Embed Size (px)
Citation preview

600.465 - Intro to NLP - J. Eisner 1
Finite-State and the Noisy Channel

600.465 - Intro to NLP - J. Eisner 2
Word Segmentation
What does this say? And what other words are substrings?
Could segment with parsing (how?), but slow.
Given L = a “lexicon” FSA that matches all English words.
How to apply to this problem? What if Lexicon is weighted? From unigrams to bigrams? Smooth L to include unseen words?
theprophetsaidtothecity

600.465 - Intro to NLP - J. Eisner 3
Spelling correction
Spelling correction also needs a lexicon L But there is distortion …
Let T be a transducer that models common typos and other spelling errors ance () ence (deliverance, ...) e (deliverance, ...) e // Cons _ Cons (athlete, ...) rr r (embarrasş occurrence, …) ge dge (privilege, …) etc.
Now what can you do with L .o. T ? Should T and L have probabilities? Want T to include “all possible” errors …
600.465 - Intro to NLP - J. Eisner 4
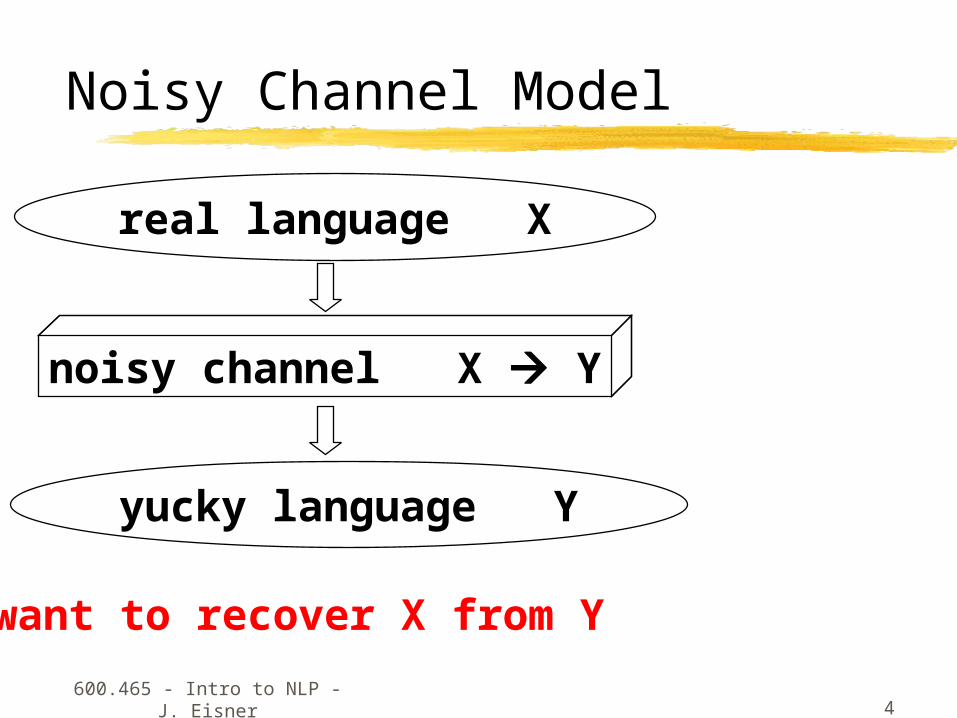
Noisy Channel Model
noisy channel X Y
real language X
yucky language Y
want to recover X from Y

600.465 - Intro to NLP - J. Eisner 5
Noisy Channel Model
noisy channel X Y
real language X
yucky language Y
want to recover X from Y
correct spelling
typos
misspelling

600.465 - Intro to NLP - J. Eisner 6
Noisy Channel Model
noisy channel X Y
real language X
yucky language Y
want to recover X from Y
(lexicon space)*
delete spaces
text w/o spaces

600.465 - Intro to NLP - J. Eisner 7
Noisy Channel Model
noisy channel X Y
real language X
yucky language Y
want to recover X from Y
(lexicon space)*
pronunciation
speech
language model
acoustic model

600.465 - Intro to NLP - J. Eisner 8
Noisy Channel Model
noisy channel X Y
real language X
yucky language Y
want to recover X from Y
tree
delete everythingbut terminals
text
probabilistic CFG

600.465 - Intro to NLP - J. Eisner 9
Noisy Channel Model
noisy channel X Y
real language X
yucky language Y
p(X)
p(Y | X)
p(X,Y)
*
=
want to recover xX from yYchoose x that maximizes p(x | y) or equivalently p(x,y)
600.465 - Intro to NLP - J. Eisner 10
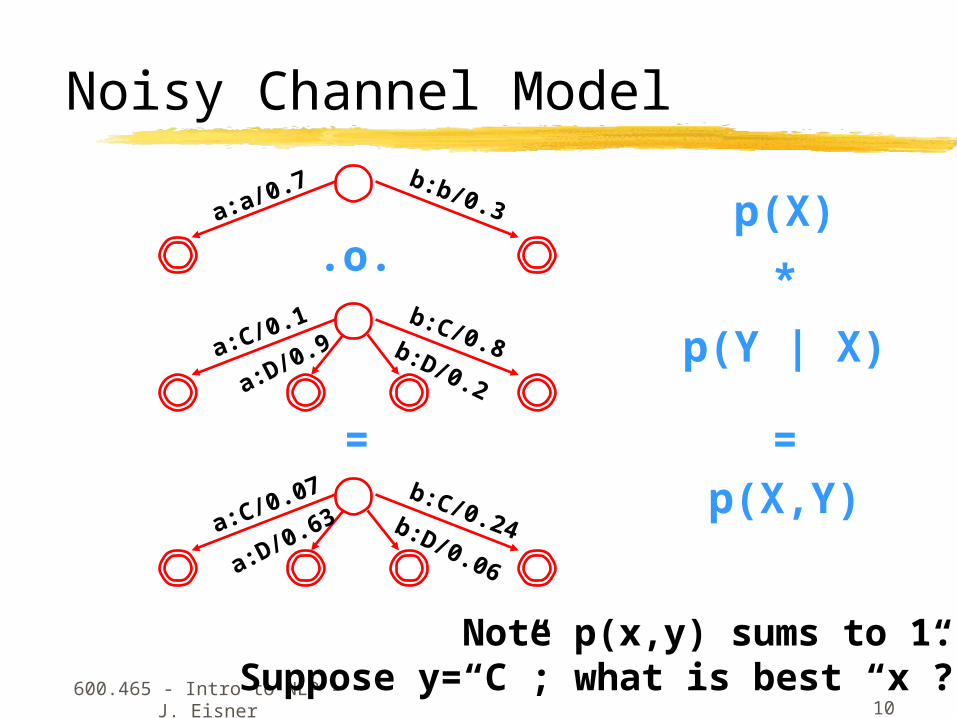
Noisy Channel Model
p(X)
p(Y | X)
p(X,Y)
*
=
a:D/0.
9a:C/0.
1 b:C/0.8b:D/0.2
a:a/0.
7 b:b/0.3
.o.
=
a:D/0.
63a:C/0.
07 b:C/0.24b:D/0.06
Note p(x,y) sums to 1.Suppose y=“C”; what is best “x”?
600.465 - Intro to NLP - J. Eisner 11
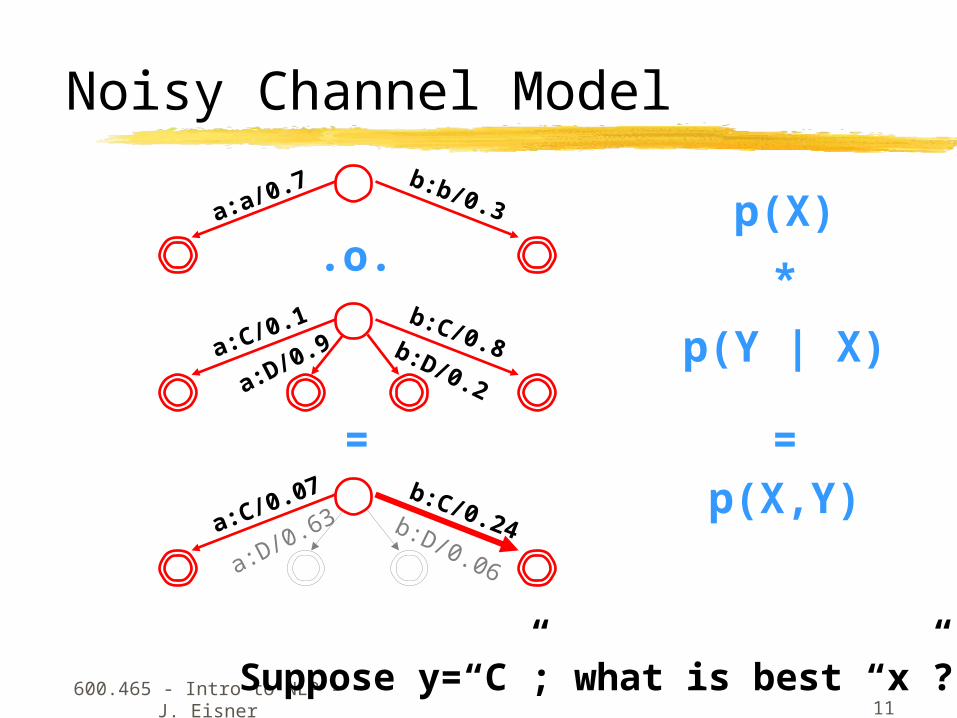
Noisy Channel Model
p(X)
p(Y | X)
p(X,Y)
*
=
a:D/0.
9a:C/0.
1 b:C/0.8b:D/0.2
a:a/0.
7 b:b/0.3
.o.
=
a:D/0.
63a:C/0.
07 b:C/0.24b:D/0.06
Suppose y=“C”; what is best “x”?
600.465 - Intro to NLP - J. Eisner 12
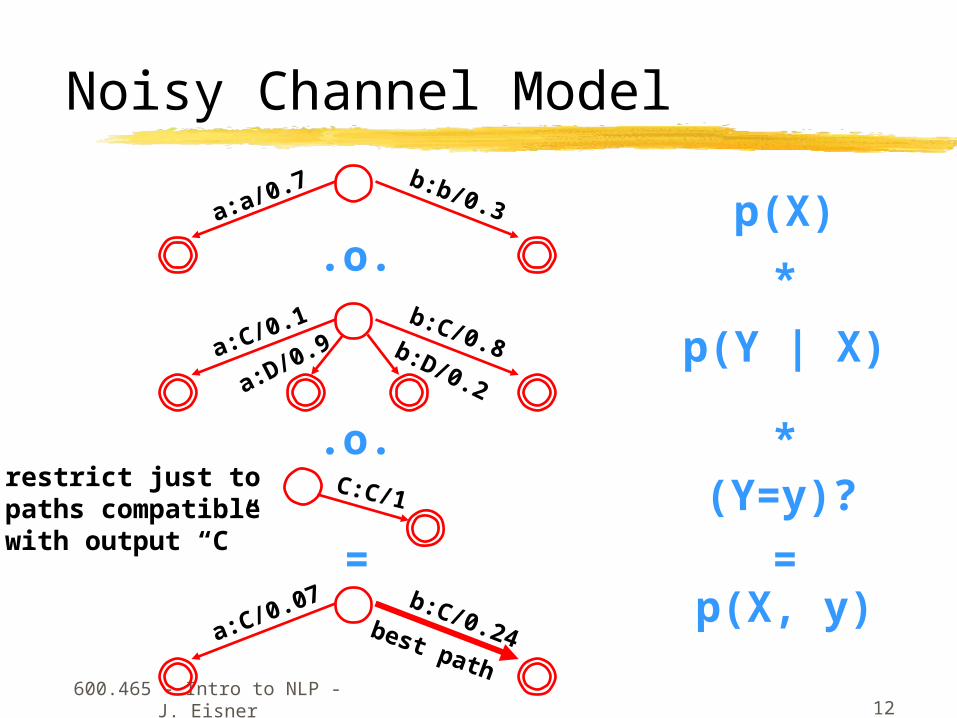
Noisy Channel Model
p(X)
p(Y | X)
p(X, y)
*
=
a:D/0.
9a:C/0.
1 b:C/0.8b:D/0.2
a:a/0.
7 b:b/0.3
.o.
=
a:C/0.
07 b:C/0.24
.o. *C:C/1 (Y=y)?
restrict just topaths compatiblewith output “C”
best path

600.465 - Intro to NLP - J. Eisner 13
Morpheme Segmentation Let Lexicon be a machine that matches all Turkish
words Same problem as word segmentation Just at a lower level: morpheme segmentation Turkish word: uygarlaştıramadıklarımızdanmışsınızcasına
= uygar+laş+tır+ma+dık+ları+mız+dan+mış+sınız+ca+sı+na(behaving) as if you are among those whom we could not cause to become civilized
Some constraints on morpheme sequence: bigram probs Generative model – concatenate then fix up joints
stop + -ing = stopping, fly + -s = flies, vowel harmony Use a cascade of transducers to handle all the fixups
But this is just morphology! Can use probabilities here too (but people often don’t)
600.465 - Intro to NLP - J. Eisner 14
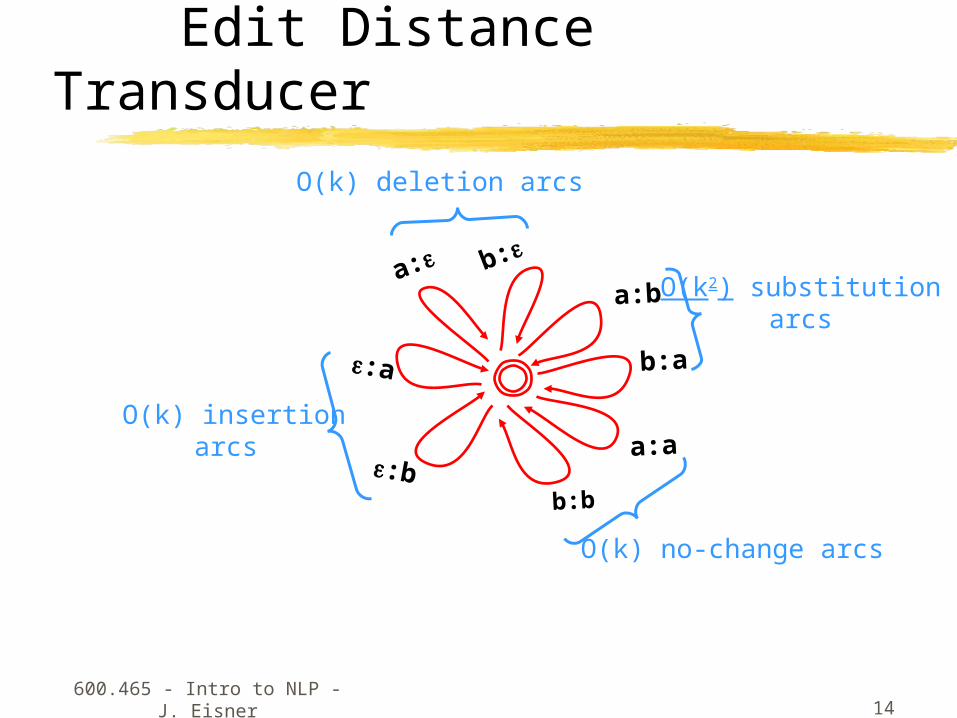
Edit Distance Transducer
a:
:a
b:
:b
a:b
b:a
a:a
b:b
O(k) deletion arcs
O(k) insertionarcs
O(k2) substitution arcs
O(k) no-change arcs
600.465 - Intro to NLP - J. Eisner 15
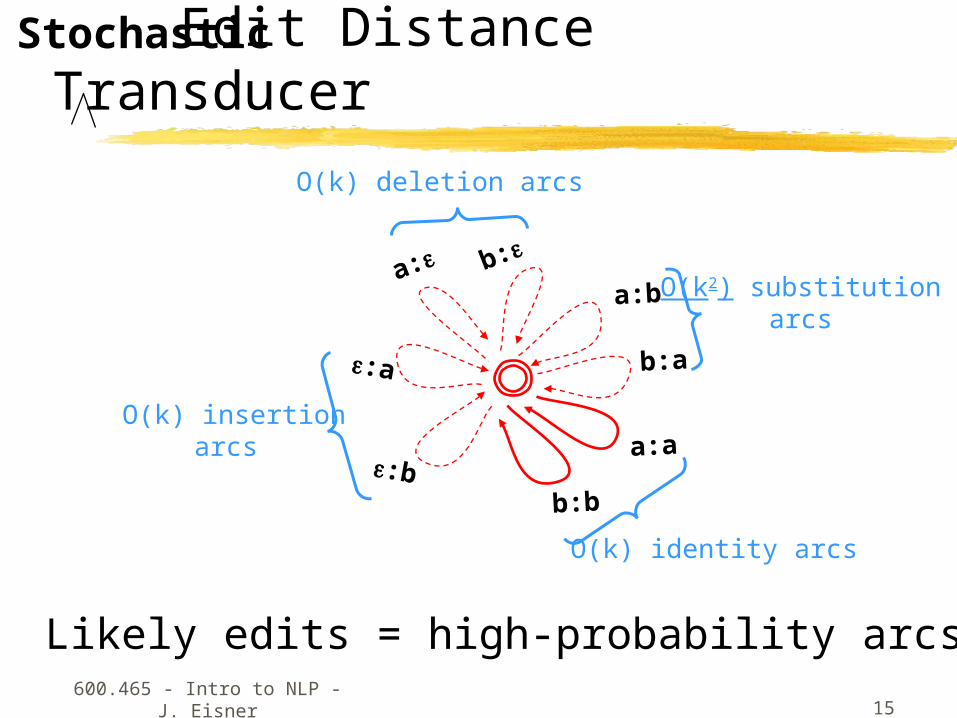
Edit Distance Transducer
a:
:a
b:
:b
a:b
b:a
a:a
b:b
O(k) deletion arcs
O(k) insertionarcs
O(k2) substitution arcs
O(k) identity arcs
Likely edits = high-probability arcs
Stochastic
600.465 - Intro to NLP - J. Eisner 16
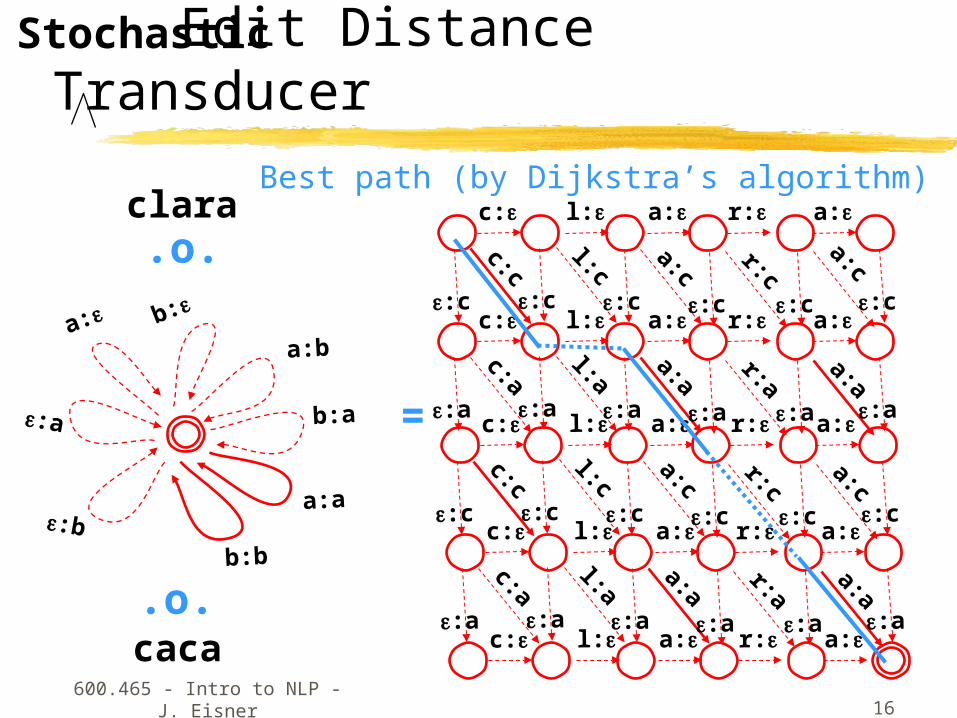
clara
Edit Distance Transducer
a:
:a
b:
:b
a:b
b:a
a:a
b:b
Stochastic
.o.
=
caca.o.
c: l: a: r: a:
:c
c:c
:c
l:c
:ca:c
:c
r:c
:c
a:c
:cc: l: a: r: a:
:a
c:a
:al:a
:a
a:a
:a
r:a
:a
a:a
:ac: l: a: r: a:
:c
c:c
:c
l:c
:c
a:c
:c
r:c
:c
a:c
:cc: l: a: r: a:
:a
c:a
:a
l:a
:a
a:a
:a
r:a
:a
a:a
:ac: l: a: r: a:
Best path (by Dijkstra’s algorithm)

Speech Recognition by FST Composition (Pereira & Riley 1996)
600.465 - Intro to NLP - J. Eisner 17
p(word seq)
p(phone seq | word seq)
p(acoustics | phone seq)
.o.
.o.
trigram language model
pronunciation model
acoustic model
.o.observed acoustics

Speech Recognition by FST Composition (Pereira & Riley 1996)
600.465 - Intro to NLP - J. Eisner 18
p(word seq)
p(phone seq | word seq)
p(acoustics | phone seq)
.o.
.o.
.o.
æ :phonecontext
phonecontext
CAT:k æ t
trigram language model



























![600.465 - Intro to NLP - J. Eisner1 Modeling Grammaticality [mostly a blackboard lecture]](https://img.dokumen.tips/doc/110x75/56649c715503460f94922c29/600465-intro-to-nlp-j-eisner1-modeling-grammaticality-mostly-a-blackboard.jpg)

