Embed Size (px)
Citation preview

UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
COMPUTAÇÃO VERDE – PLUG-IN NAGIOS PARA
GERENCIAMENTO DE DESPERDÍCIO DE ENERGIA ELÉTRICA
por
Ranieri da Rosa Tremea
Itajaí (SC), novembro de 2014

UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
COMPUTAÇÃO VERDE – PLUG-IN NAGIOS PARA
GERENCIAMENTO DE DESPERDÍCIO DE ENERGIA ELÉTRICA
Área de redes de computadores
por
Ranieri da Rosa Tremea
Relatório apresentado à Banca Examinadora do
Trabalho Técnico-científico de Conclusão do
Curso de Ciência da Computação para análise e
aprovação.
Orientador(a): Ademir Goulart, M. Sc.
Itajaí (SC), novembro de 2014

“Temos o destino que merecemos.
O nosso destino está de acordo com os nossos méritos”
Albert Einstein

AGRADECIMENTOS
Agradeço primeiramente a minha família que esteve presente em todos os momentos de
minha vida, a minha mãe Dalila que foi e continua sendo a ancora em minha vida, minha irmã
Marcia e meu cunhado Edson que me auxiliaram quando passava por momentos difíceis, minha
esposa Daniella que esteve em todos os momentos ao meu lado desde o início desta longa
caminhada.
Em especial gostaria de agradecer ao meu amigo já falecido Claudio Kornowski, que
com sua bondade e sabedoria sempre me auxiliou e me ensinou a gostar da Computação,
embora hoje eu já não possa mais lhe agradecer por tudo o que fez e onde consegui chegar,
posso dizer que este momento é apenas uma parcela de tudo o que lhe devo, pois todo o
conhecimento que adquiri nestes longos anos é em grande parte devido a este meu querido
amigo e sua família.
Gostaria ainda de agradecer a meus familiares que estiveram sempre dispostos a me
ajudar em todos os momentos de minha vida.

“Se você tem metas para um ano. Plante arroz. Se você tem metas para 10 anos. Plante uma
árvore. Se você tem metas para 100 anos então eduque uma criança. Se você tem metas para
1000 anos, então preserve o meio ambiente”
Confúcio

RESUMO
Tremea, Ranieri da Rosa. Computação Verde – Plug-in Nagios para Gerenciamento de
Desperdício de Energia Elétrica. Itajaí, 2014. 52 folhas. Trabalho Técnico-científico de
Conclusão de Curso (Graduação em Ciência da Computação) – Centro de Ciências
Tecnológicas da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2014.
No ambiente corporativo, o consumo de energia elétrica está diretamente ligado a quantidade
de equipamentos e computadores que se encontram disponíveis nesta rede. Diante destes
parâmetros, o Gerenciamento de tecnologia da informação começa a adotar iniciativas para
reduzir os danos ao meio ambiente, e então surge o Tecnologia da Informação Verde, que visa
minimizar o consumo de energia e a degradação ao meio ambiente. Sendo assim, os
administradores de rede precisam de ferramentas para exercer o controle e gerenciamento destes
equipamentos. Com a finalidade de oferecer mais um recurso para o gerenciamento da
Computação Verde é que foi projetado este trabalho. O Nagios é um software de gerenciamento
de redes e dispõe de vários plug-ins que verificam a rede em busca de objetos inativos, enquanto
que o plug-in apresentado neste trabalho tem como principal função verificar a existência de
computadores que estavam ativos após o término das atividades em um ou mais agrupamentos
de equipamentos de uma rede. Verificando dentro da rede se existem objetos que estão
consumindo energia elétrica sem necessidade e desta forma visando a redução de consumo de
energia elétrica. Para alcançar esta solução foi necessário entender principalmente o
funcionamento do Nagios, os métodos de tratamentos que ele faz com os plug-ins que trabalham
em conjunto, bem como sua estrutura modular.
Palavras-chave: Gerenciamento. Tecnologia da Informação Verde. Ativos.

ABSTRACT
In the corporate environment, the power consumption is directly linked to the amount of
equipment and computers that are available on this network. Given these parameters, the
management of information technology begins to take initiatives to reduce damage to the
environment, and then there is the Green Information Technology, which aims to minimize
energy consumption and environmental degradation. Thus, network administrators need tools
to exert control and management of these devices. Aiming to offer additional resources to
manage the Green Computing is that this study was designed. Nagios is a network management
software and has several plug-ins that check the network for inactive objects, while the plug-in
presented in this paper has as main function to verify the existence of computers that were
active after the end activities in one or more groupings of network devices. Checking into the
network if there are objects that are consuming energy unnecessarily, thereby aiming to reduce
electricity consumption. To achieve this solution has been especially needed to understand the
operation of Nagios, methods of treatments he makes the plug-ins that work together, as well
as its modular structure.
Keywords: Management. Green Information Technology. Assets.

LISTA DE FIGURAS
Elementos de uma rede. .......................................................................................... 18
Estrutura interna do Nagios. ................................................................................... 21 Definição de um host do sistema Nagios ............................................................... 25 Definição de um serviço no sistema Nagios........................................................... 25 Modelo de funcionamento do NRPE. ..................................................................... 26 Definições do plug-in NRPE. ................................................................................. 26
Rede de computadores com nível de dependências do Nagios. ............................. 29 Histórico de downloads do Sistema Nagios ........................................................... 30 Arquitetura do protocolo de comunicação SMTP. ................................................. 33
MacBook Pro desenvolvido pela Aplle. ............................................................... 39 EcoBook da Asus, revestido de bambu. ............................................................... 40 Diagrama de casos de uso do plug-in . ................................................................. 43 Diagrama de atividade do plug-in ........................................................................ 45

LISTA DE TABELAS
Tabela 1. Estados de retorno de um plug-in. ......................................................................... 26
Tabela 2. Atividade de Desenvolvimento do Plug-in. ........................................................... 46 Tabela 3. Atividade de teste do Plug-in. ................................................................................ 47 Tabela 4. Atividade de construção do protótipo do Plug-in. ................................................. 47 Tabela 5. Cronograma de atividades do TTC II .................................................................... 48

10
LISTA DE ABREVIATURAS E SIGLAS
CGIs Configuration File Options
CPU Central Processing Unit
EPA Environmental Protection Agency
GNU General Public License
GRI Global Report Initiative
HP Hewlett Packard
HTTP Hypertext Transfer Protocol
IBM International Business Machine
ICMP Internet Control Message Protocol
ISO International Organization for Standardization
ISPs Internet Service Providers
ISSO International Organization for Standardization
NRPE Nagios Remote Plugin Executor
OHSAS Occupational Health and Safety Assessment Services
RAM Random Access Memory
RFC Request for Comments
SLAs Service Level Agreements
SMS Short Message Service
SMTP Simple Mail Transfer Protocol
SNMP Simple Network Management Protocol
SSH Secure Shell
SSL Security Socket Layer
TCP/IP Transmission Control Protocol / Internet Protocol
TTC Trabalho Técnico-científico de Conclusão de Curso
UNIVALI Universidade do Vale do Itajaí
WEB World Wide Web

11
LISTA DE SÍMBOLOS
GWh Giga Watt hora
KW kilowatt
CO2 dióxido de carbono

12
SUMÁRIO
1 INTRODUÇÃO .................................................................................................................. 13 1.1 PROBLEMATIZAÇÃO ..................................................................................................... 14 1.1.1 Formulação do Problema ............................................................................................. 14 1.1.2 Solução Proposta .......................................................................................................... 14 1.2 OBJETIVOS ..................................................................................................................... 15 1.2.1 Objetivo Geral .............................................................................................................. 15
1.2.2 Objetivos Específicos .................................................................................................... 15 1.3 METODOLOGIA ............................................................................................................. 15 1.4 ESTRUTURA DO TRABALHO ........................................................................................ 16
2 FUNDAMENTAÇÃO TEÓRICA ..................................................................................... 17 2.1 GERENCIAMENTO DE REDES ..................................................................................... 17
2.1.1 Monitoramento de Redes .............................................................................................. 18 2.2 NAGIOS ........................................................................................................................... 20 2.2.1 Configurações ............................................................................................................... 22 2.2.2 Monitoramento .............................................................................................................. 23
2.2.3 Plug-in .......................................................................................................................... 26 2.2.4 Funcionalidades ............................................................................................................ 27
2.2.5 Estudos de caso ............................................................................................................. 29 2.3 SISTEMA OPERACIONAL LINUX ................................................................................. 31 2.4 SERVIDOR DE E-MAIL .................................................................................................. 32
2.5 COMPUTAÇÃO VERDE ................................................................................................. 34
2.5.1 Conceito ........................................................................................................................ 34
2.5.2 História ......................................................................................................................... 35 2.5.3 Casos de Uso ................................................................................................................ 35
2.5.4 Tecnologias ................................................................................................................... 38
3 PROJETO .......................................................................................................................... 40 3.1 ESPECIFICAÇÃO DE REQUISITOS ............................................................................. 40
3.1.1 Requisitos Funcionais ................................................................................................... 41 3.1.2 Requisitos Não Funcionais ........................................................................................... 41 3.1.3 Regras de Negócio ........................................................................................................ 42 3.2 DIAGRAMA DE CASOS DE USO ................................................................................... 43 3.2.1 Agendamento de verificações ....................................................................................... 44
3.2.2 Execução do Plug-in ..................................................................................................... 44 3.2.3 Alertas de Monitoramento ............................................................................................ 45
3.2.4 Cálculo de Gastos ......................................................................................................... 45 3.3 PLANEJAMENTO DO TTC II ......................................................................................... 46 3.3.1 Metodologia .................................................................................................................. 46 3.3.2 Cronograma .................................................................................................................. 47 3.3.3 Análise de Riscos .......................................................................................................... 48
4 CONSIDERAÇÕES FINAIS ............................................................................................ 48
5 REFERÊNCIAS ................................................................................................................ 50

13
1 INTRODUÇÃO
Com o aumento na demanda de computadores nos últimos 30 anos, e a crescente
utilização de computadores nas corporações, os administradores de redes cada vez precisam ter
o controle dos equipamentos e serviços disponíveis na rede. Assim surgiu a necessidade de um
monitoramento constante destes serviços e equipamentos. Uma solução viável com os recursos
básicos do TCP/IP (Transmission Control Protocol - Protocolo de Controle de Transmissão),
em meados de 1996, era projetar um software para fazer ping nos equipamentos e retornar
respostas com o objetivo de monitorar se esses equipamentos estavam ativos (NAGIOS, 2009).
Com esta ideia, Ethan Galstad começou a desenvolver o software para monitoração de
equipamentos e serviços em rede que hoje é conhecido como Nagios.
O Nagios é um sistema de monitoramento de redes de código aberto. Sua principal
função é a de monitorar hosts e serviços, em um determinado intervalo de tempo, mostrando e
ou alertando o administrador de rede quando um serviço ou host está com problema ou inativo
(COSTA, 2008).
Com a quantidade de equipamentos dentro de suas redes aumentando, as corporações
também começam a se preocupar com outros fatores importantes como o aumento de energia
elétrica, melhores e mais pessoal capacitado para realizar manutenção da rede, dentre outras
que fazem com que exista um aumento de custo de forma maximizada. Para resolver estes
problemas é necessário de soluções que minimizem estes desperdícios, e uma solução para o
administrador da rede pode ser o Nagios que tem como o objetivo de verificar quais são os
equipamentos que estão ainda conectados quando a atividade naquele determinado local já
encerrou.
Considerado hoje um fundamento das grandes corporações, a Tecnologia da Informação
Verde já é implantada em grande escala, com o objetivo de proteger o meio ambiente, e este
conceito não apenas engloba a redução dos equipamentos, mas sim utilização consciente e que
não degrade o meio ambiente (GARCIA; MILAGRE, 2009). O plug-in apresentado neste
trabalho visa garantir que os equipamentos ligados em qualquer rede possam ser monitorados.
Como resultado desta monitoração o plug-in irá alertar os administradores de que existe um
consumo de energia desnecessário. Assim de uma forma consciente e responsável com o meio
ambiente os gestores conseguem implantar os conceitos da Computação Verde.

14
1.1 PROBLEMATIZAÇÃO
1.1.1 Formulação do Problema
A cada dia existe um aumento de computadores disponíveis nas corporações e em
conjunto surge o aumento de consumo de energia, sendo que essa utilização de energia na área
de Tecnologia da Informação representa cerca de 1% da energia gerada no planeta (TEIXEIRA,
2007). Diante deste contexto, a governança de Tecnologia da Informação necessita ter uma
responsabilidade maior com o meio ambiente, e desta forma, precisa e necessita ter total
controle dos equipamentos ativos em sua rede, porém ainda existe uma escassez de sistemas de
computação que façam o controle de objetos ativos.
1.1.2 Solução Proposta
Perante os problemas relacionados ao controle de equipamentos ativos, verificou-se que
partindo de uma tecnologia conhecida, pode ser desenvolvido um plug-in que fassa estas
verificações. Além de agregar mais controle ao gerenciamento de Tecnologia da Informação
estaria em conformidade com o meio ambiente, e contemplaria o conceito de computação
Verde.
Este trabalho propõe um subsistema (plug-in) dependente do Nagios, que verifique em
determinados momentos quais os objetos (hosts) que estão conectados na rede e estão ativos
dentro de períodos programados e armazene esses dados. Posteriormente envie um ou mais
alertas para um ou mais administradores através de e-mail, informando quais os computadores
que permaneceram ligados desnecessariamente dentro da rede da qual este administrador é
responsável.
Os relatórios de alertas enviados utilizarão os dados armazenados e constarão um valor
aproximado do consumo de energia gasta, quantidade de hosts ativos e outras informações
relevantes. Estes relatórios servirão como base para os administradores verificarem quais os
setores da organização que estão consumindo mais energia elétrica de forma irresponsável,
enquanto os dados que serão guardados podem ser utilizados para este projeto, bem como para
outras finalidades e ou projetos dentro da computação verde.

15
1.2 OBJETIVOS
1.2.1 Objetivo Geral
O objetivo deste trabalho é desenvolver um plug-in para o Nagios que alerte um ou mais
administradores informando quais objetos da rede de computadores estão ativos. Estas
informações deverão ocorrer através de e-mail e deverá conter a quantidade de objetos ligados
em dados momentos de maneira desnecessária. Diante destas informações será possível
conscientizar e reduzir o consumo de energia elétrica, bem como preservar o meio ambiente e
readequando o Tecnologia da Informação da organização a fazer uso das boas práticas da
Tecnologia da Informação Verde.
1.2.2 Objetivos Específicos
Alertar aos administradores de rede, bem como outros responsáveis, quais os objetos
que permanecem ativos na rede de forma desnecessária com o envio de e-mails
informativos;
Armazenar as informações dos objetos ativos para o gerenciamento e controle da
Tecnologia da Informação Verde;
Processar as informações coletadas gerando relatórios de quantificação de consumo
desnecessário;
Desenvolver e documentar o plug-in usando uma linguagem de programação adequada;
Produzir uma imagem de SO com todas as configurações necessárias, para a
implementação deste plug-in no ambiente Nagios.
1.3 METODOLOGIA
Para alcançar os objetivos estabelecidos para este trabalho será necessário realizar cinco
etapas que são: Na primeira etapa, fazer a instalação do sistema operacional Linux, servidor de
e-mail, sistema Nagios e plug-ins, que deve ser realizado criando uma imagem e então será
necessário fazer as configurações no Nagios para o total funcionamento. Na segunda etapa será
necessário estudar e a compreender o sistema Nagios, bem como o funcionamento dos seus

16
plug-ins, estudando os conceitos e fundamentos encontrados na literatura, e então será possível
realizar testes e conhecer a estrutura do sistema que havia sido previamente instalado
alcançando assim a total compreensão do Sistema Nagios. A terceira etapa será estudado e
documentado a fundamentação teórica que englobará o gerenciamento e monitoramento de
redes, o sistema Nagios, seus plug-ins e suas funcionalidades, o sistema operacional Linux, o
servidor de e-mail e a Computação Verde, que será realizado buscando informações em artigos,
livros e em publicações encontradas na internet, que complementará e dará embasamento
teórico ao trabalho. A quarta etapa será o estudo da modelagem do plug-in que especificará os
requisitos, a forma em que as verificações serão efetuadas e como os alertas serão tratados. Na
quinta e última etapa será realizada a documentação que retratará todos os processos efetuados
no estudo, e ainda será efetuado nesta etapa todo o planejamento do TTC II.
1.4 ESTRUTURA DO TRABALHO
O presente documento está dividido em quatro capítulos, que são: Introdução,
Fundamentação Teórica, Projeto e Considerações Finais.
O Capítulo 1 descreve brevemente o sistema Nagios, apresentando a importância do
projeto em relação ao meio ambiente e os objetivos do projeto.
O Capítulo 2, Fundamentação Teórica, apresenta o gerenciamento e monitoramento de
redes de uma forma geral, bem como a revisão bibliográfica do sistema Nagios, suas
configurações e funcionalidades. Ainda neste capítulo é mostrado uma breve descrição do
sistema operacional Linux e o servidor de e-mail, e no final deste capítulo é apresentado os
conceitos da Computação Verde, sua história e sua importância para a área de Tecnologia da
Informação.
No Capítulo 3 encontra-se a elaboração do projeto que será desenvolvido, bem como as
especificações de requisitos a metodologia e o cronograma de planejamento para o
desenvolvimento do plug-in.
O Capítulo 4 visa contextualizar as conclusões de uma forma clara e objetiva
descrevendo a importância do monitoramento de equipamentos ligados dentro da rede de
computadores.

17
2 FUNDAMENTAÇÃO TEÓRICA
A Fundamentação Teórica apresentada neste trabalho foi dividida em 5 seções. A Seção
2.1 aborda o gerenciamento de redes de computadores onde destaca-se seus fundamentos e
conceitos com enfoque ao monitoramento de redes. A Seção 2.2 tem como principal enfoque o
conceito e a forma de comunicação do plug-in no Nagios, bem como suas diretrizes e
funcionalidades principais. A Seção 2.3 consiste de uma introdução ao sistema operacional
Linux. Na Seção 2.4 é descrito a funcionalidade do servidor de e-mail, na Seção 2.5 é descrito
o conceito da Computação Verde, que é o principal objetivo deste trabalho.
2.1 GERENCIAMENTO DE REDES
As redes atualmente são compostas por uma grande quantidade de elementos. Alguns
destes são responsáveis por compartilhar recursos e serviços e a qualidade dos serviços
prestados está diretamente relacionada ao desempenho dos serviços de rede. O objetivo da
gerencia de rede é monitorar e controlar todos esses elementos que compõem a rede e para
garantir esta qualidade geralmente são gerenciadas por várias ferramentas de monitoramento
que trazem informações desta rede (STALLINGS, 1998).
Para constituir um sistema de gerenciamento de uma rede são necessárias várias
ferramentas para monitorar e controlar todo o emaranhado de equipamentos e softwares que
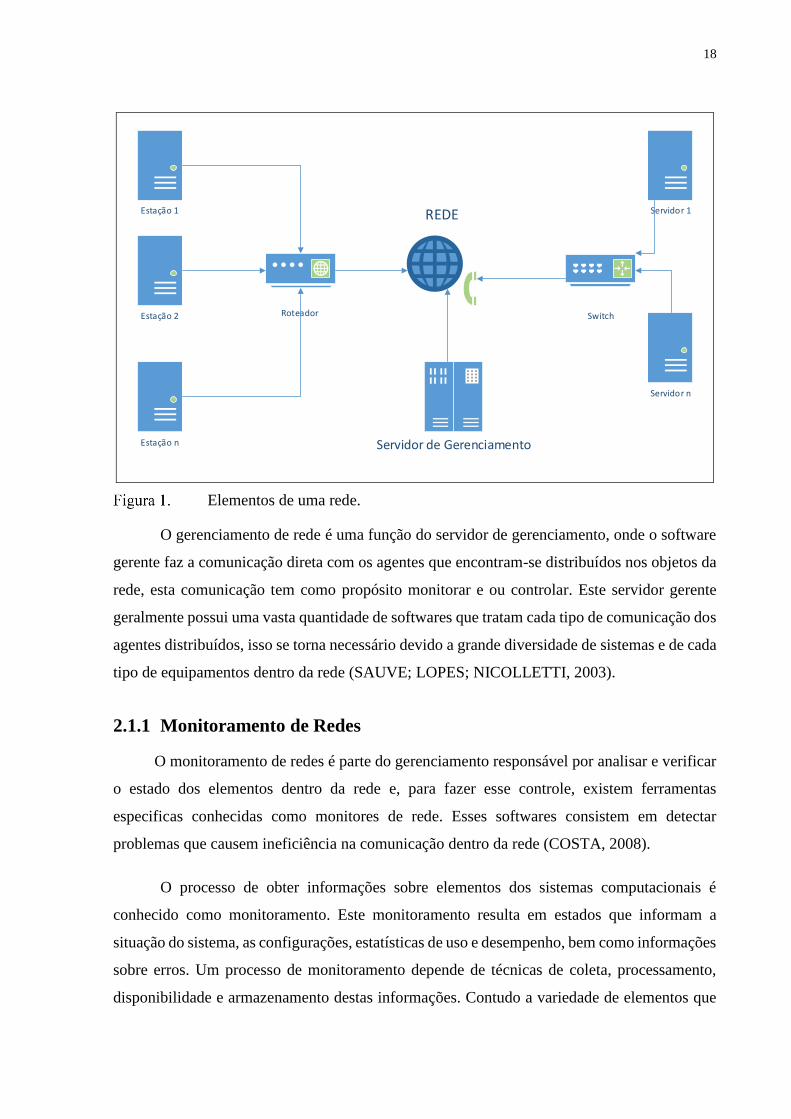
trabalham interligados. Na Figura 1 observar-se a arquitetura básica de um sistema de
gerenciamento de rede. Cada objeto da rede possui pelo menos um software agente que
responde ao servidor de gerenciamento, enquanto que no servidor de gerenciamento são
necessários mais de um software capaz de comunicar-se diretamente com as demais estações.
18
Switch
Servidor 1
Servidor de Gerenciamento
Roteador
Servidor n
Estação 1
Estação 2
Estação n
REDE
Elementos de uma rede.
O gerenciamento de rede é uma função do servidor de gerenciamento, onde o software
gerente faz a comunicação direta com os agentes que encontram-se distribuídos nos objetos da
rede, esta comunicação tem como propósito monitorar e ou controlar. Este servidor gerente
geralmente possui uma vasta quantidade de softwares que tratam cada tipo de comunicação dos
agentes distribuídos, isso se torna necessário devido a grande diversidade de sistemas e de cada
tipo de equipamentos dentro da rede (SAUVE; LOPES; NICOLLETTI, 2003).
2.1.1 Monitoramento de Redes
O monitoramento de redes é parte do gerenciamento responsável por analisar e verificar
o estado dos elementos dentro da rede e, para fazer esse controle, existem ferramentas
especificas conhecidas como monitores de rede. Esses softwares consistem em detectar
problemas que causem ineficiência na comunicação dentro da rede (COSTA, 2008).
O processo de obter informações sobre elementos dos sistemas computacionais é
conhecido como monitoramento. Este monitoramento resulta em estados que informam a
situação do sistema, as configurações, estatísticas de uso e desempenho, bem como informações
sobre erros. Um processo de monitoramento depende de técnicas de coleta, processamento,
disponibilidade e armazenamento destas informações. Contudo a variedade de elementos que

19
um sistema computacional é composto exige técnicas adequadas para cada tipo de elemento
(VERMA, 2009).
Pode-se definir três etapas como sendo fundamentais em gerenciamento:
Coleta de Dados - são processos que são executados automaticamente, que verificam o
estado dos recursos gerenciados;
Diagnóstico - é o tratamento realizado partindo dos dados coletados, onde o sistema de
gerenciamento faz por intermédio de configurações predefinidas procedimentos para
determinar as causas do problema; e
Ações ou Controle - após diagnosticada a causa de um problema, uma ação pode ser
tomada pelo sistema para controlar os recursos, sendo que esta ação pode ser
configurada previamente para realizar essas ações automaticamente dependo do nível
do evento.
Além de gerenciar é importante medir o desempenho dos elementos da rede, sendo
possível tomar medidas preventivas ou corretivas, antecipando possíveis problemas (MAURO;
SCHMIDT, 2005). Para realizar estas etapas de gerenciamento é necessário conhecer algumas
funções básicas como detecção de intrusão, desempenho, falhas, hosts, tráfego, SLAs (Service
Level Agreements) são os acordos de nível de serviço que são contratos com provedores de rede
que especificam níveis aceitáveis de performance do link (KUROSE, 2005).
Segundo Kurose (2005), para manter uma forma estruturada é necessário que algumas
funções de rede sejam monitoradas, tais como: a detecção de intrusão, o desempenho, o
gerenciamento a falhas, o gerenciamento de hosts e também o gerenciamento do tráfego.
Detecção de intrusão – é uma das grandes preocupações de muitos profissionais de
rede devido à quantidade e complexidade das ameaças tecnológicas. Com as
ferramentas de detecção um administrador pode reagir de maneira efetiva, ou mesmo
coibir ataques contra uma rede antes mesmo que eles aconteçam;
Desempenho – é considerado tecnicamente como: classificar, medir e ajustar
quipamentos diversos além da estrutura e organização de uma rede para que se obtenha
o desempenho máximo;

20
Falhas – as informações sobre falha ocorrem praticamente em tempo real, através de
um protocolo que verifica os equipamentos e conexões da rede;
Hosts – são os equipamentos ou computadores que oferecem recursos, serviços ou
aplicativos e estão distribuídos dentro na rede; e
Tráfego – equipamentos que fazem uso dos recursos de rede. Ferramentas adequadas
ajudam o administrador a perceber se o projeto da rede está adequado e a demanda é
efetivamente usada, e este monitoramento é possível verificando se os SLAs estão sendo
cumpridos devidamente pelo provedor.
2.2 NAGIOS
O Nagios é um sistema de monitoramento de redes de código aberto, que foi criado por
Ethan Galstad, no princípio dos anos 90 sob o nome de Netsaint. Inicialmente, a ferramenta
somente estava disponível na plataforma DOS e utilizava o comando ping para realizar os testes
de conectividade com os servidores. Alguns anos após, Ethan aprimorou a ferramenta para que
ela funcionasse na plataforma Linux e, a partir deste feito, o sistema foi sendo aprimorado de
forma efetiva, tendo a possibilidade de monitorar hosts e serviços mais amplamente. Hoje sua
maior e principal função é a de monitorar hosts, serviços, aplicativos e processos em intervalos
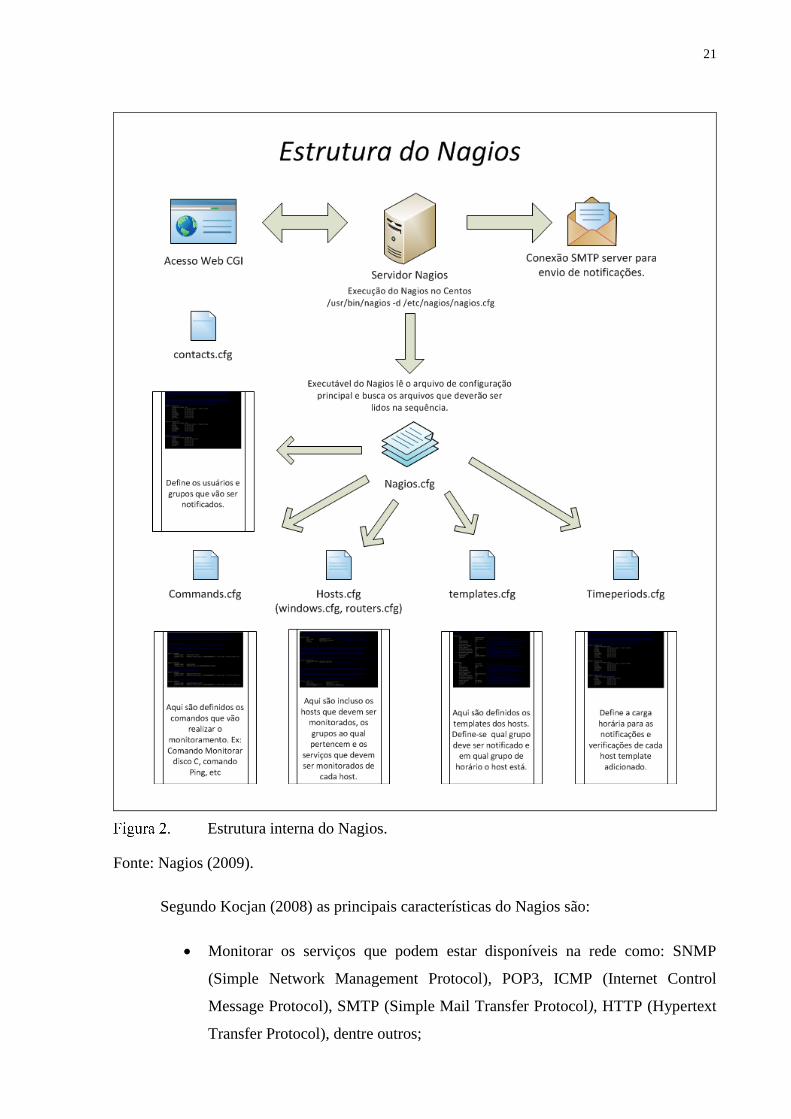
de tempo pré-definidos. Sua estrutura pode ser vista na Figura 2 (COSTA, 2008). Os plug-ins
são os grandes responsáveis por executar as funções no Nagios e são eles que tornam o sistema
Nagios uma estrutura extremamente flexível (KOCJAN, 2008).
Segundo (BARTH, 2006, p.17), “o grande diferencial do Nagios em relação com outras
ferramentas de monitoramento de rede é sua estrutura modular, podendo assim trabalhar com
programas externos que são conhecidos como plug-ins”.
21
Estrutura interna do Nagios.
Fonte: Nagios (2009).
Segundo Kocjan (2008) as principais características do Nagios são:
Monitorar os serviços que podem estar disponíveis na rede como: SNMP
(Simple Network Management Protocol), POP3, ICMP (Internet Control
Message Protocol), SMTP (Simple Mail Transfer Protocol), HTTP (Hypertext
Transfer Protocol), dentre outros;

22
Monitorar recursos de computadores, servidores e ou outros tipos de
equipamentos da rede verificando a carga do processador, o uso do espaço dos
discos, logs do sistema, etc.;
Realizar a monitoração remota através de túneis criptografados com SSH
(Secure Shell) ou SSL (Security Socket Layer);
Utilizar plug-ins que são independentes de linguagens de desenvolvimento
como: bash, C, C#, Perl, Python, PHP, dentre outras;
Fazer a verificação de serviços em paralelo, para que não exista falhas;
Organizar a rede hierarquicamente definindo equipamentos responsáveis e assim
permitindo distinção dos equipamentos que estão indisponíveis daqueles que
estão inalcançáveis;
Fazer notificações quando serviços ou equipamentos apresentam problemas ou
após ser resolvido.
Capacidade de encaminhar notificações através de e-mail, SMS (Short Message
Service), ou outra forma que um plug-in configurado o faça;
Capacidade de definir alguns manipuladores de eventos que executem tarefas
em situações determinadas antecipadamente ou para a resolução proativas de
problemas;
Suporta implementação de monitoração redundante;
Disponibiliza uma interface WEB (World Wide Web) para a visualização do
status atual da rede, notificações, histórico de problemas, arquivos de log,
relatórios do sistema, dentre outros.
2.2.1 Configurações
As configurações do Nagios são feitas em arquivos de texto. Segundo Barth (2006), os
principais arquivos de configurações do software são:

23
nagios.cfg - principal arquivo de configuração do Nagios. Neste arquivo são
feitas referências aos outros arquivos de configuração;
cgi.cfg – neste arquivo são configurados os CGIs (Configuration File Options),
que darão suporte a algumas funcionalidades extras do Nagios, também são
adicionadas as configurações e parâmetros de autorização de utilização da
interface WEB;
commands.cfg – são aqui adicionados os comandos que o Nagios poderá
executar, tais como envio de e-mail, envio de SMS, etc;
checkcommands.cfg – arquivo responsável pela configuração dos plug-ins que
estão no diretório /usr/local/nagios/libexec, adicionando o plug-in e seus
parâmetros;
contacts.cfg – local onde são cadastrados os contatos e grupos que serão
avisados caso ocorra algum alerta;
timeperiods.cfg – configuração dos períodos em que é efetuado o
monitoramento. Poderão existir vários tipos de monitoramento, e configurados
de acordo com a situação de cada necessidade;
templates.cfg – são os modelos com configurações para os diversos tipos de
ativos a serem monitorados como computadores, impressoras, switches, etc.;
resource.cfg – é onde são configurados os parâmetros de recursos. Como padrão
no Nagios já vem definido qual o caminho padrão dos plug-ins, podendo ser
adicionados outras variáveis para serem utilizadas nos arquivos
checkcommands.cfg e misccommands.cfg, na utilização de outros plug-ins.
2.2.2 Monitoramento
Para realizar o monitoramento de serviços ou hosts no Nagios existem várias formas
diferentes. Pode ser utilizado desde comandos que o Nagios disponibiliza para checagens
simples, quanto a utilização de plug-ins que são mais sofisticados e funcionam de maneira mais
eficaz trazendo informações mais eficientes (KOCJAN, 2008).

24
Com relação ao monitoramento de hosts, no Nagios existem dois casos: Hosts Windows
e Hosts Linux. A maneira na qual o monitoramento é feito muda em alguns aspectos.
Em hosts Windows a utilização do agente cliente NSClient se torna necessária. Este
envia as informações sobre uso de memória, CPU (Central Processing Unit), disco, processos
em execução para o servidor Nagios (KOCJAN, 2008).
Em hosts Linux é necessária a instalação do plug-in NRPE (Nagios Remote Plugin
Executor) que é responsável por acessar os recursos internos do sistema como uso de
processador, espaço em disco, uso de memória RAM (Random Access Memory) etc. Outra
alternativa, seria o uso de SSH para realizar conexões remotas e, em seguida, obter informações
através de comandos nativos do sistema, enviando as informações ao servidor Nagios, porém
este processo é bastante intenso utilizando muitos recursos do processador, o que o tornaria em
alguns casos inviável o seu uso, como no caso de o número de hosts e serviços forem em grande
escala.
Monitoramento no Windows
O Nagios utiliza um sistema de arquivos cfg para armazenar as configurações do sistema
de monitoramento. No caso dos serviços monitorados nos hosts Windows, o arquivo utilizado
é o windows.cfg. Nesses arquivos são adicionados os hosts e seus respectivos serviços
(BARTH, 2006). Na Figura 3 é mostrado um exemplo de um host neste arquivo, onde a
definição de um host é do tipo Windows, e as descrições de cada campo do código são:
define host - informa ao Nagios que o código a seguir, delimitado por chaves,
faz parte da declaração de um novo host no sistema;
use - faz com que o novo host herde propriedades de um modelo padrão.
host_name - define o nome do novo host;
alias – apelido que substitui o nome do host; e
address – endereço de ip do novo host.
define host
{
use Windows-server
host_name winserver

25
alias Meu Windows Server
address 192.168.1.2
}
Definição de um host do sistema Nagios
Com o monitoramento de serviços, o Nagios facilita o controle do administrador sobre
servidores e objetos da rede. A definição deste ou outros serviços também é realizada no arquivo
windows.cfg. A Figura 4 exibe como deve ser definido um serviço, segundo Barth (2006) a
descrição de cada comando deve ser:
define service - define um novo serviço;
use - possibilita a utilização de um modelo padrão que foi criado anteriormente;
host_name - nome do host no qual o recurso é monitorado;
service_description - descrição do recurso ou serviço; e
check_comand - executa o plug-in com seus parâmetros.
define service
{
use generic-service
host_name winserver
servisse_description Uptime
check_command check_nt!UPTIME
}
Definição de um serviço no sistema Nagios
Monitoramento no Linux
Para monitorar sistemas Linux com o Nagios é necessária a instalação do agente cliente
NRPE que coleta as informações do sistema e envia ao servidor Nagios como na Figura 5.
Servidor de Monitoramento Cliente Linux/Unix
Nagios NRPELocal resources
AndServicesSSL

26
Modelo de funcionamento do NRPE.
Adaptado: Nagios (2009)
Para que o servidor Nagios possa receber e processar as informações enviadas pelo
agente cliente, no arquivo command.cfg deverão constar as definições de recepção como mostra
a Figura 6.
define command
{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
Definições do plug-in NRPE.
2.2.3 Plug-in
O Nagios utiliza-se de plug-ins para fazer o monitoramento de objetos, esse
monitoramento é executado através de comandos externos que podem ser executáveis ou
scripts. O código de retorno destes comandos é interpretado pelo Nagios como sendo o
resultado desta verificação, desta forma fica claro que as verificações dos objetos são de
responsabilidade do comando externo. Os plug-ins podem monitorar qualquer tipo de objeto de
uma organização desde que exista um comando que capture o seu estado e os resultados de tais
verificações são interpretados pelo Nagios como estados de situação do objeto como está na
Tabela 1 (KOCJAN, 2008).
O Nagios ainda disponibiliza uma vasta coleção de plug-ins que são compartilhadas e
ou desenvolvidas por colaboradores, onde suas funcionalidades são utilizadas para os mais
diversos tipos de problemas, e ainda é possível desenvolver um plug-in específico para um
determinado problema utilizando uma linguagem de programação qualquer (KOCJAN, 2008).
O funcionamento do plug-in, script ou programa externo, para trabalhar com o Nagios
necessita retornar no mínimo dois tipos de ações que são o Estado de Retorno e o Retorno de
Texto.
Estados de Retorno: é o código que o plug-in irá enviar ao servidor, que deve
conter um dos vários valores conhecidos, conforme a Tabela 1.
Tabela 1. Estados de retorno de um plug-in.
Retorno Serviço Host

27
0 OK UP
1 WARNING UP ou DOWN /
UNREACHABLE
2 CRITICAL DOWN / UNREACHABLE
3 UNKNOWN DOWN / UNREACHABLE
Fonte: KOCJAN (2008).
Retorno de Texto: pelo menos uma linha de saída de texto deve ser enviada
para o retorno padrão como no Quadro 1. Opcionalmente, se existir o retorno de
dados de desempenho, deve-se separar os dados de saída usando o símbolo pipe
dos dados de desempenho como é mostrado na Quadro 2 onde os dados de saída
OUTPUT serão armazenados no macro $SERVICEOUTPUT enquanto os dados
opcionais serão armazenados no macro $SERVICEPERFDATA, além destes
dados o retorno também poderá conter outras linhas adicionais (BARTH, 2006).
Quadro 1. Exemplo de verificação de serviço de saída DISK OK – free space: / 3326 MB (56%);
Quadro 2. Amostra de saída de texto de um plug-in. TEXT OUTPUT | OPTIONAL PERFDATA
LONG TEXT LINE 1
LONG TEXT LINE 2
...
LONG TEXT LINE N | PERFDATA LINE 2
PERFDATA LINE 3
...
PERFDATA LINE N
2.2.4 Funcionalidades
As principais funcionalidades do Nagios são:
Identificar problemas antes da ocorrência;
Monitorar toda a infraestrutura de Tecnologia da Informação;
Identificar problemas no momento da ocorrência;
Compartilhar dados de disponibilidade com as partes interessadas;
Detectar falhas de segurança; e
Reduzir o tempo de inatividade.

28
O sistema Nagios é baseado nas definições e tipos de objetos que são:
Hierarquia de notificações para hosts e serviços - define períodos nos quais contatos
adicionais devem ser notificados como, por exemplo se um servidor com importância muito
alta estiver com problemas dentro de um determinado espaço de tempo, estes contatos
adicionais podem ser notificados (KOCJAN, 2008).
Comandos - são as definições de como o Nagios deve executar as verificações, e
permite o agrupamento de outros tipos de operações (KOCJAN, 2008).
Períodos de tempo - essas definições controlam quando as ações devem ser executadas
(KOCJAN, 2008).
Contatos e grupos de contato - são as informações sobre as pessoas ou grupos que
devem ser contatadas e os meios de contato (KOCJAN, 2008).
Hosts – são as informações sobre equipamentos conectados na rede, descrição de como
a verificação deve ser efetuada e quais as pessoas ou grupos que serão contatadas (KOCJAN,
2008).
Serviços - podem ser definidas várias funcionalidades ou recursos a serem monitorados
em um host, grupo de host, grupos de serviços, contatos, períodos de tempo, etc. (KOCJAN,
2008).
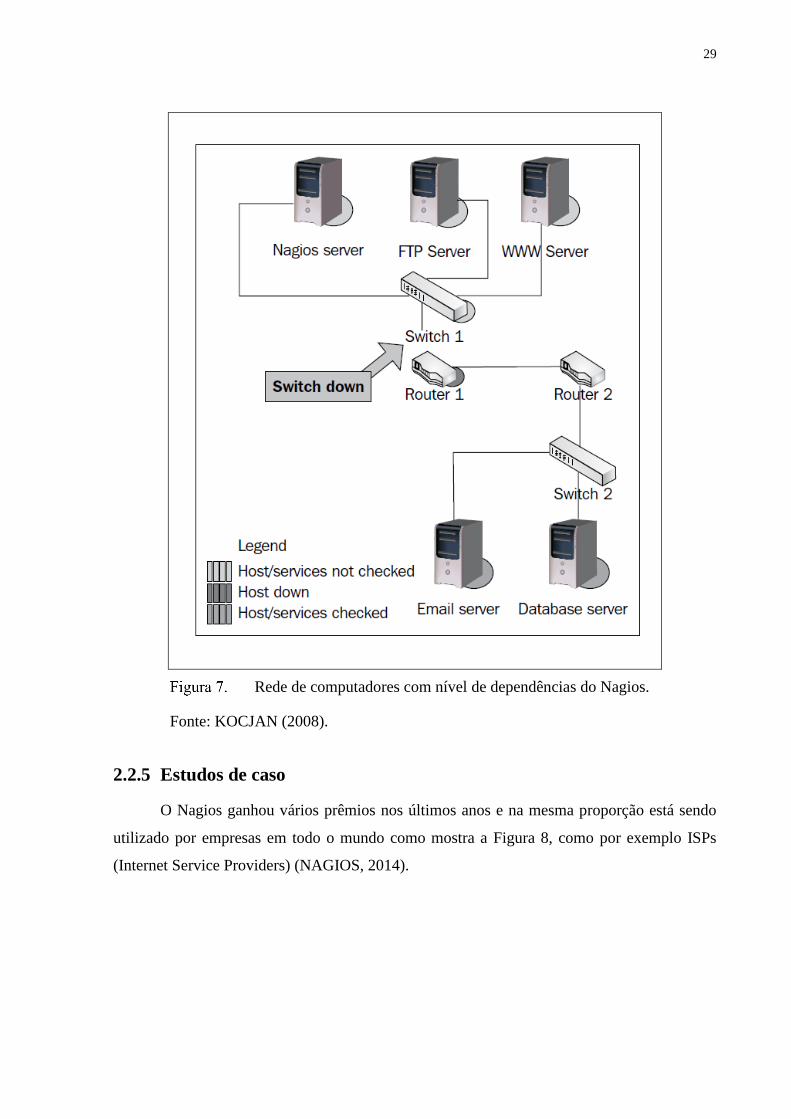
Dependências - são as configurações de quais hosts, serviços ou grupos são
dependentes de quais outros hosts, serviços ou grupos e essas dependências podem ser melhor
compreendidas como são mostradas na Figura 8 (KOCJAN, 2008).
29
Rede de computadores com nível de dependências do Nagios.
Fonte: KOCJAN (2008).
2.2.5 Estudos de caso
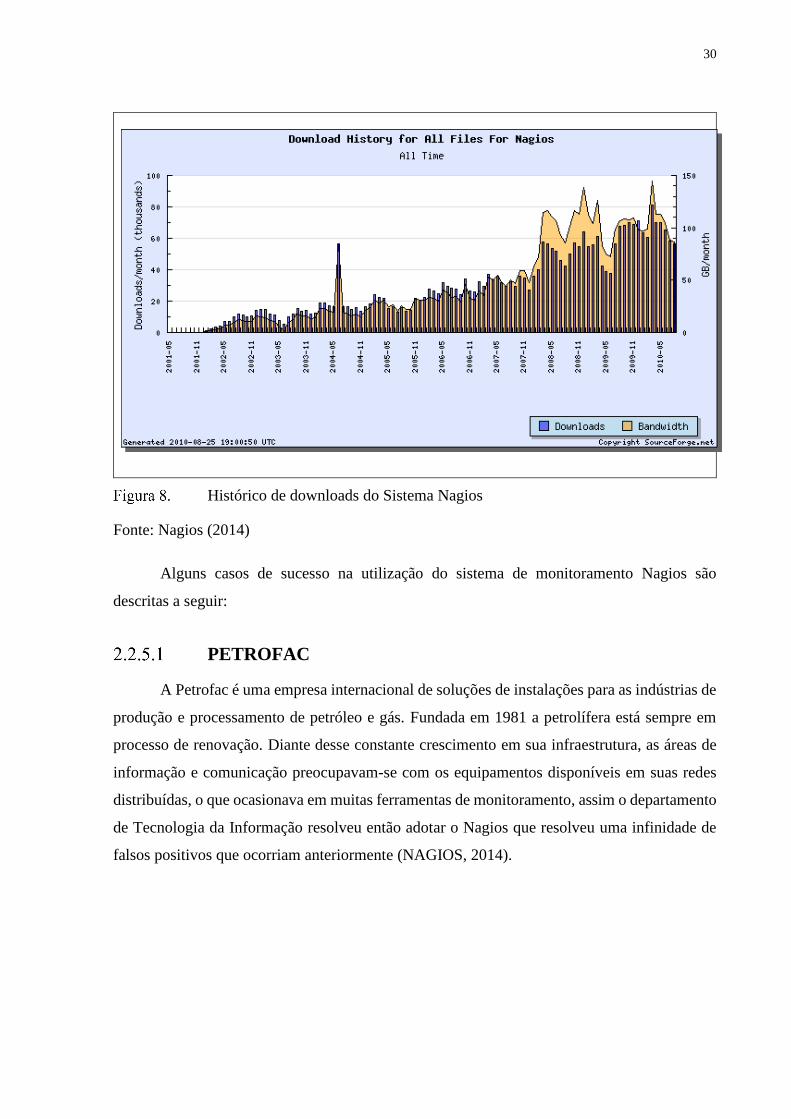
O Nagios ganhou vários prêmios nos últimos anos e na mesma proporção está sendo
utilizado por empresas em todo o mundo como mostra a Figura 8, como por exemplo ISPs
(Internet Service Providers) (NAGIOS, 2014).
30
Histórico de downloads do Sistema Nagios
Fonte: Nagios (2014)
Alguns casos de sucesso na utilização do sistema de monitoramento Nagios são
descritas a seguir:
PETROFAC
A Petrofac é uma empresa internacional de soluções de instalações para as indústrias de
produção e processamento de petróleo e gás. Fundada em 1981 a petrolífera está sempre em
processo de renovação. Diante desse constante crescimento em sua infraestrutura, as áreas de
informação e comunicação preocupavam-se com os equipamentos disponíveis em suas redes
distribuídas, o que ocasionava em muitas ferramentas de monitoramento, assim o departamento
de Tecnologia da Informação resolveu então adotar o Nagios que resolveu uma infinidade de
falsos positivos que ocorriam anteriormente (NAGIOS, 2014).

31
SUNRISE COMMUNICATIONS
A Sunrise Communications é o maior provedor de telecomunicações privada da Suíça,
com mais de dois milhões e oitocentos mil clientes que utilizam os seus serviços que vão desde
a telefonia móvel, rede fixa e internet. A infraestrutura da Sunrise na última década vem
evoluindo devido as muitas fusões e reorganizações acarretando em um enorme conjunto de
softwares de monitoramento, e os dados significantes ao longo do tempo eram perdidos. A
Sunrise resolveu consolidar seu software de monitoramento e adotar uma única solução, ou
seja, resolveu utilizar o Nagios a fim de reduzir a sobre carga operacional e economizar em
manutenção e em hardware (NAGIOS, 2014).
BANCO BANRISUL
O Banco Banrisul é o principal banco do estado do Rio Grande do Sul e 12º maior do
Brasil. Está situado na cidade de Porto Alegre e com mais de 460 (quatrocentos e sessenta)
agências espalhadas por todo o país. Detêm de uma estrutura muito complexa e ainda
comtempla uma mistura de mainframes da IBM (International Business Machine), Linux,
Microsoft e HP (Hewlett Packard), onde existem um ambiente com várias ferramentas
proprietárias para o gerenciamento de Tecnologia da Informação. Com a necessidade de
centralização do gerenciamento em larga escala foi adotada a ferramenta Nagios, que com sua
estrutura integrada, flexível e escalável deixaria disponível para gerencia de Tecnologia da
Informação toda sua estrutura vista de um único ponto, e seria ainda capaz de gerenciar
aplicativos sem os altos custos de customização que outras ferramentas proprietárias exigem
(NAGIOS, 2014).
2.3 SISTEMA OPERACIONAL LINUX
O sistema operacional Linux, foi iniciado por Linus Benedict Torvalds da Universidade
de Helsinki, ainda na década de 80. Este era um projeto particular e foi inspirado no Minix, um
pequeno sistema UNIX que foi lançado em novembro de 1986 por Andrew Tanenbaum.
A versão Linux que será utilizada neste trabalho será a distribuição derivada de códigos
fonte distribuída gratuitamente pela Red Hat Enterprise, que foi iniciada em meados de 2004 e
atualmente é mantida pelo CentOS Project. O Sistema Operacional CentOS atualmente é
utilizado em larga escala pelos usuários do Nagios que mantém grande compatibilidade com o

32
software e seus dependentes, tendo um grande diferencial de estabilidade comparado as outras
versões do Linux.
2.4 SERVIDOR DE E-MAIL
O correio eletrônico é um método que permite o envio e recebimento de mensagens
através de serviços dos servidores de e-mail. Os padrões de serviços do correio eletrônico foram
propostos em 1965 e em 1969 com o surgimento da Arpanet esses padrões foram reorganizados
tal qual como é conhecido atualmente, e o responsável pelo recebimento e envio destas
mensagens é conhecido como servidor de e-mail (RESNICK, 2001).
O servidor de e-mail, como mostra a Figura 11, tem como função encaminhar e receber
mensagens, verificando constantemente a existência de mensagens a serem enviadas. Quando
existir uma mensagem destinada ao domínio local, esta mensagem é distribuída ao usuário.
Caso a mensagem seja para outro domínio, é feita uma solicitação ao servidor de destino, que
consiste em comandos que especificam a origem, destino e a mensagem a serem transmitidas,
e assim que esta conexão existir é enviada a mensagem e este servidor destinatário. Assim que
a mensagem chega a este servidor então ela é deixada na caixa de entrada (POSTEL, 1982).
O recebimento de mensagens no servidor de e-mail é efetuado através do protocolo
SMTP que faz a troca de mensagens entre clientes e servidores e ou entre servidores, enquanto
a mensagem não encontra o servidor destinatário. Esse protocolo foi descrito em 1982 na RFC
(Request for Comments) 822, e consiste em fazer simples trocas de caracteres e atualmente é
utilizada a RFC 2822 (RESNICK, 2001).
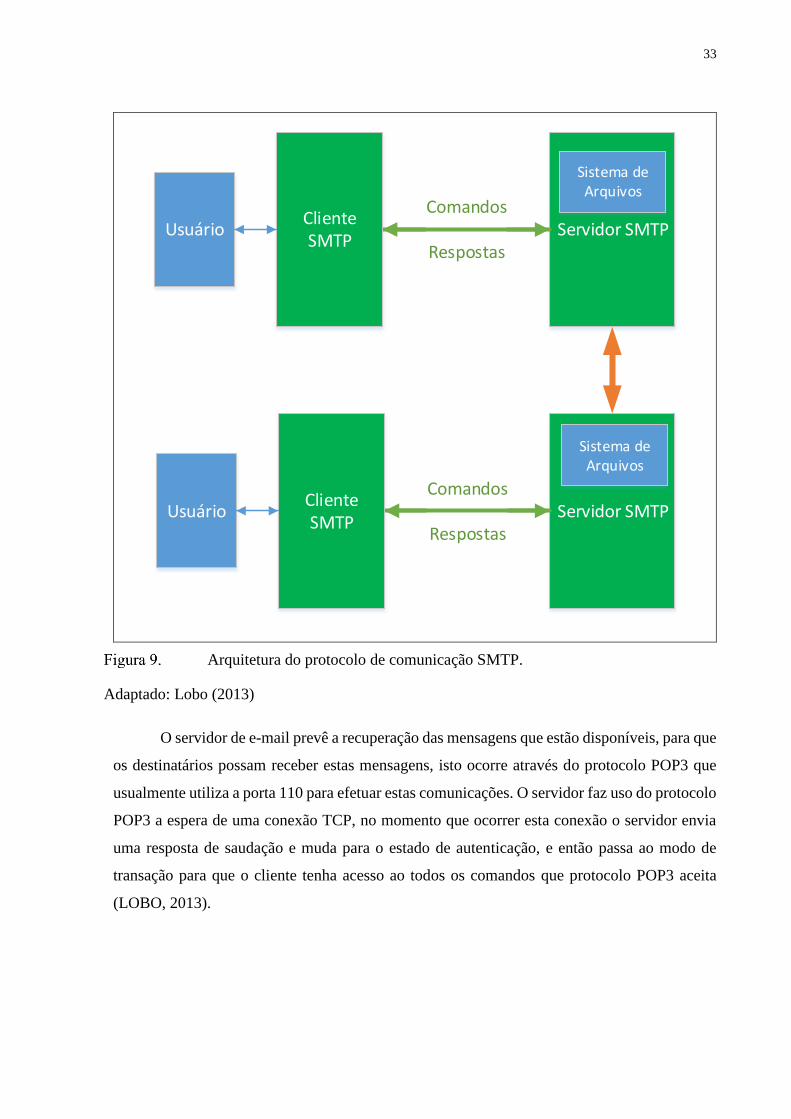
33
UsuárioComandos
Respostas
Cliente SMTP
Servidor SMTP
UsuárioComandos
Respostas
Cliente SMTP
Servidor SMTP
Sistema de Arquivos
Sistema de Arquivos
Arquitetura do protocolo de comunicação SMTP.
Adaptado: Lobo (2013)
O servidor de e-mail prevê a recuperação das mensagens que estão disponíveis, para que
os destinatários possam receber estas mensagens, isto ocorre através do protocolo POP3 que
usualmente utiliza a porta 110 para efetuar estas comunicações. O servidor faz uso do protocolo
POP3 a espera de uma conexão TCP, no momento que ocorrer esta conexão o servidor envia
uma resposta de saudação e muda para o estado de autenticação, e então passa ao modo de
transação para que o cliente tenha acesso ao todos os comandos que protocolo POP3 aceita
(LOBO, 2013).

34
2.5 COMPUTAÇÃO VERDE
A computação verde é tema que vem tomando grandes proporções em todo o mundo,
uma tendência voltada a prática sustentável e redução do impacto ao meio ambiente, o que
engloba boas práticas e uso eficiente da tecnologia. Na área de Tecnologia da Informação, dados
de pesquisas comprovam que existe um crescente consumo de energia elétrica que chegam a
quase 1% de toda a energia elétrica gerada no planeta (TEIXEIRA, 2007).
Diante destes dados surge uma preocupação com a sustentabilidade. De acordo com
estes fatores, os fabricantes começam a lançar no mercado ferramentas e produtos inovadores
buscando um melhor desempenho e reduzindo a emissão de gases danosos ao meio ambiente
(TEIXEIRA, 2007).
2.5.1 Conceito
O termo Computação Verde ou Tecnologia da Informação Verde surgiu da preocupação
ambiental do mundo corporativo e da necessidade de melhorar os recursos de tecnologia.
Englobando os conceitos de sustentabilidade, a Tecnologia da Informação Verde é considerada
um conjunto de boas práticas que tem como principais objetivos minimizar os impactos com
relação ao meio ambiente, reduzir o consumo energético, reciclar e reduzir os resíduos
produzidos.
Com estes conceitos sendo praticados é possível produzir componentes atóxicos, e
assim alcançar o máximo desempenho de uma forma sustentável, eficiente e ecologicamente
correta, impactando positivamente na preservação do meio ambiente (MOURA, 2010).
Como o conceito de Tecnologia da Informação Verde está diretamente ligado a
governança de Tecnologia da Informação Verde, precisam ser citados alguns atores envolvidos
como o GRI (Global Report Initiative) e a ISO (International Organization for
Standardization) a Norma 14001 que exige e especifica que as empresas se comprometam com
a prevenção da poluição, e ajuda no aprimoramento de um sistema gerencial de riscos
ambientais, onde tem como principais objetivos o cumprimento da legislação ambiental,
gerenciar procedimentos e planos de ação para eliminar e ou diminuir os impactos ambientais
(MAKOWER, 2009).
Esses mecanismos regulamentam as empresas como sendo ecologicamente corretas, e
para a empresa ser considerada sustentável são necessárias avaliações de todo o ciclo de vida

35
dos seus produtos, calcular as emissões de carbono e desenvolver uma estratégia para
minimização destes (ABRANCHES, 2010).
Outro mecanismo importante dentro da computação verde é o programa Energy Star
que é desenvolvido pela EPA (Environmental Protection Agency) e incentiva os fabricantes de
computadores e monitores a reduzir o consumo dos equipamentos por eles produzidos, o
programa visa fazer com que os equipamentos alcancem um consumo de 30 watts em modo
ativo e 8 watts em modo econômico (GARCIA; MILAGRE, 2009).
2.5.2 História
O conceito de sustentabilidade iniciou-se no início dos anos 70 através de debates e
movimentos ambientais sobre eco desenvolvimento. E, a partir deste feito, começou-se a
trabalhar com modelos de desenvolvimento sustentável. Em 1972 em uma Conferência das
Nações Unidas, criou-se órgãos que seriam responsáveis por cuidar apenas das questões
ambientais do planeta, onde esses deveriam se reunir regularmente para debater e solucionar
problemas socioambientais (LIMA, 2006).
No início do século XXI, com a preocupação voltada ao descarte de resíduos eletrônicos,
além da sustentabilidade já estabelecida, encadeou-se uma nova ideia que buscava minimizar o
desperdício e melhorar a eficiência. Dessa forma, a medida que a sustentabilidade tornava-se
um conceito popular, o mundo corporativo começava a criar ações que adotassem estes
paradigmas, surgindo assim um novo conceito chamado Tecnologia da Informação Verde.
Desde então uma mudança dos padrões de produção e consumo começaram, e com um ponto
incomum e importante para a sociedade, as empresas então começam a desenvolver produtos
com tecnologias inovadoras que visam prover melhor desempenho e com menor consumo de
energia elétrica ocasionando desta forma produtos e serviços ecologicamente corretos (LIMA,
2006).
A utilização de softwares que amenizem a degradação do meio ambiente também pode
ser aplicada a Tecnologia da Informação Verde, uma vez que com a otimização do
processamento são realizadas menos operações por tarefa possibilitando manter o processador
em modelo econômico (LIMA, 2006).
2.5.3 Casos de Uso

36
Várias empresas na indústria da Tecnologia da Informação, como Google, IBM, HP e
ITAUTEC, vêm aplicando grandes volumes de dinheiro para desenvolver tecnologias eco
eficientes, desde novos hardwares, novas práticas, novos arranjos e estruturas computacionais,
pois não se trata apenas de tornar os computadores mais eficientes, mas sim tornar a computação
mais eficiente (TEIXEIRA,2007).
Itautec
A empresa ITAUTEC por sua vez, tem seu mercado voltado ao aprimoramento
tecnológico, onde exige gradualmente atuações das empresas fabricantes parceiras no sentido
de utilizar tecnologias cada vez mais limpas e que possam ter seu ciclo de vida mais longo.
Sendo que estes equipamentos ao final da vida útil possam ser destinados a reciclagem
realimentando o ciclo produtivos da indústria (ITAUTEC, 2014).
Segundo a ITAUTEC (2014, não paginado):
Na Itautec a sustentabilidade há muito saiu do campo das boas ideias para ser
incorporada às nossas práticas produtivas. Desde 2001, contamos com um Sistema de
Gestão Ambiental que reúne nossas políticas, programas e práticas corporativas
dedicadas à responsabilidade socioambiental. Isto significa o uso racional dos
recursos materiais, energéticos e hídricos, além de realizarmos a separação dos
resíduos, promovendo a reciclagem, entre outras ações. Mas fomos além em nossas
iniciativas e nos tornamos a primeira empresa do Brasil no campo de Tecnologia da
Informação a fabricar equipamentos livres de chumbo. Desde 2007 fabricamos
microcomputadores e notebooks livres de substâncias nocivas ao ambiente e à saúde
humana, como o cádmio, o cromo hexavalente (um anticorrosivo para partes
metálicas) e a cadeia de bromobifenilas (usadas para evitar a propagação de chamas).
Estes materiais foram substituídos por outros, de acordo com as recomendações da
diretiva europeia RoHS, referência mundial na restrição ao uso de substâncias que
agridem o ambiente. No final de 2008, outras linhas de produtos da Itautec também
passaram a ser fabricadas em conformidade com a RoHS, com rígidos controles
ambientais. Isto consumiu investimentos em torno de R$ 3 milhões, aplicados ao
longo de dois anos na adequação de linhas de produção. A adoção de novos processos
foi ampliada à cadeia de fornecedores da empresa, fazendo com que muitos deles
adequassem seus insumos segundo a diretiva ambiental europeia. A empresa também
é pioneira no desenvolvimento do que hoje é um dos projetos mais avançados em
destinação de resíduos eletroeletrônicos em operação no Brasil. Trata-se do Centro de
Reciclagem, localizado em Jundiaí, no interior de São Paulo, onde equipamentos são
reciclados ao fim de sua vida útil. Neste espaço, os equipamentos são recebidos,
desmontados, descaracterizados, pesados e depois têm suas partes separadas por tipo
de material, que são encaminhadas a recicladores homologados pela Itautec.
A empresa Google foi fundada em 1996 sendo inicialmente chamada de BackRub, por
Larry Page e Sergey Brin, e desde então teve um crescimento estrondoso. Diariamente são

37
processados mais de um bilhão de solicitações de pesquisa e cerca de vinte petabytes de dados
nos mais de um milhão de servidores espalhados por diversos data centers distribuídos em todo
o planeta.
Os data centers do Google utilizam cerca de 50% de energia comparada a outros data
centers e estima-se que foram economizados aproximadamente um bilhão de dólares em custos
de energia até meados de 2011. Segundo os estudos realizados pela empresa, o consumo de
energia gasta pelo Google é de 0,01% do consumo total do planeta (GOOGLE, 2011).
A empresa utiliza fontes renováveis de energia como a eólica e a solar. Uma técnica
utilizada é resfriamento gratuito, que utiliza água e ar de ambientes externos para realizar o
resfriamento dos data centers o que é constantemente verificado utilizando modelagens
térmicas que localizam os pontos com maior calor e o eliminam.
Outra técnica para reduzir o consumo de energia adotada foi utilizar materiais com
maior eficiência de energia, minimizando as conversões de corrente alternada para corrente
contínua e manter as fontes o mais próximo possível dos equipamentos, obtendo cerca de 50%
menos depreciação da energia elétrica que outros servidores convencionais. Desde 2007, os
servidores antigos passaram por um processo de reciclagem, evitando assim a compra de mais
de 90.000 novos equipamentos e após este demasiado esforço a empresa conseguiu obter as
certificações ISO 14001 e OHSAS (Occupational Health and Safety Assessment Services)
180001 (GOOGLE, 2011).
Itaú
Para João Bezerra Leite, diretor de infraestrutura e operações em Tecnologia da
Informação do Itaú Unibanco, enfatiza que o correto é aderir a Computação Verde, pois
deveriam ser regulamentadas estas iniciativas que trazem um retorno concreto ao meio
ambiente e as empresas.
No ano de 2010, o banco Itaú foi um dos vencedores do prêmio Green IT Enterprise
Awards na categoria Misto de Tecnologia da Informação em instalações inovadoras, com o
projeto de virtualização de servidores, devido a estas ações o banco conseguiu reduzir o espaço
físico e também o consumo anual de energia em 3,7 GWh desde sua implantação. Além dos
servidores, houve a troca de monitores CRT por monitores de LED e o uso da computação
virtual na qual resultou em uma economia de energia estimada em 1.9 GWh em 2009, em

38
estudos realizados provou-se que foi deixado de emitir cerca de 92 toneladas de CO2 (COUTO,
2010).
Com o software Nagios implantado, o tempo gasto com instalação e manutenção em
servidores foi reduzida aumentando a eficiência do Tecnologia da Informação na organização.
Ainda enfatiza Bezerra que após esta primeira realização o Itaú Unibanco vai deixar toda a
infraestrutura em nuvem reduzindo ainda mais os custos com energia e beneficiará também o
meio ambiente (CRUZ, 2011).
Hewlett Packard
A empresa HP não mede esforços quando o assunto é produção associada às políticas
de sustentabilidade. Conforme matéria divulgada pela HP (2011), mais de 1 bilhões de KW de
energia elétrica foram economizados pela empresa através de alternativas realizadas pelos
setores especializados em fabricação, transporte, reutilização e reciclagem. Houve uma redução
de 50 % de papel e plásticos gastos nas embalagens de impressoras, aproximadamente 10 mil
servidores foram reciclados e 151 toneladas de hardwares e suprimentos foram reciclados e
comercializados. A HP criou mais de 100 postos que espalhados pelo Brasil são responsáveis
pela logística e reciclagem de baterias, hardwares e suprimentos, e a empresa ainda
disponibiliza de um setor focado na sustentabilidade ambiental que fica responsável por gestões
de pesquisa e desenvolvimento, recebendo vários prêmios como GreenBest que avalia entre
diversos atributos as qualidades ambientais da empresa e o processo de fabricação, também foi
premiada como o Prêmio Época Verde que relacionou a como sendo uma das 20 maiores
empresas verdes do Brasil e a única na área de Tecnologia da Informação (HP, 2011).
2.5.4 Tecnologias
Como já visto nas sessões anteriores, com a visão voltada a computação verde, empresas
em todo o mundo estão sendo estimuladas a desenvolver novos produtos para reduzir o
consumo de energia, e que utilizem energias limpas nos processos de fabricação. Esses novos
produtos tendem a utilizar energia solar ou energia eólica, adotando materiais biodegradáveis e
renováveis. Com estes processos, os produtos tornam-se totalmente recicláveis e contribuem na
redução de CO2, produtos esses que isentaram-se de substancias prejudiciais ao meio ambiente.
Com esta visão e na tentativa de impedir que computadores consumissem plenamente energia
elétrica mesmo quando não utilizados pelos empregados, a empresa norte-americana New
Boundary Technologies lançou em 2008 uma solução que atua sobre as políticas de sleep e

39
hibernação do Windows. Este programa de Tecnologia da Informação Verde oferece ao usuário
a inteligência de gerenciar e garantir que as políticas sejam aplicadas 100% do tempo,
diminuindo o consumo de desktops ociosos (INCORPORATIVA, 2011).
APPLE
A Apple desenvolveu um Macbook como na Figura 12, que foi construído utilizando
materiais altamente recicláveis e sem substâncias nocivas que muitas vezes estão presentes em
computadores, totalmente sem PVC e ainda atende a critérios da Energy Star. Os engenheiros
também desenvolveram software e hardware para operarem juntos, de forma a reduzir o
consumo de energia e emissão de carbono, e até mesmo o tamanho da embalagem do
equipamento foi reduzido.
MacBook Pro desenvolvido pela Aplle.
Fonte: APPLE (2014).
ASUS
A Asustek Computer tomou iniciativa relacionado ao material utilizado na confecção
de notebooks, no ano de 2007 lançou o Asus EcoBook mostrado na Figura 13, que apresenta
bambu em seu revestimento. Segundo a empresa, o cultivo e a colheita do bambu é menos
prejudicial à saúde da Terra do que a das madeiras convencionais, por isso este material foi
escolhido.

40
EcoBook da Asus, revestido de bambu.
Fonte: GLOBO (2008).
3 PROJETO
Este capítulo é destinado a retratar os processos, as especificações e a análise realizada
para satisfazer os objetivos deste projeto. A Seção 3.1 trata dos requisitos funcionais, requisitos
não funcionais e as regras de negócio. A Seção 3.2 exibe os casos de uso bem como as formas
de verificação e execuções do plug-in. A Seção 3.3 traz o planejamento do TTC II.
3.1 ESPECIFICAÇÃO DE REQUISITOS
A primeira fase do desenvolvimento do sistema é a análise de requisitos. Estes podem
ser modelados e validados através de casos de uso, e sua metodologia de desenvolvimento de
sistemas é orientado a objetos, fazendo com que o sistema a ser desenvolvido seja melhor
compreendido. Os requisitos são as condições necessárias para a obtenção de certos objetivos,
ou para o preenchimento de certos objetivos (LEITE, 1994).

41
Para construir, especificar e documentar a análise de requisitos e regras de negócio
descritos neste trabalho fora necessário visualizar o sistema de várias perspectivas diferentes,
como o usuário, analista, desenvolvedor e integrador de sistemas.
3.1.1 Requisitos Funcionais
Os requisitos funcionais definem as funções e comportamentos do sistema, que são
apresentas como os processos fundamentais, necessidades e recursos que o sistema deverá
possuir (CUNHA, 2007). Os requisitos funcionais necessários para o plug-in são:
RF01.Indicar quais hosts ou grupos de hosts que serão monitorados;
RF02.Indicar quais administradores ou grupo de administradores que serão
alertados;
RF03.Indicar em quais horários um determinado host ou grupo de host será
verificado, sendo que esses dados poderão ser alterados posteriormente;
RF04.Armazenar os dados das verificações, que são: nome host, horário de
verificação;
RF05.Realizar envio de alerta aos administradores contendo os dados
capturados;
RF06.Gerar relatórios de quantificação dos hosts e consumo de energia.
3.1.2 Requisitos Não Funcionais
Os requisitos não funcionais são os requisitos que descrevem as características que
deverão existir no sistema (CUNHA, 2007). A seguir serão descritos os requisitos necessários
para o plug-in.
RNF01.Utilizar os hosts ou grupos de hosts, contatos (administradores) e
horários definidos anteriormente do Nagios;
RNF02.O plug-in não irá buscar a potência ativa do objeto;

42
RNF03.O plug-in somente trabalhará em conforme o especificado neste
documento se o sistema Nagios e o servidor de e-mail estiverem em pleno
funcionamento e configurados adequadamente;
RNF04.O cadastramento das potências relativas ao consumo de um objeto será
efetuado no momento de configuração do plug-in, e ou posteriormente no
arquivo que conterão os dados de potência dos hosts do plug-in;
RNF05.O acesso ao plug-in somente deverá ocorrer através de linha de comando
do Linux;
RNF06.As configurações do plug-in devem ficar armazenadas em um arquivo
texto;
RF07.O Plug-in somente poderá fazer verificações se o período de verificações
for maior do que uma hora, este valor vem definido como padrão no arquivo de
configuração do plug-in, podendo ser alterado pelo administrador do Nagios;
3.1.3 Regras de Negócio
As regras de negócio definem como o sistema irá funcionar, ou seja, as formas de
comportamento do sistema (GRANDI, 2008). Diante deste contexto, as seguintes regras de
negócio são necessárias para o desenvolvimento deste plug-in.
RN01.O plug-in deve permitir a criação ou modificação de grupos de
monitoramento;
RN02. O plug-in deve permitir a criação ou modificação de contatos de alertas;
RN03. O plug-in deve permitir a criação ou modificação de períodos de
monitoramento;
RN04. O plug-in deverá fazer as verificações dos objetos da rede após o período
de verificações iniciar. No momento em que entrar neste período e a cada hora
(relativo ao RF04) o sistema deverá utilizar o comando check_ping para fazer
tais verificações;
43
RN05. O encaminhamento de alertas para os contatos será efetuado após o tempo
de agendamento terminar.
3.2 DIAGRAMA DE CASOS DE USO
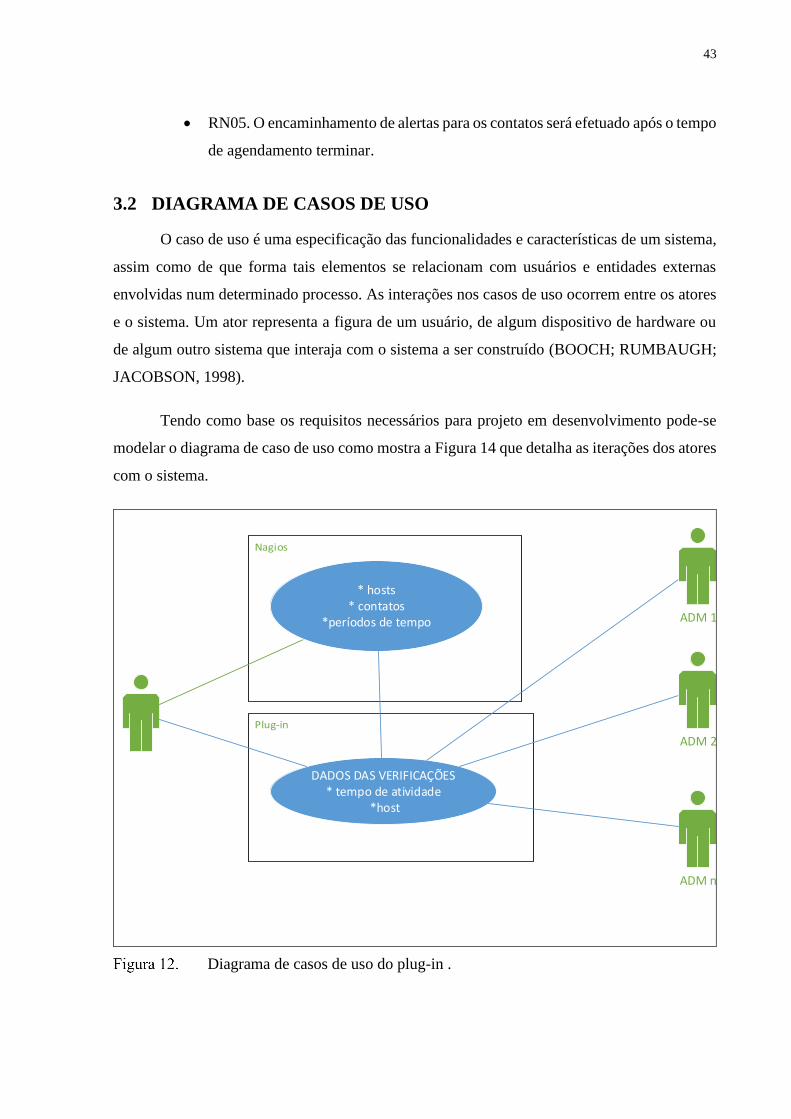
O caso de uso é uma especificação das funcionalidades e características de um sistema,
assim como de que forma tais elementos se relacionam com usuários e entidades externas
envolvidas num determinado processo. As interações nos casos de uso ocorrem entre os atores
e o sistema. Um ator representa a figura de um usuário, de algum dispositivo de hardware ou
de algum outro sistema que interaja com o sistema a ser construído (BOOCH; RUMBAUGH;
JACOBSON, 1998).
Tendo como base os requisitos necessários para projeto em desenvolvimento pode-se
modelar o diagrama de caso de uso como mostra a Figura 14 que detalha as iterações dos atores
com o sistema.
* hosts* contatos
*períodos de tempo
DADOS DAS VERIFICAÇÕES* tempo de atividade
*host
ADM n
ADM 2
ADM 1
Diagrama de casos de uso do plug-in .

44
3.2.1 Agendamento de verificações
As verificações estão relacionadas aos requisitos funcionais RF02, RF02 e RF03, que
indicarão quais equipamentos (hosts), contatos e horários em que o plug-in deverá executar a
varredura na rede em busca de atividade.
3.2.2 Execução do Plug-in
O plug-in é executado periodicamente após entrar no período programado, como pode
ser visualizado na Figura 15. A cada novo período é verificando se cada host está ligado (UP).
Estas verificações serão feitas utilizando o comando check_ping que verificará o estado de
todos os hosts cadastrados no plug-in (RN04), retornando um resultado e este resultado será
armazenado como está identificado no RF04.
Os dois resultados cabíveis ao plug-in são:
Estado Up: estando o host ligado, deverá guardar a informação contendo o nome
do host que está consumindo energia e horário da ocorrência;
Estado Down: nada será feito caso o objeto esteja desligado.

45
Período Inicial Período FinalPeríodo Inicial
+ 1hPeríodo Inicial
+ nh
Armazenamento de dados Verificação de hosts
Diagrama de atividade do plug-in
3.2.3 Alertas de Monitoramento
Os alertas de monitoramento estão relacionados aos RF01, RF05 e RF06, realizando o
envio de alerta aos contatos cadastrados no plug-in. O plug-in deverá gerar um relatório
contendo a quantidade de hosts, quais hosts e os gastos desnecessários que somaram-se neste
período, após será enviado através de e-mail aos contatos cadastrados no grupo de
monitoramento.
3.2.4 Cálculo de Gastos
O cálculo dos gastos que será apresentado no relatório de quantificação (RF06) deverá
ser realizado de acordo com o cálculo de consumo de energia elétrica que obtém como resultado
a quantidade de energia gasta dentro de um período mensal como mostra a Equação 1. Para
encontrar os gastos de todo um grupo de equipamentos é necessário realizar o cálculo de cada
equipamento do agrupamento e somar o total encontrado.

46
𝑘𝑤ℎ =𝑝𝑜𝑡ê𝑛𝑐𝑖𝑎
1000∗ 𝑡𝑒𝑚𝑝𝑜 𝑡𝑜𝑡𝑎𝑙
3.3 PLANEJAMENTO DO TTC II
3.3.1 Metodologia
Na segunda fase do Trabalho Técnico de Conclusão de Curso, será realizado a atividade
de desenvolvimento que deverá ser a primeira atividade que é mostrada na Tabela 2, e após esta
atividade será efetuado testes um ambiente real como é mostrada na Tabela 3 e a terceira
atividade será a construção do pacote final contendo o código do plug-in desenvolvido e a
documentação necessária para sua execução, tais como está na Tabela 4.
Atividade 1
Descrição Desenvolvimento do Plug-in
Recursos necessários Descrição do recurso Qtd
Computador ou Notebook
Imagem SO CentOs
Servidor E-mail
Software Nagios
01
01
01
01
Pré-requisitos TTC 1 completado.
Metodologia Desenvolvimento do código do Plug-in baseado na
documentação efetuada nas atividades do TTC 1, e se necessária
reestruturação de funcionalidades.
Indicador físico Código fonte do Plug-in e documentação.
Duração 60 dias
Tabela 2. Atividade de Desenvolvimento do Plug-in.
Atividade 2
Descrição Teste do Plug-in em ambiente real.
Recursos necessários Descrição do recurso Qtd

47
Servidor ou computador
SO CentOs
Servidor E-mail
Software Nagios
Código fonte do Plug-in
01
01
01
01
Pré-requisitos Atividade 1 completada.
Metodologia Testes de verificação de objetos ativos dentro da rede.
Indicador físico E-mails e relatórios gerados pelo plug-in.
Duração 45 dias
Tabela 3. Atividade de teste do Plug-in.
Atividade 3
Descrição Construção do protótipo do Plug-in
Recursos necessários Descrição do recurso Qtd
Computador ou Notebook
Imagem SO CentOs
Servidor E-mail
Software Nagios
Código fonte do Plug-in
01
01
01
01
Pré-requisitos Atividades 1 e 2 completadas.
Metodologia Documentação e código final do Plug-in.
Indicador físico Documentação e código do plug-in.
Duração 10 dias
Tabela 4. Atividade de construção do protótipo do Plug-in.
3.3.2 Cronograma
O cronograma para o desenvolvimento do Plug-in Nagios para Gerenciamento de
Desperdício de Energia Elétrica está dividido em 3 atividades, como mostra a Tabela 6. Devido
ao prazo ser maior do que no TTC I, será possível verificar e analisar de forma mais cautelosa
cada processo do desenvolvimento e reavaliar as análises realizadas no projeto do TTC 1,
fazendo assim com que o trabalho final tenha uma melhor qualidade e esteja em conformidade
com o projeto inicial.
Nome da Atividade Duração Início Término
Desenvolvimento do Plug-in 60 dias Seg 09/02/15 Sex 10/04/15
Teste do Plug-in em ambiente real 45 dias Seg 11/04/15 Sex 26/05/15
Construção do protótipo do Plug-in 10 dias Seg 27/05/15 Sex 06/06/15

48
Tabela 5. Cronograma de atividades do TTC II
3.3.3 Análise de Riscos
A análise de risco de um projeto inclui processos de planejamento, identificação, ação
de riscos, análise de riscos e controle de riscos. Para identificar estes riscos é necessário
determinar quais fatores podem afetar o projeto, e estes riscos ainda podem ser uma forma de
como conduzir as atividades e os riscos encontrados (PMBOK, 2008).
Riscos Controlados
Alguns riscos que poderiam ocorrer na fase de execução do projeto foram monitorados
e controlados durante a fase de documentação do projeto, dentre eles pode-se citar:
O tempo necessário para realizar a execução do projeto era curto, e para evitar
que o projeto pudesse ficar prejudicado foi realizado um acréscimo em pelo
menos um mês no tempo total do projeto.
Caso seja adicionado alguma função não presente nos requisitos deste
documento, ocasionalmente o comando check_ping poderá não trazer
informações corretas, ocasionando com que seja necessário reavaliar a analise
desenvolvida e criar um comando semelhante ao check_ping que contemple os
novos requisitos.
Riscos não controlados
Os riscos que foram previstos e que não poder-se-ão controlar são:
Caso não seja possível fazer com que o sistema Nagios encaminhe os alertas
apenas quando as verificações terminarem, será necessário fazer com que o plug-
in execute o envio de e-mails para os administradores de forma independente.
4 CONSIDERAÇÕES FINAIS
Após estudos da literatura pode-se concluir que a Computação Verde e sustentabilidade
tem um grande propósito dentro das empresas e na sociedade. Diante deste mesmo contexto,

49
este projeto mostrou que o Plug-in Nagios para Gerenciamento de Desperdício de Energia
Elétrica será uma importante ferramenta para informar as pessoas envolvidas na área de
Tecnologia da Informação. Informações estas que descrevem a quantidade de equipamentos
ligados dentro da rede de computadores de forma desnecessária, ou seja, computadores que
deveriam estar desligados e estão consumindo energia elétrica.
Este trabalho ainda destacou a importância do gerenciamento e controle nas redes de
computadores e como o sistema Nagios é consolidado como uma ferramenta dentro desta
governança de Tecnologia da Informação.
Durante o processo de documentação e desenvolvimento deste trabalho, analisou-se
adicionar algumas propostas que poderiam ser pertinentes com o propósito principal deste
trabalho, tais como: realizar o desligamento automático dos equipamentos que estavam ligados;
verificar a potência ativa de cada host; integrar o plug-in ao repositório do Nagios; etc. Após
muita pesquisa e estudo chegou-se à conclusão de que estes objetivos muitas vezes não seriam
alcançados dentro do escopo atual do projeto e em outras vezes poderiam até mesmo interferir
no objetivo do Plug-in. O plug-in é destinado a avisar e conscientizar os administradores da
quantidade de equipamentos que consumiram energia elétrica de forma desnecessária, visando
desta forma auxiliar em um uso eficiente e contemplando o conceito da Computação Verde.
Algumas destas propostas ainda poderão ser reavaliadas e incluídas no TTC II, ou serão objetos
de sugestão para futuros trabalhos.

50
5 REFERÊNCIAS
APPLE. Macbook Pro, 2014. Disponível em: < https://www.apple.com/br/macbook-pro>.
Acesso em: 23 set. 2014.
BARTH, Wolfgang. Nagios System and Network Monitoring. São Francisco: No Starch,
2006.
BOOCH, G., RUMBAUGH, J., JACOBSON, I. The unified modeling language user guide.
2 ed. Wesley: Addison, 1998.
COSTA, F.; Ambiente de redes monitorados com nagios e cacti. Rio de Janeiro: Ciência
Moderna, 2008.
COUTO, Verônica. Itaú recebe prêmio internacional de TI verde. Computer World, 2010.
Disponível em:<http://computerworld.com.br/tecnologia/2010/05/21/itau-recebe-premio-
internacional-de-ti-verde/ >. Acesso em: 03 set. 2014.
CRUZ, Bruna. Itaú, HP e Microsoft recebem prêmio de TI Verde. Revista Inter IT, 2010.
Disponível em:<http://interit.com.br/interna.php?p=sn&id=1747>. Acesso em: 01 set. 2014
CUNHA, H. S.; Uso de estratégias orientadas a metas para modelagem de requisitos de
segurança, Rio de Janeiro: Pontifícia Universidade Católica, 2007.
GARCIA, E. M., MILAGRE, J. A. Tecnologia da informação e os princípios constitucionais de
proteção ao meio ambiente. São Paulo: Revista de Direito, 2009.
GLOBO. Laptop revestido de bambu é destaque da cebit, 2008. Disponível em:
http://g1.globo.com/Noticias/Tecnologia/0,,MUL337805-6174,00.html>. Acesso em 23 set.
2014.
GOOGLE. Data centers que economizam energia, 2011. Disponível em:
<http://www.google.com/intl/pt-BR//green/bigpicture>. Acesso em: 04 set. 2014.
GRANDI, M. A.; Uma abordagem de identificação e modelagem de regras de negócio e
seus relacionamentos transversais. Marília: Eurípides Soares da Rocha, 2008.
HP, Resultados de sustentabilidade ambiental, 2011. Disponível em:
<http://www.hp.com/hpinfo/globalcitizenship/environment/gcr_Brazil_2011.pdf>. Acesso em
20 set. 2014.
INCORPORATIVA. Aprenda a economizar energia no computador, 2011. Disponível em:
<http://www.incorporativa.com.br/mostranews.php?ctg=50&id=6387>. Acesso em: 03 set.
2014.

51
IRQA, IS0 14001, 2000. Disponível em: <
http://www.lrqa.com.br/certificacao/meio_ambiente/iso14001.asp>. Acesso em: 22 set. 2014.
ITAUTEC. Guia para gestor de TI sustentável. Itautec e Sustentabilidade, 2010. Disponível
em: <http://www.itautec.com.br/media/652021/af_guia_gestor_sustentabilidade.pdf>. Acesso
em 05 set. 2014.
KOCJAN, Wojciech; Learning Nagios 3.0. Mumbai: Pact Publishing, 2008. Disponível em:
<http://www.szemtsov.net/books/Learning_Nagios_3.pdf>. Acesso em: 03 set. 2014.
KUROSE, James F. Redes de computadores e a internet. São Paulo: Pearson Addison
Wesley, 2005.
LIMA, S.F. Introdução ao conceito de sustentabilidade, aplicabilidade e limites. Unibrasil,
2006. Disponível em:
<http://apps.unibrasil.com.br/revista/index.php/negociosonline/article/viewFile/37/30>.
Acesso em: 10 set. 2014.
LEITE, J.C.S.P; Engenharia de Requisitos: Notas de Aula; Rio de Janeiro: Pontifícia
Universidade Católica, 1994;
LOBO, E., at.al.; Administração de Sistemas Linux - Serviços para internet. 2. ed.
RNP/ESR: Rio de Janeiro, 2013. Disponível em: <
https://pt.scribd.com/doc/105109227/Administracao-de-Sistemas-Linux-Servicos-para-
Internet>. Acesso em: 10 set. 2014.
MAKOWER, Joel. A economia verde: descubra as oportunidades e os desafios de uma nova
era de negócios. São Paulo: Gente, 2009.
MAURO, Douglas; SCHMIDT, Kevin. Essential SNMP. 2. ed. Sebastopol: O'Reilly Media,
2005.
MORIMOTO, C. E., Entendendo e dominando o Linux, 5ed. Ebook, 2002. Disponível em:
<http://www.guiadohardware.net>. Acesso em 14 set. 2014.
MOTA FILHO, João Eriberto. Descobrindo o Linux: entenda o sistema operacional
GNU/Linux. Segunda Edição. São Paulo: Novatec, 2007.
MOURA, Ana Lúcia. Rumo à computação verde, 2010. Disponível em:
<http://www.memoriadafisica.com.br/rhverde/index.php/2010/07/rumo-a-computacao-
verde/4880>. Acesso em: 01 set. 2014.
NAGIOS, Nagios Core version 3.x documentation, 2014. Disponível em: <
http://www.nagios.org>. Acesso em: 22 out. 2014.
Nagios, V 3.0, 2009. Disponível em: <http://nagios.sourceforge.net/docs/nagios-3.pdf>,
Acesso em 10 ago. 2014.

52
PMBOK, Guia PMBOK, um guia de conhecimento em gerenciamento de projetos. 4 ed.
Boulevar: Project Management Institute, 2008.
RESNICK, P. Internet message format, 2001. Disponível em:
<https://www.ietf.org/rfc/rfc2822.txt>. Acesso em: 10 set. 2014.
POSTEL, J., Simple Mail Transfer Protocol, RFC 821, University of Southern California,
1982. Disponível em: <https://www.ietf.org/rfc/rfc0821.txt>. Acesso em: 10 setembro 2014.
RICHTER, R.M.; TI Verde: Sustentabilidade por meio da Computação em Nuvem. São
Paulo: Centro Estadual de Ensino Tecnológico Paula Souza, 2012.
SAUVE, J., LOPES, R., NICOLLETTI, P.; Melhores práticas para a gerência de redes de
computadores. 1. ed. Rio de Janeiro: Campus, 2003.
STALLINGS, W. SNMP, SNMPv2, SNMPv3 and RMON1 and 2. 3 ed. Wesley: Addison,
1998.
TEIXEIRA, Sergio. A era da computação verde, 2007. Disponível em:
<http://planetasustentavel. abril.com.br/noticia/desenvolvimento/conteudo_238522.shtml>.
Acesso em: 11 set. 2014.
VERMA, Dinesh C. Principles of computer systems and network management. Nova
Iorque: Springer, 2009.















![Una esperanza verde [Español] (1992)](https://img.dokumen.tips/doc/110x75/631ec2994c5c8fb3a00e594b/una-esperanza-verde-espanol-1992.jpg)













