Embed Size (px)
Citation preview

A Comparison of Rule-Based versus Exemplar-Based Categorization Using the ACT-R Architecture
Matthew F. RUTLEDGE-TAYLOR, Christian LEBIERE, Robert THOMSON,
James STASZEWSKI and John R. ANDERSONCarnegie Mellon University, Pittsburgh, PA, USA
19th Annual ACT-R Workshop: Pittsburgh, PA, USA

Overview
• Categorization theories• Facility Identification Task
– Study examples of four different facilities– Categorize unseen facilities
• ACT-R Models– Rule-based versus Exemplar-based– Three different varieties of each based on information attended
• Model Results– Rule-based models are equivalent to exemplar-based models in
terms of hit-rate performance• Discussion

Categorization theories
• Rule-based theories (Goodman, Tenenbaum, Feldman & Griffiths, 2008)– Exceptions, e.g. RULEX (Nosofsky & Palmeri, 1995)– Probabilistic membership (Goodman et al., 2008)
• Prototype theories (Rosch, 1973)– Multiple prototype theories
• Exemplar theories (Nosofsky, 1986)– WTA vs weighted similarity
• ACT-R has been used previously to compare and contrast exemplar-based and rule-based approaches to categorization (Anderson & Betz, 2001)

Facility Identification Task
Building (IMINT)
Hardware
MASINT1
MASINT2
SIGINT
Notional Simulated Imagery • Four kinds of facilities
• Probabilistic feature composition

Facility Identification Task
• Probabilistic occurrences of features
Facility A Facility B Facility C Facility D
Building 1 High Mid High Mid
Building 2 High Mid High High
Building 3 High Mid Mid High
Building 4 High High Mid Mid
Building 5 Low High Mid High
Building 6 Low High High High
Building 7 Low High High Mid
Building 8 Low Mid Mid High
MASINT1 Few Many Few Many
MASINT2 Few Many Many Few
SIGINT Many Few Many Few
Hardware Few Few Few Many

Three comparisons
• Human data versus model data– Hit-rate accuracy
• Exemplar model versus rule-based model– Blended retrieval of facility chunk, VS– Retrieval of one or more rules that manipulate a probability
distribution• Cognitive phenotypes: versions of both exemplar and
rule-based models that attend to different data– Feature counts– Buildings that are present– Both

Three participant phenotypes
• Phenotype #1: Assumes buildings are key– Attentive to specific buildings in the image– Ignores the MASINT, SIGINT, and Hardware
• Phenotype #2: Assumes the numbers of each feature type is key– Attentive to counts of each facility feature– Ignores the types of buildings (just counts them)
• Phenotype #3: Attends to both specific buildings and feature counts

Facility Identification
Phenotype #1Specific Buildings only: SA model
Building #2Building #3Building #6Building #7
2
3
6
7

Facility Identification
Phenotype #2Feature type counts only: PM model
Buildings 4Hardware 1MASINT1 6MASINT2 2SIGINT 5

Facility Identification
Phenotype #3SA and PM
Building #2Building #3Building #6Building #7Hardware 1MASINT1 6MASINT2 2SIGINT 5
2
3
6
7

ACT-R Exemplar based model
• Implicit statistical learning– Commits tokens of facilities to declarative memory
• Slots for facility type (A, B, C or D)• Slots for sums of each feature type• Slot for presence (or absence) of each building (IMINT)
• Categorization– Retrieval request made to DM based on facility
features in target– Category slot values of retrieved chunk is used as
categorization decision of the model

Facility chunk

ACT-R: Chunk activation
• Ai = Bi + Si + Pi + Ɛi
• Ai is the net activation,
• Bi is the base-level activation,
• Si is the effect of spreading activation,
• Pi is the effect of the partial matching mismatch penalty, and • Ɛi is magnitude of activation noise.

Spreading Activation
• All values in all included buffers, spread activation to DM
• All facility features stored held in the visual buffer spread activation to all chunks in DM
• Primary retrieval factor for phenotype #1 (buildings)

Spreading ActivationVisual Buffer
Facility Chunk
Declarative Memory
Facility Chunk Facility Chunk Facility Chunk
b1 nil
b2 building2
b3 building3
b4 nil
b5 nil
b6 building6
b7 building7
category d
b1 nil
b2 building2
b3 nil
b4 nil
b5 nil
b6 building6
b7 building7
category d
b1 nil
b2 building2
b3 building3
b4 building4
b5 nil
b6 building6
b7 nil
category a
b1 building1
b2 nil
b3 building3
b4 nil
b5 building5
b6 nil
b7 nil
category d

Partial Matching
• The partial match is on a slot by slot basis• For each chunk in DM, the degree to which each slot
mismatches the corresponding slot in the retrieval cue determines the mismatch penalty
• Primary retrieval factor for phenotype #2 (counts)
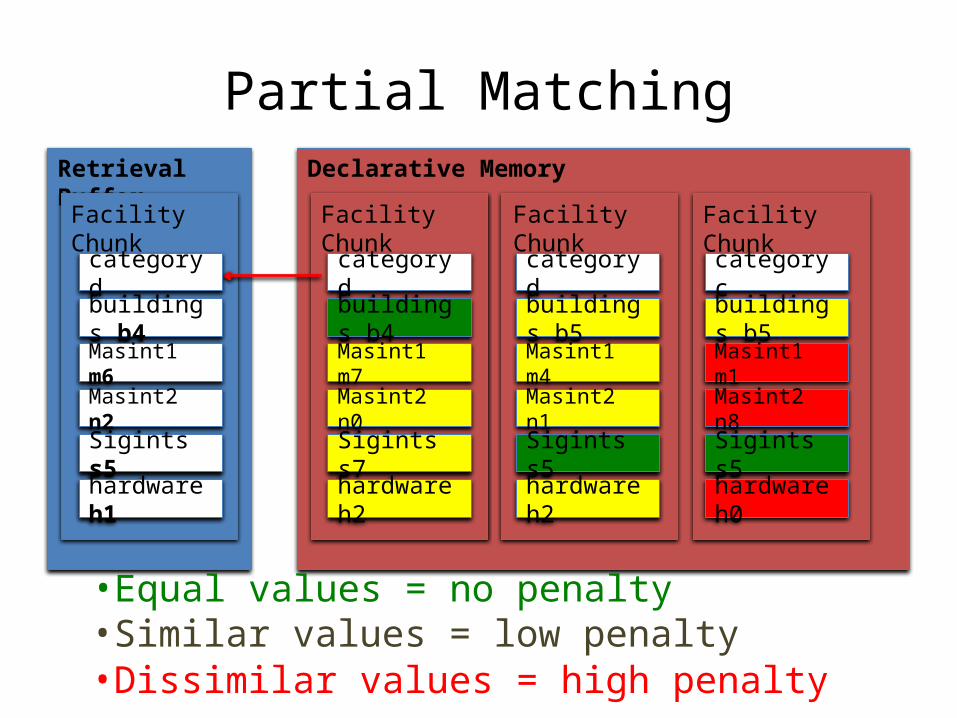
Partial MatchingRetrieval Buffer
Facility Chunk
Declarative Memory
Facility Chunk Facility Chunk Facility Chunk
buildings b4
Masint1 m6
Masint2 n2
Sigints s5
hardware h1
buildings b4
Masint1 m7
Masint2 n0
Sigints s7
hardware h2
buildings b5
Masint1 m4
Masint2 n1
Sigints s5
hardware h2
buildings b5
Masint1 m1
Masint2 n8
Sigints s5
hardware h0
category d category d category c
•Dissimilar values = high penalty•Similar values = low penalty•Equal values = no penalty
category d

Heat Map on Counts of Features

Results of Exemplar Based Model• PM only– 0.462
• SA only– 0.665
• PM + SA– 0.720
• Human Participant Accuracy: 0.535– Performance and interviews suggests
• Mix of phenotypes, with #2 (PM-like) most prevalent• Employment of some explicit rules

ACT-R Rule Based Model
• Applied a set of rules to the unidentified target facility
• Accumulated a net probability distribution over the four possible facility categories
• Facility with greatest probability is the forced choice category response by the model

ACT-R Rule Based Model
• Two kinds of rules– SA-like: applies to presence of buildings– PM-like: applies to feature counts
• Rules implemented as chunks in DM• Sets of dedicated productions for retrieving
relevant rules• High confidence in choice of rules– Based on analysis of probabilities of features

ACT-R Rule Based Model
• Example building rule
- If is present then facility A is 1.38 times more likely (than if not present)
• Example count rule
- If there are 5 MASINT1 then facility A is 3 times more likely (than if more or less)- Note: Count rules apply if count total in target is within a threshold difference of number in rule

Rule chunks

ACT-R Rule Based Model
• Three versions of the rules based model– Only apply building rules: similar to SA exemplar
model– Only apply count rules: similar to PA exemplar
model– Apply both building and count rules: similar to
combined exemplar model

ACT-R Rule Based Model Results
• Building rules only: 0.657• Count rules only: 0.476• Both building and count rules: 0.755
Strategy Rule-based Exemplar % Difference
SA / Buildings 0.657 0.655 0.30
PM / Counts 0.476 0.462 2.94
Combined 0.755 0.720 4.64

Discussion• Agreement between rule-based and exemplar models, implemented
in ACT-R, supports the equivalence of these approaches– They exploit the same available information
• The performance equivalence between the two establishes that functional Bayesian inferencing can be accomplished in ACT-R either through:– explicit, rule application– implicit, subsymbolic processes of the activation calculus, that support the
exemplar model• ACT-R learning mechanisms of the subsymbolic system in ACT-R is
Bayesian in nature (Anderson, 1990; 1993) • Blending allows ACT-R to implement importance sampling (Shi, et al.,
2010)

Acknowledgements
• This work is supported by the Intelligence Advanced Research Projects Activity (IARPA) via Department of the Interior (DOI) contract number D10PC20021. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. The views and conclusions contained hereon are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DOI, or the U.S. Government.

Blended Retrieval
• Standard retrieval– One previously existing chunk is retrieved
• Effectively, WTA closest exemplar
• Blending– One new chunk which is a blend of matching chunks is
retrieved (created)– All slots not specified in the retrieval cue are assigned
blended values– The contribution each exemplar chunk makes to blended
slot values is proportional to the activation of the chunk





























