Embed Size (px)
Citation preview

11998 Morgan Kaufmann Publishers
Chapter Six

21998 Morgan Kaufmann Publishers
Pipelining
• Improve performance by increasing instruction throughput
Ideal speedup is number of stages in the pipeline. Do we achieve this?
Instructionfetch
Reg ALUData
accessReg
8 nsInstruction
fetchReg ALU
Dataaccess
Reg
8 nsInstruction
fetch
8 ns
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 4 6 8 10 12 14 16 18
2 4 6 8 10 12 14
...
Programexecutionorder(in instructions)
Instructionfetch
Reg ALUData
accessReg
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 nsInstruction
fetchReg ALU
Dataaccess
Reg
2 ns 2 ns 2 ns 2 ns 2 ns
Programexecutionorder(in instructions)

31998 Morgan Kaufmann Publishers
Pipelining
• What makes it easy– all instructions are the same length– just a few instruction formats– memory operands appear only in loads and stores
• What makes it hard?– structural hazards: suppose we had only one memory– control hazards: need to worry about branch instructions– data hazards: an instruction depends on a previous instruction
• We will build a simple pipeline and look at these issues
• We will talk about modern processors and what really makes it hard:– exception handling– trying to improve performance with out-of-order execution, etc.

41998 Morgan Kaufmann Publishers
Basic Idea
• What do we need to add to actually split the datapath into stages?
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Instruction
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
ReaddataAddress
Datamemory
1
ALUresult
Mux
ALUZero
IF: Instruction fetch ID: Instruction decode/register file read
EX: Execute/address calculation
MEM: Memory access WB: Write back

51998 Morgan Kaufmann Publishers
Pipelined Datapath
Can you find a problem even if there are no dependencies? What instructions can we execute to manifest the problem?
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Datamemory
Address

61998 Morgan Kaufmann Publishers
Corrected Datapath
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0
Address
Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX

71998 Morgan Kaufmann Publishers
Instruction fetch stage of lw

81998 Morgan Kaufmann Publishers
Instruction decode stage of lw

91998 Morgan Kaufmann Publishers
Execution stage of lw

101998 Morgan Kaufmann Publishers
Memory stage of lw

111998 Morgan Kaufmann Publishers
Write back stage of lw

121998 Morgan Kaufmann Publishers
Execution stage of sw

131998 Morgan Kaufmann Publishers
Memory stage of sw

141998 Morgan Kaufmann Publishers
Write back stage of sw
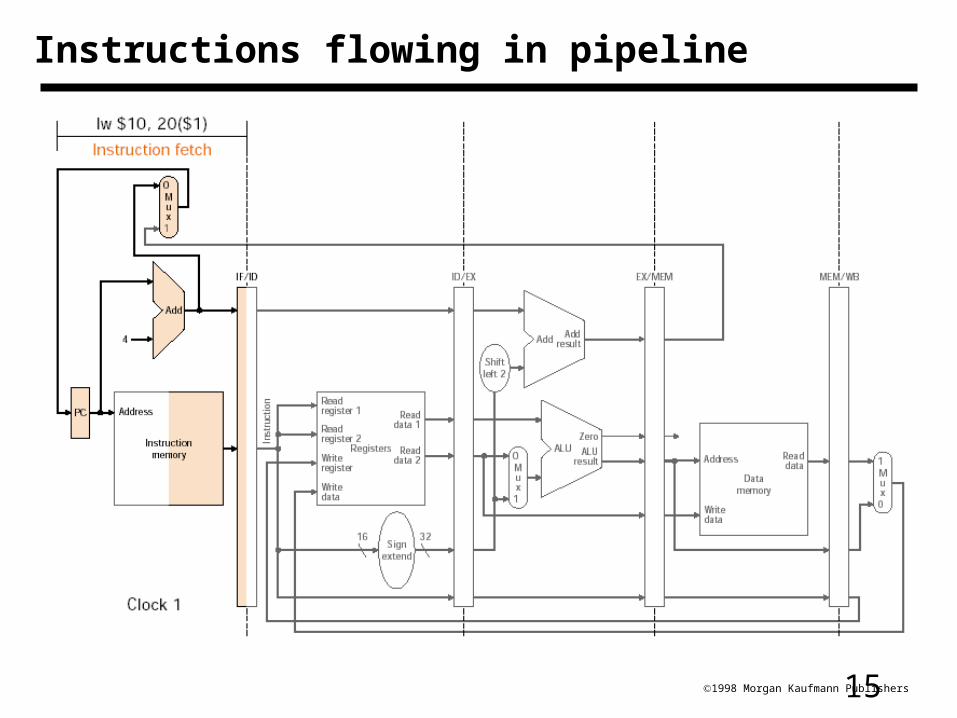
151998 Morgan Kaufmann Publishers
Instructions flowing in pipeline

161998 Morgan Kaufmann Publishers
Instructions flowing in pipeline (cont.)

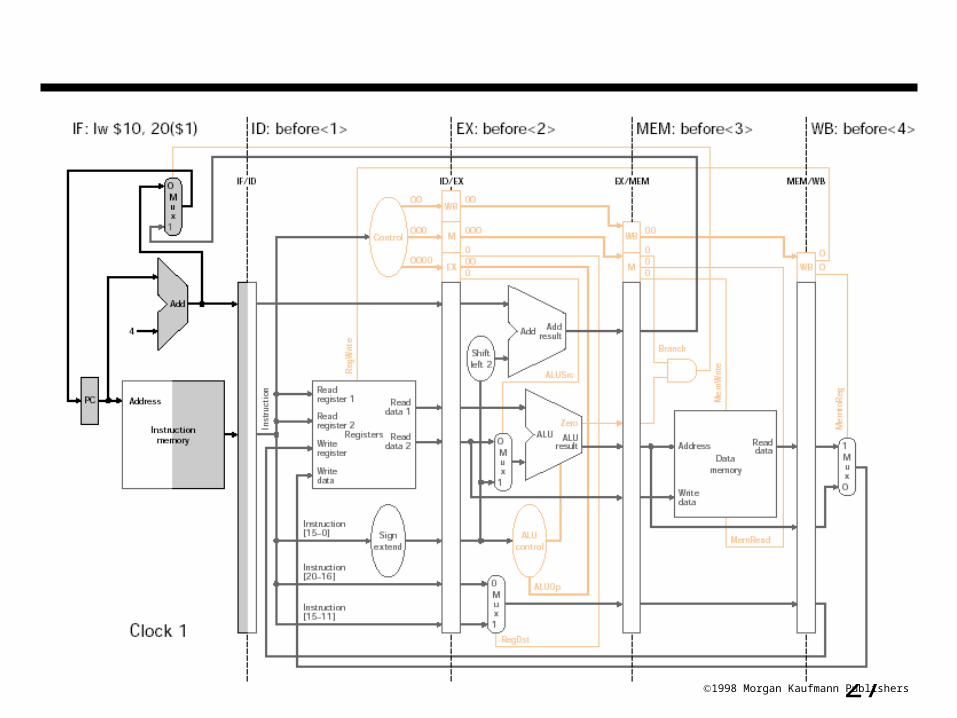
171998 Morgan Kaufmann Publishers
Instructions flowing in pipeline (cont.)

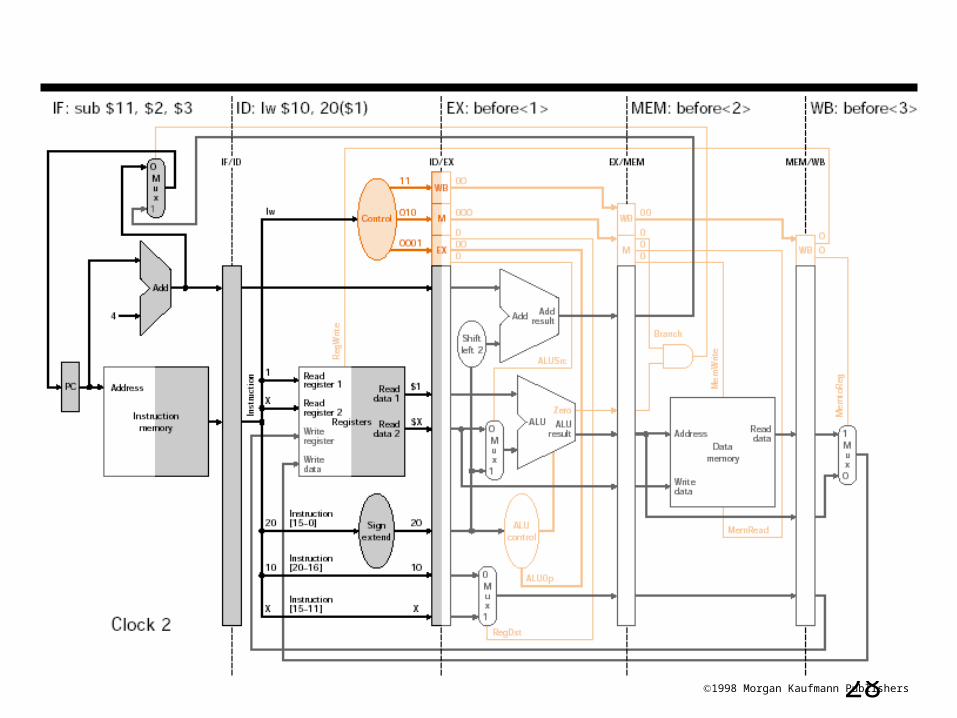
181998 Morgan Kaufmann Publishers
Instructions flowing in pipeline (cont.)

191998 Morgan Kaufmann Publishers
Instructions flowing in pipeline (cont.)

201998 Morgan Kaufmann Publishers
Instructions flowing in pipeline (cont.)
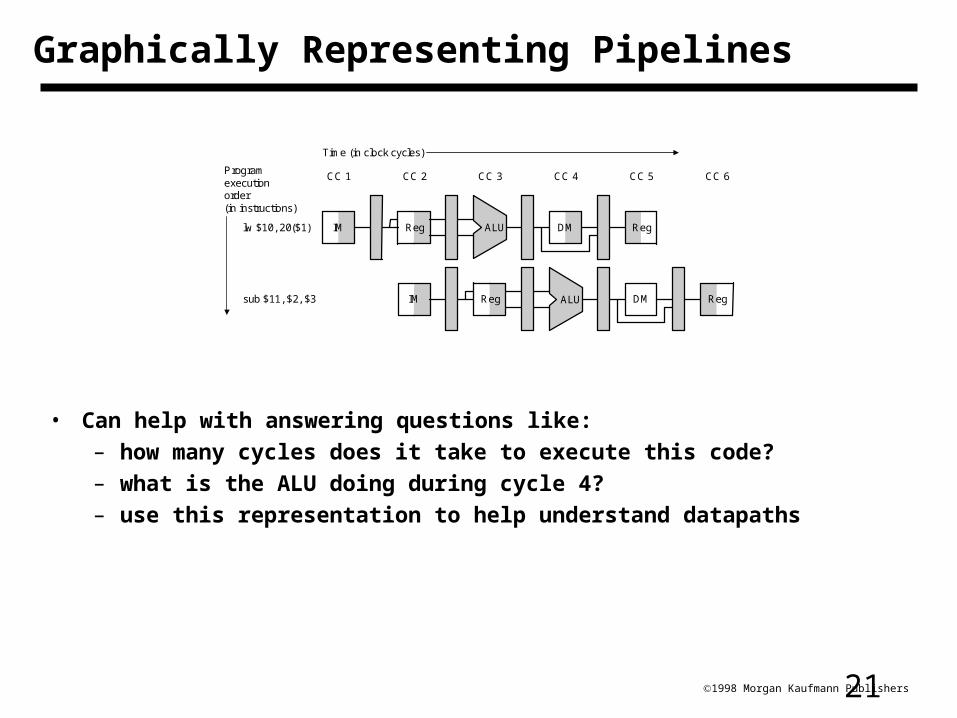
211998 Morgan Kaufmann Publishers
Graphically Representing Pipelines
• Can help with answering questions like:– how many cycles does it take to execute this code?– what is the ALU doing during cycle 4?– use this representation to help understand datapaths
IM Reg DM Reg
IM Reg DM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
lw $10, 20($1)
Programexecutionorder(in instructions)
sub $11, $2, $3
ALU
ALU

221998 Morgan Kaufmann Publishers
Pipeline Control
PC
Instructionmemory
Address
Inst
ruct
ion
Instruction[20– 16]
MemtoReg
ALUOp
Branch
RegDst
ALUSrc
4
16 32Instruction[15– 0]
0
0Registers
Writeregister
Writedata
Readdata 1
Readdata 2
Readregister 1
Readregister 2
Signextend
Mux
1Write
data
Read
data Mux
1
ALUcontrol
RegWrite
MemRead
Instruction[15– 11]
6
IF/ID ID/EX EX/MEM MEM/WB
MemWrite
Address
Datamemory
PCSrc
Zero
AddAdd
result
Shiftleft 2
ALUresult
ALU
Zero
Add
0
1
Mux
0
1
Mux
Can these operations be completed one
stage earlier?
Can these operations be completed one
stage earlier?
Think about critical path!!!
Why does IM have no control signal at all? Why does RF have
only write control?
Can ALU result be written back in MEM? Cost of RF write port!!!

231998 Morgan Kaufmann Publishers
Pipeline design considerations
• Simplification of control mechanism
– Active in every clock cycle (always enable)
• Ex: – Instruction memory has no control signal.
– Pipeline registers• Minimization of power consumption
– Explicit control for infrequent operations
• Ex: both read and write controls for data memory• Cost consideration
– Ex: alternatives of ALU write: in MEM or WB

241998 Morgan Kaufmann Publishers
• We have 5 stages. What needs to be controlled in each stage?– Instruction Fetch and PC Increment– Instruction Decode / Register Fetch– Execution– Memory Stage– Write Back
• How would control be handled in an automobile plant?
• a fancy control center telling everyone what to do?• should we use a finite state machine?
– Centralized– Distributed
Pipeline control

251998 Morgan Kaufmann Publishers
• Pass control signals along just like the data
– Generate all control signals at the decode stage…similar to the single cycle implementation
– Pass the generated control signals along the pipeline and consume the related control signals at the corresponding stage…similar to the multicycle implementation
Pipeline Control
Execution/Address Calculation stage control lines
Memory access stage control lines
Write-back stage control
lines
InstructionReg Dst
ALU Op1
ALU Op0
ALU Src Branch
Mem Read
Mem Write
Reg write
Mem to Reg
R-format 1 1 0 0 0 0 0 1 0lw 0 0 0 1 0 1 0 1 1sw X 0 0 1 0 0 1 0 Xbeq X 0 1 0 1 0 0 0 X
Control
EX
M
WB
M
WB
WB
IF/ID ID/EX EX/MEM MEM/WB
Instruction

261998 Morgan Kaufmann Publishers
Datapath with Control
PC
Instructionmemory
Inst
ruct
ion
Add
Instruction[20– 16]
Me
mto
Re
g
ALUOp
Branch
RegDst
ALUSrc
4
16 32Instruction[15– 0]
0
0
Mux
0
1
Add Addresult
RegistersWriteregister
Writedata
Readdata 1
Readdata 2
Readregister 1
Readregister 2
Signextend
Mux
1
ALUresult
Zero
Writedata
Readdata
Mux
1
ALUcontrol
Shiftleft 2
Re
gWrit
e
MemRead
Control
ALU
Instruction[15– 11]
6
EX
M
WB
M
WB
WBIF/ID
PCSrc
ID/EX
EX/MEM
MEM/WB
Mux
0
1
Me
mW
rite
AddressData
memory
Address
271998 Morgan Kaufmann Publishers
281998 Morgan Kaufmann Publishers
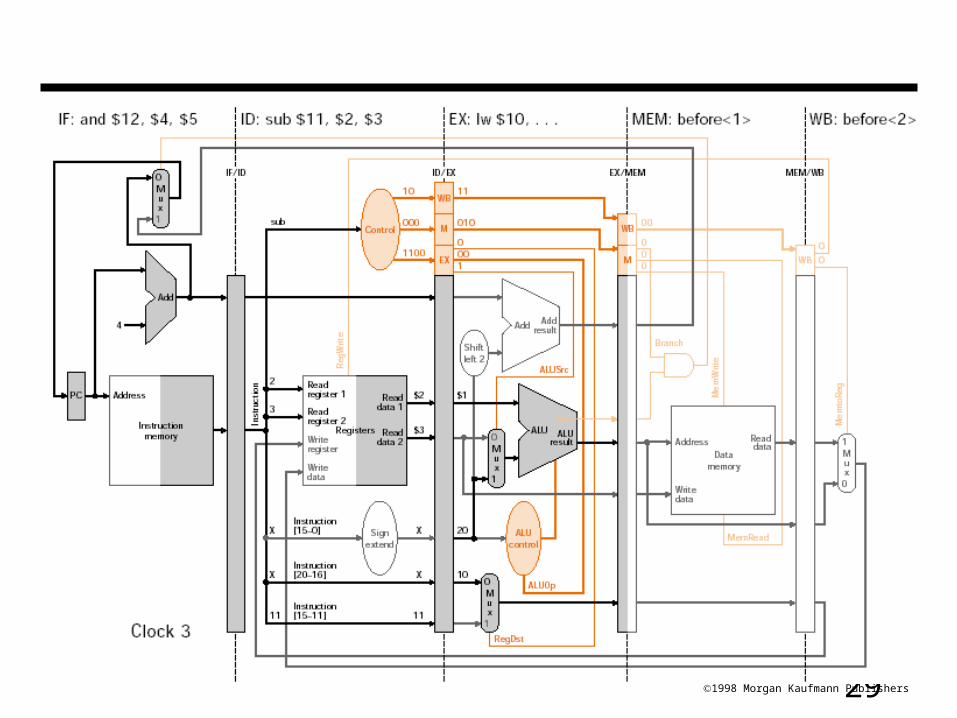
291998 Morgan Kaufmann Publishers

301998 Morgan Kaufmann Publishers
$4, $5

311998 Morgan Kaufmann Publishers

321998 Morgan Kaufmann Publishers

331998 Morgan Kaufmann Publishers

341998 Morgan Kaufmann Publishers

351998 Morgan Kaufmann Publishers

361998 Morgan Kaufmann Publishers
• Problem with starting next instruction before first is finished
– dependencies that point backward in time are data hazards
Dependencies
IM Reg
IM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecutionorder(in instructions)
and $12, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
10 10 10 10 10/– 20 – 20 – 20 – 20 – 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2:
DM Reg
Reg
Reg
Reg
DM

371998 Morgan Kaufmann Publishers
• Have compiler guarantee no hazards• Where do we insert the nops??
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
Insert NOP…• sub $2, $1, $3
NOPNOP
NOPand $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
• Problem: this really slows us down!
Software Solution

381998 Morgan Kaufmann Publishers
• Use temporary results, don’t wait for them to be written
• ALU forwarding
• Register file forwarding (latch-based register file) to handle read/write to same register (read what you just write!!!)
Forwarding
what if this $2 was $13?
IM Reg
IM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
sub $2, $1, $3
Programexecution order(in instructions)
and $12, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
10 10 10 10 10/– 20 – 20 – 20 – 20 – 20
or $13, $6, $2
add $14, $2, $2
sw $15, 100($2)
Value of register $2 :
DM Reg
Reg
Reg
Reg
X X X – 20 X X X X XValue of EX/MEM :X X X X – 20 X X X XValue of MEM/WB :
DM
Transparent latch

391998 Morgan Kaufmann Publishers
No forwarding datapath

401998 Morgan Kaufmann Publishers
With forwarding datapath

411998 Morgan Kaufmann Publishers
The control values for the forwarding multiplexors
Mux control Source Explanation
ForwardingA = 00 ID/EX The first ALU operand comes from the register file
ForwardingA = 10 EX/MEM The first ALU operand is forwarded from prior ALU result
ForwardingA = 01 MEM/WB The first ALU operand is forwarded from data memory or an earlier ALU result
ForwardingB = 00 ID/EX The second ALU operand comes from the register file
ForwardingB = 10 EX/MEM The second ALU operand is forwarded from prior ALU result
ForwardingB = 01 MEM/WB The second ALU operand is forwarded from data memory or an earlier ALU result
If (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and (EX/MEM.RegisterRd ID/EX.RegisterRs) and (MEM/WB.registerRd = ID/EX.RegisterRs)) ForwardA = 01
If (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and (EX/MEM.RegisterRd ID/EX.RegisterRt) and (MEM/WB.registerRd = ID/EX.RegisterRt)) ForwardB = 01

421998 Morgan Kaufmann Publishers
The modified datapath resolves hazards via forwarding

431998 Morgan Kaufmann Publishers

441998 Morgan Kaufmann Publishers

451998 Morgan Kaufmann Publishers
$2
Register file forwarding (through the transparent latch).
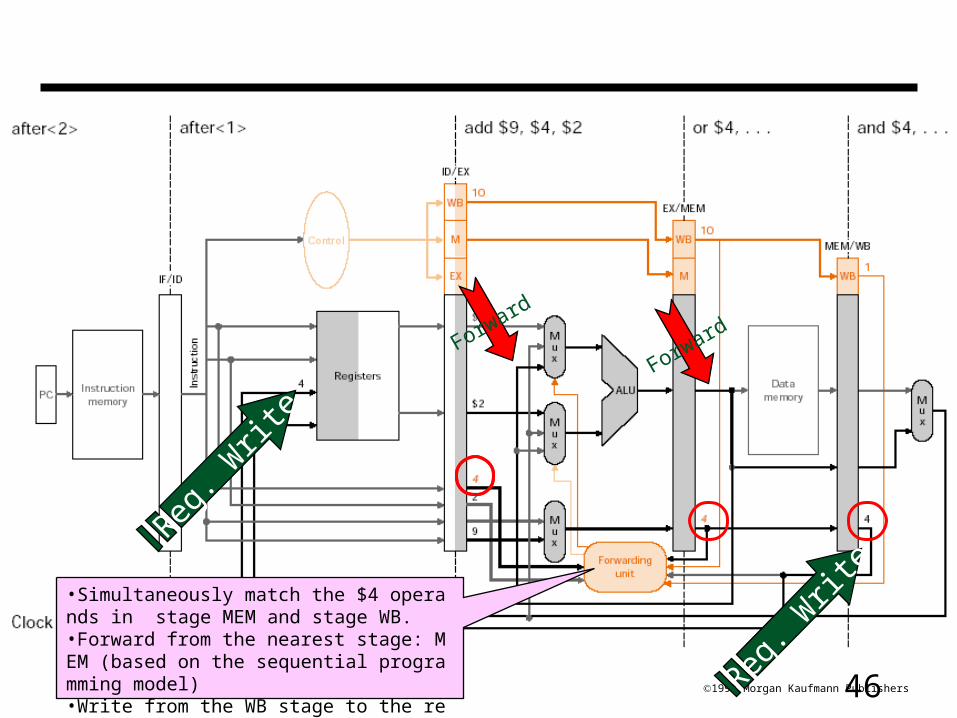
461998 Morgan Kaufmann Publishers
•Simultaneously match the $4 operands in stage MEM and stage WB.•Forward from the nearest stage: MEM (based on the sequential programming model)•Write from the WB stage to the register file (RF).
Forward
Forward
Reg. W
rite
Reg. W
rite

471998 Morgan Kaufmann Publishers
• Load word can still cause a hazard:– an instruction tries to read a register following a load instruction
that writes to the same register.
–
• Thus, we need a hazard detection unit to stall the load instruction
Can't always forward
Reg
IM
Reg
Reg
IM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
lw $2, 20($1)
Programexecutionorder(in instructions)
and $4, $2, $5
IM Reg DM Reg
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
DM Reg
Reg
Reg
DM
Latch-based RF: read what you just write!
(write then read)

481998 Morgan Kaufmann Publishers
Stalling
• We can stall the pipeline by keeping an instruction in the same stage
lw $2, 20($1)
Programexecutionorder(in instructions)
and $4, $2, $5
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
Reg
IM
Reg
Reg
IM DM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6Time (in clock cycles)
IM Reg DM RegIM
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9 CC 10
DM Reg
RegReg
Reg
bubble

491998 Morgan Kaufmann Publishers
Hazard Detection Unit
• Stall by letting an instruction that won’t write anything go forward
PCInstruction
memory
Registers
Mux
Mux
Mux
Control
ALU
EX
M
WB
M
WB
WB
ID/EX
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
unit
Forwardingunit
0
Mux
IF/ID
Inst
ruct
ion
ID/EX.MemReadIF
/ID
Wri
te
PC
Wri
te
ID/EX.RegisterRt
IF/ID.RegisterRd
IF/ID.RegisterRt
IF/ID.RegisterRt
IF/ID.RegisterRs
RtRs
Rd
Rt EX/MEM.RegisterRd
MEM/WB.RegisterRd
stall Insert NOPLOAD continues to next stage

501998 Morgan Kaufmann Publishers
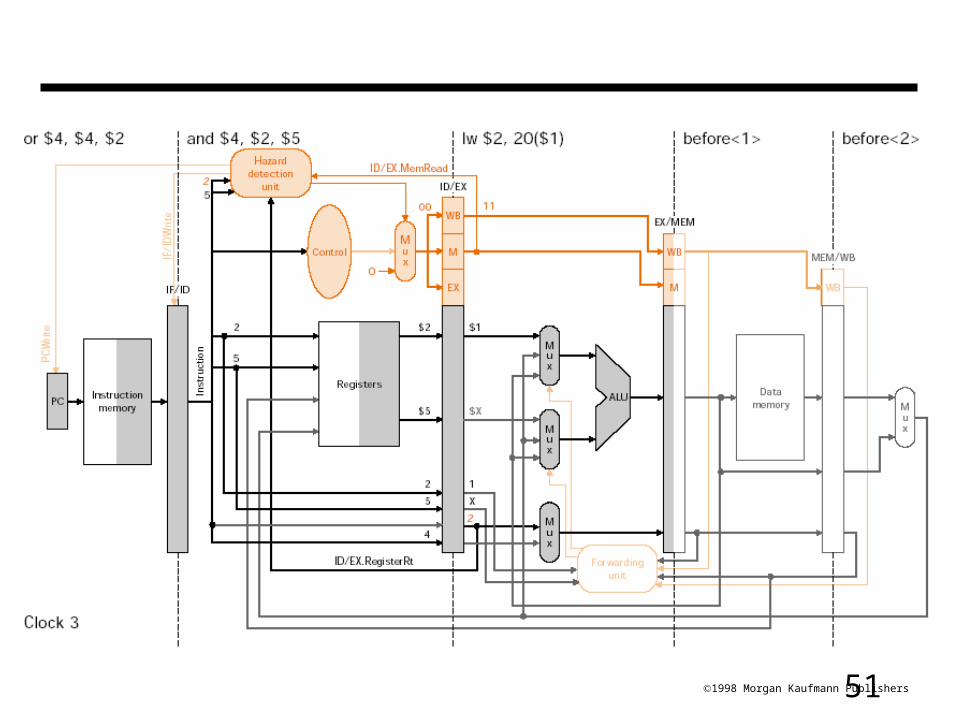
511998 Morgan Kaufmann Publishers

521998 Morgan Kaufmann Publishers

531998 Morgan Kaufmann Publishers
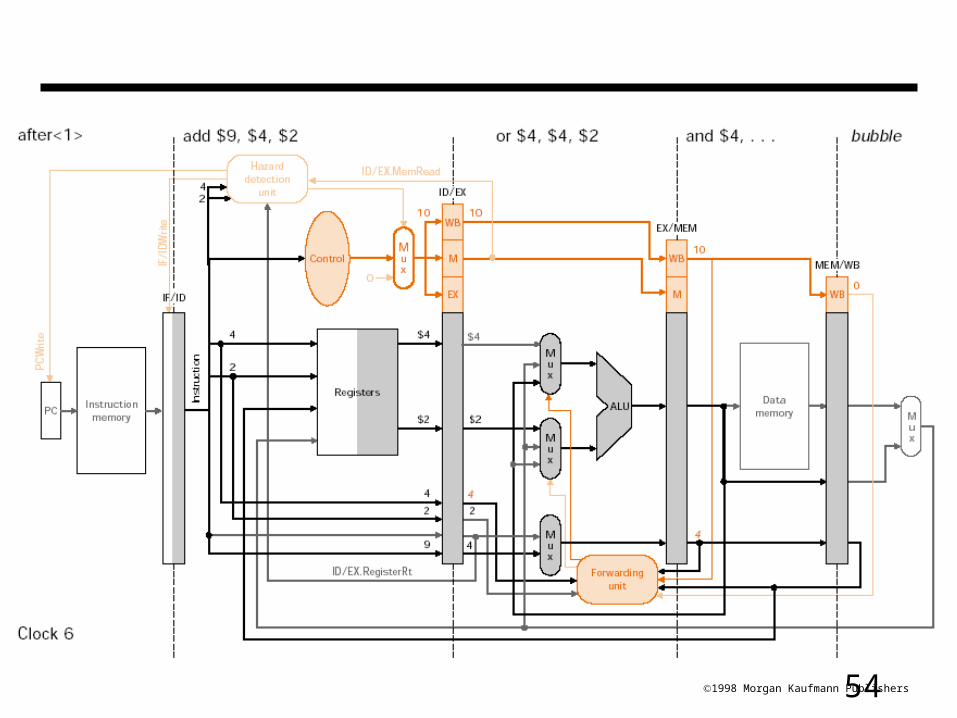
541998 Morgan Kaufmann Publishers

551998 Morgan Kaufmann Publishers

561998 Morgan Kaufmann Publishers
• When we decide to branch, other instructions are in the pipeline!
• We are predicting branch not taken– need to add hardware for flushing instructions if we are wrong
Branch Hazards
Reg
Reg
CC 1
Time (in clock cycles)
40 beq $1, $3, 7
Programexecutionorder(in instructions)
IM Reg
IM DM
IM DM
IM DM
DM
DM Reg
Reg Reg
Reg
Reg
RegIM
44 and $12, $2, $5
48 or $13, $6, $2
52 add $14, $2, $2
72 lw $4, 50($7)
CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
Reg
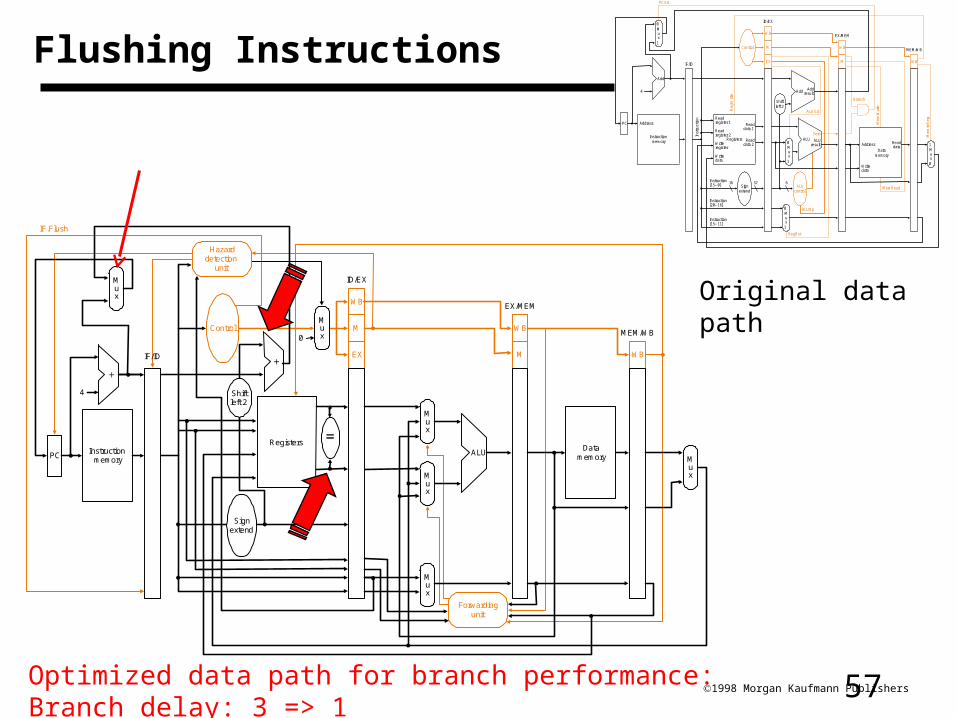
571998 Morgan Kaufmann Publishers
Flushing Instructions
Optimized data path for branch performance: Branch delay: 3 => 1
PC
Instructionmemory
Inst
ruct
ion
Add
Instruction[20– 16]
Me
mto
Re
g
ALUOp
Branch
RegDst
ALUSrc
4
16 32Instruction[15– 0]
0
0
Mux
0
1
Add Addresult
RegistersWriteregister
Writedata
Readdata 1
Readdata 2
Readregister 1
Readregister 2
Signextend
Mux
1
ALUresult
Zero
Writedata
Readdata
Mux
1
ALUcontrol
Shiftleft 2
Re
gWrit
e
MemRead
Control
ALU
Instruction[15– 11]
6
EX
M
WB
M
WB
WBIF/ID
PCSrc
ID/EX
EX/MEM
MEM/WB
Mux
0
1
Me
mW
rite
AddressData
memory
Address
PCInstruction
memory
4
Registers
Mux
Mux
Mux
ALU
EX
M
WB
M
WB
WB
ID/EX
0
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
unit
Forwardingunit
IF.Flush
IF/ID
Signextend
Control
Mux
=
Shiftleft 2
Mux
Original data path

581998 Morgan Kaufmann Publishers
Instruction Flushing for Branch

591998 Morgan Kaufmann Publishers
Instruction Flushing for Branch
(Flushed and instr.)

601998 Morgan Kaufmann Publishers
Improving Performance
• Try and avoid stalls! E.g., reorder these instructions:
lw $t0, 0($t1) lw $t0, 0($t1) lw $t2, 4($t1) lw $t2, 4($t1)sw $t2, 0($t1) sw $t0, 4($t1)sw $t0, 4($t1) sw $t2, 0($t1)
• Add a branch delay slot (delayed branch)
– the next instruction after a branch is always executed
– rely on compiler to fill the slot with something useful
add $2, $3, $4 beq $9, $10, 400
beq $9, $10, 400 add $2, $3, $4 ; always executed
sub $11, $12, $13 sub $11, $12, $13
: :• Superscalar: start more than one instruction in the same cycle

611998 Morgan Kaufmann Publishers
Utilizing the branch delay slot (compiler’s task)
:
:

621998 Morgan Kaufmann Publishers
Final data/control path for hazard handling

631998 Morgan Kaufmann Publishers
Dynamic Branch Prediction

641998 Morgan Kaufmann Publishers
Final data/control path for exception handling
1. flush instr.;
2. save PC (PC+4); Cause
3. set new PC;
4. overflowed instr. (EX) => NOP
1
2
1
3
4
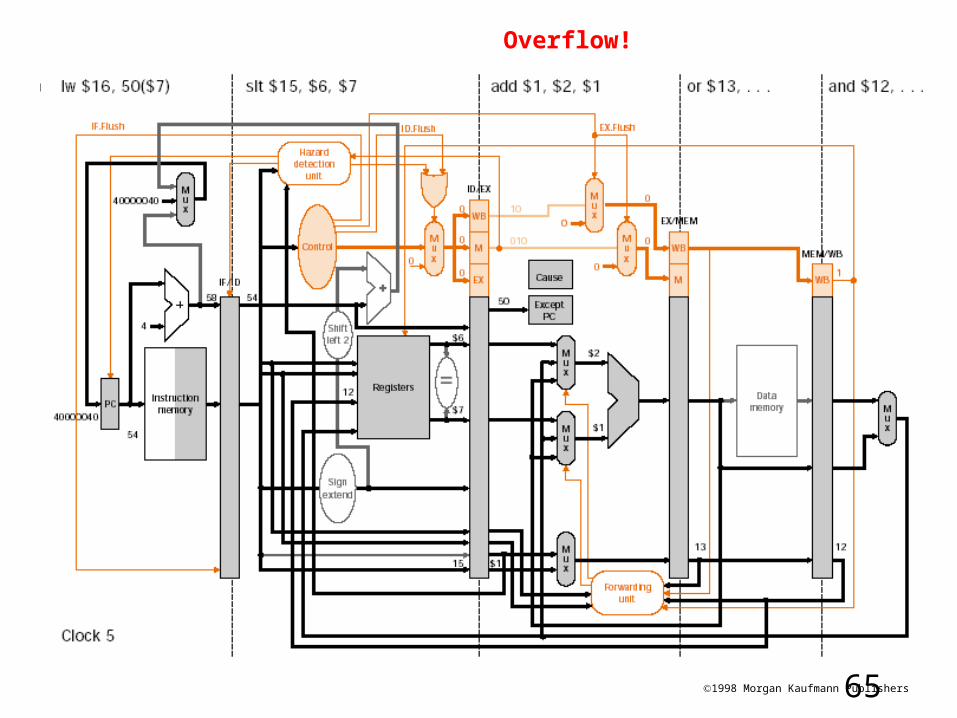
651998 Morgan Kaufmann Publishers
Overflow!

661998 Morgan Kaufmann Publishers
continue!…………Flushing (NOP’s)……………

671998 Morgan Kaufmann Publishers
…
Fig.6.56: Complete data path and control for Chap. 6

681998 Morgan Kaufmann Publishers
Instruction type Pipe stages
ALU or branch instruction IF ID EX MEM WB
Load or store instruction IF ID EX MEM WB
ALU or branch instruction IF ID EX MEM WB
Load or store instruction IF ID EX MEM WB
ALU or branch instruction IF ID EX MEM WB
Load or store instruction IF ID EX MEM WB
ALU or branch instruction IF ID EX MEM WB
Load or store instruction IF ID EX MEM WB
Suerscalar Execution

691998 Morgan Kaufmann Publishers

701998 Morgan Kaufmann Publishers
Simple Superscalar Code Scheduling
Loop : lw $t0, 0($s1) # $t0=array element ($s1 is i)
addu $t0, $t0, $s2 # add dcalar in $s2 (B)
sw $t0, 0($s1) # store result
addi $s1, $s1, -4 # decrement pointer
bne $s1, $zero, Loop # branch $s1 != 0
ALU or branch instruction Data transfer instruction Clock cycle
Loop: lw $t0, 0($s1) 1
addi $s1, $s1, -4 2
addu $t0, $t0, $s2 3
bne $s1, $zero, Loop sw $t0, 0($s1) 4
Do {
*I = *I + B;
I = I -4 ; }
While (I != 0) ;
Do {
*I = *I + B;
I = I -4 ; }
While (I != 0) ;

711998 Morgan Kaufmann Publishers
Loop Unrolling for Superscalar Pipelines
ALU or branch instruction Data transfer instruction Clock cycle
Loop: addi $s1, $s1, -16 lw $t0, 0($s1) 1
lw $t1, 12($s1) 2
addu $t0, $t0, $s2 lw $t2, 8($s1) 3
addu $t1, $t1, $s2 lw $t3, 4($s1) 4
addu $t2, $t2, $s2 sw $t0, 16($s1) 5
addu $t3, $t3, $s2 sw $t1, 12($s1) 6
sw $t2, 8($s1) 7
bne $s1, $zero, Loop sw $t2, 8($s1) 8
Do {
I = I - 16 ;
*I = *I + B;*(I+12) = *(I+12) + B;*(I+8) = *(I+8) + B; *(I+4) = *(I+4) + B;
; }
While (I != 0) ;
Do {
I = I - 16 ;
*I = *I + B;*(I+12) = *(I+12) + B;*(I+8) = *(I+8) + B; *(I+4) = *(I+4) + B;
; }
While (I != 0) ;
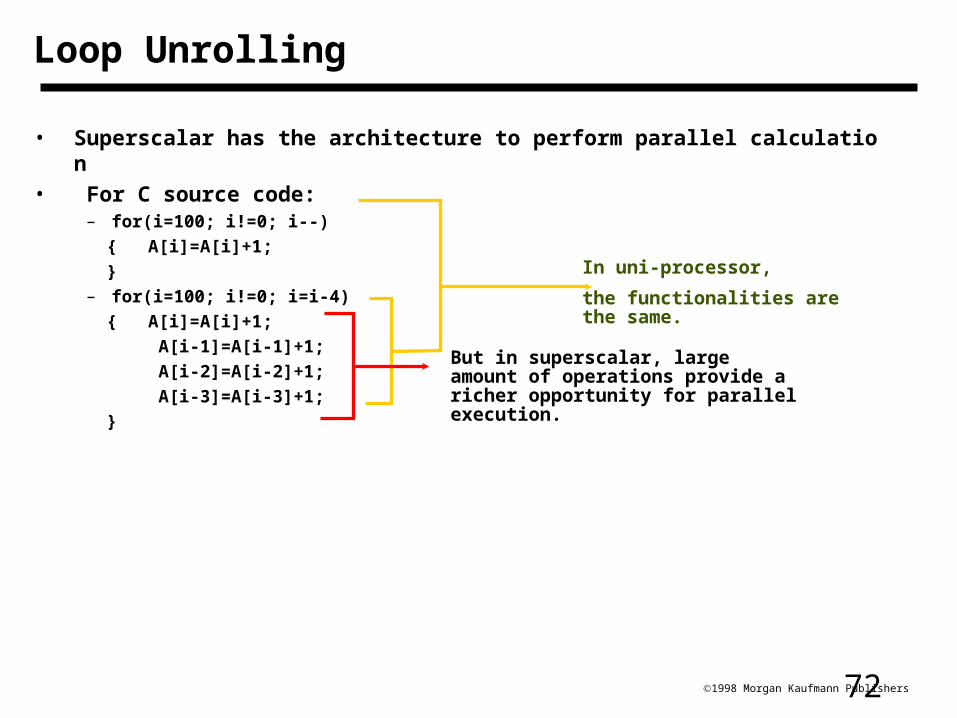
721998 Morgan Kaufmann Publishers
Loop Unrolling
• Superscalar has the architecture to perform parallel calculation• For C source code:
– for(i=100; i!=0; i--) { A[i]=A[i]+1; }– for(i=100; i!=0; i=i-4) { A[i]=A[i]+1; A[i-1]=A[i-1]+1; A[i-2]=A[i-2]+1; A[i-3]=A[i-3]+1; }
In uni-processor,
the functionalities are the same.
But in superscalar, large amount of operations provide a richer opportunity for parallel execution.

731998 Morgan Kaufmann Publishers

741998 Morgan Kaufmann Publishers

751998 Morgan Kaufmann Publishers
Dynamic Scheduling: dispatch add
R3
::
#1
::
R1R2
R3
ROB RF
reg valuereg#
value
::
#1
::
Tag #
0
1
::
Modified?
0
0R4
#1 R1 R2
FunctionalUnit
FunctionalUnit
ReservationStation
Result Bus
:add R3,R1,R2subi R4,R3,2
:
(add R3, R1, R2)

761998 Morgan Kaufmann Publishers
Dynamic Scheduling: dispatch subi
R3
R4
::
#1
::
R1R2
R3
ROB RF
reg valuereg#
value
::
#1
#2
::
Tag #
0
1
::
Modified?
0
#2 1R4
#2 #1 2#1 R1 R2
FunctionalUnit
FunctionalUnit
ReservationStation
Result Bus
:add R3,R1,R2subi R4,R3,2
:
(add R3, R1, R2)
(subi R4,R3,2)

771998 Morgan Kaufmann Publishers
Dynamic Scheduling: execute add
R3
R4
::
#1
::
R1R2
R3
ROB RF
reg valuereg#
value
107
::
#1
#2
::
Tag #
0
1
::
Modified?
0
#2 1R4
#2 #1 2
FunctionalUnit
FunctionalUnit
ReservationStation
Result Bus
:add R3,R1,R2subi R4,R3,2
:
(add R3, R1, R2)
(subi R4,R3,2)
#1 (107) = R1 + R2

781998 Morgan Kaufmann Publishers
Dynamic Scheduling: execute subi
R3
R4
::
#1
::
R1R2
R3
ROB RF
reg valuereg#
value
107
105
::
#1
#2
::
Tag #
0
1
::
Modified?
0
#2 1R4
FunctionalUnit
FunctionalUnit
ReservationStation
Result Bus
:add R3,R1,R2subi R4,R3,2
:
(add R3, R1, R2)
(subi R4,R3,2)
#2 (105) = #1 - 2

791998 Morgan Kaufmann Publishers
Dynamic Scheduling: write back add
R3
R4
::
107
::
R1R2
R3
ROB RF
reg valuereg#
value
107
105
::
#1
#2
::
Tag #
0
0
::
Modified?
0
#2 1R4
FunctionalUnit
FunctionalUnit
ReservationStation
Result Bus
:add R3,R1,R2subi R4,R3,2
:
(add R3, R1, R2)
(subi R4,R3,2)

801998 Morgan Kaufmann Publishers
Dynamic Scheduling: write back subi
R4
::
107
::
R1R2
R3
ROB RF
reg valuereg#
value
105
::
#2
::
Tag #
0
0
::
Modified?
0
105 0R4
FunctionalUnit
FunctionalUnit
ReservationStation
Result Bus
:add R3,R1,R2subi R4,R3,2
:(subi R4,R3,2)

811998 Morgan Kaufmann Publishers

821998 Morgan Kaufmann Publishers

831998 Morgan Kaufmann Publishers
Dynamic Scheduling
• The hardware performs the scheduling?
– hardware tries to find instructions to execute
– out of order execution is possible
– speculative execution and dynamic branch prediction
• All modern processors are very complicated
– DEC Alpha 21264: 9 stage pipeline, 6 instruction issue
– PowerPC and Pentium: branch history table
– Compiler technology important
• This class has given you the background you need to learn more
• Video: An Overview of Intel Pentium Processor
(available from University Video Communications)

841998 Morgan Kaufmann Publishers
Figure 6.52: The performance consequences of single-cycle, multiple-cycle and pipelined
Slower Faster
Instructions per clock (IPC = 1/CPI)
Multicycle(Section 5.5)
Single-cycle(Section 5.4)
Deeplypipelined
Pipelined
Multiple issuewith deep pipeline
(Section 6.10)
Multiple-issuepipelined
(Section 6.9)

851998 Morgan Kaufmann Publishers
Figure 6.53: Basic relationship between the datapaths in Figure 6.52
1 Several
Use latency in instructions
Multicycle(Section 5.5)
Single-cycle(Section 5.4)
Deeplypipelined
Pipelined
Multiple issuewith deep pipeline
(Section 6.10)
Multiple-issuepipelined
(Section 6.9)





























