Embed Size (px)
Citation preview

1
Fault Tolerance
•A partial failure occurs when a component in a distributed system fails.
•Conjecture: build the system in a such a way that continues to operate despite a fault.
•Objective: Provide what is know as dependable distributed systems.

2
Features of Dependable Distributed Systems
Dependability entails:• Availability
– Ready to function well at all times.
• Reliability– System continues to run without failure.
• Safety– If the system fails to operate correctly at some point
nothing catastrophic happens.
• Maintainability– In light of a failure, the latter is easily fixable.

3
Factors/Nature of Faulty Behavior
Definition: a system FAILS when it cannot meet its requirements.
1. Error is part of a system that may lead to failure.
2. Fault is the cause of an error
3. A system is fault tolerant if in the presence of faults provides its services.
4. Transient faults are the ones that appear once and then they disappear (due to provisions made in the system).
5. Intermittent systems occur, then vanish, then appear again and so on.
6. Permanent fault continues to exist until the faulty component is fixed.

4
Failure Models [Christian91]
• Different types of failures.
• Arbitrary failures are known as Byzantine failures.
Type of failure Description
Crash failure A server halts, but is working correctly until it halts
Omission failure Receive omission Send omission
A server fails to respond to incoming requestsA server fails to receive incoming messagesA server fails to send messages
Timing failure A server's response lies outside the specified time interval
Response failure Value failure State transition failure
The server's response is incorrectThe value of the response is wrongThe server deviates from the correct flow of control
Arbitrary failure A server may produce arbitrary responses at arbitrary times

5
Failure Masking by Redundancy
•Triple modular redundancy (replication of devices/equipment).
•Key mechanism to mask-out failure is redundancy(ie, add extra bits)•Three types of: (or three dimensions)
•Information redundancy (hamming code)•Time redundancy (an action is performed and then it is performed again if need – example: transaction model)•Physical redundancy (extra equipment or processes)

6
Process Resilience
Issue: what happens when processes fail and how to overcome this?
Main vehicle of solution: organize replicated processes in groups and if one fails someone else takes over.
Issues:
• Design of groups
• Reach agreement within groups when one or more parties cannot be trusted.

7
Group Process Organizationa) Communication in a flat group.b) Communication in a simple hierarchical group
A method is needed to create/delete groups as well as allow processes to enter and depart from groups.• Group Server

8
Group Server• Maintains a complete database of all groups and their
relationships.• This approach suffers for “single point of failure”
• Otherwise, some distributed technique has to be used– If (reliable) multicast is available, an outsider (process) can send
request to all groups about joining one.
– The same with a departing processes in a group/network.• Trouble: when a site has crashed.. (or is very slow).
– Leaving/Joining groups has to be synchronous with data transmissions.

9
Agreement among Processes
• Main problem: have all non-faulty processes reach a consensus on some issue and establish this consensus within finite number of steps.
• System parameters are important in providing solutions– Reliable or nor reliable communication channels
– Crash/failure semantics.

10
Distributed Problem of the Two-Armies.• Two armies:
– Red Army in the Valley (5000 people)
– Two Blue Armies on the hills (each of 4000 each)
• If the two blue armies can coordinate a combined assault they get out victorious (otherwise not!)
• Use messengers who go through the valley (ie,unreliable channel) to pass messages back and forth between the two battalions.
• As there is always doubt in the mind of the last general who received a messenger, there is continuously a messenger going from one blue army to the other..
• Protocol may have no end..

11
Byzantine Generals Problem
• The red army is still in the valley
• The n blue armies are on the hills.
• Communication between the blue armies is done pair-wise, is instantaneous, and perfect.
• m of the blue generals are traitors.
• The traitors prevent the honest generals from reaching an agreement.
• Each general is assumed to know how many troops he got.
• Approach: have the blue generals exchange information about their own troop strength and at the end of an (distributed) algorithm each general has a vector with of length n corresponding to all the armies.
• If general I is loyal then element I is his troop strength

12
Sketch of the Byzantine Generals Algorithm
• Assumption: General i has i kilosoldiers.
The Byzantine generals problem for 3 loyal generals and 1 traitor (process 3).
a) The generals announce their troop strengths (in units of 1 kilosoldiers).
b) The vectors that each general assembles based on (a)
c) The vectors that each general receives in step 3.• Reach result by taking consensus of the received messages.

13
The Algorithm does not seem to work!
• The same as in previous slide, except now with 2 loyal generals and one traitor
• Lamport showed that if there are m traitors then there must be 2m+1 loyalists in order for the algorithm to work properly!

14
Reliable Communication among Systems
• Point to Point– TCP mainly delivers the reliability (for lost messages)
• RPC semantics in presence of failure:– The client is unable to locate the server– The request message from the client to the server is lost– The server crashes after receiving the request– The reply message from the server to the client is lost– The client crashes after sending a request.

15
RPC Semantics in the presence of Failure
• Client is unable to Locate Server– Possible solution: raise an exception– Two drawbacks:
• Not always easy to write exception handler (for instance there is a big problem if the language used does not support exception handling/signaling of some sort).
• Use of exception handler may violate the overall requirement of transparency in the distributed system.
• Lost Request Message– Use of timers (to figure out whether a message has been
lost).

16
RPC Semantics in the Presence of Failures
A server in client-server communicationa) Normal caseb) Crash after execution c) Crash before execution
The main problem is the correct treatment of cases (b) and ( c): the client’s operating system cannot differentiate between these two!
Three approaches exist:
• Wait until server boots and try the operation again [At least once semantics]
• RPC gives up immediately and reports back failure [At most once semantics]– Guarantees that RPC has been carried out one time and possibly none!
• Guarantee nothing! [RPC may have been executed between one and many times!]
• Server crashes

17
RPC Semantics in the Presence of Failures
Different combinations of client and server strategies in the presence of server crashes.
Client Server
Strategy M -> P Strategy P -> M
Reissue strategy MPC MC(P) C(MP) PMC PC(M) C(PM)
Always DUP OK OK DUP DUP OK
Never OK ZERO ZERO OK OK ZERO
Only when ACKed DUP OK ZERO DUP OK ZERO
Only when not ACKed OK ZERO OK OK DUP OK

18
RPC Semantics in the Presence of Failures• Lost Reply Messages
– Use time-outs (but not certain whether the time outs are due to slow server).– Some operations can help (those that are idempotent)– Transactional requests not possible to be deal with! (choose another model).
• Client Crashes– Creates oprhan processes-orphans waist CPU cycles (for nothing).– What one can do about orphans?
• Extermination: Before an RPC is sent out create a disk-log entry• Reincarnation: Divide the time to epochs and when a client reboots
broadcasts a new epoch-obsolete remote computations are killed (on behalf of the client)
• Gentle Reincarnation: when an epoch is broadcast, each machine checks to see if it has a remote computation; if so, tries to locate their owner. If the latter is not successful, the computation is killed.
• Expiration: for each RPC give an amount of time T to complete. If not complete ask explicitly fro another T secs and so on.

19
Two-Phase Commit
a) The finite state machine for the coordinator in 2PC.b) The finite state machine for a participant.

20
Two-Phase Commit
Actions taken by a participant P when residing in state READY and having contacted another participant Q.
State of Q Action by P
COMMIT Make transition to COMMIT
ABORT Make transition to ABORT
INIT Make transition to ABORT
READY Contact another participant

21
Two-Phase Commit
Outline of the steps taken by the coordinator in a two phase commit protocol
actions by coordinator:
while START _2PC to local log;multicast VOTE_REQUEST to all participants;while not all votes have been collected { wait for any incoming vote; if timeout { while GLOBAL_ABORT to local log; multicast GLOBAL_ABORT to all participants; exit; } record vote;}if all participants sent VOTE_COMMIT and coordinator votes COMMIT{ write GLOBAL_COMMIT to local log; multicast GLOBAL_COMMIT to all participants;} else { write GLOBAL_ABORT to local log; multicast GLOBAL_ABORT to all participants;}

22
Two-Phase Commit
Steps taken by participant process in
2PC.
actions by participant:
write INIT to local log;wait for VOTE_REQUEST from coordinator;if timeout { write VOTE_ABORT to local log; exit;}if participant votes COMMIT { write VOTE_COMMIT to local log; send VOTE_COMMIT to coordinator; wait for DECISION from coordinator; if timeout { multicast DECISION_REQUEST to other participants; wait until DECISION is received; /* remain blocked */ write DECISION to local log; } if DECISION == GLOBAL_COMMIT write GLOBAL_COMMIT to local log; else if DECISION == GLOBAL_ABORT write GLOBAL_ABORT to local log;} else { write VOTE_ABORT to local log; send VOTE ABORT to coordinator;}

23
Two-Phase Commit
Steps taken for handling incoming decision requests.
actions for handling decision requests: /* executed by separate thread */
while true { wait until any incoming DECISION_REQUEST is received; /* remain blocked */ read most recently recorded STATE from the local log; if STATE == GLOBAL_COMMIT send GLOBAL_COMMIT to requesting participant; else if STATE == INIT or STATE == GLOBAL_ABORT send GLOBAL_ABORT to requesting participant; else skip; /* participant remains blocked */

24
Three-Phase Commit
a) Finite state machine for the coordinator in 3PCb) Finite state machine for a participant

25
Recovery Stable Storage
a) Stable Storageb) Crash after drive 1 is updatedc) Bad spot
26
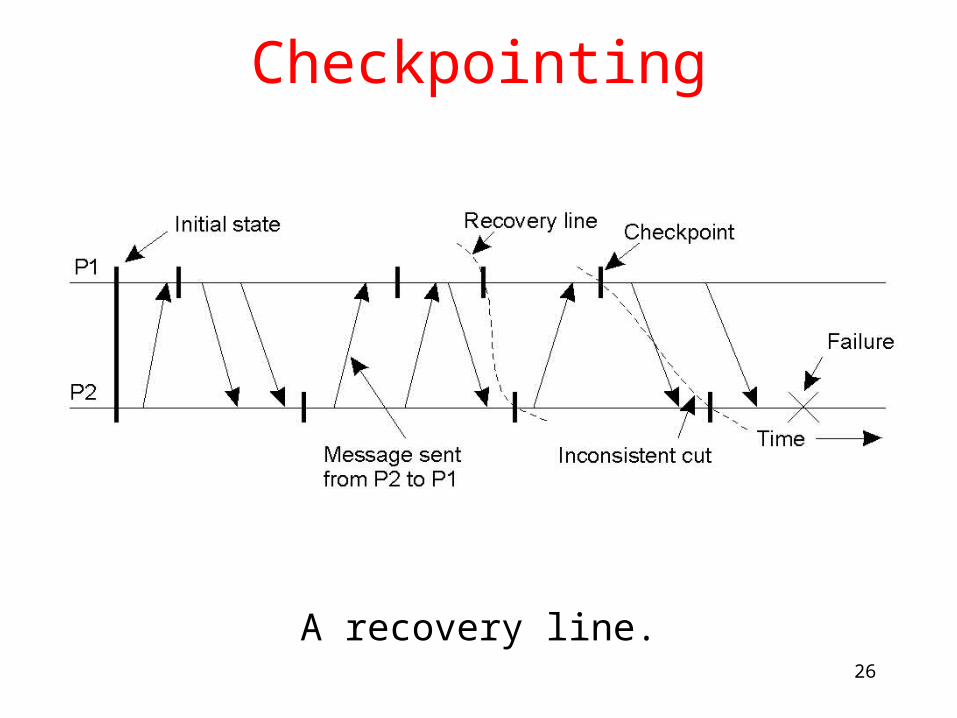
Checkpointing
A recovery line.

27
Independent Checkpointing
The domino effect.
28
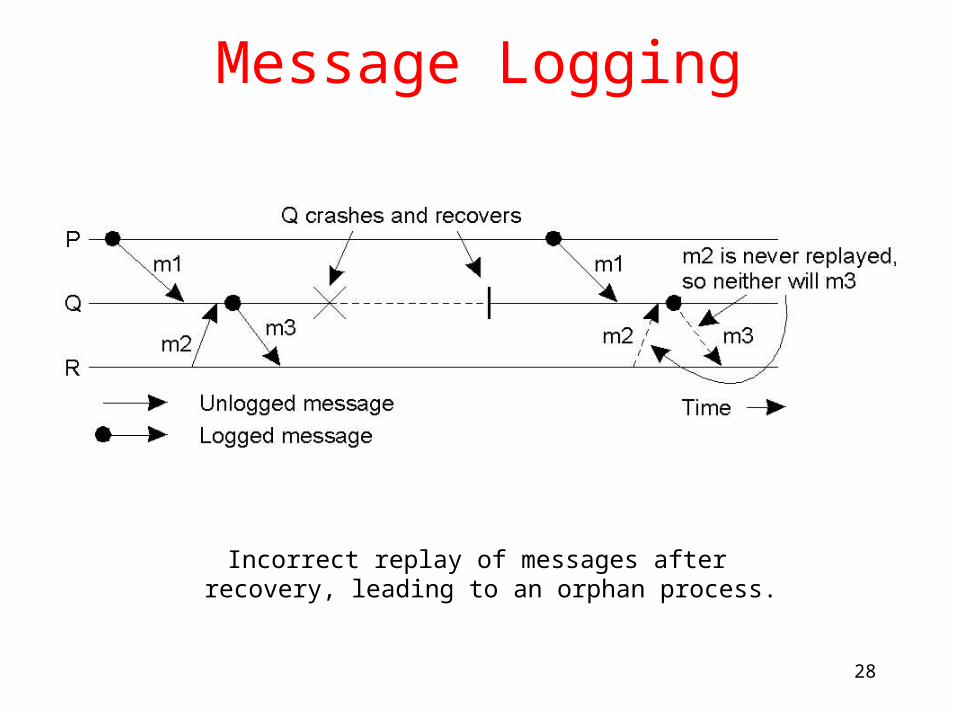
Message Logging
Incorrect replay of messages after recovery, leading to an orphan process.





























