Embed Size (px)
DESCRIPTION
認知システム論 探索(5) 先を読んで知的な行動を選択するエージェント. ゲームプレイング (Game Playing). ゲーム木と評価関数 ミニマックス法 アルファベータ法 ゲームにおけるヒューリスティクス ゲームプログラムの現在. チェス,囲碁・将棋, バックギャモン. ゲーム プレイング. 敵対するエージェント が存在する世界で 今後の行動計画を立てようとするときの 探索問題. → 「ゲーム理論」というのもあるが,この授業では 「先読みの効率化」という 探索技術 に的をしぼる. 探索問題としての特徴. - PowerPoint PPT Presentation
Citation preview

ゲームプレイング(Game Playing)
ゲーム木と評価関数
ミニマックス法
アルファベータ法
ゲームにおけるヒューリスティクス
ゲームプログラムの現在
認知システム論 探索(5)先を読んで知的な行動を選択するエージェント

ゲーム プレイング
敵対するエージェントが存在する世界で今後の行動計画を立てようとするときの探索問題
1 .敵が味方のじゃまをする →チェス,囲碁
2 .探索空間が巨大で最後まで先読みできない →不完全性
3. 偶然の要素を含むことがある →バックギャモン
4. 時間制限がある →効率と時間の使い方が重要
→ 「ゲーム理論」というのもあるが,この授業では「先読みの効率化」という探索技術に的をしぼる
探索問題としての特徴
チェス,囲碁・将棋,バックギャモン

二人ゲームの形式化
初期状態 (initial state)盤面の状態,どちらの手番か
オペレータ (operator) の集合プレイヤが指すことのできる合法手その手を指したら,盤面の状態と手番はどうなるか
終端テスト (terminal test)ゲームの終了の決定
効用関数 (utility function)ゲームの結果を数値として与える.勝ち (+1) ,負け ( - 1) ,引分け (0)
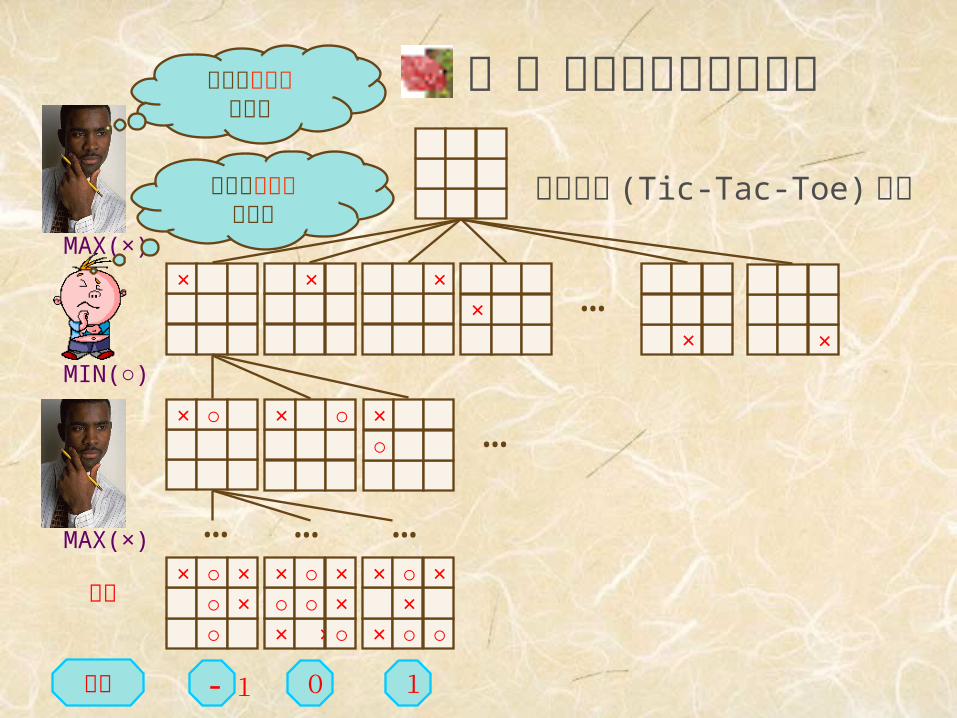
1.ゲーム木と評価関数
× ×MAX(×)
MIN(○)
××
× ×
…
× ○ × ○○× …
○○ ×
× ○ ×
× × ○○ ○ ×× ○ ×
× ○ ○×
× ○ ×
… … …
終端
10- 1
MAX(×)
効用
効用を最大化しよう
効用を最小化しよう
三目並べ (Tic-Tac-Toe) の例
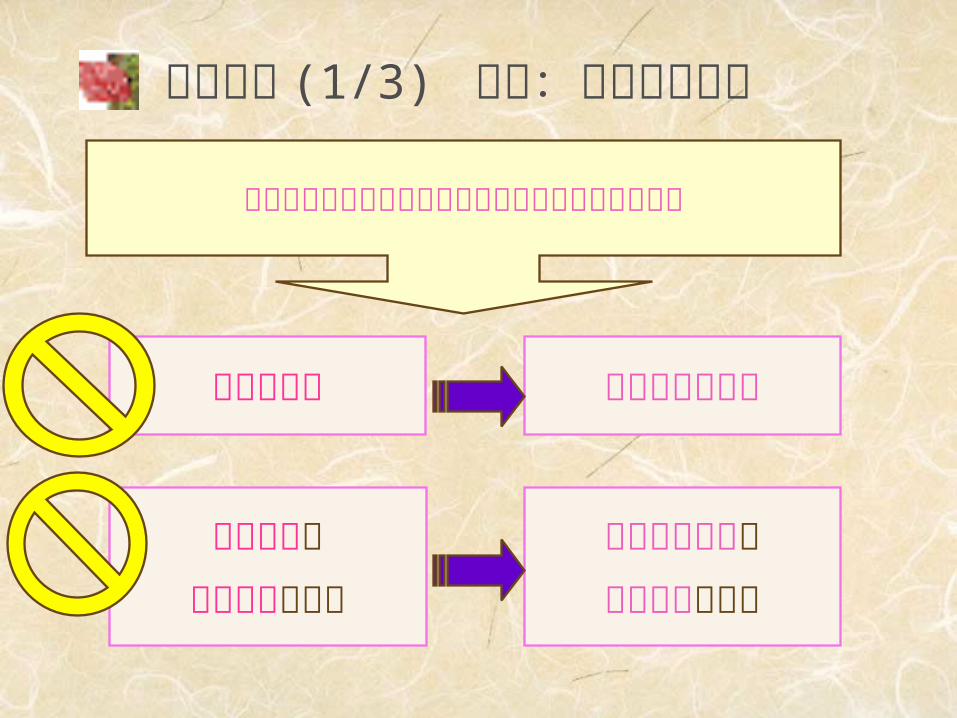
評価関数 (1/3) 動機:不完全な決定
終端状態で
効用関数を適用
打ち切り状態で
評価関数を適用
終端状態までのすべての道筋を探索する時間がない
終端テスト 打ち切りテスト
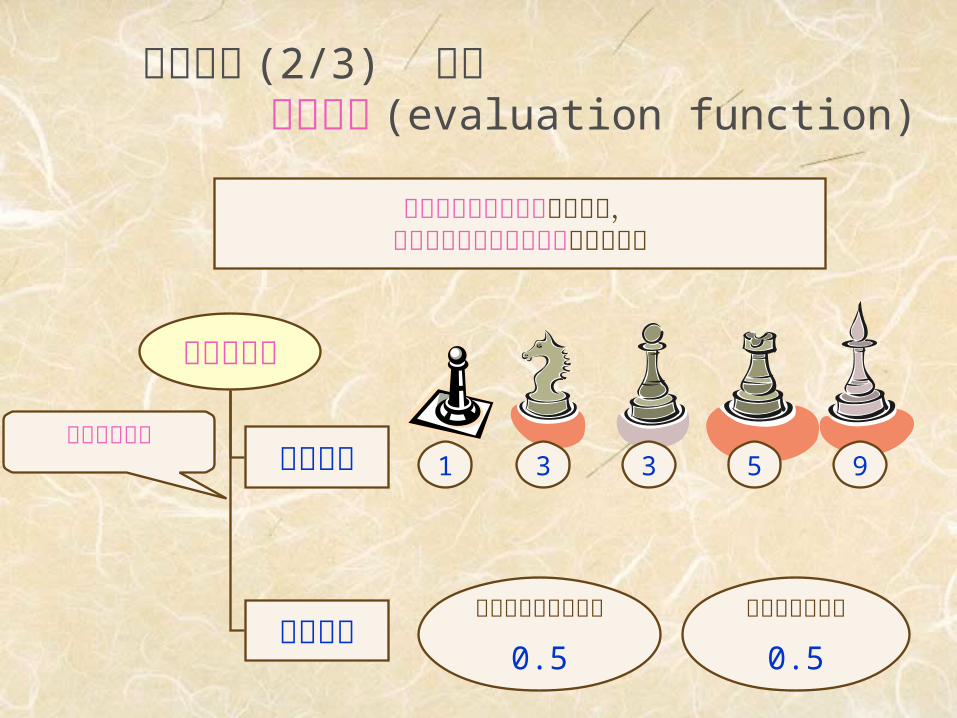
評価関数 (2/3) 定義 評価関数 (evaluation function)
ヒューリスティックを用いて,期待される効用の見積りを返す関数
チェスの例
駒の価値
駒の配置
1 3 3 5 9
ポーンストラクチャ
0.5
キングの安全性
0.5
これらの総和
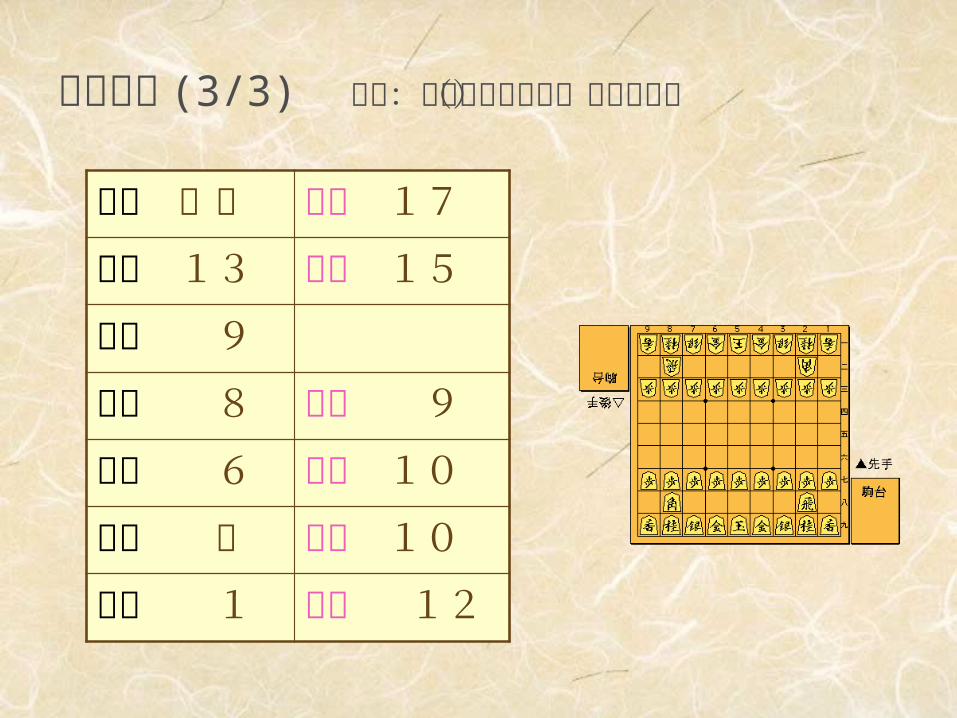
評価関数 (3/3) 参考:将棋の駒の価値(谷川浩司)
飛車 15 竜王 17
角行 13 龍馬 15
金将 9
銀将 8 成銀 9
桂馬 6 成桂 10
香車 5 成香 10
歩兵 1 と金 12

2.ミニマックス法 (minimax procedure)
MAX
MIN
3 12 8 2 4 6 14 5 2
3
3 2 2
終端
MIN MIN MIN
MAX
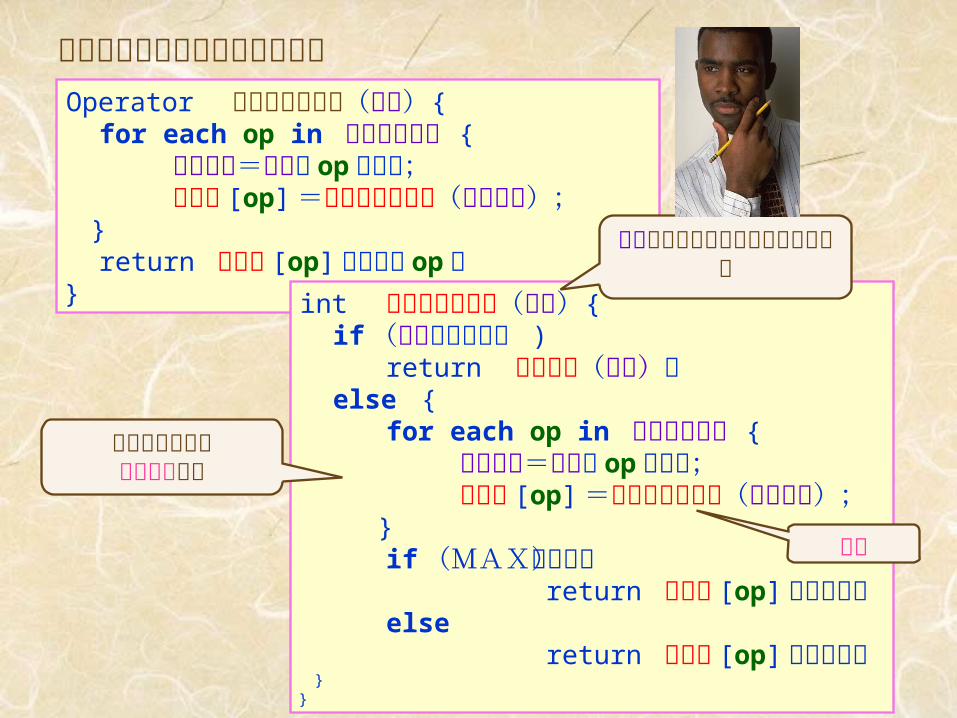
ミニマックス法のアルゴリズムOperator ミニマックス法(盤面){ for each op in 全オペレータ { 次の盤面=盤面に op を適用; 評価値 [op] =ミニマックス値(次の盤面); } return 評価値 [op] が最大な op ;}
int ミニマックス値(盤面){ if (盤面が終端状態 ) return 効用関数(盤面); else { for each op in 全オペレータ { 次の盤面=盤面に op を適用; 評価値 [op] =ミニマックス値(次の盤面); } if (MAXの手番) return 評価値 [op] の最大値; else return 評価値 [op] の最小値; }}
すべての変数は局所変数です
再帰
盤面はどちらの手番かの情報を含む

3.アルファベータ法 (α-β procedure)
MAX
MIN
3 12 8 6
3
α =3
β =2
MAX のこれまでのベスト
MIN のこれまでのベスト
≦ 6
≧ 3
ミニマックス法の効率を上げる
2
β =6
≦ 2
α β≧ で枝刈り

アルファベータ法のアルゴリズム(1/3)
Operator アルファベータ法(盤面){ α =-∞; β =+∞;
for each op in 全オペレータ { 次の盤面=盤面に op を適用; α = MAX ( α , MIN 値(次の盤面, α , β )); } return α を最大にしたオペレータ op ;}
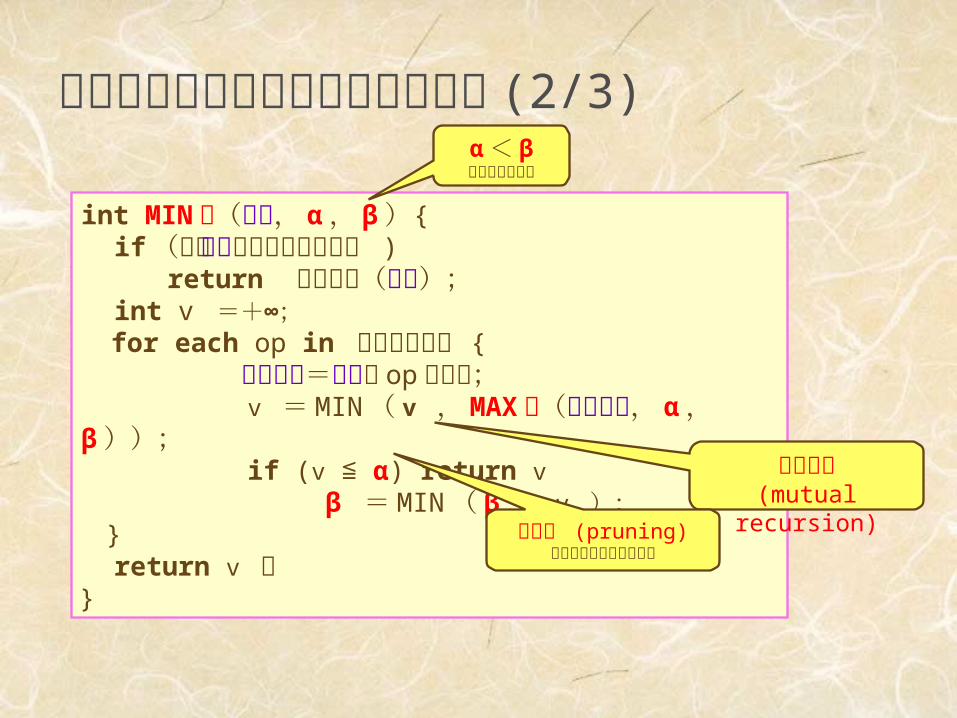
アルファベータ法のアルゴリズム(2/3)
int MIN 値(盤面, α , β ){ if (この盤面で先読みを打切り ) return 評価関数(盤面); int v =+∞; for each op in 全オペレータ { 次の盤面=盤面に op を適用; v = MIN ( v , MAX 値(次の盤面, α , β )); if (v ≦ α) return v β = MIN ( β , v ); } return v ;}
相互再帰(mutual
recursion)枝刈り (pruning)値は戻り先で無視される
α< βとして呼び出
す
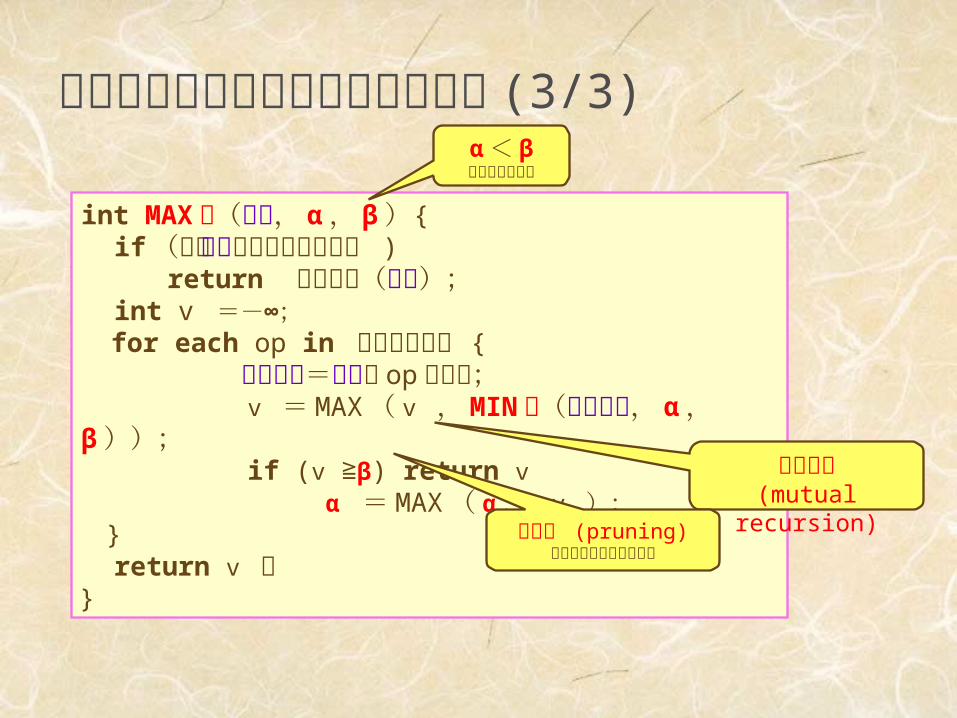
アルファベータ法のアルゴリズム(3/3)
int MAX 値(盤面, α , β ){ if (この盤面で先読みを打切り ) return 評価関数(盤面); int v =-∞; for each op in 全オペレータ { 次の盤面=盤面に op を適用; v = MAX ( v , MIN 値(次の盤面, α , β )); if (v ≧β) return v α = MAX ( α , v ); } return v ;}
相互再帰(mutual
recursion)枝刈り (pruning)値は戻り先で無視される
α< βとして呼び出
す

3.ゲームにおけるヒューリスティクス
評価関数をどう設計したらよいか?
探索をいつ打ち切ったらよいか?

評価関数の設計 (1/3) 基本
終端接点では,評価値=効用値あまり長い時間かかってはいけない実際に勝つ可能性を反映していること
勝つ確率 0.5 評価値= 1×0.5 + ( -1)×0.25 + 0×0.25= 0.25
負ける確率 0.25
引分ける確率 0.25
厳密である必要はない
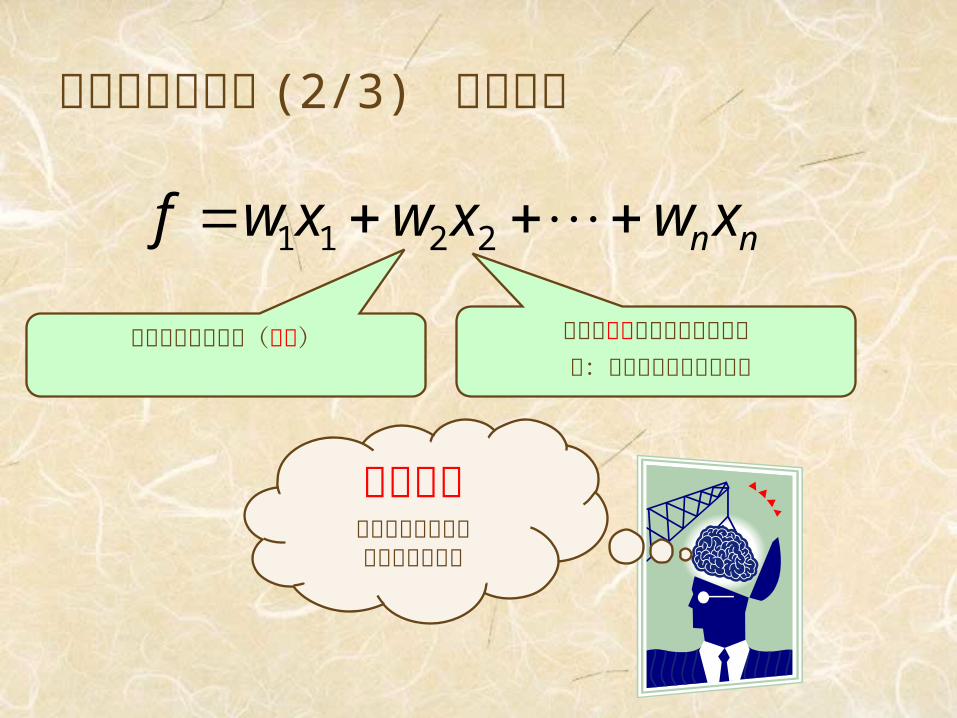
評価関数の設計 (2/3) 線形近似
nnxwxwxwf 2211
局面の特徴を数量化したもの例:盤上にあるナイトの数
その特徴の重要性(重み)
機械学習経験に合うように重みを調節する
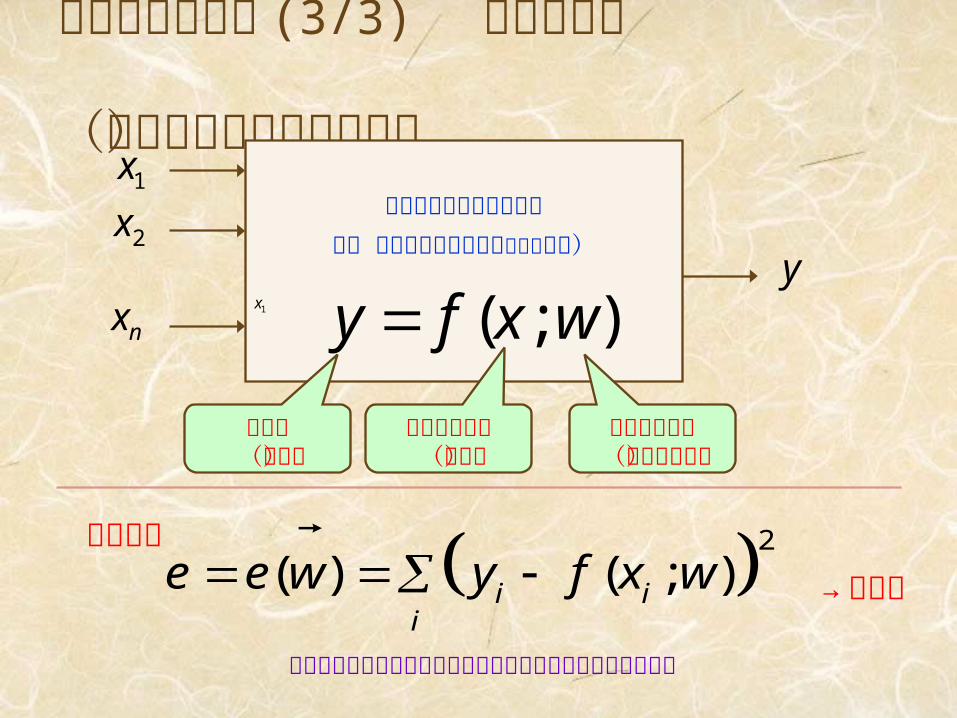
評価関数の設計 (3/3) 非線形近似 (ニューラルネットの例)
1x
ニューラルネットワーク
(w をパラメータとする非線形関数)2x
nxy
);( wxfy
1x
特徴ベクトル
(入力)
重みベクトル
(パラメータ)
評価値(出力)
2( ) ( ; )i ii
e e w y f x w 誤差関数
→ 最小化
バックプロパゲーションアルゴリズムは近似的に最小化する

探索をいつ打ち切るか (1/3) 3つの考え方一定の深さ d で打切り一定の時間まで反復深化を適用静かな局面で打切り
静かでない局面(駒が激しくぶつかっている)
静けさ探索静かな局面に達するまで深く読む
(たとえば,駒を取る手だけを読む)
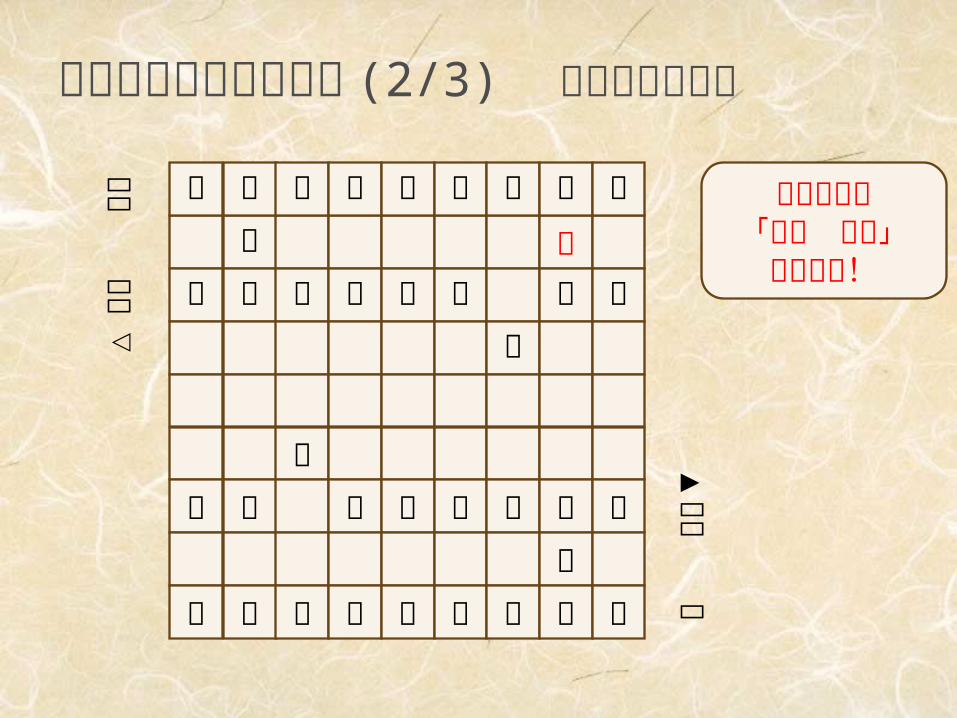
探索をいつ打ち切るか (2/3) 静かでない局面
歩
歩
香
飛
歩
歩
桂
歩歩
銀
歩
歩
金
歩
歩
玉
歩
歩
金
歩
歩
銀
馬
歩
歩
飛
桂
歩
歩
香
香 桂 銀 金 王 金 銀 桂 香
▲先手
角
△後手
なし
この局面は「先手 有利」
ではない!
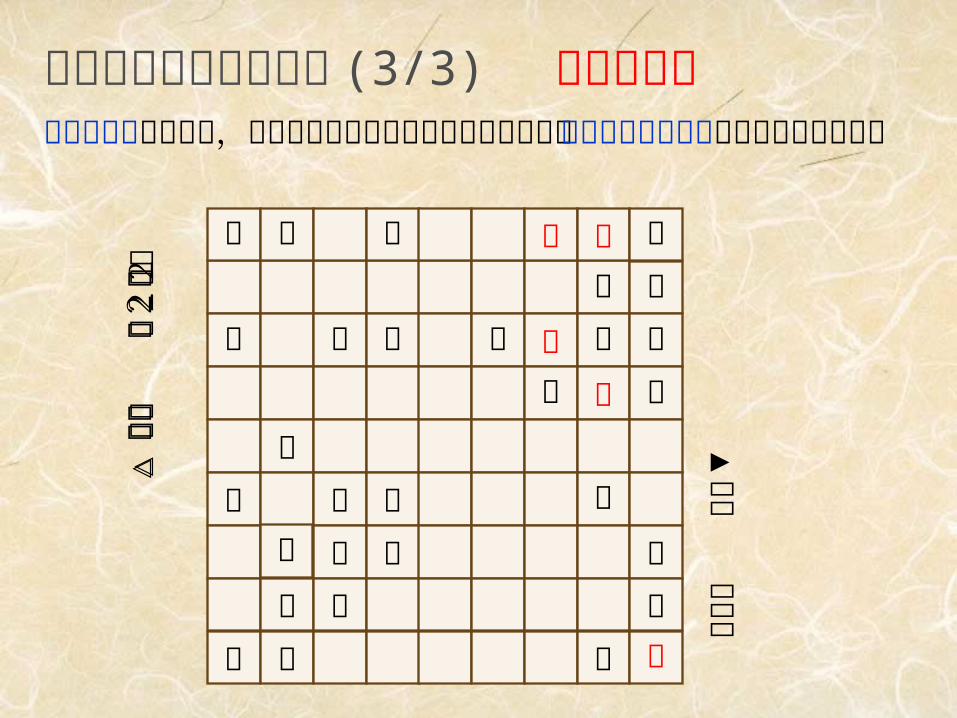
探索をいつ打ち切るか (3/3) 水平線効果無意味な手の連続で,不利な局面を見つけることのできない水平線の向こうへ追いやって安心する
歩
歩
香
歩
玉
桂
歩
歩
銀
金
歩
歩
金
歩と
歩
飛
歩と
銀
桂
王
歩
桂
歩
香
馬
香 桂 金
馬 と
香▲先手
飛金歩
△後手
銀2歩2
△後手
銀2歩
歩
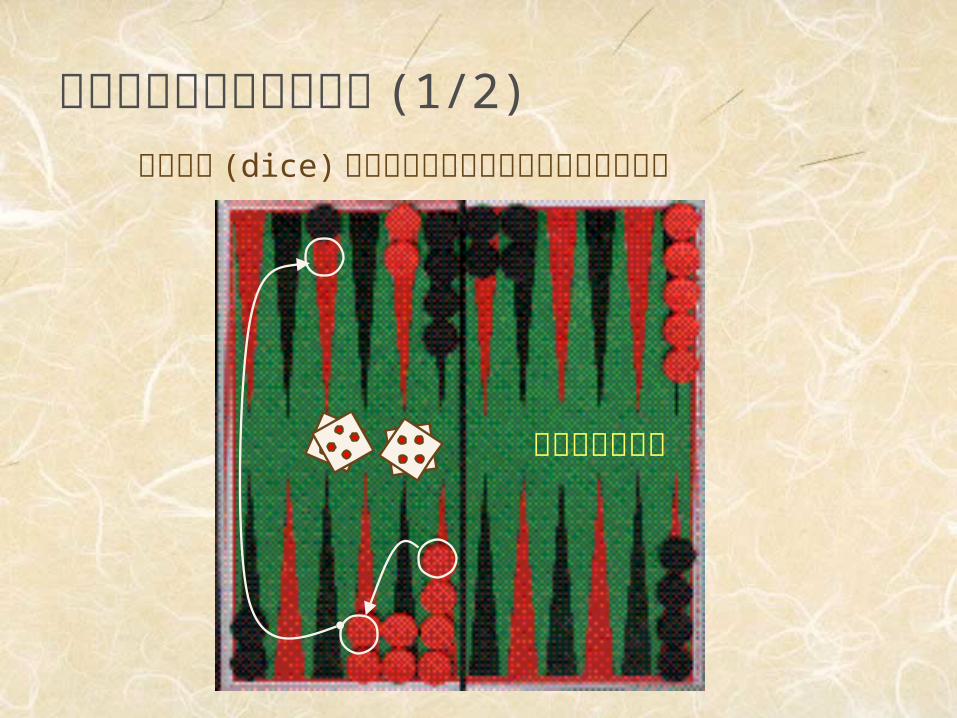
偶然の要素を含むゲーム (1/2)サイコロ (dice) の目によって取りうる手が制
限される
バックギャモン
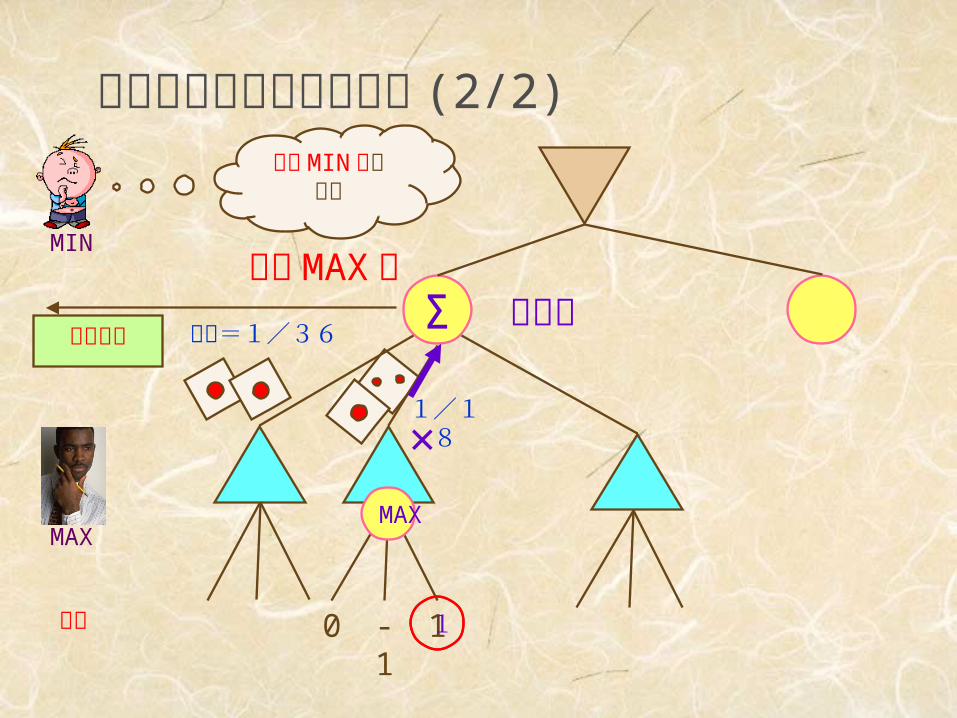
偶然の要素を含むゲーム (2/2)
MAX
MIN
終端 0 -1 1
確率=1/36
1/18
1
×
Σ期待 MAX 値
MAX
期待値
期待 MIN 値も同様
偶然節点

ゲームプログラムの現在チェス 1997年にコンピュータ( Deep
Blue )が名人 Kasparov に勝利チェッ
カーコンピュータが世界チャンピオン
オセロ ふつうのプログラムでも人間より強い
バックギャモン
世界トップレベルの実力
将棋 現役の一流プロのレベル
囲碁 アマ高段者のレベルへ( UCT ,モンテカルロ碁)





























