Embed Size (px)
Citation preview

Hybrid Tag Recommendation forSocial Annotation Systems
Jonathan Gemmell, Thomas Schimoler, Bamshad Mobasher, Robin BurkeCenter for Web Intelligence
School of Computing, DePaul UniversityChicago, Illinois, USA
{jgemmell, tschimo1, mobasher, rburke}@cdm.depaul.edu
ABSTRACTSocial annotation systems allow users to annotate resourceswith personalized tags and to navigate large and complexinformation spaces without the need to rely on predefinedhierarchies. These systems help users organize and sharetheir own resources, as well as discover new ones annotatedby other users. Tag recommenders in such systems assistusers in finding appropriate tags for resources and help con-solidate annotations across all users and resources. But thesize and complexity of the data, as well as the inherent noiseand inconsistencies in the underlying tag vocabularies, havemade the design of effective tag recommenders a challenge.Recent efforts have demonstrated the advantages of inte-grative models that leverage all three dimensions of a so-cial annotation system: users, resources and tags. Amongthese approaches are recommendation models based on ma-trix factorization. But, these models tend to lack scalabilityand often hide the underlying characteristics, or “informa-tion channels” of the data that affect recommendation effec-tiveness. In this paper we propose a weighted hybrid tagrecommender that blends multiple recommendation compo-nents drawing separately on complementary dimensions, andevaluate it on six large real-world datasets. In addition, weattempt to quantify the strength of the information channelsin these datasets and use these results to explain the per-formance of the hybrid. We find our approach is not onlycompetitive with the state-of-the-art techniques in terms ofaccuracy, but also has the added benefits of being scalableto large real world applications, extensible to incorporatea wide range of recommendation techniques, easily update-able, and more scrutable than other leading methods.
Categories and Subject DescriptorsH.2 [Database Management]: H.2.8 Database applica-tion—Data mining; H.3 [Information Storage and Re-trieval]: H.3.3 Information Search and Retrieval—Searchprocess
Permission to make digital or hard copies of all or part of this work forpersonal or classroom use is granted without fee provided that copies arenot made or distributed for profit or commercial advantage and that copiesbear this notice and the full citation on the first page. To copy otherwise, torepublish, to post on servers or to redistribute to lists, requires prior specificpermission and/or a fee.CIKM’10, October 26–30, 2010, Toronto, Ontario, Canada.Copyright 2010 ACM 978-1-4503-0099-5/10/10 ...$10.00.
General TermsAlgorithms, Experimentation, Performance
KeywordsSocial Annotation, Information Channels, Hybrid Recom-menders, Recommender Systems
1. INTRODUCTIONIn social annotation systems, information access functions
such as search, navigation and resource sharing are sup-ported by annotations, arbitrary tags applied to resourcesby individual users. Delicious1 supports users as they book-mark URLs. Citeulike2 enables researchers to manage schol-arly references. Bibsonomy3 allows users to annotate both.Social annotation systems are quickly becoming ubiquitousin a variety of domains. For example, Amazon4 and othershave incorporated social annotations into their web site.
The popularity of social annotation systems is driven inpart by the low entry barrier and the freedom to annotateresources with any tag. The aggregated connections betweenusers, resources and tags provide a rich information space forusers to explore. However, the benefits of social annotationsystems do not come without a cost. The size, noise anddimensionality of the data make navigation and informationaccess difficult. Recommender systems are therefore a crit-ical component of these applications. In this work we focuson tag recommenders which assist users during the annota-tion process by recommending tags for a selected resource.
Recent efforts in tag recommendation have proven thatintegrative models that leverage all three dimensions of asocial annotation system (users, resources, tags) produce su-perior results. Graph-based models [7] and a variety of latentvariable techniques [13, 14, 18, 19] have been investigated.These approaches tend to be computationally intensive andscale poorly. Previous work on hybrid tag recommenders [3,4] that combine several components, each exploiting differ-ent dimensions of the data, have been shown to offer compet-itive results while maintaining the simplicity, computationalefficiency and explanatory capacity of the component rec-ommenders. However, these results have focused on hybridmodels specifically designed for a particular dataset or as ameans to augment another integrative technique.
1delicious.com2citeulike.org3bibsonomy.org4amazon.com

This paper proposes a framework for constructing linearweighted hybrids that combines component recommendersinto a single integrated model. No individual component isrequired to cover all dimensions of the data, but when takentogether the components complement one another. The hy-brid is therefore able to produce results superior to what thecomponents produce alone.
To help understand our experimental results, we explorethe notion of an information channel: the power one dimen-sion possesses in predicting or modeling another dimensionof the social annotation system. To quantify the strength ofthese information channels, we develop a family of metricsbased on conditional entropy. These metrics reveal markeddifferences in the characteristics of the datasets, which arereflected in the performance of the recommendation compo-nents.
The rest of the paper is organized as follows. In Section 2we present related work. Section 3 introduces tag recom-mendation. Results of the recommendation techniques areprovided in Section 4. In Section 5 we introduce the no-tion of information channels and use them to evaluate theresults of the tag recommenders. Finally, we conclude thepaper with a summary of our findings.
2. RELATED WORKOne of the first techniques to demonstrate the value of
an integrative approach for tag recommendation in socialannotation systems was a graph-based variant [7] of the well-known PageRank algorithm. The computational burden ofcomputing the PageRank values of each user, resource andtag for every recommendation makes the algorithm ill-suitedfor large-scale deployment.
Tensor factorization is another integrative technique formaking tag recommendations. Tucker decomposition is onesuch example that factors the three dimensional taggingdata into three feature spaces and a core residual tensor [18,19]. Unlike the graph-based model, online computation ofrecommendations is highly efficient. However, the offlinecomputation required to build the model is not scalable tothe demands of real-world applications.
A pair-wise interaction tensor factorization model has alsobeen proposed, which offers far more reasonable run timesin both the construction of the model and the generation ofrecommendations [13, 14]. It optimizes the ranking of tagsgiven user-resource pairs in the training data. Tags maythen be recommended for a new user-resource pair. Thisapproach represents the current state-of-the-art in tag rec-ommendation providing both a high degree of accuracy andcomputational efficiency.
Our previous work in tag recommendation has demon-strated the benefits of hybrid recommenders [3, 4]. Oneapproach demonstrated that the graph-based models maybe improved by incorporating item-based collaborative fil-tering. Another effort resulted in a hybrid recommender forBibsonomy in the context of the PKDD-ECML 2009 chal-lenge [10]. In this paper we extend those efforts, proposinga more general framework for constructing linear weightedhybrid tag recommenders. The hybrid is constructed fromcomponent recommenders and produces results competitiveto state-of-the-art techniques.
3. TAG RECOMMENDATIONThis section begins with a discussion of the data models
for a social annotation system. We then present our pro-posed framework for the linear weighted hybrid tag recom-mender and discuss the individual components that may beincorporated into the hybrid. For comparative purposes wealso describe the state-of-the-art pair-wise interaction tensorfactorization algorithm.
3.1 Data ModelThe foundation of a social annotation system is the an-
notation: the record of a user labeling a resource with oneor more tags. A collection of annotations results in a com-plex network of interrelated users, resources and tags [11].A social annotation system can be described as a four-tuple:〈U,R, T, A〉, where U is a set of users; R is a set of resources;T is a set of tags; and A is a set of annotations. An annota-tion contains a user, resource and all tags the user appliedto the resource.
A social annotation system can also be viewed as a threedimensional matrix, URT, in which an entry URT(u,r,t) is 1if u tagged r with t. Aggregate projections of the data can beconstructed, reducing the dimensionality but sacrificing in-formation [12]. For example, the relation between resourcesand tags can be defined as RT (r, t). In this work, we cal-culate RT (r, t) as the number of users that have applied tto r. This notion strongly resembles the “bag-of-words” vec-tor space model [15] and is analogous to the idea of termfrequency common in information retrieval.
A similar two dimensional projection can be constructedfor UT , in which an entry contains the number of times auser has applied a tag to any resource. Finally, UR is a bi-nary matrix indicating whether or not a user has annotateda resource. An alternative approach would be to define anentry in the matrix as the number of tags a user has appliedto a resource. Our previous work and continued experimen-tation has shown that the binary model for UR producesbetter results.
Each resource, r, may be modeled as a vector over themulti-dimensional space of tags, where a weight, w(ti), indimension i corresponds to the importance of a particulartag, ti:
~rt = 〈w(t1), w(t2)...w(t|T |)〉 (1)
Similarly, a resource can be modeled as a vector over thespace of users where each weight, w(ui), corresponds to theimportance of a particular user, ui to produce ~ru. Analo-
gous vector models can be constructed for users ( ~ur, ~ut) andtags (~tu,~tr). We draw the weights directly from the pre-viously constructed aggregate projections UR,UT and RT.The model of a user, resource or tag is defined as a row orcolumn taken from one of the projections.
3.2 Linear Weighted HybridOur proposed framework aggregates the results of several
component recommenders in linear combination [1]. Thecomponents are freed from the burden of covering all theavailable dimensions of the data and instead specialize inonly a few. A successful hybrid creates a synergistic blendof its component parts producing results superior to whatthey could achieve alone.

We can view each component of a tag recommendationsystem as a function
ψ : U ×R × T → R,which, given a user u ∈ U and a resource r ∈ R, produces areal-valued result p as the predicted relevance of a tag t forthat particular user-resource pair: ψ(u, r, t) = p.
In the most common settings tag recommenders are usedto produce a ranked list of suggested tags for a particularuser and given a specific resource. To do so using the aboveformulation, for a given user u and resource r, we iterate overall tags, sort them by their corresponding relevance scores,and return the top n tags:
rec(u, r) = TOPnt∈Tψ(u, r, t). (2)
In our proposed hybrid framework the relevance score for atag is calculated using several component tag recommenders.These scores are then combined in a linear model. Specifi-cally, given a set of component tag recommenders C, a linearweighted hybrid tag recommender will accept a user u andresource r. It will then query each of its component recom-menders, c ∈ C, for a tag, t, and combine the results in thelinear model:
ψh(u, r, t) =∑
c∈C
αcψc(u, r, t) (3)
where ψh(u, r, t) is the linear weighted relevance score of thetag and αc is the weight given to the component, c.
It should be noted that the scores from one componentmay be drawn from a different distribution than the othercomponents. In order to ensure that the relevance scores forall component recommenders are on the same scale, we nor-malize the scores so that each ψc(u, r, t) falls in the interval[0,1].
As additional recommenders are added to the hybrid, itscomplexity grows. The challenge then becomes how to ascer-tain the correct α for each component in order to maximizethe effectiveness of the hybrid.
We use a hill climbing technique because of its speed andsimplicity. The α vector is initialized with random posi-tive numbers constrained such that the sum of the vectorequals 1. The vector is then randomly modified and testedagainst a holdout set to ascertain if it achieves better re-sults. The holdout set may be evaluated for recall, precisionor F-measure. In this work we rely on the F-measure sinceit incorporates both the recall and precision. If the resultis improved, the change is accepted; otherwise it is usuallyrejected. Occasionally a change to the α vector is acceptedeven when it does not improve the results in order to morefully explore the α space. Modifications continue until thevector stabilizes. In order to ensure that a local maximumhas not been discovered, the experiment is repeated 20 timesfrom different random starting points.
With this integrative model any tag recommender can beincorporated into the hybrid. We focus on relatively simplecomponent recommenders due to their speed and scrutabil-ity. We now present those components.
3.2.1 Popularity ModelsPerhaps the simplest recommendation strategy is merely
to recommend the most commonly used tags in the system.
Alternatively, given a user-resource pair a recommender mayignore the user and recommend the most popular tags forthat particular resource. This strategy is strictly resourcedependent and does not take into account the tagging habitsof the user. We define ψ(u, r, t) for the resource based pop-ularity recommender, popr , as:
ψ(u, r, t) =∑
v∈U
θ(v, r, t) (4)
We define θ(v, r, t) as 1 if v tagged r with t and 0 oth-erwise. In a similar fashion a recommender may ignore theresource and recommend the most popular tags for that par-ticular user. While such an algorithm would include tagsfrequently applied by the user, it does not consider the re-source information and may recommend tags irrelevant tothe current resource. We define ψ(u, r, t) for the user basedpopularity recommender, popu, as:
ψ(u, r, t) =∑
s∈R
θ(u, s, t) (5)
While popularity models are not necessarily the most ef-fective techniques, they do serve as a baseline and may bene-fit the hybrid. Popularity based recommenders require littleonline computation. They are easily built offline and can beincrementally updated.
3.2.2 User-Based Collaborative FilteringUser-based collaborative filtering [5, 9, 17] works under
the assumption that users who have agreed in the past arelikely to agree in the future. A neighborhood, Nr , of thek most similar users to u is identified through a similaritymetric such that all the neighbors have tagged r. For anygiven resource the weighted sum can then be calculated as:
ψ(u, r, t) =∑
v∈Nr
σ(u, v)θ(v, r, t) (6)
where σ(u, v) is the similarity between the users u and v.In this work we rely on cosine similarity of the user models.As before, θ(v, r, t) is 1 if v has annotated r with t and 0otherwise. When users are modeled as resources we call thisapproach KNNur. When users are modeled as tags we callthis technique KNNut.
Since the algorithm will only populate the neighborhoodwith users that have annotated r, the number of similaritiesto calculate can be quite small. The popularity of resourcesin social annotation systems follows the power law and thegreat majority of resources will benefit from this reducedcomputation, while a few will require additional computa-tional effort. As a result the algorithm scales well with largedatasets. Similarities may even be computed offline.
This approach relies on the collaboration of other users.It may be the case that an appropriate tag cannot be recom-mended because it does not appear in a neighbor’s profile.While the personalization offered by user-based filtering isan important benefit, it lacks the ability to reflect the habitsand patterns of the larger crowd.
3.2.3 Item-Based Collaborative FilteringItem-based collaborative filtering [2, 16] relies on discov-
ering similarities among resources rather than among users.We may model the resources as a vector over the user space.

We call this model KNNru. When relying on tags, the vec-tor contains the frequency with which a resource has beenannotated with the tags. We call this model KNNrt. Wedefine Nu as the k nearest resources to r drawn from theuser profile, u, and then define the relevance score of a tagfor a user-resource pair as:
ψ(u, r, t) =∑
s∈Nu
σ(r, s)θ(u, s, t) (7)
If a user has annotated resources similar to r with t thenψ(u, r, t) will be high. Otherwise the relevance score will becorrespondingly low. The strength of this approach is thatit can draw the most relevant tags from the user profile. Itsweakness is that it cannot recommend tags from outside theuser profile.
Similarity metrics need only be calculated with resourcesin the user profile. If the user profile is not exceptionallylarge, this computation can be quickly done in real time.Otherwise, similarities can be calculated offline.
3.3 Pair-wise Interaction Tensor FactorizationFor the sake of comparison, we have chosen a tag rec-
ommender based on pair-wise interaction tensor factoriza-tion [14], which formed the basis for the winning submissionof the PKDD 2009 Tag Recommendation Challenge [10].This model-based approach generates a set of factor matriceswhich resembles a special case of the Tucker decompositionof a tensor. The tensor itself is not directly induced by thedata (this could be achieved by regarding each (u, r, t) tripleas a binary cell of a tensor), but rather reflects a rankingover the tags for each user-resource pair.
The model is built by first considering observations inthe data of the form (u, r, t+, t−), where (u, r, t+) is a triplewhich is found in the data (a positive example of tag selec-tion) and (u, r, t−) is a triple not found in the data (a nega-tive example of tag selection). An iterative gradient-descentalgorithm is employed to optimize a ranking function (basedon Bayesian conditionals) that prefers positive examples inthe data over negative ones. Each of four related matricesis updated until convergence is found. The matrices repre-sent the factor-reduced components of the specialized tensorfactorization M = UkT
Uk +RkT
Rk , where Uk is the user fac-
tor matrix, Rk is the resource factor matrix, TUk is the tag
factor matrix with respect to users and TRk is the tag factor
matrix with respect to resources, k is the selected numberof factors, and M is the personalized tag-ranking tensor.
Generating a tag recommendation for a given user u andresource r is simply a matter of referring to the appropriateuser-resource column of the ranking tensor M . The rele-vance score of a tag given a user-resource pair is calculatedas:
ψ(u, r, t) =
k∑
i=1
Uk[u][i]TUk [t][i] +Rk[r][i]TR
k [t][i] (8)
4. EXPERIMENTAL EVALUATIONIn this section we describe the methods used to gather
and pre-process our six datasets. Following an outline of ourmethodology, we examine the results of our proposed linearweighted hybrid tag recommender along with its componentsand the pair-wise interaction tensor factorization model. Fi-nally we draw some general conclusions.
4.1 DatasetsOur experiments are conducted using data from six large
real-world social annotation systems. On all datasets wegenerate p-cores [8]. Users, resources and tags are removedfrom the dataset in order to produce a residual dataset thatguarantees each user, resource and tag occur in at least pannotations. We define a annotations to include a user,a resource, and every tag the user has applied to the re-source. For the larger datasets we use 20-cores. In thesmaller datasets 5-cores are used.
Several reasons exist to construct p-cores. By eliminatinginfrequent items, the size of the data is dramatically reducedallowing the application of recommendation techniques thatwould otherwise be computationally impractical. By remov-ing rarely occurring users, resource or tags, noise in the datacan be dramatically reduced. Because of their scarcity, theseare the very items likely to confound recommenders. Rec-ommendation in the so-called long tail is a valid area ofexploration, but it lies outside the scope of this paper.
Bibsonomy enables its users to annotate both URL book-marks and journal articles. The dataset was gathered on 1January 2009 encompassing the entire system. This dataset has been made available online by the system admin-istrators [6]. They have pre-processed the data to removeanomalies. A 5-core was taken. It contains 13,909 annota-tions with 357 users, 1,738 resources and 1,573 tags.
Citeulike is a popular online tool used by researchers tospecifically manage and catalog journal articles. The siteowners make their dataset freely available to download. Weuse a snapshot taken as of 17 February 2009. Once a 5-corewas computed, the remaining dataset contains 2,051 users,5,376 resources, 3,343 tags and 105,873 annotations.
MovieLens is a data set gathered from the correspondingMovieLens Web site and is administered by the GroupLensresearch lab at the University of Minnesota. It containsusers, rating of movies, and tags. A 5-core was generatedfrom the data resulting in 35,366 annotations with 819 users,2,445 resources and 2,309 tags.
Delicious is a popular Web site in which users annotateURLs. On 19 October 2008, 198 of the most popular tagswere taken from the user interface and the site was recur-sively explored. From 20 October to 15 December, the com-plete profiles of 524,790 users were collected. Due to memoryand time constraints, 10% of the user profiles was randomlyselected, and a 20-core taken for experiments. The datasetis our largest, containing 7,665 users, 15,612 resource and5,746 tags. It contains 720,788 annotations.
Amazon is one of the world’s largest retailers. The siteincludes a myriad of ways for users to express and discoveropinions of the products: ratings, editorial reviews, cus-tomer reviews, product details, and customer purchasinghabits. Recently, Amazon has added social tagging to thislist. Beginning on 1 July 2009 we recursively explored thesite to gather 1.5 million user profiles. Many users had ex-tremely small profiles or used idiosyncratic tags. After tak-ing a 20-core of the data it contained 498,217 annotationswith 8,802 users, 10,679 resource and 5,559 tags.
LastFM users upload their music profile, create playlistsand share their musical tastes online. We selected 100 ran-dom users from the system and recursively explored the“friend” network. Only about 20% of the users had anno-tated a resource. Users have the option to tag songs, artistsor albums. The tagging data here is limited to album an-

notations. Experimentation on artists and song data revealsimilar trends. A p-core of 20 was drawn from the data. Itcontains 2,368 users, 2,350 resources, 1,141 tags and 172,177annotations.
4.2 MethodologyEach user’s annotations were divided equally among five
folds. Four folds were used as training data to build the rec-ommenders. The fifth was used to train the model param-eters and ascertain the optimal weights of the componentsin the hybrids. The results of the fifth fold was then dis-carded and we performed four fold cross validation on theremaining folds. The results were averaged over each user,then over the final four folds.
The recommenders are evaluated on their ability to recom-mend tags given a user-resource pair. The user and resourcefor each annotation where submitted to the recommendersand the recommenders returned a set of tags, Tr . These werethen evaluated against the tags in the holdout annotation,Th.
Recall is a common metric for evaluating the utility ofrecommendation algorithms. It measures the percentage ofitems in the holdout set that appear in the recommendationset. Recall is a measure of completeness and is defined as:
recall =|Th ∩ Tr |
|Th|(9)
Precision is another common metric for measuring the use-fulness of recommendation algorithms. It measures the per-centage of items in the recommendation set that appear inthe holdout set. Precision measures the exactness of therecommendation algorithm and is defined as:
precision =|Th ∩ Tr|
|Tr |(10)
The recall and precision will vary depending on the sizeon the recommendation set. In the following experimentswe present the metrics with recommendation sets of sizeone through ten.
4.3 Experimental ResultsIn this section we offer some general observations about
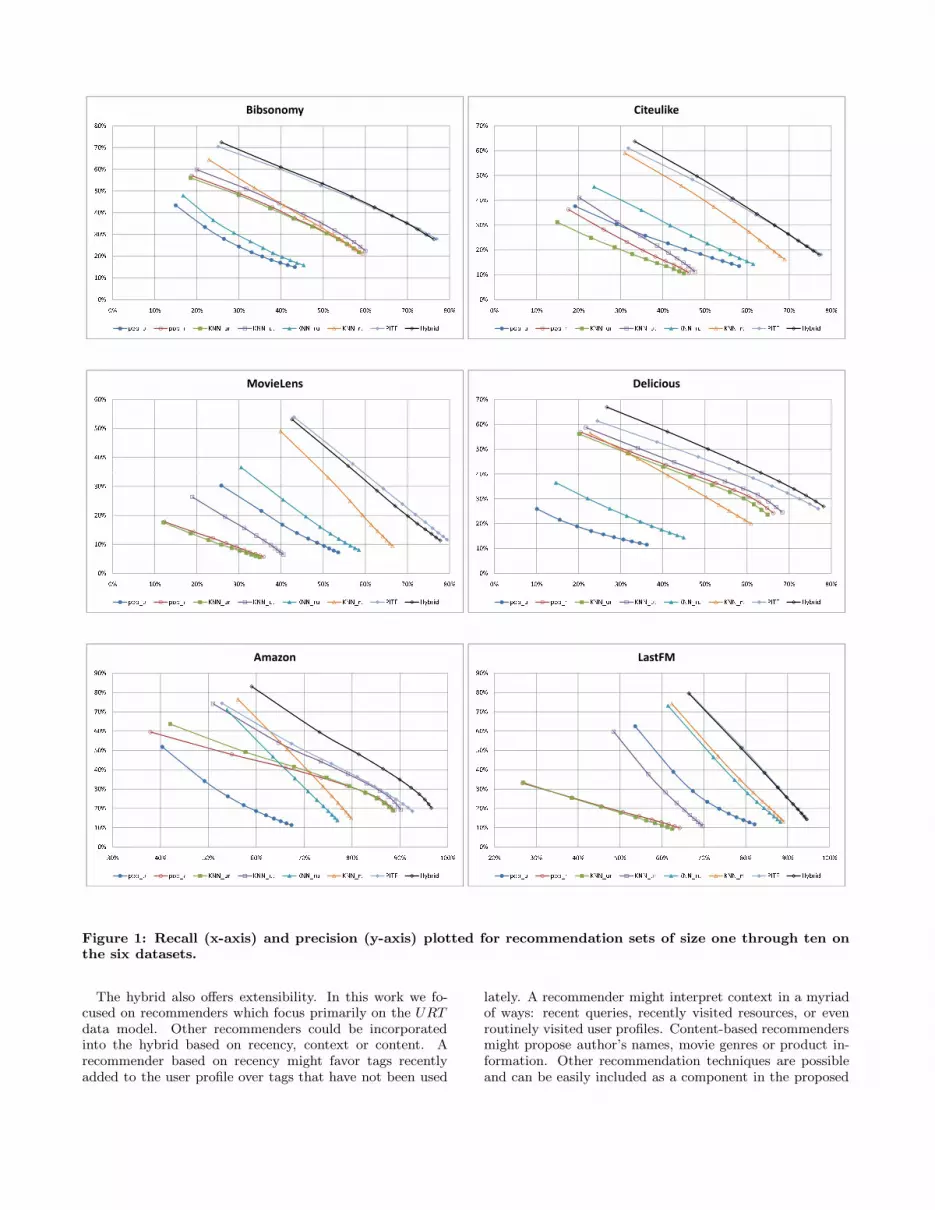
the experimental results reported in Figure 1. We then ex-amine each dataset individually before offering a summaryof our conclusions.
After tuning the variables we chose a k of 30 for all col-laborative filtering techniques. The trend was for the recalland precision to steadily increase as k was increased andthen suffer from diminishing returns. PITF , the pair-wiseinteraction tensor factorization model, was built with 64 fea-tures and a learning rate of 0.03 [14]. It was trained untilconvergence. We did experiments with 10 to 100 features.The results exhibited a sharp increase and then leveled outas the number of features approached 50.
The hybrid reported in Figure 1 is composed of the twopopularity based recommenders and four collaborative fil-tering recommenders. We have purposely constructed thehybrid with simple recommenders in order to permit insightsinto the datasets that might otherwise be obscured. By ob-serving the importance of a component to the hybrid, wemay infer the importance of the dimensions covered by that
component. The composition of the hybrids is reported inTable 1.
The hybrids do not draw upon PITF . A motivation ofthis paper is to demonstrate that hybrid recommenders canintegrate multiple dimensions of the data by exploiting sim-ple components. If PITF had been included in the hybridit would not be clear if the success of the hybrid was owed toPITF or the ability of the hybrid to produce a synergisticblend of its constituent parts. Instead, we report the PITFresults because it represents the state-of-the-art tag recom-mender and therefore offers an important point of compar-ison. While not evaluated in this paper, experimentationhas revealed that incorporating PITF into the hybrid pro-duces a small improvement over both PITF and the linearweighted hybrid.
In all six datasets the hybrid outperforms its constituentparts, revealing that a linear weighted hybrid can exploitmultiple dimensions of the data through its components.These components are not individually required to cover alldimensions of the data, and may instead focus on a particu-lar dimension such as the relationship between tags and re-sources. When aggregated into a single framework, the com-ponents provide complementary information while maintain-ing their simplicity, speed and insights into the data.
The hybrid is competitive with PITF , often surpassingit. In MovieLens PITF proves marginally better. In Bib-sonomy, Citeulike and LastFM the results are very similar.In Delicious and Amazon the hybrid is clearly superior.
The difference between Delicious and Amazon versus theother datasets is the diversity of the user profiles. Citeulikeand Bibsonomy users focus on their area of expertise. Movie-Lens and LastFM users gravitate toward particular genres ofmusic and movies. In Delicious, however, the users are ableto tag web pages from across the entire Internet. Conse-quently, the user profiles often contain numerous unrelatedtopics. Similarly, Amazon users do not restrict their anno-tations to particular categories. The user profiles reflect thediversity one might expect of a consumer visiting the world’slargest online retailer.
These diverse user profiles are difficult to characterize witha feature space model, the foundation of PITF . When rec-ommending tags, PITF cannot draw upon particular fea-tures while ignoring others. PITF may recommend a tagnot relevant to the particular context.
In contrast, user-based and item-based collaborative fil-tering is able to focus on the most relevant parts of the userprofile. User-based collaborative filtering only recommendstags applied to the query resource, narrowing the focus of therecommendation regardless of the diversity in the user pro-file. Item-based collaborative filtering techniques constructa neighborhood of resources from the user profile most sim-ilar to the query resource, effectively ignoring parts of theuser profile that are not relevant to the immediate recom-mendation task. Our proposed linear weighted hybrid in-herits the capacity to focus on specific aspects of the userprofile.
The hybrid offers additional benefits. When constructedfrom simple yet fast components, the hybrid itself main-tains these properties offering a highly scalable and easilyupdatable solution for tag recommendation. It is possibleto explain the results from the component recommendersand consequently the hybrid itself. In contrast PITF is ablack box with little explanatory capacity.
���
���
���
���
���������
��
���
���
��
��
�� ��� ��� �� �� ��� ��� ��� ���
��� � ��� � ��� �� ��� �� ��� �� ��� �� ���� ������
���
���
���
���
���������
��
���
���
��
���
�� ��� ��� �� ��� ��� ��� ��� ��
��� � ��� � ��� �� ��� �� ��� �� ��� �� ���� ������
���
���
���
���������
��
���
���
���
�� ��� ��� ��� ��� ��� ��� �� ��
��� � ��� � ��� �� ��� �� ��� �� ��� �� ���� ������
���
���
���
���
���������
��
���
���
��
���
�� ��� ��� �� ��� ��� ��� ��� ��
��� � ��� � ��� �� ��� �� ��� �� ��� �� ���� ������
���
���
���
���
���
������
��
���
��
��
���
���
�� ��� ��� ��� ��� ��� ��� ����
� ��� � ��� ������ ������ ������ ������ ���� ������
���
���
���
���
���
������
��
���
��
��
���
���
�� �� ��� ��� ��� ��� ��� ��� ����
� ��� � ��� ������ ������ ������ ������ ���� ������
Figure 1: Recall (x-axis) and precision (y-axis) plotted for recommendation sets of size one through ten onthe six datasets.
The hybrid also offers extensibility. In this work we fo-cused on recommenders which focus primarily on the URTdata model. Other recommenders could be incorporatedinto the hybrid based on recency, context or content. Arecommender based on recency might favor tags recentlyadded to the user profile over tags that have not been used
lately. A recommender might interpret context in a myriadof ways: recent queries, recently visited resources, or evenroutinely visited user profiles. Content-based recommendersmight propose author’s names, movie genres or product in-formation. Other recommendation techniques are possibleand can be easily included as a component in the proposed
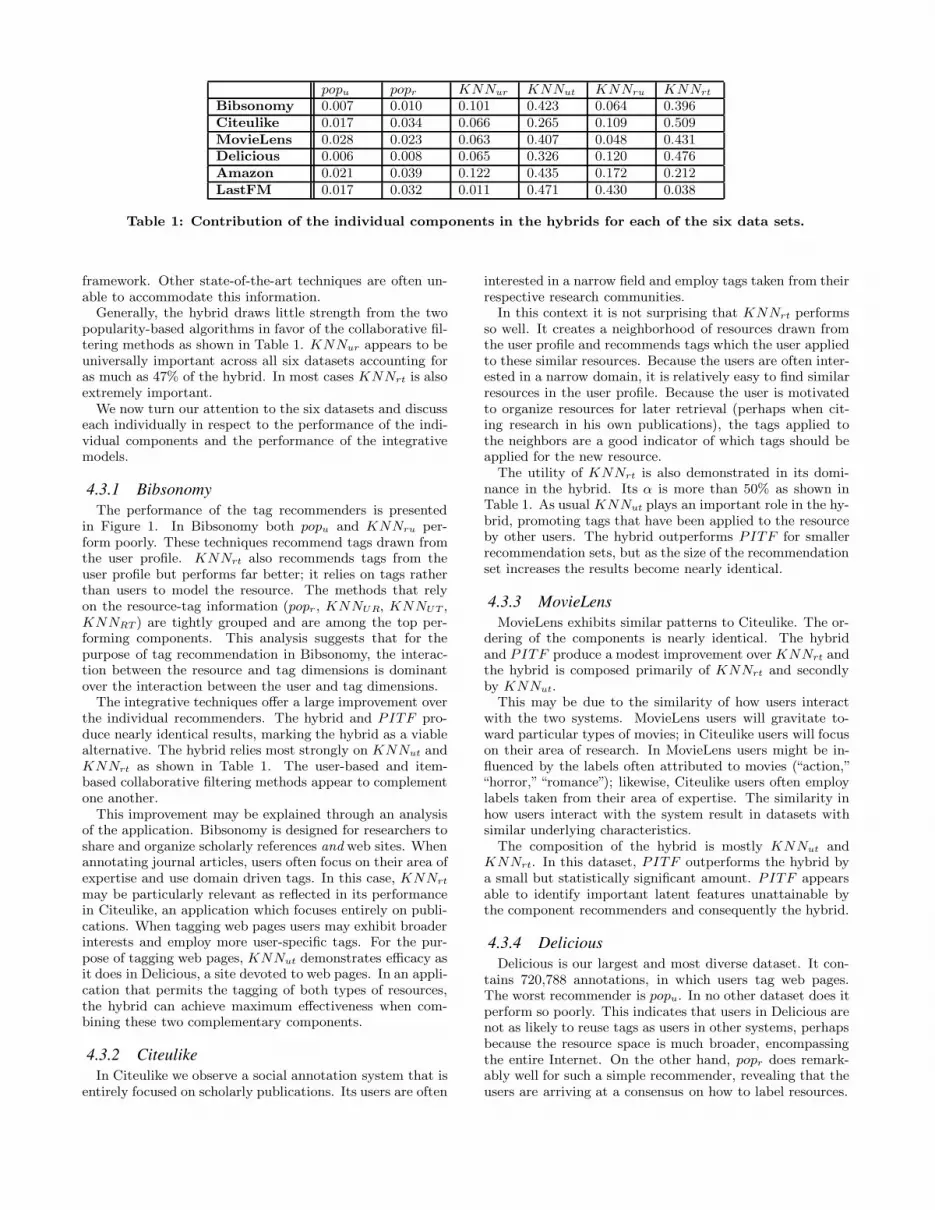
popu popr KNNur KNNut KNNru KNNrt
Bibsonomy 0.007 0.010 0.101 0.423 0.064 0.396Citeulike 0.017 0.034 0.066 0.265 0.109 0.509MovieLens 0.028 0.023 0.063 0.407 0.048 0.431Delicious 0.006 0.008 0.065 0.326 0.120 0.476Amazon 0.021 0.039 0.122 0.435 0.172 0.212LastFM 0.017 0.032 0.011 0.471 0.430 0.038
Table 1: Contribution of the individual components in the hybrids for each of the six data sets.
framework. Other state-of-the-art techniques are often un-able to accommodate this information.
Generally, the hybrid draws little strength from the twopopularity-based algorithms in favor of the collaborative fil-tering methods as shown in Table 1. KNNur appears to beuniversally important across all six datasets accounting foras much as 47% of the hybrid. In most cases KNNrt is alsoextremely important.
We now turn our attention to the six datasets and discusseach individually in respect to the performance of the indi-vidual components and the performance of the integrativemodels.
4.3.1 BibsonomyThe performance of the tag recommenders is presented
in Figure 1. In Bibsonomy both popu and KNNru per-form poorly. These techniques recommend tags drawn fromthe user profile. KNNrt also recommends tags from theuser profile but performs far better; it relies on tags ratherthan users to model the resource. The methods that relyon the resource-tag information (popr , KNNUR, KNNUT ,KNNRT ) are tightly grouped and are among the top per-forming components. This analysis suggests that for thepurpose of tag recommendation in Bibsonomy, the interac-tion between the resource and tag dimensions is dominantover the interaction between the user and tag dimensions.
The integrative techniques offer a large improvement overthe individual recommenders. The hybrid and PITF pro-duce nearly identical results, marking the hybrid as a viablealternative. The hybrid relies most strongly on KNNut andKNNrt as shown in Table 1. The user-based and item-based collaborative filtering methods appear to complementone another.
This improvement may be explained through an analysisof the application. Bibsonomy is designed for researchers toshare and organize scholarly references and web sites. Whenannotating journal articles, users often focus on their area ofexpertise and use domain driven tags. In this case, KNNrt
may be particularly relevant as reflected in its performancein Citeulike, an application which focuses entirely on publi-cations. When tagging web pages users may exhibit broaderinterests and employ more user-specific tags. For the pur-pose of tagging web pages, KNNut demonstrates efficacy asit does in Delicious, a site devoted to web pages. In an appli-cation that permits the tagging of both types of resources,the hybrid can achieve maximum effectiveness when com-bining these two complementary components.
4.3.2 CiteulikeIn Citeulike we observe a social annotation system that is
entirely focused on scholarly publications. Its users are often
interested in a narrow field and employ tags taken from theirrespective research communities.
In this context it is not surprising that KNNrt performsso well. It creates a neighborhood of resources drawn fromthe user profile and recommends tags which the user appliedto these similar resources. Because the users are often inter-ested in a narrow domain, it is relatively easy to find similarresources in the user profile. Because the user is motivatedto organize resources for later retrieval (perhaps when cit-ing research in his own publications), the tags applied tothe neighbors are a good indicator of which tags should beapplied for the new resource.
The utility of KNNrt is also demonstrated in its domi-nance in the hybrid. Its α is more than 50% as shown inTable 1. As usual KNNut plays an important role in the hy-brid, promoting tags that have been applied to the resourceby other users. The hybrid outperforms PITF for smallerrecommendation sets, but as the size of the recommendationset increases the results become nearly identical.
4.3.3 MovieLensMovieLens exhibits similar patterns to Citeulike. The or-
dering of the components is nearly identical. The hybridand PITF produce a modest improvement over KNNrt andthe hybrid is composed primarily of KNNrt and secondlyby KNNut.
This may be due to the similarity of how users interactwith the two systems. MovieLens users will gravitate to-ward particular types of movies; in Citeulike users will focuson their area of research. In MovieLens users might be in-fluenced by the labels often attributed to movies (“action,”“horror,”“romance”); likewise, Citeulike users often employlabels taken from their area of expertise. The similarity inhow users interact with the system result in datasets withsimilar underlying characteristics.
The composition of the hybrid is mostly KNNut andKNNrt. In this dataset, PITF outperforms the hybrid bya small but statistically significant amount. PITF appearsable to identify important latent features unattainable bythe component recommenders and consequently the hybrid.
4.3.4 DeliciousDelicious is our largest and most diverse dataset. It con-
tains 720,788 annotations, in which users tag web pages.The worst recommender is popu. In no other dataset does itperform so poorly. This indicates that users in Delicious arenot as likely to reuse tags as users in other systems, perhapsbecause the resource space is much broader, encompassingthe entire Internet. On the other hand, popr does remark-ably well for such a simple recommender, revealing that theusers are arriving at a consensus on how to label resources.

The two user-based collaborative filtering methods per-form similarly. Drawing upon a neighbor’s opinion about aweb site, appears to do well whether or not that neighborwas discovered by modeling users as resources or as tags. Incontrast there is a marked difference in the two item-basedmethods: KNNrt does far better than KNNru, suggest-ing once again that in the confines of tag recommendationresources are better modeled by tags than by users.PITF outperforms all the individual recommenders. The
hybrid offers a clear improvement over the other methodsincluding PITF . As with most of the datasets it stronglyrelies on KNNut and KNNrt.
4.3.5 AmazonAmazon presents one of the easier targets for tag recom-
mendation. The two integrative models achieve better than95% recall for a recommendation set with ten tags. Thehybrid clearly outperforms PITF .
In this dataset KNNur and KNNut are relatively closeand run parallel to one another. Likewise, KNNru andKNNrt do the same. This congruence suggests that multi-ple dimensions of the dataset contain valuable information.Given the task of tag recommendation, however, it appearsthat it is marginally better to model users and resources overthe tag space.
Amazon users tag products for later retrieval. Very oftenthey use tags drawn from the product space such as “action”or “dvd.” This behavior is similar to that observed in Ci-teulike. In contrast, Amazon users rarely limit themselvesto a narrow range of items. They may freely label books,electronics or clothing. As a result the user-based collabo-rative filtering is more competitive. It selects tags alreadyapplied to the resource rather than relying on tags appliedby the user to similar items. Unlike Citeulike, it is not aslikely that the user profile will contain these similar items.
4.3.6 LastFMLastFM is another easy target for tag recommenders offer-
ing more than 90% recall. The results of the two integrativeapproaches are so similar that the recall-precision lines ob-scure one another.
LastFM users appear to reuse tags to a high degree asmade evident by the success of popu. In contrast the poorresults of popr show that users do not often agree on howto label a resource. In LastFM, item-based collaborativefiltering does very well drawing upon the user’s prevalence totag similar items in a similar manner. User-based filtering,which relies on the opinions of others does poorly.
The composition of the hybrid reveals a sharp departurefrom the other datasets. It favors KNNru over KNNrt eventhough KNNrt does marginally better as an individual rec-ommender. The importance of modeling resources as usersin the hybrid may be due to the interaction of users withinthe social annotation system. An important focus of the ap-plication is the sharing and discovery of resources throughthe user space.
4.4 SummaryThese results underscore the importance of an integrative
approach to tag recommendation in social annotation sys-tems. Social annotation systems vary in how users interactwith the system. The differences between datasets make theperformance of individual recommenders unpredictable. For
example, KNNru does well in LastFM but performs poorlyin Delicious. In contrast, the integrative techniques performwell regardless of the characteristics of the data.
The proposed linear weighted hybrid offers additional ben-efits. It is easily extensible. In this work we constructedthe hybrid with popularity based and collaborative filteringtechniques, but the hybrid could be augmented with recom-mendation techniques that draw from different approachessuch as recency, content or context based recommenders.
When constructed from individual components the hybridis easily updatable and suitable for large scale deployment.The use of individual components also permits the exami-nation of the underlying characteristics of the data throughan analysis of the contributions of the components and thedimensions of the data which they exploit. Furthermore in-dividual recommendations can be explained, a capability notshared by black-box recommenders such as PITF .
In many cases the hybrid outperforms the pair-wise inter-action tensor factorization model. In Delicious and Amazonwhere the user models are most diverse the benefit is mostnoticeable. This marks our proposed linear weighted hybridas a viable state-of-the-art tag recommender.
5. USING INFORMATION CHANNELS TOEXPLAIN THE PERFORMANCE OF TAGRECOMMENDERS
Our results have demonstrated a difference in how indi-vidual component recommenders perform. In this sectionwe turn our attention to why these differences may occur.To that end we introduce the notion of information chan-nels. An information channel models the relationship be-tween the underlying dimensions of an annotation system:users, resources and tags. A strong information channel be-tween two dimensions means that information in the firstdimension will be useful in building a predictor for the sec-ond dimension. For example, a strong information channelbetween users and tags means that user characteristics willbe a good basis on which to predict tags.
We first define information channels in terms of condi-tional entropy. We then explore the impact of informa-tion channels on the previously presented component rec-ommenders. Finally, we offer a summary of our findings.
5.1 Quantifying Information ChannelsWe propose entropy and conditional entropy for the evalu-
ation of information channels. Entropy measures the amountof uncertainty associated with a dimension, in this case theuser, resource or tag dimensions. It relies heavily on proba-bilities, however the notion of probabilities in social annota-tion systems can be ambiguous. The probability of resourcemight be its likelihood to occur in a user profile, a tag profileor in an annotation. We define the probability of a resourcer as:
p(r) =
∑u∈U
∑t∈T URT (u, r, t)
y(11)
where y is defined as the number of non-zero entries in URT .We may then define the entropy as:
H(R) = −∑
r∈R
p(r)logyp(r) (12)
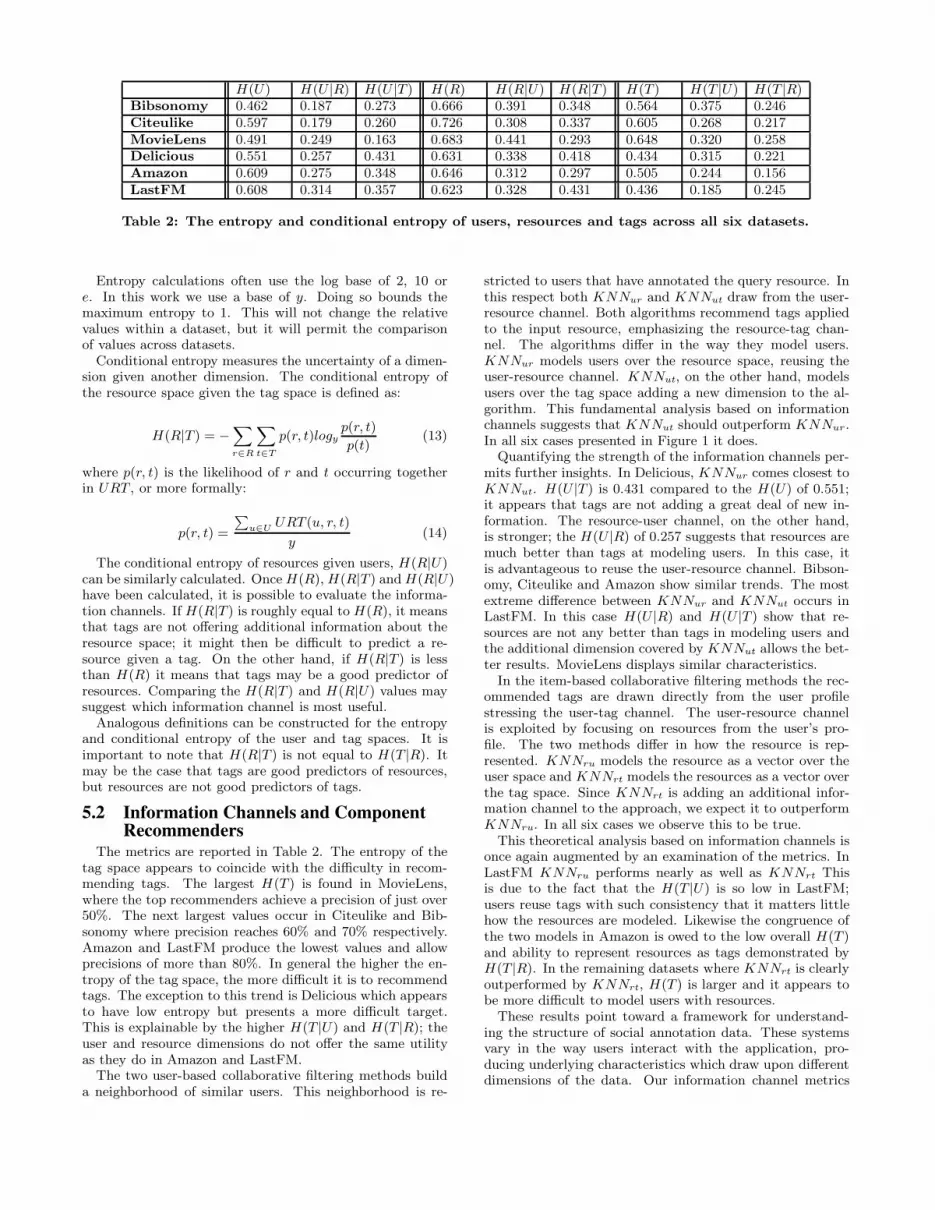
H(U) H(U |R) H(U |T ) H(R) H(R|U) H(R|T ) H(T ) H(T |U) H(T |R)Bibsonomy 0.462 0.187 0.273 0.666 0.391 0.348 0.564 0.375 0.246Citeulike 0.597 0.179 0.260 0.726 0.308 0.337 0.605 0.268 0.217MovieLens 0.491 0.249 0.163 0.683 0.441 0.293 0.648 0.320 0.258Delicious 0.551 0.257 0.431 0.631 0.338 0.418 0.434 0.315 0.221Amazon 0.609 0.275 0.348 0.646 0.312 0.297 0.505 0.244 0.156LastFM 0.608 0.314 0.357 0.623 0.328 0.431 0.436 0.185 0.245
Table 2: The entropy and conditional entropy of users, resources and tags across all six datasets.
Entropy calculations often use the log base of 2, 10 ore. In this work we use a base of y. Doing so bounds themaximum entropy to 1. This will not change the relativevalues within a dataset, but it will permit the comparisonof values across datasets.
Conditional entropy measures the uncertainty of a dimen-sion given another dimension. The conditional entropy ofthe resource space given the tag space is defined as:
H(R|T ) = −∑
r∈R
∑
t∈T
p(r, t)logyp(r, t)
p(t)(13)
where p(r, t) is the likelihood of r and t occurring togetherin URT , or more formally:
p(r, t) =
∑u∈U URT (u, r, t)
y(14)
The conditional entropy of resources given users, H(R|U)can be similarly calculated. OnceH(R),H(R|T ) andH(R|U)have been calculated, it is possible to evaluate the informa-tion channels. If H(R|T ) is roughly equal to H(R), it meansthat tags are not offering additional information about theresource space; it might then be difficult to predict a re-source given a tag. On the other hand, if H(R|T ) is lessthan H(R) it means that tags may be a good predictor ofresources. Comparing the H(R|T ) and H(R|U) values maysuggest which information channel is most useful.
Analogous definitions can be constructed for the entropyand conditional entropy of the user and tag spaces. It isimportant to note that H(R|T ) is not equal to H(T |R). Itmay be the case that tags are good predictors of resources,but resources are not good predictors of tags.
5.2 Information Channels and ComponentRecommenders
The metrics are reported in Table 2. The entropy of thetag space appears to coincide with the difficulty in recom-mending tags. The largest H(T ) is found in MovieLens,where the top recommenders achieve a precision of just over50%. The next largest values occur in Citeulike and Bib-sonomy where precision reaches 60% and 70% respectively.Amazon and LastFM produce the lowest values and allowprecisions of more than 80%. In general the higher the en-tropy of the tag space, the more difficult it is to recommendtags. The exception to this trend is Delicious which appearsto have low entropy but presents a more difficult target.This is explainable by the higher H(T |U) and H(T |R); theuser and resource dimensions do not offer the same utilityas they do in Amazon and LastFM.
The two user-based collaborative filtering methods builda neighborhood of similar users. This neighborhood is re-
stricted to users that have annotated the query resource. Inthis respect both KNNur and KNNut draw from the user-resource channel. Both algorithms recommend tags appliedto the input resource, emphasizing the resource-tag chan-nel. The algorithms differ in the way they model users.KNNur models users over the resource space, reusing theuser-resource channel. KNNut, on the other hand, modelsusers over the tag space adding a new dimension to the al-gorithm. This fundamental analysis based on informationchannels suggests that KNNut should outperform KNNur.In all six cases presented in Figure 1 it does.
Quantifying the strength of the information channels per-mits further insights. In Delicious, KNNur comes closest toKNNut. H(U |T ) is 0.431 compared to the H(U) of 0.551;it appears that tags are not adding a great deal of new in-formation. The resource-user channel, on the other hand,is stronger; the H(U |R) of 0.257 suggests that resources aremuch better than tags at modeling users. In this case, itis advantageous to reuse the user-resource channel. Bibson-omy, Citeulike and Amazon show similar trends. The mostextreme difference between KNNur and KNNut occurs inLastFM. In this case H(U |R) and H(U |T ) show that re-sources are not any better than tags in modeling users andthe additional dimension covered by KNNut allows the bet-ter results. MovieLens displays similar characteristics.
In the item-based collaborative filtering methods the rec-ommended tags are drawn directly from the user profilestressing the user-tag channel. The user-resource channelis exploited by focusing on resources from the user’s pro-file. The two methods differ in how the resource is rep-resented. KNNru models the resource as a vector over theuser space and KNNrt models the resources as a vector overthe tag space. Since KNNrt is adding an additional infor-mation channel to the approach, we expect it to outperformKNNru. In all six cases we observe this to be true.
This theoretical analysis based on information channels isonce again augmented by an examination of the metrics. InLastFM KNNru performs nearly as well as KNNrt Thisis due to the fact that the H(T |U) is so low in LastFM;users reuse tags with such consistency that it matters littlehow the resources are modeled. Likewise the congruence ofthe two models in Amazon is owed to the low overall H(T )and ability to represent resources as tags demonstrated byH(T |R). In the remaining datasets where KNNrt is clearlyoutperformed by KNNrt, H(T ) is larger and it appears tobe more difficult to model users with resources.
These results point toward a framework for understand-ing the structure of social annotation data. These systemsvary in the way users interact with the application, pro-ducing underlying characteristics which draw upon differentdimensions of the data. Our information channel metrics

based on entropy and conditional entropy attempt to revealthese characteristics and explain the performance of tag rec-ommenders across several datasets.
6. CONCLUSIONSThis paper has explored the problem of tag recommenda-
tion in social annotation systems and proposed a weightedlinear hybrid incorporating simple popularity and collabo-rative filtering components. The success of the hybrid overthe lower-dimensional components demonstrates clearly theimportance of an integrative approach that exploits multipledimensions of the data. Evaluations also show that the hy-brid matches or outperforms a state-of-the-art model-basedalgorithm based on tensor factorization (PITF ), particu-larly when the user profiles are diverse. The weighted hy-brid has the additional advantages of being more efficient,scalable, extensible and explainable than PITF .
Experiments across six real-world datasets reveal inter-esting differences between social annotation applications, aresult of the widely-varying user populations, resource typesand application characteristics found in these applications.These differences are revealed most clearly in the perfor-mance of the individual components of the hybrid, whichvary widely from dataset to dataset. By measuring char-acteristics of the data via the metrics of entropy and con-ditional entropy, we show that it is possible to explain inqualitative terms the reasons for these differences in recom-mender performance.
ACKNOWLEDGMENTSThis work was supported in part by the National ScienceFoundation Grant IIS-0916852 and a grant from the De-partment of Education, Graduate Assistance in the Area ofNational Need, P200A070536.
7. REFERENCES[1] R. Burke. Hybrid Recommender Systems: Survey and
Experiments. User Modeling and User-AdaptedInteraction, 12(4):331–370, 2002.
[2] M. Deshpande and G. Karypis. Item-Based Top-NRecommendation Algorithms. ACM Transactions onInformation Systems, 22(1):143–177, 2004.
[3] J. Gemmell, M. Ramezani, T. Schimoler,L. Christiansen, and B. Mobasher. A Fast EffectiveMulti-Channeled Tag Recommender. ECML/PKDD2009 Discovery Challenge Workshop, part of theEuropean Conference on Machine Learning andPrinciples and Practice of Knowledge Discovery inDatabases, pages 59–63, 2009.
[4] J. Gemmell, T. Schimoler, M. Ramezani,L. Christiansen, and B. Mobasher. ImprovingFolkRank With Item-Based Collaborative Filtering.Recommender Systems & the Social Web, 2009.
[5] J. Herlocker, J. Konstan, A. Borchers, and J. Riedl.An Algorithmic Framework for PerformingCollaborative Filtering. In 22nd Annual InternationalACM SIGIR Conference on Research andDevelopment in Information Retrieval, page 237.ACM, 1999.
[6] A. Hotho, R. Jaschke, C. Schmitz, and G. Stumme.BibSonomy: A social bookmark and publication
sharing system. In Proceedings of the ConceptualStructures Tool Interoperability Workshop at the 14thInternational Conference on Conceptual Structures,pages 87–102. Citeseer, 2006.
[7] A. Hotho, R. Jaschke, C. Schmitz, and G. Stumme.Information Retrieval in Folksonomies: Search andranking. Lecture Notes in Computer Science,4011:411–426, 2006.
[8] R. Jaschke, L. Marinho, A. Hotho,L. Schmidt-Thieme, and G. Stumme. TagRecommendations in Folksonomies. Lecture Notes InComputer Science, 4702:506, 2007.
[9] J. Konstan, B. Miller, D. Maltz, J. Herlocker,L. Gordon, and J. Riedl. GroupLens: ApplyingCollaborative Filtering to Usenet News.Communications of the ACM, 40(3):87, 1997.
[10] L. Marinho, C. Preisach, L. Schmidt-Thieme,I. Cantador, D. Vallet, J. Jose, H. Cao, M. Xie,L. Xue, C. Liu, et al. ECML PKDD DiscoveryChallenge 2009-DC09.
[11] A. Mathes. Folksonomies-Cooperative Classificationand Communication Through Shared Metadata.Computer Mediated Communication, (DoctoralSeminar), Graduate School of Library andInformation Science, University of IllinoisUrbana-Champaign, December, 2004.
[12] P. Mika. Ontologies are us: A unified model of socialnetworks and semantics. Web Semantics: Science,Services and Agents on the World Wide Web,5(1):5–15, 2007.
[13] S. Rendle and L. Schmidt-Thieme. Factor Models forTag Recommendation in BibSonomy. ECML/PKDD2008 Discovery Challenge Workshop, part of theEuropean Conference on Machine Learning andPrinciples and Practice of Knowledge Discovery inDatabases, pages 235–243, 2009.
[14] S. Rendle and L. Schmidt-Thieme. PairwiseInteraction Tensor Factorization for Personalized TagRecommendation. In Proceedings of the third ACMinternational conference on Web search and datamining, pages 81–90. ACM, 2010.
[15] G. Salton, A. Wong, and C. Yang. A Vector SpaceModel for Automatic Indexing. Communications ofthe ACM, 18(11):613–620, 1975.
[16] B. Sarwar, G. Karypis, J. Konstan, and J. Reidl.Item-Based Collaborative Filtering RecommendationAlgorithms. In 10th International Conference onWorld Wide Web, page 295. ACM, 2001.
[17] U. Shardanand and P. Maes. Social InformationFiltering: Algorithms for Automating SWord ofMouthT. In SIGCHI Conference on Human Factors inComputing Systems, pages 210–217. New York, NY,USA, 1995.
[18] P. Symeonidis, A. Nanopoulos, and Y. Manolopoulos.Tag recommendations based on tensor dimensionalityreduction. In Proceedings of the 2008 ACM conferenceon Recommender systems, pages 43–50. ACM, 2008.
[19] P. Symeonidis, A. Nanopoulos, and Y. Manolopoulos.A Unified Framework for Providing Recommendationsin Social Tagging Systems Based on Ternary SemanticAnalysis. IEEE Transactions on Knowledge and DataEngineering, 2009.





























