Embed Size (px)
Citation preview

A Robotic Cloud Advisory ServiceDeepak Poola, Jigar Kapasi, and Sreekrishnan Venkateswaran
IBM Corporation, India{depchand,kjigar,s krishna}@in.ibm.com
Abstract—Solution architects in large enterprises are taskedwith developing complex solutions based on client requirements.This process involves extensive skill, and knowledge of multipleproducts available within the company or in the market. Inaddition, they also need to know how different products inte-grate to form one comprehensive solution that answers clientrequirements. This approach is time consuming because thesolution space is vast. Further, the solution design process isusually not standardized, and an error in judgment can havenegative business implications. In this paper, we propose atwo-phased methodology where we first use a heuristic-driventechnique to automatically reduce the solution space into asmaller subset of viable solutions based on client requirements.These set of candidate solutions are then processed via a cognitiveconversational engine that a human domain expert can leverageto converge on the best-fit solution. While our method is generalenough to be applicable to multiple problem domains, we haveimplemented and tested our proposal for designing hybrid cloudarchitectures.
Index Terms—Hybrid cloud architecture, Decision Trees,Heuristic driven navigation, Natural Language Processing
I. INTRODUCTION
Solution architects working on large enterprise solutionsneed to develop complex hybrid cloud architectures that mustsatisfy a variety of functional and non-functional requirements.Designing a hybrid cloud is an iterative process, where anarchitect must make choices at several layers that combineto build an integrated solution. Typical solution layers in acloud, where a design choice must be made from a multitudeof options, include:
- Analyzing source workloads to determine the target hy-brid cloud platform. For example, can the requirementsbe met via an OpenStack implementation?
- Choosing the cloud orchestration platform. For instance,would VMWare vRealize [5] meet the orchestration au-tomation requirements?
- Cloud brokerage design. e.g., will IBM CloudMatrix [3]meet the multi-cloud provisioning requirements?
- Compute selection. e.g., which Virtual Machine (VM)instance types will map to the requirements of the work-loads that are being migrated?
- Storage selection. e.g., of the available on-premise blockstorage options, which ones meet the IOPS (Input/OutputOperations Per Second) requirements that enterpriseworkloads need?
- Network design. e.g., for network virtualization require-ments, which Software-Defined Network (SDN) productis the right choice, and how much custom work is needed
to integrate the chosen network overlay with the chosencloud orchestration platform?
- Performance. e.g., will the selected compute, network,and storage options meet the response time and through-put requirements of the application workloads in ques-tion?
- Resiliency. e.g., what is the right mechanism to replicatedata from a primary site to a secondary site in orderto meet Service Level Agreements (SLAs)? What is theexpected Recovery Time Objectives (RTO) in the eventof site-wide outage?
In addition to the above pertinent questions, there are otherareas such as migration considerations, cost considerations,security and compliance choices that determine the final cloudarchitecture.
Currently, architects develop these solutions based on priorexperience, reading knowledge sources, and consulting subjectmatter experts skilled in each solution layer alluded to above.However, given the number of solution layers, the myriadchoices at each layer and the inter-dependencies betweenthe solution components, this process is time consuming,error prone and non-standard. Further, making the wrongarchitectural choices translates to increased risk, cost and otheradverse business consequences.
To assist architects in this endeavor, we propose a methodol-ogy that brings in a rapid, automated and standardized processof creating a feasible and best-available-fit end-to-end solution.The overview of our proposed methodology is depicted in theFigure 1.
As the first step, the content in every solution area istranslated into decision trees. Each node in the tree representsa decision point that maps to one or more input customerrequirements. For example, a decision tree corresponding tothe storage solution layer will guide a user to choose theappropriate block storage option by making decisions onperformance requirements (IOPS, and read latency.), tenancyrequirements (dedicated vs. multi-tenant storage), capacityneeded, software-defined storage requirements, and so on.Such a decision tree is needed for each solution layer and isbuilt by associated subject matter experts as a one-time task.For instance, a network architect would build the decision treeencompassing the decision points and alternatives for the net-work layer of the cloud solution being built. Further, individualdecision trees from each solution layer are combined into amaster decision tree by logically linking the individual solutionlayer trees. Navigating a path of this master decision tree from

Heuristic-BasedAuto-pruner
ConversationalCognitiveRobot
Client Requirement and Use cases
RecommendedHybrid Cloud
Solution Architecture
ReducedSolution Tree
Fig. 1. Architectural Overview Diagram
TABLE IDESCRIPTION OF PARAMETERS
R Set of requirements (covering functional and Nonfunctional requirements). These are provided by the customer.
n Number of requirements provided.
m Number of nodes in the decision tree. M represents all nodes in the master decision tree.
p p represents the number, of all paths from the root to all leaf nodes in the master decision tree.
PATH It is a vector of CSE values for all the exhaustive p paths. PATHk represents a CSE of path k from the root to the leaf, Where1 6 k 6 p.
Qp,m Matrix with p rows (representing all paths) and m columns (representing all nodes). This matrix provides information about whichnodes belong to a particular path, where Qi,j given i 6 p and j 6 m, Qi,j = 1 if node j belongs to path i and Qi,j = 0 if node jdoes not belong to path i.
Sm,n Node weightage matrix with m rows (representing all nodes) and n columns (representing all requirements). A cell in this matrixrepresents a normalized value indicating how much a node i will satisfy a particular requirement Rj . Assuming this is on a scale of0 to 1. Where Si,j given i 6 m and j 6 n, Qi,j = 1 if node i does not satisfy requirement Rj and Qi,j = percentage of how muchnode i satisfies requirement Rj .
Tm,m Parent child association matrix with m rows and m columns. A cell in this matrix represents a either 0 or 1. Ti,j represents a cell inthe matrix, where node i is the parent node index and node j is child node index. If Ti,j is 0, it indicates the child node was selectedwhen the parent node did not meet a certain requirement. Hence, it’s weight should not be used to estimate the CSE. Else, for otherconditions the value is 1.
c(i, k) It is a function that returns the child node of node i, which is part of PATHk . Note that in a path, only one child will be selectedfor a parent node.
U Priorities given by the user for each Requirement. U is a set of priorities provided by the customer for U1 to Un, where 1 <= i <= n,such that Ui = 0 if customer explicitly does not want the requirement, Ui = 0.1 if customer has not specified the requirement, Ui =0.2-1 based on the customers priority for that requirement
the root node to a leaf node would result in a solution instance,covering all solution layers.
Nonetheless, navigating this master decision tree manuallyis not feasible due to its sheer size and complexity. Thecomplexity stems from the fact that there are a substantialnumber of leaf nodes in this tree. To estimate the numberof leaves, assume a K-ary tree (where K is the number ofarchitectural options at each node) of height H , where His proportional to the number of solution layers explainedearlier. The number of leaf nodes L, where each leaf is acandidate end-to-end architectural solution, is: L = K(H−1),which is a substantially large number, making the selectionof a path to a leaf from this large set, non-trivial. Assuminga typical end-to-end solution tree with H = 15, K = 5,the total number of leaf nodes is about 6 billion. A K-arygraph complicates the solution furthermore. Our proposedmethodology is described and illustrated for trees. However,this can be applied seamlessly for K-ary graphs as well.
We propose a two-step approach to tackle this computation-ally intensive problem. In Step 1, we propose a heuristic thatwill automatically reduce the master data tree into a smallertree composed of viable solution options that satisfy the givenrequirement constraints. In Step 2, we propose a cognitiveconversational interface with an architect’s participation, toprogressively shrink the decision tree from Step 1, to the mosteffective solution.
II. RELATED WORKS
Classification models are extensively used in several do-mains, such as, expert systems, information systems, frauddetection, retail marketing, remote sensing, etc. [17], [18].Classification models are realized through various approaches,such as, decision trees [15], neural networks [10], and geneticalgorithms [9]. Among these, decision trees are widely usedas they have reasonably higher accuracy [12] and are compu-tationally inexpensive [18].
Decision trees simplify complex decision-making process

into a group of simpler and easily consumable decisions [17].Decision-tree induction comprises of mainly three stages:creation of complete tree, pruning the tree, and post-processingthe pruned tree to achieve the required results [13].
In this paper, we focus mainly on the second stage. Here, weprune a decision tree to reduce the complex tree into a smallertree that can addresses the given input constraints. Pruning isperformed on tree-based models to judicious remove unnec-essary and redundant paths of the model, and thus developa simpler model with higher predictive accuracy [14]. Theobjective of pruning is to minimize error, loss minimization,probability estimation, and predictive accuracy [7], [14].
Several pruning methods have been proposed in the liter-ature. [20] use a rule simplification technique that utilizesthe truth level of a fuzzy rule. In [19] they propose apruning mechanism based on the minimum description lengthprinciple. Similarly, there are other pruning mechanisms suchas, cost-complexity [8], penalty pruning [11], error-basedpruning [15], [16].
Our work is different from these proposed mechanisms,as we use a heuristic based pruning methodology that issuited for expert systems and is not computationally intense.Additionally, the aim of our work is to prune to fine tune thechoices based on the input constraints.
III. PROPOSED METHODOLOGY
In this section, we explain our methodology to find thebest-fit hybrid cloud solution from a given exhaustive solutionspace. As previously mentioned, the first step is to use ourheuristic to prune the master decision tree into a sub-tree.The sub-tree is a combination of viable paths that satisfy themaximum set of customer requirements.
Before proceeding to describe the heuristic, we define a fewkey terms that are used in the rest of the paper:
1 Node: A node in the decision tree is a decision point thatmaps to one or more requirements.
2 Solution Layer and Master data tree: A solution layeris a design layer of the hybrid cloud solution being built.Solution layer examples include security, performance,availability, networking, compute, and storage. The mas-ter data tree is a decision tree combining the decisiontrees created for each solution layer.
3 Solution: A solution is an implementable choice in asolution layer made through a sequence of decisionpoints. Thus, n solution layers will have n solutions.
4 Requirement priority: A requirement is a superset offunctional and non-functional requirements. Requirementpriority is a client provided value indicating the impor-tance of a requirement to the client’s solution needs.
5 Node weight: Each node corresponds to a set of re-quirements that can be satisfied. Node weight is a vectorindicating the extent to which the node fulfills the list ofrequirements. It is assumed that the relationship betweenrequirements and nodes in the decision tree is many-to-many.
6 Path: A path is route from the root node to a leaf nodeof the master decision tree, which is a set of decisionpoints including solutions from different solution layers.The solutions inherent in a path combine to create anend-to-end hybrid cloud solution.
7 Combined Solution Estimate (CSE): CSE is the valuecomputed for a given individual path derived based onEquation 1. It signifies the extent to which a given pathmeets the requirements of a client.
A. Step 1: Heuristic to Auto-Prune the Master Decision Tree
Enterprise knowledge bases that are used to make archi-tectural choices across solution layers in an end-to-end cloudsolution, are translated into a master decision tree. The masterdecision tree is a combination of individual decision treescreated by subject matter experts for each solution layer (suchas compute, network, and storage). Each node in the treerepresents an architectural option that helps narrow downdesign choices and eventually navigates to a leaf node in thetree.
Once the master decision tree is generated, a mapping fromthe client requirements to nodes is created, which indicateswhether a given node meets one or more requirements. Thismapping is represented by the matrix Q in Equation 1.Additionally, the details of all the parameters are tabulatedin Table I.
PATHk =
m∑i=1
[Qk,i ∗
(( n∑j=1
(Si,j ∗ Uj
))∗ Ti,c(i,k)
)],
where 1 6 k 6 p(1)
Of the given requirements that a node meets, the degree offulfillment of each requirement can vary. To indicate this, wegenerate matrix S, which provides a weightage value express-ing the amount a particular node meets a given requirement, .A cell in matrix S ranges from 0 to 1, where the assigned valueis determined by the respective subject matter expert. Nodeweight is assigned per requirement based on historical dataand subject matter expertise, indicating the degree to whichthe node meets the requirement in question.
In addition, parent to child association is captured in matrixT . If a child node is selected in a path, because it does notaddress the parent node requirements, then the correspondingcell between the parent and child in matrix T is marked as0. This is done to negate the requirement weightage valueof the parent, as the chosen child does not meet the parentrequirements.
After populating matrices Q and S, we traverse the entiremaster data tree, automatically tagging all paths from the rootto leaf nodes, with the quantum of fulfillment of the clientrequirements in question. These solution paths are stored inthe PATH vector.
Using the input customer requirement priority representedby vector U , the requirement-to-node mapping matrix Q, and

Fig. 2. Sample decision tree
node weightage matrix S, we calculate the combined solutionestimate (CSE) for all paths in PATH , as per equation 1. Thecombined solution estimate for each PATH is a value thatsignifies the extent to which the path in question meets thecustomer requirements. Higher the CSE of a path, the betterit meets customer requirements.
From the derived PATH values, a new vector P̂ATHis then deduced. P̂ATH consists of a subset of paths fromPATH that meet a certain threshold of customer require-ments. For example, each path in P̂ATH has a CSE valuegreater than a pre-defined threshold and where the differencebetween two CSE values are within a pre-defined range. Thevector P̂ATH is then passed to Step 2 in our methodologywhich uses a conversational interface to help solution archi-tects further narrow choices to finalize solution.
1) Example Illustration: Sample basic decision tree ispresented in the Figure 2, which is used to illustrate ourmethodology.
Given, the decision tree, we have the following: the numberof customer requirements are n = 3, the number of nodes inthe decision tree are m = 5, and the number of exhaustivepaths in the decision tree are p = 3.
Exhaustive PATHS for the tree are:PATH1 = A→ BPATH2 = A→ C → DPATH3 = A→ C → E
The node to paths mapping for the Matrix Qp,m will be asfollows, as shown in Table II.
TABLE IIMATRIX Q
A B C D E
P1 1 1 0 0 0
P2 1 0 1 1 0
P3 1 0 1 0 1
The values for Matrix Sm,n as shown in Table III.The priorities in Matrix Un are provided by the client as
shown in Table IV.The parent child association are provided in the Table V.
TABLE IIINODE WEIGHTAGE MATRIX Sm,n
R1 R2 R3
A 0 0.2 0.3
B 0 1 0.3
C 0.5 0 0
D 0.5 0.4 0.1
E 0.2 0 0.6
TABLE IVCLIENT PRIORITIES VECTOR U
R1 R2 R3
0.8 0 0.3
Here, we illustrate by calculating the weightage of PATH2
path 2:Q2,m = [ 1, 0, 1 , 1, 0 ]
Similarly,SA,n = [0, 0.2, 0.3]SB,n = [0, 1, 0.3]SC,n = [0.5, 0, 0]SD,n = [ 0.5, 0.4, 0.1]SE,n = [ 0.2, 0, 0.6]
Further, the parent node association matrix provides, TA,B
= 1, and TB,C = 1.Combined Solution Estimate of PATH2 is according to the
Equation 1 : = (1∗(0∗0.8+0.2∗0+0.3∗0.3)∗1)+(0∗(0∗0.8+1∗0+0.3∗0.3)∗1)+(1∗(0.5∗0.8+0∗0+0∗0.3)∗1)+(1∗(0.5∗0.8+0.4∗0+0.1∗0.3)∗1)+(0∗(0.2∗0.8+0∗0+0.6∗0.3)∗1)= 0.9 + 0 + 0.4 + 0.3 + 0
Therefore, CSE of PATH2 is 1.6. Similarly, CSE of allpaths are calculated and based on the threshold P̂ATH isdeduced. The P̂ATH is passed to the Step 2 to get the finalsolution.
B. Step 2: Cognitive Conversational Engine to Converge toSolution Leaf
Using the heuristic in Step 1, we pruned the master decisiontree into a viable sub-tree that is consumable by an architectusing a conversational interface. In Step 1, our heuristic
TABLE VPARENT CHILD ASSOCIATION MATRIX Tm,m
A B C D E
A 1 0 1 1 1
B 1 1 1 1 1
C 1 1 1 1 0
D 1 1 1 1 1
E 1 1 1 1 1

Solution Layer
Decision Tree
Legend
Cloud Broker
WorkloadAssessment
Network
Compute
Storage
Performance
Security
Orchestration
Fig. 3. Master Decision Tree
captured the candidate feasible solutions that satisfy the cus-tomer requirements from the exhaustive solution space. Thisnarrowed solution space now lends itself to a conversationalexchange, that we propose implementing as an interactiverobotic architect, leveraging cognitive and natural languageprocessing (NLP) abilities embedded in tools such as IBMWatson [4].
Using this conversational interface, an architect can itera-tively explore alternatives and decisions leading to solutionsthat meet customer requirements. This exploration would beinfeasible without the heuristic in Step 1, as the solution spacewould be extremely large to be presented as a conversationalinterface. As part of the human interaction, we propose usingcognitive services such as NLP to help better understand andanalyze user responses. With aid from this robotic architect, acloud architect can use his insights of the business context, andhis prior experience to pick the best candidate among viablesolutions.
Section IV in this paper describes our implementation ofthe proposed methodology using a client use case.
IV. EVALUATING THE ROBOTIC CLOUD ADVISOR
In order to evaluate our proposal we considered a real lifeclient scenario. To address the client’s hybrid cloud require-ments, we used an IBM knowledge base that provides detailedguidance on how to build hybrid cloud solutions, coveringconsiderations and alternatives at each cloud solution layer.This information was converted into solution layer decisiontrees which were combined into a master decision tree.
Compute
Network
Cloud Management Platform
Heu
ristic
Con
vers
atio
n En
gine
Fig. 4. Sub-TreeP̂ATH derived from Master Decision Tree
Figure 3 shows abstract representation of the master solutiontree. We applied our heuristic described in Step 1 to this masterdecision tree. The detailed explanation of the heuristic alongwith an example illustration is described in Section III-A. Inthis section, we consider a client use case with a k-ary tree,where K = 2, and depth H = 9, therefore the number of leafnodes in the graph were, 28 = 256, which is the number ofall possible paths, p. The number of nodes in our tree were,m = 29−1 = 511. We have highlighted the dimensions of allthe matrices and shown the application of the heuristic for aparticular client use case, with the summary of requirementsR (i.e., n = 5) as shown below:
- The workload to be hosted on the cloud was missioncritical.
- Security and regulatory requirements.- The compute hardware deployed had to be certified for
use by the cloud management platform vendor.- Software defined networking was needed.- Software defined storage was a requirement.Given these requirements, we computed matrix Q, which
had 256 rows and 511 columns, Q256,511. Next, matrix S wascomputed, which had 511 rows and 5 columns, S511,5. Further,we took user weightages for the 5 client requirements in thevector U , and then computed the matrix T which representedthe parent-child association. Next, the heuristic was applied tocalculate the CSE of all PATHs, following which P̂ATH wasderived.
The reduced subtree, represented by P̂ATH is shown inthe Figure 4. It consisted of four viable paths. These paths
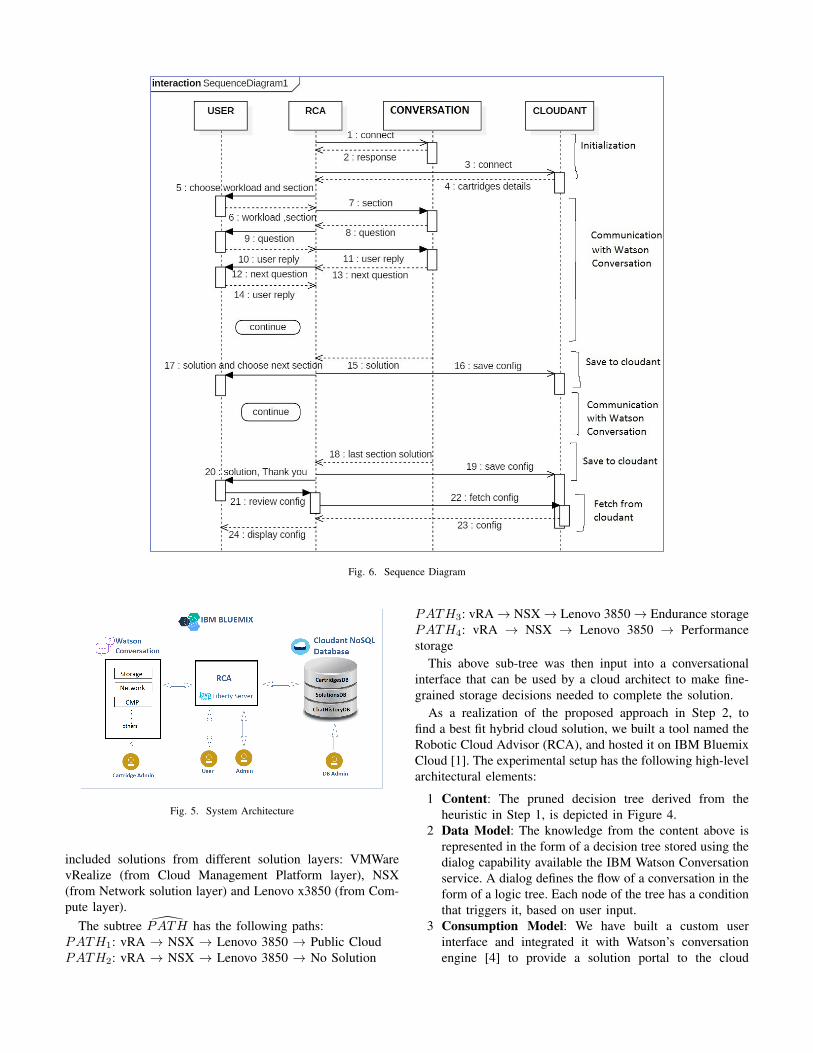
Fig. 6. Sequence Diagram
Fig. 5. System Architecture
included solutions from different solution layers: VMWarevRealize (from Cloud Management Platform layer), NSX(from Network solution layer) and Lenovo x3850 (from Com-pute layer).
The subtree P̂ATH has the following paths:PATH1: vRA → NSX → Lenovo 3850 → Public CloudPATH2: vRA → NSX → Lenovo 3850 → No Solution
PATH3: vRA→ NSX→ Lenovo 3850→ Endurance storagePATH4: vRA → NSX → Lenovo 3850 → Performancestorage
This above sub-tree was then input into a conversationalinterface that can be used by a cloud architect to make fine-grained storage decisions needed to complete the solution.
As a realization of the proposed approach in Step 2, tofind a best fit hybrid cloud solution, we built a tool named theRobotic Cloud Advisor (RCA), and hosted it on IBM BluemixCloud [1]. The experimental setup has the following high-levelarchitectural elements:
1 Content: The pruned decision tree derived from theheuristic in Step 1, is depicted in Figure 4.
2 Data Model: The knowledge from the content above isrepresented in the form of a decision tree stored using thedialog capability available the IBM Watson Conversationservice. A dialog defines the flow of a conversation in theform of a logic tree. Each node of the tree has a conditionthat triggers it, based on user input.
3 Consumption Model: We have built a custom userinterface and integrated it with Watson’s conversationengine [4] to provide a solution portal to the cloud

architect.4 Cognitive Model: : The implementation uses Watson’s
Natural Language Understanding capabilities to processrequirements. Our implementation uses architect feed-back as training data to improve the design and navigationof the decision tree.
This custom RCA application is implemented using PaaSservices from IBM Watson [4], WebSphere ApplicationServer [6], and Cloudant databases [2] as shown in Figure 5.While our implementation used these components, the samecan be implemented using similar services from other vendors.Figure 6 depicts a control flow in the RCA application. Duringinitialization, decision trees available in Cloudant are popu-lated into the RCA portal. The user chooses a decision tree ofhis choice, and through the conversational service navigatesthe tree to pick a solution. The solution, the conversation, anduser feedback is saved into Cloudant for further analysis.
With our implementation, we were able to encapsulatethe complexity of hybrid cloud solution design options intodecision trees representing the myriad architectural alternativesavailable at every solution layer. We were able to automaticallytraverse the large master decision tree to reduce it to a setof viable paths that represent potential solutions best meetingclient requirements. These were then presented to a solutionarchitect via a user-friendly conversational interface to arriveat a final best-fit hybrid cloud solution.
V. CONCLUSIONS AND FUTURE WORK
In this paper, we have proposed a methodology that involvesa heuristic and a framework that aid solutions architects to de-vise complex hybrid solution. Our proposed heuristic, traversesthrough a large graph to find viable solutions that best addressthe client requirements. The framework utilizes these viablesolutions to translate them into conversation like service, thata solution architect can use to navigate across to derive theeffective solution for a given set of requirements. We furtherhave implemented this framework using IBM Bluemix [1]infrastructure with the help of Watson services [4]. As a partof our future work, we will extend this interface to add afeedback mechanism, which will use analytics and machinelearning to develop better solutions.
ACKNOWLEDGMENT
We would like to thank Subham Parekh, Jaishree Uprety,and Rajshree Deshmukh for assisting us in developing theCognitive Conversational Engine.
REFERENCES
[1] Bluemix. https://www.ibm.com/cloud-computing/bluemix/what-is-bluemix, 2017. [Online; accessed 1-August-2017].
[2] Cloudant Database. https://www.ibm.com/analytics/us/en/technology/cloud-data-services/cloudant/, 2017. [Online; accessed 1-August-2017].
[3] IBM Cloud Broker. https://www.ibm.com/in-en/marketplace/cloud-brokerage-solutions, 2017. [Online; accessed 1-August-2017].
[4] IBM Watson. https://www.ibm.com/watson/, 2017. [Online; accessed1-August-2017].
[5] VMware vRealize. https://www.vmware.com/in/products/vrealize-automation.html, 2017. [Online; accessed 1-August-2017].
[6] Websphere. https://developer.ibm.com/wasdev/websphere-liberty/, 2017.[Online; accessed 1-August-2017].
[7] Jeffrey P. Bradford, Clayton Kunz, Ron Kohavi, Cliff Brunk, andCarla E. Brodley. Pruning decision trees with misclassification costs,pages 131–136. Springer Berlin Heidelberg, Berlin, Heidelberg, 1998.
[8] Leo Breiman, Jerome Friedman, Charles J Stone, and Richard A Olshen.Classification and regression trees. CRC press, 1984.
[9] DE Goldberg. Genetic algorithms in search, optimization, and machinelearning, 1989.
[10] R. Lippmann. An introduction to computing with neural nets. IEEEASSP Magazine, 4(2):4–22, Apr 1987.
[11] Yishay Mansour. Pessimistic decision tree pruning based on treesize. In MACHINE LEARNING-INTERNATIONAL WORKSHOP THENCONFERENCE-, pages 195–201. MORGAN KAUFMANN PUBLISH-ERS, INC., 1997.
[12] Donald Michie, D. J. Spiegelhalter, C. C. Taylor, and John Campbell,editors. Machine Learning, Neural and Statistical Classification. EllisHorwood, Upper Saddle River, NJ, USA, 1994.
[13] John Mingers. An empirical comparison of pruning methods for decisiontree induction. Machine Learning, 4(2):227–243, Nov 1989.
[14] Cristina Olaru and Louis Wehenkel. A complete fuzzy decision treetechnique. Fuzzy Sets and Systems, 138(2):221 – 254, 2003.
[15] J. Ross Quinlan. C4.5: Programs for Machine Learning. MorganKaufmann Publishers Inc., San Francisco, CA, USA, 1993.
[16] J.R. Quinlan. Simplifying decision trees. International Journal of Man-Machine Studies, 27(3):221 – 234, 1987.
[17] S. R. Safavian and D. Landgrebe. A survey of decision tree classifiermethodology. IEEE Transactions on Systems, Man, and Cybernetics,21(3):660–674, May 1991.
[18] Anurag Srivastava, Eui-Hong Han, Vipin Kumar, and Vineet Singh.Parallel Formulations of Decision-Tree Classification Algorithms, pages237–261. Springer US, Boston, MA, 2002.
[19] Xizhao Wang, Bin Chen, Guoliang Qian, and Feng Ye. On theoptimization of fuzzy decision trees. Fuzzy Sets and Systems, 112(1):117– 125, 2000.
[20] Yufei Yuan and Michael J. Shaw. Induction of fuzzy decision trees.Fuzzy Sets and Systems, 69(2):125 – 139, 1995.


















![Morze pracy[1]poola](https://img.dokumen.tips/doc/110x75/55503740b4c905de2d8b5315/morze-pracy1poola.jpg)










