Embed Size (px)
Citation preview

Applied Soft Computing 2 (2002) 11ndash23
Fast adapting value estimation-based hybrid architecture forsearching the world-wide web
Istvaacuten Koacutekai Andraacutes LorinczlowastDepartment of Information Systems Eoumltvoumls Loraacutend University Paacutezmaacuteny Peacuteter seacutetaacuteny 1D H-1117 Budapest Hungary
Accepted 21 May 2002
Abstract
The slogan thatinformation is powerhas undergone a slight change Todayinformation updatingis in the focus of interestThe largest source of information is the world-wide web Fast search methods are in need for this enormous source In thispaper a hybrid architecture that combinessoftsupport vector classification and reinforcement learning for value estimation isintroduced for the evaluation of a link (a document) and its neighboring links (or documents) called thecontextof a documentThe method is motivated by (i) large differences between such contexts on the web (ii) the facilitation of goal oriented searchusing context classifiers and (iii) attractive fast adaptation properties that could counteract diversity of web environments Wedemonstrate that value estimation-based fast adaptation offers considerable improvement over other known search methodscopy 2002 Elsevier Science BV All rights reserved
KeywordsFast adaptation Internet Reinforcement learning Search Small world SVM
1 Introduction
The number of documents on the world-wide webis way over 1 billion[1] The number of new doc-uments is over 1 million per day The number ofdocuments that change on a daily basis eg docu-ments about news business and entertainment couldbe much larger This ever increasing growth presents aconsiderable problem for finding gathering orderingthe information on the web The only search enginethat may still warrant that the information it providesis not older than 1 month is AltaVista1 However thenumber of indexed pages on AltaVista is about 250
lowast Corresponding author Tel+36-1-463-3515fax +36-1-463-3490E-mail addresslorinczinfeltehu (A Lorincz)
1 httpwwwaltavistacom
million documents Google2 on the other hand is in-dexing about 1300 million pages but Google does notwarrant any refresh rate of these documents
The problem is complex these search engines arenot up-to-date and information gathering is not alwaysefficient with these engines Search engines may offertoo many documents sometimes on the order of hun-dreds or many thousands Many web pages have novalue eg by making use of a large set of keywordsor being simply huge collections of documents origi-nating from broad sources
Specialized possibly personalized crawlers are inneed This problem represents a real challenge formethods of artificial intelligence and has been tackledby several research groups[2ndash10] One of the first at-tempts in this direction was made by Chakrabarti et al[11] who put forth the idea offocused crawling To
2 httpwwwgooglecom
1568-494602$ ndash see front matter copy 2002 Elsevier Science BV All rights reservedPII S1568-4946(02)00025-X
12 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
understand the idea let us consider crawling in gen-eral Assume that lsquoyou are at a nodersquo of the web Thisnode has been analyzed and you have to decide whatto do next It is very possible that relevant informationcan be found in the immediate neighborhood of thisnode In turn you download all the documents nextto you and start to analyze those documents Doingso you may found relevant documents or may notWhen you are done you have the option to downloadall the documents that are two steps away from youand to analyze those documents This approach is wellknown in the AI literature and is called breadth firsttechnique However the world-wide web is lsquosmallrsquothe WWW had about 800 million nodes in 1999 andthe number of minimal hops required to reach mostdocuments from any particular document was 19[12]Such connectivity structure between units is calledlsquosmall worldrsquo In turn breadth first search incurs anenormous burden as a function of depth At one point(at a given depth) breadth first search needs to be aban-doned and a decision is to be made to which node tomove next To decide on that move the values of thenodes need to be estimated from the point of view ofthe goal of the searchFocused crawlingis based onthis idea Focused crawling makes an attempt to clas-sify the content of the document If the document fallsinto the search category then the document is down-loaded and the links of the documents are followed
Diligenti et al[1] have recognized the pitfall of fo-cused crawling searched information on the web istypically hidden sites of particular interest may havea lower number of directed links then sites of gen-eral interest In turn we might face the lsquoneedle in thehaystackrsquo problem with the haystack being sites ongeneral interest The hidden property is thus the im-plicit consequence of our particular interest
Let us consider sites dealing with support vectormachines (SVMs) Sites about SVMs are not typi-cal on the web Not all sites dealing with SVM arelinked In turn focused crawling could be rather inef-ficient and this direct search for SVM sites might failOn the other hand most of the SVM sites are within(ie linked to) academic environments or within sitesdealing with information technology These topics aremuch more general and might have much more linksand a much higher lsquovisibilityrsquo In turn searching forthe environment of SVM sites could be much moreefficient A hand-waving argument can be given as
follows Documents are linked to each other Linksare made by those for whom the document has valueThese links form the one-stepcontextof the documentThe one-step context in turn may be characteristic tothe document The one-step environment of the doc-ument (ie documents that are one step away) docu-ments that are two steps away etc form the lsquocontextrsquoof the document When we search for a document bydefinition we shall encounter the environment of thedocument first In turn first we might search for theenvironment of the document This is the idea behindlsquocontext focused crawlingrsquo (CFC)[1] This idea whichis trivial for graphs with high clustering probability(eg regular lattices) could be criticized for the caseof lsquosmall worldsrsquo when documentsmdashon averagemdashareabout as far as the environment of the document How-ever the question is intriguing because the visibilitycould be much less for searched documents than thatof the environment of the searched documents
CFC does not take into consideration the varietieson the web environments may differ For examplefor small universities or for small research insti-tutes lsquoone-step contextrsquo may correspond to lsquotwo-stepcontextrsquo for large departments of large universities Ifthe order of contexts might change then CFC will goclose and will miss the documents In turn the decisionwhether to lsquostay and downloadrsquo at a given site or lsquonotto download but moversquo can be seriously jeopardizedFast adapting value estimation method may providean attractive solution to this search problem where in-formation is hidden within not-yet-experienced envi-ronments The environment of high value documentscan provide reinforcing feedback in a straightforwardfashion Interestingly reinforcement learning (RL)has not been found particularly efficient for search-ing the world-wide web[13] The efficiency of RLhowever depends strongly on feature extraction Itseems natural to explore the CFC idea as the initialfeature extraction method for RL Here we show howto combine CFC with RL to search on the web
2 Methods
21 Preprocessing of texts
There is a large variety of methods that try to clas-sify texts [14ndash27] Most of these methods are based
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 13
on special dimension reduction First the occurrenceor sometimes the frequency of selected words is mea-sured The subset of all possible words (lsquobag of wordsrsquo(BoW)) is selected by means of probabilistic mea-sures Different methods are used for the selection ofthe lsquomost importantrsquo subset The occurrences (0rsquos and1rsquos) or the frequencies of the selected words of thesubsets are used to characterize all documents Thislowmdashtypically 100mdashdimensional vector is supposedto encompass important information about the typeof the document Different methods are used to de-rive lsquocloseness measuresrsquo between documents in thelow-dimensional spaces of occurrence vectors or fre-quency vectors The method can be used both for clas-sification ie the computation of decision surfacesbetween documents of different lsquolabelsrsquo[15162326]and clustering a more careful way of deriving close-ness (or similarity) measures when no labels are pro-vided [1417222428]
We tried several BoW-based classifiers on thelsquocall for papersrsquo (CfP) problem3 CfP is considered abenchmark classification problem of documents theratio of correctly classified and misclassified docu-ments can be automated easily by checking whetherthe document has the three word phrase lsquocall forpapersrsquo or not Classifiers were developed for one-step two-step environments etc for CfP documentsWe found that these classifiers perform poorly forthe CfP problem In agreement with published results[16] supervised SVM classification was superiorto other methods SVM was simple and somewhatbetter than Bayes classification However SVM re-quires a large number of support vectors for the CfPproblem
22 SVM classification
The SVM classifier operates similarly to percep-trons SVM however has better generalizing capabil-ities see eg the comprehensive book of Vapnik[29]a tutorial material[30] comparisons with other meth-ods[3132] improved techniques[33] and references
3 The CfP problem is defined by deleting the phrase lsquocall forpaperrsquo from the document executing search on the internet andconsidering each document that contains the phrase lsquocall for paperrsquoa lsquohitrsquo
therein4 The trained SVM was used in lsquosoft modersquoThat is the output of the SVM was not a decision(yes or no) but instead the output could take con-tinuous values between 0 and 1 A saturating sigmoidfunction5 was used for this purpose In turn (i) thenon-linearity of the decision surface was not sharp(ii) for inputs close to the decision surface the clas-sifier provides a linear output The output of the sig-moid non-linearity can be viewed as the probabilityof a class These probabilities for the different classesare distinct yardsticks working on possibly differentfeatures The RL algorithm was used to estimate thevalueof these yardsticks
23 Value estimation
There is a history of value estimation methodsbased on reinforcement learning some of the im-portant stepsmdashjudged subjectivelymdashare in the citedpapers[34ndash45] A thorough review on the litera-ture and the history of RL can be found in[46] Inour approach value estimation plays a central roleValue estimation works on states (s) and providesa real number thevalue that belongs to that stateV (s) isin R Value estimation is based on theimmediaterewards(eg the number of hits) that could be gainedat the given state by executing different actions (egdownload or move) Value of a state (a node for ex-ample) is the long-term cumulative reward that canbe collected starting from that state and using apol-icy Policy is a probability distribution over differentactions for each state policy determines the proba-bility of choosing and action in a given state Policyimprovement and the finding of an optimal policy arecentral issues in RL RL procedures can be simpli-fied if all possible lsquonextrsquo states are available and canbe evaluated This is our case In this case one doesnot have to represent the policy Instead one couldevaluate all neighboring nodes of the actual state andmove to (andor download) the one with the largestestimated long term cumulated reward the estimatedvalue Typically one includes random choices for afew percentages of the steps These random choices
4 Note that SVM has no adjustable parameters5 The output can be calulated as follows
output= 1
1 + exp(minusλ times input)
14 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 1 Context of the document (document and its first and secondlsquoneighborsrsquo)
are called lsquoexplorationsrsquo The estimated value-basedgreedy choice is called lsquoexploitationrsquo
If the downloaded document contains the phraselsquocall for papersrsquo then the learning system incurs an im-mediate reward of 1 If a downloaded document doesnot contain this phrase then there is negative reward(ie a punishment) ofminus001 These numbers wererather arbitrary The relative ratio between reward andpunishment and the magnitude of the parameter ofthe sigmoid function do matter These parameters in-fluence learning capabilities Our studies were con-strained to a fixed set of parameters One may expectimprovements upon optimizing these parameters for a
Fig 2 SVM-based document classifiers (A) Classification of distance from document using SVM classifiers The CFC method maintainsa list of visited links ordered according to the SVM classification One of the links belonging to the best non-empty classifier is visitednext (B) Value estimation based on SVM classifiers Reinforcement learning is used to estimate the importance of the different classifiersduring search
Fig 3 Search pattern for breadth first crawler Search was launchedfrom neutral site A site is called neutral if there is very fewtarget document in its environment Diameter of open circles isproportional to the number of target documents downloaded Edgesare color coded There are two extremes Dark blue site wasvisited at the early stage during the search Light blue recentlyvisited site (for further details see text)
particular problem In our case search over the internetwas time consuming and prohibited this optimization
Value estimation makes use of the followingupgrade
V +(st ) = V (st ) + α(rt+1 + γV (st+1) minus V (st )) (1)
whereα is the learning ratert+1 isin R is the imme-diate reward 0lt γ lt 1 is the discount factor and
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 15
subscriptst = 1 2 indicate action number (ietime) This particular upgrade is called temporal dif-ferencing with zero eligibility ie the TD(0) upgradeTD methods were introduced by Sutton[36] Anexcellent introduction to value estimation includingthe history of TD methods and description on theapplications of parameterized function approximatorscan be found in[46] Concerning details of the RLtechnique (a) we used eligibility traces (b) Opposedto the description given above we did not need ex-plorative steps because the environments can be verydifferent and that diminished the need for exploration(c) We did not decrease the value ofα by time to keepadaptivity (d) We approximated the value function asfollows
V (s) asympnsum
i=1
wiσ(SVM(i)) (2)
where the output of theith SVM (ie theith com-ponent of the output without any lsquosignumrsquo type ofnon-linearity) is denoted by SVM(i) σ(middot) denotes thesigmoid function acting on the outputs of the SVMclassifierswi is the weight (or relevance) of theithclassifier determined by upgradeEq (1) If the qual-ity of the upgrade is measured by the mean square er-ror of the estimations then the following approximateweight upgrade can be derived for the weights (seeeg[46] for details)
wi = α(rt+1 + γV (st+1) minus V (st ))σ (SVM(i)) (3)
This upgrademdashextended with eligibility traces[3646]mdashwas used in our RL engine
3 Features and learning to search
31 Breadth first crawler
A crawler is calledbreadth first crawler if it firstdownloads the document of the launching site contin-ues by downloading the documents of all first neigh-bors of the launching site then the documents of theneighboring sites of the first neighbor sites ie thedocuments of the second neighbor sites and so on
32 Context focused crawler
A target document and its environment are illus-trated inFig 1 The goal is to locate the document
by recognizing its environment first and then thedocument within The CFC method[1] was modi-fied slightlymdashin order to allow direct comparisonsbetween the CFC method and the CFC method ex-tended by RL value estimationmdashand the followingprocedure was applied First a set of irrelevant doc-uments were collected Thekth classifier was trainedon (good) documentsk-steps away from known tar-get documents and on (bad) irrelevant documentsThe classifier was trained to output a positive number(lsquoyesrsquo) for good documents and to output a negativenumber (lsquonorsquo) for irrelevant documents The outputswere scaled into the interval(0 1) by using the sig-moid functionσ(x) = (1 + exp(minusλx))minus1 If the kthclassifiers output was close to 1mdashaccording to its de-cision surfacemdashit suggests that there might be a targetdocumentk-steps away from the actual sitedocumentIf more than one classifier outputs lsquoyesrsquo then only thebest classifier is considered in CFC Other outputsare neglected The CFC idea with SVM classifiers isshown inFig 2(A) CFC maintains a list of visitedlinks ordered according to the SVM classification Oneof the links belonging to the best non-empty classifieris visited next (this procedure is called backtracking)
The problem of the CFC method can be seen byconsidering that neighborhoods on the WWW maydiffer considerably Even if thekth classifier is the bestpossible such classifier for the whole web it mightprovide poor results in some (possibly many) neigh-borhoods For example if there is a large numberof connected documents all having the promise thatthere is a valuable document in their neighborhoodmdashbut there is in fact nonemdashthen the CFC crawler willdownload all invaluable documents before movingfurther It is more efficient to learn which classifierspredict well and to move away from regions whichhave great but unfulfilled promises
It has been suggested that classifiers could beretrained to keep adaptivity[1] The retrainingprocedure however takes too long6 and can beambiguous if CFC is combined with backtrackingMoreover retraining may require continuous super-visory monitoring and supervisory decisions Insteadof retraining we suggest to determine the relevanceof the classifiers during the search
6 Training may take on the order of a day or so on 700 MHzPentium III according to our experiences
16 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
33 CFC and RL fast adaptation during search
Reinforcement learning offers a solution here Ifthe prewired order of the classifiers is questionablethen we could learn the correct ordering There isnothing to loose here provided that learning is fastIf prewiring is perfect then the fast learning proce-dure will not modify it If the prewiring is imperfectthen proper weights will be derived by the learningalgorithm
The outputs of the SVMs can be saved Theseoutputs can be used to estimate the value of a docu-ment at any instant Value is estimated by estimatingweights for each SVM and adding up the SVM out-puts multiplied by these weights In turn one cancompute value-based ordering of the documents withminor computational effort and this reordering can bemade at each step This reordering of the documentsreplaces prewired ordering of the CFC method Thenew architecture is shown inFig 2(B)
4 Results and discussion
The CfP problem has been studied Search pattern atthe initial phase for the breadth first method is shownin Fig 3
Search patterns for the context focused crawlerand the crawler using RL-based value estimation areshown inFigs 4 and 5 The launching site of thesesearches was a lsquoneutral sitersquo a relatively large site con-taining few CfP documents (httpwwwinfeltehu)We consider this type of launching important for webcrawling it simulates the case when mail lists arenot available traditional search engines are not sat-isfactory and breadth first search is inefficient Thisparticular site was chosen because breadth first searchcould find very few documents starting from thissite
lsquoScalesrsquo onFigs 4 and 5differ from each other andfrom that ofFig 3 lsquoTrue surfed scalersquo would be re-flected by normalizing to edge thickness Radius ofopen circles is proportional to the number of down-loaded target documents The CFC is only somewhatbetter in the initial phase than the breadth first methodLonger search shows that CFC becomes considerablybetter than the breadth first method when search islaunched from this neutral site
Quantitative comparisons are shown inFig 6 Ac-cording to the figure upon downloading 20000 doc-uments the number of hits were about 50 200 and1000 for the breadth first the CFC and CFC-basedRL crawlers respectively These launches were con-ducted at about the same time We shall demonstratethat the large difference between CFC and CFC-basedRL method is mostly due to the adaptive properties ofthe RL crawler
There are two site types that have been investigatedThe first site type is the neutral site that has beendescribed before The other site was a mail server onconferences Also for some examples there are runsseparated by 1 month (March 2001) A large numberof summer conferences made announcements duringthis month
First let us examine the initial phase of the searchThis initial phase of the search (the first 200 down-loaded documents) is shown inFig 7 Accordingto this figure downloading is very efficient from themail server site in each occasion The (non-adapting)CFC based RL crawler utilizing averaged RL weightsis superior to all the other crawlersmdashalmost alldownloaded documents are hits Close to this sitethere are many relevant documents and the lsquobreadthfirst crawlerrsquo is also efficient here Nevertheless thenon-adapting CFC based RL crawler outperforms thebreadth first crawler in this domain Launching fromneutral sites is inefficient at this early phase Breadthfirst method finds no hit close to the neutral site (notshown in the figure)
Middle phase of the search is shown inFig 8 Per-formance in the middle phase is somewhat differentSometimes launches from the neutral site can findexcellent regions The non-adapting CFC based RLcrawler is still competitive if launched from the mailserver Launches from the mail list spanning 1 monthlooked similar to each other conference announce-ments barely modified the results
Search results up to 20000 documents are shownin Fig 9 This graph contains results from a subsetof the runs that we have executed These runs werelaunched from different sites the neutral site and themail list as well as a third type the lsquoconferencersquo sitehttp wwwinformatikuni-freiburgdeindexenhtmlThis latter is known to be involved in organizing con-ferences Adapting RL crawlers collected a large num-ber of documents from all site types and during the
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

12 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
understand the idea let us consider crawling in gen-eral Assume that lsquoyou are at a nodersquo of the web Thisnode has been analyzed and you have to decide whatto do next It is very possible that relevant informationcan be found in the immediate neighborhood of thisnode In turn you download all the documents nextto you and start to analyze those documents Doingso you may found relevant documents or may notWhen you are done you have the option to downloadall the documents that are two steps away from youand to analyze those documents This approach is wellknown in the AI literature and is called breadth firsttechnique However the world-wide web is lsquosmallrsquothe WWW had about 800 million nodes in 1999 andthe number of minimal hops required to reach mostdocuments from any particular document was 19[12]Such connectivity structure between units is calledlsquosmall worldrsquo In turn breadth first search incurs anenormous burden as a function of depth At one point(at a given depth) breadth first search needs to be aban-doned and a decision is to be made to which node tomove next To decide on that move the values of thenodes need to be estimated from the point of view ofthe goal of the searchFocused crawlingis based onthis idea Focused crawling makes an attempt to clas-sify the content of the document If the document fallsinto the search category then the document is down-loaded and the links of the documents are followed
Diligenti et al[1] have recognized the pitfall of fo-cused crawling searched information on the web istypically hidden sites of particular interest may havea lower number of directed links then sites of gen-eral interest In turn we might face the lsquoneedle in thehaystackrsquo problem with the haystack being sites ongeneral interest The hidden property is thus the im-plicit consequence of our particular interest
Let us consider sites dealing with support vectormachines (SVMs) Sites about SVMs are not typi-cal on the web Not all sites dealing with SVM arelinked In turn focused crawling could be rather inef-ficient and this direct search for SVM sites might failOn the other hand most of the SVM sites are within(ie linked to) academic environments or within sitesdealing with information technology These topics aremuch more general and might have much more linksand a much higher lsquovisibilityrsquo In turn searching forthe environment of SVM sites could be much moreefficient A hand-waving argument can be given as
follows Documents are linked to each other Linksare made by those for whom the document has valueThese links form the one-stepcontextof the documentThe one-step context in turn may be characteristic tothe document The one-step environment of the doc-ument (ie documents that are one step away) docu-ments that are two steps away etc form the lsquocontextrsquoof the document When we search for a document bydefinition we shall encounter the environment of thedocument first In turn first we might search for theenvironment of the document This is the idea behindlsquocontext focused crawlingrsquo (CFC)[1] This idea whichis trivial for graphs with high clustering probability(eg regular lattices) could be criticized for the caseof lsquosmall worldsrsquo when documentsmdashon averagemdashareabout as far as the environment of the document How-ever the question is intriguing because the visibilitycould be much less for searched documents than thatof the environment of the searched documents
CFC does not take into consideration the varietieson the web environments may differ For examplefor small universities or for small research insti-tutes lsquoone-step contextrsquo may correspond to lsquotwo-stepcontextrsquo for large departments of large universities Ifthe order of contexts might change then CFC will goclose and will miss the documents In turn the decisionwhether to lsquostay and downloadrsquo at a given site or lsquonotto download but moversquo can be seriously jeopardizedFast adapting value estimation method may providean attractive solution to this search problem where in-formation is hidden within not-yet-experienced envi-ronments The environment of high value documentscan provide reinforcing feedback in a straightforwardfashion Interestingly reinforcement learning (RL)has not been found particularly efficient for search-ing the world-wide web[13] The efficiency of RLhowever depends strongly on feature extraction Itseems natural to explore the CFC idea as the initialfeature extraction method for RL Here we show howto combine CFC with RL to search on the web
2 Methods
21 Preprocessing of texts
There is a large variety of methods that try to clas-sify texts [14ndash27] Most of these methods are based
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 13
on special dimension reduction First the occurrenceor sometimes the frequency of selected words is mea-sured The subset of all possible words (lsquobag of wordsrsquo(BoW)) is selected by means of probabilistic mea-sures Different methods are used for the selection ofthe lsquomost importantrsquo subset The occurrences (0rsquos and1rsquos) or the frequencies of the selected words of thesubsets are used to characterize all documents Thislowmdashtypically 100mdashdimensional vector is supposedto encompass important information about the typeof the document Different methods are used to de-rive lsquocloseness measuresrsquo between documents in thelow-dimensional spaces of occurrence vectors or fre-quency vectors The method can be used both for clas-sification ie the computation of decision surfacesbetween documents of different lsquolabelsrsquo[15162326]and clustering a more careful way of deriving close-ness (or similarity) measures when no labels are pro-vided [1417222428]
We tried several BoW-based classifiers on thelsquocall for papersrsquo (CfP) problem3 CfP is considered abenchmark classification problem of documents theratio of correctly classified and misclassified docu-ments can be automated easily by checking whetherthe document has the three word phrase lsquocall forpapersrsquo or not Classifiers were developed for one-step two-step environments etc for CfP documentsWe found that these classifiers perform poorly forthe CfP problem In agreement with published results[16] supervised SVM classification was superiorto other methods SVM was simple and somewhatbetter than Bayes classification However SVM re-quires a large number of support vectors for the CfPproblem
22 SVM classification
The SVM classifier operates similarly to percep-trons SVM however has better generalizing capabil-ities see eg the comprehensive book of Vapnik[29]a tutorial material[30] comparisons with other meth-ods[3132] improved techniques[33] and references
3 The CfP problem is defined by deleting the phrase lsquocall forpaperrsquo from the document executing search on the internet andconsidering each document that contains the phrase lsquocall for paperrsquoa lsquohitrsquo
therein4 The trained SVM was used in lsquosoft modersquoThat is the output of the SVM was not a decision(yes or no) but instead the output could take con-tinuous values between 0 and 1 A saturating sigmoidfunction5 was used for this purpose In turn (i) thenon-linearity of the decision surface was not sharp(ii) for inputs close to the decision surface the clas-sifier provides a linear output The output of the sig-moid non-linearity can be viewed as the probabilityof a class These probabilities for the different classesare distinct yardsticks working on possibly differentfeatures The RL algorithm was used to estimate thevalueof these yardsticks
23 Value estimation
There is a history of value estimation methodsbased on reinforcement learning some of the im-portant stepsmdashjudged subjectivelymdashare in the citedpapers[34ndash45] A thorough review on the litera-ture and the history of RL can be found in[46] Inour approach value estimation plays a central roleValue estimation works on states (s) and providesa real number thevalue that belongs to that stateV (s) isin R Value estimation is based on theimmediaterewards(eg the number of hits) that could be gainedat the given state by executing different actions (egdownload or move) Value of a state (a node for ex-ample) is the long-term cumulative reward that canbe collected starting from that state and using apol-icy Policy is a probability distribution over differentactions for each state policy determines the proba-bility of choosing and action in a given state Policyimprovement and the finding of an optimal policy arecentral issues in RL RL procedures can be simpli-fied if all possible lsquonextrsquo states are available and canbe evaluated This is our case In this case one doesnot have to represent the policy Instead one couldevaluate all neighboring nodes of the actual state andmove to (andor download) the one with the largestestimated long term cumulated reward the estimatedvalue Typically one includes random choices for afew percentages of the steps These random choices
4 Note that SVM has no adjustable parameters5 The output can be calulated as follows
output= 1
1 + exp(minusλ times input)
14 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 1 Context of the document (document and its first and secondlsquoneighborsrsquo)
are called lsquoexplorationsrsquo The estimated value-basedgreedy choice is called lsquoexploitationrsquo
If the downloaded document contains the phraselsquocall for papersrsquo then the learning system incurs an im-mediate reward of 1 If a downloaded document doesnot contain this phrase then there is negative reward(ie a punishment) ofminus001 These numbers wererather arbitrary The relative ratio between reward andpunishment and the magnitude of the parameter ofthe sigmoid function do matter These parameters in-fluence learning capabilities Our studies were con-strained to a fixed set of parameters One may expectimprovements upon optimizing these parameters for a
Fig 2 SVM-based document classifiers (A) Classification of distance from document using SVM classifiers The CFC method maintainsa list of visited links ordered according to the SVM classification One of the links belonging to the best non-empty classifier is visitednext (B) Value estimation based on SVM classifiers Reinforcement learning is used to estimate the importance of the different classifiersduring search
Fig 3 Search pattern for breadth first crawler Search was launchedfrom neutral site A site is called neutral if there is very fewtarget document in its environment Diameter of open circles isproportional to the number of target documents downloaded Edgesare color coded There are two extremes Dark blue site wasvisited at the early stage during the search Light blue recentlyvisited site (for further details see text)
particular problem In our case search over the internetwas time consuming and prohibited this optimization
Value estimation makes use of the followingupgrade
V +(st ) = V (st ) + α(rt+1 + γV (st+1) minus V (st )) (1)
whereα is the learning ratert+1 isin R is the imme-diate reward 0lt γ lt 1 is the discount factor and
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 15
subscriptst = 1 2 indicate action number (ietime) This particular upgrade is called temporal dif-ferencing with zero eligibility ie the TD(0) upgradeTD methods were introduced by Sutton[36] Anexcellent introduction to value estimation includingthe history of TD methods and description on theapplications of parameterized function approximatorscan be found in[46] Concerning details of the RLtechnique (a) we used eligibility traces (b) Opposedto the description given above we did not need ex-plorative steps because the environments can be verydifferent and that diminished the need for exploration(c) We did not decrease the value ofα by time to keepadaptivity (d) We approximated the value function asfollows
V (s) asympnsum
i=1
wiσ(SVM(i)) (2)
where the output of theith SVM (ie theith com-ponent of the output without any lsquosignumrsquo type ofnon-linearity) is denoted by SVM(i) σ(middot) denotes thesigmoid function acting on the outputs of the SVMclassifierswi is the weight (or relevance) of theithclassifier determined by upgradeEq (1) If the qual-ity of the upgrade is measured by the mean square er-ror of the estimations then the following approximateweight upgrade can be derived for the weights (seeeg[46] for details)
wi = α(rt+1 + γV (st+1) minus V (st ))σ (SVM(i)) (3)
This upgrademdashextended with eligibility traces[3646]mdashwas used in our RL engine
3 Features and learning to search
31 Breadth first crawler
A crawler is calledbreadth first crawler if it firstdownloads the document of the launching site contin-ues by downloading the documents of all first neigh-bors of the launching site then the documents of theneighboring sites of the first neighbor sites ie thedocuments of the second neighbor sites and so on
32 Context focused crawler
A target document and its environment are illus-trated inFig 1 The goal is to locate the document
by recognizing its environment first and then thedocument within The CFC method[1] was modi-fied slightlymdashin order to allow direct comparisonsbetween the CFC method and the CFC method ex-tended by RL value estimationmdashand the followingprocedure was applied First a set of irrelevant doc-uments were collected Thekth classifier was trainedon (good) documentsk-steps away from known tar-get documents and on (bad) irrelevant documentsThe classifier was trained to output a positive number(lsquoyesrsquo) for good documents and to output a negativenumber (lsquonorsquo) for irrelevant documents The outputswere scaled into the interval(0 1) by using the sig-moid functionσ(x) = (1 + exp(minusλx))minus1 If the kthclassifiers output was close to 1mdashaccording to its de-cision surfacemdashit suggests that there might be a targetdocumentk-steps away from the actual sitedocumentIf more than one classifier outputs lsquoyesrsquo then only thebest classifier is considered in CFC Other outputsare neglected The CFC idea with SVM classifiers isshown inFig 2(A) CFC maintains a list of visitedlinks ordered according to the SVM classification Oneof the links belonging to the best non-empty classifieris visited next (this procedure is called backtracking)
The problem of the CFC method can be seen byconsidering that neighborhoods on the WWW maydiffer considerably Even if thekth classifier is the bestpossible such classifier for the whole web it mightprovide poor results in some (possibly many) neigh-borhoods For example if there is a large numberof connected documents all having the promise thatthere is a valuable document in their neighborhoodmdashbut there is in fact nonemdashthen the CFC crawler willdownload all invaluable documents before movingfurther It is more efficient to learn which classifierspredict well and to move away from regions whichhave great but unfulfilled promises
It has been suggested that classifiers could beretrained to keep adaptivity[1] The retrainingprocedure however takes too long6 and can beambiguous if CFC is combined with backtrackingMoreover retraining may require continuous super-visory monitoring and supervisory decisions Insteadof retraining we suggest to determine the relevanceof the classifiers during the search
6 Training may take on the order of a day or so on 700 MHzPentium III according to our experiences
16 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
33 CFC and RL fast adaptation during search
Reinforcement learning offers a solution here Ifthe prewired order of the classifiers is questionablethen we could learn the correct ordering There isnothing to loose here provided that learning is fastIf prewiring is perfect then the fast learning proce-dure will not modify it If the prewiring is imperfectthen proper weights will be derived by the learningalgorithm
The outputs of the SVMs can be saved Theseoutputs can be used to estimate the value of a docu-ment at any instant Value is estimated by estimatingweights for each SVM and adding up the SVM out-puts multiplied by these weights In turn one cancompute value-based ordering of the documents withminor computational effort and this reordering can bemade at each step This reordering of the documentsreplaces prewired ordering of the CFC method Thenew architecture is shown inFig 2(B)
4 Results and discussion
The CfP problem has been studied Search pattern atthe initial phase for the breadth first method is shownin Fig 3
Search patterns for the context focused crawlerand the crawler using RL-based value estimation areshown inFigs 4 and 5 The launching site of thesesearches was a lsquoneutral sitersquo a relatively large site con-taining few CfP documents (httpwwwinfeltehu)We consider this type of launching important for webcrawling it simulates the case when mail lists arenot available traditional search engines are not sat-isfactory and breadth first search is inefficient Thisparticular site was chosen because breadth first searchcould find very few documents starting from thissite
lsquoScalesrsquo onFigs 4 and 5differ from each other andfrom that ofFig 3 lsquoTrue surfed scalersquo would be re-flected by normalizing to edge thickness Radius ofopen circles is proportional to the number of down-loaded target documents The CFC is only somewhatbetter in the initial phase than the breadth first methodLonger search shows that CFC becomes considerablybetter than the breadth first method when search islaunched from this neutral site
Quantitative comparisons are shown inFig 6 Ac-cording to the figure upon downloading 20000 doc-uments the number of hits were about 50 200 and1000 for the breadth first the CFC and CFC-basedRL crawlers respectively These launches were con-ducted at about the same time We shall demonstratethat the large difference between CFC and CFC-basedRL method is mostly due to the adaptive properties ofthe RL crawler
There are two site types that have been investigatedThe first site type is the neutral site that has beendescribed before The other site was a mail server onconferences Also for some examples there are runsseparated by 1 month (March 2001) A large numberof summer conferences made announcements duringthis month
First let us examine the initial phase of the searchThis initial phase of the search (the first 200 down-loaded documents) is shown inFig 7 Accordingto this figure downloading is very efficient from themail server site in each occasion The (non-adapting)CFC based RL crawler utilizing averaged RL weightsis superior to all the other crawlersmdashalmost alldownloaded documents are hits Close to this sitethere are many relevant documents and the lsquobreadthfirst crawlerrsquo is also efficient here Nevertheless thenon-adapting CFC based RL crawler outperforms thebreadth first crawler in this domain Launching fromneutral sites is inefficient at this early phase Breadthfirst method finds no hit close to the neutral site (notshown in the figure)
Middle phase of the search is shown inFig 8 Per-formance in the middle phase is somewhat differentSometimes launches from the neutral site can findexcellent regions The non-adapting CFC based RLcrawler is still competitive if launched from the mailserver Launches from the mail list spanning 1 monthlooked similar to each other conference announce-ments barely modified the results
Search results up to 20000 documents are shownin Fig 9 This graph contains results from a subsetof the runs that we have executed These runs werelaunched from different sites the neutral site and themail list as well as a third type the lsquoconferencersquo sitehttp wwwinformatikuni-freiburgdeindexenhtmlThis latter is known to be involved in organizing con-ferences Adapting RL crawlers collected a large num-ber of documents from all site types and during the
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 13
on special dimension reduction First the occurrenceor sometimes the frequency of selected words is mea-sured The subset of all possible words (lsquobag of wordsrsquo(BoW)) is selected by means of probabilistic mea-sures Different methods are used for the selection ofthe lsquomost importantrsquo subset The occurrences (0rsquos and1rsquos) or the frequencies of the selected words of thesubsets are used to characterize all documents Thislowmdashtypically 100mdashdimensional vector is supposedto encompass important information about the typeof the document Different methods are used to de-rive lsquocloseness measuresrsquo between documents in thelow-dimensional spaces of occurrence vectors or fre-quency vectors The method can be used both for clas-sification ie the computation of decision surfacesbetween documents of different lsquolabelsrsquo[15162326]and clustering a more careful way of deriving close-ness (or similarity) measures when no labels are pro-vided [1417222428]
We tried several BoW-based classifiers on thelsquocall for papersrsquo (CfP) problem3 CfP is considered abenchmark classification problem of documents theratio of correctly classified and misclassified docu-ments can be automated easily by checking whetherthe document has the three word phrase lsquocall forpapersrsquo or not Classifiers were developed for one-step two-step environments etc for CfP documentsWe found that these classifiers perform poorly forthe CfP problem In agreement with published results[16] supervised SVM classification was superiorto other methods SVM was simple and somewhatbetter than Bayes classification However SVM re-quires a large number of support vectors for the CfPproblem
22 SVM classification
The SVM classifier operates similarly to percep-trons SVM however has better generalizing capabil-ities see eg the comprehensive book of Vapnik[29]a tutorial material[30] comparisons with other meth-ods[3132] improved techniques[33] and references
3 The CfP problem is defined by deleting the phrase lsquocall forpaperrsquo from the document executing search on the internet andconsidering each document that contains the phrase lsquocall for paperrsquoa lsquohitrsquo
therein4 The trained SVM was used in lsquosoft modersquoThat is the output of the SVM was not a decision(yes or no) but instead the output could take con-tinuous values between 0 and 1 A saturating sigmoidfunction5 was used for this purpose In turn (i) thenon-linearity of the decision surface was not sharp(ii) for inputs close to the decision surface the clas-sifier provides a linear output The output of the sig-moid non-linearity can be viewed as the probabilityof a class These probabilities for the different classesare distinct yardsticks working on possibly differentfeatures The RL algorithm was used to estimate thevalueof these yardsticks
23 Value estimation
There is a history of value estimation methodsbased on reinforcement learning some of the im-portant stepsmdashjudged subjectivelymdashare in the citedpapers[34ndash45] A thorough review on the litera-ture and the history of RL can be found in[46] Inour approach value estimation plays a central roleValue estimation works on states (s) and providesa real number thevalue that belongs to that stateV (s) isin R Value estimation is based on theimmediaterewards(eg the number of hits) that could be gainedat the given state by executing different actions (egdownload or move) Value of a state (a node for ex-ample) is the long-term cumulative reward that canbe collected starting from that state and using apol-icy Policy is a probability distribution over differentactions for each state policy determines the proba-bility of choosing and action in a given state Policyimprovement and the finding of an optimal policy arecentral issues in RL RL procedures can be simpli-fied if all possible lsquonextrsquo states are available and canbe evaluated This is our case In this case one doesnot have to represent the policy Instead one couldevaluate all neighboring nodes of the actual state andmove to (andor download) the one with the largestestimated long term cumulated reward the estimatedvalue Typically one includes random choices for afew percentages of the steps These random choices
4 Note that SVM has no adjustable parameters5 The output can be calulated as follows
output= 1
1 + exp(minusλ times input)
14 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 1 Context of the document (document and its first and secondlsquoneighborsrsquo)
are called lsquoexplorationsrsquo The estimated value-basedgreedy choice is called lsquoexploitationrsquo
If the downloaded document contains the phraselsquocall for papersrsquo then the learning system incurs an im-mediate reward of 1 If a downloaded document doesnot contain this phrase then there is negative reward(ie a punishment) ofminus001 These numbers wererather arbitrary The relative ratio between reward andpunishment and the magnitude of the parameter ofthe sigmoid function do matter These parameters in-fluence learning capabilities Our studies were con-strained to a fixed set of parameters One may expectimprovements upon optimizing these parameters for a
Fig 2 SVM-based document classifiers (A) Classification of distance from document using SVM classifiers The CFC method maintainsa list of visited links ordered according to the SVM classification One of the links belonging to the best non-empty classifier is visitednext (B) Value estimation based on SVM classifiers Reinforcement learning is used to estimate the importance of the different classifiersduring search
Fig 3 Search pattern for breadth first crawler Search was launchedfrom neutral site A site is called neutral if there is very fewtarget document in its environment Diameter of open circles isproportional to the number of target documents downloaded Edgesare color coded There are two extremes Dark blue site wasvisited at the early stage during the search Light blue recentlyvisited site (for further details see text)
particular problem In our case search over the internetwas time consuming and prohibited this optimization
Value estimation makes use of the followingupgrade
V +(st ) = V (st ) + α(rt+1 + γV (st+1) minus V (st )) (1)
whereα is the learning ratert+1 isin R is the imme-diate reward 0lt γ lt 1 is the discount factor and
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 15
subscriptst = 1 2 indicate action number (ietime) This particular upgrade is called temporal dif-ferencing with zero eligibility ie the TD(0) upgradeTD methods were introduced by Sutton[36] Anexcellent introduction to value estimation includingthe history of TD methods and description on theapplications of parameterized function approximatorscan be found in[46] Concerning details of the RLtechnique (a) we used eligibility traces (b) Opposedto the description given above we did not need ex-plorative steps because the environments can be verydifferent and that diminished the need for exploration(c) We did not decrease the value ofα by time to keepadaptivity (d) We approximated the value function asfollows
V (s) asympnsum
i=1
wiσ(SVM(i)) (2)
where the output of theith SVM (ie theith com-ponent of the output without any lsquosignumrsquo type ofnon-linearity) is denoted by SVM(i) σ(middot) denotes thesigmoid function acting on the outputs of the SVMclassifierswi is the weight (or relevance) of theithclassifier determined by upgradeEq (1) If the qual-ity of the upgrade is measured by the mean square er-ror of the estimations then the following approximateweight upgrade can be derived for the weights (seeeg[46] for details)
wi = α(rt+1 + γV (st+1) minus V (st ))σ (SVM(i)) (3)
This upgrademdashextended with eligibility traces[3646]mdashwas used in our RL engine
3 Features and learning to search
31 Breadth first crawler
A crawler is calledbreadth first crawler if it firstdownloads the document of the launching site contin-ues by downloading the documents of all first neigh-bors of the launching site then the documents of theneighboring sites of the first neighbor sites ie thedocuments of the second neighbor sites and so on
32 Context focused crawler
A target document and its environment are illus-trated inFig 1 The goal is to locate the document
by recognizing its environment first and then thedocument within The CFC method[1] was modi-fied slightlymdashin order to allow direct comparisonsbetween the CFC method and the CFC method ex-tended by RL value estimationmdashand the followingprocedure was applied First a set of irrelevant doc-uments were collected Thekth classifier was trainedon (good) documentsk-steps away from known tar-get documents and on (bad) irrelevant documentsThe classifier was trained to output a positive number(lsquoyesrsquo) for good documents and to output a negativenumber (lsquonorsquo) for irrelevant documents The outputswere scaled into the interval(0 1) by using the sig-moid functionσ(x) = (1 + exp(minusλx))minus1 If the kthclassifiers output was close to 1mdashaccording to its de-cision surfacemdashit suggests that there might be a targetdocumentk-steps away from the actual sitedocumentIf more than one classifier outputs lsquoyesrsquo then only thebest classifier is considered in CFC Other outputsare neglected The CFC idea with SVM classifiers isshown inFig 2(A) CFC maintains a list of visitedlinks ordered according to the SVM classification Oneof the links belonging to the best non-empty classifieris visited next (this procedure is called backtracking)
The problem of the CFC method can be seen byconsidering that neighborhoods on the WWW maydiffer considerably Even if thekth classifier is the bestpossible such classifier for the whole web it mightprovide poor results in some (possibly many) neigh-borhoods For example if there is a large numberof connected documents all having the promise thatthere is a valuable document in their neighborhoodmdashbut there is in fact nonemdashthen the CFC crawler willdownload all invaluable documents before movingfurther It is more efficient to learn which classifierspredict well and to move away from regions whichhave great but unfulfilled promises
It has been suggested that classifiers could beretrained to keep adaptivity[1] The retrainingprocedure however takes too long6 and can beambiguous if CFC is combined with backtrackingMoreover retraining may require continuous super-visory monitoring and supervisory decisions Insteadof retraining we suggest to determine the relevanceof the classifiers during the search
6 Training may take on the order of a day or so on 700 MHzPentium III according to our experiences
16 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
33 CFC and RL fast adaptation during search
Reinforcement learning offers a solution here Ifthe prewired order of the classifiers is questionablethen we could learn the correct ordering There isnothing to loose here provided that learning is fastIf prewiring is perfect then the fast learning proce-dure will not modify it If the prewiring is imperfectthen proper weights will be derived by the learningalgorithm
The outputs of the SVMs can be saved Theseoutputs can be used to estimate the value of a docu-ment at any instant Value is estimated by estimatingweights for each SVM and adding up the SVM out-puts multiplied by these weights In turn one cancompute value-based ordering of the documents withminor computational effort and this reordering can bemade at each step This reordering of the documentsreplaces prewired ordering of the CFC method Thenew architecture is shown inFig 2(B)
4 Results and discussion
The CfP problem has been studied Search pattern atthe initial phase for the breadth first method is shownin Fig 3
Search patterns for the context focused crawlerand the crawler using RL-based value estimation areshown inFigs 4 and 5 The launching site of thesesearches was a lsquoneutral sitersquo a relatively large site con-taining few CfP documents (httpwwwinfeltehu)We consider this type of launching important for webcrawling it simulates the case when mail lists arenot available traditional search engines are not sat-isfactory and breadth first search is inefficient Thisparticular site was chosen because breadth first searchcould find very few documents starting from thissite
lsquoScalesrsquo onFigs 4 and 5differ from each other andfrom that ofFig 3 lsquoTrue surfed scalersquo would be re-flected by normalizing to edge thickness Radius ofopen circles is proportional to the number of down-loaded target documents The CFC is only somewhatbetter in the initial phase than the breadth first methodLonger search shows that CFC becomes considerablybetter than the breadth first method when search islaunched from this neutral site
Quantitative comparisons are shown inFig 6 Ac-cording to the figure upon downloading 20000 doc-uments the number of hits were about 50 200 and1000 for the breadth first the CFC and CFC-basedRL crawlers respectively These launches were con-ducted at about the same time We shall demonstratethat the large difference between CFC and CFC-basedRL method is mostly due to the adaptive properties ofthe RL crawler
There are two site types that have been investigatedThe first site type is the neutral site that has beendescribed before The other site was a mail server onconferences Also for some examples there are runsseparated by 1 month (March 2001) A large numberof summer conferences made announcements duringthis month
First let us examine the initial phase of the searchThis initial phase of the search (the first 200 down-loaded documents) is shown inFig 7 Accordingto this figure downloading is very efficient from themail server site in each occasion The (non-adapting)CFC based RL crawler utilizing averaged RL weightsis superior to all the other crawlersmdashalmost alldownloaded documents are hits Close to this sitethere are many relevant documents and the lsquobreadthfirst crawlerrsquo is also efficient here Nevertheless thenon-adapting CFC based RL crawler outperforms thebreadth first crawler in this domain Launching fromneutral sites is inefficient at this early phase Breadthfirst method finds no hit close to the neutral site (notshown in the figure)
Middle phase of the search is shown inFig 8 Per-formance in the middle phase is somewhat differentSometimes launches from the neutral site can findexcellent regions The non-adapting CFC based RLcrawler is still competitive if launched from the mailserver Launches from the mail list spanning 1 monthlooked similar to each other conference announce-ments barely modified the results
Search results up to 20000 documents are shownin Fig 9 This graph contains results from a subsetof the runs that we have executed These runs werelaunched from different sites the neutral site and themail list as well as a third type the lsquoconferencersquo sitehttp wwwinformatikuni-freiburgdeindexenhtmlThis latter is known to be involved in organizing con-ferences Adapting RL crawlers collected a large num-ber of documents from all site types and during the
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

14 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 1 Context of the document (document and its first and secondlsquoneighborsrsquo)
are called lsquoexplorationsrsquo The estimated value-basedgreedy choice is called lsquoexploitationrsquo
If the downloaded document contains the phraselsquocall for papersrsquo then the learning system incurs an im-mediate reward of 1 If a downloaded document doesnot contain this phrase then there is negative reward(ie a punishment) ofminus001 These numbers wererather arbitrary The relative ratio between reward andpunishment and the magnitude of the parameter ofthe sigmoid function do matter These parameters in-fluence learning capabilities Our studies were con-strained to a fixed set of parameters One may expectimprovements upon optimizing these parameters for a
Fig 2 SVM-based document classifiers (A) Classification of distance from document using SVM classifiers The CFC method maintainsa list of visited links ordered according to the SVM classification One of the links belonging to the best non-empty classifier is visitednext (B) Value estimation based on SVM classifiers Reinforcement learning is used to estimate the importance of the different classifiersduring search
Fig 3 Search pattern for breadth first crawler Search was launchedfrom neutral site A site is called neutral if there is very fewtarget document in its environment Diameter of open circles isproportional to the number of target documents downloaded Edgesare color coded There are two extremes Dark blue site wasvisited at the early stage during the search Light blue recentlyvisited site (for further details see text)
particular problem In our case search over the internetwas time consuming and prohibited this optimization
Value estimation makes use of the followingupgrade
V +(st ) = V (st ) + α(rt+1 + γV (st+1) minus V (st )) (1)
whereα is the learning ratert+1 isin R is the imme-diate reward 0lt γ lt 1 is the discount factor and
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 15
subscriptst = 1 2 indicate action number (ietime) This particular upgrade is called temporal dif-ferencing with zero eligibility ie the TD(0) upgradeTD methods were introduced by Sutton[36] Anexcellent introduction to value estimation includingthe history of TD methods and description on theapplications of parameterized function approximatorscan be found in[46] Concerning details of the RLtechnique (a) we used eligibility traces (b) Opposedto the description given above we did not need ex-plorative steps because the environments can be verydifferent and that diminished the need for exploration(c) We did not decrease the value ofα by time to keepadaptivity (d) We approximated the value function asfollows
V (s) asympnsum
i=1
wiσ(SVM(i)) (2)
where the output of theith SVM (ie theith com-ponent of the output without any lsquosignumrsquo type ofnon-linearity) is denoted by SVM(i) σ(middot) denotes thesigmoid function acting on the outputs of the SVMclassifierswi is the weight (or relevance) of theithclassifier determined by upgradeEq (1) If the qual-ity of the upgrade is measured by the mean square er-ror of the estimations then the following approximateweight upgrade can be derived for the weights (seeeg[46] for details)
wi = α(rt+1 + γV (st+1) minus V (st ))σ (SVM(i)) (3)
This upgrademdashextended with eligibility traces[3646]mdashwas used in our RL engine
3 Features and learning to search
31 Breadth first crawler
A crawler is calledbreadth first crawler if it firstdownloads the document of the launching site contin-ues by downloading the documents of all first neigh-bors of the launching site then the documents of theneighboring sites of the first neighbor sites ie thedocuments of the second neighbor sites and so on
32 Context focused crawler
A target document and its environment are illus-trated inFig 1 The goal is to locate the document
by recognizing its environment first and then thedocument within The CFC method[1] was modi-fied slightlymdashin order to allow direct comparisonsbetween the CFC method and the CFC method ex-tended by RL value estimationmdashand the followingprocedure was applied First a set of irrelevant doc-uments were collected Thekth classifier was trainedon (good) documentsk-steps away from known tar-get documents and on (bad) irrelevant documentsThe classifier was trained to output a positive number(lsquoyesrsquo) for good documents and to output a negativenumber (lsquonorsquo) for irrelevant documents The outputswere scaled into the interval(0 1) by using the sig-moid functionσ(x) = (1 + exp(minusλx))minus1 If the kthclassifiers output was close to 1mdashaccording to its de-cision surfacemdashit suggests that there might be a targetdocumentk-steps away from the actual sitedocumentIf more than one classifier outputs lsquoyesrsquo then only thebest classifier is considered in CFC Other outputsare neglected The CFC idea with SVM classifiers isshown inFig 2(A) CFC maintains a list of visitedlinks ordered according to the SVM classification Oneof the links belonging to the best non-empty classifieris visited next (this procedure is called backtracking)
The problem of the CFC method can be seen byconsidering that neighborhoods on the WWW maydiffer considerably Even if thekth classifier is the bestpossible such classifier for the whole web it mightprovide poor results in some (possibly many) neigh-borhoods For example if there is a large numberof connected documents all having the promise thatthere is a valuable document in their neighborhoodmdashbut there is in fact nonemdashthen the CFC crawler willdownload all invaluable documents before movingfurther It is more efficient to learn which classifierspredict well and to move away from regions whichhave great but unfulfilled promises
It has been suggested that classifiers could beretrained to keep adaptivity[1] The retrainingprocedure however takes too long6 and can beambiguous if CFC is combined with backtrackingMoreover retraining may require continuous super-visory monitoring and supervisory decisions Insteadof retraining we suggest to determine the relevanceof the classifiers during the search
6 Training may take on the order of a day or so on 700 MHzPentium III according to our experiences
16 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
33 CFC and RL fast adaptation during search
Reinforcement learning offers a solution here Ifthe prewired order of the classifiers is questionablethen we could learn the correct ordering There isnothing to loose here provided that learning is fastIf prewiring is perfect then the fast learning proce-dure will not modify it If the prewiring is imperfectthen proper weights will be derived by the learningalgorithm
The outputs of the SVMs can be saved Theseoutputs can be used to estimate the value of a docu-ment at any instant Value is estimated by estimatingweights for each SVM and adding up the SVM out-puts multiplied by these weights In turn one cancompute value-based ordering of the documents withminor computational effort and this reordering can bemade at each step This reordering of the documentsreplaces prewired ordering of the CFC method Thenew architecture is shown inFig 2(B)
4 Results and discussion
The CfP problem has been studied Search pattern atthe initial phase for the breadth first method is shownin Fig 3
Search patterns for the context focused crawlerand the crawler using RL-based value estimation areshown inFigs 4 and 5 The launching site of thesesearches was a lsquoneutral sitersquo a relatively large site con-taining few CfP documents (httpwwwinfeltehu)We consider this type of launching important for webcrawling it simulates the case when mail lists arenot available traditional search engines are not sat-isfactory and breadth first search is inefficient Thisparticular site was chosen because breadth first searchcould find very few documents starting from thissite
lsquoScalesrsquo onFigs 4 and 5differ from each other andfrom that ofFig 3 lsquoTrue surfed scalersquo would be re-flected by normalizing to edge thickness Radius ofopen circles is proportional to the number of down-loaded target documents The CFC is only somewhatbetter in the initial phase than the breadth first methodLonger search shows that CFC becomes considerablybetter than the breadth first method when search islaunched from this neutral site
Quantitative comparisons are shown inFig 6 Ac-cording to the figure upon downloading 20000 doc-uments the number of hits were about 50 200 and1000 for the breadth first the CFC and CFC-basedRL crawlers respectively These launches were con-ducted at about the same time We shall demonstratethat the large difference between CFC and CFC-basedRL method is mostly due to the adaptive properties ofthe RL crawler
There are two site types that have been investigatedThe first site type is the neutral site that has beendescribed before The other site was a mail server onconferences Also for some examples there are runsseparated by 1 month (March 2001) A large numberof summer conferences made announcements duringthis month
First let us examine the initial phase of the searchThis initial phase of the search (the first 200 down-loaded documents) is shown inFig 7 Accordingto this figure downloading is very efficient from themail server site in each occasion The (non-adapting)CFC based RL crawler utilizing averaged RL weightsis superior to all the other crawlersmdashalmost alldownloaded documents are hits Close to this sitethere are many relevant documents and the lsquobreadthfirst crawlerrsquo is also efficient here Nevertheless thenon-adapting CFC based RL crawler outperforms thebreadth first crawler in this domain Launching fromneutral sites is inefficient at this early phase Breadthfirst method finds no hit close to the neutral site (notshown in the figure)
Middle phase of the search is shown inFig 8 Per-formance in the middle phase is somewhat differentSometimes launches from the neutral site can findexcellent regions The non-adapting CFC based RLcrawler is still competitive if launched from the mailserver Launches from the mail list spanning 1 monthlooked similar to each other conference announce-ments barely modified the results
Search results up to 20000 documents are shownin Fig 9 This graph contains results from a subsetof the runs that we have executed These runs werelaunched from different sites the neutral site and themail list as well as a third type the lsquoconferencersquo sitehttp wwwinformatikuni-freiburgdeindexenhtmlThis latter is known to be involved in organizing con-ferences Adapting RL crawlers collected a large num-ber of documents from all site types and during the
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 15
subscriptst = 1 2 indicate action number (ietime) This particular upgrade is called temporal dif-ferencing with zero eligibility ie the TD(0) upgradeTD methods were introduced by Sutton[36] Anexcellent introduction to value estimation includingthe history of TD methods and description on theapplications of parameterized function approximatorscan be found in[46] Concerning details of the RLtechnique (a) we used eligibility traces (b) Opposedto the description given above we did not need ex-plorative steps because the environments can be verydifferent and that diminished the need for exploration(c) We did not decrease the value ofα by time to keepadaptivity (d) We approximated the value function asfollows
V (s) asympnsum
i=1
wiσ(SVM(i)) (2)
where the output of theith SVM (ie theith com-ponent of the output without any lsquosignumrsquo type ofnon-linearity) is denoted by SVM(i) σ(middot) denotes thesigmoid function acting on the outputs of the SVMclassifierswi is the weight (or relevance) of theithclassifier determined by upgradeEq (1) If the qual-ity of the upgrade is measured by the mean square er-ror of the estimations then the following approximateweight upgrade can be derived for the weights (seeeg[46] for details)
wi = α(rt+1 + γV (st+1) minus V (st ))σ (SVM(i)) (3)
This upgrademdashextended with eligibility traces[3646]mdashwas used in our RL engine
3 Features and learning to search
31 Breadth first crawler
A crawler is calledbreadth first crawler if it firstdownloads the document of the launching site contin-ues by downloading the documents of all first neigh-bors of the launching site then the documents of theneighboring sites of the first neighbor sites ie thedocuments of the second neighbor sites and so on
32 Context focused crawler
A target document and its environment are illus-trated inFig 1 The goal is to locate the document
by recognizing its environment first and then thedocument within The CFC method[1] was modi-fied slightlymdashin order to allow direct comparisonsbetween the CFC method and the CFC method ex-tended by RL value estimationmdashand the followingprocedure was applied First a set of irrelevant doc-uments were collected Thekth classifier was trainedon (good) documentsk-steps away from known tar-get documents and on (bad) irrelevant documentsThe classifier was trained to output a positive number(lsquoyesrsquo) for good documents and to output a negativenumber (lsquonorsquo) for irrelevant documents The outputswere scaled into the interval(0 1) by using the sig-moid functionσ(x) = (1 + exp(minusλx))minus1 If the kthclassifiers output was close to 1mdashaccording to its de-cision surfacemdashit suggests that there might be a targetdocumentk-steps away from the actual sitedocumentIf more than one classifier outputs lsquoyesrsquo then only thebest classifier is considered in CFC Other outputsare neglected The CFC idea with SVM classifiers isshown inFig 2(A) CFC maintains a list of visitedlinks ordered according to the SVM classification Oneof the links belonging to the best non-empty classifieris visited next (this procedure is called backtracking)
The problem of the CFC method can be seen byconsidering that neighborhoods on the WWW maydiffer considerably Even if thekth classifier is the bestpossible such classifier for the whole web it mightprovide poor results in some (possibly many) neigh-borhoods For example if there is a large numberof connected documents all having the promise thatthere is a valuable document in their neighborhoodmdashbut there is in fact nonemdashthen the CFC crawler willdownload all invaluable documents before movingfurther It is more efficient to learn which classifierspredict well and to move away from regions whichhave great but unfulfilled promises
It has been suggested that classifiers could beretrained to keep adaptivity[1] The retrainingprocedure however takes too long6 and can beambiguous if CFC is combined with backtrackingMoreover retraining may require continuous super-visory monitoring and supervisory decisions Insteadof retraining we suggest to determine the relevanceof the classifiers during the search
6 Training may take on the order of a day or so on 700 MHzPentium III according to our experiences
16 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
33 CFC and RL fast adaptation during search
Reinforcement learning offers a solution here Ifthe prewired order of the classifiers is questionablethen we could learn the correct ordering There isnothing to loose here provided that learning is fastIf prewiring is perfect then the fast learning proce-dure will not modify it If the prewiring is imperfectthen proper weights will be derived by the learningalgorithm
The outputs of the SVMs can be saved Theseoutputs can be used to estimate the value of a docu-ment at any instant Value is estimated by estimatingweights for each SVM and adding up the SVM out-puts multiplied by these weights In turn one cancompute value-based ordering of the documents withminor computational effort and this reordering can bemade at each step This reordering of the documentsreplaces prewired ordering of the CFC method Thenew architecture is shown inFig 2(B)
4 Results and discussion
The CfP problem has been studied Search pattern atthe initial phase for the breadth first method is shownin Fig 3
Search patterns for the context focused crawlerand the crawler using RL-based value estimation areshown inFigs 4 and 5 The launching site of thesesearches was a lsquoneutral sitersquo a relatively large site con-taining few CfP documents (httpwwwinfeltehu)We consider this type of launching important for webcrawling it simulates the case when mail lists arenot available traditional search engines are not sat-isfactory and breadth first search is inefficient Thisparticular site was chosen because breadth first searchcould find very few documents starting from thissite
lsquoScalesrsquo onFigs 4 and 5differ from each other andfrom that ofFig 3 lsquoTrue surfed scalersquo would be re-flected by normalizing to edge thickness Radius ofopen circles is proportional to the number of down-loaded target documents The CFC is only somewhatbetter in the initial phase than the breadth first methodLonger search shows that CFC becomes considerablybetter than the breadth first method when search islaunched from this neutral site
Quantitative comparisons are shown inFig 6 Ac-cording to the figure upon downloading 20000 doc-uments the number of hits were about 50 200 and1000 for the breadth first the CFC and CFC-basedRL crawlers respectively These launches were con-ducted at about the same time We shall demonstratethat the large difference between CFC and CFC-basedRL method is mostly due to the adaptive properties ofthe RL crawler
There are two site types that have been investigatedThe first site type is the neutral site that has beendescribed before The other site was a mail server onconferences Also for some examples there are runsseparated by 1 month (March 2001) A large numberof summer conferences made announcements duringthis month
First let us examine the initial phase of the searchThis initial phase of the search (the first 200 down-loaded documents) is shown inFig 7 Accordingto this figure downloading is very efficient from themail server site in each occasion The (non-adapting)CFC based RL crawler utilizing averaged RL weightsis superior to all the other crawlersmdashalmost alldownloaded documents are hits Close to this sitethere are many relevant documents and the lsquobreadthfirst crawlerrsquo is also efficient here Nevertheless thenon-adapting CFC based RL crawler outperforms thebreadth first crawler in this domain Launching fromneutral sites is inefficient at this early phase Breadthfirst method finds no hit close to the neutral site (notshown in the figure)
Middle phase of the search is shown inFig 8 Per-formance in the middle phase is somewhat differentSometimes launches from the neutral site can findexcellent regions The non-adapting CFC based RLcrawler is still competitive if launched from the mailserver Launches from the mail list spanning 1 monthlooked similar to each other conference announce-ments barely modified the results
Search results up to 20000 documents are shownin Fig 9 This graph contains results from a subsetof the runs that we have executed These runs werelaunched from different sites the neutral site and themail list as well as a third type the lsquoconferencersquo sitehttp wwwinformatikuni-freiburgdeindexenhtmlThis latter is known to be involved in organizing con-ferences Adapting RL crawlers collected a large num-ber of documents from all site types and during the
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

16 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
33 CFC and RL fast adaptation during search
Reinforcement learning offers a solution here Ifthe prewired order of the classifiers is questionablethen we could learn the correct ordering There isnothing to loose here provided that learning is fastIf prewiring is perfect then the fast learning proce-dure will not modify it If the prewiring is imperfectthen proper weights will be derived by the learningalgorithm
The outputs of the SVMs can be saved Theseoutputs can be used to estimate the value of a docu-ment at any instant Value is estimated by estimatingweights for each SVM and adding up the SVM out-puts multiplied by these weights In turn one cancompute value-based ordering of the documents withminor computational effort and this reordering can bemade at each step This reordering of the documentsreplaces prewired ordering of the CFC method Thenew architecture is shown inFig 2(B)
4 Results and discussion
The CfP problem has been studied Search pattern atthe initial phase for the breadth first method is shownin Fig 3
Search patterns for the context focused crawlerand the crawler using RL-based value estimation areshown inFigs 4 and 5 The launching site of thesesearches was a lsquoneutral sitersquo a relatively large site con-taining few CfP documents (httpwwwinfeltehu)We consider this type of launching important for webcrawling it simulates the case when mail lists arenot available traditional search engines are not sat-isfactory and breadth first search is inefficient Thisparticular site was chosen because breadth first searchcould find very few documents starting from thissite
lsquoScalesrsquo onFigs 4 and 5differ from each other andfrom that ofFig 3 lsquoTrue surfed scalersquo would be re-flected by normalizing to edge thickness Radius ofopen circles is proportional to the number of down-loaded target documents The CFC is only somewhatbetter in the initial phase than the breadth first methodLonger search shows that CFC becomes considerablybetter than the breadth first method when search islaunched from this neutral site
Quantitative comparisons are shown inFig 6 Ac-cording to the figure upon downloading 20000 doc-uments the number of hits were about 50 200 and1000 for the breadth first the CFC and CFC-basedRL crawlers respectively These launches were con-ducted at about the same time We shall demonstratethat the large difference between CFC and CFC-basedRL method is mostly due to the adaptive properties ofthe RL crawler
There are two site types that have been investigatedThe first site type is the neutral site that has beendescribed before The other site was a mail server onconferences Also for some examples there are runsseparated by 1 month (March 2001) A large numberof summer conferences made announcements duringthis month
First let us examine the initial phase of the searchThis initial phase of the search (the first 200 down-loaded documents) is shown inFig 7 Accordingto this figure downloading is very efficient from themail server site in each occasion The (non-adapting)CFC based RL crawler utilizing averaged RL weightsis superior to all the other crawlersmdashalmost alldownloaded documents are hits Close to this sitethere are many relevant documents and the lsquobreadthfirst crawlerrsquo is also efficient here Nevertheless thenon-adapting CFC based RL crawler outperforms thebreadth first crawler in this domain Launching fromneutral sites is inefficient at this early phase Breadthfirst method finds no hit close to the neutral site (notshown in the figure)
Middle phase of the search is shown inFig 8 Per-formance in the middle phase is somewhat differentSometimes launches from the neutral site can findexcellent regions The non-adapting CFC based RLcrawler is still competitive if launched from the mailserver Launches from the mail list spanning 1 monthlooked similar to each other conference announce-ments barely modified the results
Search results up to 20000 documents are shownin Fig 9 This graph contains results from a subsetof the runs that we have executed These runs werelaunched from different sites the neutral site and themail list as well as a third type the lsquoconferencersquo sitehttp wwwinformatikuni-freiburgdeindexenhtmlThis latter is known to be involved in organizing con-ferences Adapting RL crawlers collected a large num-ber of documents from all site types and during the
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995
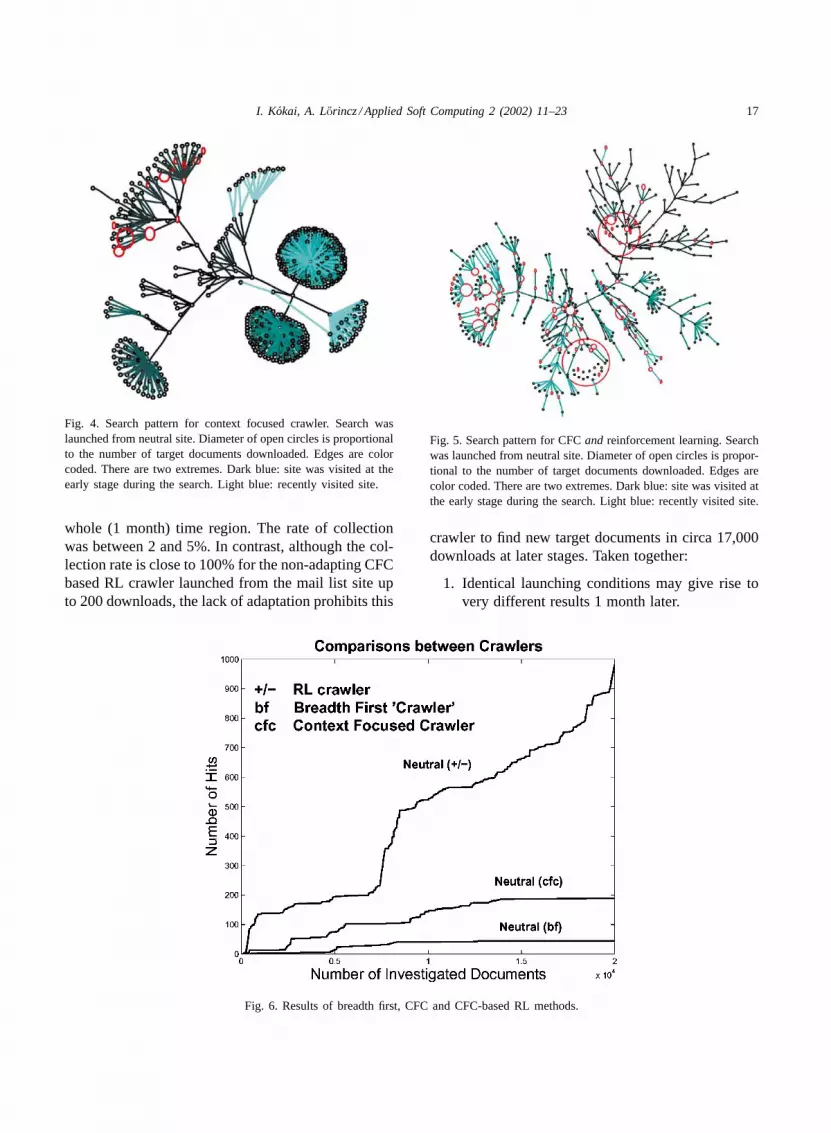
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 17
Fig 4 Search pattern for context focused crawler Search waslaunched from neutral site Diameter of open circles is proportionalto the number of target documents downloaded Edges are colorcoded There are two extremes Dark blue site was visited at theearly stage during the search Light blue recently visited site
whole (1 month) time region The rate of collectionwas between 2 and 5 In contrast although the col-lection rate is close to 100 for the non-adapting CFCbased RL crawler launched from the mail list site upto 200 downloads the lack of adaptation prohibits this
Fig 6 Results of breadth first CFC and CFC-based RL methods
Fig 5 Search pattern for CFCand reinforcement learning Searchwas launched from neutral site Diameter of open circles is propor-tional to the number of target documents downloaded Edges arecolor coded There are two extremes Dark blue site was visited atthe early stage during the search Light blue recently visited site
crawler to find new target documents in circa 17000downloads at later stages Taken together
1 Identical launching conditions may give rise tovery different results 1 month later
18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

18 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 7 Comparisons between lsquoneutralrsquo and mail server sites in the initial phase Reward and punishment are given in the legend of the figureDifferences between similar types are due to differences in launching time The largest time difference between similar types is 1 monthNeutral site (thin lines)httpwwwinfeltehu Mail list (thick lines) httpwwwnewcastleresearchecorgcaberneteventsmsg00043htmlSearch with lsquono adaptationrsquo (dotted line) was launched from mail list and used average weights from another search that was launchedfrom the same place
Fig 8 Comparisons between lsquoneutralrsquo and mail server sites up to 2000 documents Same conditions as inFig 7
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 19
Fig 9 Comparisons between different sites up to 20000 documents Same conditions as inFigs 7 and 8 Search with lsquono adaptationrsquoused average weights from another search that was launched from the same place (denoted bylowast)
Fig 10 Change of weights of SVMs upon downloads from mail site Horizontal axis occasions when weights were trained
20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

20 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
Fig 11 Change of weights of SVMs in value estimation for lsquoneutralrsquo site Horizontal axis occasions when value estimation was erroneousand weights were trained
2 Starting from a neutral site can be as effective asstarting from a mailing list for the adaptive RLcrawler
3 The lack of adaptation is a serious drawback evenif the crawler is launched from a mailing list
The importance of adaptation is also demonstrated bythe RL weights assigned during search These weightsare shown in the following figuresFig 10 depictsthe weights belonging to the different SVMs launchedfrom the mail list site At the beginning of the searchthe weights are almost perfectly ordered the largestweight is given to the SVM that predicts relevant doc-ument lsquoone step awayrsquo whereas the fourth and the fifthSVMs have the smallest weights That is RL lsquopaysattentionrsquo to the first SVM and pays less attention tothe others This order changes as time goes on Thereare regions (at around tuning step number 1700 on thehorizontal axis) where most attention is paid to thefifth SVM and smaller attention is paid to the othersThis means that the crawler will move away from the
region The order of importance changes again whena rich region is found the importance of the first SVMrecovers quickly and in turn crawling is dominatedby the weight of the first SVM the crawler lsquostaysrsquo anddownloads documents
lsquoWeight historyrsquo is different at the neutral site(Fig 11) Up to about 100 downloads very few rele-vant documents were found at this site The value ofweight of the fifth SVM is slightly positive whereasthe values of the others are negative The first and thesecond SVMs are weighted the lsquoworstrsquo weights be-longing to these classifiers are large negative numbersAt this site the order of SVMs that were trained ataround target documents is not appropriate Situationchanges quickly when a rich region is found In suchregions the first SVM takes the lead It is typical thatthe weight of the 5th SVM is ranked second That isthe adaptation concerns mostly whether the crawlershould stay or if it should move lsquofar awayrsquo In turninformation contained by the lsquocontextrsquo is relevant andcan be used to optimize the behavior of the crawler
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 21
5 Conclusions
We have suggested a novel method for web searchThe method makes use of combinations of two pop-ular AI techniques support vector machines (SVM)and reinforcement learning (RL) The method has afew adapting parameters that can be optimized dur-ing the search This parameterization helps the crawlerto adapt to different parts of the web The outputsof the SVMs together formed a set of lsquoyardsticksrsquo forthe estimation of the distance from target documentsThe value (the weight) of the different yardsticks maybe very different at different neighborhoods The pointis that (i) RL is efficient with good features (the ask-step SVMs in this case) (ii) if there are just a few pa-rameters for RL then these parameters can be trainedquickly by rewarding for target documents RL hasmany different formulations all of which could be ap-plied here Most promising are the approaches thatcan take into account (many) different criteria in thesearch objective[47ndash49] Alas RL methods are capa-ble of extracting features[50] that may complementthe prewired SVM features
Acknowledgements
This work was supported by the Hungarian Na-tional Science Foundation (Grant OTKA 32487) andby EOARD (Grant F61775-00-WE065) Any opin-ions findings and conclusions or recommendationsexpressed in this material are those of the author(s)and do not necessarily reflect the views of the Eu-ropean Office of Aerospace Research and Develop-ment Air Force Office of Scientific Research AirForce Research Laboratory We are grateful to Dr AtaKabaacuten for helpful discussions and careful reading ofthe manuscript
References
[1] M Diligenti F Coetzee S Lawrence CL Giles MGori Focused crawling using context graphs in Proceedingsof the 26th International Conference on Very LargeDatabases VLDB 2000 Cairo Egypthttpwwwnecineccomlawrencepapersfocus-vldb00focus-vldb00psgz
[2] J Cho H Garcıa-Molina L Page Efficient crawling throughURL ordering Computer Networks and ISDN Systems
30 (1ndash7) (1998) 161ndash172httpwww-dbstanfordedupubpapersefficient-crawlingps
[3] J Dean M Henzinger Finding related pages in the worldwide web WWW8Computer Networks 31 (11ndash16) (1999)1467ndash1479httpwwwresearchcompaqcomSRCpersonalmonikapapersmonika-www8-1psgz
[4] S Chakrabarti D Gibson K McCurley Surfing the Webbackwards in Proceedings of the 8th World Wide WebConference Toronto Canada 1999httpwww8orgw8-papers5b-hypertext-mediasurfing
[5] A McCallum K Nigam J Rennie K Seymore Buildingdomain-specific search engines with machine learning tech-niques AAAI-99 Spring Symposium on Intelligent Agents inCyberspace 1999httpwwwcscmuedumccallumpaperscora-aaaiss98ps
[6] R Kolluri N Mittal R Ventakachalam N Widjaja Focus-sed crawling 2000httpwwwcsutexaseduusersramkidataminingfcrawlpsgz
[7] S Lawrence Context in web search IEEE Data Eng Bull23 (3) (2000) 25ndash32
[8] A McCallum K Nigam J Rennie K Seymore Automatingthe construction of internet portals with machine learningInformation Retrieval 3 (2) (2000) 127ndash163httpwwwcscmueduafscsuserkseymorehtmlpaperscora-journalpsgz
[9] S Mukherjea WTMS a system for collecting and analyzingtopic-specific web information in Proceedings of the9th World Wide Web Conference 2000httpwww9orgw9cdrom293293html
[10] J Murdock A Goel Towards adaptive web agents inProceedings of the 14th IEEE International Conferenceon Automated Software Engineering 1999httpwwwccgatechedumoralepapersase99ps
[11] S Chakrabarti M van der Berg B Dom Focused crawlinga new approach to topic-specific Web resource discoveryin Proceedings of the 8th International World Wide WebConference (WWW8) 1999httpwwwcsberkeleyedusoumendocwww1999fpdfwww1999fpdf
[12] R Albert H Jeong A-L Barabaacutesi Diameter of theworld-wide web Nature 401 (1999) 130ndash131
[13] J Rennie K Nigam A McCallum Using reinforcementlearning to spider the web efficiently in Proceedings ofthe 16th International Conference on Machine LearningMorgan Kaufmann San Francisco CA 1999 pp 335ndash343httpwwwcscmuedu mccallumpapersrlspider-icml99spsgz
[14] A McCallum Bow a toolkit for statistical languagemodelling text retrieval classification and clustering 1996httpwwwcscmuedu mccallumbow
[15] A Blum J Mitchell Combining labeled and unlabeleddata with co-training in Proceedings of the Workshop onComputational Learning Theory (COLT) Morgan KaufmannSan Francisco CA 1998httpwwwcscmueduafscscmueduprojecttheo-11wwwwwkbcolt98finalps
[16] S Dumais J Platt D Heckerman M Sahami Inductivelearning algorithms and representations for text categorizationin Proceedings of the 7th International Conference
22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

22 I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23
on Information and Knowledge Management ICIKMrsquo98ACM 1998 httproboticsstanfordeduuserssahamipapers-dircikm98pdf
[17] S Kaski Dimensionality reduction by random mapping fastsimilarity computation for clustering in Proceedings of theInternational Joint Conference on Neural Networks Vol 1IEEE Service Center Piscataway NJ 1998 pp 413ndash418httpwebsomhutfiwebsomdocpskaski98ijcnnpsgz
[18] S Chakrabarti B Dom P Indyk Enhanced hypertextcategorization using hyperlinks in LM Haas A Tiwary(Eds) Proceedings of the SIGMOD-98 ACM InternationalConference on Management of Data ACM Press NewYorkSeattle US 1998 pp 307ndash318httpwwwalmadenibmcomcsk53irpaperssigmod98ps
[19] T Kolenda L Hansen S Sigurdsson in M Girolami(Ed) Independent Components in Text 2000httpeivindimmdtudkpublications1999kolendanips99psgz
[20] T Mitchell The role of unlabeled data in supervisedlearning in Proceedings of the 6th International Colloquiumon Cognitive Science 1999httpwwwricmuedupubfilespub1mitchelltom 19992mitchell tom 19992pdf
[21] A McCallum Multi-label text classification with amixture model trained by em 1999httpwwwcscmuedumccallumpapersmultilabel-nips99spsgz
[22] T Hofmann Learning the similarity of documents aninformation-geometric approach to document retrieval andcategorization in Neural Information Processing SystemsVol 12 MIT Press Cambridge MA 2000 pp 914ndash920
[23] K Nigam A Mccallum S Thrun T Mitchell Textclassification from labeled and unlabeled documents usingem Machine Learning 39 (23) 103ndash134httpwwwcscmuedu knigampapersemcat-mlj99psgz
[24] A Kabaacuten M Girolami Clustering of text documentsby skewness maximisation in Proceedings of the 2ndInternational Workshop on Independent Component Analysisand Blind Source Separation ICArsquo2000 Helsinki 2000pp 435ndash440
[25] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of text docu-ments in Proceedings of the 15th International Conferenceon Pattern Recognition Vol 2 IEEE Computer PressSilver Spring MD 2000 pp 182ndash185 httpcispaisleyacukvino-ci0vinokourovICPR00ps
[26] T Joachims Estimating the generalization performance ofan SVM efficiently in Proceedings of the 17th InternationalConference on Machine Learning Morgan KaufmannSan Francisco CA 2000 pp 431ndash438httpwww-aiinformatikuni-dortmunddeDOKUMENTEjoachims99epsgz
[27] S Dominich A unified mathematical definition of classicalinformation retrieval J Am Soc Information Sci 51 (7)(2000) 614ndash624
[28] A Vinokourov M Girolami A probabilistic hierarchicalclustering method for organizing collections of textdocuments Technical Report ISSN 1461ndash6122 Departmentof Computing and Information Systems University ofPaisley Paisley PA1 2BE UKhttpcispaisleyacukvino-ci0hplsakaisps
[29] V Vapnik The Nature of Statistical Learning Theory SpringerVerlag New York 1995
[30] AJ Smola B Schoumllkopf A tutorial on SupportVector Regression Technical Report NC2-TR-1998-030NeuroCOLT2 1998
[31] I Guyon VN Vapnik BE Boser LY Bottou SA SollaStructural risk minimization for character recognition inJE Moody SJ Hanson RP Lippmann (Eds) Advancesin Neural Information Processing Systems Vol 4 MorganKaufmann San Mateo CA 1992 pp 471ndash479
[32] N Cristianini J Shawe-Taylor An Introduction to SupportVector Machines Cambridge University Press CambridgeUK 1999
[33] S Keerthi S Shevade C Bhattacharyya K MurthyImprovements to Plattrsquos SMO Algorithm for SVMClassifier Design Technical Report CD-99-14 Department ofMechanical and Production Engineering National Universityof Singaporehttpguppympenusedusg mpessksmomodpsgz
[34] RE Korf Learning to Solve Problems by Searching forMacro-Operators Pitman Publishers Boston 1985
[35] S Minton Learning Search Control Knowledge AnExplanation-Based Approach Kluwer Academic PublishersDordrecht 1988
[36] R Sutton Learning to predict by the method of temporaldifferences Machine Learning 3 (1988) 9ndash44
[37] C Watkins Learning from delayed rewards PhD thesisKingrsquos College Cambridge UK 1989
[38] J Schmidhuber Neural sequence chunkers Technical ReportFKI-148-91 Technische Universitat Munchen MunchenGermany 1991
[39] S Mahadevan J Connell Automatic programming ofbehavior-based robots using reinforcement learning ArtifIntelligence 55 (1992) 311ndash365
[40] P Dayan GE Hinton Feudal reinforcement learning inAdvances in Neural Information Processing Systems Vol 5Morgan Kaufmann San Mateo CA 1993 pp 271ndash278
[41] LP Kaelbling Hierarchical learning in stochastic domainspreliminary results in Proceedings of the Tenth InternationalConference on Machine Learning Morgan Kaufmann SanMateo CA 1993
[42] GA Rummery M Niranjan On-line Q-learning usingconnectionist systems Technical Report CambridgeUniversity Engineering Department 1996
[43] ML Littman A Cassandra LP Kaelbling Learningpolicies for partially observable environments Scaling upin A Prieditis S Russell (Eds) Proceedings of the 12thInternational Conference on Machine Learning MorganKaufmann San Mateo CA 1995
[44] MJ Mataric Behavior-based control Examples fromnavigation learning and group behavior J Exp TheoretArtif Intelligence 9 (1997) 2ndash3
[45] TG Dietterich Hierarchical reinforcement learning with theMAXQ value function decomposition J Artif IntelligenceRes 13 (2000) 227ndash303
[46] R Sutton A Barto Reinforcement Learning An Intro-duction MIT Press Cambridge MA 1998
I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995

I Kokai A Lorincz Applied Soft Computing 2 (2002) 11ndash23 23
[47] NM Fraser JW Hauge Multicriteria approval applicationof approval voting concepts to MCDM problems JMulti-Criteria Decision Anal 7 (1998) 263ndash273
[48] ZGaacutebor Z Kalmaacuter C Szepesvaacuteri Multi-criteria reinforce-ment learning in Proceedings of the 15th InternationalConference on Machine Learning 1998
[49] D Dubois M Grabisch F Modave H Prade Relatingdecision under uncertainty and multicriteria decision makingmodels Int J Intelligent Syst 15 (2000) 979
[50] T Thrun A Schwartz Finding structure in reinforcementlearning in Advances in Neural Information ProcessingSystems Vol 7 Morgan Kaufmann San Mateo CA 1995





























