Embed Size (px)
Citation preview

1
Chapter 6Chapter 6
Future Processors to use Coarse-Grain Parallelism

2
Future Future pprocessors to use rocessors to use ccoarse-oarse-ggrain rain pparallelismarallelism
Chip multiprocessors (CMPs) or multiprocessor chips– integrate two or more complete processors on a single chip,– every functional unit of a processor is duplicated
Simultaneous multithreaded processors (SMPs)– store multiple contexts in different register sets on the chip,– the functional units are multiplexed between the threads,– instructions of different contexts are simultaneously executed

3
Principal Principal cchip hip mmultiprocessor ultiprocessor aalternativeslternatives
Symmetric multiprocessor (SMP)
Distributed shared memory multiprocessor (DSM)
Message-passing shared-nothing multiprocessor

4
Organizational Organizational principles of principles of multiprocessorsmultiprocessors
Pro- cessor
Pro- cessor
...
Interconnection
Shared Memory
(SMP) symmetric multiprocessor
Pro- cessor
Pro- cessor
...
(DSM) distributed-shared-memorymultiprocessor
Interconnection
LocalMemory
LocalMemory
Pro- cessor
Pro- cessor
...
Interconnection
LocalMemory
LocalMemory
message-passing(shared-nothing) multiprocessor
send receive
empty
global memory physically distributed memory
dist
ribu
ted
addr
ess
spac
essh
ared
add
ress
spa
ce

5
Typical SMPTypical SMP
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
PrimaryCache
SecondaryCache
Bus
SecondaryCache
SecondaryCache
SecondaryCache
PrimaryCache
PrimaryCache
PrimaryCache
Global Memory
6
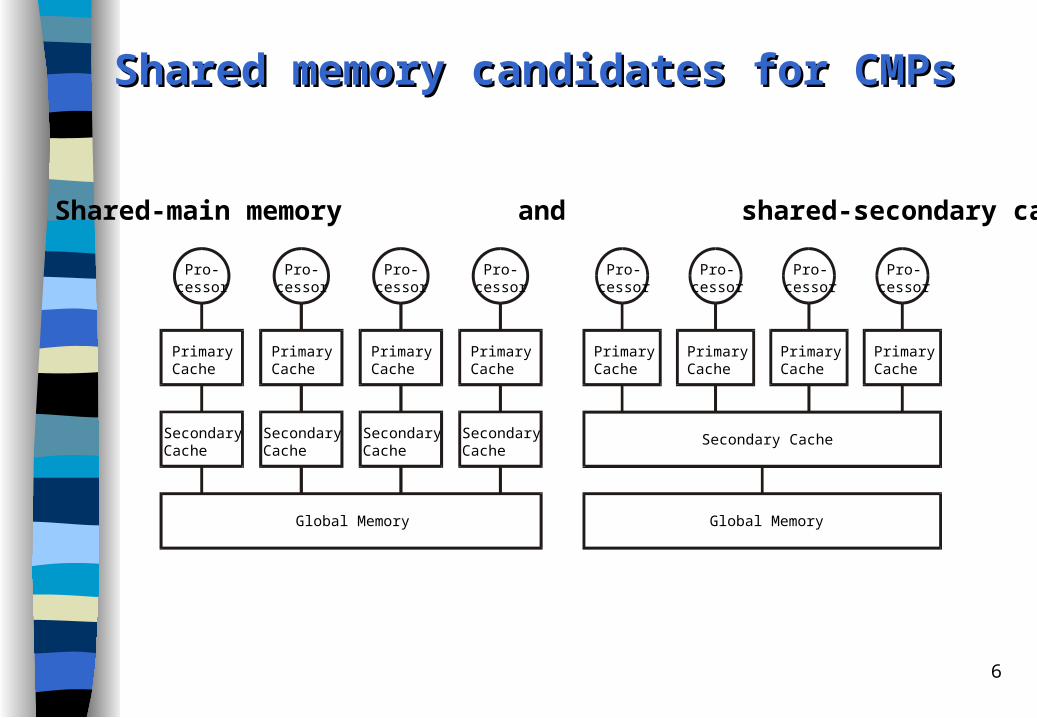
Shared memory candidates for CMPsShared memory candidates for CMPs
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
PrimaryCache
SecondaryCache
SecondaryCache
SecondaryCache
SecondaryCache
Global Memory
PrimaryCache
PrimaryCache
PrimaryCache
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
PrimaryCache
Secondary Cache
Global Memory
PrimaryCache
PrimaryCache
PrimaryCache
Shared-main memory and shared-secondary cache
7
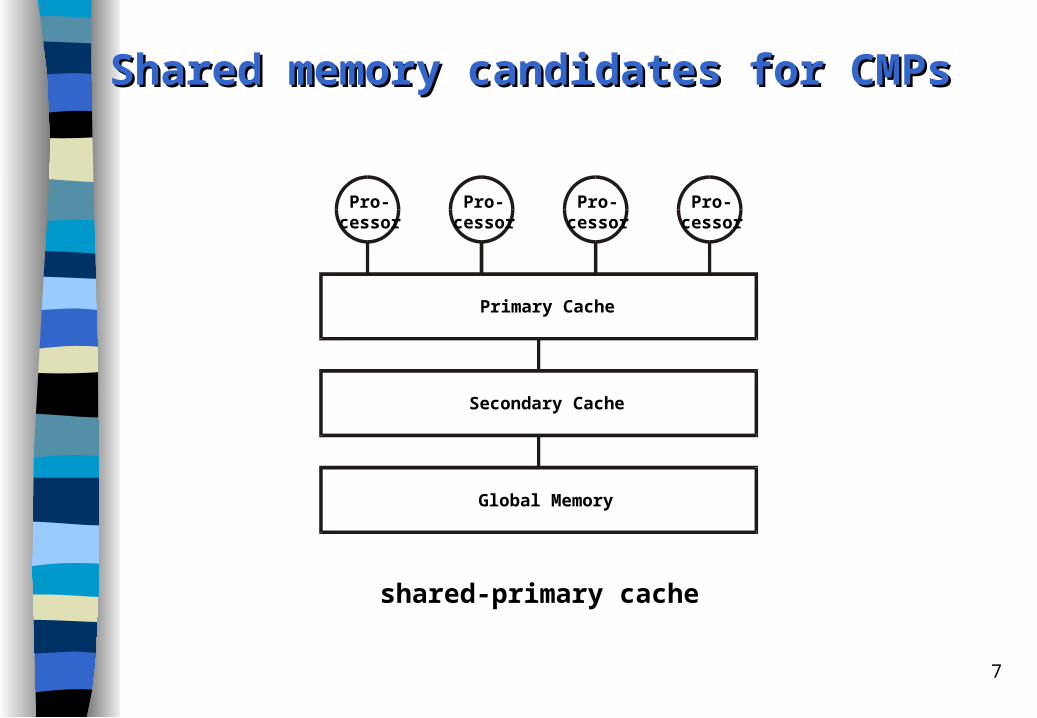
Shared memory candidates for CMPsShared memory candidates for CMPs
Pro-cessor
Pro-cessor
Pro-cessor
Pro-cessor
Secondary Cache
Global Memory
Primary Cache
shared-primary cache

8
Grain-levels for CMPsGrain-levels for CMPs
multiple processes in parallel
multiple threads from a single application implies a common address space for all threads
extracting threads of control dynamically from a single instruction stream
see last chapter, multiscalar, trace processors, ...

9
Texas Instruments TMS320C80 Multimedia Video Texas Instruments TMS320C80 Multimedia Video ProcessorProcessor
AdvancedDSP3
Par
amet
er R
AM
Dat
a R
AM
2D
ata
RA
M1
Dat
a R
AM
0I-
Cac
he
Par
amet
er R
AM
Dat
a R
AM
2D
ata
RA
M1
Dat
a R
AM
0I-
Cac
he
Par
amet
er R
AM
Dat
a R
AM
2D
ata
RA
M1
Dat
a R
AM
0I-
Cac
he
Par
amet
er R
AM
Dat
a R
AM
2D
ata
RA
M1
Dat
a R
AM
0I-
Cac
he
Par
amet
er R
AM
Dat
a R
AM
2D
ata
RA
M1
Dat
a R
AM
0I-
Cac
he
3232
64 3232
64 3232
64 3232
64
L G I
AdvancedDSP2
L G I
AdvancedDSP1
L G I
AdvancedDSP0
L G I
FPU
C/D I
MP
64
TC
TAP
VC
32
64 32
64
10
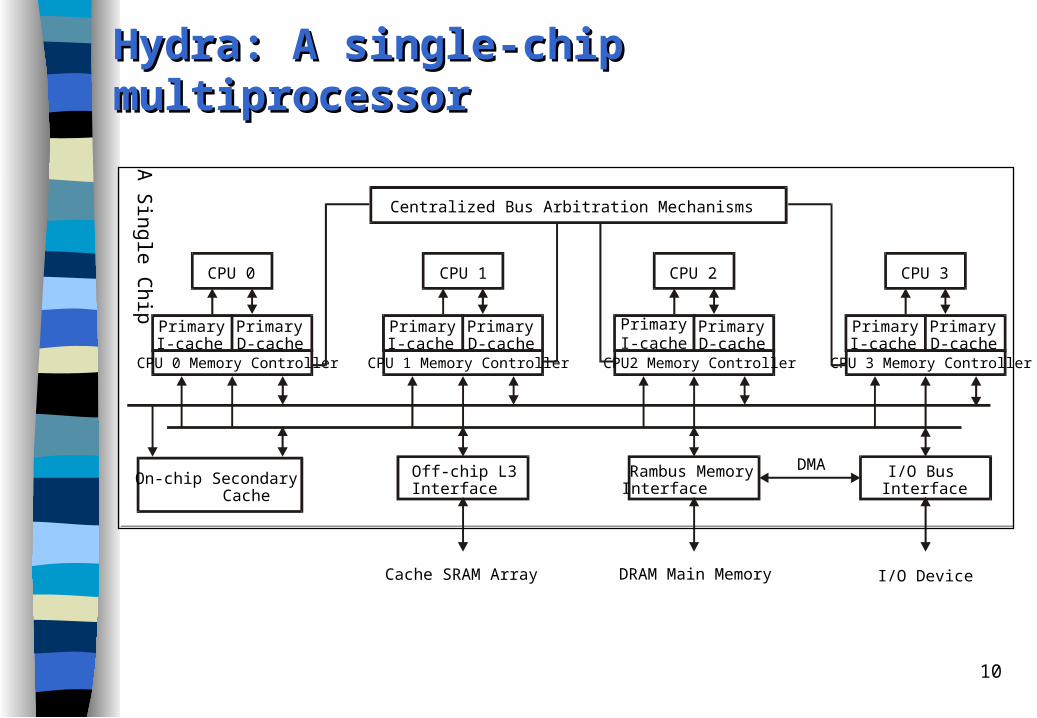
Hydra: A Hydra: A ssingle-ingle-cchip hip mmultiprocessorultiprocessor
CPU 0
Centralized Bus Arbitration Mechanisms
Cache SRAM Array DRAM Main Memory I/O Device
A S
ingle Chip
PrimaryI-cache
PrimaryD-cache
CPU 0 Memory Controller
Rambus MemoryInterface
Off-chip L3Interface
I/O BusInterface
DMA
CPU 1
PrimaryI-cache
PrimaryD-cache
CPU 1 Memory Controller
CPU 2
PrimaryI-cache
PrimaryD-cache
CPU2 Memory Controller
CPU 3
PrimaryI-cache
PrimaryD-cache
CPU 3 Memory Controller
On-chip Secondary Cache

11
Conclusions on CMPConclusions on CMP
Usually, a CMP will feature:– separate L1 I-cache and D-cache per on-chip CPU – and an optional unified L2 cache.
If the CPUs always execute threads of the same process, the L2 cache organization will be simplified, because different processes do not have to be distinguished.
Recently announced commercial processors with CMP hardware:– IBM Power4 processor with 2 processor on a single die– Sun MAJC5200 two processor on a die (each processor a 4-threaded block-
interleaving VLIW)

12
Multithreaded Multithreaded pprocessorsrocessors
Aim: Latency tolerance What is the problem?
Load access latencies measured on an Alpha Server 4100 SMP with four 300 MHz Alpha 21164 processors are:– 7 cycles for a primary cache miss which hits in the on-chip L2 cache of the
21164 processor,– 21 cycles for a L2 cache miss which hits in the L3 (board-level) cache,– 80 cycles for a miss that is served by the memory, and– 125 cycles for a dirty miss, i.e., a miss that has to be served from another
processor's cache memory.
Multithreaded processors are able to bridge latencies by switching to another thread of control - in contrast to chip multiprocessors.

13
Register set 1
Register set 2
Register set 3
Register set 4
PC PSR 1
PC PSR 2
PC PSR 3
PC PSR 4
FP
Thread 1:
Thread 2:
Thread 3:
Thread 4:
... ... ...
Multithreaded Multithreaded pprocessorsrocessors
Multithreading:– Provide several program counters registers (and usually several register
sets) on chip – Fast context switching by switching to another thread of control

14
Approaches of Approaches of mmultithreaded ultithreaded pprocessorsrocessors
Cycle-by-cycle interleaving– An instruction of another thread is fetched and fed into the execution
pipeline at each processor cycle. Block-interleaving
– The instructions of a thread are executed successively until an event occurs that may cause latency. This event induces a context switch.
Simultaneous multithreading– Instructions are simultaneously issued from multiple threads to the FUs of
a superscalar processor.
– combines a wide issue superscalar instruction issue with multithreading.

15
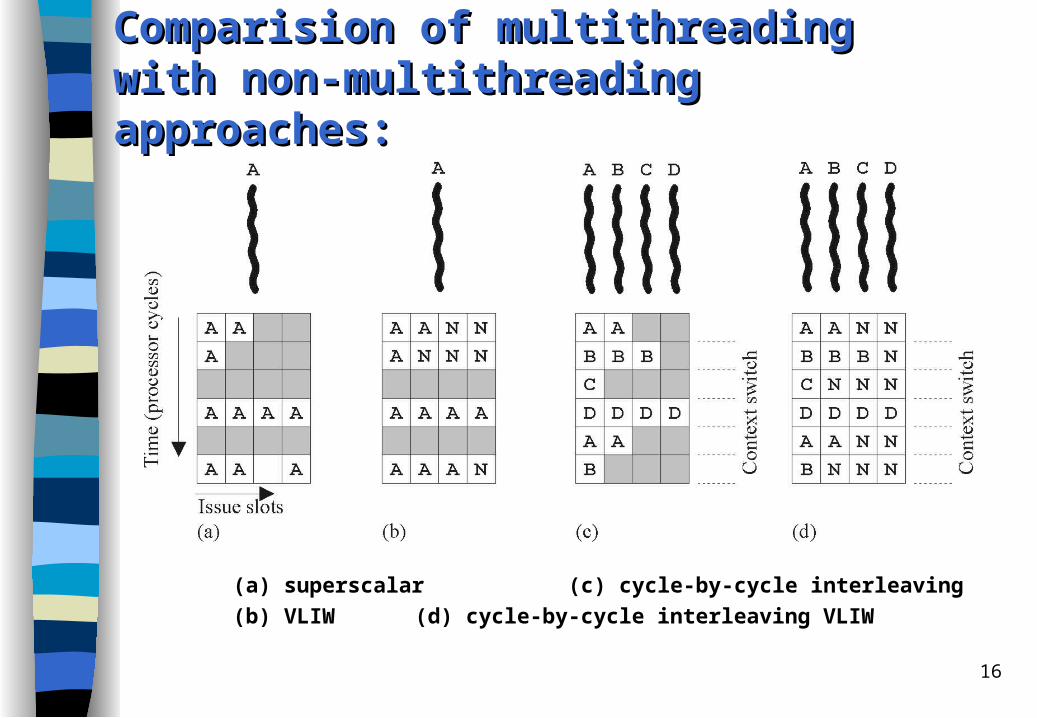
Comparision of Comparision of mmultithreading with ultithreading with nnon-on-mmultithreading ultithreading aapproaches:pproaches:
(a) single-threaded scalar(b) cycle-by-cycle interleaving multithreaded scalar (c) block interleaving multithreaded scalar
16
Comparision of Comparision of mmultithreading with ultithreading with nnon-on-mmultithreading ultithreading aapproaches:pproaches:
(a) superscalar (c) cycle-by-cycle interleaving
(b) VLIW (d) cycle-by-cycle interleaving VLIW
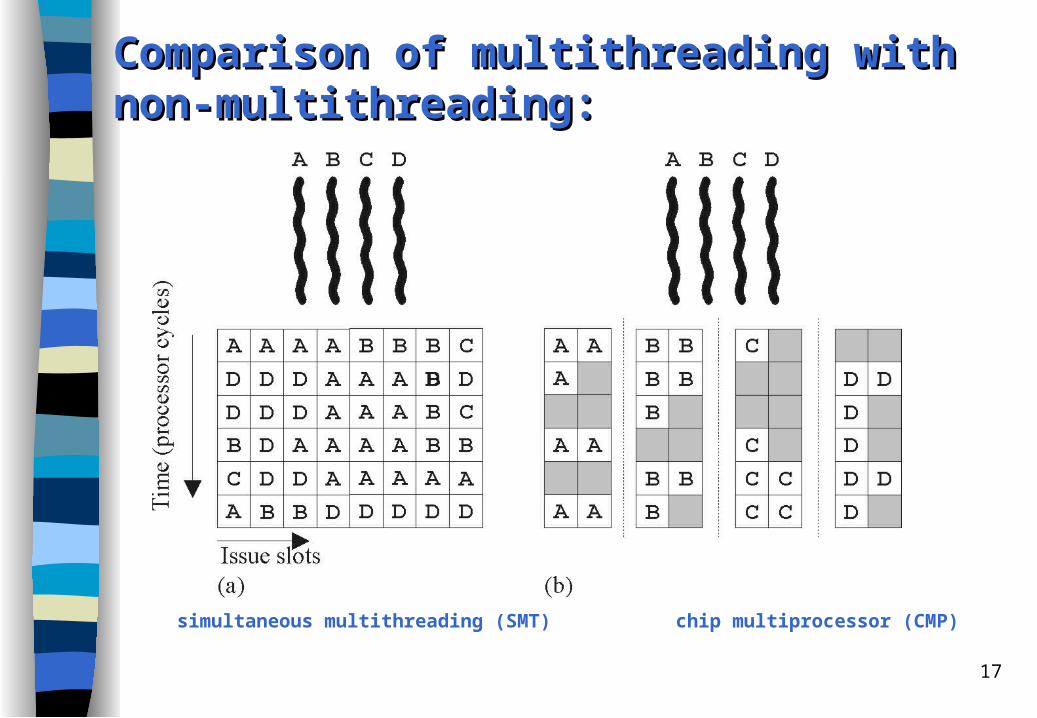
17
Comparison of Comparison of mmultithreading withultithreading withnnon-on-mmultithreading:ultithreading:
simultaneous multithreading (SMT) chip multiprocessor (CMP)

18
Cycle-by-Cycle-by-ccycle ycle iinterleavingnterleaving
the processor switches to a different thread after each instruction fetch pipeline hazards cannot arise and the processor pipeline can be easily built
without the necessity of complex forwarding paths context-switching overhead is zero cycles memory latency is tolerated by not scheduling a thread until the memory
transaction has completed requires at least as many threads as pipeline stages in the processor degrading the single-thread performance if not enough threads are present

19
Cycle-by-Cycle-by-ccycle ycle iinterleavingnterleaving- Improving single-thread performance- Improving single-thread performance
The dependence look-ahead technique adds several bits to each instruction format in the ISA.– Scheduler feeds non data or control dependent instructions of the same
thread successively into the pipeline.
The interleaving technique proposed by Laudon et al. adds caching and full pipeline interlocks to the cycle-by-cycle interleaving approach.

20
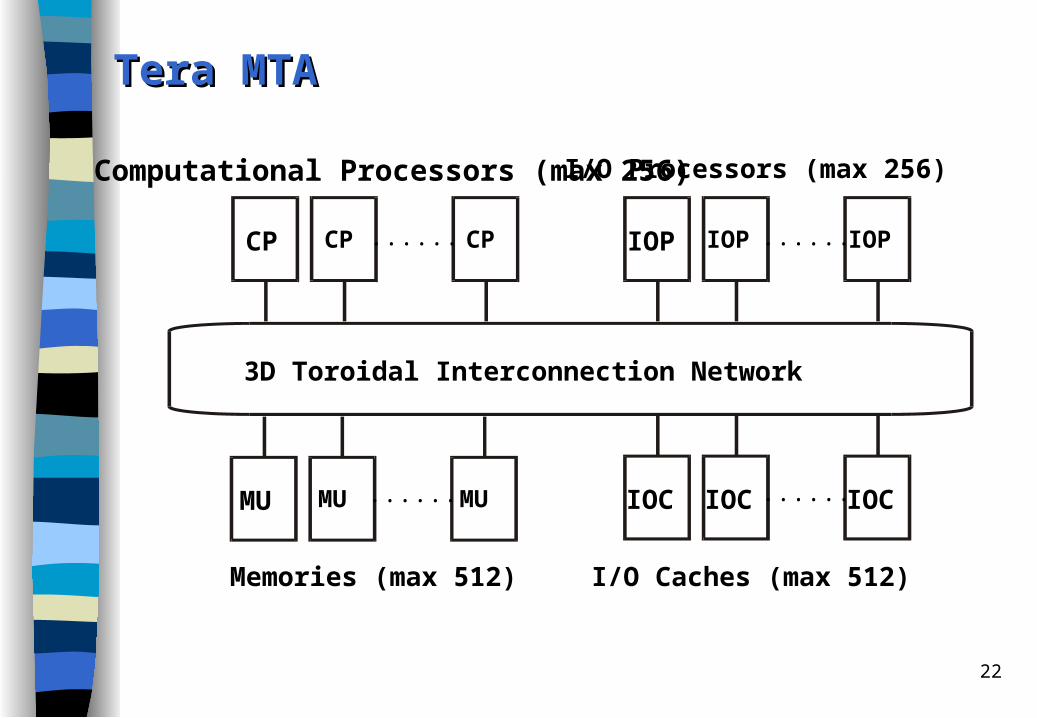
Tera MTATera MTA
cycle-by-cycle interleaving technique employs the dependence-look-ahead technique VLIW ISA (3-issue) The processor switches context every cycle (3 ns cycle period) among as many
as 128 distinct threads, thereby hiding up to 128 cycles (384 ns) of memory latency.
128 register sets
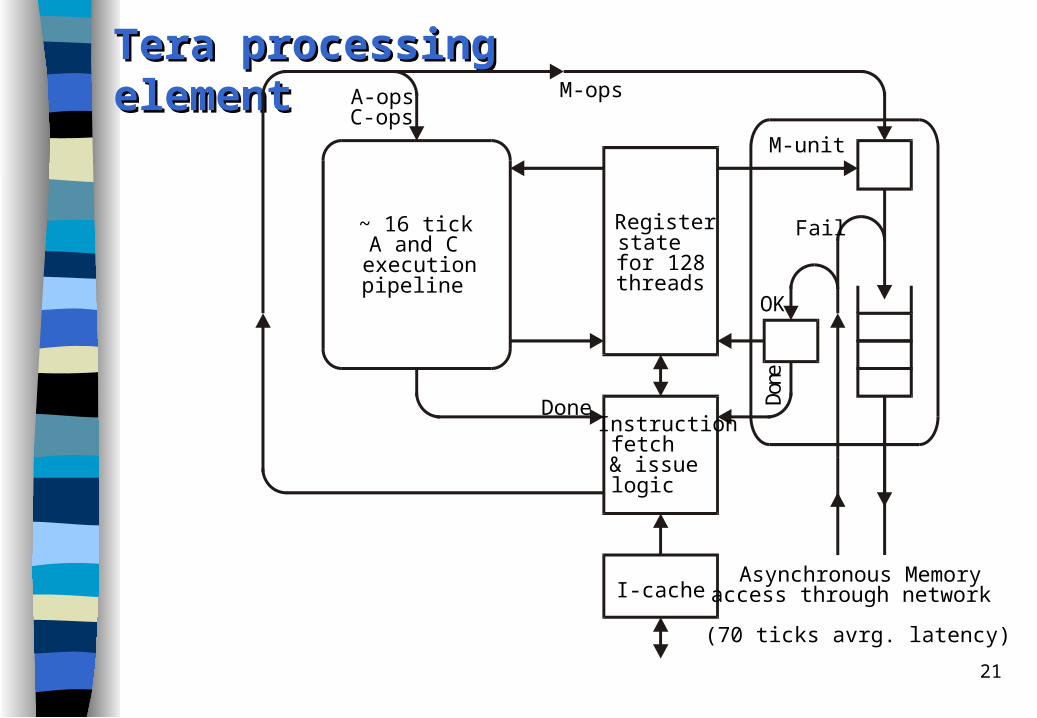
21
Tera Tera pprocessing rocessing eelementlement
Registerstatefor 128threads
Instructionfetch& issuelogic
I-cache
Done Don
e
OK
Fail~ 16 tickA and Cexecutionpipeline
M-unit
M-opsA-opsC-ops
Asynchronous Memoryaccess through network
(70 ticks avrg. latency)
22
Tera MTATera MTA
...... ......
...... ......
3D Toroidal Interconnection Network
Computational Processors (max 256)
CPCP CP
IOCMU MU MU IOC IOC
IOPIOPIOP
I/O Processors (max 256)
Memories (max 512) I/O Caches (max 512)

23
Block Block iinterleavingnterleaving
Executes a single thread until it reaches a situation that triggers a context switch.
Typical switching event: the instruction execution reaches a long-latency operation or a situation where a latency may arise.
Compared to the cycle-by-cycle interleaving technique, a smaller number of threads is needed
A single thread can execute at full speed until the next context switch. Single thread performance is similar to the performance of a comparable
processor without multithreading.
IBM NorthStar processors are two-threaded 64 bit PowerPCs with switch-on-cache-miss; implemented in departmental computers (eServers) of IBM since 10/98! (revealed at MTEAC-4, Dec. 2000)
Recent announcement (Oct. 1999): Sun MAJC5200 two processor on a die, each processor is a 4-threaded block-interleaving VLIW
24
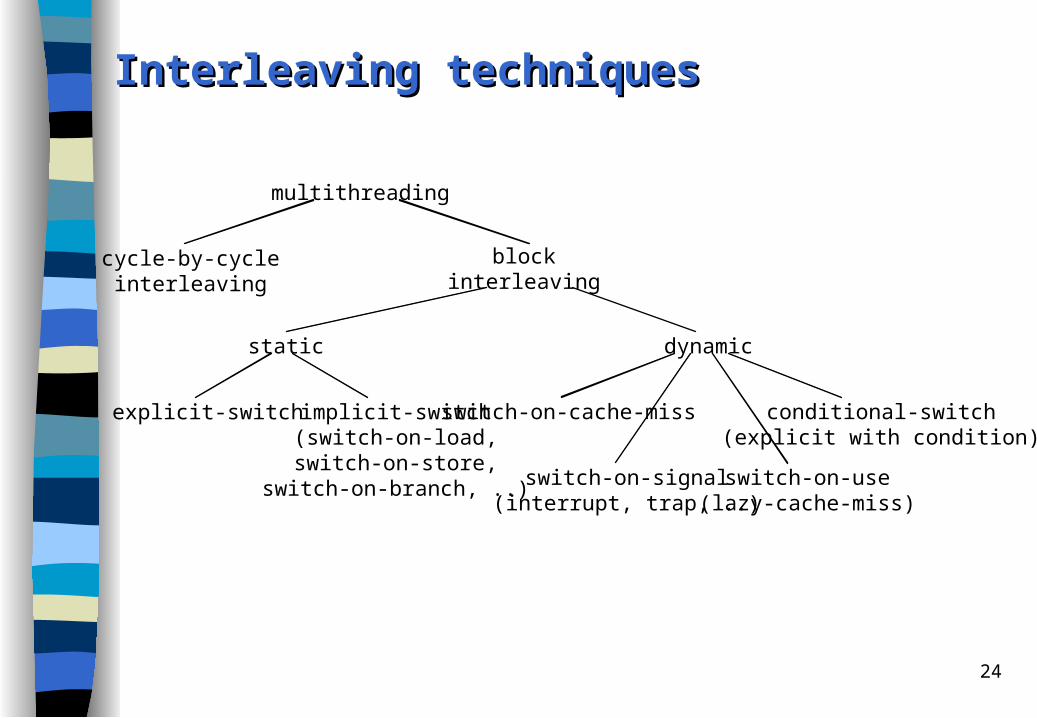
Interleaving techniquesInterleaving techniques
multithreading
cycle-by-cycleinterleaving
blockinterleaving
dynamic
switch-on-cache-miss conditional-switch(explicit with condition)
switch-on-use(lazy-cache-miss)
static
explicit-switch implicit-switch(switch-on-load,switch-on-store,
switch-on-branch, ..) switch-on-signal(interrupt, trap, ..)
25
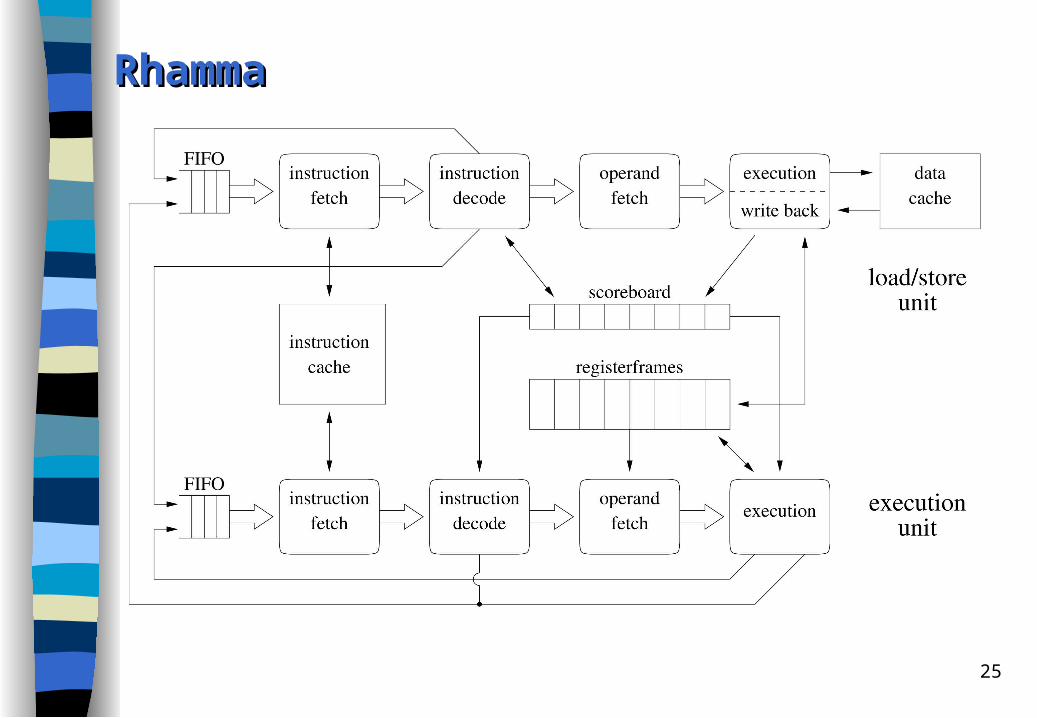
RhammaRhamma

26
Komodo-Komodo-mmicrocontrollericrocontroller
Develop multithreaded embedded real-time Java-microcontroller Java processor core
bytecode as machine language, portability across all platforms dense machine code, important for embedded applications fast byte code execution in hardware, microcode and traps
Interrupts activate interrupt service threads (ISTs) instead of interrupt service routines (ISRs) extremely fast context switch no blocking of interrupt services
Switch-on-signal technique enhanced to very fine-grain switchingdue to hardware-implemented real-time scheduling algorithms (FPP, EDF, LLF, guranteed percentage) hard real-time requirements fulfilled
For more information see: http://goethe.ira.uka.de/~jkreuzin/komodo/komodoEng.html

27
KomodoKomodo -- m microcontrollericrocontroller

28
Nanothreading and Nanothreading and mmicrothreadingicrothreading- multithreading in same register set- multithreading in same register set
Nanothreading (DanSoft processor) dismisses full multithreading for a nanothread that executes in the same register set as the main thread. – only a 9-bit PC, some simple control logic, and it resides in the same page
as the main thread. – Whenever the processor stalls on the main thread, it automatically begins
fetching instructions from the nanothread.
The microthreading technique (Bolychevsky et al. 1996) is similar to nanothreading.
All threads share the same register set and the same run-time stack. However, the number of threads is not restricted to two.

29
Simultaneous Simultaneous mmultithreading (SMT)ultithreading (SMT)
The SMT approach combines a wide superscalar instruction issue with the multithreading approach – by providing several register sets on the multiprocessor – and issuing instructions from several instruction queues simultaneously.
The issue slots of a wide issue processor can be filled by operations of several threads.
Latencies occurring in the execution of single threads are bridged by issuing operations of the remaining threads loaded on the processor.

30
Simultaneous Simultaneous mmultithreading (SMT)ultithreading (SMT) - H- Hardwareardware organization organization (1) (1)
SMT processors can be organized in two ways:
First: Instructions of different threads share all buffer resources in an extended superscalar pipeline – Thus SMT adds minimal hardware complexity to conventional superscalars,– hardware designers can focus on building a fast single-threaded
superscalar and add multithread capability on top. – Complexity added to superscalars by multithreading are thread tag for each
internal instruction representation, multiple register sets, and the abilities of the fetch and the retire units to fetch respectively retire instructions of different threads.

31
Simultaneous Simultaneous mmultithreading (SMT)ultithreading (SMT) - H- Hardwareardware organization organization (2) (2)
Second: Replicate all internal buffers of a superscalar such that each buffer is bound to a specific thread. – The issue unit is able to issue instructions of different instruction windows
simultaneously to the FUs. – Adds more changes to superscalar processors organization – but leads to a natural partitioning of the instruction window (similar to
CMP)– and simplifes the issue and retire stages.

32
Simultaneous Simultaneous mmultithreading (SMT)ultithreading (SMT)
SMT fetch unit can take advantage of the interthread competition for instruction bandwidth in two ways:– First, it can partition fetch bandwidth among the threads and fetch from
several threads each cycle. Goal: increasing the probability of fetching only non speculative instructions.
– Second, the fetch unit can be selective about which threads it fetches. The main drawback to simultaneous multithreading may be that it complicates
the instruction issue stage, which always is central to the multiple threads. A functional partitioning as demanded for processors of the 109-transistor era
is therefore not easily reached. No simultaneous multithreaded processors exist to date. Only simulations. General opinion: SMT will be in next generation microprocessors. Announcement (Oct. 1999): Compaq Alpha 21464 (EV8) will be four-threaded
SMT

33
SMT at the Universities of Washington and San DiegoSMT at the Universities of Washington and San Diego
Hypothetical out-of-order issue superscalar microprocessor that resembles MIPS R10000 and HP PA-8000.
8 threads and 8-issue superscalar organization are assumed. Eight instructions are decoded, renamed and fed to either the integer or
floating-point instruction window. Unified buffers are used When operands become available, up to 8 instructions are issued out-of-order
per cycle, executed and retired. Each thread can address 32 architectural integer (and floating-point) registers.
These registers are renamed to a large physical register le of 356 physical registers.

34
SMT at the Universities of Washington and San DiegoSMT at the Universities of Washington and San Diego
Instruction fetch
Instruction decode
Instruction issue
Execution pipelines
Floating-pointregisterfile
Integerregisterfile
Floating-pointInstructionQueue
IntegerInstructionQueue
I-cache
D-cache
Fetch Unit
PC
Decode
RegisterRenaming
Floating-pointUnits
Integerload/storeUnits
…
…

35
SMT at the Universities of Washington and San Diego SMT at the Universities of Washington and San Diego - Instruction fetching schemes- Instruction fetching schemes
Basic: Round-robin: RR.2.8 fetching scheme, i.e., in each cycle, two times 8 instructions are fetched in round-robin policy from two different 2 threads, – superior to different other schemes like RR.1.8, RR.4.2, and RR.2.4
Other fetch policies:– BRCOUNT scheme gives highest priority to those threads that are least
likely to be on a wrong path, – MISSCOUNT scheme gives priority to the threads that have the fewest
outstanding D-cache misses– IQPOSN policy gives lowest priority to the oldest instructions by penalizing
those threads with instructions closest to the head of either the integer or the floating-point queue
– ICOUNT feedback technique gives highest fetch priority to the threads with the fewest instructions in the decode, renaming, and queue pipeline stages

36
SMT at the Universities of Washington and San Diego SMT at the Universities of Washington and San Diego - Instruction - Instruction ffetching schemesetching schemes
The ICOUNT policy proved as superior! The ICOUNT.2.8 fetching strategy reached a IPC of about 5.4 (the RR.2.8
reached about 4.2 only). Most interesting is that neither mispredicted branches nor blocking due to
cache misses, but a mix of both and perhaps some other effects showed as the best fetching strategy.
Recently, simultaneous multithreading has been evaluated with– SPEC95,– database workloads, – and multimedia workloads.
Both achieving roughly a 3-fold IPC increase with an eight-threaded SMT over a single-threaded superscalar with similar resources.

37
SMT SMT pprocessor with rocessor with mmultimediaultimedia e enhancementnhancement
- Combining - Combining SMTSMT and and mmultimediaultimedia
Start with a wide-issue superscalar general-purpose processor Enhance by simultaneous multithreading Enhance by multimedia unit(s)
– Utilization of subword parallelism (data parallel instructions, SIMD)
– Saturation arithmetic– Additional arithmetic, masking
and selection, reordering and conversion instructions
Enhance by additional features useful for multimedia processing, e.g. on-chip RAM memory, special cache techniques
For more information see: http://goethe.ira.uka.de/people/ungerer/smt-mm/SM-MM-processor.html
38
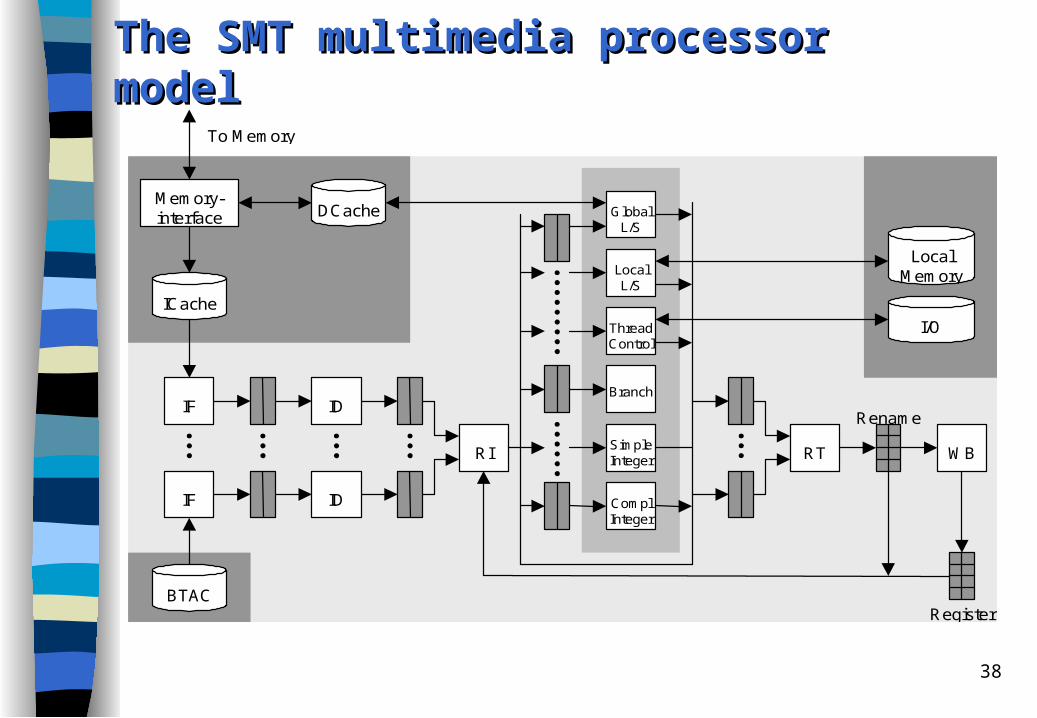
The SMT The SMT mmultimedia ultimedia pprocessor rocessor mmodelodel
Branch
ComplInteger
RT WBRI
IDIF
GlobalL/S
LocalL/S
ThreadControl
SimpleInteger
LocalMemory
I/O
Memory-interface DCache
BTAC
ICache
Rename
Register
IDIF
To Memory

39
Maximum Maximum pprocessor rocessor cconfigurationonfiguration- IPCs of 8-threaded 8-issue cases- IPCs of 8-threaded 8-issue cases
Initial maximum configuration: 2.28 16 entry reservation stations for thread, global and local load/store units
(instead of 256): 2.96 one common 256-entry reservation station unit for all integer/multimedia
units (instead of 256-entry reservation stations each): 3.27 loads and stores may pass blocked load/stores of other threads: 4.1 highest-priority-first, non-speculative-instruction-first, non-saturated-first
strategies for issue, dispatch, and retire stages: 4.34 32-entry reorder buffer (instead of 256): 4.69 second local load/store unit (because of 20.1% local load/stores): 6.07 (6.32
with dynamic branch prediction)
40
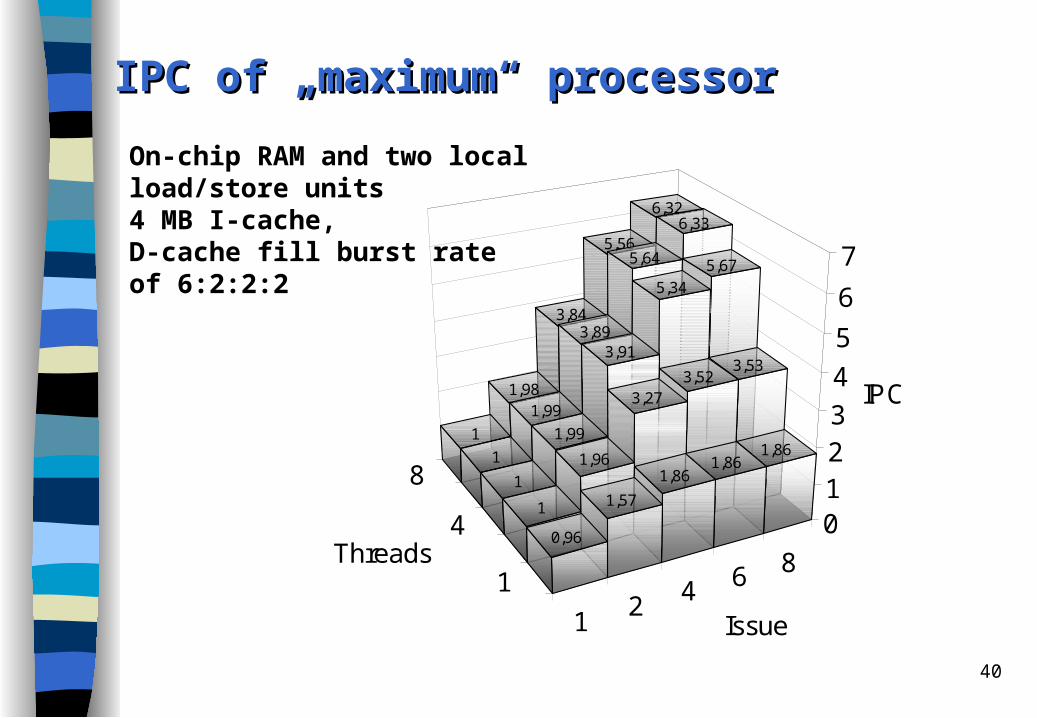
IPC of „IPC of „mmaximum“ aximum“ pprocessorrocessor
12
4 6 81
4
8
6,32
5,56
3,84
1,98
1
6,33
5,64
3,89
1,99
1
5,67
5,34
3,91
1,99
1
3,533,52
3,27
1,96
1
1,861,86
1,86
1,57
0,960123
4
5
6
7
IPC
Issue
Threads
On-chip RAM and two local load/store units4 MB I-cache,D-cache fill burst rateof 6:2:2:2

41
More More rrealistic ealistic pprocessorrocessor
4 8 16 32 641
4
8
3,41
3,16
2,91
2,54
2,12
3,41
3,17
2,91
2,54
2,12
3,3
3,1
2,9
2,54
2,12
2,342,24
2,142,02
1,81 1,31,26
1,231,17
1,08
0
1
2
3
4
IPC
D-Cache in KB
Threads
D-cache fill burst rate of 32:4:4:4issue bandwidth 8
42
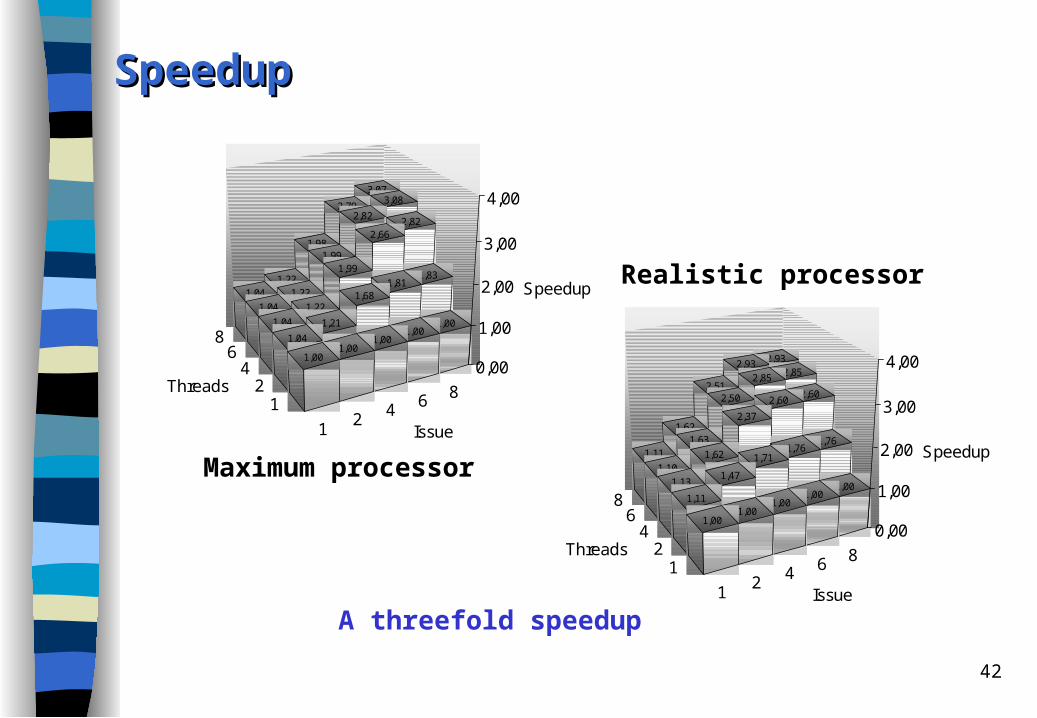
SpeedupSpeedup
12
4 6 81
24
68
3,07
2,79
1,98
1,221,04
3,08
2,82
1,99
1,22
1,04
2,822,66
1,99
1,22
1,04
1,831,81
1,68
1,21
1,04
1,001,00
1,001,00
1,000,00
1,00
2,00
3,00
4,00
Speedup
Issue
Threads
12 4 6 8
12
46
8
2,932,93
2,51
1,62
1,11
2,852,85
2,50
1,63
1,10
2,602,60
2,37
1,62
1,13
1,761,76
1,71
1,47
1,111,00
1,001,00
1,001,00
0,00
1,00
2,00
3,00
4,00
Speedup
Issue
Threads
Maximum processor
Realistic processor
A threefold speedup
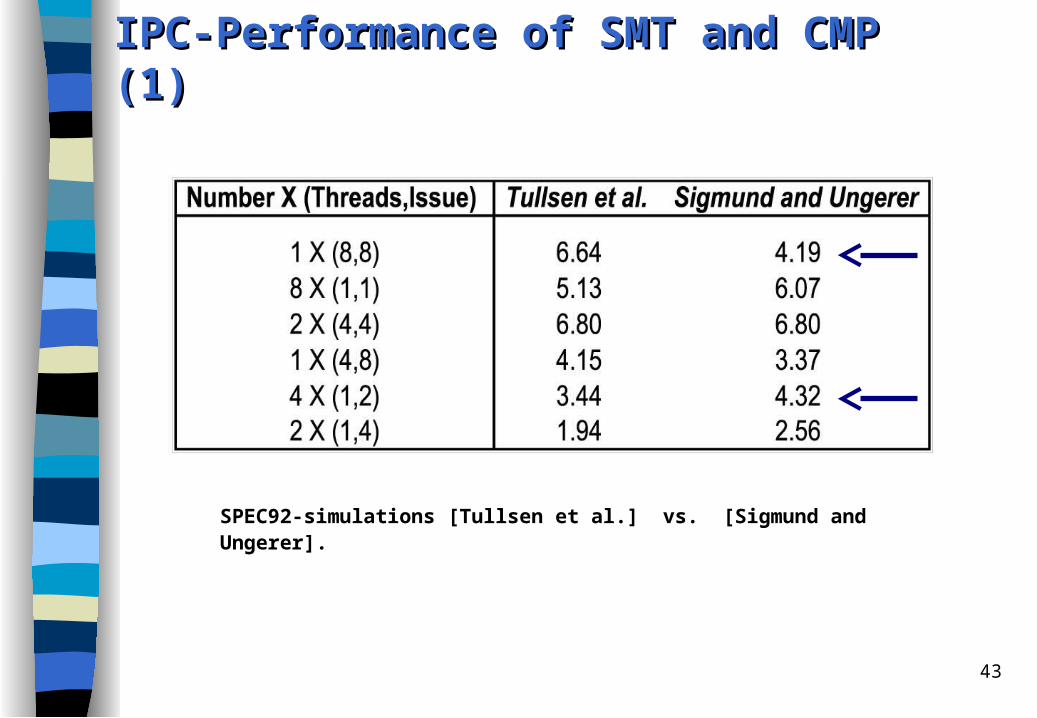
43
IPC-Performance of SMT and CMP (1)IPC-Performance of SMT and CMP (1)
SPEC92-simulations [Tullsen et al.] vs. [Sigmund and Ungerer].
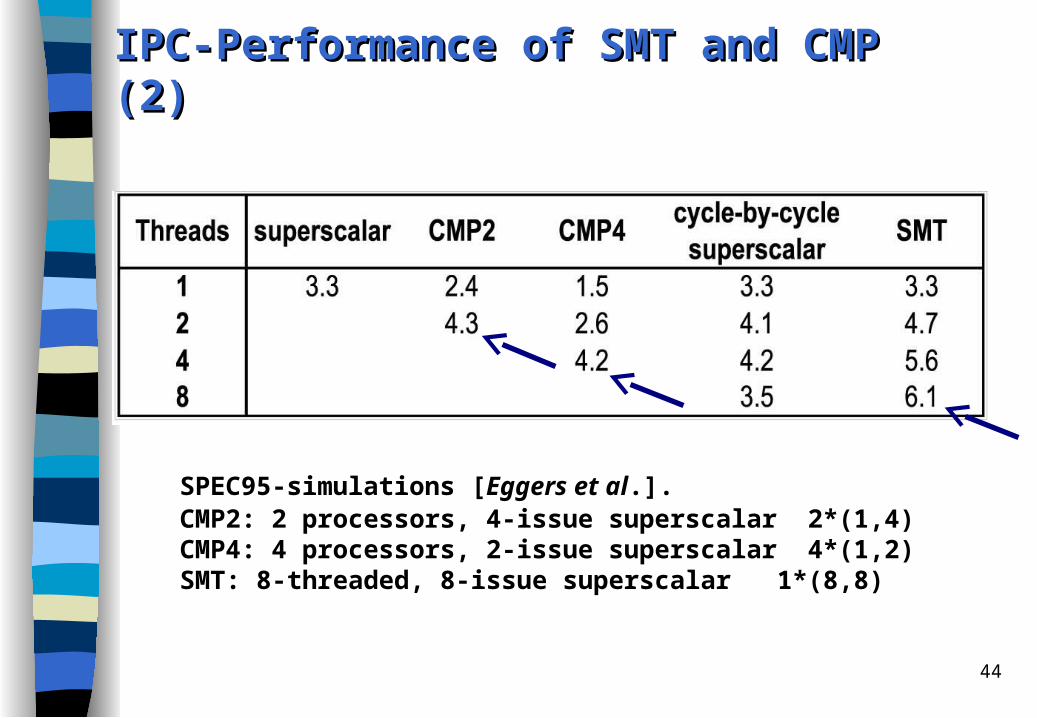
44
IPC-Performance of SMT and CMP (2)IPC-Performance of SMT and CMP (2)
SPEC95-simulations [Eggers et al.].CMP2: 2 processors, 4-issue superscalar 2*(1,4)CMP4: 4 processors, 2-issue superscalar 4*(1,2)SMT: 8-threaded, 8-issue superscalar 1*(8,8)
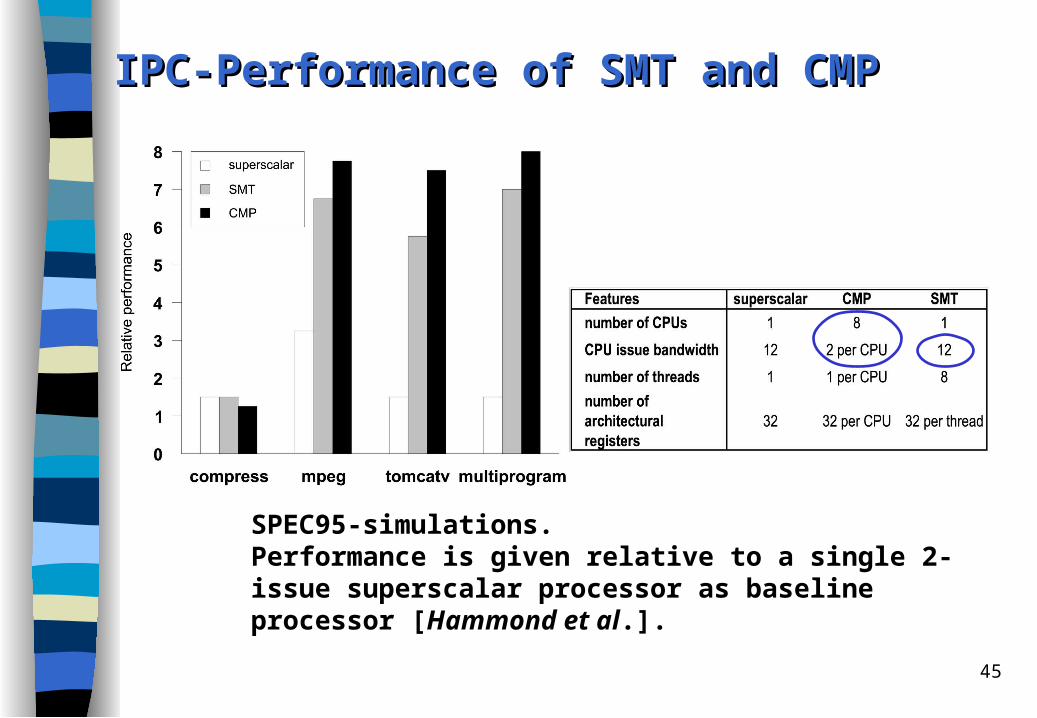
45
IPC-Performance of SMT and CMPIPC-Performance of SMT and CMP
SPEC95-simulations. Performance is given relative to a single 2-issue superscalar processor as baseline processor [Hammond et al.].

46
Comments to the Comments to the ssimulation imulation rresults esults [[HammondHammond et al et al.].]
CMP (eight 2-issue processors) outperforms a 12-issue superscalar and a 12-issue, 8-threaded SMT processor on four SPEC95 benchmark programs (by hand parallelized for CMP and SMP).
The CMP achieved higher performance than SMT due to a total of 16 issue slot instead of 12 issue slots for SMT.
Hammond et al. argue that design complexity for 16-issue CMPs is similar to 12-issue superscalars or 12-issue SMT processors.

47
SMT vs. SMT vs. mmultiprocessor ultiprocessor cchip hip [[Eggers et alEggers et al..]]
SMT obtained better speedups than the (CMP) chip multiprocessors- in contrast to results of Hammond et al.!!
Eggers et al. compared 8-issue, 8-threaded SMTs with four 2-issue CMPs.Hammond et al. compared 12-issue, 8-threaded SMTs with eight 2-issue CMPs.
Eggers et al.: – Speedups on the CMP were hindered by the fixed partitioning of their hardware
resources across the processors. – In CMP processors were idle when thread-level parallelism was insufficient. – Exploiting large amounts of instruction-level parallelism in the unrolled loops of
individual threads not possible due to CMP processors smaller issue bandwidth. An SMT processor dynamically partitions its resources among threads, and therefore
can respond well to variations in both types of parallelism, exploiting them interchangeably.

48
ConclusionsConclusions
The performance race between SMT and CMP is not yet decided. CMP is easier to implement, but only SMT has the ability to hide latencies. A functional partitioning is not easily reached within a SMT processor due to
the centralized instruction issue. – A separation of the thread queues is a possible solution, although it does
not remove the central instruction issue.– A combination of simultaneous multithreading with the CMP may be
superior.– We favor a CMP consisting of moderately equipped (e.g., 4-threaded 4-
issue superscalar) SMTs. Future research: combine SMT or CMP organization with the ability to create
threads with compiler support or fully dynamically out of a single thread– thread-level speculation– close to multiscalar





























