Embed Size (px)
Citation preview

1106 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
Analysis of Eigenvalue Decomposition-Based LateReverberation Power Spectral Density Estimation
Ina Kodrasi , Member, IEEE and Simon Doclo , Senior Member, IEEE
Abstract—Many speech dereverberation techniques require anestimate of the late reverberation power spectral density (PSD).State-of-the-art multichannel methods for estimating the late re-verberation PSD typically rely on first, an estimate of the relativetransfer functions (RTFs) of the target signal; second, a modelfor the spatial coherence matrix of the late reverberation; and fi-nally, an estimate of the reverberant speech or reverberant andnoisy speech PSD matrix. The RTFs, the spatial coherence ma-trix, and the speech PSD matrix are all prone to modeling andestimation errors in practice, with the RTFs being particularly dif-ficult to estimate accurately, especially in highly reverberant andnoisy scenarios. Recently, we proposed an eigenvalue decomposi-tion (EVD)-based late reverberation PSD estimator, which doesnot require an estimate of the RTFs. In this paper, this EVD-basedPSD estimator is further analyzed and its estimation accuracy andcomputational complexity are analytically compared to a state-of-the-art maximum likelihood (ML) based PSD estimator. It is shownthat for perfect knowledge of the RTFs, spatial coherence matrix,and reverberant speech PSD matrix, the ML-based and the EVD-based PSD estimates are both equal to the true late reverberationPSD. In addition, it is shown that for erroneous RTFs but perfectknowledge of the spatial coherence matrix and reverberant speechPSD matrix, the ML-based PSD estimate is larger than or equalto the true late reverberation PSD, whereas the EVD-based PSDestimate is obviously still equal to the true late reverberation PSD.Finally, it is shown that when modeling and estimation errors oc-cur in all quantities, the ML-based PSD estimate is larger thanor equal to the EVD-based PSD estimate. Simulation results forseveral realistic acoustic scenarios demonstrate the advantages ofusing the EVD-based PSD estimator in a multichannel Wiener fil-ter, yielding a significantly better performance than the ML-basedPSD estimator.
Index Terms—Dereverberation, PSD estimation, EVD, prewhi-tening, ML.
I. INTRODUCTION
IN HANDS-FREE speech communication applicationsthe recorded microphone signals are often corrupted by
Manuscript received September 4, 2017; revised January 24, 2018; acceptedFebruary 15, 2018. Date of publication March 2, 2018; date of current versionApril 11, 2018. This work was supported in part by the Cluster of Excellence1077 Hearing4All, funded by the German Research Foundation (DFG) and inpart by the joint Lower Saxony-Israeli Project ATHENA, funded by the State ofLower Saxony. The associate editor coordinating the review of this manuscriptand approving it for publication was Dr. Xiaodong Cui. (Corresponding author:Ina Kodrasi.)
I. Kodrasi was with the Department of Medical Physics and Acoustics, Uni-versity of Oldenburg, Oldenburg 26129, Germany, She is now with the IdiapResearch Institute, Martigny 1920, Switzerland (e-mail: [email protected]).
S. Doclo is with the Department of Medical Physics and Acoustics, Uni-versity of Oldenburg, Oldenburg 26129, Germany (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TASLP.2018.2811184
reverberation, which arises from the superposition of delayedand attenuated copies of the anechoic speech signal. Whileearly reverberation may be desirable [1], late reverberation maydegrade the perceived speech quality and intelligibility [2], [3]as well as the performance of automatic speech recognitionsystems [4], [5]. Hence, speech enhancement techniqueswhich effectively suppress the late reverberation are required.In the last decades many single-channel and multi-channeldereverberation techniques have been proposed [6]–[8], withmulti-channel techniques being generally preferred since theyare able to exploit both the spectro-temporal and the spatialcharacteristics of the received microphone signals. Commonlyused techniques for speech dereverberation are acoustic multi-channel equalization techniques [9]–[12], multi-channel linearprediction-based techniques [13]–[15], and the multi-channelWiener filter (MWF) as well as various beamformer-postfilterstructures [16]–[28]. The MWF is typically implementedas a minimum variance distortionless response (MVDR)beamformer followed by a single-channel Wiener postfil-ter [20]–[28]. Modeling the late reverberation as a spatiallyhomogeneous sound field [20]–[28], the implementation ofthe MVDR beamformer and Wiener postfilter requires (amongother quantities) an estimate of the spatial coherence matrix andof the power spectral density (PSD) of the late reverberation.While the spatial coherence matrix can be computed assuminga reasonable sound field model for the late reverberation (e.g.,diffuse), estimating the late reverberation PSD is challenging.
To estimate the late reverberation PSD several single-channelestimators based on a temporal model of reverberation [29]–[31] and multi-channel estimators based on a model for the spa-tial coherence matrix of the late reverberation [22]–[28], [32]have been proposed. The multi-channel estimators can be clas-sified as non-blocking-based estimators [23], [26], [28], wherethe target signal and late reverberation PSDs are jointly es-timated, and blocking-based estimators [22], [24], [25], [27],[32], where the late reverberation PSD is estimated at the outputof a blocking matrix aiming to block the target signal. For bothclasses of estimators, either maximum-likelihood (ML)-basedestimators [23], [25]–[27] or estimators minimizing the Frobe-nius norm of an error PSD matrix [22], [24], [28] have beenproposed. Whereas for noisy scenarios the ML-based estima-tors require an iterative optimization procedure, e.g. based onNewton’s method [25], [26] or root finding [27], in noise-freescenarios a closed-form solution for the ML estimator can bederived [23], [27]. In [33] it has been analytically shown thatthe ML-based PSD estimator from [23] yields a higher PSD
2329-9290 © 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications standards/publications/rights/index.html for more information.

KODRASI AND DOCLO: ANALYSIS OF EIGENVALUE DECOMPOSITION BASED LATE REVERBERATION PSD ESTIMATION 1107
estimation accuracy than the PSD estimator based on the Frobe-nius norm in [22]. It should be realized that all multi-channellate reverberation PSD estimators in [22]–[28], [32] require anestimate of the relative transfer functions (RTFs) of the targetsignal from the reference microphone to all microphones. In ad-dition, all estimators require a model for the spatial coherencematrix of the late reverberation and an estimate of the reverber-ant speech or reverberant and noisy speech PSD matrix. Whilethe spatial coherence matrix can be computed assuming a diffusesound field model [22]–[28] and the PSD matrix can be directlyestimated from the received microphone signals, the RTFs maybe more difficult to estimate accurately, particularly in highlyreverberant and noisy scenarios. As experimentally validatedin [34]–[36], erroneously estimated RTFs degrade the derever-beration performance of the speech enhancement system.
Recently, we proposed a multi-channel late reverberation PSDestimator which does not require an estimate of the RTFs [36],[37]. The late reverberation PSD is estimated using the eigen-value decomposition (EVD) of the reverberant speech PSD ma-trix prewhitened with the spatial coherence matrix of the latereverberation. In this paper, we further analyze this EVD-basedPSD estimator, providing novel insights in terms of 1) its esti-mation accuracy in comparison to the state-of-the-art ML-basedPSD estimator from [23], 2) its computational complexity, and3) its performance not only in reverberant scenarios as in [36],but also in the presence of additive noise. It is shown that whenthe true RTFs, spatial coherence matrix, and reverberant speechPSD matrix are known, the ML-based and EVD-based PSDestimators are equivalent and yield the true late reverberationPSD. Furthermore, it is shown that for erroneously estimatedRTFs but perfect knowledge of the spatial coherence matrixand reverberant speech PSD matrix, the ML-based PSD esti-mate is larger than or equal to the true late reverberation PSD,whereas the EVD-based PSD estimate is obviously still equalto the true late reverberation PSD. Finally, it is shown that whenmodeling and estimation errors occur in all quantities, the ML-based PSD estimate is larger than or equal to the EVD-basedPSD estimate. On the one hand, when such errors result in anoverestimation of the true late reverberation PSD for both es-timators, the ML-based PSD estimation error is larger than orequal to the EVD-based PSD estimation error. On the otherhand, when such errors result in an underestimation of the truelate reverberation PSD for both estimators, the ML-based PSDestimation error is smaller than or equal to the EVD-based PSDestimation error. Simulation results for several realistic acous-tic scenarios with different reverberation times and microphoneconfigurations demonstrate the advantages of using the EVD-based PSD estimator in the MWF, yielding a significantly betterperformance than the ML-based PSD estimator.
The paper is organized as follows. In Section II the consid-ered acoustic configuration and the used notation is introduced.In Section III the ML-based and EVD-based late reverbera-tion PSD estimators are reviewed and analytical insights onthe equivalence of both estimators are provided. In Section IVthe impact of modeling and estimation errors in the RTFs, spa-tial coherence matrix, and reverberant speech PSD matrix onthe estimation accuracy of the ML-based and EVD-based PSD
Fig. 1. Acoustic system configuration.
estimators is theoretically analyzed. In addition, the computa-tional complexity of the ML-based and EVD-based PSD esti-mators is compared. In Section V all analytical derivations areexperimentally validated and the performance of the MWF us-ing the ML-based and EVD-based PSD estimators in realisticacoustic scenarios is compared.
II. CONFIGURATION AND NOTATION
Consider a reverberant and noisy acoustic system with a singlespeech source and M ≥ 2 microphones, as depicted in Fig. 1.In the short-time Fourier transform (STFT) domain, the m-thmicrophone signal Ym (k, l) at frequency bin k and time frameindex l is given by
Ym (k, l) = Xe,m (k, l) + Xr,m (k, l)︸ ︷︷ ︸
Xm (k,l)
+Vm (k, l), (1)
with Xm (k, l) the reverberant speech component which con-sists of the direct and early reverberation component Xe,m (k, l)and the late reverberation component Xr,m (k, l), and Vm (k, l)the noise component. In vector notation, the M -dimensionalmicrophone signal vector y(k, l) can be written as
y(k, l) = xe(k, l) + xr(k, l)︸ ︷︷ ︸
x(k,l)
+v(k, l), (2)
with y(k, l) = [Y1(k, l) Y2(k, l) . . . YM (k, l)]T and x(k, l),xe(k, l), xr(k, l), and v(k, l) similarly defined. For a singlesource scenario, the direct and early reverberation componentxe(k, l) can be expressed as
xe(k, l) = S(k, l)d(k, l), (3)
where S(k, l) denotes the target signal, i.e., direct and earlyreverberation component received at the reference microphone,and d(k, l) = [D1(k, l) D2(k, l) . . . DM (k, l)]T denotes theM -dimensional vector of RTFs of the target signal from the ref-erence microphone to all microphones. The target signal S(k, l)is often defined as the direct component only, such that for cal-ibrated microphones the RTF vector d(k, l) only depends onthe direction of arrival (DOA) of the speech source and themicrophone array geometry [22], [24]–[26], [28], [32].
Assuming that the components in (2) are mutually uncor-related, the PSD matrix of the microphone signals y(k, l) is

1108 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
given by
Φy(k, l) = E{y(k, l)yH (k, l)} (4)
= Φxe (k, l) + Φxr (k, l)︸ ︷︷ ︸
Φx (k,l)
+Φv(k, l), (5)
where E denotes the expectation operator,Φx(k, l) = E{x(k, l)xH (k, l)} is the reverberantspeech PSD matrix, Φxe (k, l) = E{xe(k, l)xH
e (k, l)}is the direct and early reverberation PSD matrix,Φxr(k, l)=E{xr(k, l)xH
r (k, l)} is the late reverberationPSD matrix, and Φv(k, l)=E{v(k, l)vH (k, l)} is the noisePSD matrix. The direct and early reverberation PSD matrixΦxe (k, l) is a rank-1 matrix given by (cf. (3))
Φxe (k, l) = Φs(k, l)d(k, l)dH (k, l), (6)
with Φs(k, l) the time-varying PSD of the target signal, i.e.,Φs(k, l) = E{|S(k, l)|2}. Modeling the late reverberation as aspatially homogeneous sound field, the PSD matrix Φxr (k, l)can be expressed as
Φxr (k, l) = Φr(k, l)Γ(k), (7)
with Φr(k, l) the time-varying PSD of the late reverberation andΓ(k) the spatial coherence matrix of the late reverberation whichis assumed to be time-invariant. It is commonly assumed that thesound field modeling the late reverberation is diffuse [22]–[28],such that the spatial coherence matrix Γ(k) can be analyticallycomputed based on the microphone array geometry [38]. Us-ing (6) and (7), the reverberant speech PSD matrix Φx(k, l) canbe expressed as
Φx(k, l) = Φs(k, l)d(k, l)dH (k, l) + Φr(k, l)Γ(k). (8)
Assuming that the reverberant speech PSD matrix is givenby (8) is a commonly used assumption when deriving multi-channel late reverberation PSD estimators [21]–[28]. The ana-lytical derivations provided in this paper are also based on thisassumption. It should however be noted that (8) does not holdin practice, since 1) the late reverberation is typically not a per-fect spatially homogeneous sound field and 2) the early and latereverberation components are not perfectly uncorrelated.
Given the M -dimensional filter vector w(k, l) = [W1(k, l)W2(k, l) . . . WM (k, l)]T , the output signal Z(k, l) of thespeech enhancement system in Fig. 1 is equal to the sum ofthe filtered microphone signals, i.e.,
Z(k, l) = wH (k, l)y(k, l). (9)
Dereverberation and noise reduction techniques aim at design-ing the filter w(k, l) such that the output signal Z(k, l) is asclose as possible to the target signal S(k, l). Many such tech-niques require (among other quantities) an estimate of the latereverberation PSD Φr(k, l), e.g., [19]–[21]. For conciseness,the frequency bin k and the frame index l are omitted in theremainder of this paper, unless explicitly required.
III. ML-BASED AND EVD-BASED LATE REVERBERATION
POWER SPECTRAL DENSITY ESTIMATORS
In this section, the ML-based late reverberation PSD esti-mator from [23] and the EVD-based late reverberation PSD
estimator from [36] are reviewed and analytical insights on theequivalence of both estimators are provided. For simplicity, inthe following we assume a noise-free scenario, i.e., y = x andΦy = Φx . However, it should be noted that the considered latereverberation PSD estimators can also be used in a noisy sce-nario if an estimate of the reverberant speech PSD matrix Φx
can be obtained (cf. Section V-E).
A. ML-Based PSD Estimator
In [23] an ML-based estimator for the late reverberation PSDhas been derived, assuming the spectral coefficients of the com-ponents xe and xr to be circularly-symmetric complex Gaussiandistributed. Maximizing the likelihood function computed usingthese distributions results in the late reverberation PSD estimate
Φmlr =
1M − 1
tr{(
I − ddH Γ−1
dH Γ−1d
)
ΦxΓ−1}
, (10)
where tr{·} denotes the trace operator and I denotes theM × M -dimensional identity matrix. Estimating the late rever-beration PSD using (10) requires knowledge of the RTF vectord, the spatial coherence matrix Γ, and the reverberant speechPSD matrix Φx . While Γ can be computed assuming a diffusesound field model and Φx can be estimated from the microphonesignals, accurately estimating d may not be straightforward, par-ticularly in highly reverberant and noisy environments. As willbe analytically shown in Section IV-A, erroneous RTFs degradethe accuracy of the ML-based PSD estimate, hence resulting ina degradation of the dereverberation performance of the speechenhancement system (cf. simulation results in Section V-D).
B. EVD-Based PSD Estimator
Aiming to remove the dependency on the RTF vector d,in [36] we proposed to estimate the late reverberation PSDusing the eigenvalues of the reverberant speech PSD matrixprewhitened with the diffuse spatial coherence matrix. Usingthe Cholesky decomposition of the positive definite spatial co-herence matrix Γ, i.e.,
Γ = LLH , (11)
with L an M × M -dimensional lower triangular matrix, theprewhitened reverberant speech PSD matrix can be computedas
Φwx = L−1ΦxL−H . (12)
Substituting (8) in (12), it can be observed that the matrix Φwx
is equal to the sum of a rank-1 matrix and the identity matrixscaled by the late reverberation PSD, i.e.,
Φwx = Φs L−1d
︸ ︷︷ ︸
dw
dH L−H︸ ︷︷ ︸
dHw
+ΦrL−1ΓL−H (13)
= ΦsdwdHw + ΦrI, (14)
with the vector dw introduced in order to simplify the notation.Due to the structure in (14), the eigenvalues of the matrix Φw
x

KODRASI AND DOCLO: ANALYSIS OF EIGENVALUE DECOMPOSITION BASED LATE REVERBERATION PSD ESTIMATION 1109
(arranged in descending order) are equal to
λ1{Φwx } = σ + Φr , (15a)
λj{Φwx } = Φr , j = 2, . . . , M, (15b)
with σ the only non-zero eigenvalue of the rank-1 matrixΦsdwdH
w . Based on (15), in [36] we proposed to estimate thelate reverberation PSD using either any of the last M − 1 eigen-values of the matrix Φw
x , i.e.,
Φevdr,j = λj{Φw
x }, j = 2, . . . , M, (16)
or the mean of the last M − 1 eigenvalues of the matrix Φwx ,
i.e.,
Φevdr,μ =
1M − 1
(tr {Φwx } − λ1 {Φw
x }) , (17)
with (17) derived using the fact that the trace of a matrix is equalto the sum of its eigenvalues. Obviously, when the true spatialcoherence matrix Γ and the true reverberant speech PSD matrixΦx are known, the EVD-based PSD estimates in (16) and (17)are equal.
Estimating the late reverberation PSD using (16) or (17) onlyrequires knowledge of the spatial coherence matrix Γ and thereverberant speech PSD matrix Φx . Unlike the ML-based PSDestimator in (10), it is important to note that our EVD-basedPSD estimator does not require an estimate of the RTF vectord, which is advantageous in order to avoid propagation of RTFestimation errors into the late reverberation PSD estimate (cf.sensitivity analysis in Section IV-A and simulation results inSection V-D).
C. Equivalence of the ML-Based and EVD-Based PSDEstimators
In the following, it is shown that when the true RTF vectord, the true spatial coherence matrix Γ, and the true reverberantspeech PSD matrix Φx are known, the ML-based PSD estimatein (10) and the EVD-based PSD estimates in (16) and (17) areequivalent and equal to the true late reverberation PSD.
Since the trace is invariant under cyclic permutations, theML-based PSD estimate in (10) can be written as
Φmlr =
1M − 1
(
tr{
ΦxΓ−1} − dH Γ−1ΦxΓ−1ddH Γ−1d
)
. (18)
Using Φx from (8), the terms in (18) can be simplified to
tr{
ΦxΓ−1} = ΦsdH Γ−1d + ΦrM, (19)
dH Γ−1ΦxΓ−1ddH Γ−1d
= ΦsdH Γ−1d + Φr . (20)
Substituting (19) and (20) in (18), it can be observed that whenthe true d, Γ, and Φx are known, the ML-based PSD estimateis equal to the true late reverberation PSD, i.e.,
Φmlr =
1M − 1
(
ΦsdH Γ−1d + ΦrM − ΦsdH Γ−1d − Φr)
(21)
= Φr . (22)
Clearly, when the true Γ and Φx are known, the EVD-basedPSD estimates in (16) and (17) are also equal to the true latereverberation PSD (cf. (15)), i.e.,
Φevdr,j = Φevd
r,μ = Φr , j = 2, . . . , M. (23)
In summary, when the true RTF vector, spatial coherencematrix, and speech PSD matrix are known (which is rarely thecase in practice, cf. Section IV), the ML-based and EVD-basedestimators are equivalent and yield the true late reverberationPSD. It should be noted that this analytical result applies inpractice only to scenarios where the late reverberation is a per-fect spatially homogeneous sound field and the early and latereverberation components are perfectly uncorrelated.
IV. IMPACT OF MODELING AND ESTIMATION ERRORS ON THE
ML-BASED AND EVD-BASED PSD ESTIMATORS
The analysis in Section III-C is based on the assumption thatthe true RTF vector, spatial coherence matrix, and reverberantspeech PSD matrix are known. In practice however, modelingand estimation errors typically occur in all quantities. First, theRTF vector may differ from the true RTF vector, e.g., due toDOA estimation errors in highly reverberant and noisy sce-narios [39]–[42]. Second, since the spatial coherence matrix istypically computed assuming a perfectly diffuse sound field forthe late reverberation whereas this is not the case in practice, ittypically differs from the true spatial coherence matrix. Third,since the reverberant speech PSD matrix is typically estimatedvia recursive averaging of a single realization of the microphonesignals or by subtracting the noise PSD matrix from the reverber-ant and noisy PSD matrix (cf. Section V), it will also typicallydiffer from the true reverberant speech PSD matrix. In this sec-tion, we analyze the impact of modeling and estimation errorsin the RTFs, spatial coherence matrix, and reverberant speechPSD matrix on the estimation accuracy of the ML-based andEVD-based PSD estimators. It should again be noted that theanalytical results derived in this section apply in practice onlyto scenarios where the late reverberation is a perfect spatiallyhomogeneous sound field and the early and late reverberationcomponents are perfectly uncorrelated.
The estimated RTF vector, spatial coherence matrix, and re-verberant speech PSD matrix are denoted by d, Γ, and Φx ,respectively. Using the estimated quantities d, Γ, and Φx , theML-based PSD estimate in (18) is given by
Φmlr =
1M − 1
(
tr{
ΦxΓ−1
}
− dH Γ−1
ΦxΓ−1
d
dH Γ−1
d
)
. (24)
Using Φx and the Cholesky decomposition of Γ, i.e.,
Γ = LLH , (25)
the estimated prewhitened reverberant speech PSD matrix Φwx
can be defined similarly to (12), i.e.,
Φwx = L−1ΦxL−H , (26)

1110 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
such that the EVD-based PSD estimates in (16) and (17) aregiven by
Φevdr,j = λj{Φw
x }, j = 2, . . . , M, (27)
Φevdr,μ =
1M − 1
(
tr{Φwx } − λ1{Φw
x })
. (28)
In the presence of modeling and estimation errors in the spa-tial coherence matrix and reverberant speech PSD matrix, i.e.,Γ �= Γ and Φx �= Φx , the EVD-based PSD estimates in (27)and (28) are (typically) not equal, i.e., Φevd
r,j �= Φevdr,μ . The theo-
retical analysis in this section is conducted for the EVD-basedPSD estimate Φevd
r,μ in (28). In the simulation results in Section V,the performance also when using the EVD-based PSD estimateΦevd
r,2 (j = 2) in (27) will be investigated. It should be noted
that Φevdr,2 ≥ Φevd
r,μ , with equality holding when using M = 2microphones.
In order to evaluate the estimation accuracy of the PSD esti-mators in (24) and (28), we define the ML-based and EVD-basedPSD estimation errors ξml
r and ξevdr,μ as
ξmlr = | Φml
r − Φr︸ ︷︷ ︸
δmlr
|, ξevdr,μ = | Φevd
r,μ − Φr︸ ︷︷ ︸
δ evdr , μ
|, (29)
where | · | denotes the absolute value. If δmlr > 0 and δevd
r,μ >0, the estimators overestimate the true late reverberation PSD,whereas if δml
r < 0 and δevdr,μ < 0, the estimators underestimate
the true late reverberation PSD.
A. Impact of Erroneous RTFs
In the following, the estimation accuracy of the ML-basedPSD estimator in (24) is analyzed for erroneous RTFs, i.e.,d �= d, but perfect knowledge of the spatial coherence matrixand reverberant speech PSD matrix, i.e., Γ = Γ and Φx = Φx .Since the EVD-based PSD estimator in (28) does not dependon the RTF vector, and hence, is not affected by RTF estimationerrors, it always yields the true late reverberation PSD for Γ = Γand Φx = Φx (cf. (15)).
The ML-based PSD estimate in (24) using d �= d, Γ = Γ,and Φx = Φx is given by
Φmlr =
1M − 1
(
tr{
ΦxΓ−1} − dH Γ−1ΦxΓ−1 d
dH Γ−1 d
)
. (30)
Substituting Φx from (8), the second term in (30) can be ex-pressed as
dH Γ−1ΦxΓ−1 d
dH Γ−1 d= Φs
(dH Γ−1d)2
dH Γ−1 d+ Φr . (31)
Using (19) and (31), the ML-based PSD estimate in (30) can bewritten as
Φmlr =
Φs
M − 1
(
dH Γ−1d − (dH Γ−1d)2
dH Γ−1 d
)
︸ ︷︷ ︸
δmlr
+Φr , (32)
with δmlr the difference between the ML-based PSD estimate
and the true PSD in the presence of RTF estimation errors. In
the following, the Cauchy-Schwarz inequality is used to showthat δml
r ≥ 0 and ξmlr ≥ 0.
In order to simplify the notation, we use the vector dw in (14)and additionally define the vector dw as
dw = L−1 d, (33)
such that the difference δmlr in (32) can be expressed as
δmlr =
Φs
M − 1(dH
w dw)(dHw dw) − (dH
w dw)2
dHw dw
. (34)
Based on the Cauchy-Schwarz inequality, it can be shown that1
(dHw dw)(dH
w dw) − (dHw dw)2 > 0. (35)
Given (35) and since Φs ≥ 0, M − 1 > 0, and dHw dw > 0 (as-
suming that dw �= 0, i.e., d �= 0), we conclude that in the pres-ence of RTF estimation errors
δmlr ≥ 0 and ξml
r ≥ 0, (36)
with equality only holding when the target signal PSD is equalto zero, i.e., Φs = 0.
In summary, in the presence of RTF estimation errors but per-fect knowledge of the spatial coherence matrix and reverberantspeech PSD matrix, the ML-based PSD estimate is larger than orequal to the true late reverberation PSD, whereas the EVD-basedPSD estimate is obviously still equal to the true late reverber-ation PSD. Overestimation of the true late reverberation PSDwill lead to undesired speech distortion when used in a speechenhancement algorithm, e.g., a postfilter. This derivation canhence be valuable in practice to decide against using the ML-based PSD estimate in applications where the RTF is difficultto estimate accurately and speech distortion is unacceptable.
B. Impact of Modeling and Estimation Errors in All Quantities
In the following, the estimation accuracy of the ML-basedand EVD-based PSD estimators in (24) and (28) is analyzed inthe presence of modeling and estimation errors in the RTFs, spa-tial coherence matrix, and reverberant speech PSD matrix, i.e.,d �= d, Γ �= Γ, and Φx �= Φx . Note that the analytical resultsderived in this section also hold for scenarios when modelingand estimation errors occur only in one (or two) of the requiredquantities, with the remaining quantities (or quantity) perfectlyestimated. In realistic acoustic scenarios however, modeling andestimation errors typically occur in all quantities.
Based on the Cholesky decomposition of Γ in (25) and sincethe trace is invariant under cyclic permutations, the first term inthe ML-based estimate in (24) can be written as
tr{ΦxΓ−1} = tr{L−1ΦxL−H } = tr{Φw
x }. (37)
In order to simplify the notation, we define the vector u as
u = L−1 d, (38)
1It should be noted that since the RTF vectors d and d are linearly in-dependent, the vectors dw and dw are also linearly independent, hence, theCauchy-Schwarz inequality in (35) is sharp.

KODRASI AND DOCLO: ANALYSIS OF EIGENVALUE DECOMPOSITION BASED LATE REVERBERATION PSD ESTIMATION 1111
and express the second term in (24) as
dH Γ−1
ΦxΓ−1
d
dH Γ−1
d=
uH L−1ΦxL−H uuH u
=uH Φ
wx u
uH u. (39)
Substituting (37) and (39) in (24), the ML-based PSD estimate inthe presence of modeling and estimation errors in all quantitiescan be written as
Φmlr =
1M − 1
(
tr{Φwx } −
uH Φwx u
uH u
)
. (40)
It is well known that the Rayleigh quotient of a matrix is boundedby its maximum eigenvalue, i.e.,
uH Φwx u
uH u≤ λ1{Φw
x }, (41)
with equality only holding when the vector u corresponds tothe (scaled) eigenvector of Φ
wx associated with its largest
eigenvalue λ1{Φwx }. By comparing the PSD estimates in (28)
and (40), it can now be observed that for erroneous RTFs, spatialcoherence matrix, and reverberant speech PSD matrix, the ML-based PSD estimate is larger than or equal to the EVD-basedPSD estimate, i.e.,
Φmlr ≥ Φevd
r,μ . (42)
In order to compare the ML-based and EVD-based PSD esti-mation errors ξml
r and ξevdr,μ , we use (42) and distinguish between
the following cases:� If the true late reverberation PSD is overestimated by both
estimators, i.e., if δmlr > 0 and δevd
r,μ > 0, the ML-based PSDestimation error is larger than or equal to the EVD-basedPSD estimation error, i.e., ξml
r ≥ ξevdr,μ . As already men-
tioned, overestimation of the true late reverberation PSDis particularly detrimental to the speech quality, since itresults in speech distortion.
� If the true late reverberation PSD is underestimated by bothestimators, i.e., if δml
r < 0 and δevdr,μ < 0, the ML-based PSD
estimation error is smaller than or equal to the EVD-basedPSD estimation error, i.e., ξml
r ≤ ξevdr,μ . Underestimation of
the true late reverberation PSD results in an unnecessaryamount of residual reverberation in the output signal ofthe speech enhancement algorithms, while preserving thespeech quality.
� If the true late reverberation PSD is overestimated by theML-based estimator but underestimated by the EVD-basedestimator, i.e., if δml
r > 0 and δevdr,μ < 0, no conclusions can
be drawn on the PSD estimation errors ξmlr and ξevd
r,μ .These derivations can be valuable in practice to decide 1) to
use the ML-based PSD estimate in applications where late re-verberation suppression is more important than speech qualitypreservation, or 2) to use the EVD-based PSD estimate in ap-plications where speech quality preservation is more importantthan late reverberation suppression.
C. Computational Complexity
In this section, we provide some insights on the computationalcomplexity of the ML-based and EVD-based PSD estimators.
The computational complexity of the ML-based PSD estimatorin (10) is dominated by matrix multiplication, for which the bestknown upper bound is O(M 2.373) [43]. In contrast, the dom-inating operation for the EVD-based PSD estimators in (16)and (17) is the computation of the eigenvalues using an EVD.Although many algorithms exist for computing the EVD, weconsider the QR decomposition-based algorithm [44], which isone of the most widely used algorithms to compute eigenvalues.The complexity of the QR decomposition-based algorithm forHermitian matrices is O(M 3) [45], also when the matrix is firsttransformed into real tridiagonal form using Householder reflec-tions [44]. However, it should be noted that the EVD-based PSDestimators in (16) or (17) require only a single eigenvalue, forwhich more efficient algorithms exist, e.g., based on subspacetracking [46].
V. SIMULATION RESULTS
In this section, the impact of modeling and estimation errors inthe RTFs, spatial coherence matrix, and reverberant speech PSDmatrix on the ML-based and EVD-based PSD estimates is exper-imentally validated. In addition, the performance of the MWFusing the considered PSD estimators is compared for severalrealistic acoustic scenarios with and without background noise.In Section V-A the considered acoustic systems, algorithmicsettings, and instrumental performance measures are presented.In Section V-B the analytical results of Sections III-C and IV areexperimentally validated. For noise-free scenarios, Section V-Ccompares the dereverberation performance of the MWF usingthe ML-based and EVD-based PSD estimators when the trueRTF vector is known, whereas Section V-D compares the dere-verberation performance of the MWF using the ML-based andEVD-based PSD estimators in the presence of RTF estima-tion errors. For noisy scenarios, the dereverberation and noisereduction performance of the MWF using the ML-based andEVD-based PSD estimators is investigated in Section V-E. Thecomputation of the required quantities (RTF vector, spatial co-herence matrix, reverberant speech PSD matrix) as well as theMWF implementation is presented at the beginning of eachsection.
A. Acoustic Systems, Algorithmic Settings, and InstrumentalPerformance Measures
We have considered two acoustic systems with a single speechsource and M ∈ {2, 4} microphones. The first acoustic sys-tem AS1 consists of a circular microphone array with a radiusof 10 cm [47] and the second acoustic system AS2 consistsof a linear microphone array with an inter-microphone dis-tance of 6 cm [48]. Table I presents the room reverberationtime T60 , the DOA θ of the speech source, and the direct-to-reverberation ratio (DRR) for both considered acoustic systems.The sampling frequency is fs = 16 kHz. The speech compo-nents are generated by convolving a 38 s long clean speechsignal with the measured room impulse responses (RIRs). Thenoise components either consist of non-stationary diffuse bab-ble noise, representing background noise typically encoun-tered in large crowded rooms, or stationary uncorrelated noise,

1112 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
TABLE ICHARACTERISTICS OF THE CONSIDERED ACOUSTIC SYSTEMS
Acoustic system T60 [s] θ DRR [dB]
AS1 0.73 45◦ 1.43AS2 1.25 −15◦ −0.05
representing e.g. microphone self-noise. The speech-plus-noisesignal is preceded by a 1 s long noise-only segment. The signalsare processed in the STFT domain using a weighted overlap-addframework with a Hamming window, a frame size N = 1024samples, and an overlap of 75%. The target signal is definedas the direct component only, such that the RTF vector can becomputed based on the DOA of the speech source. The firstmicrophone is arbitrarily selected as the reference microphone.
In order to evaluate the performance, we use the per-ceptual evaluation of speech quality (PESQ) measure [49],the frequency-weighted segmental signal-to-noise ratio(fSNR) [50], the cepstral distance (CD) [51], and the short-timeobjective intelligibility measure (STOI) [52]. These instrumen-tal performance measures are intrusive measures generating asimilarity score between a test signal and a reference signal. Thereference signal used in this paper is the clean speech signal.The improvement in these instrumental measures, i.e., ΔPESQ,ΔfSNR, ΔCD, and ΔSTOI, is computed as the difference be-tween the PESQ, fSNR, CD, and STOI values of the outputsignal and the reference microphone signal. Note that a positiveΔPESQ, ΔfSNR, and ΔSTOI and a negative ΔCD indicate aperformance improvement.
B. Validation of Analytical Results
In this section, the analytical results of Sections III-C,IV-A, and IV-B are experimentally validated for the exemplaryacoustic system AS1 with M = 4 microphones. It is experi-mentally validated that when the true RTF vector, spatial co-herence matrix, and reverberant speech PSD matrix are known,the ML-based and EVD-based PSD estimates are equal to thetrue late reverberation PSD. In addition, it is experimentallyvalidated that for erroneous RTFs but perfect knowledge of thespatial coherence matrix and reverberant speech PSD matrix,the ML-based PSD estimate is larger than or equal to the truelate reverberation PSD, whereas the EVD-based PSD estimateis still equal to the true late reverberation PSD. Finally, it isexperimentally validated that in the presence of modeling andestimation errors in all quantities, the ML-based PSD estimateis larger than or equal to the EVD-based PSD estimate.
In this section, the true quantities d, Γ, and Φx are computedas follows. The true RTF vector d is computed using the trueDOA θ = 45◦ of the speech source as
d = [1 e−j2πf τ2 (θ) . . . e−j2πf τM (θ) ]T , (43)
with f the frequency and τm (θ) the relative time delay of arrivalbetween the m-th microphone and the 1st (reference) micro-phone. The true spatial coherence matrix Γ is computed from
the late reverberation components as
Γp,q (k) =∑L−1
l=0 Xr,p(k, l)X∗r,q (k, l)
√(∑L−1
l=0 |Xr,p(k, l)|2) (
∑L−1l=0 |Xr,q (k, l)|2
),
(44)
with Γp,q (k) the {p, q}-th element of Γ(k), L the total numberof time frames, and the late reverberation components generatedby convolving the clean speech signal with the late reverberanttail of the measured RIRs (and transforming the resulting signalto the STFT domain). Using d and Γ, the true reverberant speechPSD matrix Φx is computed as
Φx = ΦsddH + ΦrΓ, (45)
where the PSDs Φs and Φr are computed from the target signalXe,1 and the late reverberation component Xr,1 using recursiveaveraging with a smoothing factor α as
Φs(k, l) = α|Xe,1(k, l)|2 + (1 − α)Φs(k, l − 1), (46)
Φr(k, l) = α|Xr,1(k, l)|2 + (1 − α)Φr(k, l − 1). (47)
The target signal Xe,1 is generated by convolving the cleanspeech signal with the direct part of the RIR (and transformingthe resulting signal to the STFT domain). The used smoothingfactor is α = 0.67, corresponding to a time constant of 40 ms.It should be noted that since the objective of this section is onlyto validate the analytical results, the true Φx is computed asin (45) in order to ensure that (8) perfectly holds.
The estimated quantities d, Γ, and Φx are computed as fol-lows. The estimated RTF vector d is computed using an exem-plary erroneous DOA θ = 30◦. The estimated spatial coherencematrix Γ is computed assuming a spherically diffuse sound fieldas [38]
Γp,q (k) = sinc(
2πkfs
Ncrpq
)
, (48)
with c = 340 m/s the speed of sound and rpq the distance be-tween the p-th and q-th microphone. The reverberant speechPSD matrix Φx is estimated from the received microphone sig-nals using recursive averaging as
Φx(k, l) = αX(k, l)XH (k, l) + (1 − α)Φx(k, l − 1). (49)
Equivalence of the ML-based and EVD-based PSD estima-tors (d = d, Γ = Γ, Φx = Φx ): Using the true RTF vector din (43), the true spatial coherence matrix Γ in (44), and the truereverberant speech PSD matrix Φx in (45), the late reverbera-tion PSD is estimated using the ML-based estimator in (24) andthe EVD-based PSD estimator in (28). Fig. 2 depicts the truelate reverberation PSD Φr , the ML-based PSD estimate Φml
r ,and the EVD-based PSD estimate Φevd
r,μ averaged over all timeframes. Obviously, in this case both PSD estimates are equal tothe true late reverberation PSD, confirming the derivations inSection III-C.
Impact of erroneous RTFs (d �= d, Γ = Γ, Φx = Φx ): Usingthe estimated erroneous RTF vector d, the true spatial coherencematrix Γ in (44), and the true reverberant speech PSD matrixΦx in (45), the late reverberation PSD is estimated using the

KODRASI AND DOCLO: ANALYSIS OF EIGENVALUE DECOMPOSITION BASED LATE REVERBERATION PSD ESTIMATION 1113
Fig. 2. True and estimated late reverberation PSDs averaged over all timeframes when the true RTF vector, spatial coherence matrix, and reverberantspeech PSD matrix are known (AS1 , M = 4).
Fig. 3. Difference between the ML-based PSD estimate and the true late rever-beration PSD in the presence of RTF estimation errors but perfect knowledge ofthe spatial coherence matrix and reverberant speech PSD matrix (AS1 , M = 4).
ML-based estimator in (24) and the EVD-based PSD estimatorin (28). Clearly, the EVD-based estimator is not affected by RTFestimation errors and still yields the true late reverberation PSDΦr as in Fig. 2. Fig. 3 illustrates the difference between the ML-based PSD estimate and the true late reverberation PSD in dB,i.e., 10 log10 Φml
r − 10 log10 Φr , for all time-frequency bins. Forthe sake of clarity, the maximum difference has been limited to20 dB. It can be observed that in the presence of RTF estimationerrors, the difference between the ML-based estimate and thetrue late reverberation PSD is always larger than or equal to 0,confirming the derivations in Section IV-A. For the consideredscenario, it appears that the difference between the ML-basedestimate and the true late reverberation PSD is larger at higherfrequencies.
Impact of errors in all quantities (d �= d, Γ �= Γ, Φx �= Φx ):Using the estimated erroneous RTF vector d, the estimated spa-tial coherence matrix Γ in (48), and the estimated reverberantspeech PSD matrix Φx in (49), the late reverberation PSD isestimated using the ML-based estimator in (24) and the EVD-based estimator in (28). Fig. 4 illustrates the difference be-tween the ML-based and EVD-based PSD estimates in dB, i.e.,10 log10 Φml
r − 10 log10 Φevdr,μ , for all time-frequency bins. For
the sake of clarity, the maximum difference has been limitedto 20 dB. It can be observed that in the presence of modelingand estimation errors in all quantities, the ML-based estimate islarger than or equal to the EVD-based PSD estimate, confirmingthe derivations in Section IV-B.
C. Dereverberation Performance for Perfectly Estimated RTFs
In this section, the dereverberation performance of the MWFusing different late reverberation PSD estimators is investigated
Fig. 4. Difference between the ML-based and EVD-based PSD estimates inthe presence of modeling and estimation errors in all quantities (AS1 , M = 4).
for the noise-free case assuming that the RTF vector is per-fectly estimated, i.e., assuming that the true DOA of the speechsource is known. Both acoustic systems and configurations areconsidered.
The MWF is implemented as an MVDR beamformer wMVDR
followed by a single-channel Wiener postfilter G applied to theMVDR output, i.e.,
wMWF =Γ−1
d
dH Γ−1
d︸ ︷︷ ︸
wMVDR
Φs
Φs + Φr
dH Γ−1
d︸ ︷︷ ︸
G
, (50)
with Γ the diffuse spatial coherence matrix computed as in (48),d = d the RTF vector computed using the true DOA of thespeech source, Φr the estimated late reverberation PSD, and Φsthe target signal PSD estimated using the decision directed ap-proach [53]. Using d = d, Γ, and Φx estimated using recursiveaveraging as in (49), three different estimates are considered forthe late reverberation PSD Φr , i.e., the ML-based PSD estimateΦml
r in (24), the EVD-based PSD estimate Φevdr,μ in (28), and
the EVD-based PSD estimate Φevdr,2 (j = 2) in (27). Note that
Φevdr,2 ≥ Φevd
r,μ , with equality holding for M = 2 microphones.Figs. 5 and 6 depict the ΔPESQ, ΔfSNR, ΔCD, and ΔSTOI
values obtained using the MWF with different PSD estimatorsfor both acoustic systems and configurations. For complete-ness, the performance of the MVDR beamformer implementedas in (50) is also depicted. As expected, the performance of theMVDR beamformer and the MWF improves with increasingnumber of microphones for both acoustic systems. In addition,for both acoustic systems it can be observed that the MWFusing any of the considered late reverberation PSD estimatesimproves the performance in comparison to the MVDR beam-former. When comparing the performance of the MWF for thedifferent late reverberation PSD estimates, it can be observedthat the performance is in general rather similar independently ofthe used PSD estimate. In terms of ΔPESQ, the ML-based PSDestimate Φml
r yields a slightly better performance for acousticsystem AS1 , whereas the EVD-based PSD estimate Φevd
r,2 yieldsa slightly better performance for acoustic system AS2 . In termsof ΔfSNR, ΔCD, and ΔSTOI, the EVD-based PSD estimateΦevd
r,μ yields a slightly better performance than Φmlr and Φevd
r,2 forboth acoustic systems.
In summary, these simulation results show the applicabilityof the EVD-based PSD estimator for dereverberation, yielding

1114 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
Fig. 5. Dereverberation performance of the MVDR beamformer and the MWF for acoustic system AS1 using the true RTF vector: (a) ΔPESQ, (b) ΔfSNR,(c) ΔCD, and (d) ΔSTOI.
Fig. 6. Dereverberation performance of the MVDR beamformer and the MWF for acoustic system AS2 using the true RTF vector: (a) ΔPESQ, (b) ΔfSNR,(c) ΔCD, and (d) ΔSTOI.
Fig. 7. Dereverberation performance of the MVDR beamformer and the MWF for acoustic system AS1 with M = 4 microphones using erroneous RTF vectors:(a) ΔPESQ, (b) ΔfSNR, (c) ΔCD, and (d) ΔSTOI.
a similar or slightly better performance than the state-of-the-artML-based PSD estimator when the true RTFs are known.
D. Dereverberation Performance for Erroneous RTFs
In this section, the dereverberation performance of the MWFusing different late reverberation PSD estimators is investigatedfor the noise-free case assuming that the RTF vector is erro-neously estimated, i.e., using an erroneous DOA of the speechsource. We consider both acoustic systems and M = 4 micro-phones. The MWF is implemented as in (50), with the estimatedRTF vector d computed based on several erroneous DOAs
θ ∈ {−90◦, −75◦, . . . , 90◦}, (51)
and the remaining quantities computed as in Section V-C. Itshould be noted that independently of the estimator used for
the late reverberation PSD, the MWF implemented as in (50)is sensitive to RTF estimation errors due to the sensitivity ofthe MVDR beamformer to RTF estimation errors. However, aswill be shown, a significantly higher sensitivity of the MWFis observed when the late reverberation PSD estimator is alsoaffected by RTF estimation errors.
Figs. 7 and 8 depict the ΔPESQ, ΔfSNR, ΔCD, and ΔSTOIvalues obtained using the MWF with different late reverberationPSD estimators for both acoustic systems in the presence of RTFestimation errors. In addition, the performance obtained usingthe true RTF vector (i.e., θ = 45◦ for acoustic system AS1 andθ = −15◦ for acoustic system AS2) is depicted. For complete-ness, the performance of the MVDR beamformer implementedas in (50) is also presented. As expected, it can be observed thatthe performance of the MVDR beamformer deteriorates in thepresence of RTF estimation errors in terms of all instrumental
KODRASI AND DOCLO: ANALYSIS OF EIGENVALUE DECOMPOSITION BASED LATE REVERBERATION PSD ESTIMATION 1115
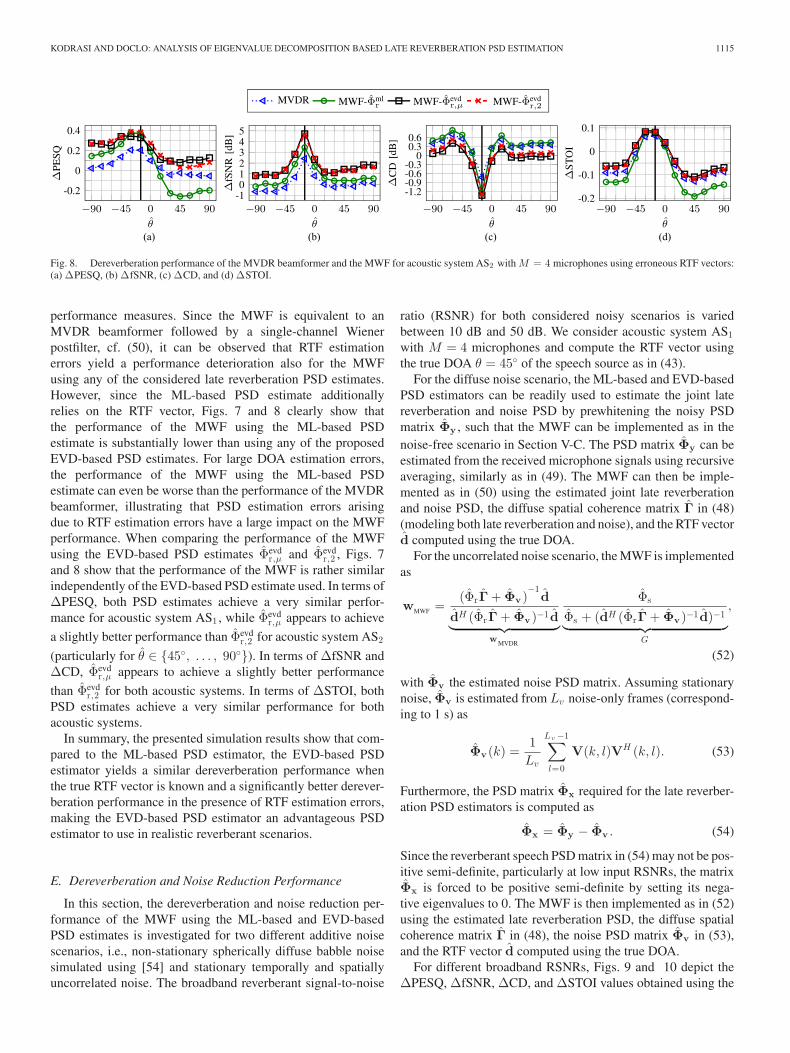
Fig. 8. Dereverberation performance of the MVDR beamformer and the MWF for acoustic system AS2 with M = 4 microphones using erroneous RTF vectors:(a) ΔPESQ, (b) ΔfSNR, (c) ΔCD, and (d) ΔSTOI.
performance measures. Since the MWF is equivalent to anMVDR beamformer followed by a single-channel Wienerpostfilter, cf. (50), it can be observed that RTF estimationerrors yield a performance deterioration also for the MWFusing any of the considered late reverberation PSD estimates.However, since the ML-based PSD estimate additionallyrelies on the RTF vector, Figs. 7 and 8 clearly show thatthe performance of the MWF using the ML-based PSDestimate is substantially lower than using any of the proposedEVD-based PSD estimates. For large DOA estimation errors,the performance of the MWF using the ML-based PSDestimate can even be worse than the performance of the MVDRbeamformer, illustrating that PSD estimation errors arisingdue to RTF estimation errors have a large impact on the MWFperformance. When comparing the performance of the MWFusing the EVD-based PSD estimates Φevd
r,μ and Φevdr,2 , Figs. 7
and 8 show that the performance of the MWF is rather similarindependently of the EVD-based PSD estimate used. In terms ofΔPESQ, both PSD estimates achieve a very similar perfor-mance for acoustic system AS1 , while Φevd
r,μ appears to achieve
a slightly better performance than Φevdr,2 for acoustic system AS2
(particularly for θ ∈ {45◦, . . . , 90◦}). In terms of ΔfSNR andΔCD, Φevd
r,μ appears to achieve a slightly better performance
than Φevdr,2 for both acoustic systems. In terms of ΔSTOI, both
PSD estimates achieve a very similar performance for bothacoustic systems.
In summary, the presented simulation results show that com-pared to the ML-based PSD estimator, the EVD-based PSDestimator yields a similar dereverberation performance whenthe true RTF vector is known and a significantly better derever-beration performance in the presence of RTF estimation errors,making the EVD-based PSD estimator an advantageous PSDestimator to use in realistic reverberant scenarios.
E. Dereverberation and Noise Reduction Performance
In this section, the dereverberation and noise reduction per-formance of the MWF using the ML-based and EVD-basedPSD estimates is investigated for two different additive noisescenarios, i.e., non-stationary spherically diffuse babble noisesimulated using [54] and stationary temporally and spatiallyuncorrelated noise. The broadband reverberant signal-to-noise
ratio (RSNR) for both considered noisy scenarios is variedbetween 10 dB and 50 dB. We consider acoustic system AS1with M = 4 microphones and compute the RTF vector usingthe true DOA θ = 45◦ of the speech source as in (43).
For the diffuse noise scenario, the ML-based and EVD-basedPSD estimators can be readily used to estimate the joint latereverberation and noise PSD by prewhitening the noisy PSDmatrix Φy , such that the MWF can be implemented as in thenoise-free scenario in Section V-C. The PSD matrix Φy can beestimated from the received microphone signals using recursiveaveraging, similarly as in (49). The MWF can then be imple-mented as in (50) using the estimated joint late reverberationand noise PSD, the diffuse spatial coherence matrix Γ in (48)(modeling both late reverberation and noise), and the RTF vectord computed using the true DOA.
For the uncorrelated noise scenario, the MWF is implementedas
wMWF =(ΦrΓ + Φv)
−1d
dH (ΦrΓ + Φv)−1 d︸ ︷︷ ︸
wMVDR
Φs
Φs + (dH (ΦrΓ + Φv)−1 d)−1︸ ︷︷ ︸
G
,
(52)
with Φv the estimated noise PSD matrix. Assuming stationarynoise, Φv is estimated from Lv noise-only frames (correspond-ing to 1 s) as
Φv(k) =1Lv
Lv −1∑
l=0
V(k, l)VH (k, l). (53)
Furthermore, the PSD matrix Φx required for the late reverber-ation PSD estimators is computed as
Φx = Φy − Φv . (54)
Since the reverberant speech PSD matrix in (54) may not be pos-itive semi-definite, particularly at low input RSNRs, the matrixΦx is forced to be positive semi-definite by setting its nega-tive eigenvalues to 0. The MWF is then implemented as in (52)using the estimated late reverberation PSD, the diffuse spatialcoherence matrix Γ in (48), the noise PSD matrix Φv in (53),and the RTF vector d computed using the true DOA.
For different broadband RSNRs, Figs. 9 and 10 depict theΔPESQ, ΔfSNR, ΔCD, and ΔSTOI values obtained using the

1116 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
Fig. 9. Dereverberation and noise reduction performance of the MWF in the presence of non-stationary diffuse babble noise (AS1 , M = 4).
Fig. 10. Dereverberation and noise reduction performance of the MWF in the presence of stationary uncorrelated noise (AS1 , M = 4).
MWF with the ML-based and EVD-based PSD estimates for thediffuse and uncorrelated noise scenarios, respectively. It can beobserved that in terms of all instrumental performance measures,all PSD estimators yield a similarly large dereverberation andnoise reduction performance. In terms of ΔPESQ, the ML-basedPSD estimate generally yields a slightly better performance thanthe EVD-based PSD estimates. In terms of ΔfSNR, ΔCD, andΔSTOI, the EVD-based PSD estimate Φevd
r,μ consistently yields
a slightly better performance than Φmlr and Φevd
r,2 .In summary, these simulation results show the applicability of
the EVD-based PSD estimator in realistic reverberant and noisyscenarios, yielding a similar or slightly better performance thanthe state-of-the-art ML-based PSD estimator when the true RTFsare known.
VI. CONCLUSION
In this paper, the recently proposed EVD-based late rever-beration PSD estimator has been analyzed and its estimationaccuracy has been analytically compared to a state-of-the-artML-based PSD estimator. It has been shown that when thetrue RTFs, late reverberation spatial coherence matrix, and re-verberant speech PSD matrix are known, the ML-based andEVD-based PSD estimators are equivalent and yield the truelate reverberation PSD. Furthermore, it has been shown that inthe presence of RTF estimation errors but perfect knowledge ofthe spatial coherence matrix and reverberant speech PSD matrix,the ML-based PSD estimate is larger than or equal to the truelate reverberation PSD, whereas the EVD-based PSD estimate isstill equal to the true late reverberation PSD. Finally, it has beenshown that in the presence of modeling and estimation errors inall quantities (which is typically the case in practice), the ML-based PSD estimate is larger than or equal to the EVD-basedPSD estimate. Simulation results for several realistic reverber-ant acoustic scenarios have demonstrated that compared to the
ML-based PSD estimator, the EVD-based PSD estimator yieldsa similar dereverberation performance when the true RTF vectoris known and a significantly better dereverberation performancein the presence of RTF estimation errors. In addition, it has beenexperimentally validated that the EVD-based PSD estimator canalso be successfully used in reverberant and noisy scenarios, aslong as an estimate of the reverberant speech PSD matrix canbe obtained. Conveniently, if the noise can also be modeledas a diffuse sound field, an estimate of the reverberant speechPSD matrix is not required and the EVD-based estimator canbe readily used to estimate the joint late reverberation and noisePSD.
REFERENCES
[1] J. S. Bradley, H. Sato, and M. Picard, “On the importance of early re-flections for speech in rooms,” J. Acoust. Soc. Amer., vol. 113, no. 6,pp. 3233–3244, Jun. 2003.
[2] R. Beutelmann and T. Brand, “Prediction of speech intelligibility in spatialnoise and reverberation for normal-hearing and hearing-impaired listen-ers,” J. Acoust. Soc. Amer., vol. 120, no. 1, pp. 331–342, Jul. 2006.
[3] A. Warzybok et al., “Subjective speech quality and speech intelligibil-ity evaluation of single-channel dereverberation algorithms,” in Proc.Int. Workshop Acoust. Echo Noise Control, Antibes, France, Sep. 2014,pp. 333–337.
[4] T. Yoshioka et al.,“Making machines understand us in reverberant rooms:Robustness against reverberation for automatic speech recognition,” IEEESignal Process. Mag., vol. 29, no. 6, pp. 114–126, Nov. 2012.
[5] F. Xiong et al., “Front-end technologies for robust ASR in reverber-ant environments—spectral enhancement-based dereverberation and au-ditory modulation filterbank features,” EURASIP J. Adv. Signal Process.,vol. 2015, no. 1, Aug. 2015.
[6] E. A. P. Habets, “Single- and multi-microphone speech dereverberationusing spectral enhancement,” Ph.D. dissertation, Technische UniversiteitEindhoven, Eindhoven, The Netherlands, Jun. 2007.
[7] P. A. Naylor and N. D. Gaubitch, Eds., Speech Dereverberation. London,U.K.: Springer, 2010.
[8] I. Kodrasi, “Dereverberation and noise reduction techniques based onacoustic multi-channel equalization,” Ph.D. dissertation, Univ. Oldenburg,Oldenburg, Germany, Dec. 2015.

KODRASI AND DOCLO: ANALYSIS OF EIGENVALUE DECOMPOSITION BASED LATE REVERBERATION PSD ESTIMATION 1117
[9] M. Miyoshi and Y. Kaneda, “Inverse filtering of room acoustics,” IEEETrans. Acoust., Speech, Signal Process., vol. 36, no. 2, pp. 145–152,Feb. 1988.
[10] F. Lim, W. Zhang, E. A. P. Habets, and P. A. Naylor, “Robust multichanneldereverberation using relaxed multichannel least squares,” IEEE/ACMTrans. Audio, Speech, Lang. Process., vol. 22, no. 9, pp. 1379–1390,Jun. 2014.
[11] I. Kodrasi and S. Doclo, “Joint dereverberation and noise reduction basedon acoustic multi-channel equalization,” IEEE/ACM Trans. Audio, Speech,Lang. Process., vol. 24, no. 4, pp. 680–693, Apr. 2016.
[12] I. Kodrasi and S. Doclo, “Sparsity-promoting acoustic multi-channelequalization techniques,” IEEE/ACM Trans. Audio, Speech, Lang. Pro-cess., vol. 25, no. 7, pp. 1512–1525, Jul. 2017.
[13] T. Nakatani, T. Yoshioka, K. Kinoshita, M. Miyoshi, and B.-H. Juang,“Speech dereverberation based on variance-normalized delayed linearprediction,” IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 7,pp. 1717–1731, Sep. 2010.
[14] T. Yoshioka and T. Nakatani, “Generalization of multi-channel linear pre-diction methods for blind MIMO impulse response shortening,” IEEETrans. Audio, Speech, Lang. Process., vol. 20, no. 10, pp. 2707–2720,Dec. 2012.
[15] A. Jukic, T. Van Waterschoot, T. Gerkmann, and S. Doclo, “Multi-channel linear prediction-based speech dereverberation with sparse pri-ors,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 23, no. 9,pp. 1509–1520, Sep. 2015.
[16] C. Marro, Y. Mahieux, and K. U. Simmer, “Analysis of noise reductionand dereverberation techniques based on microphone arrays with postfil-tering,” IEEE Trans. Speech Audio Process., vol. 6, no. 3, pp. 240–259,May 1998.
[17] S. Doclo and M. Moonen, “Combined frequency-domain dereverbera-tion and noise reduction technique for multi-microphone speech enhance-ment,” in Proc. Int. Workshop Acoust. Echo Noise Control, Darmstadt,Germany, Sep. 2001, pp. 31–34.
[18] E. A. P. Habets and J. Benesty, “A two-stage beamforming approach fornoise reduction and dereverberation,” IEEE Trans. Audio, Speech, Lang.Process., vol. 21, no. 5, pp. 945–958, May 2013.
[19] B. Cauchi et al., “Combination of MVDR beamforming and single-channel spectral processing for enhancing noisy and reverberant speech,”EURASIP J. Adv. Signal Process., vol. 2015, no. 1, 2015.
[20] O. Schwartz, S. Gannot, and E. A. P. Habets, “Multi-microphone speechdereverberation and noise reduction using relative early transfer func-tions,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 23, no. 2,pp. 240–251, Feb. 2015.
[21] A. Kuklasinski, “Multi-channel dereverberation for speech intelligibilityimprovement in hearing aid applications,” Ph.D. dissertation, AalborgUniv., Aalborg, Denmark, Sep. 2016.
[22] S. Braun and E. A. P. Habets, “Dereverberation in noisy environmentsusing reference signals and a maximum likelihood estimator,” in Proc.Eur. Signal Process. Conf., Marrakech, Morocco, Sep. 2013.
[23] A. Kuklasinski, S. Doclo, S. H. Jensen, and J. Jensen, “Maximum like-lihood based multi-channel isotropic reverberation reduction for hearingaids,” in Proc. Eur. Signal Process. Conf., Lisbon, Portugal, Sep. 2014,pp. 61–65.
[24] S. Braun and E. A. P. Habets, “A multichannel diffuse power estimator fordereverberation in the presence of multiple sources,” EURASIP J. Appl.Signal Process., vol. 2015, no. 1, Dec. 2015.
[25] O. Schwartz, S. Braun, S. Gannot, and E. A. P. Habets, “Maximum likeli-hood estimation of the late reverberant power spectral density in noisyenvironments,” in Proc. IEEE Workshop Appl. Signal Process. AudioAcoust., New Paltz, NY, USA, Oct. 2015.
[26] O. Schwartz, S. Gannot, and E. A. P. Habets, “Joint maximum likelihoodestimation of late reverberant and speech power spectral density in noisyenvironments,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process.,Shanghai, China, Mar. 2016, pp. 151–155.
[27] A. Kuklasinski, S. Doclo, S. H. Jensen, and J. Jensen, “Maximum likeli-hood PSD estimation for speech enhancement in reverberation and noise,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 24, no. 9, pp. 1595–1608, Sep. 2016.
[28] O. Schwartz, S. Gannot, and E. A. P. Habets, “Joint estimation of latereverberant and speech power spectral densities in noisy environmentsusing Frobenius norm,” in Proc. Eur. Signal Process. Conf., Budapest,Hungary, Sep. 2016, pp. 1123–1127.
[29] K. Lebart and J. M. Boucher, “A new method based on spectral subtractionfor speech dereverberation,” Acta Acoustica, vol. 87, no. 3, pp. 359–366,May/Jun. 2001.
[30] E. A. P. Habets, S. Gannot, and I. Cohen, “Late reverberant spectralvariance estimation based on a statistical model,” IEEE Signal Process.Lett., vol. 16, no. 9, pp. 770–774, Sep. 2009.
[31] S. Braun, B. Schwartz, S. Gannot, and E. A. P. Habets, “Late reverberationPSD estimation for single-channel dereverberation using relative convo-lutive transfer functions,” in Proc. Int. Workshop Acoust. Echo NoiseControl, Xi’an, China, Sep. 2016.
[32] O. Thiergart and E. A. P. Habets, “Extracting reverberant sound using a lin-early constrained minimum variance spatial filter,” IEEE Signal Process.Lett., vol. 21, no. 5, pp. 630–634, May 2014.
[33] A. Kuklasinski, S. Doclo, and J. Jensen, “Maximum likelihood PSD es-timation for speech enhancement in reverberant and noisy conditions,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process., Shanghai, China,Mar. 2016, pp. 599–603.
[34] A. Kuklasinski, S. Doclo, S. H. Jensen, and J. Jensen, “MultichannelWiener filter for speech dereverberation in hearing aids—sensitivity toDoA errors,” in Proc. AES 60th Conf. Dereverberation ReverberationAudio, Music, Speech, Leuven, Belgium, Feb. 2016.
[35] A. Kuklasinski and J. Jensen, “Multichannel Wiener filters in binauraland bilateral hearing aids—speech intelligibility improvement and ro-bustness to DoA errors,” J. Audio Eng. Soc., vol. 65, no. 1/2, pp. 8–16,Jan./Feb. 2017.
[36] I. Kodrasi and S. Doclo, “Late reverberant power spectral density esti-mation based on an eigenvalue decomposition,” in Proc. IEEE Int. Conf.Acoust., Speech, Signal Process., New Orleans, LA, USA, Mar. 2017,pp. 611–615.
[37] I. Kodrasi and S. Doclo, “EVD-based multi-channel dereverberation ofa moving speaker using different RETF estimation methods,” in Proc.Joint Workshop Hands-Free Speech Commun. Microphone Arrays, SanFrancisco, CA, USA, Mar. 2017, pp. 116–120.
[38] B. F. Cron and C. H. Sherman, “Spatial-correlation functions for variousnoise models,” J. Acoust. Soc. Amer., vol. 34, no. 11, pp. 1732–1736,Nov. 1962.
[39] B. D. Rao and K. V. S. Hari, “Performance analysis of root-music,” IEEETrans. Acoust., Speech, Signal Process., vol. 37, no. 12, pp. 1939–1949,Dec. 1989.
[40] B. Ottersten, M. Viberg, and T. Kailath, “Performance analysis of the totalleast squares ESPRIT algorithm,” IEEE Trans. Signal Process., vol. 39,no. 5, pp. 1122–1135, May 1991.
[41] S. Araki, H. Sawada, R. Mukai, and S. Makino, “Performance evaluationof sparse source separation and DOA estimation with observation vectorclustering in reverberant environments,” in Proc. Int. Workshop Acoust.Echo Noise Control, Paris, France, Sep. 2006.
[42] J. R. Jensen, J. K. Nielsen, R. Heusdens, and M. G. Christensen, “DOAestimation of audio sources in reverberant environments,” in Proc. IEEEInt. Conf. Acoust., Speech, Signal Process., Shanghai, China, Mar. 2016,pp. 176–180.
[43] A. M. Davie and A. J. Stothers, “Improved bound for complexity of matrixmultiplication,” Proc. Roy. Soc. Edinburgh, Sec. A Math., vol. 143, no. 2,pp. 351–369, Apr. 2013.
[44] G. Golub and C. Van Loan, Matrix Computations. Baltimore, MD, USA:The Johns Hopkins Univ. Press, 1996.
[45] J. M. Ortega and H. F. Kaiser, “The LLT and QR methods forsymmetric diagonal matrices,” Comput. J., vol. 6, no. 1, pp. 99–101,Jan. 1963.
[46] B. Yang, “Projection approximation subspace tracking,” IEEE Trans. Sig-nal Process., vol. 43, no. 1, pp. 95–107, Jan. 1995.
[47] K. Kinoshita et al., “A summary of the REVERB challenge: State-of-the-art and remaining challenges in reverberant speech process-ing research,” EURASIP J. Adv. Signal Process., vol. 2016, no. 1,Jan. 2016.
[48] J. Eaton, N. D. Gaubitch, A. H. Moore, and P. A. Naylor, “The ACEchallenge—Corpus description and performance evaluation,” in Proc.IEEE Workshop Appl. Signal Process. Audio Acoust., New Paltz, NY,USA, Oct. 2015.
[49] International Telecommunications Union (ITU-T), Perceptual Evalua-tion of Speech Quality (PESQ): An Objective Method for End-To-EndSpeech Quality Assessment of Narrowband Telephone Networks andSpeech Codecs, ITU-T, Geneva, Switzerland, Recommendation P.862,Feb. 2001.
[50] Y. Hu and P. C. Loizou, “Evaluation of objective quality measures forspeech enhancement,” IEEE Trans. Audio, Speech, Lang. Process., vol. 16,no. 1, pp. 229–238, Jan. 2008.
[51] S. Quackenbush, T. Barnwell, and M. Clements, Objective Measures ofSpeech Quality. Englewood Cliffs, NJ, USA: Prentice-Hall, 1988.

1118 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 26, NO. 6, JUNE 2018
[52] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short-time ob-jective intelligibility measure for time-frequency weighted noisy speech,”in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., Dallas, TX,USA, Mar. 2010, pp. 4214–4217.
[53] Y. Ephraim and D. Malah, “Speech enhancement using a minimum mean-square error short-time spectral amplitude estimator,” IEEE Trans. Acoust.,Speech, Signal Process., vol. ASSP-32, no. 6, pp. 1109–1121, Dec. 1984.
[54] E. A. P. Habets, I. Cohen, and S. Gannot, “Generating nonstationarymultisensor signals under a spatial coherence constraint,” J. Acoust. Soc.Amer., vol. 124, no. 5, pp. 2911–2917, Nov. 2008.
Ina Kodrasi (S’11–M’16) received the Master of Sci-ence degree in communications, systems, and elec-tronics from Jacobs University Bremen, Bremen,Germany, in 2010, and the Ph.D. degree from the Uni-versity of Oldenburg, Oldenburg, Germany, in 2015.From 2010 to 2015, she was an early stage Researcherwith the Signal Processing Group, University of Old-enburg, where she was a Postdoctoral Researcher inthe field of speech dereverberation and noise reduc-tion from 2015 to 2017. From 2010 to 2011, she wasalso with the Project Group Hearing, Speech and Au-
dio Technology, Fraunhofer Institute for Digital Media Technology, Oldenburg,Germany, where she worked on microphone array beamforming. Since De-cember 2017, she has been a Postdoctoral Researcher with the Idiap ResearchInstitute, Martigny, Switzerland, working in the field of signal processing forclinical applications.
Simon Doclo (S’95–M’03–SM’13) received theM.Sc. degree in electrical engineering and the Ph.D.degree in applied sciences from the Katholieke Uni-versiteit Leuven, Leuven, Belgium, in 1997 and 2003,respectively. From 2003 to 2007, he was a Postdoc-toral Fellow with the Research Foundation Flanders,Electrical Engineering Department, Katholieke Uni-versiteit Leuven, and the Cognitive Systems Labora-tory, McMaster University, Hamilton, ON, Canada.From 2007 to 2009, he was a Principal Scientist withthe Sound and Acoustics Group, NXP Semiconduc-
tors, Leuven, Belgium. Since 2009, he has been a Full Professor with theUniversity of Oldenburg, Oldenburg, Germany, and a Scientific Advisor withthe Project Group Hearing, Speech and Audio Technology, Fraunhofer Insti-tute for Digital Media Technology, Oldenburg, Germany. His current researchfocuses on signal processing for acoustical and biomedical applications, morespecifically microphone array processing, active noise control, acoustic sensornetworks, and hearing aid processing. He was the recipient of the Master ThesisAward of the Royal Flemish Society of Engineers in 1997 (with E. De Clippel),the Best Student Paper Award at the International Workshop on Acoustic Echoand Noise Control in 2001, the EURASIP Signal Processing Best Paper Awardin 2003 (with M. Moonen), and the IEEE Signal Processing Society 2008 BestPaper Award (with J. Chen, J. Benesty, and A. Huang). He is Member of theIEEE Signal Processing Society Technical Committee on Audio and AcousticSignal Processing, the EURASIP Special Area Team on Acoustic, Speech andMusic Signal Processing, and the EAA Technical Committee on Audio SignalProcessing. He was a Guest Editor for several special issues (IEEE SIGNAL
PROCESSING MAGAZINE and Elsevier Signal Processing) and is an AssociateEditor for the IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE
PROCESSING and EURASIP Journal on Advances in Signal Processing.




























