Embed Size (px)
Citation preview

1Apr 18, 2023
Chapter 3: Chapter 3: Frequency DistributionsFrequency Distributions

2
In Chapter 3:
3.1 Stemplots
3.2 Frequency Tables
3.3 Additional Frequency Charts

3
Stemplots
• Start by exploring the data with Exploratory Data Analysis (EDA)
• A popular univariate EDA technique is the stem-and-leaf plot
• The stem of the stemplot is an number-line (axis)
• Each leaf represents a data point
You can observe a lot by looking – Yogi Berra

4
Stemplot: Illustration• 10 ages (data sequenced as an ordered array)
05 11 21 24 27 28 30 42 50 52 • Draw the stem to cover the range 5 to 52:
0| 1| 2| 3| 4| 5| ×10 axis multiplier
• Divide each data point into a stem-value (in this example, the tens place) and leaf-value (the ones-place, in this example)
• Place leaves next to their stem value• Example of a leaf: 21 (plotted)
1

5
Stemplot illustration continued …
• Plot all data points in rank order:
0|5 1|1 2|1478 3|0 4|2 5|02 ×10
• Here is the plot horizontally
8 7 4 25 1 1 0 2 0------------0 1 2 3 4 5------------Rotated stemplot
6
Interpreting Distributions
• Shape
• Central location
• Spread

7
Shape• “Shape” refers to the distributional pattern• Here’s the silhouette of our data
X X X X X X X X X X ----------- 0 1 2 3 4 5 -----------
• Mound-shaped, symmetrical, no outliers • Do not “over-interpret” plots when n is small

8
Shape (cont.)Consider this large data set of IQ scores
An density curve is superimposed on the graph

9
Examples of Symmetrical Shapes

10
Examples of Asymmetrical shapes

11
Modality (no. of peaks)

12
Kurtosis (steepness)
Mesokurtic (medium) Platykurtic (flat)
Leptokurtic (steep)
skinny tails
fat tails
Kurtosis is not be easily judged by eye

13
Gravitational Center (Mean)• Gravitational center ≡
arithmetic mean • “Eye-ball method” visualize
where plot would balance on see-saw “– around 30 (takes practice)
• Arithmetic method = sum values and divide by nsum = 290n = 10
mean = 290 / 10 = 29
8 7 4 25 1 1 0 2 0------------0 1 2 3 4 5 ------------ ^ Grav.Center

14
Central location: Median• Ordered array:
05 11 21 24 27 28 30 42 50 52
• The median has depth (n + 1) ÷ 2 • n = 10, median’s depth = (10+1) ÷ 2 = 5.5 • → falls between 27 and 28 • When n is even, average adjacent values
Median = 27.5

15
Spread: Range• For now, report the
range (minimum and maximum values)
• Current data range is “5 to 52”
• The range is the easiest but not the best way to describe spread (better methods described later)

16
Stemplot – Second Example• Data: 1.47, 2.06, 2.36, 3.43, 3.74, 3.78, 3.94, 4.42
• Stem = ones-place
• Leaves = tenths-place• Truncate extra digit
(e.g., 1.47 1.4)
|1|4|2|03|3|4779|4|4(×1)
Center: median between 3.4 & 3.7 (underlined) Spread: 1.4 to 4.4 Shape: mound, no outliers

17
Third Illustrative Example (n = 25)
• Data: 14, 17, 18, 19, 22, 22, 23, 24, 24, 26, 26, 27, 28, 29, 30, 30, 30, 31, 32, 33, 34, 34, 35, 36, 37, 38
• Regular stemplot:|1|4789|2|223466789|3|000123445678×10
• Too squished to see shape

18
Third Illustration; Split Stem • Split stem-values into two ranges, e.g., first “1”
holds leaves between 0 to 4, and second “1” will holds leaves between 5 to 9
• Split-stem|1|4|1|789|2|2234|2|66789|3|00012344|3|5678×10
• Negative skew now evident)

19
How many stem-values?
• Start with between 4 and 12 stem-values
• Then, use trial and error using different stem multipliers and splits → use plot that shows shape most clearly

20
Fourth Example: n = 53 body weights
Data range from 100 to 260 lbs:

21
Data range from 100 to 260 lbs:
×100 axis multiplier only two stem-values (1×100 and 2×100) too few
×100 axis-multiplier w/ split stem 4 stem values might be OK(?)
×10 axis-multiplier 16 stem values next slide

22
Fourth Stemplot Example (n = 53)
10|016611|00912|003457813|0035914|0815|0025716|55517|00025518|00005556719|24520|321|02522|023|24|25|26|0(×10)
Shape: Positive skewhigh outlier (260)
Central Location: L(M) = (53 + 1) / 2 = 27 Median = 165 (underlined)
Spread: from 100 to 260

23
Quintuple-Split Stem Values
1*|00001111t|2222222333331f|44555551s|6667777771.|8888888889992*|01112t|22f|2s|6(×100)
Codes for stem values:* for leaves 0 and 1 t for leaves two and threef for leaves four and fives for leaves six and seven. for leaves eight and nine
For example, 120 is: 1t|2(x100)

24
SPSS Stemplot, n = 654
Frequency Stem & Leaf
2.00 3 . 0 9.00 4 . 0000 28.00 5 . 00000000000000 37.00 6 . 000000000000000000 54.00 7 . 000000000000000000000000000 85.00 8 . 000000000000000000000000000000000000000000 94.00 9 . 00000000000000000000000000000000000000000000000 81.00 10 . 0000000000000000000000000000000000000000 90.00 11 . 000000000000000000000000000000000000000000000 57.00 12 . 0000000000000000000000000000 43.00 13 . 000000000000000000000 25.00 14 . 000000000000 19.00 15 . 000000000 13.00 16 . 000000 8.00 17 . 0000 9.00 Extremes (>=18)
Stem width: 1 Each leaf: 2 case(s)
Because n large, each leaf represents 2 observations
3 . 0 means 3.0 years
Frequency counts

25
Frequency Table
• Frequency ≡ count
• Relative frequency ≡ proportion
• Cumulative [relative] frequency ≡ proportion less than or equal to current value
AGE | Freq Rel.Freq Cum.Freq.
------+----------------------- 3 | 2 0.3% 0.3% 4 | 9 1.4% 1.7% 5 | 28 4.3% 6.0% 6 | 37 5.7% 11.6% 7 | 54 8.3% 19.9% 8 | 85 13.0% 32.9% 9 | 94 14.4% 47.2%10 | 81 12.4% 59.6%11 | 90 13.8% 73.4%12 | 57 8.7% 82.1%13 | 43 6.6% 88.7%14 | 25 3.8% 92.5%15 | 19 2.9% 95.4%16 | 13 2.0% 97.4%17 | 8 1.2% 98.6%18 | 6 0.9% 99.5%19 | 3 0.5% 100.0%------+-----------------------Total | 654 100.0%

26
Class Intervals
• When data sparse, group data into class intervals
• Classes intervals can be uniform or non-uniform
• Use end-point convention, so data points fall into unique intervals: include lower boundary, exclude upper boundary
• (next slide)
27
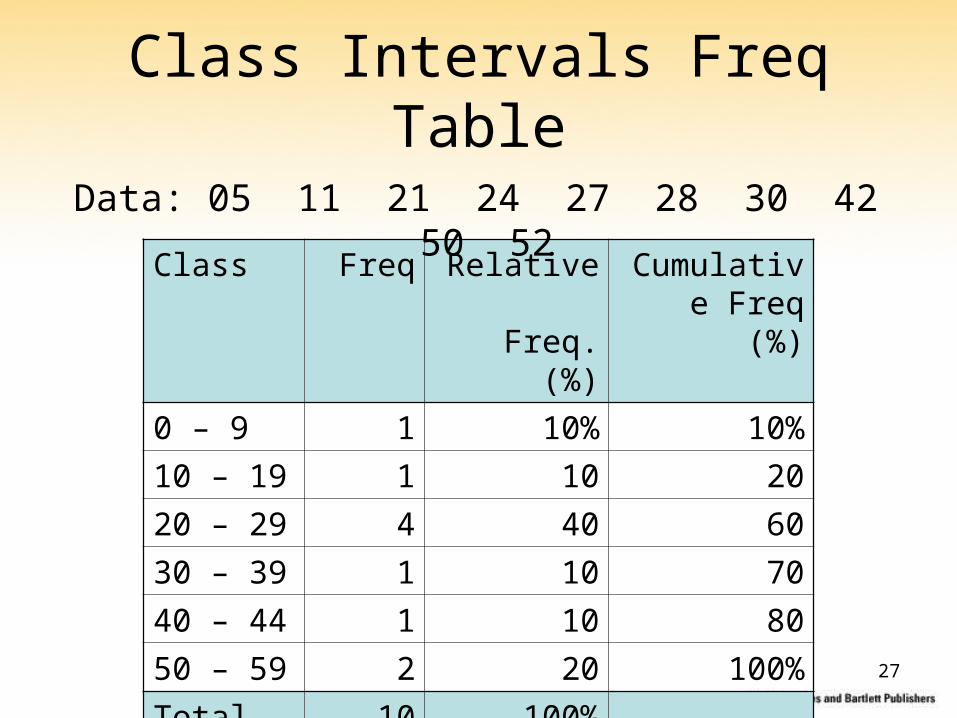
Class Intervals Freq Table
Class Freq Relative Freq. (%)
Cumulative Freq (%)
0 – 9 1 10% 10%
10 – 19 1 10 20
20 – 29 4 40 60
30 – 39 1 10 70
40 – 44 1 10 80
50 – 59 2 20 100%
Total 10 100% --
Data: 05 11 21 24 27 28 30 42 50 52

28
HistogramFor a quantitative measurement only.
Bars touch.
29
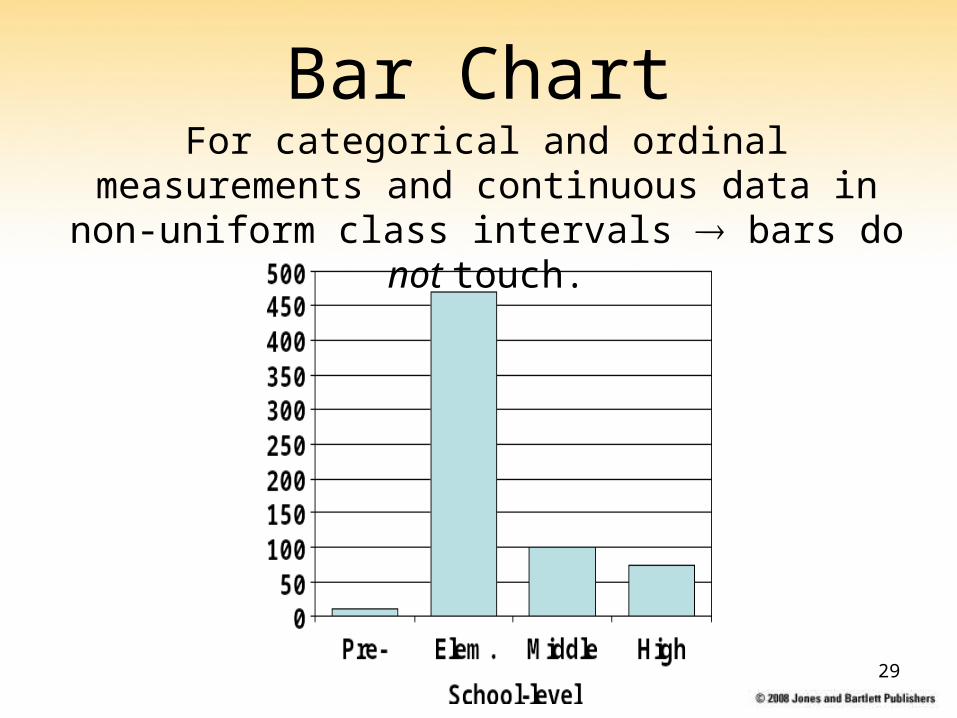
Bar ChartFor categorical and ordinal measurements and continuous data in non-uniform class
intervals bars do not touch.





























