Embed Size (px)
Citation preview


Non-Native Prosody
≥

Trends in LinguisticsStudies and Monographs 186
Editors
Walter BisangHans Henrich Hock(main editor for this volume)
Werner Winter
Mouton de GruyterBerlin · New York

Non-Native ProsodyPhonetic Description and Teaching Practice
edited by
Jürgen TrouvainUlrike Gut
Mouton de GruyterBerlin · New York

Mouton de Gruyter (formerly Mouton, The Hague)is a Division of Walter de Gruyter GmbH & Co. KG, Berlin.
�� Printed on acid-free paper which falls within the guidelinesof the ANSI to ensure permanence and durability.
Library of Congress Cataloging-in-Publication Data
Non-native prosody / edited by Jürgen Trouvain, Ulrike Gut.p. cm. � (Trends in linguistics. Studies and monographs ; 186)
Includes bibliographical references and index.ISBN 978-3-11-019524-8 (cloth : alk. paper)1. Language and languages � Study and teaching. 2. Prosodic
analysis (Linguistics) � Study and teaching. I. Trouvain, Jürgen.II. Gut, Ulrike.
P53.68.N66 20074141.6�dc22
2007021894
ISBN 978-3-11-019524-8ISSN 1861-4302
Bibliographic information published by the Deutsche Nationalbibliothek
The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie;detailed bibliographic data are available in the Internet at http://dnb.d-nb.de.
” Copyright 2007 by Walter de Gruyter GmbH & Co. KG, D-10785 BerlinAll rights reserved, including those of translation into foreign languages. No part of thisbook may be reproduced or transmitted in any form or by any means, electronic or mechan-ical, including photocopy, recording or any information storage and retrieval system, with-out permission in writing from the publisher.Cover design: Christopher Schneider, Berlin.Printed in Germany.

Preface
The present volume brings together contributions by a group of researchers and teachers with a shared interest in the description and teaching of the prosody of a second language. The idea for this book was conceived at the International Workshop on “Non-native prosody: phonetic description and teaching practice”, held at the Saarland University in Saarbrücken on March 4th and 5th 2005. The two central objectives of the workshop were to stimulate research and teaching of second language prosody and to estab-lish an interchange between researchers and language teachers. The last two decades have witnessed an increasing interest in prosody in general, yet most research on non-native speech is still restricted to segmental structures and largely disregards suprasegmental features like pitch and temporal structures; few publications as yet deal with L2 prosody. This neglect of prosody is also evident in the practical field of language teaching. Publica-tions on foreign language instruction and also teaching materials rarely deal with prosody. Despite its pedagogically oriented historical foundation, cur-rent second language acquisition research is no longer directly concerned with pedagogic issues. As a result, communication between Second Lan-guage Acquisition (SLA) researchers and language teachers has become difficult or has ceased to exist altogether.
The aim of this volume is to fill this gap and to provide a forum for ex-change for both disciplines. The first part contains contributions by SLA researchers and experts in prosody. They present descriptions of non-native prosodic structures in the areas of intonation, stress, speech rhythm and vowel reduction as well as methodological considerations on research in SLA in a format accessible to teachers. This includes overviews of current theoretical models as well as findings from empirical investigations. In the second part, some of the leading teaching practitioners and developers of phonological learning materials present a variety of methods and exercises in the area of prosody. This volume is a product of scientific and practical interchange and provides a platform and incentive for further collaboration. On the one hand, research on non-native prosody can help teachers to inter-pret and make sense of their classroom experiences and to provide them with a broad range of pedagogic options. On the other hand, researchers

vi Preface
may be encouraged to investigate aspects of non-native prosody that have been shown to be of primary importance in language classrooms. We hope that this volume will contribute usefully to this dialogue and that it shows some new trends in theoretical as well as applied linguistics.
On this occasion we would like to thank the Ministry of Education, Cul-ture and Research of the Saarland for their financial support. Without this help the workshop would not have taken place. We also would like to thank our anonymous reviewer for all the valuable comments.
Saarbrücken and Freiburg, Jürgen Trouvain and Ulrike Gut December 2006

Contents
Preface v
Introduction
Bridging research on phonetic descriptions with knowledge from teaching practice – The case of prosody in non-native speech 3 Ulrike Gut, Jürgen Trouvain and William J. Barry
Part 1: Phonetic descriptions
An introduction to intonation – functions and models 25 Martine Grice and Stefan Baumann
Phonological and phonetic influences in non-native intonation 53 Ineke Mennen
Different manifestations and perceptions of foreign accent 77 in intonation Matthias Jilka
Rhythm as an L2 problem: How prosodic is it? 97 William Barry
Temporal patterns in Norwegian as L2 121 Wim van Dommelen
Learner corpora in second language prosody research and teaching 145 Ulrike Gut
Part 2: Teaching practice
Teaching prosody in German as a foreign language 171 Ulla Hirschfeld and Jürgen Trouvain
Metacompetence-based approach to the teaching of L2 prosody: practical implications 189 Magdalena Wrembel

viii Contents
Individual pronunciation coaching and prosody 211 Grit Mehlhorn
Prosodic training of Italian learners of German: the contrastive prosody method 237 Federica Missaglia
Language index 259
Index of L1–L2 combinations 260
Subject index 261

Introduction


Bridging research on phonetic descriptions with knowledge from teaching practice – The case of prosody in non-native speech
Ulrike Gut, Jürgen Trouvain and William J. Barry
1. Introduction
The phenomenon of “non-native prosody” is of interest for a variety of groups and has been seen from different perspectives and used for different purposes. These groups include foreign language teachers, teachers of these teachers, authors of learning materials, researchers, and engineers facing the problem of non-native input for automatic speech recognizers.
Broadly speaking, we can divide the professional groups concerned with non-native prosody into two categories: linguists who carry out research on language data, and teachers who give language classes. Both groups have in common that they deal with real data and not simply hypothetical concepts of non-native prosody. As a simplification, one could claim that the former group considers non-native prosody in theory, and the latter group is con-cerned with non-native prosody in practice.
The aim of this article is to show the interests and methods of both groups, to ask for common and/or distinct interests, to uncover parallels but also differences, to describe the exchange between the two groups and to show the limitations and the benefits of a “bi-lateral” exchange of insights and knowledge. In section 2, the interests and methods of the theoretical and the practical groups are presented and the current state of the exchange between these two approaches to non-native prosody is described. Section 3 illustrates the potential for exchange with examples from the area of stress, articulation rate, speech rhythm and intonation. In the last section, we will point out requirements and solutions for the mutual benefit of both groups.

4 Ulrike Gut, Jürgen Trouvain and William J. Barry
2. Theoretical and practical approaches to non-native prosody
The aim of theoretical research in the area of second language (L2) proso-dy, as in linguistics as a whole, is to develop descriptions in the form of models and theories with predictive power. Those models and theories are based on and tested by empirical research, that is on observations and mea-surements of non-native speech, and are modified according to these obser-vations. A rich choice of research methods exists which vary along the lines of the type of language data that is analysed (experimental data or sponta-neous data) and the analysis method (e.g. qualitative versus quantitative; auditory or instrumental). Typically, speech elicited from non-native spea-kers in closely controlled conditions is analysed instrumentally (see Barry, this volume, Gut, this volume, Jilka, this volume, Mennen, this volume, van Dommelen, this volume). Based on these data, generalizations are made and formulated in models and theories of non-native prosody. Fundamental research of this type can have two main foci: a synchronic or a develop-mental focus. In the former, non-native prosody at one stage is described, whereas in the latter the aim is to find common developmental paths or stages in the acquisition process of language learners. Findings by theoreti-cal researchers are disseminated in publications and conference presenta-tions on both the national and international level, whereby “international” is often restricted to English.
The aim of language teachers is to enable language learners to produce and perceive the prosody of the target language to an adequate extent, de-pending on the learner’s needs. This might range from minimal communi-cative abilities to a near-native language competence. Teachers have a wide range of methods available, including imparting theoretical knowledge, raising awareness for language structures, practical production exercises and perceptual training. Again depending on the learner’s expectations and requirements, teachers pick a combination of these methods. Typically, language teachers learned these methods in their teacher-training courses and modify and extend their repertoire with increasing teaching experience. Occasionally, teachers are encouraged to participate in further training pro-grammes.
The two groups have different expectations and conceptions about “the other side”. Some researchers are interested in seeing their findings applied in language teaching and describe implications for teaching. They envisage the application of theoretical findings in second language research to lan-guage teaching as a top-down process, with a direct link between research-

Bridging research on phonetic descriptions 5
derived theory and classroom practice. Language teachers, conversely, wish to be provided with relevant teaching materials and methodologies. Both sides express dissatisfaction with each other, as reported by several authors (van Els and de Bot 1987:153, Ellis 1997). Often, the findings of empirical research are not clear and uncontested enough to provide a straightforward guideline for teachers. Moreover, the results of empirical research are rare-ly disseminated or presented in a way that is meaningful and immediately accessible to language teachers. In addition, the interests of researchers do not necessarily focus on areas that are considered most conspicuous and important by teachers. Lastly, the question remains whether there is a “best method” to teach L2 prosody. Due to the constantly varying nature of the classroom, teachers, based on their experience and knowledge, apply peda-gogical methods flexibly, depending on the changing dynamics of the lear-ner community and classroom context.
The relationship between the two groups concerned with non-native prosody is and always has been difficult. Researchers do rarely go to langu-age classes and teachers do rarely go to scientific conferences. An ex-change between the two poles “theoretical research” and “language class” is highly desirable but there are no institutionalised platforms for the vari-ous professional groups concerned with L2 prosody to meet. At least one intermediate group of professionals can be identified: the writers of langua-ge text books and developers of teaching materials. Ideally, they form a bridge between theoretical research and language teaching by selecting findings and (re-)formulating them in a way to make them accessible to both language teachers and language learners and by developing appropria-te learning materials. This means that they have to be simultaneously able to interpret and assess the relevance of the theoretical research and be awa-re of the requirements of language teachers. Moreover, they need to be able to transform theoretical findings into suitable exercises and come up with interesting examples. Unfortunately, very few people with these qualifica-tions exist. In the commercial sector, language material is developed under time and financial pressure so that, in reality, a thorough sifting of the nu-merous publications and conference proceedings in the area of non-native prosody is not possible.
However, even if there were sufficient professionals qualified to bridge the gap between theory and practice, in many cases they would fail because of the lack of overlap in interests between the two groups. Whereas langua-ge teachers are concerned with the acquisition of non-native prosody, re-searchers focus mainly on the description of individual stages. In most a-

6 Ulrike Gut, Jürgen Trouvain and William J. Barry
reas of L2 prosody research, a myriad of competing theories and models dealing with fine-grained details exist which predict very different acquisi-tion processes and attribute different degrees of importance to particular pedagogical strategies and learner characteristics. It is the purpose of this article to describe this gap using the problem areas of non-native stress, articulation rate, speech rhythm and intonation as examples. Furthermore, the present volume as a whole constitutes a step towards bridging the gap between theory and practice in L2 prosody and to describe ways of achie-ving a mutual interchange beneficial to both sides.
3. Theoretical-practical exchange in L2 prosody
In the following sections, we will trace the gap between theoretical resear-chers and language teachers with the examples of non-native stress, articu-lation rate, speech rhythm and intonation and show where improvement in the exchange and mutual benefits are possible.
3.1. Stress
“Stress“ in theory
Stress and accent, which give prominence to a syllable in a word or a word in a phrase, have been identified by many theoreticians as well as practitio-ners as important prosodic concepts (e.g. Fox 2001; see also Mehlhorn this volume, Missaglia, this volume, Hirschfeld and Trouvain, this volume). However, the terms “stress” and “accent” are used in contradictory ways among researchers (cf. Grice and Baumann, this volume). Sometimes, “stress” is defined as an abstract category, the prominence of a word repre-sented in the speaker’s mental lexicon, and “accent” as its observable, pho-netic realization in actual speech (e.g. Jassem and Gibbon 1980). Others use the terms with exactly the opposite meaning (e.g. Laver 1994). We use the term “stress” here in the first sense, i.e. stress as a potential accent, and we reserve “accent” for the realized “stress” (resulting in perceived promi-nence) when a word is produced in an utterance. Moreover, theoretical research in the areas of stress and accent is not only characterized by termi-nological debates but has also generated controversies on the subjects of the appropriate mode of their description, their phonetic correlates as well as their phonological role in specific languages.

Bridging research on phonetic descriptions 7
There are languages that are said not to have word stress as an abstract phonological category at all, for example Japanese (Beckman 1986). Other languages have been divided into those that have obligatory word stress and those without. Word stress can be relatively unpredictable or fixed. In the case of fixed stress, all words of a language have stress on a particular posi-tion, e.g. the last syllable (for example Turkish) or the penultimate syllable (for example Welsh). In languages with low predictability in their word stress (for example German and English), a set of phonological rules is usually needed to describe the stress patterns of words. Yet, little consensus has been reached on the appropriate description of word stress rules in these languages, and the competing proposals are typically based on ab-stract theoretical models that are not accessible to the uninitiated reader (e.g. Hayes 1984, Wiese 1996, Gamon 1996, Pater 2000).
In addition, the term stress has been applied to two domains of phonolo-gical description: word-stress, which is a phonological property of the word, and sentence-stress, where stress is seen as a differentiating property of the utterance. In the second domain, a distinction between stress and intonation is difficult to uphold (e.g. Kingdon 1939) as the relationship between accents and pitch is very intricate. In intonation languages such as English and German, pitch is anchored to accents (see also section 3.4). Other languages differ with respect to whether “pitch” or “stress” is as-sumed to have precedence. In Swedish, for example, lexically stressed syl-lables have additional tonal information (van der Hulst and Smith 1988), whereas in Japanese, the presence of tone alone is assumed to determine the position of the prominent syllables (Abe 1998).
The above-mentioned differences in terminology used to capture the prosodic differences between languages stem in part from the fact that the phonetic realization of accents can be different in different languages. In languages with “dynamic accent” such as English or German, the phonetic parameters pitch, length, loudness and articulatory precision are combined with different relative importance for the phonetic realization of stress (cf. Cruttenden 1997). In both English and German, the difference between stressed and unstressed syllables is correlated with differences in duration together with a different vowel quality, differences in pitch height and loudness. In “pitch-accent” languages (i.e. languages in which lexical words can have a distinctive tonal form) such as Swedish or Norwegian, phonetically different types of tones or pitch patterns are used to prosodi-cally differentiate words (Gårding 1998).

8 Ulrike Gut, Jürgen Trouvain and William J. Barry
“Stress” in practice
Numerous publications have shown that non-native speakers do not always produce stress on words and in sentences in a native-like manner (e.g. Backman 1979, Juffs 1990, Grosser 1997). Some authors even report “stress deafness” (Dupoux, Pallier, Sebastian and Mehler 1997): Speakers of French, a language without stress differentiation at the word level are deaf to lexical stress that Spanish speakers perceive. This “stress deafness” could affect the learning of stress-related phenomena in foreign languages. Moreover, no matter whether a researcher studies speech signals of non-native speakers or a teacher is confronted with the oral performance of language learners in the classroom, the evidence is the same: non-native speakers of some languages have more difficulties with stress and accen-tuation than non-natives of other languages. This is the case whether or not the L1 and L2 involved both have word stress. Learners of English, whose native language has different word stress rules, for example, show different strategies in producing word stress and sentence stress patterns in their L2 (Archibald 1995). What is more, incorrect stress patterns often persist despite long exposure to correct forms. Thus it would appear that “stress deafness” is not merely the result of stress typology differences (as between French and Spanish).
This dependency of the teaching of stress rules on the native and target languages involved requires a variety of didactic approaches. Target lan-guages without word stress or with fixed word stress require different teaching methods than languages with unpredictable stress. When the stress systems of native and target language coincide, stress does not need to be taught at all, though attention to particular “faux amis“ must not be neglec-ted (e.g. Spanish and Italian “teLEfono“ versus English and German “TE-lephon(e)“). In all other cases, current teaching methods typically focus on the creation of language awareness (see Mehlhorn, this volume and Wrem-bel, this volume). This is achieved by a combination of perceptual and arti-culatory training and knowledge input (see also Hirschfeld and Trouvain, this volume). Language awareness is also assumed to enhance the acquisi-tion of further foreign languages. For example, it has been proposed that a native speaker of Polish who has learned in English as a first foreign langu-age that the penultimate stress pattern of his or her native language cannot be transferred to the L2 has created phonological awareness of the impor-tance of word stress and will increase his or her sensitivity for word stress rules in further foreign languages. Thus in the acquisition of a further lan-

Bridging research on phonetic descriptions 9
guage he or she will profit from general phonological awareness developed in the acquisition of another language, even though the two languages (of course) have different phonological systems. Naturally, the creation of lan-guage awareness presupposes a reliable phonological description of the stress rules of a particular language.
Besides the phonological awareness for predicting the position of word stress a phonetic awareness is needed for the realisation of stressed syl-lables in contrast to unstressed syllables. It may be that the target language and mother tongue differ in how stress is realised with a mix of duration, pitch, intensity and articulatory precision.
3.2. Articulation rate
"Articulation rate" in theory
Listeners perceive their native language/s and those they speak with a high level of proficiency as less fast than those languages they have a poor command of or do not know at all. Abercrombie (1967: 96) puts it as fol-lows: “Everyone who starts learning a foreign language, incidentally, has the impression that its native speakers use an exceptionally rapid tempo.” Though languages may differ in terms of rate of speech production – de-pending of course on speech mode and what unit is selected for measure-ment (including or excluding pauses, spontaneous speech or reading pas-sage style) – there certainly appear to be differences in the way speech rate is perceived across languages. Some authors explain the false impression that an unknown language sounds faster than normal (i.e. than one’s own language) with phonological differences such as different patterns of sylla-bic complexity (Osser and Peng 1964).
Articulation rate plays a significant role for learners of a foreign langua-ge, not only in speech comprehension but also in speech production. It is usually taken as a correlate of a speaker’s general language proficiency or fluency and is conceptualized to correlate with the fluidity, continuity, au-tomaticity or smoothness of oral speech production. Rate of speech has been measured in many ways (cf. Trouvain 2004). This also applies in the context of language learning: Lennon (1990) measures speed rate both with words per minute unpruned and words per minute after pruning, where pruning refers to the exclusion of all repeated and self-corrected words as well as asides, i.e. comments on the narrative task itself. Towell (2002) measures the number of syllables per minute and Cucchiarini, Strik and

10 Ulrike Gut, Jürgen Trouvain and William J. Barry
Boves (2000, 2002) measure the number of phonemes per time unit. In addition, the mean length of a “run” has been analysed where a “run“ is defined as a stretch of speech between pauses (e.g. Lennon 1990, Towell 2002, Cucchiarini, Strik and Boves 2000, 2002, Freed, Segalowitz and De-wey 2004) with some researchers including filled pauses in “runs” and others not. Since a run is defined by its delimitation by pauses of a certain length, it does not necessarily represent a semantic or syntactic unit in speech. A syntactically-based chunking of speech is proposed by Lennon (1990) with the “t-unit”, which he defines as one main clause and all sub-ordinate clauses. He measures the frequency and length of pauses within “t-units”, the percentage of “t-units” followed by a pause as well as the per-centage and mean length of pauses at “t-unit” boundaries. The ratio bet-ween pauses and speech in recordings is referred to as the phonation/time ratio (Towell 2002, Cucchhiarini, Strik and Boves 2000, 2002) and is mea-sured by dividing the total duration of speech by the total duration of the recording. Finally, the amount of speech can be measured either in the total number of words produced (e.g. Freed, Segalowitz and Dewey 2004) or in the duration of speaking time per total recording time. This measurement can obviously only be used when the analysed recordings of the different speakers have a comparable length.
Experimental studies have shown that some of these quantitative meas-urements of articulation rate correlate with native speaker’s judgements of fluency (Lennon 1990, Cucchiarini, Strik and Boves 2000, 2002). How-ever, it was further found that articulation rate is not constant in natural speech (Miller, Grosjean and Lomanto 1984). Even in reading passages, the articulation rate may be adjusted (by competent readers) by giving more time to sections with greater communicative weight and less time to those that are less important to the “message”. Rate variation is therefore an im-portant concept. Hand in hand with this, of course, go all the other segmen-tal and prosodic modifications that are associated with local temporal changes (often referred to as “local speech rate”) resulting from informa-tion weighting – from lexical stress position to function-word or particle destressing and topic and focal accenting (see e.g. Eefting 1991).
“Articulation rate” in practice
In language teaching and testing, articulation rate, or speed of delivery in an L2 is taken as an important diagnostic feature. Articulation rate which also reflects the level of fluency of a non-native speaker is highly correlated

Bridging research on phonetic descriptions 11
with the level of proficiency evaluated by native listeners (Gut 2003). When grading oral examinations, teachers are often asked to score candi-dates for fluency and even in standardized testing procedures such as exams taken by the Deutscher Akademischer Austauschdienst or the British Coun-cil, candidates have to be allocated to bands with descriptions such as “flu-ent, virtually error free” or “not fully fluent with occasional inappropriate use of structures”.
Despite this central importance of a native-like speech rate in an L2, very few didactic methods for its acquisition seem to have been developed for language teaching. A common conviction seems to be that an increase in articulation rate merely constitutes a quasi-automatically acquired fea-ture of the language learner’s generally improving linguistic competence. Missaglia (this volume) describes some exercises that raise the learners’ awareness of stylistic variants and the concomitant segmental and prosodic feature changes that are associated with speech rate changes. Yet, so far, there are almost no attempts to include speech-rate variation in the teaching strategy. This is valid for varying the global rate of the same utterances in audio material as well as for more varied local rate changes in different text sorts. On the comprehension side, didactic methods focussing on articula-tion rate could include examples of different, situationally defined stylistic variants of key expressions (cf. for German “Phonetik Simsalabim” by Hirschfeld and Reinke 1998).
3.3. Speech rhythm
“Speech rhythm” in theory
“Speech rhythm” is a concept that has been the subject of intensive discus-sion and empirical investigation over many decades. In early theoretical approaches it was described as a periodic and relatively isochronous recur-rence of events such as syllables in the case of the so-called “syllable-timed” languages, and feet in the case of the so-called “stress-timed” lan-guages (Pike 1945, Abercrombie 1967). In syllable-timed languages such as French, syllables were assumed to be similar in length. Stress-timed languages, to which English was counted, in contrast, were supposed to have isochronous, i.e. regular, recurring stress beats. Since in those langua-ges the number of syllables between two stress beats varies, they are ad-justed to fit into the stress interval – hence syllable length is reported to be very variable in stress-timed languages. No convincing acoustic basis for

12 Ulrike Gut, Jürgen Trouvain and William J. Barry
either isochrony of feet in stress-timed languages or equal length of syl-lables in syllable-timed languages has ever been found (e.g. Classé 1939, Uldall 1971, Fauré, Hirst and Cafcouloff 1980, Roach 1982, Dauer 1983).
More recent approaches of measuring speech rhythm are based on the assumption that speech rhythm is a multidimensional concept which inclu-des various phonological properties of languages. Accordingly, languages are no longer classified into discrete rhythmic classes but are assumed to be located along a continuum, though the continuum is still generally de-scribed in terms of its “syllable-timed” and “stress-timed” extremes. Dauer (1983), for example, suggested that rhythmic differences between langua-ges are the result of phonological, phonetic, lexical, and syntactic facts such as variety of syllable structures, phonological vowel length distinctions, absence/presence of vowel reduction and lexical stress. Since syllables increase in length when segments are added and closed syllables are longer than open ones, speech rhythm measured in terms of syllable-duration dif-ferences reflects the syllable complexity distribution. So languages without complex syllables tend to have more equal syllabic durations than those with strongly varying complexity. Equally, overall differences in “rhythm” between languages reflect whether a language has vowel reduction or not; those classified as stress-timed do, though it may or may not be coded as a phonological alternation as it is in English, Danish or Portuguese. Many languages classified as syllable-timed either do not have lexical stress or accent is realized by variations in pitch contour. Conversely, stress-timed languages realize word level stress by a combination of length, pitch, loud-ness and quality changes, which result in clearly discernible beats, at least in deliberate or stylized production.
On the basis of this approach several phonetic measurements of “speech rhythm” have been proposed. Ramus, Nespor and Mehler (1999) segment speech into vocalic and consonantal parts and calculate the proportion of the vocalic intervals of a sentence and the standard deviation of the vocal and consonantal intervals. Other measurements focus on local relations. Grabe and Low (2002) measure the difference in duration between succes-sive vowel durations and between successive consonantal intervals. Gibbon and Gut (2001) calculate the ratio of adjacent syllable and vowel durations. These studies have succeeded in describing differences between languages (Ramus, Nespor and Mehler 1999, Grabe and Low 2002, Gut and Milde 2002) as well as between varieties of one language (Low and Grabe 1995, Gut and Milde 2002). Critics of these parametrisations, however, point out that speech rhythm is located on a higher phonological level than segments

Bridging research on phonetic descriptions 13
and that it consist of a coupling between intervals at a lower prosodic level with those at a higher level (Cummins 2002). Dauer (1983) and Barry (this volume) even suggest dispensing with the concept of “speech rhythm” al-together and recognizing that it is used merely as a cover term for a range of structural properties of a language.
“Speech rhythm” in practice
The concept of “rhythm” that a theoretically unburdened language teacher (or language learner) has is probably very different from the complex defi-nition underlying the studies mentioned in the previous section. The traditi-onal view of a syllable-timed or stress-timed distinction lies closer to the intuitively more plausible concept of rhythm as a regular beat. This brings together music and poetry, supporting the idea of utterances in different languages potentially differing in their inherent rhythm. However, even the most competent of teachers needs to understand the factors which underlie the differences between a “rhythmically correct” and an “incorrect” render-ing of an utterance she/he is offering for practice. Typology statements reflect tendencies, but teaching requires concrete utterances which encapsu-late the critical features that distinguish the L2 rhythmic type from the L1 type. Though these may be easy enough to find among the communicative-ly useful expressions that language course books introduce, the repetitive production that is essential in order to guarantee the sense of rhythmicality may be easier in some learner groups than others. Finally, the acquisition of rhythmic sensitivity must extend to an awareness of “utterance rhythm” as the product of “word sequence” x “context”, by varying the context in which a particular expression is practised.
3.4. Intonation
“Intonation” in theory
The term “intonation” is used in theoretical research with different scopes. In a broad definition, the term covers both linguistic and paralinguistic features such as tempo, voice quality and loudness which signal the emoti-onal state of the speaker (cf. Fox 2001). Less broad definitions include only linguistic phenomena produced with the prosodic features tone, stress and quantity and their physiological correlates fundamental frequency, intensi-ty, duration and spectral characteristics. The narrowest definitions of into-

14 Ulrike Gut, Jürgen Trouvain and William J. Barry
nation are restricted to only postlexical phonological phenomena thus exc-luding word stress, tone and quantity (Ladd 1996, Hirst and di Cristo 1998).
Currently, two major competing models of intonational structure are in use for the description of intonation, based on a number of fundamentally different assumptions about intonational structure and using different con-ventions of intonational transcription (see also Grice and Baumann, this volume). The contour-based approaches on the one hand take pitch move-ments or contours as the basis of intonational analysis. Intonational analysis in this approach is mainly carried out auditorily. Intonation is represented in detailed interlinear transcriptions which depict the properties of each syllable in terms of accentedness, pitch height and pitch movement. The autosegmental-metrical approach, on the other hand, proposes that intonati-on consists of sequences of minimally two and maximally three different tone levels. These tones can be realized as pitch accents, usually aligned with accented syllables, or have a delimitative function as initial or final tones of intonational phrases. Intonational analysis in this approach relies on a combination of computer-assisted instrumental and auditory techni-ques.
Cross-linguistic descriptions of the intonational system of languages are still few and far between (e.g. Delattre 1965, Fox 1981, Willems 1982, Grabe 1998, Hirst and di Cristo 1998, Jun 2005). For individual languages, tone inventories and the meaning of particular pitch movements or tone combinations have been proposed (e.g. Grice, Baumann and Benzmüller 2005 for German, and Pierrehumbert and Hirschberg (1990) for American English). In these descriptions, however, the authors stress that a specific tone or pitch contour does not have an abstract meaning but may rather be associated with a specific pragmatic meaning in given contexts. As yet, very few empirical studies exist that systematically investigate the intonati-on of non-native speech (but see Mennen, this volume, on pitch alignment and pitch range, and Jilka, this volume, on tone inventory), but native lan-guage influences have been variously described (e.g. van Els and de Bot 1987).
“Intonation” in practice
Despite the relatively uncontroversial theoretical side of intonation, the teaching of intonation still plays a minor role in the L2 classroom. This might be due to the fact that both teachers and learners of a foreign lan-guage still underestimate the consequences which deviant intonational pat-

Bridging research on phonetic descriptions 15
terns may have in communicative and attitudinal respects. The use of visu-alization techniques that enable learners to perceive differences between their own and a native speaker’s rendition of utterances with the help of computers that display the respective intonation curves is often still im-peded by the technical requirements in classrooms and the lack of suitable software tools (but see Herry and Hirst 2002 for a successful attempt).
As for the teaching of stress rules, the creation of language awareness (see Mehlhorn, this volume) and perceptual sensitization (see Wrembel, this volume) seems to constitute a prerequisite for the production of native-like intonation by language learners. In the approach suggested by Mis-saglia (this volume), in contrast, the acquisition of intonation is pictured as an unconscious by-product of teaching methods that focus on larger pro-sodic units and imitative techniques.
4. Research and practice – mutual stimulation?
In the preceding sections we illustrated the gap that exists between theoreti-cal research on L2 prosody, on the one hand, and teaching practice in lan-guage classes on the other. In this summary we would like to suggest ans-wers to the question how research and practice can benefit from each other. In particular we will discuss how research results can provide the source for course book materials for language teachers, and how we picture the pos-sible impact from state-of-the-art teaching practice on theoretical resear-chers.
“Research and Development” should ideally comprise a double orienta-tion – theory and application – and a continuum of activity which allows the practical implementation of the theoretical results. In the case of langu-age teaching at the applicational end of the activity continuum, theoretical research questions can be directed towards contrastive aspects of language structure and speech patterns, as we have illustrated in this paper. Equally valid theoretical poles from which to derive applicational answers are, on the one hand, research into learning psychology and patterns of language-learning behaviour (cf. Flege and Hillenbrand 1984, Flege 1995, Stran-ge 2002 and, on the other, research into didactics and language-teaching methodology. A comprehensive theoretical grounding of language-teaching materials clearly demands a breadth and depth of theoretical research knowledge that would go beyond anything that can be expected of anyone actively involved in teaching.

16 Ulrike Gut, Jürgen Trouvain and William J. Barry
Is it illusory, then, to expect the practical exploitation of theoretical re-search into prosody? When the results of research consist of theoretical descriptive models, the answer is probably “Yes”. But if the descriptive models provide contrastive information about different languages, they offer a theoretically solid basis for course book authors and teachers to focus exercises on, in whichever didactic and methodological framework they subscribe to. The contrastive work done within the structuralist lin-guistic framework during the 1950's and 1960's on the syntax, morphology and segmental phonology of various languages is an example of how theo-retical work can become established as the basis for developing practical teaching materials (e.g. Moulton 1962, Kufner 1971). However, it also illustrates the problems inherent in theory which did not take the reality of the learning/teaching situation into consideration. Contrasting phoneme inventories ignores allophonic or other phonetic differences (e.g. vowel-quality differences) that may lie behind identical phonetic symbols. The potential of research results for practical application, therefore, depends on their being formulated in a way which is relevant to the learner's task and understandable for the teacher.
In general, however, the direct application of research findings in the classroom must be regarded with reserve. Rather, we have shown with the examples discussed in section 3 that an intermediate step is necessary. The relevance of research findings can only be investigated in studies on actual language teaching. It is those research results that offer possibilities of di-rect application in other classroom situations. Yet, scientific studies on foreign language classroom practices are rare to find. This is especially lamentable because we believe that these kinds of investigations provide the essential link between theory and teaching practice in L2 prosody. Fur-thermore, they present the opportunity for research to benefit from state-of-the-art language teaching. For example, a possible focus could be whether the prosodic concepts of stress, intonation, speech rhythm and so forth em-ployed in teaching are the same as the theoretical concepts proposed in research. Discrepancies can spark off new directions for research. Like-wise, scientific results gathered on teaching prosody to non-native speakers with different native languages can be beneficial for research. Technologi-cal advances have brought the acquisition of speech produced in situ and its post-production processing and analysis within the reach of even small research teams and made non-intrusive collaboration between teachers and researchers a genuine possibility.

Bridging research on phonetic descriptions 17
References
Abe, Isamu 1998 Intonation in Japanese. In: Daniel Hirst and Albert di Cristo
(eds.), Intonation Systems. Cambridge: Cambridge University Press, 360–75.
Abercrombie, David 1967 Elements of General Phonetics. Edinburgh: Edinburgh University
Press. Archibald, John
1995 The acquisition of stress. In: John Archibald (ed.), Second Lan-guage Acquisition and Linguistic Theory, 81–109. Oxford: Blackwell.
Backman, Nancy 1979 Intonation errors in second-language pronunciation of eigth Spa-
nish-speaking adults learning English. Interlanguage Studies Bul-letin Utrecht 4, 239–265.
Beckman, Mary 1986 Stress and Non-stress Accent. Dordrecht: Foris.
Classé, Andre 1939 The Rhythm of English Prose. Oxford: Blackwell.
Cruttenden, Alan 1997 Intonation. Cambridge: Cambridge University Press (2nd editi-
on). Cucchiarini, Catia, Helmer Strik and Lou Boves
2000 Quantitative assessment of second language learners’ fluency by means of automatic speech recognition technology. Journal of the Acoustical Society of America 107, 989–999.
2002 Quantitative assessment of second language learners’ fluency: comparisons between read and spontaneous speech. Journal of the Acoustical Society of America 111, 2862–2873.
Cummins, Fred 2002 Speech Rhythm and Rhythmic Taxonomy. Proceedings of the
Speech Prosody 2002 conference, Aix-en-Provence (France), 121–126.
Dauer, Rebecca 1983 Stress-timing and syllable-timing reanalysed. Journal of Phone-
tics 11, 51–62. Delattre, Pierre
1965 Comparing the Phonetic Features of English, German, Spanish and French. Heidelberg: Groos Verlag.

18 Ulrike Gut, Jürgen Trouvain and William J. Barry
Dupoux, Emmanuel, Christophe Pallier, Nuria Sebastian and Jacques Mehler 1997 A destressing ‘deafness’ in French? Journal of Memory and
Language 36, 406–421. Eefting, Wieke
1991 Timing in Talking. Tempo Variation in Production and Its Role in Perception. PhD thesis, University of Utrecht.
Ellis, Rod 1997 SLA research and language teaching. Oxford: Oxford University
Press. van Els, Theo and Kees de Bot
1987 The role of intonation in foreign accent. The Modern Language Journal 71, 147–155.
Fauré, George, Daniel Hirst and Michel Chafcouloff 1980 Rhythm in English: isochronism, pitch, and perceived stress. In:
Linda Waugh and Cornelis van Schooneveld (eds.), The melody of Language, 71–79. Baltimore: University Park Press.
Flege, James E. 1995 Second-language speech learning: Theory, findings, and prob-
lems. In: Winifred Strange (ed.), Speech perception and linguistic experience: Theoretical and methodological issues, 233–273. Timonium, MD: York Press.
Flege, James E. and James Hillenbrand 1984 Limits on phonetic accuracy in foreign language speech produc-
tion. Journal of the Acoustical Society of America 76, 708–721. Fox, Anthony
1981 Fall-rise intonation in German and English. In: Charles V.J. Russ (ed.) Contrastive Aspects of English and German, 55–72. Heidel-berg: Groos Verlag.
2001 Prosodic Features and Prosodic Structure. Oxford: Blackwell. Freed, Barbara, Norman Segalowitz and Dan Dewey
2004 Context of learning and second language fluency in French: comparing regular classroom, study abroad, and intensive do-mestic immersion programs. Studies in Second Language Acqui-sition 26, 275–301.
Gamon, Michael 1996 German word stress in a restricted metrical theory. Linguistische
Berichte 162, 107–136. Gårding, Eva
1998 Intonation in Swedish. In: Daniel Hirst and Albert di Cristo (eds.), Intonation Systems. Cambridge: Cambridge University Press, 112–30.

Bridging research on phonetic descriptions 19
Gibbon, Dafydd and Ulrike Gut 2001 Measuring speech rhythm. Proceedings of Eurospeech, Aalborg
(Denmark), 91–94. Grabe, Esther
1998 Comparative Intonational Phonology: English and German.Doctoral Dissertation, Max-Planck-Institut for Psycholinguistics and University of Nijmegen.
Grabe, Esther and Ee Ling Low 2002 Durational variability in speech and the rhythm class hypothesis.
In: Carlos Gussenhoven and Natasha Warner (eds.), Papers in Laboratory Phonology 7, 515–546. Berlin: Mouton de Gruyter.
Grice, Martine, Stefan Baumann and Ralf Benzmüller 2005 German intonation in autosegmental-metrical phonology. In:
Sun-Ah Jun (ed.), Prosodic Typology, 55–83. Oxford: Oxford University Press.
Grosser, Wolfgang 1997 On the acquisition of tonal and accentual features of English by
Austrian learners. In: Allan James and Jonathan Leather (eds.), Second Language Speech – Structure and Process, 211–228. Berlin: Mouton de Gruyter.
Gut, Ulrike 2003 Prosody in second language speech production: the role of the
native language. Zeitschrift für Fremdsprachen Lehren und Ler-nen 32, 133–152.
Gut, Ulrike and Jan-Torsten Milde 2002 The prosody of Nigerian English. Proceedings of the Speech
Prosody 2002 conference, Aix-en-Provence (France), 367–370. Hayes, Bruce
1984 The phonology of rhythm in English. Linguistic Inquiry 15, 33–74.
Herry, Nadine and Daniel Hirst 2002 Subjective and objective evaluation of the prosody of English
spoken by french speakers: the contribution of computer assisted learning. Proceedings of the Speech Prosody 2002 conference,Aix-en-Provence (France), 383–387.
Hirschfeld, Ursula and Kerstin Reinke 1998 Phonetik Simsalabim. Ein Übungskurs für Deutschlernende. Ber-
lin etc.: Langenscheidt. Hirst, Daniel and Albert di Cristo
1998 A survey of intonation systems. In: Daniel Hirst and Albert di Cristo (eds.), Intonation Systems, 1–44. Cambridge: Cambridge University Press.

20 Ulrike Gut, Jürgen Trouvain and William J. Barry
van der Hulst, Harry and Norval Smith 1988 The variety of pitch accent systems: Introduction. In Harry van
der Hulst and Norval Smith (eds), Autosegmental Studies on Pitch Accent, ix–xxiv. Dordrecht: Foris.
Jassem, Wiktor and Dafydd Gibbon 1980 Re-defining English accent and stress. Journal of the Interna-
tional Phonetic Association 10, 2–16. Juffs, Alan
1990 Tone, syllable structure and interlanguage phonology: Chinese learner's stress errors. International Review of Applied Linguistics28, 99–117.
Jun, Sun-Ah (ed.) 2005 Prosodic Typology. Oxford: Oxford University Press.
Kingdon, Roger 1939 Tonetic stress marks for English. Le maitre phonétique 68, 60–
64.Kufner, Herbert L.
1971 Kontrastive Phonologie Deutsch-Englisch. Stuttgart: Klett Ladd, D. Robert
1996 Intonational Phonology. Cambridge: Cambridge University Press.
Laver, John 1994 Principles of Phonetics. Cambridge: Cambridge University Press.
Lennon, Paul 1990 Investigating fluency in EFL: a quantitative approach. Language
Learning 40, 387–417. Low, Ee Ling and Esther Grabe
1995 Prosodic patterns in Singapore English. Proceedings of the13th International Congress of Phonetic Sciences, Stockholm, 636–639.
Miller, Joanne L., François Grosjean and Concetta Lomanto 1984 Articulation rate and its variability in spontaneous speech. Pho-
netica 41, 215–225. Moulton, William G.
1962 The Sounds of English and German. Chicago: University of Chi-cago Press.
Osser, Harry and Frederick Peng 1964 A cross cultural study of speech rate. Language & Speech 7,
120–125. Pater, Joe
2000 Non-uniformity in English secondary stress: the role of ranked and lexically specific constraints. Phonology 17, 237–274.

Bridging research on phonetic descriptions 21
Pierrehumbert, Janet and Julia Hirschberg 1990 The meaning of intonational contours in discourse. In: Phil Co-
hen, Jerry Morgan and Martha Pollack (eds.), Intentions in Com-munication, 271–311. Cambridge, Mass.: MIT Press.
Pike, Kenneth 1945 The Intonation of American English. Ann Arbor: University of
Michigan Press. Ramus, Franck, Marina Nespor and Jacques Mehler
1999 Correlates of linguistic rhythm in the speech signal. Cognition73, 265–292.
Roach, Peter 1982 On the distinction between ‘stress-timed’ and ‘syllable-timed’
languages. In: David Crystal (ed.), Linguistic Controversies, Es-says in Linguistic Theory and Practice, 73–79. London: Edward Arnold.
Strange, Winifred 2002 Speech perception and language learning: Wode's developmental
model of speech perception revisited. In: Petra Burmeister, Tor-sten Piske and Andreas Rohde (eds), An Integrated View of Lan-guage Development: Papers in Honor of Henning Wode. Trier: Wissenschaftlicher Verlag Trier.
Towell, Richard 2002 Relative degrees of fluency. A comparative case study of advan-
ced learners of French. International Review of Applied Lingu-istic in Language 40, 117–150.
Trouvain, Jürgen 2004 Tempo Variation in Speech Production. Implications for Speech
Synthesis. (Doctoral Dissertation, published as Phonus 8), Phone-tics, Saarland University, Saarbrücken.
Uldall, Elisabeth 1971 Isochronous stresses in R.P. In: Louis Hammerich, Rodolfo Ja-
cobson and Eberhard Zwirner (eds.), Form and Substance, 205–210. Copenhagen: Akademisk Forlag.
Wiese, Richard 1996 The Phonology of German. Oxford: Clarendon Press.
Willems, Nico 1982 English Intonation from a Dutch Point of View. Dordrecht: Foris
Publications.


Part 1. Phonetic descriptions


An introduction to intonation – functions and models
Martine Grice and Stefan Bauman
This chapter provides an introduction to intonation in general, and is loose-ly based on an oral presentation given in the workshop “Non-native prosody: phonetic description and teaching practice” in Saarbrücken. Al-though intonation is particularly difficult for learners of a second language to master, it is seldom taught systematically. Although much of the early work on intonation was didactic in nature, recent studies have tended to be more experimental and/or theretically rigourous. This has created a gap between intonation as it is used in teaching and intonation research, making it difficult for the results of such research to be of use to teachers of a sec-ond language. It is our aim to bridge this gap. We provide an overview of the main issues dealt with in current theoretical research, discussing the different forms intonation can take and the functions it can fulfill, the one of course dependent on the other. Reflecting the context of the workshop, examples are predominantly in German with English translations, accom-panied where relevant by Italian equivalents.1
We then present the two currently most widespread models of intona-tion, which will hopefully be useful for second language teachers and text-book writers for their own research and for preparation of course material. We also aim to facilitate reading of current primary literature on aspects of intonation, in particular on languages not dealt with here. With this, we hope that results from theoretical research will find their way into the class-room.
1. Intonation
The term ‘intonation’ has been defined in at least two different ways in the literature. A narrow definition equates intonation with ‘speech melody’, restricting it to the “ensemble of pitch variations in the course of an utter-ance” (‘t Hart, Collier and Cohen 1990: 10). The crucial role of pitch varia-tions for the interpretation of utterances can be seen in the German example

26 Martine Grice and Stefan Bauman
utterances (1) and (2), in which the pitch contour is represented as a line above the words spoken.
(1) Sie hat ein Haus gekauft ‘She bought a house.’
(2) Sie hat ein Haus gekauft ‘She bought a house?!’
The examples display exactly the same string of segments. They only differ in their intonation, making (1) a statement with a (rising-)falling contour, and (2) an echo question with a (falling-)rising contour.
Pitch can be modulated in a categorical way, with the presence vs. ab-sence, or type of pitch movement, and in a gradient way, involving e.g. variations in the way a pitch movement is realised: the extent of the rise or fall, or the pitch range within which a pitch movement is realised. The two main tasks of pitch modulation are (1) highlighting, marking prominence relations (Haus is more prominent than ein), and (2) phrasing, the division of speech into chunks. However, it is not pitch alone which is responsible for these tasks. A broader definition of intonation includes loudness, and segmental length and quality, although languages differ in the extent to which they modulate these to achieve highlighting and phrasing. Like pitch, loudness, length and quality are auditory percepts. Their articulatory and acoustic correlates are given in table 1 below, adapted from Uhmann (1991: 109), (see also Baumann 2006: 12).
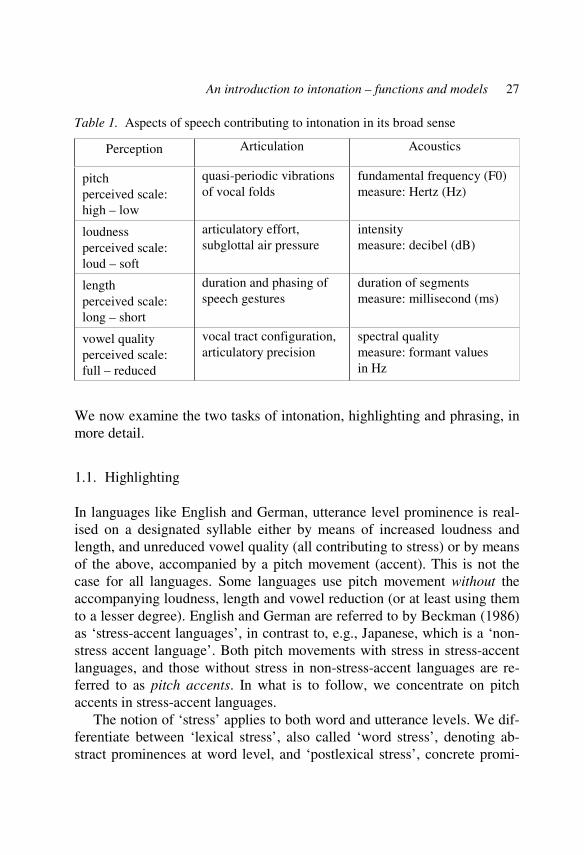
An introduction to intonation – functions and models 27
Table 1. Aspects of speech contributing to intonation in its broad sense
Perception Articulation Acoustics
pitch perceived scale: high – low
quasi-periodic vibrations of vocal folds
fundamental frequency (F0) measure: Hertz (Hz)
loudness perceived scale: loud – soft
articulatory effort, subglottal air pressure
intensity measure: decibel (dB)
length perceived scale: long – short
duration and phasing of speech gestures
duration of segments measure: millisecond (ms)
vowel quality perceived scale: full – reduced
vocal tract configuration, articulatory precision
spectral quality measure: formant values in Hz
We now examine the two tasks of intonation, highlighting and phrasing, in more detail.
1.1. Highlighting
In languages like English and German, utterance level prominence is real-ised on a designated syllable either by means of increased loudness and length, and unreduced vowel quality (all contributing to stress) or by means of the above, accompanied by a pitch movement (accent). This is not the case for all languages. Some languages use pitch movement without the accompanying loudness, length and vowel reduction (or at least using them to a lesser degree). English and German are referred to by Beckman (1986) as ‘stress-accent languages’, in contrast to, e.g., Japanese, which is a ‘non-stress accent language’. Both pitch movements with stress in stress-accent languages, and those without stress in non-stress-accent languages are re-ferred to as pitch accents. In what is to follow, we concentrate on pitch accents in stress-accent languages.
The notion of ‘stress’ applies to both word and utterance levels. We dif-ferentiate between ‘lexical stress’, also called ‘word stress’, denoting ab-stract prominences at word level, and ‘postlexical stress’, concrete promi-

28 Martine Grice and Stefan Bauman
nences at utterance level.2 Table 2 summarises the different levels of de-scription.
Table 2. Levels of description
Lexical stress word level, abstract, potential for concrete prominence Postlexical stress utterance level, concrete prominence Accent utterance level, concrete prominence
The difference between stresses and accents entails a difference in the strength or degree of (postlexical) prominence. There are at least four dif-ferent degrees of prominence at utterance level, as listed in table 3.
Table 3. Degrees of prominence
No stress/accent Stress (equivalent to ‘force accent’ or Druckakzent)
A stressed syllable is louder, longer and more strongly articulated, with less vowel reduction than an unstressed syllable
Pitch accent An accented syllable (i.e. a syllable bearing a pitch accent) has additional tonal movement on or near it
Nuclear pitch accent
the nuclear syllable is the last pitch accent in an intonation phrase, usually perceived as the most prominent one in the phrase
In (3) we provide an extended version of utterance (1) above. It might con-ceivably be produced with a nuclear pitch accent on Haus (‘house’), a non-nuclear pitch accent on the first syllable of schönes (‘beautiful’), and stress on the first syllable of Lena (and possibly also on –kauft) . All other sylla-bles can be thought of as unaccented. In this and later examples, pitch ac-cents are indicated by capital letters, stresses by small capitals.
(3) LEna hat ein SCHÖnes HAUS geKAUFT. ‘Lena bought a beautiful house.’

An introduction to intonation – functions and models 29
1.2. Phrasing
Speech is divided into chunks delimited by means of intonation. These chunks have been termed breath groups, sense groups, tone units, tone groups, phonological phrases or intonational phrases, to name but a few (see Cruttenden 1997: 29–37). The most obvious indicators of boundaries between intonation units are (filled and silent) pauses. The longer the pau-se, the stronger the perceived boundary. However, there are many cases in which a boundary is perceived although a pause is missing. This effect is often due to an abrupt change in pitch across unaccented syllables, i.e. a jump up or down in pitch which cannot be attributed to the highlighting function of intonation.
It is often difficult to decide whether an intonation unit boundary is pre-sent or not, in particular when investigating spontaneous speech. In fact, transcribers across a number of approaches to intonation have often re-ported that they need to capture different levels of phrasing – in simple terms larger and smaller phrases. Although the British School originally had only one level of intonational phrasing (Crystal 1969, for instance), large scale corpus transcription using this model carried out by Gerry Knowles and Briony Williams led to the introduction of an additional level, the major tone unit, which was able to contain a number of (minor) tone units (Williams 1996a, b).
The autosegmental-metrical model of English intonation which contrib-uted substantially to the ToBI framework (see section 3.2.) also makes a distinction between smaller, intermediate phrases and larger, intonation phrases. It is not clear whether there is a one-to-one correspondence be-tween the two systems in terms of their phrasing, but it is possible to say that in many cases an intermediate phrase corresponds to a tone unit/tone group and the intonation phrase to a major tone group (see Roach 1994 and Ladd 1996 for attempts at converting between the British School and auto-segmental metrical models).
The intuitive need for at least two different sizes of phrase can be felt when comparing utterance (3) above, which consists of only one phrase, with (4), which appears most naturally to be composed of two:
(4) Findest Du NICHT, dass Lena ein SCHÖnes HAUS gekauft hat? ‘Don’t you think that Lena has bought a beautiful house?’

30 Martine Grice and Stefan Bauman
The jump in pitch (and thus the phrase break) occurs between nicht and dass. Although the tonal break coincides with a syntactic break here, we stress that intonational phrases and syntactic phrases are independent, even if they of course often correspond.
Other instances of larger phrases containing more than one smaller phrase are lists, as in (5).
(5) Lena hat einen ROten, einen GELben und einen BLAUen Ball. ‘Lena has a red, a yellow, and a blue ball.’
In lists usually all but the last phrase end at a relatively high pitch, either as in (5) above, or with a high level pitch. The high pitch indicates that there is still at least one more item to come. After it the pitch is reset (i.e. there is a jump down), marking the beginning of the next phrase. A jump either up or down is a strong cue for a phrase break (the boundary between two phra-ses).
1.3. Consequences of highlighting and phrasing for the segments of speech
In section 1.1. we claimed that sounds are more strongly articulated when they are stressed or accented. The strength of sounds is also affected by the position of the sound in the syllable and, in turn, of the syllable within the phrase. Below we outline what is meant by strengthening, both with respect to prominence and to phrasing, and describe another phrasal effect on the duration of sounds. An account of intonation cannot ignore these effects, as they are often consciously or unconsciously used as diagnostics for the intonational analysis itself. This is particularly the case for phrasing, where intuitions about levels of phrasing based on the pitch contour are often un-clear.
If we take the sound /t/, at the beginning of a stressed syllable it is stronger than it would be at the beginning of an unstressed syllable: com-pare /t/ realisations at the beginning of ‘tomorrow’ and ‘tomcat,’ where /t/ in ‘tomcat’ is stronger (we hear greater aspiration and a longer closure). Moreover, /t/ at the beginning of a syllable bearing a pitch accent is stronger than one at the beginning of a syllable which is stressed but bears no pitch accent: Compare initial /t/ in the word ‘tomcats’ in ‘I like

An introduction to intonation – functions and models 31
TOMCATS best’ with ‘Why not? I LIKE tomcats,’ where the former /t/ is longer and more aspirated.
The strengthening of segments at the beginning of phrases (domains) is referred to as domain initial strengthening (see, e.g., Keating et al. 2003). Let us take the sound /t/ in English again. It is pronounced at the beginning of a larger phrase with greater strength than at the beginning of a smaller one. Furthermore, connected speech processes such as assimilation occur to a lesser extent across large boundaries than across small ones. This resis-tance to assimilation is also considered to be due to initial strengthening, in the sense that the segment preserves its identity, thus enhancing the contrast with adjacent segments (syntagmatic contrast), and possibly even enhanc-ing a contrast with other segments which might occur in that position (paradigmatic contrast).
At the ends of phrases there is a slowing down of the articulators, which is reflected in the signal as final lengthening. The larger the phrase, the greater the degree of final lengthening (inter alia, Wightman et al. 1992). Final lengthening leads to an increase in the duration of segments which is different from the increase obtained by stress and accent; the sounds are often pronounced less loudly and clearly than in stressed and accented syl-lables. Thus, final lengthening cannot easily be mistaken for accentual lengthening. Final lengthening has been found in a large number of lan-guages, and is assumed to have a physiological basis, although there are language-specific, and even contour-specific differences as to the degree of final lengthening present. If a phrase break occurs across a sequence of unstressed syllables, those which are at the beginning of the second phrase are often pronounced very fast, this is referred to as anacrusis. Like an abrupt change in pitch, an abrupt change in rhythm is a strong cue for a phrase break.
Now that the highlighting and phrasing tasks have been discussed, we turn to which functions they are used to express.
2. Functions of intonation
In spoken language, intonation serves diverse linguistic and paralinguistic functions, ranging from the marking of sentence modality to the expression of emotional and attitudinal nuances. It is important to identify how they are expressed in the learner's native language, so that differences between

32 Martine Grice and Stefan Bauman
the native and target languages are identified. It is particularly important to point out that many aspects of information structure and indirect speech acts are expressed differently across languages. Making learners aware of the existence of these functions will not only help them learn to express them, but will also help them to interpret what they hear in a more analytic way, thus reducing the danger of attributing unexpected intonation patterns as (solely) a function of the attitude or emotional state of the speaker.
We have seen that intonation analysis involves categorical decisions a-bout whether there is stress or accent, and, if there is an accent, which type of pitch accent it is. It also involves decisions about whether a boundary is present, and if so which pitch movement or level is used to mark it. There are also many gradient aspects to intonation, such as variation in pitch height or in the exact shape of the contour (equivalent to allophonic varia-tion in the segmental domain).
2.1. Lexical and morphological marking
Lexical and morphological marking does not belong to intonation proper but uses pitch, and to some extent also the other channels used by intona-tion. Categorical tonal contrasts at word level are characteristic of tone languages. Two quite different examples of tone languages are Standard Chinese, which has lexical contrasts such as the well-known example of the syllable ma with four different tonal contours, each which constitutes a distinct lexical item (mother, hemp, horse and scold), and the West African (Niger Congo) language Bini, which has grammatical tone: a change of tone marks the difference between tenses, e.g. low tone marking present tense and high or high-low tones marking past tense (see Crystal 1987: 172). Categorical tonal contrasts are also characteristic of so-called pitch accent languages which may also have lexical or grammatical tone. Both Swedish and Japanese are pitch accent languages. The difference between tone languages and pitch accent languages is that the former have contras-tive tone on almost all syllables, whilst the latter restrict their tonal con-trasts to specific syllables, which bear a pitch accent. However, it is diffi-cult to draw a dividing line between these two language categories (see Gussenhoven 2004: 47).
In intonation languages (the most thoroughly studied of which are gen-erally also stress accent languages) like English and German, pitch is solely a postlexical feature, i.e. it is only relevant at utterance level. All tone and

An introduction to intonation – functions and models 33
pitch accent languages have intonation in addition to their lexical and/or grammatical tone, although the complexity of their intonation systems var-ies considerably.
2.2. Syntactic functions
As we have already pointed out, syntactic structure and intonational phras-ing are strongly related, but do not have to correspond exactly. Intonation can be used to disambiguate in certain cases between two different syntac-tic structures. The attachment of prepositional phrases is often said to be signalled by intonation. For example, in (6), a phrase break after verfolgttends to lead to the interpretation that it is the man with the motorbike which Rainer is following. A phrase break after Mann would tend to lead to the interpretation that Rainer is on his motorbike and is following a man whilst riding it. In the first case the prepositional phrase modifies the noun phrase (den Mann) and in the second it modifies the verb (verfolgt). This phrasing has the same effect in the English translation.
(6) Rainer verfolgt den Mann mit dem Motorrad. ‘Rainer is following the man with the motorbike.’
However, it is often unnecessary to disambiguate between two readings, particularly if the context is clear. It should therefore not be expected that speakers will make such distinctions all of the time. A study on Italian and English syntactic disambiguation (Hirschberg and Avesani 2000) showed this particularly clearly, not only for prepositional phrase attachments, as in (7a), but also for ambiguously attached adverbials, as in (7b) (adapted from Hirschberg and Avesani 2000: 93).
(7a) Ha disegnato un bambino con una penna. ‘lit. He drew a child with a pen’ (7b) Lui le aveva parlato chiaramente. ‘lit. He to her has spoken clearly.’
The two readings of (7b) are either that it was clear that he spoke to her (the adverbial modifies the sentence) or that he spoke to her in a clear manner (the adverbial modifies the verb).

34 Martine Grice and Stefan Bauman
2.3. Information structure
An important linguistic function of intonation is the marking of information structure, in particular (a) the expression of givenness of entities within a chunk of discourse and (b) the division of utterances into focus and back-ground elements. In both (a) and (b) we are dealing with a continuum rather than a dichotomy: entities are not simply given or new, but may have an intermediate status between the two extremes, just as an utterance might contain elements which are focussed to a greater or lesser degree. We deal with (a) and (b) in sections 2.3.1. and 2.3.2. respectively.
2.3.1. Givenness
Degrees of givenness can be expressed through the choice of words. A clearly new discourse element can be expressed with a noun and indefinite article, as in the underlined noun phrase in (8). A clearly given one can be expressed as a pronoun, as in (9).
(8) Thomas isst einen Apfel. ‘Thomas eats an apple.’
(9) A: Was ist mit dem Apfel passiert? ‘What happened to the apple?’ B: Thomas hat ihn gegessen. ‘Thomas ate it.’
An intermediate degree of givenness can be expressed by the use of a defi-nite article, as in (10), where the word Apfel is considered to be more given than in (8), since it refers to a specific instance of an apple which has al-ready been introduced into the discourse in some way.
(10) Thomas isst den Apfel. ‘Thomas eats the apple.’
Of course, degrees of givenness can also be expressed through intonation. For example, the word Apfel in (11) receives a pitch accent and is thus more prominent than the same word in the second turn (B) in (12). In B’s turn Apfel is deaccented, which means that it does not receive an accent although it would be accented under default conditions, i.e. in an ‘all-new’ context such as in (11).
(11) Thomas hat Hunger. Also isst er einen APfel. ‘Thomas is hungry so he eats an apple.’

An introduction to intonation – functions and models 35
(12) A: Hast Du gesagt, dass Thomas mit einem Apfel jongliert? B: Nein, er ISST einen Apfel. ‘Did you say Thomas is juggling with an apple? No, he’s eating an apple.’
(12) is similar to an example of Cruttenden’s (2006) for English, given in (13).
(13) A: Would you like to come to dinner tonight? I’m afraid it’s only chicken. B: I don’t LIKE chicken.
Indian English, by contrast, does not deaccent, as in the example taken from Ladd (1996: 176), reproduced in (14).
(14) If you don’t give me that CIgarette I will have to buy a CIgarette.
Italian is similar to Indian English in that the nuclear pitch accent tends to go on the final lexical item regardless of whether it is given or not. In (15), the nuclear accent is on casa in both cases, whereas in English it would have gone on outside and inside.3
(15) É un lavoro che si fa fuori CAsa o dentro CAsa? ‘Is it a job which you do outside the HOME or inside the HOME.’
Cruttenden (2006) refers to examples such as those in Italian and Indian English as having reaccenting. Not all types of accent are equally strong, and therefore the context sometimes dictates not only whether an accent is present or not but also which type of accent may be used. The interested reader is referred to Baumann and Grice (2006), where degrees of given-ness are shown to be reflected in the type of accent used. A high accent is used for new information, and a step down in pitch onto the accented sylla-ble for information which is not totally given but, rather, accessible. No accent at all is used for totally given information.
2.3.2. Focus
The second aspect of information structure is the division of utterances into focus and background elements, based on the structure of the previous dis-course and the intentions of the speaker. Although there is a relation be-tween focus and newness on the one hand and background and givenness

36 Martine Grice and Stefan Bauman
on the other, the two dimensions are generally orthogonal to each other. For example, an item in focus may be given within the discourse, as the name Maria in (16) B. Compare this to (17), where Maria is both in focus and new.
(16) A: Liebst Du Maria oder Anna? ‘Do you love Maria or Anna?’ B: [ Ich liebe ]background [ MaRIa ]focus ‘I love Maria.’ given given
(17) A: Wen liebst Du? ‘Whom do you love?’ B: [ Ich liebe ]background [ MaRIa ]focus ‘I love Maria.’ given new
Both of these structures represent so-called ‘narrow focus’, that is only one element is focussed. What is important is that this element is accented irre-spective of its degree of givenness. In broad focus structures, where focus extends over a number of words, the relation between focussed elements and pitch accents is less direct. In many languages, larger focus domains are marked by only one or two pitch accents, a phenomenon called focus projection (see Selkirk 1984; Uhmann 1991). The preference as to which element receives the accent, and thus serves as focus exponent, is language specific. Ladd (1996) points out that many languages place the focus expo-nent on the argument rather than on the predicate. For example, in (18) the accent is placed on the argument, Haus, and the following predicate, kaufen, is left unaccented. This is the case even if the argument is followed by the verb, not only in German but also in English, as in (19).
(18) Ich habe kein Geld übrig. Ich muss ein HAUS kaufen. ‘I don't have any spare cash. I have to buy a HOUSE.’
(19) I don't have any spare cash. I have a HOUSE to buy.
As pointed out above, the tendency to accent the last lexical item is stronger in Italian than it is in English or German. Thus, in (20) the final word is accented despite the fact that it is a verb, as in Ladd’s (1996: 191) example.
(20) Ho un libro da LEGgere. ‘I have a book to read’.

An introduction to intonation – functions and models 37
Another important influence on the accentability of words is their ‘semantic weight’. In (21) B and C the noun phrases meinen Anwalt and jemanden are both arguments and in focus (i.e. part of the broad focus domain).4 How-ever, jemanden is semantically ‘light’, since it is an unspecific pronoun, and thus does not receive an accent (see Uhmann 1991: 200).
(21) A: Was haben Sie ihrer Aussage hinzuzufügen? ‘Do you have anything to add to your evidence?’
B: Ich habe meinen ANwalt belogen. ‘I lied to my lawyer.’ C: Ich habe jemanden beLOgen. ‘I lied to someone.’
It is important to point out that there are differences even within a language as to where the nuclear accent is placed in broad focus contexts. One ex-ample of this is Greek, where the accent tends to be placed on the argument in statements but on the predicate in polar questions (Grice, Ladd and Ar-vaniti 2000, Arvaniti, Ladd and Mennen, to appear, more on polar ques-tions in 2.4. below).
2.4. Speech acts
Intonation is used to encode distinctions such as whether an utterance is intended as a request for information (Request) or as a request for the inter-locutor to perform a particular action (Command). There are four major categories of communicative illocutionary acts: constatives, directives, commissives, and acknowledgments (Bach and Harnish 1979; Searle 1969), examples of which are statements, requests, promises, and apologies respectively. Much research has been carried out on questions, a special type of directive, and how they are marked intonationally. Although polar questions are often marked with a final rise (H% edge tone), there are a great many languages that have a rising falling pattern, constituting an LHL sequence. Intonation plays a crucial role in distinguishing polar questions from, e.g., statements if there is no distinct interrogative syntax or question particle, such as in Italian. Even in German and English it is possible to ask a question using a fragment, as in (22), in which case intonation plays the major role in disambiguating the question from a statement, providing the context does not make it entirely clear that a question seeking confirmation is being asked.

38 Martine Grice and Stefan Bauman
(22) mit LEna? ‘with LEna?’
Wh-questions are usually accompanied with a falling intonation unless there is some additional paralinguistic meaning such as an element of insis-tence or politeness. In some cases, a syntactic Wh-question in German can also be interpreted as a suggestion if uttered with a fall as in (23).
(23) Warum ziehst du nicht nach KaliFORnien? ‘Why don’t you move to California?’
2.5. Paralinguistic functions and iconicity of intonation
Intonation is often said to serve primarily an emotive function, implying an inherently iconic usage of pitch variations. Such fundamental iconicity further implies that the (paralinguistic) meaning differences in spoken lan-guage brought about by changes in pitch height are universally valid. This is, in principle, Bolinger’s view when he claims that
intonation is part of a gestural complex, a relatively autonomous system with attitudinal effects that depend on the metaphorical associations of up and down – an elaborate scheme of iconism. It assists grammar – in some instances may be indispensable to it – but is not ultimately grammatical. (1985: 106)
However, Bolinger (1985: 97–98) relativises this claim by arguing that the iconicity of intonation is only ‘symptomatic’ in nature; pitch variations do not directly mirror the meaning they help to convey, as is the case – at least to a larger extent – with onomatopoeic expressions, such as bang, smash in English and klatschen, gurren in German (see Crystal (1987: 174–175) for examples of sound symbolism in many languages).
Carlos Gussenhoven (2002, 2004) brought together research on the dif-ferent factors affecting intonational form, which have led to claims of a universal form-function relation, and, crucially, showed how they interact. It is precisely the analysis of the interaction of the different factors which has explained apparent discrepancies in the form-function relation in cross-language comparisons. Gussenhoven claims that the form-function rela-

An introduction to intonation – functions and models 39
tions are based on three biological codes: the frequency code, the produc-tion (phase) code and the effort code. Each code has affective and/or infor-mational interpretations and may have different linguistic manifestations in different languages.
According to the frequency code, which was introduced by Ohala (1983, 1984), size is suggested by pitch height: since a bigger larynx (including longer vocal folds) and a longer vocal tract produce lower frequencies, low pitch is associated with larger creatures and high pitch with smaller ones. The frequency code has affective interpretations along dimensions such as dominant~submissive or impolite~polite and more informational interpreta-tions along dimensions such as certain~uncertain or – closely related – assertive~questioning, with low pitch attributed to the first pole and high pitch to the second (Gussenhoven 2004: 80-84). The most obvious linguis-tic manifestation of the frequency code is the distinction between state-ments and polar (yes-no) questions, which is a categorical manifestation of the assertive~questioning dimension. Polar questions are marked in a great number of languages by rising or high pitch (as in example (2) versus (1) above).
For many interpretations of the frequency code, it is the contour endingswhich are particularly important (see Ohala 1983, 1984; Gussenhoven 2004: 82). However, for a large number of languages it is not a final rise but rather an accentual rise which marks polar questions. This rise is often followed by a fall. A rising-falling contour is found in many Southern va-rieties of Italian (Bari, Palermo, Neapolitan; see Grice et al. 2005). This is illustrated in example (24), taken from a recording of Bari Italian (Grice et al. 2005: 370).
(24) Lo mandi a MassimiLIAno? ‘Will you send it to Maximilian?’
A similar contour is also found in varieties of Hungarian, Romanian and Greek (Grice, Ladd and Arvaniti 2000), as well as in varieties of German, as shown in example (25) from a recording of a Palatinate dialect (Peters 2004: 384). Note that the rise-fall is on the final unaccented syllable, in contrast to (24), where the rise is on the accented syllable.

40 Martine Grice and Stefan Bauman
(25) Isch des e gute WIRTSfre:: ? ‘Is that a good barkeeper (female)?’
The end of the contour is also important for the production code, which derives its interpretations from a gradual decrease in subglottal air pressure in the course of a breath group (Lieberman 1967, Gussenhoven 2004). One consequence of the drop in subglottal pressure is a gradual lowering of pitch (along with intensity), throughout the phrase, referred to as declina-tion (Cohen and ‘t Hart 1967). The central linguistic interpretation of this code is finality~continuation, marked by low versus high endings.
Many languages have distinct contours which they use to express non-finality, see for example the contour in (5). However, as with questions, not all languages signal finality right at the end of a phrase. Palermo Italian, for instance, uses a rising type of accent instead (Grice 1995), although this rise is distinct from the question rise. A fall to low pitch can express vary-ing degrees of finality, depending on the extent of the fall and the final pitch reached.
At the beginning of a phrase, the relation is reversed: an initial high ac-cent often signals a new topic, whereas a relatively low accent at the begin-ning marks topic continuation (in German and English; see Wichmann, House and Rietveld 2000), emulating an intake of breath and therefore increased subglottal pressure, leading to faster vibration of the vocal folds (producing higher pitch).
The third biologically determined code is the effort code, which is based on the physiological phenomenon that an increased effort in producing speech leads to greater articulatory precision. This is reflected by more pronounced and wider pitch movements (see Gussenhoven 2004: 85–86). The primary informational function of this code in many languages is to express emphasis or importance achieved through gradient use of pitch height. Its most common categorical manifestation is accentuation used in the marking of focus (see section 2.3.2.) and the types of accent used to mark stages along the given~new continuum: As discussed in section 2.3.1., higher pitch is used for items which are new to the discourse, whereas a step down onto a lower pitch is used for items which are accessi-ble to the hearer through context, but are not entirely given.

An introduction to intonation – functions and models 41
To sum up, a representative sample of prosodic functions and the means used to express them are shown schematically in Figure 1.
Categorisation Intonational means of function of expression
linguistic categorical
Lexical/morphological tone languages
Syntactic structure
Information structure background – focus given – new
Speech acts command information-seeking question
Emotional state/Affect/Attitude surprise/politeness/boredom
paralinguistic gradient
Figure 1. Functions of intonation and their intonational realisation
It should be clear from the figure (and from the discussion above) that al-though categorical means are employed to make lexical distinctions as well as distinctions pertaining to information structure and speech acts, it is not possible to state either that categorical means are used to express only lin-guistic functions, or that gradient means are used only for paralinguistic functions, although this is a widespread assumption. Therefore, anyone analysing the intonational forms of a language should keep an open mind when relating form to function. Furthermore, it should not be assumed that gradient means are universally valid, since different languages interpret pitch height in different ways.

42 Martine Grice and Stefan Bauman
3. Models of intonation
In the literature on intonation, pitch modulation is either captured as pitch configurations (as in the British School, see section 3.1.), such as rise, fall, rise-fall and so on, or as a sequence of targets (as in autosegmental-metrical models, see section 3.2.). Targets specify only specific points in the F0 contour, represented phonologically as ‘tones,’. H(igh) tones correspond to high targets, referred to as ‘peaks,’ L(ow) tones to low targets, referred to as ‘valleys’ or ‘troughs’. These tones can be combined into composite pitch accents, LH representing a rise, and HL a fall, or boundary tone combina-tions, e.g. LH representing a phrase final rise. In the British School, con-figurations such as rise or fall are the primitives (basic units), whereas in the autosegmental-metrical approach they are derived, the basic building blocks being the levels High and Low.
3.1. British School
British-style analyses (e.g. Crystal 1969; Halliday 1967; O’Connor and Arnold 1973; Tench 1996; see also Kohler 1991 for German), treat intona-tion in terms of dynamic pitch contours. The most important contour and the one by which tunes are classified is referred to as the ‘nuclear tone’. It starts at the ‘nucleus’ or ‘nuclear syllable’ (Halliday’s ‘tonic’), which is said to be the utterance’s most prominent syllable, and continues to the end of the phrase.
The nucleus represents the only obligatory part of a ‘tone group’. Maximally, a tone group consists of a ‘prehead’ (unaccented syllables be-fore the first pitch accent), a ‘head’ (reaching from the first pitch accented syllable to – but not including – the nuclear syllable), a nucleus (last pitch accented syllable within the tone group) and a ‘tail’ (unaccented postnu-clear syllables). Postlexical stresses (or Druckakzente), i.e. secondary pro-minences characterised by increased length and/or loudness but lacking an abrupt pitch movement (see section 1.1.), may occur within the prehead, the head, and the tail. Example (26) shows the structure of a tone group containing all possible parts (including a potential postlexical stress on –kauft):

An introduction to intonation – functions and models 43
(26) Prehead Head Nucleus Tail
• •
• • • • •• •Mag- da- LE- na hat ein HAUS ge- kauft
‘Magdalena bought a house.’
The notation used in British-School analyses assigns a dot to every syllable, with stressed syllables larger than unstressed ones. Pitch accented syllables either represent turning points in a more or less smooth pitch contour (as the third syllable of Magdalena in (26)) or are characterised by a consider-able pitch change within the syllable (as on Haus in (26)). The latter is in-dicated by a line. Due to the form of these symbols the notation has been called ‘tadpole’ notation. It has also been termed interlinear, since the tran-scription is placed between two lines indicating the upper and lower limit of a speaker’s pitch range. The usual method of transcription within the British School is to use tonetic stress marks for the nuclear contour, the pitch movement extending from the nucleus to the end of the phrase. This is called intralinear transcription, as in (27), where the diacritic indicates a high fall.
(27) Magdalena hat ein `Haus gekauft. ‘Magdalena bought a house.’
It is also possible to mark the beginning of the head and the direction the pitch takes during the head. Online material for practicing intonation within the British School is available at http://www.eptotd.btinternet.co.uk/pow/ powin.htm.
3.2. Autosegmental-metrical models
The currently most widespread phonological framework for representing intonation is termed ‘autosegmental-metrical’, starting with the work of Pierrehumbert (1980), and treated in detail in Ladd (1996), in which the term was coined. The division of utterances into phrases and the assign-ment of relative prominence to elements within the phrase (phrasing and

44 Martine Grice and Stefan Bauman
highlighting) represent the metrical aspect, which was first proposed by Liberman and Prince (1977). The association of the tones (grouped into accents – if the language has them – and boundary tones) with the metrical structure (in other words: the association of the tune with the text) repre-sents the autosegmental aspect. The term autosegmental refers to the fact that the tune should be considered as reasonably autonomous with respect to the text – in fact they are represented as being on different tiers. A tune can thus be realised on a great many texts of different lengths and struc-tures. However, the tune has to be anchored to the text at strategic points – these are the associations between the two tiers.
The greatest advantage compared to the British School model is that to-nal information can be precisely localised on single syllables and/or at the edges of phrases. In British School studies, the only direct connection be-tween tones and text occurs on the nucleus. In most AM models, the nu-cleus does not have a special status. It is simply defined as the last fully-fledged pitch accent in a phrase, which means that there is no theoretical distinction between ‘prenuclear’ and ‘nuclear’ accents.
A widely used autosegmental-metrical framework for the description of intonation is the ToBI (‘Tones and Break Indices’) system, which was ori-ginally developed as a transcription system for American English, but has since become a general framework for developing intonation systems. There is a transcription system for Standard German, ‘GToBI’, which is based on speech data mainly from Northern German speakers (see Grice and Baumann 2002, Grice, Baumann, and Benzmüller 2005 for an over-view).
A (G)ToBI record consists of at least three different levels of descrip-tion, which can be thought of as corresponding to autosegmental tiers. These tiers contain labels for text, tones, and break indices. The text tier provides an orthographic transcription of the words spoken, the tones tier mirrors the perceived pitch contour in terms of tonal events such as pitch accents and boundary tones, and the break index tier marks the perceived strength of phrase boundaries. Pitch accents are associated with lexically stressed syllables, indicated by a starred (‘*’) tone placed within the limits of the accented word - generally at local F0 minima and maxima. Edge tones are assigned to phrase-final syllables, marked by ‘-’ or ‘%’ after the tone, signalling the edge of an intermediate (minor) phrase or a (major) intonation phrase, respectively (see section 1.2.).
As an example, the utterance in (26), which consists of a single intona-tion phrase, would be transcribed in GToBI as in (28).

An introduction to intonation – functions and models 45
(28) MagdaLEna hat ein HAUS gekauft. ‘Magdalena bought a house.’
L* H* L-%
The first (prenuclear) accent in the phrase is realised low in the speaker’s pitch range, the second (nuclear) one high, thus transcribed L* and H*, respectively. The tonal movement before and between these targets does not have to be transcribed, since no pitch minima or maxima are reached. Rather, the target points can be thought of as being joined up by quasi-linear ‘interpolation’. Finally, the falling nuclear movement is accounted for by the combination of a high accent and a low boundary tone (L-%). The combined notation of ‘-’ and ‘%’ stems from the fact that the end of each intonation phrase necessarily coincides with the end of an intermedi-ate phrase, since a hierarchical structure is assumed.5
The original ToBI model has been extended as a general framework for developing intonation systems for a large number of languages and varie-ties. Complete ToBI systems including online training materials are avail-able for English, German, Korean, Japanese and Greek. These and other ToBI systems are described in detail in a book (Jun 2005a), and training materials as well as a number of related papers can be accessed from the ToBI homepage (http://www.ling.ohio-state.edu/~tobi/).
It is difficult to say which of these two models would work best teach-ing intonation to second language learners. The British School model is intuitively straightforward and has didactic origins. It is relatively easy to relate the transcription to an auditory impression. It is, however, very diffi-cult to relate tonetic or interlinear transcriptions to F0 traces – something which might be a problem in an age where students have ever-increasing access to programmes which can estimate and display F0 contours. A fur-ther disadvantage of the British School model is that it is used less fre-quently than it used to be, so that research carried out for the purposes of preparing course materials must often be based on relatively old sources. Since pronunciation (including intonation) changes relatively quickly, both at a regional and standard level, this could be a problem, since any accom-panying tapes will sound rather outdated and stilted.
The autosegmental metrical model is more helpful for students who might be interested in looking at F0 contours as well as listening. Further, a knowledge of this model is indispensable for anyone wishing to search the current literature for information on a specific language, or for communica-tion amongst or with theoretical intonation researchers.

46 Martine Grice and Stefan Bauman
It must be stressed that both of the models are phonological in essence, and are therefore good for capturing the categories of the intonation system of a given system, but not suited for a detailed analysis into the finer pho-netic details and gradient variation within a category. In other words, these models can be used for teaching what in segmental terms would be the 'phonemes' of a language, but not the allophonic variants.
4. Summary and conclusion
In this paper we have provided an overview of the communicative func-tions attributed to intonation, starting out from the two main tasks intona-tion performs, i.e. highlighting and the division of utterances into chunks. In the languages we examined here, highlighting is achieved by means of stress and accent. However, not all languages have pitch accents and/or lexical stress, such as Korean (Jun 2005b), which uses phrasing to indicate narrow focus. All languages make use of phrasing of some kind.
Further, we have examined more specific linguistic and paralinguistic functions of intonation. At a clearly linguistic level, we have observed that intonation is not always used to disambiguate syntactically ambiguous structures but it can be in some languages in certain contexts (where dis-ambiguation is necessary). As for information structure, givenness is ex-pressed in some languages with deaccentuation, while in other languages there is no specific marking of givenness. Likewise, focus can be marked with certain types of accent. It is important to note, however, that not all languages use intonation to signal focus (e.g. Wolof; Rialland and Robert 2001).
At the more paralinguistic level there appear to be more commonalities across languages but it is precisely these commonalities which lead to mis-understandings, since one language might interpret an utterance with high pitch as friendly (e.g. British English), whereas another might interpret the same utterance as emphatic (e.g. Dutch), a result which depends on the weighting of the frequency and effort codes (Chen 2005).
Finally, we have outlined two influential models for transcribing intona-tion, the British School and the autosegmental-metrical approach. We have also provided links to further materials and exercises so that interested rea-ders can hear examples in each model, and, in the autosegmental-metrical approach, in a number of languages.

An introduction to intonation – functions and models 47
Acknowledgements
We would like to thank Barbara Gili Fivela and Michelina Savino for their intui-tions on Italian intonation, and Michelina Savino for providing the Italian re-cording.
Notes
1. The audio files of the example utterances can be found on the accompanying CD-ROM. Their numbers correspond to the numbers in the text. There is no audio file for example (14). Audio file (26) corresponds to examples (26), (27) and (28) in the text.
2. These two meanings of stress follow the British school approach, e.g. Crystal (1969). For Bolinger (1964) on the other hand, ‘stress’ is a strictly lexical feature, whereas ‘accent’ exclusively applies at the postlexical level.
3. It is important to point out that this distribution of accents in Italian is only a tendency; it is quite possible to have a nuclear accent on fuori and dentro as well.
4. They cannot be treated as entirely given, since they have not been mentioned in the immediately preceding context (here: A), and are thus candidates for pitch accents.
5. Due to the lack of a separate tonal target on the final syllable, an explicit symbol for tone immediately before the percentage ‘%’ sign can be dispensed with. This notation is meant to increase the phonetic transparency of the contour, which used to be written as ‘L-L%’.
References
Arvaniti, Amalia, D. Robert Ladd and Inneke Mennen to appear Tonal Association and Tonal Alignment: Evidence from Greek
Polar Questions and Contrastive Statements, Language and Speech.
Bach, Kent and Robert M. Harnish 1979 Linguistic Communications and Speech Acts. Cambridge, Mass. Baumann, Stefan 2006 The Intonation of Givenness – Evidence from German. Linguisti-
sche Arbeiten 508, Tübingen: Niemeyer.

48 Martine Grice and Stefan Bauman
Baumann, Stefan and Martine Grice 2006 The intonation of accessibility. Journal of Pragmatics 38 (10),
1636–1657. Beckman, Mary E. 1986 Stress and Non-Stress Accent. Dordrecht: Foris. Blum-Kulka, S.,
House, J., and Kasper, G. 1989. Cross-Cultural Pragmatics: Re-quests and Apologies. N.J.: Ablex.
Bolinger, Dwight 1964 Intonation: Around the edge of language. Harvard Educational
Review 34, 282–296. 1985 The inherent iconism of intonation. In: John Haiman (ed.), Ico-
nicity in Syntax, 97–108. Amsterdam and Philadelphia: John Benjamins.
Chen, Aoju 2005 Universal and Language-Specific Perception of Paralinguistic
Intonational Meaning. Utrecht: LOT. Cohen, Antonie and Johan ’t Hart 1967 On the anatomy of intonation. Lingua 19, 177–192.Cruttenden, Alan 1997 Intonation (Second edition). Cambridge: Cambridge University
Press. 2006 The de-accenting of old information: a cognitive universal? In:
Giuliano Bernini and Marcia L. Schwartz (eds.), Pragmatic Or-ganization of Discourse in the Languages of Europe, 311–356. The Hague: Mouton de Gruyter.
Crystal, David 1969 Prosodic Systems and Intonation in English. Cambridge: Cam-
bridge University Press. Crystal, David 1987 The Cambridge Encyclopedia of Language. Cambridge Univer-
sity Press. Grice, Martine 1995 The Intonation of Interrogation in Palermo Italian – Implications
for Intonation Theory. Tübingen: Niemeyer. Grice, Martine and Stefan Baumann 2002 Deutsche Intonation und GToBI. Linguistische Berichte 191,
267–298.Grice, Martine, Stefan Baumann, and Ralf Benzmüller 2005 German intonation in autosegmental-metrical phonology. In:
Sun-Ah Jun (ed.), Prosodic Typology. The Phonology of Intona-tion and Phrasing, 55–83. Oxford: Oxford University Press.

An introduction to intonation – functions and models 49
Grice, Martine, Mariapaola D’Imperio, Michelina Savino, and Cinzia Avesani 2005 Strategies for intonation labelling across varieties of Italian. In:
Sun-Ah Jun (ed.), Prosodic Typology. The Phonology of Intona-tion and Phrasing, 362–389. Oxford: Oxford University Press.
Grice, Martine, D. Robert Ladd, and Amalia Arvaniti 2000 On the place of phrase accents in Intonational Phonology. Pho-
nology 17, 143–185. Gussenhoven, Carlos 1983 Focus, mode, and the nucleus. Journal of Linguistics 19, 377–
417. 2002 Intonation and interpretation: Phonetics and phonology. Proceed-
ings 1st Int. Conference on Speech Prosody, Aix-en-Provence (France), 47–57.
2004 The Phonology of Tone and Intonation. Cambridge: Cambridge University Press.
Halliday, Michael A. K. 1967 Intonation and Grammar in British English. The Hague: Mouton. Hart, Johan ’t, René Collier and Antonie Cohen 1990 A Perceptual Study of Intonation: An Experimental-Phonetic
Approach. Cambridge: Cambridge University Press. Hirschberg, Julia and Cinzia Avesani 2000 Prosodic disambiguation in English and Italian. In: Antonis
Botinis (ed.), Intonation. Analysis, Modelling and Technology, 87–95. Dordrecht: Kluwer Academic Publishers.
Jun, Sun-Ah 2005a Prosodic Typology. The Phonology of Intonation and Phrasing.
Oxford: Oxford University Press. 2005b Korean Intonational Phonology and prosodic transcription. In:
Sun-Ah Jun (ed.), Prosodic Typology. The Phonology of Intona-tion and Phrasing, 201–229. Oxford: Oxford University Press.
Keating, Patricia, Taehong Cho, Cecile Fougeron, and C. Hsu 2003 Domain-initial articulatory strengthening in four languages. In:
John Local, Richard Ogden and Rosalind Temple (eds), Phonetic Interpretation (Papers in Laboratory Phonology 6), 143–161. Cambridge University Press.
Kohler, Klaus 1991 Terminal intonation patterns in single-accent utterances of Ger-
man: Phonetics, phonology and semantics. AIPUK 25, 115–185.

50 Martine Grice and Stefan Bauman
Ladd, D. Robert 1980 The Structure of Intonational Meaning: Evidence from English.
Bloomington: Indiana University Press. 1996 Intonational Phonology. Cambridge: Cambridge University
Press. Liberman, Mark and Alan Prince 1977 On stress and linguistic rhythm. Linguistic Inquiry 8, 249–336. Lieberman, Phillip 1967 Intonation, Perception, and Language. Cambridge, MA: MIT
Press. O’Connor, J.D. and G.F. Arnold 1973 Intonation of Colloquial English. London: Longman. Ohala, John J. 1983 Cross-language use of pitch: An ethological view. Phonetica 40,
1–18. 1984 An ethological perspective on common cross-language utilization
of F0 of voice. Phonetica 41, 1–16.Peters, Jörg 2004 Regionale Variation der Intonation des Deutschen. Studien zu
ausgewählten Regionalsprachen. State doctorate thesis (Habilita-tionsschrift), University of Potsdam.
Pierrehumbert, Janet B. 1980 The Phonetics and Phonology of English Intonation. PhD thesis,
MIT. Bloomington: Indiana University Linguistics Club. Rialland, Annie and Stéphane Robert 2001 The intonational system of Wolof. Linguistics 39, 893–939. Roach, Peter J. 1994 Conversion between prosodic transcription systems: “Standard
British” and ToBI. Speech Communication 15, 91–99. Searle, John 1969 Speech Acts. An Essay in the Philosophy of Language. Cam-
bridge: Cambridge University Press. Selkirk, Elisabeth 1984 Phonology and Syntax. The Relation between Sound and Struc-
ture. Cambridge, MA: MIT Press. Tench, Paul 1996 The Intonation Systems of English. London: Cassell. Uhmann, Susanne 1991 Fokusphonologie. Eine Analyse deutscher Intonationskonturen
im Rahmen der nicht-linearen Phonologie. Tübingen: Niemeyer.

An introduction to intonation – functions and models 51
Wichmann, Anne, Jill House and Toni Rietveld 2000 Discourse constraints on F0 peak timing in English. In: Antonis
Botinis (ed.), Intonation. Analysis, Modelling and Technology, 163-182. Dordrecht: Kluwer Academic Publishers.
Wightman, Colin W., Stefanie Shattuck-Hufnagel, Mari Ostendorf and Patti Price 1992 Segmental durations in the vicinity of prosodic phrase bounda-
ries. Journal of the Acoustical Society of America 92, 1707–1717.Williams, Briony 1996a The status of corpora as linguistic data. In: Gerry Knowles, Anne
Wichmann and Peter Alderson (eds.), Working with Speech: Per-spectives on research into the Lancaster/IBM Spoken English Corpus, 3–19. London and New York: Longman.
1996b The formulation of an intonation transcription system for British English. In: Gerry Knowles, Anne Wichmann and Peter Alderson (eds), Working with Speech: Perspectives on research into the Lancaster/IBM Spoken English Corpus, 38–58. London and New York: Longman.


Phonological and phonetic influences in non-native intonation
Ineke Mennen
1. Introduction
Just as poor pronunciation can make a foreign language learner very diffi-cult to understand, poor prosodic and intonational skills can have an equally devastating effect on communication and can make conversation frustrating and unpleasant for both learners and their listeners. Language teachers have lately become more aware of this and have shifted the focus of their pronunciation teaching more towards the inclusion of suprasegmen-tals alongside segmentals with a view of improving general comprehensi-bility (Celce-Murcia, Brinton and Goodwin 1996). It is therefore crucial for language teachers to be aware of current research findings in the area of foreign (second) language learning of prosody and intonation, the type of prosodic and intonational errors second language (L2) learners are likely to make, and in particular where these errors stem from. The focus of this chapter will be on intonation in L2 learning, but some related prosodic phe-nomena such as stress and rhythm will be touched upon.
There is no doubt as to the importance of intonation in communication. Intonation not only conveys linguistic information, but also plays a key role in regulating discourse and is an important indicator of speaker identity, reflecting factors such as physical state, age, gender, psychological state and sociolinguistic membership. Intonation is also important for intelligibil-ity (e.g. Laures and Weismer 1999; Maassen and Povel 1984). The use of an inappropriate intonation pattern may give rise to misunderstandings. Such misunderstanding can be major or minor depending on the context in which the intonation pattern is used. As there is no one to one correspon-dence between intonation and meaning, an appropriate meaning can often be found that fits with the ‘wrong’ intonation pattern. Furthermore, native listeners are used to a great deal of variation in the choice of intonation patterns, both within their regional variety as across varieties (e.g. Grabe, Kochanski, and Coleman, to appear).

54 Ineke Mennen
Nevertheless, some patterns will clearly not be acceptable in some va-rieties, and the cumulative effect of continuously using slightly inappropri-ate intonation should not be underestimated. Given that we derive much of our impression about a speaker’s attitude and disposition towards us from the way they use intonation in speech, listeners may form a negative im-pression of a speaker based on the constantly occurring inappropriate use of intonation. For example, the relatively flat and low intonation of German learners of English may make them sound “bleak, dogmatic or pedantic, and as a result, English listeners may consider them uncompromising and self-opinionated” (Trim 1988, as quoted in Grabe 1998), an example which illustrates that impressions based on intonation may lead to ill-founded stereotypes about national or linguistic groups. Finally, intonational errors may contribute to the perception of foreign-accent (Jilka 2000).
The aim of this chapter is to present a summary of commonly occurring problems in non-native intonation, as well as provide a reanalysis of some past and current research findings in terms of a framework of intonational analysis that separates phonological representation from phonetic imple-mentation. Section 2 describes possible influences in non-native intonation, it explains the importance of making a distinction between intonational influence at a phonological and at a phonetic level, and it briefly summa-rises the model of intonation used in this chapter. In section 3, some intona-tional properties will be described which are likely to be affected in L2 speech production. Examples will be given of previous and current research with particular attention to phonological and phonetic influences in L2 intonation. Section 4 will discuss the implications of the reanalyses and new results for teaching and research.
2. Influences in non-native intonation
In a survey of major international journals in second language acquisition of the past 25 years carried out by Gut (this volume; personal communica-tion), it was found that as few as 9 studies investigated intonation and tone. Only four of these studies were concerned with perception of intonation, the other five were production studies. A further search of conference pro-ceedings and recent PhD theses revealed an additional tenfold of studies on L2 production of intonation. Most of the limited (and not very recent) stud-ies of L2 production of intonation involve investigations of the errors made by learners from various language backgrounds when they acquire English

Phonological and phonetic influences in non-native intonation 55
as an L2 (Backman 1979; Buysschaert 1990; De Bot 1986; Grover, Jamieson, and Dobrovolsky 1987; Jenner 1976; McGory 1997; Ueyama 1997; Willems 1982). These studies provide evidence that transfer or inter-ference from the L1 is an important factor in the production of L2 intona-tion.
Many similarities of errors were found in these studies, leading to as-sumptions about whether there are universal patterns in acquiring the into-national system of a second language. For example, Backman (1979) ob-served that the errors she found in her study of the English of Spanish learners showed remarkable similarities with errors Jenner (1976) found in his study on the English of Dutch learners. Errors in the production of L2 English intonation by speakers with different language backgrounds which appear similar across studies are:
– a narrower pitch range (Backman 1979; Jenner 1976; Willems 1982) – problems with the correct placement of prominence (Backman 1979;
Jenner 1976) – replacement of rises with falls and vice versa (Adams and Munro 1978;
Backman 1979; Jenner 1976; Lepetit 1989; Willems 1982) – incorrect pitch on unstressed syllables (Backman 1979: too high;
McGory 1997: too high; Willems 1982: no gradual rise on unaccented words preceding a fall)
– difference in final pitch rise (Backman 1979: too low; Willems 1982: too high [overshoot])
– starting pitch too low (Backman 1979; Willems 1982) – problems with reset from low level to mid level after a boundary (Wil-
lems 1982) – a smaller declination rate (Willems 1982)
Although it is true that some of the observed errors are similar, it should be emphasised that they all appeared in studies of English as a second lan-guage. So the similarities might be due to idiosyncrasies of the English intonational system. Furthermore, the similarities cannot be explained by developmental factors (due to the learning process) alone. For example, the fact that both Dutch and Spanish acquiring English intonation produce a smaller pitch range compared to native English speakers does not necessar-ily indicate that a reduction of pitch range is a universal tendency in L2 acquisition. The smaller pitch range in the data of the learners could simply be a case of transfer, since both Dutch (Jenner 1976) and Spanish

56 Ineke Mennen
(Stockwell and Bowen 1965) are reported to have a smaller pitch range than English. It is therefore more likely that there is more than one process involved in the acquisition of L2 intonation, a conclusion which has also been reached in other fields of L2 acquisition.
2.1. Cross-linguistic analysis of intonation
It should be noted that a comparison of the findings described in the previ-ous section is not an easy task. The studies differ considerably with respect to the proficiency level of the learners, the languages under investigation, the number of subjects, and the framework or methodology used in the study. These differences in methodology prevent us from coming to any reliable conclusions about the similarities and differences between the lan-guages investigated in these studies and the process of L2 acquisition of intonation.
In order to establish intonational differences and similarities across lan-guages which could cause the L1 and L2 intonation systems to influence one another, a generally agreed framework for analysing intonation needs to be used. Without such a model it is difficult to compare and interpret the importance of similarities and differences across languages in a reliable and uniform way. A model which has been used successfully to describe a wide range of languages (e.g. Jun 2004) and regional varieties (e.g. Grabe, Post, Nolan, and Farrar 2000; Fletcher, Grabe, and Warren 2004; Gilles and Pe-ters 2004) is the model of intonational analysis developed by Pierrehumbert (1980) and Pierrehumbert and Beckman (1988). Mennen (2004) showed that this model can generate predictions about the degree of difficulty cer-tain aspects of L2 intonation will present to L2 learners. Together with other studies that have begun to emerge using this model in studies of L2 intonation (Jilka 2000; Mennen 1998, 1999a, 1999b, 2004; Ueyama 1997; Jun and Oh 2000), it shows the enormous potential of this model for cross-linguistic studies.
The most important principle of Pierrehumbert’s model is that it sepa-rates the phonological representation from its phonetic implementation, and intonation is viewed as consisting of a phonological and phonetic compo-nent. The phonological component consists of a set of high (H) and low (L) tones, which are further organised into pitch accents, boundary tones, and phrasal tones. The pitch accents have a starred tone to indicate their asso-ciation with the stressed syllable, and can consist of a single tone (H* or L*) or a combination of two tones (e.g. HL*, H*L). Boundary tones are

Phonological and phonetic influences in non-native intonation 57
indicated as H% or L% and associate with phrase margins. Phrasal tones are indicated as H- or L- (with a hyphen) and associate with the space be-tween the last pitch accent and the boundary tone. The phonetic realisation of underlying tone sequences is usually defined along two parameters, the scaling (i.e. the f0 value) and the alignment (i.e. the temporal relation with the segmental string) of the tones (see further section 3.1).
The distinction between a phonetic and phonological component in in-tonation is important as it suggests that languages can differ at both these levels. As a result, the L1 and L2 intonation systems may influence one another both at the level of phonological representation as well as at the level of their phonetic implementation. A phonological influence would result from intonational differences in the inventory of phonological tunes, their form, and in the meanings assigned to the tunes. A phonetic influence would result from a difference in the phonetic realisation of an identical phonological tune (Ladd 1997). An example of phonological influence is the use of rises where native speakers would use falls and vice versa, found in many studies of L2 intonation (e.g. Adams and Munro 1978; Backman 1979; Jenner 1976; Lepetit 1989; Willems 1982). An example of phoneticinfluence is the finding of a different pitch range (e.g. Mennen, this chap-ter) or a different slope of a rise (e.g. Ueyama 1997) compared to the monolingual norm. These types of influence roughly correspond to the types of influence evidenced at the segmental level, where phonological influence would result from cross-linguistic differences at the phonemic level (such as the use of the vowel /u/ instead of the target L2 vowel /y/ when that vowel is not in the L1 vowel inventory), and phonetic influence resulting from differences in phonetic detail (such as differences in the implementation of the phonological voicing contrast: long-lag instead of short-lag voice onset times in the French productions of native speakers of English, such as those observed in Flege and Hillenbrand 1984).
Separating phonological representation from its phonetic implementa-tion in non-native production of intonation makes it possible to determine the actual source of the L2 intonational error, beyond just establishing that it is due to interference from the L1. Once the source of the problem has been established it can be appropriately addressed by the language teacher and learner.

58 Ineke Mennen
3. Possible difficulties in L2 intonation
In this section a description will be given of some intonational properties which are likely to be affected in L2 speech production. Particular attention will be given to distinguishing phonetic from phonological influences in L2 intonation, where this distinction may not have been made in previous stud-ies, and where results may have been interpreted incorrectly because no distinction has been made between phonological and phonetic influences. This section is by no means an exhaustive description of all intonational properties which can be influenced by differences between the L1 and L2 intonation systems. It is intended purely as an illustration of why it is im-portant to distinguish between phonological and phonetic influences, and where this becomes relevant for language teachers.
3.1. Alignment
Alignment refers to the temporal relation of H and L tones with the seg-mental string (i.e. the timing of a peak or valley with the vowels and con-sonants in speech). Recent research has suggested that alignment exhibits certain language and dialect-specific characteristics, more or less like those found for voice onset time (Caramazza, Yeni-Komshian, Zurif, and Car-bone 1973; Flege and Hillenbrand 1984). That is, the same phonological category may be realised (aligned) differently in different languages or dialects. Differences in alignment have amongst others been found in cross-dialectal studies on Swedish (Bruce and Gårding 1978) and Danish dialects (Grønnum 1991), ethnic subvarieties of Singapore English (Lim 1995), and varieties of British English (Grabe, Post, Nolan, and Farrar 2000), and German (Atterer and Ladd 2004).
Cross-linguistic differences in alignment have not been investigated ex-tensively. However, Ladd (1996) suggests that such differences can be found when comparing the intonation of languages. He illustrates this with an example of a certain type of fall, which he describes as “a local peak associated with the accented syllable, followed by a rapid fall to low in the speaking range, followed by a more gradual fall to the end of the phrase or utterance” (Ladd 1996: 128). This fall can occur in Italian as well as in English (or German). However, its realisation is different in these two lan-guages. Where the peak in English (or German) is rather late (at or near the end of the stressed syllable), it is early in Italian. The following rapid fall in

Phonological and phonetic influences in non-native intonation 59
English (or German) takes place between the stressed and following un-stressed syllable, whereas in Italian the fall starts well before the following syllable. As a consequence, English or German learners of Italian may use their native alignment pattern when producing an Italian falling tune. In other words, the learner gets the phonological association right (i.e. the H* peak associates with the stressed syllable), but fails to produce the correct phonetic detail (i.e. the correct alignment). Figure 1 gives an example of such a mistake. As Italians would place the fall somewhere in the antepe-nultimate syllable, a delay of this fall may be interpreted by native Italians as a mistake in the placement of word stress, i.e. they may perceive this as stress on the penultimate, rather than on the antepenultimate syllable. So what in fact is a phonetic error is interpreted by native listeners as a phono-logical error. It is therefore important for language teachers to establish what the source of the error is, as well-meant exercises to teach non-native speakers the correct stress placement may in this particular example not be effective, as the error is not misplaced word stress but rather a misalign-ment of the falling contour with the stressed syllable.
M a n t o v a M a n t o v a
Figure 1. A schematic representation of alignment differences between non-native (left) and native (right) production of the Italian word ‘Mantova’, with a late peak in the non-native as compared to the native production.
It is for this reason that care needs to be taken when interpreting results on L2 intonation (especially when they are based on auditory observations only), which report errors in stress placement or replacement of rises with falls (e.g. Lepetit 1989; Backman 1979; Jenner 1976). Some of these errors, may actually be phonetic errors (alignment errors), rather than phonological errors (misplaced stress). For example, Backman (1979), in her study on intonation errors of Venezuelan Spanish adult learners of American Eng-lish, reports that the L2 learners often had problems with stress placement. However, visual inspection of some of the sample contours presented in her paper, suggests that the Spanish learners tend to have an earlier alignment
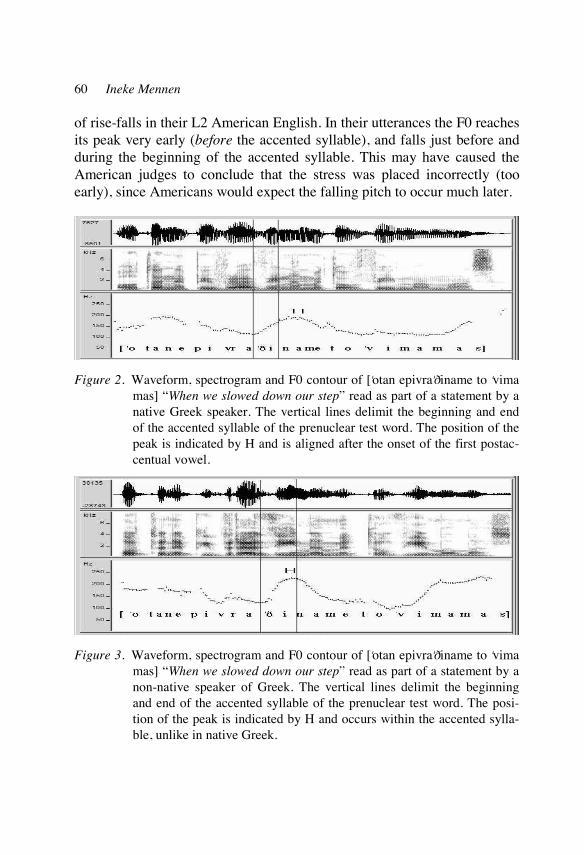
60 Ineke Mennen
of rise-falls in their L2 American English. In their utterances the F0 reaches its peak very early (before the accented syllable), and falls just before and during the beginning of the accented syllable. This may have caused the American judges to conclude that the stress was placed incorrectly (too early), since Americans would expect the falling pitch to occur much later.
Figure 2. Waveform, spectrogram and F0 contour of [?otan epivra?ainame to ?vima mas] “When we slowed down our step” read as part of a statement by a native Greek speaker. The vertical lines delimit the beginning and end of the accented syllable of the prenuclear test word. The position of the peak is indicated by H and is aligned after the onset of the first postac-centual vowel.
Figure 3. Waveform, spectrogram and F0 contour of [?otan epivra?ainame to ?vima mas] “When we slowed down our step” read as part of a statement by a non-native speaker of Greek. The vertical lines delimit the beginning and end of the accented syllable of the prenuclear test word. The posi-tion of the peak is indicated by H and occurs within the accented sylla-ble, unlike in native Greek.

Phonological and phonetic influences in non-native intonation 61
There are very few studies which attempt to determine the extent to which the native alignment pattern carries over into the pronunciation of a second language. Mennen (2004) investigated how Dutch non-native spea-kers of Greek realised cross-linguistic differences in the alignment of a phonologically identical rise. Dutch and Greek share the same phonological structure in prenuclear rises (L+H), but the phonetic properties of the rise differ. Although in both languages the rise starts just before the accented syllable, in Dutch the peak is reached within the accented syllable whereas in Greek the peak is consistently aligned after the onset of the first postac-centual vowel. It was found that even after many years of experience with the L2 and despite their excellent command of the L2, the majority of the Dutch speakers carried over the phonetic details of their L1 rise into their pronunciation of L2. Four out of five speakers aligned the rise considerably earlier than the native Greek speakers, as shown in Figure 2 and 3. Ne-vertheless, one speaker managed to align the rise as late as the native Greek speakers. Given that the subjects in this study were all very experienced with the L2 and were considered to be near-native, the findings suggest that it may be difficult – although not impossible – to learn the phonetic imple-mentation of underlying tone sequences and that this may be acquired ra-ther late in the acquisition process. It is conceivable that L2 learners may acquire phonological properties of intonation earlier than their phonetic implementation (as suggested by Mennen 1999, 2004; Ueyama 1997). Such implementation difficulties were also found in a study of German speakers of English who carried over native German patterns of alignment into their L2 English (Atterer and Ladd 2004), suggesting that this may be a more common phonetic error than previously thought.
As it is suggested in the literature that temporal properties of speech may influence the intelligibility of utterances produced by non-native speakers (Tajima, Port, and Dalby 1997), it is well possible that an adjust-ment of peak alignment will lead to improved intelligibility and less for-eign-accented speech. However, perception studies would need to be car-ried out to establish the relative contribution of alignment patterning on intelligibility and the perception of foreign-accent.
3.2. Word stress and nuclear placement
It is generally accepted that L2 learners often have difficulty with the cor-rect placement of word stress, especially in the initial stages of the learning

62 Ineke Mennen
process (e.g. Adams and Munro 1978; Archibald 1992; Fokes and Bond 1989; Wenk 1985). Also, studies on the teaching of L2 prosody suggest (although based to a large extent on impressionistic observations) that word stress needs to be given special attention in the classroom (e.g. Anderson-Hsieh, Johnson, and Koehler 1992; Buysschaert 1990).
Alongside difficulties with prominence within a word, L2 learners also seem to experience difficulty with the correct placement of prominence at the sentence level (e.g. Backman 1979; Jenner 1976). Just as a language can have phonemic contrasts, like a contrast between a voiced and a voice-less stop (/d/-/t/), the prominence system within a language is also a system of contrasts. A word is produced with more acoustic salience, or promi-nence, in order to contrast that word with other less prominent words. Just as phonemes serve to distinguish one word from another word, a system of prominence allows a speaker to contrast the relative importance of words.
Both Jenner (1976) and Backman (1979) report that language learners often move the most prominent word of the sentence (the main or nuclear accent) too far to the left in their L2 utterances. Again, it is not clear whether this is caused by a phonetic or a phonological error (as explained in the previous section). Most of the test sentences Backman (1979) pre-sents in her study consist of monosyllabic words only. If the Spanish learn-ers of English have aligned the rise-fall in a sentence like “I'm late” too early, with the peak occurring just before the onset of the word “late”, na-tive Americans may have perceived this as a prominence on “I'm”. This may have led to the perception of a shift of the nuclear accent to the left.i
For this reason, these results have to be interpreted with caution. Another reason for questioning the results obtained in the above men-
tioned studies, is the fact that the use of acoustic cues to signal stress may be different across languages. Beckman (1986), for example, suggested that even though languages use the same parameters to signal stress, their rela-tive importance is language specific. For example, Americans use all four perceptual cues to stress (F0, duration, amplitude, and spectral coefficient) to the same extent, whereas Japanese use F0 cues to a much greater extent than other cues to stress (Beckman 1986). As a consequence, when listen-ing to American English, Japanese will rely mainly on F0 cues, and may disregard other cues to stress which should influence their perception of stress.
In production there also seem to be cross-linguistic differences in the cues used to signal stress. For example, Adams and Munro (1978) found a difference in the production of sentence stress between native and non-

Phonological and phonetic influences in non-native intonation 63
native speakers of English. Adams and Munro found that the “real differ-ence between the stress production of the two groups lay not in the mecha-nisms they used to signal the feature [stress], but rather in their distribution of it...” (p. 153). In a similar study Fokes and Bond (1989) found that much the same is true for word stress.
If it is true that the acoustic correlates of stress differ across languages, results of studies relying on native speakers’ judgements of stress place-ment by non-native speakers have to be interpreted with caution. Native judges may presuppose certain acoustic cues to stress other than the ones produced by non-native speakers. It is therefore possible that the non-native speakers described in these studies do not actually produce errors in stress placement, but merely differ in the relative importance of the cues used to produce stress. A study by Low and Grabe (1999) seems to support this explanation. Their results indicate that the widely reported claim (based on native British English listener judgements) that British English and Singa-pore English differ in stress placement is not true. Their experimental data suggest that the apparent word-final stress in Singapore English (as op-posed to the word-initial stress in British English) in words like flawlessly, is not the result of a difference of lexical stress placement. Instead, it seems that Singapore English and British English differ in the phonetic realisation of stress, with more phrase-final lengthening, and a lack of “depromi-nencing” in F0 in Singapore English than in British English. As a result, Low and Grabe argue that “the location of stress (or even its presence) can-not be judged impressionistically in any cross-linguistically valid way.”
It may therefore not always be helpful to give L2 learners exercises to practice L2 stress placement as in some cases learners may already be pro-ducing stress in the appropriate position in the word or sentence. However, they may not be producing stress using the same cues as native speakers do. It is therefore important to establish whether the difficulty the learner ex-periences is caused by a phonological influence from the L1 (i.e. misplaced word or sentence stress) or by a phonetic error (i.e. use of different cues to signal stress).
3.3. Pitch range
There is growing evidence that pitch range – besides other common influ-ences such as anatomy/physiology, regional background, emotional state, and many others – is influenced by a speaker’s language background (e.g.

64 Ineke Mennen
Van Bezooijen 1995; Scherer 2000). It is thought that cultures or languages have their particular ‘vocal image’, which reflects socio-culturally desired personal attributes and social roles, and that speakers choose a pitch (within their anatomical/physiological range) that approximates the vocal image they want to project (Ohara 1992). Listeners are very sensitive to these features, as evidenced by a wealth of research that relates the independent contribution of pitch to a class of character types (e.g. Ladd, Silverman, Tokmitt, Bergmann, and Scherer 1985, Patterson 2000), showing amongst others that the wider their pitch range the more positively speakers are characterised.
There is no doubt that people hear differences in pitch range between a variety of languages. There is strong anecdotal evidence that people per-ceive differences between for example English and German – with English sounding higher and having more pitch variation than German (which is believed to be spoken with a relatively low and flat pitch). English speech (especially female) is often perceived as ‘überspannt and zu stark ‘auf-gedreht’” (over the top) by German listeners (Eckert and Laver 1994: 145). This belief has even found its way into the German film industry, which uses German dubbing actors with a lower pitch and narrower pitch range than those of original English actors (Eckert and Laver 1994). Such beliefs are also expressed in language descriptions and manuals. For example, Gibbon (1998) refers to a smaller pitch range in German compared to Eng-lish. Conversely, Germans feel that the pitch of an English speaker’s voice wanders meaninglessly if agreeably up and down (Trim 1988).
Languages are believed to differ both in the average pitch height at which they are spoken and in the range of frequencies that are usually used. Ladd (1996) refers to these dimensions of variation in terms of level (i.e. the overall pitch height) and span (i.e. the range of frequencies). Cross-linguistic comparisons of level - and to a lesser extent span - have been carried out for a wide range of languages (e.g. Braun 1994). These studies provide some evidence for the existence of language-specific differences in pitch range, and the reported differences are usually explained by assuming an influence of socio-cultural factors on pitch.
Intriguingly, while there are very few studies on bilingual production of pitch range, there is a suggestion that bilingual speakers vary their pitch range according to the language they are speaking. For example, Braun (1994) and Gfroerer and Wagner (1995) report a different level in the lan-guages of German/Turkish bilinguals (with a higher pitch in their Turkish than in their German), and Jilka (2000) reports a difference in span but not

Phonological and phonetic influences in non-native intonation 65
in level for German/American bilinguals (i.e. with a wider span in their American English).
Cross-linguistic comparisons of pitch range in L1 and L2 intonation have all been based on long term distributional measures (statistical mo-ments), and there appears to be no agreement in these studies as to what constitutes pitch range. For level, measures of mean f0 and median f0 have been used. For span, measures used include maximum minus minimum f0, four standard deviations around the mean, the difference between the 95th and 5th percentile (90% range), and the difference between the 90th and 10th percentile (80% range). More recent work by Patterson (2000) sug-gests that there are some problems using long term distributional properties of f0, since they assume an even distribution of f0 around the mean and their results may be affected by spurious measures (e.g. octave errors). These measures also showed a lack of correlation with listener judgments of speaker characteristics and therefore lacked perceptually validity (Patter-son 2000). Furthermore, the majority of cross-linguistic studies of pitch fail to control for factors influencing f0 (including regional accent, physiol-ogy/anatomy, type of speech materials), making it impossible to tease out the influence of the language itself.
An alternative way to measuring span and level is to link measures of span and level to specific turning points (i.e. local minima and maxima) in the f0 contour (Patterson 2000). Patterson (2000) showed that such meas-ures better characterise pitch range than the more commonly used long term distributional measures. Specifically, the linguistic measures were shown to be more perceptually valid in that they correlated better with listener judg-ments of speaker characteristics. Scharff (2000) recorded a small set of materials, which was subsequently analysed by Mennen (this chapter) and presented here for the first time. Span and level were investigated – using Patterson’s (2000) method – in three groups of speakers: a group of twelve monolingual native speakers of German (from the area of Stuttgart), a group of ten monolingual native speakers of English (from the area of Newcastle upon Tyne), and a group of twelve German non-native speakers of English (who all lived in or around Newcastle upon Tyne). All speakers were female between the ages of twenty and forty and they were all non-smokers. The non-native speakers were advanced speakers of English and had a length of residence in Britain of over 5 years. They were all asked to read a phonetically balanced passage (“The North Wind and The Sun”/ “Der Nordwind und die Sonne”) in their respective language(s).
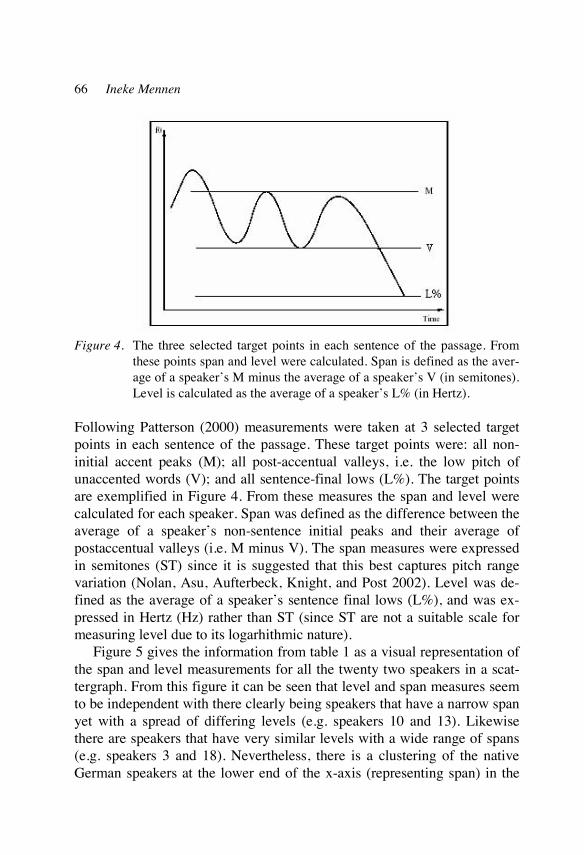
66 Ineke Mennen
Figure 4. The three selected target points in each sentence of the passage. From these points span and level were calculated. Span is defined as the aver-age of a speaker’s M minus the average of a speaker’s V (in semitones). Level is calculated as the average of a speaker’s L% (in Hertz).
Following Patterson (2000) measurements were taken at 3 selected target points in each sentence of the passage. These target points were: all non-initial accent peaks (M); all post-accentual valleys, i.e. the low pitch of unaccented words (V); and all sentence-final lows (L%). The target points are exemplified in Figure 4. From these measures the span and level were calculated for each speaker. Span was defined as the difference between the average of a speaker’s non-sentence initial peaks and their average of postaccentual valleys (i.e. M minus V). The span measures were expressed in semitones (ST) since it is suggested that this best captures pitch range variation (Nolan, Asu, Aufterbeck, Knight, and Post 2002). Level was de-fined as the average of a speaker’s sentence final lows (L%), and was ex-pressed in Hertz (Hz) rather than ST (since ST are not a suitable scale for measuring level due to its logarhithmic nature).
Figure 5 gives the information from table 1 as a visual representation of the span and level measurements for all the twenty two speakers in a scat-tergraph. From this figure it can be seen that level and span measures seem to be independent with there clearly being speakers that have a narrow span yet with a spread of differing levels (e.g. speakers 10 and 13). Likewise there are speakers that have very similar levels with a wide range of spans (e.g. speakers 3 and 18). Nevertheless, there is a clustering of the native German speakers at the lower end of the x-axis (representing span) in the

Phonological and phonetic influences in non-native intonation 67
figure, with the native English speakers clustering mostly at the higher end of the x-axis. There are some exceptions to this pattern. Two native English speakers (13 and 15) cluster at the lower end of the x-axis (similar to the majority of the native German speakers) but they also cluster at the higher end of the y-axis with a very high level. This suggests that native English speakers may either have a wider pitch span, and/or a higher level than the native German speakers.
Table 1. The means of span (in ST and Hz) and level (in Hz) measurements for each of the native speakers.
SPEAKERS LANGUAGE SPAN ST SPAN Hz LEVEL Hz1 German 6.26 98.8 170.22 German 5.71 74.1 182.63 German 4.23 52.7 159.34 German 4.82 61.0 166.75 German 5.44 72.0 182.36 German 5.98 79.0 182.67 German 6.20 75.7 149.28 German 5.96 75.4 184.09 German 5.57 69.5 149.910 German 4.59 54.3 141.611 German 5.71 58.4 134.112 German 4.53 51.9 161.913 English 4.73 69.5 215.514 English 7.48 98.0 15715 English 4.70 65.7 188.016 English 8.43 101.5 147.017 English 9.43 137.4 175.318 English 7.66 94.13 160.019 English 7.95 87.6 145.020 English 6.57 81.6 162.721 English 7.92 108.9 172.022 English 6.74 79.5 146.0
Overall German 5.42 68.6 163.7Overall English 7.16 92.39 166.9
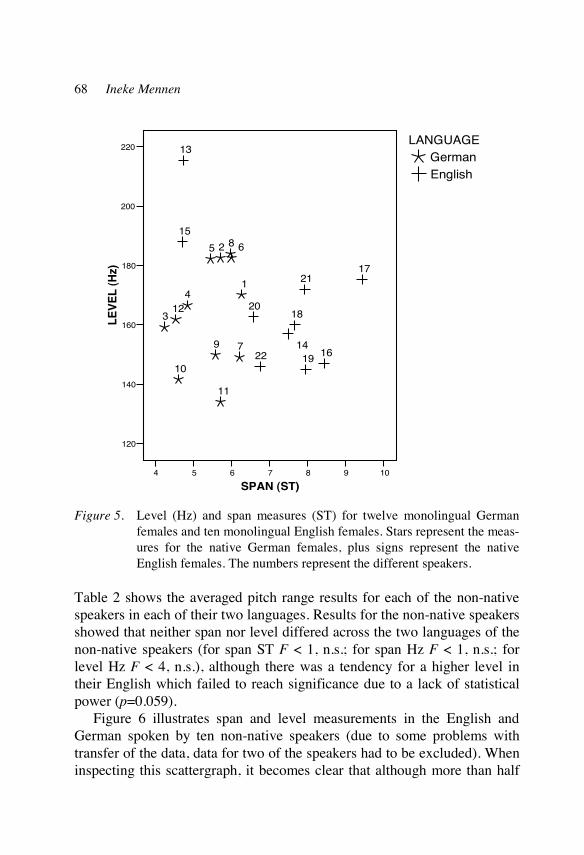
68 Ineke Mennen
4 5 6 7 8 9 10
SPAN (ST)
120
140
160
180
200
220
LEV
EL
(Hz)
1
2
3
4
5 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
LANGUAGEGermanEnglish
Figure 5. Level (Hz) and span measures (ST) for twelve monolingual German females and ten monolingual English females. Stars represent the meas-ures for the native German females, plus signs represent the native English females. The numbers represent the different speakers.
Table 2 shows the averaged pitch range results for each of the non-native speakers in each of their two languages. Results for the non-native speakers showed that neither span nor level differed across the two languages of the non-native speakers (for span ST F < 1, n.s.; for span Hz F < 1, n.s.; for level Hz F < 4, n.s.), although there was a tendency for a higher level in their English which failed to reach significance due to a lack of statistical power (p=0.059).
Figure 6 illustrates span and level measurements in the English and German spoken by ten non-native speakers (due to some problems with transfer of the data, data for two of the speakers had to be excluded). When inspecting this scattergraph, it becomes clear that although more than half
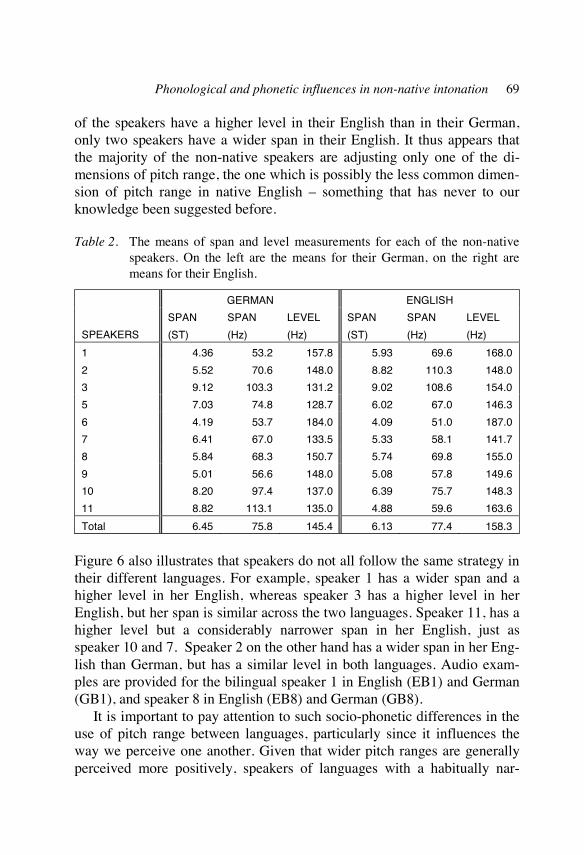
Phonological and phonetic influences in non-native intonation 69
of the speakers have a higher level in their English than in their German, only two speakers have a wider span in their English. It thus appears that the majority of the non-native speakers are adjusting only one of the di-mensions of pitch range, the one which is possibly the less common dimen-sion of pitch range in native English – something that has never to our knowledge been suggested before.
Table 2. The means of span and level measurements for each of the non-native speakers. On the left are the means for their German, on the right are means for their English.
GERMAN ENGLISH
SPEAKERS
SPAN
(ST)
SPAN
(Hz)
LEVEL
(Hz)
SPAN
(ST)
SPAN
(Hz)
LEVEL
(Hz)
1 4.36 53.2 157.8 5.93 69.6 168.0
2 5.52 70.6 148.0 8.82 110.3 148.0
3 9.12 103.3 131.2 9.02 108.6 154.0
5 7.03 74.8 128.7 6.02 67.0 146.3
6 4.19 53.7 184.0 4.09 51.0 187.0
7 6.41 67.0 133.5 5.33 58.1 141.7
8 5.84 68.3 150.7 5.74 69.8 155.0
9 5.01 56.6 148.0 5.08 57.8 149.6
10 8.20 97.4 137.0 6.39 75.7 148.3
11 8.82 113.1 135.0 4.88 59.6 163.6
Total 6.45 75.8 145.4 6.13 77.4 158.3
Figure 6 also illustrates that speakers do not all follow the same strategy in their different languages. For example, speaker 1 has a wider span and a higher level in her English, whereas speaker 3 has a higher level in her English, but her span is similar across the two languages. Speaker 11, has a higher level but a considerably narrower span in her English, just as speaker 10 and 7. Speaker 2 on the other hand has a wider span in her Eng-lish than German, but has a similar level in both languages. Audio exam-ples are provided for the bilingual speaker 1 in English (EB1) and German (GB1), and speaker 8 in English (EB8) and German (GB8).
It is important to pay attention to such socio-phonetic differences in the use of pitch range between languages, particularly since it influences the way we perceive one another. Given that wider pitch ranges are generally perceived more positively, speakers of languages with a habitually nar-
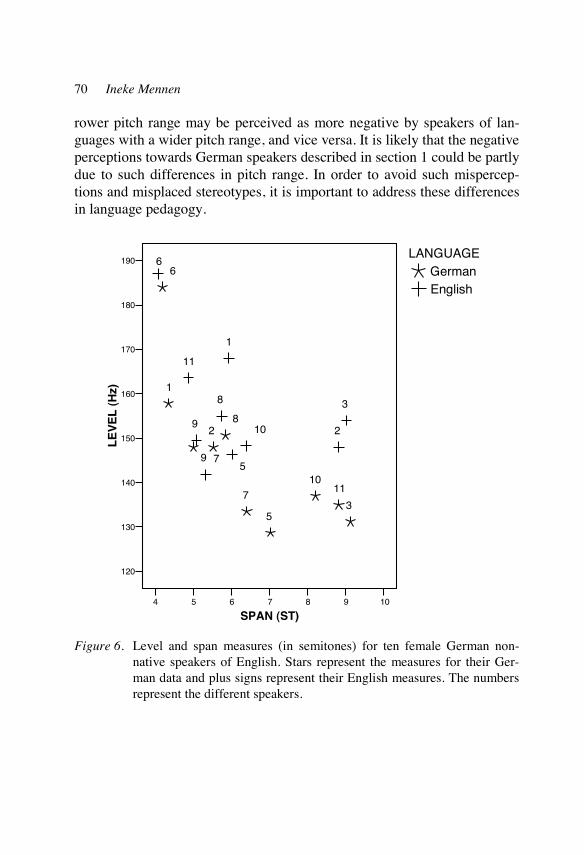
70 Ineke Mennen
rower pitch range may be perceived as more negative by speakers of lan-guages with a wider pitch range, and vice versa. It is likely that the negative perceptions towards German speakers described in section 1 could be partly due to such differences in pitch range. In order to avoid such mispercep-tions and misplaced stereotypes, it is important to address these differences in language pedagogy.
4 5 6 7 8 9 10
SPAN (ST)
120
130
140
150
160
170
180
190
LE
VE
L (
Hz) 1
2
35
6
7
8
9
1011
1
2
3
5
6
7
8
9 10
11
LANGUAGEGermanEnglish
Figure 6. Level and span measures (in semitones) for ten female German non-native speakers of English. Stars represent the measures for their Ger-man data and plus signs represent their English measures. The numbers represent the different speakers.

Phonological and phonetic influences in non-native intonation 71
4. Summary and future directions
The aim of this chapter was to provide a summary of some of the most commonly occurring problems in non-native intonation, to reanalyse some past and current research findings in terms of a framework of intonational analysis that separates phonological representation from phonetic imple-mentation, and to demonstrate the usefulness of such a distinction in L2 prosody teaching. It was suggested that L2 learners may go through differ-ent stages in the learning process and may first acquire phonological pat-terns of L2 intonation before they acquire the correct phonetic implementa-tion of these patterns. This assumption was based on studies by Mennen (1999, 2004) which showed that native Dutch speakers who speak Greek near-natively were perfectly able to produce the correct phonological tonal elements but implemented these structures by using L1 phonetic regulari-ties. This finding confirmed observations reported in a small-scale study by Ueyama (1997). Further research is necessary to verify this hypothesis quantitatively for different phonological and phonetic aspects of L2 intona-tion.
Examples were given throughout the chapter to illustrate that intona-tional errors observed in L2 speech may not be what they seem and that a perceptually similar error may in fact have different underlying causes, which can be either difficulties with the phonological structure of the L2 or with its phonetic realisation. It was emphasised that it is important for teaching purposes to distinguish between phonological and phonetic errors, so that the source of the problem can be addressed in teaching. Only by careful comparisons of the language pairs using a commonly agreed framework of intonational analysis will it be possible to establish where the errors originate from. Further analyses of different language pairs are nec-essary if we want to incorporate this in pronunciation pedagogy in foreign language teaching.
Notes
1. Unfortunately, it is not possible to inspect Jenner's (1976) data, as in his study no acoustic data are presented to support his conclusion.

72 Ineke Mennen
References
Adams, Corinne and R.R. Munro 1978 In search of the acoustic correlates of stress: Fundamental fre-
quency, amplitude, and duration in the connected utterances of some native and nonnative speakers of English. Phonetica35,125–156.
Anderson-Hsieh, Janet, R. Johnson and Kenneth Koehler 1992 The relationship between native speaker judgments of nonnative
pronunciation and deviance in segmentals, prosody, and syllable structure. Language Learning 42, 529–555.
Archibald, John 1992 Adult abilities in L2 speech: Evidence from stress. In: James
Leather and Alan James (eds.). New sounds 92. Proceedings of the 1992 Amsterdam Symposium on the acquisition of Second-Language Speech, Amsterdam: University of Amsterdam.
Atterer, Michaela and D. Robert Ladd 2004 On the phonetics and phonology of “segmental anchoring” of F0:
evidence from German. Journal of Phonetics 32, 177–197. Backman, Nancy Ellen 1979 Intonation errors in second language pronunciation of eight Span-
ish speaking adults learning English. Interlanguage Studies Bul-letin 4, 239–266.
Beckman, Mary 1986 Stress and Non-stress Accent. Dordrecht: Foris. Bezooijen, Reneé 1995 Sociocultural aspects of pitch differences between Japanese and
Dutch women. Language and Speech 38, 253–265. Braun, Angelika 1994 Sprechstimmlage und Muttersprache. Zeitschrift für Dialektolo-
gie und Linguistik, LXI. 2, 170–178. Bruce, Gösta and Eva Garding 1978 A prosodic typology for Swedish dialects. In: Eva Garding, Gösta
Bruce and Robert Bannert (eds.), Nordic Prosody, 219–228. Lund University, Department of Linguistics.
Buysschaert, Joost 1990 Learning intonation. In: James Leather and Alan James (eds.).
New sounds 92. Proceedings of the 1992 Amsterdam Symposium on the acquisition of Second-Language Speech. Amsterdam: University of Amsterdam.

Phonological and phonetic influences in non-native intonation 73
Caramazza, Alfonso, Grace H. Yeni-Komshian, E. B. Zurif and E. Carbone 1973 The acquisition of a new phonological contrast: The case of stop
consonants in French-English bilinguals. Journal of the Acousti-cal Society of America 54, 421–428.
Celce-Murcia, Marianne, Brinton Donna M. and Janet Goodwin 1996 Teaching Pronunciation. A Reference for Teachers of English to
Speakers of Other Languages. Cambridge: Cambridge University Press.
De Bot, Kees 1986 The transfer of intonation and the missing data base. In: Eric
Kellerman and Michael Sharwood Smith (eds.). Crosslinguistic influences in second language acquisition. New York: Pergamon Press.
Eckert, Hartwig and John Laver 1994 Menschen und ihre Stimmen: Aspekte der vokalen Kommunikati-
on. Weinheim: Psychologie Verlags Union. Flege, James Emil and James Hillenbrand 1984 Limits on phonetic accuracy in foreign language speech produc-
tion. Journal of the Acoustical Society of America 76, 708–721. Fletcher, Janet, Esther Grabe and Paul Warren 2004 Intonational variation in four dialects of English: the high rising
tune. In: Sun-Ah Jun (ed.). Prosodic typology. The phonology of intonation and phrasing, 390–409. Oxford: Oxford University Press.
Fokes, Joann and Z.S.Bond 1989 The vowels of stressed and unstressed syllables in nonnative
English. Language Learning 39, 341–373. Gfroerer, Stefan and Isolde Wagner 1995 Fundamental frequency in forensic speech samples. In: Angelica
Braun and Jens-Peter Köster (eds.), Studies in Forensic Phone-tics: 41–48. Trier: Wissenschaftlicher Verlag Trier.
Gibbon, Dafydd 1998 German intonation. In: Daniel Hirst and Albert di Cristo (eds.),
Intonation Systems. A Survey of Twenty Languages, 78–95. Cam-bridge: Cambridge University Press.
Gilles, Peter and Jörg Peters 2004 Regional Variation in Intonation. Tübingen: Niemeyer Verlag. Grabe, Esther 1998 Comparative Intonational Phonology: English and German. MPI
Series in Psycholinguistics 7. Wageningen: Ponsen en Looien.

74 Ineke Mennen
Grabe, Esther, Greg Kochanski and John Coleman 2005 The intonation of native accent varieties in the British Isles -
potential for miscommunication? In Katarzyna Dziubalska-Kolaczyk and Joanna Przedlacka (eds.), English pronunciation models: a changing scene. (Linguistic Insights. Studies in Lan-guage and Communication. Vol. 21). Frankfurt /Main: Peter Lang.
Grabe, Esther, Brechtje Post, Francis Nolan and Kimberley Farrar 2000 Pitch accent realization in four varieties of British English. Jour-
nal of Phonetics 28, 161–185. Grønnum, Nina 1991 Prosodic parameters in a variety of regional Danish standard
languages. Phonetica 47, 188–214. Grover, Cinthia, Donald, G Jamieson and Michael B. Dobrovolsky 1987 Intonation in English, French and German: perception and pro-
duction. Language and Speech 30, 277–296. Jenner, Bryan 1976 Interlanguage and foreign accent. Interlanguage Studies Bulletin
1, 166–195. Jilka, Matthias 2000 The Contribution of Intonation to the Perception of Foreign Ac-
cent. Ph.D. dissertation, Institute of Natural Language Process-ing. University of Stuttgart.
Jun, Sun-Ah and Mira Oh 2000 Acquisition of 2nd language intonation. Proceedings of Interna-
tional Conference on Spoken Language Processing Beijing, 4, 76–79.
Jun, Sun-Ah (ed.) 2004 Prosodic Typology. The Phonology of Intonation and Phrasing.
Oxford: Oxford University Press. Ladd, D. Robert 1996 Intonational Phonology. Cambridge: Cambridge University
Press. Ladd, D. Robert, K. E. A. Silverman, F. Tolkmitt, G. Bergmann, and Klaus R.
Scherer, 1985 Evidence for the independent function of intonation contour type,
voice quality, and f0 range in signaling speaker affect. Journal of the Acoustical Society of America 78, 435–444.
Laures, Jacqueline S. and Gary Weismer 1999 The effects of a flattened fundamental frequency on intelligibility
at the sentence level. Journal of Speech Language and Hearing Research 42, 1148a–1156.

Phonological and phonetic influences in non-native intonation 75
Lepetit, Daniel 1989 Cross-linguistic influence on intonation: French/Japanese and
French/English. Language Learning 39, 397–413. Lim, Lisa 1995 A contrastive study of the intonation patterns of Chinese, Malay
and Indian Singapore English. Proceedings of the 13th Interna-tional Congress of Phonetic Sciences, Stockholm, 402–405.
Low, Ee Ling and Esther Grabe 1999 A contrastive study of prosody and lexical stress placement in
Singapore English and British English. Language and Speech 42, 39–56.
Maassen Ben and Dirk-Jan Povel 1984 The effect of correcting fundamental frequency on the intelligi-
bility of deaf speech and its interaction with temporal aspects. Journal of the Acoustical Society of America 76, 1673–1681.
McGory, J. T. 1997 Acquisition of Intonational Prominence in English by Seoul Ko-
rean and Mandarin Chinese Speakers. Ph.D. dissertation, Ohio State University.
Mennen, Ineke 1998 Second language acquisition of intonation: the case of peak
alignment. In: M. C. Gruber, D. Higgins, K. Olson and T. Wy-socki (eds.), Chicago Linguistic Society 34, Volume II: The Pan-els, 327–341. Chicago: University of Chicago.
1999a The realisation of nucleus placement in second language intona-tion. Proceedings of the 14th International Congress of Phonetic Sciences, San Francisco, 555–558.
1999b Second Language Acquisition of Intonation: the Case of Dutch Near-Native Speakers of Greek. Ph.D. dissertation, University of Edinburgh, Edinburgh.
2004 Bi-directional interference in the intonation of Dutch speakers of Greek. Journal of Phonetics 32, 543–563.
Nolan, Francis, Eva Lina Asu, Margit Aufterbeck, Rachel Knight, and Brechtje Post,
2002 Intonational pitch equivalence: an experimental evaluation of pitch scales. Paper presented at the BAAP Colloquium, Univer-sity of Newcastle.
Ohara, Yumiko 1992 Gender dependent pitch levels: A comparative study in Japanese
and English. In: K. Hall, M. Bucholtz and B. Moonwomon (eds.), Locating power: Proceedings of the Second Berkeley Women and Language Conference 2, 478–488. Berkeley.

76 Ineke Mennen
Patterson, David 2000 A Linguistic Approach to Pitch Range Modelling. Ph.D. disserta-
tion, Department of Linguistics, University of Edinburgh. Pierrehumbert, Janet 1980 The Phonology and Phonetics of English Intonation. Ph.D. dis-
sertation, MIT. Pierrehumbert, Janet and Mary Beckman 1988 Japanese Tone Structure. Cambridge, MA: MIT Presss. Scharff, Wiebke 2000 Speaking Fundamental Frequency Differences in the Language
of Bilingual Speakers. Unpublished Masters Dissertation, Human Communication Sciences, University of Newcastle upon Tyne.
Scherer, Klaus R. 2000 A cross-cultural investigation of emotion inferences from voice
and speech: implications for speech technology. Proceedings of the 6th International Conference on Spoken Language process-ing, Beijing 2, 379–382.
Stockwell, R. and D.J. Bowen 1965 The sounds of English and Spanish. Chicago: Chicago Press. Tajima, Keiichi, Robert Port and Jonathan Dalby 1997 Effects of temporal correction on intelligibility of foreign-
accented English. Journal of Phonetics 25, 1–24. Trim, J. L. M. 1988 Some contrastive intonated features of British English and Ger-
man. In: J. Klegraf and D. Nehls (eds.) Essays on the English language and applied linguistics on the occasion of Gerhard Nickel’s 60th Birthday, 235–49. Heidelberg: Julius Groos.
Ueyama, Motoko 1997 The phonology and phonetics of second language intonation: the
case of “Japanese English”. In: Proceedings of the 5th European Conference on Speech Communication and Technology, Rhodes (Greece), 2411–2414.
Van Bezooijen, Renée 1995 Sociocultural aspects of pitch differences between Japanese and
Dutch women. Language and Speech 38, 253–265. Wenk, Brian 1985 Speech rhythms in second language acquisition. Language and
Speech 28, 157–174. Willems, Nico J. 1982 English Intonation from a Dutch Point of View. Dordrecht: Foris
Publications

Different manifestations and perceptions of foreign accent in intonation
Matthias Jilka
1. Introduction
The teaching of prosody to second language (“L2”) learners often suffers from the problem that while an individual error can be readily pointed out and corrected, it is much more difficult to formulate general rules that pro-vide guidance in speech production. Due to the inherent complexity of the intonation-related aspects of foreign-accented speech, the knowledge about the nature of such errors and the corresponding teaching methods are not as well-developed as they are with respect to the segmental aspects of a sec-ond language.
This study aims to offer a general overview of those aspects of intona-tion and their interaction with second language acquisition that need to be taken into consideration when attempting to identify and classify intona-tional foreign accent. Concrete examples of such manifestations of intona-tional foreign accent are provided by an analysis of German productions by native speakers of American English and vice versa, the English produc-tions by native speakers of German. All example utterances are available for listening on the enclosed CD-Rom.
It is obvious that non-native intonation can exhibit foreign accent and that such intonational characteristics also make crucial contributions to the overall impression of foreign accent. The – non-trivial – difficulty lies in two tasks: accurately identifying exactly those intonational deviations that actually constitute relevant manifestations of foreign accent, and ascertain-ing the respective relative significance of these deviations. Without this knowledge it will remain unclear which of the non-native speaker’s con-cepts of intonational organization are actually responsible for the foreign-accented intonation. Consequently, it would be just as unclear which spe-cific intonational characteristics should be tackled in pronunciation teach-ing.

78 Matthias Jilka
For this reason first a number of insights with respect to the identifica-tion, classification and analysis of the specific characteristics of intonation that influence the determination of the prosodic phenomena responsible for the perception of foreign accent will be presented. This should create a greater awareness of the role intonation plays in foreign accent that will be helpful especially to the community of professional language teachers, e.g. of German as a foreign language.
This study identifies four major intonation-specific factors that are as-sumed to determine the causes, manifestations and perception of foreign accent-related intonational deviations. Section 2 introduces the first of these factors, namely the problem of perspective, which states that our perception of any tonal event strongly depends on the chosen model of intonation de-scription. Following this, the possible different sources of intonation errors – ranging from straightforward transfer of a tonal event from the speaker’s native language to seemingly “unmotivated” deviations – are presented in section 3. The great variability of intonation, which is connected to the large number of potential contexts and (un)intended interpretations, is dis-cussed next in section 4, also with regard to the existence of tonal devia-tions that are not necessarily perceived as non-native by themselves but can accumulate to create such an impression. Finally, in section 5, it is demon-strated that a common overall impression of foreignness is created by the “cooperation” of several types of tonal deviations.
2. Influence of differences in perspective
Quite obviously the perception of a particular manifestation of intonational foreign accent is shaped by the chosen model of intonation description, as it is the medium which must express the corresponding tonal deviations.
This also means that it cannot be determined with absolute certainty which model if any reflects the true representation of an intonational phe-nomenon – with the exception of those cases where it can be demonstrated that a particular model is insensitive to tonal deviations that a different form of representation has shown to be relevant. It is thus just as likely that a particular model of representation will distort the causes of intonational foreign accent as it is that the different offered perspectives are all equally valid. In any case this problem reflects the uncertainties in identifying the nature of tonal deviations and how they might be related to each other.

Different manifestations and perceptions of foreign accent in intonation 79
This section attempts to illustrate the effects of the different philoso-phies of intonation models on the representation of intonation errors.
2.1. Models of intonation description
The two most widely known and used approaches to intonation description are the so-called British School (e.g., Palmer 1922, Kingdon 1958, Halliday 1967, O’Connor and Arnold 1973) and the tone sequence model (Pierre-humbert 1980), which is based on the American tradition of analyzing pitch contours as sequences of pitch levels (e.g., Pike 1945 or Trager and Smith 1951). The tone sequence model has given rise to ToBI (“Tones and Break Indices”; Silverman et al. 1992, Beckman and Ayers 1994), a system de-veloped specifically for the transcription of prosodic phenomena. Both the British school model of intonation description and ToBI, as well as the philosophical differences between them, are discussed in more detail in Grice and Baumann (this volume).
A comparison of how ToBI and the British School approach analyze and label the same original utterances should make the consequences for the perception of the same phenomena, foreign accent or not, much clearer.1 In both versions of the short utterance Tom didn’t know produced by a native speaker of American English, the British School approach in-terprets the complete intonation contour, shown in the original in the top row of Figure 1, in terms of a single nuclear tone movement. In case A it is a high-fall (tonetic stress mark “ \ ” ) on Tom which corresponds in the ToBI approach to a high pitch accent (H*) on Tom, a low phrase accent (L-) to mark the end of the intermediate phrase and a low boundary tone (L%) to mark the end of the intonation phrase. The ToBI representation is thus more complex with at least two major points of reference (the pitch accent and the boundary constellation) as opposed to just one tonal movement in the British School interpretation. This difference becomes even more pro-nounced in case B where the ToBI labels mark an additional downstepped pitch accent (!H*) on know, whereas the British School approach again associates the complete contour with one nuclear tone movement, in this case a low-fall (tonetic stress mark “ \ ”).
Such a representation is not very adaptable and less likely to be able to reflect possible variations. Indeed the narrow transcription (second row in Figure 1), which is basically a stylized reproduction of the original contour, for example does not account for the typical valley between two high pitch
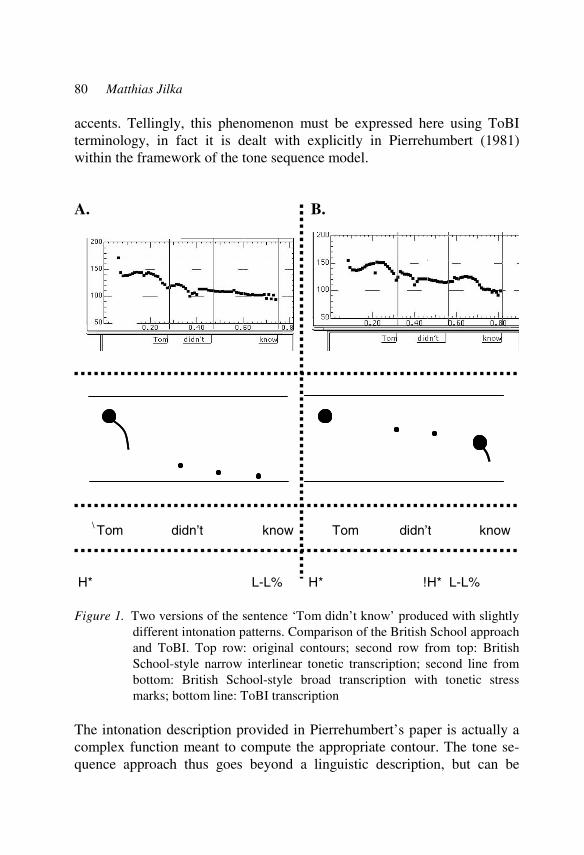
80 Matthias Jilka
accents. Tellingly, this phenomenon must be expressed here using ToBI terminology, in fact it is dealt with explicitly in Pierrehumbert (1981) within the framework of the tone sequence model.
A. B.
\ Tom didn’t know Tom didn’t know
H* L-L% H* !H* L-L%
Figure 1. Two versions of the sentence ‘Tom didn’t know’ produced with slightly different intonation patterns. Comparison of the British School approach and ToBI. Top row: original contours; second row from top: British School-style narrow interlinear tonetic transcription; second line from bottom: British School-style broad transcription with tonetic stress marks; bottom line: ToBI transcription
The intonation description provided in Pierrehumbert’s paper is actually a complex function meant to compute the appropriate contour. The tone se-quence approach thus goes beyond a linguistic description, but can be

Different manifestations and perceptions of foreign accent in intonation 81
adapted for modelling intonation in the context of F0 generation and speech synthesis (see for example Jilka, Möhler and Dogil (1999) for a tool for intonation generation on the basis of ToBI labels).
2.2. Intonation models for F0 generation and speech synthesis
In the field of speech technology quite a number of approaches to intona-tion modelling have been developed, some of them, as mentioned above, on the basis of the tone sequence model, others rather detached from strictly linguistic perspectives.
The parameter-based approach, PaIntE (short for “Parametric Intonation Events”) described in Möhler and Conkie (1998), for example, is interest-ing as it provides an alternative perspective of the phonetic dimensions of intonation events. The events themselves are designated by a linguistically-based model such as ToBI. F0 generation with the PaIntE approach at-tempts to achieve the reproduction of an identified intonation pattern by means of six descriptive parameters that determine the shape of an ap-proximation function across a three-syllable window around the accented syllable. The parameters, as depicted in Figure 2, describe the steepness of rise and fall of the tonal movement (parameters a1 and a2). Steepness is determined via a sigmoid function and is basically defined as inversely proportional to the duration of the rise or fall. The parameters c1 and c2
describe the amplitude of rise and fall (difference from valley to peak). The location of the peak expressed in milliseconds from the start of the utter-ance is represented by parameter b, while parameter d stands for the abso-lute pitch value (in Hertz) of the function’s peak. Apart from these six main parameters it is possible to derive further pa-rameters from the model. These can describe such aspects as the duration of rise or fall (trise, tfall) or the position of a peak or a valley (i.e., the beginning of a rise) with respect to a particular portion of the accented syllable.
An approach like PaIntE thus offers an alternative, more detailed view of the phonetic dimension of tonal categories as opposed to a more tradi-tional definition of those categories simply in terms of the temporal align-ment of the peak and its relative position with respect to the overall pitch range.
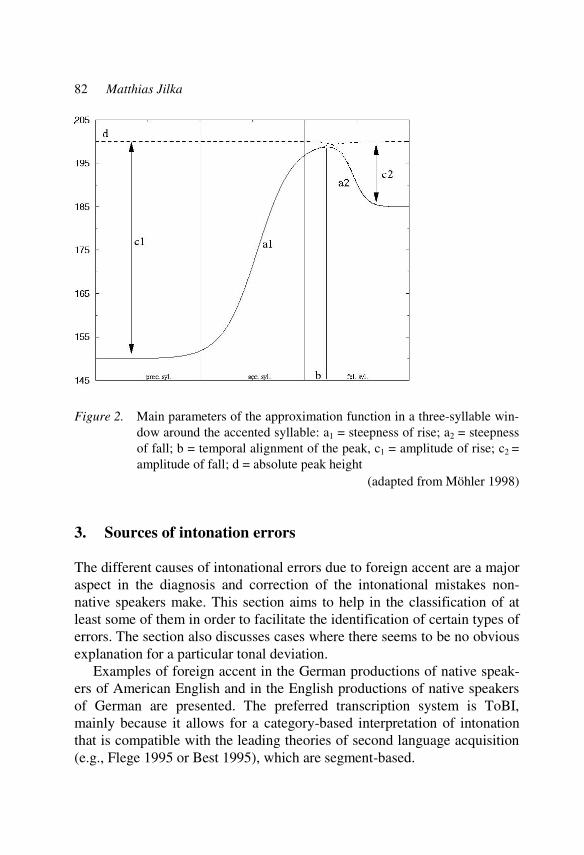
82 Matthias Jilka
Figure 2. Main parameters of the approximation function in a three-syllable win-dow around the accented syllable: a1 = steepness of rise; a2 = steepness of fall; b = temporal alignment of the peak, c1 = amplitude of rise; c2 =amplitude of fall; d = absolute peak height
(adapted from Möhler 1998)
3. Sources of intonation errors
The different causes of intonational errors due to foreign accent are a major aspect in the diagnosis and correction of the intonational mistakes non-native speakers make. This section aims to help in the classification of at least some of them in order to facilitate the identification of certain types of errors. The section also discusses cases where there seems to be no obvious explanation for a particular tonal deviation.
Examples of foreign accent in the German productions of native speak-ers of American English and in the English productions of native speakers of German are presented. The preferred transcription system is ToBI, mainly because it allows for a category-based interpretation of intonation that is compatible with the leading theories of second language acquisition (e.g., Flege 1995 or Best 1995), which are segment-based.

Different manifestations and perceptions of foreign accent in intonation 83
3.1. Transfer from the speaker’s native language
Transfer is certainly the most straightforward case of foreign accent, both as far as the segmental and the suprasegmental aspects of speech are con-cerned. The appearance of features of a speaker’s first language in his or her productions in the second language is a phenomenon that everyone is familiar with. It is similarly obvious to most people that sounds that are in some way equivalent in the two languages are affected by this process. This principle also applies both to intonation categories that occur in comparable discourse environments and to the phonetic realizations of these categories.
Transfer of a native category to the target language within a specific discourse situation
Intonational foreign accent is especially easy to recognize when a clearly defined discourse situation such as a declarative statement or a yes/no-question is produced with an inappropriate final intonation pattern. While in German and American English these two discourse situations are typi-cally produced with very similar final tunes (i.e. combinations of the nu-clear pitch accent and the phrase accents and boundary tones), there is a significant difference with respect to continuation rises. A continuation rise is meant to signal that despite the end of an intonation phrase the speaker intends to continue talking about a certain subject. Expressed with the Stuttgart ToBI system for German this tonal movement consists in a rising nuclear pitch accent that spreads to a default boundary tone (L*H %), thus a simple rise. In American English, on the other hand, the continuation rise is typically realized by an explicit rise in the boundary constellation itself (low phrase accent followed by high boundary tone: L-H%). If this rise is preceded by a rise on the nuclear pitch accent, the resulting tonal movement is made up by a rise, a fall, and yet another rise (L+H* L-H%).
The top contour in Figure 3 demonstrates this latter intonation pattern in the German utterance Denn man hatte dort auf einem Schild schon lesen können, dass frische Butter eingetroffen sei (“you could read on a sign that fresh butter had arrived”) made by an otherwise near-native sounding American speaker. The additional rise and fall on lesen können is clearly inappropriate to the ears of native German listeners (see Jilka 2000). The F0
contour for the corresponding reading of the same sentence by a German speaker is depicted in the bottom contour of Figure 3 and shows the simple rise spreading from the nuclear pitch accent on lesen to the end of the into-
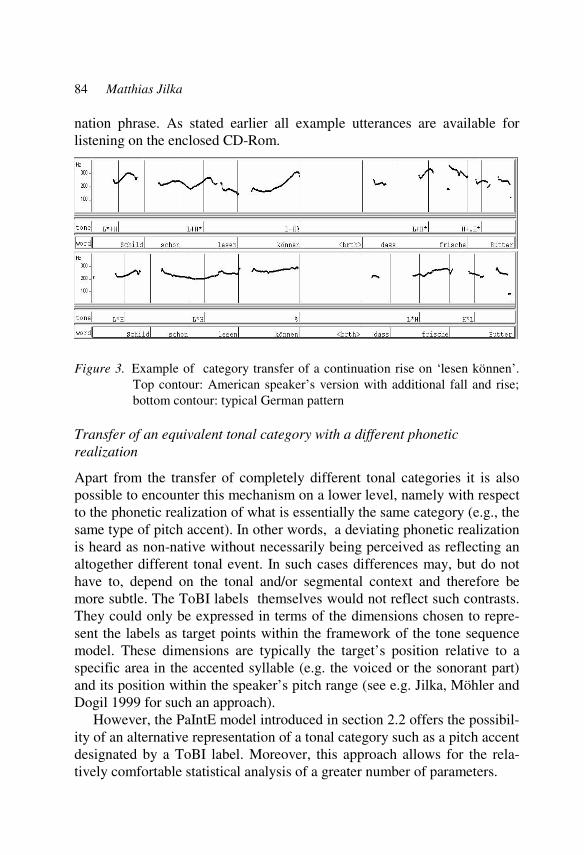
84 Matthias Jilka
nation phrase. As stated earlier all example utterances are available for listening on the enclosed CD-Rom.
Figure 3. Example of category transfer of a continuation rise on ‘lesen können’. Top contour: American speaker’s version with additional fall and rise; bottom contour: typical German pattern
Transfer of an equivalent tonal category with a different phonetic realization
Apart from the transfer of completely different tonal categories it is also possible to encounter this mechanism on a lower level, namely with respect to the phonetic realization of what is essentially the same category (e.g., the same type of pitch accent). In other words, a deviating phonetic realization is heard as non-native without necessarily being perceived as reflecting an altogether different tonal event. In such cases differences may, but do not have to, depend on the tonal and/or segmental context and therefore be more subtle. The ToBI labels themselves would not reflect such contrasts. They could only be expressed in terms of the dimensions chosen to repre-sent the labels as target points within the framework of the tone sequence model. These dimensions are typically the target’s position relative to a specific area in the accented syllable (e.g. the voiced or the sonorant part) and its position within the speaker’s pitch range (see e.g. Jilka, Möhler and Dogil 1999 for such an approach).
However, the PaIntE model introduced in section 2.2 offers the possibil-ity of an alternative representation of a tonal category such as a pitch accent designated by a ToBI label. Moreover, this approach allows for the rela-tively comfortable statistical analysis of a greater number of parameters.

Different manifestations and perceptions of foreign accent in intonation 85
An analysis of variance of rising (L*H) pitch accents in German as pro-duced by American and German speakers, for example, shows significant differences for parameter a1, the steepness of the rise (p = 0.00015), pa-rameter c1, the amplitude of the rise (p = 0.0000011) as well as the trise pa-rameter, which refers to the duration of the rise (p = 0.0029). The results must be interpreted in the following way: the rises in L*H pitch accents produced by the Americans are steeper than those produced by the Ger-mans because they have a significantly higher amplitude. The Americans’ rises are actually longer but this is outweighed by the greater amplitude. The differences in amplitude (and steepness) are not, as might be suspected, a consequence of speaker selection, i.e. the American speakers did not hap-pen to have higher voices. Peaks are on average 216.5 Hz for the Germans and 220.8 Hz for the Americans, p = 0.5177, which is clearly not signifi-cantly different. Instead the baseline values are significantly lower for the American speakers (p = 0.0184), 169.3 Hz vs. 182.4 Hz, implying that they use wider pitch ranges. The values were based on the readings of six sen-tences of varying length. In those sentences the two groups of speakers (three women and one man each) produced altogether 330 realizations of the rising pitch accents. Interestingly, the Americans produced more than twice as many (221) in those very sentences as the Germans (109), a phe-nomenon that will be discussed further in section 5.
3.2. Individual intonation errors
Many intonation errors made by second language learners are not clearly attributable to the influence of their native languages. These errors can take any form, from the occurrence of an additional pitch accent or the lack of one, to the use of deviating categorical or phonetic realizations. The inter-pretation of such cases remains speculative.
The idea that native speakers use a generally reduced, i.e., simplified prosodic inventory of default categories may have merit in some cases. This notion would be compatible with the concept of a “Basic Variety” (Klein and Perdue 1997), which states that especially in non-formal lan-guage acquisition speakers develop a primitive closed system of the target language. While that study also postulates an interaction between native and target language on the phonological level it does not discuss this in detail and concentrates mainly on how morphology, vocabulary and syntax are reduced to basic elements.

86 Matthias Jilka
In the majority of cases, however, such simplifications cannot be con-sidered to be convincing explanations. Figure 4, for example, illustrates the case of a native speaker of German who uttered the phrase I’m 31 years oldwhen she introduced herself at the beginning of the recording session. The top contour in Figure 4 shows that she produced an unusual final tune by stressing the word years with a rising pitch accent (L+H*) and maintaining that high level (transcribed here by a relatively rare “plateau” H-L% boundary tone) until the end of the phrase. This intonation pattern can of course theoretically occur in both English and German and might very well be appropriate as a continuation rise in a very specific context that requires a particular focus on years old, possibly as a contrastive or alternative element. However, such an interpretation is impossible with respect to the circumstances under which the utterance was made. There-fore the intonation contour is perceived as clearly inappropriate, and there is no immediate motivation for it in terms of a transfer from German that would explain why it was produced.
Figure 4. F0 contour of the phrase ‘I’m thirty-one years old’ uttered by a native speaker of German. Top contour: original spontaneous utterance with unusual final tune; middle contour: F0 generated declarative; bottom contour: F0 generated continuation rise
F0 generated versions based on ToBI labels (Jilka, Möhler and Dogil 1999) with alternative final tunes are acceptable on the other hand, as shown in the declarative (with the typical L-L% boundary constellation) depicted as the middle contour in Figure 4 as well as a more regular continuation rise

Different manifestations and perceptions of foreign accent in intonation 87
with the characteristic L-H% boundary configuration (bottom contour in Figure 5).
As the actual final tune (L+H* H-L%) is in no way more primitive than these alternative possibilities, we are left with the assumption of speaker-specific, individual errors. Such errors could be motivated either by a mistaken interpretation of the discourse situation or a general inability to deal with complex cognitive demands that leads to the assignment of more or less random tonal patterns.
4. The high variability of intonation
Intonation has a high potential for variation. On the one hand, speakers unconsciously produce subtle phonetic deviations either at random or due to the influence of the segmental, tonal or phrasal context. Such phonetic variation should in theory be predictable. However, research into the nu-merous manifestations and interactions of these factors is still a long way from providing an all-encompassing overview of any one language (see, e.g., van Santen and Hirschberg 1994 or Jilka and Möbius 2006).
On the other hand, speakers also consciously produce a multitude of dif-fering realizations that correspond to just as many differing interpretations. This does, of course, complicate the identification of clearly “correct” and “incorrect” intonation patterns, both in the target language and in the pro-ductions of the learners, as there is not yet sufficient knowledge about all the intonational features of any language, e.g. where they occur, what their respective form is and how they relate to the semantic content of what is being said. For this reason it is not always a trivial task to determine whether a particular intonation pattern is really inappropriate. As the possi-ble combinations and interactions between intonation, context and meaning are virtually infinite, it is quite challenging to draw conclusions about gen-eral classes of situations in which a particular type of pitch accent could be predicted to occur in a particular position.
Using the perspective (ToBI) and classification types introduced in sec-tions 2 and 3 as a basis, variability due to foreign accent can thus be ob-served on two levels, either as phonetic deviation within a tonal category (i.e., from an assumed prototypical realization in the segmental and pro-sodic context) or as the deviating use of whole categories (i.e., their choice and distribution).

88 Matthias Jilka
Indeed, not all the variability that deviates from an assumed standard form is necessarily perceived as an error, as it may only result in different, possibly unusual, interpretations that the context does not forbid. In such cases perception or rather awareness of the deviations becomes possible only via a cumulative effect, i.e. individual deviations, that by themselves alone would not trigger the impression of foreign accent, will create a chain of less and less likely interpretations that eventually leads to a point where the utterance’s intonation is incompatible with its semantic content.
The example analysis of the sentence “Und wenn auch die Mehrzahl von ihnen gerade nur so lange Zeit blieb wie der Umtausch in Anspruch nahm, so gab es doch einige, die sich hinsetzten und gleich auf der Stelle zu lesen begannen” (“And even if the majority of them only stayed as long as it took to complete the exchange, there still were some who sat down and started reading right away”) as read by a native speaker of American Eng-lish can be used to demonstrate such an effect. It shows individually ac-ceptable deviations that slowly accumulate to a combination of incompati-ble interpretations which are then perceived as an expression of foreign accent. The first unusually placed tonal category in the example (see also Figure 5) is the rising (L*H) pitch accent on “auch”, here used as a – nor-mally unstressed – focus particle in the sense of “even”. Due to the pitch accent, however, the impression is created that it is used in the more com-mon interpretation of “also” or “too”. The following falling accent on “Mehrzahl” (“majority”) reinforces this impression, as in the unmarked case of a concessive construction with “wenn auch” (“even if”) we would have expected a rise on “wenn” followed by a high-level plateau (see Müller 1998 for a discussion of focus particles and intonation in German). Similarly, the focus particle “nur” (“just”, “only”) is also assigned a pitch accent instead of the following “so” as would be expected. A rising pitch accent is also found on “Zeit” (“time”), indicating a contrastive focus ac-cent. This L*H pitch accent is immediately followed by yet another L*H accent on “blieb” (“stayed”) in the very next syllable, creating an uncom-monly narrow rise-fall-rise pattern at the phrase boundary. The distribution and high number of pitch accents encourages a forceful interpretation. The listener is led to expect the utterance to continue with the description of an extraordinary action undertaken or experienced by the children mentioned in the preceding context. Such an interpretation would for example be asso-ciated with the conjunction “dass” introducing a subsequent subordinate clause “… so lange Zeit blieb, dass … X passierte / sie X taten” (“stayed just for so long that … X happened / they did X”). As the utterance simply
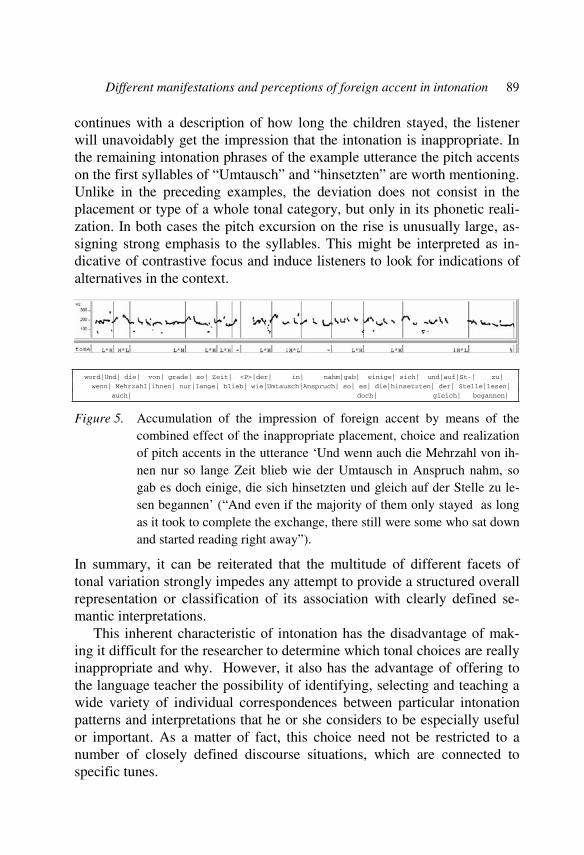
Different manifestations and perceptions of foreign accent in intonation 89
continues with a description of how long the children stayed, the listener will unavoidably get the impression that the intonation is inappropriate. In the remaining intonation phrases of the example utterance the pitch accents on the first syllables of “Umtausch” and “hinsetzten” are worth mentioning. Unlike in the preceding examples, the deviation does not consist in the placement or type of a whole tonal category, but only in its phonetic reali-zation. In both cases the pitch excursion on the rise is unusually large, as-signing strong emphasis to the syllables. This might be interpreted as in-dicative of contrastive focus and induce listeners to look for indications of alternatives in the context.
Figure 5. Accumulation of the impression of foreign accent by means of the combined effect of the inappropriate placement, choice and realization of pitch accents in the utterance ‘Und wenn auch die Mehrzahl von ih-nen nur so lange Zeit blieb wie der Umtausch in Anspruch nahm, so gab es doch einige, die sich hinsetzten und gleich auf der Stelle zu le-sen begannen’ (“And even if the majority of them only stayed as long as it took to complete the exchange, there still were some who sat down and started reading right away”).
In summary, it can be reiterated that the multitude of different facets of tonal variation strongly impedes any attempt to provide a structured overall representation or classification of its association with clearly defined se-mantic interpretations.
This inherent characteristic of intonation has the disadvantage of mak-ing it difficult for the researcher to determine which tonal choices are really inappropriate and why. However, it also has the advantage of offering to the language teacher the possibility of identifying, selecting and teaching a wide variety of individual correspondences between particular intonation patterns and interpretations that he or she considers to be especially useful or important. As a matter of fact, this choice need not be restricted to a number of closely defined discourse situations, which are connected to specific tunes.
word|Und| die| von| grade| so| Zeit| <P>|der| in| nahm|gab| einige| sich| und|auf|St-| zu|
wenn| Mehrzahl|ihnen| nur|lange| blieb| wie|Umtausch|Anspruch| so| es| die|hinsetzten| der| Stelle|lesen|
auch| doch| gleich| begannen|

90 Matthias Jilka
5. Overall impression of intonational foreign accent
Unlike the individual and immediately conspicuous cases of tonal devia-tions discussed in section 3, impressions of foreign accent caused by cumu-lative effects are not only associated with the moment when no reasonable interpretation for the overall intonation pattern is possible anymore (see section 4). Very often it is rather a process of becoming aware of pre-existing subconscious impressions that something indefinable in the speaker’s productions is unusual (provided of course that there are no other more obvious errors, for example on the segmental level). The listener may therefore perceive one complex, overall impression as opposed to discrete individual deviations following each other.
It it thus not unreasonable to postulate that when the many individual events potentially expressing foreign accent are combined, such a common overall impression is created. In other words, several intonational features together would conspire towards a specific overall intonation characteristic.
Summarizing observations made with respect to American speakers’ in-tonation in German, several features can indeed be shown to exhibit similar tendencies. A comparison of the same sentence read by native speakers of American English and German as depicted in Figure 5 shows that the Americans use twice as many pitch accents as the Germans in the same stretch of speech and that they tend to have wider pitch ranges (in section 3.1 an identical observation was confirmed by measurements within the framework of PaIntE parameters).
The American speaker’s production in our example can thus be de-scribed as comprising more tonal movements, rises and falls, with more extreme endpoints. The created perception is that of a much more lively intonation. This impression is representative of American speakers as op-posed to Germans in general. Further support for this tendency can be found in the fact that if a transfer of a tonal category takes place, it is likely to lead to additional tonal movements as well, as for example in the transfer of the continuation rise described in section 3.1, in which the comparison showed an extra fall and rise (L*H % vs. L+H* L-H%) in the American speaker’s production.
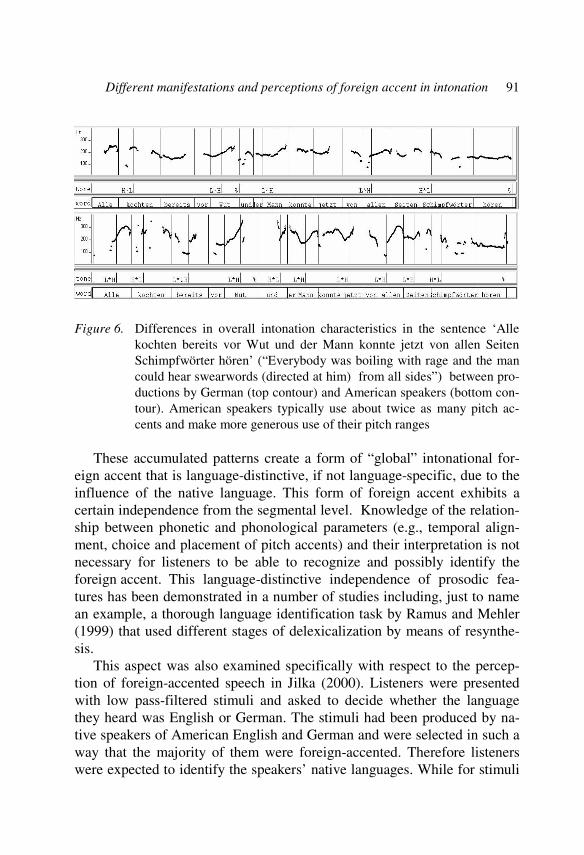
Different manifestations and perceptions of foreign accent in intonation 91
Figure 6. Differences in overall intonation characteristics in the sentence ‘Alle kochten bereits vor Wut und der Mann konnte jetzt von allen Seiten Schimpfwörter hören’ (“Everybody was boiling with rage and the man could hear swearwords (directed at him) from all sides”) between pro-ductions by German (top contour) and American speakers (bottom con-tour). American speakers typically use about twice as many pitch ac-cents and make more generous use of their pitch ranges
These accumulated patterns create a form of “global” intonational for-eign accent that is language-distinctive, if not language-specific, due to the influence of the native language. This form of foreign accent exhibits a certain independence from the segmental level. Knowledge of the relation-ship between phonetic and phonological parameters (e.g., temporal align-ment, choice and placement of pitch accents) and their interpretation is not necessary for listeners to be able to recognize and possibly identify the foreign accent. This language-distinctive independence of prosodic fea-tures has been demonstrated in a number of studies including, just to name an example, a thorough language identification task by Ramus and Mehler (1999) that used different stages of delexicalization by means of resynthe-sis.
This aspect was also examined specifically with respect to the percep-tion of foreign-accented speech in Jilka (2000). Listeners were presented with low pass-filtered stimuli and asked to decide whether the language they heard was English or German. The stimuli had been produced by na-tive speakers of American English and German and were selected in such a way that the majority of them were foreign-accented. Therefore listeners were expected to identify the speakers’ native languages. While for stimuli

92 Matthias Jilka
of varying duration identification rates (i.e. correct recognition of the speaker’s native language) were generally not significant, there was a sig-nificant (p = 0.030) correlation of 0.786 (Spearman-Rho test) between iden-tification rate and stimulus duration. For this reason a small-scale additional test with eight stimuli longer than 35 seconds was performed. As expected the speakers’ native languages were recognized in all cases, in six cases significantly so (p < 0.00005).
Such results can certainly be interpreted as confirmation of the idea pos-tulated earlier that the overall impression of foreign accent independent of semantic content slowly accumulates during a stretch of speech. The longer it is, the more hints at unusual tonal features reach the listener’s ear, until they eventually cross the threshold of awareness2.
6. Possible conclusions for language teaching
The presented characteristic aspects of intonation address potentially diffi-cult challenges for intonation research and teaching alike. It can be shown, however, that these challenges can be met to a considerable degree and that the discussion of these aspects can lead to insights that underline the use-fulness of strictly research-related problems to the development of teaching methods.
The question of the significance of perspective, i.e., the dependence on the model of intonation description, expresses a general uncertainty as to what the true representation of intonation is. This certainly is problematic for intonation research. However, from a more practical, pedagogical per-spective it can also be argued that the multitude of different representations provides the chance to deal with an intonation error from different starting points.
In section 3 the causes of some intonational deviations were shown to be either unknown or of a non-transparent nature. As a result it would be ex-tremely difficult, if not impossible, to understand these particular sources of foreign accent and develop systematic approaches to predicting and avoid-ing them. On the other hand there are some well-defined environments, especially the basic discourse situations such as declaratives, wh-questions, yes/no-questions, continuation rises etc., for which it should be possible to make sure that the final tunes associated with them are produced correctly and do not contain any obvious cases of tune transfer. A similar approach could be applied to successfully identified transfer phenomena concerning

Different manifestations and perceptions of foreign accent in intonation 93
the phonetic realization of equivalent categories. See section 3.1 for exam-ple for both types of transfer.
The importance of the high variability of intonation was discussed as a factor complicating the relationship between prosody and meaning. The virtually infinite number of tonal variations and corresponding interpreta-tions makes it impossible for intonation researchers to provide a formal description that relates all possible variations in all possible contexts to the intended corresponding interpretations. Even if such a description existed it would obviously still be unreasonable to expect a second language learner to be able to acquire and apply it. It was pointed out, however, that from the pedagogical point of view this variability also has the benefit of allowing the identification and teaching of specific tonal constellations that are guar-anteed to express the intended discourse meaning. The selection of such exemplary tonal patterns and interpretations, as well as the development of suitable teaching methods, may be challenging but is nevertheless well within the grasp of the language teaching community.
Finally, the overall characteristics of foreign accent described in sec-tion 5 contribute an essential share of the impression of foreign accent that a non-native speaker conveys. One interesting inherent property that these general characteristics have is that it is not necessary to relate them to par-ticular meanings or positions in the phrase. If specific differences exist between two languages, like they do between German and American Eng-lish, and it is possible to teach learners conscious control of these global features (e.g., “don’t extend your pitch range too much”, “use fewer pitch accents” etc.), then this measure alone should greatly reduce the impression of intonational foreign accent, even though it would not affect the more persistent tonal deviations that are due to misrepresentations of equivalent contexts or categories in the learners’ native languages.
The observations and suggestions contained in this study are made from the point of view of intonation research and do not incorporate insights from the fields of teaching methodology or even pedagogy in general. They express a relatively broad objective and would of course not lead to a com-pletely accentless pronunciation (which is not a realistic goal anyway). It can be argued, however, that their application together with a heightened awareness of the nature of intonational errors will help foreign language teachers such as teachers of German as a foreign language to develop more systematic approaches to dealing with foreign-accented intonation.
The application of speech technology in the form of F0 generation and resynthesis as demonstrated in Figure 4 should also be of use eventually,

94 Matthias Jilka
helping for example to make clear the difference between intonation con-tours that a learner has produced and more appropriate realizations genera-ted with the learner’s own voice (some commercially available products that attempt to go in this direction already exist).
Notes
1. British School transcriptions follow the models given in Cruttenden (1997: 61) 2. A number of studies have also shown that rhythmic features alone may be suf-
ficient to distinguish languages. In Jilka (2000) it is however shown, using low pass-filtered stimuli with a constant F0 of 220 Hz, that language identification rates are significantly better when intonation information is present.
References
Beckman, Mary and Gail Ayers 1994 Guidelines to ToBI Labelling. Version 2.0. Ohio State University. Best, Catherine T. 1995 A direct-realist view of cross-language speech perception. In:
Winifred Strange (ed.), Speech Perception and Linguistic Experi-ence: Theoretical and Methodological Issues, 171–204. Timo-nium, MD: York Press.
Cruttenden, Alan 1997 Intonation. Cambridge: Cambridge University Press. Flege, James E. 1995 Second language speech learning: Theory, findings and prob-
lems. In: Winifred Strange (ed.), Speech Perception and Linguis-tic Experience: Theoretical and Methodological Issues, 233–277. Timonium, MD: York Press.
Halliday, Michael A. K. 1967 Intonation and Grammar in British English. The Hague: Mouton. Jilka, Matthias 2000 The Contribution of Intonation to the Perception of Foreign
Accent. PhD Dissertation. AIMS 6(3). Stuttgart: University of Stuttgart.

Different manifestations and perceptions of foreign accent in intonation 95
Jilka, Matthias and Bernd Möbius 2006 Towards a comprehensive investigation of factors relevant to
peak alignment using a unit selection corpus. Proceedings of In-terspeech, Pittsburgh, 2054–2057.
Jilka, Matthias, Gregor Möhler and Grzegorz Dogil 1999 Rules for the generation of ToBI-based American English intona-
tion. Speech Communication 28, 83–108. Kingdon, Roger 1958 The Groundwork of English Intonation. London: Longman. Klein, Wolfgang and Clive Perdue 1997 The basic variety (or: Couldn’t natural languages be much sim-
pler?). Second Language Research 13, 301–347. Möhler, Gregor 1998 Theoriebasierte Modellierung der deutschen Intonation für die
Sprachsynthese. PhD Dissertation. AIMS 4(2). Stuttgart: Univer-sity of Stuttgart.
Möhler, Gregor and Alistair Conkie 1998 Parametric modelling of intonation using vector quantization.
Proceedings of the 3rd ESCA Workshop on Speech Synthesis,Jenolan Caves (Australia), 311–316.
Müller, Karin 1998 German Focus Particles and their Influence on Intonation. Mas-
ter’s Thesis, University of Stuttgart. O’Connor, Joseph D. and Gordon F.Arnold 1973 Intonation of Colloquial English. London: Longman. Palmer, Harold E. 1922 English Intonation. Cambridge: Heffer. Pierrehumbert, Janet 1980 The Phonology and Phonetics of English Intonation. PhD Disser-
tation. Cambridge, MA: MIT. 1981 Synthesizing intonation. Journal of the Acoustical Society of
America 70, 985–995. Pike, Kenneth 1945 The Intonation of American English. Ann Arbor: University of
Michigan Press. Ramus, Franck and Jacques Mehler 1999 Language identification with suprasegmental cues: A study based
on speech resynthesis. Journal of the Acoustical Society of Amer-ica 105, 512–521

96 Matthias Jilka
van Santen, Jan and Julia Hirschberg 1994 Segmental effects on timing and height of pitch contours. Pro-
ceedings of the 3rd International Conference on Spoken Lan-guage Processing, Yokohama (Japan), 719–722.
Silverman, Kim, Mary Beckman, John Pitrelli, Mari Ostendorf, Colin Wightman, Patti Price, Janet Pierrehumbert and Julia Hirschberg
1992 ToBI: A standard for labelling English prosody. Proceedings of the 2nd International Conference on Spoken Language Process-ing, Banff (Canada), 867–870.
Trager, George L. and Henry L. Smith 1951 An Outline of English Structure. Norman, OK: Battenburg Press.

Rhythm as an L2 problem: How prosodic is it?
William J. Barry
1. Introduction
Making L2 learners aware of pronunciation problems in general and, more specifically, of the difference between their own pronunciation and the pronunciation they are supposed to acquire is extremely difficult, as any language teacher (interested in pronunciation) will attest.1 It should there-fore be paramount that the terms we use to direct learners’ attention to problem areas should be clearly defined and easy to associate with the phe-nomenon that they need to learn. And there’s the rub! It is well-known that the pronunciation problems we face are difficult to illustrate, explain and demonstrate because:
(i) Acoustic phenomena remain as pre-categorical percepts in our con-sciousness for no more than a fraction of a second (Massaro 1972; Kallman and Massaro 1983) and as perceived categories (which al-ready resist change in our manner of dealing with them) for no more than a few seconds (Crowder and Morton 1969, and compare Crowder 1993 and de Gelder & Vroomen 1997).
(ii) We do not process the time-varying signal uniformly over time: The mechanisms we have developed in our L1 for decoding the phonetic information contained in the acoustic signal are attention-directed and the properties to which attention is directed can differ in importance from language to language (cf. for example Hazan 2002, and see Quené and Port 2005 for effects of “rhythmically” induced attention).
(iii) Our decoding mechanisms are geared primarily to the extraction of communicatively relevant information (the semantics of an utter-ance, its significance for the ongoing communication act). For this we do in fact make use of phonetic nuances of the utterance, but in terms of speaker identity interpretation (cf. Palmeri, Goldinger and Pisoni 1993), which may also serve speaker-attitude interpretation. But we are not concerned with pronunciation analysis.

98 William J. Barry
In summary, becoming aware of and learning a foreign pronunciation is problematical. But it is not impossible, as some people’s natural acqusi-tion of an acceptable L2 accent testifies. That we all do react to the diffe-rences between external models and our internal pronunciation habits is illustrated by many adults living abroad who, after many years in the fo-reign-language environment, lose their perfect native pronunciation but do not acquire perfect L2 pronunciation (cf. Markham 1997). The potential for using the acoustic differences in teaching depends, however, on directing a learner’s attention to the differences, or to quote the opening thought in this introduction: “making L2 learners aware of pronunciation problems”.
Finding a “hook” on which to hang the problem is a vital first step. Dif-ferent problems present different degrees of difficulty in finding the right hook, and prosodic problems are particularly difficult. The thesis behind this paper is that Rhythm2 presents the greatest difficulties and we therefore need to rethink the status of Rhythm in pronunciation teaching.
2. The “hooks” to swing on
Segmental problems are the easiest problems to explain because we have an orthography-to-sound relationship (itself a “spelling” problem of course) which our Western, reading- and writing-orientated education fixes in our mind. Of course, as pronunciation teachers, we have to fight continuously against the confusion between letters and sounds, but the letters (and letter combinations) provide a permanently recordable focus (on paper) for de-veloping exercises.
The PERmanent GRAPHic RECord can also be exploited in making learner’s aware of the word-stress concept. In terms of accessibility and learner awareness, word-stress is not so problematical because word iden-tity (meaning) is central to everyone’s idea of learning a language. If, by chance, there are minimal pairs relying on word-stress, then the way you reCORD them helps to strengthen the concept.

Rhythm as an L2 problem: How prosodic is it? 99
Figure 1. Microphone signal, F0 and spectrogram of a) REcord and b) reCORD
Nowadays, with the ubiquitous notebook (PC) and readily available signal-processing freeware (perhaps the most powerful package available is Praat: www.fon.hum.uva.nl/praat/), a signal-based graphic record can be pre-sented together with the auditory example (see Fig. 1, and listen to the sound-file REcord-reCORD.wav) to create the necessary link between in-tellectual understanding of the concept and experience of the phenomenon itself.
At this level, the relationship between the simple experience of syllabic prominence and the complex of prominence-bearing signal properties (du-ration, F0, intensity and vowel spectrum) can be demonstrated and may also become comprehensible beyond being merely a verbal formula.
Both the “hooks” already mentioned in connection with word-stress can be exploited for work on sentence-stress, and the learner’s awareness of the phenomenon can be easily stimulated because, here too, the natural process of decoding the meaning of an utterance results in a difference in under-standing of e.g., “I THOUGHT he aGREED” and “I THOUGHT he aGREED”. Of course, the graphic signal representation with an accompanying acoustic demonstration (see Fig. 2 and listen to the sound-file Fig2-agreed-a+b.wav) adds flesh to the skeletal understanding of the concept triggered by the purely orthographic representation.
Time (s)0 1.34376
-0.3202
0.2067
0
Time (s)0 1.34376
-10
10
Time (s)0 1.34376
0
4000
y D ê = = É = = = = = =â = = = = = = = = = = l § = = = = = == Ç = y = = = = == = = = = = y ê = = f== = = = = D â =========l § = ====== =Ç=y
a b

100 William J. Barry
Figure 2. Microphone signal and F0 trace of a) “I THOUGHT he aGREED” and b) “I THOUGHT he aGREED”
With the signal representation, the relationship is again illustrated between the complex signal structure (duration, F0, intensity and – in this case less so – vowel spectrum) and the less complex perceived difference in the prominence patterns between the sentences (with the accompanying differ-ence in their meanings).
If we now look for a “hook” on which to hang the concept of intonation, we begin to run into a number of difficulties. Firstly, the melodic pattern, which is fundamental to intonational structure, cannot be so simply, or at least not so naturally demonstrated using the orthographic manipulation tools that were so helpful for word- and sentence-stress. But careful pro-gression through the methods used in intonation description, from iconic to more abstract (see Fig 3a-d), should help to develop the learner’s aware-ness.3
Secondly, even though we recognize the primary role of tonal proper-ties in intonation, a too narrow understanding of intonation as only the me-lodic pattern carried by the fundamental frequency contour is patently wrong. The contour carrying version b) of the sentence in figure 2 (I THOUGHT he AGREED) can be seen to rise from “I” to “thought”, to re-main level for “he a-” and then to scoop down low and rise again during “-greed”.
Time (s)0 2.59565
-0.4913
0.3006
0
Time (s)0 2.59565
-10
10
Time (s)0 2.59565
0
4000
y ~ f= D q = = l § = í =Ü á § … Ö ê= = ᧠= = = =d= L y = = = = == = = = = = y = ~ f= = = =q==l §===í=Ü á§=…= Ö = ê== á § =Ç= y
a) b)

Rhythm as an L2 problem: How prosodic is it? 101
a) GR b) THOUGHT he a E I E D I THOUGHT he aGREED
c) I THOUGHT he a GREED d) I THOUGHT he a^GREED H* ^H* L-%
Figure 3. Different graphical means of conveying the tonal contour of an utter-ance, with increasing abstractness from a) to d).
Figure 4. “I THOUGHT he aGREED” and “I THOUGHT he AGREED” with same tonal contour. (top contour: original production, bottom: manipulated contour)
•• • •
•
Time (s)0 2.98785
-0.5598
0.2876
0
Time (s)0 2.98785
-10
10
Time (s)0 2.98785
0
4000
Time (s)0 2.98785
-10
10
Orig.
y = ~ f= = D q = = l § = í =Ü = = á § … Ö ê= = á § = = =d= y = = = = = = = = = y = = ~ f= = = =q = l § = í = Üá § … = Ö = ê = = = á § = = = =d=y
a b

102 William J. Barry
Figure 4, however, shows basically the same contour in a perfectly ac-ceptable realization of version a), i.e., with the secondary sentence accent on “thought” and the primary accent on “agreed” (I THOUGHT he aGREED. Listen to sound-files Fig4-orig.wav and Fig4-manip.wav).
Although the melodic contour is the same, no-one would wish to say that the intonation is the same. The two versions of the utterance (Fig. 2b and Fig. 4) clearly have a different meaning4, and that is due to the differ-ence in intonation, which is the product of the tonal movements in relation to the duration and intensity of the accented syllables.
3. A hook for Rhythm?
Having looked for and found (albeit with increasing difficulty) “hooks” to hang our awareness teaching on, we can now ask what Rhythm is? Is it something above and beyond the three prosodic structuring levels – word-stress, sentence-stress and intonation – that we have considered so far, or is it perhaps below and part of them? Before addressing that question, we need to recognize that there is a progressive overlap in the acoustic and linguistic nature of each of the phenomena as we consider them in turn: Sentence-stress makes use of the lexical stress patterns to structure its prominences (and appears to use the self-same acoustic parameters); into-nation needs the sentence-stress structure to fit its melodic pattern over.
Looking at it in another way, we see that the separation of word-stress from sentence-stress, and sentence-stress from intonation is an artificial product of the particular level of observation and analysis. In reality they are not separable: In a one-word “sentence”, word-stress is sentence-stress and it also carries the intonation contour. Similarly, in the more usual multi-word utterances, sentence-stress relies in part on the tonal movements of the intonation contour to make the important words prominent, and the tonal movement relies on the durational (and apparently to a lesser extent) intensity properties of the accented words.
What, then, is Rhythm in spoken language? One approach to the ques-tion is to try to relate the prosodic structuring of spoken language to a more general understanding of Rhythm.

Rhythm as an L2 problem: How prosodic is it? 103
3.1. Rhythm in music and spoken language
Outside language, particularly in music of the Western tradition, rhythm is commonly understood to be the repeated pattern of prominent beats and the less prominent beats between them. We talk about a whole piece of music being “rhythmic” if there is a regular strong beat. But the nature of the rhythm depends on the number of weaker beats between the strong ones. These, it seems, have to be of a predominantly constant number, though an occasional reduction or increase in the number doesn’t change the per-ceived nature of the rhythm as a whole, as long as the temporal relationship between the strong and the weak parts of the bar is kept constant. Another important feature is that rhythm is not continuous throughout a piece, but is manifested within phrases, which often have boundary properties (e.g., a weak beat before the first strong beat, a final strong beat with no accompa-nying weak beats, etc.) which are different from the regular beats within the phrase.
Projecting this common understanding of rhythm onto spoken language, we can immediately appreciate that spoken verse can be produced and per-ceived as “rhythmic” in a similar sense. This is because the words and phrases are selected to conform to one of the classical poetic metrical pat-terns of strong ( ) and weak (ˇ) syllables iambic (ˇ ), trochaic ( ˇ), dac-tylic ( ˇ ˇ), anapaest (ˇ ˇ )– often with a strict number of beats (feet) in the phrase (line). The close relationship between musical and poetic rhythm is apparent in words put to music and tunes to which words are written. How-ever, the natural production of a poetically well-formed phrase in normal speech communication, though possible, is rather rare and regarded as spe-cial (as the post-hoc observation “I was a poet and didn't know it” bears out). A further consideration which separates classical poetic metre from natural speech is its application across (Western) languages, independent of a language’s status in terms of linguistic rhythm typology. The perceptual effect in different languages of, technically, the same metrical structure can be very different.
We can thus close the case on normal spoken language rhythm being the same as musical rhythm and come to a second approach, the language-typology approach to spoken-language rhythm. Since Lloyd (1940: 25), who famously described French as having a “machine-gun rhythm” and English as having “morse-code rhythm”5 an almost mystical belief has arisen in a rhythm-based division of the languages of the world into what Pike (1946) termed “syllable-timed” and “stress-timed” languages. The

104 William J. Barry
identification of a third type – “mora-timed” – was separate from this di-chotomy and has been attributed to Bloch (1950) and to Ladefoged (1975). This characterisation is as attractive as it is problematic, both in general scientific terms and in respect of its possible application to L2 pronuncia-tion.
3.2. Rhythm in language typology
Scientifically, binary (or even ternary) features which contribute to the categorisation of language phenomena are attractive concepts which de-mand serious examination. To be phonologically relevant, however, there needs to be some structural correlate of Rhythm which is best explained by that concept rather than another (already established) phonological cate-gory. Alternatively, the term can be based on the conceptual grouping of a number of structural correlates, possibly already established at other levels of description. Ideally, these structural properties should have identifiable phonetic exponents, either in measurable aspects of speech production or in reliable perceptual reflexes.
Although there is extensive linguistically orientated and often experi-mentally supported discussion of the supposed universal rhythmic distinc-tions (cf. Bertinetto 1989 for a thorough and humorously (self-)critical dis-cussion of the literature up to that point), the majority devoted to the syllable- vs. stress-timed distinction, no single structural correlate has been found which justifies the labels as phonological categories in the normal sense or the term. On the other hand, it has been suggested (Bertinetto 1981; Dauer 1983, 1987) that differences in rhythm type are the product of a number of phonologically relevant dimensions, among which are struc-tural properties such as syllable complexity, vowel-length distinctions and word-stress, and interactional prosodic effects such as vowel-duration- and vowel- quality-dependency on stress, the coincidence (or not) of intona-tional F0 peaks and troughs and of lexical tones with accented syllables. In this respect, Rhythm becomes a phonologically relevant cover term, but no longer in the sense of a rhythm dichotomy or trichotomy. There is no rea-son to expect the properties listed by Dauer (1987) to group into two neat packages supporting the syllable- vs. stress-timed division, and the position of the mora-timed languages relative to the implied continuum (if the prop-erties group freely) is undefined.

Rhythm as an L2 problem: How prosodic is it? 105
Psycholinguistic research, on the other hand, offers some support for the perceptual reality of the rhythmic typology divisions in terms of lexical processing, at least for the languages which are cited as being prototypical for the three rhythmic types (French, English and Japanese). Cutler et al. (1986), Cutler & Otake (1994), Cutler (1997), Cutler, Murty and Otake (2003), Otake et al. (1993) have demonstrated lexical access differences in terms of the effect of the syllable or the mora on the speed of access. It must be acceded, however, that however real these processing differences are, they do not relate to any concept of Rhythm we have discussed. A per-ceptual acceptability study by Bertinetto and Fowler (1989), however, demonstrated that English listeners are relatively insensitive to durational manipulation which shortens unstressed syllables compared to Italian lis-teners (though neither is particularly sensitive to lengthening of unstressed syllables). This corresponds to the results of production analyses for Italian (Farnetani & Kori, 1990) and Greek (Arvaniti, 1994) which, for these two languages, support the “syllable-timing” claim that sequences of more than two unstressed syllables are articulated without any “eurhythmic” differen-tiation. In languages such as English, sequences of more than two un-stressed syllables are produced in such a way as to provide longer, less reduced syllables between shorter, more reduced ones, resulting in a per-ceptible alternating “rhythm”. It should be borne in mind, however, that this “rhythmic” difference occurs, and becomes apparent only in the per-ceptually less prominent parts of utterances between the more prominent syllables of sentence-accentuated (i.e. informationally important) words. The prominence patterning of the complete “information package” (possi-bly a sentence, or an intonation phrase within a longer sentence) will be necessarily more complex than the sequence of unstressed syllables alone. This may, in part, explain why no instrumental analyses looking for isochrony (either of syllables or feet) have been successful (Roach 1982 and compare Bertinetto 1989).
Instrumentally based attempts to define the rhythmic types in quantita-tive terms at the level of production can be divided mainly into two ap-proaches: those seeking syllable- vs. foot-based durational regularity or isochrony (cf. Bertinetto 1989) and those looking for differences between languages in the degree of variability in consecutive (part-of-) syllable durations (Grabe and Low 2002; Ramus, Nespor and Mehler1999; Gibbon and Gut 2001; Wagner and Dellwo 2004).
The earlier studies sought regularity, seeking some confirmation in sub-stance for the original auditory impressions. They were singularly unsuc-

106 William J. Barry
cessful, and it appears currently to be generally accepted that there is no direct acoustic, nor articulatory measure of the syllable- vs. stress-timed distinction. Studies that included mora-timing in their remit (Hoequist 1983a, 1983b) have been no more successful.
The studies quantifying the structural variability of syllables are based broadly on the theoretical framework suggested by Bertinetto (1981) and Dauer (1983, 1987), though their measures are restricted to durational de-rivatives directly or indirectly linkable to many of the structural properties. They capture either the overall variability of the syllable, vowel or conso-nantal interval durations (e.g. with the standard deviation) or the average degree of durational change from one interval to the next throughout an utterance or a corpus.
There has been considerable success in differentiating between langua-ges traditionally regarded as belonging to one of the three rhythm types (cf. Ramus 1999; Grabe and Low 2002). However, there is no reason to consi-der the measures to be a reflex of specifically rhythmic rather than general structural properties (Barry et al. 2003, Wagner and Dellwo 2004), and it has been demonstrated (Steiner 2003) that, in the Bonn database at least, any subdivision of the sound inventory into “vocalic” and “consonantal” intervals, and ultimately the distribution of /l/ and /n/ in the different langu-ages which served as language differentiators. But as measures of language classification (rather than language differentiation), they may be unreliable because they can be strongly influenced by speech rate (cf. fig. 5 from Bar-ry et al. 2003), showing a shift from more to less variable structure with increasing articulation rate (see also Engstrand & Krull 2001 for similar observations on Swedish read vs. spontaneous speech). The extent of this shift observed in Barry et al. (2003) is almost certainly, in part, an artefact of the structural basis for the calculation of articulation-rate, i.e., syllables per second. This is unreliable for spontaneous speech, since the word se-quences being compared are not identical and structurally less complex syllables are, ceteris paribus, produced more quickly than complex ones. In other words, the division of the corpus into three sub-corpora of differing articulation rates is also a division into utterances with different average syllable complexities. However, even the Bonn speech rate corpus (Dellwo et al. 2004) shows considerable inter-syllabic variability over slow-to-fast speech rates for lexically controlled (albeit read) speech (Dellwo and Wag-ner 2003). It is again the consonant variability measure (DeltaC) which shows the strongest variation (for German, English and French, though with a deviation from the general pattern for the fastest rate in English). In
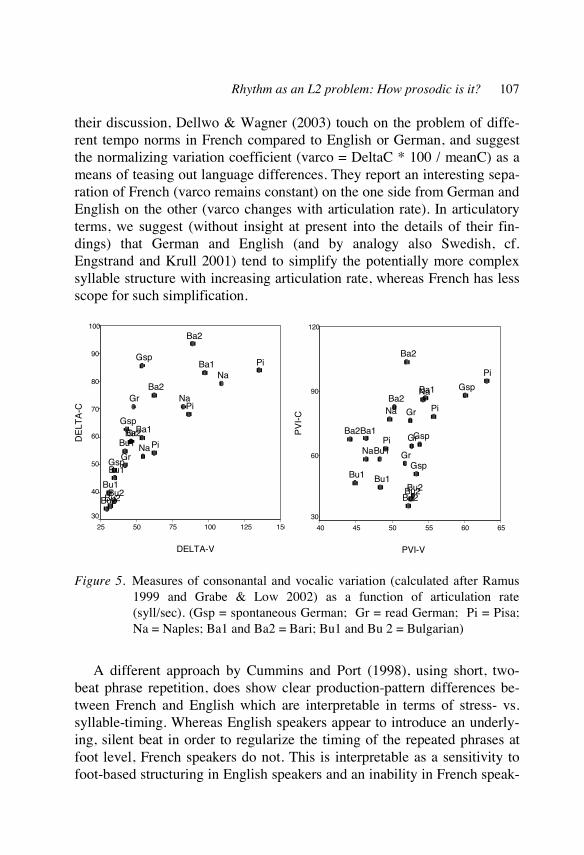
Rhythm as an L2 problem: How prosodic is it? 107
their discussion, Dellwo & Wagner (2003) touch on the problem of diffe-rent tempo norms in French compared to English or German, and suggest the normalizing variation coefficient (varco = DeltaC * 100 / meanC) as a means of teasing out language differences. They report an interesting sepa-ration of French (varco remains constant) on the one side from German and English on the other (varco changes with articulation rate). In articulatory terms, we suggest (without insight at present into the details of their fin-dings) that German and English (and by analogy also Swedish, cf. Engstrand and Krull 2001) tend to simplify the potentially more complex syllable structure with increasing articulation rate, whereas French has less scope for such simplification.
Figure 5. Measures of consonantal and vocalic variation (calculated after Ramus 1999 and Grabe & Low 2002) as a function of articulation rate (syll/sec). (Gsp = spontaneous German; Gr = read German; Pi = Pisa; Na = Naples; Ba1 and Ba2 = Bari; Bu1 and Bu 2 = Bulgarian)
A different approach by Cummins and Port (1998), using short, two-beat phrase repetition, does show clear production-pattern differences be-tween French and English which are interpretable in terms of stress- vs. syllable-timing. Whereas English speakers appear to introduce an underly-ing, silent beat in order to regularize the timing of the repeated phrases at foot level, French speakers do not. This is interpretable as a sensitivity to foot-based structuring in English speakers and an inability in French speak-
DELTA-V
150125100755025
DE
LTA
-C
100
90
80
70
60
50
40
30
Bu2Bu2Bu2Bu1
Bu1
Bu1Ba2
Ba2
Ba2
Ba1
Ba1
Pi
Pi
Pi
Na
Na
Na
Gsp
Gsp
Gsp
Gr
Gr
Gr
PVI-V
656055504540
PV
I-C
120
90
60
30
Bu2Bu2Bu2
Bu1Bu1
Bu1
Ba2
Ba2
Ba2
Ba1
Ba1
Pi
Pi
Pi
Na
Na
Na
Gsp
Gsp
Gsp
Gr
Gr
Gr

108 William J. Barry
ers to structure the utterance rhythmically above the syllable level. The question arises, however, whether the “isochronic tendency” that is observ-able across phrases when they are repeated – akin to Abercrombie's silent stressed syllable in “__ ’kyou” (observed in repeated “Thank you” utter-ances, e.g. by a bus conductor, cf. Abercrombie 1967: 36) – corresponds to a need to regularize “feet” or “stress units” within a phrase.
To summarize the attempts to pigeonhole Rhythm in linguistic terms over the past half-century, it is true to say that the many “isochrony” stud-ies have looked for something measurable that is immediately relatable to “regularly repeated beats”. They have attempted (in vain) to verify instru-mentally the original auditory observations by skilled phoneticians about contrasting “rhythmic” impressions of a small number of languages (origi-nally only two). Since the 1980s, structural differences between languages have been moved into focus, and the thrust of work has been to identify differences between languages which conspire in one but not in the other group of languages to prevent the syllables in an utterance from occurring at equal intervals. Some are based in the segmental structure, like vocalic quantity oppositions or variable syllable complexity; others are observa-tions of prosodic behaviour, like the tendency, or lack of it (a) to reduce the duration and spectral distinctiveness of unstressed syllables between ac-cented ones and (b) to compensatorily shorten accented syllables as a func-tion of the number of unstressed syllables following. The instrumental measures associated with this theoretical view (summarized above) have indeed shown that languages can be differentiated, and that they appear to divide up into groups containing languages that have traditionally been described as syllable-timed or stress-timed. However, the wide range of values across languages belonging to the “same” rhythmic group, the as-sumption of “mixed” rhythm types, and the conflicting positioning of the same language from one study to another within the language selection examined cast doubt both on the validity and on the “rhythmic” basis of the distinctions.
3.3. Rhythm in L2
In connection with the teaching and acquisition of a correct Rhythm in a foreign-language, the first question could well be whether the discussion so far has any relevance at all?

Rhythm as an L2 problem: How prosodic is it? 109
Most teachers probably associate the idea of Rhythm with the regular beats discussed and rejected as a normal phenomenon in non-poetic speech (section 3.1). A well-established German programme (for young French learners) which makes explicit use of Rhythm as an integral part of teach-ing active speech production (Andreas Fischer: www.phonetik-atelier.de) in fact uses rhythmic movement, simple rhythm instruments and silent beats to help young French learners of German to produce regular accent inter-vals and avoid the perceptually much more equal weight attached to con-secutive syllables in French. On the other hand, a more complex and ana-lytic view of rhythm in speech production is presented by Stock & Veličkova (2002, cf. also Veličkova 1990, 1993). Equally concerned with the practicalities of teaching and learning (with the focus on adult learners), they acknowledge the persistence of isochrony as the established view while discussing the possible bi-directional interpretation of Rhythm a) as the determinant of the segmental and prosodic properties associated with the rhythm-typology divisions and b) as the product of those properties (cf. also Krull and Engstrand 2003). The use in teaching of gestural support for segmental properties which affect the overall prosodic pattern of a phrase (e.g. vowel length in stressed syllables, cf. Veličkova 1990, 1993) under-lines the recognition that properties from all levels of language structure contribute to a gestalt-like experience of Rhythm in an utterance. They consequently deal with rhythmic patterns of phrases, both as stand-alone expressions and sequenced within texts, which reflect the lexical stress patterns of the words used and the information weighting of those words within the context. The question of isochrony in stress-timed languages hardly arises because many phrases, even within a longer text, do not ex-ceed two accents – even if they contain more than two accentable words. The example given by Stock and Veličkova (2002: 29) may serve as illus-tration of how the number of accents can vary for a given word sequence:
// manche kol / legen / wissen das aber / nicht // 0 0 X 0 X 0 X 0 X X X 0 X X X X
(The accents, marked with X, can vary from one to four. Only the fourth variant, with all four feet accented, deviates from the default nuclear posi-

110 William J. Barry
tion (wissen). Isochrony is testable in the fourth, and in the third variant in a more limited way by excluding the last foot from the metrical frame)
Putting it at its simplest and most extreme, we can say: Every utterance has its own particular “Rhythm-pattern”, determined by the relative com-municative weight attributed (by the particular speaker) to the particular words within the particular syntactic structure within the particular com-municative context. We thus define Rhythm as the situation- and utterance-dependent pattern of prominences and shall use the term “prominence pat-tern” instead of Rhythm from now on.
This information-based view allows for a considerable amount of varia-tion in the “rhythmic” realisation of any given sequence of words, and un-derlines the importance of the teaching maxim that nothing should be taught without contextualisation. However, given the situation and the lin-guistic pre-context, and a not-too-eccentric speaker, the actual degree of freedom is much smaller. The choice of which and how many words to make communicatively prominent, as well as the relative prominence of the accented words are fairly strictly delimited. Figure 6 shows the tight sylla-ble-duration clustering for the main accents in the sentence “Heute morgen bin ich zu spät aufgestanden” (I got up too late this morning) spoken in an unmarked manner, as if introducing a story. For the unaccented words there is more individual variation.
In unaccented multi-syllabic words, the lexical-stress pattern for cita-tion-form production can disappear, be dynamically (but not tonally) re-tained, or even shifted, depending on the language (e.g. its status within traditional rhythm-typology classes). Above all, the treatment of unstressedsyllables will depend on the language, though in spontaneous speech, the occurrence of elision and assimilation phenomena, particularly at word boundaries appears to cut across traditional rhythm-typology differences (Barry and Andreeva 2001). However, the general observation which is supposed to separate “stress-timed” from “syllable-timed” languages, namely the tendency to reduce unstressed syllables in the latter and to re-tain the full phonetic identity in the former, certainly has some language-differentiating validity. But they do not all behave in the same way. As a comparison of English, Bulgarian, Russian on the one hand with German, Dutch, Swedish on the other – all of them “reducing” languages – will show: there are very different forms and degrees of reduction. Dutch, Eng-lish, German and Swedish reduce the quantity of long vowels in unstressed position, but only English has systematic quality reduction of the vowels (towards schwa). Bulgarian and Russian do not have a long-short vowel
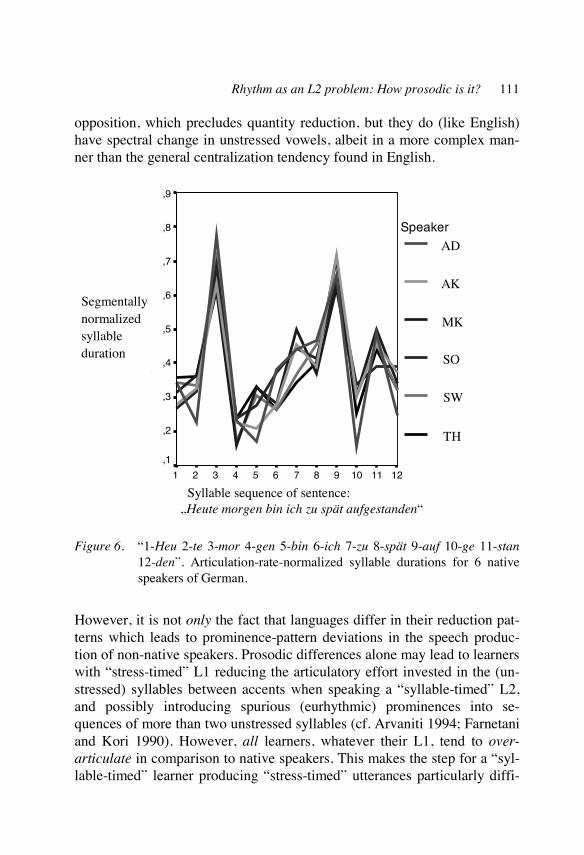
Rhythm as an L2 problem: How prosodic is it? 111
opposition, which precludes quantity reduction, but they do (like English) have spectral change in unstressed vowels, albeit in a more complex man-ner than the general centralization tendency found in English.
Figure 6. “1-Heu 2-te 3-mor 4-gen 5-bin 6-ich 7-zu 8-spät 9-auf 10-ge 11-stan12-den”. Articulation-rate-normalized syllable durations for 6 native speakers of German.
However, it is not only the fact that languages differ in their reduction pat-terns which leads to prominence-pattern deviations in the speech produc-tion of non-native speakers. Prosodic differences alone may lead to learners with “stress-timed” L1 reducing the articulatory effort invested in the (un-stressed) syllables between accents when speaking a “syllable-timed” L2, and possibly introducing spurious (eurhythmic) prominences into se-quences of more than two unstressed syllables (cf. Arvaniti 1994; Farnetani and Kori 1990). However, all learners, whatever their L1, tend to over-articulate in comparison to native speakers. This makes the step for a “syl-lable-timed” learner producing “stress-timed” utterances particularly diffi-
Syllable Sequence
121110987654321
Nor
mal
ised
Syl
labl
e/S
egm
ents
,9
,8
,7
,6
,5
,4
,3
,2
,1
Speaker
ad
ak
mk
so
sw
th
AD
AK
MK
SO
SW
TH
Segmentallynormalized syllable duration
Syllable sequence of sentence: „Heute morgen bin ich zu spät aufgestanden“
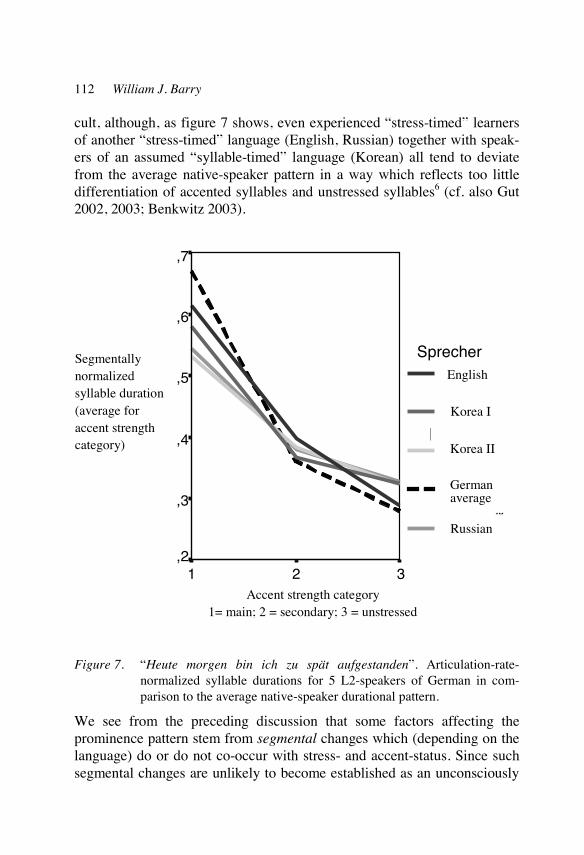
112 William J. Barry
cult, although, as figure 7 shows, even experienced “stress-timed” learners of another “stress-timed” language (English, Russian) together with speak-ers of an assumed “syllable-timed” language (Korean) all tend to deviate from the average native-speaker pattern in a way which reflects too little differentiation of accented syllables and unstressed syllables6 (cf. also Gut 2002, 2003; Benkwitz 2003).
Figure 7. “Heute morgen bin ich zu spät aufgestanden”. Articulation-rate-normalized syllable durations for 5 L2-speakers of German in com-parison to the average native-speaker durational pattern.
We see from the preceding discussion that some factors affecting the prominence pattern stem from segmental changes which (depending on the language) do or do not co-occur with stress- and accent-status. Since such segmental changes are unlikely to become established as an unconsciously
Accent Strength
SpeakerEnglish
Korea 1
Korea 2
German average
Akzentklasse
321
,7
,6
,5
,4
,3
,2
Sprecher
bb
kh-a
kh-b
D. Mittelw.
ot
Segmentally normalized syllable duration(average for accent strength category)
Accent strength category 1= main; 2 = secondary; 3 = unstressed
English
Korea I
Korea II
Germanaverage
Russian

Rhythm as an L2 problem: How prosodic is it? 113
absorbed corollary of explicit, holistic rhythmic speaking practice (even with young French children), they need to be dealt with specifically. Indeed (taking English as an example), (i) weak forms, (ii) final voiced consonants (with their longer preceding vowels), (iii) vowel-length and -quality con-trasts, (iv) consonant-cluster reductions at word-boundaries etc. are all ac-cepted points of pronunciation practice, whether the learner comes from an assumed “syllable-timed” or from a “stress-timed” language. The thesis postulated here is that the sum of these (essentially segmental) properties are the determining features of an acceptable (prosodic) prominence pat-tern. Introducing the concept of foot-based isochrony (i.e. rhythmic regu-larity) on top of all these syllable-realization exercises is not only unneces-sary, but also induces an element of stylization and artificiality which, if it actually becomes established in the learners’ production patterns, will have to be unlearned again.
4. Conclusions
The assumption behind our discussion has been that the goal of pronuncia-tion teaching is to make the learners aware of the nature of the task they have to practise. With regard to the Rhythm concept, awareness is most easily linked to the idea of isochrony, i.e. to a regular beat, traditionally considered to characterize so-called “stress-timed” languages (a regular beat of accented syllables) and “syllable-timed” languages (a regular syl-labic beat). We maintain, however, that this is both unhelpful and mislead-ing in the L2 teaching environment.
Richard Cauldwell’s (2002: 1) recent summing up of the situation corre-sponds very much to the view we have tried to present in this paper:
Although the formal events of speech – phones, strong and weak syllables, words, phrases – occur ‘in time’ (they can be plotted on a time line) they do not occur ‘on time’, (they do not occur at equal time intervals). English is not stress-timed, French is not syllable-timed. The rare patches of rhythmi-cality are either ‘elected’ – as in scanning readings of poetry and the utter-ing of proverbs – or ‘coincidental’ – the side-effects of higher order choices made by speakers. Coincidental rhythmicality is most likely to occur where there are equal numbers of syllables between stresses. In spontaneous speech, the speaker’s attention is on planning and uttering selections of

114 William J. Barry
meaning in pursuit of their social-worldly purposes, and this results in an ir-rhythmic norm which aids comprehension.
Ulrike Gut (2003) retains the term “rhythmical” in her study of prosodic behaviour in a number of different learner-groups' production of L2 Ger-man. However, operationally, she breaks Rhythm down into durational and metrical characteristics, the latter being defined as the relative prominenceof units such as syllables. It is debatable whether prominence can, ulti-mately, be separated from duration (cf. Kochanski et al. 2005, however, who consider “loudness” separately from “duration” as determinants of prominence) but this is irrelevant for teaching purposes. It is important that individually learnable properties of language be brought into focus – in-formationally important (prominent) words, informationally less important words (and syllables within multi-syllabic words), long and short vowels, spectrally reduced vowels, consonant elision, etc. The contextualized intro-duction and practice of these properties in an optimal sequence is, of course, a non-trivial task. But their command will lead to a globally correct prosody and, in time, to a sense of prosodic “rightness” for the particular communicative intention in the same way that learning verb or noun mor-phology and syntactic regularities will lead to a command of the correct form and sequence of words. In neither of these areas would one think of introducing teaching points by appealing to a sense of “Morphology” or “Syntax”. We suggest that the appeal to a general idea of “Rhythm” which is abstracted from the prominence pattern of the particular utterance is equally unproductive.
The implication of the message conveyed by this discussion will no doubt annoy those teachers who would like a lot of different pronunciation problems to be covered by one “rhythmic blanket”. But the facts remain: Prosodic differences between languages – and our discussion leads to the conclusion that correct Rhythm is the sum of the communicatively correct (i.e. contextually and situationally correct) prosodic properties – are dis-tributed over all levels of phonetic-phonological structure. Correct pronun-ciation cannot emerge from an appeal to an undefined blanket term. Knowledge and treatment of individual problems remains essential.
The articulation of individual sound, which can be “new sounds” (like /y/ for English speakers or / , / for German speakers), combinations of familiar sounds (like /kn/ for English speakers) or combinations of new with familiar sounds (alveolar non-sibilants followed by dental fricatives for most learners of English) and new distributional patterns (like final

Rhythm as an L2 problem: How prosodic is it? 115
voiced consonants for Germans) lead to a slowing down of articulatory processes in their vicinity, which inevitably affects the overall prosodic pattern. Direct prosodic repercussions arise from differences in length op-positions between languages (whether L1 and L2 both have long and short vowels or long and short consonants) and intra-syllabic phonetic length relations (e.g. long consonants following short vowels and vice versa, as is the case in Swedish). Thus we see that a considerable amount of segmen-tally orientated pronunciation work, assuming that it is satisfactorily con-textualized, contributes to rhythmically correct speech.
At the level of prosodic or pronunciation practice, correct word-stress location is an obvious and fundamental contributor to the correct rhythmic identity of an utterance. But, as we identified in the discussion, even with correct stress location, the phonetic means of realizing the stress can be different from one language to another and thus distort the rhythmic im-pression. In Italian, for example, the vowels in open syllables are length-ened when stressed, and even more lengthened when given a topical or focal accent. This leads to the well known rhythmic distortions of Italian speakers of other languages, but is, of course, also the source of rhythmic distortion for learners of Italian. French is also a language that exploits a large degree of syllabic lengthening for the informational or affective weighting of words at utterance level (despite the fact that, phonologically, French has neither phonemic vowel length distinctions nor word-stress).
It must be clear from this short selection of rhythm-distorting problems that a global appeal to language rhythm as “stress-timed” or “syllable-timed” is of no advantage. This does not mean, however, that learners of French should not be made aware of the fact that (outside the topical, focal or emphatic accents) syllables are all given as equal weight as possible, and vowels are not reduced (a statement often associated with “syllable-timing”). Nor does it mean that learners of English should not be made to practise the reduction and temporal compression of unstressed and unac-cented syllables in words and phrases (a statement often associated with “stress-timing”). It does mean that teachers need to be aware of a lot more differences between the respective L1s and L2s, of the problems that contribute to incorrect pronunciation in general, and to the incorrect rhythmic impression of utterances in particular.

116 William J. Barry
Notes
1. In fact it is so difficult that many teachers neglect pronunciation because their own awareness has lagged way behind their expertise in other areas such as grammar and vocabulary. These have the advantage of being capturable in a permanent form – in writing – for post hoc consideration.
2. We use the word Rhythm throughout the paper (with a capital R) for the term we are discussing and calling in question as an independently identifiable phe-nomenon.
3. A universal ability to register tonal differences and types of tonal movement in speech should not be taken for granted, even if the universal ability (for the non-handicapped) to communicate with speech might make us assume it. How absolutely necessary the decoding of tonal structure is for successful (contextu-alized) speech communication has not been investigated, and tonal structure is accompanied by several other signal properties, as we have already shown in figs 1 and 2. This suggests the possibility of compensatory decoding, i.e., mak-ing use of other than tonal properties for speaker-hearers insensitive to tone.
4. The fig. 2b version implies that the speaker is confirming that the fact of the other person’s agreement corresponded to his/her (i.e. the speaker’s) assump-tion. The fig. 4 version implies that the speaker’s previous assumption of agreement by the other person might not be true; it expresses some degree of protest.
5. Quoted from Abercrombie (1967), p. 171, endnote 7. 6. The three accent-strength categories over which syllable durations were calcu-
lated are: (i) tonally prominent accented syllables, (ii) unaccented syllables without vocalic reduction and (iii) unstressed syllables.
References
Abercrombie, David 1967 Elements of General Phonetics. Edinburgh: Edinburgh University
Press. Arvaniti, Amalia 1994 Acoustic features of Greek rhythmic structure. Journal of Pho-
netics 22, 239–268. Barry, William and Bistra Andreeva 2001 Cross-language similarities and differences in spontaneous
speech patterns. Journal of the International Phonetic Associa-tion 31, 51–66.

Rhythm as an L2 problem: How prosodic is it? 117
Barry, William, Bistra Andreeva, Michela Russo, Snezhina Dimitrova and Tania Kostadinova
2003 Do rhythm measures tell us anything about language type? Pro-ceedings of 15th International Congress of Phonetic Sciences, Barcelona, Vol. 3, 2693–2696.
Benkwitz, Anneliese 2004 Kontrastive phonetische Untersuchungen zum Rhythmus. (Hall-
esche Schriften zur Sprechwissenschaft und Phonetik 14). Frank-furt am Main etc.: Peter Lang.
Bertinetto Pier Marco 1981 Strutture prosodiche dell’italiano. Firenze: Accademia della
Crusca. 1989 Reflections on the dichotomy ‘stress’ vs. ‘syllable-timing’. Revue
de Phonétique Appliquée 91-92-93, 99–130. Bertinetto, Pier Marco and Carol Fowler 1989 On the sensitivity to durational modifications in Italian and En-
glish. Revista di Linguistica 1, 69–94. Bloch, Bernard 1950 Studies in colloquial Japanese IV: Phonemics. Language 26, 86–
125. Cauldwell, Richard 2002 The functional irrhythmicality of spontaneous speech: A dis-
course view of speech rhythms. Applied Language Studies: Ap-ples 2,1, 1–24.
Crowder, Robert G. and John Morton 1969 Precategorical acoustic storage (PAS). Perception and Psycho-
physics 5, 363–73.Crowder, Robert G. 1993 Short-term memory: Where do we stand? Memory and Cognition
21, 14–145. Cummins, Fred and Robert F. Port 1998 Rhythmic constraints on stress timing in English. Journal of
Phonetics 26, 145–171. Cutler, Anne, Jacques Mehler, Dennis G. Norris and Juan Seguí 1986 The syllable’s differing role in the segmentation of French and
English. Journal of Memory and Language 25, 385–400. Cutler, Anne and Takashi Otake 1994 Mora or phoneme? Further evidence for language-specific listen-
ing. Journal of Memory and Language 33, 824–844.

118 William J. Barry
Cutler, Anne 1997 The syllable’s role in the segmentation of stress languages. Lan-
guage and Cognitive Processes 12, 839–845. Cutler, Anne, Lalita Murty and Takashi Otake 2003 Rhythmic similarity effect in non-native listening? Proceedings
of the 15th International Congress of Phonetic Sciences, Barce-lona, Vol. 1, 29–332.
Dauer, Rebecca M. 1983 Stress-timing and syllable-timing reanalyzed. Journal of Phonet-
ics 11, 51–62. 1987 Phonetic and phonological components of language rhythm.
Proceedings of the 11th International Congress of Phonetic Sci-ences, Tallinn (Estonia), Vol. 5, 447–450.
Dellwo, Volker and Petra Wagner 2003 Relations between language rhythm and speech rate. Proceedings
of the 15th International Congress of Phonetic Sciences, Barce-lona, Vol. 1, 471–474.
Dellwo, Volker, Ingmar Steiner, Bianca Aschenberner, Jana Dankovičová and Petra Wagner
2004 The BonnTempo-Corpus & BonnTempo-Tools: A database for the study of speech rhythm and rate. Proceedings of the 8th Inte-national Congress of Speech and Language Processing. ICSLP, Jeju Island (Korea), 777–780.
Engstrand, Olle and Diana Krull 2001 Simplification of phonotactic structures in unscripted Swedish.
Journal of the International Phonetic Association 31, 41–50. Farnetani, Edda and Shiro Kori 1990 Rhythmic structure in Italian noun phrases: A study on vowel
duration. Phonetica 47, 50–65. Gelder, Beatrice de and Jean Vroomen 1997 Modality effects in immediate recall of verbal and non-verbal
information. European Journal of Cognitive Psychology 9(1), 97–110.
Grabe, Esther and EeLing Low 2002 Durational variability in speech and the rhythm class hypothesis.
In: Carlos Gussenhoven and Natasha Warner (eds.) Papers in Laboratory Phonology VII, 515–546, Berlin, New York: Mouton de Gruyter.
Gibbon, Dafydd and Ulrike Gut 2001 Measuring speech rhythm. Proceedings of Eurospeech 2001,
Aalborg (Denmark), 91–94.

Rhythm as an L2 problem: How prosodic is it? 119
Gibbon, Dafydd 2003 Computational modelling of rhythm as alternation, iteration and
hierarchy. Proceedings of the 15th International Congress of Phonetic Sciences, Barcelona, Vol. 3, 2489–2492.
Gut, Ulrike 2003 Prosody in second language speech production: the role of the
native language. Zeitschrift für Fremdsprachen Lehren und Ler-nen 32, 133–152.
Hazan, Valerie 2002 L'apprentissage des langues. Proceedings of XXIVemes Journees
d'etude de la parole, Nancy, 1–5. Hoequist, Charles J. 1983a Durational correlates of linguistic rhythm categories. Phonetica,
40, 19–31. 1983b Syllable duration in stress-, syllable- and mora-timed languages.
Phonetica 40, 203–237. Kallman, Howard J. and Dominic W. Massaro 1983 Backward masking, the suffix effect, and preperceptual storage.
Journal of Experimental Psychology: Learning, Memory, and Cognition 9, 312–327.
Kochanski, Greg, Esther Grabe, John Coleman and Bert Rosner 2005 Loudness predicts prominence: fundamental frequency lends
little. Journal of the Acoustical Society of America 118, 1038–1054.
Krull, Diana and Olle Engstrand 2003 Speech rhythm – intention or consequence? Cross-language ob-
servations on the hyper-hypo dimension. PHONUM 9, 133–136. Ladefoged, Peter 1975 A Course in Phonetics. New York: Harcourt Brace Jovanovich. Lloyd James, Arthur 1940 Speech Signals in Telephony. London: Sir I. Pitman & Sons. Markham, Duncan 1997 Phonetic Imitation, Accent, and the Learner. Lund: Lund Univer-
sity Press. Massaro, Dominic W. 1972 Preperceptual images, processing time, and perceptual units in
auditory perception. Psychological Review 79,124–145. Mehler, J., J.-Y. Dommergues, U. Frauenfelder and J. Seguí 1981 The syllable’s role in speech segmentation. Journal of Verbal
Learning and Verbal Behaviour 20, 298–305.

120 William J. Barry
Otake, Takashi, Giyoo Hatano, Anne Cutler and Jacques Mehler 1993 Mora or syllable? Speech segmentation in Japanese. Journal of
Memory and Language 32, 358–378. Palmeri, Thomas J., Stephen D. Goldinger and David B. Pisoni 1993 Episodic encoding of voice attributes and recognition memory
for spoken words. Journal of Experimental Psychology: Learn-ing, Memory, and Cognition 19, 309–328.
Pike, Kenneth L. 1946 The Intonation of American English. Ann Arbor: University of
Michigan Press. Quené, Hugo and Robert F. Port 2005 Effects of timing regularitiy and metrical expectancy on spoken-
word perception. Phonetica 62, 1–13. Ramus, Franck, Marina Nespor and Jacques Mehler 1999 Correlates of linguistic rhythm in the speech signal. Cognition
73, 265–292. Roach, Peter 1982 On the distinction between “stress-timed” and “syllable-timed”
languages. In: David Crystal (ed.), Linguistic Controversies, 73–79, London: Edward Arnold.
Steiner, Ingmar 2005 On the analysis of speech rhythm through acoustic parameters.
In: Bernhard Fisseni, Hans-Christian Schmitz, Bernhard Schröder and Petra Wagner (eds.) Sprachtechnologie, mobile Kommunika-tion und linguistische Ressourcen: Beiträge zur GLDV-Tagung 2005 in Bonn. (Computer Studies in Language and Speech 8). 647–658, Frankfurt/Main: Peter Lang.
Stock, Eberhard and Ludmila Veličkova 2002 Sprechrhythmus im Russischen und Deutschen. (Hallesche
Schriften zur Sprechwissenschaft und Phonetik 8), Frankfurt/M.: Peter Lang.
Veličkova, Ludmila 1990 Untersuchungen zur Theorie und Praxis des Phonetikunterrichts.
Habilitationsschrift, Halle. 1993 Die Vermittlung phonologischer Distinktionen mit einem Ges-
tensystem. Deutsch als Fremdsprache 30, 253–258. Wagner, Petra and Volker Dellwo 2004 Introducing YARD (Yet Another Rhythm Determination) and re-
introducing isochrony to rhythm research. Proceedings of Speech Prosody, Nara (Japan 227–230.
),

Temporal patterns in Norwegian as L2
Wim A. van Dommelen
1. Introduction
One of the fundamental properties of spoken language is that it, like all physical events, extends over time. Consequently, much of the last decades’ research in phonetics has been devoted to the investigation of the temporal organization of speech. An issue that has evoked much debate and stimu-lated empirical research is concerned with rhythmical differences between languages. For a discussion of the traditional classification of languages into stress-timed, syllable-timed and mora-timed, see Barry (this volume; cf. also Dauer, 1983). In spite of numerous research efforts devoted to is-sues of speech timing in general and of language-specific timing in particu-lar, our knowledge and understanding are far from complete. This is true for temporal aspects of language spoken by native speakers (L1 speech) and, even more so, for L2 speech.
The approach chosen for the present study is to analyze temporal as-pects of Norwegian as a second language spoken by speakers from various language backgrounds in comparison with native Norwegian. The rationale behind this is that we hope to obtain information not only about what devia-tions from the L1 standard occur but also whether such deviations pattern in language-specific ways. Our study consists of two main parts. Following the description of the collection of subjects, speech material and segmenta-tion in Section 2, the first part (Section 3) deals with the temporal structure of dyads consisting of a vowel followed by a consonant. A special property of the Norwegian phonological system is the quantity system which in-volves not only the vowels but also the consonants. In a stressed syllable, the vowel can be either short or long while unstressed syllables only can contain short vowels. Consonants in stressed syllables have a complemen-tary distribution of duration, being long after a short vowel (e.g. in matte[ ] ‘mat’) and short following a long vowel (e.g. in mate [ ]‘[to] feed’). The phonological specification of the VC: vs. V:C opposition has been subject of some debate, the question being whether we are dealing with a vowel or a consonant quantity opposition (cf. Kristoffersen, 2000:

122 Wim A. van Dommelen
116–120). From a phonetic viewpoint it seems reasonable to argue that the vowel is the carrier of the quantity opposition. Previous investigations have shown that the ratio V:/V is considerably larger than the C:/C ratio. Fintoft (1961) measured vowel and consonant durations in isolated Norwegian logatomes. He reported a V:/V ratio of approximately 1.9 (varying between 1.7 and 2.1 depending on the nature of the following consonant as a frica-tive, nasal or liquid). In contrast, the duration ratio of medial long vs. short consonants amounted only to approximately 1.3 (varying between 1.2 and 1.4). Quite similar relations were found by Behne, Moxness and Nyland (1996) through their measurements of the durations of long and short vow-els preceding voiced and voiceless plosives in Norwegian sentence-embedded words. From the data presented in their Figure 1, average dura-tion ratios (pooled across voiced and voiceless plosives) of 1.8 and 1.3 can be calculated for V:/V and C:/C, respectively. Also, results on the percep-tion of a long vs. short vowel followed by a voiceless stop by van Dom-melen (1999a) suggest that vowel duration is a far more important cue for the perception of vowel quantity than the consonant (cf. also Krull, Traun-müller and van Dommelen, 2003).
In our study we thus address the question of how users of Norwegian as a second language realize the VC: and V:C dyads. A point of particular interest will be the kind and amount of variation in the L2 productions. If the variation in vowel and consonant durations is relatively limited, we might be able to detect deviation patterns that are characteristic for L2 user groups from specific language backgrounds. Larger variation, on the other hand, could obscure such possible patterns and render it difficult to draw firm conclusions about typical deviations from Norwegian reference values and differences between the realizations from the L2 speaker groups.
The second part of our investigation (Section 4) is concerned with speech rhythm in L2 compared with L1 speech. In recent studies attempts have been made to classify languages according to rhythmical categories using various metrics. To investigate rhythm characteristics of eight lan-guages, Ramus, Nespor and Mehler (1999) calculated the average propor-tion of vocalic intervals and standard deviation of vocalic and consonantal intervals over sentences. Though their metrics appeared to reflect aspects of rhythmic structure, also considerable overlap was found. Grabe’s Pairwise Variability Index (PVI; see Section 4.1) is a measure of differences in vowel duration between successive syllables and has been used by, e.g., Grabe and Low (2002), Ramus (2002) and Stockmal, Markus and Bond (2005). In order to achieve more reliable results Barry et al. (2003) pro-

Temporal patterns in Norwegian as L2 123
posed to extend existing PVI measures by taking consonant and vowel in-tervals together. In her 2003 study Gut compared the speech of learners of German with English, Chinese and Romance languages as L1 with the speech of two native speakers of German. For utterances produced by these speakers she used a Rhythm Ratio (RR) to explore the temporal organiza-tion of subsequent syllables. Though the Romance language speakers pro-duced syllables that tended to be of more similar duration than those from the German speakers, the difference did not achieve statistical significance. Also the RR values for the English and Chinese subjects did not differ sig-nificantly.
The present study approaches the issue of language-specific speech rhythm indirectly by comparing the temporal structure of L2 utterances with similar utterances produced by native speakers. More specifically, we will use different measures derived from the sequences of syllables in utter-ances and use a discriminant analysis to explore whether those measures can be related to the different L2 groups investigated. For the present pur-poses, the main function of a discriminant analysis is the following. The first step is to define a number of variables (here mean syllable duration, durational differences between consecutive syllables, etc.; a complete de-scription is given in Section 4.1). Secondly, these variables are entered into the analysis together with an a priori classification which in our case repre-sents the six different groups of L2 users. The discriminant analysis then uses the variables to classify the input data into groups, importantly without any prior information about the predefined groups. The output of the analy-sis tells the user which of the variables entered into the analysis contributed significantly to the statistical grouping. The most interesting question for us is to see to which degree the purely statistical grouping of the data is in congruence with the user-defined classification according to L2 user groups. A reasonably large degree of agreement between the two classifica-tions will indicate that the chosen measures capture relevant aspects of L1-influenced speech rhythm.
2. Subjects, speech material and segmentation
A total of 37 subjects served as speakers in this study, divided into the fol-lowing seven groups. There were six second language speaker groups with the following L1s (number of speakers in parentheses): Chinese (7), Eng-lish (4), French (6), German (4), Persian (6) and Russian (4). In an attempt

124 Wim A. van Dommelen
to collect speakers having approximately the same level of proficiency in Norwegian, most of the speakers were recruited from a Norwegian course offered at the Department of Language and Communication Studies (NTNU, Trondheim). Six native speakers of Norwegian served as a control group.
The speech material used was chosen from existing recordings made for the Language Encounters project (see Acknowledgement). The recordings have been made in the department’s sound-insulated studio and were sub-sequently stored with a sampling frequency of 44.1 kHz. The material comprises readings of a short text, 120 different sentences and some spon-taneous speech. Since the sentences have been designed to contain all the Norwegian phonemes and relevant VC: and V:C dyads, this part of the material was considered most suited for a systematic investigation and, therefore, a number of sentences has been selected for the present study.
For the first part of our investigation, eight different sentences were chosen containing words with the short vowels /a/ and /ø/ (two sentences each) and their long counterparts /a:/ and /ø:/ (two sentences each) all fol-lowed by the voiceless plosive /t/. For the second part, ten different sen-tences were selected containing between 9 and 15 syllables (mean of 12.2 syllables). The total number of utterances investigated was thus 37 (subjects) x 8 (utterances) = 296 for the first part, and 37 x 10 = 370 for the second part.
The segmentation of the speech material was done by visual and audi-tory inspection of the waveform and the spectrogram of the speech signal using Praat (Boersma and Weenink, 2006). Figure 1 shows an example of how vowel and consonant durations were measured for part 1. The test word under scrutiny is møtte ([ ] ‘met’). Determining the starting point of the VC: dyad (the transition from the nasal to the vowel) is a rela-tively straight-forward task. The end of the dyad was set at the beginning of the schwa, i.e. at the end of the postaspiration. In contrast to these two points in time, defining the exact end of the vowel (= the start of the inter-vocalic plosive) is not a trivial task. The Norwegian speaker shown in the figure has produced preaspiration, the realization of which can vary but which is here characterized by a short vowel portion with breathy voice quality followed by a voiceless friction phase. Segmentation of the present speech material always followed the convention illustrated here, i.e. defin-ing preaspiration (if any) as the sum of the breathy part and the friction (both of which can be absent).
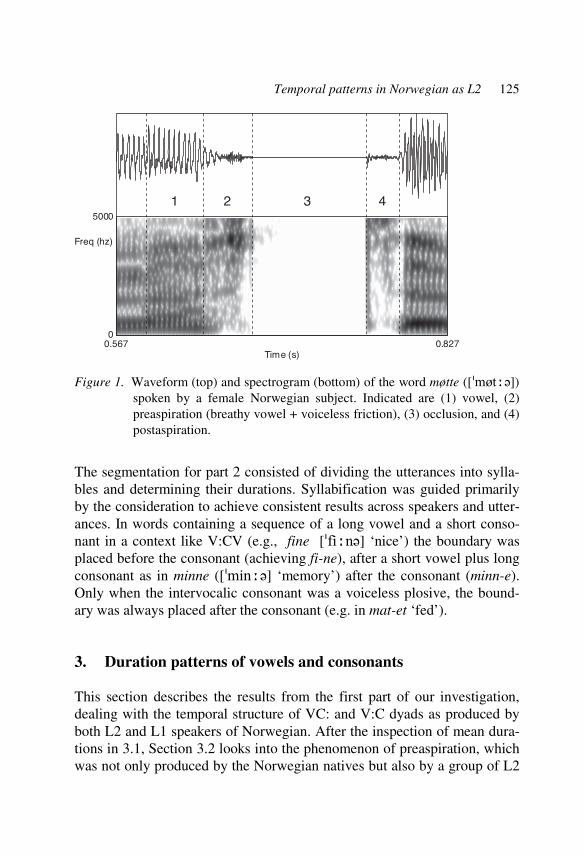
Temporal patterns in Norwegian as L2 125
0
5000
0.567 0.827Time (s)
Freq (hz)
1 2 3 4
Figure 1. Waveform (top) and spectrogram (bottom) of the word møtte ([ ]) spoken by a female Norwegian subject. Indicated are (1) vowel, (2) preaspiration (breathy vowel + voiceless friction), (3) occlusion, and (4) postaspiration.
The segmentation for part 2 consisted of dividing the utterances into sylla-bles and determining their durations. Syllabification was guided primarily by the consideration to achieve consistent results across speakers and utter-ances. In words containing a sequence of a long vowel and a short conso-nant in a context like V:CV (e.g., fine [ ] ‘nice’) the boundary was placed before the consonant (achieving fi-ne), after a short vowel plus long consonant as in minne ([ ] ‘memory’) after the consonant (minn-e). Only when the intervocalic consonant was a voiceless plosive, the bound-ary was always placed after the consonant (e.g. in mat-et ‘fed’).
3. Duration patterns of vowels and consonants
This section describes the results from the first part of our investigation, dealing with the temporal structure of VC: and V:C dyads as produced by both L2 and L1 speakers of Norwegian. After the inspection of mean dura-tions in 3.1, Section 3.2 looks into the phenomenon of preaspiration, which was not only produced by the Norwegian natives but also by a group of L2

126 Wim A. van Dommelen
users. In Section 3.3 the problem of variation is dealt with and it is argued that the interpretation of the empirical data to a large degree depends on the perspective chosen for the evaluation.
3.1. Mean vowel and consonant durations
Figure 2 depicts mean segment durations for VC: (Figure 2a) and V:C (Figure 2b) dyads as produced by the six groups of L2 users and the Nor-wegian control group. As the first thing of note for the latter group we ob-served a relatively long preaspiration (breathy vowel + friction) in both VC: (35 ms) and V:C (29 ms). Traditionally, the occurrence of preaspira-tion is considered to be restricted to a few dialectal variants, our present speakers (having dialect backgrounds from South-East Norwegian and the Trøndelag region) not belonging to them. Our data therefore suggest that preaspiration occurs more frequently in Norwegian than usually is assumed and they confirm similar findings from previous studies (van Dommelen, 1999b). Further, calculation of duration ratios for V:/V and C:/C (where preaspiration is included in the consonant) achieved values of 2.24 and 1.19, respectively. Fintoft’s (1961) material did not include postvocalic stops (see Section 1) so that a direct comparison with his results is pre-cluded. (In this connection it should be noted that preaspiration only occurs with voiceless stops.) By and large, Fintoft’s mean values of 1.9 for V:/V and 1.3 for C:/C can be said to be not too different. The same conclusion can be drawn concerning Behne, Moxness and Nyland’s (1996) ratios of 1.8 and 1.3 (averaged across voiced and voiceless plosives; see Section 1). In their description no mention is made of the occurrence of preaspiration such that their data are inconclusive in this respect.
As to the productions by the L2 speakers, Figure 2 shows that the devia-tions of the vowel and consonant durations from the L1 reference values are not as large as possibly expected. This is especially true for the V:C dyad. A more systematic pattern was found for the short vowel, which was produced with longer durations than the Norwegian mean value by all L2 speaker groups. To see how the second language users master the V:/V quantity opposition, let us compare their V:/V ratios with the value meas-ured for the reference group, which amounts to 2.24 (i.e., for V excluding preaspiration). While the German, English and Russian speakers had rela-tively high ratios (1.53, 1.38, and 1.38, respectively), the remaining groups (Chinese, French, and Persian) had less clear durational contrasts (values of

Temporal patterns in Norwegian as L2 127
0
50
100
150
200
250
300
350
Ch En Fr Ge Pe Ru No
Du
ratio
n (m
s)
C:
PA
V
0
50
100
150
200
250
300
350
Ch En Fr Ge Pe Ru No
Du
ratio
n (m
s)
C
PA
V:
(a) (b)
Figure 2. Mean segment durations (in ms) in words containing /a(:)/ and /ø(:)/ followed by a voiceless plosive spoken by different speaker groups (Chinese, English, French, German, Persian, Russian, and Norwegian). (a): V, preaspiration (PA) and C:; (b): V:, preaspiration, C.
1.07, 1.08, and 1.04, respectively). It may seem to be somewhat surprising that the Russian speakers pattern with the German and English groups though Russian lacks a vowel quantity/tenseness contrast as present in the L1s of the latter. An explanation could be sought in the Russian word stress system where vowels are lengthened when stressed (cf. Svetozarova 1998). This means that the speakers are at least familiar with conditioned vowel duration. In contrast to the apparently rather regular behaviour of the pre-sent Russian subjects, Markus and Bond (1999) report difficulties of Rus-sian talkers to employ duration as a correlate of vowel quantity in Latvian. Similarly, the Russian L2 speakers of Latvian in Bond, Markus and Stock-mal (2003) inappropriately produced short vowels with lengthening and failed to reach appropriate durations for long vowels. Prompted by these seemingly diverging results, we inspected our present data more closely. This inspection showed that the behaviour of the Russian speakers as a group is less appropriate after all. One of the subjects produced very long V: durations (mean value of 245 ms) while the other three Russian speakers produced much shorter durations (mean value of 113 ms). Given respective mean durations of 131 ms and 97 ms for the short vowels, the V:/V ratio was remarkably high for the former (1.87) and much lower for the latter (1.16). This result thus demonstrates the issue of variation within a group and so it may be worthwhile to have a closer look at the data and to investi-gate to what extent variation of individual segment durations can tell us more about L2 performance. Before doing this, however, we will focus on the transition of the vowel into the stop as produced by the English sub-jects, i.e. preaspiration.

128 Wim A. van Dommelen
3.2. Preaspiration
A detail deserving our attention is the fact that the speakers with an English background produced relatively strong preaspiration in both VC: and V:C context (with respective mean durations of 62 ms and 50 ms even longer than the productions of the Norwegian control group; 35 ms and 29 ms, respectively). For some other groups (French, German, Persian, and Rus-sian) short preaspiration portions were measured, but their short durations indicate that we are dealing with presumably physiologically conditioned transitions from the vowel into the stop. For the English speakers, however, the question is how to explain their substantial production of preaspiration. According to impressionistic observation, the proficiency in Norwegian pronunciation of this speaker group was not notably higher than for most of the other L2 groups. It seems, therefore, improbable that the English group had acquired the production of preaspiration through intensive learning and contact with Norwegian. According to occasional inspection of English speech material, preaspiration appears to occur in this language as well. Interestingly, the production of preaspiration seems to have gone unnoticed in the literature. At least, investigation of some textbooks on English pho-netics reveals that the feature of preaspiration is not mentioned and, there-fore, does not belong to the catalogue of relevant characteristics. For exam-ple, in her workbook on the pronunciation of English Kenworthy (2000) deals with aspiration, but not with preaspiration. The same is true for the introduction to phonetic science by Ashby and Maidment (2005). Lade-foged and Maddieson (1996:70–73) discuss the occurrence of the phe-nomenon preaspiration in well-known examples as Icelandic, Scottish Gaelic and Faroese but are silent on the (possible) production of preaspira-tion in English. Also the very detailed account of spoken English by Shockey (2003) only includes aspiration. Further, the absence of preaspira-tion (in contrast to postaspiration) in the textbook on English phonetics for Norwegian students by Davidsen-Nielsen (1996) suggests that this phe-nomenon does not have a very prominent position in practical phonetics in Norway. Based on the present results it might seem worthwhile for future research to have a closer look at the occurrence of preaspiration in English. It is not impossible that this feature plays a certain role in English speech sound production but until now has escaped our notice.

Temporal patterns in Norwegian as L2 129
3.3. The problem of variation
Inspection of mean segment durations can tell us a good deal about how second language users master the durational contrast long/short vowel in V:C vs. VC: dyads. But, as indicated above in Section 1, we will also have to take into account that individual tokens will to a lesser or larger extent vary round the mean. Rather differently distributed duration values can result in the same average. Table 1 gives one of the most usual measures describing dispersion, namely standard deviation (This measure was not included in Figure 2 in order to avoid overloading the picture). It can be seen from the table that the native speakers produced durations with rela-tively small variations (standard deviation for the vowels on average 15 ms, for the consonants 32 ms). For the group of L2 speakers as a whole higher values were found (pooled across the six groups 36 ms and 46 ms, respec-tively). Taking averages pooled across all four conditions of long/short vowel and long/short consonant as a measure, the German group was most consistent in their productions (mean standard deviation of 24 ms), while the mean values for the other groups were rather similar to each other (ly-ing between 42 ms for the French and 48 ms for the Chinese subjects). One might wonder whether this rather strong degree of similarity can be inter-preted as similar L2 behaviour or whether other perspectives could supply us with additional useful information.
Table 1. Standard deviations (in ms) for vowels and consonants in words con-taining /a(:)/ and /ø(:)/ followed by a voiceless plosive spoken by differ-ent speaker groups. n= number of tokens
Chinese English French German Persian Russian Norwegian
n 28 16 24 16 24 16 24
V: 48 26 37 20 36 67 20
C 45 62 44 20 45 23 28
V 38 27 25 30 41 38 10
C: 61 55 61 27 51 53 34
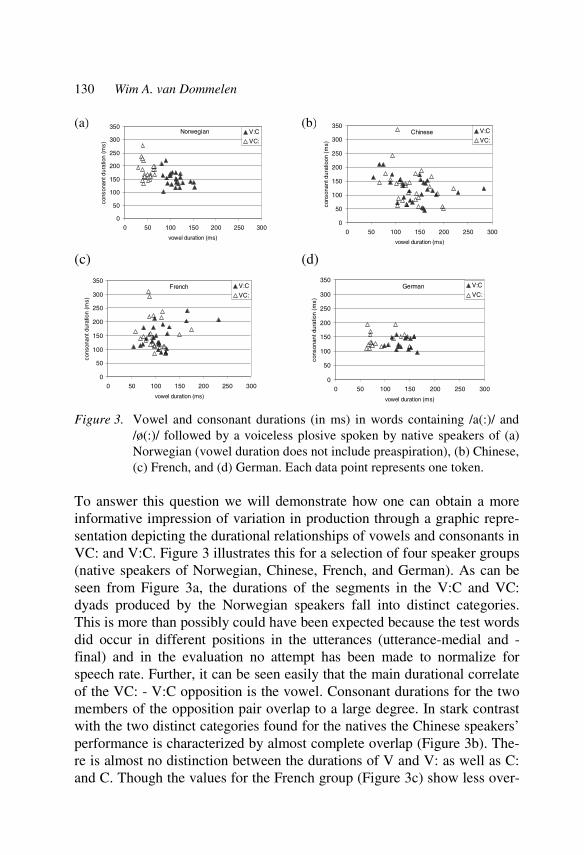
130 Wim A. van Dommelen
0
50
100
150
200
250
300
350
0 50 100 150 200 250 300
vowel duration (ms)
cons
onan
t dur
atio
n (m
s)
V:C
VC:German
(a) (b)
(c) (d)
Figure 3. Vowel and consonant durations (in ms) in words containing /a(:)/ and /ø(:)/ followed by a voiceless plosive spoken by native speakers of (a) Norwegian (vowel duration does not include preaspiration), (b) Chinese, (c) French, and (d) German. Each data point represents one token.
To answer this question we will demonstrate how one can obtain a more informative impression of variation in production through a graphic repre-sentation depicting the durational relationships of vowels and consonants in VC: and V:C. Figure 3 illustrates this for a selection of four speaker groups (native speakers of Norwegian, Chinese, French, and German). As can be seen from Figure 3a, the durations of the segments in the V:C and VC: dyads produced by the Norwegian speakers fall into distinct categories. This is more than possibly could have been expected because the test words did occur in different positions in the utterances (utterance-medial and -final) and in the evaluation no attempt has been made to normalize for speech rate. Further, it can be seen easily that the main durational correlate of the VC: - V:C opposition is the vowel. Consonant durations for the two members of the opposition pair overlap to a large degree. In stark contrast with the two distinct categories found for the natives the Chinese speakers’ performance is characterized by almost complete overlap (Figure 3b). The-re is almost no distinction between the durations of V and V: as well as C: and C. Though the values for the French group (Figure 3c) show less over-
0
50
100
150
200
250
300
350
0 50 100 150 200 250 300
vowel duration (ms)
cons
onan
t dur
atio
n (m
s)
V:C
VC:
Norwegian
0
50
100
150
200
250
300
350
0 50 100 150 200 250 300
vowel duration (ms)
cons
onan
t dur
atio
on (
ms)
V:C
VC:Chinese
0
50
100
150
200
250
300
350
0 50 100 150 200 250 300
vowel duration (ms)
cons
onan
t dur
atio
n (m
s)
V:C
VC:French

Temporal patterns in Norwegian as L2 131
lap, these speakers didn’t realize clearly distinct categories either. Pre-sumably due to the lack of a vowel quantity opposition in French both V and V: have relatively short durations. At the same time, consonant durati-on is not being used to distinguish between the two dyads. Finally, the German speakers (Figure 3d) handle the VC: - V:C distinction more like the Norwegian natives. In spite of a certain overlap in vowel durations, a certain tendency of distinguishing two categories can be noticed.
4. Quantification of rhythm
This section deals with the second part of our study of timing in L2 speech production, namely the question whether speakers from different language backgrounds produce different speech rhythms and whether typical rhyth-mical properties can be quantified. To that aim, Section 4.1 presents seven measures related to speech rhythm that have been used in a discriminant analysis. Section 4.2 presents the results for a central measure, mean sylla-ble duration. In the last section (4.3) the results of a discriminant analysis are presented showing that in fact aspects of speech rhythm can be captured by some of the measures presented here.
4.1. Definition of measures
To compare the temporal structure of the L2 utterances with the L1 refe-rence utterances, seven different types of measures were defined. In all cases calculations were related to each of the seven groups of speakers as a whole. The first measure was syllable duration averaged over all syllables of each utterance, yielding one mean syllable duration for each sentence and each speaker group, i.e. 7 (groups) x 10 (utterances)= 70 mean syllable durations in total (For all measures used in the discriminant analysis the total number of observations is n= 70). Second, the standard deviation for the syllable durations pooled over the speakers of each group was calcu-lated for each of the single utterances’ syllables. The mean standard devia-tion was then taken as the second measure, thus expressing mean variation of syllable durations across each utterance. Figure 4 may illustrate this for the 10-syllable sentence To barn matet de tamme dyrene (‘Two children fed the tame animals’) produced by the Chinese and the Norwegian speaker group. In this figure, vertical bars indicate ± 1 standard deviation. The
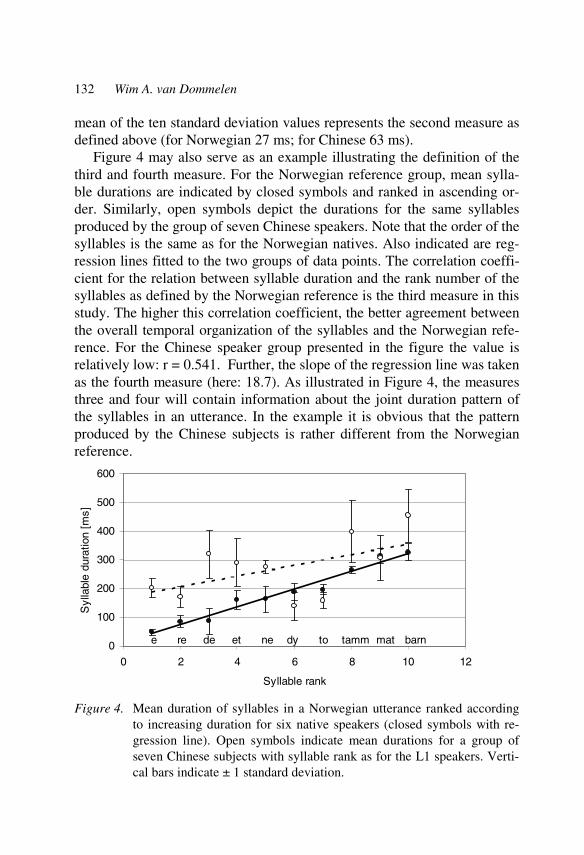
132 Wim A. van Dommelen
mean of the ten standard deviation values represents the second measure as defined above (for Norwegian 27 ms; for Chinese 63 ms).
Figure 4 may also serve as an example illustrating the definition of the third and fourth measure. For the Norwegian reference group, mean sylla-ble durations are indicated by closed symbols and ranked in ascending or-der. Similarly, open symbols depict the durations for the same syllables produced by the group of seven Chinese speakers. Note that the order of the syllables is the same as for the Norwegian natives. Also indicated are reg-ression lines fitted to the two groups of data points. The correlation coeffi-cient for the relation between syllable duration and the rank number of the syllables as defined by the Norwegian reference is the third measure in this study. The higher this correlation coefficient, the better agreement between the overall temporal organization of the syllables and the Norwegian refe-rence. For the Chinese speaker group presented in the figure the value is relatively low: r = 0.541. Further, the slope of the regression line was taken as the fourth measure (here: 18.7). As illustrated in Figure 4, the measures three and four will contain information about the joint duration pattern of the syllables in an utterance. In the example it is obvious that the pattern produced by the Chinese subjects is rather different from the Norwegian reference.
Figure 4. Mean duration of syllables in a Norwegian utterance ranked according to increasing duration for six native speakers (closed symbols with re-gression line). Open symbols indicate mean durations for a group of seven Chinese subjects with syllable rank as for the L1 speakers. Verti-cal bars indicate ± 1 standard deviation.
0
100
200
300
400
500
600
0 2 4 6 8 10 12
Syllable rank
Syl
labl
e du
ratio
n [m
s]
e re de et ne dy to tamm mat barn

Temporal patterns in Norwegian as L2 133
As measure number five speech rate was chosen, defined as the number of (actually produced) phonemes per second. This yielded one single value per utterance and speaker group, that is also here resulting in a total of n= 70 values. Subsequently, as the sixth measure for each utterance the stan-dard deviation belonging to the speech rate value was computed. The stan-dard deviation was calculated across the speakers of each group and thus indicates the degree to which mean speech rate varied within a group. Fi-nally, the seventh measure was the normalized Pairwise Variability Index (nPVI) as used by Grabe and Low (2002):
(1) nPVI = ⎥⎦
⎤⎢⎣
⎡−× ∑
−
= +++−1
1 1
1 )1/(2/)(100m
k kk
kk mdddd
In this calculation the difference of the durations (d) of two successive syl-lables is divided by the mean duration of the two syllables. This is done for all (m-1) successive syllable pairs in an utterance (m= the number of sylla-bles). Finally, by dividing the sum of the (m-1) amounts by (m-1) a mean normalized difference is calculated and expressed as percent.
For the convenience of the reader the present measures are repeated be-low:
1. mean syllable duration 2. standard deviation for syllable durations 3. correlation coefficient 4. slope of regression line 5. mean speech rate 6. standard deviation for speech rate 7. nPVI
4.2. Results: Mean syllable duration
Since the main temporal unit under scrutiny is the syllable, let us first see whether and to what extent the various speaker groups produced different syllable durations. As can be seen from Table 2, mean syllable durations vary substantially. Shortest durations were found for the natives (176 ms), while the subjects with a Chinese L1 produced the longest syllables

134 Wim A. van Dommelen
(286 ms). The other groups have values that are more native-like, in parti-cular the German speakers with a mean of 196 ms. For all speaker groups the standard deviations are quite large, which is due to both inter-speaker variation and the inclusion of all the different types of syllables. Note that the standard deviation described here was computed across all single tokens (e.g., for the Chinese n= 837) and thus differs from the second measure defined above in Section 4.1.) According to a one-way analysis of variance, the overall effect of speaker group on syllable duration is statistically signi-ficant (F(6, 4490)= 97.841; p< .0001). In order to obtain information about differences between syllable durations for all possible pairs of language groups, a Games-Howell post-hoc analysis was performed. The result sho-wed that only the difference between the two mean durations for the English group (222 ms) and the Russian group (216 ms) was non-signifi-cant. All the remaining differences turned out to be statistically significant at a level of significance p= 0.05. Therefore, it can be concluded that the measure mean syllable duration captured characteristic differences between the speaker groups.
Here one might raise the question of how to explain the differences in mean syllable duration. They need not necessarily be due to L1-dependent behaviour but could reflect differences in speech rate correlating with the subjects’ general performance level in Norwegian. A possible approach to investigating this issue could be to collect and analyze speech material from the present speaker groups for their respective L1s. But firstly, due to the considerable research efforts needed, until now we had to refrain from such an enterprise. Secondly, though L2 performance certainly is affected by L1-specific factors we can not assume a linear transfer of temporal patterns from L1 to L2. Nevertheless, previous investigations of temporal similari-ties and dissimilarities between different languages can provide us with a frame of reference. Delattre (1966) compared syllable durations in English, German, French and Spanish. His material consisted of five minutes of spontaneous speech produced by one native speaker of each of these langu-ages. Conditioning factors were syllable weight (stressed/unstressed), place (final/non-final) and type (open/closed). Mean durations of final, stressed closed/open syllables turned out to be longer for English (408 ms/335 ms) than for German (362 ms/298 ms) and French (341 ms/246 ms). For non-final syllables rather small differences between English (259 ms/192 ms) and German (246 ms/197 ms) were found (note that in French stressed syllables occur only in final position). Unstressed non-final closed/open syllable durations showed a reversed order for the three languages: French
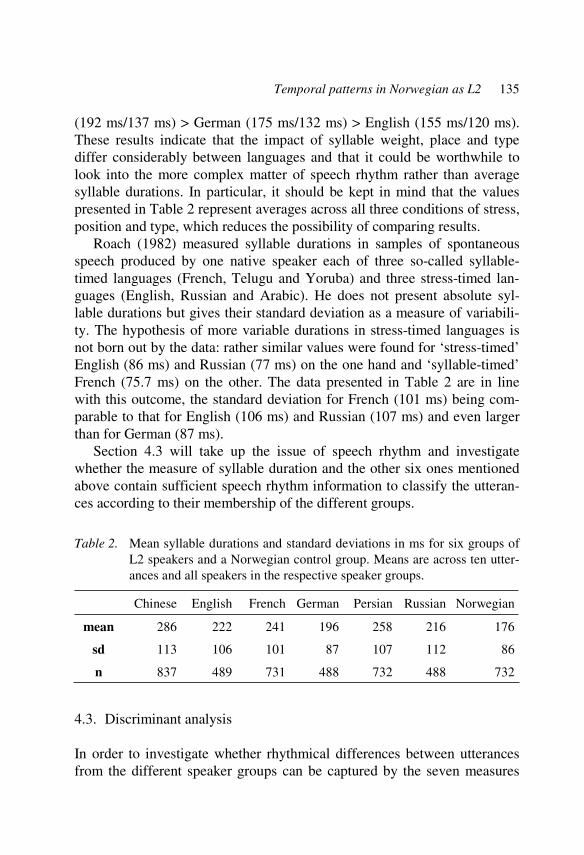
Temporal patterns in Norwegian as L2 135
(192 ms/137 ms) > German (175 ms/132 ms) > English (155 ms/120 ms). These results indicate that the impact of syllable weight, place and type differ considerably between languages and that it could be worthwhile to look into the more complex matter of speech rhythm rather than average syllable durations. In particular, it should be kept in mind that the values presented in Table 2 represent averages across all three conditions of stress, position and type, which reduces the possibility of comparing results.
Roach (1982) measured syllable durations in samples of spontaneous speech produced by one native speaker each of three so-called syllable-timed languages (French, Telugu and Yoruba) and three stress-timed lan-guages (English, Russian and Arabic). He does not present absolute syl-lable durations but gives their standard deviation as a measure of variabili-ty. The hypothesis of more variable durations in stress-timed languages is not born out by the data: rather similar values were found for ‘stress-timed’ English (86 ms) and Russian (77 ms) on the one hand and ‘syllable-timed’ French (75.7 ms) on the other. The data presented in Table 2 are in line with this outcome, the standard deviation for French (101 ms) being com-parable to that for English (106 ms) and Russian (107 ms) and even larger than for German (87 ms).
Section 4.3 will take up the issue of speech rhythm and investigate whether the measure of syllable duration and the other six ones mentioned above contain sufficient speech rhythm information to classify the utteran-ces according to their membership of the different groups.
Table 2. Mean syllable durations and standard deviations in ms for six groups of L2 speakers and a Norwegian control group. Means are across ten utter-ances and all speakers in the respective speaker groups.
Chinese English French German Persian Russian Norwegian
mean 286 222 241 196 258 216 176
sd 113 106 101 87 107 112 86
n 837 489 731 488 732 488 732
4.3. Discriminant analysis
In order to investigate whether rhythmical differences between utterances from the different speaker groups can be captured by the seven measures
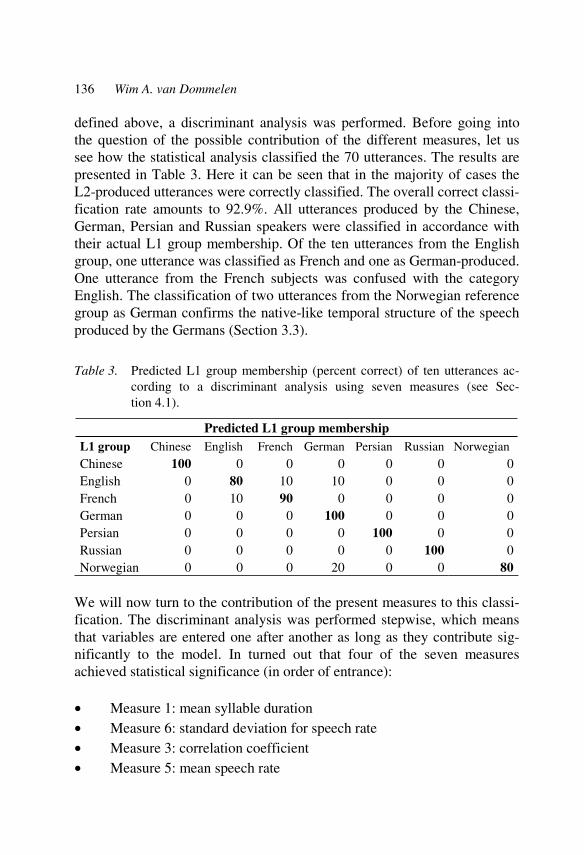
136 Wim A. van Dommelen
defined above, a discriminant analysis was performed. Before going into the question of the possible contribution of the different measures, let us see how the statistical analysis classified the 70 utterances. The results are presented in Table 3. Here it can be seen that in the majority of cases the L2-produced utterances were correctly classified. The overall correct classi-fication rate amounts to 92.9%. All utterances produced by the Chinese, German, Persian and Russian speakers were classified in accordance with their actual L1 group membership. Of the ten utterances from the English group, one utterance was classified as French and one as German-produced. One utterance from the French subjects was confused with the category English. The classification of two utterances from the Norwegian reference group as German confirms the native-like temporal structure of the speech produced by the Germans (Section 3.3).
Table 3. Predicted L1 group membership (percent correct) of ten utterances ac-cording to a discriminant analysis using seven measures (see Sec-tion 4.1).
Predicted L1 group membership L1 group Chinese English French German Persian Russian Norwegian Chinese 100 0 0 0 0 0 0English 0 80 10 10 0 0 0French 0 10 90 0 0 0 0German 0 0 0 100 0 0 0Persian 0 0 0 0 100 0 0Russian 0 0 0 0 0 100 0Norwegian 0 0 0 20 0 0 80
We will now turn to the contribution of the present measures to this classi-fication. The discriminant analysis was performed stepwise, which means that variables are entered one after another as long as they contribute sig-nificantly to the model. In turned out that four of the seven measures achieved statistical significance (in order of entrance):
• Measure 1: mean syllable duration • Measure 6: standard deviation for speech rate • Measure 3: correlation coefficient • Measure 5: mean speech rate

Temporal patterns in Norwegian as L2 137
This outcome suggests that three types of temporal information can be distinguished. First, the correlation measure containing information about the overall patterning of syllable durations. Second, the measures 1 and 5 both reflecting speech rate. Finally, measure 6 capturing aspects of varia-tion in speech rate. It seems obvious that the information contained in the measures 1 and 5 contain could overlap to a large degree or even that in-cluding one of them could make the other one redundant. In order to get an impression of these two measures’ role the discriminant analysis was run again without measure 1, mean syllable duration. This lowered the classifi-cation rate from originally 92.9% to 81.4%. Doing the same thing for measure 5, mean speech rate, resulted in an overall rate of 91.4%. These percentages suggest that the two measures indeed contain redundant infor-mation, mean syllable duration having the most predictive power.
Though the present analysis has succeeded in classifying the seven dif-ferent speaker groups according to their respective language backgrounds, the issue of L1-specific speech rhythm is far from solved. Specifically, in interpreting the results one should take into consideration that speech rate and rhythm measures have been shown to co-vary. For example, Dellwo and Wagner (2003) demonstrated that the standard deviation of consonantal intervals as used by Ramus et al. (1999) is heavily speech rate dependent. A similar conclusion was drawn by Barry et al. (2003) among other things as to Grabe and Low’s (2002) PVI measures for vowels and consonants. It is conceivable that the differences in speech rate for the present speaker groups are only partly language-dependent and vary mainly with the spea-kers’ general skills in Norwegian.
5. Conclusions
The goal of the present study has been to shed some light on temporal as-pects of Norwegian spoken as a second language. In general, it could be shown that speakers from six different native languages at the level of sin-gle vowels and consonants as well as syllables produced patterns that dif-fered from the Norwegian reference. In its generality this is, of course, a result that could be expected. Going into more detail, a central question is to what extent the data revealed deviation patterns that could be characteris-tic for the different speaker groups involved, i.e. depending on their respec-tive native languages. To answer this question, data from measurements on the temporal structure of dyads VC: and V:C were evaluated in different

138 Wim A. van Dommelen
ways. From the average durations for each of the elements under scrutiny (V, V:, C, C:) it was not easy to detect any systematic differences between L2 and L1 productions. More informative was the duration ratio V:/V in this respect. Here, there was a tendency for speakers from languages closer to the target language to have somewhat more native-like values. This ten-dency was, however, not very clear. One the one hand, the Russian speak-ers performed similar to the German and the English speakers, which does not seem to be in congruence with the degree of language family member-ship. On the other hand, the French subjects’ ratios deviated more from the Norwegian reference and were, possibly somewhat surprisingly, similar to those for the Chinese and Persian speakers. The most revealing perspective to evaluate and interpret the present data was to inspect how the durations of the long and short vowels and consonants relate to each other and what the duration patterns for the classes of VC: vs. V:C look like. Most native-like performance was found for the German speakers, thus confirming the previously observed tendencies for this group. While the data for the French subjects seemed to reflect the lack of vowel quantity in their native language, the Chinese speakers showed considerable scatter and so failed to systematically distinguish between the VC: vs. V:C categories.
A fundamental problem in interpreting data like those from the present study is the complexity of the factors that contribute to the measurable out-put. First of all, there is at present no model to predict what kind of inter-ference phenomena can be expected. From current models, Flege’s (1995) model can be used to make global predictions, but it seems difficult to make predictions about specific deviations. Apart from these L1 influences, which at least in principle could be predicted, there are many further con-tributing factors at the individual level: duration and intensity of contact with the second language, degree of familiarity with other languages, for-mal training in L2, education level, family situation as to the use of one, two or even more languages, motivation to learn a new language – just to mention some. All these factors contribute to obscure possible systematic effects to different degrees.
The results for the VC: vs. V:C dyads confronted us with the kind of in-terpretation difficulties as mentioned above. Here, it has become clear that purely phonological reasoning cannot explain the data satisfactorily. The performance of the Russians was more native-like compared to the produc-tions of the Chinese though in both native languages vowel quantity is ab-sent. Further, it is difficult to give more than a rather superficial explana-tion of the substantial variation in the performance of the Chinese, saying

Temporal patterns in Norwegian as L2 139
that this reflects the pronunciation difficulties they encounter. It is thinkable that the observed variation to a certain extent is caused by uncertainties in grapheme-to-phoneme conversion in reading. All this does not mean, how-ever, that the present results are without practical implications. For exam-ple, in the teaching of Norwegian pronunciation to German target groups there will presumably not be much need to focus on issues related to vowel quantity. Consequently, more time would be available to emphasize other aspects. Dealing with French as L1, it seems useful to make speakers aware of the long durations necessary to produce appropriate phonologically long vowels. At the same time, the complementary consonant duration differ-ences in the VC: vs. V:C opposition should be brought to the learners’ at-tention. Learners with a language background that is more distant, like the present Chinese speakers, can be expected to need and to profit from a very thorough instruction concerning the temporal aspects of Norwegian.
An unexpected outcome of the measurements was the presence of preaspiration in Norwegian produced by native speakers of English. This finding demonstrates the potential usefulness of phonetic analyses for pro-nunciation teaching. Though in many cases the human ear is unsurpassable as an instrument for judging speech productions, some relevant details might escape our attention until revealed by an instrumental analysis. So, instrumental methods may make us more aware of pronunciation phenom-ena and potentially contribute to improving teaching praxis. In the present case of preaspiration, drawing the attention of the learners of Norwegian to this detail of consonant production might help to make their pronunciation more authentic. Nowadays, with the help of the omnipresent computer and a free-ware program like Praat it does not require much specialist knowl-edge to integrate sound demonstrations in pronunciation teaching. In this way, learners could acquire a better understanding of all kinds of pronun-ciation aspects as, for example, vowel reduction, assimilation, intonation or, in a language like Norwegian, a notoriously difficult feature as the reali-zation of tonal accents.
As was expected from the outset, investigation of speech rhythm evi-denced different temporal patterns for the six speaker groups. It seems rea-sonable to ascribe the deviations at least partly to the influence of the re-spective native languages. With rhythm-related measures as input a discri-minant analysis classified L2 utterances according to their L1 membership with a relatively high degree of accuracy (92.9% correct). As to the rele-vance of the present measures of speech rhythm, only four out of the seven measures turned out to contribute significantly. Probably most closely re-

140 Wim A. van Dommelen
lated to speech rhythm, the correlation coefficient measure seems to convey relevant information about the overall patterning of syllable durations. Two further relevant measures (mean syllable duration and mean speech rate expressed in phonemes per second) are both related to speech rate and ap-pear to contain overlapping information. The fourth significant measure involved the variation in speech rate. It thus appears that a large portion of the information about the utterances’ L1 membership originates from the rate of speech deliverance. Since it is conceivable that speech rate does not represent an L1-specific factor, but varies with the level of proficiency in L2 in general, further research on this issue will be needed. At present, it can only be speculated about the reasons why three measures don’t seem to convey rhythm information.
Finally, we would like to point out that the present measures were of an exploratory character and some of them were possibly too crude to capture details of speech rhythm. Also, and presumably more importantly, opera-tionalizing speech rhythm as the temporal organization of syllables means a strong reduction which fails to do justice to the complex of interacting fac-tors involved. It is hoped, however, that future efforts studying more as-pects of speech rhythm, both in production and perception, eventually will give a better understanding of this phenomenon.
Acknowledgement
This research is supported by the Research Council of Norway (NFR) through grant 158458/530 to the project Språkmøter (Language Encoun-ters). The speech material was developed and recorded by Snefrid Holm (Department of Language and Communication Studies, NTNU) as part of her PhD project. I would like to thank Rein Ove Sikveland (Department of Language and Communication Studies, NTNU) for the segmentation of the speech material.
References
Ashby, Michael and John Maidment 2005 Introducing Phonetic Science. Cambridge: Cambridge University
Press.

Temporal patterns in Norwegian as L2 141
Barry, William J., Bistra Andreeva, Michela Russo, Snezhina Dimitrova and Tanya Kostadinova
2003 Do rhythm measures tell us anything about language type? Pro-ceedings of the 15th International Congress of Phonetic Sciences,Barcelona, 2693–2696.
Behne, Dawn, Bente Moxness and Anne Nyland 1996 Acoustic-phonetic evidence of vowel quantity and quality in
Norwegian. Fonetik 96, Papers presented at the Swedish Phonet-ics Conference, Nässlingen, 29–31 May 1996. KTH (Royal insti-tute of Technology), Speech, Music and Hearing. Quarterly Pro-gress and Status Report, TMH-QPSR 2/1996, 13–16.
Boersma, Paul and David Weenink 2006 Praat: doing phonetics by computer (Version 4.4.11) [Computer
program]. Retrieved February 23, 2006, from http://www.praat.org/. Bond, Dzintra, Dace Markus and Verna Stockmal 2003 Prosodic and rhythmic patterns produced by native and non-
native speakers of a quantity-sensitive language. Proceedings of the 15th International Congress of Phonetic Sciences, Barcelona, 527–530.
Dauer, Rebecca M. 1983 Stress-timing and syllable-timing reanalyzed. Journal of Phonet-
ics 11, 51–62.Davidsen-Nielsen, Niels 1996 English Phonetics. Translated and adapted for use in Norway by
Barbara Bird and Per Moen. Oslo: Gyldendal Norsk Forlag A/S (Seventh impression).
Delattre, Pierre 1966 A comparison of syllable length conditioning among languages.
International Review of Applied Linguistics 4, 183–198. Dellwo, Volker and Petra Wagner 2003 Relations between language rhythm and speech rate. Proceedings
of the 15th International Congress of Phonetic Sciences, Barce-lona, 471–474.
van Dommelen, Wim A. 1999a Auditory accounts of temporal factors in the perception of Nor-
wegian disyllables and speech analogs. Journal of Phonetics 27, 107–123.
1999b Preaspiration in intervocalic /k/ vs. /g/ in Norwegian. Proceed-ings of the 14th International Congress of Phonetic Sciences, San Francisco, 2037–2040.

142 Wim A. van Dommelen
Fintoft, Knut 1961 The duration of some Norwegian speech sounds. Phonetica 7,
19–39. Flege, James 1995 Second language speech learning: Theory, findings, and prob-
lems. In: Winifred Strange (ed.), Speech perception and linguistic experience: Issues in cross-language research, 233–277. Timo-nium: York Press.
Grabe, Esther and Ee Ling Low 2002 Durational variability in speech and the rhythm class hypothesis.
In: Carlos Gussenhoven and Natasha Warner (eds.), Laboratory Phonology 7, 515–546. Berlin/New York: Mouton de Gruyter.
Gut, Ulrike 2003 Prosody in second language speech production: the role of the
native language. Zeitschrift für Fremdsprachen Lehren und Ler-nen 32, 133–152.
Kenworthy, Joanne 2000 The Pronunciation of English: A Workbook. London: Arnold.
(Co-published in the USA by Oxford University Press Inc., New York.)
Kristoffersen, Gjert 2000 The Phonology of Norwegian. Oxford: Oxford University Press. Krull, Diana, Hartmut Traunmüller and Wim A. van Dommelen 2003 The effect of local speaking rate on perceived quantity: a com-
parison between three languages. Proceedings of the 15th Inter-national Congress of Phonetic Sciences, Barcelona, 1739–1742.
Ladefoged, Peter and Ian Maddieson 1996 The Sounds of the World’s Languages. Oxford: Blackwell Pub-
lishers Ltd. Markus, Dace and Dzintra Bond 1999 Stress and length in learning Latvian. Proceedings of the 14th
International Congress of Phonetic Sciences, San Fransisco, 563–566.
Ramus, Franck 2002 Acoustic correlates of linguistic rhythm: Perspectives. Proceed-
ings Speech Prosody 2002, Aix-en-Provence (France), 115–120.Ramus, Franck, Marina Nespor and Jacques Mehler 1999 Correlates of linguistic rhythm in the speech signal. Cognition
73, 265–292.

Temporal patterns in Norwegian as L2 143
Roach, Peter 1982 On the distinction between ‘stress-timed’ and ‘syllable-timed’
languages. In: David Crystal (ed.), Linguistic controversies. Es-says in linguistic theory and practice in honour of F.R. Palmer, 72–79. London, Edward Arnold.
Shockey, Linda 2003 Sound Patterns of Spoken English. Malden, USA: Blackwell
Publishing Ltd. Stockmal, Verna, Dace Markus and Dzintra Bond 2005 Measures of native and non-native rhythm in a quantity language.
Language and Speech 48, 55–63.Svetozarova, Natalia 1998 Intonation in Russian. In: Daniel Hirst and Albert di Cristo (eds.),
Intonation Systems. A Survey of Twenty Languages, 261–274. Cambridge: Cambridge University Press.


Learner corpora in second language prosody research and teaching
Ulrike Gut
1. Introduction
This article addresses methodological issues in L2 prosody research and teaching and argues for a corpus-based approach in both areas. Current research methods in L2 prosody have a number of limitations. A survey of all empirical studies on L2 prosody published in the major international journals in second language acquisition (SLA) research in the past 25 years demonstrates that research in L2 prosody tends to be based on a relatively small data base with a limited number of participants. Research on intona-tion, for example, is carried out with an average number of 22.6 partici-pants (range 2 to 75); research on word stress is based on even fewer par-ticipants, on average 7.7, ranging from 4 to 10. The analysis of the productions of only few participants, however, precludes the study of varia-tion between learners, for which representatively sized groups are neces-sary. Furthermore, empirical research on non-native prosody typically elic-its data in a relatively controlled setting and is restricted to one speech style. Most studies base their investigations on the readings of words and sentences. Arguments against experimentally elicited data are brought forth for example by Leather (1999), who argues that some phonological struc-tures may be more susceptible to errors in an experimental setting and sug-gests that “observations from artificial speech tasks cannot always be ex-trapolated to natural conditions” (p. 32). Moreover, data analysis in L2 prosody research usually focuses on just one aspect of non-native prosody such as a particular intonational structure. The relationship between differ-ent prosodic domains, however, is not investigated. Finally, studies rarely relate their findings to non-linguistic factors assumed to influence the ac-quisition of prosody in an L2. The only explanatory aspect of language learning under investigation has been the influence of the learners’ native language on their L2 prosody. If factors such as age, motivation and speech style are analysed, only one of them is studied. No longitudinal studies,

146 Ulrike Gut
where speech is collected from the same individuals at multiple intervals over a period of time, have yet been carried out.
Recently, it has been suggested that a corpus-linguistic approach should be introduced into research in language acquisition. It is widely argued that a corpus-based methodology can complement the current research methods in second language learning and possibly compensate some of their weak-nesses (Biber, Conrad, and Reppen 1994, Botley et al. 1996, Kettemann and Marko 2002, Granger, Hung and Petch-Tyson 2002, Sinclair 2004, Granger 2004). However, so far, corpus linguistics and second language research have mainly co-existed side by side and have not yet joined forces (cf. Hasselgard 1999). Due to the scarcity of learner speech corpora the analysis of learner phonology or prosody have so far been impossible (cf. Nesselhauf 2004). The recently completed LeaP (Learning Prosody) corpus fills this gap in providing a fully annotated speech corpus of learner English and learner German.
Apart from serving as a resource for empirical research, language cor-pora are increasingly used in the classroom and the recognition of their pedagogical value is growing (e.g. Ghadessy, Henry and Roseberry 2001, Kettemann and Marko 2002, Granger, Hung and Petch-Tyson 2002, Sin-clair 2004). It has been claimed that the application of corpora in the class-room supports inductive learning processes and the creation of language awareness in language students. By investigating corpora students are stimulated to enquire and speculate about language structures and develop the ability to recognize language patterns. In corpus-based “data-driven learning”, for example, students have the opportunity to work as research-ers by developing a research question and analysing it with real-language data. It has been suggested that activities based on a comparison between native and non-native corpus data enable language learners
– to focus on negative evidence and typical errors – to train their ability to notice differences between native and non-native
language use – to increase their language awareness
By observing the errors learners typically and most frequently make, stu-dents might find it easier to become aware of the features of their own in-terlanguage and possibly stimulate a restructuring of their own language use and knowledge (e.g. Granger and Tribble 1998). Due to the scarcity of

Learner corpora in second language prosody research and teaching 147
learner speech corpora the analysis of learner phonology or pronunciation in a classroom setting have so far been impossible (cf. Nesselhauf 2004).
The aim of this article is to report on the advantages and new opportuni-ties offered by the corpus-based approach in L2 prosody. Section 2 gives a brief overview of corpus linguistics, the various types of corpora that have been collected and the advantages of a corpus-based approach. In section 3, the learner corpus LeaP is described. It serves as the basis of the analysis of non-native vowel reduction in both L2 English and L2 German (Section 4). Section 5 summarizes the findings of a preliminary study on the application of the LeaP corpus in language teaching. The implications of the results of the analysis for research in L2 prosody and for the teaching of prosody are discussed in section 6.
2. Corpus linguistics
Corpus linguistics as a method to study the structure and use of language can be traced back to the 18th century (Kennedy 1998: 13). Modern corpora began to be collected in the 1960s. In modern definitions the term corpus is usually used to refer to a substantial collection of language texts or tran-scriptions of spoken language in electronic form (Biber, Conrad, and Rep-pen 1996: 4). McEnery and Wilson (2001) list representativeness, sufficient size, a machine-readable form and its function as a standard reference as typical requirements for a corpus. Representativeness refers to the fact that the collection of speech data should be maximally representative for the aspect under investigation, that is, provide researchers with an as accurate as possible picture of the occurrence and variation of the phenomena under investigation. Modern corpora have to be machine-readable so that their purpose, the rapid (semi-)automatic analysis of large amounts of data, can be realized. The computer-based storage form furthermore allows an en-richment of the corpus by annotations. In general, it is assumed that a cor-pus functions as a standard reference for the language or language variety it represents.
2.1. Types of corpora
Several types of corpora can be distinguished: Text corpora consist of col-lections of written samples of a language variety; speech corpora constitute

148 Ulrike Gut
a collection of spoken samples of a language variety. The latter is often also referred to with the term spoken language corpus. Text corpora are natu-rally not suited for the description and development of linguistic theory in the area of phonetics and phonology. Corpora can be unannotated or anno-tated. The term annotation refers to the enhancement of the primary data (audio or video recordings in the case of speech corpora) with various types of linguistic and non-linguistic information. Several types of linguistic an-notations are in use and include orthographic transcriptions, phonemic and prosodic transcriptions, part of speech tagging, semantic annotation, ana-phoric annotation and lemmatization. For example, the content of a re-cording may be transcribed orthographically, and an additional phonetic transcription may be carried out. Non-linguistic corpus annotations usually consist of meta-data, i.e. additional information about the corpus or its con-tent. This includes information about the recording (e.g. time and place), about the speakers (e.g. age, sex, native language), about the recording situation (e.g. speech style elicited, instructions) and about the corpus (e.g. who collected it, where, when, with which purpose).
A text-to-tone alignment, which links the transcriptions (annotations) with the audio or video recording, provides direct access from each anno-tated element to the primary data, i.e. the original recordings. By clicking on any annotated element the corresponding part of the recording will be played back by the annotation software. This is especially useful for the analysis of the corpus because items in question can be listened to again or additional phonetic analyses offered by the software such as a spectro-graphic analysis or pitch tracking can be carried out. In addition, this func-tion enables language teachers and language learners to make use of the corpus in the classroom. In order to create, analyse, query and distribute an annotated speech corpus, an appropriate data format is required. The cur-rently most widely used data format is based on the Extensible Markup Language (XML) technology, which allows an efficient document engi-neering of speech data by providing tools for the data collection (XML editors), for data analysis (e.g. XSL-T) and for data presentation. Corpora can be further divided into native corpora and learner corpora, the former containing language produced by native speakers, the latter containing lan-guage produced by learners of a language. Finally, corpora may contain only one language variety (monolingual corpora) or more than one lan-guage (multilingual corpora).

Learner corpora in second language prosody research and teaching 149
2.2. Corpus analysis
Two major types of corpus analysis can be distinguished: qualitative and quantitative approaches. In qualitative research, small numbers of phenom-ena are described in detail and focus lies on the variation of the data. Its main drawback is that the findings cannot be generalized to larger popula-tions with a sufficient degree of certainty. In contrast, a quantitative analy-sis of a corpus gives a precise account of the frequency and rarity of par-ticular language structures. The specific findings can be tested to discover whether they are statistically significant and can be generalized to a larger population. In early corpus-based studies quantitative analysis was re-stricted to a simple counting of occurrence of linguistic items. However, the analysis of an annotated corpus allows the computation of various statisti-cal measurements such as correlations between variables, i.e. the analysis of systematic ways in which some linguistic features vary with other lin-guistic features or how certain non-linguistic features vary with certain linguistic ones, and other multivariate measurements such as factor analy-ses and cluster analyses. The weakness of quantitative approaches lies in the risk that rare phenomena are not recognized and that fine distinctions are blurred. Corpus-based studies thus benefit most from combining both approaches (McEnery and Wilson 2001: 77).
A number of advantages of using speech corpora in research on non-native speech have been suggested (Biber, Conrad, and Reppen 1994, McEnery and Wilson, 2001, Granger 2002, 2004):
– Corpora contain objective language data which reflects authentic natural language use. A representative corpus of non-native speech constitutes a large empirical database of naturally occurring language structures and patterns of use and thus stands in contrast to the laboratory speech elicited in experimental studies on non-native speech, which has often been criticized as artificial and not generalizable (Leather 1999: 32). Corpora of non-native speech offer empirical investigations of the patterns of actual language use and allow quantitative and qualitative analyses whose results are generalizable to larger populations.
– Corpus-based research allows an examination of more varied and larger amounts of data than any other methodology in second language research. This opens up the possibility that in an explorative manner previously unsuspected linguistic phenomena may be discovered and access to previously not accessible structures and patterns of use is

150 Ulrike Gut
provided. In this manner, researchers can for the first time test strongly held convictions and intuitions about frequency and type of learner errors. Granger (2004: 123) suggests that corpus-based research in L2 provides a basis for a new way of thinking which may challenge some of the deeply-rooted ideas about learner language. Similarly, Biber, Conrad, and Reppen (1994) report from morphosyntactic and lexical studies that researchers’ intuitions can prove incorrect when tested against actual frequencies and usage in the corpus. As pointed out variously, corpora constitute the only reliable source of evidence for questions of frequency.
– A richly annotated corpus of non-native speech gives access not only to specific learner errors but provides a comprehensive description of all aspects of the learners’ interlanguage, combining information on different linguistic levels and non-linguistic information. This satisfies Leather’s (1999) call for an “ecological” approach to theoretical modelling in second language speech. He argued for paying more attention to experiential and environmental factors of the acquisition process and for research in non-native speech to take on a broader view. A corpus that extends over a wide selection of variables such as speaker learning history, learning situation, age and sex and across a variety of speech styles allows investigations of new issues such as co-occurrence of structures or the co-occurrence of certain linguistic with non-linguistic features.
– Corpora provide information about variation in non-native speech. By dividing the corpus into smaller subcorpora by, for example, grouping learners with the same native language or age at first exposure to the target language, or by comparing certain structures in non-native speech in different speech styles, the extent and type of variation in non-native speech can be analysed.
Until recently, corpus-based research in L2 prosody was impossible due to the lack of an appropriate corpus. A small number of learner speech cor-pora have been set up in the area of speech technology in the past few years, mainly collected to train speech recognition systems which can then be used in man-machine conversations such as telephone booking of train tickets (e.g. the FAE (Foreign Accented English) corpus and the VILTS (Voice Interactive Language Training System) corpus). However, none of these corpora in their present form are immediately reusable for researchers in non-native prosody since they do not contain phonetic or phonological

Learner corpora in second language prosody research and teaching 151
annotations. Recently, a prosodically annotated learner corpus has become available, which will be described in the next section.
3. The LeaP corpus
The LeaP corpus was collected between May 2001 and July 2003 as part of the LeaP (Learning Prosody in a Foreign Language) project1, which inves-tigated the acquisition of prosody by second language learners of German and of English. The corpus consists of a total of 359 fully annotated re-cordings adding up to 73.941 words. The total amount of recording time is more than 12 hours. It comprises four different types of speech:
– free speech in an interview situation (length between 10 and 30 minutes) – reading passage (length about 2 minutes) – retellings of the story (length between 2 and 10 minutes) – readings of nonsense word lists (30 to 32 words)
In the LeaP corpus, different learner groups are represented: native speak-ers of English and of German, serving as controls, especially advanced learners (near-natives), learners before and after a training course in pros-ody and learners before and after a stay abroad. The English subcorpus contains recordings with 46 non-native and 4 native speakers. The mean age of the non-native speakers is 32.3 years and ranges from 21 to 60. 32 of them are female and 14 are male, and altogether, they have 17 different native languages. The average age at first contact with English is 12.1 years, ranging from one year to 20 years of age. In the German subcorpus, the mean age of the 55 non-native speakers at the time of the recording is 28.9 years and ranges from 18 to 54 years. 35 of them are female and 20 are male. Altogether, they have 24 different native languages. The average age at first contact with German is 16.7 years, ranging from three years to 33 years of age.
A large number of additional data was collected for each recording, in-cluding data

152 Ulrike Gut
– about the recording (date, place, interviewer and language of the inter-view)
– about the non-native speaker (age, sex, native language/s, second language/s, age at first contact with target language, type of contact [formal vs. natural], duration and type of stays abroad, duration and type of formal lessons in prosody, prosodic knowledge)
– about motivation and attitudes (reasons for acquiring the language, motivation to integrate in the host country, attributed importance to competence in pronunciation compared to other aspects of language, interest, experience and ability in music and in acting)
Annotation and text-to-tone alignment of the LeaP corpus was carried out for all reading passages, retellings and two-minute extracts of each inter-view. The manual annotation comprised six tiers; two further tiers were added automatically:
– On the phrase tier, speech and non-speech events were annotated. The interviewee’s speech is divided into intonational phrases.
– On the words tier, words were transcribed orthographically. – On the syllable tier, syllables were transcribed in SAMPA. – On the segments tier, all vocalic and consonantal intervals plus the
intervening pauses were annotated. – On the tones tier, pitch accents and boundary tones were annotated. – On the pitch tier, the initial high pitch, the final low pitch and
intervening pitch peaks and valleys were annotated. – On the POS tier, part-of- speech coding was annotated automatically. – On the lemma tier, lemmata were annotated automatically.
For a recording of about one minute length, on average, 1000 events were annotated. Figure 1 illustrates the manually annotated tiers and the annota-tion process with the waveform (top) and spectrogram (middle) and the six manually annotated tiers (bottom).

Learner corpora in second language prosody research and teaching 153
Figure 1. Manual annotation in the LeaP corpus. From bottom to top the tiers are the phrase tier, the words tier, the syllable tier, the segments tier, the pitch tier and the tones tier.
4. A corpus-based analysis of vowel reduction
All previous studies investigating vowel reduction by learners of either English or German found that, in non-native speech, vowels are not re-duced to an appropriate extent. Often, full vowels instead of reduced vow-els are produced in unstressed syllables and the durational difference be-tween full vowels and reduced vowels is not sufficiently large (Wenk 1985, Bond and Fokes 1985, Mairs 1989, Flege and Bohn 1989, Zborowska 2000 for English and Kaltenbacher 1998, Gut 2003 for German). Some experi-ments involved a comparison of L2 vowel reduction with vowel reduction processes in native speech; some compared learner groups with different native languages. In some approaches learners were presented with reading material of word lists or short phrases. Less frequently, semi-spontaneous speech as in story retellings was elicited.
Many aspects of vowel reduction are still unexplored: As yet, there are no longitudinal studies on the acquisition of vowel reduction. Vowel dele-tion, which is very common in native speech (e.g. Helgason and Kohler

154 Ulrike Gut
1996 for German), has not been studied yet. Although native language in-fluence has been investigated as a possible constraint of non-native vowel reduction, cross-linguistic comparisons of target language have not yet been carried out. Furthermore, no systematic analysis of the co-variance of speech style and vowel reduction has been analysed and the correlation with other prosodic features of non-native speech has not been investigated yet.
In order to address these research questions, vowel reduction in the LeaP corpus was analysed quantitatively and qualitatively. For the quantita-tive analysis, the following measurements were taken:
mean length sfv mean length of all syllables containing a full vowel
mean length srv mean length of all syllables containing the reduced vowels / /, / / and / / (/ / in Ger-man only)
mean length sdv mean length of all syllables with a deleted vowel
percentage red/del 100x number of all syllables with either reduced or deleted vowel divided by total number of syllables
syllable ratio mean durational ratio of all syllable pairs in which a syllable with a full vowel is fol- lowed by a syllable with either a reduced or a deleted vowel
4.1. Results: Vowel reduction in native and non-native speech
Vowel reduction in non-native German differs from that in native German in nearly all measured features (see Table 1). The mean length of all types of syllables is longer in non-native German and the syllable ratio, the dur-ational difference between adjacent syllables with a full vowel and those with a reduced or deleted vowel, is lower. Only the percentage of syllables with reduced and deleted vowels is not significantly different between non-native German and native German. In all variables, the standard deviation is much higher in the speech of the learners of German compared to the native speakers. The native speaker norm was defined as the native speak-ers’ mean value ±one standard deviation. For the syllable ratio, it lies be-
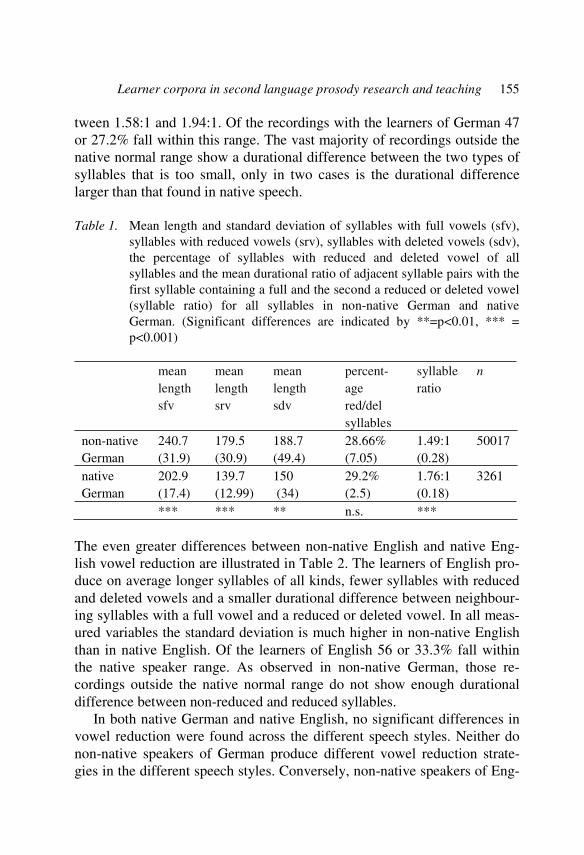
Learner corpora in second language prosody research and teaching 155
tween 1.58:1 and 1.94:1. Of the recordings with the learners of German 47 or 27.2% fall within this range. The vast majority of recordings outside the native normal range show a durational difference between the two types of syllables that is too small, only in two cases is the durational difference larger than that found in native speech.
Table 1. Mean length and standard deviation of syllables with full vowels (sfv), syllables with reduced vowels (srv), syllables with deleted vowels (sdv), the percentage of syllables with reduced and deleted vowel of all syllables and the mean durational ratio of adjacent syllable pairs with the first syllable containing a full and the second a reduced or deleted vowel (syllable ratio) for all syllables in non-native German and native German. (Significant differences are indicated by **=p<0.01, *** = p<0.001)
mean length sfv
mean length srv
mean length sdv
percent-age red/del syllables
syllable ratio
n
non-native German
240.7 (31.9)
179.5 (30.9)
188.7 (49.4)
28.66% (7.05)
1.49:1 (0.28)
50017
native German
202.9 (17.4)
139.7 (12.99)
150 (34)
29.2% (2.5)
1.76:1 (0.18)
3261
*** *** ** n.s. ***
The even greater differences between non-native English and native Eng-lish vowel reduction are illustrated in Table 2. The learners of English pro-duce on average longer syllables of all kinds, fewer syllables with reduced and deleted vowels and a smaller durational difference between neighbour-ing syllables with a full vowel and a reduced or deleted vowel. In all meas-ured variables the standard deviation is much higher in non-native English than in native English. Of the learners of English 56 or 33.3% fall within the native speaker range. As observed in non-native German, those re-cordings outside the native normal range do not show enough durational difference between non-reduced and reduced syllables.
In both native German and native English, no significant differences in vowel reduction were found across the different speech styles. Neither do non-native speakers of German produce different vowel reduction strate-gies in the different speech styles. Conversely, non-native speakers of Eng-
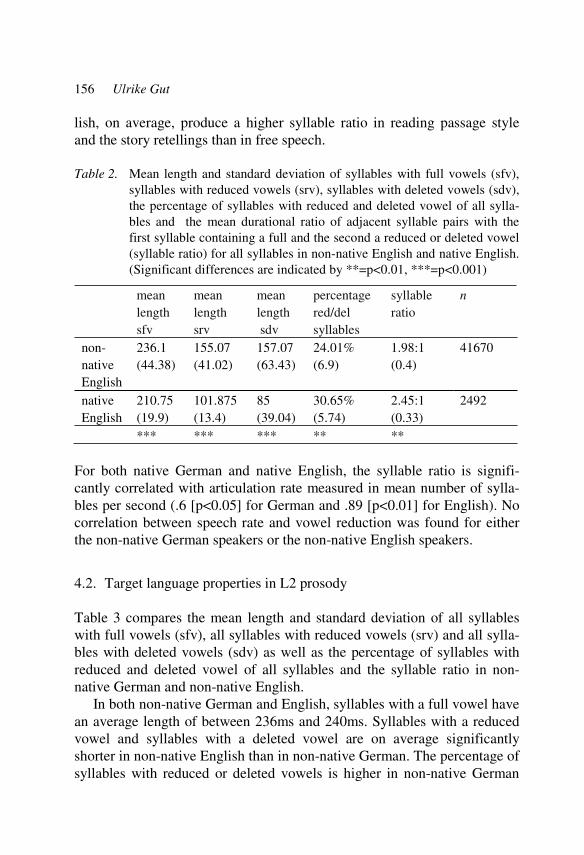
156 Ulrike Gut
lish, on average, produce a higher syllable ratio in reading passage style and the story retellings than in free speech.
Table 2. Mean length and standard deviation of syllables with full vowels (sfv), syllables with reduced vowels (srv), syllables with deleted vowels (sdv), the percentage of syllables with reduced and deleted vowel of all sylla-bles and the mean durational ratio of adjacent syllable pairs with the first syllable containing a full and the second a reduced or deleted vowel (syllable ratio) for all syllables in non-native English and native English. (Significant differences are indicated by **=p<0.01, ***=p<0.001)
mean length sfv
mean length srv
mean length sdv
percentage red/del syllables
syllable ratio
n
non-native English
236.1 (44.38)
155.07 (41.02)
157.07 (63.43)
24.01% (6.9)
1.98:1 (0.4)
41670
native English
210.75 (19.9)
101.875 (13.4)
85(39.04)
30.65% (5.74)
2.45:1 (0.33)
2492
*** *** *** ** **
For both native German and native English, the syllable ratio is signifi-cantly correlated with articulation rate measured in mean number of sylla-bles per second (.6 [p<0.05] for German and .89 [p<0.01] for English). No correlation between speech rate and vowel reduction was found for either the non-native German speakers or the non-native English speakers.
4.2. Target language properties in L2 prosody
Table 3 compares the mean length and standard deviation of all syllables with full vowels (sfv), all syllables with reduced vowels (srv) and all sylla-bles with deleted vowels (sdv) as well as the percentage of syllables with reduced and deleted vowel of all syllables and the syllable ratio in non-native German and non-native English.
In both non-native German and English, syllables with a full vowel have an average length of between 236ms and 240ms. Syllables with a reduced vowel and syllables with a deleted vowel are on average significantly shorter in non-native English than in non-native German. The percentage of syllables with reduced or deleted vowels is higher in non-native German
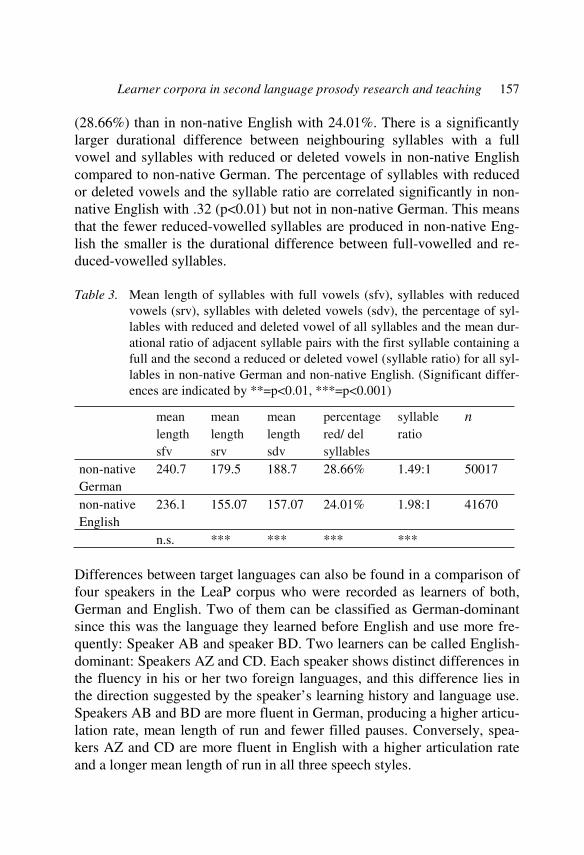
Learner corpora in second language prosody research and teaching 157
(28.66%) than in non-native English with 24.01%. There is a significantly larger durational difference between neighbouring syllables with a full vowel and syllables with reduced or deleted vowels in non-native English compared to non-native German. The percentage of syllables with reduced or deleted vowels and the syllable ratio are correlated significantly in non-native English with .32 (p<0.01) but not in non-native German. This means that the fewer reduced-vowelled syllables are produced in non-native Eng-lish the smaller is the durational difference between full-vowelled and re-duced-vowelled syllables.
Table 3. Mean length of syllables with full vowels (sfv), syllables with reduced vowels (srv), syllables with deleted vowels (sdv), the percentage of syl-lables with reduced and deleted vowel of all syllables and the mean dur-ational ratio of adjacent syllable pairs with the first syllable containing a full and the second a reduced or deleted vowel (syllable ratio) for all syl-lables in non-native German and non-native English. (Significant differ-ences are indicated by **=p<0.01, ***=p<0.001)
mean length sfv
mean length srv
mean length sdv
percentage red/ del syllables
syllable ratio
n
non-native German
240.7 179.5 188.7 28.66% 1.49:1 50017
non-native English
236.1 155.07 157.07 24.01% 1.98:1 41670
n.s. *** *** *** ***
Differences between target languages can also be found in a comparison of four speakers in the LeaP corpus who were recorded as learners of both, German and English. Two of them can be classified as German-dominant since this was the language they learned before English and use more fre-quently: Speaker AB and speaker BD. Two learners can be called English-dominant: Speakers AZ and CD. Each speaker shows distinct differences in the fluency in his or her two foreign languages, and this difference lies in the direction suggested by the speaker’s learning history and language use. Speakers AB and BD are more fluent in German, producing a higher articu-lation rate, mean length of run and fewer filled pauses. Conversely, spea-kers AZ and CD are more fluent in English with a higher articulation rate and a longer mean length of run in all three speech styles.
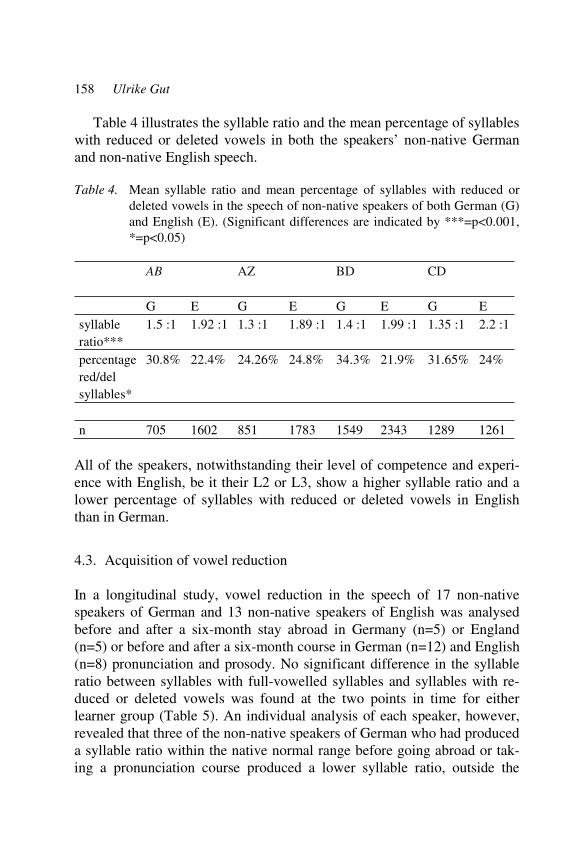
158 Ulrike Gut
Table 4 illustrates the syllable ratio and the mean percentage of syllables with reduced or deleted vowels in both the speakers’ non-native German and non-native English speech.
Table 4. Mean syllable ratio and mean percentage of syllables with reduced or deleted vowels in the speech of non-native speakers of both German (G) and English (E). (Significant differences are indicated by ***=p<0.001, *=p<0.05)
AB AZ BD CD
G E G E G E G E syllable ratio***
1.5 :1 1.92 :1 1.3 :1 1.89 :1 1.4 :1 1.99 :1 1.35 :1 2.2 :1
percentage red/del syllables*
30.8% 22.4% 24.26% 24.8% 34.3% 21.9% 31.65% 24%
n 705 1602 851 1783 1549 2343 1289 1261
All of the speakers, notwithstanding their level of competence and experi-ence with English, be it their L2 or L3, show a higher syllable ratio and a lower percentage of syllables with reduced or deleted vowels in English than in German.
4.3. Acquisition of vowel reduction
In a longitudinal study, vowel reduction in the speech of 17 non-native speakers of German and 13 non-native speakers of English was analysed before and after a six-month stay abroad in Germany (n=5) or England (n=5) or before and after a six-month course in German (n=12) and English (n=8) pronunciation and prosody. No significant difference in the syllable ratio between syllables with full-vowelled syllables and syllables with re-duced or deleted vowels was found at the two points in time for either learner group (Table 5). An individual analysis of each speaker, however, revealed that three of the non-native speakers of German who had produced a syllable ratio within the native normal range before going abroad or tak-ing a pronunciation course produced a lower syllable ratio, outside the
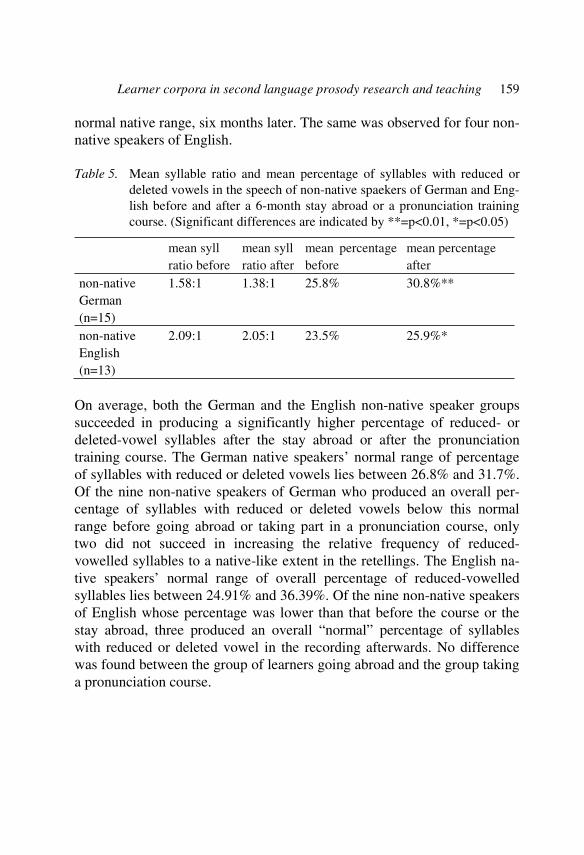
Learner corpora in second language prosody research and teaching 159
normal native range, six months later. The same was observed for four non-native speakers of English.
Table 5. Mean syllable ratio and mean percentage of syllables with reduced or deleted vowels in the speech of non-native spaekers of German and Eng-lish before and after a 6-month stay abroad or a pronunciation training course. (Significant differences are indicated by **=p<0.01, *=p<0.05)
mean syll ratio before
mean syll ratio after
mean percentage before
mean percentage after
non-native German (n=15)
1.58:1 1.38:1 25.8% 30.8%**
non-native English (n=13)
2.09:1 2.05:1 23.5% 25.9%*
On average, both the German and the English non-native speaker groups succeeded in producing a significantly higher percentage of reduced- or deleted-vowel syllables after the stay abroad or after the pronunciation training course. The German native speakers’ normal range of percentage of syllables with reduced or deleted vowels lies between 26.8% and 31.7%. Of the nine non-native speakers of German who produced an overall per-centage of syllables with reduced or deleted vowels below this normal range before going abroad or taking part in a pronunciation course, only two did not succeed in increasing the relative frequency of reduced-vowelled syllables to a native-like extent in the retellings. The English na-tive speakers’ normal range of overall percentage of reduced-vowelled syllables lies between 24.91% and 36.39%. Of the nine non-native speakers of English whose percentage was lower than that before the course or the stay abroad, three produced an overall “normal” percentage of syllables with reduced or deleted vowel in the recording afterwards. No difference was found between the group of learners going abroad and the group taking a pronunciation course.

160 Ulrike Gut
4.4. Qualitative analysis of linguistic structures
In a qualitative analysis of the vowel reduction patterns of three different learner groups, two particular inflectional morphemes in German were investigated. In German, word-final post-tonic C+<-en> and C+<-e> syl-lables as for example in treffen (‘to meet’) and diesem (dative form of the demonstrative pronoun ‘this’), where C stands for any consonant, are either produced as C+[ n] and C+[ m] with the reduced vowel schwa. In connec-ted speech, the vowel may even be deleted (e.g. Helgason and Kohler 1996).
The realization of these C+<-en> and C+<-em> were analysed for three native and 16 non-native speakers of German with different language back-grounds: English native speakers (n=5), Italian native speakers (n=6) and Mandarin Chinese native speakers (n=5). Table 6 illustrates the phonetic realisation of the word-final syllables C+<en> and C+<em> by all spea-kers. The percentages of productions without vowel (deleted), productions with a schwa / /, the a-schwa / / or a full vowel are given for each group. The German native speakers produce roughly half of the word-final sylla-bles C+<en> and C+<em> without a vowel and half with the reduced vowel [ ]. A-schwa and full vowels never occur in these syllables. The English learners show a different pattern, deleting the majority of these vowels. The Italian learners produce a similar quantity of syllables without vowel and with [ ]. In 9% of these syllables, however, a full vowel is pro-duced, which is significantly different from the German native speakers. The Chinese non-native speakers of German show a clear preference for the [ ] vowel in these positions, followed by some deleted vowels (17%) and some full vowels. A-schwa occurs in 6% of the cases, which is significantly different from the German native speakers.
There are significant differences in the vowel reduction strategies be-tween the different non-native speaker groups. An ANOVA revealed a significant (p<0.05) difference in the percentage of schwas produced in the syllables of the type C+<en> and C+<em> between the three non-native speaker groups. The Chinese produce significantly more schwas in this phonetic environment than the other two speaker groups. Deleted vowels in these syllables are produced significantly more often (p<0.01) by the Eng-lish non-native speakers of German than the other two speaker groups. A-schwas and full vowels in this environment are produced only by the Italian and the Chinese non-native speakers of German, but not by the native Eng-lish speakers.
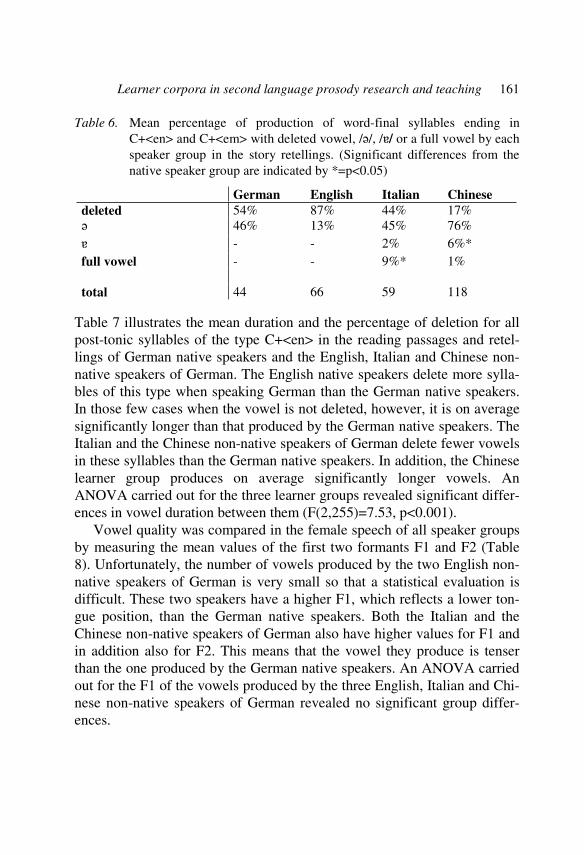
Learner corpora in second language prosody research and teaching 161
Table 6. Mean percentage of production of word-final syllables ending in C+<en> and C+<em> with deleted vowel, / /, / / or a full vowel by each speaker group in the story retellings. (Significant differences from the native speaker group are indicated by *=p<0.05)
German English Italian Chinese deleted 54% 87% 44% 17%
46% 13% 45% 76% - - 2% 6%*
full vowel - - 9%* 1%
total 44 66 59 118
Table 7 illustrates the mean duration and the percentage of deletion for all post-tonic syllables of the type C+<en> in the reading passages and retel-lings of German native speakers and the English, Italian and Chinese non-native speakers of German. The English native speakers delete more sylla-bles of this type when speaking German than the German native speakers. In those few cases when the vowel is not deleted, however, it is on average significantly longer than that produced by the German native speakers. The Italian and the Chinese non-native speakers of German delete fewer vowels in these syllables than the German native speakers. In addition, the Chinese learner group produces on average significantly longer vowels. An ANOVA carried out for the three learner groups revealed significant differ-ences in vowel duration between them (F(2,255)=7.53, p<0.001).
Vowel quality was compared in the female speech of all speaker groups by measuring the mean values of the first two formants F1 and F2 (Table 8). Unfortunately, the number of vowels produced by the two English non-native speakers of German is very small so that a statistical evaluation is difficult. These two speakers have a higher F1, which reflects a lower ton-gue position, than the German native speakers. Both the Italian and the Chinese non-native speakers of German also have higher values for F1 and in addition also for F2. This means that the vowel they produce is tenser than the one produced by the German native speakers. An ANOVA carried out for the F1 of the vowels produced by the three English, Italian and Chi-nese non-native speakers of German revealed no significant group differ-ences.

162 Ulrike Gut
Table 7. Mean duration of all vowels in the post-tonic syllables of the type C+<en> produced by the German native speakers and the three learner groups in the reading passages and retellings. (Significant differences from the native speaker group are indicated by ***=p<0.001, ** = p<0.01, *=p<0.05)
German (n=3)
English (n=5)
Italian (n=6)
Chinese (n=6)
duration 0.046 0.06* 0.054 0.068***percentage deleted 76.5% 88.9% 48.3% 32.2%
n 98 118 178 236
Table 8. Mean F1 and F2 of all vowels in the post-tonic syllables of the type C+<en> produced by the women among the German native speakers and the three learner groups in the reading passages and retellings. (Signifi-cant differences from the native speaker group are indicated by *** = p<0.001, **=p<0.01, *=p<0.05)
German (n=2)
English (n=2)
Italian (n=4)
Chinese (n=4)
F1 376 629*** 517.5** 521.9** F2 1440 1427 1968*** 1600*
n 9 4 40 122
5. The LeaP corpus in language teaching
The LeaP corpus was used as a tool for inductive learning in a University course entitled “Phonetic properties of non-native speech”, in which 21 students of English at the University of Freiburg in Germany participated. The course lasted for one semester (October 2004 to February 2005) and consisted of 15 classes comprising a mix of lecture, discussion and corpus work. In 13 classes, the students worked with the corpus, using Praat, and solved small tasks such as the measurement of vowel lengths. At the end of the term, the students carried out a group project on an empirical research question of their choice. Research questions included for example “Final devoicing in English by German learners” and “Fluency after a stay abroad”.

Learner corpora in second language prosody research and teaching 163
After the course, the students filled in a questionnaire about the corpus work. In questions 1 and 2 they were asked to rate their preferred teaching method and to estimate where they learned most. Rating options given ran-ged from 1 (best) to 5 (worst). The students, on average, preferred the dis-cussion (2.2) and lecture (2.2) over corpus work (2.5), reading (2.6) and the presentations by students (3.3). They felt they had learned most in the lec-ture parts (1.66), followed by their own reading (1.8) and the discussions (2.47). Corpus work (2.66) and the presentations by students (3.25) were rated lowest. In the third question, the students agreed that corpus work was communicative (yes: 75% / no: 25%), interesting (95% / 5%), stimulating (86% / 14%) and varied (62% / 38%). On the whole, they did not judge it to be boring (yes: 11% / no: 89%), too difficult (0% / 100%), too easy (5% / 95%) or discouraging (0% / 100%). Furthermore, 90% agreed that they had learned a lot about foreign accent and that they had become more aware of foreign accents (81%). Only 10%, however, claimed that their own accent had improved through the corpus work, but 72% believed that their langua-ge teaching will improve.
6. Summary and outlook
The aim of this article was to illustrate how a corpus-based analysis of non-native prosody can complement current research methods and to demon-strate the new opportunities it offers in L2 prosody research and teaching. For this purpose, the LeaP corpus was analysed with respect to vowel re-duction in non-native German and non-native English. Comparing non-native speech with native speech, the results obtained confirm the observa-tions reported in the small-scale studies carried out by Wenk (1985), Bond and Fokes (1985), Flege and Bohn (1989), Kaltenbacher (1998) and Gut (2003). The major difference between non-native speech and native speech lies in the lack of durational difference between syllable pairs in which a syllable with a full vowel precedes a syllable with a reduced or deleted vowel. Overall, syllables of any kind are longer and therefore non-native speech is slower than native speech. In addition, non-native speakers of English do not succeed in a quantitatively sufficient reduction or deletion of vowels. Non-native and native vowel reduction also differ in terms of its correlation with other phonological features. Whereas in native German and native English the extent of vowel reduction correlates with the speak-ing rate, no such correlation exists in non-native speech.

164 Ulrike Gut
The corpus-based analysis moreover offered the opportunity to carry out a cross-linguistic comparison between speech produced by learners of two different languages, which has not been attempted so far. It was shown that non-native German and non-native English differ significantly in terms of vowel reduction. The durational difference between non-reduced and re-duced syllables is greater in non-native English than in non-native German. The percentage of reduced syllables in non-native German, however, is greater than in non-native English. This difference between the two inter-languages can be interpreted as target-language influence, probably based on different syllable structures and morphology in the two languages. This is furthermore corroborated by the analysis of some non-native speakers of both German and English: they show distinctly different vowel reduction processes when speaking German than when speaking English.
Moreover, a comparison of vowel reduction in different speech styles was carried out. Significant effects of style were only found for non-native English, where free speech shows less vowel reduction than story retellings and reading passage style.
Apart from large-scale quantitative analyses, qualitative studies of speaker subgroups and particular linguistic structures were carried out. Several analyses showed that although there is no difference in the amount of reduced syllables between native and non-native German, the distribu-tion of these syllables differs significantly. Learners do not seem to reduce or delete vowels according to the same phonological rules as native speak-ers. In particular, certain inflectional morphemes with obligatory vowel reduction in German did not have any or very little vowel reduction in non-native speech. An acoustic analysis of the quality of the vowel produced furthermore showed significant differences in tongue position and tense-ness in non-native vowels. Some differences in the distribution and quality of reduced vowels were found for learners with different languages back-grounds. However, in many areas, the learner subgroups exhibited the same production patterns.
Finally, longitudinal data was analysed with the aim of identifying char-acteristics and factors of the acquisition process. Two learner groups were compared: one participating in a stay abroad programme and the other par-ticipating in a pronunciation training course. As concerns learning context, no difference between the two was found. Results showed that both groups improved some aspects of vowel reduction, but the variation among learn-ers was high. Whereas both learner groups improved the number of reduced syllables in the direction of native speaker values, individual learners

Learner corpora in second language prosody research and teaching 165
showed divergent learning paths. None of the learners succeeded in acquir-ing native-like differences between full-vowelled and reduced-vowelled syllables even after the course or stay abroad. This leads to the tentative proposal that the appropriate amount of vowel reduction is acquired before the appropriate phonetic realisation of it.
In summary, the article demonstrated the advantages of corpus-based re-search in L2 prosody in comparison with current experimental methods. Large-scale quantitative analyses of corpora yield generalizable results con-cerning the frequency of linguistic structures and their variation among learners, which cannot be derived from experimental studies based on the productions of a few participants. In this study, for example, a total of more than 90.000 syllables was analysed. These large-scale analyses furthermore offer insights into hitherto unresearched areas as for example variation among learners. It was demonstrated that variation is constrained by target language influences and that certain aspects of vowel reduction are ac-quired after others. However, it was also shown that quantitative analyses must be complemented by qualitative analyses. The observation of the overall frequency of reduced vowels in syllables is of limited value unless it is augmented by an investigation of particular types of linguistic struc-tures such as specific unstressed syllables.
A first application of the corpus in a university course showed that cor-pus work has some potential of raising students’ language awareness. How-ever, despite enjoying the experience, students doubt that it contributes to an improvement of their pronunciation in an L2. Further research is neces-sary to test the claims made by corpus linguists about the pedagogical value of corpus-based work in the classroom.
Notes
1. funded by the Ministry of Education, Research and Science of North-Rhine Westphalia, Germany
References
Biber, David, Susan Conrad, and Randi Reppen 1994 Corpus-based approaches to issues in applied linguistics. Applied
Linguistics 15, 169–187.

166 Ulrike Gut
Bond, Z. and Joann Fokes 1985 Non-native patterns of English syllable timing. Journal of Pho-
netics 13, 407–420. Botley, Simon, Julia Glass, Tony McEnery, and Andrew Wilson (eds.) 1996 Proceedings of Teaching and Language Corpora 1996. Lancas-
ter: UCREL technical papers volume 9. Flege, James and Ocke Schwen Bohn 1989 An instrumental study of vowel reduction and stress placement in
Spanish-accented English. Studies in Second Language Acquisi-tion 11, 35–62.
Ghadessy, Mohsen, Alex Henry, and Robert Roseberry 2001 Small Corpus Studies and ELT. Amsterdam: John Benjamins. Granger, Sylviane 2002 A bird’s eye view of learner corpus research. In: Sylvaine
Granger, Joseph Hung and Stephanie Petch-Tyson (eds.) Com-puter Learner Corpora, Second Language Acquisition and For-eign Language Teaching, 3–33. Amsterdam: Benjamins.
2004 Computer learner corpus research: current status and future pros-pects. In: Ulla Connor and Thomas Upton (eds.), Applied Corpus Linguistics. A multidimensional perspective, 123–145. Amster-dam: Rodopi.
Granger, Sylvaine and Christopher Tribble, 1998 Learner corpus data in the foreign language classroom: form-
focused instruction and data-driven learning. In: Sylviane Granger (ed.), Learner English on Computer. 199–209. London: Longman.
Granger, Sylviane, Joseph Hung and Stephanie Petch-Tyson (eds.) 2002 Computer Learner Corpora, Second Language Acquisition and
Foreign Language Teaching. Amsterdam: Benjamins. Gut, Ulrike 2003 Non-native speech rhythm in German. Proceedings of the 15th
International Congress of Phonetic Sciences, Barcelona, 2437–2440.
Hasselgard, Hilde 1999 Review of S. Granger (ed.), Learner English on Computer.
ICAME Journal 23, 148–152. Helgason Pétur and Klaus Kohler 1996 Vowel deletion in the Kiel Corpus of Spontaneous Speech. In:
Klaus Kohler, Claudia Rehor and Adrian Simpson (eds.), Sound Patterns in Spontaneous Speech, Arbeitsberichte des Instituts für Phonetik und digitale Sprachverarbeitung 30, Universität Kiel, 115–157.

Learner corpora in second language prosody research and teaching 167
Kaltenbacher, Erika 1998 Zum Sprachrhythmus des Deutschen und seinem Erwerb. In:
Heide Wegener (ed.), Eine zweite Sprache lernen, 21–38.Tübingen: Narr.
Kennedy, Graeme 1998 An Introduction to Corpus Linguistics. London: Longman. Kettemann, Bernhard and Georg Marko (eds.) 2002 Teaching and Learning by Doing Corpus Analysis. Amsterdam:
Rodopi. Leather, James 1999 Second-language speech: an introduction. Language Learning
supplement 49, 1–56.Mairs, Jane 1989 Stress assignment in interlanguage phonology: an analysis of the
stress system of Spanish speakers learning English. In: Susan Gass and Jacquelin Schachter (eds.), Linguistic Perspectives on Second Language Acquisition, 260–283. Cambridge: Cambridge University Press.
McEnery, Tony and Andrew Wilson 2001 Corpus Linguistics. Edinburgh: Edinburgh University Press. 2nd
edition. Nesselhauf, Nadja 2004 Learner corpora and their potential for language teaching. In:
John Sinclair (ed.), How to Use Corpora in Language Teaching,125–152. Amsterdam: John Benjamins.
Sinclair, John (ed.) 2004 How to Use Corpora in Language Teaching. Amsterdam: John
Benjamins. Wenk, Brian 1985 Speech rhythms in second language acquisition. Language and
Speech 28, 157–174. Zborowska, Justyna 2000 The acquisition of English speech rhythm by Polish learners.
Proceedings of New Sounds 2000, Amsterdam, 368–374.


Part 2. Teaching practice


Teaching prosody in German as foreign language
Ulla Hirschfeld and Jürgen Trouvain
1. Introduction
The “sound of a language”, which is primarily transmitted by prosodic features, does not just convey the content of an utterance, but also other important communicative information. It marks the emotional state of the speaker and it can have the effect of being calming, detesting, encouraging, warm, cold, intimate or strange. Moreover, the individual way of speaking is a key feature of a speaker’s personality, an audible “business card”. From the foreign accent and other features native speakers deduce the educational status, the social affiliation, the degree of intelligence and even certain traits of the individual character (cf. Hirschfeld 1994). For these reasons prosodic features should be taught in the first line when teaching pronun-ciation.
What can be expected from “theory” on prosodic structure and realisa-tion of prosody? What can be transmitted to teachers of German as a for-eign language (henceforth DaF for Deutsch als Fremdsprache)? In which way can it be made clear? Theories about what prosody exactly is and how it can be described are not as simple as a teacher may wish, because the rules how to realise prosody are not as clear-cut as the rules how to realise the sounds of a word. Different conditions determine the correctness and the acceptability of the prosody of an utterance such as the communicative situation and the text type. Seen from the teachers’ perspective, researchers have not always a good knowledge of what teachers are interested in. A high quality in teaching of prosody requires a fruitful dialogue between researchers and teachers. The goal of this article is to present how concepts from “theory” can be applied and integrated into foreign language teaching illustrated with examples of German as target language.
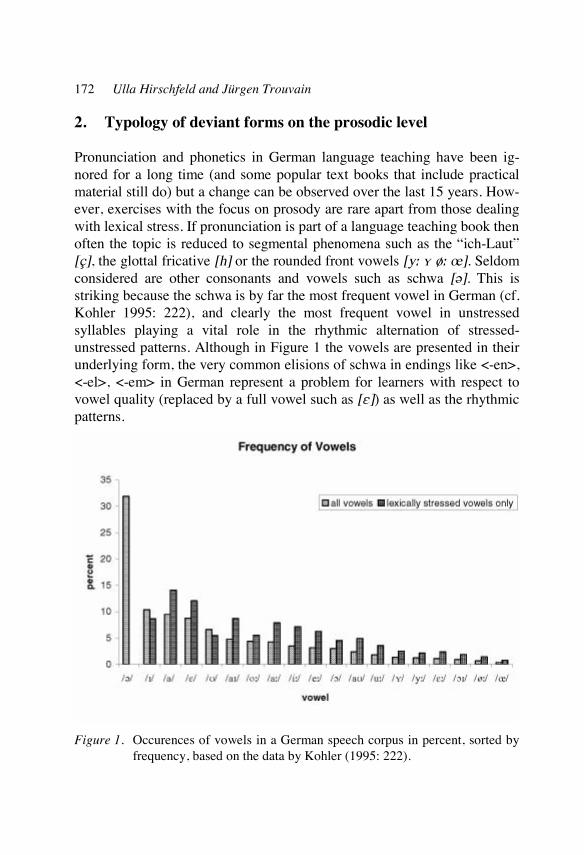
172 Ulla Hirschfeld and Jürgen Trouvain
2. Typology of deviant forms on the prosodic level
Pronunciation and phonetics in German language teaching have been ig-nored for a long time (and some popular text books that include practical material still do) but a change can be observed over the last 15 years. How-ever, exercises with the focus on prosody are rare apart from those dealing with lexical stress. If pronunciation is part of a language teaching book then often the topic is reduced to segmental phenomena such as the “ich-Laut” x ´ z, the glottal fricative x Üz or the rounded front vowels xóÁ=v=mÁ=ôz. Seldom considered are other consonants and vowels such as schwa x… z. This is striking because the schwa is by far the most frequent vowel in German (cf. Kohler 1995: 222), and clearly the most frequent vowel in unstressed syllables playing a vital role in the rhythmic alternation of stressed-unstressed patterns. Although in Figure 1 the vowels are presented in their underlying form, the very common elisions of schwa in endings like <-en>, <-el>, <-em> in German represent a problem for learners with respect to vowel quality (replaced by a full vowel such as x bz) as well as the rhythmic patterns.
Figure 1. Occurences of vowels in a German speech corpus in percent, sorted by frequency, based on the data by Kohler (1995: 222).

Teaching prosody in German as foreign language 173
In addition, many phenomena responsible for a foreign accent in Ger-man are of a supra-segmental or prosodic nature. Take for example a study with learners of German with different L1 who produced the sentence “Es regnet.” (“It is raining.”). When the accentuation fell on the last syllable of the verb (accentuation pattern “es regNET”) more than half of the German listeners (of various age) were unable to recognise the sentence correctly. In the correct pattern “es REGnet” only 5% of the listeners failed to get the message. Most listeners understood for “es regNET” sentences like “Ist sehr nett.” (“(It) is very nice.”) or “Es ist nett?” (“It is nice?”). The fact that declaratives as well as questions were understood shows that the melo-dic shape of the utterance was not clear and also that the segmental structu-re had been adapted to the suprasegmental structure. Here, the location of the accentuated vowels plays a decisive role. Too many interruptions in the form of pauses within an utterance led to further difficulties. Suprasegmen-tal deviations in combination with segmental mistakes caused a complete incomprehensibility for many listeners in this study (cf. Hirschfeld 1994: 102 ff.)
Although there is a great individual range of errors, some problems can be observed in groups of learners with a heterogeneous language back-ground. The list in Table 1 summarises possible errors attributable to the prosodic levels of prominence (of words and utterances, respectively), pitch contour and phrasing.
Table 1. Problems of L2 speech on different prosodic levels.
lexical stressphonological 1. on the wrong syllable phonetic 2. lengthening of short stressed vowels phonetic 3. too little contrast when realising stressed vs. unstressed sylla-
bles phonetic 4. lack of segmental reductions in unstressed syllables phonetic 5. melodic deviations in stressed and/or unstressed syllables (cf.
melodic contour) phonetic 6. over-strong secondary stresses in longer words, esp. com-
pound words

174 Ulla Hirschfeld and Jürgen Trouvain
Table 1. (continued)
pitch accentsphonological 1. too many pitch accents phonological 2. accent on the wrong word/s phonetic 3. incorrect or too strong secondary pitch accents phonetic 4. over-lengthening of pitch accented short vowels phonetic 5. too little contrast when realising pitch accented vs. unaccented
syllables phonetic 6. lack of segmental reductions in unaccented syllables
melodic contour (pitch range, pitch accent realisation, end of utterances)phonetic 1. melodic deviations in stressed and/or unstressed syllables phonological 2. wrong melodic contour at the end of utterances
pauses and phrasing structurephonological 1. too many pauses phonological 2. pauses at wrong locations phonetic 3. too long pauses
3. L1 influences
Some features of German prosody nearly always lead to difficulties for language learners: typical melodic contours (e.g. the accomplishing of the final low at the end of utterances), assignment and production of lexical stress, structuring and realisation of rhythm. Depending on their first lan-guage or prior acquired foreign languages, speakers exhibit different prob-lems with their German L2 prosody. The examples in Table 2 illustrate typical deviations for some languages.
Additional types of deviation are described in contrastive studies in Hirschfeld et al. (2002 ff.) where a survey of 40 languages is given.
Attention must be paid to the fact that for many language learners Ger-man is often the second foreign language after English, and sometimes even the third or fourth foreign language. Thus, interferences from prior acquired foreign languages must also be expected.
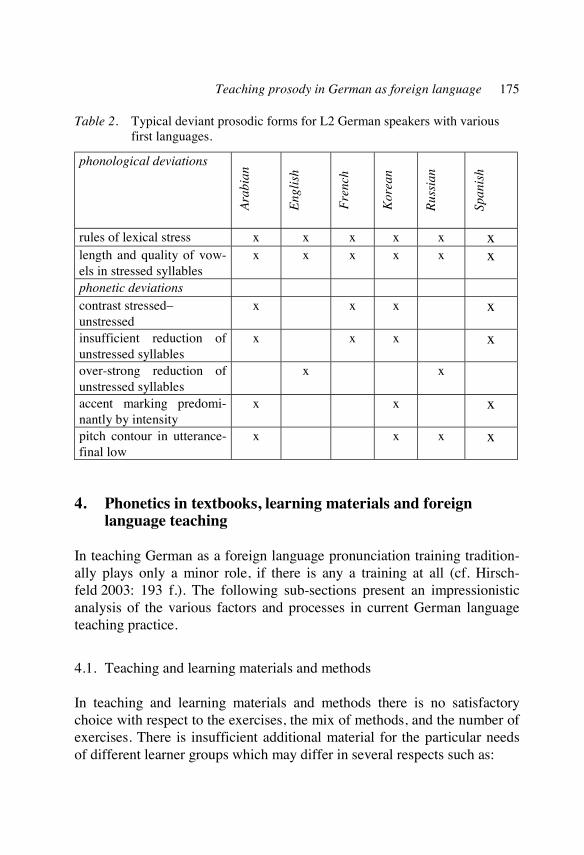
Teaching prosody in German as foreign language 175
Table 2. Typical deviant prosodic forms for L2 German speakers with various first languages.
phonological deviations
Ara
bian
Eng
lish
Fre
nch
Kor
ean
Rus
sian
Span
ish
rules of lexical stress x x x x x x length and quality of vow-els in stressed syllables
x x x x x x
phonetic deviations contrast stressed–unstressed
x x x x
insufficient reduction of unstressed syllables
x x x x
over-strong reduction of unstressed syllables
x x
accent marking predomi-nantly by intensity
x x x
pitch contour in utterance-final low
x x x x
4. Phonetics in textbooks, learning materials and foreign language teaching
In teaching German as a foreign language pronunciation training tradition-ally plays only a minor role, if there is any a training at all (cf. Hirsch-feld 2003: 193 f.). The following sub-sections present an impressionistic analysis of the various factors and processes in current German language teaching practice.
4.1. Teaching and learning materials and methods
In teaching and learning materials and methods there is no satisfactory choice with respect to the exercises, the mix of methods, and the number of exercises. There is insufficient additional material for the particular needs of different learner groups which may differ in several respects such as:

176 Ulla Hirschfeld and Jürgen Trouvain
– the learners’ first language(s) – their proficiency level in the foreign language – the age of the learner – the learning goals
The methods also have to differ in aspects such as
– the teaching traditions they are familiar with – the group characteristics (linguistically homogeneous vs. heterogeneous;
group size) – teaching situation (time; location; technical equipment).
4.2. Research on pronunciation training
There are still too few published research studies on didactic and methodo-logical issues in pronunciation teaching. This explains why the analysis of research results is still not an integral part of teachers’ education, especially at universities.
4.3. Consideration of research in learning materials
The authors of textbooks do not usually take publications in phonetic re-search into consideration, e.g. studies in contrastive phonetics, investigati-ons of norms and variation in standard German, or studies dealing with functions and effects of phonetic features in intercultural communication.
4.4. Teachers
The many peculiarities that define the teaching and learning of pronunciati-on compared to other skills are not considered in a differentiated way. Instead of dealing with pronunciation problems with individual and/or L1 causes, many teachers give up before they start, with the argument that the possible effect does not justify the effort. There is a widespread opinion that phonetics is a luxury. This attitude leads to the Cinderella role of pro-nunciation in teaching: Phonetics as the foundation of speaking and hearing in spontaneous conversation as well as of learning alphabet-based writing systems is simply ignored. Even though the situation has improved some-

Teaching prosody in German as foreign language 177
what with regard to speech sounds (and lexical stress) in the last 15 years, the teaching of prosody is still completely unsatisfactory.
A second problem is that phonologically relevant prosodic and segmen-tal characteristics and standards of pronunciation are not just transmitted by means of appropriate exercises but also by the teacher’s own speech pro-duction. In foreign language training, learners orientate themselves to their teachers. Thus, the teacher’s pronunciation plays an important role because it functions as a model (Dieling and Hirschfeld 2000: 19ff.). Many teachers of German are a bad model because they speak with their non-German accent or with a regional accent. Therefore it is important to make the tea-ching material function as a model. The teachers in question should be awa-re and admit to their accented speech.
4.5. Training of teachers
In teachers’ training, the mediation of the phonetic/phonological and the pedagogical basics is not taught sufficiently. The consequence is that many teachers feel insecure about how to introduce phonetic forms and how to make learners aware of them, how to correct deviant forms and how to help them to automate correct forms. The teachers must be prepared during all training phases
– to determine the use of the didactic methods in class, but also for indi-vidual teaching, i.e. the development of concepts of exercises for listen-ing and speaking,
– to recognise prosodic (and segmental) deviant forms, to point out the deviant forms and to correct them, ideally in an emphatic but motivating and effective way,
– to select and invent appropriate exercises, and to take care of a sufficient level of automation,
– to mediate rules and knowledge (differentiating quantity and methods for different groups of learners),
– to accept and understand their role as a model of language and speech (with the consequences for their respective foreign or regional accents).

178 Ulla Hirschfeld and Jürgen Trouvain
These requirements are much more than those we can observe in class-rooms nowadays. In the next two sections various types of exercises are presented followed by concrete examples applied in university classes.
5. Types of exercises
Many teachers of German assume that prosody is acquired by listening and imitation (“parrot method”). Most teaching materials also focus on imita-tion exercises. However, few learners are able to produce acceptable imita-tions. Especially teenagers and adult learners exhibit problems that can be attributed to various causes. Therefore, the types of exercises for the devel-opment of the perception and production skills must be carefully selected and their timing carefully organised.
The first step with listening exercises does not aim at understanding the content but at phonological and phonetic listening. The focus of phonologi-cal or phonematic listening is to distinguish and identify elements which differentiate meaning:
a. ein FACH – EINfach (English “a compartment”/ “a subject” – “simple”)
b. Ja? – Ja! (English “Yes?”/ “Really?”/ –“Yes!”)
Phonological listening is the fundament to the further processing and inter-pretation of spoken utterances. The next step, the phonetic listening, goes beyond the simple differentation of meaning: the perception of phonetic variants which occur frequently in daily situations is required, e.g. the speech melody in accented syllables or the lengthening of pauses. Here, the common practice of providing audio examples and asking learners to “lis-ten carefully” is not sufficient. Teachers as well as learners need to know where difficulties are likely to occur. This knowledge is only possible when the results of the listening are monitored. There are several ways of doing this ranging from marking syllables and words to transcribing; for quick feedback hand signals can be used.
Controllable listening exercises with minimal pairs are also recom-mended. These are easily prepared, using first and second names or geo-graphical names. In order to discriminate, two or three names can given, e.g.

Teaching prosody in German as foreign language 179
a. Which town is stressed on the last syllable? Luzern - Salzburg, Berlin - Halle - München
b. Which name does contain a long vowel in the stressed syllable? Müller - Mühler, Mehler - Meller - Möller
For an identification task the teacher gives an example in advance, e.g.
a. Which syllable is lexically stressed? The first, the second, the third or the last?
Mönchengladbach b. Is the stressed vowel a long vowel or a short vowel?
Möhler
The learner can even practise this type of listening exercises without a teacher if appropriate software is at hand such as “Phonothek interaktiv” (Hirschfeld and Stock 2000).
It is recommended that exercises for listening are linked to those for speaking by also using the listening material for imitating, reading aloud, variation and combination. Furthermore, monologue and dialogue texts, word lists and grammar exercises taken from the text book can be used as a basis for phonetic exercises – they all contain examples which are ap-propriate for practising. Examples can be used for visual highlighting, for word search, for sorting, listening, humming, articulating and reading a-loud. They can be used in different contexts and they can also be accompa-nied by gestures. Pauses, melodic contours and accent patterns can be marked in texts, either after listening or from memory. Learners can articu-late synchronously with the speakers of the audio examples. It is important that different learner strategies are stimulated and that not always the same type of exercises is offered. Exercises should vary and the requirements should continuously increase. Exercises for automation should start with rhythmic-melodic units larger than a word – the practice of single sounds and the articulation of words in isolation should be restricted to the first phase and the correction phase.
5.1. Methodological steps
We recommend a methodological procedure that has been validated across a wide range of teaching situations (cf. Hirschfeld 2003: 202):

180 Ulla Hirschfeld and Jürgen Trouvain
1. introduction of the topic, e.g. with a comprehension text 2. listening control, i.e. differentiate (compare) and identify (recognise)
prosodic features 3. imitation attempts, individually and in chorus in order to rehearse
anonymously 4. correction of deviant forms, to make the learners aware of the critical
phonetic features 5. repeated listening control 6. further imitation attempts with feedback 7. automation by repeating, reading, variation of speaking style
5.2. Typology of exercises
Providing a good mix of methods includes the provision of different types of exercises. In Dieling and Hirschfeld (2000: 47 ff.) various types of exer-cises are suggested. The most important ones are:
– listening exercises – preparatory listening exercises as warm-up exercises: e.g. first
names in rhyming, proverbs, texts – identification: e.g. recognising the stressed syllable in a first
name (Michael, Michaela, Christian, Christiane) – discrimination: e.g. compare stress position in first names (Pe-
ter = Petra, Robert # Roberta) – applied listening: e.g. first names in texts
– imitation exercises – creative production exercises
– alter, add, combine linguistic elements – in combination with work on grammar and vocabulary
– applied production exercises – read aloud, oral presentation – free speech
– acting in scenes

Teaching prosody in German as foreign language 181
5.3. Central points for exercises in prosody
The focus of exercises should differ according to the learners’ first lan-guage. Native speakers of tone languages have greater and more complex difficulties than native speakers of Germanic languages (other than Ger-man). The following topics are fundamental for the comprehension of Ger-man; they should be given a central role among the phonetic exercises:
– lexical stress – stress assignment (application of stress rules) – vowel length in stressed syllables (long vs. short) – contrast of stressed vs. unstressed syllables
– rhythm – accentuation at utterance level – alternation of stressed – unstressed syllables in rhythmic
groups – schwa
– realisation of schwa-syllables, especially elision of schwa in word-endings – as an important element of rhythmic structure
– pauses and phrase structuring – typical melodic contours
– fall-rise contour in yes/no-questions and contact-eliciting or very friendly utterances
– rise-fall contour in terminal declarative utterances – (extreme) final low at the end of utterances
6. Examples of exercises
In this section we intend to show some examples of exercises that can be applied in almost every pronunciation lesson and which can easily be va-ried. The two most important features are:
1. Apart from the phonetic topic there is always a content theme such as location names or clothing. The exercises in sections 6.1 and 6.2 can be individually modified: instead of town names one can practise the stress patterns with food terms, hobbies, names of bus stations etc. These con-tent-oriented exercises make them interesting for the learners and pro-

182 Ulla Hirschfeld and Jürgen Trouvain
vide a better memorization of the phonological pattern as well as the vo-cabulary.
2. Each exercise consists of several steps which elicit and support the ac-tivity of the learner. The exercises are not restricted to a few isolated chance collection of words and sentences which have to be heard and repeated. The structure of exercises proposed here makes a high degree of automation possible because further steps can be added continuously, i.e. the same material can be practised with different tasks.
The following exercises are taken from Hirschfeld and Reinke (1997) where further practical suggestions are given.
6.1. Lexical stress
Step 1: Listen to the town names and assign them to the stress patterns.
Berlin, Hannover, Hamburg, Magdeburg, Neuruppin …
1. 2. 3. 4.
Step 2: Listen again and repeat. Step 3: Can you find other German towns that fit to these patterns? Step 4: Draw stress patterns for towns in your own language. Step 5: Practice exercise: plan a journey in towns with bi-syllabic names
and stress on the first (second) syllable.
6.2. Vowel length
Step 1: Listen to example words (Mantel, Schal, Hose, Socke), show with your hands whether the stressed vowel is long or short.
Step 2: Write down (ten) pieces of clothing below the appropriate heading short or long in a two column-table, depending on the length of the stressed vowel.

Teaching prosody in German as foreign language 183
short long Hemd Rock ...
Hose Schal ...
Step 3: With this table, the learners have to find out by themselves what the spelling rules are that tell you whether it is a long or a short vowel. These spelling-to-sound rules for the vowels should be summarised by the teacher.
Step 4: For practice the learners are asked to “pack a suitcase for a short trip, taking only clothes that have a short vowel!”. Alternatively, or as an exercise after the “short-vowel-journey” a “long-vowel-journey” can be offered.
6.3. Melody and phrasing
Step 1: Have a look at the following lines. The sentences consist of the same words in the same order.
1 PAULA WILL PAUL NICHT
2 PAULA WILL PAUL NICHT
3 PAULA WILL PAUL NICHT
4 PAULA WILL PAUL NICHT
5 PAULA WILL PAUL NICHT
...
Step 2: Listen to the examples and add the punctuation signs. It should be done step by step, example by example, week by
week.
You end up with a list like this one:
1 PAULA WILL PAUL NICHT.2 PAULA WILL, PAUL NICHT.3 PAULA WILL? PAUL NICHT.4 PAULA, WILL PAUL NICHT?5 PAULA WILL PAUL, NICHT?

184 Ulla Hirschfeld and Jürgen Trouvain
Step 3: Find further examples and add the following punctuation signs between the words: ? ! , ; : . „ “
Step 4: Compare your results with your partner’s. Step 5: Read the different variants aloud. Your partner should correct your
performance.
6.4. Sentence or (pitch) accent
Step 1: Listen to the examples and underline the accented words. The list will look like this:
1 PAULA WILL PAUL NICHT. 2 PAULA WILL PAUL NICHT. 3 PAULA WILL PAUL NICHT. 4 PAULA WILL PAUL NICHT.
Step 2: What are the meanings of the variants? Can you imagine a situa-tion where “Paula” is in the focus of the utterance?
Step 3: Read the different sentences aloud. This can be done as a partner exercise.
6.5. Schwa
Step 1: The letter <e> is the most frequent letter in German. It corresponds sometimes to x É Áz I =x b z, or is part of x ~ fzx l fzx á Áz. But in many occa-sions the <e> has a different pronunciation as in the words hatte, rede, sage, liebe. Can you produce this e-sound in isolation?
Step 2: What are the corresponding infinitive and plural forms? What hap-pens to the written <e> in hatten, reden, sagen, lieben?
Step 3: Look at the followig word stems: red-, sag-, lieb-. What does this verb sound like in the first person singular compared to the first person plural? x Dê É ÁÇ… z vs.=xD ê É ÁÇå}z =
Step 4: Listen to the following three words: Härte, härter, Hertha. What is the difference? Can you hear the difference between the unstressed [a] and the “vocalized r”?

Teaching prosody in German as foreign language 185
Step 5: What do the comparative forms of the adjective klein sound like? Fill in Eine klein- Schwester, Ein klein- Bruder.
Step 6: Mark in the text where an <e> represents a schwa, a deleted schwa or where <e> stands for a “vocalized r”.
7. Methodological recommendations
The most important features of prosody must be made clear to both learners and teachers in an adequate way. What is the role of the teacher? How are teachers to be convinced that prosody is important? How are teachers to be taught?
Here is a summary list of the requirements for foreign-language teachers (cf. Hirschfeld 2003: 213 f.):
1. motivate 2. visualise (e.g. body movements) 3. show knowledge of phonetic characteristics 4. make learners aware of deviant forms 5. check performance in listening exercises 6. provide interesting, non-routine and creative fun exercises 7. provide enough exercises for a sufficient level of automation 8. provide exercises: better frequent & short than infrequent & long 9. focus on rhythmic-melodic units (i.e. larger than just one word) 10. integrate exercises into situations and context 11. combine exercises with work on grammar and vocabulary
In our view, teachers must be willing and able to recognise, to explain, and to correct the most serious problems in the area of prosody and pronuncia-tion in general and also to give adequate feedback. They must know rules, characteristics, and the structures of the native language/s of their language learners. They have to apply multiple methods, since the “parrot method” as the most commonly practised method is not sufficient.
8. Conclusion
This article aimed to describe the state-of-the-art of prosody and pronuncia-tion teaching in DaF. Despite some progress in the last few decades, we can

186 Ulla Hirschfeld and Jürgen Trouvain
still identify enormous deficits. These deficits concern the practice, i.e. the knowledge of teachers and the teaching materials available, as well as the theory, i.e. research in second language acquisition that does not take the practicalities of teaching in consideration. An understanding of both theory and practice is necessary to reduce these deficits. We hope that this article can contribute to this goal by showing the most important problems but also by presenting some practical solutions.
There is clearly much to do in order to develop satisfactory methods of teaching prosody. This concerns the diagnosis of phonetic, especially pro-sodic deviations, the application of exercises, and of course a measure for comparing levels of prosodic mastery. Another unsolved question that re-quires intensive discussion and research is how to assess various teaching methods. Is there any way to test learners’ progress when teachers integrate prosody into their pronunciation teaching? What is the impact of prosody training? Is there an impact of prosody training in the first place? To an-swer those questions multiple factors must be taken into account such as the learners’ L1, the group size or the learners’ proficiency level in the foreign language. However, the reality in classrooms does usually not allow the control of all those factors.
Nevertheless, experience in teaching practice has clearly shown that a systematic training of prosodic elements raises the degree of intelligibility in the foreign language (Hirschfeld 1994; Missaglia this volume). At the same time the pronunciation of vowels and consonants improves because the learners are now sensitive to features also relevant for segmental struc-ture such as duration and articulatory tension, e.g. for vowel oppositions like xá ÁJ fI=ìÁJ rI=çÁJ lz and so forth. Therefore we think that teaching prosody goes hand in hand with teaching the pronunciation of sound segments.
References
Dieling, Helga and Hirschfeld, Ursula 2000 Phonetik lehren und lernen. München: Langenscheidt. Hirschfeld, Ursula 1994 Untersuchungen zur phonetischen Verständlichkeit Deutschler-
nender. (Forum Phoneticum, Bd. 57). Frankfurt/M.: Hector.

Teaching prosody in German as foreign language 187
2003 Phonologie und Phonetik in Deutsch als Fremdsprache. In: Claus Altmayer and Roland Forster (eds.), Deutsch als Fremdsprache: Wissenschaftsanspruch – Teilbereiche – Bezugsdisziplinen, 189-233. Frankfurt/M etc.: Peter Lang.
Hirschfeld, Ursula, Heinrich P. Kelz and Ursula Müller (eds.) 2002 Phonetik international. Grundwissen von Albanisch bis Zulu. Ein
Online-Portal: www.phonetik-international.de. Waldsteinberg: Heidrun Popp Verlag.
Hirschfeld, Ursula and Kerstin Reinke 1997 Simsalabim. Übungskurs zur deutschen Phonetik (Video, Kasset-
te, Arbeitsbuch). München: Langenscheidt. Hirschfeld, Ursula and Eberhard Stock (eds.) 2000 Phonothek interaktiv (CD-ROM). München: Langenscheidt. Kohler, Klaus J. 1995 Einführung in die Phonetik des Deutschen. 2nd edition. Berlin:
Erich Schmidt Verlag.


Metacompetence-based approach to the teaching of L2 prosody: practical implications
Magdalena Wrembel
1. Introduction
A global perspective in teaching has brought about an increasingly com-mon understanding of pronunciation as being an integral part of oral com-munication (cf. e.g. Celce-Murcia 1987, Morley 1987). Traditionally, pro-nunciation instruction has been primarily associated with the accurate production of segments, however, under the influence of discourse-based approaches, suprasegmental features of language have been found to exert the greatest impact on comprehensibility and communication. This has resulted in a significant shift of priorities from the narrow segmental focus to a broader “top-down” perspective highlighting the importance of pros-ody and contextual meaning (de Bot and Mailfert 1982). Advocates of such an approach consider pronunciation to be a non-segmental, non-discrete and non-autonomous phenomenon, emphasising that only by departing from the traditional understanding of phonology in terms of discrete seg-ments it can be viewed as the phonological aspect of speech in real com-munication (cf. Pennington 1989).
In spite of the widespread consensus about the significance of prosodic features for successful communication, which has resulted in a more bal-anced treatment of segmental and suprasegmental aspects of pronunciation in some English as a Foreign Language (EFL) course books, prosody still appears to be the ‘problem child’ from the pedagogical perspective and is considered notoriously difficult to teach (cf. e.g. Dalton and Seidlhofer 1994, Celce-Murcia 1987). Prosodic patterns, especially differences in pitch movements, are usually regarded to be more difficult to perceive and pro-duce than the segmentals. According to Roach “the complexity of the total set of sequential and prosodic components of intonation and of paralinguis-tic features makes it a very difficult thing to teach” (1991: 168). There seems to be an inverse relationship between communicative importance and teachability, as suggested by Dalton and Seidlhofer (1994: 72–73), who point out that individual sound segments are high on the learnability scale

190 Magdalena Wrembel
yet they are relatively less important for communication, whereas the su-prasegmentals, or more specifically, the attitudinal function of intonation, are extremely important in discourse, yet they are more difficult to adapt for direct teaching. Consequently, prosody has not been given a prominent place in most EFL teaching materials with an exception of such publications as e.g. Brazil (1994), Bradford (1988), Laroy (1996) or Vaugham-Rees (1994).
What makes intonation teaching even more problematic is the fact that some of the most recent trends in pronunciation teaching seem to be influ-enced by a highly controversial proposal of the Lingua Franca Core – LFC (cf. Jenkins 2000) aimed at the simplification of English phonology and the reduction of the pronunciation teaching load only to those features that seem apparently essential for international intelligibility. For instance, the majority of the suprasegmental features including pitch movements or stress-timing are excluded from Jenkins’ LFC as not crucial and unteach-able. This goes counter to a commonly held view that correct intonation, rhythm and accentuation are regarded as indispensable for intelligibility (cf. Brazil 1994, Kenworthy 1990, Morley 1994) and that “all learners should be proficient in making use of pitch movements as important cues for sig-nalling salient words or syllables” (Gimson 2001: 312).
The present contribution, therefore, seeks to address the need for ade-quate methodological guidelines for teaching prosody to foreign language learners. The proposed theoretical model of phonological acquisition is aimed at presenting a rationale for developing phonological metacompe-tence in L2 learners acquiring foreign language prosody. The need for the construction of such a model has arisen from the recognition that traditional pronunciation teaching techniques are not fully adequate, particularly in the case of L2 prosody. The new rationale rests on the claim that prosody teaching should be directed at consciousness-raising and the analysis of theoretical knowledge rather than practice alone.
Teaching about the language is a contentious issue relevant to the per-ennial debate between second language acquisition researchers on the role played by explicit and implicit knowledge in developing the competence of the second language learner (for a detailed discussion of the role of con-sciousness in language learning see Wrembel 2006). A prevailing trend nowadays seems to emphasise the natural language learning ability re-flected in a naturalistic approach to acquire languages in a purely intuitive manner. The ability to analyse language in a conscious manner is fre-quently seen as a totally different kind of skill that is usually fostered in a

Metacompetence-based approach to the teaching of L2 prosody 191
traditional, formal classroom setting with varying results. The present paper intends to address this misconception and demonstrate the importance of metalinguistic knowledge and awareness as facilitators of the process of learning of second language prosody. Moreover, it aims to show that the enhancement of phonological metacompetence may be accomplished by means of an array of novel and attractive techniques and classroom prac-tices.
2. Metacompetence-oriented model of phonological acquisition
The proposed model is an attempt at providing a comprehensive framework of acquisition of L2 phonology, encompassing L2 prosody. To this end, the
Figure 1. Metacompetence-oriented model of phonological acquisition

192 Magdalena Wrembel
model is constructed as consisting of three major component blocks (cf. Fig. 1):
a) acquisition process (explicated within the framework of Natural Pho-nology),
b) metacompetence as a facilitating device, c) conditioning socio- and psycholinguistic factors.
2.1. Process of phonological acquisition
Predictions concerning the phonological acquisition of a second language are encompassed within the model of Natural Phonology (cf. e.g. Stampe 1973). According to the natural framework, learning L1 phonology does not require cognitive processing (cf. Donegan 1985), however, in second language acquisition the learner’s starting point is completely different. In the course of SLA the access to universal processes is more difficult as the phonological system of an adult learner is already established, i.e. it is lim-ited to selected processes and underlying representations as well as rules. To gain the access the learner needs to unsuppress, re-order and limit anew some processes in a conscious and controlled manner (Dziubalska-Kołaczyk 1990).
The process of second language phonological acquisition is presented schematically in Fig.1 Part 1 – Process of L2 acquisition, as an adaptation of a model proposed by Dziubalska-Kołaczyk (1990). The first stage of phonological acquisition at the level of perception consists in learning to perceive adequately L2 surface realisations (i.e. L2 outputs), which other-wise are filtered through the grid of one’s L1 and associated with L1-specific sound intentions. Formal instruction geared particularly at guided ear training and consciousness raising at the level of contrastive analysis act at this stage as intake facilitators. Explicit theoretical training may enhance the learning process also at the second stage when learners attempt to de-code L2-specific sound intentions and form mental representations on the basis of adequately perceived outputs. At the third stage conscious phono-logical knowledge helps learners to associate inputs with outputs and to work out phonological processes operating in L2. This, in turn, leads to a reactivation of universal processes and to a complete recovery of L2-specific universal preferences. The role of metacompetence at the second and third stages is that of acquisition facilitator. Finally, perception feeds

Metacompetence-based approach to the teaching of L2 prosody 193
into production and conscious knowledge of articulation assists a learner’s phonetic performance acting as a monitoring device and offering the possi-bility of reflective feedback.
2.2. Phonological metacompetence
The core construct of the model is phonological metacompetence, which is understood as conscious knowledge of and about the grammar of the lan-guage and which may be developed by making the learner metalinguistically aware of L2 phonetics and phonology. The notion of metacompetence al-ludes to the distinction in cognitive psychology between ‘declarative knowl-edge’ and ‘procedural knowledge’ that has been recently applied to Second Language Acquisition (SLA). Broadly speaking, declarative linguistic knowledge refers to a speaker’s knowledge of linguistic facts, whereas pro-cedural knowledge refers to know-how in using the language. In the course of skill development declarative knowledge is converted into procedural form, i.e. it gets proceduralised and leads to L2 competence.
The present author advocates to interpret phonological metacompetence as a multilevel construct consisting of the three following blocks: (1) metalinguistic consciousness, (2) explicit formal instruction, and (3) first language competence (see Fig. 1 Part 2 - Facilitating device).
The first subcomponent, i.e. metalinguistic consciousness, is explicated adopting Schmidt’s (1990) typology and further developed as referring to the following constructs:
(a) awareness – perception (i.e. different degrees of conscious noticing),
– language awareness raising, (b) intention – controlled/monitored production,
– learning strategies based on conscious choice, (c) knowledge – conscious theoretical knowledge of L2 phonetics and phonology.
Awareness at the level of perception corresponds to conscious noticing and understanding as a necessary condition for the input to become intake and to be stored in a learner’s temporary memory. Conscious analysis at this level consists in learners’ making a comparison between the observed pho-netic input and their own production. The second subcomponent, intention,

194 Magdalena Wrembel
is applicable to consciousness at the level of speech production and it im-plies controlled/monitored phonetic output. Metalinguistic consciousness at the level of intention involves also a deliberate choice of learning strategies corresponding to the learner’s preferred learning style. The element of knowledge pertains to L2 competence developed through conscious analy-sis of knowledge of phonetics and phonology acquired as a result of theo-retical instruction. The analysis is a precondition for declarative knowledge to be converted into procedural one.
The second building block of metacompetence, as proposed by the pre-sent author, involves explicit formal instruction. It consists in theoretical training in phonetics and phonology targeted at developing conscious knowledge of the second language phonological system. Apart from pro-viding theoretical foundations, pronunciation instruction should also offer reflective feedback on learners’ pronunciation performance and equip them with appropriate tools and strategies for self-monitoring in order to em-power them to continue the learning process outside the classroom.
Finally, phonological metacompetence is believed to benefit also from drawing on a learner’s first language competence as a complete detachment from the native tongue is neither psychologically possible nor pedagogi-cally desirable. This expectation corresponds to the notion of ‘psycholin-guistic learning strategy’ as proposed by Færch and Kasper (1986) which consists in conscious reliance on a L2 learner’s prior linguistic knowledge (of L1 or any Ln) to form hypotheses about L2, in contrast to a purely in-ductive strategy that relies solely on the L2 intake. A similar stance was embraced also in the naturalist perspective by Dziubalska-Kołaczyk (2002) who called for raising language awareness through the mediation of the first language. Making learners aware of the ‘competences’ they already possess may thus constitute a methodological remedy targeted at suppress-ing the L1 interference and reinforcing the L2 acquisition process as such.
Adopting Ellis’ (1994) stipulations on the functioning of explicit knowl-edge, it is postulated in the present model that phonological metacompe-tence may act in a threefold manner as:
1) Facilitator of intake operating at the level of perception and helping input to become conscious intake. It consists in conscious noticing of specific characteristics of L2 sounds by attracting learners’ attention to those linguistic features they have learnt about through formal explicit instruction.

Metacompetence-based approach to the teaching of L2 prosody 195
2) Acquisition facilitator as metacompetence is predicted to have the po-tential to facilitate the process of acquisition and form adequate repre-sentations by deciphering underlying intentions and preventing the mapping into the L1 system. Finally, this assistance may lead to the re-activation of latent universal processes.
3) Monitoring device exercising control of the output as conscious L2 competence helps to provide reflective feedback on the production. Moreover, metacompetence is a means of empowering L2 learners and enhancing their autonomy by equipping them with necessary tools for self-monitoring and self-correction.
2.3. Influencing factors
The third component of the present model (see Fig. 1 Part 3 - Influencing factors) is in line with the sociolinguistic perspective on the nature of lan-guage according to which the formal system of language is seen as embed-ded in its social context. In an attempt to provide a broad and reliable ac-quisition framework, the model aims at accounting for an array of socio- and psycholinguistic factors that condition, to a large extent, phonological acquisition of a second language. It is generally agreed that pronunciation, more than any other aspects of language, is influenced by personal factors and that they are particularly at play with respect to the acquisition of L2 prosody, which constitutes a focal point of personal resistance to learning. The reasons for this are that the rhythm and intonation of our mother tongue are intimately linked with our identity (cf. Laroy 1996) and having to change our normal pitch range or pitch patterns to adapt to foreign lan-guage standards appears to jeopardise our language ego and self-confidence. Therefore, it seems desirable to acknowledge the conditioning potential of these extralinguistic factors and make an attempt to control them in a conscious manner.
Factors that were selected and incorporated in the model are generally considered to have the greatest impact on SLA in general and some are more specific for the acquisition of pronunciation. To begin with, cognitive factors encompass language aptitude, intelligence and learning styles and strategies. They remain fairly fixed and are amendable to training only to a limited extent. The varying impact of learner’s intelligence or language aptitude on pronunciation attainment can be nullified or compensated for with high quality language instruction. The only element of the cognitive

196 Magdalena Wrembel
variable that can be modified and enhanced to a considerable extent in-volves language learning styles and strategies. The present model promotes equipping learners with a broader range of innovative techniques for con-scious learning as well as strategies empowering them with self-monitoring abilities and reinforcing various perceptual learning modalities through multi-modal means of presentation and practice.
Sociolinguistic factors, on the other hand, include attitude and motiva-tion, which can be further subdivided into integrative and instrumental ori-entation. It is generally agreed that positive attitudes towards the target language and its language community are conducive towards successful L2 learning. Moreover, concern for good pronunciation motivating L2 learning was found to be one of the most vital predictors of success (cf. Purcell and Suter 1980). The variables described above are susceptible to change as a result of conscious training with the view to enhancing L2 acquisition. Since a learner’s internal motivation can be reinforced by interest invoking instruction, a new tendency, advocated also by the present author, is to enrich pronunciation training by accompanying traditional classroom prac-tices with novel, more engaging teaching techniques incorporating elements of theatre arts, Neuro-Linguistic Programming (NLP) or advanced tech-nologies Computer Assisted Language Learning (CALL).
The selection criteria of conditioning factors allow also for the specific character of foreign language pronunciation learning as opposed to the learning of other components of grammar, namely a high level of sensitiv-ity to emotional and psychological factors such as identity, language ego permeability, empathy or self-esteem. It is a common understanding in modern pronunciation pedagogy that affective and psychological factors can foster or inhibit oral mimicry and thus influence pronunciation per-formance to a considerable extent. Carefully designed pronunciation in-struction should thus provide a basis for conscious change in the psycho-logical and affective dimension of learning. Awareness raising in this respect should thus be tailored at creating the most favourable socio- and psychological conditions conducive to the acquisition of the second pros-ody.
The conditioning potential of psychological and affective variables is particularly significant because foreign language pronunciation learning, especially learning L2 prosody may be a stress inducing experience. Stress, in turn, results in muscular tension and stiffened articulators, a learning disadvantage which is largely beyond learners’ control. Moreover, the anxi-ety level is likely to grow as learners’ effort and diligence does not always

Metacompetence-based approach to the teaching of L2 prosody 197
always lead to immediate improvement and success. Therefore, compre-hensive pronunciation training should incorporate confidence building and stress reducing strategies. These strategies consist in conscious efforts to-wards reducing muscular tension by means of relaxation, breathing exer-cises and articulatory warm-ups or by adopting drama voice techniques aimed at greater agility and control of articulators as well as confidence building (cf. Wrembel 2001).
Furthermore, physiological limitations of the speech apparatus and the motor element inherently involved in pronunciation learning compelled the present author to encompass also oral and auditory capacities of an individ-ual amongst the pertinent factors affecting acquisition. Oral capacities in-volve the learner’s ability to adapt to different articulatory configurations, whereas auditory capacities concern auditory sensitivity to target language sounds. The aptitude for oral mimicry, that some learners are particularly endowed with, can be reinforced by various imitation exercises such as mouthing, mirroring or modelling adapted from drama voice techniques. Auditory capacities, on the other hand, can be enhanced by consciousness raising at the perceptual level and guided ear-training.
3. Pedagogical implications; techniques for teaching L2 prosody
The proposed model of the natural approach to the acquisition of second language phonology entails practical recommendations for the teaching of L2 prosody that have been translated into a number of specific classroom practices. The scope of the proposed techniques for the development of phonological metacompetence is multifarious ranging from alternative and innovative methods integrating cognitive, affective and psycho-motor as-pects of pronunciation learning to more mainstream activities involving conscious analysis of theoretical linguistic knowledge. The former include general awareness-raising techniques incorporating extra- and para-lin-guistic elements such as gestures, mimicry or relaxation in order to foster conscious control of articulators and perceptual tuning-in. The latter corre-spond to more elaborate practices that often rely on advanced technologies providing a new range of feedback and presentation modes. The schematic presentation of the suggested techniques (see Table 1) is based on different degrees of explicitness, on the one hand, and elaboration, on the other.

198 Magdalena Wrembel
Table 1. Metacompetence developing techniques
B Articulatory control
Articulatory warm-up exer-cises Drama voice techniques: Articulatory setting exercises: * voice quality * imitation and oral mimicry
D Multimedia learning aids
Animated views of the articulators Video close-ups of the mouth Computerised displays of speech patterns Spectrograms
Ela
bora
tion
A Basic awareness-raising
Relaxation, breathing, visualisation Sensitisation: * perceptual tuning-in Awareness raising activities: * discussions * questionnaires * metaphonetic trivia * concern for pronunciation
C Informed teaching techniques
Theoretical foundations (rules) Contrastive information Pitch-contour notation Guided ear-training - analytic lis-tening Self-monitoring techniques
Explicitness (covert - overt)
3.1. Basic awareness-raising activities
The present proposal assumes that the initial stages of conscious teach-ing/learning of L2 prosody should focus on building awareness and concern for pronunciation and preparing the articulatory and auditory apparatus for the forthcoming practice. This stage (section A) involves the lowest degree of explicitness and elaboration in language consciousness raising yet it constitutes a necessary foundation for the development of phonological metacompetence. As emphasised by Dalton and Seidlhofer (1994), due to the largely subliminal nature of intonation which makes it difficult to de-scribe and teach, sensitising and awareness raising activities are particularly important. One of the major issues at this stage is to develop a concern for intonation in foreign language learning through stimulating discussions on its role in communication. Such discussions, geared at increasing learners’

Metacompetence-based approach to the teaching of L2 prosody 199
motivation and stimulating interest, can be prompted by questionnaires or tape-based tasks (examples of such questionnaires can be found in Hewings 2004, Laroy 1996, Kenworthy 1990).
Other awareness raising techniques involve the investigation of the gen-eral nature of prosody by attuning learners’ ears to pitch movements, hum-ming the tune instead of using words, recognising moods and acting out tales or using arithmetic to consciously analyse the division of speech into tone units e.g. (2+3) x 5 = 25 vs. 2+ (3 x 5) = 17 (cf. Dalton and Seidlhofer 1994). Awareness of intonation can also be developed by associating pitch movements with other impressions such as a firework rising or falling in the sky, a plane taking off or landing, as well as with various emotions they cause (e.g. anger, happiness). Since intonation is often referred to as ‘vocal gesture’ (cf. Dalton and Seidlhofer 1994: 77) an awareness-raising activity may focus on the significance of gestures in general and then lead to replac-ing gestures by vocalisations.
Other examples of metacompetence enhancing techniques at this stage involve developing physical awareness of suprasegmental features as kin-aesthetic involvement seems particularly applicable to the teaching of su-prasegmentals. Such applications of ‘whole body’ motion to practice key aspects of stress, rhythm and intonation include e.g. walking or stamping the rhythm, hands raising corresponding to word stress patterns (cf. Miller 2000), tracing intonation contours with arms or acting out pitch movements when learners are assigned particular syllables in an utterance and are re-sponsible for presenting the sentence with their bodies by assuming an ap-propriate posture corresponding to the pitch level (Acton 1998: 7):
a) on toes – the highest pitch level
b) standing – slightly raised pitch
c) knees bent, hands on knees – starting position, mid-pitch
d) squatting – general pitch of unstressed vowels
e) kneeling – utterance-final, falling pitch.
Moreover, prosodic awareness of L2 learners may be boosted by using various materials including metaphonetic trivia such as advertising leaflets, billboards, SMS and Internet-lore in which some aspects of suprasegmental phonetics come to the fore mainly through puns (cf. Sobkowiak 2003).

200 Magdalena Wrembel
They may constitute good starting points for awareness raising discussions and be particularly stimulating and memorable due to their humorous com-ponent. For instance, to illustrate the phonetic importance of an open junc-ture and semantic consequences of word stress, the learners may be pre-sented with a postcard that reads “Two lips from Amsterdam” as opposed to “Tulips” from Amsterdam (see Sobkowiak 2003: 162).
Another step to facilitate an accurate prosodic production in the second language and, in general, to improve voice quality involves conscious re-laxation of the muscles of the articulatory apparatus and assuming an ap-propriate frame of mind, which can be achieved by means of relaxation techniques including breathing exercises (e.g. breathing in, holding the breath and releasing it for the count of three) or visualisation (i.e. guided imagery exercises) (cf. e.g. Celce-Murcia, Brinton and Goodwin 1996, Acton 1997, Laroy 1996).
As far as basic awareness raising techniques at the level of perception are concerned, the model allows for the so-called sensitisation, i.e. percep-tual tuning into the language. This activity consists in getting learners used to the general auditory impression of the target language, rather than listen-ing for a particular phonetic feature, and approaching the melody of the language in terms of its affective value and aesthetic impact. For instance, when listening to English students are asked to judge whether:
– it smells like a meadow / it smells like a town, – it is like the sound of waves breaking on the beach / it is like the sound
of a mountain brook, – it sounds ideal for giving orders / it sounds ideal for courtship (Laroy
1996: 25–26).
Developing metacompetence at this stage involves making learners aware of how they perceive the target language by activating all their senses, help-ing them to overcome their prejudices and thus making their language egos more permeable.
3.2. Articulatory control exercises
Section B enumerates metacompetence developing techniques based on articulatory control that involve a higher degree of elaboration, though they are still not fully explicit in providing declarative knowledge of the pho-

Metacompetence-based approach to the teaching of L2 prosody 201
netic system of the target language. Such practices involve voice modula-tion techniques typically used by drama coaches and articulatory warm-up exercises that aim at a greater articulatory agility and, consequently, a more native-like performance. These techniques of metalinguistic and extralin-guistic awareness raising aim at regaining conscious control over the proc-ess of articulation through pre-speech physical preparation including, among others, postural alignment, muscular tension release and warming, vocal work-out, massaging face and jaw muscles, lip and tongue activation, warming the voice and releasing resonance as well as pitch, volume and speech rate modulation exercises (cf. Wessels and Lawrence 1995). Con-scious employment of theatre arts techniques contributes also to L2 pros-ody improvement from a psychological perspective by increasing learners’ self-esteem and confidence as well as enabling them to transcendent the normal limits of fluency.
A further aspect of phonological metacompetence is related to develop-ing a more authentically native-like ‘voice quality’ or ‘setting’, which can be achieved through a conscious attempt at an adaptation of a long-term articulatory posture specific for a particular target language, i.e. a characte–ristic pitch level, vowel space, tongue position and the degree of muscular activity. The present model advocates specific voice quality setting exer-cises involving, among others, oral mimicry (e.g. making an English face or finding one’s English voice) and conscious imitations of model intonation patterns. To give some examples of the controlled imitative practice one may enumerate the following:
– mouthing – miming a dialogue without words, – mirroring – repeating simultaneously with the speaker and imitating
his/her gestures and facial expressions, – tracing – repeating simultaneously without mirroring the speaker’s ges-
tures, – echoing – repeating slightly after the speaker (cf. Celce-Murcia, Brinton
and Goodwin 1996).
Particularly noteworthy are extralinguistic features (i.e. elements of body language) which tend to be incorporated into the imitative practice.
The activities described in sections A and B should be viewed as a first stage in the process of L2 prosody learning, i.e. a way to raise general pro-sodic awareness, to ‘open the ears’ and to establish strategies which can be later consolidated and extended. Some of the techniques proposed above

202 Magdalena Wrembel
fall into the scope of the so-called alternative and innovative methods that co-exist under a general label SALT (i.e. a System of Accelerative Learn-ing Techniques). The major drawbacks of such alternative techniques in-clude apparently limited practical applications, the lack of systematic fea-tures and limited empirical validation as pointed out by Pfeiffer (2001). However, their major contribution to the facilitation of L2 prosody learning concerns primarily the affective domain, whose role in the case of pronun-ciation is of paramount importance. These techniques represent a compre-hensive approach integrating cognitive, emotional and physical aspects of pronunciation learning. They are particularly geared at reducing learning inhibitions by creating a positive atmosphere, enhancing learners’ confi-dence in L2 production and incorporating extra- and para-linguistic ele-ments such as gestures, mimicry and relaxation exercises. In the current model proposed by the author alternative techniques perform an auxiliary function accompanying and enriching the repertoire of mainstream prac-tices rather than replacing it.
3.3. Mainstream techniques for informed pronunciation teaching
Section C represents more mainstream pronunciation teaching activities referred to as informed teaching techniques. Contrary to some opinions restricting prosody training to imparting motor and auditory skills, the pre-sent approach attaches a paramount importance to the cognitive aspect of phonological acquisition. Metacompetence-oriented theoretical training in the L2 prosody advocates conscious knowledge of phonetics and phonol-ogy, therefore, elements of theoretical grounding (e.g. Brazil 1994, Roach 1991, Gimson 2001) are expected to constitute an integral part of the pro-nunciation training. This recommendation is particularly valid in the con-text of teacher training, where the trainees are to become potential pronun-ciation models for their learners.
In an effort to overcome interference from the sound system of the tar-get language it is advisable to establish certain basic discriminatory skills enabling learners to distinguish consciously between features of their own language and those of the target. Therefore, it is advocated in the model to allow for contrastive exercises involving the comparison of specific issues in the target and source languages.
Conscious training of auditory skills may take various forms ranging from simple discrimination and identification tasks to more elaborate

Metacompetence-based approach to the teaching of L2 prosody 203
guided ear-training. Guided listening may included, for instance, exercises in which listeners must recognise which word is made prominent (high-lighted) by choosing a suitable context for what they hear, e.g.
A: Let’s go to Paris. OR A: Have you had a good weekend?
B: I’ve been to Paris. (Bradford 1988: 9).
The model endorses also appeals to learners’ different modalities through multisensory means of presentation and practice. The impact of theoretical phonetic training in L2 prosody may be particularly enhanced by means of visual reinforcement including pitch-contour notation. Learners may be encouraged to represent the pitch range by drawing two parallel lines de-picting the highest and the lowest limits of the range and drawing lines corresponding to pitch movements within these limits. Moreover, pitch contours may be depicted visually as arrows (cf. e.g. Vaugham-Rees 1994), bending lines (Brazil 1994), dotted lines (Roach 1999) or dots representing syllables (e.g. Gimson 2001). Similar procedures can be used to encourage stress pattern notation including: a) underlining the stressed syllable using a particular colour, b) putting a dot above or under the stressed syllable, c) writing this syllable in a different script, d) representing the stressed/un-stressed syllables by different shapes (cf. Laroy 1996: 47).
The present metacompetence-oriented framework strives to empower learners by equipping them with self-monitoring and self-correction strate-gies so that they may be involved consciously in the speech modification process. In practice, it entails helping L2 learners to develop self-rehearsal techniques (e.g. talking to oneself, audio- or videotaping presentations or rehearsing in small groups) as well as providing them with procedures for self-diagnosis and concrete self-study guidelines (e.g. Use strong, vigorous speech! Use controlled speed and pause by phrase groups. Take time to slow your rate of speech and vary tempo.
Use clear emphasis. Establish the rhythmic stress-unstress pattern of English including reductions and contractions; link words into phrase groups across word boundaries. Use lively, expressive voice qualities – adapted from Morley 1994: 87).
The present author’s recommendations concerning multimodal techni-ques of L2 prosody training as well as the application of autonomous lear-ning strategies are based on the personal experience as a phonetics teacher

204 Magdalena Wrembel
and mostly positive and enthusiastic feedback received from the students that were taught within the framework of the approach discussed above.
3.4. Elaborate and technologically advanced techniques
Finally, section D offers the highest level of elaboration and explicitness as far as phonological metacompetence enhancement techniques are con-cerned. The majority of techniques suggested therein rely on multimedia learning aids and advanced technologies. As the oral speech mechanism is readily accessible to direct observation, some computer assisted instruc-tional programs or web pages offer animated views of the articulators dur-ing speech or vocal folds in motion as an additional visual support for the conscious analysis of the articulatory process. Another option is to video tape learners’ faces during speech production and subsequently examine such close-up frames of articulators in order to analyse the articulatory gesture and the overall articulatory posture, i.e. muscular tension in the supralaryngeal tract or the position of the larynx.
Furthermore, more advanced pronunciation teaching courses available on CD-ROMs offer instant audio-visual feedback in the form of computeri-sed displays of speech patterns allowing learners to record their utterances and compare a visual display of their own intonation contours with pre-recorded native-speaker models (cf. e.g. CD-ROM Better Accent Tutor, CD-ROM Connected Speech). Identification and discrimination of pitch movements as well as nuclear stress placement can now be further en-hanced by multimedia offering visual feedback support, e.g. CD-ROMs for teaching intonation or Internet resources such as e.g. Sound Machines avai-lable at John Maidment’s web site offering programs designed to help rec-ognise the nuclear syllable and nuclear tones in presented sentences.
The perception and production of foreign sounds may be reinforced by a conscious analysis of the acoustic spectrum displayed in the form of a spec-trogram. As advocated by Schwartz (2004), conscious knowledge of acous-tic phenomena may represent a useful, albeit fairly new tool in pronuncia-tion pedagogy. Acoustic phenomena are concrete and relatively easy to identify and describe, therefore, they can be of great benefit in the learning process. Such pedagogy-oriented spectrographic analyses may thus serve as an awareness raising tool helping learners to become familiar with such acoustic phenomena as e.g. fundamental frequency (pitch) or amplitude (loudness). An experiment conducted by Schwartz and Glogowska (2004)

Metacompetence-based approach to the teaching of L2 prosody 205
demonstrated that even a brief training session focused on such acoustic phenomena as the range of pitch movement or breathy voice quality re-sulted in the learners’ perceptible acoustic progress in L2 production.
It is undeniable that technology assisted language learning techniques have a special appeal, particularly for young learners and their effectiveness may be influenced, to a large extent, by the fact that they enhance learners’ motivation and interest. They pose, however, a greater challenge to the teacher and require some specific know-how as in the case of acoustic speech analysis.
3.5. Empirical verification of the proposed techniques
The major predictions of the proposed model of pronunciation teaching were empirically validated in a study on the role of phonological metacom-petence in the acquisition of foreign language phonetics by adult advanced learners of English (Wrembel 2003, 2005). The results indicated that pho-nological awareness raising and conscious theoretical instruction in English phonetics related significantly to the improvement in the overall L2 pro-nunciation performance in the experimental group which outperformed the controls that received traditional pronunciation practice and relied solely on procedural knowledge.
An issue that merits further investigation, however, is the efficiency of particular innovative techniques for teaching L2 prosody that were presen-ted in this contribution such as e.g. articulatory warm-ups, relaxation and breathing or drama voice procedures. Their effectiveness has been corrobo-rated on the basis of the present author’s informal observations and a long-standing experience as a phonetics teacher as well as self-reported data collected from the students by means of questionnaires.
To the best of my knowledge little controlled research has been conduc-ted to validate the efficiency of these novel approaches. The evaluation of specific techniques in terms of how beneficial they are for the learner’s perception and production of L2 prosody seems to be a rather difficult task. Their impact depends to a large extent on how well they correspond to the learners’ learning styles, preferred modalities or even personalities. There-fore, it seems that the best recommendation for the teachers would be to use their classrooms as a testing ground and to try out what seems particularly applicable to specific contexts and learners’ needs.

206 Magdalena Wrembel
4. Conclusions
The major goal of the present contribution has been to provide insights into new trends in L2 prosody teaching and to illustrate them with a range of innovative techniques, and consequently, to broaden the repertoire of acti-vities used traditionally in the language classroom. It is worth stressing that the proposed list of metacompetence enhancement techniques tailored at the teaching of L2 prosody is by no means exhaustive. The present author aimed at providing a sample of varied activities of a different degree of elaboration and explicitness, thus offering an innovative perspective on the pronunciation pedagogy that may be appealing to foreign language educa-tors, learners and materials designers alike.
To sum up, the presented model constitutes a reflection of a conscious-ness-based approach to the acquisition of foreign language pronunciation and its practical implications are aimed particularly at increasing the effec-tiveness of teaching L2 prosody. It is advocated that this aim may be achieved by developing learners’ phonological metacompetence, i.e. by means of raising awareness of foreign language intonation and promoting conscious theoretical instruction therein. The major goal is to make prosody an integral part of informed pronunciation teaching by conscious employ-ment of various metacompetence-oriented techniques and activities in order to foster L2 learners’ productive and receptive skills. It is hoped that be-cause of its theoretical foundations (i.e. grounding in a specific linguistic theory) and a broad perspective of second language acquisition, the pre-sented model may be rendered particularly applicable to the teaching and learning of second language prosody.
References
Acton, William 1997 Seven Suggestions of Highly Successful Pronunciation Teaching.
The Language Teacher Online 21.2 http://langue.hyper.chubu.ac.jp/jalt/pub/tlt/97/feb/seven (date of
access: 22 Dec. 2006) 1998 The Syllablettes. Alternatives. Speak Out! 22, 5–10.
Better Accent Tutor for English http://www.betteraccent.com/ (date of access: 22 Dec. 2006)

Metacompetence-based approach to the teaching of L2 prosody 207
de Bot, Kees and Mailfert, K. 1982 The teaching of intonation: Fundamental research and classroom
applications. TESOL Quarterly 16, 71–77. Bradford, Barbara 1988 Intonation in Context. Cambridge: Cambridge University Press. Brazil, David 1994 Pronunciation for Advanced Learners of English. Cambridge:
Cambridge University Press. Celce-Murcia, Marianne 1987 Teaching Pronunciation as Communication. In: Joan Morley (ed.)
Current Perspectives on Pronunciation: Practices Anchored in Theory. TESOL, Washington, D.C. 1–12.
Celce-Murcia, Marianne, Donna Brinton and Janet Goodwin 1996 Teaching Pronunciation. A Reference for Teachers of English to
Speakers of Other Languages. Cambridge: Cambridge University Press.
Connected Speech http://www.proteatextware.com.au/cs.htm (date of access: 22
Dec. 2006) Dalton, Christiane and Barbara Seidlhofer
1994 Pronunciation. Oxford: Oxford University Press. Donegan, Patricia 1985 On the Natural Phonology of Vowels. New York: Garland. Dziubalska-Kołaczyk, Katarzyna 1990 A Theory of Second Language Acquisition within the Framework
of Natural Phonology. A Polish-English Contrastive Study. Pozna : AMU Press.
2002 Conscious competence of performance as a key to teaching Eng-lish. In: Ewa Waniek-Klimczak and Patrick Melia (eds.) Accents and Speech in Teaching English Phonetics and Phonology. EFL Perspective. Frankfurt: Peter Lang, 97–106.
Ellis, Rod 1994 The Study of Second Language Acquisition. Oxford: Oxford
University Press. Faerch, Claus and Gabriele Kasper 1986 Cognitive dimensions of language transfer. In: Eric Kellerman
and Michael Scharwood Smith (eds). Crosslinguistic Influence in Second Language Acquisition, 49–65. New York: Pergamon.
Gimson, Alfred C. 2001 Gimson’s Pronunciation of English. 6th edition. Revised by A.
Cruttenden. London: Edward Arnold.

208 Magdalena Wrembel
Hewings, Martin 2004 Pronunciation Practice Activities. Cambridge: Cambridge Uni-
versity Press. Jenkins, Jennifer 2000 The Phonology of English as an International Language. Oxford:
Oxford University Press.Kenworthy, Joanne 1990 Teaching English Pronunciation. London: Longman. Laroy, Clement 1996 Pronunciation. Oxford: Oxford University Press. Maidment, John Sound Machines
http://www.eptotd.btinternet.co.uk/vm/soundmachines.htm (date of access: 22 Dec. 2006)
Miller, Sue F. 2000 Targeting Pronunciation: the Intonation, Sounds, and Rhythm of
American English. Boston, MA: Houghton Mifflin Company. Morley, Joan 1987 Current Perspectives on Pronunciation: Practices Anchored in
Theory. Washington, DC: TESOL. 1994 Pronunciation Pedagogy and Theory, New Views, New Direc-
tions. Alexandria: TESOL. Pennington, Martha 1989 Teaching pronunciation from the top down. RELC Journal 20,
20–38. Pfeiffer, Waldemar 2001 Nauka j zyków obcych. Od praktyki do praktyki. Pozna :
WAGROS. Purcell, Edward T. and Richard W. Suter 1980 Predictors of pronunciation accuracy: A reexamination. Lan-
guage Learning 30, 271–88.Roach, Peter 1991 English Phonetics and Phonology. Cambridge: Cambridge Uni-
versity Press. Schmidt, Richard 1990 The role of consciousness in Second Language Learning. Applied
Linguistics 11, 129–158. Schwartz, Geoff 2004 Voice quality in students’ production of the English tense/lax
contrast. In: Włodzimierz Sobkowiak and Ewa Waniek-Klimczak (eds.). Dydaktyka Fonetyki J zyka Obcego Zeszyt Naukowy In-stytutu Neofilologii (3), Wydawnictwo PWSZ w Koninie, 75–79.

Metacompetence-based approach to the teaching of L2 prosody 209
Schwartz, Geoff and Małgorzata Głogowska 2004 Acoustic tools for students’ production of English long (tense)
vowels. In: Włodzimierz Sobkowiak and Ewa Waniek-Klimczak (eds.), Dydaktyka Fonetyki J zyka Obcego Zeszyt Naukowy Instytutu Neofilologii (3), Wydawnictwo PWSZ w Koninie, 80–85.
Sobkowiak, Włodzimierz 2003 Materiały ulotne jako ródło metakompetencji fonetycznej.
(Raising phonetic awareness through trivia). In: Włodzimierz Sobkowiak and Ewa Waniek-Klimczak (eds.). Dydaktyka Fonetyki J zyka Obcego. Zeszyty Naukowe PWSZ w Płocku (5), Płock: Wydawnictwo PWSZ, 151–166.
Stampe, David 1973 A Dissertation on Natural Phonology. Bloomington: Indiana
University Linguistic Club. Vaugham-Rees, Michael 1994 Rhymes and Rhythm. Hong Kong: Macmillan Publishers Ltd. Wessels, Charlyn. and Kate Lawrence 1995 Using Drama Voice Techniques in the Teaching of Pronuncia-
tion. In Brown, A. (ed.) Approaches to Pronunciation Teaching, 29–37. Hemel Hempstead: Prentice Hall International.
Wrembel, Magdalena 2003 An empirical study on the role of metacompetence in the acquisi-
tion of foreign language phonology. Proceedings of the 15th In-ternational Congress of Phonetic Sciences Barcelona (Spain), 985–988.
2005 Phonological metacompetence in the acquisition of second lan-guage phonetics. Unpublished Ph.D. dissertation, Adam Mickiewicz University, Poznan.
2006 Consciousness in Pronunciation Teaching and Learning. IATEFL PL Newsletter, Post-Conference Edition No 26 , Warszawa


Individual pronunciation coaching and prosody
Grit Mehlhorn
1. Introduction
This paper gives a general overview of the motivation, goals and methods of Individual Pronunciation Coaching (IPC). It will be shown that the fol-lowing factors influence the learner’s progress: first, the individual diagno-sis of the deviations in the target pronunciation; second, an increase of the learner’s consciousness with respect to the foreign pronunciation and the choice of individual learning strategies; and third, the permanent feedback on learning progress. These factors lead to an increased self-reflection on the part of the learner regarding their learning process, language awareness, and they also serve to foster learner autonomy.
Special attention is given to the prosodic organization of the foreign language – an aspect of pronunciation which is often neglected in foreign language teaching. The empirical examples reported here are from foreign students at German universities. However, the concept of IPC should work for other target languages as well.
2. Motivation
The difficulties experienced while learning the pronunciation1 of a foreign language are strongly dependent on the mother tongue of the learners, and on other foreign languages they have already acquired (cf. among others Kaltenbacher 1998; Gut 2003; Hirschfeld, Kelz and Müller 2003). Many of these pronunciation difficulties can be predicted to a certain degree, if one compares the phonetic systems of the mother tongue and the target lan-guage. However, this may yield overgeneralisations since learners with a very similar learning background show considerable differences in their individual pronunciation, – as Baran (2002: 315) puts it:
... even within groups where learners are of one age, mother tongue and gender; where individuals receive comparable amount and type of expo-sure; the same explicit formal training; where students are highly moti-

212 Grit Mehlhorn
vated, and their attitudes are positive; where all learners are taught by the same teacher who uses specific teaching methods and techniques, the pro-nunciation of individuals still differs sometimes even to a great extent.
Foreign language learners of the same mother tongue differ not only with respect to the amount and grade of particular deviations in the pronun-ciation of the foreign language, but also in terms of:
– their ability of segmental and prosodic differentiation, – their articulatory skills, – their cognitive learning styles (e.g. with respect to their preferred per-
ception mode), – learning strategies used, – the degree of language awareness, – their self-monitoring skills, – their motivation and – their expectations regarding their pronunciation level.
Pronunciation and prosody practice plays only a marginal role in standard foreign language teaching (Gehrmann 1999). Even if there is pronunciation teaching, only the worst mistakes are corrected. Learners are expected to repeat given forms. The mere imitation, however, does not take into ac-count the cognitive skills of adult learners.
As a consequence, even very advanced learners have no clear idea of how and where their pronunciation deviates from the pronunciation of nati-ve speakers. They seldom have adequate conscious strategies to improve their pronunciation themselves. As deficient pronunciation influences other language skills such as reading, listening, speaking and writing (de Jong and Kaunzner 2000), the whole acquisition process is slowed down. Even-tually, some prosodic deviations can lead to undesirable effects on the nati-ve hearer. In the worst case, some foreign accent features are interpreted as bad character traits of the person speaking.
Since pronunciation likewise plays only a marginal role in important German language tests like the DSH and the TestDaF2, many students con-centrate on the improvement of the skills explicitly required in the tests, but pay only little attention to the improvement of their pronunciation. There-fore, the pronunciation of many language learners shows fossilizations – much more often than their grammar or vocabulary. Indeed, for many learners, it is not enough to be exposed to the foreign language. Without a certain experience in systematic listening to sounds or intonation (Dieling

Individual pronunciation coaching and prosody 213
1989) and without awareness on what to focus on, much of the input is “filtered out”. Thus, the pronunciation of surrounding native speakers can have (only) little influence on what learners produce themselves.
Many foreign students consider their foreign accent a barrier preventing them from entering into contact with German students. Native speakers seem to have certain associations or emotional reactions when hearing a given foreign accent (Müller 1994: 182; Stibbard 1996; Cunningham-Andersson 1997: 133, 142; Gibbon 1998: 89). These associations are un-consciously related to the personality of the speaker which can even lead to a stigmatization of this person (Grotjahn 1998). Thus, foreign students more often than Germans, are afraid of taking part in seminars, let alone oral presentations or oral exams.
Although since the nineties, phonetics is represented to a greater extent in textbooks and audio material for German as a foreign language, in the classroom it is still neglected. This is in part due to the fact that in hetero-geneous learner groups with different mother tongues, it is practically im-possible to deal with pronunciation difficulties of the individual learner. Hence, lack of time is the main argument against phonetics in the foreign language classroom. Another reason is that teachers’ knowledge in this area is often limited. Therefore, many teachers restrict themselves to the imme-diate correction of only very striking pronunciation deviations. A conscious discussion of reasons for these deviations rarely takes place.
To remedy the aforementioned problems, teachers would have to ac-quire additional competences and phonetic knowledge. However, since not every teacher can be an expert for every mother tongue of his or her learn-ers, the idea of an individual coaching with special focus on foreign pro-nunciation took form. This is a new kind of individual coaching which co-exists with general language learning coaching (Kleppin 2003), coaching for tandem learners (Brammerts, Calvert, and Kleppin 2005; Schmelter 2004), and the coaching of students at the beginning of their studies (Mehl-horn 2005).
Very often, a feeling of success or sense of achievement in the foreign pronunciation is reached only after a longer period of time, after persistent practising. Therefore, the motivation of the learner plays a particularly im-portant role in this field of language learning. This is another reason for individual pronunciation coaching. With the help of the pronunciation di-agnosis and individual feedback at different times of the coaching, small, otherwise not realised progress can be shown.

214 Grit Mehlhorn
3. Goals
Individual learning coaching is based on the concept of learner autonomy3
(Riley 1997, Cotteral and Crabbe 1999, Benson 2001). The learner is seen as an individual who is capable of taking control of his or her own learning. It is an important goal of the individual learning coaching to support the learner’s independence.
There are many ways to learn German. The learners taking part in IPC have followed different paths to acquire their present level of competence in German and knowledge about German. Every learner has different diffi-culties. In IPC, they can learn in which aspects their pronunciation needs correction and how they can improve it.
Experience shows that there can be huge differences between pronun-ciation features which seem problematic to the learner and those which are perceived as deviant by the pronunciation coach. Learners of German as a foreign language, for instance, often mention the uvular [R] and the high front rounded vowels in the first place. Only few learners are aware of de-viations in the target intonation or rhythm, however. These deviations should not be neglected, however, since prosody organizes spoken lan-guage in patterns fitting the appropriate communication need. “In the speech of advanced learners, departures from what we regard as desirable are said to be more often matters of intonation than matters of how particu-lar sounds are made” (Brazil 1994: 3). Therefore, it is important to inform the learner about possible effects of deviations in the target prosody.
Detailed phonetic descriptions are avoided wherever possible, but an es-sential aim of IPC is to help the learner gain sufficient knowledge of the phonetic system of German to feel at ease when using it. Having under-stood the system, the learner will be more likely to feel in control of it; and feeling in control will almost certainly reduce the anxiety felt when speak-ing the foreign language. Supporting the self-confidence of the learner is therefore one of the fundamental goals of the individual coaching. The coach and the learner are concerned with recognising and remedying things that are peculiar to the learner. Confidence building here takes the form of making clear to the learner which phenomena they need to work on and which sounds they can safely consider to be less problematic. The diagno-sis, therefore, is aimed at enabling the learner to identify their problems on their own.

Individual pronunciation coaching and prosody 215
It is not necessarily the aim of IPC to reach a native-level pronunciation. Instead, every learner sets up their own, personal standard they want to reach in their pronunciation. The coach can help them break down overly ambitious, far-reaching goals into smaller, attainable ones.
Reducing anxiety consists largely of the development of the learner’s power of self-appraisal (Weskamp 2003). Through the permanent concern with their own pronunciation peculiarities, with the feedback given by the coach, with the comparison with a standard (e.g. a native speaker, audio media, language learning software), and with the coach-initiated self-observation and self-evaluation on the part of the learner, step by step, the self-appraisal of the learner should substitute the feedback of the coach. Eventually, the learner should be able to work on his or her pronunciation without the help of the coach. IPC has a limited time frame. The sooner the learner is able to learn independently, the better. The increase of the learn-ers’ autonomy, self-reflection and their capability of self-appraisal are fur-ther aims accompanying the improvement of the learners’ pronunciation skills.
At the beginning of the coaching process, the learner is informed about the proceeding and the possibilities of the coaching:
– The coach makes a diagnosis of the learner’s individual pronunciation. – She recommends material designed to improve the pronunciation and
shows the learner how to work with it. – The coach supports the learner in splitting up his main goals into small,
realistic sub-goals. – She helps the learner develop appropriate learning strategies and – gives feedback on the learner’s progress.
All these measures are intended to make the learner work more independ-ently. At the same time, it is necessary to make clear that work on pronun-ciation must necessarily be active. The learner will not improve his or her pronunciation by being told what to do, but by doing it. Obviously, if learn-ers are treated as autonomous persons, their progress depends almost en-tirely on their own effort. IPC is intended to provide maximum support, but does not spare the learner the effort of learning.

216 Grit Mehlhorn
4. Methods in IPC
4.1. The first coaching session
In the first coaching session, the coach inquires about the so-called learning biography. This means information about
– the mother tongue, – foreign languages, – strategies in pronunciation learning, – phonetic knowledge (i.e. knowledge about the phonetic particularities of
the mother tongue and the target language), – self-assessment of the pronunciation by the learner, – already recognized problems, – crucial experiences with his or her foreign pronunciation (e.g. perceived
misunderstandings), – aims, – time frame, etc.
This information is necessary to provide the learner with coaching that directly addresses their individual needs.
In a second step, the learner reads a short text aloud. This text is directly recorded onto the computer. This recording serves as a diagnosis and start-ing point for coaching. While the learner reads the text, the coach marks the deviations in her own copy of the text. The results are then discussed with the learner. The coach can encourage the learner to mark the items in the text which the learner should pay special attention to in the next reading task. For this purpose, the coach recommends certain notation symbols (e.g. vertical lines to mark potential breaks, accents on stressed vowels – if the stress was wrong in the first place –, marking of pitch accents, etc.). For learners preferring a visual learning style, it is helpful to be able to actually see their pronunciation problems. The learner then gets an electronic ver-sion of the text and can do further work at home. Figure 1 illustrates this marking process with an example of a learner from Mongolia. This student had problems to produce adequate German rise- and fall contours – and, evidently, marked her text accordingly.4
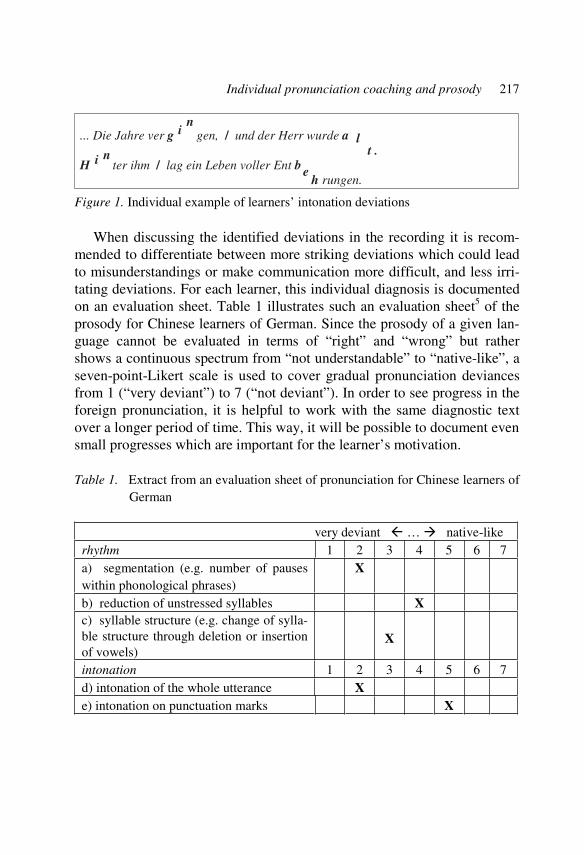
Individual pronunciation coaching and prosody 217
... Die Jahre ver g gen, / und der Herr wurde a t . H ter ihm / lag ein Leben voller Ent b rungen.
in
l
i ne
h
Figure 1. Individual example of learners’ intonation deviations
When discussing the identified deviations in the recording it is recom-mended to differentiate between more striking deviations which could lead to misunderstandings or make communication more difficult, and less irri-tating deviations. For each learner, this individual diagnosis is documented on an evaluation sheet. Table 1 illustrates such an evaluation sheet5 of the prosody for Chinese learners of German. Since the prosody of a given lan-guage cannot be evaluated in terms of “right” and “wrong” but rather shows a continuous spectrum from “not understandable” to “native-like”, a seven-point-Likert scale is used to cover gradual pronunciation deviances from 1 (“very deviant”) to 7 (“not deviant”). In order to see progress in the foreign pronunciation, it is helpful to work with the same diagnostic text over a longer period of time. This way, it will be possible to document even small progresses which are important for the learner’s motivation.
Table 1. Extract from an evaluation sheet of pronunciation for Chinese learners of German
very deviant … native-likerhythm 1 2 3 4 5 6 7 a) segmentation (e.g. number of pauses within phonological phrases)
X
b) reduction of unstressed syllables X c) syllable structure (e.g. change of sylla-ble structure through deletion or insertion of vowels)
X
intonation 1 2 3 4 5 6 7 d) intonation of the whole utterance X e) intonation on punctuation marks X
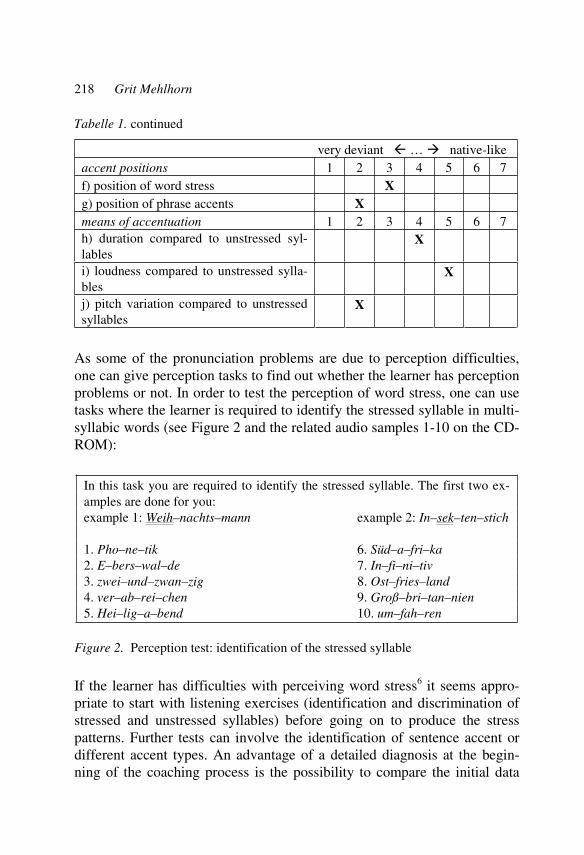
218 Grit Mehlhorn
Tabelle 1. continued
very deviant … native-like accent positions 1 2 3 4 5 6 7 f) position of word stress X g) position of phrase accents X means of accentuation 1 2 3 4 5 6 7 h) duration compared to unstressed syl-lables
X
i) loudness compared to unstressed sylla-bles
X
j) pitch variation compared to unstressed syllables
X
As some of the pronunciation problems are due to perception difficulties, one can give perception tasks to find out whether the learner has perception problems or not. In order to test the perception of word stress, one can use tasks where the learner is required to identify the stressed syllable in multi-syllabic words (see Figure 2 and the related audio samples 1-10 on the CD-ROM):
In this task you are required to identify the stressed syllable. The first two ex-amples are done for you: example 1: Weih–nachts–mann example 2: In–sek–ten–stich
1. Pho–ne–tik 6. Süd–a–fri–ka2. E–bers–wal–de 7. In–fi–ni–tiv 3. zwei–und–zwan–zig 8. Ost–fries–land 4. ver–ab–rei–chen 9. Groß–bri–tan–nien 5. Hei–lig–a–bend 10. um–fah–ren
Figure 2. Perception test: identification of the stressed syllable
If the learner has difficulties with perceiving word stress6 it seems appro-priate to start with listening exercises (identification and discrimination of stressed and unstressed syllables) before going on to produce the stress patterns. Further tests can involve the identification of sentence accent or different accent types. An advantage of a detailed diagnosis at the begin-ning of the coaching process is the possibility to compare the initial data

Individual pronunciation coaching and prosody 219
with production and perception data of the learner at a later time. This also helps to make the learning progress comprehensible, and, more impor-tantly, visible for both learner and coach.
Now that the learner knows about his individual problems, he decides which particular difficulty he wants to work on. Then, the learner and the coach discuss different approaches and possibilities for pronunciation prac-tice. The coach indicates suitable exercises7 and introduces the learner to different techniques like the use of a speaking dictionary. As not every strategy suits everyone, the adult learner chooses the one he thinks would suit him best.
Depending on the learner’s difficulties it can be useful to explain the re-lation between sounds and letters in German, to show articulation places of certain consonants, to show differences in the rhythms between L1 and L2, or to draw the attention of the learner to particular intonation patterns or stress rules. Often, it is helpful to include information structure rules, i.e., to explain which words are highlighted (focussed) and why other words are deaccented in a given text. The explicit knowledge of phonetic and pro-sodic rules concerning their own difficulties can help the learners to take control of their own pronunciation.
The explanations of the coach should not be limited to linguistic knowl-edge. She can demonstrate how to use language learning software, how to profit from listening tasks, songs, audio books or a vocabulary trainer, where the learner can find rules and exercises for his individual problems on a CD-ROM, which exercises are appropriate for which difficulty, etc. Together, the learner and the coach discuss which procedure could be help-ful for the learner’s working on his pronunciation. However, the decision about the path and direction the learner wants to take is up to the learner, since he is the one who has to put his chosen methods into action.
At the end of the session, the learner formulates his goals and defines the necessary steps to reach them, i.e., the exercises he will do until the next session. This is a kind of verbal contract between the learner and his coach and serves as a starting point for the next session. Usually, those sessions take place on a regular basis, normally every three or four weeks. The time frame for the whole coaching is a few months.

220 Grit Mehlhorn
4.2. Subsequent coaching sessions
The subsequent coaching sessions can proceed in the following phases:
1. The learner reports on his learning: what he trained and how he trained, which difficulties he encountered, in which areas he noticed a progress, which sub-goals he reached, etc.
2. Taking the learner’s self-evaluation as a starting point, a new diagnosis can be made with the help of a new recording of the learner’s pronun-ciation. The feedback from the coach with respect to the learner’s per-formance in certain aspects of pronunciation, and comparisons with former recordings serve as a means for showing to the learner his pro-gress in pronunciation.
3. The consequence of this evaluation can be either a. to maintain the strategies used, if they worked for the learner, and
to set a new sub-goal, i.e. to work on the next pronunciation dif-ficulty, or
b. to revise the procedure, if it did not suit the learner’s needs. In the latter case, the original goal would be maintained and a new strategy, i.e., other methods and/or exercises, should be tried.
4. During the coaching session, it can be necessary to make the learner aware of pronunciation rules of the target language or to explain and demonstrate new learning strategies, e.g. how to use a pronunciation dictionary, how to concentrate on certain aspects of prosody, etc.
5. A last step consists in the agreement on the next sub-goals and the learning strategies to reach them.
Depending on the learner’s personality and their capability of self-reflection, there can be slight deviations from this procedure. The above mentioned phases, however, have proven successful in the practical appli-cation of IPC. Moreover, they are able to give the sessions a fixed structure, which is often perceived as helpful (Kleppin 2003, Kleppin and Mehl-horn 2005).

Individual pronunciation coaching and prosody 221
5. Language awareness
5.1. Foreign language pronunciation and language awareness
According to Little (1999), the autonomous learner possesses language awareness. Learners come to the IPC with a certain learning need. After analyzing the learner’s performance in the diagnosis, their “awareness of [his own] learning needs” (Lernbedarfsbewusstheit, Knapp-Potthoff 1997: 13) becomes more acute, since they are now in a position to make a more concrete evaluation of their ability and the pronunciation phenomena they want to improve.
The learner needs to develop awareness and monitoring skills that will allow learning opportunities outside the coaching environment (Otlowski 1998). In order to raise language awareness, it is necessary to direct the learner’s attention to form, i.e., to how utterances are realized, e.g. where the differences between the rhythm of L1 and L2 are, how the intonation of a given sentence sounds or where the stress is put (for the concept of focus on form see Long 1991). A first step towards raised language awareness can be taken by concentrating on problematic sounds or intonation patterns. Here, language-related knowledge is helpful, e.g., knowledge about the existence of final devoicing and glottal stops in German, stress rules, the information structure of utterances or the use of certain intonation patterns. A next step of consciousness raising could consist of letting the learner hear his deviations. He listens to his recording and has to concentrate on the marked items. This is done to account for the fact that unless the learner recognizes his deviations, he is hardly able to change his prosody. Once the learner is able to hear his pronunciation difficulties, he can pay attention to the given problems while reading aloud. At the beginning, the learner marks the pronunciation phenomena he wants to focus on in the given text. A further step towards language awareness is reached when the learner succeeds in identifying the pronunciation difficulty under consideration in texts that are unknown to him. The reached receptive sensibility can be seen in noticing individual pronunciation difficulties in the speech of oth-ers, often fellow countrymen, and his own speech. In certain situations, the learner should succeed more and more in concentrating on formal aspects in the speech of native speakers, e.g. the speech melody in polite requests or the realization of reduced vowels in unstressed syllables. However, no-ticing such phenomena and being more aware of them does not mean that

222 Grit Mehlhorn
the learner can produce them automatically in an adequate way. Neverthe-less, the noticing of deviations is an important prerequisite for controlling one’s own pronunciation.
Through the raised awareness concerning the foreign pronunciation, the learner advances hypotheses concerning the target pronunciation and pros-ody, e.g. that stressed syllables are longer than unstressed ones. The coach encourages the learner to build hypotheses, on the one hand, but, on the other hand, she tries to restrict possible overgeneralizations made by the learner (e.g. in German there are short stressed vowels as well). In my ex-perience, such hypotheses and other mnemonic devices the learner has cre-ated for himself are more helpful for him than abstract phonetic rules.
If the learner has developed the ability to focus on his difficulties in a written text and has achieved a correct pronunciation, the next step consists of applying this knowledge to spontaneous speech. One possibility to reach this ultimate goal is the use of different word lists. Figure 3 demonstrates an example of a word list for a Slovak learner of German who consistently placed the word stress on the first syllable. Therefore, during the coaching she made a list with the most problematic words on which she wanted to concentrate in the following weeks.
interesSANT ‘interesting’
überSETzen ‘to translate’
AleXANdra (the name of a fellow student)
die SlowaKEI, aber: ‘Slovakia; but: der SloWAke, die SloWAkin Slovak’
das PERfekt, aber: (Das ist) perFEKT. ‘the perfect tense; but:
This is perfect.’ 8
Figure 3. Word list (main emphasis: word stress)
Then, the learner discusses with the coach in which context she will try to apply this list, e.g., in a prepared, fairly emotion-free setting such as an oral presentation. If she succeeds in these situations, she will gradually master these words in all kinds of spontaneous speech.
It is well-known that it is easier to concentrate on word stress or seg-mental particularities than on suprasegmental particularities. The question

Individual pronunciation coaching and prosody 223
is then which techniques to use to raise the learner’s awareness of prosody, making use of their individual cognitive learning styles. As many learners are visual perceivers, one can use both visual and auditory means to illus-trate certain differences between the learner’s native and the target lan-guage, e.g., the different rhythm patterns of syllable-timed and stress-timed languages.9 The picture in Figure 4 was developed by Özen (1986: 13) who treated the differences between Turkish and German.
syllable-timed
stress-timed
Figure 4. Rhythm of L1 vs. L2 (duration and pitch height of syllables)
One can use this visual means also for learners with Romance L1s if their rhythm is strikingly deviant from the German one. What this contrast illus-trates nicely is the steady rhythm of a syllable-timed language where all syllables have nearly the same length. In a stress-timed language, it is the distance between two accented syllables which has approximately the same length. Therefore, if there are many unaccented syllables between two ac-cented ones, they are produced much quicker, so that reduction takes place.
Visual displays of speech are another valuable means for raising lan-guage awareness of the various aspects of speech, especially intonation. The coach can extract a problematic sentence from the diagnosis text of the learner and transfer it to a computer program which generates the pitch contour (fundamental frequency) of the sentence. For the following exam-ple, the computer program PRAAT was used. Among several other func-tionalities (which are not crucial for our purposes), PRAAT provides a visual display and a feature that enables the user to overlay a native speaker version of a given sentence on the learner’s version. Figure 5 shows the realization of a sentence spoken by a German native speaker (in the upper half of the figure, cf. audio example 11) and the learner (here: a Russian native speaker, cf. audio example 12). The way the Russian speaker produces this sentence is characterized by a higher number of pitch accents than required, and a wider pitch range on the accented syllables.10 These prosodic features may lead to misjudge-
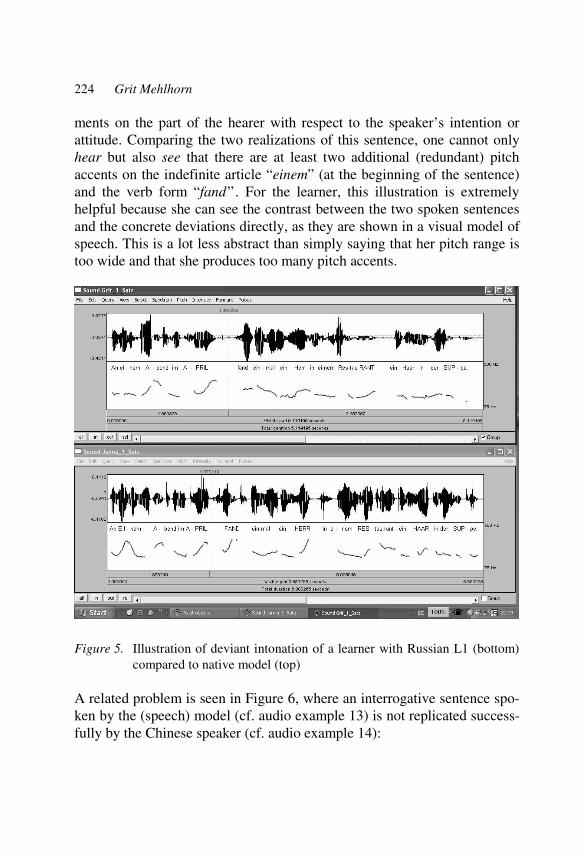
224 Grit Mehlhorn
ments on the part of the hearer with respect to the speaker’s intention or attitude. Comparing the two realizations of this sentence, one cannot only hear but also see that there are at least two additional (redundant) pitch accents on the indefinite article “einem” (at the beginning of the sentence) and the verb form “fand”. For the learner, this illustration is extremely helpful because she can see the contrast between the two spoken sentences and the concrete deviations directly, as they are shown in a visual model of speech. This is a lot less abstract than simply saying that her pitch range is too wide and that she produces too many pitch accents.
Figure 5. Illustration of deviant intonation of a learner with Russian L1 (bottom) compared to native model (top)
A related problem is seen in Figure 6, where an interrogative sentence spo-ken by the (speech) model (cf. audio example 13) is not replicated success-fully by the Chinese speaker (cf. audio example 14):

Individual pronunciation coaching and prosody 225
Figure 6. Illustration of deviant prosody of a learner with Chinese L1 (bottom) compared to German model (top)
As can be seen in the lower half of the figure, the Chinese student (uninten-tionally) splits the utterance into two intonation phrases. This is caused by the realization of a strong rise on the unstressed syllable of “Abend” – the word carrying the focus accent in this utterance – and a new “onset” on the next word “wird”, which starts very low. Furthermore, one can see that the words and syllables which should be deaccented are pronounced too long by the learner. Hence, this example shows both intonation and rhythm de-viations.
An adequate explanation of what the computer display shows should be given by the coach, i.e. information about what it represents and the articu-latory correlates of the acoustic signal. If the deviations illustrated here are explained to the learner in a comprehensive way, visible speech can be a valuable learning device for the learner. This only works if the learner is able to “read” the important information from the intonation contour. She

226 Grit Mehlhorn
has to abstract from irrelevant individual details like absolute pitch height or the overall length of the utterance, for example.
If the learner succeeds in focussing on form, then noticing can take place. The term noticing is defined as the recognition of specific structures in the target language as a consequence of focussed attention (Schmidt 1995; Eckerth and Riemer 2000). This is a prerequisite for processing these structures and their integration in the learner language. It is assumed that what learners notice in input is what becomes intake for learning (noticing hypothesis, Schmidt 1990). Noticing takes place when learners compare their own performance with the native speaker’s performance and recog-nize deviations (Schmidt and Frota 1986). In foreign language acquisition, noticing is a necessary step but not a sufficient one since noticing alone does not yet lead to a proper realisation of the target prosody. While notic-ing refers to surface phenomena, i.e. the learning of individual information as well as its anchoring in short-term memory, understanding refers to deeper levels of abstraction, like the organization and restructuring of in-formation in long-term memory (Eckerth and Riemer 2000: 230). For adult learners, it is important to understand the nature of their deviations. In IPC, the coach tries to maximize the possibilities of noticing via focus on form.This enables a reflection and awareness process which yields deeper proc-essing and hence more profound learning – even outside the coaching con-text.
The following quotations from coaching sessions show that the learners focus on their own pronunciation as well as on the pronunciation of their fellow countrymen and German native speakers:
(1) “I tried to speak simultaneously with the speaker on the CD and I noticed the different speed. „An einem Abend im April …“, the speaker makes a pause, while I continue reading … my segmentation of the text was different.”
(2) “Yesterday I took the bus. There was a woman who wanted to get off and said (citing) „Darf ich bitte vorbei?“ This was exactly the intonation, this polite in-tonation! This polite question intonation! In this moment, I heard it!”
(3) “In the beginning, I was speaking too high. Now it’s going much better.” (4) “Now, I hear much more, my own errors. And I notice other Italians making
the same errors.” (5) I just came back from Russia after a long time away. There I suddenly noticed
the newsreaders indeed speaking totally different from the German ones. She speaks somehow “emotionally”, so “excitedly”. Before, I didn’t notice that.”
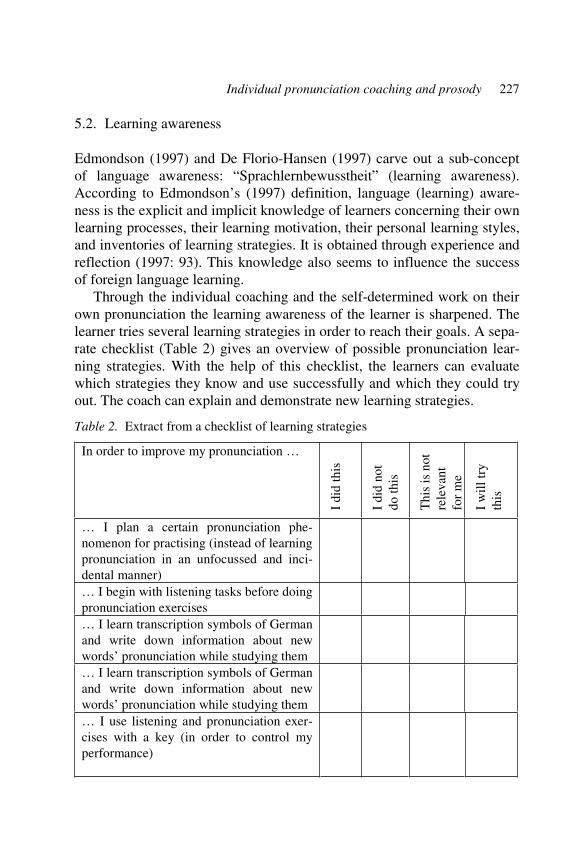
Individual pronunciation coaching and prosody 227
5.2. Learning awareness
Edmondson (1997) and De Florio-Hansen (1997) carve out a sub-concept of language awareness: “Sprachlernbewusstheit” (learning awareness). According to Edmondson’s (1997) definition, language (learning) aware-ness is the explicit and implicit knowledge of learners concerning their own learning processes, their learning motivation, their personal learning styles, and inventories of learning strategies. It is obtained through experience and reflection (1997: 93). This knowledge also seems to influence the success of foreign language learning.
Through the individual coaching and the self-determined work on their own pronunciation the learning awareness of the learner is sharpened. The learner tries several learning strategies in order to reach their goals. A sepa-rate checklist (Table 2) gives an overview of possible pronunciation lear-ning strategies. With the help of this checklist, the learners can evaluate which strategies they know and use successfully and which they could try out. The coach can explain and demonstrate new learning strategies.
Table 2. Extract from a checklist of learning strategies
In order to improve my pronunciation …
I di
d th
is
I di
d no
t do
this
Thi
s is
not
re
leva
nt
for
me
I w
ill t
ry
this
… I plan a certain pronunciation phe-nomenon for practising (instead of learning pronunciation in an unfocussed and inci-dental manner)
… I begin with listening tasks before doing pronunciation exercises
… I learn transcription symbols of German and write down information about new words’ pronunciation while studying them
… I learn transcription symbols of German and write down information about new words’ pronunciation while studying them
… I use listening and pronunciation exer-cises with a key (in order to control my performance)
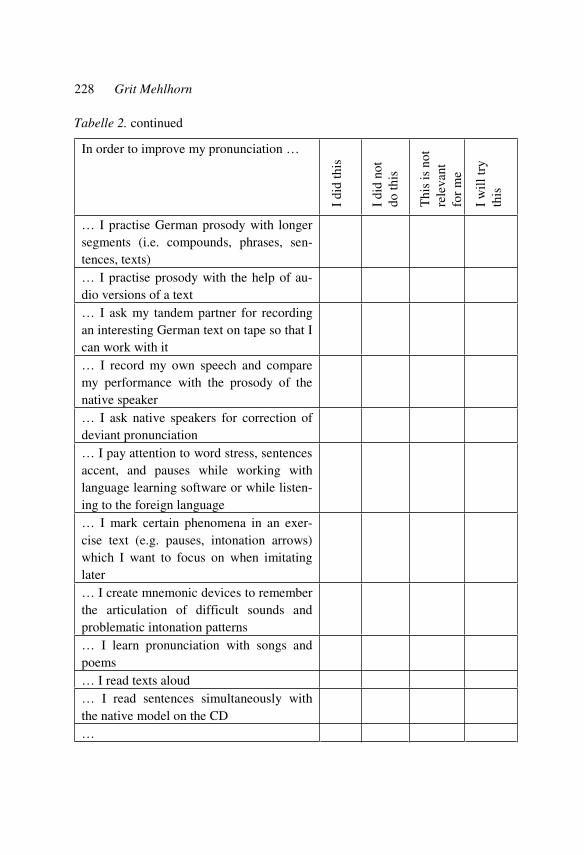
228 Grit Mehlhorn
Tabelle 2. continued
In order to improve my pronunciation …
I di
d th
is
I di
d no
t do
this
Thi
s is
not
re
leva
nt
for
me
I w
ill t
ry
this
… I practise German prosody with longer segments (i.e. compounds, phrases, sen-tences, texts)
… I practise prosody with the help of au-dio versions of a text
… I ask my tandem partner for recording an interesting German text on tape so that I can work with it
… I record my own speech and compare my performance with the prosody of the native speaker
… I ask native speakers for correction of deviant pronunciation
… I pay attention to word stress, sentences accent, and pauses while working with language learning software or while listen-ing to the foreign language
… I mark certain phenomena in an exer-cise text (e.g. pauses, intonation arrows) which I want to focus on when imitating later
… I create mnemonic devices to remember the articulation of difficult sounds and problematic intonation patterns
… I learn pronunciation with songs and poems
… I read texts aloud … I read sentences simultaneously with the native model on the CD
…

Individual pronunciation coaching and prosody 229
This is an open list to which the learner should add their individual strategies. It is helpful to fill out the same checklist after a few months and to compare it with the list of original learning strategies of the learner. This way, learner and coach are able to see which new learning strategies the learner found for himself since the first coaching session. Even the insight which learning paths do not fit the learner can help raising his language awareness.
Depending on their individual learning styles, learners prefer different strategies. The knowledge of different learning strategies and the reflection on the learning method help the learner to evaluate which procedure is ap-propriate for them (Rampillon 2000; Tönshoff 2003). Strategies and tech-niques which the learner used successfully for improving their German pronunciation should facilitate the learning of further languages in many cases. The more strategies the learner tries, the more consciously they de-cide to adopt a certain procedure.
6. The role of corrective feedback and self-evaluation
The potential of motivating the learner can be extremely high in individual coaching (Kleppin 2004) if the coach is able to give constructive feedback. Here it is important to regard the learner not as having a deficiency, but to concentrate on their learning progress. Therefore, feedback should promote the learning process but not overtax the learner. Hence, for example, it is not useful to list all segmental deviations in the analysis of a text read by the learner, if it was their goal to concentrate on the intonation in this text. Feedback should be differentiated, to allow the learner to develop sensitiv-ity with respect to his pronunciation problems, but only to an extent that does not have a negative impact on his motivation to improve his pronun-ciation.
At the same time, the learner should feel that increased language aware-ness is already a learning progress. It would be a missed opportunity of motivation if this was not treated as success itself, i.e. if the learning pro-gress would only be measured by the language production of the learner.
Eventually, the learner should be encouraged to “organize” his feedback himself. This can be done by asking acquainted native speakers to pay at-tention to certain “problematic” sounds and to correct the learner, or through the individual work with audio media and learning software, if

230 Grit Mehlhorn
these offer an informative feedback. Hardison (2004) found significant effects of computer-assisted training in the acquisition of L2 prosody and, more importantly, a generalization as to segmental accuracy and novel sen-tences (for further examples of computer-assisted prosody programs see Stibbard 1996; Chun 1998). The native speaker pitch contour displays can serve as a salient feedback for the comparison with the learner’s attempts. Students interested in technology may enjoy working with computer soft-ware. The auditory and visual feedback should contribute to their learning.
The reflection on the learning experience, the learning progress, and the evaluation of successfully used learning strategies is bound to open new perspectives for the organization of further learning (Weskamp 2003). If the learner is able to identify “weak spots” himself and to draw the right consequences from self-observation, comparison with a standard, and self-evaluation, he will no longer depend on the feedback of the coach. The language (learning) awareness he has reached, and the gain in self-confidence, which enables him to overcome his hesitation when speaking the target language, form the prerequisites for further autonomous learning and pronunciation improvement.
7. Concluding remarks
IPC is not meant to substitute, but to complement pronunciation training in the classroom and is specifically aimed at overcoming the barrier of acquir-ing a correct pronunciation. Therefore it is sensible to offer IPC to accom-pany language courses. At self-learning centres where there is a special need of individual coaching (Langner 2004), the presence of pronunciation coaches is particularly desirable.
As a rule, IPC should be voluntary. Possible target groups are foreign students, future language teachers and interpreters as well as learners who want to improve their pronunciation. Experience shows that learners who know their specific pronunciation problems and have worked independ-ently on the improvement of their pronunciation profit much more from autonomous language learning.
This article provided a detailed overview of IPC. Since little attention is given to pronunciation in foreign language classrooms and students seldom know how to practise pronunciation outside of class, IPC can play a valu-able role in enhancing learner autonomy in the areas of pronunciation that

Individual pronunciation coaching and prosody 231
cause difficulties for foreign learners. One of the key points discussed are possible methods to draw the learners’ attention to the prosodic features of German. Since there are as many different learning styles and preferences as there are learners there is no particular type of training that would suit all students. However, it seems to be beneficial to the individual learner to be acquainted with several learning strategies and to try those strategies in order to find the right method for oneself. It was argued that perception and production tests at several times of the coaching process and constructive feedback by the coach can yield a diagnosis of pronunciation deviations and, at the same time, document the learning progress of the learner. This should raise the language awareness of learners and increase their confi-dence when speaking the foreign language.
Notes
1. The term pronunciation used here refers both to the segmental and supraseg-mental aspects of learners’ utterances in the target language.
2. DSH is the abbreviation of “Deutsche Sprachprüfung für den Hochschulzu-gang ausländischer Studienbewerber“; TestDaF means “Test Deutsch als Fremdsprache“. Both tests are designed to test whether the foreign German learners’ language abilities are sufficient for studying at German universities.
3. The autonomous learner himself decides to improve his pronunciation, de-cides when and where to work with which material and which strategies he wants to use.
4. This is an extract of a text taken from the pronunciation material for German learners “Simsalabim” (Hirschfeld and Reinke 1998). In addition to the printed text, there exists a spoken version of a native speaker on audio cassette so that the learner can do further work on this text at home.
5. The evaluation sheet is an adaptation from Dieling & Hirschfeld (2000: 198) for German as a Foreign Language and was modified for Chinese learners. Apart from prosody, it contains segmental deviances for vowels, consonants, consonant clusters, etc.
6. Dupoux, Peperkamp and Núria (2001) observed in their experiments a ten-dency for “stress deafness” in native speakers of French.
7. For exercices and pronunciation material for German as a foreign language, see Hirschfeld and Trouvain (this volume).
8. A similar problem arises for learners of English as a foreign language. While the word “perfect” as a noun and an adjective demands the stress on the first syllable, the verb “to perfect” is stressed on the second syllable.

232 Grit Mehlhorn
9. Although the traditional syllable-timed/stress-timed distinction is not sup-ported by experimental findings, and the fact that the classification is by no means clear-cut (e.g., Bertinetto 1989), there are significant rhythmic differ-ences in languages like German, English and Russian on the one hand (“stress-timed” languages) and languages like French, Turkish or Chinese (“syllable-timed” languages). For the purpose of raising the learners’ aware-ness for rhythmic differences in the mother tongue and the target language, it seems legitimate to exaggerate those differences.
10. This “typical Russian” intonation seems to be responsible for negative emo-tions felt by some native speakers of German who intuitively rate this kind of speaking as “exaggerated” or “theatrical”. Müller (1994: 182) describes this as an impression of irritated, unduly emotional language. For the Russian speaker, however, this was merely a normal and, objective (i.e. in no way emo-tional) information.
References
Baran, Małgorzata 2002 The advantage of auditory perceivers and sharpeners in learning
foreign language pronunciation. In: Ewa Waniek-Klimczak and Patrick James Melia (eds.), Accents and Speech in Teaching Eng-lish Phonetics and Phonology. EFL perspective, 315–327. Frank-furt: Lang.
Benson, Phil 2001 Teaching and Researching Autonomy in Language Learning.
London: Longman. Bertinetto, Pier Marco 1989 Reflections on the dichotomy ‘stress’ vs. ‘syllable-timing’. In:
Revue de Phonétique Appliquée 91-93, 99–130. Brammerts, Helmut, Mike Calvert and Karin Kleppin 2005 Ziele und Wege bei der individuellen Lernberatung. In: Helmut
Brammerts and Karin Kleppin (eds.), Selbstgesteuertes Spra-chenlernen im Tandem. Ein Handbuch, 47–54. Tübingen: Stauf-fenburg.
Brazil, David 1994 Pronunciation for Advanced Learners of English. Cambridge
University Press. Chun, Dorothy M. 1998 Signal analysis software for teaching discourse intonation. Lan-
guage Learning & Technology 2, 61–77.

Individual pronunciation coaching and prosody 233
Cotteral, Sarah and David Crabbe (eds.) 1999 Learner Autonomy in Language Learning: Defining the Field
and Effecting Change. Frankfurt: Lang. Cunningham-Andersson, Una 1997 Native speaker reactions to non-native speech. In: Allan James
and Jonathan Leather (eds.), Second-Language Speech. Structure and Process. 133–144. Berlin, New York: Mouton de Gruyter.
De Florio-Hansen, Inez 1997 ‘Learning Awareness’ als Teil von ‘Language Awareness’. Zur
Sprachbewußtheit von Lehramtsstudierenden. Fremdsprachen Lehren und Lernen 26, 144–155.
De Jong, John H.A.L. and Ulrike Kaunzner 2000 Acoustic training and development of general language profi-
ciency. In: Ulrike Kaunzner (ed.), Pronunciation and the Adult Learner: Limitations and Possibilities. (Bibliotheca della Scuola Superiore di Lingue Moderne per Interpreti e Traduttori, Forli 27). Bologna: CLUEB.
Dieling, Helga 1989 Zu einigen Aspekten des Hörens im Fremdsprachenunterricht. In:
Christian Gutowski and Eberhard Stock (eds.), Phonetik des Deutschen: Grundlagen und Anwendungen, 30–43. Halle.
Dieling, Helga and Ursula Hirschfeld 2000 Phonetik lehren und lernen. München: Langenscheidt. Dupoux, Emmanuel, Sharon Peperkamp and Núria Sebastián-Gallés 2001 A robust method to study stress ‘deafness’. Journal of the Acous-
tical Society of America 110, 1606–1618. Eckerth, Johannes and Claudia Riemer 2000 Awareness and Motivation: Noticing als Bindeglied zwischen
kognitiven und affektiven Faktoren des Fremdsprachenlernens. In: Claudia Riemer (ed.), Cognitive Aspects of Foreign Language Learning and Teaching, 228–246. Tübingen: Narr.
Edmondson, Willis J. 1997 Sprachlernbewußtheit und Motivation beim Fremdsprachenler-
nen. Fremdsprachen Lehren und Lernen 26, 88–110. Gehrmann, Siegfried 1999 Sprechen als Tätigkeit. Koordinations- und lerntheoretische
Grundlagen des zweitsprachlichen Ausspracheerwerbs. Heidel-berg: Universitätsverlag.
Gibbon, Dafydd 1998 Intonation in German. In: Daniel Hirst and Albert Di Christo
(eds.), Intonation Systems. A Survey of Twenty Languages, 78–95. Cambridge University Press.

234 Grit Mehlhorn
Grotjahn, Rüdiger 1998 Ausspracheunterricht: Ausgewählte Befunde aus der Grundlagen-
forschung und didaktisch-methodische Implikationen. Zeitschrift für Fremdsprachenforschung 9, 35–83.
Gut, Ulrike 2003 Prosody in second language speech production: the role of the
native language. Fremdsprachen Lehren und Lernen 32, 133–151.
Hardison, Debra M. 2004 Generalization of computer-assisted prosody training: quanti-
tative and qualitative findings. Language Learning & Technology8, 34–52.
Hirschfeld, Ursula, Heinrich P. Kelz and Ursula Müller (eds.) 2003ff. Phonetik international. Von Afrikaans bis Zulu. Kontrastive Stu-
dien für Deutsch als Fremdsprache. Waldsteinberg: Heidrun Popp Verlag. (www.phonetik-international.de)
Hirschfeld, Ursula and Kerstin Reinke 1998 Phonetik Simsalabim. Ein Übungskurs für Deutschlernende.
Berlin: Langenscheidt.Kaltenbacher, Erika 1998 Zum Sprachrhythmus des Deutschen und seinem Erwerb. In:
Wegener, Heide (ed.), Eine zweite Sprache lernen. Empirische Untersuchungen zum Zweitspracherwerb, 21–38. Tübingen: Narr.
Kleppin, Karin 2003 Sprachlernberatung: Zur Notwendigkeit eines eigenständigen
Ausbildungsmoduls. Zeitschrift für Fremdsprachenforschung1/2003, 71–85.
2004 ‘Bei dem Lehrer kann man ja nichts lernen!’ Zur Unterstützung von Motivation durch Sprachlernberatung. Zeitschrift für inter-kulturellen Fremdsprachenunterricht 2/2004. http://zif.spz.tu-darmstadt.de/jg-09-2/beitrag/Kleppin2.htm (21.05.2005).
Kleppin, Karin and Grit Mehlhorn 2005 Sprachlernberatung. In: Rüdiger Ahrens and Ursula Weier (eds.),
Englisch in der Erwachsenenbildung des 21. Jahrhunderts, 71–90. Heidelberg: Universitätsverlag.
Knapp-Potthoff, Annelie 1997 Sprach(lern)bewußtheit im Kontext. Fremdsprachen Lehren und
Lernen 26, 9–23.

Individual pronunciation coaching and prosody 235
Langner, Michael 2004 Sprachenlernen – Lernberatung – Neue Medien. Didaktische
Verbundkonzeptionen in der Spannung zwischen Autonomie und Sprachunterricht. In: Christina Lang and Gerhard von der Hand (eds.), Sprachenlernen im Verbund, 101–117. Bielefeld: wbv.
Little, David 1999 Metalinguistic awareness: The cornerstone of learner autonomy.
In: Bettina Mißler and Uwe Multhaup (eds.), The Construction of Knowledge, Learner Autonomy and Related Issues in Foreign Language Learning, 3–12. Tübingen: Stauffenburg.
Long, Mike 1991 Focus on form: a design feature in language teaching methodol-
ogy. In: Kees de Bot, Ralph B. Ginsberg and Claire Kramsch (eds.), Foreign Language Research in Cross-Cultural Perspec-tive, 39–51. Amsterdam: Benjamins.
Mehlhorn, Grit 2005 Studienbegleitung für ausländische Studierende an deutschen
Hochschulen. Individuelle Lernberatung – ein Leitfaden für die Beratungspraxis. Unter Mitarbeit von Karl-Richard Bausch, Tina Claußen, Beate Helbig-Reuter und Karin Kleppin. München: Iu-dicium.
Müller, Ursula 1994 Phonetische Probleme und ihre Ursachen bei Deutschlernern mit
der Muttersprache Russisch. In: Bernd Spillner (ed.), Fachkom-munikation. Kongreßbeiträge zur 24. Jahrestagung der Gesell-schaft für Angewandte Linguistik GAL e.V. (= Forum Angewand-te Linguistik, 27), 177–183. Frankfurt: Lang.
Otlowski, Marcus 1998 Pronunciation: What are the expectations? The Internet TESL
Journal, Vol. IV, 1/1998, http://iteslj.org/Articles/Otlowski-Pro-nunciation.html (21.5.2005).
Özen, Erhan 1986 Phonetische Probleme türkischsprachiger Deutschlerner. Teil 1:
Der andere Rhythmus. Deutsch lernen. Zeitschrift für den Sprachunterricht mit ausländischen Arbeitnehmern. Heft 3, 11–55.
Rampillon, Ute 2000 Aufgabentypologie zum autonomen Lernen Deutsch als Fremd-
sprache. Ismaning: Hueber.

236 Grit Mehlhorn
Riley, Philip 1997 The guru and the conjurer: aspects of counselling for self-access.
In: Phil Benson and Peter Voller (eds.), Autonomy and Independ-ence in Language Learning, 114–131. London, New York: Longman.
Schmelter, Lars 2004 Selbstgesteuertes und potenziell expansives Fremdsprachenler-
nen im Tandem. (= Gießener Beiträge zur Fremdsprachendidak-tik), Tübingen: Narr.
Schmidt, Richard W. 1990 The role of consciousness in second language learning. Applied
Linguistics 11, 129–158. 1995 Consciousness and foreign language learning: A tutorial on the
role of attention and awareness in learning. In: Schmidt, Richard (ed.), Attention and Awareness in Foreign Language Learning,1–63. Honolulu, Hawai‘i: University of Hawai‘i, Second Lan-guage Teaching & Curriculum Center.
2001 Attention. In: Robinson, Peter (ed.), Cognition and Second Lan-guage Instruction, 3–32. Cambridge University Press.
Schmidt, Richard W. and Sylvia Nagem Frota 1986 Developing basic conversational ability in a second language: a
case study of an adult learner of Portuguese. In: Day, Richard R. (ed.), Talking to Learn: Conversation in Second Language Ac-quisition, 237–336. Rowley, MA: Newbury House.
Stibbard, Richard 1996 Teaching English intonation with a visual display of fundamental
frequency. The Internet TESL Journal, Vol. II, No. 8, 1996. http://iteslj.org/Articles/Stibbard-Intonation/ (21.5.05).
Tönshoff, Wolfgang 2003 Lernerstrategien. In: Karl-Richard Bausch, Herbert Christ and
Hans-Jürgen Krumm (eds.), Handbuch Fremdsprachenunter-richt, 331–335. Tübingen, Basel: A. Francke.
Weskamp, Ralf 2003 Self-assessment/Selbstkontrolle, Selbsteinschätzung und -einstu-
fung. In: Karl-Richard Bausch, Herbert Christ and Hans-Jürgen Krumm (eds.), Handbuch Fremdsprachenunterricht, 382–384. Tübingen, Basel: A. Francke.

Prosodic training for adult Italian learners of German: the Contrastive Prosody Method
Federica Missaglia
1. Introduction
This paper presents the Contrastive Prosody Method (CPM), a prosody-centred pronunciation training method aimed at developing prosodic com-petence in L2-German of adult Italian learners, including both beginners and advanced learners.
Using the familiarity with Italian learners’ pronunciation difficulties as the empirical starting-point, the CPM is aimed at impeding and correcting specific prosodic errors and fossilized features in L2-perception and pro-duction, mainly concerning intonation contours and word and sentence stresses. The method is also intended to develop prosodic awareness, a native-like ability to identify and discriminate between different prosodic variants relevant in transmitting, together with the verbal component of speech, the speaker’s communicative intentions and emotions. In the CPM, prosody is given priority with respect to segments not only in content, but also as a means to produce adequate speech acts and to develop communi-cative competence.
The CPM is characterized by both a bilingual and a contrastive appro-ach: the students are never considered simply language learners, i.e. poten-tial L2-speakers, but are always treated as bilingual speakers. Moreover, while training L2-prosody, the learners’ L1 is never excluded: L1-prosody is used as a means to produce and acquire accurate word and sentence stresses, and correct intonation contours in L2. Correct prosodic perception is attained by proper identification of L2-suprasegmentals, achieved by monitoring L1-suprasegmentals. This effect permeates to other levels lea-ding to native-like German prosody and segments.
Before illustrating the method in detail (section 4), I will briefly present the theoretical and empirical framework of the CPM (section 2) and I will discuss the different concepts of both the “bilingual approach” (section 3.1) and the “contrastive approach” (section 3.2) in relation to the method. Fi-

238 Federica Missaglia
nally, empirical data obtained by comparing traditional segment-centred with prosody-centred pronuniation training will be investigated in view of L2-prosody and segments (section 5).
2. Theoretical and empirical framework
The CPM was developed within a multidisciplinary theoretical framework primarily concerned with cognitive and emotional aspects of phonetic and phonological development in first and second language acquisition. Re-search on cognition and emotion in language acquisition was later imple-mented with further results in the fields of psychoacoustic and experimental phonetics, theoretical and experimental neurology (Damasio 1994, 1999, 2003; Hüther 2002), neurolinguistics and bilingualism (Paradis 1994, 1997; De Houwer 1995; Fabbro 1996; Mack 2003; Bhatia and Ritchie 2004), cognitive psychology applied to perception and categorization in phonetic and phonological acquisition (Kuhl 1993b 1995; Miller 1994; Kuhl and Meltzoff 1995, 1997), and mental representation of linguistic items (Sendlmeier 1989, 1996).
Practical experience in L2-German pronunciation training courses de-signed for Italian university students was fundamental to the CPM, together with theoretical and experimental research in phonetics and phonology applied to Italian (L1) and German (L2), but also to the specific learner group’s interlanguage (Ioup and Weinberger 1987; Missaglia 1999a). The empirical starting-point of the CPM was the error analysis of linguistic competence tests carried out with advanced Italian learners, i.e. adult lear-ners with high level L2 competence, mostly bilinguals with an intensive German scholastic background (for details see Missaglia 1997). The aim was to collect a corpus of specific interferences, i.e. the fossilized forms of near-native L2-learners, to define their competence level, which was sup-posed to be the students’ target after advanced L2-courses in an institutio-nal setting (school, university, etc.). However the errors, numerous and distributed on all phonetic levels (i.e. the segmental, intersegmental and suprasegmental level), largely surpassed the interferences which were thought to be sporadic and specific. The bilinguals’ phonological interfe-rences were mostly comparable with those of Italian high school or univer-sity students. Data involving cross-sectional research on absolute beginners and the bilingual group showed that both learner groups were not equipped

Prosodic training for adult Italian learners of German 239
to discriminate specific features of German prosody and tended to carry incompatible Italian intonation contours and stress patterns over into Ger-man contexts. The phonetic performances of the two groups – beginners vs. very advanced (bilingual) learners – did not differ significantly in qualitati-ve terms; the differences among them did not mainly concern the error types, but rather the extent or degree of error.
Most errors and interferences at the segmental level were not primarily related to incorrect pronunciation of single segments, but rather to lacking competence at the suprasegmental level. Incorrect L2-pronunciation by Italian native speakers is mainly attributable to the learners’ distorted per-ception of L2 sounds and prosody, i.e. a perception filtered by L1, rather than to defective speech or to a deficit in the speakers’ phonatory apparatus.
It appears that the so-called foreign accent may not be related to an ar-ticulatory deficit, i.e. the learners’ phonetic incapacity to produce L2 sounds, but rather to an incorrect categorial – phonological – interpretation.
Trubetzkoy (1939) already pointed to the interaction of perception and production, and recent results in the field of language acquisition corrobo-rate the theory of a perception-production interdependence (Vihman 1993, 1996; Kuhl 1995; Strange 1995a, 1995b). Experiments on the transition from universal perception and production patterns towards language-specific patterns, i.e. from the perception of phonetic differences by new-born babies towards a categorial perception of L1 sounds after the 6th and 10th month (for vowels and consonants, respectively, cf. Kuhl et al. 1992; De Boysson-Bardies 1993; Werker and Polka 1993; Vihman 1996; Werker 2003) led to the hypothesis that sound categories are mentally represented as phonetic prototypes (for the prototype concept in cognitive psychology see Rosch 1973, 1975; in phonetics Kuhl 1992; Miller 1994), rather than as abstract phonemes or as bundles of distinctive features, as was stated in traditional structuralist linguistics.
Kuhl’s Native Language Magnet Theory (Kuhl 1991, 1993; Kuhl and Iverson 1995) holds that phonetic prototypes, i.e. the central and most rep-resentative instances of phonological categories, act as perception magnets. They attract the sounds belonging to the same category and hinder native speakers from perceiving acoustic differences between prototypes and pho-netically similar sounds. The perception patterns based on phonetic proto-types are language-specific insofar as the perception categories tally with the phonological categories of the language. On the basis of language-specific perception patterns, analogous production patterns are established, enabling native speakers to produce L1 sounds correctly. L1 phonetic pro-

240 Federica Missaglia
totypes act as phonetic magnets in L2 perception and production, too, thus leading to the so-called foreign accent.
In the light of prototype theory it can be assumed that the phonetic and prosodic errors made by Italians when speaking German are generated whi-le learning L2; the fact that they are common to advanced learners and be-ginners leads to hypothesize that they turn up in the very first contact with L2, then fossilize, thus hindering the production of correct German utteran-ces. The phonetic stumbling block seems to hinder even the first access to L2.
Experimental data (Missaglia 1997) further showed that correct pro-nunciation is largely dependent on the self-control of intonation – also in L1 – and on the correct accentuation of German words and sentences. With minimal effort, both beginners and advanced learners were able to master German pronunciation. Once learners acquired a rudimental prosodic com-petence, many phonological interferences disappeared, suggesting that ac-centuation and intonation have a controlling function over syllables and segments. Correct prosodic perception and production have proved to have positive consequences on the segmental level. On the contrary, work with segments alone, such as traditional structural exercises for the language lab, exercises with minimal pairs, substitution exercises, pattern practice and pattern drills have not proved to be productive. The correction of single segments has no lasting effect and it has negative consequences on the in-tonation contour and the melody of the sentence. Thus in Second Language Acquisition (SLA) correct prosody is to be considered primary with respect to segments also because prosodic deviations have a more negative influen-ce on the communicative effect of speech acts than segmental mistakes.
Within this theoretical and empirical framework, we began training a-dult Italian learners on L2-German prosody with a learner-centred, bilingu-al approach.
3.1. The bilingual approach
The bilingual approach in L2-German pronunciation training was the result of theoretical and practical understanding in the field of research on bilin-gualism and especially of the discovery that the distinction between bilin-guals and L2-learners is relative (for a discussion see Missaglia 1997). The differences between bilinguals and L2-learners mainly concern specific modalities of access to mental representation of L1 and L2 items (Paradis

Prosodic training for adult Italian learners of German 241
2003) rather than degree of competence. The CPM’s bilingual approach is based on the assumption that learners should not be considered simply lear-ners, isolating them from their reality, i.e. that of speaking two languages and of living with two languages. Starting from their first encounter with L2, each learner is not simply to be viewed as a potential L2-speaker, but has to be considered a bilingual individual, i.e. the “locus of the [linguistic] contact” (Weinreich 1953: 1); language learners are bilingual speakers whose linguistic processes and competence can be studied and described within the framework of research on bilingualism. Thus L1 should not be seen as an obstacle to L2-acquisition, but rather as the threshold connecting L1 with L2.
Errors belong to each interlanguage (Selinker 1972; Corder 1981) or ap-proximative system (Nemser 1971), i.e. to each stage along the road which leads to bilingualism, as do other speaker-specific characteristics. For this reason in the CPM errors are considered positively, namely as indicators of problematic aspects of the two linguistic systems and also of the characte-ristics of the learners’ interlanguage.
Recognizing the phonetic circumstances both in the L1 and in the lear-ners’ interlanguage has proved to be compulsory in bilingual and contrasti-ve pronunciation training for L2-learners.
3.2. The contrastive approach
In the CPM prosody is treated within a contrastive German-Italian frame-work. With the key word “contrastive” we usually refer to a traditional research area, to contrastive grammar and contrastive analysis and the deri-ved error analysis. Our studies on German and Italian phonetics in contact (and in contrast) are founded on error analysis. But in the CPM the mea-ning of the keyword “contrastive” is far from that attributed to it by the Contrastive Analysis Hypothesis (Lado 1957).
Monolingual and contrastive representations of German and Italian pho-netics and phonology show great differences and few similarities concer-ning both segments and prosody. Most – even recent – contrastive descrip-tions of German and Italian phonetics and phonology are still dominated by a phonematic perspective. They aim at determining the phonemes’ functio-nal role and, reflecting the methodological implications of traditional Contrastive Analysis, at listing and comparing “common” and “language-specific” phonemes.

242 Federica Missaglia
The structural differences between the two languages’ phonemic sys-tems and the description of articulatory and auditory characteristics should help learners to avoid mistakes related to production and perception diffi-culties and should thus simplify L2-acquisition. The real – i.e. phonetic – quality of sounds is not investigated and it is not clear whether and to what extent in native speakers’ articulation different or identical phonetic realiza-tion corresponds to so-called “common” phonemes.
Practical experience in L2 pronunciation training shows that lists of structural differences and phonetic transcriptions do not automatically lead to native-like German pronunciation, because the phonetic quality of so-called “common” or “very similar” phonemes, i.e. phonemes which are represented by the same IPA-symbol, can be very different. The differences concern mostly vowels, as they are inherently more susceptible to modifi-cation or cross-language influence than consonants.
The representation of German and Italian vowels with separate vowel charts in which “corresponding” vowels appear at the same height is not appropriate because L2-learners are led to assume that “corresponding” vowels are phonetically identical. The consequence is that they simply car-ry identical presumed L1 sounds over to L2, both in L2 production and perception.
Our empirical results show great phonetic differences in German vowel production and perception by German and Italian native speakers. The data involve auditory experiments determining the relevance of quantitative and qualitative perception differences in the German vowel system for German native speakers and adult Italian learners and also articulatory and acoustic analyses of the variations in German vowel production by German and Italian native speakers (for details see Missaglia 2004).
It can be hypothesized that the structural – phonological – and phonetic differences between the German and the Italian vowel inventory (15 vs. 7 vowel phonemes in stressed position; 9 vs. 5 in unstressed position) lead to different language-specific perceptual categories and thus to different auditory strategies by native speakers. Contrary to German, in which vo-wels in stressed position differ phonetically in concomitant quality and quantity, in the Italian vowel system quantity and quality are not correlated; this may cause difficulties when Italian native speakers must identify and discriminate between most German vowels. The co-existence of four con-comitant phonetic features for most phonological oppositions in the Ger-man vowel inventory, which enables German native speakers to use diffe-rent strategies to discriminate between stressed vowels (Sendlmeier 1981),

Prosodic training for adult Italian learners of German 243
can hinder correct vowel production and perception by Italian learners, but it can also be used in L2-pronunciation training. In fact, even if vowel quantity is not relevant at the segmental level in Italian, the experimental results on vowel perception showed that for Italians to discriminate most German vowel pairs, quantity rather than quality was phonologically rele-vant. This fact can be explained by the specific characteristics of the Italian vowel system and by the Italians’ sensitivity towards differences in vowel duration. In Italian vowel duration has no phonological relevance at the segmental level, i.e. it is not relevant for distinguishing the vowel phone-mes (Bertinetto 1981), but it has a positive influence from an interlingual point of view due to its phonological significance at the suprasegmental level.
L2 pronunciation can effectively be trained only when L2 sounds are perceived adequately; an adequate mental representation of L2 phonetic items must be established, which can be controlled with a sort of monitor during sound, word and sentence production (see Sendlmeier 1989b, 1994).
The great differences between native speakers of German and Italian concern both vowel perception and production. For the qualitative analysis of vowel production by Italian learners in comparison with German native speakers, vowels were acoustically measured by extracting F1 and F2 va-lues. A contrastive formant chart best shows the great differences and little similarities in German vowel production by Italian and German speakers:
300
500
700
900
10001400180022002600 F2
F1
DM
IMa
a
aÜaÜ
I
I
iÜ iÜ
eÜ eÜ
´
EE
å å
´
yÜ
Y
Y
yÜ
O O
oÜ
oÜ
U
uÜ
uÜiU
Figure 1. Contrastive formant chart with mean values of German vowel produc-tion by German (DM) and Italian (IM) native speakers (for details see Missaglia and Sendlmeier 1999).

244 Federica Missaglia
The experimental data on vowel production founded on acoustic analy-ses suggest that the German vowels produced by Italian learners are in some way filtered by the corresponding Italian vowels. Italian learners seem to correlate L2-phonemes lacking in the phoneme system of L1 with Italian vowels which are perceived as more similar. It can be hypothesized that the filtering of L2 centralized lax vowels and their realization as the corresponding tense vowels depends on the phonological system of L1 rather than on the effective phonetic realization of L1. In fact, acoustic experiments with Italian native speakers (Albano Leoni, Cutugno and Savy 1995) showed that in spontaneous speech Italians produce many reduced and centralized vowels, which are perceived phonologically, i.e. as the corresponding decentralized Italian phonemes.
Starting from prototype theory the experimental data on vowel produc-tion by German and Italian native speakers can be explained as follows: mentally represented language-specific Italian prototypes are activated in both L1 and in L2. L2-learners have interiorized the phonological system and the phonetic prototypes of L1, whereas the interiorization of the correct phonological system and of the phonetic prototypes of L2 is still incomple-te. For L2 sound discrimination and production this lack of L2-prototypes is compensated by the unconscious recurrence to L1-specific phonetic pro-totypes and selective perception patterns.
The difficulties in producing correct German vowels by Italian learners depend on L1-specific perception patterns and on interlingual differences in the phonetic and phonological use of the articulation area by languages with different vowel inventories. Italian native speakers are used to wide articulatory and acoustic variations and they tend not to perceive – and consequently, not to produce – slight acoustic differences of tenseness, openness and centralization, because in the Italian vowel system the diffe-rences between the seven stressed vowels are great enough to allow greater freedom in vowel articulation. This freedom leads Italian native speakers to pronounce tense vowels more open and centralized than would be necessa-ry for discriminating and identifying them. This is the main reason why it is so difficult for Italian learners to acquire the German vowel system con-sisting of 15 phonemes, as they are confronted with a language in which small spectral differences are important for vowel discrimination.
These experimental data have important implications for L2-pronunciation training. It can be hypothesized that, besides segmental proto-types, prosodic prototypes are also established, concerning for example stress pattern, intonation contour and rhythm. These prosodic prototypes

Prosodic training for adult Italian learners of German 245
may influence and distort L2-perception. Speakers of a syllable-timed lan-guage may establish prototypes which reflect the phonological characte-ristics of their mother tongue. When in contact with a stress-timed language these prototypes may cause difficulties in L2 perception, such as in relation to discrimination and identification of stress position, intonation contour, quantity relations, vowel quality and degrees of prominence.
Prosodic and rhythmic differences between a stress-timed language such as German (Kohler 1982, 1983, 1991) and a syllable-timed language such as Italian (Bertinetto 1977, 1989a, 1989b) may explain why Italian learners have less production and perception difficulties with German segments than with German prosody, vowel reduction processes and consonant clusters.
In German, traditionally a stress-timed language, deaccenting processes are extremely important; they are even more relevant than accenting pro-cesses, as at the level of intersegmental co-ordination processes they mostly lead to reductions and assimilations (Kohler 1979, 1990). Unstressed vow-els undergo strong reductions tending towards schwa (Meinhold 1962, 1967), and voiced consonants in the syllable coda are devoiced (Auslaut-verhärtung). For Italian speakers vowel reductions and centralizations in unstressed positions and final devoicing are difficult tasks to accomplish because in Italian, traditionally a syllable-timed language, there is no pho-nological distinction between stressed and unstressed vowels and conso-nants in syllable onset and in syllable coda.
Thus many segmental mistakes depend on the fact that Italian learners spontaneously carry L1 perception patterns and distribution rules over to L2, emphasizing accurate articulation and elaborate pronunciation of seg-ments over correct prosodic realization. Deviations from the rhythmical structure of the stress-timed German language have a negative influence on communication with German native speakers.
4. The method
Familiarity with Italian learners’ difficulties in L2-German prosodic per-ception and production and the knowledge of specific features of German and Italian phonetics and phonology led to the Contrastive Prosody Method (Missaglia 1999b). The CPM is characterized by systematic attention to intonation contours, stress patterns and especially deaccenting processes with the consequent typical reduction phenomena of German. Furthermore,

246 Federica Missaglia
the CPM systematically directs the learners’ attention towards communica-tively adequate prosodic realizations of speech acts in L1 and L2, whereas segmental aspects are largely neglected. In the initial phases of the training, learners deal with prosody and phonetics intuitively, and they are taught rules explicitly later on.
The training is performed with authentic German texts (dialogues, songs, modern poetry, etc.), which, due to their characteristics, must be read aloud. The exercises rely on two rules: (1) the learners have to imagine real communicative situations and act accordingly; and (2) they have to produce only one strong stress in each sentence deaccenting and reducing all the words without sentence accent. For Italian learners this means a drastically perceived reduction of all secondary stresses towards the prima-ry stress. Italian learners with little knowledge of word and sentence accent rules in German initially do not know which element bears the primary stress. As they cannot rely on their L2-competence, they have to work with the only language they know they can handle without running the risk of making mistakes, i.e. the mother tongue. So they start practicing by treating their Italian as if it were German. By trial and error, learners can experi-ment with their mother tongue, where they are certain not to make pronun-ciation mistakes, monitoring it as if it were German. With minimal effort, both beginners and advanced students are able to make themselves masters of German pronunciation. Not caring about the difficulties connected with the production of segments foreign to the mother tongue, learners produce utterances monitoring the generic (prosodic) elements of the communicati-ve situation.
They produce Italian sentences with only one strong stress and deaccent all the other words, trying to exaggerate each word accent, whereas the other learners judge whether the Italian sentences produced sound unnatural or spontaneous. At this stage the learners only rely on their L1-competence. Only when they realize which accent cannot be eliminated in Italian – and this is often a surprising discovery – do they realize with their mother-tongue sentences which word is endowed with the primary stress.
At this point the learner switches to German assuming that the German equivalent of the accented word in the Italian sentence dominates the Ger-man sentence, too; in the first phases of the training it is important to pre-sent the learners with texts in which the German and the Italian primary stresses coincide.
When producing the German sentence the learner exaggerates only the sentence accent by deaccenting all other elements. Thus a perfect German

Prosodic training for adult Italian learners of German 247
speech act is produced effortlessly: by exaggerating the sentence accent, there is little energy for voiced consonants in syllable coda and for long tense vowels in an unstressed position. The reduction and centralization of unstressed vowels, the disappearance of schwa-epenthesis and the final devoicing are automatically accomplished.
The aim of the CPM is not to produce sentences, but speech acts, in which prosody is felt as the interface between grammar and the speaker’s affective reality, for example his emotions, fears, anxiety, etc. Realistic, i.e. natural and spontaneous speech acts, have to be produced first with Italian sentences which correspond to the German sentences of the exercise, em-bedding them into self-constructed virtual situations. Following the premi-ses of a bilingual approach, the didactic units centred on prosody do not exclude the mother tongue, but make regular use of translations. The lear-ners are not given translations in L1, they have to construct them starting from the situation given by the sentence/text.
The learners are autonomous, they never repeat model-sentences: cor-rect pronunciation is attained without the teacher’s instructions and rules; the learners never have models to repeat and imitate, but utterances – from their peers – to judge and improve. They act inside a group of learners, who listen to the sentences of the other learners and judge their acceptability in L1 and in L2. The reference point of each trial, phonetic variant and self-correction are the learners’ speech acts. The method’s principle is that lear-ning is efficient only when it is self-learning inside a group of peers. Not being dependent on an external model offered by the teacher gives the lear-ners a feeling of security and of success, which leads to a positive change of the learning attitude: the learners quickly realize that they are able to produce German sentences on their own.
The learners are autonomous and nobody is excluded from the acquisiti-on process, as everyone – both the speaker and the listeners – must respec-tively activate their language awareness in order to produce prosodically correct sentences (the former) and control their communicative efficiency (the latter). “Perfection” is reached only when the group’s members judge the sentences as not scholastic but normal-sounding and adequate in reflec-ting the speaker’s intentions and emotions. When the speech acts in L1 are considered efficient, i.e. natural sounding, the speaker has to produce an equivalent German speech act, then he must quickly switch from Italian to German and back again. By often switching from one language to the other, the learners improve their speed in code-switching. The prosodic correction of the German speech acts is performed by comparing them with the lear-

248 Federica Missaglia
ner’s Italian model; for the prosodic control of Italian and German speech acts the judges are the other learners. The first step in this teamwork is to find an agreement on the norms determining the communicative efficiency of speech acts, both in L2 and L1. The most difficult task is the production of prosodically correct sentences in L1, whereas passing to L2 becomes extremely easy, given that the rules and regularities deduced from Italian are applied with minimal adaptations. Thus learners acquire prosodic com-petence first in L1, and then profit from the experience in Italian for the acquisition of prosodic competence in German. In fact, what is trained is the learners’ awareness towards prosodic aspects, a sort of prosodic aware-ness, which has to be reached first in L1, as it can be controlled more easily and without anxiety. In a further step, prosodic awareness will enhance the acquisition of L2 prosodic competence.
The positive effect of the training method depends on the fact that the German sentences of the exercises are translated into realistic Italian sen-tences by the learners themselves. Moreover, in a first step the Italian sen-tences have to be realized as speech acts which (1) sound natural and (2) present only one strong stress (the sentence accent). Only when the peers judge that these two conditions are met in the Italian sentences, the second step is reached and the original German sentences can be realized. The aim is again to produce speech acts with only one strong stress, which at the same time sound natural to the judging peers. Practical experience with the CPM shows that prosody as a basis for a contrastive approach in pronuncia-tion training is useful, because from the beginning learners effortlessly and unconsciously avoid mistakes which otherwise would hinder them from correctly perceiving, producing and acquiring L2. Furthermore, this has positive consequences on their learning attitude as they soon realize that their sentences “sound German”.
5. Prosody-centred vs. segment-centred pronunciation training in second language acquisition
To check the validity of the CPM, a systematic control of the method in comparison with traditional segment-centred pronunciation training was introduced on an experimental basis (Missaglia 1999b). An empirical in-vestigation under controlled conditions with a pre- and post-test design was performed by comparing the phonetic performance of an experimental
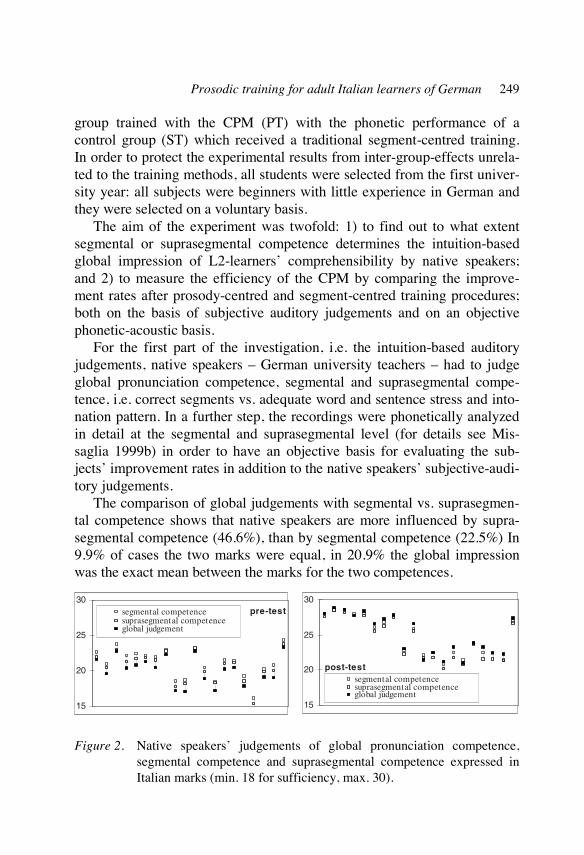
Prosodic training for adult Italian learners of German 249
group trained with the CPM (PT) with the phonetic performance of a control group (ST) which received a traditional segment-centred training. In order to protect the experimental results from inter-group-effects unrela-ted to the training methods, all students were selected from the first univer-sity year: all subjects were beginners with little experience in German and they were selected on a voluntary basis.
The aim of the experiment was twofold: 1) to find out to what extent segmental or suprasegmental competence determines the intuition-based global impression of L2-learners’ comprehensibility by native speakers; and 2) to measure the efficiency of the CPM by comparing the improve-ment rates after prosody-centred and segment-centred training procedures; both on the basis of subjective auditory judgements and on an objective phonetic-acoustic basis.
For the first part of the investigation, i.e. the intuition-based auditory judgements, native speakers – German university teachers – had to judge global pronunciation competence, segmental and suprasegmental compe-tence, i.e. correct segments vs. adequate word and sentence stress and into-nation pattern. In a further step, the recordings were phonetically analyzed in detail at the segmental and suprasegmental level (for details see Mis-saglia 1999b) in order to have an objective basis for evaluating the sub-jects’ improvement rates in addition to the native speakers’ subjective-audi-tory judgements.
The comparison of global judgements with segmental vs. suprasegmen-tal competence shows that native speakers are more influenced by supra-segmental competence (46.6%), than by segmental competence (22.5%) In 9.9% of cases the two marks were equal, in 20.9% the global impression was the exact mean between the marks for the two competences.
pre-test
15
20
25
30segmental competencesuprasegmental competenceglobal judgement
post-test
15
20
25
30
segmental competencesuprasegmental competenceglobal judgement
Figure 2. Native speakers’ judgements of global pronunciation competence, segmental competence and suprasegmental competence expressed in Italian marks (min. 18 for sufficiency, max. 30).
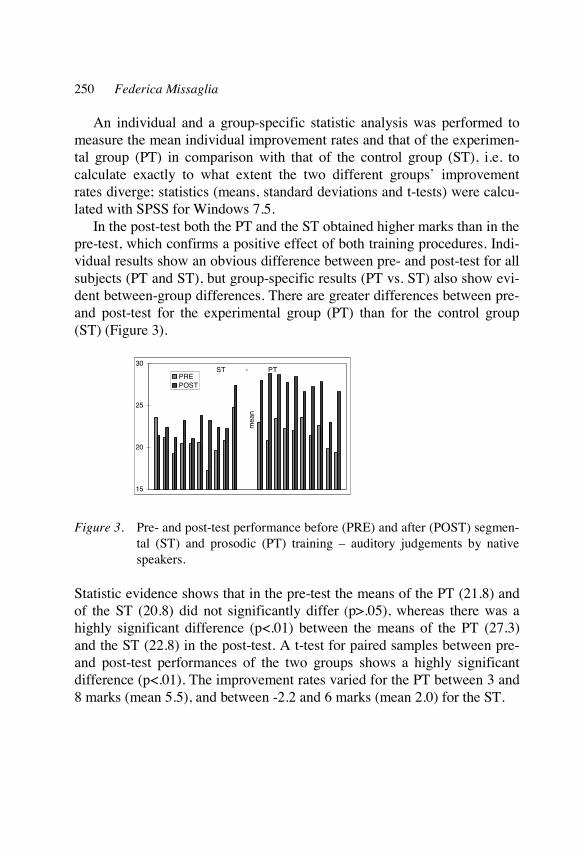
250 Federica Missaglia
An individual and a group-specific statistic analysis was performed to measure the mean individual improvement rates and that of the experimen-tal group (PT) in comparison with that of the control group (ST), i.e. to calculate exactly to what extent the two different groups’ improvement rates diverge; statistics (means, standard deviations and t-tests) were calcu-lated with SPSS for Windows 7.5.
In the post-test both the PT and the ST obtained higher marks than in the pre-test, which confirms a positive effect of both training procedures. Indi-vidual results show an obvious difference between pre- and post-test for all subjects (PT and ST), but group-specific results (PT vs. ST) also show evi-dent between-group differences. There are greater differences between pre- and post-test for the experimental group (PT) than for the control group (ST) (Figure 3).
Figure 3. Pre- and post-test performance before (PRE) and after (POST) segmen-tal (ST) and prosodic (PT) training – auditory judgements by native speakers.
Statistic evidence shows that in the pre-test the means of the PT (21.8) and of the ST (20.8) did not significantly differ (p>.05), whereas there was a highly significant difference (p<.01) between the means of the PT (27.3) and the ST (22.8) in the post-test. A t-test for paired samples between pre- and post-test performances of the two groups shows a highly significant difference (p<.01). The improvement rates varied for the PT between 3 and 8 marks (mean 5.5), and between -2.2 and 6 marks (mean 2.0) for the ST.
15
20
25
30ST - PT
mea
n
PREPOST
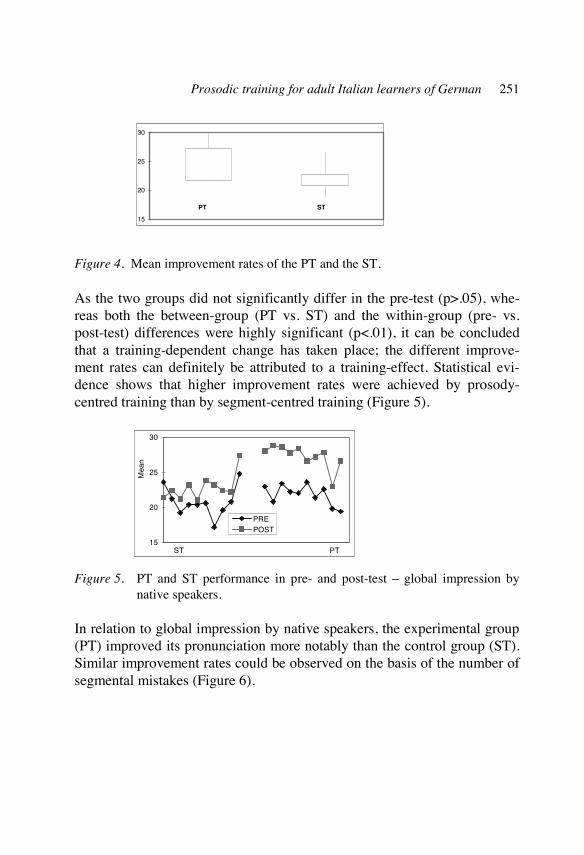
Prosodic training for adult Italian learners of German 251
15
20
25
30
PT ST
Figure 4. Mean improvement rates of the PT and the ST.
As the two groups did not significantly differ in the pre-test (p>.05), whe-reas both the between-group (PT vs. ST) and the within-group (pre- vs. post-test) differences were highly significant (p<.01), it can be concluded that a training-dependent change has taken place; the different improve-ment rates can definitely be attributed to a training-effect. Statistical evi-dence shows that higher improvement rates were achieved by prosody-centred training than by segment-centred training (Figure 5).
15
20
25
30
ST PT
Mea
n
PREPOST
Figure 5. PT and ST performance in pre- and post-test – global impression by native speakers.
In relation to global impression by native speakers, the experimental group (PT) improved its pronunciation more notably than the control group (ST). Similar improvement rates could be observed on the basis of the number of segmental mistakes (Figure 6).
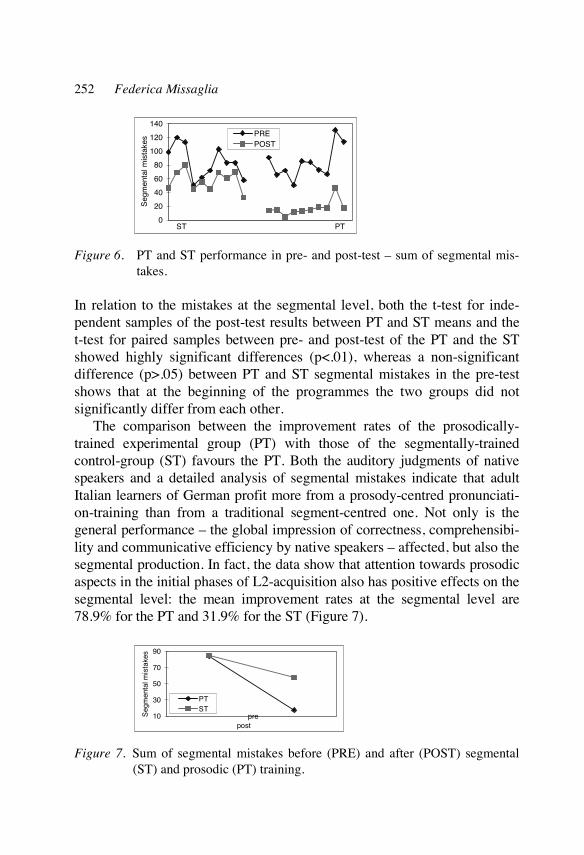
252 Federica Missaglia
0
20
40
60
80
100
120
140
ST PT
Seg
men
tal m
ista
kes PRE
POST
Figure 6. PT and ST performance in pre- and post-test – sum of segmental mis-takes.
In relation to the mistakes at the segmental level, both the t-test for inde-pendent samples of the post-test results between PT and ST means and the t-test for paired samples between pre- and post-test of the PT and the ST showed highly significant differences (p<.01), whereas a non-significant difference (p>.05) between PT and ST segmental mistakes in the pre-test shows that at the beginning of the programmes the two groups did not significantly differ from each other.
The comparison between the improvement rates of the prosodically-trained experimental group (PT) with those of the segmentally-trained control-group (ST) favours the PT. Both the auditory judgments of native speakers and a detailed analysis of segmental mistakes indicate that adult Italian learners of German profit more from a prosody-centred pronunciati-on-training than from a traditional segment-centred one. Not only is the general performance – the global impression of correctness, comprehensibi-lity and communicative efficiency by native speakers – affected, but also the segmental production. In fact, the data show that attention towards prosodic aspects in the initial phases of L2-acquisition also has positive effects on the segmental level: the mean improvement rates at the segmental level are 78.9% for the PT and 31.9% for the ST (Figure 7).
10
30
50
70
90
pre post
Seg
men
tal m
ista
kes
PTST
Figure 7. Sum of segmental mistakes before (PRE) and after (POST) segmental (ST) and prosodic (PT) training.

Prosodic training for adult Italian learners of German 253
The experimental results indicate that L2-learners trained with prosody-centred and segment-centred programmes improve at different rates, both according to global impression by native speakers, which showed to be strongly influenced by suprasegmental competence, and at the segmental level. In both cases statistical evidence favours prosody-centred pronuncia-tion training; statistically significant different improvement rates in the two procedures illustrate the more positive effects of a prosody-centred training on L2-German pronunciation giving evidence of the priority of prosody in L2 pronunciation training and in L2 phonetic acquisition.
The positive results concerning both the investigated aspects – L2 seg-ments and prosody – as well as the emotional component involved in the acquisition process evidence the need to invert the traditional priorities in L2 pronunciation training and to give prosody a primary role in second language acquisition.
References
Albano Leoni, Federico, Francesco Cutugno and Renata Savy 1995 The vowel system of Italian connected speech. Proceedings of
the 13th International Congress of Phonetic Sciences, Stock-holm, 396–399.
Bathia, Tej K. and William C. Ritchie 2004 The Handbook of Bilingualism. Oxford/Cambridge, MA: Black-
well. Bertinetto, Pier Marco 1977 «Syllabic Blood» ovvero l’italiano come lingua ad isocronismo
sillabico. Studi di Grammatica Italiana 6, 69–96. 1981 Strutture prosodiche dell’italiano. Accento, quantità, sillaba,
giuntura, fondamenti metrici. Firenze: presso l’Accademia della Crusca.
1989a Reflections on the dichotomy ‘stress’ vs. ‘syllable-timing’. Revue de Phonétique Appliquée 91–93, 99–130.
1989b Syllabic isochronism in Italian and English. Quaderni del Labo-ratorio di Linguistica. Scuola Normale Superiore di Pisa 3, 9–16.
Corder, Pit S. 1981 Error Analysis and Interlanguage. Oxford: Oxford University
Press.

254 Federica Missaglia
Damasio, Antonio R. 1994 Descartes’ Error: Emotion, Reason and the Human Brain, New
York: G.P. Putnam’s Sons. 1999 The Feeling of what Happens. Body and Emotion in the Making
of Consciousness. New York: Harcourt Brace. 2003 Looking for Spinoza. Joy, Sorrow and the Feeling Brain. Or-
lando: Harcourt. De Boysson-Bardies, Bénédicte 1993 Ontogeny of language-specific syllabic productions. In: Bé-
nédicte De Boysson-Bardies (ed.), Developmental Neurocogni-tion: Speech and Face Processing in the First Year of Life, 353–363. Dordrecht: Kluwer.
De Houwer, Annick 1995 Bilingual language acquisition. In: Paul Fletcher and Brian
MacWhinney (eds.), The Handbook of Child Language, 219–250.Oxford/Cambridge, MA: Blackwell.
Fabbro, Franco 1996 Il cervello bilingue. Neurolinguistica e poliglossia. Roma: Astro-
labio. Hüther, Gerald 20023 Bedienungsanleitungen für ein menschliches Gehirn, Göttingen:
Vandenhoeck & Ruprecht [2001]. Ioup, Georgette and Steven H. Weinberger 1987 Interlanguage Phonology: The Acquisition of a Second Language
Sound System. Cambridge, MA: Newbury House. Kohler, Klaus J. 1979 Kommunikative Aspekte satzphonetischer Prozesse im Deut-
schen. In: Heinz Vater (ed..), Phonologische Probleme des Deut-schen, 13–39. Tübingen: Narr.
1982 Rhythmus im Deutschen. Arbeitspapiere des Instituts für Phone-tik der Univerisität Kiel 19, 89–105.
1983 Stress-timing and speech rate in German: A production model. Arbeitspapiere des Instituts für Phonetik der Univerisität Kiel 20, 5–53.
1990 Segmental reduction in connected speech in German: Phonologi-cal facts and phonetic explanations. In: William J. Hardcastle and Alain Marchal (eds.) Speech Production and Speech Modelling, 69–92. Dordrecht: Kluwer.
1991 Isochrony, units of rhythmic organisation and speech rate. Pro-ceedings of the 12th International Congress of Phonetic Sciences,Aix-en Provence (France), 257–261.

Prosodic training for adult Italian learners of German 255
Kuhl, Patricia K. 1991 Human adults and human infants show a ‘perceptual magnet
effect’ for the prototypes of speech categories, monkeys do not. Perception and Psychophysics 50, 93–107.
1992 Speech prototypes: Studies on the nature, function, ontogeny and phylogeny of the ‘centers’ of speech categories. In: Yo’ichi Tohkura, Eric Vatikiotis-Bateson and Yoshinori Sagisaka (eds.), Speech Perception, Production and Linguistic Structure, 239–264. Tokyo/Ohmscha/Amsterdam/Oxford: IOS.
1993a Innate predispositions and the effects of experience in speech perception: The native language magnet theory. In: Bénédicte De Boysson-Bardies (ed.), Developmental Neurocognition: Speech and Face Processing in the First Year of Life, 259–274. Dord-recht: Kluwer.
1993b Early linguistic experience and phonetic perception: Implications for theories of developmental speech perception. Journal of Pho-netics 2, 125–139.
1995 Vocal learning in infants: Development of perceptual-motor links for speech. Proceedings of the 13th International Congress of Phonetic Sciences, Stockholm, 146–149.
Kuhl, Patricia K. and Andrew N. Meltzoff 1995 Mechanisms of developmental change in speech and language.
Proceedings of the 13th International Congress of Phonetic Sci-ences, Stockholm, 132–139.
1997 Evolution, nativism, and learning in the development of language and speech. In: Alison Gopnik (ed.), The Inheritance and Innate-ness of Grammars, 7–44. New York: Oxford University Press.
Kuhl, Patricia K. and Paul Iverson 1995 Linguistic experience and the ‘Perceptual Magnet Effect’. In:
Winifred Strange (ed.), Speech Perception and Linguistic Experi-ence. Theoretical and Methodological Issues in Cross-language Speech Research, 121–154.York: Timonium.
Kuhl, Patricia K., Karen A. Williams, Francisco Lacerda, Kenneth N. Stevens and Björn Lindblom
1992 Linguistic experience alters phonetic perception in infants by 6 months of age. Science 255, 606–608.
Lado, Robert 1957 Linguistics Across Cultures. Applied Linguistics for Language
Teachers. Ann Arbor: University of Michingan Press.

256 Federica Missaglia
Mack, Molly 2003 The phonetic systems of bilinguals. In: Mary T. Banich and
Molly Mack (eds.), Mind, Brain and Language. Multidisciplinary Perspectives, 309–349. Mahwah/London: Erlbaum.
Meinhold, Gottfried 1962 Die Realisierung der Silben (-… å), (-… ã), (-… ä) in der deutschen
hochgelauteten Sprache. Zeitschrift für Phonetik, Sprachwissen-schaft und Kommunikationsforschung 15, 1–19.
1967 Geschwächte Lautformen (‘weak forms’) in der deutschen Stan-dardaussprache. Wissenschaftliche Zeitschrift der Friedrich-Schiller-Universität Jena 16/5: 609–612.
Menn, Lisa and Carol Stoel-Gammon 1995 Phonological development. In: Paul Fletcher and Brian
MacWhinney (eds.), The Handbook of Child Language, 335–359. Oxford/Cambridge, Mass.: Blackwell.
Miller, Joanne L. 1994 On the internal structure of phonetic categories: A progress re-
port. Cognition 50, 271–285. reprint (1995) in: Jacques Mehler and Susana Franck (eds.), Cognition on Cognition, 333–347. Amsterdam: Elsevier.
Missaglia, Federica 1997 Studi sul bilinguismo scolastico italo-tedesco. Brescia: La Scuo-
la. 1999a Phonetische Aspekte des Erwerbs von Deutsch als Fremdsprache
durch italienische Muttersprachler. Frankfurt a. M.: Hector. 1999b Contrastive prosody in SLA: An empirical study with Italian
learners of German. Proceedings of the 14th International Con-gress of Phonetic Sciences, San Francisco, 551–554.
2004 Distorted perception and production of L2-German vowels by adult Italian learners. In: Jean Drevillon, Jean Vivier and Agnès Salinas (eds.), Psycholinguistics. A Multidisciplinary Science of 2000: What Implications, What Applications?, 305–314. Paris: Europia.
Missaglia, Federica and Walter F. Sendlmeier 1999 Die Realisierung deutscher Vokale durch italienische Mutter-
sprachler – Eine experimentalphonetische Untersuchung. Zeit-schrift für Fremdsprachenforschung 10/1, 73–95.
Nemser, William 1971 Approximate systems of foreign language learners. International
Revue of Applied Linguistics 9/2, 115–123.

Prosodic training for adult Italian learners of German 257
Paradis, Michel 1994 Neurolinguistic aspects of implicit and explicit memory: Implica-
tions for bilingualism and SLA. In: Nick Ellis (ed.), Implicit and Explict Learning of Languages, 393–419. London: Academic Press.
1997 The cognitive neuropsychology of bilingualism. In: Annette M.B. De Groot and Judith F. Kroll, Tutorials in Bilingualism. Psycho-linguistic Perspectives, 331–354. Mahwah. Erlbaum.
2003 Differential use of cerebral mechanisms in bilinguals. In: Mary T. Banich and Molly Mack (eds.), Mind, Brain, and Language. Mul-tidisciplinary Perspectives, 351–370. Mahwah/London: Erlbaum.
Rosch, Eleanor 1973 Natural categories. Cognitive Psychology 4, 328–350. 1975 Cognitive reference points. Cognitive Psychology 7, 532–547. Saffran, Jenny R., Richard N. Aslin and Elissa L. Newport 1996 Statistical learning by 8-month-old infants. Science 274, 1926–
1928. Selinker, Larry 1972 Interlanguage. International Review of Applied Linguistics, 10/3,
209–231. Sendlmeier, Walter F. 1981 Der Einfluß von Qualität und Quantität auf die Perzeption beton-
ter Vokale des Deutschen. Phonetica 38, 291–308. 1989a Perception and mental representation of speech. Linguistics 27,
381–404. 1989b Aufmerksamkeitssteuerung als Methode eines Hörtrainings im
Fremdsprachenunterricht. Deutsche Sprache 17, 40–51. 1994 Phonetisch-rezeptive Aspekte des Fremdsprachenerwerbs. Zeit-
schrift für Fremdsprachenforschung 5, 26–42. 1996 Mentale Repräsentation von Lautsprache. Zeitschrift für Semiotik
18/2–3, 235–249. Strange, Winifred 1995a Cross-language studies of speech perception: A historical review.
In: Winifred Strange (ed.), Speech Perception and Linguistic Ex-perience. Issues in Cross-language Research, 3–45. Maryland, York: Timonium.
1995b Phonetics of second-language acquisition: Past, present, future. Proceedings of the 13th International Congress of Phonetic Sci-ences, Stockholm, 76–83.
Trubetzkoy, Nicolaj S. 1939 Grundzüge der Phonologie. Göttingen: Vandenhoeck & Ruprecht
[1962].

258 Federica Missaglia
Vihman, Marilyn M. 1993 Variable paths to early word production. Journal of Phonetics 21,
61–82. 1996 Phonological Development. The Origins of Language in the
Child, Cambridge, Mass./Oxford: Blackwell. Weinreich, Uriel 1953 Languages in Contact: Findings and Problems. New York: Pub-
lications of the Linguistic Circle of New York. Werker, Janet F. 2003 The acquisition of language-specific phonetic categories in in-
fancy, Proceedings of the 15th International Congress of Pho-netic Sciences, Barcelona, 21–25.
Werker, Janet F. and Linda Polka 1993 The ontogeny and developmental significance of language-
specific phonetic perception. In: Bènédicte De Boysson-Bardies (ed.), Developmental Neurocognition: Speech and Face Process-ing in the First Year of Life, 275–288. Dordrecht: Kluwer.

Language index
Arabic, 135
Bini, 32 Bulgarian, 107, 110
Chinese, 32
Danish, 12, 58 Dutch, 46, 55, 110
English, 7f., 11f., 27, 32, 37, 40, 46, 58f., 62, 64, 67, 83, 103, 105–107, 110, 112, 128, 134f., 155f.
Faroese, 128 French, 11, 103, 106f., 115, 131, 134f.
German, 7, 27, 32, 37–40, 58f., 64, 67, 83, 106f., 110, 134f., 155f., 160ff., 172, 223, 242, 245 German/Turkish bilinguals, 64 Greek, 37, 39, 60, 105
Hungarian, 39
Icelandic, 128 Indian English, 35 Italian, 33, 35–37, 39f., 58f., 105, 107, 115, 242f., 245
Japanese, 7, 27, 32, 62
Korean, 46, 112
Norwegian, 7, 121, 124, 126, 130, 132, 135
Polish, 8 Portuguese, 12
Romanian, 39 Russian, 110, 112, 127, 135
Scottish Gaelic, 128 Singapore English, 58, 63 Spanish, 55, 134 Swedish, 7, 32, 58, 106f., 110, 115
Telugu, 135Turkish, 7, 223
Welsh, 7
Yoruba, 135

Index of L1–L2 combinations
L1 Chinese – L2 German 112, 160ff., 225 L1 Chinese – L2 Norwegian 126, 129f., 132, 134f., 138f. L1 Dutch – L2 English 55 L1 Dutch – L2 Greek 60f., 71 L1 English – L2 French 57 L1 English – L2 German 82, 85, 90, 112, 114, 123, 160ff. L1 English – L2 Italian 59 L1 English – L2 Norwegian 126, 128f., 134f., 138f. L1 French – L2 German 109 L1 French – L2 Norwegian 126, 129f., 134f., 138f. L1 French – L2 Spanish 8 L1 German – L2 English 54, 61, 65, 69, 86, 114
L1 German – L2 Italian 59 L1 German – L2 Norwegian 126, 129f., 134f., 138f. L1 Italian – L2 German 160ff., 238f., 242-244, 252 L1 Japanese – L2 English 62 L1 Korean – L2 German 112 L1 Persian – L2 Norwegian 126, 129, 134f., 138f. L1 Polish – L2 English 8 L1 Russian – L2 German 112, 223f. L1 Russian – L2 Latvian 127 L1 Russian – L2 Norwegian 126, 129, 134f., 138f. L1 Spanish – L2 English 53, 59, 62 L2 English 155f. L2 German 154f., 173, 175

Subject index
accent, 6 dynamic, 7 alignment (see tonal alignment) articulation rate, 9 autosegmental-metrical model, 14, 43f., 56f., 79f.
consonant quantity, 121f. in L2, 126f., 129–131 corpus (see language corpora)
declination, 40 domain initial strengthening, 30f.
effort code, 40
final lengthening, 31 fluency, 9f. focus, 35 frequency code, 39
information structure, 34f. interlinear transcription, 14 intonation contour, 14 intonation language, 32f. intonation, 14, 25, 100 and focus, 35–37 and marking of information structure, 34f. and speech acts, 37f. autosegmental-metrical model of, 14, 43f., 56f., 79f. British School model of, 42f., 79f. foreign-accented, 82–92
highlighting function, 27f. in L2, 53f., 55, 82–89, 174 model for speech synthesis, 81f.
paralinguistic function, 38–41
teaching of, 14 teaching material for, 223ff. intonational phonology and phonetics, 57 intonational phrasing, 29f. in L2, 174 teaching material for, 183 isochrony, 11, 105
L2 consonant quantity, 126f., 129–131 L2 intonation, 53f., 55, 82–89, 174 L2 phonological acquisition process, 192
and extralinguistic factors, 195-197
L2 phrasing, 174 L2 pitch accent, 174 L2 pitch level, 66–70L2 pitch range, 67f. in L2, 67f. measurement of, 65f. L2 pitch span, 66–70L2 prosody research methodology, 145 L2 sentence stress, 61–63, 173 L2 speech rhythm, 111–113, 131–137 L2 tonal alignment, 59–61L2 vowel reduction, 153–162, 247

262 Subject index
language awareness, 8, 193f., 221, 247f. teaching material for, 198–200, 221–226language corpora, 147–149 as a research method,
149–151 in teaching, 146, 162f. learner autonomy, 214, 247 learning awareness, 227–229
phonological metacompetence, 193 teaching of, 198, 202–204pitch accent language 7, 32 pitch accent, 27 pitch level, 64f. pitch movement, 26 pitch range, 26, 63f. pitch span, 64f. preaspiration, 128 in L2, 128
rhythm, 11f., 102–108 and language typology, 11f., 104–108 in L2, 111–113, 131–137 in music, 103 measurement of, 12f. teaching of, 13, 109, 113–115
sentence stress, 6, 98f. in L2, 61–63, 174 teaching material for, 184, 246f. speech act, 37f., 246 in L2, 246f. speech rate, 9 measurement of, 9f. teaching of, 10f. variation of, 10 speech rhythm (see rhythm) stress, 6, 27f. deafness, 8 fixed, 6 phonetic realisation, 7
teaching of, 8
ToBI, 44f., 79f. tonal alignment, 58 tone language, 32
vowel quantity, 121f. vowel reduction in L2, 153–162, 247 teaching material for, 182, 184
word stress, 6, 98f. perception of, 218 teaching materials for, 178, 182





























