Embed Size (px)
Citation preview

1
The challenge of L2 sandhi – vowel hiatus in Polish English1
Geoffrey Schwartz1, Grzegorz Aperliński
1, Anna Balas
1, Arkadiusz Rojczyk
2
1 Faculty of English – Adam Mickiewicz University in Poznań
2 Institute of English – University of Silesia, Katowice-Sosnowiec
Abstract
The production and perception of L2 vowel hiatus, like other sandhi phenomena, is a largely
unexplored area in the field of L2 phonology. This paper presents a production and perception
study of vowel hiatus in the speech of Polish learners of English. Polish and English appear to
show systematic differences in the realization of hiatus. Textbook descriptions of English
refer to ‘glide insertion’ and ‘linking/intrusive [r]’ as the preferred hiatus fillers in traditional
vernacular dialects. By contrast, in Polish hiatus is typically realized with glottal stops,
glottalization, or increases in spectral tilt. These differences suggest that vowel glottalization
may be a form of L1 interference in Polish English. The production results indicate that the
suppression of glottalization is an integral part of L2 phonological acquisition for advanced
Polish learners. The listening tests revealed that the realization of vowel hiatus (modal vs.
glottalized) has an effect on L1 English listeners’ ratings of foreign accentedness, but L2
learners’ ratings of comprehensibility are largely unaffected by the glottalization of hiatus.
Issues of phonological representation underlying the study and its hypotheses are also
discussed.
1 Introduction
Experimental research into second language (L2) phonology has focused to a large degree on
segmental features and contrasts. Two of the more popular areas of study have been vowel
contrasts (e.g. Escudero and Boersma, 2004) and the implementation of laryngeal features
(e.g. Flege and Eefting, 1987). In both areas the somewhat elusive notion of cross-language
phonetic similarity has played a significant role in the formulation of predictions with regard
to success of acquisition. This type of research has become quite copious, as can be witnessed
in literature reviews found in volumes such as Hansen Edwards and Zampini (2008),
addressing acquisition from the point of view of production and perception, and exploring
didactic implications. By contrast, the transfer and acquisition of external sandhi, phonological processes
that span word boundaries, have been for the most part neglected in L2 speech research.
Beyond the relatively well-known areas of liaison and enchaînement in L2 French (e.g.
Howard, 2008; Shoemaker, 2010; Sturm, 2013), the acquisition of boundary effects in L2
speech remains largely unexplored. Zsiga (2011) notes this gap, and offers a review of
previous research in which only a few studies dealing with a small number of L1-L2 pairings
are discussed (Catalan-English: Cebrian, 2000; English-Russian: Zsiga, 2003; Spanish-
German: Lleo&Vogel, 2004; Korean-English: Zsiga, 2011).
One such sandhi phenomenon is the resolution of vowel hiatus at word boundaries.
This paper examines the acquisition of V#V sequences by Polish learners of English. Polish
and English appear to show systematic differences in the realization of hiatus. Textbook
descriptions of English refer to ‘glide insertion’ and ‘linking/intrusive [r]’ as the preferred
hiatus fillers in traditional vernacular dialects. By contrast, in Polish hiatus is typically
1 This research was supported by a grant from the Polish National Science Centre (Narodowe Centrum Nauki).
Project number 2012/05/B/HS2/04036

2
realized with glottal stops (Dukiewicz and Sawicka, 1995), glottalization, or increases in
spectral tilt (Schwartz, 2013a). Thus, acquisition of L2 English hiatus by Polish learners
entails the suppression of glottalization. This seemingly straghtforward cross-linguistic
difference is complicated by the fact that glottalization of vowel hiatus also occurs in English,
where it functions primarily as a marker of higher-level prosodic constituents (e.g. Dilley et
al., 1996). An additional complication may be observed in recent studies (e.g. Britain and
Fox, 2008; Davidson and Erker, to appear), which suggest that glottalization in English is
increasing in frequency in linguistically diverse urban areas. Nevertheless, since English
pronunciation instruction in Poland and many other countries is based on traditional
vernacular varieties, we shall consider non-glottalized hiatus, produced with modal phonation,
as the target for acquisition. Our study presents production data from 21 Polish students of English performing
both reading and imitation tasks. The reading task is intended to gauge the level of acquisition
of non-glottalized hiatus at the time of the experiment, while the imitation task seeks to elicit
modally produced hiatus by means of phonetic convergence with a model voice (Babel, 2012;
Honorof et al., 2011; Pardo et al., 2012). In addition, we present data from listening tests, in
which L1 English speakers rate modal vs. glottalized tokens on a scale of foreign
accentedness, while non-native speakers assess the comprehensibility of tokens containing
glottalized and non-glottalized hiatus. The production results suggest that suppressing
glottalization is indeed an integral part of L2 phonological acquisition for advanced Polish
learners, and that the production of modal voiced vowel is facilitated by both the imitation
task as well as the lexical frequency of the vowel-initial word. The listening tests revealed that
glottal vs. modal productions in vowel hiatus have greater impact on L1 listeners’ ratings of
accentedness than on L2 learners’ ratings of comprehensibility.
In introducing our experiments and discussing the results, we focus on issues of
phonological representation. In particular, we hypothesize that initial vowels in the two
languages are characterized by a representational difference; in Polish they are more
prominent prosodic entities that show a greater tendency than the corresponding segments in
English to be realized with glottalization. The representational hypothesis is formulated in the
Onset Prominence framework (OP; Schwartz, 2013b), which incorporates the phonetic
ambiguity of the initial portion of vocalic segments in CV sequences. This portion of the
signal, represented as the Vocalic Onset (VO) node of structure, is phonetically vocalic, yet
typically bears cues to the identity of the preceding consonant. We suggest that Polish and
English differ with respect to whether this node of structure is incorporated into the
representation of initial vowels. VO specification is posited for Polish vowels, and is reflected
in the tendency for glottalization and the formation of prosodic boundaries before word-initial
vowels. In English this node is absent, and initial vowels typically acquire an onset via
resyllabification or the ‘insertion’ of linking consonants. The rest of this paper will proceed as follows. We start by providing background on
the phonetics and phonology of vowel hiatus in English and Polish. This is followed by a
description of the production experiment. Then we present a description of the listening tests
that were carried out. This is followed by general discussion on the wider implications of our
study for the field of L2 phonology. Finally, we conclude with a brief clarification of the
phonological approach underlying our hypotheses and the interpretation of the results.
2 Vowel hiatus in English and Polish
This section will present background on vowel hiatus in English and Polish. We start by
considering previous descriptions. This is followed by a presentation of conceptual issues

3
underlying the phonology of hiatus. Finally, we introduce the Onset Prominence framework,
and derive the representational hypothesis underlying the experimental studies.
2.1 Previous descriptions hiatus in the two languages
Phonological descriptions of English hiatus resolution (e.g. McCarthy, 1993) typically refer to
a categorical process of glide insertion (see Ed [sijed], new image [nuwɪmədʒ]; McCarthy,
1993), as well as linking or intrusive /r/ in non-rhotic dialects (Uffmann, 2007). By contrast,
recent phonetic studies cast doubt on the assumed categorical nature of the process. Davidson
and Erker (to appear) present evidence against ‘glide insertion’ by English speakers in New
York City. Glottalization of hiatus is typically observed when the word-initial vowel is
stressed. In other cases, they found that VV and V#V sequences differ systematically from
VjV and V#jV sequences. We are left to conclude that traditional descriptions of ‘glide
insertion’ reflect the segmental transcriptions afforded to earlier authors’ percepts of non-
glottalized vowel hiatus. In other words, non-glottalized hiatus may have been misheard as
containing glides. The descriptions of hiatus found in works with more of an applied or pedagogical
orientation resist classifying ‘glide insertion’ as a categorical phenomenon. Cruttenden (2001)
notes that in vocalic sequences at word boundaries, slight linking glides might be audible, but
they are not as distinct as phonemic glides. He also mentions that linking glides in English
might be substituted with a glottal stop, especially before a vowel in an accented syllable.
Cruttenden also states that the use of glottal stops in English is not as common as in some
other languages, e.g. German, and is limited to emphatic utterances. Lecumberri and
Maidment (2000: 64) see utterance-initial glottal stop insertion in emphatic speech as a
universal phenomenon. Wells (2008: 345) claims that glottalization is optionally used to add
emphasis to syllable-initial vowels or to avoid hiatus in neighboring syllables (V#V).
According to Wells, British English speakers might use a glottal stop to avoid r-liaison.
Roach (2009: 117), in weighing the relative importance of various elements of
English pronunciation, suggests that sandhi processes should be a priority: ‘It would not be
practical or useful to teach all learners of English to produce assimilations; practice in making
elisions is more useful, and it is clearly valuable to do exercises related to rhythm and linking’
(emphasis ours). However, in the chapter on linking he does not address V#V sequences.
Instead, he focuses on linking and intrusive /r/ and the effect of a word boundary position on
the realization of consonantal allophones in pairs such as keep sticking and keeps ticking.
Cook (1991: 66) claims that in English two vowels across a word boundary are connected
with a slight glide, but warns against exaggerating it. Hewings and Goldstein (1999: 91) also
report that speakers join vowels across word boundaries with a ‘very short’ glide to ‘link the
vowels together to make the flow of speech smoother and to avoid a gap between the words’.
On the other hand, a fairly widely used pronunciation course by Lujan (2006) devotes little
attention to C#V linking, without even mentioning hiatus. As might be expected, there has been significantly less written about vowel hiatus in
Polish. In a phonological study, Rubach (2000) suggests that glide insertion is the norm for
word-internal hiatus, though he does not consider word boundaries, and no phonetic data is
presented beyond impressionistic transcriptions. Other descriptions (Dukiewicz and Sawicka,
1995; Gussmann, 2007), suggest that glottal stop insertion, though not obligatory, is the
preferred way of resolving hiatus. This may be observed both at word boundaries and at
word-internal morpheme boundaries. This suggestion is supported by data from Schwartz
(2013a).2 Data from 17 speakers showed a range of realizations from full glottal stops, to
2 Malisz et al (2013) look at initial vowel glottalization in Polish and German, and found a lower rate of
glottalization in Polish than for German. They did not do a comparison with English, though comparing their

4
glottalization realized as non-modal phonation, to drops in pitch and amplitude (cf.
Hillenbrand and Houde 1996). The data showed no signs of anything that might be interpreted
as a ‘glide’. In the most rapidly produced tokens without visible glottalization, the first vowel
in V#V sequences was often elided, while the second vowel was produced with increased
spectral tilt (cf. Sluijter and van Heuven 1996; Crosswhite, 2003). In sum, the literature on vowel hiatus in English and Polish suggests a slightly more
nuanced reality than the categorical claims of glide and glottal stop insertion found in some
phonological studies. Nevertheless, it appears that one systematic generalization may be
made. Modal hiatus appears to be the norm in English, which in earlier descriptions led to the
perception of an ‘inserted glide’. However, glottalization may also be found, typically before
stressed initial vowels. In Polish, glottalization dominates, and modal hiatus still entails the
marking of the initial vowel by means of raised spectral tilt. Thus it appears as if initial
vowels in Polish are more prominent prosodic entities than initial vowels in English. In what
follows, we offer a phonological interpretation of the hiatus phenomena.
2.2 Hiatus resolution – phonological interpretations
Phonological descriptions typically refer to the ‘resolution’ of vowel hiatus. This term
suggests a marked or non-optimal status for V#V sequences, in which the second vowel
violates ONSET, a prosodic constraint against vowel-initial syllables. The most frequent repair
strategies across languages include the coalescence of the vowels, or the appearance of a
consonant between them. Common hiatus fillers include glottal stops and [h]. The glides [j]
and [w] are also common when the first vowel is front or round. In essence, then, the
appearance of consonants in hiatus positions is generally taken to mean the ‘insertion’ of a
consonantal onset, be it a glottal stop, a glottal fricative, a glide, or a linking/intrusive rhotic.
In the parlance of Optimality Theory (Prince & Smolensky, 1993), insertions constitute a
violation of the faithfulness constraint DEP, which punishes output segments that are absent
from input representations.
From a logical standpoint, there is an alternative view on the origins of hiatus filling
consonants. Instead of the insertion of an entity that is absent from the underlying
representation, hiatus consonants may be interpreted as the realization of an entity that is
present in the underlying representation. That is, one may envision hiatus resolution as the
satisfaction of MAX, a faithfulness constraint that punishes the deletion of input features. In
the case of linking [r] in non-rhotic dialects of English (far – far away), this interpretation is
suggested by the presence of the letter r in the orthography. By contrast, other hiatus fillers in
English are generally accepted to be absent from the underlying input representations; their
appearance is assumed to be the result of insertion processes. The same interpretation is commonly applied to the appearance of glottal stops or
glottal marking in hiatus sequences. For example, the well-known process of harter Einsatz in
German, by which morpheme-initial vowels are realized with a glottal attack, is often referred
to as ‘glottal stop insertion’ (e.g. Wiese, 2000). We suggest that in languages in which glottal
marking is relatively common, including German and Polish, its appearance might better be
characterized as the preservation of an underlying element of the phonological representation.
In what follows, we will briefly introduce how this hypothesis is derived within the Onset
Prominence representational environment.
2.3 The OP environment and the representation of initial vowels
results with studies of English (e.g. Dilley et al., 1996) suggests that glottalization is more common in Polish.
Also, they did not specifically address the hiatus context, and they focused on glottalization as a marker of
higher-level prosodic structure in spontaneous speech and prepared (read) speeches.

5
In the OP environment, both segmental representations and prosodic constituents such as
syllables are constructed from the hierarchy in (1), which is derived from the phonetic events
observed in a stop-vowel sequence in initial position.
(1) The CV building block of the Onset Prominence representational hierarchy
Manner of articulation is encoded on the basis of the layers of structure contained by a given
segmental tree. This is shown in (2), which provides structures for a labial stop, nasal,
fricative, approximant, and vowel. The binary nodes are active elements in the individual
representations, while the unary nodes serve as place holders to indicate the relative
hierarchical position occupied by a given segmental structure. The segmental symbols may be
interpreted as shorthand for place and laryngeal specifications.
(2) Manner distinctions in the OP environment
In the hierarchy in (1), the segmental affiliation of the VO node is ambiguous. This single
layer of structure may be claimed by multiple segment types. On its own, VO represents the
class of approximants and glides as in (2). In (2), we also see that VO may be active in the
representation of obstruents and nasals, representing formant transitions that cue consonant
place of articulation (e.g. Wright, 2004). At the same time, the VO node is derived from a
portion of the signal that is phonetically a vowel. As a result, we might expect to find it built
into the representation of vowels as well as consonants. In (3) we see two types of vowel
representation, with or without an active VO node.
(3) Vowels with our without VO specification

6
The presence or absence of VO in vowel representations offers a useful perspective on the
prosodically ambiguous behavior of onsetless syllables across languages (see Schwartz
2013a). Briefly stated, VO-specification allows initial vowels to satisfy prosodic constraints
requiring onset consonants. This may be manifested as an apparent ‘empty consonant’ (e.g.
Marlett & Stemberger, 1983), or simply as prosodic well-formedness for processes such as
stress assignment or reduplication (cf. Downing, 1998 for discussion of prosodically ill-
formed onsetless syllables). With respect to the representation of initial vowels in Polish and English, we propose
VO specification for the former, but not the latter. That is, Polish initial vowels may be
thought of as containing a built-in consonant. One area in which this claim is manifest is in
the greater tendency for glottalization of initial vowels in Polish (Schwartz, 2013a). In
English, glottalization is associated primarily with higher-level prosodic constituents (e.g.
Dilley et al., 1996). Moreover, Polish word-initial syllables have been claimed to bear
secondary stress (Dogil, 1999),3 which in the case of initial vowels suggests a prominent
prosodic status as represented by the VO node in OP structures. The OP perspective on vowel hiatus is revealed when we look at the mechanisms by
which segmental structures combine into prosodic constituents. Consider (4). On the left we
see individual segmental structures for English cry, while on the right we see the word as a
single prosodic constituent. The fundamental process at work here is called absorption, by
which lower-level vowel and sonorant structures are fused with the higher level obstruents
that precede them. In cry, the vowel is absorbed into the rhotic, which is in turn merged with
structure of the initial stop. The absorption process shown in (4) is prosodically motivated. Without it, individual
segments such as /r/ or /k/ in cry would be forced to stand alone as prosodic constituents.
Absorption thus implies the presence of a minimality constraint for well-formed syllables.
Such a constraint combines two commonly invoked restrictions on syllable structure, both of
which are satisfied by means of absorption. The requirement for onset consonants is satisfied
by absorbing /aɪ/ into the structure of the rhotic, while a constraint against syllabic obstruents
is alleviated when the rhotic-vowel sequence merges with the /k/.
(4) Segmental and constituent (right) structures for English cry
When two OP vowel structures are adjacent, absorption may not take place since the
two trees are at the same level of the hierarchy. In such cases, a different mechanism,
submersion, may be motivated to ensure prosodic well-formedness. This is shown in (5). The
two trees on the left show a /ua/ sequence. The second vowel may not be absorbed, since the
structure to its left is not higher in the hierarchy. Instead, it is submerged under the first tree,
3 Newlin-Łukowicz (2012) found minimal acoustic support for Dogil’s claim. However, she did not measure
spectral balance, an established cue to prominence in many languages (Sluijter & van Heuven 1996, Plag et al.
2011) including Polish (Crosswhite, 2003).

7
producing the single structure /ua/ that we see in the third tree from the left. Such a sequence
may be perceived as [wa], yet its labial element is distinct from the lexical glide /w/ (the
rightmost tree), in which it is housed at the VO level. This representational distinction
captures the phonetic differences between underyling and hiatus glides observed by
Cruttenden (2001), and Davidson and Erker (to appear), as well as phonological differences in
other languages (cf. Levi, 2008).
(5) Submersion of the second vowel in a VV sequence
In (5), we see that submersion prevents the formation of a boundary at vowel hiatus.
Submersion is also the process that we claim as the origin of vowel quantity and weight
distinctions, which are a generally accepted feature of English, but are unattested in Polish.
When the second vowel in V#V sequences is specified with the VO, as we claim for Polish,
submersion is not motivated since the VO-specified vowel is already a well-formed prosodic
constituent. As such, it may be strengthened by means of promotion (Schwartz, 2013b), a
fortition process by which VO-specified vowels and approximants are raised to the highest
level of the OP hierarchy normally occupied by stop closure. Promoted vowels show a greater
tendency to be realized with glottalization. When glottalization is not produced, their
prominence may be preserved by increases in spectral tilt (Schwartz, 2013a). Beyond the mechanism shown in (5), submersion is a process with far-reaching
prosodic implications, offering additional insight into the behavior of consonants in both VC
and VCV contexts, with deeper predictions for the form and behavior of larger prosodic
constituents. We will return to submersion in the General Discussion section, considering its
implications for the study of L2 speech.
3 Experiment 1 – hiatus production in reading and shadowing tasks
The phonological considerations discussed above lead to a hypothesis that L1 Polish
interference may result in a tendency for glottalization of vowel hiatus in the speech of Polish
learners of English. To test this hypothesis we conducted an experiment in which we elicited
data from learners producing English V#V sequences. We compared learners from two groups
and in two tasks, reading and imitation. We hypothesize that glottalization will be more
prevalent in the speech of less advanced learners, and in the reading task. If these hypotheses
are supported, it may be taken as evidence in favor of representations for English that are
conducive to linking of V#V sequences, and Polish representations that favor glottalization as
a hiatus filler. The reading task may be assumed to provide information about the state of acquisition
at the time of recording, while the imitation task offers some perspective into learners’
potential for acquisition. In recent years, phonetics research has investigated the performance
of L1 speakers in shadowing tasks. The features that have been found to undergo phonetic
convergence include fundamental frequency (Goldinger, 1997), VOT (Shockley et al., 2004),
and vowel quality (Pardo et al., 2012). This research has investigated the role of episodic

8
memory (Goldinger, 1998) with the goal of testing exemplar-based models of speech
perception (e.g. Johnson, 1997). Findings of phonetic convergence with model productions in
shadowing tasks may be said to support the hypotheses of exemplar-based perception, insofar
as such productions reflect how they were perceived.
As yet, experiments employing the imitation paradigm have been largely limited to L1
speech. However, it is not difficult imagine the benefits of using imitation study in L2
phonological research. Repetition, of course, has always had a prominent position in foreign
language pronunciation instruction. This fact suggests a parallel with L1 phonetic
accommodation. At the same time, one might expect L1-based perceptual constraints (Best,
1995; Best and Tyler, 2007) to hinder L2 speakers’ convergence with a native stimulus. The
question that remains is to what extent these constraints may be overridden in shadowing
tasks. In a series of experiments investigating problematic areas for Polish learners of English,
Rojczyk (2012, 2013) and Rojczyk et al. (2013) found evidence of phonetic convergence in
VOT, formant frequencies of the vowel /æ/, and the suppression of coda stop release. In the
current study, we seek to build on this research and investigate the extent to which shadowing
facilitates Polish learners’ suppression of vowel glottalization in hiatus sequences.
Participants
Twenty one Polish learners of English participated in the experiment. All were majors in
English studies at either the University of Silesia (UŚ) in Sosnowiec or Adam Mickiewicz
University in Poznań (UAM). The 21 students comprised two groups. The first group (N=12)
included first year students, while the second group (N=9) was made up of students in higher
years. None had spent more than three months in an English-speaking country.
The division into the two groups is motivated as follows. In the first year of English
studies in Polish universities, students receive intensive pronunciation instruction (2*90
minutes/week). In the second year, this instruction is reduced to one meeting a week, while
students in the third year and above no longer receive explicit instruction in pronunciation.
The first year group had completed one semester of instruction at the time of the recordings.
The higher years’ group had completed a minimum of three semesters. The first two
semesters of instruction concentrate on segmental features. Word boundary effects receive a
small amount of attention, but only in the second year. Thus, it may be assumed that the first
year group was unfamiliar with sandhi processes associated with English V#V sequences,
while the higher years’ group had some awareness of these phenomena.
Materials
Data were elicited from student productions of an English sentence list containing 26 V(r)#V
sequences.4 The list of target sequences may be found in Appendix 1. The stimuli also
contained fillers, as well as tokens used in a separate experiment. The recordings were made
in soundproof recording studios in the English departments at each of the two universities.
The studios were equipped with a computer monitor upon which the stimulus data were
presented. In the first task, subjects were instructed to read the sentence presented on a slide
in a Power Point presentation. In the second task, the presentation of the slide was
accompanied by an audio recording of one of five native speakers of English (2 US English
speakers, 3 British English speaker) producing the stimulus. Students were instructed to
repeat after the model voice, which in each case produced the V#V sequence without visible
glottalization. The imitation task was performed immediately after the reading task. The
4 Three of the tokens contained a Vr#V sequences in which ‘linking’ /r/ may be expected in non-rhotic dialacts.
One target token contained the context for ‘intrusive’ /r/.

9
students received course credit for their participation. A total of 1092 tokens were obtained
(26 items * 2 tasks * 21 speakers).
Analysis
The V#V tokens were inspected with the help of the Praat program (Boersma & Weenink,
2011) with the aim of establishing the likelihood of modal and glottalized realizations of the
target sequences. Despite variation in the realization of glottal events (cf. Redi & Shattuck-
Hufnagel, 2001), preliminary analysis allowed us to establish three categories for vowel
realization. These categories are illustrated in Figures 1-3. Modally voiced hiatus is
exemplified in Figure 1, showing the V#V sequence in saw everything.
Figure 2 provides an example of a glottalized token in the sequence stay out. The selected
portion of the display reveals a creaky voice quality that is visible as a period of irregularity in
the periodicity of the vowel wave.
In Figure 3, we see a full glottal stop in the production of English see all. The selected portion
of the display is characterized by silence associated with full glottal closure.

10
Hillenbrand & Houde (1996) revealed that local drops in pitch and amplitude of modally
produced VV tokens may be perceived as glottal stops. Our tokens included a small
percentage of such cases. However, because of difficulties involved in the quantification of
such drops in amplitude and pitch, such tokens were coded simply as modal. Thus, a small
number of the tokens categorized as modal may have been realized with a feature associated
with the perception of glottalization. The annotation was performed by three out of the four authors of this paper. Of the 21
speakers, 19 were analyzed by a single annotator. The other two speakers were analyzed by
all three annotators to calibrate the analysis and check for consistency. With regard to the
coding of the initial vowels, the calibration analyses revealed a high level of agreement in the
case of tokens coded as modal (unanimous agreement in 90.5% of cases; Fleiss’ Kappa = 0.78
for two categories, modal vs. non-modal). When all three categories were included, some
discrepancies arose in the choice between tokens coded as glottalized and those containing a
full glottal stop (complete agreement in 61% of cases; Fleiss’ Kappa = 0.54 for the three
categories). Tokens for which two out of three annotators agreed were assigned to the
category selected by the majority. In the rare cases in which the three annotators assigned
tokens to three different categories, the first author made the final decision.
Results
The first results we will present are focused on the reading task, with the aim of characterizing
the participants’ level of acquisition of modal-voiced hiatus at the time of the experiment. The
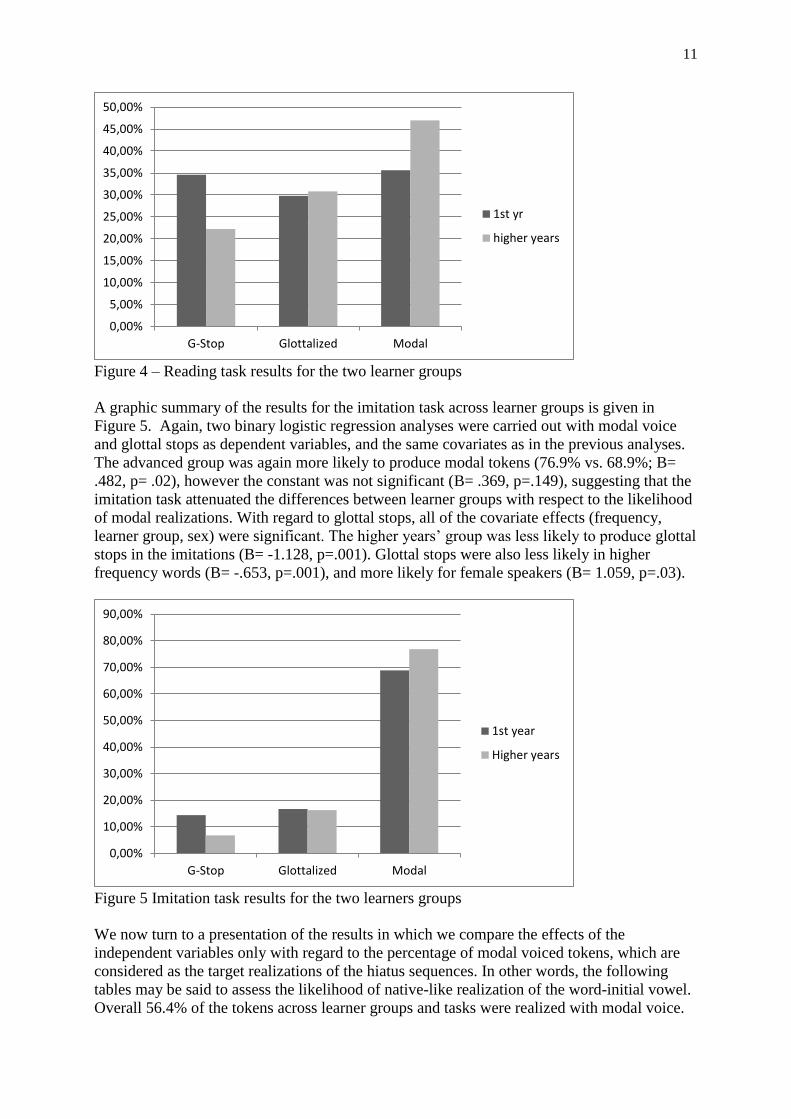
vowel realizations for the reading task for both learner groups are summarized in Figure 4.
The 1st year group produced modal hiatus in 35.6% of the tokens, compared to 47% for the
higher years’ group. The 1st year group also produced a noticeably higher percentage of full
glottal stops (34.6% vs 22.2%). Two binary logistic regression analyses were carried out on
the reading data (for the full tables of all the regression analyses, see Appendix 2). The first
analysis examined modal tokens (yes or no) as the dependent variable while the second
analysis looked at full glottal stops (yes or no). In both cases, learner group, lexical frequency,
5 and sex were posited as covariates. The results revealed that learner group (higher years; B=
.440, p=.016) and lexical frequency (B=.675; p<.001) were significant predictors of modal
voice in hiatus tokens. The second analysis, with glottal stops as the dependent variable,
revealed that the higher years’ group was less likely to produce full glottal stops (B= -1.128,
p=.001). Significant effects were also found for female speakers (B=1.059, p=.03) and higher
frequency words (B= -.653, p=.001).
5Token frequency was coded on a three point scale according to the Francis-Kucera corpus. Values below 120
were categorized as ‘least frequent’, from 121-240 was ‘more frequent’, and above 240 was ‘most frequent’.
11
Figure 4 – Reading task results for the two learner groups
A graphic summary of the results for the imitation task across learner groups is given in
Figure 5. Again, two binary logistic regression analyses were carried out with modal voice
and glottal stops as dependent variables, and the same covariates as in the previous analyses.
The advanced group was again more likely to produce modal tokens (76.9% vs. 68.9%; B=
.482, p= .02), however the constant was not significant (B= .369, p=.149), suggesting that the
imitation task attenuated the differences between learner groups with respect to the likelihood
of modal realizations. With regard to glottal stops, all of the covariate effects (frequency,
learner group, sex) were significant. The higher years’ group was less likely to produce glottal
stops in the imitations (B= -1.128, p=.001). Glottal stops were also less likely in higher
frequency words (B= -.653, p=.001), and more likely for female speakers (B= 1.059, p=.03).
Figure 5 Imitation task results for the two learners groups
We now turn to a presentation of the results in which we compare the effects of the
independent variables only with regard to the percentage of modal voiced tokens, which are
considered as the target realizations of the hiatus sequences. In other words, the following
tables may be said to assess the likelihood of native-like realization of the word-initial vowel.
Overall 56.4% of the tokens across learner groups and tasks were realized with modal voice.
0,00%
5,00%
10,00%
15,00%
20,00%
25,00%
30,00%
35,00%
40,00%
45,00%
50,00%
G-Stop Glottalized Modal
1st yr
higher years
0,00%
10,00%
20,00%
30,00%
40,00%
50,00%
60,00%
70,00%
80,00%
90,00%
G-Stop Glottalized Modal
1st year
Higher years
12
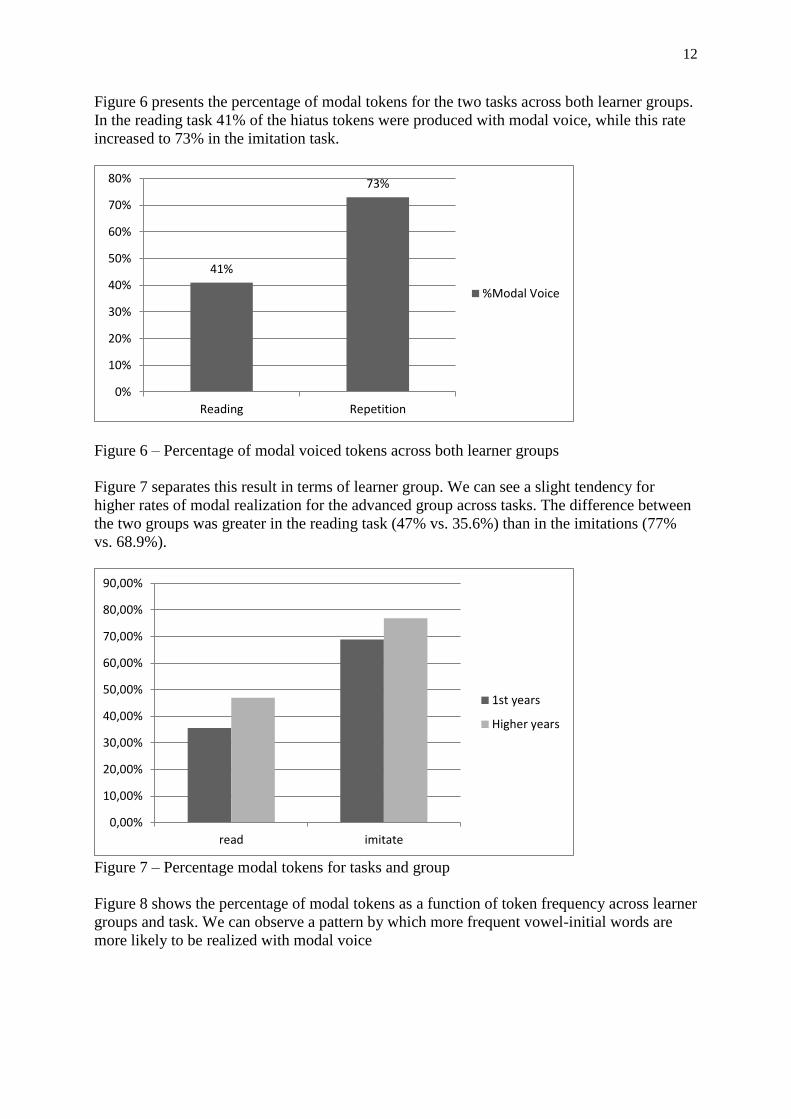
Figure 6 presents the percentage of modal tokens for the two tasks across both learner groups.
In the reading task 41% of the hiatus tokens were produced with modal voice, while this rate
increased to 73% in the imitation task.
Figure 6 – Percentage of modal voiced tokens across both learner groups
Figure 7 separates this result in terms of learner group. We can see a slight tendency for
higher rates of modal realization for the advanced group across tasks. The difference between
the two groups was greater in the reading task (47% vs. 35.6%) than in the imitations (77%
vs. 68.9%).
Figure 7 – Percentage modal tokens for tasks and group
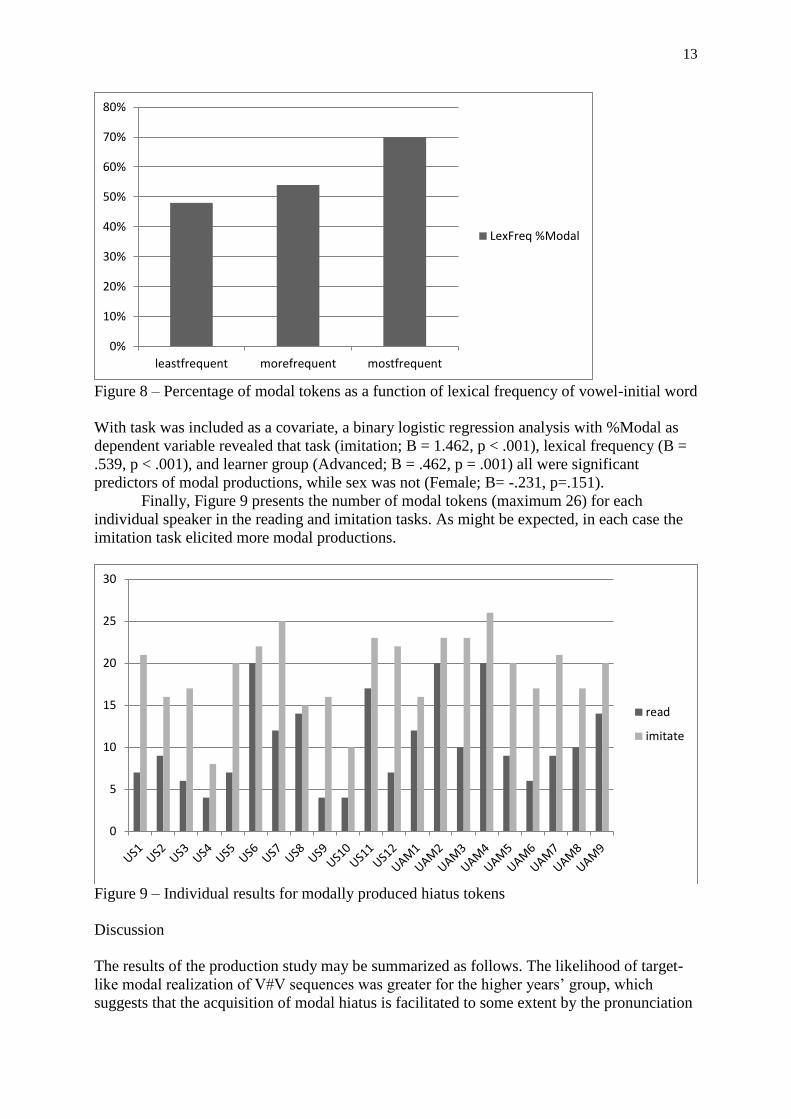
Figure 8 shows the percentage of modal tokens as a function of token frequency across learner
groups and task. We can observe a pattern by which more frequent vowel-initial words are
more likely to be realized with modal voice
41%
73%
0%
10%
20%
30%
40%
50%
60%
70%
80%
Reading Repetition
%Modal Voice
0,00%
10,00%
20,00%
30,00%
40,00%
50,00%
60,00%
70,00%
80,00%
90,00%
read imitate
1st years
Higher years
13
Figure 8 – Percentage of modal tokens as a function of lexical frequency of vowel-initial word
With task was included as a covariate, a binary logistic regression analysis with %Modal as
dependent variable revealed that task (imitation; B = 1.462, p < .001), lexical frequency (B =
.539, p < .001), and learner group (Advanced; B = .462, p = .001) all were significant
predictors of modal productions, while sex was not (Female; B= -.231, p=.151).
Finally, Figure 9 presents the number of modal tokens (maximum 26) for each
individual speaker in the reading and imitation tasks. As might be expected, in each case the
imitation task elicited more modal productions.
Figure 9 – Individual results for modally produced hiatus tokens
Discussion
The results of the production study may be summarized as follows. The likelihood of target-
like modal realization of V#V sequences was greater for the higher years’ group, which
suggests that the acquisition of modal hiatus is facilitated to some extent by the pronunciation
0%
10%
20%
30%
40%
50%
60%
70%
80%
leastfrequent morefrequent mostfrequent
LexFreq %Modal
0
5
10
15
20
25
30
read
imitate

14
instruction these learners had received at their universities. We attribute vowel glottalization
to L1 phonological interference. Modal hiatus was also facilitated by the lexical frequency of
the vowel-initial word, as well as the imitation task, and to a small degree the sex of the
speaker. These additional results, which may be claimed to be attributable to non-
phonological factors, present a fundamental theoretical challenge: to tease apart the
phonological and non-phonological aspects of hiatus glottalization. We shall discuss each of
these factors in turn. The lexical frequency effect may be conceptualized in terms of Lindblom’s (1990)
H&H theory, according to which speaker behavior is governed by the need to minimize
articulatory effort, while at the same time producing sufficient discriminability. Glottalization
is perceptually salient and increases discriminability, yet entails increased effort of additional
laryngeal gestures. According to Lindblom, higher frequency words will be recognized even
with reduced discriminability, so these words are still recoverable with modal hiatus that is
produced with lesser articulatory effort. The next result we take up is the effect of the imitation task. While shadowing elicited
a much higher rate of target-like modally voiced hiatus realizations, the task attenuated to
some extent the difference in performance between the two learner groups. This result could
perhaps be interpreted as an indication of greater effects of repetition in early stages of
acquisition. That is, the 1st year group showed greater improvement in their imitations. In
accordance with previous studies involving shadowing, it is possible that phonologically-
induced perceptually constraints are overridden by the task. The greater impact of imitation
for 1st year students may also find a parallel in novelty effects found for early learners (e.g.
Chang, 2012). A related study on C#V sequences in Polish English (Schwartz et al., 2013)
found that imitation had a larger impact on first year learners’ productions. The implications
of these findings, however, are not entirely clear. It could be that the first year group showed
greater improvement simply because they had more ‘room’ to improve. The final variable that we examined was the sex of the speaker. In American English,
studies have shown that females have a greater tendency to use creaky phonation for non-
linguistic purposes (Yuasa 2010). In our study, females were somewhat less likely to produce
modal-voiced hiatus, and were more likely to produce full glottal stops. However, on the basis
of our results, we cannot make any firm conclusions with regard to the use of non-modal
phonation as a function of sex.
The factors affecting the likelihood of glottalization in our study, in particular lexical
frequency and the shadowing task, are compatible with usage-based or exemplar-based
models of phonology and speech perception (Johnson, 1997; Bybee, 2001; Pierrehumbert,
2001). In such models, episodic memory traces play an instrumental role in the formation of
phonological categories such as segments and syllables. These categories are not primitives,
but rather emergent properties that form on the basis of auditory input. An important
assumption of exemplar theory is that gradient phonetic detail is recorded in each exemplar of
a category, and is therefore an integral part of category representation. This is to be expected
given the role of episodic memory in the hypothesized mechanism of category development.
Assuming the validity of the exemplar approach, one may therefore suggest that the putative
extra-grammatical effects observed in the present study are indeed phonological. The question
that remains concerns the compatibility of exemplar models with the representations proposed
upon which our research hypothesis is based. One issue that exemplar theory has not, to our knowledge, explicitly addressed is the
representational nature of emergent phonological categories. In other words, it is not stated
what the exemplars are exemplars of. The Onset Prominence model seeks to fill this gap. The
OP environment is derived from a hierarchy of phonetic events that is an integral part of the
auditory input for every user of spoken language. In this input, the phonetic properties

15
associated with manner of articulation provide auditory structure, providing a locus for
gradient phonetic details associated with place and laryngeal features. We suggest that the OP
representational hierarchy is indeed compatible with exemplar-based models. The benefit of
these representations for exemplar theory lies in the fact that they provide specific predictions
about the relative perceptual role of different types of gradient phonetic detail. In the case of
place and laryngeal cues, phonetic detail defines boundaries between categories. By contrast,
the perception of manner appears to be privative in nature. For example, a stop may be
produced with incomplete closure (Crystal and House, 1988), but this does not necessarily
imply the presence of sufficient frication noise to induce the perception of a separate manner
category (fricative). While questions about the phonological status of hiatus realization constitute one part
of our study, there is an additional important question that must be considered. In particular,
the glottalization of vowels has not been the focus of a large number of L2 studies,
presumably since its phonological status is not universally acknowledged. In a related study
of C#V sequences in the speech of Polish learners of English, Schwartz et al. (2013) looked at
the interaction between glottalization and final devoicing. Final devoicing, of course, is an
‘established’ feature of Polish-accented English and a major focus of pronunciation
instruction. Glottalization of hiatus, on the other hand, is not so intimately connected with
familiar segmental errors. Thus, the consequences of hiatus glottalization for the perception of
L2 English are not obvious. We seek to address this question by means of listening tests
described in the following section.
4 Experiment 2 - Accentedness and comprehensibility of glottalized and modal hiatus
The aim of this experiment was to assess the effect of vowel hiatus realization on the
perceived comprehensibility and accentedness of non-native speech (cf. Derwing & Munro,
1997; Munro, 2008). To explore the relationship between these variables, two separate on-
line listening tests were carried out. In the first, directed at L1 speakers of English, listeners
rated the foreign accentedness of glottalized and modal tokens. In the second, distributed to
Polish learners of English, participants rated the comprehensibility of glottalized and modal
tokens.
4.1 Participants and stimuli
Two groups of participants took part in the experiment:
1. 31 native speakers of Polish (for the comprehensibility test)
2. 41 native speakers of English (for the accentedness test) Data on the participants’ knowledge of English, exposure to non-native accents of English as
well as other known languages were collected, but proved not to have any significant effects
in relation to the aims of the study and therefore will not be reported on. The experimental stimuli were taken from recordings obtained in the production study.
Each stimulus consisted of utterances of between three and seven words. The total number of
tokens used was 36. Out of these, 12 pairs (i.e. 24 tokens) contained non-native utterances
with vowel hiatuses. That is, each member of the pair was the same utterance, but one was
produced with a modal realization of the hiatus, while the other had a glottalized realization.
The tokens were checked by two professional pronunciation teachers for additional
segmental errors. Four glottalized tokens were judged to contain additional pronunciation
errors, while three tokens with modal realization were found to exhibit additional errors.
Appendix 3 provides a summary of the utterance pairs and errors identified. Aside from the

16
12 pairs, the stimuli contained six additional tokens of native English utterances taken from
target recordings used for the repetition task in the production study. Finally, six other non-
native without vowel hiatuses were used to act as distractors.
4.2 Procedure
Two perception surveys were created for the purposes of the study. One survey was designed
to study how easily native speakers of Polish would comprehend the stimuli, while the other
examined the degree of accentedness perceived by native speakers of English. The surveys
were built using the Google Forms software and were additionally customized by hand to
include audio files and additional data validation. The surveys were made available online and
distributed using their URL addresses. Cooke et al. (2013) discuss the merits and drawbacks
associated with web-based speech perception studies. We feel that the merits outweigh the
drawbacks. One advantage is the highly voluntary nature of the participants. Another
advantage is the feasibility of recruiting a large number of L1 English listeners in a non-
English speaking country, particularly those who do not have everyday experience with
Polish-accented English. Nevertheless, we are in the process of attempting to replicate this
study in an on-site experiment. Both surveys consisted of two parts. The first part was comprised of a short linguistic
background questionnaire that was followed by the second part in that included perception
tasks. Each perception task contained a recording and a question to answer, i.e. ‘Which of the
descriptions below best describes the speaker's pronunciation?’. The task was to answer the
question by choosing one of the five available options. In the comprehensibility survey, the
listeners had to rate how well they understood the utterances (5 – very easy to understand; 1 –
very difficult to understand). In the accentedness survey, the listeners rated the degree of non-
native accent in the utterances (5 – clearly native; 1 – clearly foreign). All descriptions and
instructions in both surveys were delivered in English.
While completing the surveys listeners could not compare two recordings to each
other. Only one question could be viewed at a time and the participants could not continue to
the next question without first answering the current one. It was also impossible to return to a
previously answered question. The participants could only rely on their own impressions
when making perception judgments. In addition, each survey attempt was unique in the sense
that the order of all perception tasks was randomized when the survey was accessed. This
helped limit the effect of question order on the responses. As mentioned above, the experiment was conducted via the internet. Consequently, the
participants completed the tasks remotely on their own computers. The surveys were
distributed among the participants using the following URL addresses:
http://goo.gl/uWNDGZ (comprehensibility study) http://goo.gl/Hsypq7 (accentedness study)
Each participant was instructed to complete the survey only once and to use headphones to
listen to the stimuli in order to ensure sound fidelity. All participants were unaware of the
purpose of the experiment.
When participants accessed the surveys they were first asked to provide information
about their linguistic background and then they moved on to the experiment proper that
consisted of 36 perception tasks. No indication of this division was given to the participants. When completing the surveys, the participants were presented with only one question at a
time. In each question, the participants were instructed to do the following:
1. Click on a play button and listen to a short recording of an utterance. The recordings
could be replayed if needed.

17
2. Answer the question by choosing one of the five available options numbered 1–5. The
participants could not proceed without first answering the current question. No
feedback was presented for answering a question. 3. Click on ‘next’ to continue to the next question.
The participants continued until they answered all the questions. At this point, the ‘submit’
button became active and the listeners could click on it to send their responses. A
confirmation screen concluded the experiment.
4.3 Data Analysis
A total of 2628 responses were obtained in the experiment (comprehensibility survey: 36
tokens * 31 listeners = 1116; accentedness survey: 36 tokens * 42 listeners = 1512). The 438
responses to filler tokens without vowel hiatuses were excluded from the analysis. The
remaining 2190 responses (comprehensibility = 930; accentedness = 1260) were used to
calculate the mean values of comprehensibility and accentedness ratings for each participant.
The means were then analyzed by taking into account the following factors: Realization (whether the hiatuses in the utterance tokens were produced with a non-
native glottal or modal realization or were produced by a native speaker, i.e. had a
native modal realization) Other errors (whether the stimuli contained other errors that could influence the rating
or not) The mean comprehensibility and accentedness rating values for all stimuli types (glottal vs.
modal vs. native) were calculated and compared using a repeated measures ANOVA to
determine the effect vowel hiatus realization (glottalized vs. modal vs. native) on
comprehensibility and perceived accentedness of speech. In addition, the same means and
statistical analyses were obtained for tokens with and without other pronunciation errors in
order to evaluate the effects of these errors on the listeners’ judgments.
4.4 Results
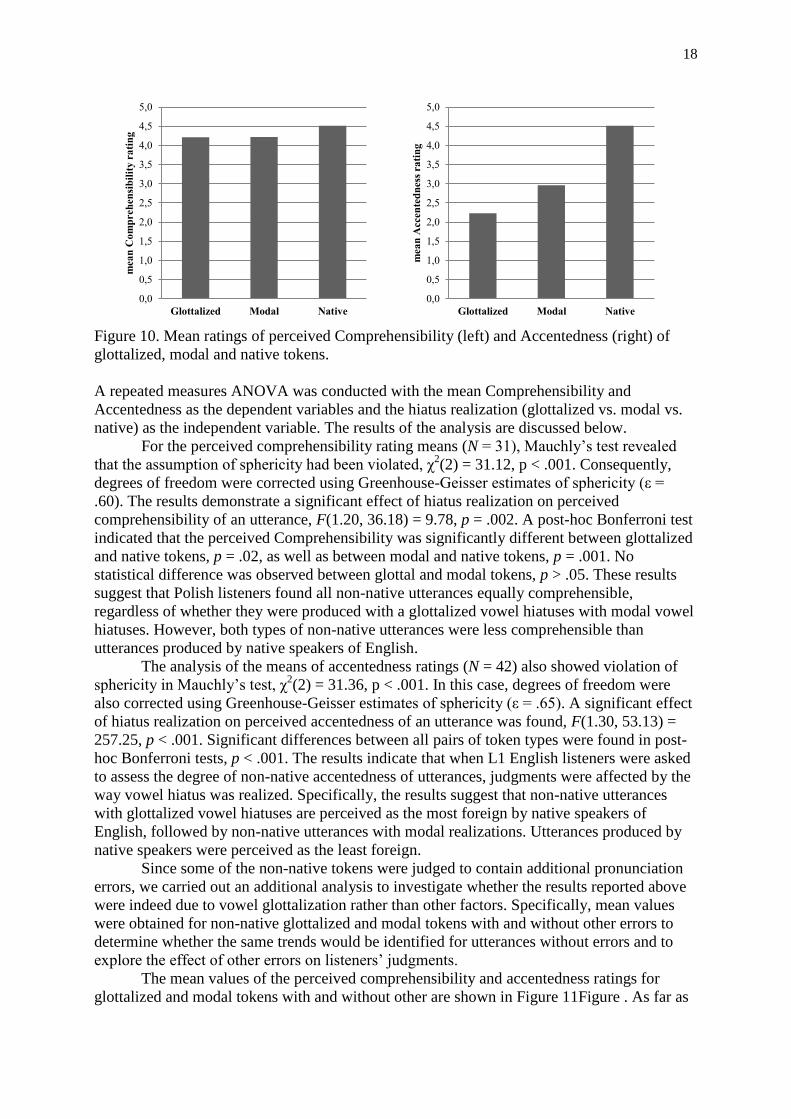
The mean values of the perceived comprehensibility and accentedness ratings for all three
stimuli types are presented in Figure 10. The mean value of the comprehensibility rating was
almost exactly the same for glottalized tokens (M = 4.21, SD = .47) and modal tokens (M =
4.22, SD = .41). Slightly higher comprehensibility ratings were assigned to tokens produced
by native speakers of English (M = 4.51, SD = .48). As for the mean values of the
accentedness rating, the lowest score was found for glottalized (M = 2.23, SD = .47), followed
by modal tokens (M = 2.96, SD = .52). Tokens produced by native speakers obtained the
highest scores for accentedness (M = 4.51, SD = .56).
18
Figure 10. Mean ratings of perceived Comprehensibility (left) and Accentedness (right) of
glottalized, modal and native tokens.
A repeated measures ANOVA was conducted with the mean Comprehensibility and
Accentedness as the dependent variables and the hiatus realization (glottalized vs. modal vs.
native) as the independent variable. The results of the analysis are discussed below. For the perceived comprehensibility rating means (N = 31), Mauchly’s test revealed
that the assumption of sphericity had been violated, χ2(2) = 31.12, p < .001. Consequently,
degrees of freedom were corrected using Greenhouse-Geisser estimates of sphericity (ε =
.60). The results demonstrate a significant effect of hiatus realization on perceived
comprehensibility of an utterance, F(1.20, 36.18) = 9.78, p = .002. A post-hoc Bonferroni test
indicated that the perceived Comprehensibility was significantly different between glottalized
and native tokens, p = .02, as well as between modal and native tokens, p = .001. No
statistical difference was observed between glottal and modal tokens, p > .05. These results
suggest that Polish listeners found all non-native utterances equally comprehensible,
regardless of whether they were produced with a glottalized vowel hiatuses with modal vowel
hiatuses. However, both types of non-native utterances were less comprehensible than
utterances produced by native speakers of English. The analysis of the means of accentedness ratings (N = 42) also showed violation of
sphericity in Mauchly’s test, χ2(2) = 31.36, p < .001. In this case, degrees of freedom were
also corrected using Greenhouse-Geisser estimates of sphericity (ε = .65). A significant effect
of hiatus realization on perceived accentedness of an utterance was found, F(1.30, 53.13) =
257.25, p < .001. Significant differences between all pairs of token types were found in post-
hoc Bonferroni tests, p < .001. The results indicate that when L1 English listeners were asked
to assess the degree of non-native accentedness of utterances, judgments were affected by the
way vowel hiatus was realized. Specifically, the results suggest that non-native utterances
with glottalized vowel hiatuses are perceived as the most foreign by native speakers of
English, followed by non-native utterances with modal realizations. Utterances produced by
native speakers were perceived as the least foreign. Since some of the non-native tokens were judged to contain additional pronunciation
errors, we carried out an additional analysis to investigate whether the results reported above
were indeed due to vowel glottalization rather than other factors. Specifically, mean values
were obtained for non-native glottalized and modal tokens with and without other errors to
determine whether the same trends would be identified for utterances without errors and to
explore the effect of other errors on listeners’ judgments.
The mean values of the perceived comprehensibility and accentedness ratings for
glottalized and modal tokens with and without other are shown in Figure 11Figure . As far as
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
Glottalized Modal Native
mea
n C
om
preh
en
sib
ilit
y r
ati
ng
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
Glottalized Modal Native
mea
n A
ccen
ted
ness
ra
tin
g
19
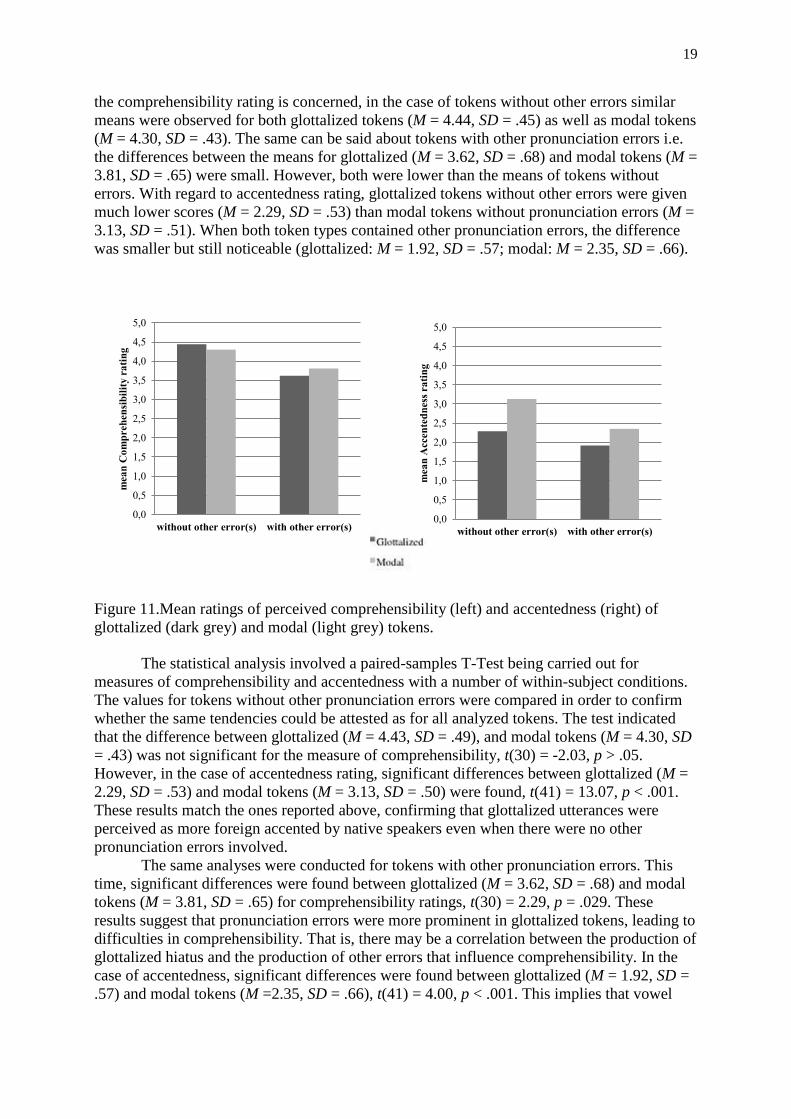
the comprehensibility rating is concerned, in the case of tokens without other errors similar
means were observed for both glottalized tokens (M = 4.44, SD = .45) as well as modal tokens
(M = 4.30, SD = .43). The same can be said about tokens with other pronunciation errors i.e.
the differences between the means for glottalized (M = 3.62, SD = .68) and modal tokens (M =
3.81, SD = .65) were small. However, both were lower than the means of tokens without
errors. With regard to accentedness rating, glottalized tokens without other errors were given
much lower scores (M = 2.29, SD = .53) than modal tokens without pronunciation errors (M =
3.13, SD = .51). When both token types contained other pronunciation errors, the difference
was smaller but still noticeable (glottalized: M = 1.92, SD = .57; modal: M = 2.35, SD = .66).
Figure 11.Mean ratings of perceived comprehensibility (left) and accentedness (right) of
glottalized (dark grey) and modal (light grey) tokens.
The statistical analysis involved a paired-samples T-Test being carried out for
measures of comprehensibility and accentedness with a number of within-subject conditions.
The values for tokens without other pronunciation errors were compared in order to confirm
whether the same tendencies could be attested as for all analyzed tokens. The test indicated
that the difference between glottalized (M = 4.43, SD = .49), and modal tokens (M = 4.30, SD
= .43) was not significant for the measure of comprehensibility, t(30) = -2.03, p > .05.
However, in the case of accentedness rating, significant differences between glottalized (M =
2.29, SD = .53) and modal tokens (M = 3.13, SD = .50) were found, t(41) = 13.07, p < .001.
These results match the ones reported above, confirming that glottalized utterances were
perceived as more foreign accented by native speakers even when there were no other
pronunciation errors involved. The same analyses were conducted for tokens with other pronunciation errors. This
time, significant differences were found between glottalized (M = 3.62, SD = .68) and modal
tokens (M = 3.81, SD = .65) for comprehensibility ratings, t(30) = 2.29, p = .029. These
results suggest that pronunciation errors were more prominent in glottalized tokens, leading to
difficulties in comprehensibility. That is, there may be a correlation between the production of
glottalized hiatus and the production of other errors that influence comprehensibility. In the
case of accentedness, significant differences were found between glottalized (M = 1.92, SD =
.57) and modal tokens (M =2.35, SD = .66), t(41) = 4.00, p < .001. This implies that vowel
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
without other error(s) with other error(s)
mea
n C
om
preh
en
sib
ilit
y r
ati
ng
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
without other error(s) with other error(s)
mea
n A
ccen
ted
ness
ra
tin
g

20
glottalization continued to play a crucial part in in increasing the foreign accentedness of even
in comparison to modal tokens containing other foreign accent features. The effect of the glottalization of vowel hiatus on foreign accent perception is further
evidenced when the scores for tokens without other errors and for tokens with other
pronunciation errors are compared. A paired samples T-Test demonstrated a significant
difference in comprehensibility between glottalized tokens without other errors (M = 4.44, SD
= .45) and modal tokens with pronunciation errors (M = 3.81, SD = .65), t(30) = 8.08, p <
.001. Errors in modal tokens seemed to significantly impact the ease of understanding the
utterances and could be therefore interpreted as being more prominent. However, the same
test revealed that the difference between mean accentedness scores for glottalized tokens
without other errors (M = 2.29, SD = .53) and modal tokens with errors (M =2.35, SD = .66),
were non-significant, t(41) = -.62, p > .05. These results indicate that while the errors in
modal tokens could have impacted comprehensibility, the glottalization of vowel hiatus, even
alone, was just as indicative of foreign accents as the pronunciation errors in modal tokens.
4.5 Discussion
On the whole, the results of the listening tests revealed greater consequences of glottal vs.
modal hiatus for accentedness ratings than for comprehensibility ratings. This is seen in
significant difference in listener ratings between modal and glottal tokens for accentedness,
but not for comprehensibility. Indeed, the high scores for comprehensibility suggest a ceiling
effect by which all the tokens were relatively easy to comprehend. The relatively high
proficiency in English of the Polish speaking respondents probably contributed to this result.
Only three of the Polish participants rated their level of English as intermediate or below, the
remainder were advanced or proficient. In the future we are planning identification and
discrimination tasks to test intelligibility, which we feel will better assess the perceptual
consequences of vowel hiatus realization (see Munro, 2008).
Despite the apparent ceiling effect, there are a few interesting patterns to be observed
in the comprehensibility ratings. The first is that the native tokens were rated as the easiest to
understand. One might expect modally produced hiatus to have detrimental effects on the
comprehensibility of native speech for non-native listeners. English sandhi processes are
associated with a less salient word boundary. According to Cebrian (2000), L2 learners are
subject to a Word Integrity constraint, by which they are predicted to be relatively insensitive
to L2 sandhi processes. Assuming the validity of the Word Integrity hypothesis, the
comprehensibility ratings for the native tokens may come as a surprise. It is possible that the
high proficiency level of the respondents is an indication that they have overcome the Word
Integrity constraint, and the high ratings reflect the absence of other segmental errors.
Alternatively, the Word Integrity hypothesis needs to be reassessed (see Zsiga, 2011 for
evidence and arguments against Word Integrity). Although the differences in comprehensibility ratings between modal and glottalized
tokens were not significant overall, in the case of tokens containing additional segmental
errors, those with glottalized hiatus were rated as more difficult to understand than those with
modal hiatus. While the presence of other errors makes it impossible to claim that
glottalization was the primary factor influencing the ratings, this result could suggest an
overall correlation between glottalization and the presence of other segmental errors in the
speech of L2 learners. Further work is underway to investigate this possibility. With regard to accentedness ratings, our results point to a more direct effect of hiatus
glottalization. Overall glottalized tokens were rated lower than modal tokens (2.23 vs 2.96).
These differences held in tokens both with and without other segmental errors. Interestingly,
the magnitude of this difference was greater in the case of the tokens without additional

21
errors. Such tokens may be claimed to have isolated the effects of the glottalized hiatus
realization. Finally, in the accentedness ratings, modal tokens with other errors were judged
the same or even slightly more native-like (2.35) than glottalized tokens without other errors
(2.29). This finding suggests that L1 English listeners are particularly sensitive to target-like
boundary realization in making accentedness judgments.
5 General Discussion
We turn now the wider implications of our study for the study of L2 phonology. In particular,
we consider issues of phonological representation, investigating the question of ‘what’ is
acquired in L2 speech acquisition. Our experiments have explored a hypothesis that cross-
language differences in the representation of initial vowels govern the placement of a prosodic
boundary in V#V sequences in Polish and English, and that these differences may surface in
the speech of Polish learners of English. In the Onset Prominence framework, Polish initial
vowels are posited as inherently more prominent prosodic entities than initial vowels in
English. As a consequence, they show a greater tendency to be realized with glottal marking
that preserves the salience of the second vowel in V#V sequences. By contrast, in traditional
vernacular dialects of English, prosodically weaker vowels may be joined with the preceding
constituent and are realized without any changes in phonation type.
At this point we consider further implications of the representational differences we
claim underlie the realization of vowel hiatus in the two languages. The key parameter of
submersion was introduced in Section 2 in the context of vowel hiatus. In 5.1, we shall see
that this parameter may extend further into cross-language phonological comparison, unifying
descriptions of vowel hiatus, vowel lengthening, and the behavior of consonants in VC and
VCV contexts. In applying the representational devices of the OP environment to the study of
L1-L2 phonological interaction, we also note the implications of a framework in which
segments and prosodic constituents are constructed from the same representational materials.
Many riddles of interlanguage phonology appear to reside in the gaps between segmental and
prosodic interference. In 5.2 we apply the OP perspective to one such problem: perceptual
epenthesis after coda consonants by Korean learners of English (de Jong & Park, 2012).
5.1 Implications of submersion.
The process of submersion was introduced in (5), which illustrated how adjacent vowel
sequences may merge to form long vowels within words, as well as modal hiatus at word
boundaries. Submersion is a process with far-reaching prosodic implications. It is a form of
phonological recursion of the type proposed by van der Hulst (2010). In his view, coda
consonants may be seen as ‘syllables inside syllables’. In the OP environment, submersion
unifies this view of codas with the representation of long vowels. Additionally, submersion
offers insight into the behavior of consonants in both VC and VCV contexts, with deeper
predictions for the form and behavior of larger prosodic constituents. Let is consider first the behavior of coda consonants. In (6), we see a string of
segmental structures for the English word click. Due to its high position in the
representational hierarchy, the final /k/ may not undergo absorption into the preceding
constituent. To satisfy prosodic prohibitions on syllabic stops, the /k/ is submerged under the
preceding vowel. On the left we see the string of segmental structures, on the right we see the
syllabified form.
(6) Submersion of final /k/ in English click

22
Polish has borrowed the word click, reproducing it as klik, shown in (7).
(7) Polish klik (left) and English click
On the right, the final stop in English click is submerged under the preceding constituent. On
the left the final /k/ in Polish klik is not submerged. In Polish, restrictions against syllabic
stops are satisfied by adjoining the coda to the preceding constituent at a higher level of
structure. From the representations in (7), it is predicted that coda stops in Polish and English
should behave differently. Indeed, in the two languages there is a systematic difference in the
behavior of the final /k/ with regard to the release of the stop. In Polish the release is
obligatory (Dukiewicz & Sawicka 1995), while in English it is frequently suppressed. The
English coda is in a lower prosodic position in the OP hierarchy. Associating lower
hierarchical levels with prosodic weakness, we should expect the English coda to be subject to
lenition processes such as the suppression of release. Submersion appears to be obligatory in
English, as evidenced by the restriction that stressed syllables either contain a long vowel or
coda consonant. Submersion in English is not limited to individual segments – entire syllables may also
be lowered under the preceding constituent. In (8) we offer a representation of the English
word pity. This results in a larger ‘foot’ structure in which the onset to the second syllable is
underneath the first syllable. Such a configuration encodes a generalization sometimes
referred to as ‘ambisyllabicity’ (Kahn 1976), by which the second syllable ‘captures’ the coda
of the first, which is in a prosodically weak position. As a result, the second consonant in a
trochaic CVCV foot is subject to lenition (see Jensen, 2000; Harris, 2004). The /t/ in this word
is realized as a tap or a glottal stop in various vernacular dialects of English. A segmentally
‘similar’ word in Polish, PIT-y ‘tax returns’, would not contain submerged structure. The two

23
constituents would be adjoined at a higher level of structure, and the /t/ is not subject to
lenition processes. The larger foot structure in (8) may also find parallels in the relative
prominence of stressed and unstressed vowels in the two languages. English, of course, is
characterized by significant vowel reduction, while in Polish vowel reduction is less dramatic.
(8) English pity
In sum, our discussion points to an opposition between English and Polish with regard to
relations between individual segmental structures and the primitive CV tree in (1). English
offers the possibility of submersion, associated with long vowels, weak coda consonants, and
weak consonants in VCV contexts. Submersion is absent in Polish. Codas and intervocalic
consonants are generally not subject to weakening, and vowel quantity distinctions are absent.
The submersion parameter also has implications for boundary formation. Submersion of
initial vowels in English has prosodic motivation originating in the lack of VO specification.
The less prominent status of English initial vowels leads weakening processes by which
prosodic constituents do not always respect the boundaries imposed by individual lexical
items. By contrast, in Polish, VO specification and promotion serve to ensure that for the most
part, the terms ‘initial’ and ‘final’ as defined by lexical entries receive a more rigid
interpretation in relation to the phonological shape of words.
A crucial feature of the Onset Prominence model is that segmental representations and
prosodic constituents are constructed of the same structural materials, rather than being joined
by association lines. This perspective provides insight on the relationship between segments
and syllables, which has long been a source of debate in phonological theory (cf. cue vs.
prosodic licensing; e.g. Steriade, 1997), and persistent riddles in the study of L2 phonological
acquisition. In what follows, we apply the OP perspective to one such riddle: perceptual
epenthesis by Korean learners of English (de Jong & Park, 2012).
5.2 Reconciling models of L2 vowel epenthesis
The phenomenon of vowel epenthesis is extremely common among L2 learners, both in
production and perception. The apparent motivation for this process is to repair structures that
are phonotactically illicit in the L1. These may include clusters of consonants, as well as
consonants in coda position. Korean learners of English have received much attention in this
regard. Particularly puzzling is that fact that Korean speakers often epenthesize, both in
production and perception, after L2 coda stops, even though their L1 allows stops in coda
position. De Jong & Park (2012) studied perceptual epenthesis by Korean learners of English.
Their stated goal was to test the predictions of two explanations for epenthesis. According to

24
the first, which attributes epenthesis to ‘functional reparsing’, the process is motivated by the
need to license consonant manner and laryngeal contrasts in a new prosodic position.6 That is,
it serves to ease the task of identifying the consonant in question. In the other model, under
the heading of ‘perceptual misanalysis’, epenthesis is the reinterpretation of consonant release
as the ‘onset’ to an additional syllable, whose ‘nucleus’ is filled by an epenthetic vowel. De
Jong and Park note that authors who have argued for these models often claim that segment-
based and syllable-based explanations for epenthesis are incompatible. To test the two models De Jong & Park (2012) carried out a perceptual experiment in
which L1 Korean listeners engaged in two tasks with stimuli from American English: a
syllable counting task and a segment identification task. Their predictions with regard to the
aforementioned models were as follows. A negative relationship between segment
identification and syllable counting would provide support for the contrast-based model. That
is, more accurate segment identification comes at the cost of less accurate prosodic parsing,
since the additional syllable is claimed to aid in identification of the newly reparsed
consonant. No correlation between the two tasks would support the syllable-based model.
Finally, they posit that a positive relationship between the two tasks would support an
alternative model in which segmental identification and prosodic parsing are two aspects of
the same perceptual process. Their findings showed a positive correlation between syllable
counting and segmental features across individual subjects. Learners who were more accurate
in the syllable counting task (i.e. less likely to hear epenthetic vowels) tended to be more
accurate in identifying segmental features. Thus, it appears that neither of the two tested
models was supported. Rather, as they point out, ‘the present results suggest an overall model
. . . wherein listeners jointly interpret the details of segments and the syllabic position from an
integrated percept (De Jong & Park, 2012: 150)’.
The integrated percept proposed by De Jong & Park may be captured in the Onset
Prominence representational environment, in which segmental and syllabic structures are
constructed from the same hierarchy. Crucially, manner of articulation is a prosodic
specification rather than a segmental feature. Instead of a segmental specification attaching to
prosodic structure by means of association lines, manner is prosodic structure. Thus, any
percept of manner is inevitably integrated with prosody, as De Jong & Park propose. It is also
worth noting that manner accuracy showed the most robust correlation with syllable counting
accuracy in De Jong & Park’s experiment (2012: 145, Figure 4).
5.2.1 Coda adaptation and Korean phonotactic constraints
Epenthesis in the adaptation of English codas into Korean has been classified as a case of
‘unnecessary repair’ (Kang 2011), since L1 Korean does allow coda stops. However, Korean
codas are restricted in two important ways. First, the suppression of stop release is obligatory.
In addition, manner and laryngeal contrasts are neutralized. To provide some perspective on Korean phonotactic constraints, OP representations
for the three Korean labial stops are proposed in (9). Crucially, the framework allows for the
possibility that different melodic specifications may be housed at different levels of the OP
hierarchy in accordance with their phonetic realization. Place is specified as a [labial]
annotation on the Closure node. This is to be expected since it is the location of the closure
that defines stop place of articulation. By contrast, laryngeal features, whose phonetic
realization may be impeded by stop closure, may be assigned at lower levels. This is shown in
(9). Aspiration, which is of course associated with aperiodic noise, is shown as a [spread
glottis] specification on the Noise node. Tenseness is represented as a [constricted glottis]
6 Since Korean features unreleased stops in which place is encoded in coda positions, it might be expected that
Korean listeners should be quite accurate at identifying the place of articulation of coda consonants.

25
([cg]) annotation on the VO node. This feature is associated with a stiffer voice quality on the
onset of the following vowel (e.g. Ladefoged & Maddieson 1996), so the VO node is a natural
structural position for [cg] specifications. With these representations in mind, we may turn to
the representation of codas in Korean, which are characterized by the presence of place
contrasts, but neutralized manner and laryngeal contrasts.
(9) Proposed representations of Korean /p/, /pʰ/, and /p*/
In the OP environment, Korean codas may be attributed to submersion, producing the
structure in (10).
(10) Korean CVC sequence
To explain the fact that Korean maintains place contrasts in coda stops, but neutralizes
laryngeal constrasts, we need only propose a constraint against multiple layers of submerged
structure. That is, Korean, like many other languages, appears to restrict the size of syllable
rimes. The claim would be that Korean only allows a single node under the VT level. The
laryngeal specification, which as we saw in (10) are housed on lower-level nodes, loses its
structural housing and is not realized in this position. This is shown in (10) as the crossed-out
labels of the lower Noise and VO nodes. Thus, the apparent mismatch in Korean between a
licensed place contrast and neutralized laryngeal contrast may be explained as a single
constraint on the size of prosodic constituents.7 With the submerged Noise and VO nodes
eliminated in (10), it also falls out naturally that coda stops in Korean are always produced
without an audible release. The only remaining part of the stop is Closure; the lower nodes
associated with stop release have been eliminated.
Kang (2003) provides evidence that the presence of epenthesis in English loanwords in
Korean is closely related to the probability that the English coda stops are produced with an
audible release. Epenthesis is expected when the target language coda is more likely to
contain a release burst, which in Korean only occurs in syllable onsets. Thus, released stops
are adapted with an additional prosodic constituent whose prominence is enhanced by the
7 This restriction may capture the fact that coda fricatives are also realized as unreleased stops. Space restrictions
prevent us from explaining this in detail.

26
epenthetic vowel. Polish requires stop release in codas.8 In these cases we would claim that
these stops are not submerged under the preceding rhyme. Rather, they remain at their
underlying level of the OP hierarchy. Moreover, epenthesis after coda is standard in the
speech of Korean learners of Polish (Dziubalska-Kołaczyk, p.c.). It is not subject to the same
variability found in Korean English. Kang attributes the link between epenthesis in Korean English and target language
stop release to ‘perceptual similarity’, arguing for the importance of a non-contrastive
phonetic detail, stop release, in the mechanism of loanword adaptation. From the OP
perspective, stop release, though non-contrastive, is not merely a phonetic detail. It is
predictable on the basis of phonological parameters and constraints. The lack of release is
surely a systemic element of Korean phonology; it should be representable in phonological
terms. The OP environment offers phonological tools for the representation of such non-
contrastive phenomena. At the same time, OP representations allow for a unified description
of a range diverse phonological patterns. For example, the claim that submersion is absent
from Polish accounts for the following aspects of Polish phonology: the obligatory release of
coda stops, the lack of vowel length distinctions, the lack of lenition in VCV contexts, and the
tendency for glottalized realization of initial vowels.
6 Final remarks
This paper has presented acoustic and perceptual data on the realization of word-boundary
vowel hiatus in the speech of Polish learners of English. Since the theoretical perspective
from which our research hypotheses were formed lies outside the mainstream viewpoint of
most researchers in generative and applied linguistics, we shall conclude by offering some
clarification of the assumptions underlying our study.
The integration of segmental and prosodic structures in the OP environment is inspired
by the view of phonetic implementation espoused by Natural Phonology (e.g. Donegan and
Stampe 1979). In NP, phonological representations interact directly with speech, without an
intervening level of categorical phonetics. That is, ‘the feature and prosodic specifications of
the phonological representation are interpreted through the action of speaking, in an automatic
but highly contextually-determined way’ (Donegan, 2002: 58). This interpretation is
envisioned in terms of the application and suppression of phonetically-motivated
phonological processes. OP representations facilitate the explicit implementation of this idea,
allowing for more nuanced descriptions of phonetically-motivated phonological behavior than
those afforded by the standard principles of articulatory ease and perceptual clarity. Crucially,
instead of being thought of in linear segmental terms (Øʔ, Ø j, ʔ Ø, etc.), natural
processes are envisioned as adjustments to a hierarchical representation.
This is evident in the present study of vowel hiatus and hiatus resolution, which
suggests that learner success may be facilitated not only through the acquisition of L2
processes, but also through the suppression of L1 processes. Process application and
suppression are closely linked in the NP approach. At the same time, OP structures offer a
new and insightful view on the representational motivation and consequences of NP
processes. For example, vowel glottalization has clear motivation as a listener-friendly
fortition, yet beyond this characterization it has two different interpretations. In languages like
Polish, it preserves or strengthens a segmental structure that defines a prosodic boundary. By
contrast, in languages like English glottalization, when it occurs, adds to the structure of an
initial vowel to introduce a boundary. What is referred to as ‘glide insertion’ is subject to a
8 In current work, we are examining the acquisition of English unreleased stops by Polish learners of English.

27
different interpretation. It appears to be a perceptual process that is not reflected consistently
in production. In this sense it is similar to other perceptual processes in NP (Donegan and
Stampe, 1979), such as the perceptual denasalization process that occurs when English
speaking listeners hear the nasalized vowel in went [w nt] as an oral vowel. In production,
the modal hiatus that induces the glide percept is a speaker-friendly process insofar as it does
not require additional glottal constriction on the V#V sequence. At the same time, however,
the modal realization reflects submersion, a prosodically motivated process with deeper
implications for English phonology. Our study applies a new perspective on NP process application to the field of L2 speech
acquisition. We are not aware of other SLA research linking the glottalization of vowels or its
suppression to other aspects of segmental phonology. The main innovation in our approach
lies in abandoning the assumption that glottalization and modal hiatus/glide insertion are
separate processes. Rather we suggest that the various realizations of vowel hiatus reflect
different aspects of process application within a single representational hierarchy.
References
Babel, M. (2012). Evidence for phonetic and social selectivity in spontaneous phonetic
imitation. Journal of Phonetics 40: 177-189.
Best, C. T. (1995). A direct realist perspective on cross-language speech perception. In W.
Strange (Ed.), Speech perception and linguistic experience: Issues in cross-language research (pp. 171-204). Timonium, MD: York Press.
Best, C. T., & Tyler, M. D. (2007). Nonnative and second-language speech perception:
Commonalities and complementarities. In M. J. Munro & O.-S. Bohn (Eds), Second
language speech learning – the role of language experience in speech perception and
production (pp. 13-34). Amsterdam: John Benjamins.
Boersma, P. & Weenink, D. (2011). Praat: doing phonetics by computer. [Computer
program].Version 5.2.18.
Britain, D. & S. Fox. (2008). Vernacular universals and the regularisation of hiatus resolution.
Essex Research Reports in Linguistics, 57, 1-42. Bybee, J. (2001). Phonology and Language Use. Cambridge: Cambridge University Press.
Cebrian, J. (2000). Transferability and productivity of L1 rules in Catalan-English
interlanguage. Studies in Second Language Acquisition, 22, 1-26. Chang, C. 2012. Rapid and multifaceted effects of second language learning on first language
speech production. Journal of Phonetics 40, 249-268.
Cook, A. 1991. American Accent Training. Hauppauge, NY: Barron’s Educational Series, Inc. Cooke, M., J. Barker, M. Lecumberri (2013). Crowdsourcing in Speech Perception, In M.
Eskenazi, G. Levow, H. Meng, G. Parent and D. Sundermann (Eds.), Crowdsourcing
for Speech Processing. 137-172. Hoboken, NJ: John Wiley and Sons.
Crosswhite, K. (2003). Spectral tilt as a cue to word stress in Macedonian, Polish, and
Bulgarian. In Sole, M.J., D. Recasens & J. Romero (eds.). Proceedings of XVth
International Congress of Phonetic Sciences, Barcelona, 767-770. Cruttenden, A. 2001. Gimson’s Pronunciation of English (6
th ed.). London: Arnold.
Crystal, T. & A.S. House. (1988). The duration of American English stop consonants: an
overview. Journal of Phonetics, 16, 285-294.
Davidson, L. and D. Erker. (To appear). Hiatus resolution in American English: the case
against glide insertion. Language.

28
Derwing, T. M., & Munro, M. J. (1997). Accent, intelligibility, and comprehensibility:
Evidence from four L1s. Studies in Second Language Acquisition, 19, 1-16.
Dogil, G. (1999). The phonetic manifestation of word stress in Polish, Lithuanian, Spanish,
and German. In H. van der Hulst (ed.), Word Prosodic Systems in the Languages of
Europe (pp. 273-311). New York: Mouton de Gruyter. Donegan, P. (2002). Phonological processes and phonetic rules. In: Future Challenges for
Natural Linguistics, ed. Katarzyna Dziubalska-Kołacyk and Jarosław Weckworth, pp.
57-81. (LINCOM Studies in Theoretical Linguistics 30.) Muenchen: LINCOM
EUROPA
Donegan, P. and D. Stampe. (1979). The study of natural phonology. In: Current Approaches
to Phonological Theory (Conference on the Differentiation of Current Phonological
Theories, Bloomington, Sept. 30-Oct. 1, 1977), ed. Daniel A. Dinnsen, pp. 126-173.
Bloomington: Indiana University Press
Downing, Laura. 1998. On the prosodic misalignment of onsetless syllables. Natural
Language & Linguistic Theory, 16, 1-52.
De Jong, K. & H. Park. (2012). Vowel epenthesis and segmental identity in Korean learners
of English. Studies in Second Language Acquisition, 34, 127-155. Dilley, L., S. Shattuck-Hufnagel & M. Ostendorf. (1996). Glottalization of word-initial
vowels as a function of prosodic structure. Journal of Phonetics, 24, 423-444.
Dukiewicz, L. & I. Sawicka. (1995). Gramatyka współczesnego języka polskiego – fonetyka i fonologia [Grammar of modern Polish – phonetics and phonology]. Krakow:
Wydawnictwo Instytutu Języka Polskiego PAN. Escudero, P. & Boersma, P. (2004). Bridging the gap between L2 speech perception research
and phonological theory. Studies in Second Language Acquisition, 26, 551-585.
Flege, J. and W. Eefting (1987). Cross language switching in stop consonant perception and
production by Dutch learners of English. Speech Communication 6, 185-202. Goldinger, S. (1997). Perception and production in an episodic lexicon. In Johnson, K.
Mullennix, J. W. (eds.). Talker Variability in Speech Processing (pp. 33-66). San
Diego: Academic Press. Goldinger, S. (1998). Echoes of echoes? An episodic theory of lexical access. Psychological
Review, 105 (2), 251-279.
Gussmann, E. (2007). The phonology of Polish. Oxford: Oxford University Press. Hansen Edwards, J. & M. Zampini. Phonology and Second Language Acquisition.
Amsterdam: John Benjamins. Harris, J. (2004). Release the captive coda: the foot as a domain of phonetic interpretation. In
J. Local, R. Ogden & R. Temple (eds.), Phonetic interpretation: Papers in Laboratory
Phonology 6, 103-129. Cambridge: Cambridge University Press.
Hewings, M. and S. Goldstein. 1999. Pronunciation plus: Practice through interaction.
Cambridge: Cambridge University Press. Hillenbrand, J. and R. Houde. 1996. The role of F0 and amplitude in the perception of
intervocalic glottal stops. Journal of Speech and Hearing Research 39. 1182–1190
Honorof, D. N., Weihing, J., Fowler, C. A. (2011). Articulatory events are imitated under
rapid shadowing. Journal of Phonetics 39: 18-38. Howard, M. (2008). 'On the role of naturalistic and classroom exposure in the acquisition of
socio-phonological variation: A longitudinal study of French liaison'. Journal of
Applied Linguistics, 5 (2), 159-179. van der Hulst, H. 2010. A note on recursion in phonology. In H. van der Hulst, (ed.).
Recursion and Human Language, 301-342. Berlin: Mouton de Gruyter.
Jensen, J. (2000). Against ambisyllabicity. Phonology 17: 187-235.

29
Johnson, K. (1997). Speech perception without speaker normalization: an exemplar model. In
K. Johnson & J. Mullennix, (Eds.). Talker variability in speech processing (pp. 145-
166). San Diego: Academic Press. Kahn, D. (1976). Syllable-based generalizations in English phonology. PhD dissertation,
Massachusetts Institute of Technology.
Kang, Y. (2003) Perceptual similarity in loanword adaptation: English post-vocalic word-final
stops to Korean. Phonology 20 (2): 219-273.
Kang, Y. (2011) Loanword phonology. In van Oostendorp, Marc, Colin Ewen, Elizabeth
Hume, and Keren Rice, eds., Companion to Phonology. Wiley-Blackwell.
Ladefoged, P. and I. Maddieson. (1996). The Sounds of the World’s Languages. Oxford:
Blackwell.
Lecumberri, M. and J. Maidment (2000). English transcription course. Oxford: Routledge.
Levi, S. (2008). Phonemic vs. derived glides. Lingua, 118,1956-1978.
Lindblom, B. (1990). Explaining phonetic variation: a sketch of the H&H theory. In Speech
Production and Speech Modelling, edited by W. J. Hardcastle and A. Marchal (The
Netherlands: Kluwer Academic), pp. 403-439.
LLeo, C. & I. Vogel. (2004). Learning new segments and reducing domains in German L2 phonology: The role of the Prosodic Hierarchy. International Journal of
Bilingualism, 8, 79-104. Lujan, A.B. 2006. The American Accent Guide (2
nd ed.). Salt Lake City: Lingual Arts.
McCarthy, J. 1993. A case of surface constraint violation. Canadian Journal of Linguistics,
38.169-95.
Malisz, Z, M. Żygis & B. Pompino-Marschall. (2013). Rhythmic structure effects on
glottalisation: a study of different speech styles in Polish and German. Laboratory
Phonology, 4, 119-158. Marlett, S. & J. Stemberger. (1983). Empty consonants in Seri. Linguistic Inquiry, 14, 617-
639.
Munro, M. J. (2008). Foreign accent and speech intelligibility. In Hansen Edwards, J. G. &
Zampini, M. L. (Eds.). Phonology and Second Language Acquisition (pp. 193-218).
Amsterdam: John Benjamins.
Newlin-Łukowicz, L. (2012). Polish Stress: looking for phonetic evidence of a bidirectional
system. Phonology, 29(2), 271-329.
Pardo, J. S., Gibbons, R., Suppes, A. & Krauss, R. M. (2012). Phonetic convergence in
college roommates. Journal of Phonetics, 40, 190-197. Pierrehumbert, J. (2001) Exemplar dynamics: Word frequency, lenition, and contrast. In J.
Bybee and P. Hopper (eds.) Frequency effects and the emergence of lexical structure.
John Benjamins, Amsterdam. 137-157.
Plag, I., G. Kunter, & M. Schramm. (2011). Acoustic correlates of primary and secondary
stress in North American English. Journal of Phonetics,39, 362-374.
Prince, A. & P. Smolensky. 1993. Optimality Theory: Constraint interaction in a generative grammar. Rutgers University Optimality Archive.
Redi, L. & S. Shattuck-Hufnagel. (2001). Variation in the realization of glottalization in
normal speakers. Journal of Phonetics, 29, 407-429. Roach, P. 2009. English Phonetics and Phonology. Cambridge: Cambridge University Press
Rojczyk, A. (2012). Phonetic and phonological mode in second-language speech. VOT
imitation. Paper presented at EUROSLA 2012, Poznań, Poland, September 5-8 2012. Rojczyk, A. (2013). Phonetic imitation of L2 vowels in a rapid shadowing task. In Lewis, J &
LeVelle, K. (eds). Proceedings of the 4th Pronunciation in Second Language Learning
and Teaching Conference (pp. 66-76). Ames, IA: Iowa State University.

30
Rojczyk, A., Porzuczek, A. & Bergier, M. (2013). Immediate and distracted imitation in
second-language speech: Unreleased plosives in English. Research in Language, 11, 3-
18. Rubach, J. (2000). Glides and glottal stop insertion in Slavic languages – a DOT accoutn.
Linguistic Inquiry, 31 (2), 271-317. Schwartz, G. (2013a). Vowel hiatus at Polish word boundaries – phonetic realization and
phonological implications. Poznań Studies in Contemporary Linguistics, 49 (4), 557-
585. Schwartz, G. (2013b). A representational parameter for onsetless syllables. Journal of
Linguistics, 49 (3), 613-646. DOI: http://dx.doi.org/10.1017/S0022226712000436. Schwartz, G., A. Balas & A. Rojczyk. (to appear). External sandhi in L2 segmental phonetics
– final (de)voicing in Polish English. In Proceedings of New Sounds 2013.
Shockley, K., Sabadini, L. & Fowler, C. A. (2004). Imitation in shadowing words. Perception
and Psychophysics, 66, 422-429. Shoemaker, E. (2010). Nativelike Attainment in L2 Listening: The segmentation of spoken
French. In Dziubalska-Kołaczyk, K., M. Wrember & M. Kul (eds.) Proceedings of the
6th international symposium on second language speech, New Sounds 2010, Poznań,
Sluijter, Agaath M.C. & Vincent J. van Heuven. 1996. Spectral balance as an acoustic
correlate of linguistic stress. Journal of the Acoustical Society of America, 100, 2471-
2485.
Steriade, D. 1997. Phonetics in phonology – the case of laryngeal neutralization. Ms. UCLA.
Sturm, J. (2013). Liaison in L2 French: The effects of instruction. In. J. Levis & K. LeVelle
(Eds.). Proceedings of the 4th
Pronunciation in Second Language Learning and
Teaching Conference, Aug. 2013 (pp. 157-166). Ames, IA: Iowa State University.
Uffmann, C. 2007. Intrusive [r] and optimal epenthetic consonants. Language Sciences,
29.451-76.
Wells, J.C. Longman Pronunciation Dictionary (3rd
ed.). Harlow: Pearson Education Limited.
Wiese, R. (2000). The phonology of German. Oxford: Clarendon Press. Wright, R. (2004). Perceptual cue robustness and phonotactic constraints. In Hayes, B., R.
Kirchner and D. Steriade (eds). Phonetically Based Phonology. Cambridge: Cambridge University Press, 34-57.
Yuasa, I. (2010). Creaky voice: a new feminine voice quality for young urban-oriented
upwardly mobile American women? American Speech, 85, 315-37. Zsiga, E. (2003). Relearning consonant timing. Studies in Second Language Acquisition, 25,
399-432. Zsiga, E. (2011). External sandhi in a second language: The phonetics and phonology of
obstruent nasalization in Korean and Korean-accented English. Language 87. 289 - 345.

31
Appendix 1 – stimuli for production experiment
1-stay out 2-try out
3-see all 4-way out 5-go out 6-know everything 7-saw everything
8-play it 9-know Alex 10-how interesting
11-know after 12-grow excellent 13-try each 14-they always
15-go every day 16-they actually 17-car always 18-your idea
19-the other 20-the end 21-they asked
22-be afraid
23-tell me all 24-I often 25-sure I
26-holiday activities
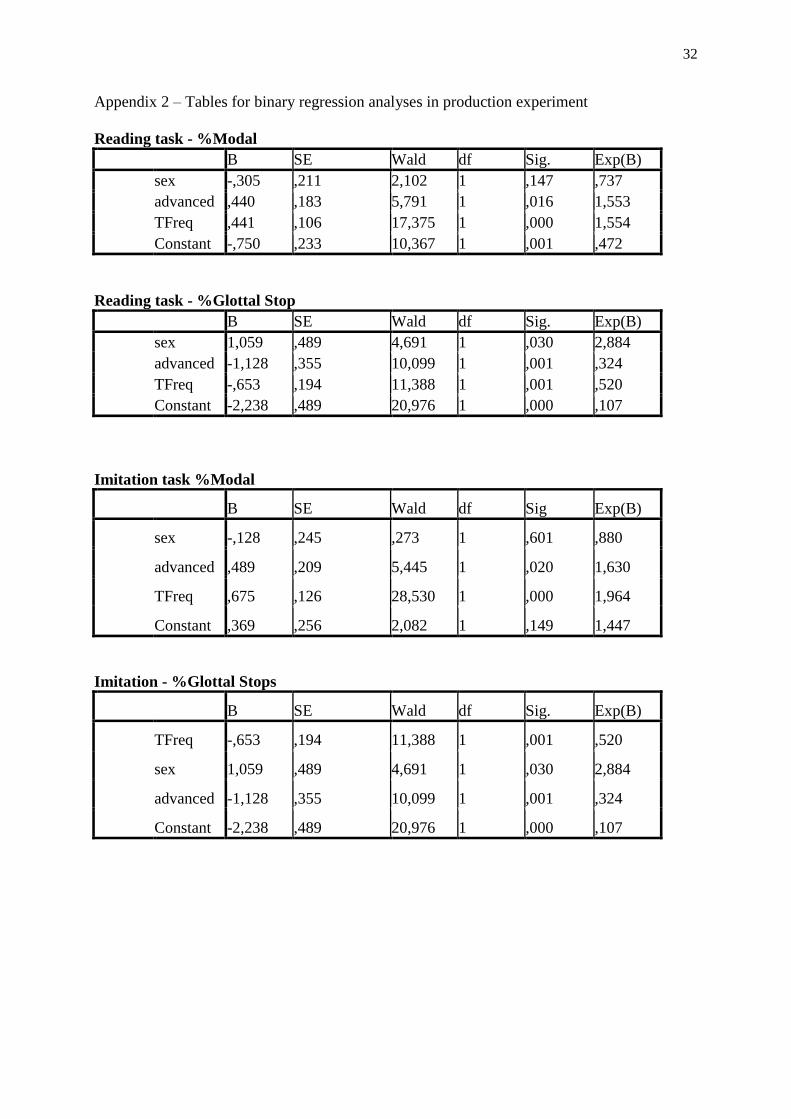
32
Appendix 2 – Tables for binary regression analyses in production experiment
Reading task - %Modal
B SE Wald df Sig. Exp(B)
sex -,305 ,211 2,102 1 ,147 ,737
advanced ,440 ,183 5,791 1 ,016 1,553
TFreq ,441 ,106 17,375 1 ,000 1,554
Constant -,750 ,233 10,367 1 ,001 ,472
Reading task - %Glottal Stop
B SE Wald df Sig. Exp(B)
sex 1,059 ,489 4,691 1 ,030 2,884
advanced -1,128 ,355 10,099 1 ,001 ,324
TFreq -,653 ,194 11,388 1 ,001 ,520
Constant -2,238 ,489 20,976 1 ,000 ,107
Imitation task %Modal
B SE Wald df Sig Exp(B)
sex -,128 ,245 ,273 1 ,601 ,880
advanced ,489 ,209 5,445 1 ,020 1,630
TFreq ,675 ,126 28,530 1 ,000 1,964
Constant ,369 ,256 2,082 1 ,149 1,447
Imitation - %Glottal Stops
B SE Wald df Sig. Exp(B)
TFreq -,653 ,194 11,388 1 ,001 ,520
sex 1,059 ,489 4,691 1 ,030 2,884
advanced -1,128 ,355 10,099 1 ,001 ,324
Constant -2,238 ,489 20,976 1 ,000 ,107
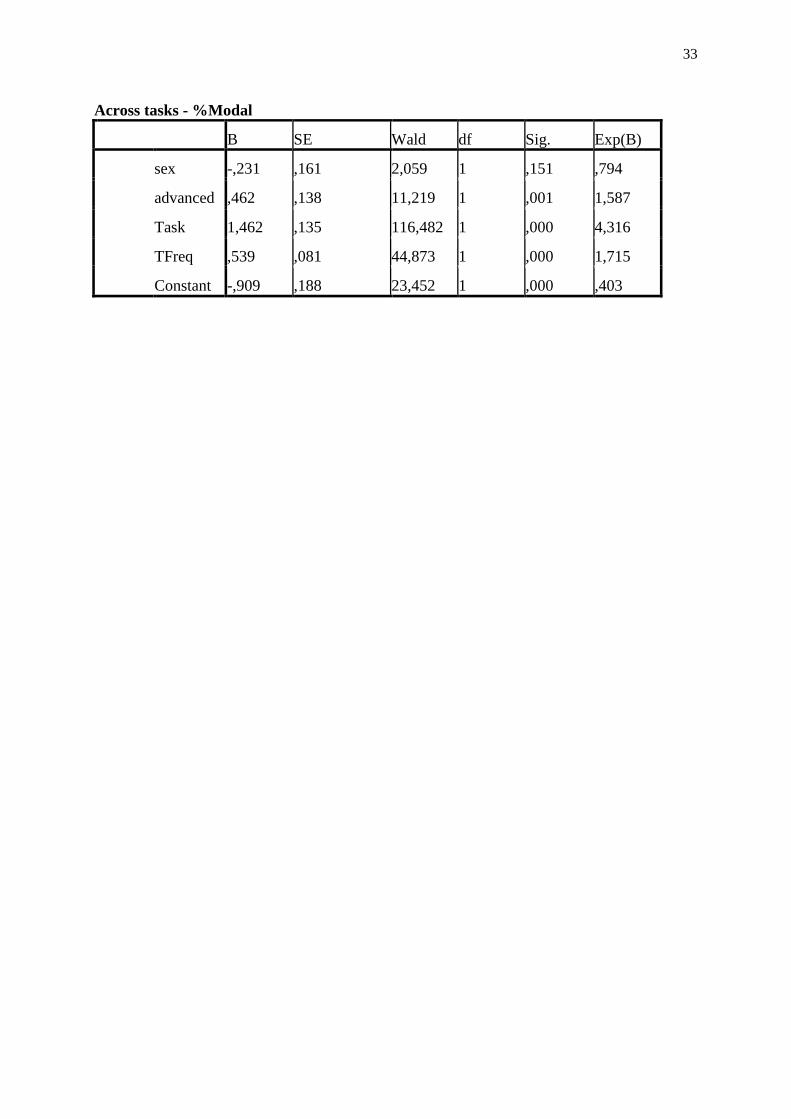
33
Across tasks - %Modal
B SE Wald df Sig. Exp(B)
sex -,231 ,161 2,059 1 ,151 ,794
advanced ,462 ,138 11,219 1 ,001 1,587
Task 1,462 ,135 116,482 1 ,000 4,316
TFreq ,539 ,081 44,873 1 ,000 1,715
Constant -,909 ,188 23,452 1 ,000 ,403
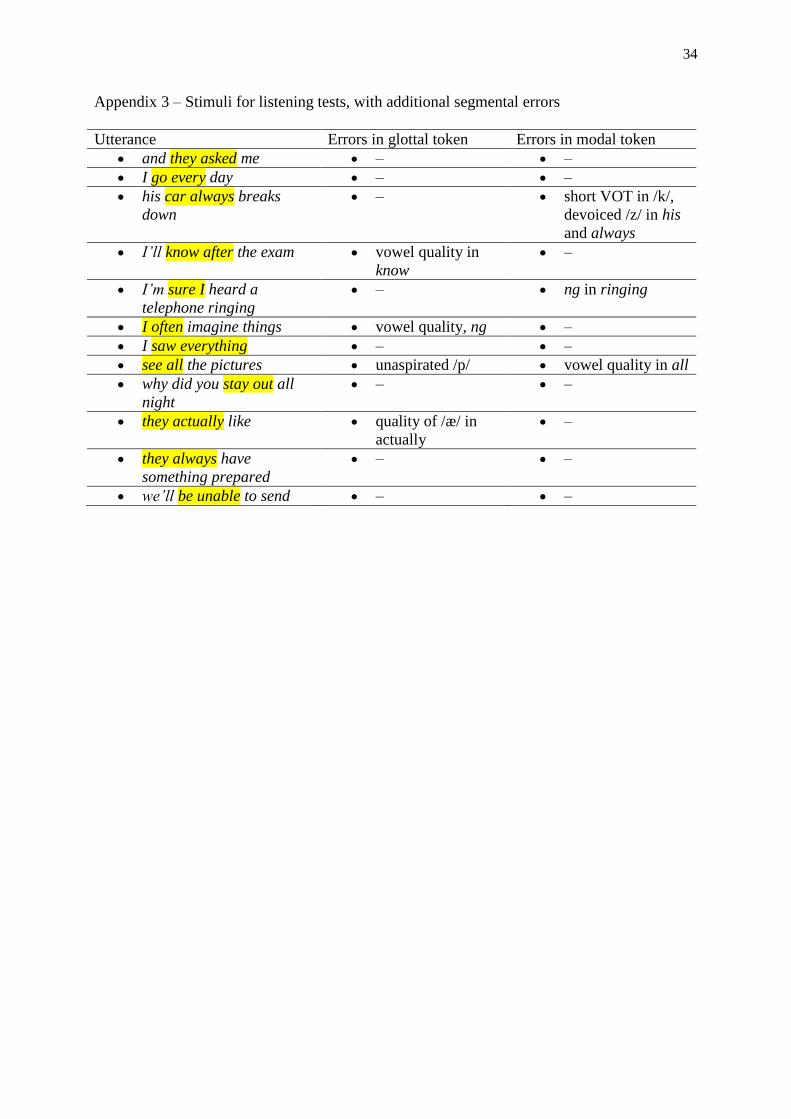
34
Appendix 3 – Stimuli for listening tests, with additional segmental errors
Utterance Errors in glottal token Errors in modal token
and they asked me – –
I go every day – –
his car always breaks
down – short VOT in /k/,
devoiced /z/ in his
and always
I’ll know after the exam vowel quality in
know –
I’m sure I heard a
telephone ringing – ng in ringing
I often imagine things vowel quality, ng –
I saw everything – –
see all the pictures unaspirated /p/ vowel quality in all
why did you stay out all
night – –
they actually like quality of /æ/ in
actually
–
they always have
something prepared
– –
we’ll be unable to send – –




















