Embed Size (px)
Citation preview

1
USING CLASS WEIGHTING IN INTER-CLASS MLLR
Sam-Joo Doh and Richard M. Stern
Department of Electrical and Computer Engineering
and School of Computer Science
Carnegie Mellon University
October 20, 2000

Robust Speech Group2Carnegie Mellon
Outline
Introduction
Review Transformation-based adaptation Inter-class MLLR
Application of weights For different neighboring classes
Summary

Robust Speech Group3Carnegie Mellon
Introduction
We would like to achieve Better adaptation using small amount of adaptation data
Enhance recognition accuracy
Current method Reduce the number of parameters Assume transformation function
Transformation-based adaptation Example: Maximum likelihood linear regression

Robust Speech Group4Carnegie Mellon
Introduction (cont’d)
Transformation-based adaptation Transformation classes are assumed to be independent It does not achieve reliable estimates for multiple classes using a small amount of adaptation data
Better idea ? Utilize inter-class relationship to achieve more reliable
estimates for multiple classes

Robust Speech Group5Carnegie Mellon
Transformation-Based Adaptation
Estimate each target parameter (mean vector)
Robust Speech Group6Carnegie Mellon
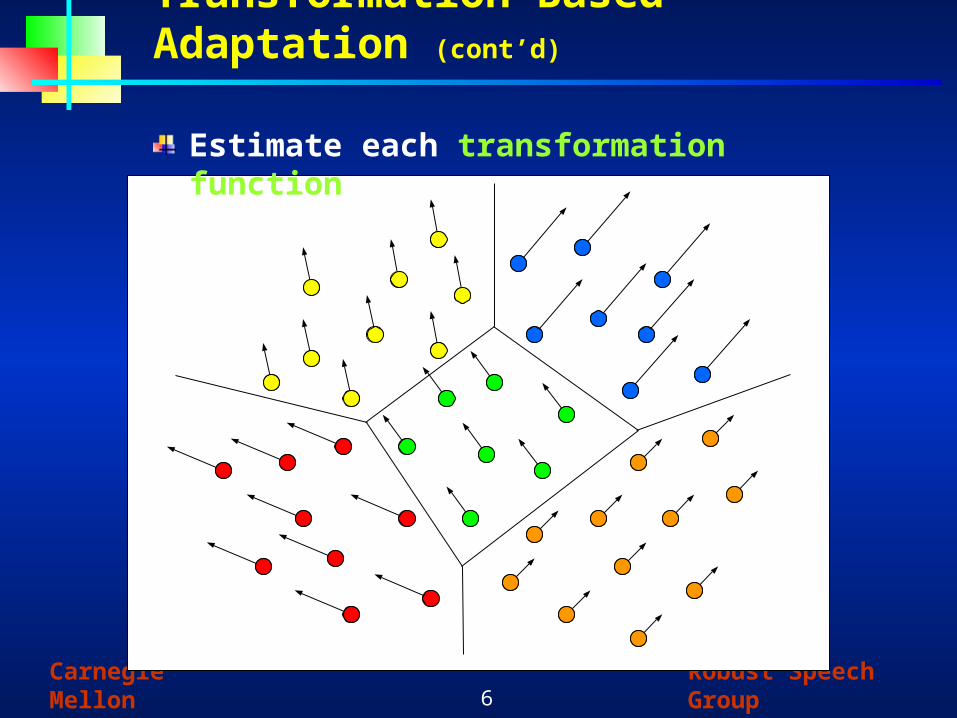
Transformation-Based Adaptation (cont’d)
Estimate each transformation function

Robust Speech Group7Carnegie Mellon
Transformation-Based Adaptation (cont’d)
Trade-off
Better estimationof transformation function
More details
of target parameters
Number of transformation classes
Quality

Robust Speech Group8Carnegie Mellon
Previous Works
Consider Correlations among model parameters
Mostly in Bayesian framework
Considering a few neighboring models: Not effective
Considering all neighboring models: Too much computation
It is difficult to apply correlation on multi-Gaussian mixtures: No explicit correspondence

Robust Speech Group9Carnegie Mellon
Previous Works (cont’d)
Using correlations among model parameters
Robust Speech Group10Carnegie Mellon
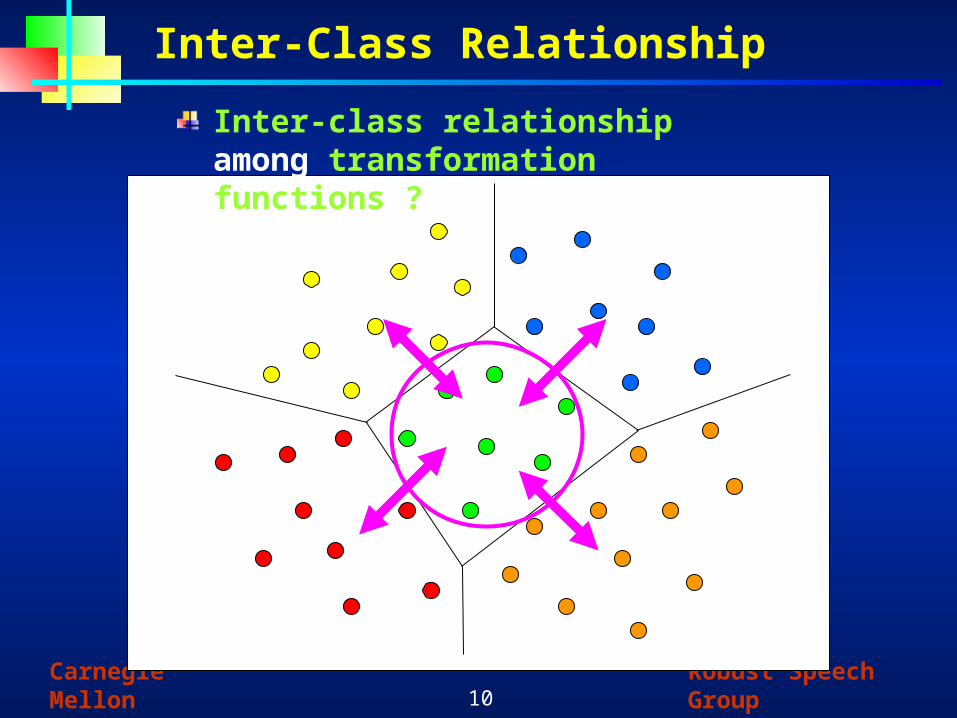
Inter-Class Relationship
Inter-class relationshipamong transformation functions ?
Robust Speech Group11Carnegie Mellon
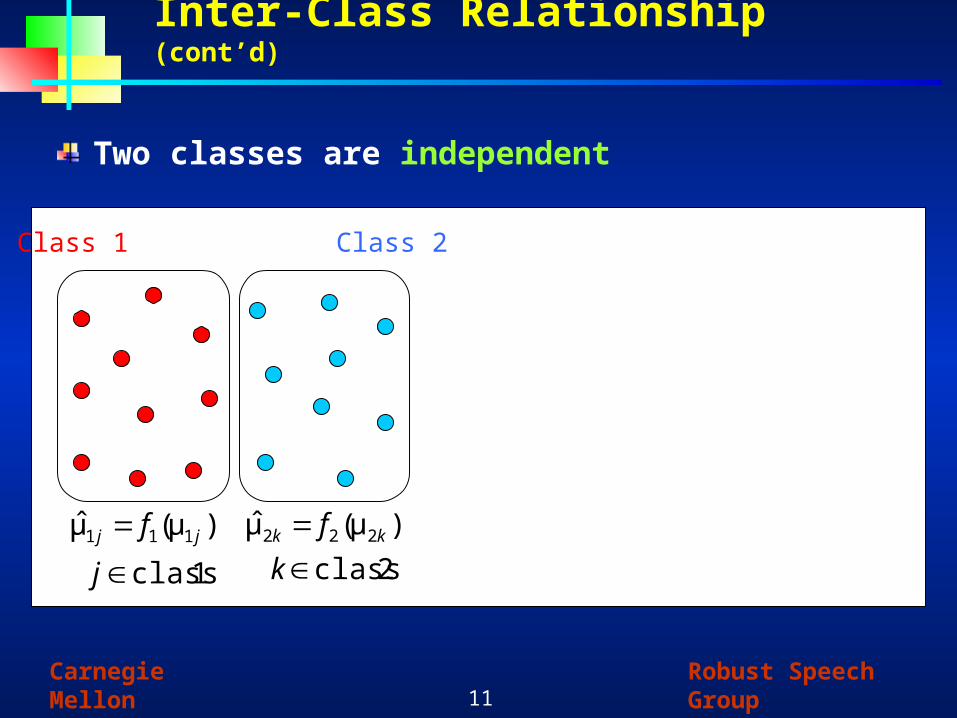
Inter-Class Relationship (cont’d)
Two classes are independent
Class 1 Class 2
2class
),(μμ̂ 222
k
f kk
1class
),(μμ̂ 111
j
f jj
Robust Speech Group12Carnegie Mellon
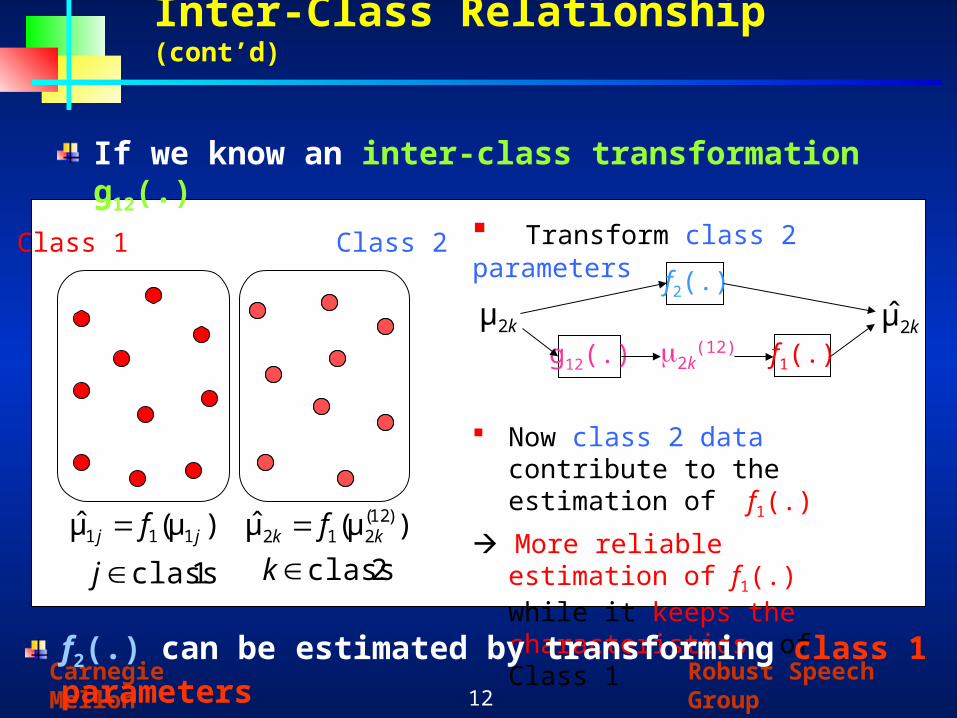
Inter-Class Relationship (cont’d)
If we know an inter-class transformation g12(.)
Now class 2 data contribute to the estimation of f1(.)
More reliable estimation of f1(.) while it keeps the characteristics of Class 1
Transform class 2 parameters
k2μ k2μ̂f2(.)
f1(.)g12(.) 2k(12)
Class 1 Class 2
2class
),(μμ̂ 222
k
f kk
1class
),(μμ̂ 111
j
f jj
2class
),(μμ̂ )12(212
k
f kk
f2(.) can be estimated by transforming class 1 parameters

Robust Speech Group13Carnegie Mellon
Use Linear Regression for inter-class transformation
class Target : 1 Class ,b A 11 kkk μμ̂
11
11
b A
b A
μ̂ k)(μ
)μ()12(
1212
k
k dT
tkk t k k t to C o k Q
1 Class
1 T) μ ( ) μ )( ( 1 1 1 1b A b A
Estimate (A1, b1) to minimize Q
k C
t k k
t o
k
t
t
Gaussian of matrix covariance :
time at Gaussian with being of y probabilit :
time at vector feature input :
posteriori a ) (
Where
tk
k t k k t to C o k2 Class
) 12 ( 1 T ) 12 () μ ( ) μ )( ( 1 1 1 1b A b A
Inter-class MLLR
2 Class ,b A 22 kkk μμ̂
Robust Speech Group14Carnegie Mellon
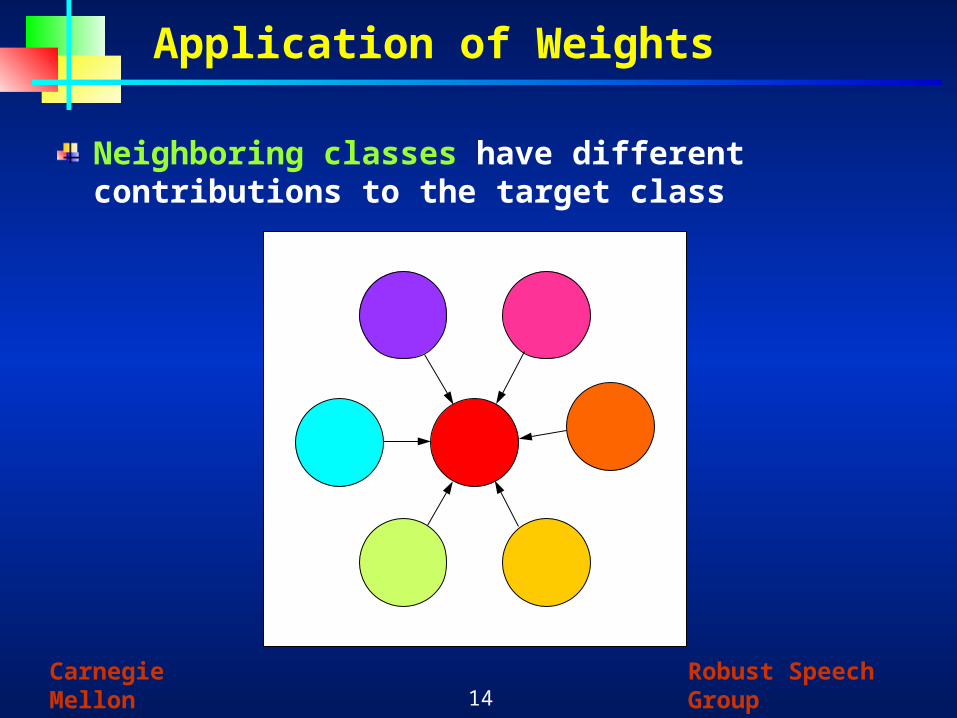
Application of Weights
Neighboring classes have different contributions to the target class

Robust Speech Group15Carnegie Mellon
Application of Weights (cont’d)
Application of weights to the neighboring classes We assume in neighboring class n
The error using (A1, b1) in neighboring class n
11 b A )1(μμ̂ nkk
tn
kt eo 11 b A )1(μ
tnk
nk t k
nk t t
tkk t k k t t
o C o k
o C o k Q
Neighbor n Class 1 1
T1 1
1 Class 1 1
T1 1
b A b A
b A b A
) μ ( ) μ )( (
) μ ( ) μ )( (
) 1( 1 ) 1(
1
Weighted least squares estimation: Use the variance of the error for weight Large error Small weight Small error Large weight

Robust Speech Group16Carnegie Mellon
Number of Neighboring Classes
Limit the number of neighboring classes
Sort neighboring classes Set threshold for the number of samples
Use “closer” neighboring class first
Count the number of samples used
Use next neighboring classes until the number of samples
exceed the threshold

Robust Speech Group17Carnegie Mellon
Experiments
Test data 1994 DARPA, Wall Street Journal (WSJ) task 10 Non-native speaker x 20 test sentences (Spoke 3: s3-94)
Baseline System: CMU SPHINX-3 Continuous HMM, 6000 senones 39 dimensional features
• MFCC cepstra + delta + delta-delta + power
Supervised/Unsupervised adaptation Focus on small amounts of adaptation data
13 phonetic-based classes for inter-class MLLR
Robust Speech Group18Carnegie Mellon
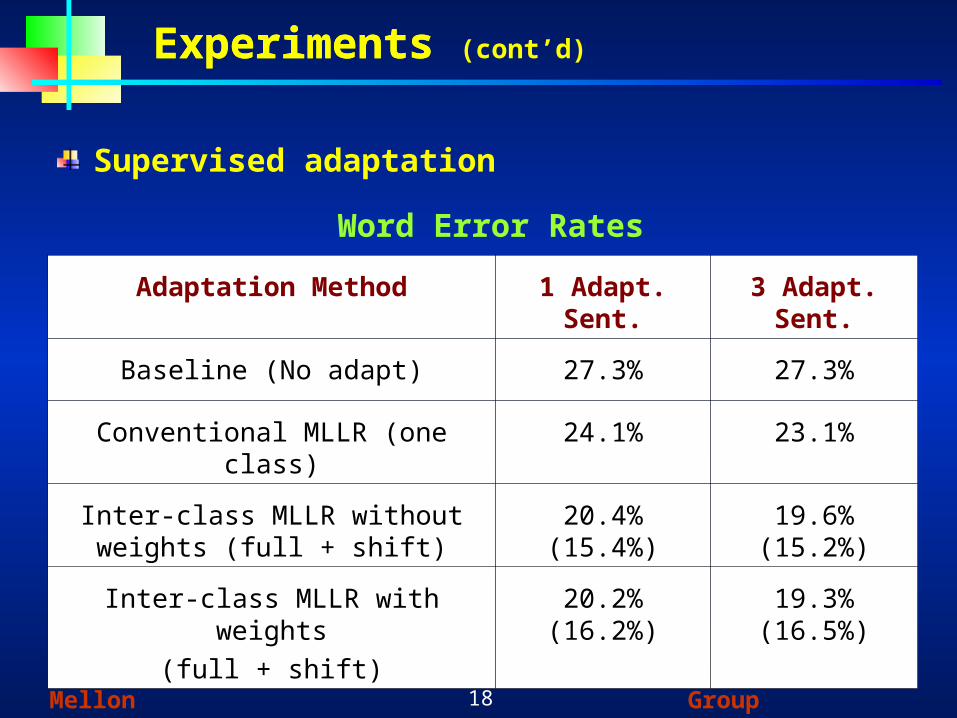
ExperimentsExperiments (cont’d)
Adaptation Method 1 Adapt. Sent. 3 Adapt. Sent.
Baseline (No adapt) 27.3% 27.3%
Conventional MLLR (one class) 24.1% 23.1%
Inter-class MLLR without weights (full + shift)
20.4% (15.4%) 19.6% (15.2%)
Inter-class MLLR with weights
(full + shift)
20.2% (16.2%) 19.3% (16.5%)
Supervised adaptation
Word Error Rates
Robust Speech Group19Carnegie Mellon
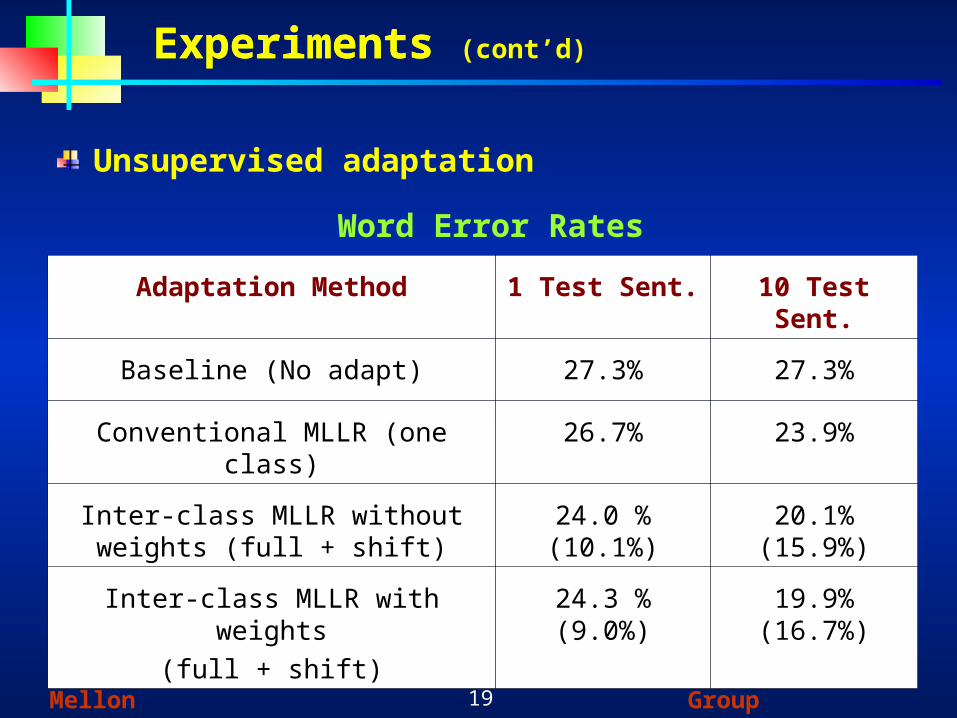
ExperimentsExperiments (cont’d)
Adaptation Method 1 Test Sent. 10 Test Sent.
Baseline (No adapt) 27.3% 27.3%
Conventional MLLR (one class) 26.7% 23.9%
Inter-class MLLR without weights (full + shift)
24.0 % (10.1%) 20.1% (15.9%)
Inter-class MLLR with weights
(full + shift)
24.3 % (9.0%) 19.9% (16.7%)
Unsupervised adaptation
Word Error Rates
Robust Speech Group20Carnegie Mellon
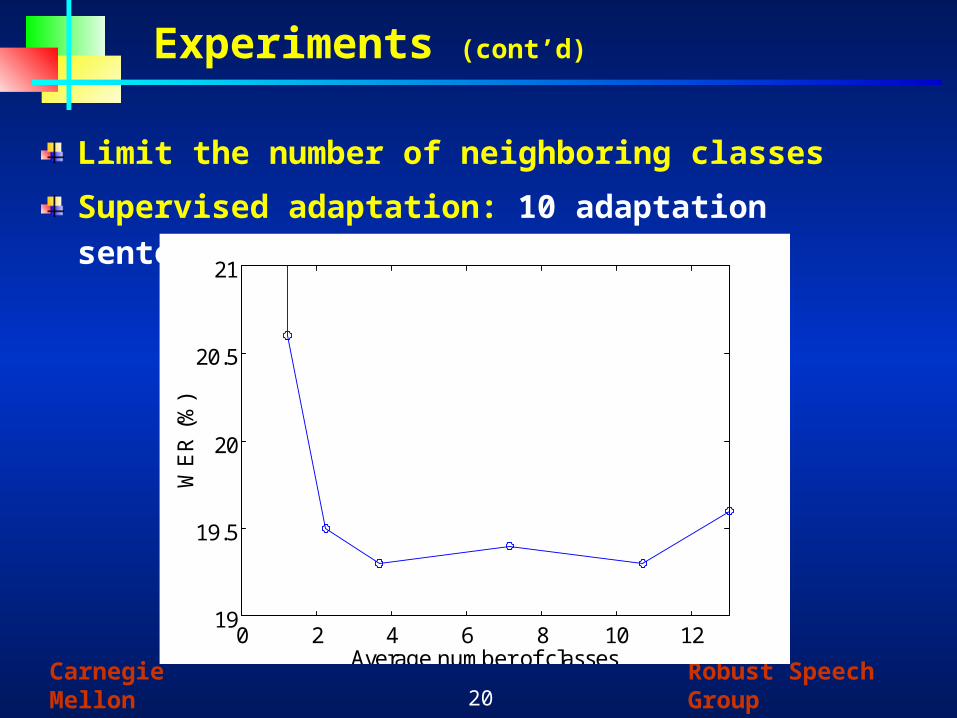
Experiments (cont’d)
Limit the number of neighboring classes
Supervised adaptation: 10 adaptation sentences
0 2 4 6 8 10 1219
19.5
20
20.5
21
Average number of classes
WE
R (
%)

Robust Speech Group21Carnegie Mellon
Summary
Application of weights Use weighted least square estimation Was helpful for supervised case Was not helpful for unsupervised case
(with small amount of adaptation data)
Number of neighboring classes Use smaller number of neighboring classes
as more adaptation data are available

Robust Speech Group22Carnegie Mellon
Summary
Inter-class transformation It can have speaker-dependent information We may prepare several sets of inter-class
transformations
Select appropriate set for a new speaker
Combination with Principal Component MLLR Did not provide additional improvement

Robust Speech Group23Carnegie Mellon
Thank you !





























