Embed Size (px)
Citation preview

13
Copyright 1996-1998 by Axel T. Schreiner. All Rights Reserved.
2Arithmetische AusdrückeAus einer geeigneten(!) Grammatik kann man nach der Methode des Rekursiven Abstiegs vonHand ein Programm entwickeln, das zum Beispiel arithmetische Ausdrücke übersetzen oderinterpretieren kann.
Sehr einfache Sprachen kann man methodisch auch ohne Werkzeuge implementieren —allerdings läßt sich ein derartiges Programm in der Regel nur mühsam erweitern.
Programmgeneratoren vereinfachen die Arbeit, beeinflussen aber die Architektur derImplementierung mehr oder weniger stark.
In diesem Abschnitt werden eine Reihe von Techniken und Werkzeugen betrachtet, mitdenen man Compiler und Interpreter implementieren kann. In jedem Fall werden Zeilen vonder Standard-Eingabe gelesen, arithmetische Ausdrücke analysiert und als Bäume gespeichertund bewertet. Unabhängig von der jeweiligen Technik wird möglichst viel Code, nachMöglichkeit durch Vererbung, wiederverwendet.
In erster Linie geht es darum, für den Compilerbau wichtige Aspekte derJava-Programmierung zu wiederholen: Pakete, Sichtbarkeit, einige Core-Klassen,verschiedene Varianten von Inneren Klassen und Vererbung. Die Benutzung der Werkzeugewird zwar erläutert, aber zu Gunsten einer breiten Perspektive von Techniken wird hier aufeine intensive Diskussion jedes einzelnen Werkzeugs verzichtet.
Themen2-1 Syntaxbeschreibungen und Bäume 142-2 Rekursiver Abstieg — expr/java 192-3 Ein LL(1)-basierter Parser-Generator — expr/javacc 332-4 Automatische Baumgenerierung — expr/jjtree 402-5 Ein LR(1)-basierter Parser-Generator — expr/jay 442-6 Ein Java-basierter LR(1) Parser-Generator — expr/cup 592-7 Ein Java-basierter Scanner-Generator — expr/jlex 662-8 Ein Parser aus Objekten — expr/oops 722-9 Ein Visitor-Generator für Objektbäume — expr/jag 892-10 Code-Generierung 1002-11 Reguläre Ausdrücke — re 120

14
Syntaxgraphen
Wirth beschrieb die Syntax von Pascal durch benannte, gerichtete Graphen, in denen blaue,runde Knoten Eingabesymbole darstellen und schwarze, eckige Knoten auf Graphenverweisen. Für arithmetische Ausdrücke sieht das etwa so aus:
term
*
/
productproduct
+
-
sum
+
-
%
Number
( )sum
term
Jeder Graph beschreibt eine Phrase, das heißt, letzlich eine akzeptable Folge vonEingabesymbolen. Um zu kontrollieren, ob eine Folge akzeptabel ist, durchläuft man denGraphen und prüft dabei an blauen Knoten die Folge; an schwarzen Knoten muß man andereGraphen ebenso durchlaufen und prüfen.
Für eine sum muß man also wenigstens ein product finden, danach kann nach plus oderminus jeweils ein weiteres product folgen. Das product muß aus wenigstens einem termbestehen, der zum Beispiel eine Number sein kann.
Das Spiel wird problematisch, wenn die runden Knoten keine eindeutigen Wegweiserdarstellen.

15
Grammatikregeln — Backus-Naur-Form (BNF)
Formal besteht eine Grammatik aus einer Menge von Eingabesymbolen, einer Menge vonGrammatikbegriffen, daraus einem Startbegriff, und einer Menge von Regeln, das heißt,bestimmten Paaren von Folgen von Grammatikbegriffen und Eingabesymbolen; alle Mengenund Folgen müssen endlich sein.
Typischerweise schreibt man nur die Regeln auf und verlangt bei kontextfreien Grammatiken,daß die linke Seite einer Regel immer ein Grammatikbegriff sein muß. Nach Konvention stehtder Startbegriff auf der linken Seite der ersten Regel und man faßt rechte Seiten zum gleichenGrammatikbegriff als Alternativen zusammen. Die Wiederholungen der Syntaxgraphen mußman durch rekursive Verweise modellieren. Für arithmetische Ausdrücke sieht das etwa soaus:
sum : product | sum ’+’ product | sum ’-’ product ;product : term | product ’*’ term | product ’/’ term | product ’%’ term ;term : ’+’ term | ’-’ term | ’(’ sum ’)’ | Number ;
: trennt linke und rechte Seite, | trennt Alternativen, ; steht nach allen rechten Seiten zumgleichen Grammatikbegriff. Eingabesymbole werden mit einfachen Anführungszeichen zitiert.Da Number nicht links vorkommt, muß Number (implizit) eine Klasse von Eingabesymbolenrepräsentieren. Man könnte auch folgende Regeln hinzufügen:
Number : digit | Number digit ;digit : ’0’ | ’1’ | ’2’ | ’3’ | ’4’ | ’5’ | ’6’ | ’7’ | ’8’ | ’9’ ;
16
Erweiterte Backus-Naur-Form (EBNF)
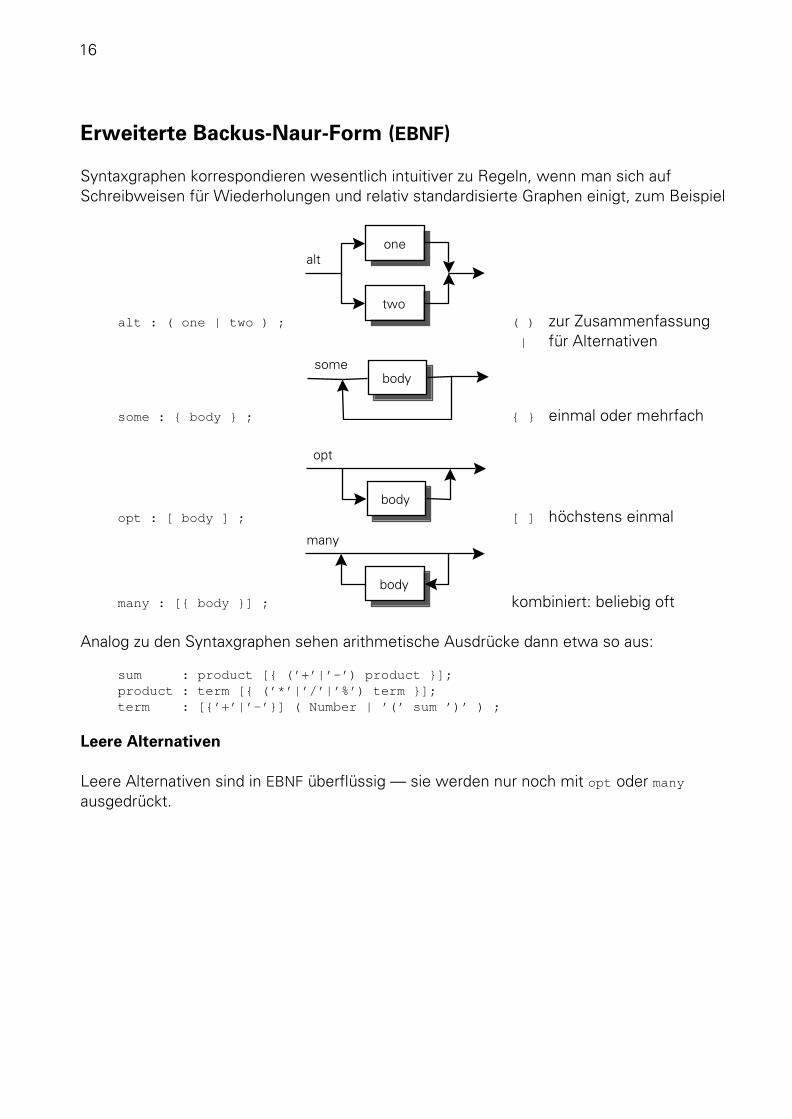
Syntaxgraphen korrespondieren wesentlich intuitiver zu Regeln, wenn man sich aufSchreibweisen für Wiederholungen und relativ standardisierte Graphen einigt, zum Beispiel
alt : ( one | two ) ;
one
two
alt
( ) zur Zusammenfassung | für Alternativen
some : { body } ;
bodysome
{ } einmal oder mehrfach
opt : [ body ] ;
body
opt
[ ] höchstens einmal
many : [{ body }] ;
body
many
kombiniert: beliebig oft
Analog zu den Syntaxgraphen sehen arithmetische Ausdrücke dann etwa so aus:
sum : product [{ (’+’|’-’) product }];product : term [{ (’*’|’/’|’%’) term }];term : [{’+’|’-’}] ( Number | ’(’ sum ’)’ ) ;
Leere Alternativen
Leere Alternativen sind in EBNF überflüssig — sie werden nur noch mit opt oder many
ausgedrückt.

17
Syntax-Baum
Eine kontextfreie Grammatik erzeugt orientierte Bäume: Ein Grammatikbegriff ist ein Knotenund eine seiner rechten Seiten legt fest, wohin der Knoten verzweigt. Aus der Regel
term : ’+’ term | ’-’ term | ’(’ sum ’)’ | Number ;
können zum Beispiel folgende Bäume entstehen:
term
( sum )
term
+ term
term
Number
term
- term
Prinzipiell funktioniert das auch mit EBNF. Aus
term : [{’+’|’-’}] ( Number | ’(’ sum ’)’ ) ;
können folgende Bäume entstehen, allerdings mit beliebigen Graden in manchen Knoten:
term
-+ ( sum )...
term
-+ ... Number
Eine Folge von Eingabesymbolen bildet einen Satz zu einer Grammatik, wenn es einen Baumgibt, dessen Wurzel der Startbegriff und dessen Blätter, von links nach rechts, dieEingabesymbole in Folge sind.
Die Grammatik heißt mehrdeutig, wenn zu irgendeinem Satz verschiedene derartige Bäumekonstruiert werden können.

18
Interpreter-Baum
Für praktische Zwecke interessant sind vereinfachte Bäume, bei denen die Knoten mancheEingabesymbole repräsentieren und sich die Verzweigungen am Syntaxbaum orientieren. Aus
term
+ term
term
- term
term
( sum )
term
Number
werden zum Beispiel
term
-
term sum Number
wobei allerdings die grünen Knoten noch durch Bäume ersetzt werden müssen. Aus
-sum product
sum
product
term
Number
term
Number
wird dann nur
-
Number Number
Die vereinfachten Bäume enthalten alle Informationen, die zur Bewertung nötig sind. Da sieaus den Syntaxbäumen hergeleitet werden, enthalten die Syntaxbäume auch Bedeutung, wiezum Beispiel Vorrang, und deshalb kann Mehrdeutigkeit bei einer Grammatik nicht akzpetiertwerden.

19
Rekursiver Abstieg — expr/java
Expression liest Zeilen mit arithmetischen Ausdrücken von der Standard-Eingabe, codiert sieals Bäume und bewertet sie mit float -Arithmetik. Ist als Argument -c angegeben, wird einVector aller Bäume zur Standard-Ausgabe geschrieben. Dieser Vector kann mit Go eingelesen und in allen arithmetischen Typen bewertet werden:
$ cd expr/java; make 2 | make 3CLASSPATH=../.. java expr.java.Expression -cCLASSPATH=../.. java expr.java.Go2+332768 * 2147483648 + 1284 * 92233720368547758074 * 9.2byte short int long float double5 5 5 5 5.0 5.0-128 128 128 70368744177792 7.0368744E13 7.0368744177792E13-4 -4 -4 -4 3.6893488E19 3.6893488147419103E1936 36 36 36 36.8 36.8
Jedes makefile enthält die Ziele 1 bis 6 . 2 liest von der Standard-Eingabe und schreibtBäume zur Standard-Ausgabe, 3 bewertet derartige Bäume. Einige der Beispiele sind sogewählt, daß man erkennt, wie die Wertebereiche je nach Typ der Bewertung verlassenwerden.
Expression demonstriert den Umgang mit StreamTokenizer zur Analyse eines Texts, dieProgrammierung eines Parsers mit der Methode des Rekursiven Abstiegs, und die Ausgabevon persistenten Objekten.
Scanner ist eine Unterklasse von StreamTokenizer , die zum Beispiel Kommentarestandardisiert und ein Problem bei interaktiver Benutzung umgeht. Scanner wird in denanderen Beispielen wiederverwendet, wenn keine Programmgeneratoren zur lexikalischenAnalyse zum Einsatz kommen.
Die Bäume werden aus Node-Objekten konstruiert. Node erweitert Number und erlaubtdamit auch den Einsatz von Ausdrücken an Stelle von Konstanten. Node ist das Laufzeitsystemfür alle Beispiele in diesem Abschnitt.
Go zeigt schließlich, wie man persistente Objekte wieder einliest und verwendet. Auch Go
wird für alle Beispiele in diesem Abschnitt verwendet.
Expression beruht auf einem Beispiel aus dem Java-Skript , das allerdings nicht fürWiederverwendung konzipiert war. Ein Vergleich der beiden Implementierungen ist rechtinstruktiv.

20
Analyse mit Rekursivem Abstieg — expr/java/Expression.java
Aus (geeigneten) Syntaxgraphen kann man sofort Erkenner-Funktionen konstruieren:
product
+
-
sum
{expr/java/Expression.java sum} /** recognizes sum: product [{ (’+’|’-’) product }]; @param s source of first input symbol, advanced beyond sum. @return tree with evaluators. @see Expression#line */ public static Number sum (Scanner s) throws Exception, IOException { Number result = product (s); for (;;) switch (s.ttype) { case ’+’ :
s.nextToken();result = new Node.Add(result, product (s));continue;
case ’-’ :s.nextToken();result = new Node.Sub(result, product (s));continue;
default:return result;
} }
{}
Scanner liefert Eingabesymbole, hier zumeist Zeichen; das nächste Symbol steht nachAufruf von nextToken() in ttype zur Verfügung . Die Funktionen müssen verbrauchteSymbole entsorgen.
In Node sind Klassen verschachtelt, aus denen Bäume gebaut werden können. Alle dieseKlassen sind Unterklassen von Number .
Es lohnt sich, grundsätzlich Kommentare für javadoc anzulegen . Leider unterstützt erstjavadoc im JDK 1.2 die Inneren Klassen und die Architektur wurde zwischen beta3 und beta4sehr stark modifiziert.

21
term
*
/
product
%
{expr/java/Expression.java product} /** recognizes product: term [{ (’*’|’%’|’/’) term }]; @param s source of first input symbol, advanced beyond product. @return tree with evaluators. @see Expression#sum */ public static Number product (Scanner s) throws Exception, IOException { Number result = term (s); for (;;) switch (s.ttype) { case ’*’ :
s.nextToken();result = new Node.Mul(result, term (s));continue;
case ’/’ :s.nextToken();result = new Node.Div(result, term (s));continue;
case ’%’ :s.nextToken();result = new Node.Mod(result, term (s));continue;
default:return result;
} }
{}
Die Methoden sind static , denn der Parser hat keinen zentralen Zustand — wie zum Beispieleine Symboltabelle oder globalen Zugriff auf den Scanner.

22
+
-
Number
( )sum
term
{expr/java/Expression.java term} /** recognizes term: ’+’term | ’-’term | ’(’sum’)’ | Number; @param s source of first input symbol, advanced beyond term. @return tree with evaluators. @see Expression#sum */ public static Number term (Scanner s) throws Exception, IOException { switch (s.ttype) { case ’+’ : s.nextToken(); return term (s); case ’-’ : s.nextToken(); return new Node.Minus( term (s)); case ’(’ : s.nextToken(); Number result = sum(s); if (s.ttype != ’)’ ) throw new Exception("expecting )"); s.nextToken(); return result; case s.TT_WORD: result = s.sval.indexOf(".") < 0 ? (Number)new Long(s.sval)
: (Number)new Double(s.sval); s.nextToken(); return result; } throw new Exception("missing term"); }} // end of class Expression
{}
Das Verfahren wird als Rekursiver Abstieg bezeichnet, weil sich die Erkennungsfunktionen inder Regel rekursiv aufrufen, und weil sie den Syntax-Baum von der Wurzel (sum) hin zu denBlättern (term ) aufbauen.

23
sum beschreibt keine Eingabezeile, denn die muß mit einem Zeilentrenner abgeschlossen sein,der in term natürlich nichts zu suchen hat. Es ist ganz praktisch, wenn man Zeilen auch noch ineiner eigenen Methode erkennt:
{expr/java/Expression.java line} /** recognizes line: sum ’\n’; an empty line is silently ignored. @param s source of first input symbol, may be at end of file. @return tree for sum, null if only end of file is found. @throws Exception for syntax error. @throws IOException discovered on s. */ public static Number line (Scanner s) throws Exception, IOException { for (;;) switch (s.nextToken()) { default:
Number result = sum(s);if (s.ttype != s. TT_EOL) throw new Exception("expecting nl");return result;
case s.TT_EOL: continue; // ignore empty line case s.TT_EOF: return null; } }
{}
Zur Erkennung einer Zeile wird ein Symbol vorausgelesen. Anschließend muß nach einer sum
definitiv ein Zeilentrenner gefunden werden. Er wird durch den nächsten Aufruf von line()
entsorgt (Stilbruch!).
Leere Zeilen werden stillschweigend ignoriert.
Zum Schluß liefert line() keinen Baum mehr sondern null .
Fehler werden mit einer eigenen Unterklasse von Exception berichtet, damit sie separatabgefangen werden können. Diese Klasse ist static , denn sie ist nur verschachtelt inExpression , ihre Objekte beziehen sich nicht auf Expression -Objekte.
{expr/java/Expression.java Exception} /** indicates parsing errors. */ public static class Exception extends java.lang.Exception { public Exception (String msg) { super(msg); } }
{}

24
{expr/java/Expression.java}package expr.java;
import java.io.InputStreamReader;import java.io.IOException;import java.io.ObjectOutputStream;import java.util.Vector;
/** recognizes, stores, and evaluates arithmetic expressions. */public abstract class Expression { /** reads lines from standard input, parses, and evaluates them or writes them as a Vector to standard output if -c is set. @param args if -c is specified, a Vector is written. */ public static void main (String args []) { boolean cflag = args.length > 0 && args[0].equals("-c"); Vector lines = cflag ? new Vector() : null; Scanner scanner = new Scanner(new InputStreamReader(System.in)); try { do
try { Number n = Expression.line(scanner); if (n != null) if (cflag) lines.addElement(n); else System.out.println(n.floatValue());} catch (java.lang.Exception e) { System.err.println(scanner +": "+ e); while (scanner.ttype != scanner.TT_EOL
&& scanner.nextToken() != scanner.TT_EOF) ;}
while (scanner.ttype == scanner.TT_EOL); if (cflag) {
ObjectOutputStream out = new ObjectOutputStream(System.out);out.writeObject(lines);out.close();
} } catch (IOException ioe) { System.err.println(ioe); } }
{}

25
Das Hauptprogramm erzeugt einen Scanner für die Standard-Eingabe und eventuell einenVector , um Bäume zu speichern. line() liefert jeweils einen Baum, der dann entwedergespeichert oder bewertet und ausgedruckt wird.
Zur Ausgabe von Objekten dient ein ObjectOutputStream , da Vector und alle Baumknotenals Serializable definiert sind. Hier muß unbedingt close() aufgerufen werden, um denletzten Puffer auszugeben.
Nach Fehlern positioniert man den Scanner explizit auf das nächste Zeilenende; beiIOException sollte man jedoch unbedingt abbrechen — auch wenn man gerade nach einemZeilentrenner sucht.
Scanner ist eine Unterklasse von StreamTokenizer und liefert deshalb eine Positionsangabefür toString() , die sich gut für Fehlermeldungen eignet.
Expression ist eine abstrakte Klasse, da man sinnvollerweise keine Objekte anlegen sollte.Trotzdem kann man die static vereinbarten Methoden aufrufen.
Um Kontrolle über die Sichtbarkeit von Namen zu behalten, sollte man grundsätzlich package
verwenden — der dort angegebene Paket-Pfad muß mit dem Dateipfad ausgehend von einerKomponente von CLASSPATH bis zum Quellverzeichnis übereinstimmen oder vollständig ineinem Archiv liegen, das auf dem CLASSPATH angegeben ist. Die Ziele 4 bis 6 im makefile zeigen, wie man mit derart archivierten Klassen arbeitet.
Außerdem sollte man bei import kein Muster angeben — damit ist aus der vorliegendenQuelle schon klar, woher alle Klassennamen stammen müssen. Verschachtelte Klassen wieNode.Add werden durch import von Node geliefert, aber auch aus ihrem Namen ist klar, woman sie zu suchen hat.

26
Umgang mit StreamTokenizer — expr/java/Scanner.java
StreamTokenizer sollte auf einen Reader aufgesetzt werden, liest dann Bytes(!) und gibtZeichen im Bereich 0..255 als Symbole durch nextToken() und in ttype ab. Da einStreamTokenizer intern immer ein Byte vorausliest, eignet sich die Klasse für interaktivenBetrieb nur, wenn man, wie Scanner , diesen Aspekt durch Einfügen künstlicher Zeichen aneinem Zeilentrenner umgeht.
Was unter einem Symbol zu verstehen ist, kann durch Definition verschiedenerZeichenklassen beeinflußt werden:
commentChar leitet einen Kommentar bis zum Zeilenende ein. Außerdem könnenslashStarComments() und slashSlashComments() verlangtwerden.
ordinaryChars werden einzeln als Resultat von nextToken() und in ttype geliefert.quoteChar leitet einen String bis zum Partner oder Zeilen- oder Datei-Ende ein,
wird als Resultat und in ttype geliefert, mit dem String in sval ;Ersatzdarstellungen wie \a , \b , \f , \n , \r , \t , \v und \ ooo werdenumgewandelt.
whitespaceChars werden ignoriert — ein Zeilentrenner kann mit eolIsSignificant()
als TT_EOL angefordert werden.parseNumbers damit werden Ziffern, minus(!) und Punkt(!) zur Fortsetzung von
wordChars , und wenn ein Wort wie eine Gleitkommazahl(!)aussieht, wird sein Wert in double nval abgelegt und TT_NUMBER
geliefert.wordChars leiten ein Wort ein, das mit Ziffern fortgesetzt werden kann, wenn
diese mit parseNumbers definiert wurden; als Resultat und in ttype
wird TT_WORD geliefert, mit dem Wort in sval .
Da die Voreinstellungen für StreamTokenizer merkwürdig sind, sollte man bei KonstruktionresetSyntax() aufrufen und dann die Zeichenklassen selbst festlegen.
Scanner konstruiert Voreinstellungen, die für die hier betrachteten arithmetischen Ausdrückesinnvoll sind.

27
{expr/java/Scanner.java}package expr.java;
import java.io.BufferedReader;import java.io.FilterReader;import java.io.IOException;import java.io.Reader;import java.io.StreamTokenizer;
/** lexical analyzer for arithmetic expressions.Comments extend from # to end of line.Words are composed of digits and decimal point(s).White space consists of control characters and space and is ignored;however, end of line is returned.Fixes the lookahead problem for TT_EOL.
*/public class Scanner extends StreamTokenizer { /** kludge: pushes an anonymous Reader which inserts
a space after each newline. */ public Scanner (Reader r) { super (new FilterReader(new BufferedReader(r)) { protected boolean addSpace; // kludge to add space after \n public int read () throws IOException {
int ch = addSpace ? ’ ’ : in.read();addSpace = ch == ’\n’;return ch;
} }); resetSyntax(); commentChar(’#’); // comments from # to end-of-line wordChars(’0’, ’9’); // parse decimal numbers as words wordChars(’.’, ’.’); whitespaceChars(0, ’ ’); // ignore control-* and space eolIsSignificant(true); // need ’\n’ }}
{}
StreamTokenizer hätte eleganter wiederverwendbar definiert werden können, aber die Klasseeignet sich auch so durchaus zur Zerlegung typischer Programmiersprachen.
Muß man ganze und dezimale Zahlen unterscheiden, muß man wohl wie hier Zahlen alsWorte erkennen und später nacharbeiten:
case s.TT_WORD: result = s.sval.indexOf(".") < 0 ? (Number)new Long(s.sval)
: (Number)new Double(s.sval);

28
Bäume für arithmetische Ausdrücke — expr/java/Node.java
Das Laufzeitsystem soll Zahlenwerte speichern und in nachträglich wählbaren, beliebigenTypen, byte bis double , manipulieren. Es bietet sich an, Baumknoten von Number abzuleitenund alle Methoden wie intValue() usw. so zu implementieren, daß bei Bedarf dieUnterbäume bewertet und dann arithmetisch kombiniert werden.
Node ist die Basisklasse aller Baumknoten. Zur Vereinfachung wird hier die Arithmetik nur auflong und double abgebildet:
package expr.java;
import java.io.Serializable;
/** base class to store and evaluate arithmetic expressions. Defines most value-functions so that subclasses need only deal with long and double arithmetic. */public abstract class Node extends Number implements Serializable { /** maps byte arithmetic to long. @return truncated long value. */ public byte byteValue () { return (byte)longValue(); }
[In Node.java muß relativ viel Text für verschiedene Operationen bzw. Datentypen repliziertwerden, deshalb werden hier nur einzelne Methoden gezeigt.]
Node wird als Serializable vereinbart, damit Bäume über Object-Streams transportiertwerden können.

29
/** represents a binary operator. Must be subclassed to provide evaluation. */ protected abstract static class Binary extends Node { /** left operand subtree.
@serial left operand subtree. */ protected Number left;
/** right operand subtree.@serial right operand subtree.
*/ protected Number right;
/** builds a node with two subtrees.@param left left subtree.@param right right subtree.
*/ protected Binary (Number left, Number right) { this.left = left; this.right = right; } }
Binary und analog Unary sind die Basisklassen für binäre bzw. monadische Operationen. DerKonstruktor speichert die Unterbäume und erzwingt dadurch in abgeleiteten Klassen diekorrekte Struktur. In diesen Klassen könnte man auch in toString() eine Darstellung desLaufzeitbaums implementieren.
left und right sind nicht transient markiert und werden folglich serialisiert. javadoc im JDK1.2 verlangt, daß die tatsächlich serialisierten Felder explizit kommentiert werden, undproduziert daraus einen Bericht über die persistenten Daten.
Das Laufzeitsystem geht davon aus, daß der Compiler korrekten Code generiert; deshalb wirdzum Beispiel nicht verifiziert, daß die Unterbäume wirklich existieren.

30
/** implements addition. */ public static class Add extends Binary { /** builds a node with two subtrees.
@param left left subtree.@param right right subtree.
*/ public Add (Number left, Number right) { super(left, right); }
/** implements long addition.@return sum of subtree values.
*/ public long longValue () { return left.longValue() + right.longValue(); }
/** implements double addition.@return sum of subtree values.
*/ public double doubleValue () { return left.doubleValue() + right.doubleValue(); } }
Für Operatoren müssen dann nur noch die arithmetischen Methoden für die verschiedenenDatentypen implementiert werden, die entsprechend auf die Werte der Unterbäume zugreifenkönnen.
Da das ganze System auf Number aufbaut, kann man Literale direkt als Long oder Double
(oder beliebige andere Unterklassen von Number) repräsentieren.
Node ist ein typischer, völlig polymorpher Interpreter: Literale werden so gespeichert, daß sieWerte beliebigen Typs abliefern; Operatoren kombinieren Werte in beliebigen Typen. Go demonstriert, daß man zur Laufzeit den Datentyp wählen und dann noch verschiedeneResultate bekommen kann.
Der Vorteil eines derartigen Laufzeitsystems ist natürlich, daß beim Übersetzen keineSemantikprüfung nötig ist. Der Nachteil ist, daß die Polymorphie relativ teuer erkauft wird undpraktisch nur in Interpretern zur Verfügung steht. Prinzipiell könnte man bei einerCodegenerierung Datentypen wählen und hart binden.

31
Objekte einlesen und bearbeiten — expr/java/Go.java
Go liest einen Vector mit Bäumen für arithmetische Ausdrücke aus der Standard-Eingabe undbewertet sie in verschiedenen Typen.
{expr/java/Go.java}package expr.java;
import java.io.ObjectInputStream;import java.util.Vector;
/** executes arithmetic expressions from standard input. */public class Go { /** loads a vector with Number elements from standard input and evaluates them. @param args ignored */ public static void main (String args []) { try { ObjectInputStream in = new ObjectInputStream(System.in); Vector lines = (Vector)in.readObject(); System.out.println("byte\tshort\tint\tlong\tfloat\tdouble"); for (int i = 0; i < lines.size(); ++ i) {
Number n = (Number)lines.elementAt(i);System.out.println(n.byteValue()+"\t"+n.shortValue()
+"\t"+n.intValue()+"\t"+n.longValue()+"\t"+n.floatValue()+"\t"+n.doubleValue());
} } catch (Exception e) { System.err.println(e); } }}
{}
Persistente Objekte werden mit einem ObjectOutputStream geschrieben und mit einemObjectInputStream wieder eingelesen. Der Stream enthält nur die Objekt-Daten; dieKlassen müssen beim Einlesen vorhanden oder über den CLASSPATH oder einenClassLoader erreichbar sein, sonst gibt es die üblichen Exceptions.
readObject() kann ein Objekt nur liefern, wenn seine tatsächliche Klasse gefunden wird.Das Resultat wird man normalerweise umwandeln.
Liest man einen ObjectInputStream bis zum Ende, muß man eine EOFException abfangen.

32
Fazit
StreamTokenizer eignet sich zur schnellen Konstruktion von Scannern, wenn dieKonventionen passen. Das Beispiel demonstriert, daß leider eine Unterscheidung von ganzenund Gleitkomma-Zahlen mühsam ist; außerdem stoßen Operatoren auf Schwierigkeiten, dieaus mehreren Zeichen bestehen.
Rekursiver Abstieg eignet sich zur schnellen Konstruktion von Parsern ohne Werkzeuge, wennman überblickt, daß sich die Grammatik dazu eignet. Die resultierenden Parser sind nichtunbedingt pflegefreundlich.
Gegenbeispiel zum Rekursiven Abstieg ist zum Beispiel Linksrekursion:
sum : product | sum ’+’ product | sum ’-’ product ;
In diesem Fall würde ein naiver Erkenner in eine rekursive Schleife gehen. Rechtsrekursionerzeugt zwar einen Baum, interpretiert Operatoren aber rechts-assoziativ und eignet sichdaher kaum für arithmetische Ausdrücke.
Ein weiteres Gegenbeispiel:
output : ’write’ sum [{ ’,’ sum }] [ ’,’ ] ’;’ ;
Ein nachfolgendes Komma soll bedeuten, daß kein Zeilentrenner ausgegeben wird. Hierüberblickt der Rekursive Abstieg nicht, ob nach einem Komma eine sum gesucht werden soll,oder ob ein Semikolon die Anweisung abschließt. Zur Lösung würde man zweiEingabesymbole vorausschauen müssen.
Serialisierung ist eine elegante Technik, einen Interpreter betriebsbereit zu speichern oderDaten zum Beispiel von einem Compiler zu einem Analyseprogramm oder Generator zuübermitteln. Arbeitet man sorgfältig, kann man die Analyse (Expression ) vollständig vomLaufzeitsystem (Node) trennen.

33
Ein LL(1)-basierter Parser-Generator — expr/javacc
Die Methode des Rekursiven Abstiegs führt nahezu automatisch von einem geeignetenSyntaxgraphen zu einem Parser. Der Gedanke liegt nahe, diesen Vorgang zu automatisieren,das heißt, EBNF an Stelle von Kontrollstrukturen in Parser-Funktionen zu verwenden. Indiesem Abschnitt wird der Umgang mit JavaCC skizziert, einem in Java implementiertenParser-Generator, der auf der Basis von EBNF Funktionen zum Rekursiven Abstieg generiert.Mehr Details zu JavaCC kann man in der zugehörigen Dokumentation und im Java-Skript finden.
Ob sich ein Syntaxgraph oder eine in EBNF formulierte Grammatik für das Verfahren eignen,hängt davon ab, ob man an jeder Verzweigung eindeutig, nur auf der Basis von den nächstenEingabesymbolen, entscheiden kann, mit welchem Teil der Grammatik die Erkennungfortgesetzt werden muß. Backtracking ist zwar theoretisch möglich, praktisch aber sehrineffizient und kaum gangbar, da man die Konsequenzen einer Erkennung in der Regel nichtmehr rückgängig machen kann.
sum : product [{ (’+’|’-’) product }];
Ob man nach dem ersten product nochmals nach product sucht, hängt davon ab, ob alsEingabesymbol + oder - angeboten wird. Wenn allerdings auch noch eine Regel wie
cat : sum [{ ’+’ sum }];
zur Grammatik gehört, könnte man nach dem product bei + nicht entscheiden, ob man sum
oder product suchen muß. Intuitiver ist, daß man bei
output : ’write’ expr [{ ’,’ expr }] [ ’,’ ] ’;’ ;
vermutlich zwei Eingabesymbole kennen muß, um bei einem Komma entscheiden zu können,ob noch eine expr benötigt wird.
Nach Knuth spricht man von LL(k): Vorgehen von links nach rechts, Ableitung von links (vonder Wurzel des Parse-Baums) her, also top-down, mit k Eingabesymbolen Vorausschau.Später wird gezeigt , wie man berechnen kann, ob eine Grammatik LL(1) ist; bei JavaCCkann man lokal auch mit LL(k) und k > 1 arbeiten.
Ein Parser-Generator ist immer auch ein Prüfprogramm: JavaCC entscheidet, ob eineGrammatik LL(k) ist - normalerweise mit k = 1. Ist eine Grammatik LL(k), so ist sie nichtmehrdeutig.

34
Prinzip
JavaCC liest eine Quelle und erzeugt normalerweise eine Parser-Klasse, einen Scanner undeine Reihe von Hilfsklassen. Die Quelle enthält in der Regel nacheinander: eine Gruppe vonOptionen zur Steuerung der Übersetzung ; Java-Code, der mindestens die Parser-Klassedefinieren muß ; Regeln mit regulären Ausdrücken, die mindestens die uninteressantenEingabezeichen definieren ; und schließlich die Parser-Methoden:
void sum(): Grammatikbegriff als Funktionskopf { } lokale Variablen, siehe unten { rechte Seite als Funktionskörper product() Grammatikbegriff als Funktionsaufruf ( "+" product() Eingabesymbol als String (oder TOKEN-Name) | "-" product() | für Alternativen )* ( ... )* für beliebig viele Wiederholungen }
Schon hier ist die Syntax problematisch, da zum Beispiel die Klammern teilweise zu EBNFgehören und teilweise Funktionsaufrufe markieren.
Für die Funktionen können beliebige Resultattypen und Parameter sowie throws mitExceptions vereinbart werden, wobei jedoch nur der Funktionsname als Grammatikbegriffsignifikant ist — wenigstens für JavaCC selbst.
Ablaufverfolgung
Mit der Option -debug_parser generiert JavaCC eine sehr detaillierte Ablaufverfolgung.

35
Aktionen
In der bisher skizzierten Form der Regeln kann man — mit relativ hohem Schreibaufwand —eine Grammatik prüfen. Das Ziel ist jedoch, mit einem erkannten Satz etwas anzufangen, alsomindestens, einen Parse-Baum zu konstruieren. Dazu verwendet man lokale Variablen,Resultate der Parser-Funktionen sowie Aktionen — Java-Code in geschweiften Klammern, derim Zuge der Erkennung ausgeführt wird:
{expr/javacc/Expression.jj rules}Number sum(): // sum: product [{ (’+’|’-’) product }]; { Number s, r; } // returns tree { s = product () ( "+" r = product () { s = new Node.Add(s, r); } | "-" r = product () { s = new Node.Sub(s, r); } )* { return s; } }
Number product (): // product: term [{ (’*’|’%’|’/’) term }]; { Number p, r;} // returns value { p = term () ( "*" r = term () { p = new Node.Mul(p, r); } | "%" r = term () { p = new Node.Mod(p, r); } | "/" r = term () { p = new Node.Div(p, r); } )* { return p; } }
Number term (): // term: ’+’term | ’-’term | ’(’sum’)’ | Number; { Number t; } // returns value { "+" t = term () { return t; } | "-" t = term () { return new Node.Minus(t); } | "(" t = sum() ")" { return t; } | < LONG> { return new Long(token.image); } | < DOUBLE> { return new Double(token.image); } }
{}
Funktionsresultate müssen durch return in Aktionen erzeugt werden. Beim Aufrufer könnensie dann an lokale Variablen als Teil der Grammatikbegriffe (Funktionsaufrufe) innerhalb derrechten Seite einer Regel zugewiesen werden. Die lokalen Variablen stehen innerhalb derAktionen ebenfalls zur Verfügung.

36
Eingabesymbole
Angaben wie <LONG> beziehen sich auf benannte reguläre Ausdrücke, die typischerweise vorden Regeln in der Quelle stehen:
{expr/javacc/Expression.jj inputs}SKIP: // defines input to be ignored { " " | "\r" | "\t" | < "#" (~ ["\n"])* > // comment from # to end of line } // re: many of negated character class
TOKEN: // defines token names { < EOL: "\n" > | < LONG: ( <DIGIT> )+ > // re: some | < DOUBLE: ( <DIGIT> )+ "." ( <DIGIT> )* // re: some many
| "." ( <DIGIT> )+ > | < #DIGIT: ["0" - "9"] > // private re }
{}
Im SKIP -Block stehen Muster für Folgen von Eingabezeichen, die ignoriert werden sollen.Muster für Kommentare kann man entweder hier oder in SPECIAL_TOKEN-Blocks vereinbaren;im letzteren Fall sind sie über eine Komponente .specialToken in Aktionen erreichbar.
Im TOKEN-Block können Muster wie LONG benannt werden, für die in der Parser-Klasse dannKonstanten definiert sind; für DIGIT gibt es im vorliegenden Fall keine Konstante.
Funktionalität und zumeist auch Syntax der Muster orientieren sich an egrep, wobei allerdingsLiterale grundsätzlich als Strings angegeben werden müssen. Insgesamt entsteht auch hierein kurioses Mix mehrdeutig verwendeter Metazeichen wie | für Alternativen im Block und imMuster.

37
Fehlerbehandlung
Wenn ein Eingabesymbol nicht paßt, erzeugt ein JavaCC-Parser eine ParseException , dieletztlich den äußersten Funktionsaufruf zu Fall bringen würde. ParseException ist eineUnterklasse von Exception ; eine entsprechende throws -Klausel wird implizit zu denParse-Methoden hinzugefügt.
Um frühzeitig auf Eingabefehler zu reagieren, kann man im EBNF-Bereich der Regeln(Funktionen) try -Blöcke einsetzen, die allerdings explizit generierte Exceptions bisher nichtauffangen können. Bei Bedarf kann der Funktionskopf eine throws -Klausel enthalten.
{expr/javacc/Expression.jj rules}Number line(): // line: sum ’\n’; { Number e; } // returns tree, null at eof { try { ( e = sum() <EOL> { return e; } | <EOL> { return line(); } | <EOF> { return null; } ) } catch (ParseException err) {
System.err.println(err);for (;;) switch (getNextToken().kind) { case EOF: return null; case EOL: return line(); }
} }
{}
Auch hier entsteht ein kurioses Syntax-Mix: Ein äußerer Block kann Alternativen direktenthalten, ein try -Block nicht. Der catch -Bereich des try -Blocks ist eine Aktion; dort werdendie TOKEN-Namen direkt als Konstanten angegeben, während sie im EBNF-Bereich mit < >zitiert werden müssen.
getNextToken() liefert im Parser vom TokenManager das nächste Eingabesymbol. .kind isteine Komponente, die man mit TOKEN-Namen vergleichen sollte.
Man sieht hier, daß man auch in Aktionen parsieren kann: Die for -Schleife eliminiert den Resteiner defekten Zeile und versucht, über einen rekursiven Aufruf die nächste korrekte Zeile zufinden. Diese Technik ist zwar elegant aber nicht pflegefreundlich.

38
Parser-Klasse
Am Anfang der Quelle steht ein Block von Java-Code, der die Parser-Klasse definieren muß, indie dann die Parser-Funktionen eingefügt werden:
{expr/javacc/Expression.jj}PARSER_BEGIN(Expression)
package expr.javacc;
import java.io.InputStreamReader; import java.io.IOException; import java.io.ObjectOutputStream; import java.util.Vector; import expr.java.Node;
/** recognizes, stores, and evaluates arithmetic expressions using a parser generated with javacc. */ public class Expression { /** reads lines from standard input, parses, and evaluates them. or writes them as a Vector to standard output if -c is set. @param args if -c is specified, a Vector is written. */ public static void main (String args []) { boolean cflag = args.length > 0 && args[0].equals("-c"); Vector lines = cflag ? new Vector() : null; Expression parser = new Expression(new InputStreamReader(System.in)); try { Number n = null; do {
n = parser.line(); if (n != null) if (cflag) lines.addElement(n); else System.out.println(n.floatValue());} while (n != null);
if (cflag) { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(lines); out.close(); } } catch (IOException ioe) { System.err.println(ioe); }
catch (ParseException pe) { } // cannot happen } }
PARSER_END(Expression){}
Konstruktoren werden implizit für InputStream und Reader als Argumente erzeugt; JavaCC istnicht mehr deprecated.
Das Startsymbol der Grammatik spielt keine besondere Rolle - jede Parser-Funktion kannexplizit aufgerufen werden.

39
Fazit
JavaCC ist vollständig in Java implementiert und wird kommerziell entwickelt und gepflegt. Dabei Bedarf lokal LL(k) verwendet werden kann, sind die Erkenner sehr mächtig. Da alleFunktionen separat aufgerufen werden können, kann man auch verschiedene Teile einesParsers nebeneinander in der gleichen Applikation einsetzen.
Prinzipiell könnte das System auch zur Generierung von Scannern herangezogen werden,allerdings kenne ich die Schnittstelle zum TokenManager nicht genau genug. Die Muster zurGenerierung von Scannern sind wesentlich mächtiger als etwa StreamTokenizer .
Ich finde die Syntax (noch) nicht gelungen: Durch die Vermischung von EBNF und Java-Code inForm von Funktionsköpfen, -aufrufen, Zuweisungen und try -Blöcken entsteht eine sehrunübersichtliche Repräsentierung der Grammatik — erst JJDoc fördert die eigentlicheGrammatik wieder zutage, wenigstens, soweit sie außerhalb der Aktionen sichtbar ist:
line := ( sum <EOL> | <EOL> | <EOF> )sum := product ( "+" product | "-" product )*product := term ( "*" term | "%" term | "/" term )*term := "+" term
| "-" term| "(" sum ")"| <LONG>| <DOUBLE>
Auch die Syntax für Muster ist gewöhnungsbedürftig. Bei SKIP dürfen Strings durch | alsAlternativen angegeben werden, komplexere Muster (mit weiteren Alternativen) müssen aberin < > stehen.
ParseException bildet Syntaxfehler konsequent auf einen Java-Mechanismus ab. Leider istaber die Implementierung (derzeit) so, daß andere Exceptions verdeckt werden können. Eshilft nicht, daß try -Blöcke in der Syntaxbeschreibung von JavaCC (derzeit) nicht erwähnt sind.
JavaCC erzeugt viele Klassen und Interfaces. Wenigstens einige davon sollten meinesErachtens innere Klassen sein. Speziell bei der Fehlerbehandlung muß man unangenehm vieleInterna kennen.

40
Automatische Baumgenerierung — expr/jjtree
Für JavaCC gibt es einen Präprozessor JJTree, der die Generierung von Parse-Bäumenweitgehend automatisieren soll. Hier wird nur in Ausschnitten skizziert, wie man dasvorhergehende Beispiel erweitert, um in den Genuß von JJTree zu kommen. Mehr Detailskann man in der zugehörigen Dokumentation und im Java-Skript finden.
Prinzip
Bei vielen Phrasen gibt man an Stelle einer Aktion einen Klassennamen und die AnzahlAbkömmlinge an, die der Baumknoten enthalten soll:
void sum(): // sum: product [{ (’+’|’-’) product }]; {} { product() ( "+" product() #Add(2) // Add with 2 descendants | "-" product() #Sub(2) )* }
Parallel zum Aufruf der Methode existiert ein Stack, auf dem die erzeugten Knoten abgelegtwerden. #Add(2) bedeutet, daß zwei Knoten vom Stack zu einem Add-Knoten verknüpftwerden, der dann neu auf den Stack gelegt wird. Eingabesymbole erzeugen implizit keineKnoten.
Zum Schluß würden alle noch auf dem Stack befindlichen Knoten zu einem Knoten für denAufruf der Methode zusammengefaßt werden; der Klassenname richtet sich nach derMethode, kann aber überschrieben werden. Die folgenden Optionen verhindern dies:
options { MULTI = true; // use many class names, not just SimpleNode NODE_DEFAULT_VOID = true; // only generate explicitly requested nodes NODE_PREFIX = ""; // don’t prefix them with AST VISITOR = true; // create Visitor interface}
Kombiniert man Aktionen und Dekoration mit Klassennamen, kann man die Knoten explizitmanipulieren:
void term(): // term: ’+’term | ’-’term | ’(’sum’)’ | Number; {} { "+" term() // no need to make node | "-" term() #Minus // insert sign change node | "(" sum() ")" | ( <LONG> { jjtThis.val = new Long(token.image); } ) #Lit // needs .val | ( <DOUBLE> { jjtThis.val = new Double(token.image); } ) #Lit }
Gibt man keine Anzahl an, werden alle derzeit lokal vorhandenen Knoten zusammengefaßt,bei #Minus also der von term() produzierte Knoten, bei #Lit kein Knoten. jjtThis bezieht sichauf den offenen Knoten, in dem bei Lit in einer eigens hinzugefügten Komponente .val derZahlenwert gespeichert wird.

41
Feinheiten
Klassennamen für Knoten werden an Phrasen angehängt. Die Phrase ist damit derGeltungsbereich für jjtThis . Innerhalb des Geltungsbereichs sind die Abkömmlinge nochnicht im Knoten eingetragen und nur sehr mühsam erreichbar.
Die letzte Aktion im Geltungsbereich weicht davon ab: für sie ist der Knoten komplett. Daskann man zum Beispiel dazu mißbrauchen, von line() im Regelfall den Parse-Baum zu liefern:
expr.jjtree.Node line() #Add: // line: sum \n {} // returns null at eof { try {
( sum() <EOL> hier ist der Knoten noch offen | <EOL> { return line(); } | <EOF> { return null; }
) hier auch noch } catch (ParseException err) { System.err.println(err); for (;;)
switch (getNextToken().kind) {case EOF: return null;case EOL: return line();}
} erst jetzt folgt syntaktisch die letzte Aktion { return jjtThis.jjtGetChild(0); } nur der Abkömmling wird zum Resultat }
JJTree generiert die Knoten-Klassen. Sie stammen alle von SimpleNode ab, einer‘‘einfachen’’ Implementierung für das an sich verlangte Interface Node .
Hier wird ein temporärer Knoten erzeugt, nur damit man ihm dann den für sum() konstruiertenAbkömmling entnehmen kann. Der Knoten könnte eine SimpleNode sein, aber dann generiertJJTree leider eine Visitor -Methode doppelt.
Die Lösung dient hier mehr zur Illustration. Den Parse-Baum kann man auch als .rootNode()
dem in der Parser-Klasse Expression als jjtree vorhandenen JJTExpressionState entnehmen.

42
Visitor
Wirklich elegant ist (wenigstens im Prinzip), wie man einen mit JJTree konstruierten Baumverarbeiten soll: Per Option VISITOR kann ein Interface ExpressionVisitor erzeugt werden,das für jede Knoten-Klasse eine Methode enthält. Man kann das Interface so implementieren,daß ein Parse-Baum traversiert wird, wobei jeder Knoten genau einmal einemExpressionVisitor -Objekt geliefert wird.
Hier bietet sich an, damit zum Parse-Baum einen Interpreter-Baum aus den früherbetrachteten Node-Objekten zu konstruieren:
protected static class Gen implements ExpressionVisitor {
public Object visit(Add node, Object data) {return new Node.Add(
(Number)node.jjtGetChild(0).jjtAccept(this, data),(Number)node.jjtGetChild(1).jjtAccept(this, data));
}
...
public Object visit(Lit node, Object data) {return node.val;
} }
data könnte im Rahmen der Traverse von der Wurzel zu den Blättern des Parse-Baumsdurchgereicht werden.
Die Visitor -Schnittstelle forciert eine sehr saubere Trennung zwischen Parse-Baum undInterpreter-Baum: zur Analyse dient ein Baum auf der Basis von SimpleNode und erst miteinem Visitor wird ein persistenter Baum auf der Basis von expr.java.Node erzeugt.

43
Hauptprogramm
Das Hauptprogramm ändert sich wenig gegenüber dem Hauptprogramm für einen nur vonJavaCC generierten Parser. Bevor jedoch ein neuer Baum gebaut werden kann, muß reset()
aufgerufen werden:
public static void main (String args []) { boolean cflag = args.length > 0 && args[0].equals("-c"); Vector lines = cflag ? new Vector() : null; Expression parser = new Expression(new InputStreamReader(System.in)); ExpressionVisitor gen = new Gen(); try {
for (;; jjtree.reset() ) { expr.jjtree.Node node = parser.line(); if (node == null) break; Number n = (Number)node.jjtAccept(gen, null); if (cflag) lines.addElement(n); else System.out.println(n.floatValue());}if (cflag) { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(lines); out.close();}
} catch (IOException ioe) { System.err.println(ioe); }catch (ParseException pe) { }
}
Fazit
Zusammen mit JavaCC wird auch JJTree kommerziell in Java entwickelt und gepflegt. DieVisitor-Schnittstelle ist sehr elegant und ohne Werkzeug kaum zuverlässig zu beherrschen.Man kann Visitor problemlos mehrmals implementieren und damit zum Beispiel Code fürverschiedene Architekturen erzeugen.
Demgegenüber sind Syntax und Konventionen zur Manipulation der Knoten während derKonstruktion in der Regel nur durch Studium des generierten Codes zu erahnen. Insgesamtüberwiegen für mich diese Probleme, denn die Konstruktion eines Baums an sich ist auchohne Präprozessor eher trivial.

44
Ein LR(1)-basierter Parser-Generator — expr/jay
Prinzip
Auf Knuth geht eine Technik zur Parser-Erzeugung zurück, die Horning in einem Artikel inCompiler Construction, An Advanced Course (ISBN ??) sehr gut erklärt hat und die inGeneratoren wie jay und cup implementiert ist:
extra : ^
sum EndOfInput ;
Zur Grammatik nimmt man eine Regel mit dem Startsymbol hinzu und markiert den Punkt vordem Startsymbol. Eine markierte Regel heißt Konfiguration. Diese erste Konfiguration führtzum Ausgangszustand des Parsers; zum Schluß möchte man EndOfInput erreichen.
sum: ^ product;
sum: ^ product ’+’ sum;
sum: ^ product ’-’ sum;
product: ^ term;
product: ^ term ’*’ product;
product: ^ term ’%’ product;
product: ^ term ’/’ product;
term: ^ ’+’ term;
term: ^ ’-’ term;
term: ^ ’(’ sum ’)’;
term: ^ Number;
Da die Markierung vor einem Grammatikbegriff steht, nimmt man (transitiv) dessen rechteSeiten hinzu und markiert jeweils den Anfang. Eine Menge von Konfigurationen ist einZustand.

45
Neue Zustände ergeben sich, indem man in jeder Konfiguration einzeln die Markierung um einSymbol verschiebt und, falls nötig, wieder rechte Seiten hinzunimmt. Die Menge der Zuständeist endlich, gleiche Zustände werden natürlich zusammengefaßt. Insgesamt entsteht eineMatrix aus Zuständen und Übergängen, die durch Symbole ausgelöst werden.
term: Number ^ ;
Erreicht die Markierung das Ende einer Regel, nennt man die Konfiguration komplett. Ist sie ineinem Zustand zusammen mit anderen Konfigurationen, liegt ein Konflikt vor. Dies kann oftentschärft werden, wenn man die Konfigurationen noch um Lookahead-Mengen erweitert,siehe Horning.
Die Matrix kann man a priori berechnen und dabei die Grammatik prüfen. Eingabesymboleverursachen dann Übergänge; die Zustände legt man dabei auf einen Stack. Erreicht man einekomplette Konfiguration, wurde offensichtlich eine Regel erkannt: Man entfernt genügendZustände vom Stack und führt einen Übergang mit dem zugehörigen Grammatikbegriff durch.
state 0$accept : . line $end (0)line : . (2)
Constant shift 1’+’ shift 2’-’ shift 3’(’ shift 4$end reduce 2
line goto 5sum goto 6product goto 7term goto 8

46
yacc und bison
yacc [Johnson, 1978] und bison [Corbett und Stallman] akzeptieren jeweils eine Tabelle vonGrammatikregeln in BNF und Aktionen und konstruieren eine Funktion zur Analyse einerSymbolfolge:
Wenn ein Stück der Eingabe der rechten Seite einer Regel genügt, wird die zugehörigeAktion ausgeführt, und die Teilfolge wird durch den Grammatikbegriff links ersetzt.
Regeln wirken als Muster, können sich aber praktisch gegenseitig aufrufen. Aktionen könnenfür yacc und bison in C und Dialekten wie Objective C oder C++ formuliert werden.
yacc und bison sind Prüfprogramme: Eine Grammatik wird auf Einhaltung bestimmterBedingungen (LALR(1), impliziert nicht-Mehrdeutigkeit) kontrolliert.
yacc und bison sind Programmgeneratoren: Regeln dienen als Kontrollstruktur zur Auswahlvon Aktionen. bison ist aufwärtskompatibel zu yacc.
Aus einer Tabelle ohne Anweisungen wird ein Programm erzeugt, das mit einem Scannerbereits feststellen kann, ob eine Symbolfolge einer Grammatik genügt.
jay
jay entstand durch Modifikation der yacc-Quellen von BSD-Lite . jay übernimmt denAlgorithmus von yacc, generiert jedoch ein Java-Programm, das optional eine verbesserteAblaufverfolgung enthält. Aktionen werden in Java formuliert.
jay arbeitet als Filter für ein Programmskelett , das bedingt übersetzt wird. Prinzipiell könnteman dieses Skelett auch abändern, um Schnittstellen und Paketierung zu beeinflussen.

47
Eingabe
Eine jay- oder yacc-Quelle besteht aus drei Teilen, die durch Zeilen mit %% getrennt sind.
Im ersten Teil müssen unter anderem die Eingabesymbole benannt werden, damit dafürZahlenwerte definiert werden können. Einzelne(!) Zeichen können direkt zitiert werden.Außerdem wird der Typ der Objekte auf dem Wert-Stack festgelegt.
Im zweiten Teil stehen die Grammatikregeln in BNF und Aktionen in Java bzw. C. Aktionenkönnen auch eingebettet sein, dadurch entstehen anonyme Grammatikbegriffe.
{expr/jay/Expression.jay rules}%token <Number> Constant%type <Number> line, sum, product, term%%
line : sum // $$ = $1| /* null */ { $$ = null; }
sum : product // $$ = $1| sum ’+’ product { $$ = new Node.Add($1, $3); }| sum ’-’ product { $$ = new Node.Sub($1, $3); }
product : term // $$ = $1| product ’*’ term { $$ = new Node.Mul($1, $3); }| product ’/’ term { $$ = new Node.Div($1, $3); }| product ’%’ term { $$ = new Node.Mod($1, $3); }
term : ’+’ term { $$ = $2; }| ’-’ term { $$ = new Node.Minus($2); }| ’(’ sum ’)’ { $$ = $2; }| Constant // $$ = $1
{}
In den Aktionen bezieht sich $$ auf einen Wert, der parallel zum Grammatikbegriff auf denZustandsstack gebracht wird, und $i auf Werte, die für die Symbole der rechten Seite aufdem Stack sind. Ist keine Aktion angegeben, gilt $$ = $1, das heißt, der erste Wert wirdübernommen. Man ahnt, wie hier wieder ein Interpreter-Baum konstruiert wird.

48
Funktionsweise
yacc generiert einen Push-Down-Automaten: Eingabesymbol und Zustand auf dem Stackdefinieren die Operation des Automaten.
Operation
Zeichenfolge Scanner Eingabesymbol
Zustand••
Wert••
Mit der Option -v generiert yacc in der Datei y.output eine Beschreibung des PDA.
shift zustand Eingabesymbol wird akzeptiert, neuer Zustand wird dafür auf dem Stackabgelegt.
reduce regel Stack enthält Phrase (Folge von Zuständen), die durch Grammatikbegriffersetzt werden kann – der Syntaxbaum wächst. Entsprechend vieleZustände werden entfernt.
goto zustand Ein von reduce erzeugter Grammatikbegriff wird akzeptiert, der neueZustand wird dafür auf dem Stack abgelegt.
yacc berechnet vor allem die Übergangsmatrix – das geht nicht immer!
Konsequenzen
Zu jedem Symbol einer Regel korrespondiert immer ein Platz auf dem Syntax-Stack undparallel dazu auf dem Wert-Stack.
Auf dem Syntax-Stack liegen Zustände, auf den Wert-Stack kann man selbst Werte bringen:
Bei yacc kann der Scanner in yylval den Wert ablegen, der durch shift auf denWert-Stack wandert, bei jay ist das das Resultat von value() in yyInput .
Bei reduce , also am Schluß einer erkannten Regel, findet die Aktion statt, und die kannauf den Wert-Stack mit $i und auf das goto -Resultat mit $$ zugreifen.
Der Typ aller Elemente des Wert-Stacks kann definiert werden (bei yacc ist int voreingestellt,bei jay wird zunächst Object verwendet).

49
Scanner
Im dritten Teil der Grammatik-Quelle kann nahezu beliebiger Java- bzw. C-Code stehen. Dortkann man bei jay zum Beispiel das Interface yyInput implementieren, von dem der Parserseine Eingabe erwartet (yacc benötigt eine Funktion yylex() ):
{expr/jay/Expression.jay scanner}%% /** lexical analyzer for arithmetic expressions. @see expr.java.Scanner */ public static class Scanner extends expr.java.Scanner implements yyInput { public Scanner (Reader r) { super(r); }
/** moves to next input token.Consumes end of line and pretends (once) that it is end of file.@return false at end of file and once at each end of line.
*/ public boolean advance () throws IOException { if (ttype != TT_EOF) nextToken(); return ttype != TT_EOF && ttype != TT_EOL; }
/** determines current input, sets value to Long or Double for Constant.@return Constant or token’s character value, 0 at end of line/file.
*/ public int token () { value = null; switch (ttype) { case TT_EOF: return 0; // should not happen case TT_EOL: return 0; // should not happen case TT_WORD: value = sval.indexOf(".") < 0 ? (Number)new Long(sval)
: (Number)new Double(sval);return Constant;
default: return ttype; } }
/** value associated with current input. */ protected Object value;
/** produces value associated with current input.@return value.
*/ public Object value () { return value; } }
{}

50
Die Parser-Klasse
yacc erzeugt eine Funktion yyparse() , die bei Erfolg 0 liefert. jay muß eine Java-Quelle, alsoeine Klassendefinition erzeugen. Diese beginnt in einem Code-Abschnitt in %{ %} im erstenTeil der Grammatik-Quelle und endet mit } im dritten Teil:
{expr/jay/Expression.jay}%{ package expr.jay;
import java.io.InputStreamReader; import java.io.IOException; import java.io.Reader; import java.io.ObjectOutputStream; import java.util.Vector; import expr.java.Node;
/** recognizes, stores, and evaluates arithmetic expressions using a parser generated with jay. */ public class Expression { /** reads lines from standard input, parses, and evaluates them
or writes them as a Vector to standard output if -c is set.@param args if -c is specified, a Vector is written.
*/ public static void main (String args []) { boolean cflag = args.length > 0 && args[0].equals("-c"); Vector lines = cflag ? new Vector() : null; Scanner scanner = new Scanner(new InputStreamReader(System.in)); Expression parser = new Expression(); try {
while (scanner.ttype != scanner.TT_EOF) try { Number n = (Number)parser.yyparse(scanner); if (n != null) if (cflag) lines.addElement(n); else System.out.println(n.floatValue()); } catch (yyException ye) { System.err.println(scanner+": "+ye); }if (cflag) { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(lines); out.close();}
} catch (IOException ioe) { System.err.println(ioe); } }%}
{expr/jay/Expression.jay zzz}}
{}

51
Man muß mindestens die Klasse anlegen, in der jay die Methode yyparse() , einige innereKlassen und Methoden sowie int -Konstanten für die definierten Eingabesymbole erzeugt :
public class Expression { public static final int Constant = 257; /** thrown for irrecoverable syntax errors and stack overflow. */ public static class yyException extends java.lang.Exception {
... } /** must be implemented by a scanner object to supply input to the parser. */ public interface yyInput { /** move on to next token.
@return false if positioned beyond tokens.@throws IOException on input error.
*/ boolean advance () throws java.io.IOException; /** classifies current token.
Should not be called if advance() returned false.@return current %token or single character.
*/ int token (); /** associated with current token.
Should not be called if advance() returned false.@return value for token().
*/ Object value (); } /** simplified error message. @see yyerror(String, String[]) */ public void yyerror (String message) { yyerror(message, null); } /** (syntax) error message. Can be overwritten to control message format. @param message text to be displayed. @param expected vector of acceptable tokens, if available. */ public void yyerror (String message, String[] expected) {
... } /** kludge: fixed maximum size of the state/value stack. This is not final so that it can be overwritten outside of invocations of yyparse(). */ protected int yyMax = 256; /** executed at the beginning of a reduce action. Used as $$ = yyDefault($1), prior to the user-specified action, if any. Can be overwritten to provide deep copy, etc. @param first value for $1, or null. @return first. */ protected Object yyDefault (Object first) { return first; }

52
/** the generated parser, with debugging messages. Maintains a state and a value stack, currently with fixed maximum size. @param yyLex scanner. @param yydebug debug message writer implementing yyDebug, or null. @return result of the last reduction, if any. @throws yyException on irrecoverable parse error. */ public Object yyparse (yyInput yyLex, Object yydebug)
throws java.io.IOException, yyException {
... } /** the generated parser. Maintains a state and a value stack, currently with fixed maximum size. @param yyLex scanner. @return result of the last reduction, if any. @throws yyException on irrecoverable parse error. */ public Object yyparse (yyInput yyLex)
throws java.io.IOException, yyException {
... }
...}
yyparse() benötigt ein yyInput -Objekt, von dem die Eingabesymbole abgeholt werden, undliefert als Resultat den Wert, den die letzte Aktion erzeugt; yyInput ist eigentlich von derParser-Klasse unabhängig.
Der Wert-Stack enthält bei jay in jedem Fall Object . Mit %type und %token kann manspeziellere Klassen für Eingabesymbole und Grammatikbegriffe vereinbaren, die als $i
angesprochen werden :
%type <A> nonterminal%token <A> terminal%%
nonterminal : terminal { $$ = $i; } weist Klasse A an Object zunonterminal : terminal führt bei jay yyDefault() ausnonterminal : terminal { $$ = $<>i; } weist Object an Object zunonterminal : terminal { $$ = $<B>i; } weist B an Object zu
Bei yacc beziehen sich die <...> auf Alternativen einer union als Wert-Stack, die mit %union
vereinbart wird.

53
Struktogramm des Parsers
Das folgende ‘‘Struktogramm’’ [Schreiner, unix/mail 3/91] skizziert die Architektur des vonyacc generierten Parsers und zeigt, wo Ablaufverfolgung und Fehlerbehandlung eingreifen:
yyanim_init
yystack:
yyanim_push
yynewstate:
yylex()
Operation aus Tabelle:
shift
accept
error
reduce
-- yyerrflag (bis 0)yyanim_shift state
goto yystack
return 0
yyerrflag
0
1,2
3
yyerror()
yyerrflag = 3
bis Stack leer
error
verwendbaryyanim_shift error
goto yystack
yyanim_pop
return 1
if eof return 1yyanim_discard
goto yynewstateyyanim_reduce rule, length
if ... yyanim_goto{ Aktion }
goto yystack

54
Vorrang
Vor allem arithmetische Ausdrücke können mehrdeutig spezifiziert und durch eine Tabelle mitAssoziativität und zeilenweise steigendem Vorrang eindeutig gemacht werden:
%left ’+’ ’-’ links-assoziativ%right ’^’ rechts-assoziativ%nonassoc DUMMY nicht assoziativ, z.B. Vergleiche%%expr : expr ’+’ expr | expr ’^’ expr
| ’-’ expr %prec DUMMY expliziter Vorrang
shift/reduce-Konflikt
Enthält ein Zustand ‘‘auch’’ eine komplette Konfiguration, kann der Parser vor einemEingabesymbol einen Grammatikbegriff reduzieren oder das Eingabesymbol nochhinzunehmen :
statement: IF condition THEN statement| IF condition THEN statement ELSE statement
yacc bildet die längste Phrase — erwünscht!
if (a < b)then if (c < d)
then ...
else gehört zum innersten if – das längste statement ist gesucht.
reduce/reduce-Konflikt
Enthält ein Zustand mehrere komplette Konfigurationen, kann der Parser vor einemEingabesymbol mehrere Grammatikbegriffe reduzieren :
statement: Variable ’=’ condition| Variable ’=’ expression
condition: expression| expression ’<’ expression
yacc bildet die erste Phrase — selten erwünscht!

55
Animation
Mit der Option -t generiert jay einen Parser, dem man mit yyparse() zusätzlich ein Objektübergeben kann, das für das Interface jay.yydebug.yyDebug eine Ablaufverfolgungimplementieren muß. jay.yydebug.yyDebugAdapter realisiert das als Diagnose-Ausgabe,jay.yydebug.yyAnim ist ein Frame , der die Ablaufverfolgung in Anlehnung an Holub grafisch darstellt; bei der Konstruktion kann mit den Bits IN und OUT eine TextArea eingeblendet werden, die als Terminal für Ein- und/oder Ausgabe dient:
Drückt man continue, fährt der Parser jeweils fort, bis eine Ausgabe in eine Fläche erfolgt ist,deren Checkbox gesetzt ist.
Manche Implementierungen der JVM blockieren, wenn sie auf Eingabe vom Terminal warten;in diesem Fall muß man die Animation unbedingt mit der TextArea betreiben.
yyAnim enthält ein yyAnimPanel , an das yyDebug -Aufrufe weitergeleitet werden, undeventuell eine TextArea samt Checkbox . Falls verlangt, wird ein yyInputStream alsKeyListener eingetragen, der dann als System.in hinterlegt wird , und ein yyPrintStream
, der alle Ausgaben in die TextArea umlenkt, wird als System.out und System.err hinterlegt.Zusätzliche Threads sind dabei nicht nötig, da Eingaben im Event-Thread erfolgen und derParser seine Ausgaben im main-Thread tätigt, wodurch auch die Animation bei Ausgabe durchSynchronisation dieser Threads angehalten werden kann.
Die Bausteine eignen sich auch für ein unsigniertes Applet; dort muß man allerdings eineneigenen Thread für den Parser verwalten und den Scanner direkt mit den Streams verbinden.

56
Reaktion auf Eingabefehler
Paßt ein Eingabesymbol nicht mehr zur angefangenen Phrase auf dem Stack, und kann davorauch nicht reduziert werden, liegt ein Eingabefehler vor.
yyparse() stellt jetzt das fiktive Eingabesymbol error in die Eingabe und ruft yyerror() auf.jay erzeugt einen Parser, der dabei nach Möglichkeit einen Vektor mit den akzeptablenEingabesymbolen als Strings übergibt.
Falls nötig wird der Stack abgeräumt, bis error zum Stack paßt, oder bis der Stack leer ist.
Im ersten Fall geht die Erkennung mit error wie mit einem normalen Symbol weiter. Imzweiten Fall endet yyparse() in Java mit yyException oder liefert in C nicht Null.
Erst wenn nach error drei echte Symbole durch shift verarbeitet wurden, wird yyerror()
bei einem neuen Fehler wieder aufgerufen.
Durch die Aktion yyErrorFlag = 0; in Java beziehungsweise yyerrok; in C spiegelt man dasvor — es gibt eine Endlosschleife, wenn diese Aktion direkt zu error gehört!
Prinzipien zur Fehlerbehandlung
Man muß zusätzliche Regeln verwenden, bei denen error an plausiblen Stellen steht.
Solche Regeln sollten möglichst nahe am Startsymbol stehen — als Notbremse.
Solche Regeln sollten möglichst weit weg vom Startsymbol stehen — schnelle Erholung.
In der Praxis macht man wichtige Wiederholungen so robust wie irgend möglich. Details sieheSchreiner/Friedman Compiler bauen mit UNIX .

57
Beispiele zur Fehlerbehandlung
Recover liest Zeilen mit verschiedenen Folgen und demonstriert Fehlerbehandlung beitypischen Wiederholungen. Durch Ablaufverfolgung kann man kontrollieren, ob Wörterignoriert werden.
%%line : // null
| line OPT opt ’\n’ { yyErrorFlag=0; System.out.println("opt"); }| line SEQ seq ’\n’ { yyErrorFlag=0; System.out.println("seq"); }| line LIST list ’\n’ { yyErrorFlag=0; System.out.println("list"); }
Optionale Folge
Recover akzeptiert Zeilen, die opt und eine Folge von null oder mehr Wörtern enthalten; einFehler wäre zum Beispiel ein Komma:
opt : // null| opt WORD { yyErrorFlag = 0; }| opt error
Folge
Recover akzeptiert Zeilen, die seq und eine Folge von ein oder mehr Wörtern enthalten; Fehlerwären zum Beispiel kein Wort oder ein Komma:
seq : WORD| seq WORD { yyErrorFlag = 0; }| error| seq error
Liste
Recover akzeptiert Zeilen, die list und eine Folge von ein oder mehr Wörtern enthalten, diedurch Komma getrennt sind; Fehler wären zum Beispiel kein Wort oder kein Komma:
list : WORD| list ’,’ WORD { yyErrorFlag = 0; }| error| list error| list error WORD { yyErrorFlag = 0; }| list ’,’ error
Als Fehlerbehandlung wird error überall dort eingefügt, wo ein Eingabesymbol stehen könnte.Genau nach einem Eingabesymbol wird yyErrorFlag = 0; verwendet. Man kann ausprobieren,daß alle Alternativen nötig sind.

58
Fazit
yacc und seine Abkömmlinge haben sehr einfache Konventionen und sind mächtiger als dieLL(1)-Parser. Die Syntax für Regeln und Aktionen ist trivial zu erlernen. yacc erlaubtMehrdeutigkeiten und kann Vorrangtabellen benutzen; dies vereinfacht die Konstruktion vonGrammatiken und macht die Parser effizienter.
jay ist in C implementiert; die Quellen dürfen weitergegeben werden. jay kann zwar auf vielenPlattformen übersetzt werden, ist aber weniger portabel als eine neue Implementierung inJava wie cup. Die Modifikationen für jay verursachten jedoch kaum Aufwand; es lohnte sich,die seit vielen Jahren bewährte Implementierung der Algorithmen einfach zu übernehmen.[Corbett implementiert allerdings %nonassoc anders als Johnson. Eine triviale Vorrangtabellemit einer einzigen Zeile mit %nonassoc bleibt wirkungslos.] Das derzeitige skeleton verwendet einen Stack fixer Länge.
yacc und bison können nur mühsam mehr als einen Parser in einem Programm zulassen. jayverpackt den Parser in eine vom Benutzer definierte Klasse, dadurch bleibt der Namensraumrecht sauber.
In C kann man eine union als Typ des Wert-Stacks verwenden. In Java ist man ganz auf eineKlasse angewiesen. Das ist nicht so effizient; unter Umständen muß man yyDefault() alstiefe Kopie implementieren, außerdem kann man auf die triviale Aktion $$ = $1; nicht bauen,wenn die rechte Seite einer Regel leer ist. Da aber in der Regel wohl ein Baum gebaut wird,besteht der Wert-Stack aus gleichartigen Objekten und das Fehlen einer union ist irrelevant.
yacc kann den C-Compiler mittels #line dazu zwingen, Fehlermeldungen bezüglich derAktionen direkt auf die Grammatik-Quelle zu beziehen; dies ist in Java nicht möglich.
In Java kommt man eleganter zu einer Ablaufverfolgung und Animation als in C.

59
Ein Java-basierter LR(1) Parser-Generator — expr/cup
cup (Constructor of Useful Parsers) ist eine Neuimplementierung von LR(1) in Java,angelehnt an yacc. Die Syntax bezieht sich direkter auf Java und ist wesentlich formaler. Dergenerierte Parser stammt von java_cup.runtime.lr_parser ab, der Scanner mußjava_cup.runtime.Symbol liefern. Die Generierung kann durch sehr viele Phrasen undOptionen beeinflußt werden, außerdem kann man Methoden der Basisklasse überschreiben.
Die Reihenfolge der Eingabe zu cup ist vorgeschrieben. Wir folgen hier der logischenEntwicklungsreihenfolge, die ziemlich genau umgekehrt verlaufen dürfte.
Grammatik
Die Regeln stehen am Schluß der Eingabe zu cup:{expr/cup/Expression.cup rules}
lines ::= /* null */ {: RESULT = new Vector(); :}| lines:l sum:s NL {: l.addElement(s); RESULT = l; :}| lines:l NL {: RESULT = l; :}| lines:l error NL {: RESULT = l; :};
sum ::= product:p {: RESULT = p; :}| sum:s ADD product:p {: RESULT = new Node.Add(s, p); :}| sum:s SUB product:p {: RESULT = new Node.Sub(s, p); :};
product ::= term:t {: RESULT = t; :}| product:p MUL term:t {: RESULT = new Node.Mul(p, t); :}| product:p DIV term:t {: RESULT = new Node.Div(p, t); :}| product:p MOD term:t {: RESULT = new Node.Mod(p, t); :};
term ::= ADD term:t {: RESULT = t; :}| SUB term:t {: RESULT = new Node.Minus(t); :}| LPAR sum:s RPAR {: RESULT = s; :}| CONSTANT:c {: RESULT = c; :};
{}
In den Aktionen bezieht sich RESULT auf einen Wert, der parallel zum Grammatikbegriff auf denZustandsstack gebracht wird; andere Namen werden durch Anbringen an den Symbolen derRegel vereinbart. Es gibt keine voreingestellte Aktion — das führt zu Nullzeiger-Fehlern.

60
Eingabesymbole, Typen und Vorrang
Vor den Regeln definiert man alle(!) Symbole und Wertklassen und legt eventuell auchVorrang und Assoziativität einzelner Eingabesymbole fest:
{expr/cup/Expression.cup names}terminal NL, ADD, SUB, MUL, DIV, MOD, LPAR, RPAR;terminal Number CONSTANT;
non terminal Number sum, product, term;non terminal Vector lines;
{}
Anders als bei yacc können Eingabesymbole nicht zitiert werden und man kann diegenerierten Konstanten nicht beeinflussen. Wird keine Klasse angegeben, gibt es keinenzugehörigen Wert.
Paket und Parser-Klassen
Am Anfang der Eingabe stehen optional package - und import -Anweisungen sowie zweiCode-Teile, in denen zusätzliche Komponenten für die Aktionen- und Parser-Klasse definiertwerden können:
{expr/cup/Expression.cup}package expr.cup;
import java.io.InputStreamReader;import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Reader;import java.util.Vector;import java_cup.runtime.Symbol;import expr.java.Node;
parser code {:{}
Name und Abstammung der Parser-Klasse sind vordefiniert; der Name kann aber durch-parser beim Aufruf von cup festgelegt werden.

61
Scanner
Man kann den Scanner als Teil der Parser-Klasse implementieren:{expr/cup/Expression.cup lex}
/** methods required from scanner. */ public interface Input { /** recognizes and returns the next complete token. */ Symbol token () throws java.io.IOException; }
/** handcrafted lexical analyzer for arithmetic expressions. @see expr.java.Scanner */ protected static class Scanner extends expr.java.Scanner
implements Input, sym { public Scanner (Reader r) { super(r); }
/** recognizes and returns the next complete token. */ public Symbol token () throws java.io.IOException { if (ttype != TT_EOF)
nextToken(); // not past end of file
switch (ttype) { case TT_EOF: return new Symbol(EOF); case TT_EOL: return new Symbol(NL); case TT_WORD: return new Symbol(CONSTANT,
sval.indexOf(".") < 0 ? (Number)new Long(sval): (Number)new Double(sval));
case ’+’: return new Symbol(ADD); case ’-’: return new Symbol(SUB); case ’*’: return new Symbol(MUL); case ’/’: return new Symbol(DIV); case ’%’: return new Symbol(MOD); case ’(’: return new Symbol(LPAR); case ’)’: return new Symbol(RPAR); default: return new Symbol(error); } } }:};
scan with {: return scanner.token();:};
{}
Die Schnittstelle zum Parser besteht in einer Methode scan() , die Symbol liefern muß. IhrKörper wird durch die Klausel scan with festgelegt. Hier wurde ein Interface Input eingeführt,um später einen generierten Scanner leicht einfügen zu können. sym ist generiert undenthält Konstanten für die Eingabesymbole.

62
Hauptprogramm
Zur Initialisierung muß der Scanner hinterlegt werden, damit ihn scan() finden kann.{expr/cup/Expression.cup}
/** lexical analyzer. */ protected Input scanner;
/** creates a parser. @param scanner lexical analyzer as required by cup. */public Expression (Input scanner) { this.scanner = scanner;}
/** uses a locally handcrafted scanner. @see Expression#main(java.lang.String[], expr.cup.Expression.Input) */public static void main (String args []) { main(args, new Scanner(new InputStreamReader(System.in)));}
/** reads lines from standard input, parses, and evaluates them. or writes them as a Vector to standard output if -c is set. @param args if -c is specified, a Vector is written. @param scanner for reuse with a JLex-generated scanner. */public static void main (String args [], Input scanner) { boolean cflag = args.length > 0 && args[0].equals("-c"); try { Symbol s = new Expression(scanner).parse(); if (s != null && s.value != null) if (cflag) {
ObjectOutputStream out = new ObjectOutputStream(System.out);out.writeObject(s.value);out.close();
} elsefor (int n = 0; n < ((Vector)s.value).size(); ++ n) System.out.println(((Number)((Vector)s.value).elementAt(n))
.floatValue()); } catch (Exception e) { System.err.println(scanner+": "+e); }}
{}
Das Hauptprogramm wurde hier aufgetrennt, damit ein anderer Scanner angegeben werdenkann.

63
Ablaufverfolgung
Ruft man debug_parse() statt parse() auf, sieht man etwa folgendes:
# Initializing parser# Current Symbol is #10# Reduce with prod #0 [NT=4, SZ=0]# Goto state #1# Shift under term #10 to state #9# Current token is #3# Reduce with prod #15 [NT=3, SZ=1]# Goto state #7# Reduce with prod #8 [NT=2, SZ=1]# Goto state #2# Reduce with prod #5 [NT=1, SZ=1]# Goto state #3# Shift under term #3 to state #15# Current token is #10# Shift under term #10 to state #9# Current token is #2# Reduce with prod #15 [NT=3, SZ=1]# Goto state #7# Reduce with prod #8 [NT=2, SZ=1]# Goto state #16# Reduce with prod #6 [NT=1, SZ=3]# Goto state #3# Shift under term #2 to state #27# Current token is #0# Reduce with prod #2 [NT=4, SZ=3]# Goto state #1# Shift under term #0 to state #8# Current token is #0# Reduce with prod #1 [NT=0, SZ=2]# Goto state #-1
Das ist höchstens nützlich, wenn man mit der Option -dump die Tabellen darstellen läßt, aberselbst dann muß man die Nummern der Eingabesymbole in den generierten Quellen suchen.

64
Fehlerbehandlung
Recover liest Zeilen mit verschiedenen Folgen und demonstriert Fehlerbehandlung beitypischen Wiederholungen. Durch Ablaufverfolgung kann man kontrollieren, ob Wörterignoriert werden.
Das Prinzip wird von yacc übernommen: Im Fehlerfall wird nach einer Regel mit error gesuchtund von dort aus weiter parsiert.
Der Algorithmus unterscheidet sich aber subtil vom Algorithmus für yacc: Es muß einenÜbergang mit error geben, error im Lookahead allein reicht nicht aus. Konkret muß dieoptionale Folge so umformuliert werden:
opt ::= /* null */| opt WORD| error| opt error;
Die zusätzliche Alternative provoziert einen shift/reduce-Konflikt, der durch die Option -expect
1 akzeptiert werden muß.
Wird error akzpetiert, versucht der Parser, so viele Eingabesymbole zu erkennen, wie dieMethode error_sync_size() verlangt; erst wenn das gelingt, wird mit diesen Symbolen dieParsierung fortgesetzt. Man kann die Methode zwar überschreiben, aber nicht so gezielt, wiedas mit yyerrok; bei yacc beziehungsweise yyErrorFlag bei jay möglich ist.
Konkret führt das dazu, daß bei einer Eingabe
optopt,
zum Schluß die Parsierung mit einer Exception abbricht:
# Error recovery fails at EOFCouldn’t repair and continue parsejava.lang.Exception: Can’t recover from previous error(s)

65
Fazit
cup ist in Java implementiert und folglich auf vielen Plattformen sofort verfügbar. Abgesehenvon einer etwas barocken Syntax, reichlichen Einschränkungen zur Anordnung der Eingabenund vielen Verabredungen im Laufzeitsystem, funktioniert cup praktisch so wie yacc und jay.Die Quellen sind frei verfügbar; die Homepage zu cup liegt im Bereich von Appels Buch ,so daß man auf Support hoffen kann.
Die Abhängigkeit von lr_parser und Symbol ist unpraktisch; außerdem generiert cup mehrerefreistehende Klassen — für Parser, Aktionen und Eingabesymbolnummern. DieAktionen-Klasse verwendet $ im Namen, das könnte Probleme geben.
Fehlerbehandlung funktioniert (leider nur fast) wie für yacc; man kann die Wiederaufnahmeder Parsierung bei wichtigen Eingabesymbolen schlecht beeinflussen. Insgesamt ist eineerfolgreiche Fehlerbehandlung deutlich schwieriger.
cup kann Zeichenpositionen in der Eingabe verwalten; damit könnte man sehr präziseFehlermeldungen generieren. Die Ablaufverfolgung eignet sich nicht zur Animation.

66
Ein Java-basierter Scanner-Generator — expr/jlex
lex und flex
lex [Lesk, 1978] und flex [Paxson] akzeptieren jeweils eine Tabelle von egrep-artigen Musternund C-Anweisungen und konstruieren eine C-Funktion yylex() zur Texterkennung oder-verarbeitung:
Wenn ein Stück der (Standard-)Eingabe einem Muster genügt, wird die zugehörigeC-Anweisung ausgeführt. Nicht erkannte Teile der Eingabe werden kopiert.
lex und flex sind Programmgeneratoren: Muster dienen als Kontrollstruktur zur Auswahl vonAktionen. Abgesehen davon, daß flex seine Eingabe puffert, sind die Programme ziemlichkompatibel.
Beispiel: Zeilennumerierung{JLex/zb/num.l}
%{ C-Text am Anfang/* * Zeilen numerieren */%}
%% trennt Abschnitte
\n ECHO; leere Zeilen kopieren^.*$ printf("%d\t%s", yylineno, yytext);
{}
Übersetzung
$ lex -t num.l > num.c$ cc -o num num.c -ll
$ flex -l -t num.l > num.c"num.l", line 11: warning, dangerous trailing context"num.l", line 11: warning, dangerous trailing context"num.l", line 11: warning, dangerous trailing context$ cc -o num num.c -L/usr/local/gnu/lib -lfl
Die Bibliothek enthält u.a ein Hauptprogramm, das yylex() einmal aufruft. Die Fehlermeldungbezieht sich offenbar auf die Verwendung von $.

67
jlex
jlex [Berk 1996] ist eine Neuimplementierung von lex in Java. Die Syntax der Tabelleunterscheidet sich wenig, aber im Vorspann sind sehr viele Java-ismen zu beachten.Insgesamt ist das System stärker auf Zusammenarbeit mit einem Parser zugeschnitten.
{JLex/zb/Num.lex}
import java.io.IOException; Java-Text am Anfang
%%
Optionen im zweiten Abschnitt%public öffentliche Klasse%class Num Klassenname
%type void Resultat der Scanner-Funktion%eofval{ Aktion bei Dateiende
return;%eofval}
%line Zeilen mitzählen (yyline)
%{ Java-Code in der Klassepublic static void main (String args []) { Num num = new Num(System.in); try { num.yylex(); } catch (IOException ioe) { System.err.println(ioe); }}
%}
%%
Muster im dritten Abschnitt\n { System.out.println(); }.*$ { System.out.println((yyline+1)+"\t"+yytext()); }
{}
Das Musterelement ^ zur Erkennung eines Zeilenanfangs fehlt. Zeilen werden ab 0 gezählt.Der erkannte Text wird per Methode als String (statt in einem Vektor) geliefert.

68
Muster
Für jlex-Muster gelten annähernd die Regeln von egrep:
" abc ..." zitierte Zeichen stellen sich selbst dar\n \t \b \f \r Zeilentrenner, Tab, Backspace, Seitenvorschub, Wagenrücklauf\ ooo \x hh oktal, hexadezimal\^ C control-Zeichen\ x ein zitiertes Zeichen. ein beliebiges Zeichen (aber kein Zeilentrenner)[ abd - x ...] ein Zeichen aus einer Klasse[^ abd - x...] ein Zeichen nicht aus einer Klasse$ Treffer an Zeilenende
x* null oder mehrmalsx+ ein oder mehrmalsx? optional: null oder einmal
xy nacheinanderx | y alternativ( ...) Vorrang steuern
{ name} im zweiten Abschnitt definiertes Muster
Der Vorrang der Musteroperationen variiert leider. Wenn eine Menge von Musternmehrdeutig ist, hat der längste erkannte Text Vorrang und bei gleicher Länge das ersteMuster.

69
Typische Muster{JLex/zb/Pat.lex}
import java.io.IOException;%%%public%class Pat%type void%eofval{
return;%eofval}%{
public static void main (String args []) { Pat pat = new Pat(System.in); try { pat.yylex(); } catch (IOException ioe) { System.err.println(ioe); }}
%}
alpha = [a-zA-Z_] Man kann Teilmuster vereinbarenalnum = [a-zA-Z_0-9]oct = [0-7]dec = [0-9]hex = [0-9a-fA-F]sign = [+-]?exp = ([eE]{sign}{dec}+)L = [lL]X = [xX]
%%
"/*"([^*]|"*"+[^/*])*"*"+"/" { System.out.println("C\t"+yytext()); }"{"[^}]*"}" { System.out.println("Pascal\t"+yytext()); }"(*"([^*]|"*"+[^*)])*"*"+")" { System.out.println("Pascal\t"+yytext()); }"//".*$ { System.out.println("C++\t"+yytext()); }
\"([^\"\\\n]|\\.|\\\n)*\" { System.out.println("C\t"+yytext()); }’([^’\n]|’’)+’ { System.out.println("Pascal\t"+yytext()); }
0{oct}+ { System.out.println("int oct\t"+yytext()); }0{oct}+{L} { System.out.println("long oct\t"+yytext()); }0{X}{hex}+ { System.out.println("int hex\t"+yytext()); }0{X}{hex}+{L} { System.out.println("long hex\t"+yytext()); }{dec}+ { System.out.println("int\t"+yytext()); }{dec}+{L} { System.out.println("long\t"+yytext()); }
{dec}+"."{dec}*{exp}?|{dec}*"."{dec}+{exp}?|{dec}+{exp} { System.out.println("double\t"+yytext()); }
’([^’\\\n]|\\[^0-7\n]|\\[0-7][0-7]?[0-7]?)’ { System.out.println("char\t"+yytext()); }
{alpha}{alnum}* { System.out.println("name\t"+yytext()); }
.|\n { }{}

70
Scanner
Mit jlex kann man sehr leicht Scanner implementieren: Die Muster beschreibenEingabesymbole und die Aktionen liefern die relevanten Informationen als Resultat vonyylex() . Zur Markierung einer Fehlerposition sollte man eine Methode wie toString()
implementieren.{expr/jlex/Scanner.lex}
package expr.jlex;
import expr.cup.sym;import java_cup.runtime.Symbol;
%%
%public%class Scanner
%type Symbol
%function token Funktion umbenennen%eofval{ return new Symbol(sym.EOF);%eofval}
comment = ("#".*)space = [\ \t\b\015]+digit = [0-9]integer = {digit}+real = ({digit}+"."{digit}*|{digit}*"."{digit}+)
%%
{space} { }{comment} { }{integer} { return new Symbol(sym.CONSTANT, new Long(yytext())); }{real} { return new Symbol(sym.CONSTANT, new Double(yytext())); }\n { return new Symbol(sym.NL); }"+" { return new Symbol(sym.ADD); }"-" { return new Symbol(sym.SUB); }"*" { return new Symbol(sym.MUL); }"/" { return new Symbol(sym.DIV); }"%" { return new Symbol(sym.MOD); }"(" { return new Symbol(sym.LPAR); }")" { return new Symbol(sym.RPAR); }. { return new Symbol(sym.error); }
{}

71
Expression
Im vorhergehenden Abschnitt wurde main() so implementiert, daß man leicht einen anderenScanner einfügen kann:
{expr/jlex/Expression.java}package expr.jlex;
import java.io.InputStreamReader;import java.io.Reader;
public class Expression extends expr.cup.Expression { /** uses a scanner built by JLex. @see expr.cup.Expression#main */ public static void main (String args []) { main(args, new Scanner(new InputStreamReader(System.in))); }
/** wraps lexical analyzer generated by JLex. Required because JLex cannot label generated class as implementing Input. @see expr.cup.Expression */ protected static class Scanner extends expr.jlex.Scanner implements Input { public Scanner (Reader r) { super(r); } }}
{}
Leider kann man bei jlex nicht angeben, daß ein Scanner ein Interface implementiert.
Fazit
jlex ist in Java implementiert und folglich auf vielen Plattformen sofort verfügbar. DasVerfahren ist sehr mächtig und nützlich, nicht nur für Scanner sondern auch für Filter, diezeilenübergreifend arbeiten sollen. jlex kann auch Zeichenpositionen in der Eingabe verwalten.
Die Anpassung für Java benötigt leider eine Vielzahl von Phrasen im zweiten Abschnitt, umdie generierte Klasse zu beeinflussen.

72
Ein Parser aus Objekten — expr/oops
oops ist ein vollständig objekt-orientierter, LL(1)-basierter, im Prinzip sprachunabhängigerParser-Generator, den wir [Kühl und Schreiner] zur Zeit entwickeln. Er wird hier skizziert, umeinen Einblick zu geben, wie man einen Parser-Generator überhaupt konstruiert, und um neueIdeen für ein völlig objekt-orientiertes System vorzustellen. oops hat (zur Zeit) keineFehlerbehandlung.
oops wurde von Wirth’s generalparser inspiriert , der allerdings seine Grammatik nichtprüfte.
T-Diagramme
Compiler werden heute sehr häufig in ihrer eigenen Sprache implementiert. VonMcKeeman(?) stammt die Idee, Übersetzungsvorgänge als sogenannte T-Diagrammedarzustellen, um das Bootstrapping derartiger Compiler zu illustrieren:
Quelle Ziel
Imp
übersetzt Quelle in Ziel, geschrieben in Imp.
Sprachimplementierungen werden durch senkrechte Balken symbolisiert:
Imp
Sys
Sprache Imp ist auf Plattform Sys ablauffähig.
73
Einer der bisher betrachteten Compiler wird folgendermaßen übersetzt:
expr .ser
jay jay Java
C
Java .cls
.cls
C
386
.cls
any
expr .ser
Java
expr .ser
.cls
.cls
anyjay javac
gccUNIX JVM
Einen in einer Untermenge C0 geschriebenen C-Compiler für Windows kann man mit einem
System ? herstellen, auf dem C0 verfügbar ist:
C .exe
C0 C .exe
C0
C .exe
.exe
.exe
386C0
?

74
Idee
Die bisher betrachteten Compiler entstanden nach folgendem Muster:
Compiler- Generator
Grammatik
Daten
Compiler
Interpreter-Baum
Der Compiler bearbeitet dann Daten, die der Grammatik genügen. Ändert man dieBeschriftung etwas, entsteht oops:
Compiler- Generator
EBNF
Grammatik
oops
Interpreter-Baum
Wenn man einen Compiler aus EBNF herstellt, muß er aus einer Grammatik, die in EBNFgeschrieben ist, ein Resultat produzieren, nämlich einen Compiler. Vergleicht man beideZeichnungen, ist dieser Compiler ein Compiler-Generator, eben oops:
Interpreter-Baum
Daten
Resultat
oopsGrammatik
Daten, die der Grammatik genügen, sind dann Programme, das Resultat sind übersetzteProgramme — bei uns vermutlich neue Interpreter-Bäume...
Mit T-Diagrammen stellt man dar, daß das System zum Beispiel mit jay entwickelt werdenund sich dann selbst übersetzen könnte. Es müßte nicht von Java abhängen...

75
oops mit jay entwickeln
Compiler- Generator
EBNF oops
jay übersetzt eine Grammatik, die EBNF in BNF beschreibt , in oops:
%token <Id> id // identifier%token <Lit> lit // quoted string%type <Parser> parser%type <Rule> rule%type <Alt> alt%type <Seq> seq%type <Some> some%type <Opt> opt%%
parser : rule { $$ = new Parser($1); }| parser rule { $1.add($2); }
rule : id ’:’ alt ’;’ { $$ = new Rule(prefix, defaultClass,$1, $3.node());
}
alt : seq { $$ = new Alt($1.node()); }| alt ’|’ seq { $1.add($3.node()); }
seq : /* empty */ { $$ = new Seq(); }| seq id { $1.add($2); }| seq lit { $1.add($2); }| seq some { $1.add($2.node()); }| seq opt { $1.add($2.node()); }| seq ’(’ alt ’)’ { $1.add($3.node()); }
some : ’{’ alt ’}’ { $$ = new Some($2.node()); }
opt : ’[’ alt ’]’ { $$ = new Opt($2.node()); }

76
Eine Grammatik mit oops übersetzen
Interpreter-Baum
oopsGrammatik
oops konstruiert für eine in EBNF formulierte Grammatik einen Interpreter, der aus Klassen imPaket oops.parser besteht:
one
two
alt
Alt verwendet Unterbäume, um eine Alternativezu erkennen.
one twoseq
Seq verwaltet Unterbäume, um nacheinandereine Folge zu erkennen.
bodysome
Some verwaltet einen Unterbaum, so daß etwaswenigstens einmal erkannt werden muß.
body
opt
Opt hat einen Unterbaum, der nicht unbedingtetwas erkennen muß.
Die Methode node() sorgt unter anderem dafür, daß bei entsprechenden Verschachtelungenauch Many erzeugt wird:
body
many
Many verwaltet einen Unterbaum, so daß etwasbeliebig oft erkannt wird.
Parser enthält verschiedene Tabellen und vor allem einen Vektor mit Rule -Objekten , diejeweils zu einem Grammatikbegriff einen Unterbaum enthalten, der erkannt werden muß. Lit
beschreibt ein Eingabesymbol, Id verweist entweder auf einen Grammatikbegriff odereinen Token , der eine Äquivalenzklasse von Eingabesymbolen repräsentiert.

77
Ein Programm mit einer oops-Grammatik übersetzen
Interpreter-Baum
Daten
Resultat
oopsGrammatik
Jeder Knoten im Interpreter-Baum versteht eine Methode parse() , die durchparse -Nachrichten an die Unterbäume des Knotens im Interpreter-Baum mit RekursivemAbstieg arbeitet.
{expr/oops/expr.oops.ebnf}// arithmetic expressions
lines : [{ [ sum ] "\n" }];sum : product [{ sum.add | sum.sub }];sum.add : "+" product;sum.sub : "-" product;product : term [{ product.mul | product.div | product.mod }];product.mul : "*" term;product.div : "/" term;product.mod : "%" term;term : Number | "+" term | term.minus | "(" sum ")";term.minus : "-" term;
{}
public void parse (Scanner scanner, Goal goal) throws IOException
Jeder Rule -Knoten sorgt dabei dafür, daß zu Beginn ein Objekt mit der Klasse seinesGrammatikbegriffs angelegt wird. Dieses Objekt erhält für jedes akzeptierte Symbol eineshift -Nachricht und am Ende der Regel eine reduce -Nachricht mit dem Interface Goal :
public interface Goal extends Serializable { void shift (Lit sender); // quoted string void shift (Token sender, Object node); // token, node from scanner void shift (Goal sender, Object node); // nonterminal, node from reduce Object reduce ();}
Die Hilfsklassen GoalAdapter und GoalDebugger sind triviale Implementierungen, dieeinfach die vom ersten Token oder Goal gelieferte node bei reduce() abliefern.
Implementiert eine Klasse das Interface Reduce oder ReduceLit statt Goal , liefert einGoalReducer nur bei reduce() einen Array aller node -Objekte, der bei ReduceLit auch nochdie Lit -Objekte enthält.

78
Beispiel — expr/oops
Zu jedem Grammatikbegriff muß eine Klasse mit dem Namen des Grammatikbegriffsexistieren, die Goal , Reduce , oder ReduceLit implementiert. Ist das nicht der Fall, wirdentweder eine mit -c angegebene defaultClass (zum Beispiel GoalDebugger ) oderGoalAdapter verwendet.
Für
lines : [{ [ sum ] "\n" }];
sammelt man einfach die für sum gelieferten Unterbäume in einem Vector :{expr/oops/lines.java}
package expr.oops;import java.util.Vector;import oops.parser.Goal;import oops.parser.GoalAdapter;
/** collect lines: [{ [ sum ] ’\n’ }] in a Vector. */
public class lines extends GoalAdapter { /** stores a tree for each sum. @serial lines Vector with one tree per sum */ protected Vector lines = new Vector();
/** presents result of reduction. @param sender just received reduce(). @param node was created by sender. */ public void shift (Goal sender, Object node) { lines.addElement(node); }
/** concludes rule recognition. @return Vector of sum trees. */ public Object reduce () { return lines; }}
{}

79
Beisum : product [{ sum.add | sum.sub }];sum.add : "+" product;sum.sub : "-" product;
erhält man für jedes product durch shift(Goal, Object) einen Unterbaum, den man aber jenach Art des Operators mit Node.Add oder Node.Sub speichern muß. Das geht sehr leicht übereine Rückfrage beim Absender :
{expr/oops/sum.java}package expr.oops;import oops.parser.Goal;import oops.parser.GoalAdapter;import expr.java.Node;
/** collect sum: product [{ ’+’ product | ’-’ product }] as a Node tree. */
public class sum extends GoalAdapter { /** presents result of reduction. This is saved, or combined with the current tree. @param sender just received reduce(); must implement build. @param node was created by sender; must be a Number. */ public void shift (Goal sender, Object node) { if (result == null) result = node; else result = ((build)sender).build((Number)result, (Number)node); }
/** callback to build a tree. */ public interface build { Object build (Number a, Number b); }
/** builds a Node.Add tree. */ public static class add extends GoalAdapter implements build { public Object build (Number a, Number b) { return new Node.Add(a, b); } }
/** builds a Node.Sub tree. */ public static class sub extends GoalAdapter implements build { public Object build (Number a, Number b) { return new Node.Sub(a, b); } }}
{}

80
Beiproduct : term [{ product.mul | product.div | product.mod }];product.mul : "*" term;product.div : "/" term;product.mod : "%" term;
arbeitet man natürlich mit Vererbung. Man muß nur die Absender implementieren :{expr/oops/product.java}
package expr.oops;import oops.parser.GoalAdapter;import expr.java.Node;
/** collect product: term [{ ’*’ term | ’/’ term | ’%’ term }] as a Node tree. */
public class product extends sum {
/** builds a Node.Mul tree. */ public static class mul extends GoalAdapter implements build { public Object build (Number a, Number b) { return new Node.Mul(a, b); } }
/** builds a Node.Div tree. */ public static class div extends GoalAdapter implements build { public Object build (Number a, Number b) { return new Node.Div(a, b); } }
/** builds a Node.Mod tree. */ public static class mod extends GoalAdapter implements build { public Object build (Number a, Number b) { return new Node.Mod(a, b); } }}
{}

81
Beiterm : Number | "+" term | term.minus | "(" sum ")";term.minus : "-" term;
sammeln GoalAdapter das von Number beziehungsweise einem Grammatikbegriff geliefertenode -Objekt und ein modifizierter GoalAdapter konstruiert Node.Minus :
{expr/oops/term.java}package expr.oops;import oops.parser.GoalAdapter;import expr.java.Node;
public class term extends GoalAdapter { public static class minus extends GoalAdapter { public Object reduce () { return new Node.Minus((Number)result); } }}
{}

82
Eine Grammatik mit oops prüfen
Nicht jede Grammatik eignet sich für Rekursiven Abstieg. Damit oops ein praktikablesWerkzeug ist, muß die Grammatik geprüft werden, wenn der Baum aus Parser und anderenKlassen konstruiert wird.
oops akzeptiert eine in EBNF formulierte Grammatik, also Syntaxgraphen, und repräsentiert sieals Baum. Ob der Baum als Parser erfolgreich sein kann, wird aus der Sicht der einzelnenKnoten-Klassen betrachtet:
"x"
Number
Lit und Token sollen Eingabesymbole erkennen. Das ist festumrissen.
one twoseq
Seq soll eine Folge von Dingen erkennen. Auch hier bestehtkeine Wahlmöglichkeit.
one
two
alt
Alt muß entscheiden, welcher Unterbaum (Teilgraph) aktiviertwerden soll.
body
opt
Opt muß entscheiden, ob sein Unterbaum aktiviert werden soll.
body
many
Many trifft diese Entscheidung mehrfach.
bodysome
Some trifft sie nach dem ersten Durchgang.

83
Betrachtet man die Situation für Alt einmal genauer:
one
two
alt
Offenbar müssen sich die Eingabesymbole vollständig unterscheiden, die am Anfang von oneund am Anfang von two vorkommen können.
body
opt
Bei Opt (und anderen) müssen sich aber auch die Eingabesymbole unterscheiden, die amAnfang von body und im Anschluß an Opt vorkommen können.
Das gilt unter Umständen auch für Alt :
body
two
alt
opt
Wenn eine Alternative leer sein kann, müssen sich alle voneinander und von den nachfolgendmöglichen Eingabesymbolen unterscheiden.
Zur Prüfung einer Grammatik sollte jeder Knoten zwei Mengen von Eingabesymbolenberechnen:
lookahead kann am Anfang vorkommen,follow kann danach vorkommen.
Anschließend muß jeder Knoten feststellen, ob er mit einem Eingabesymbol eindeutigentscheiden kann, wie er sich verhalten soll.

84
public Set setLookahead (Parser parser)
rhs:lhsRule : Parser schickt setLookahead der Reihe nach an jedeRule und diese, falls nötig, an ihren Unterbaum rhs; dessenlookahead ist lookahead der Rule .
"x"
Lit : lookahead enthält genau das Eingabesymbol selbst.
Number
Token : wie Lit .
lhsId : verweist auf Rule . Wenn diese noch mit setLookahead
beschäftigt ist, ist der Parser nicht anwendbar. Sonst kenntoder berechnet sie ihre lookahead-Menge.
one
two
alt
Alt : lookahead ist die Summe der Unterbäume.
bodysome
Some: lookahead kommt vom Unterbaum.
body
opt
Opt : lookahead kommt vom Unterbaum, aber keine Eingabeist ebenfalls möglich.
body
many
Many: wie Opt .
one two
seq
Seq: lookahead kommt vom ersten Unterbaum; akzeptiert erauch keine Eingabe, addiert man den zweiten Unterbaum etc.
Um Id eine Chance zu geben, darf Seq nur die unbedingt nötigen Unterbäume befragen.

85
public Set setFollow (Parser parser, Set follow)
Diese Methode erhält den lookahead des Nachfolgers und liefert den eigenen lookahead.Diesmal wird Seq vollständig traversiert und deshalb setLookahead intern vorausgeschickt.
rhs:lhs
Rule : Parser schickt setFollow an die erste Rule und diese anihren Unterbaum rhs. Mangels anderer Kenntnisse ist followzuerst eine leere Menge.
"x"
Lit : follow ist uninteressant.
Number
Token : wie Lit .
one
two
alt
Alt : follow wird notiert und jedem Unterbaum geschickt.
bodysome
Some: follow wird notiert und an den Unterbaum geschickt.
body
opt
Opt : wie Some.
body
many
Many: wie Opt .
one two
seq
Seq: follow wird notiert und dem letzten Unterbaum twogeschickt. An den vorhergehenden, one, wird der lookaheadvon two geschickt; akzeptiert two auch keine Eingabe, kommtfollow noch hinzu etc.
lhs
Id : verweist auf Rule . Vergrößert follow die dort bisher alsfollow notierte Menge, muß das Verfahren iteriert werden.
Wenn die vom Parser an die erste Rule geschickte Nachricht setFollow terminiert, muß jedeRule erreicht worden sein; es kann also keine Rule ohne follow geben.

86
public void checkLL1 (Parser parser)
rhs:lhsRule : Parser schickt checkLL1 an die erste Rule und diese anihren Unterbaum rhs .
"x"
Lit : nichts zu prüfen.
Number
Token : wie Lit .
body
two
alt
opt
Alt : wenn lookahead (also eine Alternative) keine Eingabeakzeptiert, muß lookahead von follow verschieden sein.Außerdem müssen alle Unterbäume paarweise verschiedenelookahead-Mengen besitzen.
bodysome
Some: lookahead muß von follow verschieden sein.
body
opt
Opt : wie Some.
body
many
Many: wie Opt .
one twoseq
Seq: hier muß sich nur jeder Unterbaum selbst prüfen.
lhs
Id : wenn lookahead (also die rhs der Rule ) keine Eingabeakzeptiert, muß lookahead von der follow-Menge diesesKnotens verschieden sein..

87
Scanner
Wenn man den Compiler betreibt, muß man die Eingabesymbole mit den lookahead-Mengender Knoten vergleichen, um zu entscheiden, welche Unterbäume aktiviert werden sollen. DieKnoten des von oops generierten Parsers enthalten folglich die lookahead-Mengen auch zurLaufzeit.
Lit - und Token -Knoten enthalten Eingabesymbole in ihren lookahead-Mengen. Es muß alsomöglich sein, diese Mengen mit jeweils einem Element leicht herzustellen.
Diese Überlegungen führten zu folgendem Interface für Scanner für oops-Parser:{oops/parser/Scanner.java}
package oops.parser;import java.io.IOException;import java.io.Reader;
/** describes what a scanner for an oops-generated parser must do. */public interface Scanner { /** initialize, read one symbol ahead. @param parser is used to screen symbols. */ void scan (Reader in, Parser parser) throws IOException; /** move on to next token. @return false if atEnd() becomes true. */ boolean advance () throws IOException; /** @return true if positioned beyond tokens. */ boolean atEnd (); /** @return single-element lookahead set, null for unidentifiable token. */ Set tokenSet (); /** @return node corresponding to token. */ Object node ();}
{}
Parser enthält Tabellen, die Strings und Token auf die nötigen Mengen abbilden, und stelltsie mit entsprechenden Methoden zur Verfügung — deshalb ist scan() im Interfacevorgesehen, denn ein Konstruktor kann dort nicht vorgegeben werden.

88
Fazit
oops ist ein Experiment — ein objekt-orientiertes LL(1) System, dessenImplementierungssprache ausgetauscht werden kann, ohne daß sich dies in der Grammatikmanifestiert. Wenn man die Konstruktion von Bäumen automatisiert und auf eine Bibliothekaufsetzt, kann man (nahezu?) den gleichen Compiler in verschiedenen Sprachenimplementieren, wenn jeweils die Bibliothek vorhanden ist.
Da die Knoten zur Laufzeit die lookahead-Mengen enthalten und die follow-Mengen enthaltenkönnten, sollte es möglich sein, für eine automatische, mächtige Fehlerbehandlung zu sorgen.
Durch die Aufteilung auf Klassen ist die LL(1)-Prüfung einigermaßen überschaubar. Der sonstübliche Warshall-Algorithmus zur Berechnung der transitiven Hülle ist (weniger effizient?) inder Iteration über Rule versteckt.

89
Ein Visitor-Generator für Objektbäume — expr/jag
Mit jag können Traversen für Objektbäume implementiert werden. jag liest eine Tabelle vonMustern, die im Baum erkannt werden sollen, und in Java formulierten Aktionen, die dannausgeführt werden. Die Aktionen können unter anderem entscheiden, ob und wieUnterbäume traversiert werden sollen.
jag beruht letztlich auf Wilcox’ Template-Codierer, mit dem etwa 1970 das PL/1-System beiCornell implementiert wurde. Der entscheidende Unterschied ist, daß nur Klassen zurFormulierung von Mustern benötigt werden.
jag ist als Compiler mit jay und jlex implementiert, der Java-Code ausgibt, und beruht aufeinem Laufzeitsystem , das die Auswahl der Aktionen bewerkstelligt. Gegenüber meinenfrüheren, als Interpreter arbeitenden Systemen hat dies den Vorteil, daß die Aktionen sehrmächtig sind, ohne daß man die Transparenz von Auswahl und Traversier-Entscheidungverliert. Der Nachteil ist ein wesentlich aufwendigerer Übersetzungsvorgang für Traversierer.
jag ist ebenfalls ein experimentelles Werkzeug. Es dient hier primär dazu, die Prinzipieneffizienter Code-Generierung für typische Rechnerarchitekturen möglichst kompaktvorzustellen.

90
Node
Blätter des Objektbaums dürfen zu beliebigen Klassen gehören, Knoten müssen folgendesInterface implementieren:
{jag/Node.java}package jag;
public interface Node { /** @return number of subtrees. */ int degree ();
/** provides access to subtrees. @param n index of subtree, from 0. @return root of n’th subtree. @throws IndexOutOfBoundsException if n is out of range. @throws NullPointerException if there are no subtrees. */ public Object sub (int n);}
{}
Dies kann man in einer neuen Klasse Node etwa folgendermaßen erreichen:
package expr.jag;import java.io.Serializable;
public abstract class Node implements jag.Node, Serializable {
protected Serializable sub [];
public int degree () { return sub == null ? 0 : sub.length; }
public Object sub (int n) { return sub[n]; }
public abstract static class Binary extends Node { public Binary (Serializable left, Serializable right) { sub = new Serializable[2]; sub[0] = left; sub[1] = right; } }
public interface Commutative extends Serializable { }
public static class Add extends Binary implements Commutative { public Add (Serializable left, Serializable right) { super(left, right); } }
Commutative ist ein Beispiel, wie man Operator-Eigenschaften auf die Klassenhierarchieabbilden kann.

91
jlex und jay
Mit jlex kann man auch leicht Scanner konstruieren, die zu Parsern passen, die von jaygeneriert wurden:
{expr/jag/Scanner.lex}package expr.jag;%%%public%class Scanner%implements Expression.yyInput
%type boolean%function advance%eofval{ return false;%eofval}%{
/** current input. */protected int token;/** determines current input. @return token value or character. */public int token () { return token;}/** value associated with current input. */protected Object value;/** produces value associated with current input. @return value. */public Object value () { return value;}
%}comment = ("#".*)space = [\ \t\b\015]+digit = [0-9]integer = {digit}+real = ({digit}+"."{digit}*|{digit}*"."{digit}+)%%
{space} { }{comment} { }{integer} { value = new Long(yytext()); token = Expression.Constant;
return true;}
{real} { value = new Double(yytext()); token = Expression.Constant; return true;}
.|\n { value = null; token = yytext().charAt(0); return true;}
{}

92
Expression
Abgesehen vom Betrieb der Traversierer wird Expression nahezu unverändert übernommen(Vererbung ist nicht möglich, da Node ersetzt wird):
{expr/jag/Expression.jay}%{ package expr.jag;
import java.io.FileInputStream; import java.io.InputStreamReader; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; import java.io.Serializable; import java.util.Vector; import jag.Jag;
/** recognizes, stores, and processes arithmetic expressions using a parser generated with jay and jlex and visitors generated with jag. */ public class Expression { /** reads lines from standard input, parses, and visits them
with generators specified as arguments. Each generator operateseither on the original tree or on the object returned by thepreceding generator.@param args filenames of visitors.
*/ public static void main (String args []) { if (args == null || args.length == 0) {
System.err.println("no visitors specified"); System.exit(1); } try {
Scanner scanner = new Scanner(new InputStreamReader(System.in));Expression parser = new Expression();Vector lines = (Vector)parser.yyparse(scanner);
{}

93
{expr/jag/Expression.jay rules} } catch (Exception e) { System.err.println(e); } }%}%token <Serializable> Constant%type <Vector> lines%type <Serializable> sum, product, term%%
lines : /* null */ { $$ = new Vector(); }| lines sum ’\n’ { $1.addElement($2); }| lines ’\n’ // $$ = $1
sum : product // $$ = $1| sum ’+’ product { $$ = new Node.Add($1, $3); }| sum ’-’ product { $$ = new Node.Sub($1, $3); }
product : term // $$ = $1| product ’*’ term { $$ = new Node.Mul($1, $3); }| product ’/’ term { $$ = new Node.Div($1, $3); }| product ’%’ term { $$ = new Node.Mod($1, $3); }
term : ’+’ term { $$ = $2; }| ’-’ term { $$ = new Node.Minus($2); }| ’(’ sum ’)’ { $$ = $2; }| Constant // $$ = $1
%%}
{}

94
Traverse
In der (eindeutigen) Postfix-Notation folgen die Operatoren ihren Operanden. Man gewinnt sieaus einem Baum durch eine Postorder-Traverse, bei der die Wurzeln nach ihren Unterbäumenbearbeitet werden :
{expr/jag/Postfix.jag}package expr.jag;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;import jag.Jag;
/** generates methods to traverse a Node tree to generate postfix. */public class Postfix { public static void main (String args []) { final Jag jag = new Jag();%%
Double: { ‘" "+$0.floatValue()‘; };Long: { ‘" "+$0.longValue()‘; };
Node.Add: { ‘" add"‘; };Node.Mul: { ‘" mul"‘; };Node.Sub: { ‘" sub"‘; };Node.Div: { ‘" div"‘; };Node.Mod: { ‘" mod"‘; };Node.Minus: { ‘" minus"‘; };
Node: Serializable Serializable { $1; $2; $0; } | Serializable { $1; $0; };
%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (java.io.IOException e) { System.err.println(e); System.exit(1); } }}
{}
Dies erzeugt etwa folgende Ausgabe:
$ java expr.jag.Expression Postfix.gen2 + 3 2 3 add

95
Format
Die Eingabe für jag hat drei Teile, die durch %% getrennt sind. Im ersten Teil muß mitJava-Code eine final oder Instanzen-Variable Jag jag vereinbart werden. Der zweite Teilenthält die Tabelle mit Einträgen aus Mustern und Aktionen, die in jag aufgebaut wird. Derdritte Teil enthält abschließenden Java-Code. Normalerweise wird man dort jag serialisieren.
Eintrag besteht aus einer Klasse und einer Folge von Mustern und Aktionen. Die Klasseeines Knotens oder eine Oberklasse oder ein Interface, jeweils mit wachsendemAbstand von der Klasse, werden unter den Einträgen gesucht.
Muster ist eine Liste von null oder mehr Klassen. Die Klassen der Unterbäume einesKnotens müssen an die Klassen der Liste eines Musters zugewiesen werdenkönnen, dann wird die zugehörige Aktion gewählt. Da die Muster sequentielldurchsucht werden, muß man Muster mit spezielleren Klassen am Anfang einesEintrags aufführen.
null an Stelle einer Klasse bedeutet, daß an dieser Stelle kein Unterbaum vorhandenist. Darauf darf dann auch nicht verwiesen werden.
... Folgen dem Muster drei Punkte, werden auch Knoten erkannt, die mehr als dieangegebenen Unterbäume besitzen.
Aktion ist Java-Code mit spezieller Syntax zum Verweis auf oder zur Traverse vonKnoten und zur Ausgabe:
‘ ...‘ wird ersetzt durch jag.getOut().print( ...) , vereinfacht also Ausgaben.
$n verweist auf die Wurzel eines Unterbaums, mit Typumwandlung zur Klasse.$0 verweist auf den Knoten selbst, mit Typumwandlung zur Klasse.
$n; traversiert einen Unterbaum.$0; führt eine Aktion zur Klasse des Knotens aus, deren Muster eine leere Liste ist.{$ n} {$0} funktionieren analog, werden aber nicht implizit mit ; terminiert.
Fehlt die Aktion komplett, wird nach einem anderen passenden Eintrag für den Knotengesucht. Eine Aktion wird folgendermaßen übersetzt:
public final Object action (Object object, Object parm) { Object result = null; jag.gen(((jag.Node)object).sub(0), parm); jag.gen(((jag.Node)object).sub(1), parm); jag.gen0(object, parm); return result;}
object ist der Knoten, parm wird beim Start der Traverse angegeben, result kann in derAktion gesetzt und beim Aufrufer in Form von {$ n} verwendet werden. Die Aktion sollte keineNamen einführen, die mit einem Unterstrich beginnen.

96
Implementierung
Traversierer beruhen im Wesentlichen auf zwei Klassen: Jag implementiert die Suche nachden Einträgen, die zu Knoten passen, und Jag.Rule implementiert die Prüfung eines Mustersund die zugehörige Aktion.
Jag ist ein Hashtable, der Class -Objekte auf Rule -Arrays abbildet. Extern sichtbar istfolgendes:
public class Jag extends Hashtable { public Object gen (Object object, Object parm) public static class NoRuleException extends RuntimeException public Object gen0 (Object object, Object parm) public void setOut (PrintStream out) public PrintStream getOut () public static class Rule implements Serializable { public Rule (Class sub []) public Object action (Object object, Object parm) public boolean matches (int degree, Node node) }}
Ein Aufruf von gen() startet die Traverse oder führt sie rekursiv weiter und liefert das Resultatder äußersten action() . Eine Jag.NoRuleException zeigt an, daß keine passende Rule
gefunden wurde. gen() implementiert die Suche nach passenden Einträgen.
gen0() dient zur Suche und Ausführung einer Rule mit leerem Muster. setOut() und getOut()
kontrollieren die Ausgabe der mit ‘ ...‘ formulierten Aktionen.
Rule enthält einen Array mit Klassen für die Unterbäume, der im Konstruktor unveränderlichgesetzt wird. Von Rule wird für jede spezifizierte Aktion eine lokale Unterklasse erzeugt, in deraction() mit der Aktion überschrieben wird.
matches() berücksichtigt primär degree als gesuchte Array-Länge; nur wenn dies positiv ist,wird die Node inspiziert — damit kann nach Regeln ohne Muster gesucht werden, selbst wenndie Node Unterbäume besitzt. Falls Rule nicht abgeleitet wurde und matches() Erfolg hat,liefert matches() eine NoRuleException — damit wird in gen() und gen0() erzwungen, daß dieSuche mit Einträgen für Oberklassen fortgesetzt wird.
jag ist quasi ein Präprozessor, der die Konstruktion eines Jag -Objekts, also einesTraversierers, vereinfacht. Abgesehen von einfachen semantischen Prüfungen (nur ein Eintragpro Klasse? keine Aktionen bezüglich nicht-existenter Unterbäume?) wird im Wesentlichen derursprünglich von Hand entworfene Java-Code zur Konstruktion eines Jag -Objektsumgesetzt. Die jay-Implementierung des Parsers enthält einige Kontext-Tricks mit Variablenwie $0 und die jlex-Implementierung des Scanners stützt sich sehr stark auf Zustände, umRegeln, Aktionen und Ausgabe-Aktionen verschieden zu analysieren.

97
Betrieb
Im einem Programm können mehrere Traversierer, auch simultan, betrieben werden.Beispielsweise wird Expression mit serialisierten Traversierern aufgerufen und wendet sienacheinander auf jeden vom Parser in Vector lines eingetragenen Baum an:
{expr/jag/Expression.jay jag}Jag jag [] = new Jag[args.length];for (int a = 0; a < args.length; ++ a) { jag[a] = (Jag) new ObjectInputStream(new FileInputStream(args[a]))
.readObject(); // load generator jag[a].setOut(System.err); // redirect output}
Vector output = new Vector();for (int l = 0; l < lines.size(); ++ l) { Object tree = lines.elementAt(l); for (int a = 0; a < args.length; ++ a) { Object result = jag[a].gen(tree, null); // run generator if (result == null) System.err.println(); else tree = result; } if (tree != null) output.addElement(tree);}if (output.size() != 0) { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(output); out.close();}
{}
Liefert ein Traversierer ein Resultat, wird es hier als Baum für den nächsten Traversiererverwendet. Ist zum Schluß aller Traversen das Resultat nicht null , wird es in Vector output
eingetragen. Ist er nicht leer, wird dieser Vector zum Schluß serialisiert und kann dannmöglicherweise mit expr.java.Go weiterverwendet werden:
$ java expr.jag.Expression Postfix.gen Value.gen | java expr.java.Go2 + 3 2 3 addbyte short int long float double5 5 5 5 5.0 5.0

98
Beispiel: Bewertung
Um einen Baum zu bewerten, erzeugt man in jeder Aktion ein Double -Objekt:{expr/jag/Value.jag}
package expr.jag;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;
/** evaluates a Node tree with double arithmetic. */public class Value { public static void main (String args []) { final jag.Jag jag = new jag.Jag();%%
Number: { result = ($0); };
Node.Add: Serializable Serializable { result = new Double(((Number){$1}).doubleValue()
+ ((Number){$2}).doubleValue());};Node.Sub: Serializable Serializable { result = new Double(((Number){$1}).doubleValue()
- ((Number){$2}).doubleValue());};Node.Mul: Serializable Serializable { result = new Double(((Number){$1}).doubleValue()
* ((Number){$2}).doubleValue());};Node.Div: Serializable Serializable { result = new Double(((Number){$1}).doubleValue()
/ ((Number){$2}).doubleValue());};Node.Mod: Serializable Serializable { result = new Double(((Number){$1}).doubleValue()
% ((Number){$2}).doubleValue());};Node.Minus: Serializable { result = new Double(-((Number){$1}).doubleValue());};
%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (IOException e) { System.err.println(e); System.exit(1); } }}
{}

99
Beispiel: Generieren eines expr.java.Node Baums
Statt Double kann man natürlich auch die bisher verwendeten Knoten erzeugen:{expr/jag/Tree.jag}
package expr.jag;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;
/** creates an expr.java.Node tree from a Node tree. */public class Tree { public static void main (String args []) { final jag.Jag jag = new jag.Jag();%%
Number: { result = ($0); };
Node.Add: Serializable Serializable { result = new expr.java.Node.Add((Number){$1}, (Number){$2});};Node.Sub: Serializable Serializable { result = new expr.java.Node.Sub((Number){$1}, (Number){$2});};Node.Mul: Serializable Serializable { result = new expr.java.Node.Mul((Number){$1}, (Number){$2});};Node.Div: Serializable Serializable { result = new expr.java.Node.Div((Number){$1}, (Number){$2});};Node.Mod: Serializable Serializable { result = new expr.java.Node.Mod((Number){$1}, (Number){$2});};Node.Minus: Serializable { result = new expr.java.Node.Minus((Number){$1});};
%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (IOException e) { System.err.println(e); System.exit(1); } }}
{}

100
Code-Generierung
Im folgenden wird mit jag Code für eine Reihe von idealisierten Maschinen generiert. AlsBeispiel dient immer der arithmetische Ausdruck - (1 % ( 2 + 3 * 4 - 5 / 6 )) , der demfolgenden Baum entspricht:
-
%
1
2
+
3 4
*
-
5 6
/
Prinzipiell könnte man Postfix erzeugen und auf jeder Maschine einfach einen Stacksimulieren, aber es gibt Lösungen, die der Architektur gerechter werden.
Zur Analyse der Beispiele sollte man beachten, daß möglichst wenig Speicherplatz verbrauchtwerden sollte. Dazu ist es sehr wichtig, daß man je nach Operator die Reihenfolge variiert, inder die Unterbäume besucht werden — ein wesentlicher Grund für die Konstruktion von jag.

101
Beispiel: Code für eine 0-Adreß-Maschine
Eine 0-Adreß- oder Stack-Maschine führt ihre Berechnungen mit Werten von einem (prinzipiellunendlichen) Stack durch — Arithmetikbefehle wie add haben folglich keine explizitenArgumente.
Stack
Arithmetikpop
pop
links
rechts
push
Zusätzlich muß es load - und store -Befehle geben, die Werte zwischen einem Speicher unddem Stack transferieren.
Eine naive Postfix-Traverse liefert zwar 0-Adreß-Code, aber sie benötigt unnötig viel Platz aufdem Stack. Für den Ausdruck - (1 % ( 2 + 3 * 4 - 5 / 6 )) kann zum Beispiel folgenderCode erzeugt werden:
load 1.0load 4.0load 3.0mulload 2.0addload 5.0load 6.0divsubmodminus

102
Der Trick besteht darin, bestimmte Situationen bei kommutativen Operatoren auszunützen: {jag/arith/G0.jag}
package arith;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;import expr.jag.Node;
/** generates methods to traverse a Node tree to generate 0-address code. */public class G0 { public static void main (String args []) { final jag.Jag jag = new jag.Jag();%%
Double: { ‘"\tload\t"+$0.floatValue()+"\n"‘; };
Node.Add: { ‘"\tadd\n"‘; };Node.Mul: { ‘"\tmul\n"‘; };Node.Sub: { ‘"\tsub\n"‘; };Node.Div: { ‘"\tdiv\n"‘; };Node.Mod: { ‘"\tmod\n"‘; };Node.Minus: { ‘"\tminus\n"‘; };
Node.Commutative: Double Serializable { $2; $1; $0; };
Node: Serializable Serializable { $1; $2; $0; } | Serializable { $1; $0; };
%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (IOException e) { System.err.println(e); System.exit(1); } }}
{}

103
Beispiel: Code für eine 1-Adreß-Maschine
Eine 1-Adreß-Maschine gleicht einem Taschenrechner mit Display. Arithmetikbefehle habenein Argument und verknüpfen es mit dem Display:
Speicher
Arithmetik,Resultat
load
store
add
Zusätzlich zu den Arithmetikbefehlen muß es load und store geben, um den Display ladenund entladen zu können.
Für den Ausdruck - (1 % ( 2 + 3 * 4 - 5 / 6 )) kann zum Beispiel folgender Code erzeugtwerden:
load 5.0div 6.0store temp1load 4.0mul 3.0add 2.0sub temp1store temp1load 1.0mod temp1store temp1load 0.0sub temp1
Der Code wird deutlich verbessert, wenn es einen 0-Adreß-Befehl minus gibt, der dasVorzeichen des Displays umkehrt.

104
{jag/arith/G1.jag}package arith;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;import expr.jag.Node;
/** generates methods to traverse a Node tree to generate 1-address code. */public class G1 { public static void main (String args []) { final jag.Jag jag = new jag.Jag(); final jag.Temp temp = new jag.Temp();%%
Double: { ‘" load "+$0.floatValue()+"\n"‘; };
Node.Add: { ‘" add "‘; };Node.Mul: { ‘" mul "‘; };Node.Sub: { ‘" sub "‘; };Node.Div: { ‘" div "‘; };Node.Mod: { ‘" mod "‘; };
Node.Minus: Double { ‘" load -("+$1.floatValue()+")\n"‘;}
| Serializable { $1; ‘" store temp"+temp.get()+"\n"‘; ‘" load 0.0\n"‘; ‘" sub temp"+temp.free()+"\n"‘;};
Node.Commutative: Double Serializable { $2;
$0; ‘$1.floatValue()+"\n"‘;};
Node: Serializable Double { $1;$0; ‘$2.floatValue()+"\n"‘;
} | Serializable Serializable { $2;
‘" store temp"+temp.get()+"\n"‘;$1;$0; ‘"temp"+temp.free()+"\n"‘;
};%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (IOException e) { System.err.println(e); System.exit(1); } }}
{}

105
Temp
Zwischenergebnisse müssen gelegentlich aus dem Display abgespeichert werden. DieSpeicherzellen können als Stack mit einer Klasse Temp verwaltet werden, die als Hilfsmittelzum Paket jag gehört:
{jag/Temp.java}package jag;
import java.io.Serializable;
/** implements indices for a stack of runtime words. */public class Temp implements Serializable { /** current stack level. */ protected transient int n; // starts life at zero
/** creates a new level. @return current level. */ public int get () { return ++ n; }
/** references current level. @return current level. */ public int ref () { return n; }
/** discards current level. @return discarded level. */ public int free () { return n --; }}
{}

106
Beispiel: Code für eine 2-Adreß-Maschine
2-Adreß-Maschinen sind die theoretische Version der heute gebräuchlichsten Architektur. Siesind theoretisch wichtig, weil ihr Code (Tripel) leicht optimiert und auf andere Architekturenabgebildet werden kann. Ein Arithmetikbefehl hat zwei Argumente, verknüpft sie, undüberschreibt dann eines davon mit dem Resultat:
SpeicherArithmetik
links
rechts
sum
Zusätzlich zu den Arithmetikbefehlen sollte es noch einen Befehl move zur Übertragung vonWerten geben.
Für den Ausdruck - (1 % ( 2 + 3 * 4 - 5 / 6 )) kann zum Beispiel folgender Code erzeugtwerden:
move temp1,0.0move temp2,1.0move temp3,5.0div temp3,6.0move temp4,3.0mul temp4,4.0add temp4,2.0sub temp3,temp4mod temp2,temp3sub temp1,temp2
Der Code wird deutlich verbessert, wenn es einen 1-Adreß-Befehl minus gibt, der dasVorzeichen einer Speicherzelle umkehrt.

107
Um explizite Speicherverwaltung zu vermeiden, kann man das Resultat immer in derSpeicherzelle erzeugen, die Temp.get() als nächste anlegen würde:
Node.Minus: Double { ‘" move temp"+temp.get()+","+"-("‘; $1; ‘")\n"‘;
temp.free();}
| Serializable { ‘" move temp"+temp.get()+","+"0.0\n"‘;
$1; ‘" sub temp"+temp.ref()+","
+"temp"+temp.get()+"\n"‘;temp.free(); temp.free();
};
Node.Commutative: Double Double // revert to superclass of node | Double Serializable { $2;
$0; ‘"temp"+temp.get()+","‘;$1; ‘"\n"‘;
temp.free();};
Node: Double Double { ‘" move temp"+temp.get()+","‘;$1; ‘"\n"‘;
$0; ‘"temp"+temp.free()+","‘;$2; ‘"\n"‘;
} | Serializable Double { $1;
$0; ‘"temp"+temp.get()+","‘;$2; ‘"\n"‘;
temp.free();}
| Double Serializable { ‘" move temp"+temp.get()+","‘;$1; ‘"\n"‘;
$2;$0; ‘"temp"+temp.ref()+","
+"temp"+temp.get()+"\n"‘;temp.free(); temp.free();
} | Serializable Serializable { $2;
temp.get();$1;$0; ‘"temp"+temp.ref()+","
+"temp"+temp.get()+"\n"‘;temp.free(); temp.free();
};
Node.Commutative demonstriert, wie man bei der Ersetzung von Spezialfällen auf diesequentielle Suche in den Regeln Rücksicht nehmen muß. Die Code-Generierung für dieRegister-Maschine zeigt, wie eine intelligentere Speicherverwaltung mehr Platz spart.

108
Beispiel: Code für eine 3-Adreß-Maschine
3-Adreß-Maschinen sind theoretisch wichtig, weil ihr Code (Quadrupel) leicht optimiert unddann auf andere Architekturen abgebildet werden kann. Ein Arithmetikbefehl hat dreiArgumente, verknüpft zwei und überschreibt das dritte mit dem Resultat.
Speicher
Arithmetik
links
rechts
sum
Zusätzlich zu den Arithmetikbefehlen sollte es noch einen Befehl move zur Übertragung vonWerten geben.
Für den Ausdruck - (1 % ( 2 + 3 * 4 - 5 / 6 )) kann zum Beispiel folgender Code erzeugtwerden:
mul temp1,3.0,4.0add temp1,2.0,temp1div temp2,5.0,6.0sub temp1,temp1,temp2mod temp1,1.0,temp1sub temp1,0.0,temp1

109
Um explizite Speicherverwaltung zu vermeiden, kann man das Resultat immer in derSpeicherzelle erzeugen, die Temp.get() als nächste anlegen würde:
Node.Minus: Double { ‘" move temp"+temp.get()+","+"-("‘; $1; ‘")\n"‘;
temp.free();}
| Serializable { $1; ‘" sub temp"+temp.get()+","
+"0.0,"+"temp"+temp.free()+"\n"‘;
};
Node: Double Double { $0; ‘"temp"+temp.get()+","‘;$1; ‘","‘;$2; ‘"\n"‘;
temp.free();}
| Serializable Double { $1;$0; ‘"temp"+temp.get()+","
+"temp"+temp.ref()+","‘;$2; ‘"\n"‘;
temp.free();}
| Double Serializable { $2;$0; ‘"temp"+temp.get()+","‘;
$1; ‘","+"temp"+temp.ref()+"\n"‘;
temp.free();}
| Serializable Serializable { $1;temp.get();$2;$0; ‘"temp"+temp.ref()+","
+"temp"+temp.ref()+","+"temp"+temp.get()+"\n"‘;
temp.free(); temp.free();};
Offensichtlich kann man leichter 3-Adreß- als 2-Adreß-Code generieren. Trotzdem hat sichdiese Architektur nicht durchgesetzt, denn die 3-Adreß-Programme benötigen mehrSpeicherplatz als 2-Adreß-Programme, weil die Befehle in der Regel Platz verschwenden.

110
Beispiel: Mixed-Mode Code für eine Register-Maschine
Die Register-Maschine ist ein Spezialfall einer 2-Adreß-Maschine. Es gibt relativ wenige,schnelle Register mit einfachen Adressen, die als Quelle und Ziel der Arithmetikbefehledienen. Moderne RISC-Architekturen haben sehr viele Register; trotzdem istRegister-Verwaltung nicht trivial, denn Register werden auch zur Adressierung des Speichersbenötigt.
Register
Arithmetiklinks rechts
Speicher
sum
Für den Ausdruck - (1 % ( 2 + 3 * 4 - 5 / 6 )) kann zum Beispiel folgender Code erzeugtwerden:
load r0, 3mul r0, 4add r0, 2load r1, 5div r1, 6subr r0, r1load r1, 1modr r1, r0load r0, 0subr r0, r1
Der Code ist deutlich kürzer als 0-Adreß-Code, da die Register nicht als Stack verwaltetwerden.

111
Der Parser kann Long und Double erzeugen. Die Register-Maschine besitzt verschiedeneRegister und Befehle für Ganzzahl- und Gleitkomma-Arithmetik, und im Stil von C muß zurArithmetik Double verwendet werden, wenn wenigstens ein Operand diesen Typ besitzt.Hilfsklassen R.Long und R.Float die beide von R abstammen, verwalten die Register, und ihreObjekte repräsentieren den Resultattyp eines codierten Befehls:
{expr/jag/Reg.jag rules}Node: Long Long { result = new R.Long((String){$0},
new R.Long($1), $2);}
| Number Number { result = new R.Float((String){$0},new R.Float($1), $2);
} | Long Serializable { R right = (R)$2;
result = right instanceof R.Long ?(R)new R.Long((String){$0},
new R.Long($1),right) :(R)new R.Float((String){$0},
new R.Float($1),right);}
| Number Serializable { R right = (R)$2; result = new R.Float((String){$0},
new R.Float($1), right);}
| Serializable Long { R left = (R)$1; result = left instanceof R.Long ?
(R)new R.Long((String){$0}, left, $2) :(R)new R.Float((String){$0}, left, $2);
} | Serializable Number { R left = (R)$1;
result = new R.Float((String){$0}, left, $2);}
| Serializable Serializable {R left = (R){$1}, right = (R)$2;if (left instanceof R.Long && right instanceof R.Long) result = new R.Long((String){$0}, left, right);else result = new R.Float((String){$0}, left, right);
};{}

112
Der Code kann noch durch folgende Spezialfälle verbessert werden:{expr/jag/Reg.jag rules}
Node.Commutative: Long Long // revert to superclass of node | Number Number // revert to superclass of node | Long Serializable { R right = (R)$2;
result = right instanceof R.Long ?(R)new R.Long((String){$0}, right,$1) :(R)new R.Float((String){$0}, right,$1);
} | Number Serializable { R right = (R)$2;
result = new R.Float((String){$0}, right,$1);};
{}
Die Wurzeln enthalten wie üblich die Maschinenbefehle. Minus wird auf sub abgebildet:{expr/jag/Reg.jag rules}
Node.Add: { result = "add"; };Node.Mul: { result = "mul"; };Node.Sub: { result = "sub"; };Node.Div: { result = "div"; };Node.Mod: { result = "mod"; };
Node.Minus: Long { result = new R.Long("sub",new R.Long(new Long(0)), $1);
} | Number { result = new R.Float("sub",
new R.Float(new Float(0)), $1);}
| Serializable { R right = (R)$1; if (right instanceof R.Long) result = new R.Long("sub",
new R.Long(new Long(0)),right); else result = new R.Float("sub",
new R.Float(new Long(0)),right);};
{}

113
Die Registerverwaltung muß zwischen zwei Ausdrücken reinitialisiert werden. Dazu kann einkleiner Trick dienen: Jag wird so abgeleitet, daß der Generator seinen obersten Aufruf daranerkennt, daß kein Argument übergeben wird:
{expr/jag/Reg.jag}package expr.jag;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;
/** generates register machine code for a mixed-mode Node tree. */public class Reg { public static void main (String args []) { final jag.Jag jag = new jag.Jag() { public Object gen (Object object, Object parm) {
Object result = super.gen(object, this);if (parm == null) { R.reset(); result = null; }return result;
} };%%
{expr/jag/Reg.jag tail}%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (IOException e) { System.err.println(e); System.exit(1); } }}
{}
Die Code-Generierung ist nicht eingerichtet auf triviale Ausdrücke, die nur aus einerKonstanten bestehen.

114
Registerverwaltung — R
R ist abstrakt und repräsentiert ein Register als Index in einen Array, in dem die Belegungnotiert wird. Dieser Array müßte verfeinert werden, wenn man bei Überbelegung Register inden Speicher verdrängt.
Konkrete Unterklassen von R repräsentieren Long - und Double -Arithmetik. Die Konstruktorenerzeugen Maschinenbefehle und notieren die Resultatregister.
Die nötigen Konstruktoren ergeben sich durch Besichtigung der jag-Regeln. R.Float hat einenzusätzlichen Konstruktor zur Umwandlung von Long in Double .
{expr/jag/R.java}package expr.jag;
/** manages registers and output for a register machine. Nested classes use package access to register descriptions. */public abstract class R { /** makes all registers available. */ public static void reset () { for (int r = 0; r < Long.reg.length; ++ r) Long.reg[r] = false; for (int r = 0; r < Float.reg.length; ++ r) Float.reg[r] = false; }
/** allocates a register. @throws RuntimeException if there is no register available. */ protected static int get (boolean reg []) { for (int r = 0; r < reg.length; ++ r) if (! reg[r]) {
reg[r] = true;return r;
} throw new RuntimeException("no more registers"); }
/** register containing this result. */ protected int rX;

115
/** describes a result in a general register. */ public static class Long extends R { /** number of general registers for integer arithmetic. */ public static final int regs = 8;
/** true if general register is in use. */ protected static boolean reg [] = new boolean[regs];
/** loads a number into a new general register.@throws RuntimeException if there is no register available.
*/ public Long (java.lang.Long number) { rX = R.get(reg); System.err.println("\tload\tr"+rX+", "+number.longValue()); }
/** combines a general register and a number.@param left general register.
*/ public Long (String opcode, R left, java.lang.Long right) { rX = ((Long)left).rX; // ensure left is Long System.err.println("\t"+opcode+"\tr"+rX+", "+right.longValue()); }
/** combines two general registers.@param left general register, used as result.@param right general register, freed.
*/ public Long (String opcode, R left, R right) { rX = ((Long)left).rX; // ensure left is Long System.err.println("\t"+opcode+"r\tr"+rX+", r"+right.rX); reg[right.rX] = false; ((Long)right).rX = -1; // ensure right is Long and gets trashed } }

116
/** describes a result in a floating point register. */ public static class Float extends R { /** number of registers for floating point arithmetic. */ public static final int regs = 8;
/** true if floating point register is in use. */ protected static boolean reg [] = new boolean[regs];
/** loads a number into a new floating point register.@throws RuntimeException if there is no register available.
*/ public Float (Number number) { rX = R.get(reg); System.err.println("\tloadf\tfr"+rX+", "+number.floatValue()); }
/** transfers a number into a new floating point registerand frees the general register.@param r general register.@throws RuntimeException if there is no register available.
*/ public Float (R r) { rX = R.get(reg); System.err.println("\tloadfr\tfr"+rX+", r"+r.rX); Long.reg[r.rX] = false; ((Long)r).rX = -1; // ensure r is Long and gets trashed }
/** combines a register and a number.@param left register, converted to floating point if necessary.
*/ public Float (String opcode, R left, Number right) { if (! (left instanceof Float)) left = new Float(left); rX = left.rX; System.err.println("\t"+opcode+"f\tfr"+rX+", "+right.floatValue()); }
/** combines two registers.@param left register, converted to floating point, used as result.@param right register, converted as needed, freed.
*/ public Float (String opcode, R left, R right) { if (! (left instanceof Float)) left = new Float(left); rX = left.rX; if (! (right instanceof Float)) right = new Float(right); System.err.println("\t"+opcode+"fr\tfr"+rX+", fr"+right.rX); reg[right.rX] = false; right.rX = -1; // ensure right gets trashed } }}
{}

117
Test
Die Code-Generierung für die Register-Maschine hängt nur von einer Baum-Ebene ab. Esbietet sich an, alle vier binären und zwei monadischen Muster zu testen. Dabei muß manallerdings auch jeweils zwei mögliche Typen sowie die Vereinfachung durch Kommutativitätberücksichtigen — aus 6 werden dadurch 28 Testfälle.
Widen ist ein Traversierer, der arithmetische Ausdrücke dadurch vervielfältigt, daß er fürDouble -Werte jeweils auch Long -Werte einsetzt:
{expr/jag/Widen.jag}package expr.jag;
import java.io.IOException;import java.io.ObjectOutputStream;import java.io.Serializable;
/** widens a mixed-mode Node tree by exploding Double(n) into n and n. */public class Widen { public static void main (String args []) { final jag.Jag jag = new jag.Jag() { public Object gen (Object object, Object parm) {
Object result = super.gen(object, this);if (parm == null && result != null) { String[] r = (String[])result; result = null; for (int i = 0; i < r.length; ++ i) System.err.println(r[i]);}return result;
} };%%
Node.Add: { result = " + "; };Node.Mul: { result = " * "; };Node.Sub: { result = " - "; };Node.Div: { result = " / "; };Node.Mod: { result = " % "; };Node.Minus: { result = "- "; };
Long: { result = new String[] { ""+$0.longValue() };};
Double: { result = new String[] { ""+$0.longValue(), ""+$0.longValue()+"." };};

118
Node: Serializable Serializable {String[] left = (String[]){$1}, right = (String[])$2;String[] rs = new String[left.length * right.length];for (int l = 0; l < left.length; ++ l) for (int r = 0; r < right.length; ++ r) rs[l + r*left.length] = "("+left[l]+{$0}+right[r]+")";result = rs;
} | Serializable {
String[] sub = (String[])$1;String[] rs = new String[sub.length];for (int s = 0; s < sub.length; ++ s) rs[s] = "("+{$0}+sub[s]+")";result = rs;
};
%% try { ObjectOutputStream out = new ObjectOutputStream(System.out); out.writeObject(jag); out.close(); } catch (IOException e) { System.err.println(e); System.exit(1); } }}
{}
Alle Testfälle bearbeitet man etwa so:
$ { java expr.jag.Expression Widen.gen >/dev/null; } 2>&1 | java expr.jag.Expression Reg.gen > /dev/null1.+2.3.-4.5.+(6+7.)8.-(9+10.)(11+12.)-13.(14+15.)-(16+17.)-18.-(19+20.)

119
Fazit
Es ist genügend oft demonstriert worden, daß sich das Prinzip von jag — Baumtraversenbasierend auf Mustererkennung mit programmierbarer Traversierrichtung — sehr gut zureffizienten Code-Generierung eignet. Man kommt schnell zu einer prinzipiellen Lösung undkann diese durch die Erkennung von Spezialfällen laufend verbessern.
Die vorliegenden Beispiele sollten dokumentieren, daß eine Mustererkennung nur auf derBasis von Klassen und ihren hierarchischen Beziehungen ausreichend mächtig ist. DieMehrfachvererbung durch Interfaces scheint dabei nicht ernsthaft zu verwirren; sie kann sogarelegant ausgenützt werden.
jag war leicht zu implementieren und sollte leicht zu erlernen sein, da nur sehr wenigePrinzipien beachtet werden müssen. Ein Compiler ist Interpretern deutlich überlegen, dieszeigt insbesondere das relativ realistische Beispiel der Register-Maschine.
Die mögliche Serialisierung der Code-Generatoren erlaubt eine weitgehende Entkopplung vonFrontend und Backend eines Compilers. Die Regelbasierung sollte es möglich machen,jag-Traversierer für eine Knoten-Bibliothek zu implementieren, für die dann unabhängigFrontends entwickelt werden können.
Die Register-Maschine zeigt, daß man prinzipiell semantische Aspekte in dieCode-Generierung hineinziehen könnte, aber das sollte man eigentlich schon früher imCompiler berücksichtigen.
Das Testverfahren kann man natürlich durch Shell-Skripte und Vergleich mit früherenAusführungen verfeinern (regression testing).

120
Reguläre Ausdrücke — re/Re.java
Auf UNIX-Plattformen existieren normalerweise Kommandos und Funktionen zur Suche mitTextmustern, den sogenannten regulären Ausdrücken. Der Begriff bezieht sich darauf, daßdiese Textmuster mit endlichen Automaten implementiert werden können, die ihrerseits zusogenannten regulären Grammatiken korrespondieren.
grep-Muster erkennen Teilausdrücke, erlauben keine Alternativen, wurdenursprünglich mit Backtracking implementiert.
egrep-Muster erkannten ursprünglich keine Teilausdrücke, erlauben Alternativen,werden durch Berechnung und anschließenden Betrieb desdeterministischen(!) endlichen Automaten implementiert.
abc ... die meisten Zeichen stellen sich selbst dar\ x ein zitiertes Zeichen stellt sich unbedingt selbst dar. ein beliebiges Zeichen[ abd - x...] ein Zeichen aus einer Klasse[^ abd - x ...] ein Zeichen nicht aus einer Klasse^ Treffer an Textanfang$ Treffer an Textende
x* null oder mehrmalsegrep x+ ein oder mehrmalsegrep x? optional: null oder einmal
xy nacheinanderegrep x | y alternativ
( ...) Vorrang steuern
In diesem Abschnitt wird eine Implementierung von regulären Ausdrücken für Java skizziert,die auf paralleler Interpretation des nicht-deterministischen Automaten beruht und über eineAblaufverfolgung verfügt. Die Lösung geht letztlich auf einen Artikel von Richards zurück, derdiesen Ansatz in BCPL implementierte.

121
Analyse
public class Re {
public static void main (String args [])
erlaubt die Optionen -a oder --anchored und -doder --debug und benötigt ein Textmuster. Dieanschließend angegebenen Dateien oder dieStandard-Eingabe werden nach diesem Musterdurchsucht.
protected boolean debug; wird im Hauptprogramm gesetzt, um dieAblaufverfolgung auszulösen.
public Re (String pattern) verwendet rekursiven Abstieg und konstruierteinen Musterbaum aus einem String mit einemTextmuster.
public boolean anchoredMatch (String text)
untersucht, ob text vollständig dem Textmustergenügt.
public boolean match (String text) untersucht, ob ein Teil von text dem Textmustergenügt.
protected static class Chars dient zur lexikalischen Analyse, gibt einen Stringzeichenweise ab.
protected final Alt re (Chars c) erkennt seq [{ "|" seq }];
protected final Seq seq (Chars c) erkennt item [{ item }];
protected final Node item (Chars c) erkennt atom ["*"|"?"|"+"];
protected final Node atom (Chars c) erkennt "^" | "$" | "." | x | "\"x | "[ ]" |"[^ ]" | "(" re ")";

122
Automat
Der Zustand des endlichen Automaten besteht aus allen aktiven Musterknoten, die dasnächste Eingabezeichen erkennen könnten. match() versucht zu erkennen, mit enter()
werden im Erfolgsfall die unmittelbar nachfolgenden Knoten informiert. Verschiedene Bitssorgen für effiziente Traversen.
protected abstract static class Node {
protected Activate parent; ermöglicht Rückkehr zur Wurzel.
protected boolean active; markiert aktiven Knoten.
protected boolean entered; markiert, daß Knoten enter() schon erhielt.
public final void setActive () falls !active : aktiviert Knoten und Pfad zurWurzel.
public void clearActive () top-down Traverse, löscht active .
public void clearEntered () top-down Traverse, löscht entered .
public abstract boolean enter () falls !entered , setzt entered , aktiviert Blatt,traversiert Unterbaum, liefert dann true , fallsNachfolger enter() erhalten soll.
public abstract boolean match (int c)
falls active , löscht active , vergleicht Eingabe undliefert true , falls Nachfolger enter() erhalten soll.
public static final int BEG = -1, END = -2;
repräsentieren Eingabe von Textanfang und -ende. }
Damit liegt fest, welche Methoden in den verschiedenen Musterknoten-Klassenimplementiert werden müssen, zum Beispiel:
protected static class Any extends Node { public boolean enter () { if (entered) return false; entered = true; this.setActive(); return false; }
public boolean match (int c) { if (!active) return false; active = false; if (c == BEG) this.setActive(); // stay active past BEG return c >= 0; // false on BEG/END } }

123
Treiber
enter() aktiviert die Nachfolger. entered begrenzt die Tiefe dieser Traverse. Vor jedemmatch() muß dieses Bit gelöscht werden. patternActive wird im Zuge von enter() undsetActive global gesetzt; ist dieses Bit gelöscht, kann nichts mehr gefunden werden.
public boolean anchoredMatch (String text) { if (debug) System.out.println("anc\t"+pattern.toString());
// entered, active unknown int n = 0; patternActive = false; pattern.clearActive(); pattern.clearEntered();
// entered, active false boolean result = pattern.enter();
// entered unknown, active set if (patternActive && usedBeg) { if (debug) System.out.println("\t"+pattern.active()+"\nbeg"); patternActive = false; pattern.clearEntered();
// entered false, active set result = pattern.match(Node.BEG);
// entered unknown, active set }
for (; patternActive && n < text.length(); ++ n) { if (debug) System.out.println("\t"+pattern.active()+"\n"+text.charAt(n)); patternActive = false; pattern.clearEntered();
// entered false, active set result = pattern.match(text.charAt(n));
// entered unknown, active set }
if (patternActive && usedEnd && n >= text.length()) { if (debug) System.out.println("\t"+pattern.active()+"\nend"); patternActive = false; pattern.clearEntered();
// entered false, active set result = pattern.match(Node.END); }
if (debug) System.out.println("\t"+pattern.active()); return result && n >= text.length(); }
Die freie Suche ist erfolgreich beendet, sobald match() oder enter() Erfolg haben. Außerdemwird vor jedem Zeichen das gesamte Muster durch Aufruf von enter() zusätzlich neuaktiviert.

124
Beispiele
$ java re.Re --anchored --debug ’axel’axelanc (axel)
aa
xx
ee
ll
true
Bei der verankerten Suche wird das Muster nur einmal aktiviert. Bei einfachen Texten mußjedes Eingabezeichen den nachfolgenden Knoten aktivieren.
$ java re.Re debug ’xa|yb’axbyb ((xa)|(yb)) x ya x yx xa yb x yy x ybbtrue
Bei der freien Suche wird das Muster immer wieder zusätzlich aktiviert. Bei Alternativen mußjede Alternative aktiviert werden.
Fazit
Die Ablaufverfolgung illustriert, daß eigentlich alle möglichen Wege durch das Muster parallelverfolgt werden. Der deterministische Automat hat als Zustände Mengen von einfachenMusterpositionen. Die Leistung von Programmen wie egrep oder lex besteht darin, diesenAutomaten zu optimieren.
Die objektorientierte Implementierung verteilt das Problem der Nachfolger-Information elegantauf die einzelnen Klassen. Die vorliegende Lösung ist aber ineffizient.





























