Embed Size (px)
Citation preview

1
BHS Third International Symposium, Managing Consequences of a Changing Global Environment, Newcastle 2010© British Hydrological Society
Probabilistic flood forecasting in England and Wales – can it give us what we crave?
Stefan Laeger1, Richard Cross1, Kevin Sene2, Albrecht Weerts3, Keith Beven4, Dave Leedal4, Robert J. Moore5, Mike Vaughan1, Tim Harrison1 and Chris Whitlow6
1Environment Agency; 2Atkins; 3Deltares; 4Lancaster University; 5Centre for Ecology and Hydrology; 6Edenvale Young Consulting
AbstractProbabilistic flood forecasting has a number of benefits. It represents the inherent uncertainties associated with flood forecasts and can improve the utility of forecasts for flood warning in situations of greater uncertainty, such as in convective storms or for longer lead-times. Overall, it allows certain actions to be taken earlier in a more informed way and provides a more complete picture of potential flood risk as an event develops. In response to drivers such as the Pitt Review, various probabilistic flood forecasting techniques have been developed and applied with some success in recent years. This paper outlines some techniques that have been developed and trialled in the UK and discusses those showing most promise for operational flood forecasting. An over-arching framework for assessing uncertainties in fluvial forecasting in a risk-based manner is also presented. This framework aims to help practitioners in operational flood forecasting to select and implement appropriate techniques which can add value to the forecasting process and are robust enough to use operationally. The paper ends with a brief review of how probabilistic flood forecasting techniques can be of most value to practitioners. Both the opportunities and the barriers to be overcome are discussed in relation to the wider use of probabilistic techniques in operational flood forecasting. This leads to the conclusion that, if used appropriately, probabilistic techniques can add valuable information to operational flood forecasting. However, application of such techniques should not be seen as a ‘universal panacea’ addressing all current challenges in flood forecasting.
Introduction
The Environment Agency provides a Flood Warning and Forecasting Service to people at risk from flooding in England and Wales. For fluvial flood forecasting, rainfall-runoff, channel flow routing and hydraulic river models have traditionally been used. These are often combined into linked model cascades (‘integrated catchment models’) and utilise various forms of data assimilation to help improve forecasts. Outputs from forecasting models are currently deterministic with one model run delivering the flood forecast which is assumed to be the best representation. Forecasting Duty Officers then have to use experience and judgement to provide guidance on the likely error range when interpreting forecasts in the context of decision-support for flood warning and incident management. The accuracy of flood forecasts is influenced by the accuracy of the input data together with uncertainties in the structure, states and parameters of the model. Having a sound understanding of these modelling uncertainties is vital to assess and improve the flood forecasting service the Environment Agency provides. In recent years, the probabilistic treatment of modelling uncertainties has advanced from research to a range of near-operational techniques and provides an opportunity to quantify and ultimately reduce uncertainty in flood forecasting and modelling. For example, in the UK progress has been made in quantifying the uncertainties associated with quantitative precipitation forecasting (QPF) and how to propagate these through flood forecasting models (Environment Agency 2010a; Golding, 2009; Bowler et al., 2006). In addition, QPF
ensembles, such as MOGREPS (Bowler et al, 2008), have been successfully linked to storm surge forecasting models to provide longer lead times for coastal forecasting whilst also allowing an assessment of confidence in these forecasts by capturing the uncertainty around them (Hawkes et al, 2009; Flowerdew et al, 2008) Historically, practitioners in flood risk management have applied a number of techniques to account for major sources of uncertainty. Examples are the use of factors of safety, sensitivity testing and assumptions analysis (what if 40 mm of rain falls in 6 hours), taking a precautionary approach, and of course improving the underlying data and models. Probabilistic modelling techniques are another way to capture uncertainties when modelling or forecasting for complex systems. This provides an understanding of the ‘robustness’ of the forecast results to the underlying assumptions made. Here, we define a robust probabilistic method as giving acceptable values of POD (probability of detection) and FAR (false alarm rate) across a wide range of forecasting situations, and better values than for deterministic forecasting. The major advantage of probabilistic techniques compared to more traditional deterministic approaches is that they not only allow investigation of the range of possible outcomes but also they assign a probability. If these probabilities can be formulated such that they reflect the expected natural occurrence, information is available on forecast reliability, and provided that the underlying assumptions are understood, they provide a good basis for risk-based management and decision-making. This allows the user to take account not only of the probability but

2
also the potential consequences of flooding (which might affect the level of acceptable risk in deciding on suitable mitigation actions) and also to target further investments or improvements of models or data to areas which give most benefit (Hall and Solomatine, 2008). Probabilistic flood forecasting has a number of benefits (Krzysztofowicz, 2001). It represents, quantifies and, where data assimilation can be used, sometimes constrains the inherent uncertainties associated with flood forecasts. This can improve the utility of forecasts for flood incident management in situations of greater uncertainty, such as in convective storms or for longer lead-times. Overall, it allows for certain actions to be taken earlier in a more informed way and provides a more complete picture of potential risk as a flood event develops. In particular, the ability to extend forecasting lead times and to capture not only the most likely but also rarer, more extreme events through applying probabilistic techniques has attracted much attention and research effort (Thielen et al., 2009; Buizza, 2008; Golding, 2009).
A general framework for assessing uncertainties in fluvial flood forecasting
In order to assess and, where possible, reduce uncertainties in flood forecasting in a structured manner, a generic uncertainty framework has been developed (Environment Agency, 2010b). It aims to assist flood forecasting experts involved in commissioning, maintaining and improving models when deciding on how to deal with uncertainties in flood forecasting, which approaches are suitable in what circumstances and how they should be applied. The framework is based around the following assessment criteria:
Level of risk Operational requirements Lead time requirements Main sources of uncertainty Types of model and available data Run times Performance measures
The level of risk at the forecasting locations of interest has an important influence on what approach is chosen. It influences the level of required accuracy and gives an indication of how much effort it is worth expending. Based on this initial risk assessment, two broad categories can be distinguished:
A qualitative approach suitable for a rapid first assessment of potential modelling solutions (Method A)
A main model selection approach which aims to arrive at a reasonable compromise between technical, cost, benefit and other considerations (Method B)
The remaining assessment criteria can be evaluated at two levels: a simpler one for Method A and a more detailed one for Method B. Equally important is a good understanding of the operational requirements: specifically how flood forecasts will be used operationally and which activities and decisions will be informed and ultimately triggered by them. Different activities may require different levels of certainty and confidence which may influence the choice of uncertainty estimation technique. In particular, a key decision is whether probabilistic uncertainty information is required in real time, or whether offline assessments are sufficient, for instance to steer further model and data improvements.
If real-time uncertainty information is required, it is important to understand the lead requirements and planned uses and choose appropriate techniques to match these. This is because the utility of probabilistic information is likely to vary with forecasting lead-time since different activities in flood incident management and forecasting are likely to take place at different time horizons. For instance, for a large-scale flood event, Golding (2009) outlined a possible sequence of activities ranging from hours to 3–5 days ahead. A comparison of lead-time with catchment response time can indicate whether rainfall forecasts, rainfall observations, flow/level forecasts or flow/level observations are required to achieve the required lead-time (e.g. Lettenmaier and Wood, 1993). Different sources of uncertainty will also be associated with this information and hence be important at different lead-times. To give an example, for longer forecasting lead-times or for fast responding catchments, rainfall forecasts will be the most important source of uncertainty whereas for longer, slow responding rivers, other factors, such as rating curve uncertainty or the accuracy of observed rainfall estimates over a catchment, may matter more once the rain has fallen and is entering the river channel. Given the catchment type and the required lead-time, the most important sources of uncertainty and their contribution to the overall uncertainty can then be determined. This can either be based on previous information, such as offline performance assessments of flood forecasting models, or a broad-brush assessment can be conducted based on generic sources of uncertainties for particular catchment types. However, there may also be complicating factors which should be considered, such as permeable catchments, the influence of urban drainage networks and others. The types of forecasting model that are available at the forecasting location is another consideration. Depending on the general model type, such as rainfall-runoff and hydrodynamic river models, and model implementation, some uncertainty techniques may be more appropriate or easier to apply than others. Also, different sources of uncertainty may be associated with certain model types. In addition, the availability of data — both historical and in real-time — greatly influences the choice of techniques, as well as whether uncertainty can be constrained through the assimilation of real-time observations. The run-times of forecasting models, including the required computer processing time, are another key consideration. Assessing uncertainties often requires additional model runs and different techniques will have different computational requirements. If there are specific organisational run-time requirements, it needs to be determined whether these can be achieved with the uncertainty techniques in consideration. For instance, more computational intensive techniques, such as ensemble Kalman Filters coupled with hydrodynamic river models, may not always be appropriate if short run-time requirements have to be met. Finally, existing estimates for model performance may already be available which could indicate which locations in the catchment or parts of the model are particularly uncertain and should be focussed on. This allows improvement efforts to be concentrated on areas where the benefits will be greatest: for instance in order to meet predefined performance targets. Based on these assessment criteria, suitable uncertainty techniques can be selected. These can broadly be categorised into:
Techniques for forward uncertainty propagation in which the uncertainty is assumed to be known or specified in advance, and is used to determine the likely range or

3
distribution of model outputs. Data assimilation and conditioning approaches in which
the model outputs are conditioned on current and historical observations and/or real-time observed data are assimilated to update and improve a forecast.
Forward uncertainty propagation (FUP) is based either solely on prior assumptions about the nature of the different sources of uncertainty considered, or on an error model calibrated on past performance. In general, analytical methods for error propagation cannot be used because of the nonlinear nature of the hydrological and hydraulic models used in forecasting. Thus propagation often makes use of Monte Carlo sampling methods involving many model runs. For simple forecasting models this is possible within the time scales required for forecasting, but more complex hydraulic models may require more computational resources than are available. However, when forecasting flood events, it is expected that any new event will be different in some way from all past events. Thus it may be useful to use data available in real-time to assess the current forecasting error and adapt the uncertainty estimates as a new event develops. This will also often allow the prior estimates of uncertainty to be constrained. Methods for adaptive forecasting include a simple adaptive gain that can be applied to the outputs from any deterministic model run, Kalman filter and ensemble Kalman filter methods, and Data-based mechanistic (DBM) methods (Young, 2002; Romanowicz et al., 2006, 2008; Smith and Beven, 2010). When multiple model forecasts are available, Bayesian model averaging approaches can also be used. Many of these methods are reviewed in Beven (2009). In particular, simpler calibrated error methods, such as quantile regression and ARMA error prediction, offer possibilities for use. These are used to estimate the errors associated with a single deterministic run of the forecasting model. Calibration on past events allows an expectation of the errors associated with a new event to be estimated. Overall, FUP methods are useful to improve the understanding of the importance of different sources of uncertainty so that efforts can be targeted to reduce them. Often it may be sufficient and more effective to do this off-line, for instance as part of model performance reviews. Where real-time data are available and if the remaining assessment criteria, such as lead-time can be achieved, data assimilation and conditioning approaches are a very attractive
proposition since they are capable of capturing the total uncertainty in the forecast, whatever its sources.
Experiences from probabilistic fluvial flood forecasting
This section reports on recent experiences of probabilistic fluvial flood forecasting obtained from near operational case studies involving the use of the following techniques:
Gain updating and Kalman Filter approaches (including the DBM methodology)
Quantile regression ARMA error prediction with uncertainty estimation
Several examples are provided of results from the following case study catchments: the Upper Calder in North East England, the Upper Severn in the Midlands, and the Lower Eden in North West England.
Gain updating and Kalman Filter approaches (including the DBM methodology)Theoretical basisThese two related methods are grounded in a stochastic approach to data assimilation first described by Kalman (1960). The Kalman filter is a two-step recursive procedure:
1. Form a prediction of the system state(s) and error (co)variance using an internal state space model
2. Collect data and form a correction of the output of step 1.
Repeated application of step 1 is used to produce a forecast when there is a time lag between the effects of the input data on the output. Estimates of state error (co)variance provide a direct means to generate confidence bounds for the state estimate. Within the context of this paper, the Kalman filter methodology has been applied to both Data Based Mechanistic (DBM) real-time river level forecasting and Adaptive Gain estimation. A description of the mathematical detail of both methods can be found in Young (2006) and Leedal et al. (2009).
ResultsCase studies of the application of DBM real-time flood
Figure 1 A six-hour forecast using the DBM system within NFFS for Sheepmount (Carlisle). This section shows the approach to the peak level during the seriousJanuary2005floodevent.Notethatatthetimeoftheforecast,theobservations(inblue)areonlyavailableuptothetimeindicatedbythe vertical red line.
4
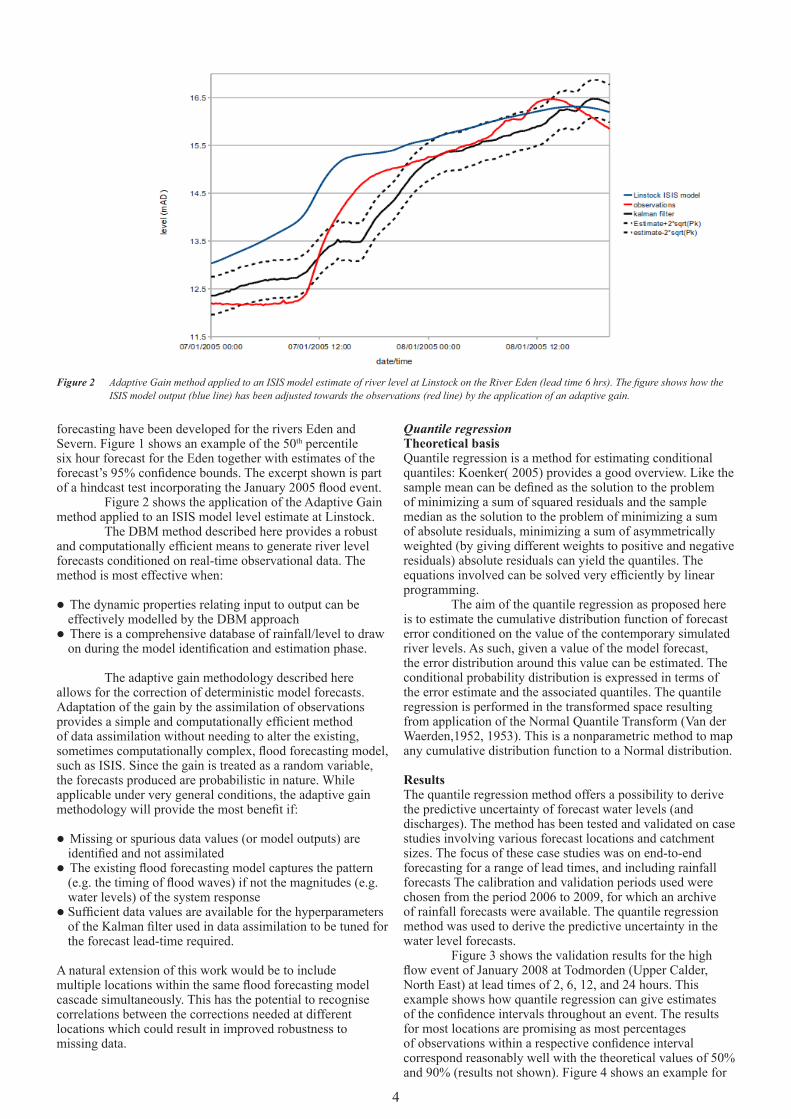
forecasting have been developed for the rivers Eden and Severn. Figure 1 shows an example of the 50th percentile six hour forecast for the Eden together with estimates of the forecast’s 95% confidence bounds. The excerpt shown is part of a hindcast test incorporating the January 2005 flood event. Figure 2 shows the application of the Adaptive Gain method applied to an ISIS model level estimate at Linstock. The DBM method described here provides a robust and computationally efficient means to generate river level forecasts conditioned on real-time observational data. The method is most effective when:
The dynamic properties relating input to output can be effectively modelled by the DBM approach
There is a comprehensive database of rainfall/level to draw on during the model identification and estimation phase.
The adaptive gain methodology described here allows for the correction of deterministic model forecasts. Adaptation of the gain by the assimilation of observations provides a simple and computationally efficient method of data assimilation without needing to alter the existing, sometimes computationally complex, flood forecasting model, such as ISIS. Since the gain is treated as a random variable, the forecasts produced are probabilistic in nature. While applicable under very general conditions, the adaptive gain methodology will provide the most benefit if:
Missing or spurious data values (or model outputs) are identified and not assimilated
The existing flood forecasting model captures the pattern (e.g. the timing of flood waves) if not the magnitudes (e.g. water levels) of the system response
Sufficient data values are available for the hyperparameters of the Kalman filter used in data assimilation to be tuned for the forecast lead-time required.
A natural extension of this work would be to include multiple locations within the same flood forecasting model cascade simultaneously. This has the potential to recognise correlations between the corrections needed at different locations which could result in improved robustness to missing data.
Quantile regressionTheoretical basisQuantile regression is a method for estimating conditional quantiles: Koenker( 2005) provides a good overview. Like the sample mean can be defined as the solution to the problem of minimizing a sum of squared residuals and the sample median as the solution to the problem of minimizing a sum of absolute residuals, minimizing a sum of asymmetrically weighted (by giving different weights to positive and negative residuals) absolute residuals can yield the quantiles. The equations involved can be solved very efficiently by linear programming. The aim of the quantile regression as proposed here is to estimate the cumulative distribution function of forecast error conditioned on the value of the contemporary simulated river levels. As such, given a value of the model forecast, the error distribution around this value can be estimated. The conditional probability distribution is expressed in terms of the error estimate and the associated quantiles. The quantile regression is performed in the transformed space resulting from application of the Normal Quantile Transform (Van der Waerden,1952, 1953). This is a nonparametric method to map any cumulative distribution function to a Normal distribution.
ResultsThe quantile regression method offers a possibility to derive the predictive uncertainty of forecast water levels (and discharges). The method has been tested and validated on case studies involving various forecast locations and catchment sizes. The focus of these case studies was on end-to-end forecasting for a range of lead times, and including rainfall forecasts The calibration and validation periods used were chosen from the period 2006 to 2009, for which an archive of rainfall forecasts were available. The quantile regression method was used to derive the predictive uncertainty in the water level forecasts. Figure 3 shows the validation results for the high flow event of January 2008 at Todmorden (Upper Calder, North East) at lead times of 2, 6, 12, and 24 hours. This example shows how quantile regression can give estimates of the confidence intervals throughout an event. The results for most locations are promising as most percentages of observations within a respective confidence interval correspond reasonably well with the theoretical values of 50% and 90% (results not shown). Figure 4 shows an example for
Figure 2 AdaptiveGainmethodappliedtoanISISmodelestimateofriverlevelatLinstockontheRiverEden(leadtime6hrs).Thefigureshowshowthe ISIS model output (blue line) has been adjusted towards the observations (red line) by the application of an adaptive gain.

5
Figure 3 Validation of quantile regression for the January 2008 event for 2, 6, 12, and 24 hours lead times. The light and dark grey area represents the 90% and50%confidenceintervalsrespectively,thedottedlinethe50%estimateandtheblackdotstheobservations.
Figure 4 Example of quantile regression used in forecast-mode displayed in NFFS (Upper Severn, November 2009).
6
Abermule (Upper Severn, Midlands) of how things may look like in NFFS. For most locations, the forecasted probabilities match well with the observed probabilities. For example, two probabilistic verification techniques which have proved useful for validation are quantile plots and sharpness plots. The method is calibrated off-line. The calibrated conditional quantiles (on the forecasted water level or discharge) are then used online, which makes the method computationally very cheap. Another advantage is that the method is intuitive and therefore fairly easy to understand and explain.
ARMA error prediction with uncertainty estimationTheoretical basisA direct way of quantifying flood forecast uncertainty is to seek ways of estimating probability (confidence) bands on the forecast. This may be done without decomposing the individual sources of uncertainty: instead, we can look directly at the structure of the forecast errors. A classical way of doing this is to analyse the simulation-mode errors from the model used for forecasting (e.g. rainfall-runoff, channel flow routing), to apply an autoregressive-moving average (ARMA) model to these errors and employ the theoretical probability limits, under limiting assumptions (normality and constant variance of the residual errors), to obtain forecast uncertainty bands. For hydrological forecasting applications, a proportional error model is invoked to address the normality assumptions of the approach: thus errors are defined as the log of the ratio of observed to model simulated flow. This aligns with model error being greater at higher river flows. The ARMA model parameters and the variance of the proportional errors together allow uncertainty bands to be calculated for any probability interval. This is a parametric method for estimating forecast probability bands and is referred to here as the ‘parametric ARMA approach’ (Moore et al., 2010).
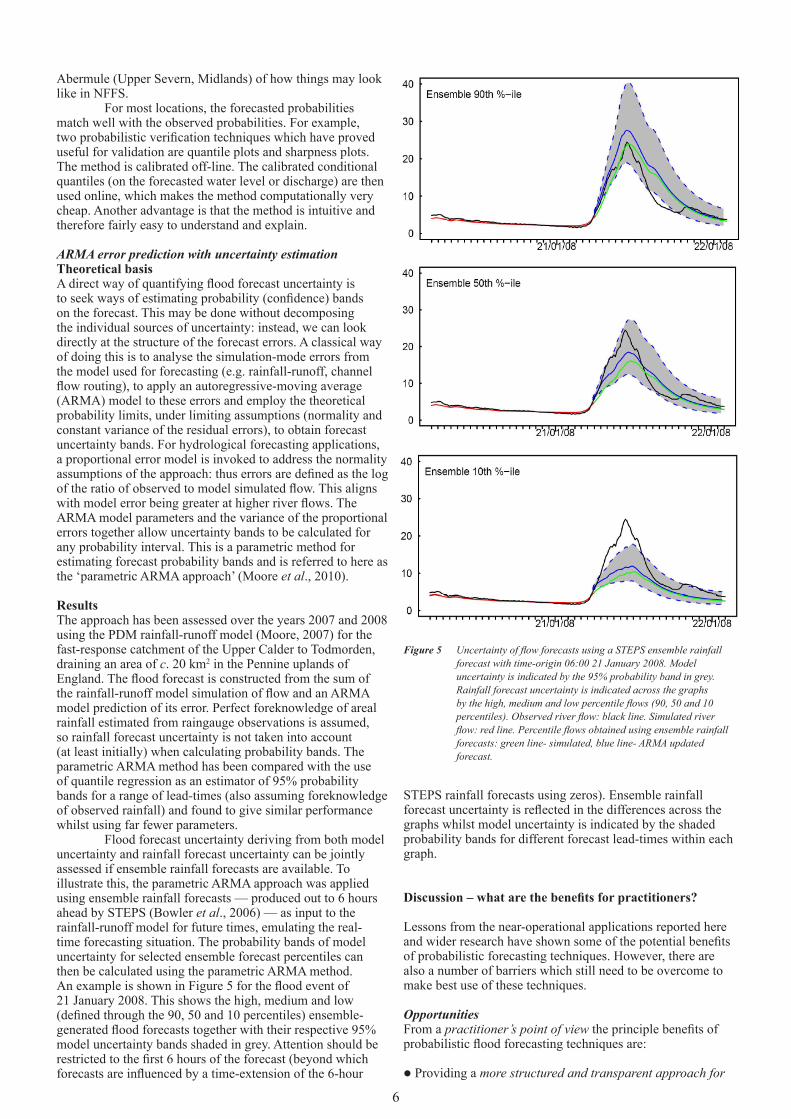
ResultsThe approach has been assessed over the years 2007 and 2008 using the PDM rainfall-runoff model (Moore, 2007) for the fast-response catchment of the Upper Calder to Todmorden, draining an area of c. 20 km2 in the Pennine uplands of England. The flood forecast is constructed from the sum of the rainfall-runoff model simulation of flow and an ARMA model prediction of its error. Perfect foreknowledge of areal rainfall estimated from raingauge observations is assumed, so rainfall forecast uncertainty is not taken into account (at least initially) when calculating probability bands. The parametric ARMA method has been compared with the use of quantile regression as an estimator of 95% probability bands for a range of lead-times (also assuming foreknowledge of observed rainfall) and found to give similar performance whilst using far fewer parameters. Flood forecast uncertainty deriving from both model uncertainty and rainfall forecast uncertainty can be jointly assessed if ensemble rainfall forecasts are available. To illustrate this, the parametric ARMA approach was applied using ensemble rainfall forecasts — produced out to 6 hours ahead by STEPS (Bowler et al., 2006) — as input to the rainfall-runoff model for future times, emulating the real-time forecasting situation. The probability bands of model uncertainty for selected ensemble forecast percentiles can then be calculated using the parametric ARMA method. An example is shown in Figure 5 for the flood event of 21 January 2008. This shows the high, medium and low (defined through the 90, 50 and 10 percentiles) ensemble-generated flood forecasts together with their respective 95% model uncertainty bands shaded in grey. Attention should be restricted to the first 6 hours of the forecast (beyond which forecasts are influenced by a time-extension of the 6-hour
STEPS rainfall forecasts using zeros). Ensemble rainfall forecast uncertainty is reflected in the differences across the graphs whilst model uncertainty is indicated by the shaded probability bands for different forecast lead-times within each graph.
Discussion – what are the benefits for practitioners?
Lessons from the near-operational applications reported here and wider research have shown some of the potential benefits of probabilistic forecasting techniques. However, there are also a number of barriers which still need to be overcome to make best use of these techniques.
OpportunitiesFrom a practitioner’s point of view the principle benefits of probabilistic flood forecasting techniques are:
Providing a more structured and transparent approach for
Figure 5 UncertaintyofflowforecastsusingaSTEPSensemblerainfall forecast with time-origin 06:00 21 January 2008. Model uncertainty is indicated by the 95% probability band in grey. Rainfall forecast uncertainty is indicated across the graphs bythehigh,mediumandlowpercentileflows(90,50and10 percentiles).Observedriverflow:blackline.Simulatedriver flow:redline.Percentileflowsobtainedusingensemblerainfall forecasts: green line- simulated, blue line- ARMA updated forecast.

7
assessing uncertainties and their effects on flood forecasts regardless of the experience of individual forecasters. This should help to provide a clear audit trail of the information available and how it has (or not) influenced operational decisions.
Increasing lead times through using rainfall forecast ensembles (albeit often with additional uncertainty at longer lead times) However, work still needs to be done to assess the readiness of duty officers and professional partners to utilise these forecasts.
Allowing for calculated precautionary actions to be taken in high risk locations in response to low probability forecasts
Providing additional information to support marginal decisions
Allowing to target model, telemetry and data improvements to the areas where they matter most. Offline assessments of model performance after floods events can play a major role in this.
Overall, probabilistic flood forecasting can provide important evidence to support truly risk-based Flood Incident Management by allowing to match activities and resources to areas of highest risk and greatest benefit whilst still allowing calculated precautionary actions. Where risk is low, it may be that a high probability of detection is required before triggering a response, whilst a high risk area may justify precautionary activities at lower probabilities.
BarriersA number of barriers which currently hinder the utility and wider use of probabilistic forecasting techniques are set down below.
Technical complexity, required efforts and skills — some uncertainty estimation approaches are quite complex and require significant effort and specialist skills to implement them operationally. Once implemented, outputs can be generated automatically but forecasters require a good understanding of how to interpret and use the outputs as part of operational flood incident management.
Confidenceinprobabilisticinformation— it is evident that not all the uncertainties involved in flood forecasting are readily represented as simple probabilistic variables. Some uncertainties arise as a result of lack of knowledge in the representation of inputs, runoff generation and routing processes, flood plain geometry and infrastructure, effects of obstructions etc. Such uncertainties can only be approximated probabilistically and thus confidence in real-time uncertainty estimates therefore needs to be built up, for instance through validation against observations over the course of events and long continuous periods.
Appropriate interpretation and communication —more research is required on the best methods to present uncertainty estimates to flood forecasters and other emergency operations staff and how that information might be used in decision making.
Computational requirements —continuing advances in computing power, use of parallel processing and emulators alleviate this barrier to some extent. However, probabilistic forecasting is likely to continue to require more resources compared to deterministic approaches – although some simpler approaches can be implemented at low computational cost.
Use of low probability or very uncertain forecasts — if forecast probabilities become very low or uncertain, there is limited scope to use this information in a meaningful way to support operational activities during flood events. Currently some probabilistic approaches produce excessively wide
uncertainty bands: narrowing these presents a major (perhaps the central) challenge in formal uncertainty assessment.
Supporting improved decision making — probabilistic flood forecasting provides additional information but also requires additional efforts. These can only be justified if it can be shown how value has been added to the flood incident management and forecasting process by leading to more robust or transparent decisions and ideally, to reduce flood impacts.
Where should we go from here?
Experience with fluvial and coastal probabilistic flood forecasting techniques in England and Wales, and more widely, has shown that these can add value to the flood incident management and forecasting process by providing more comprehensive and ‘honest’ information as a flood event develops. However, it is also clear that there are many barriers which hinder the effective and wider use of the techniques. Several core principles are proposed here which can help in ensuring that probabilistic flood forecasting techniques are used appropriately and to greatest benefit. These are illustrated below:
1.The additional modelling effort needs to be proportional to the planned use and decisions to be made. Understanding the uncertainties in operational flood forecasting is important but should not be done for its own sake.
2.The probabilistic modelling approach should be robust and focus on providing the kind of uncertainty information which is of most use operationally. For example, in lower risk locations, off-line assessments determining the most important sources of uncertainty may be all that is needed to guide data and model improvements. For high risk locations, or where longer lead-times are required, ensemble prediction systems can potentially add value (e.g. Thielen et al., 2009).
3.Where available, it is highly recommended to use observed data to quantify and constrain uncertainty through data assimilation in real-time.
4.Probabilistic flood forecasts need to be communicated clearly and tailored to the end user. It should be made clear which sources of uncertainty are modelled and how well they are understood.
5.Clear guidance must be provided on how to interpret probabilistic information. Users must be made aware of the underlining assumptions and that all probabilistic estimates are contingent on these assumptions. Only if they are properly understood can the probability estimates be interpreted and used correctly. Users must also be aware that forecasts and outcomes outside of the predicted range are possible.
6.In order to maintainconfidence, information should be provided which shows how probabilistic forecasts have been validated and how they compare against historical information. This is standard practice for deterministic forecasts and is really critical in order to convince users of the robustness of probabilistic outputs.
7.Flood Incident Management activitiesmustbenefitfromtheadditional information provided by probabilistic forecasts. There may be locations where additional information on possible more extreme scenarios can be easily used to increase preparedness or inform operational decisions based on clear and pre-defined procedures. However, there will also be applications where the utility of probabilistic outputs is more limited (Hall and Solomatine, 2008) and a ‘wait and see’ approach is acceptable.

8
8.In the initial stages of implementation, it is suggested that real-time probabilistic and deterministic forecasts should be run in parallel to allow practitioners to gain experience and explore the benefits of probabilistic flood forecasting. Forecast performance measures can provide the necessary information needed to evaluate the two approaches.
Overall, this leads to the conclusion that, if used appropriately, probabilistic techniques can add valuable information to operational flood forecasting. They will support some of the attributes practitioners ‘crave’, such as longer forecasting lead-times and more transparent consideration of uncertainties. However, application of such techniques should not be seen as a ‘universal panacea’ addressing all current challenges in flood forecasting. In particular, there are still many areas where further research is required, such as in quantifying and reducing overall uncertainties in an end-to-end forecasting system, validating probabilistic forecasts over the long-term to allow an assessment of accuracy and reliability and, most importantly, developing effective ways for presenting and using probabilistic flood forecast information to support sound operational decision-making.
Acknowledgements
We should like to thank an anonymous reviewer for providing very constructive feedback.
References
Beven, K.J. 2009. Environmental Modelling: An Uncertain Future? Routledge, London.
Bowler, N.E., Pierce, C.E. and Seed, A.W. 2006. STEPS: A probabilistic precipitation forecasting scheme which merges an extrapolation nowcast with downscaled NWP. Quart. J. Roy. Meteorol. Soc., 132, 2127–2155.
Bowler, N.E., Arribas, A., Mylne, K.R., Robertson, K.B. and Beare, S.E. 2008. The MOGREPS short-range ensemble prediction system. Quart. J. Roy. Meteorol. Soc., 134, 703–722.
Buizza, R. 2008. The value of probabilistic prediction. Atmos.Sci. Lett., 9, 36–42.
Environment Agency 2010a. Hydrological Modelling using Convective Scale Rainfall Modelling. Science Report – SC060087. Environment Agency, Bristol, UK, 240pp. Available from http://evidence.environment-agency.gov.uk/FCERM/Libraries/FCERM_Project_Documents/Phase_3_Hydrological_modelling_using_convective_scale_rainfall_modelling.sflb.ashx
Environment Agency 2010b Risk-based Probabilistic Fluvial Flood Forecasting for Integrated Catchment Models: Phase 2 Report. Science Report – SR SC080030. Environment Agency, Bristol, UK (in press).
Golding, B. 2009. Long lead time flood warnings: reality or fantasy? Meteorol. Applic., 16, 3–12.
Hall, J. and Solomatine, D. 2008. A framework for uncertainty analysis in flood risk management decisions. Int. J. River Basin Manage., 6, 85–98.
Krzystowicz, R. 2001. The case for probabilistic forecasting in hydrology. J. Hydrol., 249, 2–9.
Kalman, R.E. 1960. A new approach to linear filtering and prediction problems. J. Basic Eng., 82D, 35–45.
Koenker, R. 2005. Quantile Regression. Cambridge University Press, Cambridge, UK.
Leedal, D., Beven, K. and Young, P. 2009. Data assimilation and adaptive real-tme forecasting of water levels in the Eden catchment, UK. In: Samuels et al. (eds), Flood Risk Management:ResearchandPractice. Taylor and Francis. London, UK, 221pp.
Lettenmaier, D.P. and Wood E F. 1993. Hydrologic forecasting. In: Maidment, R.D. (ed.), Handbook of Hydrology, 26.1–26.30, McGraw-Hill.
Moore, R.J. 2007. The PDM rainfall-runoff model. Hydrol. Earth Syst. Sci., 11, 483–499.
Moore, R.J., Robson, A.J., Cole, S.J., Howard, P.J., Weerts, A. and Sene, K. 2010. Sources of uncertainty and probability bands for flood forecasts: an upland catchment case study. Geophys. Res. Abs., 12, EGU2010.
Romanowicz, R.J., Young, P.C. and Beven, K.J. 2006. Data assimilation and adaptive forecasting of water levels in the River Severn catchment, United Kingdom. Water Resour. Res., 42, W06407
Romanowicz, R.J., Young, P.C., Beven, K.J. and Pappenberger, F. 2008. A Data Based Mechanistic approach to nonlinear flood routing and adaptive flood level forecasting. Adv. Water Resour., 31,1048–1056
Smith, P.J. and Beven, K.J. 2010. Forecasting river levels during flash floods using Data Based Mechanistic models, online data assimilation and meteorological forecasts. Proc.BHSInt.Symp.RoleofHydrologyinManagingConsequences of a changing Global Environment.
Thielen, J., Bogner, K., Pappenberger, F., Kalas, M., del Medico, M. and de Roo, A. 2009. Monthly-, medium-, and short-range flood warning: testing the limits of predictability. Meteorol. Applic., 16, 77–90.
Van der Waerden, B.L. 1952. Order tests for two-sample problem and their power. I. Indagat. Math., 14, 453–458.
Van der Waerden, B.L., 1953. Order tests for two-sample problem and their power. II, III. Indagat. Math., 15, 303–310, 311–316.
Young, P.C. 2002. Advances in real-time flood forecasting. Phil.Trans.Roy.Soc.A., 360, 1433–1450.
Young, P.C. 2006.‘Updating algorithms in flood forecasting. FRMRC Research Report UR5, available at: www.floodrisk.org.uk.





























