Embed Size (px)
Citation preview

1
Efficient Clustering of High-Dimensional Data Sets
Andrew McCallumWhizBang! Labs & CMU
Kamal NigamWhizBang! Labs
Lyle UngarUPenn

2
Large Clustering Problems
• Many examples
• Many clusters
• Many dimensions
Example Domains• Text
• Images
• Protein Structure

3
The Citation Clustering Data
• Over 1,000,000 citations
• About 100,000 unique papers
• About 100,000 unique vocabulary words
• Over 1 trillion distance calculations

4
Reduce number of distance calculations
• [Bradley, Fayyad, Reina KDD-98] – Sample to find initial starting points for
k-means or EM
• [Moore 98]– Use multi-resolution kd-trees to group similar
data points
• [Omohundro 89]– Balltrees

5
The Canopies Approach
• Two distance metrics: cheap & expensive
• First Pass– very inexpensive distance metric– create overlapping canopies
• Second Pass– expensive, accurate distance metric– canopies determine which distances calculated

6
Illustrating Canopies

7
Overlapping Canopies

8
Creating canopies with two thresholds
• Put all points in D• Loop:
– Pick a point X from D
– Put points within Kloose of X in canopy
– Remove points within Ktight of X from D loose
tight

9
Canopies
• Two distance metrics– cheap and approximate– expensive and accurate
• Two-pass clustering– create overlapping canopies– full clustering with limited distances
• Canopy property– points in same cluster will be in same canopy

10
Using canopies with GAC
• Calculate expensive distances between points in the same canopy
• All other distances default to infinity
• Sort finite distances and iteratively merge closest

11
Computational Savings
• inexpensive metric << expensive metric
• number of canopies: c (large)
• canopies overlap: each point in f canopies
• roughly f*n/c points per canopy
• O(f 2 *n 2/c) expensive distance calculations
• complexity reduction: O(f2/c)
• n=106; k=104; c=1000; f small:
computation reduced by factor of 1000
12
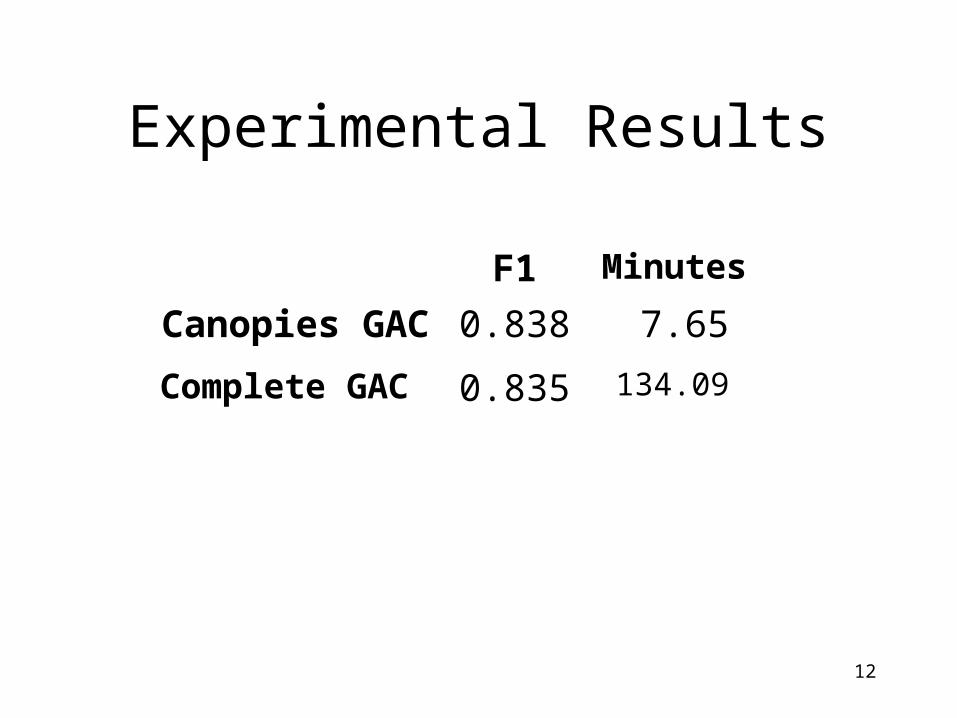
Experimental Results
134.090.835Complete GAC
7.650.838Canopies GAC
MinutesF1

13
Preserving Good Clustering
• Small, disjoint canopies big time savings
• Large, overlapping canopies original accurate clustering
• Goal: fast and accurate– requires good, cheap distance metric

14
Reduced Dimension Representations

15
• Clustering finds groups of similar objects
• Understanding clusters can be difficult
• Important to understand/interpret results
• Patterns waiting to be discovered

16
A picture is worth 1000 clusters

17
Feature Subset Selection
• Find n features that work best for prediction
• Find n features such that distance on them best correlates with distance on all features
• Minimize:
Discrepancy= (dijnew
i<j∑ −dij
old)2

18
Feature Subset Selection
• Suppose all features relevant
• Does that mean dimensionality can’t be reduced?
• No!
• Manifold in feature space is what counts, not relevance of individual features
• Manifold can be lower dimension than feats

19
PCA: Principal Component Analysis
• Given data in d dimensions
• Compute:– d-dim mean vector M– dxd-dim covariance matrix C– eigenvectors and eigenvalues– Sort by eigenvalues– Select top k<d eigenvalues– Project data onto k eigenvectors

20
PCA
Mean vector M: mi =
xipts∑
1pts∑

21
PCA
Covariance C: cij =E (xi −mi )(xj −mj)

22
PCA
• Eigenvectors– Unit vectors in directions of maximum variance
• Eigenvalues– Magnitude of the variance in the direction of each
eigenvector
M ⋅ x=λ ⋅x
(M−λI) ⋅x=0
M ⋅ej =λ j ⋅ej

23
PCA
• Find largest eigenvalues and corresponding eigenvectors
• Project points onto k principal components
• where A is a d x k matrix whose columns are the k principal components of each point
λ1,λ2,λ3,...e1,e2,e3,...
x'=At x−M( )

24
PCA via Autoencoder ANN

25
Non-Linear PCA by Autoencoder

26
PCA
• need vector representation
• 0-d: sample mean
• 1-d: y = mx + b
• 2-d: y1 = mx + b; y2 = m`x + b`
m+ akieii=1
dnew
∑⎛ ⎝
⎞ ⎠ −xk
⎡ ⎣
⎤ ⎦ k=1
n
∑2

27
MDS: Multidimensional Scaling
• PCA requires vector representation
• Given pairwise distances between n points?
• Find coordinates for points in d dimensional space s.t. distances are preserved “best”

28

29

30
MDS
• Assign points to coords xi in d-dim space
– random coordinate values– principal components– dimensions with greatest variance
• Do gradient descent on coordinates xi of each point j until distortion is minimzed

31
J ee =
(dijnew−dij
old)2
i<j∑
(dijold)2
i<j∑
Distortion

32
J ff =dijnew−dij
old
dijold
⎛
⎝ ⎜
⎞
⎠ ⎟
2
i<j∑
Distortion

33
J ef =
(dijnew−dij
old)2
dijold
i<j∑
dijold
i<j∑
Distortion

34
Gradient Descent on Coordinates
dJeedxk
=2
dkjnew−dkj
old( )
j≠k∑
xk −xjdkjnew
⎛
⎝ ⎜
⎞
⎠ ⎟
dijold
( )2
i<j∑

35
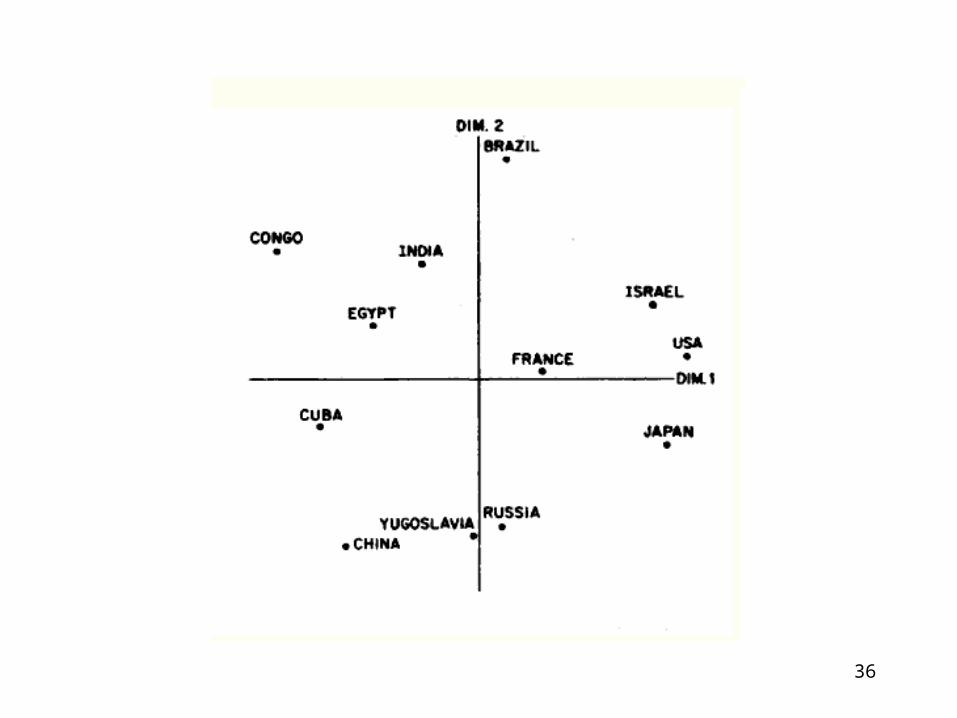
Subjective Distances
• Brazil• USA• Egypt• Congo• Russia• France• Cuba• Yugoslavia• Israel• China
36

37

38
How Many Dimensions?
• D too large– perfect fit, no distortion– not easy to understand/visualize
• D too small– poor fit, much distortion– easyto visualize, but pattern may be misleading
• D just right?

39

40

41

42
Agglomerative Clustering of Proteins

43





























