Embed Size (px)
Citation preview

1
A Generic Approach for Obtaining HigherEntertainment in Predator/Prey Games
Georgios N. Yannakakis and John Hallam
Abstract— This paper constitutes a sequel to our previous workfocused on investigating cooperative behaviors, adaptive learningand on-line interaction towards the generation of entertainmentin computer games. A human-verified metric of interest (i.e.player entertainment) of predator/prey games and a neuro-evolution on-line learning (i.e. during play) approach are used toserve this purpose. Experiments presented here demonstrate thegenerality of the proposed approach, in its ability to overcomethe difficulties of learning in real-time and generate interestingpredator/prey games, over game type, complexity, topology, initialopponent behavior and player type.
Index Terms— computer games, entertainment modeling, ma-chine learning, cooperation, on-line interaction
I. INTRODUCTION
IN our previous work [1], we defined criteria that con-tribute to the satisfaction for the player which map to
characteristics of the opponent behavior in computer games.According to our hypothesis, the player-opponent interaction— rather than the audiovisual features, the context or thegenre of the game — is the property that primarily contributesthe majority of the quality features of entertainment in acomputer game [1]. Based on this fundamental assumption, weintroduced a metric for measuring the real-time entertainmentvalue of predator/prey games which was established as anefficient and reliable entertainment metric by the approvalof human judgement [2]. More specifically, Yannakakis andHallam [2] reveal a high correlation between the human notionof interest and the proposed interest metric in one of the mostrepresentative test-beds of this computer game genre, that isPac-Man.
According to our second hypothesis entertainment is gen-erated when adaptive learning procedures occur in real-time.That allows for opponents to learn while playing againstthe player and adapt with regards to his/her strategy. Usingthe Pac-Man game as a test-bed [1], [3] and focusing onthe non-player characters’ (NPC’s) behavior, a robust on-lineneuro-evolution learning mechanism was presented which wascapable of increasing the game’s interest value as well askeeping that interest value at high levels while the game wasbeing played. Moreover, it was found that when the game’sentertainment value is at high levels, cooperative action amongthe opponents is present which furthermore contributes toplayer satisfaction.
G. N. Yannakakis is with the School of Informatics, Institute of Perception,Action and Behaviour, The University of Edinburgh, EH8 9LE, UK (e-mail:[email protected]).
J. Hallam is with the Mærsk Mc-Kinney Møller Institute for ProductionTechnology, University of Southern Denmark, Campusvej 55, DK-5230Odense M, Denmark (e-mail: [email protected]).
The approach embeds a replacement method of the worst-fitindividuals while playing the game. This mechanism demon-strated high robustness and adaptability to changing hand-crafted player strategies in a relatively simple playing stage.Additional experiments in a predator/prey game of a more ab-stract design called ‘Dead End’ [4] displayed the effectivenessof the proposed methodology in dissimilar games of the samegenre and expanded the applicability of the method.
In the work presented here, we attempt to test the proposedon-line learning mechanism’s ability to generate interestinggames over a number of computer game dimensions. Thesedimensions include (a) the (high-level) concept of the game;(b) the environment of the game and particularly the com-plexity of the game world (i.e. stage) and its topologicalfeatures; (c) the opponents’ behavior when the game startsand (d) the player’s gaming skills. Experiments presented heredemonstrate the generality of the methodology with respect tothe aforementioned dimensions and verify our hypothesis thatthe proposed on-line learning mechanism constitutes a generictool for obtaining predator/prey games of high entertainmentindependently of game type, game complexity and topology,initial opponent behavior and player.
We have chosen predator/prey games as the initial genre ofour game research since, given our aims, they provide us withunique properties. In such games we can deliberately abstractthe environment and concentrate on the characters’ behavior.The examined behavior is cooperative since cooperation isa prerequisite for effective hunting behaviors. Furthermore,we are able to easily control a learning process through on-line interaction. In other words, predator/prey games offera well-suited arena for initial steps in studying cooperativebehaviors generated by interactive on-line learning mecha-nisms. Other genres of game (e.g. first person shooters) offersimilar properties; however predator/prey games are chosenfor their simplicity as far as their development and design areconcerned.
II. ENTERTAINMENT METRICS
The current state-of-the-art in machine learning in gamesis mainly focused on generating human-like [5], [6] andintelligent [7], [8] characters. Even though complex opponentbehaviors emerge through various learning techniques, thereis no further analysis of whether these behaviors contributeto the satisfaction of the player. In other words, researchershypothesize — for instance by observing the vast number ofmulti-player on-line games played daily on the web — that bygenerating human-like opponents [9] they enable the player to

2
gain more satisfaction from the game. According to Taatgenet al. [10] believability of computer game opponents, whichare generated through cognitive models, is strongly correlatedwith enjoyable games. These hypotheses might be true upto a point; however, since a notion of interest has not beenexplicitly defined, there is no evidence that a specific opponentbehavior generates enjoyable games. This statement is the coreof Iida’s work on entertainment metrics for variants of chessgames [11].
Inspired by Iida’s metric of entertainment and based on Mal-one’s theoretical approach on entertainment factors, namelychallenge, curiosity and fantasy, for simple arcade games[12] and Csikszentmihalyi’s theory of flow [13], Yannakakisand Hallam [1] introduced an efficient metric of real-timeentertainment for computer games. This metric has been usedfor variants of predator/prey games and has been successfullycross-validated with human notion of entertainment [2].
III. EVOLUTIONARY LEARNING IN REAL-TIME
Evolutionary computation is not very well studied andexplored in the area of computer games (unlike card or boardgames simulated in computers — e.g. chess). In particular, theprimary reason against its use for learning while playing (on-line) is its slow convergence and that undesired/unpredictablebehaviors may emerge. However, real-time adaptation whichintelligent opponents exhibit is the main feature that motivatesresearch on on-line evolutionary learning. Very recently, suc-cessful on-line neuro-evolution applications [14], [3] demon-strate the feasibility of the method through more efficientlearning procedures and careful representation design.
Evolutionary learning of neural controlled NPCs is the coreof the work of Yannakakis et al. [1], [3], [4], [15]. Among theircontributions, a robust and highly adaptive on-line evolution-ary learning mechanism is presented. The predator/prey genreof games is this approach’s test-bed. In the same researchdirection, Stanley et al. [14] are applying neuro-evolution tech-niques for the emergence of adaptive behaviors (e.g. capture-the-flag and wall-avoidance) in the ‘NERO’ training gamein real-time. For this game, the NeuroEvolution AugmentingTopologies (NEAT) method [16] has been used to evolvelarge populations of NPCs through an on-line replacementmechanism of the worst-fit NPCs. In NERO, both the gamegenre (training) and the number (fifty) of NPCs contribute tothe efficiency and the convergence time of the mechanism.Both leave space for unpredictable and/or unwanted emergentopponent behaviors to be accepted and/or ignored by theplayer. On the other hand, in [3], on-line evolutionary learningis successfully applied in a computer game of four opponentswhere no concession is made by the player for unrealisticbehaviors.
IV. LEARNING IN REAL-TIME CHALLENGES
We can distinguish the challenges we will come across inthis paper into the ones generated by the game design per seand the ones generated by learning on-line in computer games.The on-line learning challenges are introduced in this section.We make this distinction here since the difficulties arising from
learning in real-time will be faced globally throughout thepaper.
The drawbacks we have to overcome when designing alearning (neuro-evolution) mechanism for real-time opponentadaptation are as follows:• Real-time performance. An on-line learning approach
should perform fast in real-time since only a single CPUis available for the majority of computer games [17]. Notealso, that most commercial computer games use over 90%of the CPU for their graphics engines alone.
• Realism. On-line neuro-evolution provides the potentialfor adaptive opponents but it may also generate unrealisticopponent behaviors. In most computer games the playerinteracts with a very small number of opponents in themajority of gameplay instances. Unrealistic behaviorsare, therefore, easily noticeable and may lead to lowentertainment for the player.
• Fast adaptation. A successful on-line learning approachshould adapt quickly to changes in the player’s strategy.Otherwise, the game becomes boring. This constitutesa big challenge for the design of the on-line learningmechanism given the computational power resources,the realistic behavior condition presented before and thesmall number of opponents that normally interact withthe player in computer games.
The predator/prey games used in this paper face all afore-mentioned challenges of on-line learning design since exper-iments are held in a single 1GHz CPU and the number ofopponents is less than or equal to five.
V. REAL-TIME INTEREST
A complete methodology for defining a generic measure ofinterest for predator/prey games is introduced in [2]. The ap-proach proposed portrays the criteria that make predator/preygames interesting, quantifies and combine all these criteria ina mathematical formula and uses a test-bed game in orderto have this formulation of interest cross-validated against theinterest the game produces when it is played by human players.Results from this work showed that the perceived human en-tertainment is highly correlated (correlation coefficient equals0.4444, p-value equals 1.17 · 10−8) with the interest metricproposed and demonstrated the reliability of the metric. Anoutline of the methodology followed in [2] in order to obtainthe interest metric is presented here.
The methodology is primarily focused on the opponents’behavior contributions to the interest value of the game be-cause, we believe, the computer-guided opponent character cancontribute to the majority of qualitative features that make agame interesting. The player, however, may contribute to itsentertainment through its interaction with the opponents of thegame and, therefore, it is implicitly included in the interestformulation presented here.
By observing the opponents’ behavior of various preda-tor/prey games we attempted to empirically extract the featuresthat may generate entertainment for the player. These featureswhere experimentally cross-validated against various oppo-nents of different strategies and redefined when appropriate.

3
Hence, by following the theoretical principles of Malone’sintrinsic factors for engaging gameplay [12] and the basicconcepts of flow (the mental state in which players are soinvolved in something that nothing else matters) [13], thecriteria that collectively define interest on any predator/preygame are:
1) When the game is neither too hard nor too easy. Inother words, the game is interesting when opponentsmanage to kill the player sometimes but not always. Inthat sense, highly-effective opponent behaviors are notinteresting behaviors and vice versa.
2) When there is diversity in opponents’ behavior over thegames. That is, when the non-player characters are ableto find different ways of hunting and killing the playerin each game so that their strategy is less predictable.
3) When opponents’ behavior is aggressive rather thanstatic. That is, predators that move constantly all overthe game world and cover it uniformly. This behaviorgives the player the impression of an intelligent strategicopponents’ plan which increases the player’s curiosity(“what will happen next?”). According to Malone [12],curiosity is one of the three main features that generateentertainment in computer games.
The metrics for the three criteria, as defined in [2], areestimated by T (appropriate level of challenge metric; basedon the difference between maximum player’s lifetime tmax
and average player’s lifetime E{tk} over N games — Nis 50 in this paper), S (behavior diversity metric; based onstandard deviation of player’s lifetime over N games) andE{Hn} (spatial diversity metric; based on stage grid-cell visitaverage entropy of the opponents over N games) respectively.All three metrics are combined linearly thus
I =γT + δS + εE{Hn}
γ + δ + ε(1)
where I is the interest value of the predator/prey game; γ, δand ε are criterion weight parameters.
The above-mentioned interest metric can be applied effec-tively to any predator/prey computer game because it is basedon generic features of this category of games. These featuresinclude the time required to kill the prey as well as the preda-tors’ distribution across the game field. We therefore believethat (1) — or a similar measure of the same concepts —constitutes a generic interest approximation of predator/preycomputer games. Moreover, given the two first interest criteriapreviously defined, the approach generalizes to all computergames. Indeed, no player likes any computer game that is toohard or too easy to play and, furthermore, any player wouldenjoy diversity throughout the play of any game. The thirdinterest criterion is applicable to games where spatial diversityis important which, apart from predator/prey games, may alsoinclude action, strategy and team sports games according tothe computer game genre classification of Laird and van Lent[5].
VI. THE PAC-MAN GAME
The first test-bed studied is a modified version of theoriginal Pac-Man computer game released by Namco. The
player’s (PacMan’s) goal is to eat all the pellets appearingin a maze-shaped stage while avoiding being killed by thefour Ghosts. The game is over when either all pellets in thestage are eaten by PacMan, Ghosts manage to kill PacMan ora predetermined number of simulation steps is reached withoutany of the above occurring. In that case, the game restarts fromthe same initial positions for all five characters.
The game is investigated from the opponents’ viewpoint andmore specifically how the Ghosts’ emergent adaptive behaviorscan collectively contribute to the player’s entertainment. Thegame field (i.e. stage) consists of corridors and walls whereasboth the stage’s dimensions and its maze structure are pre-defined. For the experiments presented in this paper we usea 19 × 29 grid maze-stage where corridors are one grid-cellwide.
A. PacMan
In [1], three fixed Ghost-avoidance and pellet-eating strate-gies for the PacMan player, differing in complexity andeffectiveness are presented. Each strategy is based on decisionmaking applying a cost or probability approximation to theplayer’s 4 neighbor cells (i.e. up, down, left and right). Wepresent them briefly in this paper.
• Cost-Based (CB) PacMan: moves towards a cost min-imization path that produces effective Ghost-avoidanceand (to a lesser degree) pellet-eating behaviors but onlyin the local neighbor cell area.
• Rule-Based (RB) PacMan: is a CB PacMan plus anadditional rule for more effective and global pellet-eatingbehavior.
• Advanced (ADV) PacMan: the ADV moving strategygenerates a more global Ghost-avoidance behavior builtupon the RB PacMan’s good pellet-eating strategy.
B. Ghosts
A multi-layered fully connected feedforward neural con-troller, where the sigmoid function is employed at each neuron,manages the Ghosts’ motion. Using their sensors, Ghosts in-spect the environment from their own point of view and decidetheir next action. Each Ghost’s perceived input consists ofthe relative coordinates of PacMan and the closest Ghost. Wedeliberately exclude from consideration any global sensing,e.g. information about the dispersion of the Ghosts as a whole,because we are interested specifically in the minimal sensingscenario. We make this choice by following principles of theanimat approach [18] which provides the ground for realisticNPC behaviors in computer games [19] and the potential ofscaling up to more complex game environments. The neuralnetwork’s output is a four-dimensional vector with respectivevalues from 0 to 1 that represents the Ghost’s four movementoptions (up, down, left and right respectively). Each Ghostmoves towards the available — unobstructed by walls —direction represented by the highest output value. Availablemovements include the Ghost’s previous cell position.

4
Fig. 1. A snapshot of the Dead End game.
VII. THE DEAD END GAME
Conceptually, the primary dissimilarities between Pac-Manand Dead End (the game presented in this section) are foundin:
• The player’s objectives.• The type of opponent motion; in both games the move-
ment directions are limited to up, down, left or right butwhile the Ghosts’ magnitude of motion is measured ingrid cells the Dead End opponents’ magnitude of motionis measured in pixels. Moreover, the ratio of the player’sover the opponents’ maximum speed is 4/3 and 2 for thegames of Dead End and Pac-Man respectively.
• The absence of objects-walls in Dead End.
The Dead End game field (i.e. stage) is a two-dimensionalsquare world that contains a white rectangular area named“Exit” (see Fig. 1) at the top. For the experiments presentedin this paper we use a 215× 215 pixel stage (see Fig. 1). Thecharacters visualized in the Dead End game (as illustrated inFig. 1) are a dark grey circle of radius 10 pixels representingthe player, named ‘Cat’, and a number of light grey square(of dimension 20 pixels) ghost-like characters representing theopponents, named ‘Dogs’. Cat and Dogs are initially placedin the game field so that there is a suitably large distancebetween them. The aim of the Cat, starting from a randomlychosen position at the bottom of the stage, is to reach the Exitby avoiding the Dogs or to survive for a predetermined largeperiod of time of 50 simulation steps. On the other hand, Dogsare aiming to defend the Exit and/or catch the Cat within thatperiod of time. The game’s fundamental concepts are inspiredby previous work of Yannakakis et al. [20] while the firstuse of the game as a test-bed for experiments on emergentcooperative opponent behaviors is introduced in [21].
At each simulation step, the Cat moves at four thirds theDogs’ maximum speed, and since there are no dead ends,it is impossible for a single Dog to complete the task ofkilling it. Since the player moves faster than its opponents,the only effective way to kill the Cat is for a group of Dogsto hunt cooperatively. When the game is over, then a new gamestarts from the same initial positions for the Dogs but from adifferent, randomly chosen, position at the bottom of the stagefor the Cat.
A. Cat
In [15], we introduced three hand-crafted Dog-avoidanceand/or Exit-achieving strategies for the Cat, differing in com-plexity and effectiveness. These are briefly described here asfollows:• Randomly-Moving (RM) Cat: takes a movement deci-
sion by selecting a uniformly distributed random pickeddirection at each simulation step of the game. The prob-ability of selecting the direction towards the Exit linearlyincreases over the simulation steps by 0.2% per step.
• Exit-Achieving (EA) Cat: moves directly towards theExit. Its strategy is based on moving so as to reduce thegreatest of its relative coordinates from the Exit.
• Potential Field-Based (PFB) Cat: this constitutes themost efficient Dog-avoidance and Exit-achieving strategyof the three different fixed-strategy types of player. Adiscrete Artificial Potential Field (APF) [22], speciallydesigned for the Dead End game, controls the PFBplayer’s motion. The overall APF causes a force to acton the Cat which guides it along a Dog-avoidance Exit-achievement path. For a more detailed presentation of thePFB Cat, see [15] (appears as ‘CB player’).
B. Dogs
Dogs’ motion — like the Ghosts’ motion presented inSection VI-B — is managed by a feedforward neural controllerwhere the hyperbolic tangent sigmoid function is employedat each neuron. The neural network’s input array determinesthe Dog’s perceived information and consists of the relativecoordinates of (a) the Cat, (b) the closest Dog and (c) theExit. A Dog’s input includes information for only one neighborDog as this constitutes the minimal information for emergingcooperative teamwork. We are primarily interested in theminimal sensing scenario and therefore global information isdeliberately not considered. The neural network’s output is atwo-dimensional vector with respective values from −1 to 1that represent movement in the X (positive sign correspondsto up, negative to down) and Y (positive sign corresponds toleft, negative to right) directions. Each Dog moves towardsthe direction represented by the highest absolute output valueat the magnitude determined by this value multiplied by theDog’s maximum speed (i.e. 20 pixels/simulation step).
VIII. FIXED STRATEGY OPPONENTS
Apart from the neural controlled opponents, two additionalnon-evolving strategies have been tested for controlling theopponent’s motion for both games. These strategies are used asbaseline behaviors for comparison with any neural controlleremerged behavior.• Random (R): opponents that randomly decide their next
available movement. Available movements have equalprobabilities of being picked.
• Followers (F): opponents designed to follow the playerconstantly. Their strategy is based on moving (at maxi-mum speed) so as to reduce the greatest of their relativecoordinates from the player.

5
Fig. 2. The 4 different stages of the Pac-Man game. Complexity increasesfrom left to right: Easy (A and B), Normal and Hard.
IX. GAME COMPLEXITY
In order to distinguish between environments of differentcomplexity within the same predator/prey game, we require anappropriate measure to quantify this feature. Because of thedifferent features of the two games examined, two differentmeasures are proposed. For the Pac-Man game this measure,C, is
C = 1/E{L} (2)
where E{L} is the average corridor length of the stage (seealso [3]).
According to (2), complexity is inversely proportional tothe average corridor length of the stage. That is, the longerthe average corridor length, the easier for the opponents toblock the player and, therefore, the less complex the stage.
Fig. 2 illustrates the four different stages used for theexperiments presented here. Complexity measure values forthe Easy A, Easy B, Normal and Hard stages are 0.16, 0.16,0.22 and 0.98 respectively. Furthermore, given that a) blocksof walls should be included b) corridors should be one grid-square wide and c) dead ends should be absent, Hard stage isthe most complex Pac-Man stage of that size for the Ghoststo play.
For the Dead End game, complexity is measured by thenumber of opponents since conceptually the game environmentis free of wall blocks1. That is, the more Dogs in the gamethe easier their hunting task. Five, four and three Dog gameenvironments have been used for the experiments presented inthis paper.
A. Topology
Stages of the same complexity, measured by (2), may differin topology (i.e. layout of blocks on the stage). Thus the caseof Easy A and Easy B stages (see Fig. 2) have the samecomplexity value but are topologically different. The choiceof these two Pac-Man stages is made so as to examine theon-line learning mechanism’s ability to generate interestingopponents in equally complex stages of different topology —that is, to investigate the topology’s impact on the generationof interesting games.
1The number of Ghosts can give an indication for the complexity of thePac-Man game as well; however, by following the original version of thegame containing four Ghosts we keep this variable constant.
X. INTEREST PARAMETER VALUES FOR THE GAMES
In this section we present the procedures followed to obtainthe appropriate parameter values of the interest estimate (1)for both games tested. As previously defined, tmax is the max-imum evaluation period of play, or else the maximum lifetimeof the player. For Pac-Man this number corresponds to theminimum simulation period required by the RB PacMan (bestpellet-eater) to clear the stage of pellets. In the experimentspresented here tmax is 300 for the Easy stage, 320 for theNormal stage and 466 for the Hard stage. In the game of DeadEnd tmax determines the maximum game length (i.e. until awin or a kill is occurred) recorded against any opponent Dogsand it is 50 simulation steps for the RM and PFB Cat and 10simulation steps for the EA Cat.
In order to obtain values for the interest formula weightingparameters γ, δ and ε we select empirical values based on thespecific game. For Pac-Man we select γ = 1, δ = 2 and ε = 3;a sensitivity analysis for these values, in [2], showed that theinterest value does not change significantly even when a 40%change in the parameter value occurs. For Dead End, diversityin game play is of greatest entertainment value. The averagegame length is much smaller when compared to Pac-Manand, therefore, we believe that generating diverse behaviorswithin this period of play should be weighted more thanthe challenge (T ) and the spatial diversion (E{Hn}) criteria.Given the above-mentioned statements and by adjusting thesethree parameters so that the interest value escalates as theopponent behavior changes from Random to Follower, wecome up with γ = 1, δ = 2 and ε = 1.
Since the interest value changes monotonically with respectto each of the three criterion values T , S, E{Hn}, sensitivityanalysis is conducted on the above interest metric parametersaiming to portray the relation between these parameters aswell as their weighting degree in the interest formula. Wetherefore proceed by seeking opponent behaviors that generateten different T, S and E{Hn} values, equally spread in the[0,1] interval. Given these thirty values as input, γ, δ and εparameters are systematically changed one at a time so thattheir percentage difference lies in the interval [−50%, 50%].We believe that fifty is a large enough percentage differenceto demonstrate potential significant impact on the observedvalue. Each time a parameter change occurs, the absolutepercentage difference of the game’s interest value is computed.The function between the absolute percentage differences ofthe interest value and the percentage differences of the interestweighting parameters is illustrated in Fig. 3(a) and Fig. 3(b).
As seen from Fig. 3(a), δ and ε demonstrate significantdifferences (i.e. greater than 5%) in I when decreased by40% and 30% respectively. The ε parameter also significantlychanges the I value when it is increased by 35%. Finally, forγ no significant change in I is observed even when changedby up to 50%. Results obtained illustrate that exploring theimpact of combinations of parameter changes (comprehensiveapproach) would not be necessary since significant changesoccur only in the rather extreme cases of ε < 0.7, ε > 1.35and δ < 1.2. In addition, such an approach would increase thesize of different interest value calculations up to 104.

6
-50 -40 -30 -20 -10 0 10 20 30 40 500
1
2
3
4
5
6
7
8
9A
bsol
ute
perc
enta
ge d
iffer
ence
of I
nter
est
Percentage difference of parameter values
γδε
(a) Average
-50 -40 -30 -20 -10 0 10 20 30 40 500
2
4
6
8
10
12
14
Sta
ndar
d de
viat
ion
of a
bsol
ute
pe
rcen
tage
diff
eren
ces
of In
tere
st
Percentage difference of parameter values
γδε
(b) Standard deviation
Fig. 3. Average and standard deviation of absolute percentage differencesof I over ten runs for each weighting parameter.
XI. ON-LINE LEARNING
On-line learning is based on the idea of opponents thatlearn while they are playing against the player: Ghosts orDogs that adapt to any player’s behavior and learn from itsstrategy instead of being characters of predictable and, to adegree, uninteresting behaviors. Furthermore, this approach’sadditional objective is to keep the game’s interest value at highlevels as long as it is being played.
Beginning from any initial group of homogeneous off-linetrained (see [1] and [15] for more details on Pac-Man and DeadEnd off-line training mechanisms respectively) opponents, theOLL mechanism transforms them into a group of heteroge-neous characters that are conceptually more interesting to playagainst. In OLL, an opponent trained off-line is cloned anumber of times equal to the number of opponents playingthe game, and its clones are placed in the game field to playagainst a selected fixed player type in a selected stage. Then,at each generation:
Step 1 Each opponent is evaluated every ep simulationsteps via (3), while the game is played — ep is25 simulation steps in this paper.
fOLL =ep∑
i=1
{DP,i −D′
P,i
}(3)
where
DP,i = |xi+1o − xi
p|+ |yi+1o − yi
p| (4)
D′P,i = |xi
o − xip|+ |yi
o − yip| (5)
and (xio, y
io), (xi
p, yip) are respectively the cartesian
coordinates of the opponent and the player at theith simulation step. This fitness function promotesopponents that move towards the player within anevaluation period of ep simulation steps.
Step 2 A pure elitism selection method is used where onlythe fittest solution is able to breed. The fittest parentclones an offspring with a probability pc that isinversely proportional to the normalized predatorscell visit entropy (i.e. pc = 1−Hn). If there is nocloning, then go back to Step 1, else continue toStep 3.
Step 3 Mutation occurs in each gene (connection weight)of each offspring’s genome with a probability pm
(e.g. 0.02). For the Dead End and the Pac-Mangame, a uniform and a gaussian random distributionis respectively used to define the mutated valueof the connection weight. Thus, for Pac-Man, themutated value is obtained from (6),
wm = N (w, 1−Hn) (6)
where wm is the mutated connection weight valueand w is the connection weight value to be mutated.
Step 4 The mutated offspring is evaluated briefly via (3)in off-line mode, that is, by replacing the least-fit member of the population and playing an off-line (i.e. no visualization of the actions) shortgame of ep simulation steps. The fitness valuesof the mutated offspring and the least-fit opponentare compared and the better one is kept for thenext generation. This pre-evaluation procedure forthe mutated offspring attempts to minimize theprobability of group behavior disruption by low-performance mutants. If the least-fit opponent isreplaced, then the mutated offspring takes its posi-tion in the game field as well. This algorithm stepis applied to the Pac-Man game only.
The algorithm is terminated when a predetermined numberof games has been played or a number of generations has beenachieved.
We mainly use short simulation periods (i.e. ep = 25)to evaluate opponents in OLL, so as to accelerate the on-line evolutionary process. The same period is used for theevaluation of mutated offspring; this is based on two primaryobjectives: 1) to apply a fair comparison between the mutatedoffspring and the least-fit opponent (i.e. same evaluation
7
period) and 2) to avoid undesired high computational effortwhile playing. However, the evaluation function (3) constitutesan approximation of the examined opponent’s overall perfor-mance for large simulation periods. Keeping the right balancebetween computational effort and performance approximationis one of the key features of this approach and, therefore,we use minimal evaluation periods capable of achieving goodperformance estimation.
Note that, there are specific dissimilarities between the OLLapproach applied to Pac-Man and Dead End. The purpose ofthese differences is the investigation of the pre-evaluation pro-cess’ impact on the algorithm’s performance. See Section XVIfor a comprehensive discussion of this topic.
XII. PAC-MAN EXPERIMENTS
Off-line trained (OLT) emergent solutions (see [1] for moredetails of off-line training) are the OLL mechanisms’ initialpoints in the search for more interesting games. OLT behaviorsare classified into the following categories:• Blocking (B): These are OLT Ghosts that tend to wait for
PacMan to enter a specific area that is easy for them toblock and kill. Their average normalized cell visit entropyvalue E{Hn} lies between 0.55 and 0.65.
• Aggressive (A): These are OLT Ghosts that tend to followPacMan all over the stage in order to kill it (E{Hn} ≥0.65).
• Hybrid (H): These are OLT Ghosts that tend to behaveas a Blocking-Aggressive hybrid which proves to beineffective at killing PacMan (E{Hn} < 0.55).
A. OLL experiment
The OLL experiment is described as follows. a) Pick ninedifferent emerged Ghosts’ behaviors produced from off-linelearning experiments — Blocking (B), Aggressive (A) andHybrid (H) behaviors emerged by playing against each of3 PacMan types — for each one of the three stages; b)starting from each OLT behavior, apply the OLL mechanismby playing against the same type of PacMan player and inthe same stage the Ghosts have been trained in off-line. Initialbehaviors for the Easy B stage are OLT behaviors emergedfrom the Easy A stage. This experiment intends to demonstratethe effect of the topology of a stage in the interest value of thegame; c) calculate the interest value of the game every 100games during each OLL attempt.
The interest value is calculated by letting the Ghosts play100 non-evolution games in the same stage against the PacMantype they were playing against during OLL. In order tominimize the non-deterministic effect of the PacMan’s strategyon the Ghost’s performance and interest values as well asto draw a clear picture of these averages’ distribution, weapply the following bootstrapping procedure. Using a uniformrandom distribution we pick 10 different 50-tuples out of the100 above-mentioned games. These 10 samples of data, of 50games each, are used to determine the games’ average interestvalue as well as its confidence interval values. The outcomeof the OLL experiment is presented in Fig. 4 and Fig. 5.
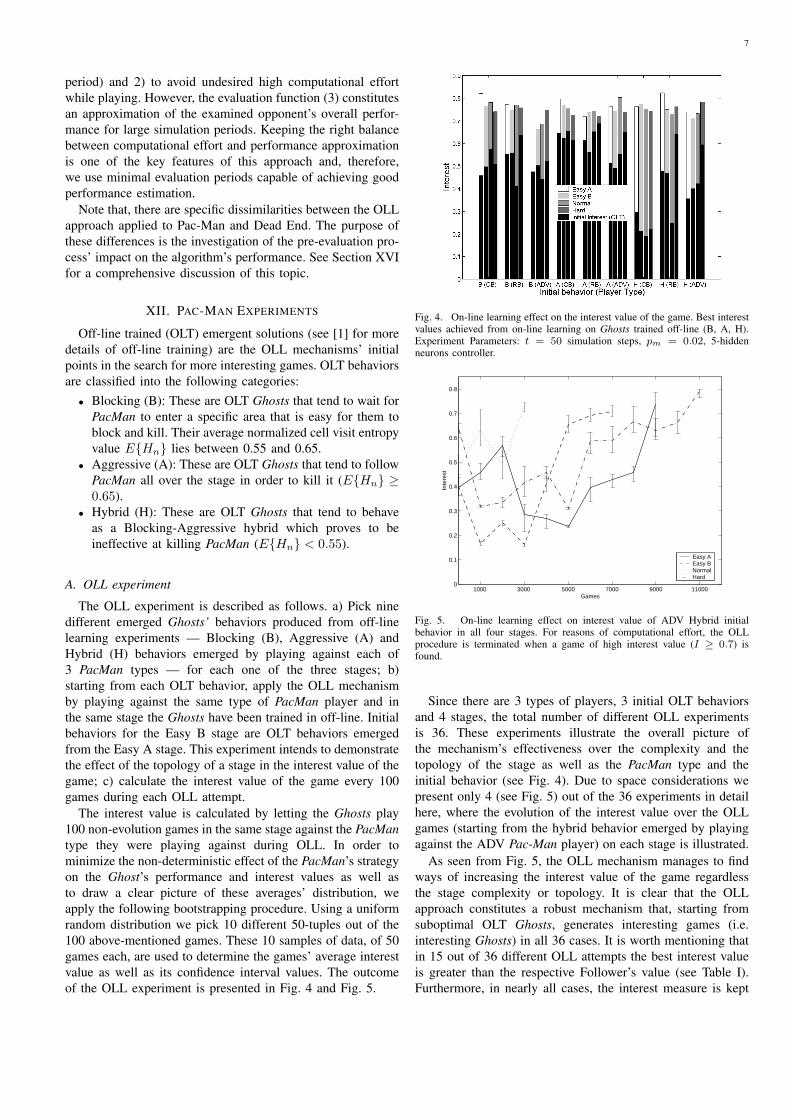
Fig. 4. On-line learning effect on the interest value of the game. Best interestvalues achieved from on-line learning on Ghosts trained off-line (B, A, H).Experiment Parameters: t = 50 simulation steps, pm = 0.02, 5-hiddenneurons controller.
1000 3000 5000 7000 9000 110000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Games
Inte
rest
Easy AEasy BNormalHard
Fig. 5. On-line learning effect on interest value of ADV Hybrid initialbehavior in all four stages. For reasons of computational effort, the OLLprocedure is terminated when a game of high interest value (I ≥ 0.7) isfound.
Since there are 3 types of players, 3 initial OLT behaviorsand 4 stages, the total number of different OLL experimentsis 36. These experiments illustrate the overall picture ofthe mechanism’s effectiveness over the complexity and thetopology of the stage as well as the PacMan type and theinitial behavior (see Fig. 4). Due to space considerations wepresent only 4 (see Fig. 5) out of the 36 experiments in detailhere, where the evolution of the interest value over the OLLgames (starting from the hybrid behavior emerged by playingagainst the ADV Pac-Man player) on each stage is illustrated.
As seen from Fig. 5, the OLL mechanism manages to findways of increasing the interest value of the game regardlessthe stage complexity or topology. It is clear that the OLLapproach constitutes a robust mechanism that, starting fromsuboptimal OLT Ghosts, generates interesting games (i.e.interesting Ghosts) in all 36 cases. It is worth mentioning thatin 15 out of 36 different OLL attempts the best interest valueis greater than the respective Follower’s value (see Table I).Furthermore, in nearly all cases, the interest measure is kept

8
TABLE IFIXED STRATEGY Ghosts’ (R, F) INTEREST VALUES. VALUES ARE
OBTAINED BY AVERAGING 10 SAMPLES OF 50 GAMES EACH.
Play AgainstStage CB RB ADV
Easy A 0.5862 0.6054 0.5201Easy B 0.5831 0.5607 0.4604Normal 0.5468 0.5865 0.5231R
Hard 0.3907 0.3906 0.3884Easy A 0.7846 0.7756 0.7759Easy B 0.7072 0.6958 0.6822Normal 0.7848 0.8016 0.7727Fi
xed
Beh
avio
rs
F
Hard 0.7727 0.7548 0.7627
at the same level independently of stage complexity or — inthe case of Easy A and B stages — stage topology. Giventhe confidence intervals (±0.05 maximum, ±0.03 on average)of the best interest values, it is revealed that the emergentinterest value is not significantly different from stage to stage.Comprehensive results from the Easy A stage [1] present OLLexperiments where OLT Ghosts play against all PacMan typesinstead of just the type that was used for their off-line training.The outcome of these experiments demonstrates the generalityof the OLL over this additional variation.
However, a number in the scale of 103 constitutes anunrealistic number of games for a human player to play. Onthat basis, it is very unlikely for a human to play so manygames in order to notice the game’s interest value increasing.The reason for the OLL process being that slow is a matter ofkeeping the right balance between the process’ speed and its‘smoothness’ (by ‘smoothness’ we define the interest value’smagnitude of change over the games). A solution to thisproblem is to consider the initial long period of disruptionas an off-line learning procedure and start playing as soon asthe game’s interest value is increased.
XIII. DEAD END EXPERIMENTS
Exactly as in the Pac-Man game, some well-behaved Dogsare required initially from the OLL mechanism in its attemptto generate interesting Dead End games. Off-line trained emer-gent solutions (see [15] for more details on off-line trainingfor the Dead End game) serve this purpose. OLT obtainedbehaviors are classified into the following two categories:• Defensive (D): These are OLT Dogs that tend to flock
close and around the Exit and wait for the Cat to approachin order to kill it. Their average normalized cell visitentropy value E{Hn} is less than 0.7.
• Aggressive (A): These are OLT Dogs that tend to followthe Cat all over the stage in order to kill it (E{Hn} ≥0.7).
Defending the Exit, as an emergent behavior, is much easierthan hunting cooperatively and more effective when playingagainst the EA Cat. Thus, when off-line training occurs againstthe EA Cat, aggressive Dog behavior is not emerged becauseit constitutes a sub-optimal behavior.
A. OLL experiment
The OLL experiment for the Dead End game is describedas follows. a) Pick five different emerged Dogs’ behaviorsproduced from off-line learning experiments — Defensive (D)against each of the three Cat types and Aggressive (A) againstthe RM and the PFB Cat — for each one of the three gameenvironments — containing eight, four and three Dogs; b)starting from each OLT behavior, apply the OLL mechanismby playing against each Cat type separately and in the samestage where off-line training occurred. This makes a total offifteen different OLL attempts for each game environment. c)calculate the interest value (by following the bootstrappingprocedure presented in Section XII-A) of the game every 100generations during each OLL attempt. In contrary to the Pac-Man game, generations instead of games are picked as thealgorithm’s simulation time unit because of the large differenceon the average game length between the EA Cat (i.e. tmax =10) and the RM and PFB Cat (i.e. tmax = 50). For comparisonpurposes to the OLL experiments in the Pac-Man game, theexpected value of the generations g per games G ratio E{g/G}is calculated. This equals 0.943 for the RM and PFB Cat and3.846 for the EA Cat.
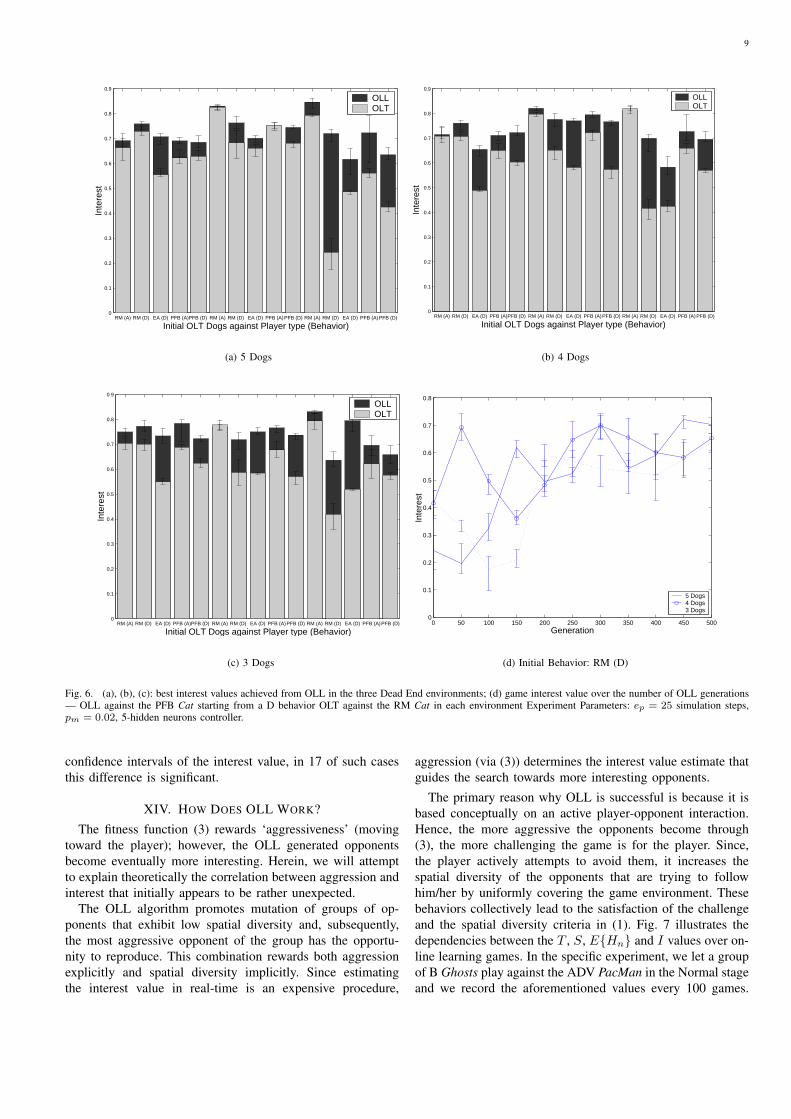
Given that there are three game environments explored,the total number of different OLL experiments is 45, whichillustrate a complete picture of the mechanism’s effectivenessover the complexity of the game, the Cat type and the initialbehavior (see Fig. 6). Three of these experiments are presentedin detail due to space considerations. More specifically, inFig. 6(d), the evolution of the interest value over the OLLgenerations (starting from a D behavior trained against theRM Cat and playing against the PFB Cat) on each stage isillustrated.
TABLE IIFIXED STRATEGY Dogs’ (R, F) INTEREST VALUES. VALUES ARE
OBTAINED BY AVERAGING 10 SAMPLES OF 50 GAMES EACH.
Play AgainstEnvironment RM EA PFB
5 Dogs 0.491 0.498 0.4254 Dogs 0.614 0.436 0.156R3 Dogs 0.561 0.312 0.2365 Dogs 0.607 0.778 0.7834 Dogs 0.684 0.791 0.768
Fixe
dB
ehav
iors
F3 Dogs 0.624 0.797 0.772
As seen from Fig. 6, OLL is successful at augmenting theinterest value of the game regardless the stage complexity,stage topology, the Cat type and the initial behavior. On thatbasis, in the majority of the experiments, OLL is capableof producing games of higher than the initial interest valueas well as maintaining that high interest value for a longperiod. More comprehensively, in 42 out of 45 OLL scenariosthe interest value of the game is increased in fewer than500 generations and in 37 cases this increase is statisticallysignificant. Also, in 23 cases the best interest value achievedagainst a Cat type is greater than the respective interest valuegenerated by the Followers (see Table II). Given the calculated
9
RM (A) RM (D) EA (D) PFB (A)PFB (D) RM (A) RM (D) EA (D) PFB (A)PFB (D) RM (A) RM (D) EA (D) PFB (A)PFB (D)0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Initial OLT Dogs against Player type (Behavior)
Inte
rest
OLLOLT
(a) 5 Dogs
RM (A) RM (D) EA (D) PFB (A)PFB (D) RM (A) RM (D) EA (D) PFB (A)PFB (D) RM (A) RM (D) EA (D) PFB (A) PFB (D)0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Initial OLT Dogs against Player type (Behavior)
Inte
rest
OLLOLT
(b) 4 Dogs
RM (A) RM (D) EA (D) PFB (A)PFB (D) RM (A) RM (D) EA (D) PFB (A)PFB (D) RM (A) RM (D) EA (D) PFB (A)PFB (D)0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Initial OLT Dogs against Player type (Behavior)
Inte
rest
OLLOLT
(c) 3 Dogs
0 50 100 150 200 250 300 350 400 450 5000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Inte
rest
Generation
5 Dogs4 Dogs3 Dogs
(d) Initial Behavior: RM (D)
Fig. 6. (a), (b), (c): best interest values achieved from OLL in the three Dead End environments; (d) game interest value over the number of OLL generations— OLL against the PFB Cat starting from a D behavior OLT against the RM Cat in each environment Experiment Parameters: ep = 25 simulation steps,pm = 0.02, 5-hidden neurons controller.
confidence intervals of the interest value, in 17 of such casesthis difference is significant.
XIV. HOW DOES OLL WORK?The fitness function (3) rewards ‘aggressiveness’ (moving
toward the player); however, the OLL generated opponentsbecome eventually more interesting. Herein, we will attemptto explain theoretically the correlation between aggression andinterest that initially appears to be rather unexpected.
The OLL algorithm promotes mutation of groups of op-ponents that exhibit low spatial diversity and, subsequently,the most aggressive opponent of the group has the opportu-nity to reproduce. This combination rewards both aggressionexplicitly and spatial diversity implicitly. Since estimatingthe interest value in real-time is an expensive procedure,
aggression (via (3)) determines the interest value estimate thatguides the search towards more interesting opponents.
The primary reason why OLL is successful is because it isbased conceptually on an active player-opponent interaction.Hence, the more aggressive the opponents become through(3), the more challenging the game is for the player. Since,the player actively attempts to avoid them, it increases thespatial diversity of the opponents that are trying to followhim/her by uniformly covering the game environment. Thesebehaviors collectively lead to the satisfaction of the challengeand the spatial diversity criteria in (1). Fig. 7 illustrates thedependencies between the T , S, E{Hn} and I values over on-line learning games. In the specific experiment, we let a groupof B Ghosts play against the ADV PacMan in the Normal stageand we record the aforementioned values every 100 games.

10
Fig. 7. Comparison figure of T , S, E{Hn} and I . Initial opponent behavior:Blocking.
Fig. 8. Correlation coefficients of OLL generated T , S and E{Hn} valuesover I value intervals.
As seen from Fig. 7, OLL initially increases the Ghosts’spatial diversity (E{Hn}) which furthermore produces moreappropriate challenge for the player (T ) through the player-opponent interaction. Ultimately, the game reaches its highestinterest value when the player discovers new ways of playingthat the opponents can counter (increase of behavior diversity— S).
Additional evidence of the OLL approach’s behavior ispresented in Fig. 8 where the correlation coefficients (rc)between T , S and E{Hn} values over the I value intervals areillustrated. A number of instances of these 128 values is ob-tained from three OLL experiments (B, A and H initial Ghosts)against the ADV PacMan in the Normal stage. According toFig. 8, when I < 0.6, T and S are highly correlated andE{Hn} is highly anticorrelated with both T and S. When0.6 ≤ I < 0.7, T and S are slightly anticorrelated (rc =−0.0974) and E{Hn} is highly correlated and anticorrelatedwith T (rc = 0.5247) and S (rc = −0.7296) respectively.Finally, when I ≥ 0.7, all three interest criteria are highlycorrelated. These correlation coefficients denote that highspatial diversity is likely to produce higher challenge (when
I ≥ 0.6) and furthermore higher Ghosts’ behavior diversitywhen I ≥ 0.7.
XV. ADAPTABILITY EXPERIMENTS
On-line learning in Dead End revealed adaptive behavior tonew — unknown during off-line training — playing strategiesthat lead to the improvement of the player’s entertainment(see Fig. 6). Additional experiments are held here in the Pac-Man game in order to further demonstrate the mechanism’sadaptability.
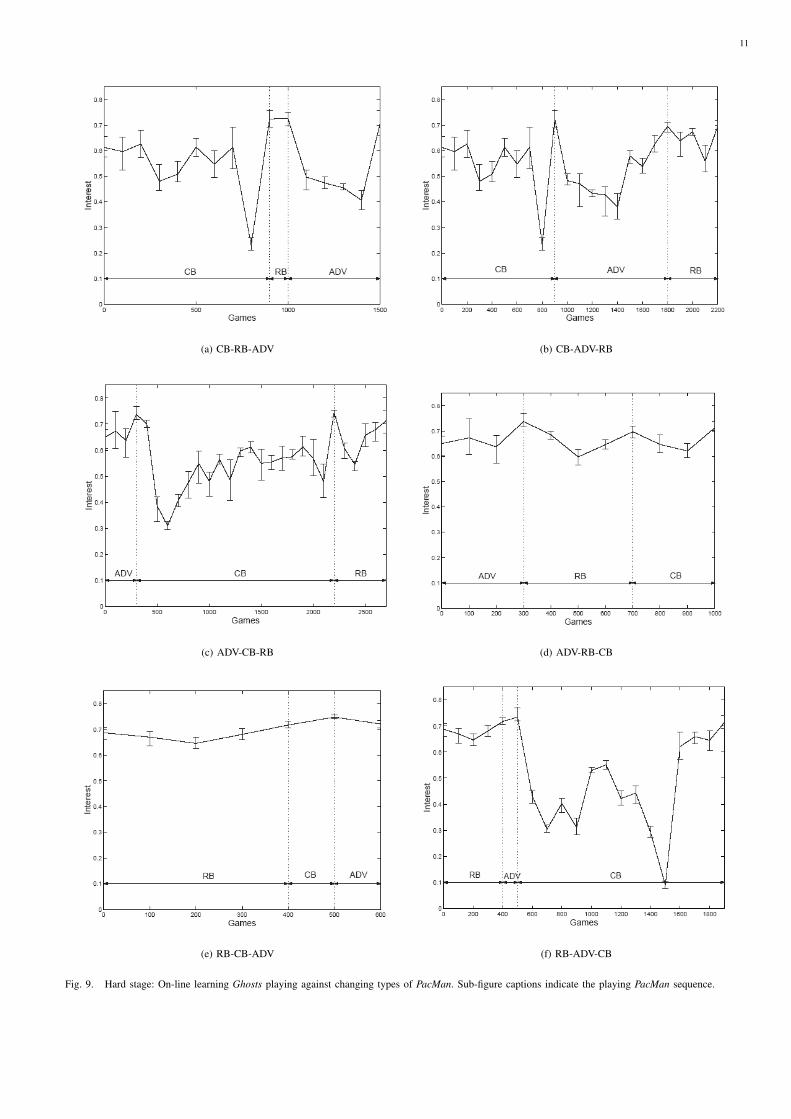
In order to test the OLL approach’s ability to adapt to achanging environment (i.e. change of the PacMan’s strategy),the following experiment is proposed. Beginning from aninitial behavior of high interest value Iinit we apply the OLLmechanism against a specific PacMan type. During the on-line process we keep changing the type of player as soon asinteresting games (i.e. I ≥ Iinit) are produced. The processstops when all three types of players have played the game.We repeat this process for all four stages examined; however,for space considerations, results presented here are obtainedfrom experiments in the most difficult adaptability case-study,that is the Hard stage.
Since we have three types of players, the total numberof different such experiments is 6 (all different player typesequences) for each stage. These experiments illustrate theoverall picture of the approach’s behavior against any sequenceof PacMan types. As seen in Fig. 9, OLL is able to quicklyrecover form a sudden change in the player’s strategy evenin the most difficult stage and boost the game’s interestvalue at high levels after sufficient games (i.e. 100 to 1500)have been played. The mechanism demonstrates a similaradaptive behavior for all 6 different sequences of PacManplayers and all four stages which illustrates its independenceof the sequence of the changing PacMan type and the stagecomplexity.
Results obtained from this experiment provide evidence forthe approach’s ability to adapt to new types of players as wellas its efficiency in producing interesting games against humanplayers.
XVI. DISCUSSION
This section provides a discussion of the proposed method-ology for obtaining predator/prey games of high entertainmentvalue, by outlining a summary of its demonstrated generalityover the dimensions of game variants, game complexity, playerand initial behavior. Moreover, this section portrays the basicassumptions drawn for this work and solutions to potentialdrawbacks emerging when games scale up.
A. Predator/Prey Game Variants
For the experiments presented here we used two preda-tor/prey games differing in the characters’ motion type, stageenvironment and player objectives. Interest reached high val-ues and the OLL mechanism demonstrated robustness andadaptability when applied to both Pac-Man and Dead Endgames. However, no effective comparison between the twogames’ generated interest values can be derived and therefore
11
(a) CB-RB-ADV (b) CB-ADV-RB
(c) ADV-CB-RB (d) ADV-RB-CB
(e) RB-CB-ADV (f) RB-ADV-CB
Fig. 9. Hard stage: On-line learning Ghosts playing against changing types of PacMan. Sub-figure captions indicate the playing PacMan sequence.

12
no answer can be given to which game is more interesting bydesign. Based on the games’ main features and differences,we believe that these two test-beds cover a large portion ofthe properties met in the predator/prey computer game genre.
B. OLL Variants
Regarding the OLL approach variants used for the twogames, experiments project a smooth but rather slow changeof the interest value in Pac-Man whereas in Dead End aquite noisy (unstable) but relatively fast change is noticed.Moreover, the more complex the Dead End game environ-ment (i.e. fewer Dogs) is, the more distinctive this instabilitybecomes. The aforementioned dissimilarity in the interestvalue evolution is fully determined by (a) the pre-evaluationprocedure and (b) the gaussian mutation operator that existin the Pac-Man version of the OLL mechanism. According tothe former, the probability of disruptive phenomena caused byunsuccessful mutations is minimized and, therefore, evolutionis decelerated for the sake of smooth changes in emergentbehaviors. According to the latter, the variance of the gaussianmutation is inversely proportional to the entropy of a group ofGhosts. Hence, the higher the Ghosts’ cell visit entropy, theless disruptive the mutation process.
If we attempt to compare the two mechanisms used, the Pac-Man OLL variant appears as a more sophisticated algorithmthat is designed to skip undesired opponent behaviors anderratic changes of the I value with the cost of convergencetime. On the contrary, the Dead End OLL variant is a hill-climber that generates interesting games faster with the costof instability.
C. Game Complexity & Topology
The OLL’s ability to generate games of high interest valuewas tested over varying game complexity, which correspondsto the Easy, Normal and Hard stages for Pac-Man and tofive, four and three Dog environments for Dead End. Resultsobtained from these experiments demonstrate the approach’sgenerality since interesting games emerge independently ofgame complexity.
In addition to stages of different complexity, topologicallydifferent Pac-Man stages of equal complexity (Easy A andEasy B) were used as test-beds for the approach. Obtainedinterest values showed that the topology of the stage does notseem to hinder the OLL’s adaptive features surfacing.
D. Player
As far as the playing strategy is concerned, three hand-crafted players have been designed for each game. Indepen-dently of playing strategy, the mechanism adapted to theirplaying style in order to boost the game’s interest value. Morespecifically, in the Pac-Man game, the best OLL generatedinterest values were not significantly different regardless theplayer type.
The main assumption for both games is that players overallhave a basic level of gaming skills in each game. In thatsense, the computer guided Pac-Man players are models of
some well-behaved, average-skill players based on similarmotion patterns that do not leave much space for significantdifferences in their performance. In addition, humans whohave tested Pac-Man validate this assumption since theirgenerated interest values against the same opponent werenot significantly different [2]. However, further studies usingplayer modelling have displayed its positive impact on thegeneration of more interesting Pac-Man games over a longergame time scale [23].
According to the overall observed behavior of the I value itappears that, in addition to the opponent, the player may alsoplay a significant role in its own entertainment. The player maydetermine the game’s plot to a degree and this occurs due toits interaction with the opponents. In that sense, the interestvalue is affected by the player more in extreme scenarios suchas unacceptably low (i.e. unable to control the player andsense the features of the game environment) or expert (i.e.unbeatable) gaming skills.
For instance, both EA and RM (in a lesser degree) types ofCat belong to the above-mentioned category of game-playingby following a trivial low-quality game strategy. Contrary tothe PFB Cat and all PacMan types used, the aforementionedplayer types do not interact with their opponents, whichfurthermore, leads to a poor estimation of the game’s Ivalue. Thus, EA Cat appears to generate significantly moreinteresting games than the RM Cat and the PFB Cat. Notethat the averages of the best interest values achieved from OLLexperiments presented in Section XIII-A are 0.7641, 0.7240and 0.7118 when playing against the EA, the RM and the PFBCat respectively. Even though such playing strategies (e.g.EA and RM Cat) are rare among humans they constitute alimitation of the interest value estimation.
E. Initial Behavior
Five different behaviors emerged from off-line trainingprocedures were selected as initial points in the search formore interesting games. For the Pac-Man game we categorizedOLT emerged behaviors into blocking, aggressive and hybridwhereas for the Dead End game the OLT behaviors obtainedwere characterized as either aggressive or defensive. Giventhese diverse initial behaviors, the OLL mechanism exhibitedhigh robustness and fast adaptability in increasing the game’sinterest value. Moreover, results showed that convergence timeof highly interesting games is dependent on the initial interestvalue.
XVII. CONCLUSIONS
Predator strategies in predator/prey computer games arestill nowadays based on simple rules which generate complexopponent behaviors [24]. However, by the time the playergains more experience and playing skills the game becomesrather predictable and, therefore, somewhat uninteresting. Acomputer game becomes interesting primarily when there isan on-line interaction between the player and his opponentswho demonstrate adaptive behaviors [25].
Given some criteria for defining interest in predator/preygames we applied a methodology for explicitly measuring

13
a human-verified entertainment value in real-time in suchgames. We saw that by using the proposed on-line learningmechanism in two dissimilar games, maximization of the indi-vidual objective function (see (3)) leads to maximization of thegame’s interest value. Apart from being robust, the proposedmechanism demonstrates high and fast adaptability to newtypes of player (i.e. playing strategies). Results obtained fromthese experiments demonstrate the approach’s generality sinceinteresting games emerge independently of game concept,stage complexity, initial opponent behavior and player type.
Based on the experiments presented in this paper, theneuro-evolution methodology proposed reveals features thatovercome the three main challenges of learning in real-timein games (see Section IV). More specifically, interesting gameswere generated using a single CPU (real-time performance);the probability of generating unwanted behaviors is minimized(Pac-Man version of OLL) when the game generates highlevels of interestingness; and the opponents’ adaptability timereaches the levels of tens of games when the initial opponentbehavior is highly interesting.
A. Extensibility
Experiments over variants of predator/prey games of dif-ferent complexity and their features have demonstrated themethodology’s robustness throughout this paper. Here, we dis-cuss the potential of the methodology in other genres of multi-opponent games where the complication of the opponents’tasks may differ. More specifically, we analyze the extensi-bility of the interest metric proposed, the on-line evolutionarylearning mechanism and the neuro-controller used.
1) Interest Metric: As already mentioned in Section V,the criteria of challenge and behavior’s diversity may beeffectively applied for measuring the real-time entertainmentvalue of any genre of games. Spatial diversity may in a sensealso contribute to the interest value of specific genres (e.g.team-sport, real-time strategy and first-person shooter games).As long as game developers can determine and extract thefeatures of the opponent behavior that generate excitement forthe player, a mathematical formula can be designed in orderto collectively represent them.
2) Learning Methodology: The proposed on-line evolu-tionary learning method may also be successfully applied toany game during active real-time player-opponent interactions.Extracted features of this interaction may be used in orderto estimate the fitness of the involved opponents accordingto their tasks. The replacement of the worst-fit opponent(s)method may be applied in frequent game periods to enhancethe group’s fitness. See also Stanley et al. [14] for a successfulapplication of this method in the NERO game.
Artificial evolution can explore complex search spacesefficiently and when combined with neural networks it candemonstrate fast adaptability to dynamic and changing en-vironments. Therefore neuro-evolution is recommended forlearning in real-time. However, convergence time and unpre-dictability of the emergent behaviors constitute the disadvan-tages of the methodology which can be dealt with by carefuldesign of the learning mechanism. Player modeling techniques
are able to decrease convergence time down to realistic periodsof time (i.e. tens of games) and furthermore proliferate theefficiency and justifiability of learning in real-time [23].
3) Controller: Artificial neural networks serve successfullythe adaptability requirements for predator/prey reactive gamesin real-time. However, as the complexity of the opponents’tasks increases there might be a need for more sophisticatedstructures of distributed representation. Memory of previousbehaviors learned through the player-opponent interaction mayvery well be essential when a combination of various tasksis required. Recurrent neural networks or augmented neuralnetwork topologies with hidden states [16] may be moreappropriate when the opponents’ tasks proliferate. Moreover,a hierarchy of neuro-controllers that serve different opponenttasks could also provide the on-line learning mechanism withmore flexibility and faster adaptability.
REFERENCES
[1] G. N. Yannakakis and J. Hallam, “Evolving Opponents for Interesting In-teractive Computer Games,” in From Animals to Animats 8: Proceedingsof the 8th International Conference on Simulation of Adaptive Behavior(SAB-04), S. Schaal, A. Ijspeert, A. Billard, S. Vijayakumar, J. Hallam,and J.-A. Meyer, Eds. Santa Monica, LA, CA: The MIT Press, July2004, pp. 499–508.
[2] ——, “Towards Optimizing Entertainment in Computer Games,” June2005, submitted to Applied Artificial Intelligence.
[3] ——, “A generic approach for generating interesting interactive pac-manopponents,” in Proceedings of the IEEE Symposium on ComputationalIntelligence and Games, G. Kendall and S. Lucas, Eds., Essex Univer-sity, Colchester, UK, 4–6 April 2005, pp. 94–101.
[4] ——, “Interactive Opponents Generate Interesting Games,” in Proceed-ings of the International Conference on Computer Games: ArtificialIntelligence, Design and Education, Microsoft Campus, Reading, UK,November 2004, pp. 240–247.
[5] J. E. Laird and M. van Lent, “Human-level AI’s killer application:Interactive computer games,” in Proceedings of the Seventh NationalConference on Artificial Intelligence (AAAI), 2000, pp. 1171–1178.
[6] C. Thurau, C. Bauckhage, and G. Sagerer, “Learning human-like Move-ment Behavior for Computer Games,” in From Animals to Animats8: Proceedings of the 8th International Conference on Simulationof Adaptive Behavior (SAB-04), S. Schaal, A. Ijspeert, A. Billard,S. Vijayakumar, J. Hallam, and J.-A. Meyer, Eds. Santa Monica, LA,CA: The MIT Press, July 2004, pp. 315–323.
[7] A. Nareyek, “Intelligent agents for computer games,” in Computers andGames, Second International Conference, CG 2002, T. Marsland andI. Frank, Eds., 2002, pp. 414–422.
[8] S. Lucas, “Evolving a neural network location evaluator to play Ms.Pac-Man.” in Proceedings of the IEEE Symposium on ComputationalIntelligence and Games, G. Kendall and S. Lucas, Eds., Essex Univer-sity, Colchester, UK, 4–6 April 2005, pp. 203–210.
[9] M. Freed, T. Bear, H. Goldman, G. Hyatt, P. Reber, A. Sylvan, andJ. Tauber, “Towards more human-like computer opponents,” in WorkingNotes of the AAAI Spring Symposium on Artificial Intelligence andInteractive Entertainment, 2000, pp. 22–26.
[10] N. A. Taatgen, M. van Oploo, J. Braaksma, and J. Niemantsverdriet,“How to construct a believable opponent using cognitive modeling inthe game of set,” in Proceedings of the fifth international conference oncognitive modeling, 2003, pp. 201–206.
[11] H. Iida, N. Takeshita, and J. Yoshimura, “A metric for entertainmentof boardgames: its implication for evolution of chess variants,” inIWEC2002 Proceedings, R. Nakatsu and J. Hoshino, Eds. Kluwer,2003, pp. 65–72.
[12] T. W. Malone, “What makes computer games fun?” Byte, vol. 6, pp.258–277, 1981.
[13] M. Csikszentmihalyi, Flow: The Psychology of Optimal Experience.New York: Harper & Row, 1990.
[14] K. Stanley, B. Bryant, and R. Miikkulainen, “Real-time evolution inthe NERO video game,” in Proceedings of the IEEE Symposium onComputational Intelligence and Games, G. Kendall and S. Lucas, Eds.,Essex University, Colchester, UK, 4–6 April 2005, pp. 182–189.

14
[15] G. N. Yannakakis, J. Levine, and J. Hallam, “An Evolutionary Approachfor Interactive Computer Games,” in Proceedings of the Congress onEvolutionary Computation (CEC-04), June 2004, pp. 986–993.
[16] K. Stanley and R. Miikkulainen, “Evolving neural networks throughaugmenting topologies,” Evolutionary Computation, vol. 10, no. 2, pp.99–127, 2002.
[17] S. Woodcock, “Game AI: The State of the Industry 2000-2001: It’s notJust Art, It’s Engineering,” August 2001.
[18] J. A. Meyer and A. Guillot, “From SAB90 to SAB94: Four yearsof animat research,” in From Animals to Animats 3: Proceedings ofthe Third International Conference on Simulation of Adaptive Behavior(SAB-92), 1994.
[19] A. J. Champandard, AI Game Development. New Riders Publishing,2004.
[20] G. N. Yannakakis, J. Levine, J. Hallam, and M. Papageorgiou, “Per-formance, robustness and effort cost comparison of machine learningmechanisms in FlatLand,” in Proceedings of the 11th MediterraneanConference on Control and Automation MED’03. IEEE, June 2003.
[21] J. K. Park, “Emerging complex behaviors in dynamic multi-agentcomputer games,” M.Sc. Thesis, University of Edinburgh, 2003.
[22] O. Khatib, “Real-time obstacle avoidance for manipulators and mobilerobots,” Int. J. for Robotics Research, vol. 5, no. 1, pp. 90–99, 1986.
[23] G. N. Yannakakis and M. Maragoudakis, “Player modeling impact onplayer’s entertainment in computer games,” in Proceedings of the 10th
International Conference on User Modeling; Lecture Notes in ComputerScience, vol. 3538. Edinburgh: Springer-Verlag, 24–30 July 2005, pp.74–78.
[24] Wikipedia, the Free Encyclopedia, “Pac-Man,” June 2005. [Online].Available: http://en.wikipedia.org/wiki/Pac-man
[25] G. N. Yannakakis and J. Hallam, “A scheme for creating digital enter-tainment with substance,” in Proceedings of the Workshop on Reasoning,Representation, and Learning in Computer Games, 19th InternationalJoint Conference on Artificial Intelligence (IJCAI), August 2005, pp.119–124.





























