantees on throughputand worst case delay. The novel contribution to this field of re-search is the high performance and low latency of the sort/re-trieve circuit, which utilizes distributed memories to achieveparallel and pipelined processing that enables high speed tagretrieval in a guaranteed fixed time. The circuit is capable ofsupporting guaranteed QoS for future real-time services via ahighly scalable implementation of WFQ packet scheduling. Thecircuit has been implemented using 130-nm silicon technologyand supports line speeds of 40 Gb/s, which is an order of mag-nitude greater than emerging industry standards.
The rest of this paper is laid out as follows. The Introductioncontinues to discuss the need for QoS and how it can be en-abled by deploying packet scheduling. A hardware-based WFQscheduler architecture that has been derived is introduced andthe need for effective finishing tag retrieval is explained. Ananalysis of theoretical models for searching and sorting tags isthen carried out, followed by a performance analysis of prac-tical implementation options. The final circuit architecture isthen derived, which comprises a search tree, matching circuitry,tag storage memory, and a translation table. The full circuit ar-chitecture is then implemented on silicon and the results are pre-sented.
A. Delivering QoS
The current best-effort model that the Internet operates doesnot provide bandwidth or real-time guarantees, however, fairqueueing scheduling does allow such guarantees to be deliv-ered. The motivation behind this research is to derive hardwarecapable of supporting finishing tag sorting and retrieval for fairqueueing scheduling. Fair queueing packet scheduling allowsQoS to be guaranteed to specific packet flows in terms of prop-agation delay and the allocation of available bandwidth.
Providing QoS is vital for future streaming applications be-cause they require a high level of guaranteed bandwidth in orderto operate reliably and with customer satisfaction. Additionally,end-to-end delays for such packet flows must also be kept withincertain limits if, for example, a conversation or other interactionis to be practical. At present QoS is only met by underutilizingnetwork resources, this is inefficient and is not sustainable asuser demand increases. Implementing QoS at the core and edgeof the network using fair queueing scheduling allows serviceproviders to deliver next generation services both effectively andefficiently.
1063-8210/$25.00 © 2008 IEEE

782 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 16, NO. 7, JULY 2008
B. Router Design and Packet Scheduling
A number of scheduling techniques deal with the issue of QoSand traffic management. Most aim to emulate the ideal sched-uling capabilities of generalized processor sharing (GPS), whichis a fluid model, where packets are organized into logical queueswith an infinitesimally small amount of data serviced from eachnon-empty queue in turn. This achieves fair allocation of band-width but is not practical since packets are not transmitted ascomplete entities. It does, however, provide a theoretical stan-dard against which the performance of practical scheduling poli-cies can be assessed.
Methods such as weighted round robin (WRR) [2] anddeficit round robin (DRR) [3] were developed to offer a levelof QoS. WRR is the simplest, where weights are allocated todifferent flows in order to apportion priority. However, WRRrequires the average packet size to be known so that normalizedweights can be calculated. DRR is able to process variablesize packets without knowing their mean size. Extensions ofthe DRR approach have also been implemented. Class-basedqueueing (CBQ) [4] adopts a hierarchical approach to DRR. Afurther derivation of DRR called modified deficit round robin(MDRR) adds prioritization to try to provide a minimum delayfor differentiated services. Cisco have implemented MDRRto allow VoIP to be prioritized. The principal drawback fora typical round robin approach is that it cannot provide foreffective bounded delays.
Although round robin and its derivatives work well forfixed-sized packets, they have thus far proven to be unable toguarantee delay bounds for variable sized packets. Therefore,they are unsuitable for providing full QoS for networks suchas the Internet. A number of more advanced algorithms knownas fair queueing scheduling have been developed which actmore closely to GPS. WFQ [1], which is discussed more fullyin Section II, uses a “virtual time” to track the progress ofsimulated GPS and allocates a finishing time to all packets in-dicating when they are to be serviced. This allows a worst caseend-to-end queueing delay to be guaranteed for all connections.WFQ outperforms round robin because it approximates GPSwithin one packet transmission time regardless of the arrivalpatterns.
A number of fair queueing-based derivatives have also beendeveloped, which vary in terms of ease of implementation andperformance parameters, although all are based on a system ofallocating time stamps to packets. Worst case fair weighted fairqueueing is more complex than WFQ but has betterworst case fairness [5]. The drawbacks are that it is complex interms of both updating the virtual clock and, like WFQ, sortingfinishing tags at the output. Another proposal calledpossesses all the properties of , but has a less complexprocedure for updating the virtual clock [6]. The disadvantagewith , however, is that it requires two sort operationsper packet.
It is clear that the best choice for delivering QoS on the IPnetwork is fair queueing. Although the scheduler architecturethat is now presented uses WFQ, it is important to stress thatthe tag sorting architecture that has been derived can operatewith any of the family of fair queueing algorithms that requiresfinishing tag timestamps to be sorted.
Fig. 1. WFQ scheduler architecture fully implemented in hardware.
II. SCHEDULER ARCHITECTURE
A scheduler has been developed to enable sophisticated trafficmanagement policies to be deployed on the Internet, includingthe delivery of specifiable levels of QoS for individual connec-tions. The architecture is comprised of three main components:a WFQ tag computation circuit [8], a packet buffer [9], and a tagsort/retrieve circuit, highlighted in Fig. 1, which is the focus ofthis paper. The modular design approach allows each separateentity within the scheduler to be designed and configured inde-pendently. It also allows the system to be extremely scalable andflexible. For instance, any fair queueing based algorithm can beinserted into the architecture in place of the WFQ calculationcircuit, e.g., . The scheduler operates by generating andprocessing “finishing tags” for each packet that it receives. Thetags are time stamps that tell the system when each associatedpacket should be serviced in relation to all other packets in thescheduler.
When a packet enters the scheduler on the left of Fig. 1 theWFQ tag computation circuit generates a tag for that packet.The packet is stored in the shared buffer memory and the asso-ciated tag is sent to the tag sort/retrieve circuit. Here, all tags inthe system are stored in order of value. When a packet leavesthe scheduler, the lowest tag value is read from the sort/retrievecircuit and a pointer stored along with it indicates the locationof the associated packet in the packet buffer. This means thepackets are served in the correct sequence required by the WFQpolicy.
A. Fair Queuing and WFQ Tag Computation
There are a number of algorithms that aim to emulate theideal scheduling capabilities of GPS in order to guarantee QoSparameters for different connections. In GPS, packets are orga-nized into logical queues where an infinitesimally small amountof data is serviced from each non-empty queue in turn. Thisachieves a fair allocation of bandwidth but is not practical be-cause it requires packets to be transmitted as incomplete entities.
Numerous algorithms have been developed to perform asclose to GPS as possible, while retaining packet integrity. WFQ[1] uses a “virtual time” to track the progress of simulatedGPS, allowing a worst case end-to-end queueing delay tobe guaranteed for connections. Several other schemes havebeen developed such as fair weighted fair queueing ,which is fairer than WFQ but is also more complex [5] and

MCLAUGHLIN et al.: SCALABLE PACKET SORTING CIRCUIT FOR HIGH-SPEED WFQ PACKET SCHEDULING 783
frame-based fair queueing (FBFQ), which is less complex thanWFQ, but is almost as fair [7].
The operation of the WFQ algorithm involves a number ofcalculations. One in particular is especially relevant to the tagsort/retrieve operation
Next (1)
where
Next time of next scheduled departure;
virtual time;
minimum time stamp;
time;
connection number;
set of busy sessions;
weight of th session.
Next in (1) is a point in real time related to the departureof the next tag in the scheduler [8]. It is used in the WFQ al-gorithm to calculate future virtual time values and, amongother values, is dependant on which is the minimum timestamp value yet to leave the system, i.e., the smallest tag yet tobe served in the tag sort/retrieve circuit. This highlights how thetag sort/retrieve operation is integral to the operation of the en-tire scheduler architecture and has an impact on its performancefrom input to output. Compared to the scheduling algorithmsthemselves, there has been little work focusing on this importantissue in the research community and no satisfactory solution iscurrently available.
B. Tag Sort/Retrieve Circuit
This is a critical operation for fair queueing scheduling. Thefinishing tag lookup must be possible at line speed to be effec-tive. This represents a bottleneck, especially for software. In in-dustry, fair queueing algorithms are normally implemented insoftware and while the specific operation of sorting tags canbe achieved using established software algorithms [10], untilnow no satisfactory circuit design has existed to facilitate theprocess effectively in hardware. It should be noted that the vanEmde Boas method is unsuitable for implementation in hard-ware [11]. The “binning” technique, developed for a credit-based fair queueing (CBFQ) hardware implementation [12], hasbeen suggested as a solution, however, this method is unsatis-factory because it aggregates values together in groups and isinherently inaccurate.
Other possible solutions based on traditional associativememory arrangements also fall short of the performance re-quired. The primary reason for this is that techniques such ashashing and content addressable memories (CAMs) cannot de-liver the smallest value from a set within a fixed and predictabletime period. The architecture developed can achieve this, whichwill be discussed in Section II-C.
Most work in this field has based the tag sorting mecha-nism on queue/heap methods. These are generally limited to
performance, which is slower than the multi-bit tree
Fig. 2. Sort and search model concepts.
design presented. Various types of calendar queues have beenimplemented [14], [15], however, it has been shown that theseare limited in their size and scalability. A 2-D calendar queue(TCQ) [16] claims performance [equivalent to
], however, it produces a degradation of the delayguarantees provided by the WFQ algorithm. It also cannot beimplemented as fast as the multi-bit tree presented. The LFVCalgorithm has the same performance as TCQ but also similardrawbacks relating to the level of QoS delivered [17].
A recent development is stratified round robin (SRR), whichuses “finite universe priority queues” to sort packets among tensof classes [11]. However, as previously stated, round robin isinherently less fair than fair queueing. The number of trafficclasses is also greatly limited compared to the architecture that ispresented as part of this paper. A primary reason given for devel-oping SRR was the bottleneck of sorting tags in fair queueing.
C. Search and Sort Models
The key aim was to produce an associative memory config-uration capable of storing all the finishing tags in the schedulerand returning the smallest tag within a guaranteed fixed time.A fixed time is important because the operation of the othermodules in the scheduler (see Fig. 1) depend on synchronizingaround a fixed time. There are two functions in an associativememory: data storage and a lookup function to enable access tothe data. There are two fundamental options for the tag lookupmemory architecture.
1) Sort the tags as they arrive and then access the smallest tagvalue as required.
2) Store tags as they arrive and search through the memory tofind the smallest tag when required.
These will be referred to as the “sort” and “search” modelsrespectively and in this section searching or sorting will gener-ically be referred to as a “lookup.” Both models are illustratedin Fig. 2. The models can be assessed in terms of the time allo-cated to each function and how the time available between dataentry and data request is managed:
lookup time;time data is stored in memory;time taken for read process;time taken for write process.

784 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 16, NO. 7, JULY 2008
TABLE ICOMPARING LOOKUP METHODS AVAILABLE
The time that data is stored in the memory is variableand depends on the value allocated to a tag by the schedulingpolicy. It can, therefore, be considered an arbitrary value for thepurposes of comparing models. The important factors to con-sider are the lookup time, which is variable, and the read andwrite times, which can be assumed to be constant for this inves-tigation. The central point to emphasize is that the sort modelallows the lookup function to be performed at the input of thedata flow, compared to the search model where it is performedat the output.
The sorting model is preferable because it allows the serviceof the smallest tag to be separated from the lookup operation.This separation means that the service of the tags depends onlyon the time taken to access the tag storage memory , whichis both fixed and faster than performing a lookup . For thesort operation only the average time taken to complete a lookupfor each tag is important, because effectively acts as a bufferbetween the fixed and variable times of and . This is unlikethe search model, where the time taken to service the smallesttag will depend on the performance of the search operation. Theonly guarantee that can be given for the length of time this takesis the worst case performance of the search, , which is almostcertain to be longer than in the sort model.
D. Lookup Performance
A comparison of the operational complexities for variousoptions is shown in Table I along with information on whichlookup model they conform to. The first four methods arestandard software implementations and the remaining five areall hardware based. Although it can be difficult to make a directcomparison, some key features have been selected to illustratethe relative effectiveness and suitability of each option. In termsof speed of operation, the software speed is based on com-plexity of algorithm and for hardware the number of accesses
to memory has been used. In each case, the slowest limitingfactors have been used, i.e., worst case time for finding theminimum values, inserting new values, backup search paths,etc. Since the circuit must operate over a fixed time to fit withinthe overall scheduler architecture, the worst case results arenecessary. Note that the performance for any implementationoperating under the search model can only be guaranteed toa worst case scenario. In addition, note that using any othermeasure of performance would also be invalid because a searchthat is longer than anticipated would mean tags leaving thecircuit later than scheduled by the fair queueing algorithm. Thisis not acceptable for a reliable scheduling policy.
For the hardware methods, the worst case number of memoryaccesses required per lookup and have been calculated as fol-lows.
The number of accesses required for the binning method islimited only by the number of bins, which equals the total rangedivided by the span of an individual bin. A search in a binaryCAM must use an iterative technique based on incrementing asearch by one value at a time, which is very slow. A TCAM canuse a bit-wise iterative search using masked bits and a tree canalso use a bitwise search, which reduces the worst case max-imum search to a linear relationship with the word width. Amulti-bit tree further reduces this by the branching factor by an-alyzing more than one bit in parallel. It can be seen that per-forming lookups using the tree can be achieved with the lowestcomplexity compared to all the other options. Having previouslyestablished the sort model as the preferred option, it now be-comes clear that the multi-bit tree is the best option availablebecause of its operating speed and conformity to the sort model.The tree acts as a sort function and the linked list acts as thestorage memory.
The most practical of the remaining options are binary CAM,TCAM, and the binning technique, which operate using thesearch model. The binning, CAM, and tree techniques are allhardware based. The table shows that for the software models(except LFVC), the binning technique and the CAMs, the per-formance is in direct proportion to the number of tags beingstored. Only the TCAM and tree implementations have lookuptimes proportional to the widths of the tags, which is an expo-nential reduction. Additionally, the tree implementation lookuptime is also inversely proportional to the branching factor usedin the tree, which further reduces the search time ( in theimplementation presented).
The option of a hash solution has not been included for com-parison. The variables associated with such an implementationinclude the hash function itself, the size of table compared to thenumber of tags it must store, collision resolution and an iterativepolicy to find the smallest value. For hardware, it would be par-ticularly difficult to calculate worst case performance bounds fora general implementation. However, taking into account that thenature of the iterative search required would be similar to that ofa binary CAM and that collision resolution would be required,it is likely that the worst case performance would be worse than
.Table I shows that the speed performance of the multi-bit
tree-based architecture is better than the alternatives. In addi-tion, it also conforms to the sort model as previously outlined;

MCLAUGHLIN et al.: SCALABLE PACKET SORTING CIRCUIT FOR HIGH-SPEED WFQ PACKET SCHEDULING 785
consequently, the service of the smallest tag is dependant onlyon the time taken to access the tag storage memory. It alsocompares favorably against existing standard approaches wherethe software algorithm will require several accesses to memoryduring operation. The multi-bit tree is well suited for implemen-tation using multiple distributed memories to enable high-speedparallel processing in hardware. The following section showsthe derivation of the tag retrieval circuit based on the multi-bittree.
III. CIRCUIT ARCHITECTURE
The key aim was to produce an associative memory configu-ration that can return the smallest available finishing tag withina guaranteed fixed time in hardware at line speeds. It was alsodesired that the design can support any fair queueing algorithmthat generates tags or time stamps. For the scheduler developedin Fig. 1, it is required that all the tag values be stored in thetag storage memory in sorted order. This enables the lowestvalue to be readily accessible by the packet buffer read controlat all times and also be available for the calculation outlinedin (1). A sorting mechanism and memory structure have beendeveloped that allow incoming tags to be inserted into the tagstorage memory in the correct order relative to all other tags inthe memory.
A custom implementation has been derived where the searchand memory elements of the design have been separated so thatthey can be independently scalable and configurable, allowingdifferent parameters of memory size and search granularity tobe realized. The circuit architecture consists of a number of dis-tributed memory elements accessed by a set of custom designedlogic circuits that enable data lookup.
The design uses linked-list structures to organize the entriesin the tag storage memory. This component is an integral partof the overall sorting procedure, since how the tags are stored isinexorably linked to the processes used to sort them. It is alsoimportant that the process of adding and removing tag valuesfrom this memory does not become a bottleneck in the data flow.The linked list configuration allows the tags to be stored in orderof value, which means that the smallest tag value, i.e., the tag tobe serviced next, is always known. This allows instant accessto successive packets at the output and also enables tags to bedeleted from the end of the list as they depart, which removesanother potential bottleneck procedure that can be problematicin software, where heaps or queues are used.
New tags are inserted into the sorted list by using a lookup tree(or trie specifically) in conjunction with a translation table. Amulti-bit tree is used to store whether a value is already presentin the tag storage memory by storing a tag marker. This infor-mation is used to place the new tag beside its closest match inthe linked list. For values that are present, the translation tableindexes the position of each entry and provides a connection be-tween entries in the tree and the linked list. Separating the searchfunction from the data storage allows the lookup function to beimplemented very efficiently in hardware.
The architecture is treated as three separate entities that areall part of one data flow as shown in Fig. 3. The first circuit isthe tree that performs the lookup function; the second part is the
Fig. 3. Tag sort/retrieve circuit and tag storage architecture.
translation table, which connects the tree to the third part, thetag storage memory. Additionally, custom designed circuitry isused to perform the closest match operations in the nodes of thetree.
A. Search Tree
The architecture was developed and implemented with stan-dard cell logic and uses a tree with three levels, handling 12-bitwords. This means literals of 4 bits are represented in each levelby 16-bit nodes. The branching factor in each level is there-fore 16, since each node has 16 child nodes. Since the tree hasthree levels, three identical matching circuits are required to per-form a matching function at each level. The tag storage memoryrequires four clock cycles to complete a read/write cycle (seeFig. 9) and together the three level tree and translation table re-quire four clock cycles to throughput one tag, this arrangementallows the operations of the separate components to be synchro-nized most efficiently. The width of the nodes could also be ex-panded to 32 bits to enable 15-bit words. This would also requirethe added expense of a larger translation table with 32-k entries.This would increase the granularity of search possible and thereis no practical reason why this could not be done despite the ad-ditional area cost. Another option available is to use node widthsthat are not equal in each level, this option is discussed furtherin [13]. The main reason for not using this option is that the totalsearch time will be most affected by the search time needed forthe widest node. If all nodes are equal width, all will execute inequal time.
The tree records all the tag values already present in thesystem by storing a tag marker. When adding a new tag to thesystem, the tree is used to find the closest existing tag markerin the tree and hence the closest existing tag in the system.To facilitate this search, custom matching circuitry has beendeveloped to operate on the nodes of the tree. Fig. 4 shows theoperation of a very simple multi-bit tree that stores the values001001, 110101, and 110111. In each level the desired literal iscompared to the literal present in the tree and an exact or nextsmallest match is returned. The example uses 6-bit values withthree 2-bit literals shown. If a non-exact match occurs in anylevel, i.e., a smaller value than requested, all subsequent levelsreturn their maximum value. This process first of all finds asubset of values smaller than the desired value and secondlyfinds the largest value out of this subset, i.e., the value closestto the desired value. Consider an example where a new tag has

786 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 16, NO. 7, JULY 2008
Fig. 4. Simple multi-bit tree search.
arrived with a value of 110110, which must now be sorted andstored.
1) The search in the root level at the top of the tree will lookfor a “1” or “0” in the very right hand position of the noderelated to the literal “11.” The memory bit “1” here indi-cates that this literal is present, so the search continues tothe child node below it.
2) In this node, the “01” position is checked and again a “1” isfound indicating that a tag marker beginning with “1101”is already in the memory.
3) In this node in the third level, the search will return theliteral “01.” This is because there is a “0” in the “10” po-sition, so the matching circuit instead looks for the literalwith the next smallest value after “10.”
The final result is that the tree returns a closest match of“110101” for the incoming tag “110110.” This value will thenpass to the translation table to be used in the next stage. Thefinal part of the process is writing the new tag marker into thetree. The only node that requires an update is the node in Step3), where the value “0111” will be written to indicate that theliteral in position “10” is now present.
It is possible, especially when there are few tags in the systemand the tree is sparsely populated, that a search path can fail, i.e.,no literal smaller than the one being searched for can be found.In this case a backup path is followed. A second search operatesin parallel with the normal search to find the closest match inthe case where no match is available from the primary search.It is not known if no match is available from the primary searchuntil it operates. If a primary match is not available, the backupfrom the previous level is used—this is the next smallest bit inthe parent node. If no such bit exists then the next smallest bitin the node two levels up is used. The tree will always have asmaller value available because the WFQ algorithm always pro-duces tags larger than, or equal to, the smallest tag already inthe system. When the desired backup bit is found the remainingsearch follows a path using the most significant bit in each node.The backup path will always return a match because a smallertag marker value from previous levels will always be available,unless the tree is empty, in which case it will enter an initializa-tion mode where only a write to the tree is necessary.
Fig. 5 shows a search conducted to find the closest match for avalue of 110100. The search is successful in the first and secondlevels, however, in the third level there is no match in the “00”position, highlighted as Point “A.” At this point, a search wouldusually be made in the third level node for a literal lower thanthe unsuccessful request, i.e., lower than, or to the left of “00.”
Fig. 5. Search illustrating backup path.
This is not possible and it is necessary to have a backup path.At each node two lookup operations take place. The primarysearch is for a matching literal, or the next smallest literal thatexists. The secondary lookup is for the next literal less than thattargeted by the primary search. This is illustrated at Point “B” inFig. 5. When the original search fails at Point “A” this secondarybackup match is followed.
When using the backup path, the largest literals available arefollowed in each subsequent node. As can be seen from Fig. 5,this ensures that the match returned is the next lowest to thevalue search for. Note that in the second level of the originalsearch no backup path is found because there is only one literalin that particular node. In such a case, the backup path fromthe previous level is always used. If there were literals “00” and“10” as indicated at Point “C,” there would be a backup availablein the second level and this path would be used in the event of afailed match in the subsequent node.
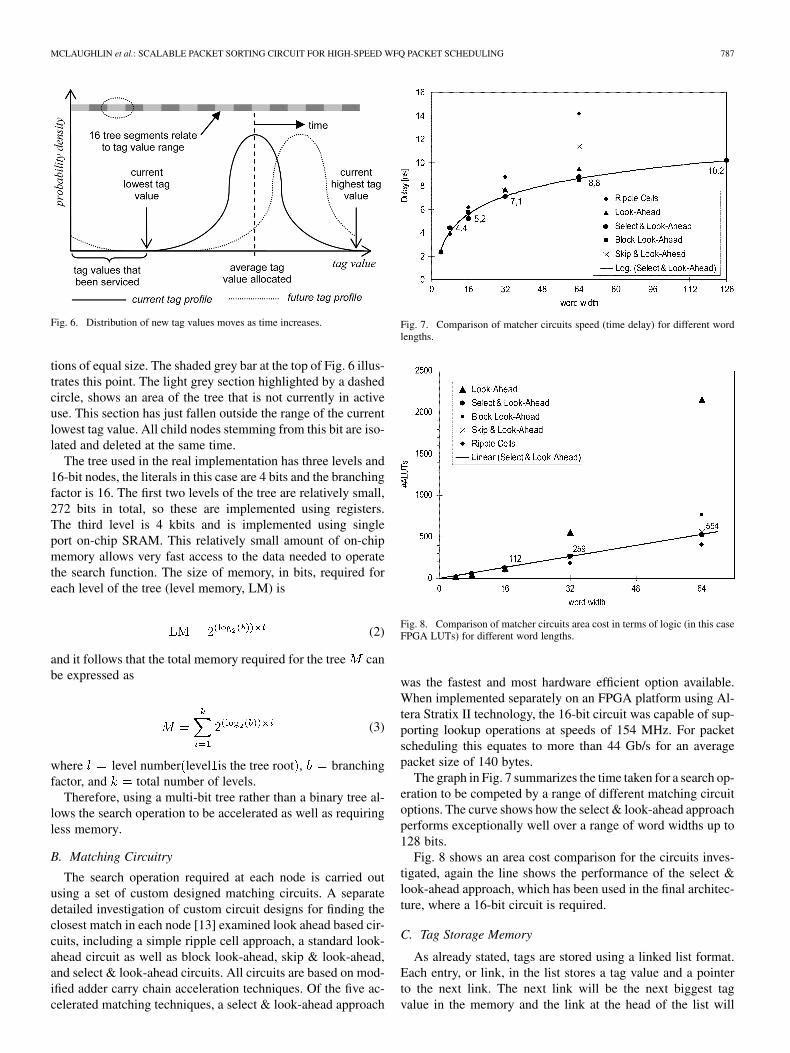
Having examined the search and insertion functions, the finalconsideration is removing entries from the tree. To understandthis it is important to first understand the cyclical nature of gen-erating finishing tags in the overall scheduler architecture. Inorder to prevent the values of the finishing tags increasing to in-finity as time increases, the WFQ policy implemented resets thevalues it allocates to zero after a finite maximum value has beenreached. By this time, a section of the smallest values previouslyallocated will have been serviced and removed from the system.These values will now be available to be reused again.
At any instant in time, new tags will be produced with a min-imum value greater than the current lowest tag value, and amaximum in the region of the current highest tag value (it canobviously be greater than the current highest). Consequently,there will be a distribution profile of new tag values ranging ap-proximately between the current lowest and highest tag values.This will be determined by the prevailing traffic profile, and ithas been approximated using a normal distribution as shown inFig. 6. The exact nature of the distribution will vary with thetraffic profile experienced, for example, streaming VoIP is likelyto produce a distribution weighted to the left, while a diverse mixof traffic will have a classic bell curve. As time progresses for-ward (as illustrated in Fig. 6) the average point will shift forwardas tags are serviced, a range of values behind the current lowesttag value will be vacated. In the tree the related tag markers mustbe deleted so that the part of the tree they occupy can be reusedwhen the WFQ calculation reaches the start of this range again.
The top level of the tree is a single 16-bit node that effectivelydivides the total range of values of the tree into 16 separate sec-
MCLAUGHLIN et al.: SCALABLE PACKET SORTING CIRCUIT FOR HIGH-SPEED WFQ PACKET SCHEDULING 787
Fig. 6. Distribution of new tag values moves as time increases.
tions of equal size. The shaded grey bar at the top of Fig. 6 illus-trates this point. The light grey section highlighted by a dashedcircle, shows an area of the tree that is not currently in activeuse. This section has just fallen outside the range of the currentlowest tag value. All child nodes stemming from this bit are iso-lated and deleted at the same time.
The tree used in the real implementation has three levels and16-bit nodes, the literals in this case are 4 bits and the branchingfactor is 16. The first two levels of the tree are relatively small,272 bits in total, so these are implemented using registers.The third level is 4 kbits and is implemented using singleport on-chip SRAM. This relatively small amount of on-chipmemory allows very fast access to the data needed to operatethe search function. The size of memory, in bits, required foreach level of the tree (level memory, LM) is
(2)
and it follows that the total memory required for the tree canbe expressed as
(3)
where level number level is the tree root , branchingfactor, and total number of levels.
Therefore, using a multi-bit tree rather than a binary tree al-lows the search operation to be accelerated as well as requiringless memory.
B. Matching Circuitry
The search operation required at each node is carried outusing a set of custom designed matching circuits. A separatedetailed investigation of custom circuit designs for finding theclosest match in each node [13] examined look ahead based cir-cuits, including a simple ripple cell approach, a standard look-ahead circuit as well as block look-ahead, skip & look-ahead,and select & look-ahead circuits. All circuits are based on mod-ified adder carry chain acceleration techniques. Of the five ac-celerated matching techniques, a select & look-ahead approach
Fig. 7. Comparison of matcher circuits speed (time delay) for different wordlengths.
Fig. 8. Comparison of matcher circuits area cost in terms of logic (in this caseFPGA LUTs) for different word lengths.
was the fastest and most hardware efficient option available.When implemented separately on an FPGA platform using Al-tera Stratix II technology, the 16-bit circuit was capable of sup-porting lookup operations at speeds of 154 MHz. For packetscheduling this equates to more than 44 Gb/s for an averagepacket size of 140 bytes.
The graph in Fig. 7 summarizes the time taken for a search op-eration to be competed by a range of different matching circuitoptions. The curve shows how the select & look-ahead approachperforms exceptionally well over a range of word widths up to128 bits.
Fig. 8 shows an area cost comparison for the circuits inves-tigated, again the line shows the performance of the select &look-ahead approach, which has been used in the final architec-ture, where a 16-bit circuit is required.
C. Tag Storage Memory
As already stated, tags are stored using a linked list format.Each entry, or link, in the list stores a tag value and a pointerto the next link. The next link will be the next biggest tagvalue in the memory and the link at the head of the list will

788 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 16, NO. 7, JULY 2008
Fig. 9. Writing a new tag into linked list.
be the smallest tag value. The list is implemented off chip,using SRAM. Currently, QDRII and RLD RAM versions arealso under development. A key point to note is that the totalnumber of tag values that can be stored in the linked list islimited only by the size of RAM used. The tag storage memoryand the tag sort/retrieve circuit are independently scalable andconfigurable. The granularity or accuracy of sorting the tagsdepends on the tag sort/retrieve circuit, while the size (wordwidth) and number of tags stored is decided by the size of RAMused for tag storage. The process of entering a new tag into thelinked list requires four clock cycles, specifically two read andtwo write cycles to the memory. The process is illustrated inFig. 9.
1) An “empty” linked list is maintained to provide easy accessto unused memory locations. One read access is requiredto find the next available unused location.
2) In the example, a tag with a value of 16 is being inserted.The search for tag 16 in the tree will return the location oftag 15 in the linked list. Link 15 is read from the list, whichalso has a pointer to link 17.
3) Link 15 is written back into the memory with a pointer tolink 16.
4) Link 16 is written into the memory with a pointer to link17, thus maintaining the order of the list and the continuityof the linked structure.
Initially all locations in the memory are empty and there areno links or pointers. Assuming there are memory locations, acounter is incremented from 0 to as new tags are added.Each new tag is allocated an address in the memory equal to thevalue of the counter, until the maximum counter value of isreached. Before then, a number of tags will have been servicedand removed from the memory. When this happens, the pointerto the next tag in the linked list is held in a register, but the linkitself is left unchanged and neither it nor its pointer is deleted.In this way, an “empty” list of unused links is maintained, witha pointer to the link at the head of the chain held in anotherregister. After the counter reaches there are effectivelytwo separate lists distributed through the memory—one is thelinked list of sorted tag values and the other is the empty list ofavailable memory locations.
Fig. 10 shows a simplified example of the state of the tagstorage memory soon after initialization. There are 12 memorylocations available. Five of these are being used to store thelinked list of sorted tags. Four show links that have beenremoved from the sorted list because their tags have been
Fig. 10. Linked list of tags and empty list, before initialization counter hasreached maximum capacity.
served and these now form the empty linked list. The final threememory locations have yet to be used. Assuming the locationsare numbered 0–11, the counter will currently read “9” and thenext tag to be added will be added in address location 9.
It is possible that the tag storage memory will simultaneouslyreceive a request to store a new tag at the same time as a re-quest to read and remove the smallest tag. This process can beachieved in the four clock cycles already allocated. Instead ofreading a link from the empty linked list, the smallest tag (“6”in Fig. 10) is accessed instead. Its forward link to the next valueis stored in a register so that the physical position of the smallesttag in the memory is always known. The link itself can be reusedto store the incoming new tag using the same process outlinedin Fig. 9.
One final, important property of the linked list arrangementshould be noted. Depending on the accuracy of the WFQ com-putation, tag values may be rounded off so that theoretically twoor more tags of the same value can exist in the scheduler at onetime. The sequential storage nature of the linked list allows afirst come first served policy to be applied in this case.
D. Translation Table
By using a linked list and a tree, the search and store func-tions of the sort/retrieve circuit are separated. The linked listcan, therefore, store any number of tags, independent from thegranularity of search possible with the tree. The translation tableprovides the essential bridge between these two components al-lowing them to be separately scalable. The table records thephysical memory address of each tag in the linked list and isaddressed using the tag value itself. For each possible tag valuethat the tree can store, there must be a corresponding entry in theaddress translation table. The size of translation table requiredcan therefore be expressed as follows:
(2)
where number of entries in translation table, width ofnodes in multi-bit tree, number of levels in tree.
The granularity of the tree search determines the size of thetranslation table, so the translation table can be considered partof the search function. As discussed Section III-C, two or moretags of the same value can exist. In this case, the translation tablewill track the most recent tag to have entered the linked list. It isthis property specifically that allows the search and store func-tions to be independent and separately scalable. Fig. 11 showshow duplicate entries are treated.

MCLAUGHLIN et al.: SCALABLE PACKET SORTING CIRCUIT FOR HIGH-SPEED WFQ PACKET SCHEDULING 789
Fig. 11. Inserting duplicate tag values.
In Step 1), the tree will search and find the position of thetag with the value “5” and the new tag will be inserted after theexisting tag “5.” When the second “5” is inserted into the list, thepointer in the translation table is changed from the position ofthe older “5” to the position of the newest “5.” In the second stepwhen tag “6” is to be added to the list the tree search will returnthe position of the newest tag “5” and the “6” will be insertedafter it. Following this method ensures that any result from thesearch tree will always be valid since the corresponding entryin the translation table will always indicate the most recentlyadded of any duplicate value.
IV. IMPLEMENTATION
The layout has been generated and post-layout verificationhas been carried out. Functional verification has been achievedusing field-programmable gate array (FPGA) prototyping of thehardware, including full deployment of the complete schedulerarchitecture described in Fig. 1. It is not intended that the circuitpresented operates as a standalone SoC in itself, rather it is a keycore and part of the scheduler presented. The circuit in Fig. 12was implemented using UMC 130-nm standard cell technology.The design was described in VHDL and synthesized using Syn-opsis Physical Compiler. Place and routing of the layout wascarried out with Cadence SoC Encounter. The post layout syn-thesis results are shown in Table II.
The chip layout shows eight large blocks of memory on theleft-hand side which store the address translation table and asmaller cluster of memory on the bottom right that stores thesearch tree. Most of the logic required for the chip is locatedalong the right side of the layout. The results show that the powerconsumption of the memory blocks is comparatively low, withthe majority due to the lookup logic and associated interconnect.The memory consists of 32 small distributed memory blockscomprising the bottom level of the tree and 8 larger blocks forthe address translation table.
By using external SRAM for the tag storage memory (seeFig. 1), it is possible to store and service 30 million packets atany instance in time. The number of sessions supported by thescheduler is scalable up to 8 million concurrent sessions (virtualqueues). With the SoC circuit generated, a throughput of over35.8 million packets per second is possible. Based on a con-servative estimate for an average IP packet size of 140 bytes,
Fig. 12. Physical layout of tag sort/retrieve circuit.
TABLE IIPOST LAYOUT SYNTHESIS RESULTS (CADENCE SOC ENCOUNTER)
the circuit can operate at line speeds of 40 Gb/s. Non-publishedwork extracted from datasheets and technical notes of semicon-ductor vendors offering WFQ based solutions to router vendors,indicate throughput rates for packet scheduling and traffic man-agement in the region of 5–10 Gb/s.1 2 Despite the unavailabilityof more specific relevant performance data, since this is a bot-tleneck area it can be suggested that our approach outperformsthe state of the art in the field by a factor of approximately 4.
V. CONCLUSION
This paper describes the implementation of a hardwarearchitecture for high performance IP traffic management.The fair queueing scheduling policy is based on well knownpacket scheduling algorithms conventionally implemented insoftware. This research focuses on a novel architecture usedto facilitate the operation of these algorithms at high speed.The architecture itself is not based on an algorithm, rather the
1[Online]. Available: https://www.amcc.com/MyAMCC/jsp/public/product-Detail/product_detail.jsp?productID=nPX5700
2[Online]. Available: http://www.idt.com/?id=120

790 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 16, NO. 7, JULY 2008
innovation lies in the derivation of an efficient circuit architec-ture comprised of distributed memories allowing parallel andpipelined processing.
A standard cell based circuit design has been presented thatenables high speed packet sorting for a WFQ based Internetpacket scheduler, implemented entirely in hardware and capableof supporting line speeds of 40 Gb/s. The novel architecture hasa number of key advantages over the previous state of the artin this area. In particular this includes a fixed and predictablelookup time and the ability to guarantee that the lowest tag valuewill always be found. Furthermore, having analyzed a range ofalternative options, including standard software arrangements, ithas been shown than the multi-bit tree-based design presentedoffers the optimum solution available, both in terms of speedand performance.
Based on overall performance metrics, such as the numbers ofvirtual queues, sessions and throughput supported, it can be es-timated that our solution can outperform the current technologyavailable in commercial routers by up to an order of magnitude.Classical physical layer products such as SONET/SDH support10–40 Gb/s, however network layer related products such as IPare currently in the market operating at 2.5 Gb/s per channel,usually running on 10–40 Gb/s physical layer. Products are cur-rently being developed for 10 Gb/s channels and in coming yearsit is believed that full 40 Gb/s channels on IP layer will be-come the benchmark. The presented architecture and its stan-dard cell implementation represent a state-of-the-art solution fornext generation 40 Gb/s traffic management. Due to the flexibledesign used, it is further scalable for future terabit QoS routertechnologies.
The impact of this unique architecture is that it is scalable interms of the number of tags, sessions, and packets supported,delivering high performance with low latency. It is thereforesuitable for throughput speeds beyond 40 Gb/s, which is be-yond current industry capabilities. This makes the design idealfor deployment in edge and core networks, where QoS is cur-rently only achieved with traffic aggregation. The functionalityoffered will allow traffic management to be delivered at highspeed using fair queueing to enable service level agreements(SLA) and service differentiation to be deployed. This enablingtechnology allows industrial demand for customized QoS to berealized at all network levels, from access right through to thecore.
REFERENCES
[1] A. Demers, S. Keshav, and S. Shenker, “Analysis and simulation of afair queuing algorithm.,” in Proc. ACM SIGCOMM, 1989, pp. 1–12.
[2] S. Gupta and M. Zarki, “Traffic classification on scheduling in ATMnetworks,” Telecommun. Syst. Model. Anal. Des. Manag., vol. 2, pt. 1,pp. 51–69, 1993.
[3] M. Shreedhar and G. Varghese, “Efficient fair queuing using deficitround robin,” ACM SIGCOMM, vol. 25, no. 4, pp. 231–242, Sep. 1995.
[4] S. Floyd and V. Jacobson, “Link-sharing and resource managementmodels for packet networks,” IEEE/ACM Trans. Netw., vol. 3, no. 4,pp. 365–386, Aug. 1995.
[5] J. C. R. Bennett and H. Zhang, “WF2Q: Worst-case fair weighted fairqueuing,” in Proc. INFOCOM, 1996, pp. 120–128.
[6] J. C. R. Bennett and H. Zhang, “Hierarchical packet fair queuing algo-rithms,” IEEE Trans. Netw., vol. 5, no. 5, pp. 675–689, Oct. 1997.
[7] D. Stidialis and A. Varma, “Efficient fair queuing algorithms forpacket-switched networks,” IEEE/ACM Trans. Netw., vol. 6, no. 2, pp.164–174, Apr. 1998.
[8] C. McKillen and S. Sezer, “A WFQ finishing tag computation archi-tecture and implementation,” in Proc. IEEE Int. SoC Conf., Sep. 2004,pp. 270–273.
[9] S. O’Kane, C. Toal, and S. Sezer, “Design and implementation of ashared buffer architecture for a gigabit ethernet packet switch,” in Proc.IEEE Int. SoC Conf., Sep. 2005, pp. 283–286.
[10] P. van Erode Boas, R. Kaas, and E. Zijlstra, “Design and implemen-tation of an efficient priority queue.,” Math. Syst. Theory, vol. 10, pp.99–127, 1977.
[11] S. Ramabhadran and J. Pasquale, “The stratified round robin scheduler:Design, analysis and implementation,” IEEE/ACM Trans. Netw., vol.14, no. 6, pp. 1362–1373, Dec. 2006.
[12] B. Bensaou, D. Tsang, and K. Chan, “Credit based fair queuing(CBFQ): A simple service scheduling algorithm for packet- switchednetwork.,” IEEE Trans. Netw., vol. 9, no. 5, pp. 591–604, Sep. 2001.
[13] F. Kupzog, K. McLaughlin, S. Sezer, H. Blume, T. Noll, and J. Mc-Canny, “Design and analysis of matching circuit architectures for aclosest match lookup,” in Proc. IEEE A-ICT, Guadeloupe, Feb. 2006,pp. 224–229.
[14] J. L. Rexford, A. G. Greenberg, and F. G. Bonomi, “Hardware-effi-cient fair queueing architecture for high-speed networks,” in Proc. IN-FOCOM, Mar. 1996, pp. 638–346.
[15] D. C. Stephens, J. C. R. Bennett, and H. Zhang, “Implementing sched-uling algorithms in high speed networks,” IEEE J. Sel. Areas Commun.,vol. 17, no. 6, pp. 1145–1158, Jun. 1999.
[16] A. Francini and F. Chiussi, “A weighted fair queueing scheduler withdecoupled bandwidth and delay guarantees for the support of voicetraffic,” in Proc. IEEE GLOBECOM, 2001, pp. 1821–1827.
[17] S. Suri, G. Varghese, and G. Chandramenon, “Leap forward vir-tual clock: a new fair queuing scheme with guaranteed delays andthroughput fairness,” in Proc. INFOCOM, 1997, pp. 558–566.
Kieran McLaughlin received the M.Eng. degreein electrical and electronic engineering and thePh.D. in advanced search and sort architecturesfor network processing from Queen’s UniversityBelfast, Northern Ireland, U.K., in 2003 and 2006,respectively.
He was with the System on Chip Research Groupunder Dr. Sakir Sezer within the ECIT Institute atQueen’s University, where he is currently a ResearchEngineer. His research interests include high speedlookup architectures for network processing in hard-
ware, including packet scheduling, classification, and address lookup.
Sakir Sezer received the Dipl. Ing. degree in elec-trical and electronic engineering from the RWTHAachen University, Aachen, Germany, and thePh.D. degree from the Queen’s University Belfast,Northern Ireland, U.K.
From 1995 to 1998, he worked with NortelNetworks and Amphion Semiconductors. As a StaffEngineer, he contributed to the development ofASICs, for access and high-speed communicationsystems. In October 1998, he joined Queen’s Uni-versity Belfast to lead research and teaching in the
areas of communication and digital systems. He is currently Research Directorand Head of the SoC Research Division in the School of Electronics, ElectricalEngineering, and Computer Science, Queen’s University.
Holger Blume received the Dipl. Ing. degree inelectrical engineering and the Ph.D. degree innonlinear fault tolerant interpolation of intermediateimages from the University of Dortmund, Dortmund,Germany, in 1992 and 1997, respectively.
From 1993 to 1998, he worked as a ResearchAssistant with the Working Group on Circuits andSystems for Information Processing of Prof. Dr. H.Schröder in Dortmund. In 1998, he joined the Chairof Electrical Engineering and Computer Systems ofProf. Dr. T. G. Noll, RWTH Aachen University, as a
Senior Engineer. His main research interests include the field of design spaceexploration and heterogeneous reconfigurable systems on chip for multimediaapplications.
Dr. Blume is chairman of the German chapter of the IEEE Solid State CircuitsSociety.

MCLAUGHLIN et al.: SCALABLE PACKET SORTING CIRCUIT FOR HIGH-SPEED WFQ PACKET SCHEDULING 791
Xin Yang received the B.Sc. degree in electronic sci-ence from the Nankai University, Nankai, P.R. China,in 1997, and the M.Eng. degree in electrical and com-puter engineering from National University of Singa-pore, Singapore, in 2004. She is currently working to-ward the Ph.D. degree in system-on-chip from ECITInstitute, Queen’s University Belfast, Northern Ire-land, U.K.
During her research towards the Master’s degree,she was also attached to the Institute of Microelec-tronics (IME), Singapore, where she worked on su-
perjunction MOSFET devices. From 1998 to 2000, she was with the BeijingLeyard Electronic Technology Co. Ltd, China, where she worked on the devel-opment of real-time image processing and dynamic display control system forLED display boards, using FPGAs and EPLDs. Her current research interestsinclude memory architectures for network processing systems.
Friederich Kupzog was born in Cologne, Germany,in 1979. He received the Diploma Engineer degreein electrical engineering and information technologyfrom RWTH Aachen University of Technology,Aachen, Germany, in February 2006. The focus ofhis studies was on communications and VLSI circuitdesign. His diploma thesis dealt with a WFQ packetsorter design.
He joined the Institute of Computer Technology,Vienna Technical University, Austria, Germany,in March 2006 as a Research Assistant. His new
research interest lies in applications of modern information and communicationtechnologies in the field of energy efficiency, renewable energy resources, andenergy transmission/distribution. Currently he is writing his Ph.D. thesis in thisarea.
Tobias G. Noll received the Ing. (grad.) degreein electrical engineering from FachhochschuleKoblenz, Koblenz, Germany in 1974, the Dipl-Ing.degree in electrical engineering from TechnicalUniversity of Munich, Munich, Germany, in 1982,and the Dr.-Ing. degree from Ruhr-University ofBochum, Bochum, in 1989.
From 1974 to 1976, he was with the Max-Planck-Institute of Radio Astronomy, Bonn, Germany, wherehe was active in the development of microwave wave-guide and antenna components. From 1976 to 1982,
he was with the MOS Integrated Circuits Department and from 1982 to 1984,he joined the MOS-Design Team Trainee Program, Siemens AG, Munich. Since1984, he was with the Corporate Research and Development Department ofSiemens and, since 1987, he headed a group of laboratories concerned with thedesign of algorithm specific integrated CMOS circuits for high-throughput dig-ital signal processing. In 1992, he joined the Electrical Engineering Faculty ofthe University of Technology RWTH Aachen, Aachen, Germany, where he is aProfessor, holding the chair of Electrical Engineering and Computer Systems.In addition to teaching, he is involved in research activities on VLSI architec-tural strategies for high-throughput digital signal processing, circuits concepts,and design methodologies with a focus on low power CMOS and deep submi-crometer issues, as well as on digital signal processing for medicine electronics.
Dr. Noll was a recipient of the ITG-Preis of the InformationstechnischeGesellschaft (ITG) in 1992. He served as an Associate Editor of the IEEEJOURNAL OF SOLID-STATE CIRCUITS and of the IEEE TRANSACTIONS ON
CIRCUITS AND SYSTEMS—PART I: REGULAR PAPERS, was on the US-ProgramSubcommittee on Signal Processing of ISSCC, and is a member of the Sci-entific and Technical Advisory Committee of the Supervisory Board of theForschungszentrum Jülich GmbH, Jülich, Germany. He is a member of theAcademy of Science of the state North-Rhine Westfalia.







![A Comprehensive Survey of Downlink Scheduling Algorithms ...disadvantage of the WFQ algorithm is that it does not consider the start time of a packet. The authors in [15] concluded](https://img.dokumen.tips/doc/110x75/5ea02dcd65903652b255499a/a-comprehensive-survey-of-downlink-scheduling-algorithms-disadvantage-of-the.jpg)





















