Embed Size (px)
Citation preview

`
1
Master Thesis Presentation22nd April 2004
Venkatesh Raghavan
Advisor: Prof. Elke Rundensteiner Reader : Prof. Micha Hofri
VAMANA A High Performance, Scalable and Cost Driven XPath
Engine

2
Outline Motivation
Related Work
Background for VAMANA Approach
Our Physical Algebra
Query Execution Engine
Query Optimization
Experimental Evaluation
Conclusions

3
MotivationMany applications are migrating to native XML database.
Need for an XML query engine High Performance
Support queries to that emphasize the structural semantics of XML query languages.
Efficient querying engine and database management system tailored for XML data.
Scalable To support large XML document.s Support all 13 XPath axes.
Cost Based Schema independent cost model provides dynamically calculated heuristics. Intelligent cost-based transformations, further improving performance.

4
Outline Motivation
Related Work
Relational Solutions
DOM Solutions
Current Index Based Solutions
Background for VAMANA Approach
Our Physical Algebra
Query Execution Engine
Query Optimization
Experimental Evaluation
Conclusions

5
Relational Solution Mature data management tools
Query processing Crash recovery Concurrency control
Shredding XML documents
XPeranto [6] and Rainbow [7]
Many mapping algorithms From XML Schema to Relations: A Cost-based Approach
to XML Storage [24]
Workload based query mapping algorithm
.xml

6
Flip-side
Data Model mismatch Tables Vs XML semi-structured data model
Semantic mismatch SQL Vs Xquery
Data Fragmentation Increase query execution cost (More Joins) High update cost
Overhead Relational Mapping adds overhead
Managing data Handling order.

7
DOM Solution W3C - Document Object Model is language independent API for
accessing various parts of XML document. Traditional top-down tree traversal. Disadvantages
Very main memory intensive. On an average 4-5 times the file size [11] . Most of the DOM based engines do not support all XPath axes. Even if they do
Imagine Pixar rendering “Finding Nemo” in Windows machine. Requires complex recursive traversal for even for a few XPath
axes.

8
… Galax [9] (developed by Bell and AT\&T labs)
They do not support all XPath axes. Performs very poorly against large XML documents Non-cost driven logical level optimization
Jaxen [22]
Java API to support different XML API (JDom, DOM, ElectricXML,dom4j
Can handle document having file sizes 10Mb Intel Celeron PC with 512MB of RAM
IPSI, Pathan, etc.

9
Current Index Solutions Apache Xindice[13]
User-defined pattern indexes Capable to index small to medium size documents < 5Mb
Natix [23]
The XML data tree is partitioned into small sub-trees and
each sub-tree is stored into a data page.
TOX [25] (University of Toronto)
ToX storage engine stores the XML documents in either a relational database or an object oriented database.

10
Contd. TIMBER [14] (University of Michigan, University of British Columbia and AT&T labs)
TAX Algebra Pattern trees
Query execution Structural joins
Query Optimization Estimating costs of all promising sets of evaluation plans. Problem is the exponential increase in possibilities for complex query. They claim to only select from an elite set of possible evaluation plans.
Cost Estimation Primary Histograms
Expensive to maintain for frequent updates Counting Twigs – Frequently occuring co-related
sub-path queries.

11
Outline Motivation
Related Work
Background for VAMANA Approach
Multi-Axis Storage Structure
Running Example
Our Physical Algebra
Query Execution Engine
Query Optimization
Experimental Evaluation
Conclusions
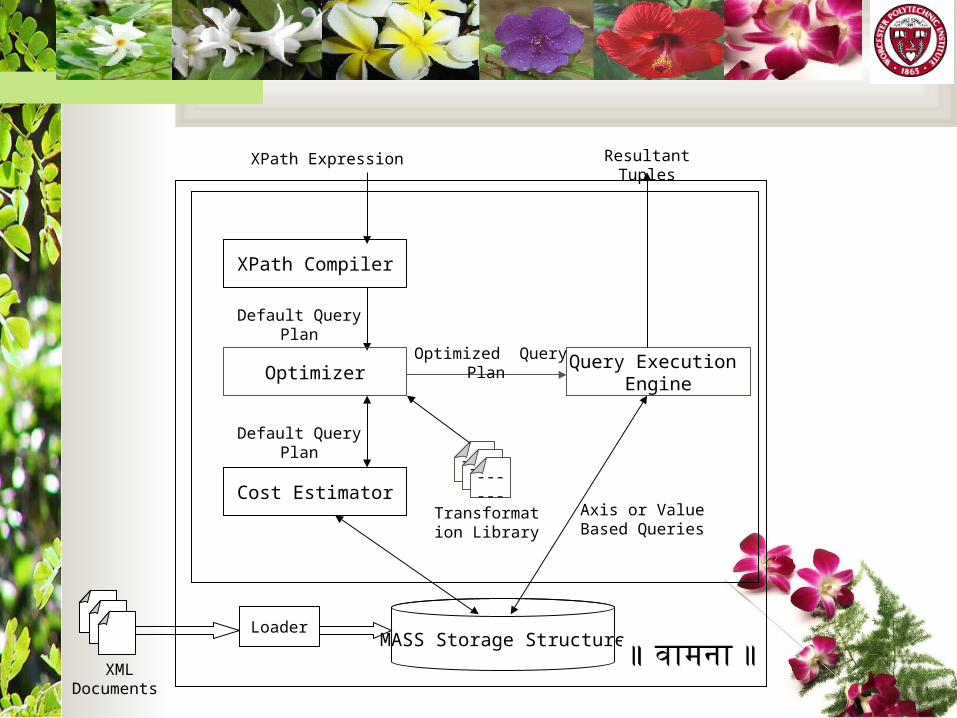
12
XML Documents
MASS Storage StructureLoader
XPath Compiler
XPath Expression
Default Query Plan
Axis or Value Based Queries
Cost Estimator
OptimizerQuery Execution
Engine
------
------------
Transformation Library
Default Query Plan
Optimized Query Plan
Resultant Tuples

13
Multi-Axis Storage Structure Efficient storage and access structure for XML document.
XPath axes, nodetests, range position predicates. Provides statistics for costing.
Number of tuples per page. Count.
Fast Lexicographical keys Four Clusters + Value-based index
Clustering Axes
CL1 and CL3 self, parent, ancestor, ancestor-or-self, descendent, descendent-or-self,
preceding, following
CL2 and CL4
self, child, following-sibling, preceding-sibling, attribute,
namespace

14
Running Examples
E.g. 1: descendant::name/parent::*/self::person/address
E.g. 2: //province[text() = “Vermont” ]/ancestor::person
<person id="person41">
<name>Muneo Yemenis</name>
...
<phone>+0 (807) 6372999</phone>
…
<province>Vermont</province>
…
<person id="person0">
<name>Krishna Merle</name>
<emailaddress>mailto:[email protected]</emailaddress>
…

15
Outline Motivation
Related Work
Background for VAMANA Approach
Our Physical Algebra
VAMANA Approach
Operators
Context Node
Query Execution Engine
Query Optimization
Experimental Evaluation
Conclusions

16
VAMANA Approach Data-Flow style of querying.
Data flows Control flows
Pipelined-iterative fashion Avoid temporary copies of intermediate results whenever possible. Facilitates the reduction of I/O operations
All tuples for a particular context node are clustered together. Sequential traversal over node sets . Hence minimal I/O and key comparisons.
Used in most of commercial relational database system. Structural joins
Best Case : When maximum number of tuples in the join - pairs
Worst Case : Few of joins - pairs

17
Operators
Node Base
Root Operator R
Step Operator Φ
Literal Operator L
Exist Operator
Binary Operator
Join Operator J
β
ξ
where, op symbol of the operator type.
cond represents a set of conditions applied by the operator
id is an identifier that uniquely identifies in given plan P

18
Context Node
We extend the idea..
The context node of any given VAMANA operator opidcond
defines uniquely the position of an XML node in the index structure. The position is obtained by the structural path information encoded in the context node.
“..context node is defined as the current node being processed…”
– XPath (1.0 & 2.0)

19
Concepts
Context Side
Predicate SideContext Child
//a/b[/c]
//a
/b
/c
EXIST
Predicate Child

20
Dynamic Context Set
//a
root
/b
a,a,a,a,a,b
MASS index

21
XPath Compiler
Φ4 parent::*
Φ2 child::phone
Φ3 self::person
Φ2 ancestor::person
Φ6 //::province
Φ5 child::text L4
‘Vermont’
β3EQ
a. Q1 b. Q2
Φ5 descendant::name
R1 R1
Q1: descendant::name/self::*/parent::person/address
Q2: //province[text() = “Vermont” ]/ancestor::person

22
Outline Motivation
Related Work
Background for VAMANA Approach
Our Physical Algebra
Query Execution Engine
Query Optimization
Experimental Evaluation
Conclusions

23
Execution States An operator can be in
INITIAL Has not yet started fetching tuples.
FETCHING When the operator has not yet exhausted all nodes from MASS that meets
its condition(s). When the operator is waiting for its context-child to return tuples. When the operator is waiting for the predicate condition to process the
nodes.
OUT_OF_NODE When the operator has exhausted all the nodes from MASS that satisfy the
condition(s) specified by the node. When the context-child has no further tuples to return operator.

24
Step1: Setting Context for the “leaf operators on context-path”
Φ2 ancestor::person
//province[text()=“Vermont”]/ancestor::person
Φ6 //::province
β3EQ
L4 ‘Vermont’ Φ5
child::text
OUT_OF_NODE
FETCHING
INTIAL
R1

25
Step2: Ask the root node for tuples.
Φ2 ancestor::person
Φ6 //::province
R1
a.d.y.a

26
Φ6 //::province
a.d.y.a
β3EQ
L4 ‘Vermont’ Φ5
child::text
a.d.y.aa.d.y.a
a.d.y.a.a
a.d.y.a.a “Massachussets”

27
Φ6 //::province
a.d.y.a
β3EQ
L4 ‘Vermont’ Φ5
child::text
a.d.y.aa.d.y.a
28
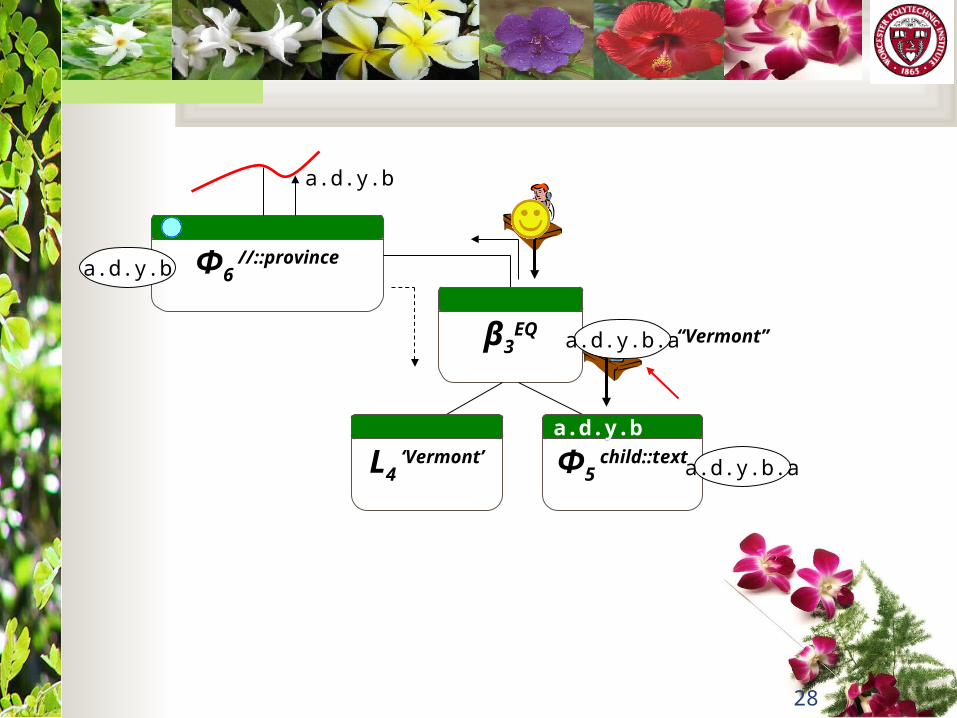
Φ6 //::province
a.d.y.b
β3EQ
L4 ‘Vermont’ Φ5
child::text
a.d.y.a
a.d.y.b.a
a.d.y.b.a “Vermont”
a.d.y.b
a.d.y.b
a.d.y.b

29
Φ6 //::province
R1
a.d.y.b
Φ2 ancestor::person
a.d.y.b
a.d.y

30
Outline Motivation
Related Work
Background for VAMANA Approach
Our Physical Algebra
Query Execution Engine
Query Optimization
Query Clean-Up
Cost Model
Transformation
Experimental Evaluation
Conclusions

31
Optimization
Cost Estimator Transformation Optimal Query Plan (P opt )
Transformed Query Plan (P t )
Default Query Plan (P )
Query Plan (P “) + Heuristics (L( P “) )
Clean Up
Query Plan (P I )
32
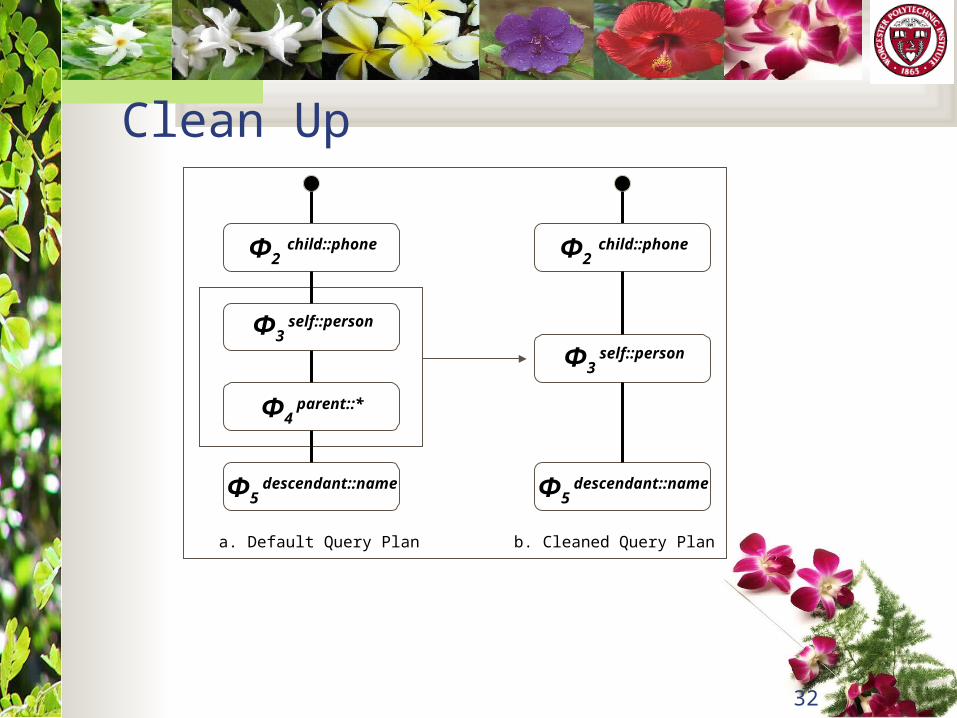
Clean Up
Φ4 parent::*
Φ2 child::phone
Φ3 self::person
Φ5 descendant::name
Φ2 child::phone
Φ3 self::person
Φ5 descendant::name
a. Default Query Plan b. Cleaned Query Plan

33
VAMANA Cost Model The cost is usually calculated with respect to the root of the XML
document or a node specified by the user.
Query costs are obtained from the actual data rather than a data dictionary and thus are always up to date.
Our cost model, does not suffer the overhead of parsing the entire document. This is the case for does histogram-based costing like StaTiX[14].
Starting from the leaf operators we propagate the cost upwards towards the root operator.

34
VAMANA Cost Model
COUNT(opidcond)
This heuristics is only calculated for step operators (Φidaxis::nodetest). It
represents the count of the number of XML nodes in the underlying index structure that satisfy the node test of the step operator axis::nodetest.
MASS provides an API to efficiently gather count of a particular node test in its storage structure.
TC(opidcond)
For a literal operator(Lid value), text count is the number of occurrences
of a particular literal value in the index structure.

35
Contd..IN (opi)
The maximum number of tuples that the operator opi will receive in total from its context child.
Case 1: For a leaf step operator on the context path of the query plan, the total
number of tuples received is equal to the number of tuples available in the underlying index structure, i.e. IN(opi ) = COUNT(opi ).
Case 2: For all non-leaf operator(s), IN(opi ) = OUT(opj), where opj is the
context child of opi. Case 3:
For all leaf step operator(s) on the predicate path of query plan, the total number of tuples received is equal to the number of tuples received by its predicate operator.

36
Contd..OUT(opi)
The maximum number of tuples that the current operator opi returns
Case 1: A leaf step operator on the context path of the query plan returns all the
tuples that occur in the underlying index structure with respect to the context of the leaf operator, i.e., OUT(opi )= COUNT(opi ).
Case 2: A literal operator(s) returns the same values every time a request for
tuples is received. To facilitate the optimization of literal operators by using a value-index, we define output as OUT(opi ) = TC(opi ).
Case 3: For binary predicate operators that have value-based
equivalence, the OUT(opi) is calculated as followsMinimum(# tuples from parent operator, TC of the literal value)

37
Contd.. Non-leaf operators
Context path Predicate path
Leaf operators predicate path

38
Contd..
“Cost determined with respect to context node provider”

39
Example 1:
OUT : 1256
Φ2 child::address
Count : 1256
IN : 4825
Φ3 parent::person
Count : 2550
IN : 4825

40
Example 2:
OUT : 4825
Φ3 parent::person
Count : 2550
IN : 4825
Φ6 descendant::name
Count : 4825
OUT : 4825

41
Heuristics
Ratio = IN/OUT
Inverted index <scaled(IN/OUT), opi >.
δ i = scale0..1 (IN/OUT)
Higher the ratio, better the selectivity.

42
Transformation Library XPath equivalence rules [5] extend for VAMANA physical
algebra.
Rule 1 : /descendant::n/parent::m/.. //m[child::n]/..
Rule 2 : /descendant-or-self::n/child::m/.. //m[parent::n]/..
Rule 3 : p/following-sibling::n/parent::m p[following-sibling::n]parent::m
Rule 4 : /child::m/preceding-sibling::n descendant::n[following-sibling::n]
Binary predicate Value based equivalence.
Value-index optimization

43
δ i N i
1
0
0
COUNT = 4825IN = 4825 OUT = 4825
Φ5 descendant::name
COUNT = 2550 IN = 4825 OUTT = 4825
Φ3 parent::person
COUNT = 1256IN = 4825 OUT = 1256
Φ2 child::address
R1
Q1

44
COUNT = 4825IN = 4825 OUT = 4825
Φ5 descendant::name
COUNT = 2550 IN = 4825 OUT = 4825
Φ3 parent::person
COUNT = 1256IN = 4825 OUT = 2550
Φ2 child::address
R1
Φ5 child::name
Φ3 //::person
Φ2 child::address
R1
ξ6
a. Initial Query Plan b. Transformed Query Plan
COUNT = 1256
IN = 2550 OUT = 2550
COUNT = 2550
IN = 2550 OUT = 2550
IN = 4825 OUT = 2550
COUNT = 4825
IN = 2550 OUT = 4825
/descendant::n/parent::m/.. //m[child::n]/..

45
COUNT = 4825IN = 1256 OUT = 4825
Φ5 child::name
COUNT = 2550 IN = 1256 OUT = 1256
Φ3 parent::person
COUNT = 1256IN = 1256 OUT = 1256
Φ2 //::address
R1
IN = 4825 OUT = 1256
ξ6
Optimal Query Plan
IN = 1256 OUT = 1256
ξ7
/descendant-or-self::n/child::m/.. //m[parent::n]/..

46
Running Example 2:
Φ2 ancestor::person
COUNT = 2550
IN =1256 OUT = 1256
Φ6 //::province
COUNT = 1256
IN = 1256 OUT = 1256
β3EQ
Φ5 child::text L4
‘Vermont’
R1
TC = 13
IN = 1256 OUT = 13
COUNT = 304819
IN = OUT =304819

47
Φ2 ancestor::person
Φ6 //::province
Φ5 child::text L4
‘Vermont’
β3EQ
R1
Φ2 ancestor::person
Φ6 parent::province
Φ5 value:: ‘Vermont’
R1
a. Default Query Plan b. Transformed Query Plan

48
Can we produce BAD queries? No! Our optimization aims to reduce the number of tuples the parent
operator receives. Hence we try to push the most selective operators downward. An operator is considered for transformation only if:
It is selective. There exist an equivalent transformation rule.
i.e. its parent is not affected by the transformation. The number of tuples filtered generated by the operator is reduced.
Now, whether the transformation process ends is another question. To solve this infinite running we have to brute stop
the optimization process after a specific number of iterations.

49
Outline Motivation
Related Work
Background for VAMANA Approach
Our Physical Algebra
Query Execution Engine
Query Optimization
Experimental Evaluation
Criterions
Queries
Results
Conclusions

50
Experimental Evaluation XMark[17] auction database. Compared the CPU execution time of the test queries over
different XPath engines Galax [9]
Jaxen [22] Others
IPSI [10]
Pathan [11]
Xindices [14]
Variable factors Document size
Factor (100Kb, 1Mb, 5Mb, 10Mb, 20Mb, 30Mb, 40Mb, 50Mb) Queries

51
XPath Queries XMark [17] Queries not very useful in evaluation XPath queries. Criterions for selecting the queries
Cover major forward and reverse XPath axes. Experimentally prove the correctness of the execution strategy. Empirically prove that optimization does not make the query more expensive
Query List Q1 : //person/address Q2 : //watches/watch/ancestor::person Q3 : /descendant::name/parent::*/parent::person/address Q4 : //itemref/following-sibling::price/parent::* Q5 : //province[text()="Vermont"]/ancestor::person
DNF-2hrs : Did Not Finish – In 2 Hours DNF-MO : Did Not Finish – Memory Overflow NS : Not Supported

52
Improved PerformanceQ1: //person/address
Q2: //watches/watch/ancestor::person

53
Correctness of Query OptimizationQ3: /descendant::name/parent::*/parent::person/address

54
Q5: //province[text()="Vermont"]/ancestor::person
Q4: //itemref/following-sibling::price/parent::*
55
Outline Motivation
Related Work
Background for VAMANA Approach
Our Physical Algebra
Query Execution Engine
Query Optimization
Experimental Evaluation
Conclusions

56
Conclusion Efficient, cost driven XML query execution (XPath) Execution Engine
VAMANA's index-only pipelined execution is novel to XML query evaluation as most of the existing engines use structural joins for query evaluation.
Physical algebra that supports such execution for any given valid XPath expression.
Cost Model The VAMANA cost model is simple but very effective for identifying highly
selective nodes. And the costing can be specific to a particular XML document or even to a specific point in the XML document
The dynamic cost estimation support makes costing up-to-date in environments which have frequent XML updates.
The model is well supported by a set of transformation rules used for operator optimization.
Our experiments shows the correctness, effectiveness and feasibility of our model.

57
Future Work
VAMANA is the building block for the next phase of developing a XQuery Engine.
VAMANA currently implements only a subset of the XPath equivalence rules stated in [5].
The current cost model can be exploited for XQuery optimization.

58
Acknowledgement Advisor : Prof. Elke Rundensteiner
Reader : Prof. Micha Hofri
MASS-VAMANA team: Kurt W. Deschler
Developing MASS Helping me in design, development of VAMAN Architecture Unix and systems related issues
Tammy L Worthington XPath Compiler
Faculty : Inputs from Professor Dan Dougherty
Research Group : DSRG
Systems : Jesse Banning & Micheal Voorhis

59

60
References [1]1. T. Bray, J. Paoli, C. Sperberg-McQueen, E. Maler and F.Yergeau. Extensible Markup Language (XML) 1.0
W3C Recommendation. Available at http://www.w3.org/TR/2004/REC-xml-20040204/, Feb 2004.2. J. Clark and S. DeRose. XML Path Language (XPath) 1.0, W3C Recommendation. Available at
http://www.w3.org/TR/xpath, 2002.3. A. Berglund, S. Boag, D. Chamberlin. M. F. Fernandez, M. Kay, J. Robie and J. Sim ' e on, XML Path
Language (XPath) 2.0, W3C Working Draft. Available at http://www.w3.org/TR/xpath20/, Nov 2003.4. K. Deschler and E. Rundensteiner. MASS- Multi Axis Storage Structure , CIKM, New Orleans, USA, Nov
20035. D. Olteanu, H. Meuss, T. Furche, and F. Bry. Symmetry in XPath. Proceedings of Seminar on Rule
Markup Techniques, no. 02061, Schloss Dagstuhl, Germany, Feb 2002.6. M. Carey, J. Kiernan, J. Shanmugasundaram, E. Shekita and S. N. Subramanian. XPERANTO:
Middleware for Publishing Object-Relational Data as XML Documents , The VLDB Journal, pages 646-648, 2000.
7. X. Zhang, M. Mulchandani, S. Christ, B. Murphy and E. Rundensteiner. Rainbow: Mapping-Driven XQuery Processing System , SIGMOD, page 614, 2002. Kweelt. From http://kweelt.sourceforge.net.
8. Galax system. Available at http://db.bell-labs.com/galax/.9. IPSI-XQ - XQuery demonstrator. Available at http://www.ipsi.fraunhofer.de10. Pathan, Available at http://software.decisionsoft.com11. A. Marian and J. Sim ' e on. Projecting XML Documents , VLDB'2003. Berlin, Germany, September 200312. W. Meier. eXist: An Open Source Native XML Database. Web and Database-Related Workshops, Erfurt,
Germany, October 2002.13. Apache Xindice. Available at: http://xml.apache.org/xindice/ 14. H. Jagadish, S. Al-Khalifa, A. Chapman, L. Lakshmanan, A. Nierman, S. Paparizos, J. Patel, D. Srivastava,
N. Wiwatwattanan, Y. Wu and C. Yu. TIMBER: A native XML database , The VLDB Journal, 11(4): 274-291, 2002.

61
Reference [2]15. J. Freire, J. Haritsa, M. Ramanath, P. Roy, and J. Simeon. Statix: Making XML count. In Proc. of
SIGMOD, pages 181-191, 2002.16. XMark - The XML Benchmark project. www.xml-benchmark.org 17. R. Goldman and J. Widom. DataGuides: Enabling Query Formulation and Optimization in Semi-
structured Databases , the 23rd Int. Conf. on Very Large Databases (VLDB), Athens, Greece, pages 436-445, 1997.
18. T. Milo and D. Suciu. Index structure for path expression , In Proceedings of 7th International Conference on Database Theory, pages 277-295, 1999.
19. Q. Li and B. Moon. Indexing and Querying XML Data for Regular Path Expressions , Proceedings of 27th International Conference on Very Large Database (VLDB'2001), Rome, Italy, pages 361-370, September 2001.
20. S. Boag, D. Chamberlin, M. Fern ' a ndez, D. Florescu, J. Robie, J. Sim ' e on, An XML Query Language (XQuery) 1.0, W3C Working Draft. Available at http://www.w3.org/TR/xquery/, Nov 2003.
21. B. McWhirter and J. Strachnan. Jaxen: Universal XPath Engine . Available at http://jaxen.org/.22. C.C. Kanne and G. Moerkotte, Efficient storage of XML data . In Proc. ICDE Conf., poster abstract, page
198, San Diego, USA, 2000.23. P. Bohannon and J. Freire and P. Roy and J. Simeon, From (XML) Schema to Relations: A Cost-based
Approach to XML Storage , ICDE, 200224. T. Worthington and E. Rundenstiner, XPath Processor , WPI MQP Report, April 2002.25. Flavio Rizzolo, Alberto Mendelzon. Indexing XML Data with ToXin , WebDB, pages 49-54, Santa Barbara,
USA, 2001.26. Z. Chen, H. Jagadish, F. Korn, N. Koudas, S. Muthukrishnan, R. Ng and D. Srivastava, Counting Twig
Matches in a Tree , ICDE, pages 595-604, 2001.27. Document Object Model (DOM), Available at http://www.w3.org/DOM/.




























