Embed Size (px)
Citation preview

1
Indexing and Searching(File Structures)
Modern Information Retrieval (Chapter 8) With G. Navarro

2
File Struces Inverted Files Signatures PAT Trees Sequential Searching Compression

3
Inverted Files
Information Retrieval: Data Structures and Algorithms(Chapters 3)
W.B. Frakes and R. Baeza-Yates (Eds.) 1992.

4
Inverted Files
Characteristics A word-oriented mechanism based on sorted list of keywords,
with each keyword having links to the documents containing that keyword.
Preprocessing Each document is assigned a list of keywords or attributes. Each keyword (attribute) is associated with relevance weights.

5
1. The input text is parsed into a list of words along with theirlocation in the text. (time and storage consuming operation)
2. This list is inverted from a list of terms in location order to a list of terms in alphabetical order.
3. Add term weights, or reorganize or compress the files.
Inversion of Word List
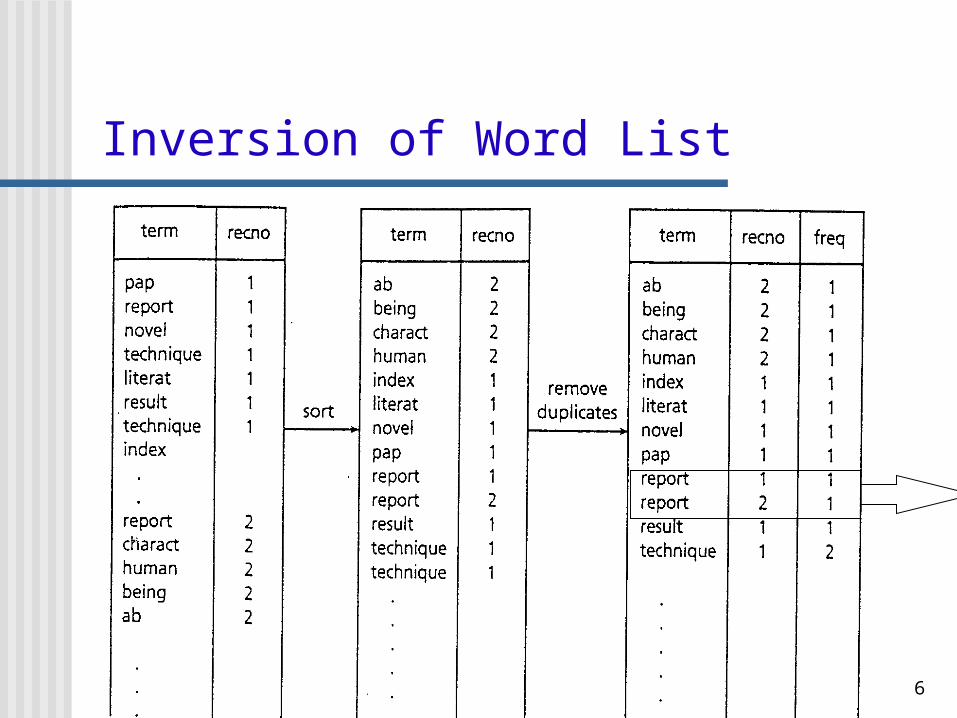
6
Inversion of Word List

7
Structure and Construction
Structure (split the index into two files) Vocabulary: O(n) according to Heaps’ Law Occurrences : depends on the addressing granularity
Construction The vocabulary is stored in lexicographical order and points
to posting list. Posting file : the lists of occurrences are stored contiguousl
y

8
(document #, frequency)
Dictionary and Postings File

9
Vocabulary and Posting File

10
Structures used in Inverted Files
Vocabulary Sorted Arrays Hashing Structures Keyword Trees: Tries (digital search trees)
The Search Procedure Vocabulary search Retrieval of occurrences Manipulation of occurrences

11
Size of an Inverted File Block addressing
The text is divided in blocks, and the occurrences point to the blocks instead of full inverted indices where exact occurrences are recorded
Small collection Medium collection Large Collection
Granularity (1MB) (200MB) (2GB)
Words 45% 73% 36% 64% 35% 63%
Documents 19% 26% 18% 32% 26% 48%
64K blocks 27% 41% 18% 32% 5% 0%
256K blocks 18% 25% 1.70% 2.40% 0.50% 0.70%

12
Cost
Advantage easy to implement
Disadvantage updating the index is expensive

13
Signature Files
Information Retrieval: Data Structures and Algorithms (Chapters 4)
W.B. Frakes and R. Baeza-Yates (Eds.) Englewood Cliffs, NJ: Prentice Hall, 1992.

14
Signature Files
Characteristics Word-oriented index structures based on hashing Low overhead (10%~20% over the text size) at the cost
of forcing a sequential search over the index Suitable for not very large texts Inverted files outperform signature files for most
applications

15
Construction and Search
Word-oriented index structures base on hashing Maps words to bit masks of B bits Divides the text in blocks of b words each The mask is obtained by bitwise ORing the signatures of all th
e words in the text block. Search
Hash the query to a bit mask W If W & Bi = W, the text block may contain the word

16
Example Four blocks:
This is a text. A text has many words. Words are made from letters. 000101 110101 100100 101101
Hash(text) = 000101 Hash(many)= 110000 Hash(words)= 100100 Hash(made)= 001100 Hash(letters)= 100001
Block 4: 001100 OR 100001
101101

17
False Drop
Assumes that m bits are randomly set in the mask Let =m/B For b words, the probability that a given bit of the ma
sk is set is 1-(1-1/B)bm 1-e-b
Hence, the probability that the l random bits are also set is Fd =(1-e-b)False alarm
Fd is minimized for =ln(2)/b Fd = 2-m
m = B ln2/b

18
Assume documents span exactly one logical block the size of document signature F = the size of block signature B
Sequential Signature File (SSF)

19
Classification of Signature-Based Methods
Horizontal partitioningGrouping similar signatures together and/or providing an index on the signature matrix may result in better-than-linear search.
Vertical partitioningStoring the signature matrix column-wise improves the response time on the expense of insertion time.

20
Classification of Signature-Based Methods
Vertical partitioning without compression
bit-sliced signature files (BSSF, B’SSF)frame sliced (FSSF)generalized frame-sliced (GFSSF)
with compressioncompressed bit slices (CBS)doubly compressed bit slices (DCBS)no-false-drop method (NFD)

21
Classification of Signature-Based Methods
Sequential storage of the signature matrix without compression
sequential signature files (SSF) with compression
bit-block compression (BC)variable bit-block compression (VBC)
Horizontal partitioning data independent partitioning
Gustafson’s methodpartitioned signature files
data dependent partitioning2-level signature files5-trees

22
Criteria
The storage overhead The response time on single word queries The performance on insertion, as well as whether
the insertion maintains the “append-only” property

23
Vertical Partitioning
Ideaavoid bringing useless portions of the document signature in main memory
Methods store the signature file in a bit-sliced form or in a frame-
sliced form store the signature matrix column-wise to improve the
response time on the expense of insertion time

Bit-Sliced Signature Files (BSSF)
Transposed bit matrix
transpose
represent
documents
documents(document signature)

F bit-files
search: (1) retrieve m bit-files. e.g., the word signature of free is 001 000 110 010 the document contains “free”: 3rd, 7th, 8th, 11th bit are set i.e., only 3rd, 7th, 8th, 11th files are examined. (2) “and” these vectors. The 1s in the result N-bit vector
denote the qualifying logical blocks (documents).(3) retrieve text file through pointer file.
insertion: require F disk accesses for a new logical block (document), one for each bit-file, but no rewriting
documents

26
Frame-Sliced Signature File (FSSF)
Ideas Random disk accesses are more expensive than sequential
ones Force each word to hash into bit positions that are closer to
each other in the document signature these bit files are stored together and can be retrieved with a
few random accesses Procedures
The document signature (F bits long) is divided into k frames of s consecutive bits each.
For each word in the document, one of the k frames will be chosen by a hash function.
Using another hash function, the word sets m bits in that frame.

27
documents
frames
Each frame will be kept in consecutive disk blocks.
Frame-Sliced Signature File (Cont.)

28
FSSF (Continued)
Example (n=2, B=12, s=6, f=2, m=3)Word Signaturefree 000000 110010text 010110 000000
doc. signature 010110 110010 Search
Only one frame has to be retrieved for a single word query. I.E., only one random disk access is required.e.g., search documents that contain the word “free”->because the word signature of “free” is placed in 2nd frame,only the 2nd frame has to be examined.
At most k frames have to be scanned for an k word query. Insertion
Only f frames have to be accessed instead of F bit-slices.

Horizontal Partitioning
documents
1. Goal: group the signatures into sets, partitioning the signature matrix horizontally.2. Grouping criterion

30
Partitioned Signature Files
Using a portion of a document signature as a signature key to partition the signature file.
All signatures with the same key will be grouped into a so-called “module”.
When a query signature arrives, examine its signature key and look for the
corresponding modules scan all the signatures within those modules that have
been selected

31
Suffix Trees

32
Suffix Trees and Suffix Arrays
Each position in the text is considered as a text suffix
Index points are selected form the text, which point to the beginning of the text positions which will be retrievable

33

34
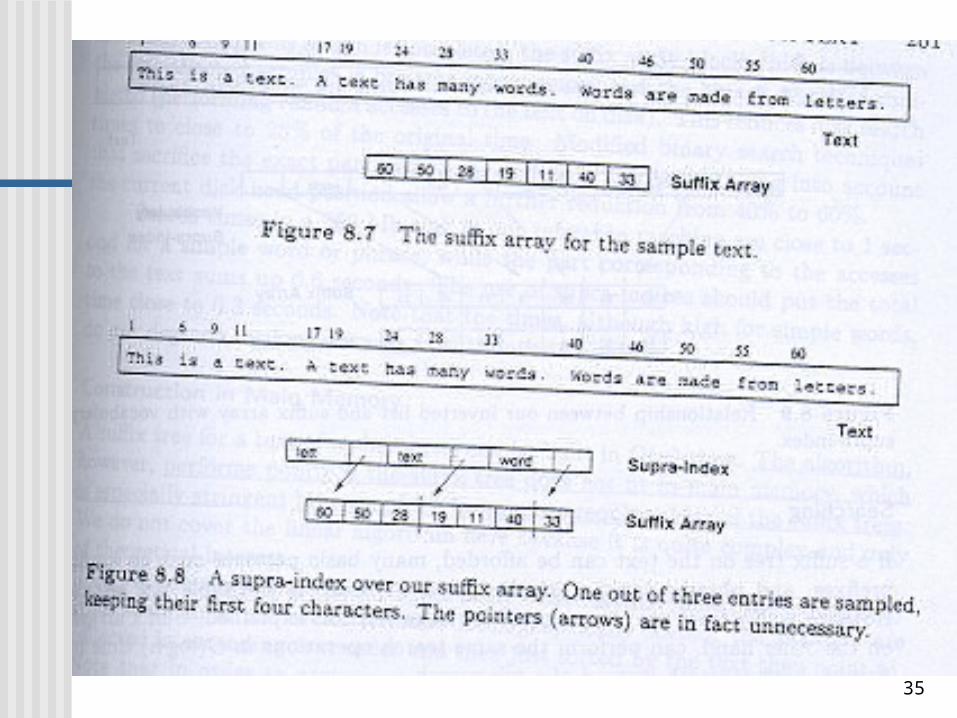
Suffix arrays
The main drawbacks of Suffix Array are its costly construction process.
Allow binary searches done by comparing the contents of each pointer.
Supra-indices (for large suffix array)
35

36
37
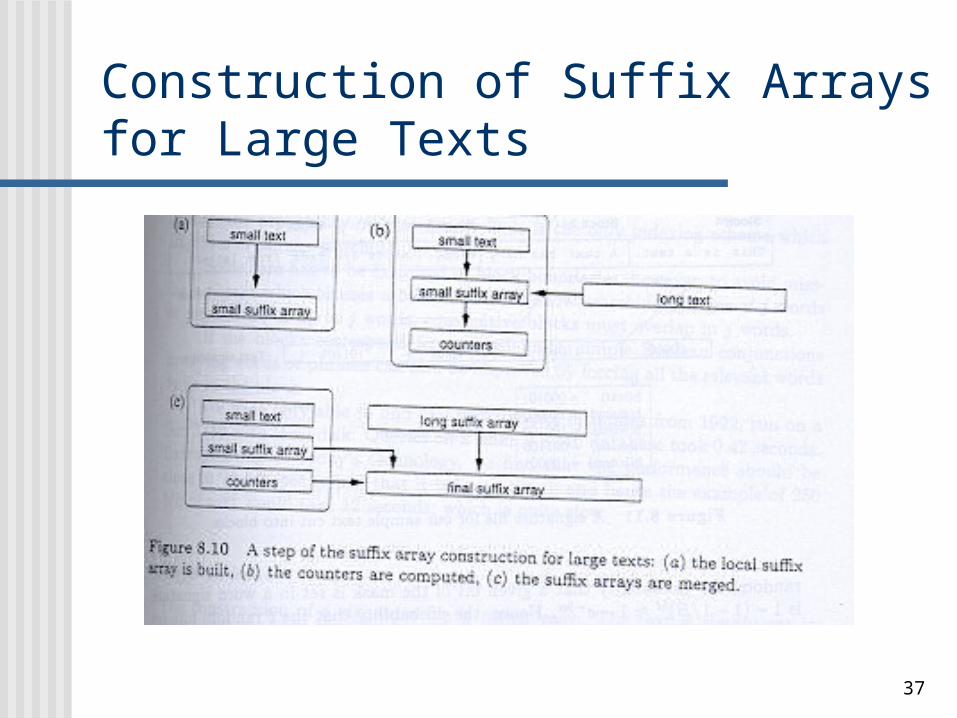
Construction of Suffix Arrays for Large Texts

38
Sequential Searching

39
Algorithms
Brute Force Knuth-Morris-Pratt Boyer-Moore Family Shift-Or Suffix Automaton

40
Knuth-Morris-Pratt

41
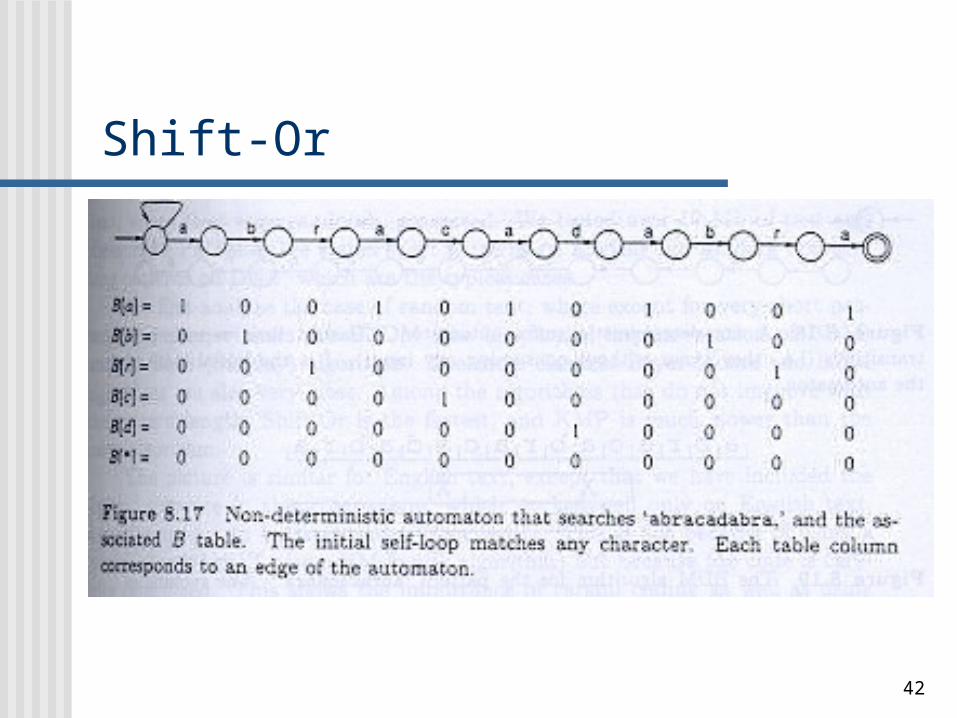
Boyer-Moore Family
42
Shift-Or

43
Suffix Automaton

44

45
Pattern Matching

46
Algorithms
Searching allowing errors Dynamic Programming Automaton
Regular Expressions and Extended patterns Pattern Matching Using Indices
Inverted files Suffix Trees and Suffix Arrays

47
Dynamic Programming

48
Automaton

49
Regular Expressions

50
Pattern Matching Using Indices Inverted Files
The types of queries such as suffix or substring queries, searching allowing errors and regular expressions, are solved by a sequential search
The restriction is to find approximate matches or regular expressions that span many word.

51
Pattern Matching Using Indices
Suffix Trees Suffix trees are able to perform complex searches
• Word, prefix, suffix, substring, and Range queries• Regular expressions• Unrestricted approximate string matching
Useful in specific areas• Find the longest substring• Find the most common substring of a fixed size

52
Pattern Matching Using Indices
Suffix Arrays Some patterns can be searched directly in the suffix array wi
thout simulation the suffix tree Word, prefix, suffix, subword search and range search

53
Compression
Compressed text--Huffman coding Taking words as symbols Use an alphabet of bytes instead of bits
Compressed indices Inverted Files Suffix Trees and Suffix Arrays Signature Files





























