Embed Size (px)
Citation preview

CENG 501 Deep Learning
Week 2
Sinan Kalkan
© AlchemyAPI

Administrative Issues
• Registrations• Access to Moodle (https://odtuclass.metu.edu.tr/)• Project paper selection– https://docs.google.com/spreadsheets/d/1tzPHq_Vgu6gCwNyXJHGv
qeA6pgU67H0nKYjqkisWfKc/edit?usp=sharing– Deadline: 29 March + 1-2 weeks
Spring 2021 Sinan Kalkan 2

Deep learning and other approaches
3Fig.: I. Goodfellow
Sprin
g 20
21Si
nan
Kal
kan
Previously on CENG501!

So what does Deep (Machine) Learning bring/provide?
• (Hierarchical) Compositionality� Cascade of non-linear transformations� Multiple layers of representations
• End-to-End Learning� Learning (goal-driven) representations� Learning to feature extraction
• Distributed Representations� No single neuron “encodes” everything� Groups of neurons work together
4Slide Credit: Marc'Aurelio Ranzato, Yann LeCun
Sprin
g 20
21Si
nan
Kal
kan
Previously on CENG501!

5
Building A Complicated Function
Given a library of simple functions
Compose into a
complicate function
Idea 2: Compositions• Deep Learning
• Grammar models
• Scattering transforms…
f(x) = g1(g2(. . . (gn(x) . . .))
Slide Credit: Marc'Aurelio Ranzato, Yann LeCunSpring 2021Sinan Kalkan
Previously on CENG501!

Trainable Classifier
Low-LevelFeature
Mid-LevelFeature
High-LevelFeature
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]
“car”
Deep Learning = Hierarchical Compositionality
Slide Credit: Marc'Aurelio Ranzato, Yann LeCun 6Spring 2021Sinan Kalkan
Previously on CENG501!
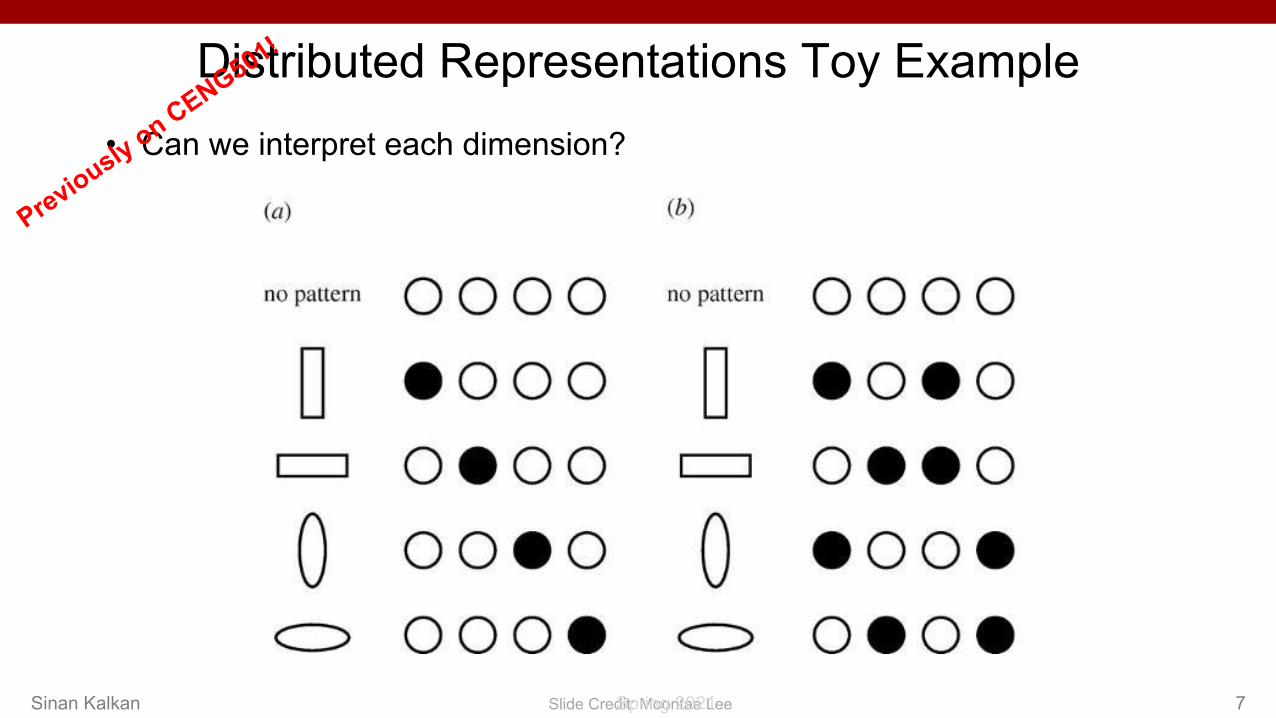
Distributed Representations Toy Example• Can we interpret each dimension?
7Slide Credit: Moontae Lee Spring 2021Sinan Kalkan
Previously on CENG501!

It can make mistakes
• T. Xu, J. White, S. Kalkan, H. Gunes, "Investigating Bias and Fairness in Facial Expression Recognition", ECCV2020 Workshop: ChaLearn Looking at People workshop ECCV: Fair Face Recognition and Analysis, 2020.
• J. Cheong, S. Kalkan, H. Gunes, "The Hitchhiker’s Guide to Bias and Fairness in Facial Affective Signal Processing", IEEE Signal Processing Magazine.
8Joy Buolamwini & Timnit Gebru
Sprin
g 20
21Si
nan
Kal
kan
Previously on CENG501!

9
Beery, Sara, Grant Van Horn, and Pietro Perona. "Recognition in terra incognita." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
Sprin
g 20
21Si
nan
Kal
kan
Previously on CENG501!

Today
• Introduction to machine learning
• Towards deep learning� History of deep learning� Biological neuron� Artificial neuron� Perceptron learning� Linear classification/regression� Non-linear classification/regression� Multi-layer perceptrons
10
Sprin
g 20
21Si
nan
Kal
kan

A CRASH COURSE ONMACHINE LEARNING
11
Facial images in this part of the lecture are from the JAFFE database: https://figshare.com/articles/journal_contribution/jaffe_desc_pdf/5245003
Spring 2021 Sinan Kalkan

Sinan Kalkan
machine learningWhat is ?
Finding “hidden” structures in data “automatically”.
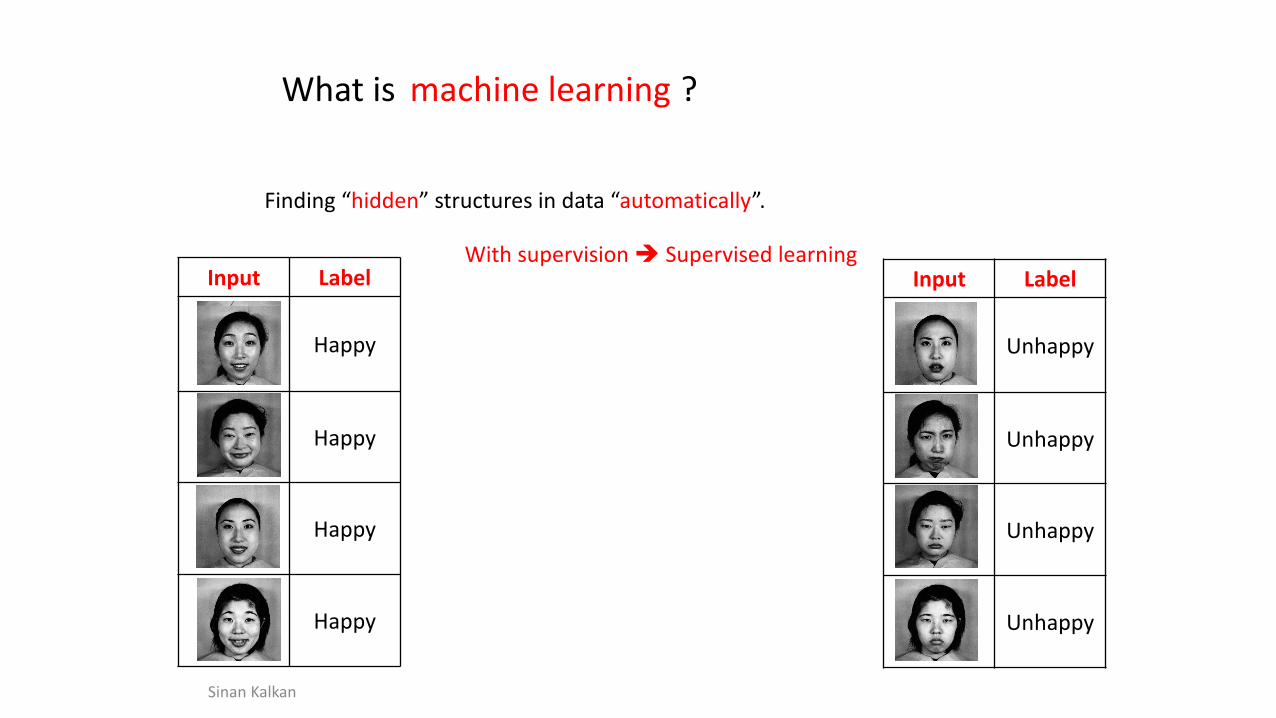
Input Label
Unhappy
Unhappy
Unhappy
Unhappy
Input Label
Happy
Happy
Happy
Happy
Sinan Kalkan
machine learningWhat is ?
Finding “hidden” structures in data “automatically”.
With supervision è Supervised learning

Sinan Kalkan
machine learningWhat is ?
𝐱 ∈ ℐ
Happy
Unhappy
𝐲 ∈ 𝒪

Sinan Kalkan
machine learningWhat is ?
𝐱 ∈ ℐ
Happy
Unhappy
𝐲 ∈ 𝒪𝐲 = 𝑓(𝐱)
… … ……
𝑓 ?

Testing
Training
Machine learning pipeline
“Learn”Learned
Models or Classifiers
Data with label(label: happy, unhappy)
- Size- Texture- Color- Histogram of
oriented gradients- SIFT- Etc.
ExtractFeatures
ExtractFeatures
Predict
Happy or Unhappy
Test input
Spring 2021 Sinan Kalkan 16

GenerativeDiscriminativeGeneral Approaches
Find separating line (in general: hyperplane)
Fit a function to data(regression).
Learn a model for each class.
Spring 2021 Sinan Kalkan 17

Supervised
Instance Label
happy
unhappy
unhappy
happy
unhappy
Unsupervised
General Approaches (cont’d)
Extract Features
Learn a model
Extract Features
Learn a model
e.g. SVM
e.g. k-meansclustering
Spring 2021 Sinan Kalkan 18

General Approaches (cont’d)
Generative Discriminative
Supervised
Unsupervised
Spring 2021 Sinan Kalkan 19
Neural Networks
Support Vector MachinesNeural Networks
K-Nearest NeighborsDecision TreesRandom Forest
Mixture Models K-means

Outline for the Machine Learning Part
Supervised Learning
Unsupervised Learning
Other Forms of Learning
General Issues in Learning
Evaluation
Spring 2021 Sinan Kalkan 20

SUPERVISED LEARNING
Spring 2021 Sinan Kalkan 21

Supervised Machine Learning
• Find the following mapping, given the training set 𝐱!, 𝐲! !"#$ :
𝐲 = 𝑓 𝐱
𝑓: 𝕏 → 𝕐.
• Targets can be for classification or regression
• Methods: – K Nearest Neighbors, Support Vector Machines,
Decision Trees, Random Forest, Neural Networks
Spring 2021 Sinan Kalkan 22
Input Target Value
0.95
0.80
0.65
0.88
Target Class
Happy
Happy
Happy
Happy

Supervised Machine Learning MethodsK Nearest Neighbors
• Advantages:– No training– Simple
• Disadvantages:– Slow testing time (more efficient
versions exist)– Needs a lot of memory
Fig: http://cs231n.github.io/classification/Spring 2021 Sinan Kalkan 23
k shall be 3

Supervised Machine Learning MethodsSupport Vector Machines
Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
wTx + b = 0
wTx + b < 0wTx + b > 0
Binary classification can be viewed as the task of separating classes in feature space:
𝐲 = 𝑓(𝐱) = sign(𝐰𝑻𝐱 + 𝑏)
Spring 2021 Sinan Kalkan 24

Supervised Machine Learning MethodsSupport Vector Machines
• How many lines are there?• Which one is optimal?
25Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
Spring 2021 Sinan Kalkan

Supervised Machine Learning MethodsSupport Vector Machines
• Distance from example xi to the separator is 𝑟 = 𝐰!𝐱"#$𝐰
• Examples closest to the hyperplane are support vectors. • Margin ρ of the separator is the distance between support vectors.
r
ρ
26Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
Maximum Margin Classification• Maximizing the margin is good
according to intuition.• Implies that only support vectors
matter; other training examples are ignorable.
Spring 2021 Sinan Kalkan

Supervised Machine Learning MethodsSupport Vector Machines
What we know:• w . x+ + b = +1 • w . x- + b = -1 • w . (x+-x-) = 2
“Predict Class =
+1”
zone
“Predict Class =
-1”
zonewx+b=1
wx+b=0
wx+b=-1
X-
x+
wwwxx 2)(=
×-=
-+
r
ρ = Margin Width
27
Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
Spring 2021 Sinan Kalkan

Supervised Machine Learning MethodsSupport Vector Machines
• Then we can formulate the optimization problem:
which can be reformulated as:
or as the following in more compact form:
Find w and b that maximizes:
𝜌 = %𝐰 ,
such that: 𝑦𝑖(𝐰𝑻𝐱𝑖 + 𝑏) ≥ 1 for all (xi, yi), i=1..n
Find w and b that minimizes:
𝚽(𝐰) = 𝐰 2 = 𝐰𝑇𝐰,
such that: 𝑦𝑖(𝐰𝑻𝐱𝑖 + 𝑏) ≥ 1 for all (xi, yi), i=1..n
29Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
min𝐰∈ℝ(,)∈ℝ
𝐰 * −6!
𝛼! 𝑦𝑖(𝐰𝑻𝐱𝑖 + 𝑏) − 1
Spring 2021 Sinan Kalkan

Supervised Machine Learning MethodsSupport Vector Machines
Limitation: Not robust to noisy data: • Solution: Allow some margin of
error for each sample point
30Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
Find w and b that minimizes:
𝚽(𝐰) = 𝐰 2 = 𝐰𝑇𝐰,
such that: 𝑦𝑖(𝐰𝑻𝐱𝑖 + 𝑏) ≥ (1 − 𝜖)) for all (xi, yi), i=1..n
and 𝜖# +⋯+ 𝜖$ < 𝐶. Spring 2021 Sinan Kalkan
Take C as …

Supervised Machine Learning MethodsSupport Vector Machines
Limitation: Not suitable for non-linearly separable data
• Solution: Expand the feature space using a “kernel”, a function calculating some similarity between samples as a dot product:
𝐾 𝐱) , 𝐱* = 𝜙 𝐱) ⋅ 𝜙(𝐱*)
• Example kernels:– Polynomial
𝐾 𝐱! , 𝐱" = 𝐱! ⋅ 𝐱" + 1#
– Radial-basis Function:
𝐾 𝐱! , 𝐱" = exp −𝛾6$
(𝑥!$−𝑥"$)%
31Borrowed mostly from the slides of: ML Group, Uni of Texas at Austin; Mingyue Tan, Uni of British Columbia
0 x
0 x
0
x2
x
Spring 2021 Sinan Kalkan

Supervised Machine Learning MethodsDecision Trees
T. Mitchell, “Machine Learning”, McGraw Hill, 1997.
Spring 2021 Sinan Kalkan 33

Supervised Machine Learning MethodsDecision Trees
• At each node 𝑚, we divide the space based on a simple rule:
𝑥! > 𝜃+• Following the nodes, we reach
leaves.• Classification: Leaves are
labels• Regression: Leaves are
numerical values (a function of local values)
Fig: Oya Celiktutan.Spring 2021 Sinan Kalkan 34

Supervised Machine Learning MethodsRandom Forest
• Instead of a single strong classifier, have many weak classifiers and combine their answers.
Fig: https://towardsdatascience.com/understanding-random-forest-58381e0602d2
Spring 2021 Sinan Kalkan 36
Take 9 trees

UNSUPERVISED LEARNING
Fig: http://www.nlpca.org/
Spring 2021 Sinan Kalkan 37

Unsupervised Machine Learning
• Learning without labels• Goal: Discover a better
representation of data• Uses:
– Dimensionality reduction– Data visualization– Preparation for supervised learning– Clustering
• Methods:– Principle/Independent Component
Analysis, k-Means/x-Means Clustering, Manifold learning methods, …
Spring 2021 Sinan Kalkan 38

Unsupervised Machine Learning MethodsClustering with k-Means
Spring 2021 Sinan Kalkan 39
k shall be 2
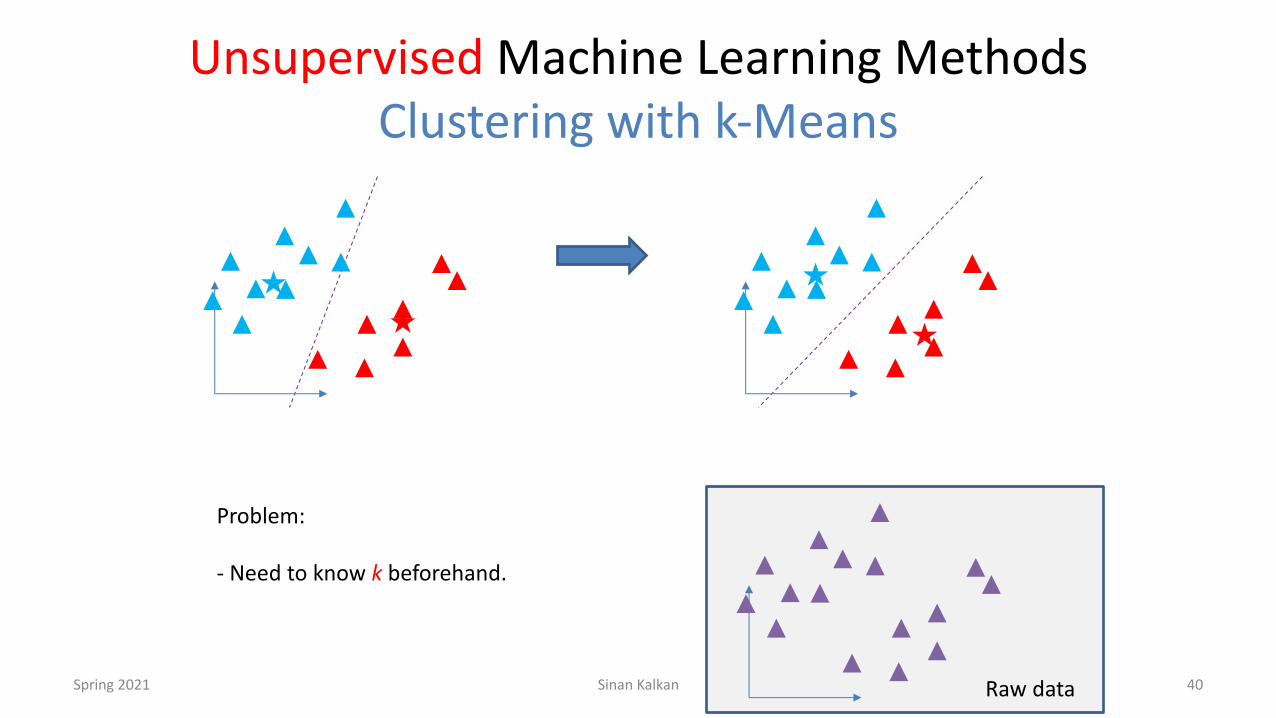
Unsupervised Machine Learning MethodsClustering with k-Means
Raw data
Problem:
- Need to know k beforehand.
Spring 2021 Sinan Kalkan 40

Unsupervised Machine Learning MethodsDimensionality Reduction
Principle Component Analysis• Analyze variance in the
data• Find new set of axes
such that along the first axis, variance is the highest; along the second, variance is the second highest etc.
Fig: http://cs231n.github.io/neural-networks-2/
Fig: http://www.nlpca.org/
Spring 2021 Sinan Kalkan 41

OTHER FORMS OF LEARNING
Self-supervised learningWeakly-supervised learningZero-shot/Few-show learningReinforcement LearningMeta-learningLife-long learning
Spring 2021 Sinan Kalkan 42

Self-supervisedLearning
• Form supervision from data itself by predicting one portion of data from another portion
• An introductory read: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
Spring 2021 Sinan Kalkan 43Fig.: Doersch et al., 2015

Weakly-supervised LearningE.g. weakly supervised object detection
There is at least one penguin in this photo
Spring 2021 Sinan Kalkan 44

Few-shot/Zero-shot Learning
Fig: https://preparingforgre.com/item/42488
Spring 2021 Sinan Kalkan 45
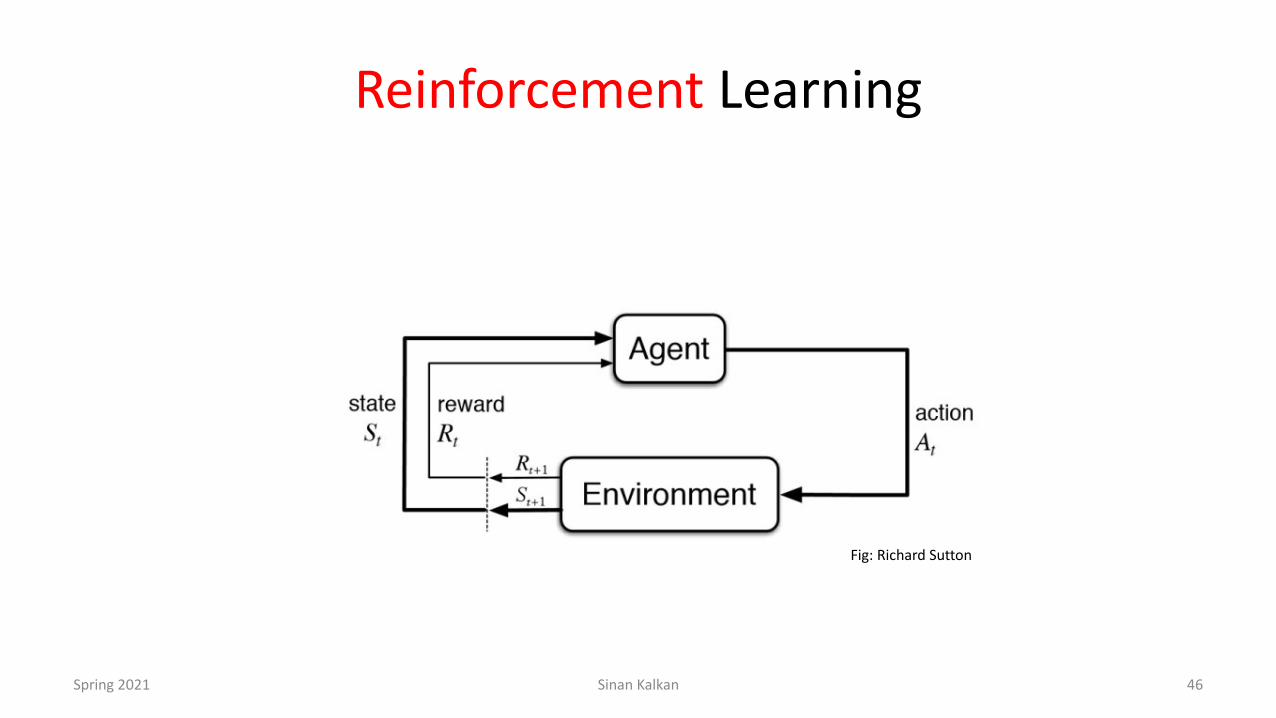
Reinforcement Learning
Fig: Richard Sutton
Spring 2021 Sinan Kalkan 46

Meta Learning
• One learning module shaping/controlling another
Spring 2021 Sinan Kalkan 47
F. I. Dogan, I. Bozcan, M. Celik, S. Kalkan, "CINet: A Learning Based Approach to Incremental Context Modeling in Robots",IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018.

Lifelong Learning
I. Dogan, H. Celikkanat, S. Kalkan, "A Deep Incremental Boltzmann Machine for Modeling Context in Robots", International Conference on Robotics and Automation (ICRA), pp. 2411-2416, IEEE, 2018.
Spring 2021 Sinan Kalkan 48

ISSUES IN MACHINE LEARNING
Spring 2021 Sinan Kalkan 49
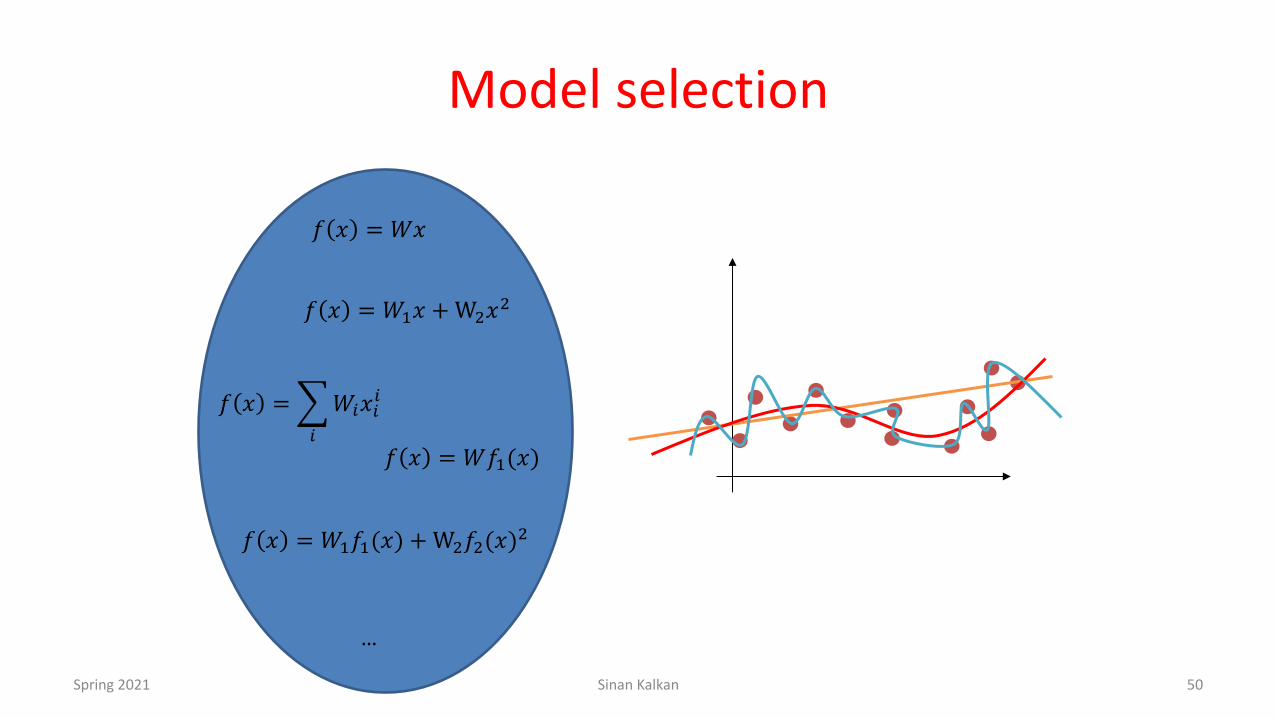
Model selection
𝑓 𝑥 = 𝑊𝑥
𝑓 𝑥 =4%
𝑊%𝑥%%
𝑓 𝑥 = 𝑊#𝑥 +W&𝑥&
𝑓 𝑥 = 𝑊𝑓#(𝑥)
𝑓 𝑥 = 𝑊#𝑓#(𝑥) +W&𝑓&(𝑥)&
…
Spring 2021 Sinan Kalkan 50

Model ComplexityModels range in their flexibility to fit arbitrary data
complex model
unconstrained
large capacity mayallow it to memorizedata and fail tocapture regularities
simple model
constrained
small capacity mayprevent it from representing allstructure in data
low bias
high variance
high bias
low variance
Slide Credit: Michael Mozer51Spring 2021 Sinan Kalkan

Bias-Variance Dilemma
underfit overfit
Erro
r on
Test
Set
Slide Credit: Michael Mozer52Spring 2021 Sinan Kalkan

EVALUATION
Spring 2021 Sinan Kalkan 53

How to evaluate performance
• Hold-out method:
Spring 2021 Sinan Kalkan 54
Training set Test set
Training set Test setValidation set

Cross-validation
• K-fold cross validation
Fig: https://scikit-learn.org/stable/modules/cross_validation.htmlSpring 2021 Sinan Kalkan 55

Cross-validation
Exhaustive validation:
– Leave-p-out (LPO) cross validation• One iteration: Use p samples as the validation set
and others as training set• Repeat this for all possible combinations of p
samples.
– Leave-one-out (LOO) is LPO with p=1
Spring 2021 Sinan Kalkan 56

Cross-validation
• Group/subject-based validation: Determine the folds based on group/subject information
• Leave one subject out (LOSO) cross validation• Divide dataset into k subsets with respect to subject identifiers
Training and test sets contain the same subjects
Training and test sets do NOT contain the same subjects
Spring 2021 Sinan Kalkan 57

Evaluation MetricsClassification
Credit: Oya CeliktutanSpring 2021 Sinan Kalkan 58

Evaluation MetricsClassification
• Always try to quantify the predictions that have not been made.
• Recall & F-measure are frequently used
Credit: Oya CeliktutanSpring 2021 Sinan Kalkan 59

Evaluation MetricsRegression
Credit: Oya CeliktutanSpring 2021 Sinan Kalkan 60
2
2
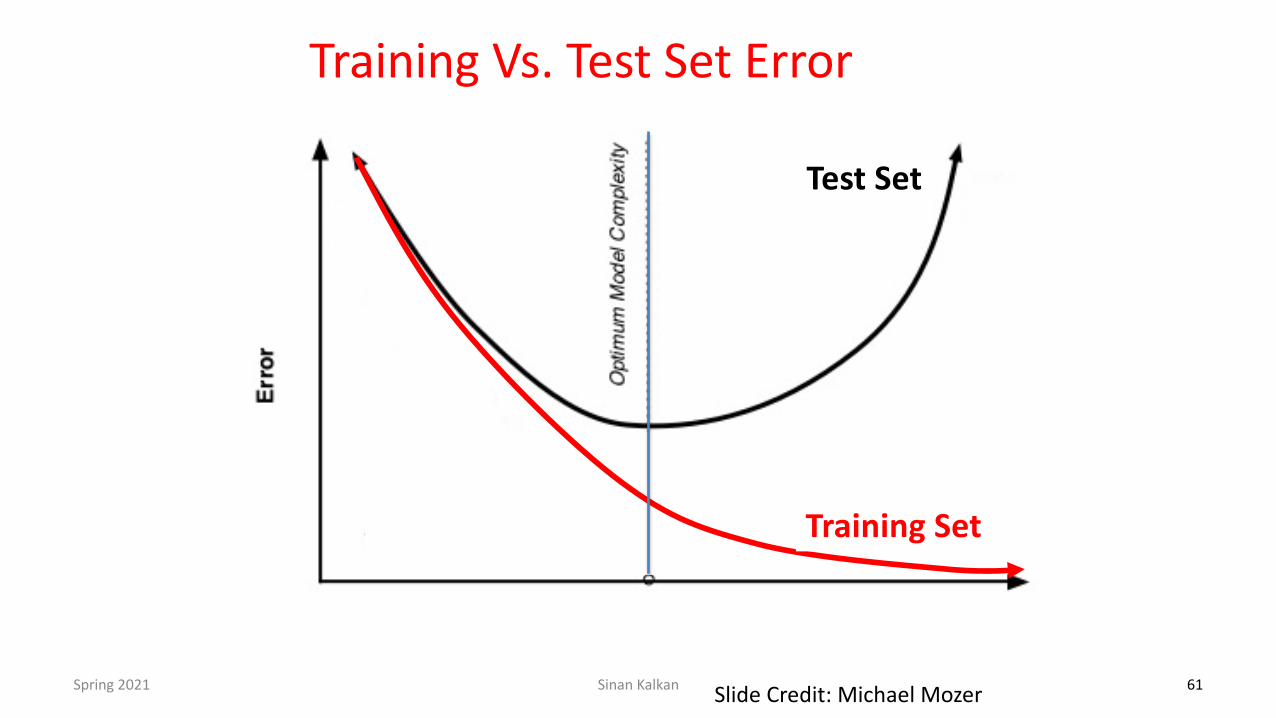
Training Vs. Test Set Error
Test Set
Training Set
Slide Credit: Michael Mozer 61Spring 2021 Sinan Kalkan

EXAMPLE
Spring 2021 Sinan Kalkan 62

Facial Emotion Recognition
- Using SVM and MLP on Google Colab + sci-kit learn:https://colab.research.google.com/drive/1mZimbXBAJlqgl-04phHxXRYku6EvgUOw
Spring 2021 Sinan Kalkan 63





























