Embed Size (px)
Citation preview

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
Facial feature extraction for face recognition: a review
Elham Bagherian, Rahmita Wirza O.K. Rahmat Department of multimedia
University Putra Malaysia, 43400 UPM Serdang, Selangor D.E., Malaysia [email protected], [email protected]
Abstract
Over the last decade facial feature extraction has been actively researched for face recognition. This paper provides an up-to-date review of major human facia recognition research. Earlier sections we presented an overview of face recognition and its applications. In later sections, a literature review of the most recent face recognition technique is presented. The most prominent feature extraction and the techniques are also given. Finally, we summarized all research results discussed. 1. Introduction
Face recognition is one of biometric methods identifying individuals by the features of face. Research in this area has been conducted for more than 30 years; as a result, the current status of face recognition technology is well advanced. Many commercial applications of face recognition are also available such as criminal identification, security system, image and film processing. Accurate localization and tracking facial features are important in applications such as vision-based human machine interaction, face-based human identification, animation, entertainment, etc. From the sequence of images captured by camera, the goal is to find best match with given image. Using a pre-stored image database, the face recognition
system should be able to identify or verify one or more persons in the scene.
Before face recognition is performed, the system should determine whether or not there is a face in a given image or given video, a sequence of images. This process is called face detection. Once a face is detected, face region should be isolated from the scene for the face recognition. The face detection and face extraction are often performed simultaneously. The overall process is depicted in Fig 1. Face recognition can be done in both a still image and video, which has its origin in still-image face recognition. Current 2D face recognition systems encounter difficulties in handling facial variations due to head poses and lighting condition [1]. Different approaches of face recognition for still images can be categorized into tree main groups such as holistic approach, feature-based approach, and hybrid approach [2]. 1.1. Holistic Approach
In holistic approach, the whole face region is taken into account as input data into face detection system. Examples of holistic methods are eigenfaces (most widely used method for face recognition), probabilistic eigenfaces, fisherfaces, support vector machines, nearest feature lines (NFL) and independent-component analysis approaches. They are all based on principal component-analysis (PCA) techniques that can be used to simplify a dataset into lower dimension while retaining the characteristics of dataset. 1.2. Feature-based Approach
In feature-based approaches, local features on face such as nose, and then eyes are segmented and then used as input data for structural classifier. Pure
geometry, dynamic link architecture, and hidden Markov model methods belong to this category.
1.3. Hybrid Approach
The idea of this method comes from how human vision system perceives both local feature and
Figure 1: face recognition

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
whole face. There are modular eigenfaces, hybrid local feature, shape normalized, and component-based methods in hybrid approach. Human facial features play a significant role in perceiving faces. Neurophysiologic Research and studies have determined that eyes, mouth, and nose are amongst the most important features for recognition [3]. Thus, when a human face is represented as an image, it is very natural for these features to depict distinguishing characteristics not present in other facial components such as forehead, cheeks and chin. The eyes, the mouth, and the nostrils are the local minima of a facial image, whereas, the tip of the nose is a local maximum. However, for the purpose of compression herein, the facial features of interest are only the eyes and the mouth. Feature detection starts with eye detection. An accurate and robust eye detector is desirable to help estimate the position, size, and orientation of the face region, and thus improve the shape constraints for the feature search [4]. When a facial intensity image is represented as a surface, the brightness values form deep valleys in the facial feature regions, allowing topological methods to be used for their localization. The key idea in the methodology is to model the eyes and mouth as ravines on the image surface. For this purpose, first present a brief background on differential geometry and topology basics, which is followed by the feature extraction technique developed. 2. Face recognition techniques
This section gives an overview on the major human face recognition techniques that apply mostly to frontal faces, advantages and disadvantages of each method are also given. The methods considered are eigenfaces (eigenfeatures), neural networks, dynamic link architecture, hidden Markov model, geometrical feature matching, and template matching. The approaches are analyzed in terms of the facial representations they used. 2.1. Neural networks The attractiveness of using neural networks could be due to its non linearity in the network. Hence, the feature extraction step may be more efficient than the linear Karhunen-Loève methods which choose a dimensionality reducing linear projection that maximizes the scatter of all projected samples [5]. The authors reported 96.2% correct recognition on ORL database of 400 images of 40 individuals. The classification time is less than 0.5 second, but the training time is as long as 4 hours features in a hierarchical set of layers and provides partial invariance to translation, rotation, scale, and deformation. However, when the number of persons increases, the computing expense will
become more demanding. In general, neural network approaches encounter problems when the number of classes (i.e., individuals) increases. Moreover, they are not suitable for a single model image recognition test because multiple model images per person are necessary in order for training the systems to “optimal” parameter setting. 2.2. Geometrical Feature Matching
Geometrical feature matching techniques are based on the computation of a set of geometrical features from the picture of a face. The overall configuration can be described by a vector representing the position and size of the main facial features, such as eyes and eyebrows, nose, mouth, and the shape of face outline. One of the pioneering works on automated face recognition by using geometrical features was done by T. Kanade [6]. Their system achieved a peak performance of 75% recognition rate on a database of 20 people using two images per person, one as the model and the other as the test image. I.J. Cox et al [7] introduced a mixture-distance technique which achieved 95% recognition rate on a query database of 685 individuals. Each face was represented by 30 manually extracted distances. B.S. Manjunath et al [8] Used decomposition to detect feature points for each face image, which greatly reduced the storage requirement for the database. Typically, 35-45 feature points per face were generated. The matching process utilized the information presented in a topological graphic representation of the feature points. After compensating for different centred location, two cost values, the topological cost, and similarity cost, were evaluated. In summary, geometrical feature matching based on precisely measured distances between features may be most useful for finding possible matches in a large database. However, it will be dependent on the accuracy of the feature location algorithms. Current automated face feature location algorithms do not provide a high degree of accuracy and require considerable computational time to the right person was 86% and 94% of the correct person's faces were in the top three candidate matches. 2.3. Graph Matching
Graph matching is another approach to face recognition. M. Lades et al [9] presented a dynamic link structure for distortion invariant object recognition, which employed elastic graph matching to find the closest stored graph. Dynamic link architecture is an extension to classical artificial neural networks. Memorized objects are represented by sparse graphs, whose vertices are labelled with a multi resolution description in terms of a local power spectrum and whose edges are

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
labelled with geometrical distance vectors. Object recognition can be formulated as elastic graph matching which is performed by stochastic optimization of a matching cost function. They reported good results on a database of 87 people and a small set of office items comprising different expressions with a rotation of 15 degrees. The matching process is computationally expensive, taking about 25 seconds to compare with 87 stored objects on a parallel machine with 23 transporters. L. Wiskott et al [10] extended the technique and matched human faces against a gallery of 112 neutral frontal view faces. Probe images were distorted due to rotation in depth and changing facial expression. Encouraging results on faces with large rotation angles were obtained. They reported recognition rates of 86.5% and 66.4% for the matching tests of 111 faces of 15 degrees rotation and 110 faces of 30 degrees rotation to a gallery of 112 neutral frontal views. In general, dynamic link architecture is superior to other face recognition techniques in terms of rotation invariance; however, the matching process is computationally expensive. 2.4. Eigenfaces Eigenface is one of the most thoroughly investigated approaches to face recognition. It is also known as Karhunen- Loève expansion, eigenpicture, eigenvector, and principal component. L. Sirovich and M. Kirby [11, 12] used principal component analysis to efficiently represent pictures of faces. They argued that any face images could be approximately reconstructed by a small collection of weights for each face and a standard face picture (eigenpicture). The weights describing each face are obtained by projecting the face image onto the eigenpicture. M. Turk and A. Pentland [13] used eigenfaces, which was motivated by the technique of Kirby and Sirovich, for face detection and identification. In mathematical terms, eigenfaces are the principal components of the distribution of faces, or the eigenvectors of the covariance matrix of the set of face images. The eigenvectors are ordered to represent different amounts of the variation, respectively, among the faces. Each face can be represented exactly by a linear combination of the eigenfaces. It can also be approximated using only the “best” eigenvectors with the largest eigenvalues. The best M eigenfaces construct an M dimensional space, the “face space”. The authors reported 96 percent, 85 percent, and 64 percent correct classifications averaged over lighting, orientation, and size variations, respectively. Their database contained 2,500 images of 16 individuals. As the images include a large quantity of background area, the above results are influenced by background. The authors explained the robust
performance of the system under different lighting conditions by significant correlation between images with changes in illumination. However, M.A. Grudin [14] showed that the correlation between images of the whole faces is not efficient for satisfactory recognition performance. Illumination normalization [12] is usually necessary for the eigenfaces approach. L. Zhao and Y.H. Yang [15] proposed a new method to compute the covariance matrix using three images each was taken in different lighting conditions to account for arbitrary illumination effects, if the object is Lambertian A. Pentland, B. Moghaddam [16] extended their early work on eigenface to eigenfeatures corresponding to face components, such as eyes, nose, and mouth. They used a modular eigenspace, which was composed of the above eigenfeatures (i.e., eigeneyes, eigennose, and eigenmouth). This method would be less sensitive to appearance changes than the standard eigenface method. The system achieved a recognition rate of 95 percent on the FERET database of 7,562 images of approximately 3,000 individuals. In summary, eigenface appears as a fast, simple, and practical method. However, in general, it does not provide invariance over changes in scale and lighting conditions. Recently, in A. Pentland, B. Moghaddam [16] experiments with ear and face recognition, using the standard principal component analysis approach, showed that the recognition performance is essentially identical using ear images or face images and combining the two for multimodal recognition results in a statistically significant performance improvement. For example, the difference in the rank-one recognition rate for the day variation experiment using the 197-image training sets is 90.9% for the multimodal biometric versus 71.6% for the ear and 70.5% for the face. There is substantial related work in multimodal biometrics. For example L. Hong and A. Jain [17]Used face and fingerprint in multimodal biometric identification, and P. Verlinde et al [18] used face and voice. However, use of the face and ear in combination seems more relevant to surveillance applications. 2.5. Fisherface
Belhumeur et al [19] propose fisherfaces method by using PCA and Fisher’s linear discriminant analysis to produce subspace projection matrix that is very similar to that of the eigen space method. However this method can solve one of the main issues that arise in Pentland’s eigenfaces method [20], one of the main drawbacks of eigen face approach is that the scatter being maximized can also be due to within-class scatter, which can increase detection error rate if there is a significant variation in pose or lighting condition within same
978-1-4244-2328-6/08/$25.00 © 2008 IEEE
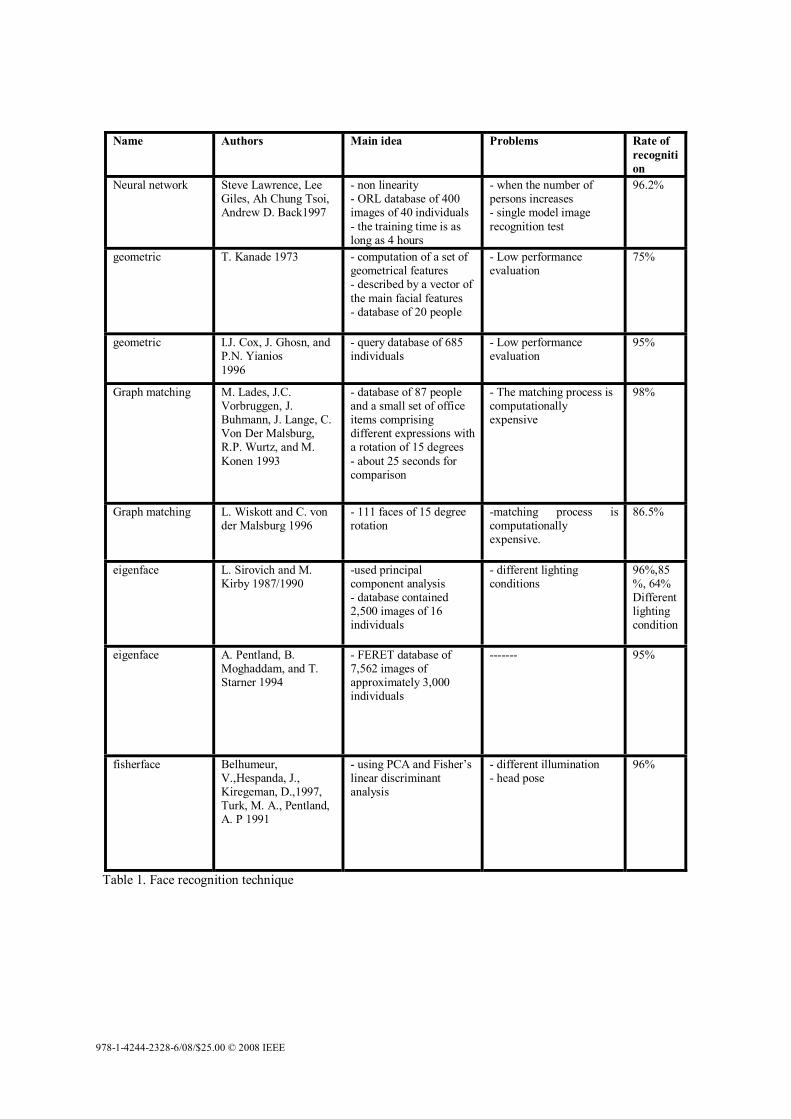
Table 1. Face recognition technique
Name Authors Main idea Problems Rate of recognition
Neural network Steve Lawrence, Lee Giles, Ah Chung Tsoi, Andrew D. Back1997
- non linearity - ORL database of 400 images of 40 individuals - the training time is as long as 4 hours
- when the number of persons increases - single model image recognition test
96.2%
geometric T. Kanade 1973 - computation of a set of geometrical features - described by a vector of the main facial features - database of 20 people
- Low performance evaluation
75%
geometric I.J. Cox, J. Ghosn, and P.N. Yianios 1996
- query database of 685 individuals
- Low performance evaluation
95%
Graph matching M. Lades, J.C. Vorbruggen, J. Buhmann, J. Lange, C. Von Der Malsburg, R.P. Wurtz, and M. Konen 1993
- database of 87 people and a small set of office items comprising different expressions with a rotation of 15 degrees - about 25 seconds for comparison
- The matching process is computationally expensive
98%
Graph matching L. Wiskott and C. von der Malsburg 1996
- 111 faces of 15 degree rotation
-matching process is computationally expensive.
86.5%
eigenface L. Sirovich and M. Kirby 1987/1990
-used principal component analysis - database contained 2,500 images of 16 individuals
- different lighting conditions
96%,85%, 64% Different lighting condition
eigenface A. Pentland, B. Moghaddam, and T. Starner 1994
- FERET database of 7,562 images of approximately 3,000 individuals
------- 95%
fisherface Belhumeur, V.,Hespanda, J., Kiregeman, D.,1997, Turk, M. A., Pentland, A. P 1991
- using PCA and Fisher’s linear discriminant analysis
- different illumination - head pose
96%

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
face images. Considering these changes due to different illumination and head pose are almost always greater than variation due to difference in face identity, a robust detection system should be able to handle the problem. Since, the fisherfaces approach takes advantage of within-class information; minimizing variation within each class, yet maximizing class separation, the problem with variations in the same images such as different lighting conditions can be overcome. Please refer to table 1, which provides the comparison of face recognition techniques. 3. Facial Feature Extraction
The importance of facial features for face recognition cannot be overstated. Many face recognition systems need facial features in addition to the holistic face, as suggested by studies in psychology. It is well known that even holistic matching methods, for example, eigenfaces proposed by Turk and Pentland [13] and Fisherfaces, which proposed by Belhumeur et al [19], need accurate locations of key facial features such as eyes, nose, and mouth to normalize the detected face. Facial features can be of different types: region [21, 22], key point (landmark) [23, 24], and contour [25, 26]. Generally, key point features provide more accurate and consistent representation for alignment purposes than region-based features, with lower complexity and computational burden than contour feature extraction. Three types of feature extraction methods can be distinguished: (1) generic methods based on edges, lines, and curves; (2) feature-template-based methods that are used to detect facial features such as eyes; (3) structural matching methods that take into consideration geometrical constraints on the features. Early approaches focused on individual features; for example, a template-based approach was described in Hallinan [43] to detect and recognize the human eye in a frontal face. These methods have difficulty when the appearances of the features change significantly, for example, closed eyes, eyes with glasses, open mouth. To detect the features more reliably, recent approaches have used structural matching methods, for example, the Active Shape Model Compared to earlier methods, these recent statistical methods are much more robust in terms of handling variations in image intensity and feature shape. An even more challenging situation for feature extraction is feature “restoration,” which tries to recover features that are invisible due to large variations in head pose. The best solution here might be to hallucinate the missing features either by using the bilateral symmetry of the face or using learned information. For example, a view-based statistical method
claims to be able to handle even profile views in which many local features are invisible. 3.1. Ranking of significance of facial features
Hair, face out-line, eyes, mouth have been determined to be important for perceiving and remembering faces, and found that the upper part of the face is more useful for face recognition than the lower part. The eyes are an important feature that can be consistently identified. Previous works on facial feature and fiducially points detection The facial feature detection and the fiducially point estimation are fundamental steps for several applications. Regarding the facial feature localization, several techniques have been proposed; each one transforms the original data into a space were the features are more highlighted. First of all we recall the techniques to be applied to video sequences, where head motion allows determining roughly head and facial feature positions [27,28,29] Technical Report Such techniques try to match a face model (e.g. CANDIDE) to the moving region; the model vertices correspond to the features, and thus inform on their rough positions. In case of still images, face localization is a much more complex problem, which is very often ignored when the facial features are searched for; thus, mug shots are normally used to test the feature detection algorithms. In this framework, we can identify two categories: the techniques, which adopt an exhaustive search, and the ones, which introduce some heuristics to reduce the feature search area. In the first case all the pixels are evaluated to verify whether a feature is cantered in that pixel or not; we observe that all the techniques in this category work on grey level images. One example is the template-based techniques (e.g. [30, 31]) the typical appearance of each feature is characterized with a template, used to look for that feature in the probe image. It is evident that when a template is defined, both the feature scale and appearance are fixed. Thus this technique suffers of a strong scale and poses dependency. Another example of this category is the method introduced by Heisele et al [32], the whole image is scanned, and the portion of it cantered in correspondence to each pixel is evaluated in a multi-resolution way: squares of (58 × 58) pixels, obtained from the image at the different scales, are given as input to SVMs trained to recognize a specific feature (left eye, right eye, and mouth). Moreover, a second level classifier verifies the global face. This technique works on face images of dimensions between (80 × 80) and (130×130) pixels. Moreover it deals with face rotation (up to 40_), and the presence of glasses. In order to reduce the search area, different feature

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
characterizations have been proposed; perhaps the simplest is based on the fact that the grey levels corresponding to the features are darker than the skin ones. A.Nikolaidis et al [33, 34, 35] introduced the methods that having localized the face region, detect the features by projecting horizontally and vertically the grey levels: eyes, for example, correspond to the rows with the minima values. Such techniques can be applied to vertical face images only, can deal with small rotations around the vertical axis, and do not deal with glasses and beard. T. Kawaguchi et al [36] after having roughly localized the face, the corresponding sub image is binaries, and the search area is limited to the obtained darkest regions. The eyes are then searched for by means of a Hough-like technique, used to look for the most probable circles, and validated by means of a template representing two eyes placed side by side. The system is scale dependent, works on vertical face images only, while it deals with rotation of the head around the vertical axis up to 30_. No expression variation or occlusion is admitted. The second category consists of techniques, which reduce the feature search area by introducing an image transformation to facilitate the feature identification. An example is the technique proposed by Hsu et al [37] International Conference Image Processing. Where a colour combination and a morphological characterization are used to select hypothetical eyes and mouths: each possible triplet has to be validated according to the knowledge of the distances among them. The system has shown to be scale and pose independent, besides to be very efficient in the skin region detection (the computational time of the validation step varies greatly according to the number of triplet to be considered). Another transformation is the one proposed by Herpers et al [38], where a saliency map is obtained applying a bank of high pass filters: with high probability the features correspond to the maxima in the saliency map; thus the maxima are extracted and the corresponding portions of image are verified to be a feature by means of deformable templates: applying for example an eye deformable template, the authors conclude the sub-image is effectively an eye if at the end of the optimization step the template is not ‘too’ deformed. The method works on frontal face images, acquired at different illuminations and scales, but it is not robust to different poses, expressions, and occlusions. Moreover it is computationally expensive. Another characterization is based on the Gabor wavelet transform adopted by Smeraldi and Bigun [39] in a first stage three SVMs are trained to recognize respectively left eyes, right eyes, and mouths. These classifiers receive as input the responses of a bank of Gabor wavelets applied to several images representing both positive and negative examples.
The filters vary in orientation and scale. Afterwards, given a probe image, the algorithm chooses randomly a position, apply the bank of Gabor wavelet filters to it, and gives the obtained responses as input to the SVMs in order to classify it as one of the features or discard it. The subsequent position choices are driven by the knowledge of the features relative positions. The system works on frontal images with a given scale. It deals with glasses, beard, and partial eye occlusions, different expressions and poses. Finally, we report the characterization adopted by Hamouz et al [40] the features are localized applying subsequent steps: at first the corner points are extracted by means of the Harris method [41] then the corresponding image portions are evaluated by means of a PCA characterization and thus accepted or rejected. 4. Techniques of facial feature extraction 4.1. Geometry-based
The features are extracted using geometric information such as relative positions and sizes of the face components. This technique is proposed by Kanade [42] the eyes, the mouth and the nose base are localized using the vertical edge map. These techniques require threshold, which, given the prevailing sensitivity, may adversely affect the achieved performance 4.2. Template-based
This technique, match facial components to previously designed templates using appropriate energy functional. The best match of a template in the facial image proposed by Yuille et al [43] will yield the minimum energy, where these algorithms require a priori template modelling, in addition to their computational costs, which clearly affect their performance. Genetic algorithms have been proposed for more efficient searching times in template matching. 4.3. Colour segmentation techniques Colour segmentation technique makes use of skin colour to isolate the face. Any non-skin colour region within the face is viewed as a candidate for eyes and/or mouth. The performance of such techniques on facial image databases is rather limited, due to the diversity of ethnical backgrounds [44]

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
4.4. Appearance-based approaches
The concept of “feature” in these approaches differs from simple facial features such as eyes and mouth. Any extracted characteristic from the image is referred to a feature. Methods such as principal component analysis (PCA), independent component analysis, and Gabor-wavelets [45] are used to extract the feature vector. These approaches are commonly used for face recognition rather than person identification. Refer to table 2, which provides the comparison of advantages and disadvantages of facial feature extraction techniques.
5. Conclusion
In this paper we reviewed the works done in
facial feature extraction, with respect to resource discovery. We also focused and evaluated different techniques and ideas, used to reduce the bandwidth consumption during this process. References [1] Face Recognition Vendor Test (FRVT).
<http://www.frvt.org/>. [2] Zhao, W., Chellappa, R., Phillips, P. J.,
Rosenfeld, A., 2003, Face recognition: A literature survey, ACM Computing Surveys (CSUR), V. 35, Issue 4, pp. 399-458
[3] H.D. Ellis, “Introduction to aspects of face
processing: Ten questions in need of answers”, in Aspects of Face Processing, H. D. Ellis, M. Jeeves, F. Newcombe, and A. Young Eds. Dordrecht:Nijhoff, 1986, pp.3-13.
[4] Yan Tong, Yang Wang, Zhiwei Zhu, and Qiang Ji, Robust Facial Feature Tracking under Varying Face Pose and Facial Expression, Pattern Recognition journal, Vol. 40, No. 11, pp. 3195-3208, 2007
[5] KIRBY, M. AND SIROVICH, L. 1990. Application of the Karhunen-Loeve procedure for the characterization of human faces. IEEE Trans. Patt. Anal. Mach. Intell. 12
[6] T. Kanade, “Picture processing by computer complex and recognition of human faces,” technical report, Dept. Information Science, Kyoto Univ., 1973
[7] I.J. Cox, J. Ghosn, and P.N. Yianios, “Feature-Based face recognition using mixture-distance,” Computer Vision and Pattern Recognition, 1996
[8] B.S. Manjunath, R. Chellappa, and C. von der Malsburg, “A Feature based approach to face recognition,” Proc. IEEE CS Conf. Computer Vision and Pattern Recognition, pp. 373-378, 1992
[9] M. Lades, J.C. Vorbruggen, J. Buhmann, J. Lange, C. Von Der Malsburg, R.P. Wurtz, and M. Konen, “Distortion Invariant object recognition in the dynamic link architecture,”
Ttable1 2.advantages and disadvantages of facial feature extraction
Techniques of facial feature extraction
Advantages Disadvantages
Geometry-based -With low resolution face images, we also evaluate a simple geometric features. -Small data base. -Simple manner -Recognition rate 95%
- large number of features are used.
Template- based
-recognition rate 100% -simple manner.
-computational complexity -description between templates and images has a long time -Template matching is only effective when query and model images have the same scale, orientation and illumination properties.
Colour segmentation- based
-small data base -simple manner
-recognition rate 85% - imllumination,hue,rate of quality are effective on recognition rate. -discontinuity between colours -in profile and closed eyes have a problem
appearance-based -small number of features. -recognition rate 98%
-needs good quality images -large size of data base -Illumination

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
IEEE Trans. Computers, vol. 42, pp. 300-311, 1993.
[10]L. Wiskott and C. von der Malsburg, “Recognizing faces by dynamic link matching,” Neuroimage, vol. 4, pp. 514-518, 1996
[11]L. Sirovich and M. Kirby, “Low-Dimensional procedure for the characterisation of human faces,” J. Optical Soc. of Am., vol. 4, pp. 519-524, 1987.
[12] M. Kirby and L. Sirovich, “Application of the Karhunen- Loève procedure for the characterisation of human faces,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 12, pp. 831-835, Dec.1990
[13] M. Turk and A. Pentland, “Eigenfaces for recognition,” J. Cognitive Neuroscience, vol. 3, pp. 71-86, 1991
[14] M.A. Grudin, “A compact multi-level model for the recognition of facial images,” Ph.D. thesis, Liverpool John Moores Univ., 1997
[15]L. Zhao and Y.H. Yang, “Theoretical analysis of illumination in pcabased vision systems,” Pattern Recognition, vol. 32, pp. 547-564, 1999.
[16] A. Pentland, B. Moghaddam, and T. Starner, “View-Based and modular eigenspaces for face recognition,” Proc. IEEE CS Conf. Computer Vision and Pattern Recognition, pp. 84-91, 1994
[17] L. Hong and A. Jain, “Integrating faces and fingerprints for personal identification,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 20, no. 12, pp. 1295-1307, Dec. 1998.
[18] P. Verlinde, G. Matre, and E. Mayoraz, “Decision fusion using a multilinear classifier,” Proc. Int’l Conf. Multisource-Multisensor Information Fusion, vol. 1, pp. 47-53, July 1999
[19] Belhumeur, V., Hespanda, J., Kiregeman, D., 1997, Eigenfaces vs. fisherfaces: recognition using class specific liear projection, IEEE Trans. on PAMI, V. 19, pp. 711-720.
[20] Turk, M. A., Pentland, A. P., Eigenfaces for recognition, 1991, Cognitive Neurosci., V. 3, no.1, pp.71-86
[21] Y. Ryu and S. Oh, “Automatic extraction of eye and mouth fields from a face image
using eigenfeatures and multiplayer perceptrons,” Pattern Recognition, vol. 34, no. 12,pp. 2459–2466, 2001.
[22] D. Cristinacce and T. Cootes, “Facial feature detection using adaboost with shape
constraints,” in Proc. 14th British Machine Vision Conference, Norwich, UK, Sep.2003, pp. 231–240.
[23] L. Wiskott, J.M. Fellous, N. Kruger, and C. von der Malsburg, “Face recognition by
elastic bunch graph matching,” IEEE Trans. Pattern Analysis and Machine Intelligence,vol. 19, no. 7, pp. 775–779, 1997.
[24] K. Toyama, R. Feris, J. Gemmell, and V. Kruger, “Hierarchical wavelet networks forfacial feature localization,” in Proc. IEEE International Conference on Automatic Face and Gesture Recognition, Washington D.C., 2002, pp. 118–123.
[25] T.F. Cootes, G.J. Edwards, and C.J. Taylor, “Active appearance models,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 23, no. 6, pp. 681–685, Jun. 2001.
[26] J. Xiao, S. Baker, I. Matthews, and T. Kanade, “Real-time combined 2D+3D active appearance models,” in Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004, pp. 535–542.
[27]J. Ahlberg. a system for face localization and facial feature extraction.
[28] L. Zhang. tracking a face in a knowledge-based analysis-synthesis Coder. International Workshop on Coding Techniques for very low bit- Rate video coding (VLBV 95), 1(2), 1995.
[29] Z. Zhang. Image-based modeling of objects and human faces. Proceed- ings SPIE ’01, 2001
[30]R. Brunelli and T. Poggio. Face recognition: Features versus templates. IEEE Transactions PAMI, 15(10):1042–1062, 1993
[31] C.H. Lin and J.L. Wu. Automatic facial feature extraction by genetic Algorithms. IEEE Transactions on Image processing, 8(6):—, 1999
[32]B. Heisele, P. Ho, and T. Poggio. Face recognition with support vector machines: global vesus component-based approach. Proceedings IEEE International Conference on Computer Vision (ICCV2001), pages 688– 694, 2001.;
[33]A.Nikolaidis and I. Pitas. Facial feature extraction and pose determination,
[34]S. Tsekeridou and I. Pitas. Facial feature extraction in frontal views using biometric analogies. in Proc. of the IX European Signal Processing Conference, I:315–318, 1998
[35]L. Rujie and Y. Baozong. Automatic eye feature extraction in human face images. Computing and Informatics, 20:289–301, 2001
[36]T. Kawaguchi, D. Hidaka, and M. Rizon. Detection of eyes from human faces by hough transform and separability filter. Proceedings ICIP, Vancouver, I:49–52, 2000.,
[37]R. Hsu and A.K. Jain. Face modeling for recognition. Proceedings IEEE
[38]R. Herpers and G. Sommer. An attentive processing strategy for the analysis of facial features. In H. Wechsler, P. J. Phillips, V. Bruce, F. Fogelman Souli´e, and T. S. Huang,

978-1-4244-2328-6/08/$25.00 © 2008 IEEE
editors, Face recognition, pages 457–468. Springer, London, 1998
[39]F. Smeraldi and J. Bigun. Retinal vision applied to facial features detection and face authentication. Pattern recognition letters, 23:463– 475, 2002.
[40]M. Hamouz, J. Kittler, J.K. Kamarainen, and H. K¨alvi¨ainen. Hypotheses-driven affine invariant localization of faces in verification systems. Proceedings AVBPA 2003, pages 276–284, 2003
[41] C.J. Harris and M. Stephens. A combined corner and edge detector. Proceedings of 4th Alvey Vision Conference, pages 147–151, 1988
[42]T. Kanade, Computer Recognition of Human faces, Basel and Stuttgart: Birkhauser, 1997.
[43]A. Yuille, D. Cohen, and P. Hallinan, “Facial feature extraction from faces using deformable templates”, Proc. IEEE Computer Soc. Conf. On Computer Vision and Pattern Recognition, pp. 104-109, 1989.
[44]T.C. Chang, T.S. Huang, and C. Novak, “Facial feature extraction from colour images”, Proceedings of the 12th IAPR International Conference on Pattern Recognition, vol. 2, pp. 39-43, Oct 1994.
[45]Y. Tian, T. Kanade, and J.F. Cohn, “Evaluation of Gabor-wavelet-based facial action unit recognition in image sequences of increasing complexity”, Proceedings of the Fifth IEEE International Conference on Automatic Face and Gesture Recognition, pp. 218 –223, May 2002.




























