Embed Size (px)
Citation preview

4. Formal Grammars and Parsing and Top-down Parsing
Chih-Hung Wang
Compilers
References1. C. N. Fischer, R. K. Cytron and R. J. LeBlanc. Crafting a Compiler. Pearson Education Inc., 2010.2. D. Grune, H. Bal, C. Jacobs, and K. Langendoen. Modern Compiler Design. John Wiley & Sons, 2000.3. Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and Tools. Addison-Wesley, 1986. (2nd Ed. 2006)1

2
IntroductionContext-free Grammar
The syntax of programming language constructs can be described by context-free grammar
Important aspectsA grammar serves to impose a structure on the
linear sequence of tokens which is the program.Using techniques from the field of formal languages,
a grammar can be employed to construct a parser for it automatically.
Grammars aid programmers to write syntactically correct programs and provide answer to detailed questions about the syntax.

3
The role of the parser

Context-Free GrammarsA context-free grammar(CFG) is a compact,
finite representation of a language, defined by the following four components:A finite terminal alphabet ΣA finite non-terminal alphabet NA start symbol S NA finite set of productions P
4

A Simple Expression Grammar
5

Leftmost DerivationsA sentential form produced via a leftmost
derivation is called a left sentential form.The production sequence discovered by a
large class of parsers (the top-down parsers) is a leftmost derivation. Hence, these parsers are said to produce a leftmost parse.
Example: f(V+V)
6
Elm Prefix(E)
lm f(E)
lm f(V Tail)
lm f(V+E)
lm f(V+V Tail)
lm f(V+V)

Rightmost DerivationsAs a bottom-up parser discovers the
productions that derive a given token sequence, it traces a rightmost derivation, but the productions are applied in reverse order.
Called rightmost or canonical parseExample: f(V+V)
7
Erm Prefix(E)
rm Prefix(V Tail)
rm Prefix(V+E)
rm Prefix(V+V Tail)
rm Prefix(V+V)
rm f(V+V)

Parse TreeIt is rooted by the start symbol SEach node is either a grammar symbol or
8

Properties of CFGsThe grammar may include useless symbolsThe grammar may allow multiple, distinct
derivations (parse trees) for some input string.
The grammar may include strings that do not belong in the language, or the grammar may exclude strings that are in the language.
9

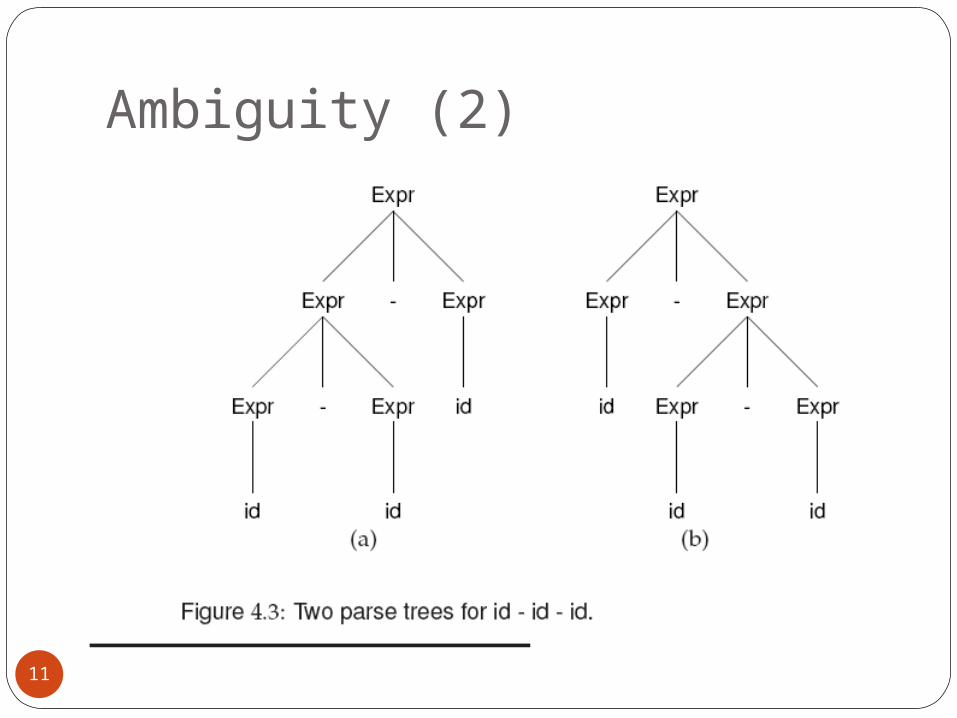
Ambiguity (1)Some grammars allow a derived string to
have two or more different parse trees (and thus a nonunique structure).
Example: 1. Expr →Expr – Expr 2. | idThis grammar allows two different parse
tree for id - id - id.
10
Ambiguity (2)
11

Parsers and RecognizersTwo approaches
A parser is considered top-down if it generates a parse tree by starting at the root of the tree, expanding the tree by applying productions in a depth-first manner.
The bottom-up parsers generate a parse tree by starting the tree’s leaves and working toward its root.
12

13
Two approaches of ParserDeterministic left-to-right top-down
LL methodDeterministic left-to-right bottom-up
LR methodLeft-to-right
The sequence of tokens is processed from left to right
DeterministicNo searching is involved: each token brings
the parser one step closer to the goal of constructing the syntax tree

Parsers (Top-down)
14

15
Parsers (bottom-Up)

16
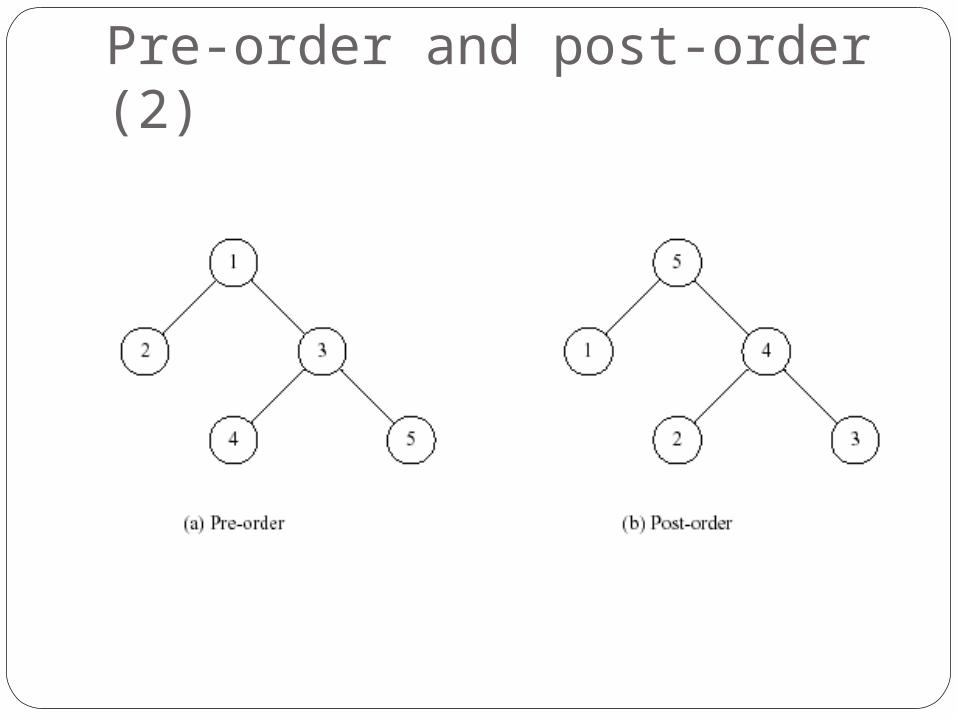
Pre-order and post-order (1)The top-down method constructs the
syntax tree in pre-orderThe bottom-up method constructs the
syntax tree in post-order
17
Pre-order and post-order (2)

18
Principles of top-down parsing
The main task of a top-down parser is to choose the correct alternatives for known non-terminals

19
Principles of bottom-up parsingThe main task of a bottom-up parser is to
repeatedly find the first node all of whose children have already been constructed.

20
Creating a top-down parser manuallyRecursive descent parsing
Simplest way but has its limitations

21
Recursive descent parsing program (1)

22
Recursive descent parsing program (2)

23
DrawbacksThree drawbacks
There is still some searching through the alternatives
The method often fails to produce a correct parser
Error handling leaves much to be desired

24
Second problems (1)Example 1
Index_element will never be triedIDENTIFIER ‘[‘

25
Second problems (2)Example 2
The recognizer will not recognize ab

26
Second problems (3)Example 3
Recursive descent parsers cannot handle left-recursive grammars

27
Creating a top-down parser automaticallyThe principles of constructing a top-down
parser automatically derive from those of writing one by hand, by applying precomputation.
Grammars which allow the construction of a top-down parser to be performed are called LL(1) grammars.

28
LL(1) parsingFIRST set
The sets of first tokens produced by all alternatives in the grammar.
We have to precompute the FIRST sets of all non-terminals
The first sets of the terminals are obvious.Finding FIRST() is trivial when starts with
a terminal.FIRST(N) is the union of the FIRST sets of its
alternatives.First()={a Σ| * a}

29
Predictive recursive descent parserThe FIRST sets can be used in the
construction of a predictive parser because it predicts the presence of a given alternative without trying to find out if it is there.

30
Closure algorithm for computing the FIRST set (1)Data definitions

31
Closure algorithm for computing the FIRST set (2)Initializations

32
Closure algorithm for computing the FIRST set (3)Inference rules

33
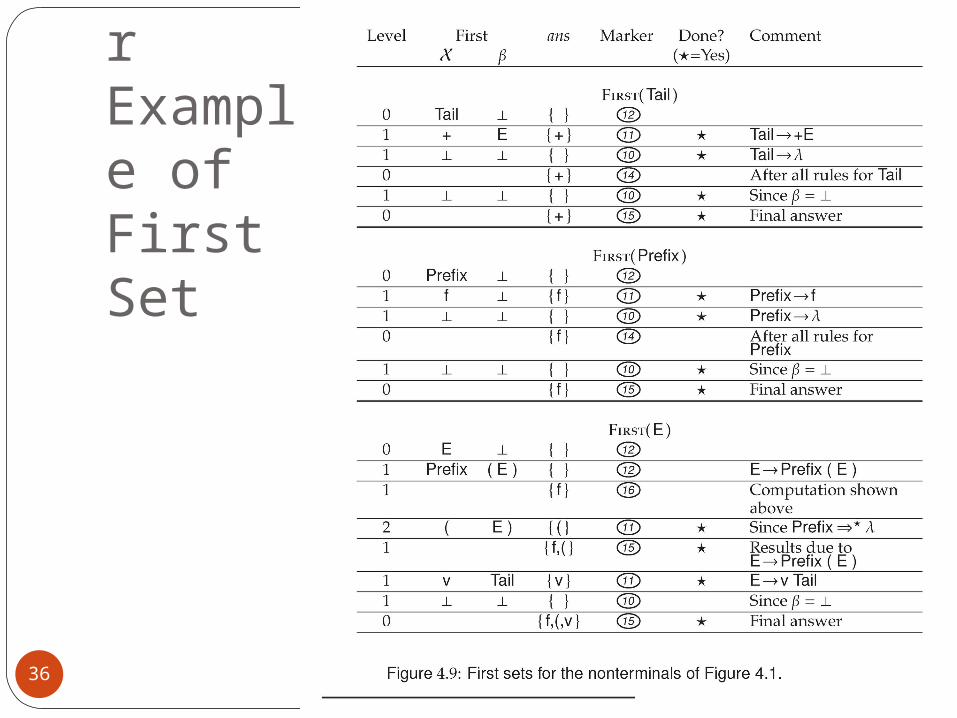
FIRST sets example(1)Grammar

34
FIRST sets example(2)The initial FIRST sets

35
FIRST sets example(3)The final FIRST sets
Another Example of First Set
36

37
Another Example of First Set (II)

Algorithms of Computing First(α)
38

39
The predictive parser (1)

40
The predictive parser (2)

41
PracticeFind the FIRST sets of all alternative of the
following grammar.E -> TE’E’->+TE’|T->FT’T’->*FT’|F->(E)|id

42
Nullable alternativesA complication arises with the case label
for the empty alternative (ex. rest_expression). Since it does not itself start with any token, how can we decide whether it is the correct alternative?

43
FOLLOW setsFollow sets
Determining the set of tokens that can immediately follow a given non-terminal N.
LL(1) parser‘LL’ because the parser works from Left to right
identifying the nodes in what is called Leftmost derivation order.
‘(1)’ because all choices are based on a one token look-ahead.Follow(A)={b Σ |S+ Ab β}

44
Closure algorithm for computing the FOLLOW sets

45
The first and follow sets

Another Example of Follow Set
46

Another Example of Follow Set (II)
47

Algorithm of Follow(A)
48

49
Recall the predictive parser
rest_expression ‘+’ expression | FIRST(rest_expr) = {‘+’, }void rest_expression(void) { switch (Token.class) { case '+': token('+'); expression(); break; case EOF: case ')': break; default: error();
}
}
FOLLOW(rest_expr) = {EOF, ‘)’}

50
LL(1) conflictsExample
The codes

51
LL(1) conflictsFIRST/FIRST conflict
term IDENTIFIER | IDENTIFIER ‘[‘ expression ‘]’ | ‘(’ expression ‘)’

52
LL(1) conflictsFIRST/FOLLOW conflict
FIRST set FOLLOW set S A ‘a’ ‘b’ { ‘a’ } {}A ‘a’ | {‘a’, } {‘a’}

53
LL(1) conflictsleft recursion
expression expression ‘-’ term | term Look-ahead token
LL(1) method predicts the alternative Ak for a non-terminal N
FIRST(Ak) (if is nullable then FOLLOW(N))
LL(1) grammarNo FIRST/FIRST conflictsNo FIRST/FOLLOW conflictsNo multiple nullable alternatives
No non-terminal can have more than one nullable alternative.

54
Solve the LL(1) conflictsTwo options
Use a stronger parserMake the grammar LL(1)

55
Making a grammar LL(1)manual labour
rewrite grammaradjust semantic actions
three rewrite methodsleft factoringsubstitutionleft-recursion removal

56
Left-factoringterm IDENTIFIER | IDENTIFIER ‘[‘ expression ‘]’
factor out common prefix
term IDENTIFIER after_identifierafter_identifier | ‘[‘ expression ‘]’
‘[’ FOLLOW(after_identifier)

57
SubstitutionA a | B c | S p A q
replace non-terminal by its alternative S p a q | p B c q | p q
ExampleS A ‘a’ ‘b’
A ‘a’ | replace non-terminal by its alternative
S ‘a’ ‘a’ ‘b’ | ‘a’ ‘b’

58
Left-recursion removalThree types of left-recursion
Direct left-recursionN N|…
Indirect left-recursion Chain structure
N A … A B … … Z N …
Hidden left-recursionN N|… ( can produce )

59
Left-recursion removalN N |
replace by
N MM M |
example
expression expression ‘-’ term | term
...
expression term expression_tail_option
expression_tail_option ‘-’ term expression_tail_option |
N

60
Practicemake the following grammar LL(1)
expression expression ‘+’ term | expression ‘-’ term | term
term term ‘*’ factor | term ‘/’ factor | factor
factor ‘(‘ expression ‘)’ | func-call | identifier | constant
func-call identifier ‘(‘ expr-list? ‘)’expr-list expression (‘,’ expression)*

61
Answerssubstitution
F ‘(‘ E ‘)’ | ID ‘(‘ expr-list? ‘)’ | ID | constantleft factoring
E E ( ‘+’ | ‘-’ ) T | TT T ( ‘*’ | ‘/’ ) F | FF ‘(‘ E ‘)’ | ID ( ‘(‘ expr-list? ‘)’ )? | constant
left recursion removalE T (( ‘+’ | ‘-’ ) T )*T F (( ‘*’ | ‘/’ ) F )*

62
Undoing the semantic effects of grammar transformationsWhile it is often possible to transform our
grammar into a new grammar that is acceptable by a parser generator and that generates the same language, the new grammar usually assigns a different structure to strings in the language than our original grammar did
Fortunately, in many cases we are not really interested in the structure but rather in the semantics implied by it.

63
Semantics
Non-left-recursive equivalent

64
Automatic conflict resolution (1)There are two ways in which LL parsers
can be strengthenedBy increasing the look-ahead
Distinguishing alternatives not by their first token but by their first two tokens is called LL(2).
Disadvantages: the parser code can get much bigger.
By allowing dynamic conflict resolversWhen the conflict arises during parsing, some of
conditions are evaluated to solve it.The parser generator LLgen requires a conflict
resolver to be placed on the first of two conflicting alternatives.

65
If-else statement in C
else_tail_option: both FIRST set and FOLLOW set contain the token ‘else’
Conflict resolver
Automatic conflict resolution (2)

66
The LL(1) push-down automationTransition table for an LL(1) parser

67
Push-down automation (PDA)Type of moves
Prediction moveTop of the prediction stack is a non-terminal N.N is removed from the stackLook up the prediction tablePush the alternative of N into the prediction stack
Match moveTop of the prediction stack is a terminal
TerminationParsing terminates when the prediction stack is
exhausted.

68
Prediction move in an LL(1) PDA

69
Match move in an LL(1) PDA

70
Predictive parsing with an LL(1) PDA

71
PDA example (1)
aap + ( noot + mies ) EOF
input
input
prediction stack
state(top of stack)
look-ahead token
IDENT + ( ) EOF
input expression EOF
expression EOF
expression term rest-expr
term rest-expr
term IDENT ( expression )
rest-expr + expression

72
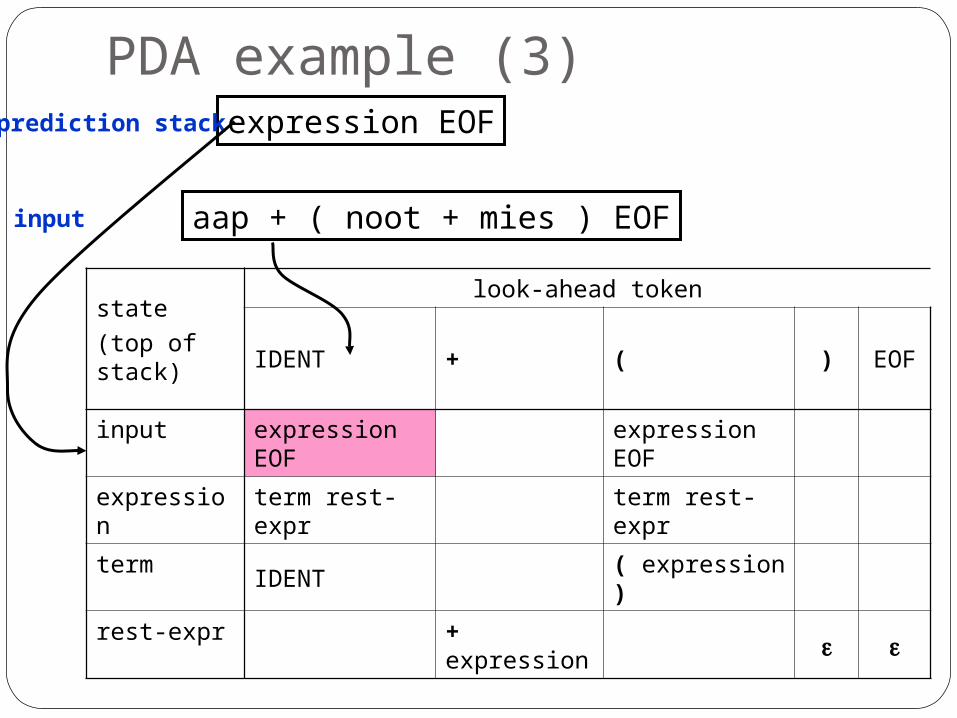
PDA example (2)
aap + ( noot + mies ) EOF
input
input
prediction stack
state(top of stack)
look-ahead token
IDENT + ( ) EOF
input expression EOF
expression EOF
expression term rest-expr
term rest-expr
term IDENT ( expression )
rest-expr + expression
replace non-terminal by transition entry
73
PDA example (3)
aap + ( noot + mies ) EOF
expression EOF
input
prediction stack
state(top of stack)
look-ahead token
IDENT + ( ) EOF
input expression EOF
expression EOF
expression term rest-expr
term rest-expr
term IDENT ( expression )
rest-expr + expression

74
PDA example (4)
aap + ( noot + mies ) EOF
expression EOF
input
prediction stack
state(top of stack)
look-ahead token
IDENT + ( ) EOF
input expression EOF
expression EOF
expression term rest-expr
term rest-expr
term IDENT ( expression )
rest-expr + expression
replace non-terminal by transition entry

75
PDA example (5)
aap + ( noot + mies ) EOF
term rest-expr EOF
input
prediction stack
state(top of stack)
look-ahead token
IDENT + ( ) EOF
input expression EOF
expression EOF
expression term rest-expr
term rest-expr
term IDENT ( expression )
rest-expr + expression

76
PDA example (6)
aap + ( noot + mies ) EOF
term rest-expr EOF
input
prediction stack
state(top of stack)
look-ahead token
IDENT + ( ) EOF
input expression EOF
expression EOF
expression term rest-expr
term rest-expr
term IDENT ( expression )
rest-expr + expression
replace non-terminal by transition entry

77
PDA example (7)Please continue!!Example of parsing (i+i)+i

Another Example (1)
78

Another Example (2)
79

LL Parser Table
80

Trace of an LL(1) Parse
81

Obtaining LL(1) GrammarsMost LL(1) prediction conflicts can be
grouped into two categories: common prefix and left recursion
82

Common Prefixes
83
Factoring method

Algorithm of Factoring
84

Left Recursion
85

Algorithm of Eliminating Left Recursion
86

87
LLgenLLgen is part of the Amsterdam Compiler Kittakes LL(1) grammar + semantic actions in C
and generates a recursive descent parserThe non-terminals in the grammar can have
parameters, and rules can have local variables, both again expressed in C.
LLgen features:repetition operatorsadvanced error handlingparameter passingcontrol over semantic actionsdynamic conflict resolvers

88
LLgen
start from LR(1) grammarmake grammar LL(1)
use repetition operators
%token DIGIT;
main : [line]+
;
line : expr '\n'
;
expr : term [ '+' term ]*
;
term : factor [ '*' factor ]*
;
factor : '(' expr ')‘
| DIGIT
;
LLgen
• add semantic actions• attach parameters to grammar rules
• insert C-code between the symbols

89
Minimal non-left-recursive grammar for expressions

90
LLgen code for a parser
Grammar Semantics

91
LLgen code for a parserThe code from previous page resides in a
file called parser.g. LLgen converts the file to one called parser.c, which contains a recursive descent parser.

92
LLgen interface to lexical analyzer

93
LLgen interface to back-end
•LLgen handles syntax errors by inserting missing tokens and deleting unexpected tokens
•LLmessage() is invoked to notify the lexical analyzer





























