Embed Size (px)
Citation preview

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 11
A Product Feature Inference Model For Mining Implicit Customer Preferences Within Large Scale
Social Media Networks
DETC2015-47225
Suppawong TuarobComputer Science and Engineering
Conrad S. TuckerEngineering Design and Industrial and Manufacturing Engineering
The Pennsylvania State University
{suppawong,ctucker4}@psu.edu
Monday, August 03, 201510:00 AM-11:40 AM

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 2
Overview
• Motivation
• Problem Statement
• Related Literature
• Methodology
• Case Study
• Results
Introduction

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 3
Introduction: Social Media
Introduction

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 4
Introduction : Usage of Social Media Data in Product Design
• Identify notable product features.
• Predicting product demands.
• Estimate domain-wide popularity.
• Identify lead users and potential latent (“hidden”) product features.
Introduction

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 5
Introduction: Implicit Information in Social Media
“Implicit speech” is a
sophisticated form of language usage in which the speaker
conveys the information in an implicit manner, and is
becoming a standard of social media usage.
Explicit:
“Dell venue pro size is perfect. not
too small not to big.”
Implicit (Sarcasm):“I actually believed all that crazy
stuff about the IPhone 5 when really its just longer with a bigger screen.”
Implicit (Vagueness):“Here’s a phone I wouldn't mind
getting….NokiaN9”
Introduction
Tuarob, Tucker http://www.engr.psu.edu/datalab/ 6
Motivation: Implicit Information in Social Media
Motivation
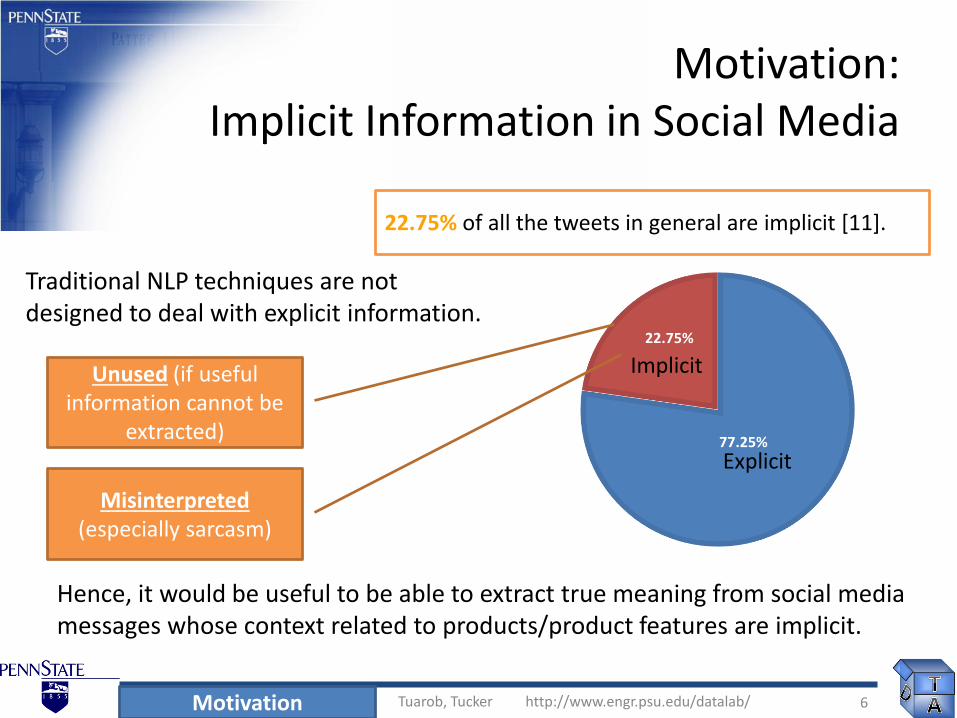
22.75% of all the tweets in general are implicit [11].
Traditional NLP techniques are not designed to deal with explicit information.
77.25%
22.75%
Implicit
Explicit
Unused (if useful information cannot be
extracted)
Misinterpreted(especially sarcasm)
Hence, it would be useful to be able to extract true meaning from social media messages whose context related to products/product features are implicit.

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 7
Problem Definition
We present a mathematical model based on the heterogeneous co-word network patterns in order to translate implicit context towards a particular product or product feature into the explicit equivalence
“I can't express how much I love the price of iPhone 5 on black Friday”
iPhone 5 is cheap
on Black Friday.
Nouns Verbs Adjectives
today sale price
need wait buy
good free cheap
Sentiment = Neutral (0)[can’t] -1[love] +1
Sentiment = Positive (3)
Ideally:
This work:Translator
Problem Definition

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 8
Related Literature
• Sentiment analysis • Sentiment quantification (Thelwall et al. [22])
• Profile influence on sentiment (Kucuktunc et al. [23])
• Knowledge extraction• Mining tips in Yahoo! Answers (Weber et al.
[24])
• Mining disease related information (Paul and Dredze [25], Tuarob et al. [3,4])
• Mining trends [28–30]
• Implicit information processing• Sarcasm detection [12,31,32]
Assume information is explicit.
Does not translate into equivalent explicit form.
Literature
Tuarob, Tucker http://www.engr.psu.edu/datalab/ 9
Methodology: Overview
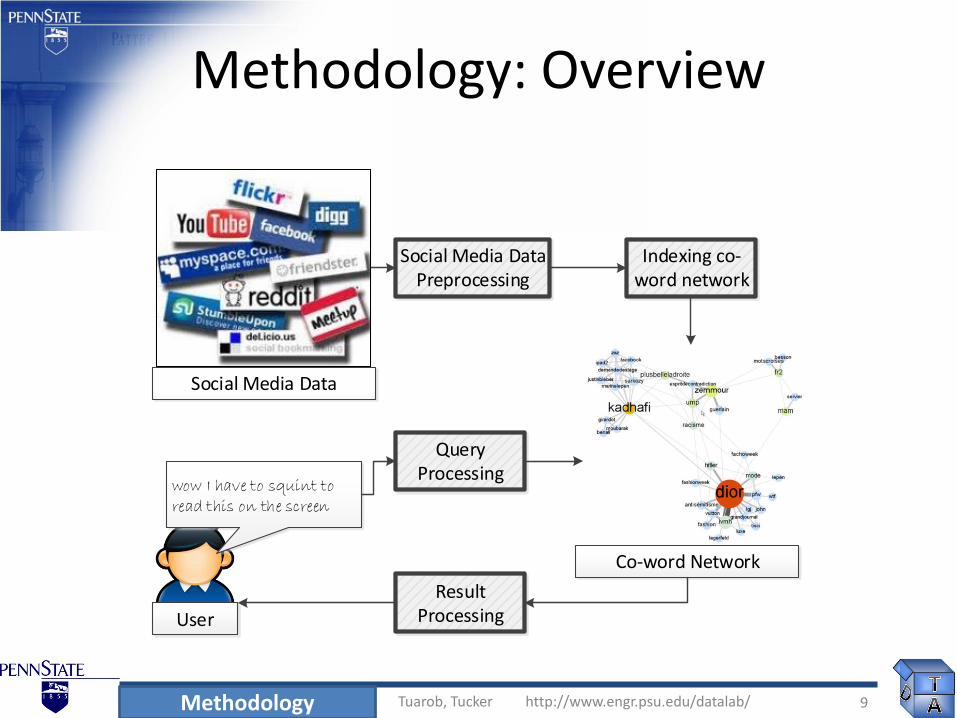
Social Media DataPreprocessing
Social Media Data
Indexing co-word network
Query Processing
Result Processing
Co-word Network
User
wow I have to squint to read this on the screen
Methodology

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 10
Methodology: Co-word Network
A co-word (word co-occurrence) network is an undirected,
weighted graph where each node is a pair of ⟨Word,POSTag⟩ (e.g., ⟨squint,V⟩ and ⟨iPhone 4,PRODUCT⟩) that represents a POS tagged word, and each edge weight is the frequency of co-occurrence.
Intuition: Though a message may be implicit, the similar combination of the words may have been used by other users who express their messages more explicitly.
Methodology

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 11
Methodology: Data Preprocessing
Social Media DataPreprocessing
Social Media Data
Indexing co-word network
Query Processing
Result Processing
Co-word Network
User
wow I have to squint to read this on the screen
1. Extracting sentiment. [-5, +5]2. Detect target product. 3. Part of speech tagging. (for
disambiguation purposes)4. Cleaning: lowercasing, removing hashtags,
usernames, hyperlinks, and stopwords.5. Extract product features.
@rebecca1234 I have to squint the screen to read this on Nokia N9. :( @ O V P V D N P V D P PROD E
POS Tagged Words:{<have, V>, <squint, V>, <screen, N>,
<read, V>, <Nokia N9, PROD>}
Product: Nokia N9
Feature: screen
Sentiment: -1
Methodology

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 12
Methodology: Co-Word Network Generation
Social Media DataPreprocessing
Social Media Data
Indexing co-word network
Query Processing
Result Processing
Co-word Network
User
wow I have to squint to read this on the screen
For each message:1. Convert each tagged word into a node.2. Edge weight is incremented if two nodes
co-occur in the same message.
POS Tagged Words:{<have, V>, <squint,
V>, <screen, N>, <read,
V>, <Nokia N9, PROD>}
PROD:Nokia N9V:have
N:screenV:read
V:squint
1
1
1
1
1 1
1
1
1
1
1
Methodology

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 13
Methodology: Query Processing
Social Media DataPreprocessing
Social Media Data
Indexing co-word network
Query Processing
Result Processing
Co-word Network
User
wow I have to squint to read this on the screen
A query is a free text message with implicit content. Ex. “I can’t express how much I love the price of iPhone 5 on black Friday”
1. User input a textual query Qtext
2. QText is transformed into a compound query Q, by extracting nodes from QText and combining them into a set.
QText: @rebecca1234 I have to squint the screen to read this on Nokia N9. :( @ O V P V D N P V D P PROD E
Q:{<have, V>, <squint, V>, <screen, N>, <read, V>, <Nokia N9, PROD>}
Methodology

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 14
Methodology: Result Processing
Social Media DataPreprocessing
Social Media Data
Indexing co-word network
Query Processing
Result Processing
Co-word Network
User
wow I have to squint to read this on the screen
A result is a set of top K words relevant to the query Q.
Methodology

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 15
Methodology: Sample Query
Methodology
Graphical example of the words co-occurring with the query compound: {have, squint, screen, read, Nokia}

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 16
Case Study: Smartphones and Twitter Data
• Product Domain (Smartphones)
– 27 smartphone models
• Social Media Data (Twitter Messages)
– 2.1 billions tweets in the United States during the period of 31 months, from March 2011 to September 2013.
Case Study

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 17
Monthly distribution of Twitter discussion of each smartphonemodel across the 31 month period of data collection
Case Study

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 18
Case Study: Co-word Network
95,999 nodes2,288,723 edgesAverage Degree = 47.7Average Utilization = 160

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 19
Case Study: Sample Results
Sample Number TweetTarget Product
FeatureManual Context Interpretation
Manual Sentiment Evaluation
Sentiment Level (From Implicit Context)
Explicit TranslationSentiment Level (From
Translated Explicit Context)Nouns Verbs Adjectives
1I can't express how much I love the price of iPhone 5 on black Friday price Price is cheap. Positive Neutral (0)
today sale price
need wait buygood free
cheapPositive (3)
2I have to squint the screen to read this on Nokia N9 screen
Screen should be bigger.
Negative Neutral (0)screen angle
iphoneneed fix upgrade
bigger larger extra
Negative (-1)
3
@markgurman I passed on the iPhone 5 to get a FINGERPRINT SENSOR?! Apple can't innovate shit.
fingerprint sensor
Fingerprint sensor is not ground-breaking.
Negative Neutral (0)fingerprint
sensor scannerneed wait
upgradewrong bad
disappointingNeutral (0)
4
At last my iPhone 5 is lighter. It was about time apple listened to our complaints of sore arms due to its weight
weight iPhone 5 is light. Positive Negative (-1)apple screen
weightneed wait lose happy light thin Negative (-1)
5
I LOVE when my iPhone 5 charger stops working #deepsarcasm Have to use my moms iPhone
charger Charger is broken. Negative Positive (1)charger battery
lifehate wait
dislikebroken stupid
badNegative (-1)
Sentiment computed for the implicit sample messages tend to be neutral (SentimentLevel ≈ 0).
Such messages tend to have equally high volumes of both Positive and Negative scores, causing the Emotion Strength score to converge to 0.

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 20
Conclusions
• We presented a mathematical model for mapping an implicit product related social media message to a set of words which infer its explicit meaning.
• We illustrated the efficacy on a manual sample tweets messages related to smartphone products.

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 21
Future Directions
• We still need to validate the methodology on a much larger dataset.
– Need hand-labelled ground truth data
– Need automatic evaluation
• Need to be able to automatically identify implicit messages
– Can implement existing methods, which may or may not work on social media settings.

Tuarob, Tucker http://www.engr.psu.edu/datalab/ 22
References[1] Sakaki, T., Okazaki, M., and Matsuo, Y., 2010. “Earthquake shakes twitter users: real-time event detection by social sensors”. In Proceedings of the 19th international conference on World wide web, WWW ’10, ACM, pp. 851– 860. [2] Caragea, C., McNeese, N., Jaiswal, A., Traylor, G., Kim, H., Mitra, P., Wu, D., Tapia, A., Giles, L., Jansen, B., et al., 2011. “Classifying text messages for the haiti earthquake”. In Proceedings of the 8th International Conference on Information Systems for Crisis Response and Management (ISCRAM2011). [3] Tuarob, S., Tucker, C. S., Salathe, M., and Ram, N., 2014. “An ensemble heterogeneous classification methodology for discovering health-related knowledge in social media messages”. Journal of Biomedical Informatics. [4] Tuarob, S., Tucker, C. S., Salathe, M., and Ram, N., 2013. “Discovering health-related knowledge in social media using ensembles of heterogeneous features”. In Proceedings of the 22Nd ACM International Conference on Conference on Information & Knowledge Management, CIKM ’13, ACM, pp. 1685–1690. [5] Bollen, J., Mao, H., and Zeng, X., 2011. “Twitter mood predicts the stock market”. Journal of Computational Science, 2(1), pp. 1–8. [6] Zhang, X., Fuehres, H., and Gloor, P., 2012. “Predicting asset value through twitter buzz”. Advances in Collective Intelligence 2011, pp. 23–34. [7] Tuarob, S., and Tucker, C. S., 2013. “Fad or here to stay: Predicting product market adoption and longevity using large scale, social media data”. In Proc. ASME 2013 Int. Design Engineering Technical Conf. Computers and Information in Engineering Conf.(IDETC/CIE2013). [8] Tuarob, S., and Tucker, C. S., 2015. “Quantifying product favorability and extracting notable product features using large scale social media data”. Journal of Computing and Information Science in Engineering. [9] Tuarob, S., and Tucker, C. S., 2014. “Discovering next generation product innovations by identifying lead user preferences expressed through large scale social media data”. In Proceedings of ASME International Design Engineering Technical Conferences & Computers and Information in Engineering Conference 2014, ASME. [10] Tuarob, S., and Tucker, C. S., 2015. “Automated discovery of lead users and latent product features by mining large scale social media networks”. Journal of Mechanical Design. [11] Maynard, D., and Greenwood, M. A., 2014. “Who cares about sarcastic tweets? investigating the impact of sarcasm on sentiment analysis”. In Proceedings of LREC. [12] Tsur, O., Davidov, D., and Rappoport, A., 2010. “Icwsm-a great catchy name: Semi-supervised recognition of sarcastic sentences in online product reviews.”. In ICWSM. [13] Davidov, D., Tsur, O., and Rappoport, A., 2010. “Semisupervised recognition of sarcastic sentences in twitter and amazon”. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Association for Computational Linguistics, pp. 107–116. [14] Muecke, D. C., 1982. Irony and the Ironic. Methuen. [15] Gibbs, R.W., 1986. “Onthepsycholinguisticsofsarcasm.”. Journal of Experimental Psychology: General, 115(1), p. 3. [16] Gibbs, R. W., and Colston, H. L., 2007. Irony in language and thought: A cognitive science reader. Psychology Press. [17] Asur, S., and Huberman, B. A., 2010. “Predicting the future with social media”. In Web Intelligence and Intelligent Agent Technology (WI-IAT), 2010 IEEE/WIC/ACM International Conference on, Vol. 1, IEEE, pp. 492–499. [18] Stone, T., and Choi, S.-K., 2014. “Visualization tool for interpreting user needs from user-generated content via text mining and classification”. In ASME 2014 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, American Society of Mechanical Engineers, pp. V02AT03A009– V02AT03A009. [19] Zhao, W. X., Jiang, J., Weng, J., He, J., Lim, E.-P., Yan, H., and Li, X., 2011. “Comparing twitter and traditional media using topic models”. In Advances in Information Retrieval. Springer, pp. 338–349. [20] YaJuan, D., WEIF uRu, C. Z., Heung, Z. M., and SHUM, Y., 2012. “Twitter topic summarization by ranking tweets using social influence and content quality”. In Proceedings ofthe24thInternationalConferenceonComputationalLinguistics, pp. 763–780. [21] Wang, Y., Wu, H., and Fang, H., 2014. “An exploration of tie-breaking for microblog retrieval”. In Advances in Information Retrieval. Springer, pp. 713–719. [22] Thelwall, M., Buckley, K., and Paltoglou, G., 2011. “Sentiment in twitter events”. J. Am. Soc. Inf. Sci. Technol., pp. 406–418. [23] Kucuktunc, O., Cambazoglu, B. B., Weber, I., and Ferhatosmanoglu, H., 2012. “A large-scale sentiment analysis for yahoo! answers”. In Proceedings of the fifth ACM international conference on Web search and data mining, WSDM ’12, ACM, pp. 633–642. [24] Weber, I., Ukkonen, A., and Gionis, A., 2012. “Answers, not links: extracting tips from yahoo! answers to address how-to web queries”. In Proceedings of the fifth ACM international conference on Web search and data mining, WSDM ’12, ACM, pp. 613–622. [25] Blei, D. M., Ng, A. Y., and Jordan, M. I., 2003. “Latent dirichlet allocation”. J. Mach. Learn. Res., 3, Mar., pp. 993–1022. [26] Paul, M. J., and Dredze, M., 2011. A model for mining public health topics from twitter. Tech. rep. [27] Paul, M. J., and Dredze, M., 2011. “You are what you tweet: Analyzing twitter for public health.”. In ICWSM, pp. 265–272. [28] Ramage, D., Dumais, S. T., and Liebling, D. J., 2010. “Characterizing microblogs with topic models.”. ICWSM, 10, pp. 1–1. [29] Prier, K. W., Smith, M. S., Giraud-Carrier, C., and Hanson, C. L., 2011. “Identifying health-related topics on twitter”. In Social computing, behavioral-cultural modeling and prediction. Springer, pp. 18–25. [30] Jin, O., Liu, N. N., Zhao, K., Yu, Y., and Yang, Q., 2011. “Transferring topical knowledge from auxiliary long texts for short text clustering”. In Proceedings of the 20th ACM international conference on Information and knowledge management, ACM, pp. 775–784. [31] Gonz?lez-Ib?? nez, R., Muresan, S., and Wacholder, N., 2011. “Identifying sarcasm in twitter: a closer look”. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2, Association for Computational Linguistics, pp. 581–586. [32] Reyes, A., Rosso, P., and Veale, T., 2013. “A multidimensional approach for detecting irony in twitter”. Language Resources and Evaluation, 47(1), pp. 239–268. [33] Ahlqvist, T., 2008. Social media roadmaps: exploring the futures triggered by social media. VTT. [34] Thelwall, M., Buckley, K., Paltoglou, G., Cai, D., and Kappas, A., 2010. “Sentiment in short strength detection informal text”. J. Am. Soc. Inf. Sci. Technol., 61(12), Dec., pp. 2544–2558. [35] Guo, W., Li, H., Ji, H., and Diab, M. T., 2013. “Linking tweets to news: A framework to enrich short text data in social media.”. In ACL (1), Citeseer, pp. 239–249. [36] Ramaswamy, S. “Comparing the efficiency of two clustering techniques”. [37] Fox, E., 2008. Emotion science: cognitive and neuroscientific approaches to understanding human emotions. Palgrave Macmillan. [38] Cutting, D., Kupiec, J., Pedersen, J., and Sibun, P., 1992. “A practical part-of-speech tagger”. In Proceedings of the Third Conference on Applied Natural Language Processing, ANLC ’92, Association for Computational Linguistics, pp. 133–140. [39] Ozgur, A., Cetin, B., and Bingol, H., 2008. “Co-occurrence network of reuters news”. International Journal of Modern Physics C, 19(05), pp. 689–702. [40] Jia, S., Yang, C., Liu, J., and Zhang, Z., 2012. “An improved information filtering technology”. In Future Computing, Communication, Control and Management. Springer, pp. 507–512. [41] Tuarob, S., Mitra, P., and Giles, C. L., 2012. “Improving algorithm search using the algorithm co-citation network”. In Proceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries, JCDL ’12, ACM, pp. 277–280. [42] Tuarob, S., Bhatia, S., Mitra, P., and Giles, C., 2013. “Automatic detection of pseudocodes in scholarly documents using machine learning”. In Document Analysis and Recognition (ICDAR), 2013 12th International Conference on, pp. 738–742. [43] Evans, D. A., Handerson, S. K., Monarch, I. A., Pereiro, J., Delon, L., and Hersh, W. R., 1998. Mapping vocabularies using latent semantics. Springer. [44] Tuarob, S., Pouchard, L. C., and Giles, C. L., 2013. “Automatic tag recommendation for metadata annotation using probabilistic topic modeling”. In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries, JCDL ’13, ACM, pp. 239–248. [45] Tuarob, S., Pouchard, L., Mitra, P., and Giles, C., 2015. “A generalized topic modeling approach for automatic document annotation”. International Journal on Digital Libraries, pp. 1–18. [46] Thelwall, M., 2013. “Heart and soul: Sentiment strength detection in the social web with sentistrength”. Cyberemotions, pp. 1–14. [47] Tuarob, S., Strong, R., Blomberg, J., Chandra, A., Chowdhary, P., Oh, S., and Tucker, C., 2015. “Automatic discovery of service name replacements using ledger data”. In Services Computing (SCC), 2015 IEEE International Conference on, IEEE.
References





























