Embed Size (px)
Citation preview

Int J Speech Technol (2008) 11: 157–165DOI 10.1007/s10772-009-9048-2
Text segmentation of spoken meeting transcripts
Bernadette Sharp · Caroline Chibelushi
Received: 17 July 2009 / Accepted: 13 October 2009 / Published online: 12 November 2009© Springer Science+Business Media, LLC 2009
Abstract Text segmentation has played an important role ininformation retrieval as well as natural language processing.Current segmentation methods are well suited for writtenand structured texts making use of their distinctive macro-level structures; however text segmentation of transcribedmulti-party conversation presents a different challenge givenits ill-formed sentences and the lack of macro-level textunits. This paper describes an algorithm suitable for seg-menting spoken meeting transcripts combining semanticallycomplex lexical relations with speech cue phrases to buildlexical chains in determining topic boundaries.
Keywords Text segmentation · Lexical chaining ·Multi-party transcript analysis
1 Introduction
The problem of text segmentation has been the recent focusof many researchers as more and more applications requirethe tracking of topics whether for summarization (Zech-ner 2001), automatic genre detection (Pevzner and Hearst2002), question answering (Chai and Jin 2004), retrievaltasks of textual documents (Oard et al. 2004) or patentanalysis (Tsenga et al. 2007). Since 9/11 text segmenta-tion became one of the common techniques used to detectthe threads contained in instant messaging and internet chat
B. Sharp (�) · C. ChibelushiStaffordshire University, FCET, Beaconside, Stafford ST18 0AD,UKe-mail: [email protected]
C. Chibelushie-mail: [email protected]
forums for various applications, including information re-trieval, expert recognition and even crime prevention (Ben-gel et al. 2004). The increasing interest in segmenting con-versations is reflected in the multiple applications analysinga variety of corpora ranging from news broadcasts (Mulbregtet al. 1998), to emails (Lampert et al. 2009), chat rooms(Bengel et al. 2004) and spoken lectures (Kawahara et al.2001), and adopting different units of analysis, ranging fromutterance (Gruenstein et al. 2005; Strayer et al. 2003; Bo-ufaden et al. 2001), paragraph and sentence (Hearst 1994),phrase and discourse markers (Kawahara et al. 2001), towords (Flammia 1998; Mulbregt et al. 1998).
Text segmentation can be carried out on audio, video andtextual data; its aim is to partition a text into topically con-tiguous segments using a number of topic shift indicators indelimiting their boundaries. Typical topic boundaries haveincluded repetitions such as patterns of word and/or wordn-gram repetition, word frequency, linguistic cue words,phrases and synonyms. Surface characteristics of the lan-guage can be used to identify shifts in topic. As Arguelloand Rosé (2006) explain, in dialogue, though topic analy-sis focuses mainly on thematic content, boundaries shouldbe placed in locations that are natural turning points in thediscourse.
In this paper we present an algorithm for text segmen-tation relevant to transcribed meetings involving a multi-party conversation. While previous research has focusedmostly on well structured documents such as expositorytexts, broadcast news and monologues, consisting of cohe-sive stories, our corpus contains incomplete sentences, rep-etitions, social chatting, interrupts and visual cues. Conse-quently, the analysis of these transcripts is a challenging taskgiven their poor structure, spontaneous nature of communi-cation and often argumentative nature as well as their infor-mal style. Unlike expository texts they can include digres-

158 Int J Speech Technol (2008) 11: 157–165
sions, interjections and lack both punctuation and macro-level text units such as headings and paragraphs. Linguisticcues such as intonation and the use of pauses are common inspeech; however these were not transcribed, adding anotherdimension of complexity to our research.
The motivation for our research project stems from theneed to address the problem of rework as many softwareprojects spend 40% to 50% of their efforts on avoidable re-work (Boehm and Basili 2001). Hence one of the aims ofour project is to analyse a set of transcribed meetings dis-cussing software development, in order to identify the topicsdiscussed at these meetings and extract the decisions, theirassociated issues and actions over the life cycle of the soft-ware project. These elements can then be fed into a softwaretool to support project managers in overseeing decisions andactions that could lead to avoidable rework.
In this paper we begin by reviewing the methodologiesassociated with text segmentation and then we describe ourTracker Text Segmentation (TTS) approach to segmentingtranscribed meeting conversations. Finally we discuss theresults and the limitations of our algorithm, and concludeour research by outlining future research directions.
2 Previous work
Research into segmentation of transcribed spoken textshas been largely motivated by the topic detection andtrack (TDT) programme, which was an integral part of theDARPA Translingual Information Detection, Extraction andSummarization (TIDES) program. As a result a numberof algorithms were developed with the aim of discover-ing topically related material in the newswire and broad-cast news domain. The literature review of text segmen-tation techniques reveals two distinct approaches: statisti-cally based and linguistically driven methods. Some sta-tistical approaches tend to be based on probability distri-butions (Beeferman et al. 1999), machine learning tech-niques ranging from neural networks (Bilan and Naka-gawa 2005) to support vector machines (Reynar 1998) andBayesian inference (Stokes 2003; Eisenstein 2009) whileothers treat text as an unlabelled sequence of topics using ahidden Markov model (Yamron et al. 1998; Youmans 1991;Mulbregt et al. 1998). Linguistic based text segmentationapproaches are derived from the lexical cohesion theoryof Halliday and Hasan (1976). They rely on terms repe-tition to detect topic changes (Reynar 1998; Hearst 1994;Youmans 1991), n-gram word or phrases (Levow 2004) orword frequency (Senda and Yamada 2001; Reynar 1999;Beeferman et al. 1997) as well as lexical chaining to identifytopic changes (Stokes 2004; Manning 1998) and prosodicclues to mark shifts to new topics (Levow 2004). To improvethe accuracy of a text segmentation algorithm Choi et al.(2001) applied Latent Semantic Analysis (LSA), a technique
aimed at extracting and representing the contextual-usagemeaning of words by statistical computations applied to alarge corpus (Landauer and Dumais 1997). However mostlexical cohesion-based segmentation approaches use lexicalrepetition as a form of cohesion and ignore the other types oflexical cohesion such as synonym, hypernymy, hyponymy,meronymy (Stokes 2004). Galley et al. (2003) make useof linguistic and acoustic cues to detect topic shifts fromspeech. A different approach is adopted by Passoneau andLitman (1997) who combine decision trees with linguisticfeatures extracted from spoken texts.
The above segmentation methods are well suited forwritten and structured texts making use of their distinc-tive macro-level structures which are deficient in transcribedspeech texts. The topic boundaries in our transcripts areoften fuzzy, some topics are re-visited at different stagesof the meeting; furthermore some participants do not al-ways follow the intended agenda, rendering the segmenta-tion process a more difficult task. As a result we neededto develop a segmentation method which could handle thecomplexity and the lack of structure yet building on themacro-level structures pertinent to transcribed texts such asthe notion of utterance, the spontaneous speech cue phrases,and domain specific knowledge to build an effective seman-tic lexical chaining. Cue phrases act as linguistic markersused by speakers to announce and/or indicate the impor-tance of the next utterance; they function as explicit indi-cators of discourse structure and can help identify segmentboundaries (Hirschberg and Litman 1993).
3 The corpus
Our research project, known as the Tracker project, is basedon 17 transcripts recorded from three diverse meeting en-vironments: industrial, organisational and educational. Eachtranscript represents a multi-party conversation, containingan accurate and unedited record of the meetings and corre-sponding speakers. The meeting transcripts vary in size from2,479 to 25,670 words involving 310 to 1431 utterances; fewhave a pre-set agenda.
In this paper, we focus the analysis on 7 transcriptswhich relate to meetings relevant to software developmentprojects. Typical issues discussed in these meeting were sys-tems demonstration, project management, software integra-tion and staff recruitment. The duration of the meetings var-ied from 30 to 120 minutes.
4 Tracker text segmentation (TTS) algorithm
Tracker text segmentation (TTS) algorithm is based onthe TextTiling method developed by Hearst which was ap-plied in hypertext and information retrieval tasks. TextTil-

Int J Speech Technol (2008) 11: 157–165 159
Table 1 Speech cue phrasesextracted from our corpus The reason we are having this meeting So that’s it, really for that mode
This meeting is about can we get some business done then
The main issue is Can we start with agenda items
The first problem is We could jump over to
The first item so do you want to move onto next one
The first agenda item shall we whiz through onto
The first item on agenda We seem to be down to
Tell you what before we finish Any other Business
do you want to move on-to the next one The other thing is
ing is a technique aimed at dividing an expository text intomulti-paragraph sub-topical segments making use of pat-terns of lexical co-occurrence and distribution within texts,based solely on term repetition, and avoiding other kindsof discourse cues namely synonyms which are consideredas thematically-unrelated (Hearst 1997, 1994, 2002). It in-volves tokenization, lexical score determination which com-pares the similarity of adjacent segments and boundary iden-tification. It applies the concept of a sliding window overthe vector-space representation of the text. At each posi-tion, the cosine correlation between the upper and lowerregions of the sliding window is computed to predict thesegment boundary. Whilst TextTiling subdivides a text intopseudo-sentences of a predefined size, referred to as token-sequences (Hearst 1994), our algorithm uses the concept ofutterance as the base unit of analysis, which is defined as aunit of speech bounded by silence. In dialogue, each turn bya speaker may be considered an utterance (Crystal 1991).
In a meeting with discussion on specific issues, one canassume that a given speaker’s utterance will relate to con-cepts that have been previously mentioned by other speak-ers. These concepts, and the relations between them, providethe basis for a set of cohesive chains that can help in extract-ing the key topics discussed in these meetings. Halliday andHasan (1976) identified five cohesive resources which allowa text to ‘hang together as a whole’, namely lexical cohesion,reference, substitution, conjunction and ellipsis. Lexical co-hesion is based on semantic relationships between conceptsand can include repetition, synonymy, near synonymy andcollocation. Reference can include demonstratives, definitearticle, pronouns and adverbs. Conjunction tends to connectutterances through verbs, prepositions and nouns (e.g. be-cause, therefore, given that. . . , the reason is. . . ). Substitu-tion occurs when another word replaces the concept beingdiscussed. Typical ellipsis found in our transcripts includeexpressions such ‘yes I did it’, ‘did it work’.
Although our cohesive chains algorithm is based on thenotion of the cohesion resources of Halliday and Hasan, itfocuses primarily on noun and compound nouns in build-ing the lexical chains. It employs not only the lexical cohe-
Fig. 1 TTS segmentation approach
sion relationships between terms, such as word repetition,word collocation, synonymy, hypernymy (ISA relation), hy-ponymy (kind-of relation) and meronymy (part-of relation),but it is also able to capture the hierarchical and the tran-sitivity relationships by making use of WordNet (Fellbaum1998) and our built-in domain specific semantic network.These lexical chains serve as the basis for text segmentation.
The algorithm also makes use of discourse markers andspeech cue phrases, which are pragmatic markers and playan important role in signalling topic changes; they also pro-vide a commentary on the following utterance (Fraser 1996).A list of these markers is given in Table 1.
There are four main phases performed by TTS: (i) pre-processing, (ii) initial segmentation, (iii) intermediate and(iv) final segmentation (Fig. 1). A detailed description ofTTS can be found in Chibelushi (2008).

160 Int J Speech Technol (2008) 11: 157–165
4.1 Pre-processing stage
The pre-processing stage is common to many text segmen-tation approaches. It involves tokenization, POS tagging us-ing Wmatrix, case folding and identification of compoundconcepts. Wmatrix is a semantic analyser which uses thePOS-tagged text to assign semantic tags to capture the gen-eral sense field of words from a lexicon of single words andmulti-word combinations (Rayson 2003). By combining theresults from Wmatrix and WordNet with the algorithm foridentifying compound words developed by Sharp (1989) weare able to build the hierarchical and the transitivity relation-ships between these concepts which provide the basis for thelexical chaining in the subsequent phases.
4.2 Initial segmentation
This phase involves the segmentation of the stream of tran-scribed meetings into topically cohesive items of discussion.It is based on the sliding window approach developed byHearst (1994) and later adopted by Reynar (1998). The slid-ing window divides the text into multi-paragraph blocks andthen using a vector space model to represent each sentenceit measures the similarity of two consecutive blocks usingthe cosine value, which is a measure widely used in Infor-mation Retrieval systems to evaluate the similarity betweena query and a document. Instead of using paragraphs as thecore base for segmentation our algorithm is based on thenotion of utterance. Consequently the cosine function mea-sures the similarity between utterances, referred to hence-forth as the Utterance Cosine Similarity (UCS).
An utterance Ui is defined as Ui = {W1 . . .Wn}, whereby,Wi can be a noun (e.g. laptop) or a compound noun con-cept (e.g. software development). A transcript vector matrixis generated consisting of a set of term frequency vectors
fi which capture the presence or absence of a given con-cept and record its frequency in each utterance. For exam-ple, in a transcript, consisting of 2 utterances and containing4 distinct concepts (i.e. size, board, laptop and edge), thefrequency vector fi for each utterance is represented as fol-lows:
U1: Can you change the size of the board on this laptop?U2: You can change the size of the board here, you just need
to draw round the edge of the board and see where itappears on the board.
f1 = {1,1,1,0}f2 = {1,3,0,1}In order to identify the similarity (sim) between two ut-terances Ui and Uj , we apply the UCS measure, denotedsim(Ui,Uj ), and defined as follows:
sim(Ui,Uj ) = cos(fi, fj ) =∑
k fik × fjk√
(∑
k f 2ik) × (
∑k f 2
jk)
where 0 ≤ cos(fi, fj ) ≤ 1.∑
k fik × fjk is the inner product of fi and fj , whichmeasures how much the two vectors have in common.√
(∑
k f 2ik) × (
∑k f 2
jk) is a product of the two vector
lengths which is used to normalise the vectors.The cosine similarity measure assumes that similar terms
tend to occur in similar segments. In such instances, the an-gle between them will be small, and the cosine similaritymeasure will be closer to 1. Utterances with little in com-mon will have dissimilar terms, the angle between them willbe close to π/2 and the UCS measure will be close to zero.
A UCS matrix can then be prepared based on the com-parison of each utterance with every other utterance in thetranscript. An example of this matrix is shown in Fig. 2. The
Fig. 2 An example of a UCSmatrix

Int J Speech Technol (2008) 11: 157–165 161
Fig. 3 Lexical chains intranscript 120902TR
Fig. 4 Sliding window effect
blank lines in Fig. 2 contain zero vectors; these zeros are re-moved for clarity. Following the analysis of our corpus thethreshold value was set to .5 yielding the temporary windowsegments.
4.3 Intermediate segmentation
This phase is based on the work of Morris and Hirst (1991)proposing the use of lexical chains to determine the struc-ture of a given text. It involves two processes: the building oflexical chains by connecting semantically related nouns andcompound nouns in an attempt to discover the boundaries ofeach topic, and the identification of their strength and signif-icance in order to ascertain the correctness of the boundariesof the temporary window segments. Figure 3 shows a plot ofthe lexical chains for transcript 120902TR. A number of lex-ical chains start at window 1, A appears to dominate in thefirst two windows, followed by B in the following windowsand taken over by C which fades away in window 9. In this
transcript the lexical chain A, with the highest frequency,appeared to describe the main topic of conversation, and istherefore referred to as the topic chain. Lexical chains B andC, the less frequent chains, tended to cover sub-topics.
If two chains have the same frequency, they are usedto slide the window, the chain that covers the biggest areaof the transcript segment is chosen as the active chain andused to modify the window size. This step is based on thealgorithm of Passoneau and Litman (1997) which explainsthat ‘a high concentration of chain-begin and end points be-tween the two adjacent textual units is a good indication ofa boundary point between two distinct news stories’.
4.4 Final segmentation
The final segmentation phase examines the new expandedwindow segment and search for any speech cue phrases toconfirm its boundaries (Fig. 4). Unlike the domain indepen-dent cues used by Kan et al. (1998) and the domain spe-

162 Int J Speech Technol (2008) 11: 157–165
Table 2 TTS lexical chaining results
Transcript ID No of words No. of lexicalchains
No. ofparticipants
000403AL 2479 90 2
120802TR 13962 428 9
290701TR 11471 667 10
120901TR 12062 682 4
000GM0F 19977 895 9
200602TR 25670 965 7
000BR00 20746 1076 5
cific cues used by Reynar (1998), our speech cue phraseswere transcript dependent and manually compiled from ourcorpus. The final lexical chains varied from 90 to 1076. Itappears that the number of participants in each transcripthas played no role in the boundary identification of lexicalchains. Table 2 shows the results of TTS lexical chainingalgorithm applied on 7 transcripts.
5 Evaluation and results
The segmentation was evaluated by comparing TTS againstthe two common techniques, TextTiling and C99 (Choi etal. 2001). Three types of evaluation metrics were used, Pk
(Beeferman et al. 1997), P ′k and WindowDiff. These three
metrics have become standard criteria for evaluating textsegmentation methods as precision and recall are found in-adequate for text segmentation. Pk , which measures theprobability of a randomly chosen pair of words within awindow of length k words being inconsistently classified, isshown to penalize false negatives more than false positivesand tends to allow some errors to go unpenalized. Conse-quently Pevzner and Hearst (2002) proposed two metrics,P ′
k and WindowDiff, given below, to address the shortcom-ings of P ′
k .
(i) Pk(ref ,hyp) =∑
1≤i≤j≤n
D(i, j)(δref (i, j)⊕ δhyp(i, j))
where ref is reference segmentation and hyp is hypothesizedsegment. The value k is calculated by setting it to half theaverage expected segment size. δref (i, j) and δhyp(i, j) arebinary indicators functions set to 1, if sentences i and j arein the same topic segment. The operator ⊕ symbolises anXNOR function and is set to 1 when its arguments are equaland to 0 otherwise. D measures the distance probability dis-tribution which is estimated based on the average segment
in a collection.
(ii) P ′Miss
=∑N−k
i=1 [1 − �hyp(i, i + k)] • [1 − δref (i, i + k)]∑N−k
i=1 [1 − δref (i, i + k)](iii) P ′
FalseAlarm
=∑N−k
i=1 [1 − �hyp(i, i + k)] • [δref (i, i + k)]∑N−k
i=1 [δref (i, i + k)]where
�hyp(i, i + k) ={
1, if r(i, k) = h(i, k)
0, otherwise
(iv) WindowDiff(ref ,hyp) = 1
N − k
N−k∑
i=1
(|b(ref i , ref i+k)
− b(hypi ,hypi+k)| > 0)
where N represents the number of textual units in the tran-script, k is the size of the window based on the average seg-ment size in the transcript, and (bi,j ) represents the numberof boundaries between positions i and j in the transcript.
The TTS results were very promising and showed thatTTS has outperformed both algorithms (Fig. 5). Whilst Text-Tiling identified more segments than any of the other algo-rithms, TTS is the closest to the manual segmentation. Inparticular, TextTiling was the most underperforming algo-rithm for this corpus, possibly due to the following reasons:
a. Its lexical cohesion-based algorithm depends mainly onrepetition. There are many cases in our transcripts whereconsecutive utterances contained no repetitions and con-sequently TextTiling identified them as four different top-ics;
b. It is dependent on sentence-based structure rather thanutterance-based structure. The similarity measure usedin TextTiling compares pair of sentences, and is conse-quently relevant to structured and well punctuated textsbut unsuitable for our ill-structured corpus;
c. The use of a fixed window size is unsuitable.
As part of the study we have asked 6 postgraduate re-searchers in computer science, 5 of whom were not familiarwith the content of these transcripts, to manually segmentthese transcripts. They were given training and some guid-ance in text segmentation. Table 3 shows a great variationamong the participants whose results also differ from thesegmentation carried out by the 6th researcher who was fa-miliar with the content and the research. It is also interestingto note that the average number of segments identified bythe 5 participants appears to be closer to the findings of the6th researcher, highlighting the challenging nature of textsegmentation.

Int J Speech Technol (2008) 11: 157–165 163
Fig. 5 Evaluation of TTS
Table 3 Results of human textsegmentation Transcript Number of segments generated by
Participant Participant Participant Participant Participant Researcher
1 2 3 4 5 (Reference basis)
041102TR 12 5 3 11 9 7
070703TR 3 7 9 5 8 6
120902TR 19 5 12 21 13 16
130901TR 35 22 18 17 10 24
290602TR 21 11 9 12 15 13
120802TR 5 7 13 8 14 10
200606TR 3 5 3 2 7 6
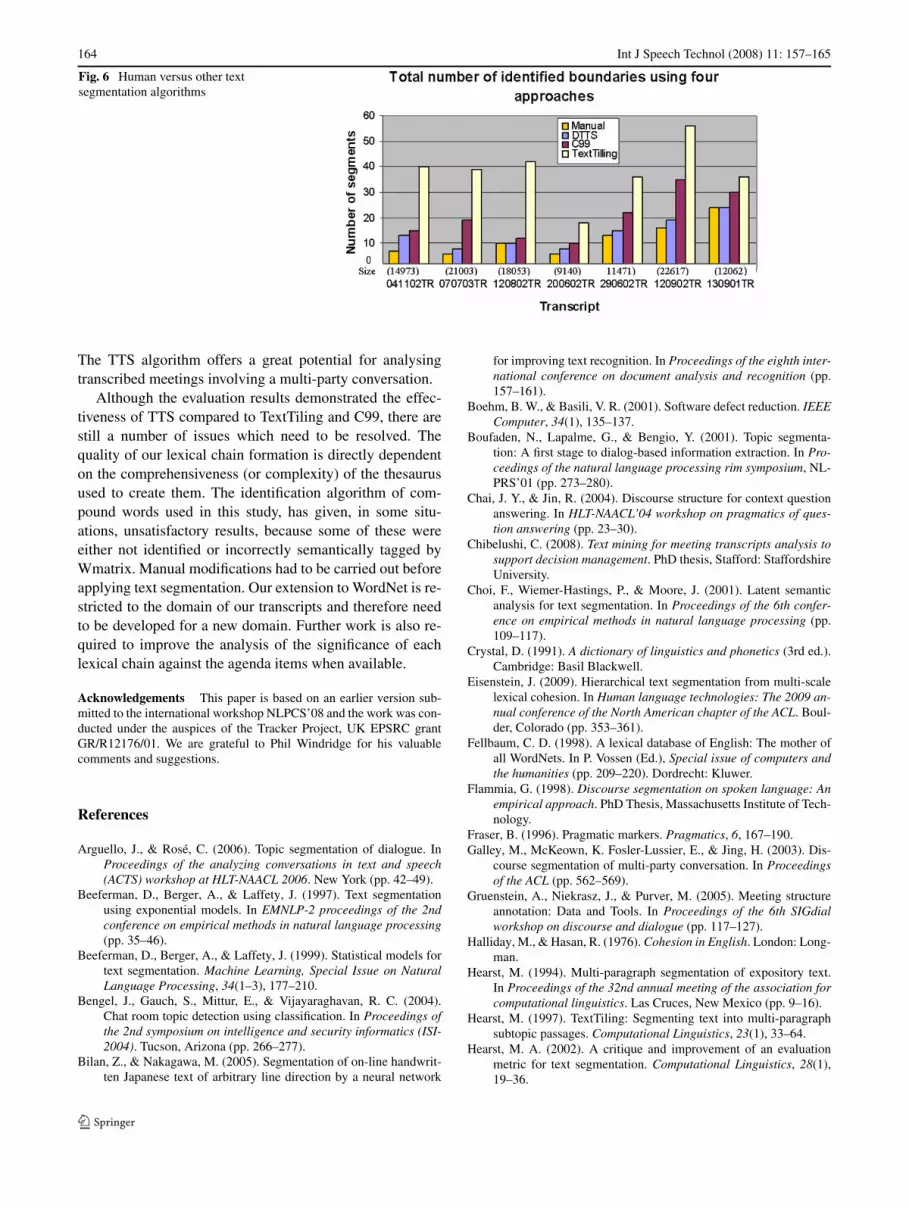
Furthermore the results show a great variation betweenthe human and computational segmentation highlighting thetendency by the human participants to divide the transcriptsinto smaller segments if unfamiliar with the content. The lastcolumn, which lists the result of the segmentation carried outby the 6th researcher, was used to compare against the TTS,TextTiling and C99 algorithms. Again the TTS results arevery promising as Fig. 6 shows that they are the closest tothe human segmentation process.
6 Conclusions
This paper has described an algorithm that advocates the useof rich semantic lexical relationships to build lexical chainsaided by speech cue phrases. The study has extended theuse of cosine similarity measure to transcribed speech textsand improved the performance of lexical chaining methodsand text segmentation algorithms by incorporating complexsemantic relations and context specific speech cue phrases.
164 Int J Speech Technol (2008) 11: 157–165
Fig. 6 Human versus other textsegmentation algorithms
The TTS algorithm offers a great potential for analysingtranscribed meetings involving a multi-party conversation.
Although the evaluation results demonstrated the effec-tiveness of TTS compared to TextTiling and C99, there arestill a number of issues which need to be resolved. Thequality of our lexical chain formation is directly dependenton the comprehensiveness (or complexity) of the thesaurusused to create them. The identification algorithm of com-pound words used in this study, has given, in some situ-ations, unsatisfactory results, because some of these wereeither not identified or incorrectly semantically tagged byWmatrix. Manual modifications had to be carried out beforeapplying text segmentation. Our extension to WordNet is re-stricted to the domain of our transcripts and therefore needto be developed for a new domain. Further work is also re-quired to improve the analysis of the significance of eachlexical chain against the agenda items when available.
Acknowledgements This paper is based on an earlier version sub-mitted to the international workshop NLPCS’08 and the work was con-ducted under the auspices of the Tracker Project, UK EPSRC grantGR/R12176/01. We are grateful to Phil Windridge for his valuablecomments and suggestions.
References
Arguello, J., & Rosé, C. (2006). Topic segmentation of dialogue. InProceedings of the analyzing conversations in text and speech(ACTS) workshop at HLT-NAACL 2006. New York (pp. 42–49).
Beeferman, D., Berger, A., & Laffety, J. (1997). Text segmentationusing exponential models. In EMNLP-2 proceedings of the 2ndconference on empirical methods in natural language processing(pp. 35–46).
Beeferman, D., Berger, A., & Laffety, J. (1999). Statistical models fortext segmentation. Machine Learning, Special Issue on NaturalLanguage Processing, 34(1–3), 177–210.
Bengel, J., Gauch, S., Mittur, E., & Vijayaraghavan, R. C. (2004).Chat room topic detection using classification. In Proceedings ofthe 2nd symposium on intelligence and security informatics (ISI-2004). Tucson, Arizona (pp. 266–277).
Bilan, Z., & Nakagawa, M. (2005). Segmentation of on-line handwrit-ten Japanese text of arbitrary line direction by a neural network
for improving text recognition. In Proceedings of the eighth inter-national conference on document analysis and recognition (pp.157–161).
Boehm, B. W., & Basili, V. R. (2001). Software defect reduction. IEEEComputer, 34(1), 135–137.
Boufaden, N., Lapalme, G., & Bengio, Y. (2001). Topic segmenta-tion: A first stage to dialog-based information extraction. In Pro-ceedings of the natural language processing rim symposium, NL-PRS’01 (pp. 273–280).
Chai, J. Y., & Jin, R. (2004). Discourse structure for context questionanswering. In HLT-NAACL’04 workshop on pragmatics of ques-tion answering (pp. 23–30).
Chibelushi, C. (2008). Text mining for meeting transcripts analysis tosupport decision management. PhD thesis, Stafford: StaffordshireUniversity.
Choi, F., Wiemer-Hastings, P., & Moore, J. (2001). Latent semanticanalysis for text segmentation. In Proceedings of the 6th confer-ence on empirical methods in natural language processing (pp.109–117).
Crystal, D. (1991). A dictionary of linguistics and phonetics (3rd ed.).Cambridge: Basil Blackwell.
Eisenstein, J. (2009). Hierarchical text segmentation from multi-scalelexical cohesion. In Human language technologies: The 2009 an-nual conference of the North American chapter of the ACL. Boul-der, Colorado (pp. 353–361).
Fellbaum, C. D. (1998). A lexical database of English: The mother ofall WordNets. In P. Vossen (Ed.), Special issue of computers andthe humanities (pp. 209–220). Dordrecht: Kluwer.
Flammia, G. (1998). Discourse segmentation on spoken language: Anempirical approach. PhD Thesis, Massachusetts Institute of Tech-nology.
Fraser, B. (1996). Pragmatic markers. Pragmatics, 6, 167–190.Galley, M., McKeown, K. Fosler-Lussier, E., & Jing, H. (2003). Dis-
course segmentation of multi-party conversation. In Proceedingsof the ACL (pp. 562–569).
Gruenstein, A., Niekrasz, J., & Purver, M. (2005). Meeting structureannotation: Data and Tools. In Proceedings of the 6th SIGdialworkshop on discourse and dialogue (pp. 117–127).
Halliday, M., & Hasan, R. (1976). Cohesion in English. London: Long-man.
Hearst, M. (1994). Multi-paragraph segmentation of expository text.In Proceedings of the 32nd annual meeting of the association forcomputational linguistics. Las Cruces, New Mexico (pp. 9–16).
Hearst, M. (1997). TextTiling: Segmenting text into multi-paragraphsubtopic passages. Computational Linguistics, 23(1), 33–64.
Hearst, M. A. (2002). A critique and improvement of an evaluationmetric for text segmentation. Computational Linguistics, 28(1),19–36.

Int J Speech Technol (2008) 11: 157–165 165
Hirschberg, J., & Litman, D. (1993). Empirical studies on the disam-biguation and cue phrases. Computational Linguistics, 19, 501–530.
Kan, M., Klavans, J. L., & McKeown, K. R. (1998). Linear segmenta-tion and segment relevance. In Proceedings of the sixth workshopon very large corpora (pp. 197–205).
Kawahara, T., Nanjo, H., & Furui, S. (2001). Automatic transcriptionof spontaneous lecture speech. In Proceedings of the IEEE work-shop on automatic speech recognition and understanding (pp.186–189).
Lampert, A., Dale, R., & Paris, C. (2009). Segmenting email messagetext into zones. In Proceedings of empirical methods in naturallanguage processing, Singapore, August 6–7.
Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato’s prob-lem: The latent semantic analysis theory of the acquisition, in-duction, and representation of knowledge. Psychological Review,104, 211–240.
Levow, G. A. (2004). Prosodic cues to discourse segment boundariesin human-computer dialogue. In Proceedings of the 5th sigdialworkshop on discourse and dialogue (pp. 93–96).
Manning, C. (1998). Rethinking text segmentation models: An informa-tion extraction case study (Technical Report SULTRY-98-07-01).University of Sydney.
Morris, J., & Hirst, G. (1991). Lexical cohesion, the thesaurus, and thestructure of text. Computational Linguistics, 17(1), 211–232.
Mulbregt, P., Carp, I., Gillick, L., Lowe, S., & Yamron, J. (1998). Textsegmentation and topic tracking on broadcast news via hiddenMarkov model approach. Proceedings of the ICSLP-98, 6, 2519–2522.
Oard, D., Ramabhadran, B., & Gustman, S. (2004). Building an in-formation retrieval test collection for spontaneous conversationalspeech. In Proceedings of the 27th annual international. ACM SI-GIR conference on research and development in information re-trieval. Sheffield (pp. 41–48).
Passoneau, R., & Litman, D. (1997). Discourse segmentation by hu-man and automated means. Computational Linguistics, 23(1),103–139.
Pevzner, L., & Hearst, M. (2002). Evaluation metric for text segmen-tation. Computational Linguistics, 1(28), 19–36.
Rayson, P. (2003). Matrix: A statistical method and software tool forlinguistic analysis through corpus comparison. PhD thesis. Lan-caster: Lancaster University.
Reynar, J. (1999). Statistical models for topic segmentation. In Pro-ceedings of the association for computational linguistics (pp.357–364).
Reynar, J. (1998). Topic segmentation: Algorithms and applications.PhD Thesis. University of Pennsylvania.
Senda, S., & Yamada, K. (2001). A Maximum-likelihood approachto segmentation-based recognition of unconstrained handwritingtext. In Proceedings of the sixth international conference on doc-ument analysis and recognition (pp. 184–188).
Sharp, B. (1989). Elaboration and testing of new methodologies in au-tomatic abstracting. PhD Thesis. Birmingham: Aston University.
Stokes, N. (2003). Spoken and written news story segmentation us-ing lexical chains. In HLT-NAACL proceedings, student researchworkshop. Edmonton (pp. 49–54).
Stokes, N. (2004). Applications of lexical cohesion analysis in the topicdetection and tracking domain. PhD Thesis. Dublin: UniversityCollege Dublin.
Strayer, S. E., Heeman, P. A., & Yang, F. (2003). Reconciling controland discourse structure. In J. van Kuppevelt & R. Smith (Eds.),Current and new directions in discourse and dialogue (pp. 305–323). Dordrecht: Kluwer.
Tsenga, Y. H., Linb, C. J., & Lin, Y. L. (2007). Text mining tech-niques for patent analysis. Information Processing & Manage-ment, 43(5), 1216–1247.
Yamron, J., Carp, I., Gillick, L., Lowe, S., & Mulbregt, P. V. (1998).A hidden Markov model approach to text segmentation and eventtracking. In Proceedings of ICASSP’98 (pp. 333–336).
Youmans, G. (1991). A new tool for discourse analysis: The vocabularymanagement profile. Languages, 763–789.
Zechner, K. (2001). Automatic summarization of spoken dialogues inunrestricted domains. PhD Thesis. Carnegie Mellon University.





























