Embed Size (px)
Citation preview

Proceedings of NAACL-HLT Fourth Workshop on Computational Linguistics for Literature, pages 79–88,Denver, Colorado, June 4, 2015. c©2015 Association for Computational Linguistics
Towards a better understanding of Burrows’s Deltain literary authorship attribution
Stefan Evert and Thomas ProislFAU Erlangen-Nurnberg
Bismarckstr. 691054 Erlangen, [email protected]@fau.de
Fotis Jannidis, Steffen Pielstrom,Christof Schoch and Thorsten Vitt
Universitat WurzburgAm Hubland
97074 Wurzburg, [email protected]
Abstract
Burrows’s Delta is the most established mea-sure for stylometric difference in literary au-thorship attribution. Several improvements onthe original Delta have been proposed. How-ever, a recent empirical study showed thatnone of the proposed variants constitute a ma-jor improvement in terms of authorship attri-bution performance. With this paper, we tryto improve our understanding of how and whythese text distance measures work for author-ship attribution. We evaluate the effects ofstandardization and vector normalization onthe statistical distributions of features and theresulting text clustering quality. Furthermore,we explore supervised selection of discrimi-nant words as a procedure for further improv-ing authorship attribution.
1 Introduction
Authorship Attribution is a research area in quantita-tive text analysis concerned with attributing texts ofunknown or disputed authorship to their actual au-thor based on quantitatively measured linguistic evi-dence (Juola, 2006; Stamatatos, 2009; Koppel et al.,2008). Authorship attribution has applications e.g.in literary studies, history, and forensics, and usesmethods from Natural Language Processing, TextMining, and Corpus Stylistics. The fundamental as-sumption in authorship attribution is that individualshave idiosyncratic habits of language use, leadingto a stylistic similarity of texts written by the sameperson. Many of these stylistic habits can be mea-sured by assessing the relative frequencies of func-tion words or parts of speech, vocabulary richness,
and other linguistic features. This, in turn, allowsusing the relative similarity of the texts to each otherin clustering or classification tasks and to attribute atext of unknown authorship to the most similar of a(usually closed) set of candidate authors.
One of the most crucial elements in quantitativeauthorship attribution methods is the distance mea-sure used to quantify the degree of similarity be-tween texts. A major advance in this area has beenDelta, as proposed by Burrows (2002), which hasproven to be a very robust measure in different gen-res and languages (Hoover, 2004b; Eder and Ry-bicki, 2013). Since 2002, a number of variantsof Burrows’s Delta have been proposed (Hoover,2004a; Argamon, 2008; Smith and Aldridge, 2011;Eder et al., 2013). In a recent publication, empir-ical tests of authorship attribution performance forDelta as well as 13 precursors and/or variants ofit have been reported (Jannidis et al., 2015). Thatstudy, using three test corpora in English, Germanand French, has shown that Burrows’s Delta remainsa strong contender, but is outperformed quite clearlyby Cosine Delta as proposed by Smith and Aldridge(2011). The study has also shown that some of thetheoretical arguments by Argamon (2008) do notfind empirical confirmation. This means that, in-triguingly, there is still no clear theoretical modelwhich is able to explain why these various distancemeasures yield varying performance; we don’t havea clear understanding why Burrows’s Delta and Co-sine Delta are so robust and reliable.
In the absence of compelling theoretical ar-guments, systematic empirical testing becomesparamount, and this paper proposes to continue such
79

investigations. Previous work has focused on featureselection either in the sense of deciding what typeof feature (e.g. character, word or part-of-speech n-grams) has the best discriminatory power for author-ship attribution (Forsyth and Holmes, 1996; Rogatiand Yang, 2002), or in the sense of deciding whichpart of the list of most frequent words yields thebest results (Rybicki and Eder, 2011). Other pub-lications explored strategies of deliberately pickinga very small numbers of particularly disciminativefeatures (Cartright and Bendersky, 2008; Marsdenet al., 2013). Our strategy builds on such approachesbut differs from them in that we focus on word un-igrams only and examine how the treatment of theinput feature vector (i.e., the list of word tokensused and their frequencies) interacts with the per-formance of distance measures. Each distance mea-sure implements a specific combination of standard-ization and/or normalization of the feature vector.In addition, the feature vector can be preprocessedin several ways before submitting it to the distancemeasure.
In the following, we report on a series of exper-iments which assess the effects of standardizationand normalization, as well as of feature vector ma-nipulation, on the performance of distance measuresfor authorship attribution.
Although we use attribution success as our per-formance indicator, our ultimate goal is not so muchto optimize the results, but rather to gain a deeperunderstanding of the mechanisms behind distancemeasures. We hope that a deeper theoretical under-standing will help choose the right parameters in au-thorship attribution cases.
2 Notation
All measures in the Delta family share the same ba-sic procedure for measuring dissimilarities betweenthe text documents D in a collection D of size nD.1
• Each text D ∈ D is represented by a profile ofthe relative frequencies fi(D) of the nw mostfrequent words (mfw) w1, w2, . . . wnw .• The complete profile of D is given by the fea-
ture vector f(D) = (f1(D), . . . , fnw(D)).• Features are re-scaled, usually with a linear
1The notation introduced here follows Argamon (2008) andJannidis et al. (2015).
transformation, in order to adapt the weightgiven to each of the mfw. The most com-mon choice is to standardize features using az-transformation
zi(D) =fi(D)− µi
σi
where µi is the mean of the distribution of fi
across the collectionD and σi its standard devi-ation (s.d.). After the transformation, each fea-ture zi has mean µ = 0 and s.d. σ = 1.• Dissimilarities between the scaled feature vec-
tors are computed according to some distancemetric. Optionally, feature vectors may firstbe normalized to have length 1 under the samemetric.
Different choices of a distance metric lead to vari-ous well-known variants of Delta. The original Bur-rows’s Delta ∆B (Burrows, 2002) corresponds to theManhattan distance between feature vectors:
∆B(D,D′) = ‖z(D)− z(D′)‖1
=nw∑i=1
|zi(D)− zi(D′)|
Quadratic Delta ∆Q (Argamon, 2008) corre-sponds to the squared Euclidean distance:
∆Q(D,D′) = ‖z(D)− z(D′)‖22=
nw∑i=1
(zi(D)− zi(D′))2
and is fully equivalent to Euclidean distance√
∆Q.Cosine Delta ∆∠ (Smith and Aldridge, 2011)
measures the angle α between two profile vectors
∆∠(D,D′) = α
which can be computed from the cosine similarity ofx = z(D) and y = z(D′):
cosα =xTy
‖x‖2 · ‖y‖2where xTy =
∑nwi=1 xiyi is the dot product and
‖x‖2 =√∑nw
i=1 x2i denotes the length of the vector
x according to the Euclidean norm. All three vari-ants of Delta agree in using standardized frequenciesof the most frequent words as their underlying fea-tures.
80

3 Understanding the parameters of Delta
Different versions of Delta can be obtained by set-ting the parameters of the general procedure outlinedin Sec. 2, in particular:• nw, i.e. the number of words used as features in
the frequency profiles;• how these words are selected (e.g. taking the
most frequent words, choosing words based onthe number df of texts they occur in, etc.);• how frequency profiles f(D) are scaled to fea-
ture vectors z(D)• whether feature vectors are normalized to unit
length ‖z(D)‖ = 1 (and according to whichnorm); and• which distance metric is used to measure dis-
similarities between feature vectors.We focus here on three key variants of the Deltameasure:
(i) the original Burrows’s Delta ∆B because it isconsistently one of the best-performing Delta vari-ants despite its simplicity and lack of a convincingmathematical motivation (Argamon, 2008);
(ii) Quadratic Delta ∆Q because it can be derivedfrom a probabilistic interpretation of the standard-ized frequency profiles (Argamon, 2008); and
(iii) Cosine Delta ∆∠ because it achieved thebest results in the evaluation study of Jannidis et al.(2015).
All three variants use some number nw of mfwas features and scale them by standardization (z-transformation). At first sight, they appear to differonly with respect to the distance metric used: Man-hattan distance (∆B), Euclidean distance (∆Q), orangular distance (∆∠).
There is a close connection between angular dis-tance and Euclidean distance because the (squared)Euclidean norm can be expressed as a dot product‖x‖22 = xTx. Therefore,
‖x− y‖22 = (x− y)T (x− y)
= xTx + yTy − 2xTy
= ‖x‖22 + ‖y‖22 − 2‖x‖2‖y‖2 cosα
If the profile vectors are normalized wrt. the Eu-clidean norm, i.e. ‖x‖2 = ‖y‖2 = 1, Euclideandistance is a monotonic function of the angle α:
‖x− y‖22 = 2− 2 cosα
10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
German (z−scores)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaQuadratic DeltaCosine Delta
(a)
10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
English (z−scores)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaQuadratic DeltaCosine Delta
(b)
10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
French (z−scores)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaQuadratic DeltaCosine Delta
(c)
Figure 1: Clustering quality for German, English andFrench texts in our replication of Jannidis et al. (2015)
As a result, ∆Q and ∆∠ are equivalent for nor-malized feature vectors. The difference betweenQuadratic and Cosine Delta is a matter of the nor-malization parameter at heart; they are not based ongenuinely different distance metrics.
3.1 The number of features
As a first step, we replicate the findings of Jannidiset al. (2015). Their data set is composed of threecollections of novels written in English, French andGerman. Each collection contains 3 novels eachfrom 25 different authors, i.e. a total of 75 texts.The collection of British novels contains texts pub-lished between 1838 and 1921 coming from ProjectGutenberg.2 The collection of French novels con-
2www.gutenberg.org
81

tains texts published between 1827 and 1934 origi-nating mainly from Ebooks libres et gratuits.3 Thecollection of German novels consists of texts fromthe 19th and the first half of the 20th Century whichcome from the TextGrid collection.4
Our experiments extend the previous study inthree respects:
1. We use a different clustering algorithm,partitioning around medoids (Kaufman andRousseeuw, 1990), which has proven to be veryrobust especially on linguistic data (Lapesa andEvert, 2014). The number of clusters is set to25, corresponding to the number of differentauthors in each of the collections.
2. We evaluate clustering quality using a well-established criterion, the chance-adjusted Randindex (Hubert and Arabie, 1985), rather thancluster purity. This improves comparabilitywith other evaluation studies.
3. Jannidis et al. (2015) consider only three arbi-trarily chosen values nw = 100, 1000, 5 000.Since clustering quality does not always im-prove if a larger number of mfw is used, thisapproach draws an incomplete picture and doesnot show whether there is a clearly defined op-timal value nw or whether the Delta measuresare robust wrt. the choice of nw. Our evaluationsystematically varies nw from 10 to 10 000.
Fig. 1(a) shows evaluation results for the Germantexts; Fig. 1(b) and 1(c) show the corresponding re-sults on English and French data. Our experimentsconfirm the observations of Jannidis et al. (2015):• For a small number of mfw as features (roughlynw ≤ 500), ∆B and ∆Q achieve the same clus-tering quality. However, ∆Q proves less robustif the number of features is further increased(nw > 500), despite the convincing probabilis-tic motivation given by Argamon (2008).• ∆∠ consistently outperforms the other Delta
measures, regardless of the choice of nw. It isrobust for values up to nw = 10 000, degradingmuch more slowly than ∆B and ∆Q.• The clustering quality achieved by ∆∠ is very
impressive. With an adjusted Rand index above90% for a wide range of nw, most of the texts in
3www.ebooksgratuits.com4www.textgrid.de/Digitale-Bibliothek
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●● ●●
●
●● ●●●●●●●●●●●● ●● ●
●●●●● ●●●
●
●●●●● ●●●● ●●● ●●●●●●●
the
and to of a I in
was
that he
dow
n
mig
ht
thin
k
such
mad
e
gold
Rob
ert
sky
coul
dn
hone
st
0.00
0.02
0.04
0.06
English
rela
tive
freq
uenc
y
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
101.
102.
103.
104.
105.
901.
902.
903.
904.
905.
Figure 2: Distribution of relative frequencies for selectedEnglish words (numbers at the top show mfw rank)
the collections are correctly grouped by author.It is obvious from these evaluation graphs that an ap-propriate choice of nw plays a crucial role for ∆Q,and to a somewhat lesser extent also for ∆B . In allthree languages, clustering quality is substantiallydiminished for nw > 5 000. Since there are alreadynoticeable differences between the three collections,it has to be assumed that the optimal nw dependson many factors – language, text type, length of thetexts, quality and preprocessing of the text files (e.g.spelling normalization), etc. – and cannot be knowna priori. It would be desirable either to re-scale therelative frequencies in a way that gives less weightto “noisy” features, or to re-rank the most frequentwords by a different criterion for which a clear cut-off point can be determined.
Alternatively, more robust variants of Delta suchas ∆∠ might be used, although there is still a gradualdecline, especially for the French data in Fig. 1(c).Since ∆∠ differs from the least robust measure ∆Q
only in its implicit normalization of the feature vec-tors, vector normalization appears to be the key torobust authorship attribution.
3.2 Feature scaling
Burrows applied a z-transformation to the frequencyprofiles with the explicit intention to “treat all ofthese words as markers of potentially equal power”(Burrows, 2002, p. 271). Fig. 2 and 3 illustrate thisintuition for some of the most frequent words in theEnglish collection.
Without standardization, words with mfw ranksabove 100 make a negligible contribution to the fre-quency profiles (Fig. 2). The evaluation graph inFig. 4 confirms that Delta measures are hardly af-fected at all by words above mfw rank 100 if no z-
82

●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●●
●
●● ●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●●
●
●●
●
●●
●
●
●●●
●
●●●
●
●
the
and to of a I in
was
that he
dow
n
mig
ht
thin
k
such
mad
e
gold
Rob
ert
sky
coul
dn
hone
st
−2
02
46
8
English
stan
dard
ized
rel
. fre
q.
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
101.
102.
103.
104.
105.
901.
902.
903.
904.
905.
Figure 3: Distribution of standardized z-scores
10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
German (relative frequencies)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaQuadratic DeltaCosine Delta
Figure 4: Clustering quality of German texts based onunscaled relative frequencies (without standardization)
transformation is applied. While results are robustwith respect to nw, the few mfw that make a no-ticeable contribution are not sufficient to achieve areasonable clustering quality. After standardization,the z-scores show a similar distribution for all fea-tures (Fig. 3).
Argamon (2008) argued that standardization isonly meaningful if the relative frequencies roughlyfollow a Gaussian distribution across the texts ina collection D, which is indeed the case for high-frequency words (Jannidis et al., 2015). Withsome further assumptions, Argamon showed that∆Q(D,D′) can be used as a test statistic for author-ship attribution, with an asymptotic χ2
nwdistribution
under the null hypothesis that both texts are from thesame author. It can also be shown that standardiza-tion gives all features equal weight in ∆Q in a strictsense, i.e. each feature makes exactly the same aver-age contribution to the pairwise squared Euclideandistances (and analogously for ∆∠).
This strict interpretation of equal weight does nothold for ∆B , so Burrows’s original intention hasnot been fully realized. Fig. 5 displays the actualcontribution made to each feature to ∆B(D,D′),i.e. to the pairwise Manhattan distances between
●●●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●●
●●
●●●
●
●
●●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●●●●
●
●●●
●
●
●●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●●
●●●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●●
●
●●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●●●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●
●
●●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●●
●
●
●
●●
●
●
●●
●●●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●●
●
●●●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●●
●
●
●●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●
●●
●●●
●
●
●
●
●
●
●●
●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●●●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●●
●
●
●
●
●●●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●●
●
●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●●
●●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●
●
●●
●
●●
●
●●
●●
●
●
●
●
●
●●●●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●●
●
●
●●
●●
●
●
●
●
●
●●
●
●●
●●●●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●●●●
●
●
●
●
●
●●●
●
●●
●●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●●
●
●
●●
●
●●
●
●
●
●
●●●
●●●
●
●
●
●
●
●
●
●
●
●
●●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●
●●
●
●
●●
●
●
●
●●●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●●●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●●
●
●
●●
●●
●
●
●
●
●●
●
●●
●
●●
●●●●
●
●●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●●●
●
●
●
●
0 10000 20000 30000 40000 50000
0.0
0.1
0.2
0.3
0.4
0.5
0.6
German
most frequent words
mea
n co
ntrib
utio
n to
Man
hatta
n di
stan
ces df = 75
df = 50df = 25df = 1
Figure 5: Average contribution of features to pairwise∆B distances; colour indicates document frequency (df )
z-transformed feature vectors z(D) and z(D′). Itshows that less frequent words have a moderatelysmaller weight than the mfw up to rank 5 000.Words that occur just in a small number of texts(their document frequency df , indicated by pointcolour in Fig. 5) carry a low weight regardless oftheir overall frequency.
Our conclusion is that ∆B appears to be more ro-bust than ∆Q precisely because it gives less weightto the standardized frequencies of “noisy” wordsabove mfw rank 5 000 in contrast to the claim madeby Burrows. Moreover, it strongly demotes wordsthat concentrate in a small number of texts, whichare likely idiosyncratic expressions from a particularnovel (e.g. character names) or a narrow sub-genre.It is plausible that such words are of little use for thepurpose of authorship attribution.
Surprisingly, ranking the mfw by their contribu-tion to ∆B (so that e.g. words with df < 10 arenever included as features) is less effective thanranking by overall frequency (not shown for spacereasons). We also experimented with a number ofalternative scaling methods – including the scalingsuggested by Argamon (2008) for a probabilistic in-terpretation of ∆B – obtaining consistently worseclustering quality than with standardization.
3.3 Vector normalizationAs shown at the beginning of Sec. 3, the main differ-ence between ∆∠ (the best and most robust measurein our evaluation) and ∆Q (the worst and least robustmeasure) lies in the normalization of feature vectors.This observation suggests that other Delta measuressuch as ∆B might also benefit from vector normal-ization. We test this hypothesis with the evaluation
83

10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
German (z−scores)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaBurrows Delta / L1Cosine DeltaBurrows Delta / L2Quadratic Delta / L1
10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
English (z−scores)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaBurrows Delta / L1Cosine DeltaBurrows Delta / L2Quadratic Delta / L1
10 20 50 100
200
500
1000
2000
5000
1000
0
020
4060
8010
0
French (z−scores)
# features
adju
sted
Ran
d in
dex
(%)
Burrows DeltaBurrows Delta / L1Cosine DeltaBurrows Delta / L2Quadratic Delta / L1
Figure 6: The effect of vector normalization on clusteringquality (L2 = Euclidean norm, L1 = Manhattan norm)
shown in Fig. 6.The quality curves for ∆Q with Euclidean nor-
malization are in fact identical to the curves for Co-sine Delta (∆∠) and are not shown separately here.∆B is also improved substantially by vector normal-ization (contrast the black curve with the red andblue ones), resulting in clustering quality equal to∆∠, although ∆B might be slightly less robust fornw > 5 000. Interestingly, it seems to make littledifference whether an appropriate normalization isused (L1 for ∆B and L2 for ∆Q) or not (vice versa).
Our tentative explanation for these findings is asfollows. We conjecture that authorial style is primar-ily reflected by the pattern of positive and negativedeviations zi of word frequencies from the “norm”,i.e. the average frequency across the text collection.This characteristic pattern is not expressed to thesame degree in all texts by a given author, leadingto differences in the average magnitude of the values
zi and hence the length ‖z(D)‖ of the feature vec-tors. If this is indeed the case, vector normalizationmakes the stylistic pattern of each author stand outmore clearly because it equalizes the average mag-nitude of the zi.
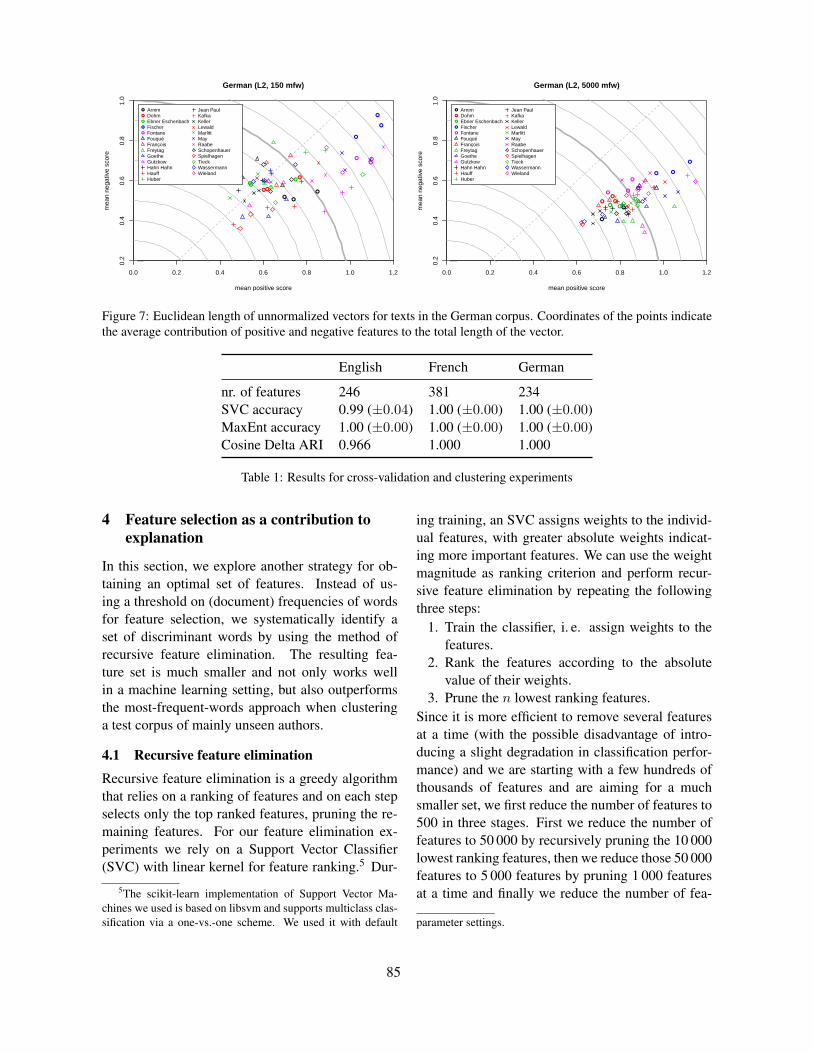
Fig. 7 visualizes the Euclidean length of featurevectors for texts written by different German au-thors. In the situation depicted by the left panel(nw = 150) normalization has no substantial effect,whereas in the situation depicted by the right panel(nw = 5 000) unnormalized ∆Q performs muchworse than normalized ∆∠ (cf. Fig. 1(a)).
Each point in the plots represents the feature vec-tor z(D) of one text. The distance from the originindicates its Euclidean (L2) norm ‖z(D)‖2, relativeto the average vector length
√nw. All points on a
circle thus correspond to feature vectors of the sameEuclidean length. The angular position of a textshows the relative contribution of positive features(zi > 0, i.e. words used with above-average fre-quency) and negative features (zi < 0, words usedwith below-average frequency) as a rough indicatorof its stylistic pattern. Texts below the dashed diag-onal thus have more (or larger) positive deviationszi, texts above the diagonal have more (or larger)negative deviations. In both panels, some authorsare characterized quite well by vector length and thebalance of positive vs. negative deviations. For otherauthors, however, one of the texts shows a muchlarger deviation from the norm than the other two,i.e. larger Euclidean length (Freytag and Spielhagenin the right panel). Similar patterns can be observedfor the Manhattan (L1) norm as well as among theEnglish and French novels. In such cases, normal-ization reduces the distances between texts from thesame author and thus improves clustering quality.
Fig. 7 also reveals a plausible explanation for thepoor evaluation results of ∆Q as nw is increased.Because of the skewed distribution of zi for lower-frequency words (see Fig. 3), the contribution ofpositive values to the Euclidean norm outweighs thenegative values (but this is not the case for the Man-hattan norm and ∆B). Therefore, all points in theright panel are below the diagonal and their stylis-tic profiles become increasingly similar. Differencesin vector length between texts from the same authorhave a stronger influence on ∆Q distances in this sit-uation, resulting in many clustering errors.
84
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.2
0.4
0.6
0.8
1.0
German (L2, 150 mfw)
mean positive score
mea
n ne
gativ
e sc
ore
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
ArnimDohmEbner EschenbachFischerFontaneFouquéFrançoisFreytagGoetheGutzkowHahn HahnHauffHuber
Jean PaulKafkaKellerLewaldMarlittMayRaabeSchopenhauerSpielhagenTieckWassermannWieland
0.0 0.2 0.4 0.6 0.8 1.0 1.2
0.2
0.4
0.6
0.8
1.0
German (L2, 5000 mfw)
mean positive score
mea
n ne
gativ
e sc
ore
●
●
●
●
●
●
●
●●
●
●
●
●
●●
●
●
●
●
●
ArnimDohmEbner EschenbachFischerFontaneFouquéFrançoisFreytagGoetheGutzkowHahn HahnHauffHuber
Jean PaulKafkaKellerLewaldMarlittMayRaabeSchopenhauerSpielhagenTieckWassermannWieland
Figure 7: Euclidean length of unnormalized vectors for texts in the German corpus. Coordinates of the points indicatethe average contribution of positive and negative features to the total length of the vector.
English French German
nr. of features 246 381 234SVC accuracy 0.99 (±0.04) 1.00 (±0.00) 1.00 (±0.00)MaxEnt accuracy 1.00 (±0.00) 1.00 (±0.00) 1.00 (±0.00)Cosine Delta ARI 0.966 1.000 1.000
Table 1: Results for cross-validation and clustering experiments
4 Feature selection as a contribution toexplanation
In this section, we explore another strategy for ob-taining an optimal set of features. Instead of us-ing a threshold on (document) frequencies of wordsfor feature selection, we systematically identify aset of discriminant words by using the method ofrecursive feature elimination. The resulting fea-ture set is much smaller and not only works wellin a machine learning setting, but also outperformsthe most-frequent-words approach when clusteringa test corpus of mainly unseen authors.
4.1 Recursive feature elimination
Recursive feature elimination is a greedy algorithmthat relies on a ranking of features and on each stepselects only the top ranked features, pruning the re-maining features. For our feature elimination ex-periments we rely on a Support Vector Classifier(SVC) with linear kernel for feature ranking.5 Dur-
5The scikit-learn implementation of Support Vector Ma-chines we used is based on libsvm and supports multiclass clas-sification via a one-vs.-one scheme. We used it with default
ing training, an SVC assigns weights to the individ-ual features, with greater absolute weights indicat-ing more important features. We can use the weightmagnitude as ranking criterion and perform recur-sive feature elimination by repeating the followingthree steps:
1. Train the classifier, i. e. assign weights to thefeatures.
2. Rank the features according to the absolutevalue of their weights.
3. Prune the n lowest ranking features.Since it is more efficient to remove several featuresat a time (with the possible disadvantage of intro-ducing a slight degradation in classification perfor-mance) and we are starting with a few hundreds ofthousands of features and are aiming for a muchsmaller set, we first reduce the number of features to500 in three stages. First we reduce the number offeatures to 50 000 by recursively pruning the 10 000lowest ranking features, then we reduce those 50 000features to 5 000 features by pruning 1 000 featuresat a time and finally we reduce the number of fea-
parameter settings.
85

(a) English (b) French (c) German
Figure 8: Distributions of document frequencies for selected features
unscaled full fs rescaled full fs selected fs
SVC accuracy 0.91 (±0.03) 0.57 (±0.13) 0.84 (±0.14)MaxEnt accuracy 0.95 (±0.03) 0.95 (±0.03) 0.90 (±0.08)Cosine Delta ARI 0.835 0.835 0.871
Table 2: Evaluation results for the selected features on the second additional test set compared to all features (forCosine Delta clustering, 2 000 mfw are used in this case)
tures to 500 by pruning the 100 lowest ranking fea-tures at a time.
Once we have reduced the number of features to500, we try to find an optimal number of featuresby pruning only one feature at a time, doing a strati-fied threefold cross-validation on the data after eachpruning step to test classification accuracy.
Since Support Vector Machines are not scale-invariant, we rescaled each feature to [0, 1] dur-ing preprocessing. Simply rescaling the data shouldwork better than standardization because it preservessparsity (the standardized feature matrix is dense, re-placing every zero by a small negative value). As anadditional preprocessing step we removed all wordswith a document frequency of 1.
4.2 Examination and validation
The recursive feature elimination process canchoose from an abundance of features, and thereforeit is no surprise that it is able to find a subset of fea-tures that yields perfect results for both classification(accuracy was determined using stratified threefoldcross-validation and is given as the mean plus/minustwo standard deviations) and clustering using ∆∠.6
Cf. Table 1 for an overview of the results.Figures 8(a)-8(c) show the distribution of the doc-
6We used agglomerative clustering with complete linkage.
ument frequencies of those features. For all corporathere are some highly specific features that occuronly in a fraction of the texts, but most selected fea-tures have a rather high document frequency.
The features which turn out to be maximally dis-tinctive of authors show a number of interesting pat-terns. For example, they are not limited to functionwords. This is a relevant finding, because it is of-ten assumed that function words are the best indica-tors of authorship. However, content words may bemore prone to overfitting than function words. Also,in the English and French collections, a small num-ber of roman numerals are included (such as “XL” or“XXXVVII”), which may be characteristic of novelswith an unusually high number of chapters. This, inturn, may in fact be characteristic of certain authors.Finally, in the German collection, a certain numberof words show historical orthographic variants (suchas “Heimath” or “giebt”). These are most likely ar-tifacts of the corpus rather than actual stylistic char-acteristics of certain authors.
Perfect cross-validation and clustering resultssuggest that there may be severe overfitting. In orderto verify how well the set of selected features per-forms on unseen data, we used two additional eval-uation data sets:
1. An unbalanced set of 71 additional unseen nov-
86

els by 19 authors from the German collection;2. An unbalanced set of 155 unseen novels by 34
authors, with at least 3 novels per author (6 au-thors are also in the original collection).
For the first test set, we trained an SVC and a Max-imum Entropy classifier (MaxEnt) on the originalGerman corpus using the set of 234 selected fea-tures and evaluated classifier accuracy on the testset. Both SVC and MaxEnt achieved 0.97 accuracyon that test set, indicating that the selected featuresare not overfit to the specific novels in the trainingcorpus but generalize very well to other works fromthe same authors. Since this test set includes single-tons (a single novel by an author), cross-validationand clustering experiments cannot sensibly be con-ducted here.
For the second test set, we evaluated classificationaccuracy with stratified threefold cross-validationusing only the set of 234 selected features. We alsoclustered the texts using ∆∠ based on the same fea-tures. To have a point of reference, we furthermoreevaluated classification and clustering using the fullfeature set, once using relative frequencies and onceusing rescaled relative frequencies. For the cluster-ing we used the 2 000 mfw as features, which our ex-periments in Section 3.1 showed to be a robust andnearly optimal number. The results are summarizedin Table 2.7
Comparing evaluation results for the 234 se-lected features from the original corpus with the fullrescaled feature set, we see a considerable increasein SVC accuracy (due to the smaller number of fea-tures),8 a small decrease in MaxEnt accuracy andan increase in clustering quality, indicating that theselected features are not overfitted to the trainingdata and generalize fairly well to texts from other
7Clustering results on the unscaled and rescaled full featuresets are identical because of the z-transformation involved incosine delta.
8While Support Vector Machines are supposed to be effec-tive for data sets with more features than training samples, theydon’t deal very well with huge feature sets that exceed the train-ing samples by several orders of magnitude. For this reason,the poor performance of SVC on the full features set was tobe expected. It is surprising, however, that SVC performs muchbetter on unscaled features. We believe this to be a lucky coinci-dence: The SVC optimization criterion prefers high-frequencywords that require smaller feature weights; they also happen tobe the most informative and robust features in this case.
authors. Nevertheless, the difference in clusteringaccuracy between the first and the second test set in-dicates that these features are author-dependent tosome extent.
5 Conclusion
The results presented here shed some light on theproperties of Burrows’s Delta and related text dis-tance measures, as well as the contributions of theunderlying features and their statistical distribution.Using the most frequent words as features and stan-dardizing them with a z-transformation (Burrows,2002) proves to be better than many alternativestrategies (Sec. 3.2). However, the number nw offeatures remains a critical factor (Sec. 3.1) for whichno good strategy is available. Vector normalizationis revealed as the key factor behind the success ofCosine Delta. It also improves Burrows’s Delta andmakes all measures robust wrt. the choice of nw
(Sec. 3.3). In Sec. 4 we showed that supervised fea-ture selection may be a viable approach to furtherimprove authorship attribution and determine a suit-able value for nw in a principled manner.
Although we are still not able to explain in fullhow Burrows’s Delta and its variants are able to dis-tinguish so well between texts of different author-ship, why the choices made by Burrows (use of mfw,z-scores, and Manhattan distance) are better thanmany alternatives with better mathematical justifi-cation, and why vector normalization yields excel-lent and robust authorship attribution regardless ofthe distance metric used, the present results consti-tute an important step towards answering these ques-tions.
References
Shlomo Argamon. 2008. Interpreting Burrows’s Delta:Geometric and Probabilistic Foundations. Literaryand Linguistic Computing, 23(2):131 –147, June.
John Burrows. 2002. Delta: a Measure of Stylistic Dif-ference and a Guide to Likely Authorship. Literaryand Linguistic Computing, 17(3):267 –287.
Marc-Allen Cartright and Michael Bendersky. 2008.Towards scalable data-driven authorship attribution.Center for Intelligent Information Retrieval.
Maciej Eder and Jan Rybicki. 2013. Do birds of a featherreally flock together, or how to choose training sam-
87

ples for authorship attribution. Literary and LinguisticComputing, 28(2):229–236, June.
Maciej Eder, Mike Kestemont, and Jan Rybicki. 2013.Stylometry with R: a suite of tools. In Digital Hu-manities 2013: Conference Abstracts, pages 487–489,Lincoln. University of Nebraska.
R. S. Forsyth and D. I. Holmes. 1996. Feature-findingfor text classification. Literary and Linguistic Com-puting, 11(4):163–174, December.
David L. Hoover. 2004a. Delta Prime? Literary andLinguistic Computing, 19(4):477 –495, November.
David L. Hoover. 2004b. Testing Burrows’s Delta.Literary and Linguistic Computing, 19(4):453 –475,November.
Lawrence Hubert and Phipps Arabie. 1985. Comparingpartitions. Journal of Classification, 2:193–218.
Fotis Jannidis, Steffen Pielstrom, Christof Schoch, andThorsten Vitt. 2015. Improving Burrows’ Delta - Anempirical evaluation of text distance measures. In Dig-ital Humanities Conference 2015, Sydney.
Patrick Juola. 2006. Authorship attribution. Founda-tions and Trends in Information Retrieval, 1(3):233–334.
Leonard Kaufman and Peter J. Rousseeuw. 1990. Find-ing Groups in Data: An Introduction to Cluster Anal-ysis. John Wiley and Sons, New York.
M. Koppel, J. Schler, and S. Argamon. 2008. Computa-tional methods in authorship attribution. Journal of theAmerican Society for information Science and Tech-nology, 60(1):9–26.
Gabriella Lapesa and Stefan Evert. 2014. A large scaleevaluation of distributional semantic models: Parame-ters, interactions and model selection. Transactions ofthe Association for Computational Linguistics, 2:531–545.
John Marsden, David Budden, Hugh Craig, and PabloMoscato. 2013. Language individuation and markerwords: Shakespeare and his maxwell’s demon. PloSone, 8(6):e66813.
Monica Rogati and Yiming Yang. 2002. High-performing feature selection for text classification. InProceedings of the eleventh international conferenceon Information and knowledge management, CIKM’02, pages 659–661, New York, NY, USA. ACM.
Jan Rybicki and Maciej Eder. 2011. Deeper delta acrossgenres and languages: do we really need the most fre-quent words? Literary and Linguistic Computing,26(3):315–321, July.
Peter W. H. Smith and W. Aldridge. 2011. Im-proving Authorship Attribution: Optimizing Burrows’Delta Method*. Journal of Quantitative Linguistics,18(1):63–88, February.
Efstathios Stamatatos. 2009. A survey of modern author-ship attribution methods. J. Am. Soc. Inf. Sci. Technol.,60(3):538–556, March.
88





























