Embed Size (px)
Citation preview

1
Parallel Processing
A PerspectiveHardware and Software

2
Introduction to PP
From “Efficient Linked List Ranking Algorithms and Parentheses Matching as a New Strategy for Parallel Algorithm Design”, R. Halverson
Chapter 1 – Introduction to Parallel Processing

3
Parallel Processing Research
1980’s – Great Deal of Research & Publications
1990’s – Hardware not too successful so the research area “dies” – Why???
Early 2000’s – Begins Resurgence? Why??? Will it continue to be successful this time ???
2010 – Multicore, Graphics processing units

4
Goal of PP Why bother with Parallel Processing? Goal: Solve problems faster! In reality, faster but efficient! Work-Optimal: parallel algorithm runs
faster than sequential algorithm in proportion to the number of processors used.
Sometimes work-optimal is not possible

Performance Metrics
Running time Speedup = T1 /Tp
Work = p * Tp
Work Optimal: Work = O(T1) Linear speedup
Scalable: if algorithm performance increases linearly with the number of processors utilized
5

6
PP Issues
Processors: number, connectivity, communication
Memory: shared vs. local Data structures Data Distribution Problem Solving Strategies

7
Parallel Problems
One Approach: Try to develop a parallel solution to a problem without consideration of the hardware. Apply: Apply the solution to the
specific hardware and determine the extra cost, if any
If not acceptably efficient, try again!

8
Parallel Problems
Another Approach: Armed with the knowledge of strategies, data structures, etc. that work well for a particular hardware, develop a solution with a specific hardware in mind.
Third Approach: Modify a solution for one hardware configuration for another

9
Real World Problems Inherently Parallel – nature or structure
of the problem lends itself to parallelism
Examples Mowing a lawn Cleaning a house Grading papers
Problems are easily divided into sub-problems; very little overhead

10
Real World Problems
Not Inherently Parallel – parallelism is possible but more complex to define or with (excessive) overhead cost
Examples Balancing a checkbook Giving a haircut Wallpapering a room Prefix sums of an array

11
Some Computer Problems Are these “inherently parallel” or not?
Processing customers’ monthly bills Payroll checks Building student grade reports from class
grade sheets Searching for an item in a linked list A video game program Searching a state driver’s license
database Is problem hw, sw, data? Assumptions?

12
General Observations
What characteristics make a problem inherently parallel?
What characteristics make a problem difficult to parallelize?
* Consider hw, sw, data structures.

13
Payroll Problem
Consider 10 PUs (processing unit) with each employee’s information stored in a row of an array, A.
Label P0, P1,…P9
A[100] – 0 to 99
For i = 0 to 9Pi process A[i*10] to A[((i+1)*10)-1]

14
Code for PayrollFor i = 0 to 9
Pi process A[i*10] to A[((i+1)*10)-1]
Each PU runs a process in parallelFor each Pi , i = 0 to 9 do //separate
processFor j = 0 to 9
Process A[i*10 + j]
15
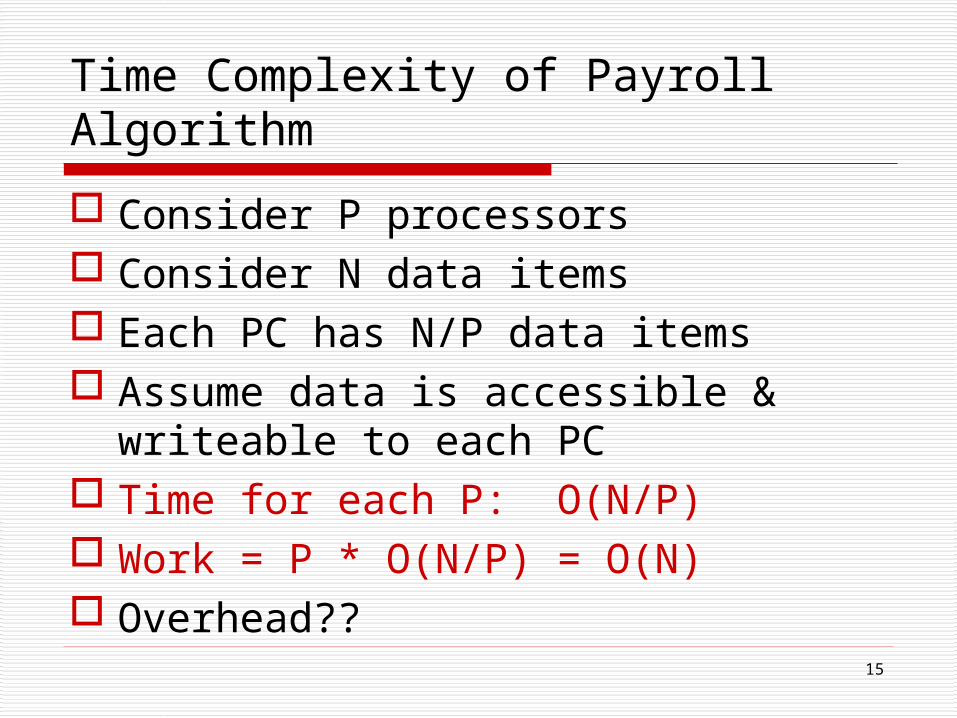
Time Complexity of Payroll Algorithm
Consider P processors Consider N data items Each PC has N/P data items Assume data is accessible &
writeable to each PC Time for each P: O(N/P) Work = P * O(N/P) = O(N) Overhead??

16
Payroll Questions??
Now we have a solution, must be applied to hardware. Which hardware?
Main question: Where is the array and how is it accessed by each processor?
One shared memory or many local memories?
Where are the results placed?

17
What about I/O??
Generally, in parallel algorithms, I/O is disregarded.
Assumption: Data is stored in the available memory.
Assumption: Results are written back to memory.
Data input and output are generally independent of the processing algorithm.

18
Balancing a Checkbook Consider same hardware & data array Can still distribute and process in the
same manner as the payroll Each block computes deposits as addition &
checks a subtraction; totals the page (10 totals)
BUT then must combine the 10 totals to the final total
This is the overhead!

19
Complexity of Checkbook Consider P processors Consider N data items Each PC has N/P data items Assume data is accessible & writeable Time for each section: O(N/P) Combination of P subtotals Time for combining: O(P) to O(log P)
Depends on strategy used Total: O(N/P + P) to O(N/P + log P)

20
PerformanceComplexity - Perfect Parallel Algorithm If the best sequential algorithm for a
problem is O(f(x)) then the parallel algorithm would be O(f(x)/P)
This happens if little or no overheadActual Run Time Typically, takes 4 processors to
achieve ½ the actual run time

21
Performance Measures Run Time: not a practical measurement
Assume T1 & Tp are run times using 1 & p processors, respectively
Speedup: S = T1/Tp Work: W = p * Tp (aka Cost) If W = O(T1) the it is Work (Cost)
Optimal & achieves Linear Speedup

22
Scalability
An algorithm is said to be Scalable if performance increases linearly with the number of processors i.e. double the processors, cut time in
half Implication: Algorithm sustains
good performance over a wide range of processors.

23
Scalability What about continuing to add processors? At what point does adding more processors
stop improving the run time? Does adding processors ever cause the
algorithm to take more time? What is the optimal number of processors? Consider W = p * Tp = O(T1)
Solve for p Want W to be optimal for different numbers of
processors

24
Models of Computation
Two major categories Shared memory
e.g. PRAM Fixed connection
e.g. Hypercube There are numerous versions of
each Not all are totally realizable in hw

25
Sidenote: Models
Distributed Computing Use of 2 or more separate
computers used to solve a single problem
A version of a network Clusters
Not really a topic for this course

26
Shared Memory Model PRAM – parallel random access
machine A category with 4 variants
EREW-CREW-ERCW-CRCW All communication through a
shared global memory Each PC has a small local memory

27
Variants of PRAM
EREW-CREW-ERCW-CRCW Concurrent read: 2 or more processors
may read the same (or different) memory location simultaneously
Exclusive read: 2 or more processors may access global memory location only if each is accessing a unique address
Similarly defined for write

28
Shared Memory Model
Shared Global Memory
P0 P1 P2 P3
M M M M

29
Shared Memory
What are some implications of the variants in memory access of the PRAM model?
What is the strongest model?

30
Fixed Connection Models
Each PU contains a Local Memory Distributed memory No shared memory
PUs are connected through some type of Interconnection Network Interconnection network defines the model
Communication is via Message Passing Can be synchronous or asynchronous

31
Interconnection Networks
Bus Network (Linear) Ring Mesh Torus Hypercube

32
Hypercube Model Distributed memory, message passing,
fixed connection, parallel computer N = 2r number of nodes E = r 2r-1 number of edges Nodes are numbered 0 – N in binary
such that any 2 nodes differing in one bit are connected by an edge
Dimension is r

33
Hypercube ExamplesN = 2, 4
0 1
N = 2
Dimension = 1N = 4
Dimension = 2
10 11
00 01

34
Hypercube ExampleN = 8
110111
010 011
100 101
000 001
N = 8
Dimension = 3

35
Hypercube Considerations Message Passing Communication
Possible Delays Load Balancing
Each PC has same work load Data Distribution
Must follow connections

36
Consider Checkbook Problem
How about distribution of data? Often initial distribution is
disregarded What about the combination of the
subtotals? Reduction is by dimension O(log P) = r

37
Design Strategies
Paradigm: a general strategy used to aid in the development of the solution to a problem

38
ParadigmsExtended from Sequential Use
Extended from sequential use Divide-and-Conquer
Always used in parallel algorithmsDivide data vs. Divide code
Branch-and-Bound Dynamic Programming

39
ParadigmsDeveloped for Parallel Use Deterministic coin tossing Symmetry breaking Accelerating cascades Tree contraction Euler Tours Linked List Ranking All Nearest Smaller Values (ANSV) Parentheses Matching

40
Divide-and-Conquer
Most basic parallel strategy Used in virtually every parallel
algorithm Problem is divided into several sub-
problems that can be solved independently; results of sub-problems are combined into the final solution
Example: Checkbook Problem

41
Dynamic Programming
Divide & Conquer technique used when sub-problems are not independent; share common sub-problems
Sub-problem solutions are stored in table for use by other processes
Often used for optimization problems Minimum or Maximum Fibonacci Numbers

42
Branch-and-Bound
Breadth-first tree processing technique
Uses a bounding function that allows some branches of the tree to be pruned (i.e. eliminated)
Example: Game programming

43
Symmetry Breaking
Strategy that breaks a linked structure (e.g. linked list) into disjoint pieces for processing
Deterministic Coin Tossing Using a binary representation of index,
nonadjacent elements are selected for processing
Often used in Linked List Ranking Algorithms

44
Accelerated Cascades
Applying 2 or more algorithms to a single problem,
Change from one to another based on the ratio of the problem size to the number of processors – Threshold
This “fine tuning” sometimes allows for better performance

45
Tree Contraction (aka Contraction)
Nodes of a tree are removed; information removed is combined with remaining nodes
Multiple processors are assigned to independent nodes
Tree is reduced to a single node which contains the solution
E.G. Arithmetic Expression computation; Addition of a series of numbers

46
Euler Tour
Create duplicate nodes in a tree or graph with edge in opposite direction to create a circuit
Allows tree or graph to be processed as a linked list

47
Linked List Ranking Halverson’s area of dissertation
research ProblemDefinition:
Given a linked list of elements, number the elements in order (or in reverse order)
For list of length 20+

Linked List Ranking
Euler Tours Tree Searches List packing Connectivity Tree Traversals
Spanning Trees & Forests
Connected Components
Graph Decomposition
48
Applied to a wide range of problems

49
All Nearest Smaller Values
Given a sequence of values, for each value x, which predecessor elements are smaller than x
Successfully applied to Depth first search of interval graph Parentheses matching Line Packing Triangulating a monotone polynomial

50
Parentheses Matching
In a properly formed string of parentheses, find the index of each parentheses mate
Applied to solve Heights of all nodes in a tree Extreme values in a tree Lowest common ancestor Balancing binary trees

Parentheses Matching
1 2 3 4 5 6 7 8 9 10 11 12
( ( ) ( ( ( ) ) ) ( ) ) 12 3 2 9 8 7 6 5 4 11 10 1
51

52
Parallel Algorithm Design
Identify problems and/or classes of problems for which a particular strategy will work
Apply to the appropriate hardware Most of the paradigms have been
optimized for a variety of parallel architectures

53
Broadcast Operation
Not a paradigm, but an operation used in many parallel algorithms
Provide one or more items of data to all the processors (individual memories)
Let P be the number of processors. For most models, broadcast operation is O(log P) time complexity

54
Broadcast Shared Memory (EREW)
P0 writes for P1; P0 & P1 write for P2 & P3; P0 – P3 write for P4 – P7
Then each PU has a copy to be read in one time unit
Hypercube P0 sends to P1; P0 & P1 send to P2 & P3,
etc.
Both are O(log P)

55
Remainder of this Course
Principles & Techniques of parallel processing & parallel algorithm development on a variety of models
Application using CUDA nVidia Graphics card processors
Overview of new models & languages Student presentations





























