Embed Size (px)
Citation preview

2011 © University of Michigan 1
Developing an Intelligent and Socially
Oriented Search Query
Recommendation Service for
Facilitating Information Retrieval in
Electronic Health RecordsKai Zheng, PhD, Qiaozhu Mei, PhD, David A. Hanauer, MD
University of Michigan
- On Behalf of William Wilcox, Danny Wu, and Lei Yang

2011 © University of Michigan
Information Retrieval in EHR
• Millions of patient records• Specialized language• Rich, implicit intra/inter
document structures• Deep NLP/Text Mining is
necessary• Complicated information
needs• Privacy is a big concern
2?

2011 © University of Michigan
Problem Statement
• Electronic health records (EHR), through its capability of acquiring and storing vast volumes of data, provides great potential to help create a “rapid learning” healthcare system
• However, retrieving information from narrative documents stored in EHRs is extraordinarily challenging, e.g., due to frequent use of non-standard terminologies and acronyms
3

2011 © University of Michigan
Problem Statement (Cont.)
• Similar to how Google has changed the way people find information on the web, a Google-like, full-text search engine can be a viable solution to increasing the value of unstructured clinical narratives stored in EHRs
• However, average users are often unable to construct effective and inclusive search queries due to their lack of search expertise and/or domain knowledge
4

2011 © University of Michigan
Proposed Solution
• An intelligent query recommendation service that can be used by any EHR search engine to– Artificial Intelligence: augment human cognition so
that average users can quickly construct high quality queries in their EHR search
– Collective (social) Intelligence: engender a collaborative and participatory culture among users so that search queries can be socially formulated and refined, and search expertise can be preserved and diffused across people and domains
5

2011 © University of Michigan
A Typical IR System Architecture
query
Documents
results
QueryRep
DocRep
Ranking
INDEXING
SEARCHINGINTERFACE
6
UsersFeedback
QUERY MODIFICATION

2011 © University of Michigan
EMERSE
• EMERSE - Electronic Medical Record Search Engine• Full-text search engine• Created by David Hanauer• Widely used in UMHS
since 2005 (and VA)• Boolean keyword queries• Routinely utilized by frontline clinicians, medical coding
personnel, quality officers, and researchers at the University of Michigan Health System
• The test platform for the solutions being built through this project
7

2011 © University of Michigan 8

2011 © University of Michigan
Specific Aims of the Project
• Aim #1: Developing AI-based Query Recommendation Algorithms
• Aim #2: Leveraging Social Intelligence to Enhance EHR Search
• Aim #3: Defining a Flexible Service Architecture
9

2011 © University of Michigan
Aim #1: Developing AI-based Query Recommendation
Algorithms• Clinicians find great difficulty to formulate
queries to express their information needs• EMERSE provide “semi-automatic” query
suggestion (synonyms, spelling, etc.)• Example: uti uti "urinary tract infection" • 25% adoption rate! • Text mining/machine learning methods to
automatically select alternative query terms• Technical details left later in the talk
10

2011 © University of Michigan
Aim #2: Leveraging Social Intelligence to Enhance EHR
Search• Enhancing AI-based algorithms with social
intelligence:– Allow users to bundle search terms and share– Social appraisal– Classifying search terms bundles for easy retrieval– Other community features– Enhancing collaboration among user communities
across institutions
11

2011 © University of Michigan
Aim #3: Defining a Flexible Service Architecture
• A service-oriented architecture serving general search knowledge
• Locally implementable APIs• Implementation of the community features
12

2011 © University of Michigan 13
System Architecture

2011 © University of Michigan
To Challenge Us – Why Bother?
• Q1: Is this different from PubMed?– EHRs have very different properties
• Q2: Is this different from Google?– Very different information needs in EHR search
• Q3: Could “social search” even work?
14

2011 © University of Michigan
Dictated Notes vs Typed Notes
• Hypothesis: there exists a considerable amount of lexical and structural differences. Such differences could have a significant impact on the performance of natural language processing tools, necessitating these two different types of documents being differentially treated
• Data: 30,000 dictated notes and 30,000 typed notes of deceased patients, randomly sampled
• Same genre: encounter notes that physicians composed to describe an outpatient encounter or to communicate with other clinicians regarding patient conditions
15
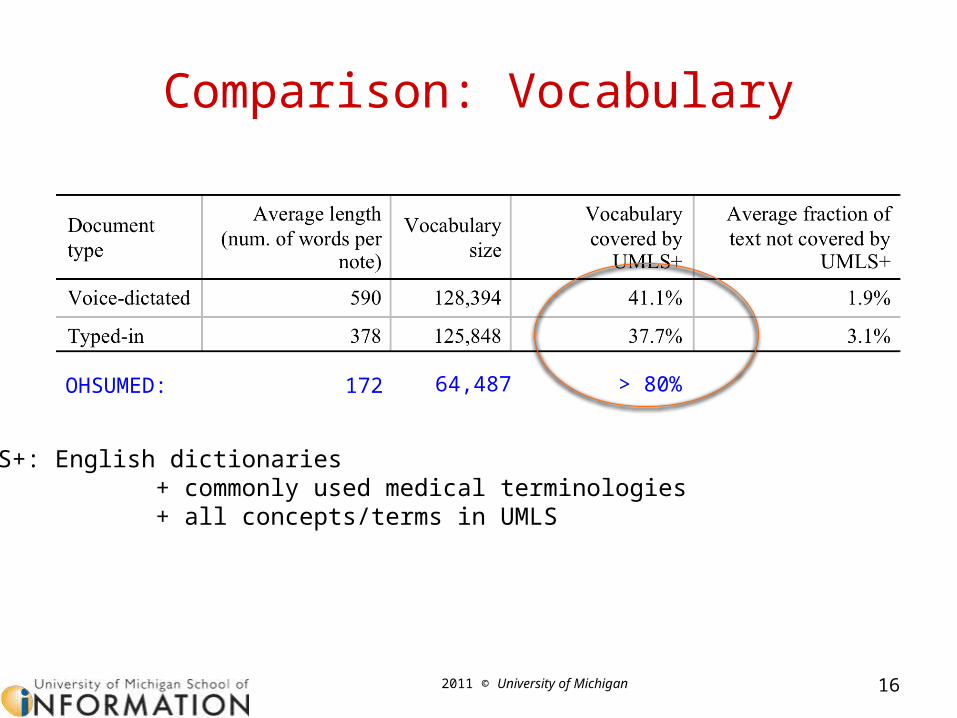
2011 © University of Michigan
Comparison: Vocabulary
16
UMLS+: English dictionaries + commonly used medical terminologies + all concepts/terms in UMLS
OHSUMED: > 80% 172 64,487

2011 © University of Michigan
Comparison: Acronym Usage
17

2011 © University of Michigan
Comparative Analysis: Perplexity
18
Words repeat less
Higher perplexity/randomness
Less functional wordsSparser information!
Fewer occurrences
* Typed notes have higher variance of almost all document measures

2011 © University of Michigan
Lessons Learned
• Clinical notes are much noisier than biomedical literature
• Among them, notes typed-in by physicians are much noisier and sparser than notes dictated.
• What about different genres of notes?• These differences of linguistic properties imply
potential difficulty in natural language processing
19

2011 © University of Michigan
Analysis of EMERSE Query Log
• 202,905 queries collected over 4 years• 533 users (medical professionals in UMHS)• 35,928 user sessions (sequences of queries)
20
Hours of a day Days of a week (Mon - Sun)

2011 © University of Michigan
Query Distribution – Not a Power Law!
21
Long tail –but no fat head

2011 © University of Michigan
A Categorization of EHR Search Queries
22
Using the top-level concepts of SNOMED CT
Almost no navigational queries; most queries are informational/transactional

2011 © University of Michigan
Comparison to Web Search
• Almost no navigational queries (Web: ~ 30%);• Average query length (Web: 2.3):
– User typed in: 1.7– All together (typed in + query suggestions + bundles): 5.0
• Queries with Acronym: 18.9% (Web: ~5%)• Dictionary coverage: 68% (Web: 85%-90%)• Average length of session: 5.64 queries (Web: 2.8)• Query suggestions adopted: 25.9% (Web: < 10%)
23

2011 © University of Michigan
Lessons Learned
• Medical search is much more challenging than Web search– More complicated information need– Longer queries, more noise
• Users have substantial difficulty to formulate their queries– Longer search sessions– High adoption rate of system generated suggestions
24
Question: Can the users help each other to formulate queries?

2011 © University of Michigan
“Social” (Collaborative) Search in EMERSE
• Changing a search experience into a social experience• Users create search bundles (bundled query)
– Collection of keywords that are found effective as a query– Reuse search bundles– Share them with other users
• Public sharing vs. private sharing• Search knowledge diffuses from bundle creators to
bundle users
25
- Zheng, Mei, Hanauer. Collaborative search in electronic health records. JAMIA 2011

2011 © University of Michigan 26
Example: a Search Bundle
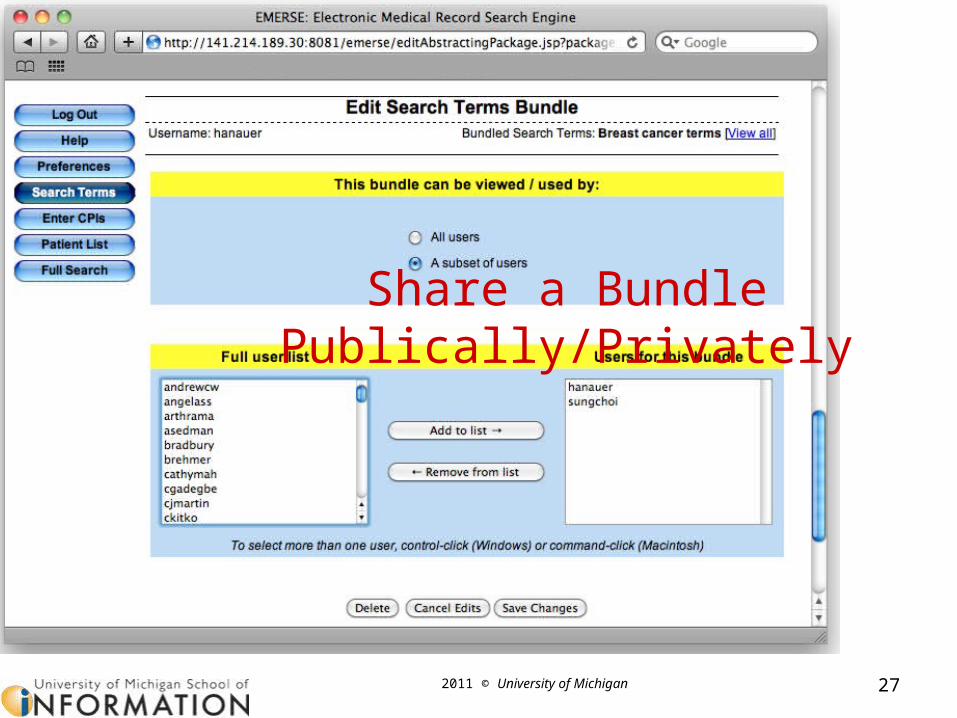
2011 © University of Michigan 27
Share a Bundle Publically/Privately

2011 © University of Michigan
The Effectiveness of Collaborative Search
• Search bundles (as of Dec. 2009): – 702 bundles– 58.7% of active users– Almost half of the pageviews– 19.3% of all queries (as of Dec. 2010)
– 27.7% search sessions ended with a search bundle (as of Dec. 2010)
– Bundle creator: 188– Bundle sharers: 91– Bundle leechers: 77
28

2011 © University of Michigan
Example Bundles
GVHD: "GVHD” "GVH” "Graft-Versus-Host-Disease” "Graft-Versus-Host Disease” "Graft Versus Host Disease” "Graft Versus Host” "Graft-Versus-Host” "Graft vs. Host Disease” "Graft vs Host Disease” "Graft vs. Host” "Graft vs Host"
29

2011 © University of Michigan
Example Bundle (cont.)
Myocardial infarction: NSTEMI STEMI ~AMI "non-st elevation” "non st elevation” "st
elevation MI” "st elevation” "acute myocardial infarction” "myocardial infarction” "myocardial infarct” "anterior infarction” "anterolateral infarction” "inferior infarction” "lateral infarction” "anteroseptal infarction” "anterior MI” "anterolateral MI” "inferior MI” "lateral MI” "anteroseptal MI” infarcted infarction infarct infract "Q wave MI” "Q-wave MI” "Q wave” "Q-wave” "st segment depression” "t wave inversion” "t-wave inversion” "acute coronary syndrome” "non-specific ST wave abnormality” "non specific ST wave abnormality” "ST wave abnormality” "ST-wave abnormality” "CPK-MB” "CPK MB” "troponin” ~^MI -$"MI \s*\d{5}” -systemic
30

2011 © University of Michigan
Bundle Sharing Across Departments
31

2011 © University of Michigan 32
Bundle Sharing Across Individual Users
Red links: cross department links

2011 © University of Michigan
Bundle Sharing Facilitated Diffusion of Information
• Quantitative network analysis of search knoweldge diffusion networks
• Giant component exists• Small world (high clustering coefficient & short paths)• Publically shared bundles better facilitates knowledge
diffusion– Privately shared bundles adds on top of public bundles
• Users tends to share bundles to people in the same department; but specialty is a more natural representation of communities. (based on modularity)
33

2011 © University of Michigan
Lessons Learned
• Medical search is much more challenging than Web search
• Users have substantial difficulty to formulate their queries– Longer search sessions– High adoption rate of system generated suggestions– High usage of search bundles
• Collaborative search has facilitated the sharing/diffusion of search knowledge– Public bundles are more effective than private– 30% bundle users are leechers; half of the bundle creators don’t
share
34

2011 © University of Michigan
Automatic Query Recommendation: Methods
• Similarity based (kNN)• Pseudo-feedback• Semantic term expansion• Network-based ranking• Learning to rank (much labeled training data
needed)
35

2011 © University of Michigan
Automatic Query Recommendation: Available
Information• Information to leverage:
– Co-occurrence within queries– Transition in query sessions– Co-occurrence within clinical documents– Annotation by ontological concepts– Ontology structures– Morphological closeness– Clickthrough
36

2011 © University of Michigan
A Network View
37

2011 © University of Michigan
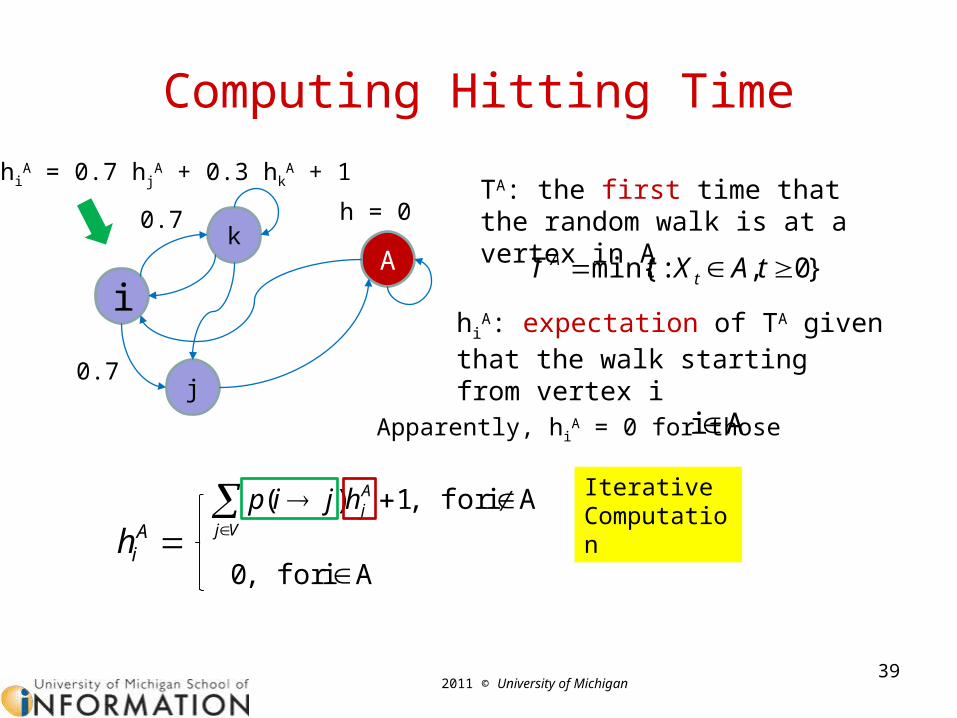
Random Walk and Hitting Time
38
i
k
A
jP = 0.7
P = 0.3
• Hitting Time– TA: the first time that the random
walk is at a vertex in A
• Mean Hitting Time– hi
A: expectation of TA given that the walk starts from vertex i
0.3
0.7
2011 © University of Michigan
Computing Hitting Time
39
i
kA
j
TA: the first time that the random walk is at a vertex in A
}0,:min{ tAXtT tA
A ifor ,1)( Vj
Ajhjip
Aih
A ifor ,0
Iterative Computation
hiA: expectation of TA given that the
walk starting from vertex i
A i
h = 0
hiA = 0.7 hj
A + 0.3 hkA + 1
0.7
0.7
Apparently, hiA = 0 for those
2011 © University of Michigan
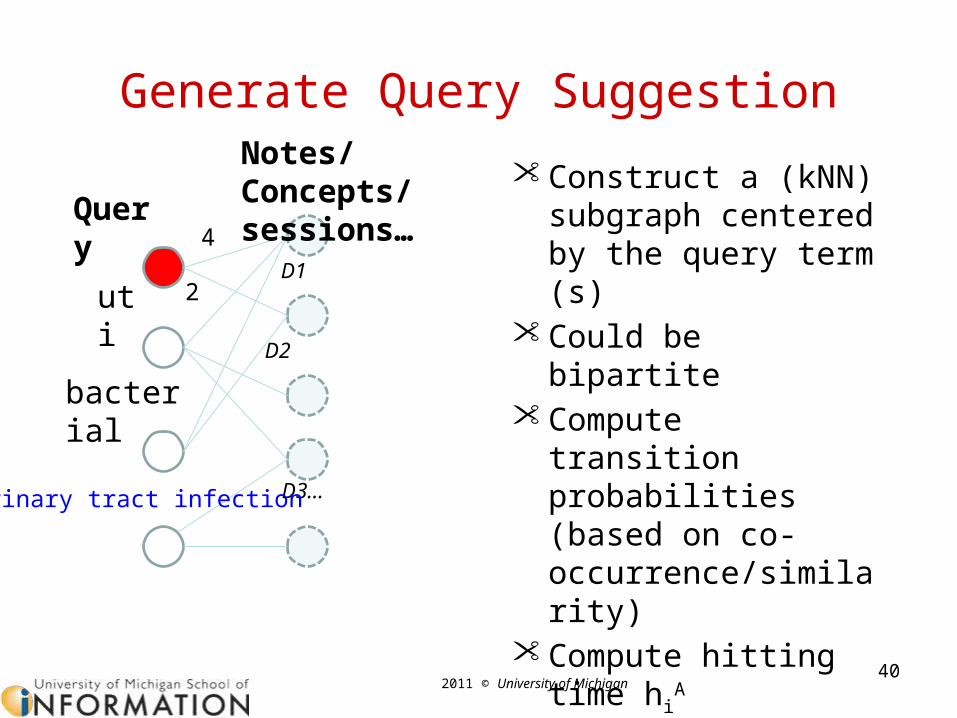
Generate Query Suggestion
40
uti
bacterial
D1
D2
D3…
4
2
Query
Notes/Concepts/sessions…
• Construct a (kNN) subgraph centered by the query term (s)
• Could be bipartite• Compute transition
probabilities (based on co-occurrence/similarity)
• Compute hitting time hiA
• Rank candidate queries using hi
A
urinary tract infection

2011 © University of Michigan
Other Network-based Methods
• Stationary distribution• Absorbing probability• Commute time• Other measures• More general: network regularization
41

2011 © University of Michigan
Ranking with Multiple Networks
42
Ranking/Transductive Learning with Multiple Views (e.g., Zhou et al. 2007, Muthukrishnan et al. 2010)
C
BA D
A
B
D
C
A
C
BD
Distributional similarityOntology structures
Query transitions
……
Suggested Queries

2011 © University of Michigan
Evaluation
• Cranfield evaluation (adopted by TREC)– Sample information needs queries– Fixed test document collection– Pool results of multiple candidate systems– Human annotation of relevance judgments– IR Evaluation (e.g., MAP, NDCG)
• Directly rating by users (bucket testing)
43

2011 © University of Michigan
Towards the Next Generation EHR Search Engine
• Better understanding of information needs by medical professionals – frontline clinicians, administrative personnel, and
clinical/translational researchers
• Better natural language processing for patient records • Better mechanisms of automatic query recommendation
in the medical context• Better ways to facilitate collaborative search and
preserve search knowledge• Better ways to improve the comprehensibility of medical
data by patients and families (future)
44

2011 © University of Michigan
Publications to Date
• Kai Zheng, Qiaozhu Mei, David A. Hanauer. Collaborative search in electronic health records. JAMIA. 2011;18(3):282–91.
• Lei Yang, Qiaozhu Mei, Kai Zheng, David A. Hanauer. Query log analysis of an electronic health record search engine. AMIA Annual Symposium Proc. 2011. (forthcoming)
• Kai Zheng, Qiaozhu Mei, Lei Yang, Frank J. Manion, Balis UJ, David A. Hanauer. Voice-dictated versus typed-in clinician notes: Linguistic properties and the potential implications on natural language processing. AMIA Annual Symposium Proc. 2011. (forthcoming)
45

2011 © University of Michigan
Thanks!
46





























