Embed Size (px)
DESCRIPTION
Как понять, чего хочет пользователь, без единого запроса? Строим рекомендательную систему. Андрей Федоровский , [email protected] Дмитрий Исайкин, [email protected] Варвара Логачева , [email protected]. Рекомендательные системы: зачем они?. - PowerPoint PPT Presentation
Citation preview

Как понять, чего хочет пользователь, без единого запроса?
Строим рекомендательную систему.
Андрей Федоровский, [email protected]Дмитрий Исайкин, [email protected]
Варвара Логачева, [email protected]

Рекомендательные системы: зачем они?
Цель – изучить вкусы пользователя и понять, какие объекты из коллекции он оценит выше других.
Анализируем- Его оценки объектов и лог его действий- Оценки и действия других пользователей

Как это делать?

Как это делать?
1) Показать 10 самых лучших объектов

Как это делать?
1) Показать 10 самых лучших объектов2) Совместная встречаемость объектов
в сессиях

Как это делать?
1) Показать 10 самых лучших объектов2) Совместная встречаемость объектов
в сессиях3) Ввести рубрикацию/теги объектов

Как это делать?
1) Показать 10 самых лучших объектов2) Совместная встречаемость объектов
в сессиях3) Ввести рубрикацию/теги объектов
Малое число тегов на объектНет отрицательных отношений

Подходы

Подходы
Content-based: теги = ключевые термины из описания объекта

Подходы
Content-based: теги = ключевые термины из описания объектаCollaborative filtering: учет оценок других пользователей

Подходы
Content-based: теги = ключевые термины из описания объектаCollaborative filtering: учет оценок других пользователейNeighbourhood-based CF: учитываем оценки близких пользователей

Подходы
Content-based: теги = ключевые термины из описания объектаCollaborative filtering: учет оценок других пользователейNeighbourhood-based CF: учитываем оценки близких пользователей
В каком пространстве?

Подходы
Content-based: теги = ключевые термины из описания объектаCollaborative filtering: учет оценок других пользователейNeighbourhood-based CF: учитываем оценки близких пользователейMatrix factorization: построение профилей из скрытых признаков

Требования к системе
1) Масштабирование до миллиардов оценок2) Высокая скорость работы3) Универсальная работа с разными
наборами данных4) Явные оценки и неявные (логи действий)5) Добавление новых оценок, объектов,
пользователей без рестарта

Требования к системе
1) Масштабирование до миллиардов оценок2) Высокая скорость работы3) Универсальная работа с разными
наборами данных не получилось 4) Явные оценки и неявные (логи действий)5) Добавление новых оценок, объектов,
пользователей без рестарта

MF
- профили пользователей - профили объектов

ISMF

RISMF

BRISMF

Оптимизация параметров системы
1) Градиентные методы не подходят. Выбрали покоординатный спуск.
2) Переобучение:1) Несколько запусков, разные семплы2) Регуляризация в модели3) Validation set

Неявные данные
50к оценок против 400М действий

Неявные данные
50к оценок против 400М действийПроблема – матрица НЕразрежена.

Неявные данные
50к оценок против 400М действийПроблема – матрица НЕразрежена.Синтетические явные оценки:

Неявные данные
50к оценок против 400М действийПроблема – матрица НЕразрежена.Синтетические явные оценки:
NB: Чем плотнее матрица, тем лучше идет обучение. Поэтому лучше начинать с ядра.NB2: Объекты с единичными оценками кластеризуем
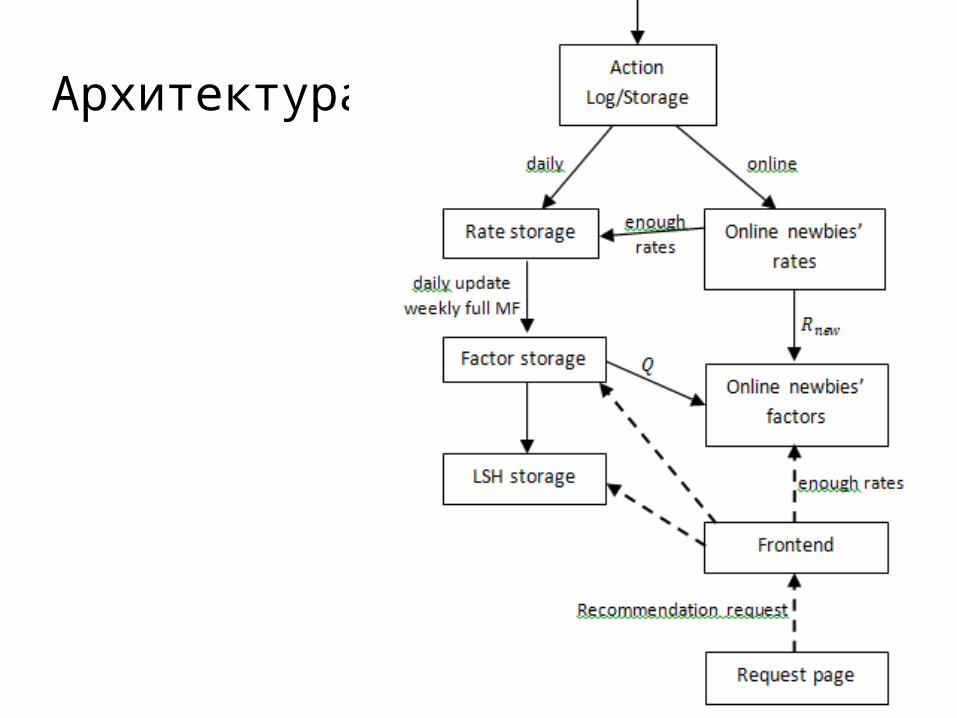
Архитектура

Построение выдачи
RMSE – качество на всей коллекции.А нам важны 10 лучших для пользователя.

Построение выдачи: мера качества
RMSE – качество на всей коллекции.А нам важны 10 лучших для пользователя.ARP: есть T результатов. Лучшие – на местах
ARP = 0 – идеал. ARP = 1 – идеально плохо.

Построение выдачи: сортировка
𝑅𝑒𝑙𝑒𝑣𝑎𝑛𝑐𝑒𝐵𝑖𝑎𝑠=𝐵+𝑏𝑢+𝑏𝑖+∑𝑗=1
𝑘
𝑝𝑢𝑗𝑞𝑖𝑗

Построение выдачи: сортировка

Построение выдачи: скорость
Случайные проекции LSH - гиперплоскости в Задано разбиение на сектора, а - их m-битная нумерация.Сортируем только объекты, близкие к пользователю (попавшие в один сектор)
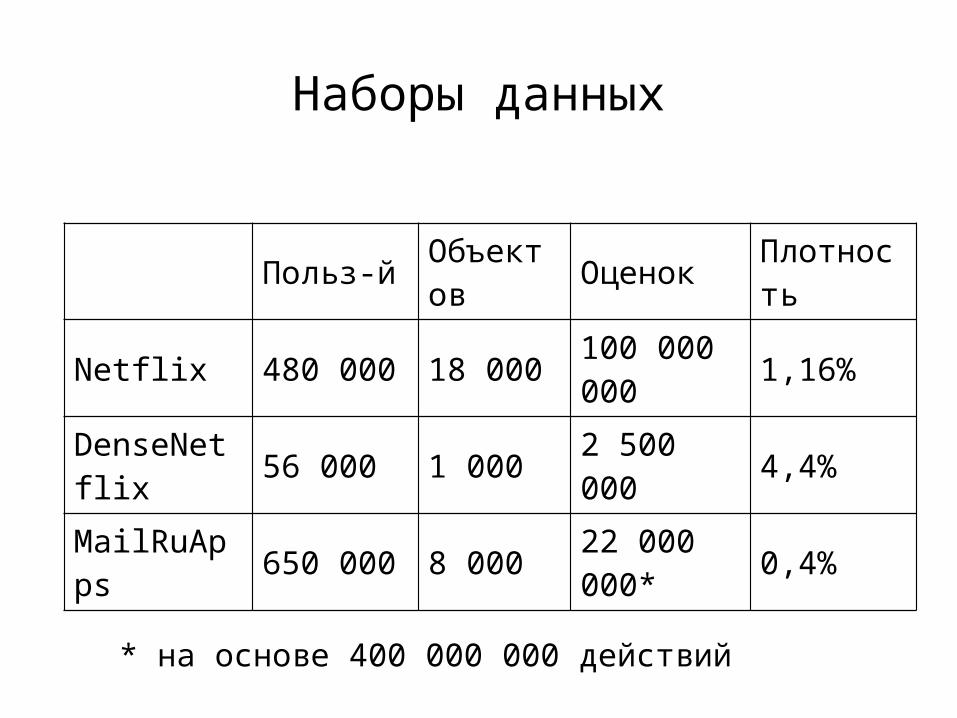
Наборы данных
Польз-й Объектов Оценок Плотность
Netflix 480 000 18 000 100 000 000 1,16%
DenseNetflix 56 000 1 000 2 500 000 4,4%
MailRuApps 650 000 8 000 22 000 000* 0,4%* на основе 400 000 000 действий
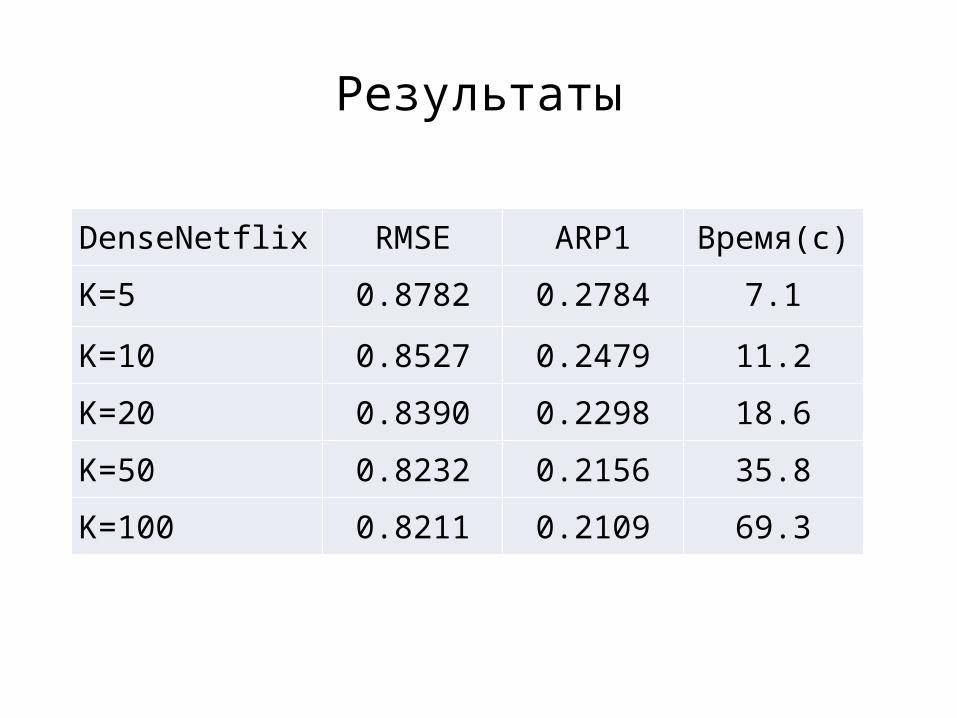
Результаты
DenseNetflix RMSE ARP1 Время(с)
K=5 0.8782 0.2784 7.1
K=10 0.8527 0.2479 11.2
K=20 0.8390 0.2298 18.6
K=50 0.8232 0.2156 35.8
K=100 0.8211 0.2109 69.3

Результаты
MailRuApps ARP1 Время(мс)
Full-Bias 0.16781257Full-SP 0.1349
LSH1-Bias 0.189619LSH1-SP 0.1529
LSH4-Bias 0.175651LSH4-SP 0.1412
UB-Bias 0.1783219UB-SP 0.1407

Результаты
1) Адаптировали BRISMF для неявных данных
2) LSH4 выдает приемлемое качество с высокой скоростью
3) Система умеет добавлять новые оценки, пользователей, объекты на лету, без пересчета матриц.

Спасибо! Вопросы?





























