Embed Size (px)
Citation preview

1132 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
Multirate Scheduling of VBRVideo Traffic in ATM NetworksDebanjan Saha, Sarit Mukherjee, and Satish K. Tripathi,Fellow, IEEE
Abstract—One of the major attractions of asynchronous trans-fer mode (ATM) networks for transporting bursty video traffic isits ability to exploit the multiplexing gains of packet switchingwhile providing quality of service guarantees. Unfortunately,most of the multiplexing mechanisms proposed in the literaturefail to exploit the multiplexing gains of ATM. In this paper,we propose a multirate service mechanism that allows a sessionto be served at different rates at different times. Applicationsgenerating bursty data, such as variable bit-rate (VBR) video,can take advantage of multirate service by requesting a high rateof service for brief periods of bursty arrivals and a much lowerrate of service for all other times. Consequently, the applicationscan improve their delay performance without reserving a highbandwidth for the entire duration of the sessions. Furthermore,the scheduler can multiplex the peaks and the lulls in servicerates of different sessions and improve the utilization of thesystem. Using MPEG video traces from a number of applications,we show that multirate servers outperform single-rate PGPS(packet-by-packet generalized processor sharing) servers andCBR (constant bit-rate) servers in terms of number of connectionsadmitted, while providing the same level of service guarantees.We also investigate the performance of multirate service whenservice quality need not be guaranteed. We refer to this aspredictive service. We propose a measurement-based admissioncontrol procedure for predictive service, and show that it helpsincrease the size of the admissible region even further.
Index Terms—ATM, multirate, scheduling, VBR video.
I. INTRODUCTION
ONE of the major attractions of asynchronous transfermode (ATM) networks is its ability to exploit the mul-
tiplexing gains of packet switching while providing quality ofservice guarantees. A number of service architectures havebeen proposed [1] to realize this goal. At the heart of allof these service architectures is a multiplexing policy thatis used to allocate link capacities to competing connectionsat the switching nodes. The manner in which multiplexing isperformed has a profound effect on what service guarantees areprovided and to what extent the multiplexing gain is exploited.
Multiplexing mechanisms proposed for ATM networks canbe broadly divided into two classes: 1) ones that provide
Manuscript received May 1, 1996; revised October 2, 1996. The work of S.Mukherjee was supported in part by the AFOSR under Grant F49620-93-C-0063. The work of S. K. Tripathi was supported in part by NSF Grant CCR9318933 and by an IBM equipment grant.
D. Saha is with the IBM T. J. Watson Research Center, Yorktown Heights,NY 10598 USA.
S. Mukherjee is with the Department of Computer Science and Engineering,University of Nebraska, Lincoln, NE 68588 USA.
S. K. Tripathi was with the Department of Computer Science, Universityof Maryland, College Park, MD 20742 USA. He is now with the College ofEngineering, University of California, Riverside, CA 92521 USA.
Publisher Item Identifier S 0733-8716(97)04194-2.
guarantees on maximum delay at the switching nodes and 2)ones that guarantee a minimum throughput. The multiplexingdisciplines providing delay guarantees [24], [5] typically usestatic or dynamic priority-based scheduling to bound theworst case delay of a connection at each switching node.The end-to-end delay is computed as the sum of the delaysat the switching nodes on the path of the connection. Themultiplexing disciplines providing throughput guarantees [2],[7], [15], [25], [20], [19], [18] typically use variations of fairqueueing or frame-based scheduling to guarantee a minimumrate of service at each switching node. Knowing the trafficarrival process, this rate guarantee can be translated intoguarantees on other performance metrics, such as delay, delayjitter, worst case buffer requirement, etc.
Rate-based schemes are preferred over schemes providingdelay guarantees primarily because of their simplicity. Typi-cally, they offer a fixed rate of service to a connection for theentire duration of its lifetime. While a fixed rate of serviceis adequate for constant bit-rate traffic, it is quite unsuitablefor bursty traffic, such as variable bit-rate (VBR) video. Forexample, an MPEG-coded [13] video stream generates trafficat significantly different rates at different times, and no single-rate service is sufficient to transport it across the network.
We propose a multirate service mechanism to address thisproblem. In our scheme, a connection is served at differentrates at different times. For example, a session can be servicedat the peak rate during the times of bursty arrivals and at alower rate at all other times. In general, we can have morethan two rates of service. The length and the service rate ofeach of the service periods are specified by the applications atthe time of connection setup. A multirate service discipline issuperior to its single-rate counterpart in two ways. It allows theapplications generating bursty data to request a higher rate ofservice for the periods of bursty arrivals and a lower averagerate of service at other times. Consequently, applications canimprove their delay performance without reserving a highbandwidth for the entire duration of the session. The schedulercan exploit this feature by multiplexing the peaks and the lullsin service rates of different sessions, and thereby increasingthe utilization of the system. The complexity of the schedulingmechanism underlying multirate service is comparable to thatof packet-by-packet processor sharing (PGPS) [15] and self-clocked fair queueing (SFQ) [8]. Recently, it has been shown[22] that variations of PGPS and SFQ can be implemented with
complexity, where is the queue length.We consider two different service models: 1) guaranteed
service and 2) predictive service. In the guaranteed service
0733–8716/97$10.00 1997 IEEE

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1133
model, each connection is guaranteed a lossless deliverywith a specific end-to-end delay and jitter. Although someapplications cannot do without a guaranteed service, thereexists a large class of applications that are robust againstoccasional cell losses and delay violations. The predictiveservice is designed for these applications. In predictive service,each connection is promised a specific grade of service withthe understanding that it may be violated at times. If theapplications are robust to these violations, the lack of strictguarantees can help increase the system utilization. The sched-uling mechanisms used for both guaranteed and predictiveservices are the same. They differ only in the admission controlprocess. In the guaranteed case, we always assume the worstcase scenario. A new connection is admitted if and only ifits admittance does not violate the service qualities promisedto all connections, assuming worst case traffic arrivals. Inthe predictive service, the same admission control processis administered with the difference that, instead of the worstcase estimate, we use a measurement-based estimate of trafficarrivals [10].
Using MPEG video traces from a variety of real-life appli-cations (including news clips, basketball games, class lecture,and music videos), we have shown that multirate serversoutperform single-rate PGPS servers and CBR servers in termsof the number of connections admitted while providing thesame level of service guarantees. We also investigate theperformance of multirate scheduling in the context of pre-dictive service. We propose a measurement-based admissioncontrol procedure for predictive service, and show that it helpsincrease the size of the admissible region even further.
Except for some very recent works, multirate service mech-anisms have not undergone a very through investigation. In[6], a hop-by-hop shaping mechanism is proposed. It can beadapted to provide multirate service. However, the impact ofthis service mechanism on real-life application traffic is notaddressed. A multiple time scale characterization of traffichas been proposed in [11] and [12]. In [11] and [12], theimprovement in network utilization due to this enhancedtraffic characterization is demonstrated in the context of rate-controlled static priority scheduling (RCSP). Authors showthat when the characterization of the sources is sufficientlyaccurate, a high network utilization is achievable. However, itis difficult to characterize a source accurately using commonlyused usage parameter control (UPC) mechanisms, such asleaky buckets.
The rest of the paper is organized as follows. In Section II,we discuss how a bursty source can be smoothed to a multiratesource. Section III is dedicated to the scheduling mechanism,its realization, and the admission control algorithm. Numericalresults are presented in Section IV. We conclude in Section V.
II. TRAFFIC PROFILES
In order to understand the suitability of multirate servicefor bursty traffic, let us consider an application generat-ing MPEG-coded video. From uncompressed video data, anMPEG encoder produces a sequence of encoded frames.There are three types of encoded frames:(intracoded),(predicted), and (bidirectional). The sequence of frames is
Fig. 1. Example of an MPEG coded stream.
specified by two parameters: the distance betweenandframes, and the distance between frames. For example,when is 2 and is 5, the sequence of encoded framesis (see Fig. 1). The pattern repeatsindefinitely. The interarrival time between two successiveframes is fixed, and depends on the frame rate. In general,an frame is much larger than a frame, and a frame ismuch larger than a frame. Typically, the size of an frameis larger than the size of a frame by an order of magnitude.Let us assume that and are the sizes of and
frames, respectively.1
Now, consider the problem of choosing a single rate ofservice for the video stream described above. We can eitherchoose a long-term average rate, a short-term peak rate, orany rate in between. If we choose the peak rate of service,that is, delay in the network is minimal. However, sincethe source generates traffic at the peak rate only for a smallfraction of the time, a peak rate allocation leads to severeunderutilization of network resources. If we choose the averagerate of service, that is, the networkutilization is high, but only at the cost of increased networkdelay. Clearly, neither the average rate nor the peak rate isa good choice. As a matter of fact, no single rate is goodchoice since the source generates traffic at different rates atdifferent times. The ideal approach is to have a service curve[4]2 that mimics the traffic generation pattern of the source.Unfortunately, this is not a feasible since: 1) it is difficult tocapture the traffic generation pattern of an arbitrary sourceaccurately, and 2) it results in a complex service curve that isvery difficult to realize using a simple scheduling mechanism.
A good approximation to this ideal service policy is tomodel a bursty source as a multirate source that generatestraffic at a few different rates over different periods of time. Wecan then use a service curve that resembles this approximatedsource. For example, we can approximate the MPEG videosource described above as one that generates traffic at the peakrate over a period of time but maintains an averagerate of over a period of length Weshow in the next section that a service curve that mimics thetraffic generation pattern of this approximated source is easilyrealizable using a simple scheduling mechanism.
In the rest of the discussion, we assume that the trafficgenerated by a source is passed through a shaper beforeentering the network. The shaper smoothes an arbitrarily bursty
1In general,jIj; jP j; and jBj are random variables. However, it is notunreasonable to assume thatjIj is larger thanjP j and jP j is larger thanjBj:
2A service curve is defined as the plot of service received against time.

1134 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
Fig. 2. Shaping with multiple leaky buckets.
source to a multirate source that generates traffic at a finitenumber of different rates over different periods of time. Theservice curve used at the network nodes mimics the trafficenvelope enforced by the shaper. Besides smoothing traffic,the shaper also plays the dual role of policing a connection sothat it conforms to its advertised traffic envelope.
Several shaping mechanisms enforcing different classes oftraffic envelopes have been proposed in the literature. Themost popular among them areleaky bucket, jumping window,andmoving window[16]. In this paper, we restrict ourselves toleaky-bucket shapers only. However, the techniques developedhere can be extended to moving- and jumping-window shapersalso. A leaky-bucket shaper consists of a token counter and atimer. The counter is incremented by one eachunits of time,and can reach a maximum value A cell is admitted intothe system/network if and only if the counter is positive. Eachtime a cell is admitted, the counter is decremented by one.The traffic generated by a leaky-bucket regulator consists of aburst of up to cells, followed by a steady stream of cells witha minimum intercell time of A single leaky bucket enforcesa specific rate constraint on a source, typically a declaredpeak or average rate. To enforce multiple rate constraints, wecan use multiple leaky buckets, each enforcing different rateconstraints. For example, two leaky buckets arranged in seriescan be used to enforce a short-term peak rate and a long-termaverage rate on a source.
The traffic envelope enforced by a composite leaky bucketis the intersection of the traffic envelopes of the constituentleaky buckets. In Fig. 2, a composite leaky bucket consistingof leaky buckets and is shown. Thecomposite traffic envelope is marked by the dark line. Theexact shape of the envelope depends on the number of com-ponents and the associated parameters. Inappropriate choiceof shaper parameters may give rise to redundant componentswhich may not have any role in defining the traffic envelope.For example, is a redundant component in the compositeshaper shown in Fig. 2. For ease of exposition, in the rest ofthe paper, we assume that all traffic sources are shaped usingtwo leaky buckets. One of the buckets monitors the short-termpeak rate of the source, and the other controls the long-termaverage rate.
So far, we have focused on characterizing traffic comingout of shapers and entering the network. The more difficult
problem is to choose appropriate shaper parameters giventhe characterization of the traffic source [9], [14], [17], [23].We assume that the source is orchestrated, that is, we knowthe exact form of the traffic generated by the source. Wecharacterize a traffic source as a finite sequence of tuples ofthe form where is the volume of data generatedat time Although all traffic sources can be mapped intothis model, it is particularly useful for characterizing videosources. In the rest of the discussion, we assume that’s and
’s are all known.First, let us consider the simpler problem of choosing the
parameters for a simple leaky bucket. A single leaky bucket ischaracterized by where is the size of the bucket and
is the rate of token generation. Let us denote bythe number of tokens available at time Precisely speaking,
is equal to the number of tokens in the token bucketwhen it holds a nonzero number of tokens. When there are notokens in the token bucket, equals the number of cellsin the shaper buffer with the sign reversed (negative). Thatis, represents the current state of the shaper. A positivevalue represents a credit, and a negative value represents adebit. The following lemma expresses in terms ofand the traffic arrival pattern.
Lemma 2.1:Given an arrival sequenceand a leaky bucket , the number of tokens
(positive or negative) present at time can be expressedas
where is the sum of ’s from toProof: We prove this by induction.Base Case:For we have which
is the number of tokens in the leaky bucket at the systeminitialization time.
Inductive Hypothesis:Assume that the premise holds forall To prove that it holds for all we need to showthat it holds for
This completes the proof.If is the size of shaper buffer, to guarantee lossless
shaping, we have to satisfy the set of constraints, shown atthe bottom of the next page (top).
This is a linear programming formulation [21] (the linearconstraints), and can be easily solved when the objective func-tion is linear. For some specific nonlinear objective functionsalso, the problem is solvable.
This linear programming formulation can be extended to acomposite leaky bucket. Assumeleaky buckets suchthat and for We denote bythe number of tokens (credit or debit) available in bucketUsing the results from Lemma 2.1, we can expressin terms of and the traffic arrival pattern. Let

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1135
Fig. 3. Service curve of a session.
denote the number of tokens available for the composite leakybucket at time instant Observe that is the minimumof ’s, where
Now, if is the size of the shaper buffer, to guaranteelossless shaping, we have to satisfy the set of conditions shownat the bottom of the page (bottom).
Given a linear objective function, we can use commonlyavailable solvers to find ’s and ’s satisfying the constraintset. The results derived in this section are used in Section IVto obtain the leaky-bucket parameters for PGPS that maximizethe number of connections admitted, given a traffic trace.
III. M ULTIRATE SERVICE
In this section, we discuss a scheduling mechanism torealize a multirate service curve. We also present the admissioncontrol algorithms for both guaranteed and predictive services.In general, the service curve [4] for a session can be anyconvex function of piecewise linear components, where eachcomponent corresponds to a different rate of service over aperiod of time. For simplicity, we assume that the servicecurve (see Fig. 3) consists of two components and
where and The envelopeenforces the higher rate component over a shorter time frame.The envelope enforces the lower rate componentover a longer period. Observe that the service curve mimics
Fig. 4. Multirate scheduling.
the traffic envelope enforced by a dual leaky-bucket shaper
A. Scheduling Mechanism
The scheduling mechanism is a generalization of time-stamp-based priority scheduling. As the cells arrive, theyare stamped with their expected transmission deadlines. Wecompute the transmission deadline ofth cell of a sessionwith a service curve as the following:
In the expressions above, is the transmission deadline ofthe th cell of a session that follows a service curve with slope(or rate) and an initial credit of cells. We assume thatis the arrival time of the th cell, and cell transmission timeis the unit of time. Similarly, is the transmission deadline

1136 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
Fig. 5. Architecture of the buffer manager.
of the th cell of a session that follows the service curve withrate and an initial credit of cells. We get by taking themaximum of and Note that system time is initializedto 0 at system start-up, and both and to
The time-stamping algorithm is an extension to the algo-rithms used in virtual clock, PGPS, and SFQ. In each one ofthese, a session is assigned a single rate of service, sayAs the cells from this session arrive, they are time stampedas follows:
In the above expression, is the expected finish time ofthe th cell of the session, and is its arrival time. The virtualclock, PGPS, and SFQ differ in the way they assign the arrivaltime Now, if the service curve is a little more complex thana simple rate curve and has a bounded burst componentlikea leaky bucket, we can revise the time-stamping algorithm asfollows:
The implication of having a burst component is that thesession starts with an initial credit of cells, and canaccumulate a credit of up to cells during the periods ofinactivity. This credit is reflected in the time stamp as thesubtractive factor Note that is the point wherethe service curve in Fig. 3 intersects the time axis. The servicecurve in our case is the composition (minimum) of two suchsegments, and Hence, the time stamp on thecell is the maximum of and A time stamp computedthis way may be negative. We round up the negative timestamps to zero.
The cells from different sessions are placed in a single queuesorted in the increasing order of their time stamps. The cellsare served from the head of the queue if and only if the timestamp on the cell at the head of the queue is less than or equalto current time. In Fig. 4, we formally describe the algorithm.
B. Realization of the Scheme
In this section, we outline the architecture of a buffermanager (Fig. 5) that can be used to implement the schedulingmechanisms in an output-buffered switch. It consists of acell pool, an idle address FIFO, a connection table, and asequencer. The cells are stored in the cell pool. The connectiontable stores session states of different connections. The idleaddress FIFO contains addresses of the current empty celllocations in the pool. The sequencer stores a tuple consistingof the buffer address and time stamp for each cell in the cellpool. The tuples are ordered in the increasing order of thetime stamps.
When a new cell arrives, it is stored in the cell pool atthe address given by the idle address FIFO. While the cell isbeing stored in the cell pool, its connection (virtual channel)identifier is extracted. The connection identifier is used toretrieve the session state of the connection from the connectiontable. Once the session state is extracted, the time stamp forthe cell is computed, and an entry consisting of the bufferaddress of the cell and the time stamp is inserted into thesequencer. During each transmission cycle, the tuple at thehead of the sequencer is examined. If the time-stamp field inthe selected entry is greater than or equal to the current time,the corresponding cell is scheduled for transmission. The cellbuffer address is returned to the idle address FIFO.
The most complex part of the buffer manager is the se-quencer. It is a priority queue ordered in the increasing orderof the time stamps. For a detailed design and implementationof the sequencer, refer to [3]. Note that any implementation oftime-stamp-based scheduling such as PGPS, SFQ, or virtualclock has to use a sequencer or a similar component. The onlyadditional complexity in our scheme is the computation of thesecond time stamp, which is minor compared to the length ofthe data path from the reception of a cell to its transmission.
C. Properties of the Scheduling Algorithm
In order to analyze the properties of the scheduling al-gorithm, we introduce the concept of a universal utilization

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1137
Fig. 6. Universal utilization curve.
Fig. 7. Updating the universal utilization curve.
curve or UUC. Informally, the UUC is the superposition ofnormalized service curves of all sessions assuming that theystart their busy periods at the same time. It is a convexand piecewise linear function where each linear segmentrepresents the aggregate rate of arrivals of all sessions overthat period. We normalize the aggregate rate by the link speed.We represent the UUC as a sequence of tuples where
and are the effective utilization3 and length of the thsegment of the UUC, respectively. The utilization of one ormore segments of the UUC may exceed one. However, inorder for the system to be stable, the utilization of the lastsegment has to be less than one. Fig. 6 shows the UUC whentwo sessions and are activeat a switching node. In this example, the UUC consists of threesegments where We can compute ’sfrom the time axis coordinates of the points of inflection ofthe service curves. If is the link speed, we can compute
’s as and
As connections join and leave the system, the UUC canbe updated incrementally. For example, the UUC in Fig. 7consists of three segments where Whena new connection joins the system, it isupdated to the new UUC shown in the figure. In this example,the new UUC has one more segment than the previous one.The new break point in the UUC coincides with the point ofinflection of the service curve of the new connection. The stepsinvolved in computing the new UUC is straightforward. All
3We define effective utilization of the system as the ratio of aggregate rateof arrivals and rate of clearance, i.e., link speed.
Fig. 8. Buffer build-up at the switch.
segments of the UUC on the left of the point of inflection of theservice curve are incremented by and all segments on theright of the point of inflection are incremented by Notethat the point of inflection is at Updatingof the UUC is linear in time with the number segments inthe UUC which, in the worst case, is equal to the numberof connections in the system. When a connection leaves thesystem, the UUC can be updated incrementally in a similarfashion. In the following, we present a few key results onbuffer requirements and session delays.
Lemma 3.1:Given the anda set of session the maximumbacklog at a switching node is bounded by
where is the link speed, andProof: The worst case backlog occurs when all sessions
start their busy periods4 at the same time. The termon the right-hand side of the expression represents the bufferrequired to absorb the initial bursts from all the sessions. Thesecond term corresponds to the build-up due to the mismatchbetween the arrival rate and the service rate. Observe thatthe rate of arrival into the switch is greater than the rate ofdeparture from the switch when is greater than one. Forexample, in Fig. 8, buffer accumulation continues over theinterval of length During this interval, the product oflink speed and is more than Consequently, the shadedarea under the curve is the maximum size of accumulation.Note that the rate of accumulation at any point of time is
where is the utilization of the system at that point.Clearly, the summation on the right-hand side enumerates tothe total accumulation over the duration for whichremainsabove one.
Lemma 3.2:Given thethe maximum backlog of a session characterized by
4The busy period of a session is defined to be the time interval duringwhich the session is backlogged.

1138 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
cannot exceed
whereProof: The backlog of a session increases as long as
stays over one. The session backlog reaches its highest pointwhen the UUC changes its slope from toIf the service curve of the session consisted only of thesegment the maximum session backlog would havebeen If the service curve consistedonly of the maximum session backlog would havebeen Since the actual service curveis the minimum of these two segments, the maximum sessionbacklog cannot exceed the minimum of the backlogs computedusing each of these segments in isolation.
Lemma 3.3: Given the themaximum delay suffered by any cell belonging to a sessioncharacterized by cannot exceed
where is the maximum session backlog,and and are such that
Proof: We compute the worst case bound on delay byenumerating the time taken to clear the worst possible backlog.We compute the clearing times in two cases: 1) using servicesegment and 2) using service segment Ifwe consider the service curve the maximum delaysuffered by any cell is the time required to clear a backlog of
The backlog is cleared only after drops below1. Assume that is the first that is less than one.Hence, the time to clear the backlog of is equal to
where is a fraction of and
Similarly we can find the time required to clear the backlogwhen is the service curve. The worst case delay is theminimum of the two.
One of the interesting points to note here is that theaggregate rate of arrivals can exceed the link capacity fora finite length of time. The buffers in the switch are usedto absorb this mismatch between the arrival and the servicerates. This is an important difference between the multirateservice discipline proposed and the ones that offer a single-rate guarantee. In single-rate PGPS, for example, input traffic
TABLE ICHARACTERISTICS OF THEMPEG TRACES; SIZE
IS IN BYTES AND FRAME SEQUENCE IS IBBPBB
is shaped using a single leaky bucket, and is characterized bya tuple where is the burst size and is the arrival rate.In order to achieve stability, PGPS keeps the aggregate arrivalrate from all sessions at all times below the link speed. Anotherpoint to note here is that the scheduler does not introduce anydelay if the UUC is always less than one. Hence, we cancompute the end-to-end delay of a session using Lemma 3.3if we know the UUC’s of all the switching nodes on the pathof the connection.
D. Admission Control
We discuss admission control policies for two differentclasses of service: 1) guaranteed service and 2) predictiveservice. In the guaranteed service, each session is guaranteeda certain target delay and lossless delivery of data. In thepredictive service, designed for adaptive applications preparedto tolerate occasional cell losses and delay violations, a sessionis promised a delay target with the understanding that it may beviolated at times and there may be cell losses once in a while.In the following, we discuss the admission control algorithmsfor each of these classes of service.
Guaranteed Service:We assume that each session is char-acterized by The process of admitting anew connection includes three steps: 1) computing the newUUC, 2) checking that the worst case system backlog doesnot exceed switch buffer limit, and 3) checking that the delaybound for each connection is satisfied. In the following, wediscuss each of these steps in detail.
The UUC can be updated incrementally. Note that the newUUC has at most one more point of discontinuity whichcoincides with the point of inflection of the service curve ofthe new connection. Also, the value of for each segment ofthe curve goes up by or depending on whether thesegment is on the left or on the right of the point of inflectionintroduced by the new connection.
Using the result from Lemma 3.1, we can check if theadmission of the new connection can lead to buffer overflow.As we update the UUC, we can add up for

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1139
(a) (b)
(c) (d)
Fig. 9. MPEG compressed video traces. Frame sequence isIBBPBB.
each segment until changes from values higher than oneto less than one. Once this sum is known, checking for thebuffer overflow is trivial. For the purpose of quick and easycomputation, it may be worthwhile to keep the cumulative sumalong with for each segment of the UUC. We can alsocompute the maximum backlog of each session in the samepass. These results are prerequisite to delay computation forindividual sessions.
We can compute the session delays using the results fromLemma 3.3. For quick computation, we can store the cumu-lative sum of starting from the point wherechanges from values greater than one to less than one. Notethat delay bounds of all the sessions can be computed in onepass, and it is of complexity, where is the numberof connections.
Predictive Service:In the predictive service, a session isgiven a loose guarantee on delay and loss. We exploit thislaxity to improve network utilization and expedite admission
control checks. In predictive service, the utilization of thesystem is measured rather than computed. When a new flow isto be admitted, delay and buffer occupancy are estimated basedon the measured utilization. In the following, we explain theprocedure in detail.
We measure the utilization of the system over different timescales. Let us assume that the measurement is taken overthree time scales and where Themeasurement process counts the number of arrivalsand over a period of and respectively. Wecompute the utilization of the system in and as
and respectively.From these measurements, we can estimate the UUC as
where andThe measured values of and are updated every
unit of time, where To be on theconservative side, we update’s with the highest recordedin the last measurement period

1140 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
(a) (b)
Fig. 10. Comparison with PGPS server—percentage improvement in number of connections admitted for the basketball trace.
(a) (b)
Fig. 11. Comparison with PGPS server—percentage improvement in number of connections admitted for the MTV video trace.
The admission control test for a new connection, character-ized by consists of the following steps.
• Estimate the new UUC of the system after the admittanceof the new flow from the current UUC and the servicecurve of the new connection. If the utilization of the lastsegment of the updated UUC is greater than one, theconnection is rejected right away.
• If any segment of the UUC is greater than one, weestimate system buffer occupancy using Lemma 3.1.If where is a multiplicative factor less thanone, and is the switch buffer size, the connection isrejected.
• Delay estimates for each connection, including the newone, are recomputed using the modified UUC andthe original traffic specification of each connection.
If the delay estimate of any connection exceeds thepromised/requested maximum bound, the connection isrejected.
Estimation of system utilization is a very important compo-nent of the admission control algorithm. The number and thelengths of the measurement periods determine the accuracyof the measurement, and consequently impact the size ofthe admissible region and discrepancy between the estimatedand actual delay and loss characteristics. The value ofalso has a significant impact on the system performance.The higher the value (less than one), the more optimisticis the admission control process. However, a higher valueof also increases the risk of buffer overflows and celllosses. On the other hand, a conservative choice ofreducesthe chance of cells losses, but only at the cost of lowerutilization.

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1141
(a) (b)
Fig. 12. Comparison with PGPS server—percentage improvement in number of connections admitted for the news clip trace.
(a) (b)
Fig. 13. Comparison with PGPS server—percentage improvement in number of connections admitted for the lecture trace.
IV. NUMERICAL RESULTS
In this section, we compare the performance of a multirateserver with that of single rate servers employing PGPS andconstant bit-rate (CBR) service in providing guaranteed ser-vice. We investigate multiplexing gains of predictive serviceover that of guaranteed service. We also present numericalresults comparing multirate and single-rate predictive ser-vices.
In our study, we used four 320 240 video clips (seeTable I), each approximately 10 min long. In order to under-stand the effects of traffic variability on the performance ofmultirate service, we selected videos with different degreesof scene changes. The first video is an excerpt from a veryfast scene-changing basketball game. The second clip is amusic video (MTV) of the rock group REM. It is composed
of rapidly changing scenes in tune with the song. The thirdsequence is a clip fromCNN Headline Newswhere the scenealternates between the anchor reading news and different newsclips. The last one is a lecture video with scenes alternatingbetween the speaker talking and the viewgraphs. The onlymoving objects here are the speaker’s head and hands. Fig. 9plots frame sizes against frame number (equivalently, time)for all four sequences for an appreciation of the burstinessin different sequences. In all traces, frames are sequencedas IBBPBB and the frame rate is 30 frames/s. Observe that,in terms of the size of GOP5 and that of an average frame,basketball and lecture video are at the two extremes (the largest
5The repeating sequence (IBBPBB in this case) is called a GOP or groupof pictures.

1142 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
(a) (b)
Fig. 14. Comparison with CBR service—percentage improvement in number of connections admitted for the basketball trace.
(a) (b)
Fig. 15. Comparison with CBR service—percentage improvement in number of connections admitted for the MTV video trace.
and the smallest, respectively), with the other two videos inbetween.
Guaranteed Service:For this study, we consider a networkconsisting of nodes in tandem, connected by OC-3 (155Mbit/s) links and transporting fixed-size ATM cells. Data fromthe source are passed through a shaper and then fed to thenetwork. All connections traverse from the source to the sinkthrough five switches. We assume that the end-to-end delaybound is 300 ms.
The sets of graphs of Figs. 10–13 compare the numberof connections admitted when PGPS is used in conjunctionwith a leaky-bucket shaper and multirate service is used inconjunction with a dual leaky-bucket shaper. We use resultsfrom Section II to compute the leaky-bucket parameters thatmaximize the number of connections admitted by the PGPS
server. The choice of shaper parameters for multirate serviceis bit more ad hoc.6 We pick 0 and use the results fromSection II to find the minimum that guarantees losslessshaping. We use two different values for The first plotfor each set (for a particular sequence) uses 1000 cellsand the second plot uses 3000 cells. In each case, we findthe corresponding lowest that guarantees lossless shaping.We have plotted the percentage improvement in the numberof connections admitted using a multirate server over that ofthe PGPS server for different switch and shaper buffer sizes.We have also experimented with other values ofand have
6This is because we do not have a closed-form delay bound for multirateservice, and hence we cannot use the linear programming formulation to findthe optimal parameters.
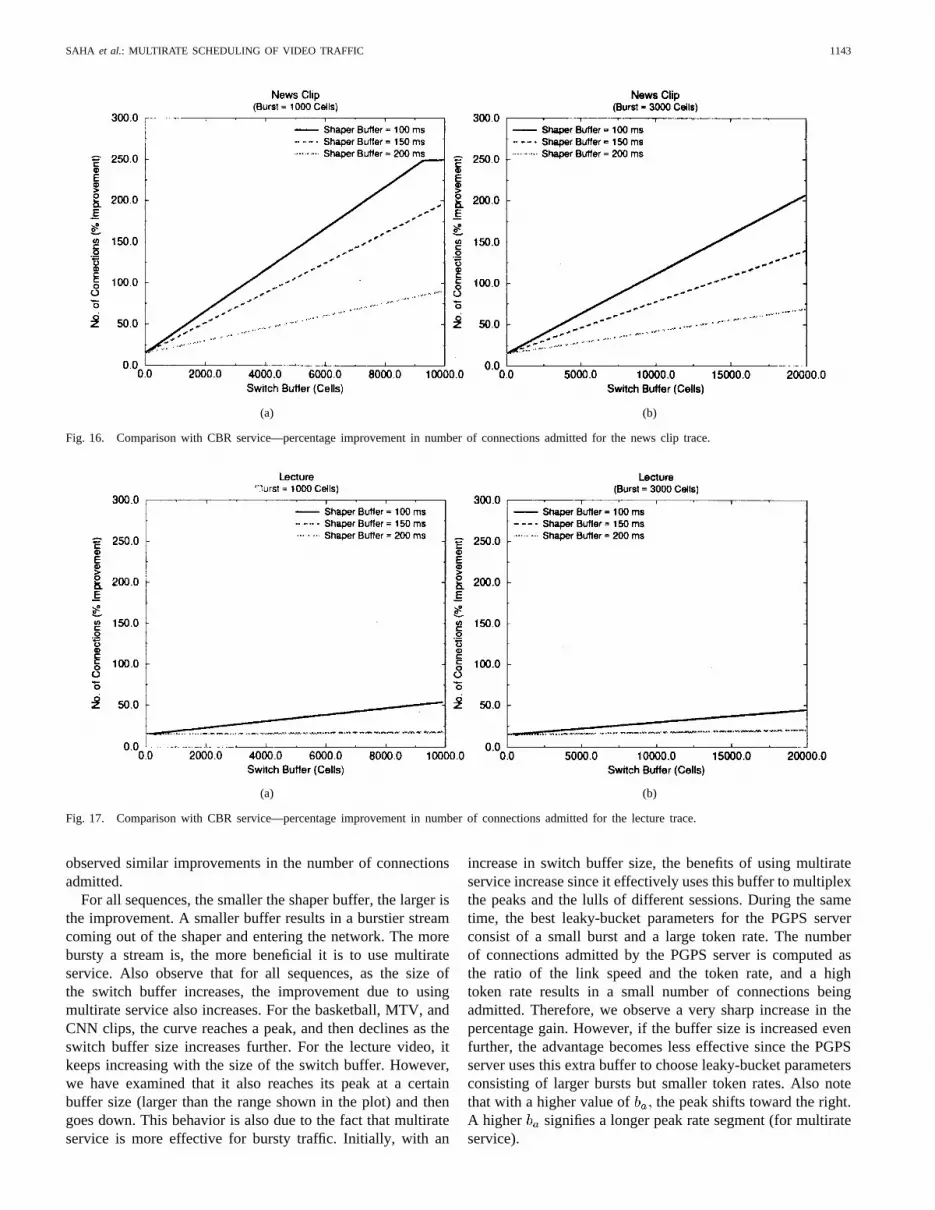
SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1143
(a) (b)
Fig. 16. Comparison with CBR service—percentage improvement in number of connections admitted for the news clip trace.
(a) (b)
Fig. 17. Comparison with CBR service—percentage improvement in number of connections admitted for the lecture trace.
observed similar improvements in the number of connectionsadmitted.
For all sequences, the smaller the shaper buffer, the larger isthe improvement. A smaller buffer results in a burstier streamcoming out of the shaper and entering the network. The morebursty a stream is, the more beneficial it is to use multirateservice. Also observe that for all sequences, as the size ofthe switch buffer increases, the improvement due to usingmultirate service also increases. For the basketball, MTV, andCNN clips, the curve reaches a peak, and then declines as theswitch buffer size increases further. For the lecture video, itkeeps increasing with the size of the switch buffer. However,we have examined that it also reaches its peak at a certainbuffer size (larger than the range shown in the plot) and thengoes down. This behavior is also due to the fact that multirateservice is more effective for bursty traffic. Initially, with an
increase in switch buffer size, the benefits of using multirateservice increase since it effectively uses this buffer to multiplexthe peaks and the lulls of different sessions. During the sametime, the best leaky-bucket parameters for the PGPS serverconsist of a small burst and a large token rate. The numberof connections admitted by the PGPS server is computed asthe ratio of the link speed and the token rate, and a hightoken rate results in a small number of connections beingadmitted. Therefore, we observe a very sharp increase in thepercentage gain. However, if the buffer size is increased evenfurther, the advantage becomes less effective since the PGPSserver uses this extra buffer to choose leaky-bucket parametersconsisting of larger bursts but smaller token rates. Also notethat with a higher value of the peak shifts toward the right.A higher signifies a longer peak rate segment (for multirateservice).

1144 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
(a) (b)
(c) (d)
Fig. 18. Percentage improvement in number of connections admitted, predictive versus guaranteed service.
If we analyze the results for different sequences, we observethat the improvement due to multirate service is the lowestfor the lecture video. This can be explained from the factthat it is the least bursty of all the clips. Here, even witha small amount of shaper buffer, the difference betweenthe peak and the average rate is not as much as the othermore bursty clips. Consequently, the multiplexing gain is alsoless.
Graphs in Figs. 14–17 compare multirate service with CBRservice. We used the same setup as described above. ForCBR service, we compute the the minimum rate of servicefor each video sequence for different shaper buffer sizes forlossless shaping. As in the last example, for multirate service,we use 0, and use the results from Section II to findthe minimum that guarantees lossless shaping. We usetwo different values for The first plot for each set (for aparticular sequence) uses 1000 cells and the second plotuses 3000 cells. In each case, we find the correspondinglowest that guarantees lossless shaping. We have plotted
the percentage improvement in the number of connectionsadmitted using multirate service over that of the CBR servicefor different switch and shaper buffer sizes. The results showssimilar characteristics as observed in the comparison betweenmultirate and PGPS server. However, as expected, the orderof improvement in the number of connections admitted bythe multirate server is much larger in this case, and doesnot saturate for most switch buffer sizes considered in ourstudy.
Predictive Service:For this study, we consider the samenetwork configuration used for the guaranteed case. Weassume that desired end-to-end delay is 300 ms. The graphsof Fig. 18 compare the number of connections admitted forguaranteed and predictive services, both using multiratescheduling. Note that while we compute the number ofconnections admitted in the guaranteed case, the numberof connections admitted in the predictive case is obtainedthrough simulation. To make the comparison fair, we useresults from only those simulation runs that result in zero

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1145
(a) (b)
(c) (d)
Fig. 19. Percentage improvement in number of connections admitted using multirate scheduling for predictive service.
cell loss. At each switching node, we estimate the UUCby measuring utilization over three time scales,cell time, cell time, and cell time.The measurement period is cell time. Wevary the buffer utilization factor to achieve losslessdelivery.
In Fig. 18, we have plotted the percentage improvement inthe number of connections admitted in the predictive serviceover that of guaranteed service. We observe that for all videosequences, the improvement in the number of connectionsadmitted increases initially with the increase in switch buffersize. For basketball, MTV video, and the news clips, theincrease in improvement ceases at a certain switch buffersize. For the lecture sequence, it actually decreases withincreasing buffer size. The initial increase in improvementwith an increase in switch buffer size is because of the factthat predictive service effectively uses this buffer to multiplextraffic. The rate of increase is higher for the lower switch
buffer due to the fact that, during this time, the multiplexinggain is hardly exploited by the deterministic scheme. However,as the buffer size keeps increasing, so does the number ofconnections, and ultimately the multiplexing gain tapers off.At this point, the number of connections admitted in bothguaranteed and predictive services becomes (more or less)constant (at different values, of course). The decrease in thepercentage improvement for the lecture sequence comes asa bit of surprise. This is because the lecture video is quitesmooth to start with. Therefore, as the buffer in the switchincreases, the deterministic policy can do much better inexploiting multiplexing gain than for the other bursty clips.With the increase in buffer size, the multiplexing gain achievedby both the schemes becomes comparable, and the gainstarts to fall (note that the absolute number of connectionsadmitted by the predictive scheme is more than a factor oftwo higher than that of the the deterministic scheme at alltimes).

1146 IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS, VOL. 15, NO. 6, AUGUST 1997
The next set of graphs (Fig. 19) compares the number ofconnections admitted using multirate and single-rate predictiveservice. We used the same experimental setup and the sameset of traffic parameters as used in the comparative studyof the multirate and PGPS servers for guaranteed service.The only difference is in the admission control algorithm.We used the measurement-based admission control algorithmwith 50 cell time, 250 cell time, and500 cell time. The measurement period is 1000 celltime. We vary the buffer utilization factor to achievelossless delivery. We plot the percentage improvement in thenumber of connections admitted using multirate service overthat of single-rate service. When the switch buffer size is inthe range of 100–500 cells, we get 100–200% improvementfor all sequences. However, with increasing buffer size, theimprovement due to multirate service goes down and stabilizesat around 50%.
From the results presented in this section, we make thefollowing conclusions.
• For guaranteed service, the multirate server outperformsthe single-rate PGPS server. Multirate scheduling is moreeffective for bursty traffic.
• The benefits of using multirate scheduling goes down asthe buffering in the switch increases. Note, however, thatmost of the currently available switches use no more thancouple of hundred cells of buffer per port. Due to spaceand power limitations on the switch wafer, this number isnot expected to increase dramatically in the near future. Inthis operating range, the benefits of multirate schedulingare very significant.
• If hard guarantees on service quality is not a require-ment, predictive service can be used to improve systemutilization significantly. For typical switches currentlyavailable, multirate scheduling far outperforms single-ratescheduling.
V. CONCLUSION
We have proposed a multirate service mechanism for ATMnetworks that is particularly suitable for transporting VBRvideo traffic. We have shown how this multiplexing mech-anism can be effective in providing both deterministic andempirical service guarantees. The major contributions of thispaper are as follows.
• A scheduling mechanism that can provide different ratesof service at different times. It is particularly suitable forbursty traffic, such as VBR video.
• We have shown that multirate scheduling can outperformPGPS in terms of the number connections admitted whilemaintaining the same level of service guarantees. Ourexperiments with video traces demonstrate that multiratescheduling can be very effective for VBR video traffic.
• We have shown that by relaxing the service guaranteesand using a measurement-based admission controlprocess, we can improve the system utilization signif-icantly. Our experiments using real-life video tracesdemonstrate that we can achieve a factor of two
improvement in utilization with almost no degradationin service quality.
This study can be extended in many ways. In the predictivemode of service, the number and the lengths of measurementintervals have a profound impact on the stability and theutilization of the system. We are currently in the process ofanalyzing these interactions. Another interesting direction forfuture work is to apply multirate scheduling for data traffic.For example, it can be used to provide short response timesto telnet sessions by reserving a high peak rate for a shortduration and low average rate. Theftp sessions, on the otherhand, can be optimized for throughput by reserving a relativelyhigher average rate of service, and a peak rate that is the sameas or close to the average rate.
REFERENCES
[1] C. M. Aras, J. F. Kurose, D. S. Reeves, and H. Schulzrinne, “Real-timecommunication in packet-switched networks,”Proc. IEEE, vol. 82, Jan.1994.
[2] S. Keshav, C. R. Kalmanek, and H. Kanakia, “Rate controlled serversfor very high speed networks,” inProc. IEEE GLOBECOM, Dec. 1990.
[3] H. J. Chao, “Architecture design for regulating and scheduling user’straffic in ATM networks,” in Proc. SIGCOMM, Aug. 1992.
[4] R. L. Cruz, “Quality of service guarantees in virtual circuit switchednetworks,” IEEE J. Select. Areas Commun., vol. 13, Aug. 1995.
[5] L. Georgiadis, R. Guerin, and A. Parekh, “Optimal multiplexing onsingle link: Delay and buffer requirements,” inProc. IEEE INFOCOM,June 1994.
[6] L. Georgiadis, R. Guerin, V. Peris, and K. N. Sivarajan, “Efficientnetwork QoS provisioning based on per node traffic shaping,” inProc.IEEE INFOCOM, Mar. 1996.
[7] S. J. Golestani, “A framing strategy for congestion management,”IEEEJ. Select. Areas Commun., vol. 9, Sept. 1991.
[8] , “A self-clocked fair queuing scheme for broadband applications,in Proc. IEEE INFOCOM, June 1994.
[9] F. Guillemin, C. Rosenberg, and J. Mignault, “On characterizing anATM source via the sustainable cell rate traffic descriptor,” inProc.IEEE INFOCOM, Apr. 1995.
[10] S. Jamin, P. Danzig, S. Shenker, and L. Zhang, “A measurement-basedadmission control algorithm for integrated services packet networks,”in Proc. SIGCOMM, Oct. 1995.
[11] E. W. Knightly, “H-BIND: A new approach to providing statisticalperformance guarantees to VBR traffic,” inProc. IEEE INFOCOM,Mar. 1996.
[12] E. W. Knightly and H. Zhang, “Traffic characterization and switchutilization using a deterministic bounding interval dependent trafficmodel,” in Proc. IEEE INFOCOM, Apr. 1995.
[13] D. Legall, “MPEG—A video compression standard for multimediaapplications,”Commun. ACM, vol. 34, no. 4, 1991.
[14] B. L. Mark and G. Ramamurthy, “Real-time estimation of UPC pa-rameters for arbitrary traffic sources in ATM networks,” inProc. IEEEINFOCOM, Mar. 1996.
[15] A. K. Parekh and R. G. Gallager, “A generalized processor sharingapproach to flow control in integrated services network: The single nodecase,”IEEE/ACM Trans. Networking, vol. 1, June 1993.
[16] E. Rathgeb, “Modeling and performance comparison of policing mech-anisms for ATM networks,”IEEE J. Select. Areas Commun., vol. 9, no.3, 1991.
[17] A. R. Reibman and A. W. Berger, “Traffic descriptors for VBR videoteleconferencing over ATM networks,”IEEE/ACM Trans. Networking,vol. 3, June 1993.
[18] D. Reininger, D. Raychaudhuri, B. Melamed, B. Sengupta, and J. Hill,“Statistical multiplexing of VBR MPEG compressed video on ATMnetworks,” in Proc. IEEE INFOCOM, 1993.
[19] J. L. Rexford, A. G. Greenberg, and F. G. Bonomi, “Hardware-efficientfair queueing architecture for high-speed networks,” inProc. IEEEINFOCOM, Mar. 1996.
[20] D. Saha, S. Mukherjee, and S. K. Tripathi, “Carry-over round robin: Asimple cell scheduling mechanism for ATM networks,” inProc. IEEEINFOCOM, Mar. 1996.
[21] J. K. Strayer,Linear Programming and Its Applications. Berlin, Ger-many: Springer-Verlag, 1989.

SAHA et al.: MULTIRATE SCHEDULING OF VIDEO TRAFFIC 1147
[22] S. Suri, G. Varghese, and G. P. Chandranmenon, “Leap forward virtualclock: AnO(log log N) fair queuing scheme with guaranteed delaysand throughput fairness,” Dept. Comput. Sci., Washington Univ., St.Louis, MO, Tech. Rep., 1996.
[23] D. E. Wrege and J. Liebeherr, “Video traffic characterization formultimedia networks with a deterministic service,” inProc. IEEEINFOCOM, Mar. 1996.
[24] H. Zhang and D. Ferrari, “Rate controlled static priority queuing,” inProc. IEEE INFOCOM, 1993.
[25] L. Zhang, “Virtual clock: A new traffic control algorithm for packetswitching networks,” inProc. IEEE SIGCOMM, 1990.
Debanjan Sahawas born on October 3, 1969. Hereceived the B.Tech. degree in computer science andengineering from the Indian Institute of Technology,Kharagpur, in 1990, and the M.S. and Ph.D. degreesin computer science from the University of Mary-land, College Park, in 1992 and 1995, respectively.
He is currently with the Communications Sys-tems Division, IBM T. J. Watson Research Center,Yorktown Heights, NY. His research interests in-clude high-speed networking, multimedia applica-tions, and real-time systems.
Sarit Mukherjee received the B.Tech. degree incomputer science and engineering from the IndianInstitute of Technology, Kharagpur, in 1987, and theM.S. and Ph.D. degrees in computer science fromthe University of Maryland, College Park, in 1990and 1993, respectively.
Currently, he is an Assistant Professor in theDepartment of Computer Science and Engineering,University of Nebraska, Lincoln. His research inter-ests include high-speed network architectures andprotocols, multimedia applications, modeling, and
performance evaluation.Dr. Mukherjee is a member of the IEEE Communications Society and
ACM SIGCOMM.
Satish K. Tripathi (M’86–SM’86–F’97) attendedthe Banaras Hindu University, the Indian Statis-tical Institute, the University of Alberta, Edmon-ton, Alta., Canada, and the University of Toronto,Toronto, Ont., Canada. He received the Ph.D. degreein computer science from the University of Torontoin 1978.
From 1978 to 1996, he was on the faculty ofthe Department of Computer Science, Universityof Maryland, College Park. He served as the De-partment Chair during 1988–1995. He is currently
the Johnson Chair Professor and the Dean of Engineering, University ofCalifornia, Riverside. For the last 20 years, he has been actively involvedin research related to performance evaluation, networks, real-time systems,and fault tolerance. He has published more than 100 papers in internationaljournals and refereed conferences. In the networking area, his current projectsare in mobile computing, ATM networks, and operating systems.
Dr. Tripathi has served as a member of the Program Committee and ProgramChairman for various international conferences. He has guest edited specialissues of many journals, and serves on the editorial boards ofTheoreticalComputer Science, Multimedia Systems, IEEE TRANSACTIONS ON COMPUTERS,and IEEE/ACM TRANSACTIONS ON NETWORKING. He has edited books onperformance evaluation and parallel computing, and has authored a book onmultimedia systems.





























