Embed Size (px)
Citation preview

1
Chapter 7: Clock Synchronization,
Coordination &Agreement

2
Clock Synchronization, Coordination & Agreement
Introduction Clocks, events & process states Physical & logical clocks Global statesMulticast communication Consensus & related problem

3
Objectives To study mathematical tools for an execution of DS, by exploring the notions of physical, logical time & global states.
To know the utility of synchronized clocks in DS & variability in network delays that stands in the way of accurate synchronization.
To understand the construction of a snapshot algorithm.
To know the practical importance of global states for reasoning about debugging, deadlocks etc.
To appreciate impact of whether we use a synchronous or asynchronous system model on algorithms we can construct.

4
Introduction
• We need to measure time accurately:• to know the time an event occurred at a computer• to do this we need to synchronize its clock with an authoritative
external clock
• Algorithms for clock synchronization useful for• concurrency control based on timestamp ordering• authenticity of requests e.g. in Kerberos
• There is no global clock in a distributed system• this chapter discusses clock accuracy and synchronisation
• Logical time is an alternative• It gives ordering of events - also useful for consistency of replicated
data

5
Computer clocks and timing events
• Each computer in a DS has its own internal clock – used by local processes to obtain the value of the current time– processes on different computers can timestamp their events – but clocks on different computers may give different times– computer clocks drift from perfect time and their drift rates differ from
one another. – clock drift rate: the relative amount that a computer clock differs from
a perfect clock
Even if clocks on all computers in a DS are set to the same time, their clocks will eventually vary quite significantly unless corrections are applied

6
Clocks, events and process states
A distributed system is defined as a collection P of N processes pi, i = 1,2,… N
Each process pi has a state si consisting of its variables (which it transforms as it executes)
Processes communicate only by messages (via a network) Actions of processes:
– Send, Receive, change own state
Event: the occurrence of a single action that a process carries out as it executes e.g. Send, Receive, change state
Events at a single process pi, can be placed in a total ordering denoted by the relation between the events.

7
Clocks
We have seen how to order events (happened before)
To timestamp events, use the computer’s clock-physical clock
At real time, t, the OS reads the time on the computer’s hardware clock Hi(t)

8
Skew between computer clocks in a distributed system
Computer clocks are not generally in perfect agreement
Skew: the difference between the times on two clocks (at any instant)
Computer clocks are subject to clock drift (they count time at different rates)
Clock drift rate: the difference per unit of time from some ideal reference clock
Ordinary quartz clocks drift by about 1 sec in 11-12 days. (10-6 secs/sec).
High precision quartz clocks drift rate is about 10-7 or 10-8 secs/sec
Network Figure 11.1

9
Coordinated Universal Time (UTC)
International Atomic Time is based on very accurate physical clocks (drift rate 10-13)
UTC is an international standard for time keeping It is based on atomic time, but occasionally adjusted to
astronomical time It signal, are synchronized and broadcast from radio stations
on land and satellite (e.g. GPS) Computers with receivers can synchronize their clocks with
these timing signals Signals from land-based stations are accurate to about 0.1-
10 millisecond Signals from GPS are accurate to about 1 microsecond

10
Synchronizing physical clocks
External synchronization– A computer’s clock Ci is synchronized with an external
authoritative time source. Internal synchronization
– The clocks of a pair of computers are synchronized with one another.
Internally synchronized clocks are not necessarily externally synchronized, as they may drift collectively
if the set of processes P is synchronized externally within a bound D, it is also internally synchronized within bound 2D
Clock failure – faulty of clock, crash failure and arbitrary failure

11
Synchronization in a synchronous system (recall…)
a synchronous distributed system is one in which the following bounds are defined (ch. 2 p. 50):– the time to execute each step of a process has known lower and
upper bounds– each message transmitted over a channel is received within a known
bounded time– each process has a local clock whose drift rate from real time has a
known bound

12
Cristian’s and Berkeley algorithm
Cristian’s algorithm – used of a time server , connected to a device that receives signal from
UTC– Synchronized computer clock externally– a single time server might fail, render synchronization impossible
temporarily.– so they suggest the use of a group of synchronized servers– it does not deal with faulty servers – so berkeley algorithm is
introduced

13
Cristian’s and Berkeley algorithm
Berkeley algorithm (also 1989)– An algorithm for internal synchronization of a group of computers– A master(coordinator comp) polls to collect clock values from the
others (slaves- other comp)– The master uses round trip times to estimate the slaves’ clock values– It takes an average (eliminating any above some average round trip
time or with faulty clocks)– It sends the required adjustment to the slaves (better than sending the
time which depends on the round trip time)– Measurements
15 computers, clock synchronization 20-25 millisecs drift rate < 2x10-5
If master fails, can elect a new master to take over (not in bounded time)

14
Network Time Protocol (NTP)
1
2
3
2
3 3
A time service for the Internet - synchronizes clients to UTC
Figure 11.3
Reliability from redundant paths, scalable, uthenticates time sources
Primary servers are connected to UTC sources
Secondary servers are synchronized to primary servers
Synchronization subnet - lowest level servers in users’ computers

15
NTP - synchronisation of servers
The synchronization subnet can reconfigure if failures occur, e.g.– a primary that loses its UTC source can become a secondary– a secondary that loses its primary can use another primary
Modes of synchronization: Multicast
A server within a high speed LAN multicasts time to others which set clocks assuming some delay (not very accurate)
Procedure call A server accepts requests from other computers (like Cristiain’s algorithm). Higher
accuracy. Useful if no hardware multicast.
Symmetric Pairs of servers exchange messages containing time information Used where very high accuracies are needed (e.g. for higher levels)

16
Messages exchanged between a pair of NTP peers
Ti
Ti-1Ti-2
Ti- 3
Server B
Server A
Time
m m'
Time
All modes use UDP Each message bears timestamps of recent events:
– Local times of Send and Receive of previous message– Local times of Send of current message
Recipient notes the time of receipt Ti ( we have Ti-3, Ti-2, Ti-1, Ti)
In symmetric mode there can be a non-negligible delay between messages
Figure 11.4

17
Logical time and logical clocks (Lamport 1978)
Instead of synchronizing clocks, event ordering can be used
p1
p2
p3
a b
c d
e f
m1
m2
Physicaltime
Figure11.5
the happened before relation is the relation of causal ordering
1. If two events occurred at the same process pi (i = 1, 2, … N) then they occurred in the order observed by pi, that is
2. when a message, m is sent between two processes, send(m) happened before receive(m)
a b (at p1) c d (at p2) b c because of m1 also d f because of m2
Not all events are related by consider a and e (different processes and no chain of messages to relate them)
they are not related by ; they are said to be concurrent; write as a || e

18
Global State
The ‘snapshot’ algorithm of Chandy and Lamport (1985)
Determine global states of DS Goal algorithm: record a set of process and channel
states (a snapshot) for a set of process pi where i = 1, 2, 3, … N
Algorithm record state locally at processes, it does not give a method for gathering the global states at one site.

19
Global State (Cont.)
Algorithm assumes:- neither channel nor process fail- channel are unidirectional and provide FIFO message delivery- graph of processes and channels is strongly connected (there is path between two processes)- any process may initiate a global snapshot at a time- process may continue their execution and send and receive normal messages while the snapshot take place

20
Revision of IP multicast (section 4.5.1 page165)
IP multicast – an implementation of group communication– built on top of IP (note IP packets are addressed to computers) – allows the sender to transmit a single IP packet to a set of computers that form
a multicast group (a class D internet address with first 4 bits 1110)– Dynamic membership of groups. Can send to group with or without joining it– To multicast, send a UDP datagram with a multicast address– To join, make a socket join a group enabling it to receive messages to group
Multicast routers – Local messages use local multicast capability. Routers make it efficient by
choosing other routers on the way. Failure model
– Omission failures some but not all members may receive a message. e.g. a recipient may drop message, or a multicast router may fail
– IP packets may not arrive in sender order, group members can receive messages in different orders

21
Introduction to multicast
Multicast communication requires coordination and agreement. The aim is for members of a group to receive copies of messages sent to the group
Many different delivery guarantees are possible – e.g. agree on the set of messages received or on delivery ordering
A process can multicast by the use of a single operation instead of a send to each member– For example in IP multicast aSocket.send(aMessage)– The single operation allows for:
efficiency I.e. send once on each link, using hardware multicast when available, e.g. multicast from a computer in London to two in Beijing
delivery guarantees e.g. can’t make a guarantee if multicast is implemented as multiple sends and the sender fails. Can also do ordering

22
System model
The system consists of a collection of processes which can communicate reliably over 1-1 channels
Processes fail only by crashing (no arbitrary failures) Processes are members of groups - which are the
destinations of multicast messages In general process p can belong to more than one group Operations
– multicast(g, m) sends message m to all members of process group g– deliver (m) is called to get a multicast message delivered. It is different from
receive as it may be delayed to allow for ordering or reliability.
Multicast message m carries the id of the sending process sender(m) and the id of the destination group group(m)
We assume there is no falsification of the origin and destination of messages
23
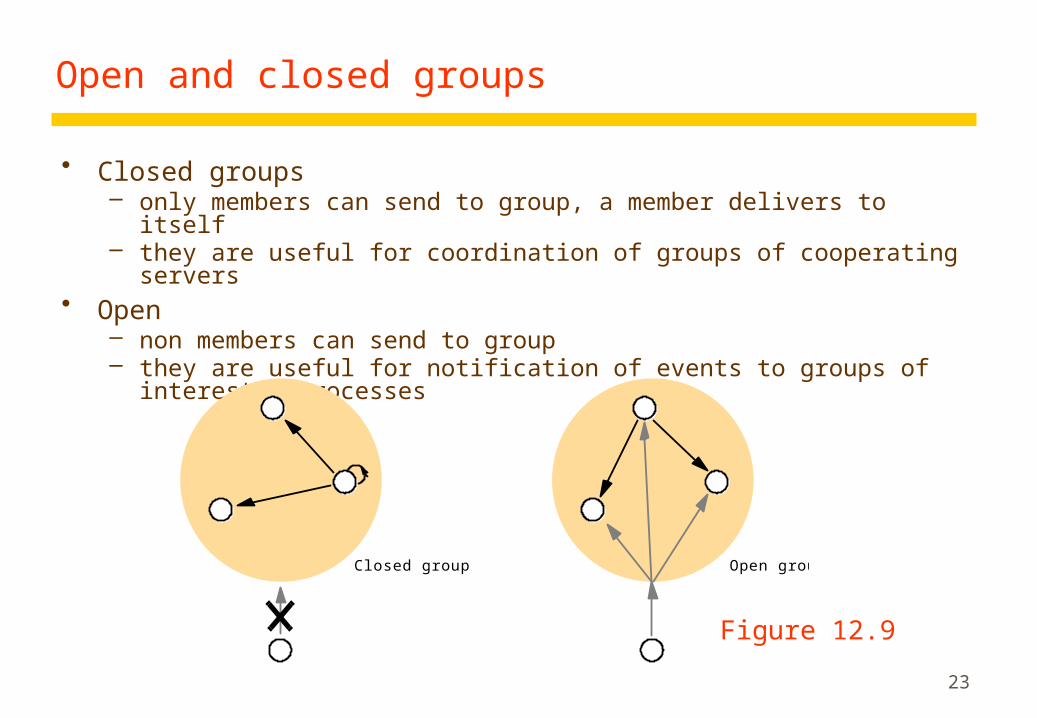
Open and closed groups
Closed groups – only members can send to group, a member delivers to itself – they are useful for coordination of groups of cooperating servers
Open – non members can send to group – they are useful for notification of events to groups of interested processes
Closed group Open group
Figure 12.9

24
Reliability of one-to-one communication(Ch.2 page 57)
The term reliable 1-1 communication is defined in terms of validity and integrity as follows:
validity: – any message in the outgoing message buffer is eventually delivered
to the incoming message buffer;
integrity:– the message received is identical to one sent, and no messages are
delivered twice.
integrity by use checksums, reject duplicates (e.g. due to retries). If allowing for malicious users, use security techniques
validity - by use of acknowledgements and retries

25
Basic multicast
A correct process will eventually deliver the message, as long as multicaster does not crash– note that IP multicast does not give this guarantee
The primitives are called B-multicast and B-deliver
A straightforward but ineffective method of implementation:– use a reliable 1-1 send (i.e. with integrity and validity as above)
To B-multicast(g,m): for each process p & g, send(p, m);On receive (m) at p: B-deliver (m) at p

26
Reliable multicast
The protocol is correct even if the multicaster crashes it satisfies criteria for validity, integrity and agreement it provides operations R-multicast and R-deliver Integrity - a correct process, p delivers m at most once.
Also p e group(m) and m was supplied to a multicast operation by sender(m)
Validity - if a correct process multicasts m, it will eventually deliver m
Agreement - if a correct process delivers m then all correct processes in group(m) will eventually deliver m
integrity as for 1-1 communication
validity - simplify by choosing sender as the one process
agreement - all or nothing - atomicity, even if multicaster crashes
27
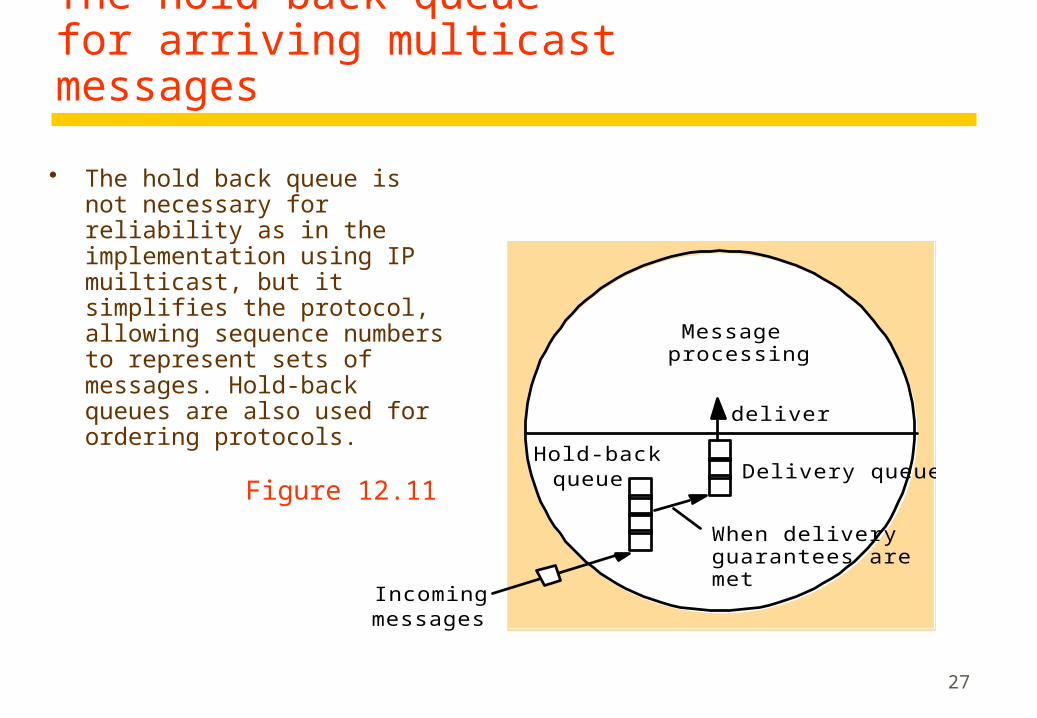
The hold-back queue for arriving multicast messages
The hold back queue is not necessary for reliability as in the implementation using IP muilticast, but it simplifies the protocol, allowing sequence numbers to represent sets of messages. Hold-back queues are also used for ordering protocols.
Messageprocessing
Delivery queueHold-back
queue
deliver
Incomingmessages
When delivery guarantees aremet
Figure 12.11

28
Reliability properties of reliable multicast over IP
Integrity - duplicate messages detected and rejected.IP multicast uses checksums to reject corrupt messages
Validity - due to IP multicast in which sender delivers to itself Agreement - processes can detect missing messages. They
must keep copies of messages they have delivered so that they can re-transmit them to others.
discarding of copies of messages that are no longer needed : – when piggybacked acknowledgements arrive, note which processes have
received messages. When all processes in g have the message, discard it.– problem of a process that stops sending - use ‘heartbeat’ messages.

29
Ordered multicast (Cont.)
The basic multicast algorithm delivers messages to processes in an arbitrary order. A variety of orderings may be implemented:
FIFO ordering– If a correct process issues multicast(g, m) and then multicast(g,m’ ), then
every correct process that delivers m’ will deliver m before m’ . Causal ordering
– If multicast(g, m) multicast(g,m’ ), where is the happened-before relation between messages in group g, then any correct process that delivers m’ will deliver m before m’ .
Total ordering– If a correct process delivers message m before it delivers m’, then any other
correct process that delivers m’ will deliver m before m’. Ordering is expensive in delivery latency and bandwidth consumption

30
Total, FIFO and causal ordering of multicast messages
these definitions do not imply reliability, but we can define atomic multicast - reliable and totally ordered.
F3
F1
F2
T2
T1
P1 P2 P3
Time
C3
C1
C2
Figure 12.12
Notice the consistent ordering of totally ordered messages T1 and T2.They are opposite to real time.The order can be arbitraryit need not be FIFO or causal
Note the FIFO-related messages F1 and F2
and the causally related messages C1 and C3
Ordered multicast delivery is expensive in bandwidth and latency. Less expensive orderings (e.g. FIFO or causal) are chosen for applications for which they are suitable

31
Display from a bulletin board program
Users run bulletin board applications which multicast messages One multicast group per topic (e.g. os.interesting) Require reliable multicast - so that all members receive messages Ordering:
Bulletin board: os.interesting
Item From Subject
23 A.Hanlon Mach
24 G.Joseph Microkernels
25 A.Hanlon Re: Microkernels
26 T.L’Heureux RPC performance
27 M.Walker Re: Mach
endFigure 11.13
total (makes the numbers the same at all sites)
FIFO (gives sender order
causal (makes replies come after original message)

32
Implementation of totally ordered multicast
The general approach is to attach totally ordered identifiers to multicast messages– each receiving process makes ordering decisions based on the identifiers – similar to the FIFO algorithm, but processes keep group specific sequence
numbers– operations TO-multicast and TO-deliver
we present two approaches to implementing total ordered multicast over basic multicast
1. using a sequencer (only for non-overlapping groups)
2. the processes in a group collectively agree on a sequence number for each message

33
Discussion of sequencer protocol
Since sequence numbers are defined by a sequencer, we have total ordering.
Kaashoek’s protocol uses hardware-based multicast The sender transmits one message to sequencer, then
the sequencer multicasts the sequence number and the messagebut IP multicast is not as reliable as B-multicast so the sequencer stores
messages in its history buffer for retransmission on request members notice messages are missing by inspecting sequence numbers

34
The ISIS algorithm for total ordering
this protocol is for open or closed groups
2
1
1
2
2
1 Message
2 Proposed Seq
P2
P3
P1
P4
3 Agreed Seq
3
3
Figure 12.15
1. the process P1 B-multicats a message to members of the group
3. the sender uses the proposed numbers to generate an agreed number
2. the receiving processes propose numbers and return them to the sender

35
Discussion of ordering in ISIS protocol
Hold-back queue ordered with the message with the smallest sequence
number at the front of the queue when the agreed number is added to a message, the queue
is re-ordered when the message at the front has an agreed id, it is
transferred to the delivery queue– even if agreed, those not at the front of the queue are not transferred
every process agrees on the same order and delivers messages in that order, therefore we have total ordering.
Latency– 3 messages are sent in sequence, therefore it has a higher latency than
sequencer method– this ordering may not be causal or FIFO

36
Causally ordered multicast
We present an algorithm of Birman 1991 for causally ordered multicast in non-overlapping, closed groups. It uses the happened before relation (on multicast messages only)– that is, ordering imposed by one-to-one messages is not taken into
account
It uses vector timestamps - that count the number of multicast messages from each process that happened before the next message to be multicast

37
Comments on multicast protocols
we need to have protocols for overlapping groups because applications do need to subscribe to several groups
multicast in synchronous and asynchronous systems– all of our algorithms do work in both
reliable and totally ordered multicast – can be implemented in a synchronous system– but is impossible in an asynchronous system (reasons discussed in
consensus section - paper by Fischer et al.)

38
Summary
accurate timekeeping is important for distributed systems. algorithms (e.g. Cristian’s and NTP) synchronize clocks in
spite of their drift and the variability of message delays. for ordering of an arbitrary pair of events at different
computers, clock synchronization is not always practical. the happened-before relation is a partial order on events that
reflects a flow of information between them. Lamport clocks are counters that are updated according to
the happened-before relationship between events. vector clocks are an improvement on Lamport clocks,
– we can tell whether two events are ordered by happened-before or are concurrent by comparing their vector timestamps

39
Summary (Cont.)
Multicast communication can specify requirements for reliability and ordering, in terms of integrity, validity and agreement
B-multicast – a correct process will eventually deliver a message
provided the multicaster does not crash reliable multicast
– in which the correct processes agree on the set of messages to be delivered;
– we showed two implementations: over B-multicast and IP multicast

40
Summary (Cont.)
delivery ordering– FIFO, total and causal delivery ordering. – FIFO ordering by means of senders’ sequence numbers– total ordering by means of a sequencer or by agreement
of sequence numbers between processes in a group– causal ordering by means of vector timestamps
the hold-back queue is a useful component in implementing multicast protocols





























