Embed Size (px)
Citation preview

• 1
1
TDT4215 - Introduction TDT4215 - Introduction
TDT4215 Web-intelligence Main topics: • Information Retrieval • Large textual document collections • Text mining • NLP for document analysis • Ontologies for document management • Examples from Clinical Decision Support How to extract knowledge from large document collections?
2
TDT4215 - Introduction
Lectures and Exercises Lectures • Øystein Nytrø • Guests:
- Laura Slaughter from Oslo University Hospital - A leading guru on clinical ontologies and decision support (TBA)
• Mondays 10.15-13.00 in F3 (that’s right, three hours!)
Exercises • PhD student Nafiseh Shabib • Tuesdays 16.15-18.00 in F4 All relevant information will be published at http://www.idi.ntnu.no/emner/tdt4215/

• 2
3
TDT4215 - Introduction
Curriculum
• Baeza-Yates & Ribeiro-Neto: Modern Information Retrieval. Addison-Wesley, 2011. (selected chapters)
• Manning, Raghavan and Schütze: Introduction to Information Retrieval. Cambridge University Press, 2008. (selected chapters, available for download)
• Compendium from IDI (selected book chapters and papers)
• Details are published at the homepage of the course
4
TDT4215 - Introduction
Assessment
• Group project: 25% of grade – Groups of 3-5 people – Discuss a particular theoretical topic – Develop an information retrieval / text mining application – Evaluate application – To be carried out the first half of the term (25th Feb – 7th Apr) – Nafiseh Shabib is responsible for the group project
• Individual written examination: 75% of grade – 4th of June – 4 hours written examination (discussions, calculations, no programming) – Based on everything we will learn in the course

• 3
5
TDT4215 - Introduction
Course Characteristics
• Experimental science: – No clear answers or theories – Lots of formulas (that are hard to justify) – Reappearance of logics & reasoning in web context
• Relevance: – Concerns real-world problems – A basis for knowledge management applications:
Search engines, document management systems, publication systems, digital libraries, enterprise business applications, business/web intelligence systems, semantic interoperation/integration software, etc.
• Multi-disciplinary: – Combines techniques from several other sciences:
Statistics, linguistics, conceptual modeling, artificial intelligence, knowledge representation, query processing and databases, etc.
6
TDT4215 - Introduction
Projects and Exercises Important
• One mandatory project: – Practice in setting up an application – How to evaluate the quality of IR/TM applications? – How to extract knowledge from specific types of text? Which
techniques for which types of text?
• Exercises: – Examples from lectures – Understand how formulas are used in practice – Be comfortable with “unproven theories” – Representative for examination questions
• Exercises are important!

• 4
7
TDT4215 - Introduction
Lecture Plan (1)
8
TDT4215 - Introduction
Lecture Plan (2)

• 5
9
TDT4215 - Introduction
Lecture Plan (3)
10
TDT4215 - Introduction
From Documents to Knowledge
• Document collections • Knowledge and documents • Document retrieval • Text Mining • Ontologies
80% of organizational data is textual with no proper structure!

• 6
11
TDT4215 - Introduction
Information Retrieval Text Mining
Ontology
Text
Retrieve document Discover knowledge
Knowledge elicitation
Knowledge representation
Morpho-syntax
Semantics
Existing New
Overall approach
12
TDT4215 - Introduction
Document Collections
• Domain-dependent or domain-independent • Structured or non-structured text • Formatted or non-formatted documents • Textual or multimedia documents • Monolingual and multilingual document collections • Centralized or non-centralized document management • Confidential or non-confidential • Controlled or free addition of documents • Stable or non-stable collections
Information system
Document collection
User

• 7
13
TDT4215 - Introduction
Case 1: SAP at STATOIL
• SAP used for major internal business processes • Named user accounts: 29,000
Concurrent users: 3,200 • System complexities:
894,000 customers 18,000 vendors 382,000 materials
• Work orders created each month: 11,000 • Sales orders created each month: 245,000 (11,600 per day)
• Documents produced each month: 2,25 million • Growth of database: 35 GB per month (Aug 2001)
• Document characteristics: highly structured, textual and tabular,
formatted, controlled addition, high growth, non-centralized, possibly multilingual
14
TDT4215 - Introduction
Case 2: Reengineering project at Hydro Agri • Objective: Reengineer organization and implement SAP R3 to support business
processes • Project duration: July 1995 – March 1999 • Costs: USD 126 million • Staffing: 500+ (140 external consultants) • Document management: Specialized Lotus Notes databases
• Document production: • SHARE Training: 1061 docs 868 MB • SHARE Test: 1632 docs 218 MB • SHARE Development: 12859 docs 218 MB • HAE User document.: 1312 docs 133 MB
• TOTAL: 16864 docs 1437 MB
359 per month 12 per day

• 8
15
TDT4215 - Introduction
Text is Difficult
• Most organizational knowledge encoded in textual documents
• Unstructured or semi-structured text difficult to retrieve, interpret or analyze
• Particular problems: – Inconsistent documents – Incomplete descriptions – Duplicates – Different terminologies/languages/abbreviations/perspectives
16
TDT4215 - Introduction
Knowledge and Documents
• One particular document is needed E.g.: What textbook is used in TDT4215?
• Several documents provide partial answers E.g.: What is the definition of “text mining”?
• All documents contribute to answer E.g.: Who writes about Rosenborg?
• Words versus concepts • Manual inspection versus automatic reasoning

• 9
17
TDT4215 - Introduction
Document Retrieval
• Information retrieval = information access • Retrieve documents that satisfy a user’s information
need from a document collection – Document indexing – Query interpretation – Ranking of retrieved documents – Linguistics and statistics
Document representations Document
representations Document
representations Document
representations
query formulation
display documents to user
identify relevant information
18
TDT4215 - Introduction
Document Retrieval Example
• AllTheWeb from Fast Search & Transfer (2002)
• Index: 2,1 GB documents • Languages supported: 52 • Linguistics used: Lemmatization, language
identification, phrasing, anti-phrasing, text categorization, clustering, offensive content reduction, finite-state automata
• 30 mill. queries a day
• www.alltheweb.com is today part of Yahoo and uses the Inktomi search engine
• The old AllTheWeb search engine used Yahoo’s verticals

• 10
19
TDT4215 - Introduction
Why is Web Search so Difficult?
• Volume of data: – Document explosion – Document dynamics – Distributed over many computers
and platforms
– Google (2008): estimated about 40 billion pages (over 1 trillion unique urls)
• Multitude of languages: – Multi-lingual web – 40-50 languages used on the web – Many text encoding standards
0246810121416
English
German
Japanese
Chinese
French
Spanish
Russian
Italian
Korean
Portuguese
Dutch
Swedish
Polish
Language
% w
eb p
ages
19992001
60
64 62
66 64
Ref: http://news.netcraft.com
20
TDT4215 - Introduction
Why is Web Search so Difficult?
• Document Quality: – Misspellings – Spam and offensive content – Little text – All topics
• User Behavior: – Misspellings – Query length: avg 2.4 terms – Query session: 8 queries – Half of the documents viewed are among
top three documents on result page
évènements 76,000 événements 420,000 evenements 35,000 evénements 95,000 evènements 22,000 évenements 9,000
Query No. of documents
1. chatroulette 2. ipad 3. justin bieber 4. nicki minaj 5. friv 6. myxer 7. katy perry 8. twitter 9. gamezer 10. facebook
Top 10 queries according to Zeitgeist 2010

• 11
21
TDT4215 - Introduction
Text Mining Part I
• Text mining = Linguistic analysis? • Task:
Analyze linguistic or statistical content of single documents – Transform document or add information to document – Tagging, lemmatization, NP recognition, etc.
• Example: Lemmatization for document retrieval
<html> <body> The professor’s assistant reads two papers... </body> </html>
<html> <body> The professor’s <lem> professor</lem> assistant reads <lem>read</lem> two papers <lem>paper</lem>... </body> </html>
Index document
22
TDT4215 - Introduction
Text Mining Example 1
• Marmot (from UMass) – Sentences are separated and segmented into noun phrases, verb
phrases, and prepositional phrases – Recognizes dates and duration phrases – Scopes conjunctions and disjunctions
David Brown, University for Industry visits the OU John Dominque Wed, 15 Oct 1997 David Brown, the Chairman of the University for Industry Design and Implementation Advisory Group and Chairman of Motorola, visited the OU as part of a fact finding exercise, prior to drafting his initial 100 Days Report to HM Government. David was accompanied by Jeanette Pugh, Josh Hillman and Nick Pearce.
Vargas-Vera et al.: Knowledge Extraction by using an Ontology-based Annotation tool
SUBJ (1) : DAVID BROWN %COMMA% UNIVERSITY PP (2) : FOR INDUSTRY VB (3) : VISITS OBJ1 (4) : THE OU PUNC(5) : %PERIOD%

• 12
23
TDT4215 - Introduction
Text Mining Part II
• Text mining = knowledge discovery (in text)? • Task:
Discover or derive new information from large document collections
– find patterns across datasets/documents – separate signal from noise – statistical (and linguistic) approach
• Techniques: – Concept extraction – Ontology construction – TOC construction – Clustering – Text categorization – Subtechniques:
information extraction, text analysis
D avid B rown, U niversity for Industry visits the O U
J ohn D ominque W ed, 1 5 O ct 1 997D avid B rown, the C hairman of the U niversity for Industry D esign and Implementation A dvisory G roup and C hairman of M otorola, visited the O U as part of a fact finding exercise, prior to drafting his initial 1 00 D ays Report to H M G overnment. D avid was accompanied by J eanettePugh, J osh H illman and N ick Pearce.
D avid B rown, U niversity for Industry visits the O U
J ohn D ominque W ed, 1 5 O ct 1 997D avid B rown, the C hairman of the U niversity for Industry D esign and Implementation A dvisory G roup and C hairman of M otorola, visited the O U as part of a fact finding exercise, prior to drafting his initial 1 00 D ays Report to H M G overnment. D avid was accompanied by J eanettePugh, J osh H illman and N ick Pearce.
D avid B rown, U niversity for Industry visits the O U
J ohn D ominque W ed, 1 5 O ct 1 997D avid B rown, the C hairman of the U niversity for Industry D esign and Implementation A dvisory G roup and C hairman of M otorola, visited the O U as part of a fact finding exercise, prior to drafting his initial 1 00 D ays Report to H M G overnment. D avid was accompanied by J eanettePugh, J osh H illman and N ick Pearce.
D avid B rown, U niversity for Industry visits the O U
J ohn D ominque W ed, 1 5 O ct 1 997D avid B rown, the C hairman of the U niversity for Industry D esign and Implementation A dvisory G roup and C hairman of M otorola, visited the O U as part of a fact finding exercise, prior to drafting his initial 1 00 D ays Report to H M G overnment. D avid was accompanied by J eanettePugh, J osh H illman and N ick Pearce.
D avid B rown, U niversity for Industry visits the O U
J ohn D ominque W ed, 1 5 O ct 1 997D avid B rown, the C hairman of the U niversity for Industry D esign and Implementation A dvisory G roup and C hairman of M otorola, visited the O U as part of a fact finding exercise, prior to drafting his initial 1 00 D ays Report to H M G overnment. D avid was accompanied by J eanettePugh, J osh H illman and N ick Pearce.
Knowledge
24
TDT4215 - Introduction
Text Mining Example 2 • Document collection from X • What is the content?
• Prominent terms:
• Terms used together in text – Journalforskriften:
– Mental retardasjon:
Helsestasjon, helseorganisasjon, journalsystemet, kvalitetsrådgiverprogrammet, miljørettet, Journalopplysninger, sped, helsekortet, skolehelsetenesta, journalforskriften, passord,
kravspesifikasjon
Datatilsyn, riksarkivar, oppbevaring, pasientjournaler, Retting, journalopplysninger, sletting,
Personregisterloven, journal
Syndrom, cerebral, alkoholforbruk, mor, hørsel, ben, Misdannelse, leveår, forekomst

• 13
25
TDT4215 - Introduction
Text Mining Example 3
• X = Kompetansesenteret for IT i Helsevesenet (KITH) • Objective: “KITH skal være helsevesenets sentrale rådgiver og
kompetanse-organ for bred, samordnet og kostnadseffektiv realisering og anvendelse av informasjons- og kommunikasjonsteknologi."
• Terms used together in text – KITH:
• What does this say about KITH?
Helsevesen, hefte, informasjonssikkerhet, Håndbok, standard, pasientjournaler, evt,
Minimum, utarbeiding
26
TDT4215 - Introduction
Keyphrase Extraction

• 14
27
TDT4215 - Introduction
Ontologies
• Definition of ontology: – Description of entities or concepts and how they are related – Conceptualization of some domain
• Purpose: – Semantic description of document collection – Semantic interoperability – Controlled vocabulary for document retrieval
• Approaches: – Conceptual modeling – Document analysis and text mining – Standardization work
28
TDT4215 - Introduction
Ontology Example 1 • Construct ontological model from STATOIL intranet text
collection (T. Brasethvik, NTNU)
⊆ ⊆ IntranetIntranetIntranet
• 15
29
TDT4215 - Introduction
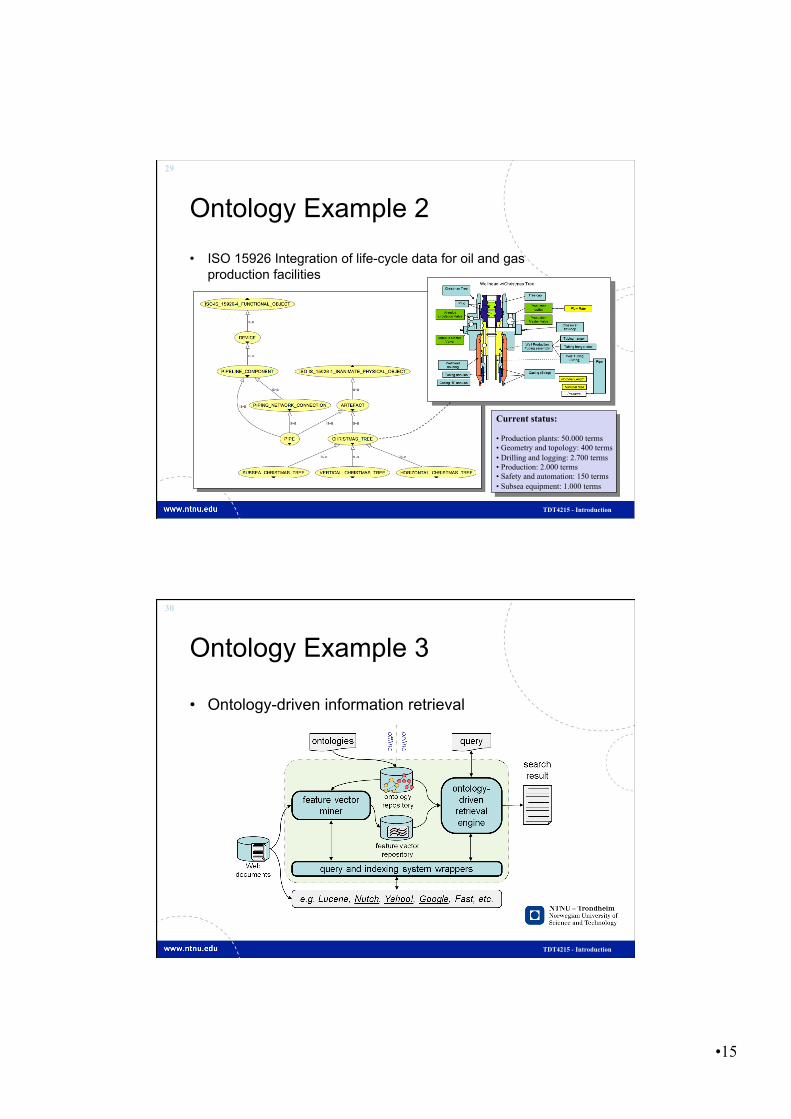
Ontology Example 2
• ISO 15926 Integration of life-cycle data for oil and gas production facilities
Current status: • Production plants: 50.000 terms • Geometry and topology: 400 terms • Drilling and logging: 2.700 terms • Production: 2.000 terms • Safety and automation: 150 terms • Subsea equipment: 1.000 terms
30
TDT4215 - Introduction
Ontology Example 3
• Ontology-driven information retrieval

• 16
31
TDT4215 - Introduction
Conclusions
• Characteristics of document collections • Technologies for document and knowledge
management: – Document retrieval – Text mining – Ontologies
• Details of technologies




























