Embed Size (px)
Citation preview

ExProM 2015
Second Workshop on Extra-Propositional Aspects ofMeaning in Computational Semantics (ExProM 2015)
Proceedings
June 5, 2015Denver, Colorado, USA

Funding for student travel grants was provided by the National Science Foundation under Grant No.1523586.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of theauthor(s) and do not necessarily reflect the views of the National Science Foundation.
c©2015 The Association for Computational Linguistics
Order print-on-demand copies from:
Curran Associates57 Morehouse LaneRed Hook, New York 12571USATel: +1-845-758-0400Fax: [email protected]
ISBN 978-1-941643-44-0
ii

Introduction
During the last decade, semantic representation of text has focused on extracting propositional meaning,i.e., capturing who does what to whom, when and where. Several corpora are available, and existingtools extract this kind of knowledge, e.g., semantic role labelers trained on PropBank, NomBank orFrameNet. But propositional semantic representations disregard significant meaning encoded in humanlanguage. For example, while sentences (1-2) below share the same propositional meaning regardingverb carry, they do not convey the same overall meaning. In order to truly capture what these sentencesmean, extra-propositional aspects of meaning (ExProM) such as uncertainty, negation and attributionmust be taken into account.
1. Thomas Eric Duncan likely contracted the disease when he carried a pregnant woman sick withEbola.
2. Thomas Eric personally told me that he never carried a pregnant woman with Ebola.
The Extra-Propositional Aspects of Meaning (ExProM) in Computational Linguistics Workshopfocuses on a broad range of semantic phenomena beyond propositional meaning, i.e., beyond linkingpropositions and their semantic arguments with relations such as AGENT (who), THEME (what),LOCATION (where) and TIME (when).
ExProM is pervasive in human language and, while studied from a theoretical perspective,computational models are scarce. Humans use language to describe events that do not correlate with areal situation in the world. They express desires, intentions and plans, and also discuss events that didnot happen or are unlikely to happen. Events are often described hypothetically, and speculation can beused to explain why something is a certain way without a strong commitment. Humans do not always(want to) tell the (whole) truth: they may use deception to hide lies. Devices such as irony and sarcasmare employed to play with words so that what is said is not what is meant. Finally, humans not onlydescribe their personal views or experiences, but also attribute statements to others. These phenomenaare not exclusive of opinionated texts. They are ubiquitous in language, including scientific works andnews as exemplified below:
• A better team might have prevented this infection.
• Some speculate that this was a failure of the internal communications systems.
• Infected people typically don’t become contagious until they develop symptoms.
• Medical personnel can be infected if they don’t use protective gear, such as surgical masks andgloves.
• You cannot get it from another person until they start showing symptoms of the disease, likefever.
• You can only catch Ebola from coming into direct contact with the bodily fluids of someone whohas the disease and is showing symptoms.
iii

• We’ve never seen a human virus change the way it is transmitted.
• There is no reason to believe that Ebola virus is any different from any of the viruses that infecthumans and have not changed the way that they are spread.
In its 2015 edition, the Extra-Propositional Aspects of Meaning (ExProM) in Computational LinguisticsWorkshop was collocated with the Conference of the North American Chapter of the Association forComputational Linguistics (NAACL) in Denver, CO. The workshop took place on June 5, 2015, andthe program consisted of five papers (4 long papers and 1 short paper) and an invited talk by LauriKarttunen. ExProM 2015 is a a follow-up of two previous events: the 2010 Negation and Speculationin Natural Language Processing Workshop (NeSp-NLP 2010) and ExProM 2012.
We would like to thank the authors of papers for their interesting contributions, the members of theprogram committee for their insightful reviews, and Lauri Karttunen for giving the invited talk. We aregrateful to the National Science Foundation for a grant to support student travel to the workshop.
iv

Organizers:
Eduardo Blanco, University of North Texas, USARoser Morante, VU University Amsterdam, The NetherlandsCaroline Sporleder, Universität Trier, Germany
Program Committee:
Tim Baldwin - The University of MelbourneEmily M. Bender - University of WashingtonCosmin Adrian Bejan - Vanderbilt UniversityGosse Bouma - University of GroningenTommaso Caselli - VU University AmsterdamJacob Eisenstein - Georgia TechEdward Grefenstette - Google DeepMindZhou Guadong - Soochow UniversityIvan Habernal - TU DarmstadtIris Hendrickx - Radboud UniversityLori Levin - Carnegie Mellon UniversityMaria Liakata - University of WarwickErwin Marsi - Norwegian University of Science and TechnologyMalvina Nissim - University of GroningenSampo Pyysalo - University of TurkuChristopher Potts - Stanford UniversityGerman Rigau - UPV/EHUEllen Riloff - University of UtahPaolo Rosso - Universidad Politècnica de ValenciaJosef Ruppenhofer - Universität HildesheimRoser Saurí - Universitat Pompeu FabraErik Velldal - University of OsloBonnie Webber - University of EdinburghByron C. Wallace, UT AustinMichael Wiegand - Saarland University
Invited Speaker:
Lauri Karttunen, Stanford University
v


Table of Contents
Translating Negation: A Manual Error AnalysisFederico Fancellu and Bonnie Webber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
Filled Pauses in User-generated Content are Words with Extra-propositional MeaningInes Rehbein . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
A Compositional Interpretation of Biomedical Event FactualityHalil Kilicoglu, Graciela Rosemblat, Michael Cairelli and Thomas Rindflesch . . . . . . . . . . . . . . . 22
Committed Belief Tagging on the Factbank and LU Corpora: A Comparative StudyGregory Werner, Vinodkumar Prabhakaran, Mona Diab and Owen Rambow . . . . . . . . . . . . . . . . . 32
Extending NegEx with Kernel Methods for Negation Detection in Clinical TextChaitanya Shivade, Marie-Catherine de Marneffe, Eric Fosler-Lussier and Albert M. Lai . . . . . .41
vii


Workshop Program
Friday June 5 2015
8:00–09:00 Breakfast
9:15–9:30 Opening remarks
9:30–10:30 Invited Talk: Lauri Karttunen
10:30–11:00 Coffee break
11:00–12:30 Session 1
11:00–11:30 Translating Negation: A Manual Error AnalysisFederico Fancellu and Bonnie Webber
11:30–12:00 Filled Pauses in User-generated Content are Words with Extra-propositional Mean-ingInes Rehbein
12:00–12:30 A Compositional Interpretation of Biomedical Event FactualityHalil Kilicoglu, Graciela Rosemblat, Michael Cairelli and Thomas Rindflesch
12:30–2:00 Lunch break
ix

Friday June 5 2015 (continued)
14:00–14:30 Session 2
14:10–14:30 Committed Belief Tagging on the Factbank and LU Corpora: A Comparative StudyGregory Werner, Vinodkumar Prabhakaran, Mona Diab and Owen Rambow
14:30–15:00 Extending NegEx with Kernel Methods for Negation Detection in Clinical TextChaitanya Shivade, Marie-Catherine de Marneffe, Eric Fosler-Lussier and AlbertM. Lai
15:00–15:30 Discussion and closing remarks
x

Proceedings of the Second Workshop on Extra-Propositional Aspects of Meaning in Computational Semantics (ExProM 2015), pages 1–11,Denver, Colorado, June 5, 2015. c©2015 Association for Computational Linguistics
Translating Negation: A Manual Error Analysis
Federico Fancellu and Bonnie WebberSchool of Informatics
University of Edinburgh11 Crichton Street, Edinburgh
f.fancellu[at]sms.ed.ac.uk , bonnie[at]inf.ed.ac.uk
Abstract
Statistical Machine Translation has come along way improving the translation qualityof a range of different linguistic phenom-ena. With negation however, techniques pro-posed and implemented for improving transla-tion performance on negation have simply fol-lowed from the developers’ beliefs about whyperformance is worse. These beliefs, however,have never been validated by an error analysisof the translation output. In contrast, the cur-rent paper shows that an informative empiri-cal error analysis can be formulated in termsof (1) the set of semantic elements involvedin the meaning of negation, and (2) a smallset of string-based operations that can char-acterise errors in the translation of those ele-ments. Results on a Chinese-to-English trans-lation task confirm the robustness of our anal-ysis cross-linguistically and the basic assump-tions can inform an automated investigationinto the causes of translation errors. Conclu-sions drawn from this analysis should guidefuture work on improving the translation ofnegative sentences.
1 Introduction
In recent years, there has been increasing interest inimproving the quality of SMT systems over a widerange of linguistic phenomena, including corefer-ence resolution (Hardmeier et al., 2014) and modal-ity (Baker et al., 2012). Amongst these, however,translating negation is still a problem that has notbeen researched thoroughly.
This paper takes an empirical approach towards
understanding why negation is a problem in SMT.More specifically, we try to answer two main ques-tions:
1. What kind of errors are involved in translatingnegation?
2. What are the causes of these errors during de-coding?
While previous work (section 2) has shown thattranslating negation is a problem, it has not ad-dressed either of these questions.
The present paper focuses on the first one; weshow that tailoring to a semantic task, string-basederror categories standardly used to evaluate the qual-ity of the machine translation output, allows usto cover the wide range of errors occurring whiletranslating negative sentences (section 3). We re-port the results of the analysis of a HierarchicalPhrase Based Model (Chiang, 2007) on a Chinese-to-English translation task (section 4), where weshow that all error categories occur to some extentwith scope reordering being the most frequent (sec-tion 5).
Addressing question (2) requires connecting theassumptions behind this manual error analysis to er-rors occurring along the translation pipeline. Assuch, we complete the analysis by briefly introducean automatic method to investigate the causes of theerrors at decoding time (section 6).
Conclusion and future works are reported in sec-tion 7 and 8.
1

2 Previous Work
In recent years, automatic recognition of negationhas been the focus of considerable work. Follow-ing Blanco and Moldoval (2011) and Morante andBlanco (2012) detecting negation is a task of unrav-eling its structure, i.e. locating in a text its four maincomponents:
• Cue: the word or multi-word unit inherentlyexpressing negation (e.g. ‘He is not driving acar’)
• Event: the lexical element the cue directlyrefers to (e.g. ‘He is not driving a car’)
• Scope: all the elements whose falsity wouldprove negation to be false; given that the cue isnot included, the scope is often discontinuous(e.g. ‘He is not driving a car’)
• Focus: the portion of the statement negationprimarily refers to (e.g. ‘He is not drivinga car).
The *SEM 2012 shared task represented a first at-tempt to apply machine learning methods to theproblem of automatically detect the aforementionedelements in English. In particular CRFs and SVMs,making use of syntactic (both constituent and de-pendency based) clues, were shown to lead to thebest results in a supervised machine learning setting(Read et al., 2012; Chowdhury and Mahbub, 2012).The shared task also saw the release of a fully an-notated corpus in the literature domain, which rep-resents, along with the BioScope corpus (Szarvas etal., 2008), the only resource specifically annotatedfor negation.
There were also a few attempts in automaticallydetecting negation in Chinese texts. Li et al. (2008)designed a negation detection algorithm based onsyntactic patterns; similarly, Zheng et al. (2014)implemented an FSA for automatic recognition ofnegation structures in Chinese medical texts, using alist of manually defined cues and the syntactic struc-tures they appear in.
In a bilingual setting such as the SMT, however,most work has only considered negation as a sideproblem. For this reason, no actual analysis on thetype of errors involved in translating negation or
their causes has been specifically carried out. Thestandard approach has been to formulate an hypoth-esis about what can go wrong when translating nega-tion, modify the SMT system in a way aimed at re-ducing the number of times that happens, and thenassume that any increase in BLEU score - the stan-dard automatic evaluation metric used in SMT - con-firms the initial hypothesis. Collins et al. (2005)and Li et al. (2009) consider negation, along withother linguistic phenomena, as a problem of struc-tural mismatch between source and target; Wetzeland Bond (2012) consider it instead as a problem oftraining data sparsity; finally Baker et al. (2012) andFancellu and Webber (2014) consider it as a modelproblem, where the system needs enhancement withrespect to the semantics of negation. Given thatall these works assess the quality of translation ofnegative sentences using an n-gram overlap metric,there is no certainty whether any improvement de-rives from a better rendering of negation or fromother, non-negation related elements.
Evaluating the semantic adequacy of the SMToutput has also stimulated interest in recent years.Traditional error categories, such as the ones pre-sented in (Vilar et al., 2006), are mostly based onn-gram overlap between hypothesis and referenceand so are the most widely used automatic evalu-ation metrics used in SMT (e.g. BLEU (Papineniet al., 2002) and TER (Snover et al., 2009)). Incontrast, MEANT (Lo and Wu, 2010, 2011) and itshuman counterpart, HMEANT, attempt to abstractfrom simple string matching and assess the degree ofsemantic similarity between machine output and ref-erence sentence. To do so, both sides are annotatedusing Propbank-like semantic labels, and the fillersmatched if both sides contain the same event. To as-sign a score to the test set evaluated, an F1 measureover precision and recall of matched fillers is thencomputed.
3 Methodology
3.1 Manual Annotation
First, we start with the assumption that negation is alanguage independent semantic phenomenon whichcan be defined as a structure. This assumption im-plies that it should be possible to annotate any lan-guage using the elements in this structure – cue,
2

event and scope. Isolating a small set of seman-tic elements involved in the construction of negationis useful in the context of SMT to reduce negationinto tangible elements at the string level. Moreovereach of the three elements above represents differ-ent translation problems: if, for instance, translatingthe cue mainly involves ensuring the presence of anegation marker, translating the scope involves in-stead ensuring that semantic elements are translatedin the right domain and most of the times, aroundthe negated event.
We carried out the annotation of cue, event andscope on both the source Chinese sentences and thecorrespondent translation output by the SMT sys-tem, following the guidelines released during theSEM* 2012 shared task (Morante et al., 2011). Toour understanding, this is the first work that appliesthese guidelines to a language other than English.It is however worth noticing that while these guide-lines were released with the goal in mind of auto-matically extracting information from text, with aparticular emphasis on factuality, the present workfocuses on translation, where each negation instanceis taken into consideration as potential source of er-ror. This leads to some differences in the annotationprocess, especially in the case of the event:
1. While the original guidelines do not annotatenegation scoping on non-factual events, suchas in conditional clauses (‘if he doesn’t come,I will blame you’), the demands of translationrequire it to be annotated.
2. While the original guidelines do not includemodals or auxiliaries in the event annotation (inorder to minimise the number of annotated ele-ments), getting these elements correct in trans-lation is needed to distinguish a correct vs. par-tially correct event (cf. section 3.2).
3. For the same reason as (2), the event in a nom-inal predicate includes all its modifiers.
4. All these points apply to Chinese as well; in ad-dition, in the case of resultative constructions(e.g. fu bu qi lit. ‘pay not lift-RES.’, ‘could notpay, can not afford’) we considered the resulta-tive particle as part of the event.
With respect to scope, the current work makes asimple approximation: scope is often discontinu-ous, with multiple semantic units whose translationsmight impact the overall translation of the scope dif-ferently. To facilitate error analysis we approximatethe scope in terms of its constituent semantic fillers,here taken to be Propbank-like semantic arguments.In doing so, we consider the scope as the semanticdomain of negation, where the constituent elementsare expected to remain in its boundaries and to pre-serve their semantic role (or take an equivalent one)during translation.
Example (1) illustrates our annotation schemeover the first instance of bu (not) in a Chinese sourcesentence.
(1) [women]filler
Webucue
notpaichuevent
exclude[qızhongamidst
youthere is
dan xınworried
deof
huıcan
laicome
zhudongvoluntarily
jiaodai]filler
confess,,danbut
paorun
de qıRES
bunot
gengeven
duome?more QRef: [We]filler do notcue [rule out]event
[the possibility that some timid ones mightcome out and voluntarily confess]filler , butwould n’t many more just run away?
As shown in (1) the scope around the first mainclause can be split into two arguments - a subjectand an object - around the verb paichu(rule out) soerror analysis can be carried on each individually.We instead consider the second instance of bu/notas ‘non-functional negation’ and do not annotate itsince it is just part of the question and does not con-stitute itself a negation instance.
3.2 Manual Error Analysis
A subsequent task is to define categories that areable to cover potential errors in translating negation.Our analysis aims at applying a small set of string-based operations traditionally used in SMT to theaforementioned elements of negation. We considerthree main operations and apply them to each of thethree elements of negation for a total of 9 main con-ditions:
3

• Deletion: one of the three sub-constituents ofnegation is present in the source Chinese sen-tence but not in the machine output. This corre-sponds to the missing words category in (Vilaret al., 2006).
• Insertion: the negation element is not presentin the source sentence but has been insertedin the machine output. This resembles the ex-tra words sub-category in the incorrect wordsclass.
• Reordering: whether the element has beenmoved outside its scope. Since some seman-tic elements can also move inside the scope andtake a role which they did not have in the orig-inal source sentence, we define the former re-ordering error as out-of-scope reordering errorand the latter intra-scope reordering error. Thereordering category represents an adaptation ofthe original word order category.
Since we are not concerned with errors regardingstyle, punctuation or unknown words, other opera-tions were left aside.
For a better understanding at when during thetranslation process (a.k.a. the decoding process) andwhy the error occurs, we also investigated the traceof rules used to build the 1-best machine output.This is particularly useful in the case of deletion:this may occur because a certain Chinese word orsequence of Chinese words (generally referred inSMT as phrases) has not been seen during training(so called out-of-vocabulary items - OOVs) and thesystem is therefore unable to translate them.
After the elements of negation have been an-notated in both the source sentences and machineoutputs, we use the same heuristic as (H)MEANT(Lo and Wu, 2011) to decide whether a translatedunit is correct or partially correct. We also considercorrect translations that are synonyms of the sourcenegation element since they are taken to convey thesame meaning. This also includes those elementsthat are negated in the source but are rendered inthe machine output by means of a lexical elementinherently expressing negation (e.g. fails) or byparaphrase into positive (e.g. bu tong, lit. ‘notsimilar’→ different). We consider partially correcttranslated elements that do not contain errors which
impact the overall meaning. In the case of the event,this might be related to tense agreement or wrongmodality, whilst in the case of the scope it is usuallyrelated to the fact that secondary elements are nottranslated correctly but the overall meaning is stillpreserved.
As in HMEANT, we compute precision, recalland F1 measure using the following formulaewhere e ∈ E = {cue,event,filler}. However, unlikeHMEANT, we do not normalise the number ofcorrect fillers by the number of total fillers in thepredicate.
P =(∑
ecorrect + 0.5 ∗∑epartial)∑
ehyp
R =(∑
ecorrect + 0.5 ∗∑epartial)∑
esrc
F1 = 2 ∗ P ∗R
P + R
4 System
We carried out the error analysis on the output ofthe Chinese-to-English hierarchical phrase basedsystem submitted by the University of Edinburghfor the NIST12 MT evaluation campaign.
Hierarchical phrase-based (or HPB) systems are aclass of SMT systems that use syntax-like rules andhierarchical tree structures to build an hypothesistranslation given a test source sentence and a modelpreviously trained on a bilingual corpora. Unlikepure syntax models, HPBMs do not make use ofsyntactic constituent tags for non-terminals butinstead use an X as placeholder for recursion. Arule used in a Hierarchical Phrase based systemlooks like the following,
ne veux plus X1→ do not want X1 anymore
where the French source (also referred to asthe left hand side - LHS of the rule) and the Englishtarget side (the right hand side - RHS) allows arbi-trary insertion of another rule where the placeholderX is located.
The system was trained on approximately 2.1million length-filtered segments in the news domain,with 44678806 tokens on the source and 50452704on the target, with MGIZA++ (Gao and Vogel,
4

2008) used for alignment. The system was tunedusing MERT (Minimal Error Rate Training, (Och,2003)) on the NIST06 set.
Two different test sets were considered to assessdifferences that might be associated with genre:the NIST MT08 test set, containing data from thenewswire domain and the IWSLT14 tst2012 testset, containing transcriptions of TED talks. Wehypothesise that the difference in genre can influ-ence the kinds of negation related error occurringduring translation: as a collection of planned spokeninspirational talks, we expect the IWSLT’14 test setto contain shorter sentences, and on average, moreinstances of negation. On the contrary, we expectthe NIST MT08, where data are from the writtenlanguage domain, to contain longer sentences andfewer instances of negation.
In order to carry out future work on the effect ofword segmentation on the elements on negation,we built two different systems (and therefore ruletables), one from data segmented using the LDC-WordSegmenter and the other using the StanfordWord Segmenter. The former matches the segmen-tation of the NIST08 test set, whilst the latter theone of the IWSLT14 test set.
Out of the 1397 segments in the IWSLT2014 setand the 1357 segments in the NIST MT08 set, 250sentences for each set were randomly chosen tocarry out the manual evaluation.
5 Results
5.1 Manual Analysis
5.1.1 NIST MT08The results of the manual evaluation for the NIST
MT08 test set are reported in Table 1. It can beeasily seen that getting the cue right is easier thantranslating event and scope correctly. The cue is infact usually a one-word unit and related errors con-cern almost entirely whether the system has deletedit during translation or not. Event and scope insteadare usually multi-word units whose correctness alsodepends on whether they interact correctly with theother negation elements.
In those cases where the cues were deleted duringtranslation, the trace shows that they were all causedby a rule application that does not contain negationon the English right hand side. Also worth notic-
ing is that, in these cases, the negation cue in thesource side is lexically linked to the event (‘bushao’, ‘not few, many’) or lexically embedded in it (e.g.‘de budao, ‘cannot obtain’). No cases of cues be-ing deleted were found where the cue is a distinctunit. Also, no cases of cues were found of cues be-ing deleted because of not being seen during training(out-of-vocabulary items).
Other cue-related errors involve the cue being re-ordered with respect to scope. In one case, cue re-ordering happens within the same scope, where thecue is moved from the main clause to the subordi-nate. In three other cases, the cue is instead trans-lated outside its source scope and attached to a dif-ferent event. The two cases are exemplified in (2)and (3) respectively.
(2) [ta]filler
Shecongbucue
never[yınweibecause
woI
geito
tahim
tıraise
guoASP
yıjıan]filler
opinionerso
[duito
wo]filler
Ihuai youevent
have[pıanjıan]filler
bias[...]
Ref: He never showed any bias against me[because i ’d complained to him]sub [...]
Hyp: he never mentioned to him becausemy opinions and i have bias against china[...]
(3) [...][...]
jiuthen
huıcan
renweithink
bunot
cunzaiexist
Ref: [...] people would think [that [theydo]scope not [exist]scope]sub
Hyp: [...] do not think [there is a]sub
As for the translation of events, a trend similar tothe translation of cues can be observed, althoughthe percentage of deletions is higher than the cue.The trace shows that in 3 out of 11 cases, deletionis caused by an OOV item, i.e. a Chinese phrasewhich is not seen in training and for which the sys-tem has not learned any translation. The remainingcases resemble the cue case, insofar as no rule con-tains the target side event. Another problem arisingwith events is that some fillers in the source mighthave erroneously become events in the machine out-put and vice versa; we found 3 events on the sourcebecoming fillers in the target and 7 fillers on the
5

source becoming events in the machine output, asshown in (4).
(4) zheThis
yıgeone
jieduanstage
deof
biaxianshow
shıis
[duanqıshort-term
xiaoguo]filler
resultbudacue+event
not big[...][...]
Ref: what this stage brings forward is : mod-est success in the short-term [...]
Hyp: this is a stage performance are notcue
[short-term effect]event
The fact that most of reordering errors are filler-related is connected to the lack of semantic-relatedinformation during the translation process, a com-mon problem in machine translation systems. Sincethere is no explicit guidance as to which events thefillers should be attached to and in what order, in-scope and out-of-scope problems are to be expected.
Around 10% of filler-related errors were causedby deletion. An investigation of the trace showsthat in all 9 cases, the system has knowledge of thesource words in the rule table but has applied a rulethat does not contain the filler on the target side.
Finally, in the case of fillers, we notice that 2 ofthe incorrect fillers in the hypothesis were due to theinsertion in the scope of fillers not present in thesource side. The trace shows that this kind of erroris generated by rules that contain on the right handside extra material not related to the source side. Wehypothesised that these rules might have been cre-ated during training where English words that didnot correspond to any Chinese source words werearbitrarily added to neighbouring phrases. For in-stance, in (5) a rule that translates yizhıyu (‘to theextent of’) into ‘to the extent of they’ is used, addinga filler to following negation scope.
(5) [...][...]
yızhıyuto the extent
wufanot possible
yuwith
ou zhouEurope
mengguounion
zhengchangnormally
zhankaiopen
hezuocooperation
Ref: [...] even made it is impossible to carryout cooperation with their European allies asnormal .
Hyp: [...] to the extent that [they]filler areunable to conduct normal with its europeanallies cooperation
NIST MT08 test setAverage Sentence Length 28Number of negated sentences 54 21.6%Cue per sentence ratio 1.22%
Src HypCues 66 57Events 66 57Fillers 98 80
# R% # P% F1
Correct cues 58/66 87.87 53/57 92.98 90.35Correct events 34/66 51.51 29/57 50.88+ Partial events 34 + 8/66 57.6 29 + 8/57 57.9 57.74Correct fillers 48/98 48.97 45/80 56.25+ Partial fillers 48 + 9/98 58.16 45 + 9/80 67.5 62.48Deleted cues 4/66 6Deleted events 11/66 16.6Deleted fillers 9/98 9.18Inserted fillers 2/80 2.5Reordered cues same scope 1/66 1.5 1/57 1.75Reordered cues out of scope 3/66 4.5Reordered events same scope 3/66 4.5 7/57 12.2Reordered events out of scope 1/66 1.5Reordered fillers same scope 8/98 8.16 5/80 6.25Reordered fillers out of scope 21/98 21.41
Table 1: Results from the error analysis of the 250 sen-tences randomly extracted from the NIST MT08 test set.
5.1.2 IWSLT ’14 Tst2012 TED Talks
Results for the TED talks test set are reported inTable 2. It can be observed that results on all threecategories are better than the NIST08 test set, inparticular for the F1 measure of correct events andscope. A reduction in the percentage of reorderedfillers on the overall number translation errors mightbe connected to the fact that on average sentencesin the TED talk, also given their domain, are shorterthan the sentences in the NIST08 test set and there-fore there is less chance of operating long range re-ordering.
We can also observe that genre has an effect onthe number of negation cues; despite sentences be-ing shorter, we found more negative instances in theTED talks.
As for the errors in the NIST08 test set, we anal-ysed the trace output after the completion of thetranslation process to see whether deletions werecaused by incorrect rule application or by the pres-ence of OOV items not seen during training. Out of7 cases of cue deletion, 3 of event deletion and 5 offiller deletion, only one was caused by the presenceof an OOV vocabulary item in the source. However,as shown in (6), the OOV error is generated by awrong segmentation of two elements in the source,buzhi and zenme, which end up being collapsed in asingle word unit.
6

(6) buzhızenmedo not know how
yonguse
womenwe
bunot
nengbe able
wanquancompletely
lıjieunderstand
deof
fangshimethod
[...][...]
Ref: ways we cannot fully understand thatwe don’t know how to use [...]
Hyp: was converted to the way we cannotfully understand [..]
This seem to exclude OOV items as a problem intranslating negation for the present system and whatwe are left with is a problem of negative elementsnot correctly reproduced on the target side of therules.
Finally, we have found two cases of insertion, onecue and the other event related. Overall, cases ofinsertion are rare and do not constitute a real prob-lem for the system here considered. In general, asfor event and scope, a rule application that does notcontain one of these two elements on the Chineseleft hand side but inserts it in the English right handside might be just fortuitous. As in the case of (5), itmight have been that a rule containing extra materialwas preferred because a better fit in that specific con-text (a LM score is in fact part of the scoring func-tion of a SMT system). Insertion of the cue deservesinstead a better investigation. The results shows thatdeletion is sometimes associated with rules whoseChinese (left-hand) side contains a cue whilst theEnglish side does not. This is most certainly causedby the training process where rules are extracted ac-cording to what portion of the source Chinese sen-tence is aligned to what portion in the target Englishsentence. If an Chinese sentence contains negationbut the English does not, a rule learnt from that pairmight learn that a negation cue corresponds to some-thing positive. This should theoretically happen theother way around and if so, the application of theserules should lead to insertion. Further analysis of therule table and the sentences used in training mightclarify this point.
6 Towards An Automatic Error Analysis
This manual error analysis assesses the quality ofthe 1-best translation output by the system. Morecan be done: (i) we can determine which componentof the system is responsible for each error so as toknow where to intervene and (ii) we can automate
IWSLT14 tst2012 TED talksAverage Sentence Length 18Number of negated sentences 61 24.4%Cue per sentence ratio 1.13%
Src HypCues 69 54Events 69 52Fillers 103 83
# R% # P% F1
Correct cues 61/69 88.4 53/54 98 92.95Correct events 48/69 69.56 40/52 76.92+ Partial events 48 + 3/69 71.73 40 + 3/52 79.8 75.55Correct fillers 64/103 62 64/83 77+ Partial fillers 64 + 3/103 63.59 64 + 3 /83 78.9 70.42Deleted cues 7/69 10.14Deleted events 5/69 7.2Deleted fillers 4/103 3.8Inserted cue 1/54 1.8Inserted fillers 1/83 1.2Reordered events same scope 5/69 7.2 1/52 1.9Reordered events out of scope 4/69 5.7Reordered fillers same scope 2/103 1.9 6/83 7.2Reordered fillers out of scope 13/103 12.62
Table 2: Results from the error analysis of the 250 sen-tences randomly extracted from the IWSLT2014 test set.
the whole process of error finding. Both actions canbe referred to as automatic error analysis, given thatthey rely on (semi-)automatic method to analyse er-rors in translating negation, although they differ inthe scope of their analysis: (i) represents an exten-sion of the manual error analysis, whilst (ii) aims atautomating it.
Although out of the scope of the present work, webriefly sketch our current work on (i) whilst leaving(ii) for future work. The reason for this is becausethe assumption behind this as many other manualanalysis, i.e. that a small set of string-based errorcategories can be used to characterise different kindof translation errors (here semantic), can be easilyprojected in the automatic error analysis. Moreover,the importance and indispensability of a manual er-ror analysis is highlighted when devising an auto-matic error analysis. This is obvious in the case of(i), where, in order to find the causes of the errors,we need to know what these are. However, even wesucceed in (ii) and we are able to spot errors auto-matically, we still need a manual error analysis asa benchmark to assess the quality of any automaticmethod.
When we talk about detecting errors during de-coding, we try to determine the reason why our sys-tem is behaving differently to what we expect. Theseexpectations depends on the source side negation el-ement processed at each step during decoding andare closely linked to both the set of string-based er-
7

ror category and the set of negation sub-constituentsused in this manual error analysis:
1. The cue has to be translated correctly; no cuedeletion or insertion should occur.
2. The event has to be translated correctly; noevent deletion or insertion should occur.
3. The cue has to be connected to right event; nocue or event reordering should occur.
4. The semantic arguments in the source scopeshould be translated and reproduced in linewith the target language semantics; no dele-tion, insertion or reordering of the semanticfillers should occur.
An ideal system would meet all the above conditionsin translating negation in each cell of the decodingchart1; if not, we have to inspect the decoding charttrace and classify the errors occurred. The goal hereis to find which part of the translation system is re-sponsible for each error category. There are threemain type of errors, each one connected to one com-ponent of the translation pipeline:
• Induction errors, where the correct translationfor a given element is absent from the searchspace. These errors depends on how many tar-get translations are fetched from the rule tablewhen a given source span is translated (defaultis 20). The more we consider, the more likely isfor the correct translation to be inserted in thesearch space. The system component related tothis category is the rule table.
• Search errors, where the correct translationfetched from the rule table disappears from thesearch space before making it to the final cell,due to pruning or other optimisation heuristics.The system component responsible for this er-ror is the search space.
• Model errors, where the system ranks badtranslations better than better translations. Thecomponent responsible is the scoring function.
1Hierarchical phrase-based decoder uses a variant ofbottom-up CKY chart algorithm
Induction errors occur when no negation element isfound in any hypothesis built in any of the chart cell;search errors occur when, by enlarging the searchspace, hypotheses meeting the expected conditionsthat were previously absent from the chart are nowpresent; finally, model errors occur where hypothe-sis meeting one or more expectation are present butrank lower than the ones that do not.
Since these expectations are based on source sideelements we need a way to project source side nega-tion elements into a target language; for expectation(1) and (2), we are experimenting with two differ-ent methods: (i) via an automatically extracted listof potential cues and a bilingual dictionary enrichedwith paraphrases; (ii) by extracting cues and eventsfrom the multiple reference translations set. To en-sure that expectation (3) and (4) are met we insteaduse a dependency parse.
Preliminary results on the translation of the cuealone (expectation (1)) in the NIST08 MT test setshows that it is uniquely a problem of model er-ror, where good hypotheses are ranked lower thanbad ones. A comparison between the scores ofgood and bad hypotheses show, when the former arenot ranked properly, shows that it is the translationmodel the main responsible for such bad ranking.
7 Conclusion
The present paper presents an analysis of the errorsinvolved in translating negation. We showed that itis possible to build a clear and robust error analysisusing (1) the set of semantic elements involved inthe meaning of negation (cue, event and scope) and(2) a sub-set of string-based operations traditionallyused in SMT error analysis (deletion, insertion andreordering).
Results of a manual error analysis on a Chinese-to-English output shows that this analysis is easilyportable to a language other than English and allowsus to cover a wide range of potential errors occur-ring during translating. Our findings also show thatamongst the three elements of negation here consid-ered, the scope is the most problematic and reorder-ing is in general the most frequent error in Chinese-to-English translation. In the case of deletion orinsertion of negation elements, we also found thatthe errors are attributable to a rule application that
8

prefers positive translations over negative and aretherefore not caused by OOV items not seen duringtraining.
Using the assumptions and the results of the man-ual error analysis, we also introduced an automaticway to inspect the causes of the errors in the de-coding chart trace. Preliminary results show thatthe scoring function is the main responsible for cuedeletion errors observed.
We hope that the methodology and the results ofthe present work can guide future work on improv-ing the translation of negative sentences.
8 Future Work
In the present paper, we have successfully appliedthe manual error analysis to the output of a Chinese-to-English Hierarchical Phrase-based system. Fu-ture work will extend this method to other languagepairs and different SMT systems. We in fact ex-pect these two variables to impact the kind of er-rors found in translation. Chinese and English arein fact very similar in the way they express nega-tion: adverbial negation is the most frequent wayof expressing negation (Blanco and Moldoval, 2011;Fancellu and Webber, 2012); morphological nega-tion (or affixal) or lexically embedded negation ispresent in both languages and affect mainly adjec-tives; events can be both nominal, verbal and ad-jectival. If we however extend this analysis to alanguage pair where negation is expressed throughdifferent means (e.g. English and Czech), it is un-likely we will find the same error distribution. More-over, hierarchical phrase-based models are in factnon-purely syntax driven methods that are able todeal with high levels of reordering. That howeveralso means that (a) there is no concept of syntac-tic constituent boundaries and (b) when reorderingis performed incorrectly there is a high degree of el-ement scrambling. For this reason phrase-based sys-tems (where reordering is limited) and syntax-basedsystems (where an explicit knowledge of constituentboundaries is present) are likely to yield different re-sults.
Finally, this paper has only discussed manualdetection of translation errors involving negation.Other ongoing work tries instead to automate thisprocess.
9 Acknowledgements
This work was supported by the GRAM+ grant. Theauthors would like to thank Adam Lopez for hiscomments and suggestions and the three anonymousreviewers for their feedback.
References
Baker, Kathryn and Bloodgood, Michael and Dorr,Bonnie J and Callison-Burch, Chris and Filardo,Nathaniel W and Piatko, Christine and Levin,Lori and Miller, Scott (2012). Modality and nega-tion in SIMT use of modality and negation insemantically-informed syntactic MT. Computa-tional Linguistics, 38(2):411–438.
Blanco, Eduardo and Moldoval, Dan (2011). SomeIssues on Detecting Negation from Text. In Pro-ceedings of the 24th Florida Artificial IntelligenceResearch Society Conference (FLAIRS-24), pages228–233, Palm Beach, FL, USA.
Chiang, David (2007). Hierarchical phrase-based translation. Computational Linguistics,33(2):201–228.
Chowdhury, Md and Mahbub, Faisal (2012). FBK:Exploiting phrasal and contextual clues for nega-tion scope detection. In Proceedings of the FirstJoint Conference on Lexical and ComputationalSemantics-Volume 1: Proceedings of the mainconference and the shared task, and Volume 2:Proceedings of the Sixth International Workshopon Semantic Evaluation, pages 340–346.
Collins, Michael and Koehn, Philipp and Kucerova,Ivona (2005). Clause restructuring for statisti-cal machine translation. In Proceedings of the43rd Annual Meeting on Association for Compu-tational Linguistics, pages 531–540.
Fancellu, Federico and Webber, Bonnie (2012). Im-proving the performance of chinese-to-englishHierarchical phrase-based models (HPBM) onnegative data using n-best list re-ranking. Mas-ter’s thesis, School of Informatics, University ofEdinburgh.
Fancellu, Federico and Webber, Bonnie (2014). Ap-plying the semantics of negation to SMT throughn-best list re-ranking. EACL 2014, page 598.
9

Gao, Qin and Vogel, Stephan (2008). Parallel imple-mentations of word alignment tool. In SoftwareEngineering, Testing, and Quality Assurance forNatural Language Processing, pages 49–57.
Hao-Min, Li and Li, Ying and Duan, Hui-Long andLv, Xu-Dong (2008). Term extraction and nega-tion detection method in chinese clinical docu-ment. Chinese Journal of Biomedical Engineer-ing, 27(5).
Hardmeier, Christian and Tiedemann, Jorg andNivre, Joakim (2014). Translating pronouns withlatent anaphora resolution. In NIPS 2014 Work-shop on Modern Machine Learning and NaturalLanguage Processing.
Li, Jin-Ji and Kim, Jungi and Kim, Dong-Il and Lee,Jong-Hyeok (2009). Chinese syntactic reorderingfor adequate generation of Korean verbal phrasesin Chinese-to-Korean SMT. In Proceedings of theFourth Workshop on Statistical Machine Transla-tion, pages 190–196.
Lo, Chi-kiu and Wu, Dekai (2010). Evaluating ma-chine translation utility via semantic role labels.In Seventh International Conference on LanguageResources and Evaluation (LREC-2010), pages2873–2877.
Lo, Chi-kiu and Wu, Dekai (2011). MEANT: aninexpensive, high-accuracy, semi-automatic met-ric for evaluating translation utility via semanticframes. In Proceedings of the 49th Annual Meet-ing of the Association for Computational Linguis-tics: Human Language Technologies-Volume 1,pages 220–229.
Morante, Roser and Blanco, Eduardo (2012). *SEM2012 shared task: Resolving the scope and focusof negation. In Proceedings of the First Joint Con-ference on Lexical and Computational Semantics-Volume 1: Proceedings of the main conferenceand the shared task, and Volume 2: Proceedingsof the Sixth International Workshop on SemanticEvaluation, pages 265–274.
Morante, Roser and Schrauwen, Sarah and Daele-mans, Walter (2011). Annotation of negation cuesand their scope, Guidelines v1.0. Computationallinguistics and psycholinguistics technical reportseries, CTRS-003.
Och, Franz Josef (2003). Minimum error rate train-ing in Statistical Machine Translation. In Pro-ceedings of the 41st Annual Meeting on Asso-ciation for Computational Linguistics-Volume 1,pages 160–167.
Papineni, Kishore and Roukos, Salim and Ward,Todd and Zhu, Wei-Jing (2002). BLEU: a methodfor automatic evaluation of machine translation.In Proceedings of the 40th annual meeting onassociation for computational linguistics, pages311–318.
Read, Jonathon and Velldal, Erik and Øvrelid, Liljaand Oepen, Stephan (2012). Uio 1: constituent-based discriminative ranking for negation resolu-tion. In Proceedings of the First Joint Conferenceon Lexical and Computational Semantics-Volume1: Proceedings of the main conference and theshared task, and Volume 2: Proceedings of theSixth International Workshop on Semantic Evalu-ation, pages 310–318.
Snover, Matthew G and Madnani, Nitin and Dorr,Bonnie and Schwartz, Richard (2009). TER-Plus: paraphrase, semantic, and alignment en-hancements to Translation Edit Rate. MachineTranslation, 23(2-3):117–127.
Szarvas, Gyorgy and Vincze, Veronika and Farkas,Richard and Csirik, Janos (2008). The bioscopecorpus: annotation for negation, uncertainty andtheir scope in biomedical texts. In Proceedingsof the Workshop on Current Trends in BiomedicalNatural Language Processing, pages 38–45.
Vilar, David and Xu, Jia and Haro, Luis Fernandoand Ney, Hermann (2006). Error analysis of sta-tistical machine translation output. In Proceed-ings of LREC, pages 697–702.
Wetzel, Dominikus and Bond, Francis (2012). En-riching parallel corpora for statistical machinetranslation with semantic negation rephrasing. InProceedings of the Sixth Workshop on Syntax, Se-mantics and Structure in Statistical Translation,pages 20–29.
Zheng Jia and Haomin Li and Meizhi Ju and Yin-sheng Zhang and Zhenzhen Huang and Caixia Geand Huilong Duan (2014). A finite-state automatabased negation detection algorithm for chineseclinical documents. In Progress in Informatics
10

and Computing (PIC), 2014 International Con-ference on, pages 128–132.
11

Proceedings of the Second Workshop on Extra-Propositional Aspects of Meaning in Computational Semantics (ExProM 2015), pages 12–21,Denver, Colorado, June 5, 2015. c©2015 Association for Computational Linguistics
Filled pauses in User-generated Content areWords with Extra-propositional Meaning
Ines RehbeinSFB 632 “Information Structure”
Potsdam [email protected]
Abstract
In this paper, we present a corpus study in-vestigating the use of the fillers ah (uh) andahm (uhm) in informal spoken German youthlanguage and in written text from social me-dia. Our study shows that filled pauses oc-cur in both corpora as markers of hesita-tions, corrections, repetitions and unfinishedsentences, and that the form as well as thetype of the fillers are distributed similarly inboth registers. We present an analysis offillers in written microblogs, illustrating thatah and ahm are used intentionally and can adda subtext to the message that is understand-able to both author and reader. We thus ar-gue that filled pauses in user-generated con-tent from social media are words with extra-propositional meaning.
1 Introduction
In spoken communication, we can find a high num-ber of utterences that are disfluent, i.e. that includehesitations, repairs, repetitions etc. Shriberg (1994)estimates the ratio of disfluent sentences in spon-taneous human-human communication to be in therange of 5-6%.
One particular type of disfluencies are filledpauses (FP) like ah (uh) and ahm (uhm). FP area frequent phenomenon in human communicationand can have multiple functions. They can be putat any position in an utterance and are used when aspeaker encounters planning and word-finding prob-lems (Maclay and Osgood, 1959; Arnold et al.,2003; Goffman, 1981; Levelt, 1983; Clark, 1996;
Barr, 2001; Clark and Fox Tree, 2002), or as strate-gic devices, e.g. as floor-holders or turn-taking sig-nals (Maclay and Osgood, 1959; Rochester, 1973;Beattie, 1983). Filled pauses can function asdiscourse-structuring devices, but they can also ex-press extra-propositional aspects of meaning beyondthe propositional content of the utterance, e.g. asmarkers of uncertainty or politeness (Fischer, 2000;Barr, 2001; Arnold et al., 2003).
Examples (1)-(6) illustrate the use of FP to markrepetitions (1), repairs (2), breaks (3) and hesitations(4) (the last one often used to bridge word find-ing problems). FPs can also express astonishment(5), excitement or negative sentiment (6). Extra-linguistic reasons also come into play, such as thelack of concentration due to fatigue or distraction,which might lead to a higher ratio of FP in the dis-course.
(1) I will uh I will come tomorrow.(2) I will leave on Sat uh on Sunday.(3) I think I uh have you seen my wallet?(4) I have met Sarah and Peter and uhm Lara.(5) Sarah is Michael’s sister. Uh? Really?(6) A: He cheated on her. B: Ugh! That’s bad!
The role of fillers in spoken language has beendiscussed in the literature (for an overview, see Cor-ley and Stewart (2008)). Despite this, work on pro-cessing disfluencies in NLP has mostly consideredthem as mere performance phenomena and focusedon disfluency detection to improve automatic pro-cessing (Charniak and Johnson, 2001; Johnson andCharniak, 2004; Qian and Liu, 2013; Rasooli and
12

Tetreault, 2013; Rasooli and Tetreault, 2014). Farfewer studies have focused on the information thatdisfluencies contribute to the overall meaning of theutterance. An exception are Womack et al. (2012)who consider disfluencies as extra-propositional in-dicators of cognitive processing.
In this paper, we take a similar stand and present astudy that investigates the use of filled pauses in in-formal spoken German youth language and in writ-ten, but conceptually oral text from social media,namely Twitter microblogs.1 We compare the useof FP in computer-mediated communication (CMC)to that in spoken language, and present quantitativeand qualitative results from a corpus study showingsimilarities as well as differences between FP in boththe spoken and written register. Based on our find-ings, we argue that filled pauses in CMC are wordswith extra-propositional meaning.
The paper is structured as follows. Section 2 givesan overview on the different properties of spokenlanguage and written microblogs. In section 3 wepresent the data used in our study and describe theannotation scheme. Section 4 reports our quantita-tive results which we discuss in section 5. We com-plement our results with a qualitative analysis in sec-tion 6, and conclude in section 7.
2 Filled Pauses in Spoken and WrittenRegisters
Clark and Fox Tree (2002) propose that FP are wordswith meaning, but so far there is no conclusive evi-dence to prove this. While experimental results haveshown that disfluencies do affect the comprehensionprocess (Brennan and Schober, 2001; Arnold et al.,2003), this is no proof that listeners have access tothe meaning of a FP during language comprehen-sion but could also mean that FP are produced “un-intentionally [...], but at predictable junctures, andlisteners are sensitive to these accidental patterns ofoccurrence.” (Corley and Stewart, 2008), p.12.
To show that fillers are words in a linguistic sense,i.e. lexical units that have a specific semantics thatis understandable to both speaker and hearer, onewould have to show that speakers are able to pro-duce them intentionally and that recipients are able
1See the model of medial and conceptual orality and literacyby Koch & Oesterreicher (1985).
to interpret the intended meaning of a filler.Assuming that fillers are not linguistic words but
simply noise in the signal, caused by the high de-mands on cognitive processing in spoken onlinecommunication, we would not expect to find themin medially written communication such as user-generated content from social media, where the pro-duction setting does not put the same time pressureon the user as there is in oral face-to-face commu-nication. However, a search for fillers on Twitter2
easily proves this wrong, yielding many examplesfor the use of FP in medially written text (7).
(7) Oh uh.. I got into the evolve beta.. yet I haveno idea what this game is.. uhm..
Both, informal spoken dialogues and microblogscan be described as conceptually oral, meaning thatboth display a high degree of interactivity, signalledby the use of backchannel signals and question tags,and are highly informal with grammatical featuresthat deviate from the ones in the written standard va-riety (e.g. violations of word order constraints, casemarking, etc.). Both registers show a high degree ofexpressivity, e.g. interjections and exclamatives, andmake use of extra-linguistic features (spoken lan-guage: gestures, mimics, voice modulation; micro-text: emoticons, hashtags, use of uppercased wordsfor emphasis, and more).
Differences between the two registers concern thespatio-temporal setting of the interaction. Whilespoken language is synchronous and takes placein a face-to-face setting, microblogging usuallyinvolves a spatial distance between users and istypically asynchronous, but also allows users tohave a quasi-synchronous conversation.3 Quasi-synchronous here means that it is possible to com-municate in real time where both (or all) communi-cating partners are online at the same time, tweetingand re-tweeting in quick succession, but without theneed for turn-taking devices as there is a strict first-come-first-serve order for the transmission of the di-alogue turns. As a result, microblogging does notput the same time pressure on the user but permitsthem to monitor and edit the text. This should ruleout the use of FP as markers of disfluencies such
2https://twitter.com/search-home3See (Durscheid, 2003; Jucker and Durscheid, 2012) for an
account of quasi-synchronicity in online chatrooms.
13

as repairs, repetitions or word finding problems, andalso the use of FP as strategic devices to negotiatewho takes the next turn. Accordingly, we would notexpect to observe any fillers in written microblogs iftheir only functions were the ones specified above.
However, regardless of the limited space fortweets,4 microbloggers make use FP in microtext.This suggests that FP do indeed serve an importantcommunicative function, with a semantics that mustbe accessible to both the blogger and the recipient.
3 Annotation Experiment
This section describes the data and setup used in ourannotation experiment.
3.1 Data
The data we use in our study comes from two dif-ferent sources. For spoken language, we use theKiezDeutsch-Korpus (KiDKo) (Wiese et al., 2012),a corpus of self-recordings of every-day conversa-tions between adolescents from urban areas. All in-formants are native speakers of German. The corpuscontains spontaneous, highly informal peer groupdialogues of adolescents from multiethnic Berlin-Kreuzberg (around 266,000 tokens excluding punc-tuation) and a supplementary corpus with adoles-cent speakers from monoethnic Berlin-Hellersdorf(around 111,000 tokens). On the normalisation layerwhere punctuation is included, the token counts addup to around 359,000 tokens (main corpus) and149,000 tokens (supplementary corpus).
The first release of KiDKo (Rehbein et al., 2014)includes the transcriptions (aligned with the audiofiles), a normalisation layer, and a layer with part-of-speech (POS) annotations as well as non-verbaldescriptions and the translation of Turkish code-switching.
The data was transcribed using an adapted versionof the transcription inventory GAT 2 (Selting et al.,1998), also called GAT minimal transcript, whichuses uppercased letters to encode the primary accentand hyphens in round brackets to mark silent pausesof varying length.
The microblogging data consists of German-language Twitter messages from different regions
4The maximum length of a tweet is limited to 140characters.
KiDKo Twitterah 646 35.8 6403 0.6ahm 360 19.9 4182 0.4both 1,006 55.7 10,585 1.0# tokens 180,558 10,000 105,074,399 10,000
Table 1: Distribution of ah and ahm in KiDKo and Twit-ter microtext (raw counts (grey column) and normalisednumbers (white column) per 10,000 tokens).
of Germany, and includes 7,311,960 tweets with105,074,399 tokens. For retrieving the tweets weused the Twitter Search API5 which allows one tospecify the user’s location by giving a latitude anda longitude pair as parameters for the search. Overa time period of 6 months we collected tweets from48 different locations.6 The corpus was automati-cally augmented with a tokenisation layer and POStags.7
A string search in both corpora, looking for vari-ants of ah and ahm (including upper- and lowercasedspelling variants with multiple a, with and withouta h, and with one or more m) shows the followingdistribution (Table 1). Filled pauses are far less fre-quent in microblogs compared to spoken language,but due to the large amount of data we can easilyextract more than 10,000 instances from the Twit-ter corpus. Note that the tweets in our corpus comefrom different registers like news, ads, public an-nouncements, sports, and more, with only a smallportion of private communication. When constrain-ing the corpus search to the subsample of privatetweets, we will most likely find a higher proportionof FP in the social media data.
In summary, we observe a higher amount of FP inspoken language than in Twitter microblogs. How-ever, in both corpora variants of ah outnumber ahmby roughly the same factor. This observation is com-patible with the results of (Womack et al., 2012) whoreport that around 60% of the FP in their corpus ofEnglish diagnostic medical narratives are nasal filledpauses (uhm, hm) and around 40% are non-nasal(uh, er, ah).
5https://dev.twitter.com/docs/api6Note that the Twitter geoposition parameter can only ap-
proximate the regional origin of the speakers as the locationwhere a tweet has been sent is not necessarily the residence orplace of birth of the tweet author.
7Unfortunately, for legal reasons we are not allowed to dis-tribute the data.
14

Categories Position1 Repetition B/I2 Repair B/I3 Break B/I4 Hesitation B/I5 Question B/I6 Interjection B/I7 Unknown
Table 2: Labels used for annotating the fillers (B: be-tween utterances; I: integrated in the utterance).
3.2 Annotating Fillers in Spoken Languageand in Microtext
To be able to compare the use of fillers in spokenlanguage with the one in Twitter microtext, we ex-tract samples from the two corpora including 500 ut-terances/tweets with at least one use of ah and 500tweets with at least one instance of ahm. At the timeof the investigation, the transcription of KiDKo wasnot yet completed, and we only found 360 utterancesincluding an ahm in the finished transcripts.
For annotation, we used the BRAT rapid annota-tion tool (Stenetorp et al., 2012). Our annotationscheme is shown in Table 2. We distinguish be-tween different categories of fillers, namely betweenFP that mark repetitions, repairs, hesitations, or thatoccur at the end of an unfinished utterance/tweet(breaks). We also annotated variants of ah and ahmwhich were used as question tags or interjections,but do not consider them as part of the disfluencymarkers we are interested in. The Unknown labelwas used for instances which either do not belongto the filler class and shouldn’t have been extracted,such as example (8), or which couldn’t be disam-biguated, usually due to missing context.
(8) Haaahahh !!!
Each filler is labelled with its category and posi-tion. By position we mean the position of the fillerin the utterance or tweet. Here we distinguish be-tween fillers which occur between (B) utterances/atthe beginning or end of tweets (example 9b) andthose which are integrated (I) in the utterance/tweet(9a). The numbers in the first column of Table 2correspond to examples (1)-(6).
Twitter KiDKoSample ah ahm ah ahm
1 n.a. n.a. 0.79 0.752 n.a. 0.84 0.73 0.643 0.80 0.83 0.78 0.844 0.87 0.87 0.78 0.755 0.86 0.86 0.74 n.a.
avg. κ 0.84 0.85 0.76 0.75
Table 3: Inter-annotator agreement (κ) for 3 annotators.
(9) a. dasthis
’s’s
irgendsome
sosuch
’na
ahuh
(-) RAPperrapper
derwho
...
...
this is some uh rapper who ... (Hesitation-I)
b. ahuh
weißknow
ichI
nichnot
uh I don’t know (Hesitation-B)
3.3 Inter-Annotator Agreement
The data was divided into subsamples of 100 utter-ances/tweets. Each sample was annotated by threeannotators. Table 3 shows the inter-annotator agree-ment (Fleiss’ κ) on the KiDKo and Twitter samples.We report agreement for all but three samples whichwe used to train the annotators, refine the guidelinesand to discuss problems with the annotaton scheme.As we had only 360 instances of ahm from KiDKo,we divided them into three samples with 100 utter-ances and a fourth sample with 60 utterances.
Table 3 shows that the annotation of fillers is notan easy task. The disagreements in the annotationsconcern both the category and the position of the FP.In some cases the annotators agree on the label butdisagree on the position of the filler (10a). This canbe explained by the fact that spoken language (andsometimes also tweets) does not come with sentenceboundaries, and it is often not clear where we shouldsegment the utterance. In example (10a) two anno-tators interpreted the reparandum as part of the ut-terance and thus assigned REPAIR-I, while the thirdannotator analysed am Samstag (on Saturday) as anew utterance, resulting in the label REPAIR-B.
15
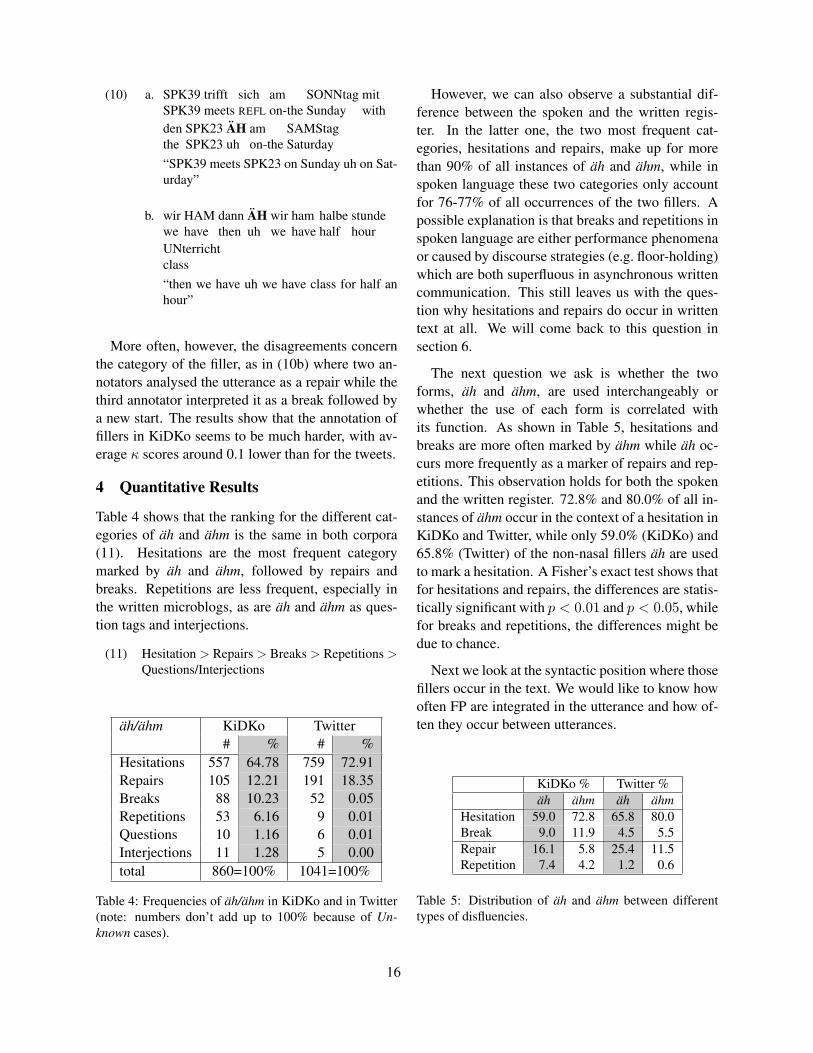
(10) a. SPK39SPK39
trifftmeets
sichREFL
amon-the
SONNtagSunday
mitwith
denthe
SPK23SPK23
AHuh
amon-the
SAMStagSaturday
“SPK39 meets SPK23 on Sunday uh on Sat-urday”
b. wirwe
HAMhave
dannthen
AHuh
wirwe
hamhave
halbehalf
stundehour
UNterrichtclass“then we have uh we have class for half anhour”
More often, however, the disagreements concernthe category of the filler, as in (10b) where two an-notators analysed the utterance as a repair while thethird annotator interpreted it as a break followed bya new start. The results show that the annotation offillers in KiDKo seems to be much harder, with av-erage κ scores around 0.1 lower than for the tweets.
4 Quantitative Results
Table 4 shows that the ranking for the different cat-egories of ah and ahm is the same in both corpora(11). Hesitations are the most frequent categorymarked by ah and ahm, followed by repairs andbreaks. Repetitions are less frequent, especially inthe written microblogs, as are ah and ahm as ques-tion tags and interjections.
(11) Hesitation > Repairs > Breaks > Repetitions >Questions/Interjections
ah/ahm KiDKo Twitter# % # %
Hesitations 557 64.78 759 72.91Repairs 105 12.21 191 18.35Breaks 88 10.23 52 0.05Repetitions 53 6.16 9 0.01Questions 10 1.16 6 0.01Interjections 11 1.28 5 0.00total 860=100% 1041=100%
Table 4: Frequencies of ah/ahm in KiDKo and in Twitter(note: numbers don’t add up to 100% because of Un-known cases).
However, we can also observe a substantial dif-ference between the spoken and the written regis-ter. In the latter one, the two most frequent cat-egories, hesitations and repairs, make up for morethan 90% of all instances of ah and ahm, while inspoken language these two categories only accountfor 76-77% of all occurrences of the two fillers. Apossible explanation is that breaks and repetitions inspoken language are either performance phenomenaor caused by discourse strategies (e.g. floor-holding)which are both superfluous in asynchronous writtencommunication. This still leaves us with the ques-tion why hesitations and repairs do occur in writtentext at all. We will come back to this question insection 6.
The next question we ask is whether the twoforms, ah and ahm, are used interchangeably orwhether the use of each form is correlated withits function. As shown in Table 5, hesitations andbreaks are more often marked by ahm while ah oc-curs more frequently as a marker of repairs and rep-etitions. This observation holds for both the spokenand the written register. 72.8% and 80.0% of all in-stances of ahm occur in the context of a hesitation inKiDKo and Twitter, while only 59.0% (KiDKo) and65.8% (Twitter) of the non-nasal fillers ah are usedto mark a hesitation. A Fisher’s exact test shows thatfor hesitations and repairs, the differences are statis-tically significant with p < 0.01 and p < 0.05, whilefor breaks and repetitions, the differences might bedue to chance.
Next we look at the syntactic position where thosefillers occur in the text. We would like to know howoften FP are integrated in the utterance and how of-ten they occur between utterances.
KiDKo % Twitter %ah ahm ah ahm
Hesitation 59.0 72.8 65.8 80.0Break 9.0 11.9 4.5 5.5Repair 16.1 5.8 25.4 11.5Repetition 7.4 4.2 1.2 0.6
Table 5: Distribution of ah and ahm between differenttypes of disfluencies.
16

KiDKo % Twitter %B I B I
ah Hesitations 24.6 34.4 42.6 23.2Repairs 0.1 16.0 0.6 24.8Repetitions 0.0 7.4 0.2 1.0
ahm Hesitations 31.4 41.4 62.4 17.6Repairs 0.0 5.8 0.4 11.1Repetitions 0.0 4.2 0.0 0.6
Table 6: Position of ah and ahm in correlation to theircategory.
Fox et al. (2010) present a cross-linguistic studyon self-repair in English, German and Hebrew, andobserve that self-corrections in English often includethe repetition of whole clauses, i.e. English speak-ers “recycle” back to the subject pronouns (Fox etal. 2010:2491). In their German data this patternwas less frequent. Fox et al. (2010) conclude thatmorpho-syntactic differences between the languageshave an influence on the self-repair practices in thespeakers.
Our findings are consistent with Fox et al. (2010)in that we mostly observe the repetition of words,not of clauses (Table 6). Nearly all fillers whichmark repetitions are integrated in the utterance ortweet, only a few occur between utterances/tweets.Fillers as markers of repairs are also mostly inte-grated.
For hesitations, the most frequent category, weget a more diverse picture. In our spoken languagedata, ah and ahm are more often integrated in theutterance, while for tweets FP as hesitation markersmostly appear at the beginning or end of the tweet.
So far, our quantitative investigation showed somestriking similarities in the use of filled pauses in thetwo corpora. In both registers, the ranking of thedifferent disfluency types marked by the FP were thesame. Furthermore, we showed that speakers/usersare sensitive to the surface form of a FP and prefer touse ah in repairs and ahm in hesitations, regardlessof the medium they use for communication.
5 Discussion
In this section we will look at related work on FPand try to put our findings into context. Previouswork on the difference between nasal and non-nasalfillers (Barr, 2001; Clark and Fox Tree, 2002) has
described nasal fillers such as uhm, hm as indicatorsof a high cognitive load, while their non-nasal vari-ants indicate a lower cognitive load during speechproduction. Clark and Fox Tree (2002) have pro-posed the filler-as-word hypothesis, stating that FPlike uh and uhm are words in a linguistic sense withthe basic meaning that a minor (uh) or major (uhm)delay in speaking is about to follow. This analysis isbased on a corpus study showing that silent pausesfollowing a nasal filler are longer than silent pausesafter a non-nasal filler. Beyond the basic meaning,FP can have different implicatures, depending on thecontext they are used in, such as indicating that thespeaker wants to keep the floor, is planning the next(part of the) utterance, or wants to cede the floor. Toillustrate this, Clark and Fox Tree (2002) use good-bye which has the basic meaning “express farewell”but, when uttered while someone is approaching thespeaker, can have the implicature “Go away”.
We take the filler-as-word hypothesis of Clark andFox Tree (2002) as our starting point and see howadequate it is to describe the use of FP in written mi-croblogs (section 6). However, we try to avoid theterm implicature which seems problematic in thiscontext, as we are not dealing with implicatures builton regular lexical meanings but rather with impli-catures on top of non-propositional meaning. As aside-effect, the implicatures based on filled pausesare not cancellable.
The analysis of Clark and Fox Tree (2002) is notuncontroversial (see, e.g., Womack et al. (2012) fora short discussion on that matter). O’Connell andKowal (2005) criticise that the corpus study of Clarkand Fox Tree (2002) is based on pause length as per-ceived by the annotators (instead of being analysedby means of acoustic measurements).
Furthermore, it might be possible that the seman-tics of FP to indicate the length of a following de-lay only applies to English. Belz and Klapi (2013)have measured pause lengths after nasal and non-nasal fillers in German L1 and L2 dialogues from aMAP task and could not find a similar correlationbetween filler type and pause length.
In summary, it is not clear whether the differentfindings are due to methodological issues, or mightbe particular to certain languages and text types.Shriberg (1994), p.130 suggests that for English,models of disfluencies based on the ATIS corpus,
17

a corpus of task-oriented dialogues about air travelplanning, might not be able to predict the behaviourof disfluencies in spoken language corpora with datarecorded in a less restricted setting.
The MAP task corpora used in Belz andKlapi (2013), for example, includes dialogues whereone speaker instructs another speaker to reproducea route on a map. Due to the functional design, thecontent of the dialogues is constrained to solving thetask at hand and thus the language is expected to dif-fer from the one used in the London–Lund corpus(Svartvik, 1990), a corpus of personal communica-tion, that was used by Clark and Fox Tree (2002).
Fox Tree (2001) presents a perception experimentshowing that uh helps recognizing upcoming words,while the nasal um doesn’t. In our study we found astrong correlation between the category of the fillerand its form (nasal vs. non-nasal). Nasal fillers weremostly used in the context of hesitations, which isconsistent with their ascribed basic function as indi-cators of longer pauses (Clark and Fox Tree, 2002).The tendency to use ah within repairs might be ex-plained by Fox Tree (2001)’s findings that non-nasalfillers help to recognise the next word. Thus, wewould expect a preference for non-nasal FP to beused as an interregnum before the repair.
Other evidence comes from Brennan andSchober (2001) who present experiments wherethe subjects had to follow instructions and selectobjects on a graphical display. They showed thatinsertions of uh after a mid-word interruption inthe instruction helped the subjects to correctlyidentify the target object, as compared to the sameinstruction where the filler was replaced by a silentpause. They conclude that fillers help to recoverfrom false information in repairs.8
So far, our findings are consistent with previouswork outlined above, but do not rule out other ex-planations. A major argument against the analysisof FP as linguistic words is that so far there is noconclusive evidence that speakers do produce themintentionally (Corley and Stewart, 2008).
Our corpus study provides this evidence by show-ing that FP in CMC are produced deliberately andintentionally. Furthermore, we observed a statis-
8Unfortunately, they did not compare the effect of uh in re-pairs to the one obtained by a nasal filler like um.
tically significant correlation between filler form(nasal or non-nasal) and filler category, which alsopoints at ah and ahm being separate words with dis-tinguishable meanings.
In the next section, we show that FP in CMC canadd a subtext to the original message that can be un-derstood by the recipients, and that the informationthey add goes beyond the contribution made by non-verbal channels such as facial expressions or ges-tures. We illustrate this, based on a qualitative anal-ysis of our Twitter data.
6 Extra-propositional Meaning of FP inSocial Media Text
New text from social media provides us with agood test case to investigate whether filled pausesare words with (extra-propositional) meaning, asthe production of written text is to a far greaterextent subject to self-monitoring processes. Thismeans that we can confidently rule out that the useof fillers in tweets is due to performance problemscaused by the time pressure of online communica-tion. Another important point is that communica-tion on Twitter is not synchronous but can be time-delayed and works on a first-come-first-serve basis.This is quite important, as it means that we can alsoexclude the discourse-strategic functions of FP (e.g.floor-holding and turn-taking) as possible explana-tions for the use of fillers in user-generated micro-text.
We conclude that there have to be other explana-tions for the use of filled pauses as markers of hesi-tations and repairs in microblogs. Consider the fol-lowing examples (12)-(14).
(12) MeinMy
...
...aahuh
Gluckwunsch!congratulation!
RTRT
@germanpsycho:@germanpsycho:
IchI
binam
nunnow
verheiratet.married.
“My ... uh congratulations! RT @ger-manpsycho: I’m married now.”
(13) DieThis one
hathas
aberPTCL
schonebeautiful
ahmuhm
Augen.eyes.
“This one has really beautiful uhm eyes.”
(14) IchI
frageask
fur,for,
ahm,uhm,
einena
Freund.friend.
“I’m asking for uhm a friend.”
18

The fillers in the examples above add a new layerof meaning to the tweet which results in an inter-pretation different from the one we get without thefiller. While a simple “Congratulations!” as answerto the message “I’m married now” would be inter-preted as a polite phrase, the mere addition of thefiller implies that this tweet should not be taken atface value and has a subtext along the lines “Actu-ally, I really feel sorry for you”. The same is true for(13) where the subtext can be read as “In fact, we’retalking about some other bodyparts here”. In exam-ple (14), the subtext added by the filler will mostprobably be interpretated as “I’m really asking formyself but won’t admit it”.9
In the next examples (15)-(17), also hesitations,the filler is used to express the author’s uncertaintyabout the proposition.
(15) 3000030000
ee
furfor
diethe
2h2h
dbdb
Showshow
furfor
regiotv...regiotv...
ahm...?uhm...?
IchI
weissknow
gradjust now
auchalso
nich..not..
“30000 e for the 2h db show for regiotv...uhm...? I don’t know right now, either..”
(16) TorGoal
furfor
#Arminia#Arminia
durch,by
aah,uuh,
wirwe
glaubenbelieve
Schutz.Schutz.“Goal for #Arminia by uuh, we believeSchutz.”
(17) @zinken@zinken
ah..uh..
soaround
98%98%
“@zinken uh.. around 98%”
Thus, the most general commonality between theexamples above is that the speaker does not makea commitment concerning the truth content of themessage.
The following examples (18)-(21) show instancesof ah and ahm in repairs where the FP occur as in-terregnum between reparandum and repair.10
I will leave you on Sat︸ ︷︷ ︸ uh︸ ︷︷ ︸ on Sunday︸ ︷︷ ︸REPARANDUM INTERREGNUM REPAIR
9In fact, this adds an interesting meta-level to the utterance,as by inserting the filler the author draws attention to the factthat there is something she seemingly wants to hide.
10We follow the terminology of Shriberg (1994).
The tweet author enacts a slip of the tongue, eitherby using homonymous or near-homonymous words(Diskus (discus) – Discos (discos), hangst (hang) –Hengst (stallion)) or by using analogies and conven-tionalised expressions (off – on, resist – contradict).The “mistake” was made with humorous intentionand is then corrected. The filler takes again the slotof the interregnum and serves as a marker of the in-tended pun.
(18) ObWhether
Diskuswerferdiscus-throwers
fruherin the past
immeralways
inin
Diskusdiscus
ahuh
Discosdiscos
geubttrained
haben,have,
etwaperhaps
alsas
Rauswerferbouncers
amat the
Eingang?entrance?
“In the past, have discus-throwers always trainedin discus uh discos, maybe as bouncers at theentrance?”
(19) DuYou
Hengst!stallion!
ah,uh,
hangst.hang.
“You stallion! uh, hang.”
(20) MacBookMacBook
aus,off,
Handymobile
aus,off,
TVTV
aus.off.
BuchBook
an,on,
ahh,uhh,
aufgeklappt.open.
“MacBook off, mobile off, TV off. Book on,uhh, open.”
(21) werwho
konntecould
Diryou
schonPTCL
widerstehen,resist,
ahm,uhm,
ichI
meinemean
widersprechen.contradict.
“who could resist you, uhm, I mean contradict.”
In the next set of examples, (22)-(24), a tabooword or word with a strong negative connotationis reformulated into something more socially ac-ceptable (minister of propaganda→ district mayor;madness → spirit; tantalise → educate). Often,this is done with a humorous intention, but alsoto express negative sentiment (e.g. in (22) towardsBuschkowsky, or in (23) towards Apple).
(22) Exakt.Exactly.
WieHow
esit
dasthe
Buchbook
vonof
euremyour
RMVP Minister GoebbelsRMVP minister Goebbels
ahuh
Bezirksburgermeisterdistrict mayor
BuschkowskyBuschkowsky
soso
beschriebendescribed
hat.has
:-):-)
19

“Exactly. Just as the book of your ministerof propaganda Goebbels uh district mayorBuschkowsky has described :-)”
(23) DuYou
hasthave
denthe
AppleApple
Wahnsinn...madness...
ah,uh,
Spiritspirit
einfachsimply
nochstill
nichtnot
verstandenunderstood
;);)
“You haven’t yet understood the Apple mad-ness... uh spirit ;)”
(24) ......
eina
bisserllittle bit
Nachwuchsnew blood
qual...tant...
ahmuhm
ausbildeneducating“... tant[alising] the new blood uhm educating”
These examples show that the use of ah and ahmin tweets is intentional and highly edited. The twoforms are used to express the speaker’s uncertaintyabout the propositional content of the message, or asa signal that the speaker does not warrant the truthof the message. Other functions include the use offillers as markers of humorous intentions and of neg-ative sentiment (see Table 7). Note that the mean-ings are not necessarily distinct but often overlap.
We thus argue that FP in user-generated contentfrom social media are linguistic words that are pro-duced intentionally and have an extra-propositionalmeaning that can be understood by the recipients.
Meaning DescriptionUNCERTAINTY Speaker is uncertain about
the propositional contentTRUTH CONTENT Speaker does not warrant
the truth content of theproposition
HUMOR Marker of humorous intentionEVALUATION Marker of negative sentiment
Table 7: Extra-propositional meaning of fillers in CMC.
7 Conclusions
The results from our corpus study show that fillers inuser-generated text from social media are linguisticwords that are produced intentionally and functionas carriers of extra-propositional meaning.
This finding has consequences for work on Senti-ment Analysis and Opinion Mining in social mediatext, as it shows that FP are used as a marker of ironyand humour in Twitter, and also indicate uncertainty
and negative sentiment. Thus, filled pauses might beuseful features for irony detection, sentiment analy-sis, or to assess the strength of an opinion in onlinedebates.
Acknowledgments
This research was supported by a grant from theGerman Research Association (DFG) awarded toSFB 632 “Information Structure”. I am grateful toSoren Schalowski and Josef Ruppenhofer for valu-able comments and discussions that contributed tothis work. I would also like to thank our annotators,Nadine Reinhold and Emiel Visser, and the anony-mous reviewers for their thoughtful comments.
ReferencesJennifer E. Arnold, Maria Fagnano, and Michael K.
Tanenhaus. 2003. Disfluencies signal theee, um, newinformation. Journal of Psycholinguistic Research,32(1):25–36.
Dale J. Barr, 2001. Trouble in mind: paralinguisticindices of effort and uncertainty in communication,pages 597–600. Paris: L’Harmattan.
Geoff W. Beattie. 1983. Talk: an analysis of speechand non-verbal behaviour in conversation. MiltonKeynes: Open University Press.
Malte Belz and Myriam Klapi. 2013. Pauses follow-ing fillers in L1 and L2 German Map Task dialogues.In The 6th Workshop on Disfluency in SpontaneousSpeech, DiSS.
Susan E. Brennan and Michael F. Schober. 2001. Howlisteners compensate for disfluencies in spontaneousspeech. Journal of Memory and Language, 44:274–296.
Eugene Charniak and Mark Johnson. 2001. Edit de-tection and parsing for transcribed speech. In Pro-ceedings of the Second Meeting of the North AmericanChapter of the Association for Computational Linguis-tics on Language Technologies, NAACL.
Herbert H. Clark and Jean E. Fox Tree. 2002. Using uhand um in spontaneous speech. Cognition, 84:73–111.
Herbert H. Clark. 1996. Using language. Cambridge:Cambridge University Press.
Martin Corley and Oliver W. Stewart. 2008. Hesitationdisfluencies in spontaneous speech: The meaning ofum. Language and Linguistics Compass, 2:589–602.
Christa Durscheid. 2003. Medienkommunikationim Kontinuum von Mundlichkeit und Schriftlichkeit.Theoretische und empirische Probleme. Zeitschrift furangewandte Linguistik, 38:3756.
20

Kerstin Fischer. 2000. From cognitive semantics to lex-ical pragmatics: the functional polysemy of discourseparticles. Mouton de Gruyter: Berlin, New York.
Barbara Fox, Yael Maschler, and Susanne Uhmann.2010. A cross-linguistic study of self-repair: evidencefrom English, German and Hebrew. Journal of Prag-matics, 42:2487–2505.
Jean E. Fox Tree. 2001. Listeners’ uses of um and uhin speech comprehension. Memory and Cognition,2(29):320–326.
Erving Goffman, 1981. Radio talk, pages 197–327.Philadelphia, PA: University of Pennsylvania Press.
Mark Johnson and Eugene Charniak. 2004. A tag-basednoisy channel model of speech repairs. In Proceed-ings of the 42Nd Annual Meeting on Association forComputational Linguistics, ACL.
Andreas H. Jucker and Christa Durscheid. 2012. Thelinguistics of keyboard-to-screen communication. Anew terminological framework. Linguistik Online,6(56):39–64.
Peter Koch and Wulf Oesterreicher. 1985. Spracheder Nahe – Sprache der Distanz. Mundlichkeit undSchriftlichkeit im Spannungsfeld von Sprachtheorieund Sprachgeschichte. Romanistisches Jahrbuch,36:15–43.
Willem J.M. Levelt. 1983. Monitoring and self-repair inspeech. Cognition, 14:41–104.
Howard Maclay and Charles E. Osgood. 1959. Hesita-tion phenomena in spontaneous English speech. Word,15:19–44.
Daniel C. O’Connell and Sabine Kowal. 2005. Uhand um revisited: Are they interjections for signal-ing delay? Journal of Psycholinguistic Research,34(6):555–576.
Xian Qian and Yang Liu. 2013. Disfluency detectionusing multi-step stacked learning. In Proceedings ofthe 2013 Conference of the North American Chapterof the Association for Computational Linguistics: Hu-man Language Technologies, NAACL-HLT.
Sadegh Mohammad Rasooli and Joel Tetreault. 2013.Joint parsing and disfluency detection in linear time.In Proceedings of the 2013 Conference on EmpiricalMethods in Natural Language Processing, EMNLP.
Sadegh Mohammad Rasooli and Joel Tetreault. 2014.Non-monotonic parsing of fluent umm i mean disflu-ent sentences. In Proceedings of the 14th Conferenceof the European Chapter of the Association for Com-putational Linguistics, EACL.
Ines Rehbein, Soren Schalowski, and Heike Wiese. 2014.The KiezDeutsch Korpus (KiDKo) release 1.0. In The9th International Conference on Language Resourcesand Evaluation, LREC.
Sherry R. Rochester. 1973. The significance of pauses inspontaneous speech. Journal of Psycholinguistic Re-search, 2(1):51–81.
Margret Selting, Peter Auer, Birgit Barden, JorgBergmann, Elizabeth Couper-Kuhlen, SusanneGunthner, Uta Quasthoff, Christoph Meier, Pe-ter Schlobinski, and Susanne Uhmannet. 1998.Gesprachsanalytisches Transkriptionssystem (GAT).Linguistische Berichte, 173:91–122.
Elizabeth Ellen Shriberg. 1994. Preliminaries to a The-ory of Speech Disfluencies. Ph.D. thesis, University ofCalifornia at Berkeley.
Pontus Stenetorp, Sampo Pyysalo, Goran Topic, TomokoOhta, Sophia Ananiadou, and Jun’ichi Tsujii. 2012.Brat: a Web-based Tool for NLP-Assisted Text Anno-tation. In Proceedings of the Demonstrations at the13th Conference of the European Chapter of the Asso-ciation for Computational Linguistics, EACL.
Jan Svartvik. 1990. The London Corpus of Spoken En-glish: Description and Research. Lund: Lund Univer-sity Press.
Heike Wiese, Ulrike Freywald, Soren Schalowski, andKatharina Mayr. 2012. Das KiezDeutsch-Korpus.Spontansprachliche Daten Jugendlicher aus urbanenWohngebieten. Deutsche Sprache, 2(40):797–123.
Kathryn Womack, Wilson McCoy, Cecilia OvesdotterAlm, Cara Calvelli, Jeff B. Pelz, Pengcheng Shi,and Anne Haake. 2012. Disfluencies as extra-propositional indicators of cognitive processing. InProceedings of the Workshop on Extra-PropositionalAspects of Meaning in Computational Linguistics, Ex-ProM ’12.
21

Proceedings of the Second Workshop on Extra-Propositional Aspects of Meaning in Computational Semantics (ExProM 2015), pages 22–31,Denver, Colorado, June 5, 2015. c©2015 Association for Computational Linguistics
A Compositional Interpretation of Biomedical Event Factuality
Halil Kilicoglu, Graciela Rosemblat, Michael J. Cairelli, Thomas C. RindfleschNational Library of MedicineNational Institutes of Health
Bethesda, MD, 20894{kilicogluh,grosemblat,mike.cairelli,trindflesch}@mail.nih.gov
Abstract
We propose a compositional method to as-sess the factuality of biomedical events ex-tracted from the literature. The composi-tion procedure relies on the notion of se-mantic embedding and a fine-grained clas-sification of extra-propositional phenom-ena, including modality and valence shift-ing, and a dictionary based on this classi-fication. The event factuality is computedas a product of the extra-propositional op-erators that have scope over the event. Weevaluate our approach on the GENIA eventcorpus enriched with certainty level andpolarity annotations. The results indicatethat our approach is effective in identify-ing the certainty level component of factu-ality and is less successful in recognizingthe other element, negative polarity.
1 Introduction
The scientific literature is rich in extra-propositional phenomena, such as speculations,opinions, and beliefs, due to the fact that thescientific method involves hypothesis generation,experimentation, and reasoning to reach, oftententative, conclusions (Hyland, 1998). Biomedi-cal literature is a case in point: Light et al. (2004)estimate that 11% of sentences in MEDLINEabstracts contain speculations and argue thatspeculations are more important than establishedfacts for researchers interested in current trendsand future directions. Such statements may alsohave an effect on the reliability of the underlyingscientific claim. Despite the prevalence andimportance of such statements, natural languageprocessing systems in the biomedical domain have
largely focused on more foundational tasks, in-cluding named entity recognition (e.g., disorders,drugs) and relation extraction (e.g., biologicalevents, gene-disease associations), the former taskaddressing the conceptual level of meaning andthe latter addressing the propositional level.
The last decade has seen significant researchactivity focusing on some extra-propositional as-pects of meaning. The main concern of the stud-ies that focused on the biomedical literature hasbeen to distinguish facts from speculative, tenta-tive knowledge (Light et al., 2004). The stud-ies focusing on the clinical domain, on the otherhand, have mainly aimed to identify whether find-ings, diseases, symptoms, or other concepts men-tioned in clinical reports are present, absent, oruncertain (Uzuner et al., 2010). Various corporahave been annotated for relevant phenomena, in-cluding hedges (Medlock and Briscoe, 2007) andspeculation/negation (Vincze et al., 2008; Kim etal., 2008). Several shared task challenges withsubtasks focusing on these phenomena have beenorganized (Kim et al., 2009; Kim et al., 2012).Supervised machine learning and rule-based ap-proaches have been proposed for these tasks. Ingeneral, these studies have been presented as ex-tensions to named entity recognition or relationextraction systems, and they often settle for as-signing discrete values to propositional meaningelements (e.g., assessing the certainty of an event).
Kilicoglu (2012) has proposed a unified frame-work for extra-propositional meaning, encompass-ing phenomena discussed above as well as dis-course level relations, such as Contrast and Elabo-ration, generally ignored in the studies of extra-propositional meaning (Morante and Sporleder,2012). The framework uses semantic embeddingas the core notion, predication as the represen-22

tational means, and semantic composition as themethodology. It relies on a fine-grained linguisticcharacterization of extra-propositional meaning,including modality, valence shifters, and discourseconnectives. In the current work, we present acase study of applying this framework to the taskof assessing biomedical event factuality (whetheran event is characterized as a fact, a counter-fact,or merely a possibility), an important step in de-termining current trends and future directions inscientific research. For evaluation, we rely on themeta-knowledge corpus (Thompson et al., 2011),in which biological events from the GENIA eventcorpus (Kim et al., 2008) have been annotated withseveral extra-propositional phenomena, includingcertainty level, polarity, and source. We discuss inthis paper how two of these phenomena relevant tofactuality (certainty and polarity) can be inferredfrom the semantic representations extracted by theframework. Our results demonstrate that certaintylevels can be captured correctly to a large extentwith our method and indicate that more researchis needed for correct polarity assessment.
2 Related Work
Modality and negation are the two linguistic phe-nomena that are often considered in computa-tional treatments of extra-propositional meaning.Morante and Sporleder (2012) provide a compre-hensive overview of these phenomena from boththeoretical and computational linguistics perspec-tives. In the FactBank corpus (Saurı and Puste-jovsky, 2009), events from news articles are anno-tated with their factuality values, which are mod-eled as the interaction of epistemic modality andpolarity and consist of eight values: FACT, PROB-ABLE, POSSIBLE, COUNTER-FACT, NOT PROBA-BLE, NOT CERTAIN, CERTAIN BUT UNKNOWN,and UNKNOWN. Saurı and Pustejovsky (2012)propose a factuality profiler that computes thesevalues in a top-down manner using lexical andsyntactic information. They capture the interac-tion between different factuality markers scopingover the same event. de Marneffe et al. (2012) in-vestigate veridicality as the pragmatic componentof factuality. Based on an annotation study thatuses FactBank and MechanicalTurk subjects, theyargue that veridicality judgments should be mod-eled as probability distributions. They show thatcontext and world knowledge play an importantrole in assessing veridicality, in addition to lex-
ical and semantic properties of individual mark-ers, and use supervised machine learning to modelveridicality. Szarvas et al. (2012) draw from pre-vious categorizations and annotation studies to in-troduce a unified subcategorization of semanticuncertainty, with EPISTEMIC and HYPOTHETICAL
as the top level categories. Re-annotating threecorpora with this subcategorization and analyzingtype distributions, they show that out-of-domaindata can be gainfully exploited in assessing cer-tainty using domain adaptation techniques, despitethe domain- and genre-dependent nature of theproblem.
In the biomedical domain, several corpora havebeen annotated for extra-propositional phenom-ena, in particular, negation and speculation. TheGENIA event corpus (Kim et al., 2008) containsbiological events from MEDLINE abstracts anno-tated with their certainty level (CERTAIN, PROB-ABLE, DOUBTFUL) and assertion status (EXIST,NON-EXIST). The BioScope corpus (Vincze etal., 2008) consists of abstracts and full-text arti-cles as well as clinical text annotated with negationand speculation markers and their scopes. Whilethey clearly address similar linguistic phenomena,the representations used in these corpora are sig-nificantly different (cue-scope representation vs.tagged events), and there have been attempts atreconciling these representations (Kilicoglu andBergler, 2010; Stenetorp et al., 2012). BioNLPshared tasks on event extraction (Kim et al., 2009;Kim et al., 2012) and CoNLL 2010 shared task onhedge detection (Farkas et al., 2010) have focusedon GENIA and BioScope negation/speculation an-notations, respectively. Supervised machine learn-ing techniques (Morante et al., 2010; Bjorne etal., 2012) as well as rule-based methods (Kilicogluand Bergler, 2011) have been attempted in extract-ing these phenomena and their scopes. Wilburet al. (2006) propose a more fine-grained anno-tation scheme with multi-valued qualitative di-mensions to characterize scientific sentence frag-ments: certainty (complete uncertainty to com-plete certainty), evidence (from no evidence toexplicit evidence), polarity (positive or negative),and trend/direction (increase/decrease, high/low).In a similar vein, Thompson et al. (2011) annotateeach event in the GENIA event corpus with fivemeta-knowledge elements: Knowledge Type (In-vestigation, Observation, Analysis, Method, Fact,Other), Certainty Level (considerable speculation,23

some speculation, and certainty), Polarity (neg-ative and positive), Manner (high, low, neutral),and Source (Current, Other). Their annotationsare more semantically precise as they are appliedto events, rather than somewhat arbitrary sentencefragments used by Wilbur et al. (2006). Miwa etal. (2012) use a machine learning-based approachto assign meta-knowledge categories to events.They cast the task as a classification problem anduse syntactic (dependency paths), semantic (eventstructure), and discourse features (location of thesentence within the abstract). They apply theirsystem to BioNLP shared task data, as well, over-all slightly outperforming the state-of-the-art sys-tems.
3 Methods
We provide a brief summary of the frameworkhere, mainly focusing on predication representa-tion, embedding predicate categorization, and thecompositional algorithm.
3.1 PredicationsThe framework uses the predication construct torepresent all levels of relational meaning. A pred-ication consists of a predicate P and n logical ar-guments (logical subject, logical object, adjuncts).They can be nested; in other words, they cantake other predications as arguments. We callsuch constructs embedding predications to distin-guish them from atomic predications that can onlytake atomic terms as arguments. While some em-bedding predications operate at the basic proposi-tional level, extra-propositional meaning is exclu-sively captured by embedding predications. Weuse the notion of semantic scope to characterizethe structural relationships between predications.A predication Pr1 is said to embed a predicationPr2 if Pr2 is an argument of Pr1. Similarly, a pred-ication Pr2 is is said to be within the semanticscope of a predication Pr1, if a) Pr1 embeds Pr2,or b) there is a predication Pr3, such that Pr1 em-beds Pr3 and Pr2 is within the semantic scope of orshares an argument with Pr3. Scope relations playan important role in the composition procedure. Apredication also encodes the source (S) and scalarmodality value of the predication (MVSc). A for-mal definition of predication, then, is:
Pr := [P, S,MVSc, Arg1..n], n >= 1
By default, the source of a predication is the writerof the text (WR). The source may also indicate a
term or predication that refers to the source (i.e.,who said what is described by the predication?what is the evidence for the predication?). Thescalar modality value of the predication is a valuein the [0,1] range on a relevant modality scale(Sc), which is assigned according to lexical prop-erties of the predicate P and modified by its dis-course context. By default, an unmarked, declara-tive statement has the scalar modality value of 1 onthe EPISTEMIC scale (denoted as 1epistemic), cor-responding to a fact.
3.2 CategorizationWith the embedding categorization, we aim to pro-vide a fine-grained characterization of the kindsof extra-propositional meanings contributed bypredicates that indicate embedding. A synthe-sis of various linguistic typologies and classifi-cations, the categorization is similar to the cer-tainty subcategorization proposed by Szarvas etal. (2012); however, it not only targets certainty-related phenomena, but is rather a more generalcategorization of embedding predicates that in-dicate extra-propositional meaning. We distin-guish four main classes of embedding predicates:MODAL, RELATIONAL, VALENCE SHIFTER andPROPOSITIONAL; each class is further dividedinto subcategories. For the purposes of this pa-per, MODAL and VALENCE SHIFTER categoriesare most relevant (illustrated in Figure 1).
A MODAL predicate associates its embeddedpredication with a modality value on a scale de-termined by the semantic category of the modalpredicate (e.g., EPISTEMIC scale, DEONTIC scale).The scalar modality value (MVSc) indicates howstrongly the embedded predication is associatedwith the scale Sc, 1 indicating strongest posi-tive association and 0 negative association. VA-LENCE SHIFTER predicates do not introduce newscales but trigger a scalar shift of the embeddedpredication on the associated scale.
The MODAL subcategories relevant for factual-ity computation and examples of predicates be-longing to these categories are as follows:
• EPISTEMIC predicates indicate a judgementabout the factual status of the embeddedpredication (e.g., may, possible).
• EVIDENTIAL predicates indicate the type ofevidence (observation, inference, etc.) forthe embedded predication (e.g., demonstrate,suggest).24

Figure 1. Embedding predicate types.
• DYNAMIC predicates indicate ability or will-ingness towards an event (e.g., able, want).
• INTENTIONAL predicates indicate effort ofan agent to perform an event (e.g., aim).
• INTERROGATIVE predicates indicate ques-tioning or inquiry towards the embeddedevent (e.g., investigate).
• SUCCESS predicates indicate degree of suc-cess associated with the embedded predica-tion (e.g., manage, fail).
Each subcategory is associated with its ownmodality scale, except the EVIDENTIAL category,which is associated with the EPISTEMIC scale.The categories listed above also have secondaryepistemic readings, in addition to their primaryscale; for example, INTERROGATIVE predicatescan indicate uncertainty. The EPISTEMIC scaleis the most relevant scale to investigate factual-ity. Our model of this scale and how modal aux-iliaries correspond to it is illustrated in Figure 2.It is similar to the characterization of factualityvalues by Saurı and Pustejovsky (2012), althoughnumerical epistemic values are assigned to predi-cations (MVepistemic), rather than discrete values
like Probable or Fact. In this, the characteriza-tion follows that of Nirenburg and Raskin (2004),which lends itself more readily to the type of op-erations proposed for scalar modality values.
Figure 2. The epistemic scale with characteristicvalues and corresponding modal auxiliaries.
The SCALE SHIFTER subcategory of valenceshifters also plays a role in factuality assessment.Predicates belonging to this category change thescalar modality value of the predications in theirscope. The subtypes of this category are NEGA-TOR, INTENSIFIER, DIMINISHER, and HEDGE. ADIMINISHER predicate (e.g., hardly) lowers themodality value, while an INTENSIFIER increasesit (e.g., strongly). On the other hand, a negationmarker belonging to the NEGATOR category (e.g.,no in no indication) inverts the modality value ofthe embedded predication. The HEDGE categorycontains attribute hedges (e.g., mostly, in gen-eral) (Hyland, 1998), whose effect is to make theembedded predication more vague. We model thisby decreasing, increasing or leaving unchangedthe modality value depending on the position ofthe embedded predication on the scale.
Lexical and semantic knowledge about predi-cates belonging to embedding categories are en-coded in a dictionary, which currently consists of987 predicates, 544 of them belonging to MODAL
and 95 to SCALE SHIFTER categories. A very pre-liminary version of this dictionary was introducedin Kilicoglu and Bergler (2008). It was later ex-tended and refined using several corpora and lin-guistic classifications (including Saurı (2008) andNirenburg and Raskin (2004)). Since predicatescollected from external resources do not neatly fitinto embedding categories and we target deeperlevels of meaning distinctions, the dictionary con-struction involved a fair amount of manual refine-25

ment. The dictionary encodes the lemma and part-of-speech of the predicate as well as its extra-propositional meaning senses. Each sense consistsof five elements:
1. Embedding category, such as ASSUMPTIVE.
2. Prior scalar modality value (if any).
3. Embedding relation classes indicate the se-mantic dependencies used to identify the log-ical object argument of the predicate.
4. Scope type indicates whether the predicate al-lows a wide or narrow scope reading (for ex-ample, in I don’t think that P, because thinkallows narrow scope reading, the negation istransferred to its complement (I think that notP)).
5. Argument inversion (true/false) determineswhether the object and subject argumentsshould be switched in semantic interpreta-tion.
Lemma mayPOS MD (modal)Sense.01 Category SPECULATIVE
Scalar modality value 0.5Embedding rel. classes AUX
Sense.02 Category PERMISSIVEScalar modality value 0.6Embedding rel. classes AUX
Table 1. Dictionary entry for may.
The entry in Table 1 indicates that the modalauxiliary may is associated with two modal senses(i.e., it is ambiguous) with differing scalar modal-ity values. It also indicates that a predication em-bedded by SPECULATIVE may will be assignedthe epistemic value of 0.5 initially. Scope typeand argument inversion attributes are not explic-itly given, indicating default values for each.
3.3 CompositionSemantic composition is the procedure of bottom-up predication construction using the knowledgeencoded in the dictionary and syntactic informa-tion in the form of dependency relations. De-pendency relations are extracted using the Stan-ford CoreNLP toolkit (Manning et al., 2014). Weuse the Stanford collapsed dependency format (deMarneffe et al., 2006) for dependency relations.We illustrate the salient steps of this procedure ona sentence from the GENIA event corpus (sen-tence 9 from PMID 10089566 shown in row (1)
in Table 2). For brevity, the simplified version ofthe sentence is given in row (2), in which textualspans are substituted with the corresponding eventannotations.
As the first step in the procedure, the syntacticdependency graphs of sentences of a document arecombined and transformed into a semantically en-riched, directed, acyclic semantic document graphthrough a series of dependency transformations.The nodes of the semantic graph correspond totextual units of the document and the direction ofthe arcs reflects the direction of the semantic de-pendency between its endpoints. The transforma-tion is guided by a set of rules, illustrated on row(3). For example, the first three transformationsare due to the Verb Complex Transformation rule,which reorders the dependencies that a verb is in-volved in such that semantic scope relations withthe auxiliaries and other verbal modifiers are madeexplicit. The resulting semantic dependencies onthe right indicate that involve is within the scope ofnot, which in turn is in the scope of may, and theentire verb complex may not involve is within thescope of thus, which indicates a discourse relation.
The next steps of the compositional algorithm,argument identification and scalar modality valuecomposition, play a role in factuality assessment1.Argument identification is the process of determin-ing the logical arguments of a predication, basedon the bottom-up traversal of the semantic graph.It is guided by argument identification rules, eachof which defines a mapping from a lexical cate-gory and an embedding class to a logical argumenttype. Such a rule applies to a predicate specifiedin the dictionary that belongs to the lexical cate-gory and serves as the head of a semantic depen-dency labeled with the embedding relation class.With argument identification rules, we determine,for example, that the second instance of may in theexample, has as its logical object, the predicationindicated by operate, since there is an AUX em-bedding relation between may and operate, whichsatisfies the constraint defined in the embeddingdictionary (Table 1).
Scalar modality value composition is the proce-dure of determining the relevant scale for a pred-ication and its modality value on this scale. Thefollowing principles are applied:
1. Initially, every predication is assigned to1The compositional steps that we do not discuss here are
source propagation and argument propagation.26

(1) Thus HIV-1 gp41-induced IL-10 up-regulation in monocytes may not involve NF-kappaB, MAPK,or PI3-kinase activation, but rather may operate through activation of adenylate cyclaseand pertussis-toxin-sensitive Gi/Go protein to effect p70(S6)-kinase activation.
(2) Thus E27 may not E32, E33, or E34, but rather may E39 and E40.(3) advmod(involve,thus) ADVMOD(thus,may)
aux(involve,may) AUX(may,not)neg(involve,not) NEG(not,involve)prep of(activation,cyclase) PREP OF(activation,adenylate cyclase)
(4) involve:CORRELATION(E32,WR,0.5epistemic,E27, E28)not:NEGATOR(EM53,WR,0.5epistemic,E32)may:SPECULATIVE(EM57,WR,1.0epistemic,EM53)operate:REGULATION(E39,WR,0.5epistemic,E38,E27)may:SPECULATIVE(EM58,WR,1.0epistemic,E39)
Table 2. Composition example for 10089566:S9.
EPISTEMIC scale with the value of 1 (i.e., afact).
2. A MODAL predicate places its logical objecton the relevant MODAL scale and assigns toit its prior scalar modality value, specified inthe dictionary.
3. A SCALE SHIFTER predicate does not intro-duce a new scale but changes the existingscalar modality value of its logical object.
4. The scalar influence of an embedding pred-icate (P) extends beyond the predications itembeds to another predication in its scope(Pre), if one of the following constraints ismet:
• P is associated with the epistemic scaleand the intermediate predications (Pri)are either of SCALE SHIFTER type or areassociated with epistemic scale• P is of SCALE SHIFTER type and at
most one intermediate predication is ofMODAL type• P is of a non-epistemic MODAL type and
Pri all belong to SCALE SHIFTER type
Assuming that we have a predicate P which in-dicates an embedding predication Pr and a pred-ication (Pre) under its scalar influence, the scalarmodality value of Pre is updated differently, basedon whether the predicate P is a MODAL or aSCALE SHIFTER predicate. All update opera-tions used for MODAL predicates are given in Ta-ble 3 and those for SCALE SHIFTER predicates
in Table 4. For MODAL predicates, the compo-sition is modeled as the interaction of the priorscalar modality value of the embedding predicate(MVSc(Pmodal)) in the first column and the cur-rent scalar modality value associated with the em-bedded predication (MVSc(Pre)) in the second col-umn, resulting in the value shown in the third col-umn (MVSc(Pre)
′). When P is a scale-shifting
predicate, the update procedure is guided by itstype, as illustrated in Table 4. X and Y representarbitrary values in the range of [0,1].
MVSc(Pmodal) MVSc(Pre) MVSc(Pre)′
(1) = X = 1.0 X(2) = X = 0.0 1-X(3) > Y > 0.5 ∧ = Y min(0.9, Y+0.2)(4) < Y ∧ >= 0.5 > 0.5 ∧ = Y min(0.5,Y-0.2)(5) < 0.5 > 0.5 ∧ = Y 1-Y(6) >= 0.5 < 0.5 ∧ = Y Y(7) < 0.5 < 0.5 ∧ = Y 1- Y
Table 3. The composition of scalar modality val-ues in MODAL contexts.
For the example shown in Table 2, the com-putation in row (1) of Table 3 applies when weencounter the SPECULATIVE may node dominat-ing the operate node in the semantic graph: sinceMVepistemic(may)=0.5 and operate at the time ofcomposition has epistemic value of 1, its scalarmodality value gets updated to 0.5.
When not, a NEGATOR, is encountered in com-position, the scalar modality value of its embeddedpredication (involve) is updated to 0, due to row(2) in Table 4 (1-1=0). In the next step of com-position, when the first instance of SPECULATIVE
may is encountered, the nodes in its scope, not and27

Type MVSc(Pre) MVSc(Pre)′
(1) NEGATOR = 0.0 0.5(2) NEGATOR > 0.0 ∧ = Y 1-Y(3) INTENSIFIER (= 0.0 ∨ = 1.0)
∧ = YY
(4) INTENSIFIER >= 0.5 ∧ = Y min(0.9,Y+0.2)(5) INTENSIFIER < 0.5 ∧ = Y max(0.1,Y-0.2)(6) DIMINISHER (= 0.0 ∨ = 1.0)
∧ = YY
(7) DIMINISHER >= 0.5 ∧ = Y max(0.5,Y-0.2)(8) DIMINISHER < 0.5 ∧ = Y max(0.4,Y+0.2)(9) HEDGE = 0.0 0.2(10) HEDGE = 1.0 0.8(11) HEDGE = Y Y
Table 4. The composition of scalar modality val-ues in SCALE SHIFTER contexts.
involve, have epistemic values of 1 and 0, respec-tively. The scalar modality value of not gets up-dated to min(0.5,1-0.2)=0.5 (row (4) in Table 3).Row (2) in Table 3 applies to involve, resulting in0.5 as its new epistemic value (1-0.5).
Row (4) in Table 2 shows the annotations gen-erated by the system. The system takes as in-put GENIA event annotations (e.g., CORRELA-TION and REGULATION), which we expand withscalar modality values and sources. For example,E32..E34, three events triggered by involve and an-notated as CORRELATION events in GENIA, haveepistemic value of 0.5 and WR as the source (onlyone of the events, E32, is shown for brevity). Thesystem also generates other embedding predica-tions (indicated with EM) corresponding to fine-grained extra-propositional meaning. To clarify,the content of first three predications (first anevent and the latter two extra-propositional) areexpressed in natural language below:
• E32: Correlation between gp41-induced IL-10 upregulation and NF-kappaB activation isPOSSIBLE according to the author.
• EM53: That there is no correlation betweengp41-induced IL-10 upregulation and NF-kappaB activation is POSSIBLE according tothe author.
• EM57: That it is possible there no correla-tion between gp41-induced IL-10 upregula-tion and NF-kappaB activation is a FACT ac-cording to the author.
3.4 Data and EvaluationWe assessed our methodology on the meta-knowledge corpus (Thompson et al., 2011), in
which GENIA events are annotated with certaintylevels (CL) and polarity. This corpus consistsof 1000 MEDLINE abstracts and contains 34,368event annotations. Uncertainty is only annotatedin this dataset for events with Analysis knowledgetype. Such events correspond to 17.6% of the en-tire corpus. Of all Analysis events, 33.6% are an-notated with L2 (high confidence), 11.4% with L1(low confidence), and 55% with L3 (certain) CLvalues. Polarity, on the other hand, is annotatedfor all events (6.1% negative).
Factuality values are often modeled as discretecategories (e.g., PROBABLE, FACT). Thus, to eval-uate our approach, we converted the scalar modal-ity values associated with predications (MVSc) todiscrete CL and polarity values using mappingrules, shown in Table 5. The rules were based onthe analysis of 100 abstracts that we used for train-ing.
Condition AnnotationMVepistemic = 0 ∨ MVepistemic = 1 L3MVepistemic > 0.6 ∧ MVepistemic < 1 L2MVepistemic > 0 ∧ MVepistemic <= 0.6 L1MVpotential > 0 L2MVinterrogative = 1 ∨ MVintentional = 1 L1MVepistemic = 0 ∨ MVpotential = 0 ∨MVsuccess = 0
Negative
Table 5. Mapping scalar modality values to eventcertainty and polarity.
We evaluated CL mappings in two ways: a) werestricted it only to Analysis type events, the onlyones annotated with L1 and L2 values, and b) weevaluated them on the entire corpus. For polarity,we only considered the entire corpus. As evalu-ation metrics, we calculated precision, recall, andF1 score as well as accuracy on the discrete valueswe obtained by the mapping.
Another evaluation focused more directly onfactuality. We represented the gold CL-polaritypairs as numerical values and calculated the aver-age distance between these values and those gen-erated by the system. The lower the distance, thebetter the system can be considered. In this evalua-tion scheme, annotating a considerably speculative(L1) event as somewhat speculative (L2) is penal-ized less than annotating it as certain (L3). Wemapped the gold annotations to the numerical val-ues as follows: L3-Positive → 1, L2-Positive →0.8, L1-Positive → 0.6, L1-Negative → 0.4, L2-Negative→ 0.2, L3-Negative→ 0.28
4 Results and Discussion
The results of mapping the system annotations todiscrete values annotated in the meta-knowledgecorpus are provided in Table 6.
Type Precision Recall F1 AccuracyCL evaluation limited to Analysis eventsCL 81.75L3 78.43 95.57 86.15L2 90.65 61.46 73.25L1 83.22 76.28 79.60Evaluation on the entire test setCL 95.13L3 97.27 97.74 97.51L2 73.08 61.55 66.61L1 61.42 76.28 68.05Polarity 95.32Positive 95.99 99.15 97.54Negative 74.17 37.04 49.41
Table 6. Evaluation results.
When the CL evaluation is limited to Anal-ysis events, we obtain an accuracy of approxi-mately 82%. The baseline considered by Miwaet al. (2012) is the majority class, which wouldyield an accuracy of 55% for these events. TheirCL evaluation is not limited to Analysis events,and they report F1 scores of 97.6%, 66.5%, and74.9% for L3, L2, and L1 levels, respectively, onthe test set. Restricting the system to Analysisevents, we obtain the results shown at the top ofthe table (86.2%, 73.3%, and 79.6%). Lifting theAnalysis restriction, we obtain the results shown atthe bottom (97.5%, 66.6%, and 68.1% for L3, L2,and L1, respectively). The results are very similarfor L3 and L2 levels, while our system somewhatunderperformed on L1. With respect to negativepolarity, our system performed poorly (49.4% vs.Miwa et al.’s 63.4%), while the difference was mi-nor for positive polarity (97.5% vs. 97.7%).
In comparing to Miwa et al.’s results, severalpoints need to be kept in mind. First, in contrastto their study, we have not performed any trainingon the corpus data, except determining the map-ping rules shown in Table 5. Secondly, knowingwhether an event is an Analysis event or not is asignificant factor in determining the CL value andtheir machine learning features are likely to haveexploited this fact, whereas we did not attempt toidentify the knowledge type of the event. Thirdly,
L1 and L2 values appear only for Analysis events,therefore the evaluation scenario that only consid-ers Analysis events is likely to overestimate theperformance of our system on L1 and L2 and un-derestimate it on L3.
While our system performed similarly to Miwaet al.’s with regards to positive polarity, our map-pings for negative polarity were less successful,which suggests that modeling negative polarity asthe lower end of several modal scales (the last rowof Table 5) may not be sufficient for correctly cap-turing the polarity values. Our preliminary analy-sis of the results indicate that scope relationshipsbetween predications could play a more significantrole. In other words, whether an event is in thescope of a predication trigger by a NEGATOR pred-icate may be a better predictor of negative polarity.
With the evaluation scheme that is based on av-erage distance, we obtained a distance score of0.12. For the majority class baseline, this scorewould be 0.21. Our score shows clear improve-ment over the baseline; however, it is not directlycomparable to Miwa et al.’s results. This evalua-tion scheme, to our knowledge, has not previouslybeen used to evaluate factuality and we believe itis better suited to the gradable nature of factuality.
Analyzing the results, we note that many errorsare due to problems in dependency relations andtransformations that rely on them. Errors in de-pendency relations are common due to complex-ity of the language under consideration, and theseerrors are further compounded by hand-craftedtransformation rules that can at times be inad-equate in capturing semantic dependencies cor-rectly. In the following example, the prepositionalphrase attachment error caused by syntactic pars-ing (to suppress. . . is attached to the main verbresult, instead of to ability) prevents the systemfrom identifying the semantic dependendency be-tween ability and suppress, causing a L2 recall er-ror. While the system uses a transformation ruleto correct some prepositional phrase attachmentproblems, this particular case was missed.
• The reduction in gene expression resultedfrom the ability of IL-10 to suppress IFN-induced assembly of signal transducer . . .
• prep to(result,suppress) vs.prep to(ability,suppress)
Prior scalar modality values in the dictionaryhave been manually determined and are fixed.29

They are able to capture the meaning subtletiesto a large extent and the composition procedureattempts to capture the meaning changes due tomarkers in context. However, some uncertaintymarkers are clearly more ambiguous than others,leading to different certainty level annotations insimilar contexts and our method may miss thesedifferences due to the fixed value in the dictionary.For example, the adjective potential has been al-most equally annotated as an L1 and L2 cue in themeta-knowledge corpus. This also seems to con-firm the finding of de Marneffe et al. (2012) thatworld knowledge and context have an effect on theinterpretation of factuality.
We also noted what seem like annotation errorsin the corpus. For example, in the sentence L-1beta stimulation of epithelial cells did not gen-erate any ROIs, the event expressed with genera-tion of ROIs seems to have negative polarity, eventhough it is not annotated as such in the corpus.
5 Conclusion
We presented a rule-based compositional methodfor assessing factuality of biological events. Themethod is linguistically motivated and emphasizesgenerality over corpus-specific optimizations, andwithout making much use of the corpus for train-ing, we were able to obtain results that are compa-rable to the performance of the state-of-the-art sys-tems for certainty level assignments. The methodwas less successful with respect to polarity assess-ment, suggesting that the hypothesis that negativepolarity can be modeled as corresponding to thelower end of the modal scales may be inadequate.In future work, we plan to develop a more nuancedapproach to negative polarity.
Acknowledgments
This work was supported by the intramural re-search program at the U.S. National Library ofMedicine, National Institutes of Health.
ReferencesJari Bjorne, Filip Ginter, and Tapio Salakoski. 2012.
University of Turku in the BioNLP’11 Shared Task.BMC Bioinformatics, 13 Suppl 11:S4.
Marie-Catherine de Marneffe, Bill MacCartney, andChristopher D. Manning. 2006. Generating typeddependency parses from phrase structure parses. InProceedings of the 5th International Conference on
Language Resources and Evaluation, pages 449–454.
Marie-Catherine de Marneffe, Christopher D. Man-ning, and Christopher Potts. 2012. Did it hap-pen? The pragmatic complexity of veridicality as-sessment. Computational Linguistics, 38(2):301–333.
Richard Farkas, Veronika Vincze, Gyorgy Mora, JanosCsirik, and Gyorgy Szarvas. 2010. The CoNLL-2010 Shared Task: Learning to Detect Hedges andTheir Scope in Natural Language Text. In Proceed-ings of the Fourteenth Conference on ComputationalNatural Language Learning — Shared Task, pages1–12.
Ken Hyland. 1998. Hedging in scientific research ar-ticles. John Benjamins B.V., Amsterdam, Nether-lands.
Halil Kilicoglu and Sabine Bergler. 2008. Recogniz-ing speculative language in biomedical research ar-ticles: a linguistically motivated perspective. BMCBioinformatics, 9 Suppl 11:s10.
Halil Kilicoglu and Sabine Bergler. 2010. A High-Precision Approach to Detecting Hedges and TheirScopes. In Proceedings of the Fourteenth Confer-ence on Computational Natural Language Learning,pages 70–77.
Halil Kilicoglu and Sabine Bergler. 2011. EffectiveBio-Event Extraction using Trigger Words and Syn-tactic Dependencies. Computational Intelligence,27(4):583–609.
Halil Kilicoglu. 2012. Embedding Predications.Ph.D. thesis, Concordia University.
Jin-Dong Kim, Tomoko Ohta, and Jun’ichi Tsujii.2008. Corpus annotation for mining biomedicalevents from literature. BMC Bioinformatics, 9:10.
Jin-Dong Kim, Tomoko Ohta, Sampo Pyysalo, Yoshi-nobu Kano, and Jun’ichi Tsujii. 2009. Overviewof BioNLP’09 Shared Task on Event Extraction.In Proceedings of Natural Language Processingin Biomedicine (BioNLP) NAACL 2009 Workshop,pages 1–9.
Jin-Dong Kim, Ngan Nguyen, Yue Wang, Jun’ichi Tsu-jii, Toshihisa Takagi, and Akinori Yonezawa. 2012.The Genia Event and Protein Coreference tasks ofthe BioNLP Shared Task 2011. BMC Bioinformat-ics, 13 Suppl 11:S1.
Marc Light, Xin Y. Qiu, and Padmini Srinivasan. 2004.The language of bioscience: facts, speculations, andstatements in between. In BioLINK 2004: LinkingBiological Literature, Ontologies and Databases,pages 17–24.
Christopher D. Manning, Mihai Surdeanu, John Bauer,Jenny Finkel, Steven J. Bethard, and David Mc-Closky. 2014. The Stanford CoreNLP natural lan-guage processing toolkit. In Proceedings of 52nd30

Annual Meeting of the Association for Computa-tional Linguistics: System Demonstrations, pages55–60.
Ben Medlock and Ted Briscoe. 2007. Weakly su-pervised learning for hedge classification in scien-tific literature. In Proceedings of the 45th Meet-ing of the Association for Computational Linguis-tics, pages 992–999.
Makoto Miwa, Paul Thompson, John McNaught, Dou-glas B. Kell, and Sophia Ananiadou. 2012. Extract-ing semantically enriched events from biomedicalliterature. BMC Bioinformatics, 13:108.
Roser Morante and Caroline Sporleder. 2012. Modal-ity and negation: An introduction to the special is-sue. Computational Linguistics, 38(2):223–260.
Roser Morante, Vincent van Asch, and Walter Daele-mans. 2010. Memory-based resolution of in-sentence scopes of hedge cues. In Proceedings ofthe Fourteenth Conference on Computational Natu-ral Language Learning, pages 40–47.
Sergei Nirenburg and Victor Raskin. 2004. Ontologi-cal Semantics. The MIT Press, Cambridge, MA.
Roser Saurı and James Pustejovsky. 2009. FactBank:a corpus annotated with event factuality. LanguageResources and Evaluation, 43(3):227–268.
Roser Saurı and James Pustejovsky. 2012. Are YouSure That This Happened? Assessing the FactualityDegree of Events in Text. Computational Linguis-tics, 38(2):261–299.
Roser Saurı. 2008. A Factuality Profiler for Eventual-ities in Text. Ph.D. thesis, Brandeis University.
Pontus Stenetorp, Sampo Pyysalo, Tomoko Ohta,Sophia Ananiadou, and Jun’ichi Tsujii. 2012.Bridging the gap between scope-based and event-based negation/speculation annotations: A bridgenot too far. In Proceedings of the Workshop onExtra-Propositional Aspects of Meaning in Compu-tational Linguistics, pages 47–56.
Gyorgy Szarvas, Veronika Vincze, Richard Farkas,Gyorgy Mora, and Iryna Gurevych. 2012. Cross-genre and cross-domain detection of semantic uncer-tainty. Computational Linguistics, 38(2):335–367.
Paul Thompson, Raheel Nawaz, John McNaught, andSophia Ananiadou. 2011. Enriching a biomedi-cal event corpus with meta-knowledge annotation.BMC Bioinformatics, 12:393.
Ozlem Uzuner, Imre Solti, and Eithon Cadag. 2010.Extracting medication information from clinicaltext. JAMIA, 17(5):514–518.
Veronika Vincze, Gyorgy Szarvas, Richard Farkas,Gyorgy Mora, and Janos Csirik. 2008. The Bio-Scope corpus: biomedical texts annotated for uncer-tainty, negation and their scopes. BMC Bioinformat-ics, 9 Suppl 11:S9.
W. John Wilbur, Andrey Rzhetsky, and Hagit Shatkay.2006. New directions in biomedical text annota-tions: definitions, guidelines and corpus construc-tion. BMC Bioinformatics, 7:356.
31

Proceedings of the Second Workshop on Extra-Propositional Aspects of Meaning in Computational Semantics (ExProM 2015), pages 32–40,Denver, Colorado, June 5, 2015. c©2015 Association for Computational Linguistics
Committed Belief Tagging on the FactBank and LU Corpora:A Comparative Study
Gregory J. WernerDepartment of Computer Science
George Washington UniversityWashington, DC, [email protected]
Vinodkumar PrabhakaranDepartment of Computer Science
Columbia UniversityNew York, NY, USA
Mona DiabDepartment of Computer Science
George Washington UniversityWashington, DC, [email protected]
Owen RambowCenter for Computational Learning Systems
Columbia UniversityNew York, NY, USA
Abstract
Level of committed belief is a modality in nat-ural language, it expresses a speak-er/writersbelief in a proposition. Initial work explor-ing this phenomenon in the literature bothfrom a linguistic and computational model-ing perspective shows that it is a challengingphenomenon to capture, yet of great interestto several downstream NLP applications. Inthis work, we focus on identifying relevantfeatures to the task of determining the levelof committed belief tagging in two corporaspecifically annotated for the phenomenon:the LU corpus and the FactBank corpus. Weperform a thorough analysis comparing tag-ging schemes, infrastructure machinery, fea-ture sets, preprocessing schemes and data gen-res and their impact on performance in bothcorpora. Our best results are an F1 score of75.7 on the FactBank corpus and 72.9 on thesmaller LU corpus.
1 Introduction
Level of Committed belief (LCB) is a linguisticmodality expressing a speaker or writer’s (SW) levelof commitment to a given proposition, which couldbe their own or a reported proposition. Modelingthis type of knowledge explicitly is useful in deter-mining an SWs cognitive state, also referred to asperson’s private state (Wiebe et al., 2005). Wiebe etal. (2005) use the definition of (Quirk et al., 1985),who defines a private state to be an “internal (state)
that cannot be directly observed by others”. Deter-mining the cognitive state of an SW can be relevantto several natural language processing (NLP) taskssuch as question answering, information extraction,confidence determination in people’s deduced opin-ions, determining the veracity of information, under-standing power/influence relations in linguistic com-munication, etc. As an example, in (Rosenthal andMcKeown, 2012), LCB was used to improve theirclaim detector which in turn allowed for improve-ments in influence prediction.
Initial work addressed the task of automaticallyidentifying LCB of the SW. Approaches to date haverelied on supervised models dependent on manu-ally annotated data. There are two standard anno-tated corpora, the LU corpus (Diab et al., 2009) andFactBank (Saurı and Pustejovsky, 2009). Thoughin effect aiming for the same objective, both cor-pora use different terminology, different annotationstandards, and they cover different genres. Previ-ous studies performed on these corpora were con-ducted independently. In this work, we explore bothcorpora systematically and investigate their respec-tive proposed tag sets. We experiment with mul-tiple machine learning algorithms, varying the tagsets as we go along. Our goal is to build an auto-matic LCB tagger that is robust in a multi-genre con-text. Eventually we aim to adapt this tagger to otherlanguages. The LCB tagging task aims at automat-ically identifying beliefs which can be ascribed to aSW, and at identifying the strength level by which
32

he or she holds them. Across languages, many dif-ferent linguistic devices are used to denote this atti-tude towards an uttered proposition, including syn-tax, lexicon, and morphology. In this work we fo-cus our investigation of LCB tagging in English andwe only address the problem from the perspective ofthe SW. We do not address nested LCB where theSW is reporting the LCB of other people (leading tonested attributions, as done in FactBank followingthe MPQA Sentiment corpus (Wiebe et al., 2005).
2 Background
Initial work on LCB was undertaken by Diab et al.(2009), who built the LU corpus that contains be-lief annotations for propositional heads in text. Theyused a 3-way distinction of belief tags: CommittedBelief (CB) where the SW strongly believes in theproposition, Non-committed belief (NCB) where theSW reflects a weak belief in the proposition, andNon Attributable Belief (NA) where the SW is not(or could not be) expressing a belief in the propo-sition (e.g., desires, questions etc.). The LU cor-pus comprises over 13,000 word tokens from sixteendocuments covering four genres: 9 newswire docu-ments, 4 training manuals, 2 correspondences and1 interview. One of the issues with this annotationscheme is that the annotations for NCB conflate thecases where the SW explicitly conveys the weaknessof belief (e.g., using modal auxiliaries such as may)and the cases where the SW is reporting someoneelse’s belief about a proposition. In this paper, wetease apart these original NCB cases and arrive ata 4-way belief distinction using the original anno-tations in the LU corpus (details to be discussed inSection 3.1).
The LCB tagger developed using the original LUcorpus (Prabhakaran et al., 2010) obtained a bestperformance (64% F-measure) using the Yamcha1
machine learning framework which leverages Sup-port Vector Machines in a supervised manner, anda performance of 59% F-measure using the Condi-tional Random Fields (CRF) algorithm. Their exper-iments were limited in scope because the LU Corpusis fairly small. This led to an under-representationof NCB tags in the training corpus and a relativelyshallow understanding of how LCB tagging per-
1http://chasen.org/∼taku/software/yamcha/
forms across genres. In this paper, we performa detailed investigation through extensive machinelearning experiments to understand how the size ofdata and genre variations affect the performance ofan LCB tagger. We also systematically measure theimpact of augmenting the training data with moredata as well as measuring performance differenceswhen the training data comprises a single genre vs.multiple genres. It should be noted that althoughwe experiment with similar machine learning frame-works, our results are not directly comparable sincethe Prabhakaran et al. (2010) work applied cross val-idation to the LU-3 corpus, while we did not followthe same experimental strategy. Additionally, in thiswork we use a lot more features than those reportedin the previous study.
A closely related corpus is FactBank (FB; Saurıand Pustejovsky (2009)), which captures factualityannotations on top of event annotations in TimeML.FactBank is annotated on the genre of newswire.FactBank models the factuality of events at threelevels: certain (CT), probable (PB) and possible(PS), and distinguishes the polarity (e.g., CT- meanscertainly not true). Moreover it marks an unknowncategory (Uu), which refers to uncommitted or un-derspecified belief. It also captures the source ofthe factuality assertions, thereby distinguishing theSW’s factuality assertions from those of a sourceintroduced by the author. Despite the terminologydifference between FactBank (“factuality”) and LU(“committed belief”), they both address the sametype of linguistic modality phenomenon namelylevel of committed belief. Accordingly, with theappropriate mapping, both corpora can be used inconjunction to model LCB. From a computationalperspective, FactBank differs from the LU corpusin two major respects (other than the granularityin which they capture annotations): 1) FactBankis roughly four times the size of the LU corpus,and 2) FactBank is more homogeneous in terms ofgenre than the LU corpus as it consists primarily ofnewswire. In this paper, we unify the factuality an-notations in Factback and the level of committed be-lief annotations present in the LU corpus to a 4-waycommitted-belief distinction.2
2For an additional discussion of the relation between factu-ality and belief, see (Prabhakaran et al., 2015)
33

3 Approach
Following previous work (Prabhakaran et al., 2010),we adopt a supervised approach to the LCB prob-lem. We experiment with the two available manuallyannotated corpora, the LU and FB corpora. Goingbeyond previous approaches to the problem reportedin the literature, our goal is to create a robust LCBsystem while gaining a deeper understanding of thephenomenon of LCB as an expressed modality bysystematically teasing apart the different factors thataffect performance.
3.1 Annotation Transformations
The NCB category of the LU tagging scheme cap-tures two different notions: that of uncertainty of thespeaker/writer and that of belief being attributed tosomeone other than the SW. Accordingly, we manu-ally split the NCB into the NCB tag and the ReportedBelief tag (ROB). Reported belief is the case wherethe SW’s intention is to report on someone else’sstated belief, whether or not they themselves believeit. An example of this would be the sentence Johnsaid he studies everyday. While the ‘say’ proposi-tion is an example of committed belief (CB) on thepart of the SW, the SW makes no assertion about the‘study’ proposition attributed to John, and thereforestudies is labeled ROB. This relabeling of the NCBtag into NCB and ROB was carried out manuallyby co-authors Werner and Rambow, who are nativespeakers of English. The inter-annotator agreementwas 93%. The cases where there were contentionswere discussed and an adjudication process was fol-lowed where a single annotation was agreed upon.This was a relatively fast process since the numberof NCB annotated data is very small in the originalLU corpus (176 instances). This conversion resultedin the LU-4 corpus designating the fact that this ver-sion of the LU corpus is a 4-way annotated corpus.This is in contrast to the original version of LU cor-pus with the 3-way distinction, LU-3.
To illustrate the difference between each of thetags in the LU-4 corpus, we provide a few examplesfrom the annotated corpus. The sentence 1 showsthe contrast between the committed belief in the au-thor knowing and the non-committed belief in theauthor being uncertain of it (a flu vaccine) working.The other two tags are demonstrated in the sentence
2 where the author is saying Reed accused howeverReed is the one talking about failing and not the au-thor. To contrast we note that although Reed is at-tributed the notion of failing, neither the author norReed demonstrate any belief of the verb to probe andtherefore it is not-attributable to any source men-tioned in this sentence.
(1) But we only <CB> know </CB> that it might<NCB> work </NCB> because of laboratorystudies and animal studies uh uh
(2) Democratic leader Harry Reed <CB> accused</CB> Republicans of <ROB> failing </ROB>
to <NA> probe </NA> allegations ...
In order to render the FactBank (FB) corpus compa-rable to the LU-4 corpus, we mapped tags in the FBcorpus into the 4-way tag scheme adopted in the LU-4 framework. Accordingly, we mapped CT directlyinto CB, PB and PS directly into NCB, and Uu wasmapped into either NA or ROB. We used the num-ber and identity of sources to determine if the Uuof FB was due to belief expressed by a source otherthan the SW. Specifically, if the same proposition ismarked Uu for the SW, but the annotations also cap-ture factuality attributed to another source, then weconclude the tag should be ROB. If there is no otherattribution on the proposition other than the Uu at-tributed to the SW, we consider the tag to be NA.We refer to the resulting version of the FB corpus asFB-4. It is worth noting that because the genre of theFB corpus is newswire, it has a relatively large num-ber of ROB annotations. Moreover, FB explicitlymarks LCB with respect to various nested sources.However in our mapping, we only consider the an-notations from the perspective of the SW.
We give a few examples of the original FactBankwork as to compare and contrast the notion of be-lief carried in each corpus. In sentence 3, we haveclear cut mapping between the certainty of the au-thor in think and committed belief. Likewise, doingis a non-committed belief. In each case, the polar-ity is discarded in our transformations. The sentence4 reveals the case where teaches takes on a reportedbelief meaning as it is given both a certain tag for theschool and an unknown tag for the author. An ex-ample where Uu does not constitute reported beliefis shown in the sentence 5, where only one entity’s
34

belief is conveyed, and that is of the author.
(3) . . . Yeah I <CT+> think </CT+> he’s <PR+> do-ing </PR> the right thing
(4) The school <CT+> says </CT+> it <CT+>
<Uu> teaches </Uu> </CT+> the children to begood Muslims and good students.
(5) I <CT+> urge <CT+> you to <Uu> do <Uu>
the right thing . . .
The tag distribution breakdown in the corpora is il-lustrated in Table 1.
CB NCB ROB NA Total
LU-3 631 176 589 13485
LU-4 631 15 161 589 13485
FB-4 3837 156 2074 661 82845
Table 1: Label distribution in the LU-3, LU-4 and FB-4corpora.
3.2 Experimental Set Up
3.2.1 Corpus CombinationWe experiment with the three corpora LU-3 (with
the labels CB, NCB and NA), LU-4 and FB-4(each with the labels CB, NCB, NA, and ROB). Wepresent results on each of the corpora and their com-binations for training and testing. In general we splitour corpora at the sentence level into training andtest sets with 5/6 for training and 1/6 for test by re-serving every sixth sentence for the test set.
3.2.2 FeaturesWe use a number of features proposed by Prab-
hakaran et al. (2010), as well as a few more re-cent additions, and we hold them constant acrossour different experimental conditions. This featureset comprises the following base set of lexical andsyntactic based features. General Features for eachtoken include its lemma, part of speech (POS), aswell as the lemma and POS of two preceding andfollowing tokens. Dependency features include sib-ling’s lemma, sibling’s POS, child’s lemma, child’sPOS, parent’s lemma, parent’s POS, ancestors’ lem-mas, ancestor’s POS, reporting ancestor’s POS, re-porting ancestor’s lemma, dependency relationship
said
Frist
Republican leader Bill
hijacked
Senate
the
was
Figure 1: Dependency tree for example sentence.
and lemma of the closest ancestor whose POS isa noun, dependency relationship and lemma of theclosest ancestor whose POS is a verb, token underthe scope of a conditional (if/when), ancestor underthe scope of a conditional (if/when). We use theDependency Parser provided in the Stanford NLPtoolkit. A pictorial explanation of some of these de-pendency features is given in Figure 1 and Table 2for the sentence “Republican leader Bill Frist saidthe Senate was hijacked”.
Feature Name Value
PosTag VBN
Lemma hijack
WhichModalAmI nil
UnderConditional N/A
AncestorUnderConditional N/A
FirstDepAncestorofPos {hijack, NIL}, {say, ccomp}DepAncestors {say,VBD}Siblings {Frist, NNP}Parent {say, VBD, say-37.7-1}Child {Senate, NNP}, {be, VBD}DepRel {ccomp}
Table 2: Representative features for the token hijackedin the example sentence.
3.2.3 Machine Learning InfrastructureWe experiment with five machine learning algo-
rithms. A. Conditional Random Fields (CRF) toallow for comparison with previous work; B. Lin-ear Support Vector Machines (LSVM); C. QuadraticKernel Support Vector Machines (QSVM); D. NaiveBayes (NB); and, E. Logistic Regression (LREG).We provide NB as a generative contrast to the dis-criminative SVM and CRF methods. Moreover,
35

QSVM quite often yields better results at the ex-pense of longer runtime, hence, we explore if thatis the case within the LCB task.
The parameters for each of the five algorithms areheld constant across all experiments and not tunedfor specific configurations. The notable parametersthat are used are listed in Table 3.
Algorithm Notable Parameters
CRF Gaussian Variance=10, Orders = 1, It-erations = 500
LSVM Linear Kernel (t=0), Classification(z=c), Cost Factor (j=1), Biased Hy-perplane (b=1), Do not remove incon-sistent training examples (i=0)
QSVM Polynomial Kernel (t=1), Quadratic(d=1), Classification (z=c), Cost Fac-tor (j=1), Biased Hyperplane (b=1), Donot remove inconsistent training exam-ples (i=0)
NB DefaultLREG Default
Table 3: Parameter settings per algorithm.
3.2.4 Tools
A list of major NLP tools used is illustrated inTable 4. We used the CoreNLP pipeline for to-kenization, sentence splitting, part of speech de-termination, lemmatization, named entity recogni-tion, dependency parsing and coreference resolu-tion. ClearTK provided us easy access to the ma-chine learning algorithms we used which includesSVM Light for both SVM kernels and Mallet forCRF. It also provides us the backbone for our an-notation structure.
4 Experiments
4.1 Evaluation metric
We ran 30 experiments, which are all the possiblepermutations of the three variables, listed above: dowe split the NCB tag into 2 tags, what corpora dowe train on, and what machine learning algorithm dowe use. We report results using the overall weightedmicro average F1 score.
Name Source Ver.
CoreNLP (Manning et al., 2014) 3.5
ClearTK (Bethard et al., 2014) 2.0
UIMA https://uima.apache.org/ 2.6
uimaFIT (Ogren and Bethard, 2009) 2.1
Mallet (McCallum, 2002) 2.0.7
SVM Light (Joachims, 1999) 6.0.2
Table 4: NLP Tools Used.
4.2 Condition 1: Impact of splitting NCB tag inthe LU corpus
We show the overall impact of splitting the NCBtag in the original LU corpus into two tags: NCBand ROB. The training and test corpora are from thesame corpus, i.e. training and test sets are from LU-3 or LU-4. The results are reported on the respectivetest sets using the F1 score. The hypothesis is that a4-way tagging scheme should result in better overallscores if the tagging scheme indeed captures a moregenuine explicit representation for LCB. Table 5 il-lustrates the results yielded from the 5 ML algo-rithms. We note that the 4-way tagging outperformsthe 3-way tagging for CRF and LSVM, however, theNB algorithm doesn’t seem as sensitive to the tag-ging scheme (3 vs. 4 tags), and QSVM and LREGseem to be better performing in the 3 tag setting thanthe 4 tag setting. This might be a result of the num-ber of tags in the 4-way tagging scheme breakingup the space for NCB’s considerably. Overall thehighest score is obtained by LSVM (72.89 F1 score)for LU-4, namely in the 4-way tagging scheme, sug-gesting that a 4-way split of the annotation space isan appropriate level of annotation granularity.
4.3 Condition 2: Impact of size and corpusgenre homogeneity on LCB performance
In this condition we attempt to tease apart the im-pact of corpus size (FB being 4 times the size ofthe LU corpus) as well as corpus homogeneity, sinceFB is relatively homogeneous in genre compared tothe LU corpus. Similar to Condition 1, we showthe results yielded by all 5 ML algorithms. Resultsare reported in Table 6. Our hypothesis is that theoverall results obtained on the FB should outper-
36
Test Set Algorithm Overall F-score
LU-4 CRF 71.33
LU-4 LSVM 72.89LU-4 QSVM 68.10
LU-4 NB 61.61
LU-4 LREG 70.75
LU-3 CRF 68.25
LU-3 LSVM 69.77
LU-3 QSVM 69.21
LU-3 NB 61.58
LU-3 LREG 71.26
Table 5: Condition 1: LU-3 and LU-4 results usingmicro average F1 score on their respective test data.
form those obtained on the LU corpus. Note thatthe results in the Table 6 are not directly comparableacross corpora since the test sets are different: eachexperimental condition is tested within the same cor-pus, i.e. FB-4 is trained using FB-4 training dataand tested on FB-4 test data, and LU-4 is trainedusing LU-4 training data and tested on LU-4 testdata. However, the results validate our hypothesisthat more data which is more homogeneous resultsin a better LCB tagger.
It is noted that the various ML algorithms per-form differently for LU-4 vs. FB-4. In order, forFB-4, QSVM outperforms LREG which in turn out-performs LSVM, CRF and NB. In contrast, for LUthe LSVM is the best performing ML algorithm fol-lowed by CRF, QSVM, LREG, and finally NB. Thelinear kernel SVM, LSVM, has the closest perfor-mance between the two, yet the difference is stillstatistically significant.
A deeper analysis on each of the four tags showsa remarkable difference in F1-measure for reportedbelief (ROB) for the two corpora as illustrated in Ta-ble 7. ROB is significantly better identified in theFB-4 corpus compared to the LU-4 corpus. Thisis expected since the FB-4 corpus has significantlymore ROB tags in the training data. The number ofROB tags in training sets for LU-4 is 100 and forFB-4 it is 1800. The NA tag on the other hand per-forms better in the LU-4 corpus than in the FB-4 as
Test Set Algorithm Overall F-score
FB-4 CRF 73.34
FB-4 LSVM 74.36
FB-4 QSVM 75.57FB-4 NB 66.22
FB-4 LREG 74.67
LU-4 CRF 71.33
LU-4 LSVM 72.89LU-4 QSVM 68.10
LU-4 NB 61.61
LU-4 LREG 70.75
Table 6: Condition 2: FB-4 and LU-4 results usingmicro average F1 score on their respective test data.
seen in Table 8. The number of NA tags in the LU-4training data is 460, while in the FB-4 training data(which is much larger) there are 600. In the caseof FB-4 they only constitute a small percentage ofthe overall data compared to their percentage in theLU-4 corpus.
Test Set Algorithm P R F
LU-4 CRF 66.67 40.00 50.00LU-4 LSVM 39.13 45.00 41.86
LU-4 QSVM 50.00 15.00 23.08
LU-4 NB 0.00 0.00 0.00
LU-4 LREG 41.67 25.00 31.25
FB-4 CRF 76.79 73.22 74.97
FB-4 LSVM 76.08 72.13 74.05
FB-4 QSVM 72.86 79.23 75.92FB-4 NB 57.27 67.76 62.08
FB-4 LREG 74.59 73.77 74.18
Table 7: ROB results in FB-4 and LU-4 Corpora.
37
Test Set Algorithm P R F
LU-4 CRF 70.59 77.42 73.85
LU-4 LSVM 80.21 82.80 81.48LU-4 QSM 64.91 79.57 71.50
LU-4 NB 66.32 67.74 67.02
LU-4 LREG 76.00 81.72 78.76
FB-4 CRF 52.38 44.72 48.25
FB-4 LSVM 50.74 56.10 53.28
FB-4 QSVM 61.76 51.22 56.00FB-4 NB 0.00 0.00 0.00
FB-4 LREG 54.63 47.97 51.08
Table 8: NA results in FB-4 and LU-4 corpora.
4.4 Condition 3: Measuring impact of trainingdata size on performance: combiningtraining FB-4 and LU-4 data
In this condition, we wanted to investigate the im-pact of training using the combined FB-4 and LU-4training corpora on 3 test sets: LU-4 Test, FB-4 Testand LU-4 Test + FB-4 Test. A reasonable hypothesisis that, with a larger corpus created by combining thetwo individual corpora we will see better results onany test corpus. Table 9 illustrates the experimentalresults for this condition where the training data forboth corpora are combined.
The worst overall results are obtained on the LU-4 test set, while the best are obtained on the FB-4 test set. This is expected since the size of thetraining data coming from the FB-4 corpus over-whelms that of the LU corpus and the LU corpus isrelatively diverse in genre, potentially adding noise.Also we note that the results on the LU-4 corpus aremuch worse than the results obtained and illustratedin Table 5 when the training data was significantlysmaller, yet of strictly the same genre of the testdata. This observation seems to suggest that homo-geneity between training and test data for the LCBtask trumps training data size. We also note that thisobservation is furthermore supported by the slightdegradation in performance in the FB-4 test set com-pared to the performance results reported in Table 6for the ML algorithms CRF and QSVM. However,we observe that LREG, NB and LSVM each was
Test Set Algorithm Overall F-score
LU-4 CRF 56.30
LU-4 LSVM 61.10LU-4 QSVM 58.05
LU-4 NB 45.32
LU-4 LREG 59.90
FB-4 CRF 73.02
FB-4 LSVM 74.99
FB-4 QSVM 75.00
FB-4 NB 67.37
FB-4 LREG 75.23
FB-4 + LU-4 CRF 70.47
FB-4 + LU-4 LSVM 72.85
FB-4 + LU-4 QSVM 72.48
FB-4 + LU-4 NB 64.02
FB-4 + LU-4 LREG 72.88
Table 9: Condition 3: Micro average F1 score resultsobtained on three sets of test data while trained using a
combination of FB-4 and LU-4 training data.
able to generalize better from the augmented datawhen additionally using the LU-4 training data, butthe improvements were relatively insignificant (lessthan 1%). This may be attributed to the addition ofthe LU-4 training data, which adds noise to the LCBtraining task leading to inconclusive results. Testingon a combined corpus shows that LREG algorithmyields the best results.
4.5 Condition 4: Machine Learning AlgorithmPerformance
From the first three conditions, we are able to con-clude how reliably certain machine learning algo-rithms outperform others. In our research, wehave mainly focused on SVM Light’s linear kernel(LSVM) and expect it to perform quite well. Cer-tainly, we would expect it to outperform the CRFs,as they did in previous work. Changing the linearkernel to a quadratic kernel might give us some im-provement at the expense of training time since ittakes much longer to complete. Our intuition as faras CRFs being outperformed by SVMs seem to hold
38

uniformly as Tables 5, 6 and 9 illustrate. To aug-ment the linear kernel SVM, the quadratic kernelonly gives an improvement in some cases.
The NB models performed predictably poorly.Surprisingly, the LREG models appear to be ro-bust, with performance that is comparable to the bestSVM models (LSVM and QSVM) in our experi-ments. In fact, for the FB-4 case, LREG performedslightly better than either LSVM or QSVM. Giventhe efficiency of LREG in terms of training and test-ing, and its comparable performance to SVMs, us-ing LREG for feature exploration in the context ofLCB tagging makes it a very attractive ML frame-work to tune parameters with, keeping the more so-phisticated ML algorithms for final testing.
Sometimes it is other components that cause anerror. Take this example sentence from the LSVMalgorithm acting on the LU corpus: It also checks onguard posts. Checks has been annotated CB and cor-rectly so by the human involved. The tagger markschecks as O, or lacking author belief, because thetoken checks has been labeled a noun by the part-of-speech checker. A more proper miss can be foundon the sentence You know what’s sort of interest-ing Paula once again taken from the LU corpus. Al-though labeled as NA, the token know is labeled asCB. Since it has the feel of a question the annotatorhas stated that there is no committed belief on thepart of the author. This is one that the algorithm it-self has clearly gotten wrong. The CRF on the samesentence chose O, or lack of belief. NB got the to-ken correct. LREG chose O. QSVM took the sameapproach as the LSVM labeling it as CB. This illus-tration shows the worse performing algorithm on theLU-4 corpus being the only correct answer showingperhaps that detecting phrases and sentences formedas questions are harder to analyze.
5 Conclusions
The results suggest that 4-way LCB tagging is an ap-propriate LCB granularity level. Training and test-ing on the FB-4 corpus results in overall better per-formance than training and testing on the LU cor-pus. We have seen that the LCB task is quite sensi-tive to the consistency in genre across training andtest data, and that more out-of-genre data is not al-ways the best route to overall performance improve-
ment. SVMs were one of the best performing MLplatforms in the context of this task as well as Lo-gistic regression.
Acknowledgements
This paper is based upon work supported by theDARPA DEFT Program. The views expressed arethose of the authors and do not reflect the officialpolicy or position of the Department of Defense orthe U.S. Government. We also thank the anonymousreviewers for their constructive feedback.
ReferencesSteven Bethard, Philip Ogren, and Lee Becker. 2014.
ClearTK 2.0: Design Patterns for Machine Learningin UIMA. In Proceedings of the Ninth InternationalConference on Language Resources and Evaluation(LREC’14), pages 3289–3293, Reykjavik, Iceland, 5.European Language Resources Association (ELRA).
Mona Diab, Lori Levin, Teruko Mitamura, Owen Ram-bow, Vinodkumar Prabhakaran, and Weiwei Guo.2009. Committed Belief Annotation and Tagging. InProceedings of the Third Linguistic Annotation Work-shop, pages 68–73, Suntec, Singapore, August.
Thorsten Joachims. 1999. Making Large-Scale SVMLearning Practical. In Bernhard Scholkopf, Christo-pher J.C. Burges, and A. Smola, editors, Advancesin Kernel Methods - Support Vector Learning, Cam-bridge, MA, USA. MIT Press.
Christopher D. Manning, Mihai Surdeanu, John Bauer,Jenny Finkel, Steven J. Bethard, and David McClosky.2014. The Stanford CoreNLP Natural Language Pro-cessing Toolkit. In Proceedings of 52nd Annual Meet-ing of the Association for Computational Linguis-tics: System Demonstrations, pages 55–60, Baltimore,Maryland, June.
Andrew Kachites McCallum. 2002. MALLET:A Machine Learning for Language Toolkit.http://www.cs.umass.edu/ mccallum/mallet.
Philip Ogren and Steven Bethard. 2009. Building TestSuites for UIMA Components. In Proceedings ofthe Workshop on Software Engineering, Testing, andQuality Assurance for Natural Language Processing(SETQA-NLP 2009), pages 1–4, Boulder, Colorado,June.
Vinodkumar Prabhakaran, Owen Rambow, and MonaDiab. 2010. Automatic Committed Belief Tagging.In Coling 2010: Posters, pages 1014–1022, Beijing,China, August. Coling 2010 Organizing Committee.
Vinodkumar Prabhakaran, Tomas By, Julia Hirschberg,Owen Rambow, Samira Shaikh, Tomek Strzalkowski,
39

Jennifer Tracey, Michael Arrigo, Rupayan Basu,Micah Clark, Adam Dalton, Mona Diab, LouiseGuthrie, Anna Prokofieva, Stephanie Strassel, GregoryWerner, Janyce Wiebe, and Yorick Wilks. 2015. ANew Dataset and Evaluation for Belief/Factuality. InProceedings of the Fourth Joint Conference on Lexicaland Computational Semantics (*SEM 2015), Denver,USA, June.
Randolph Quirk, Sidney Greenbaum, Geoffrey Leech,and Jan Svartvik. 1985. A Comprehensive Grammarof the English Language. Longman, London.
Sara Rosenthal and Kathleen McKeown. 2012. Detect-ing Opinionated Claims in Online Discussions. In Se-mantic Computing (ICSC), 2012 IEEE Sixth Interna-tional Conference on, pages 30–37. IEEE.
Roser Saurı and James Pustejovsky. 2009. Fact-Bank: A Corpus Annotated with Event Factuality.Language Resources and Evaluation, 43:227–268.10.1007/s10579-009-9089-9.
Janyce Wiebe, Theresa Wilson, and Claire Cardie. 2005.Annotating Expressions of Opinions and Emotionsin Language. Language Resources and Evaluation,39(2-3):165–210.
40

Proceedings of the Second Workshop on Extra-Propositional Aspects of Meaning in Computational Semantics (ExProM 2015), pages 41–46,Denver, Colorado, June 5, 2015. c©2015 Association for Computational Linguistics
Extending NegEx with Kernel Methods forNegation Detection in Clinical Text
Chaitanya Shivade†, Marie-Catherine de Marneffe§, Eric Fosler-Lussier†, Albert M. Lai∗†Department of Computer Science and Engineering,
§Department of Linguistics,∗Department of Biomedical Informatics,
The Ohio State University, Columbus OH 43210, [email protected], [email protected]
[email protected], [email protected]
Abstract
NegEx is a popular rule-based system usedto identify negated concepts in clinical notes.This system has been reported to perform verywell by numerous studies in the past. In thispaper, we demonstrate the use of kernel meth-ods to extend the performance of NegEx. Akernel leveraging the rules of NegEx and itsoutput as features, performs as well as therule-based system. An improvement in per-formance is achieved if this kernel is cou-pled with a bag of words kernel. Our exper-iments show that kernel methods outperformthe rule-based system, when evaluated withinand across two different open datasets. Wealso present the results of a semi-supervisedapproach to the problem, which improves per-formance on the data.
1 Introduction
Clinical narratives consisting of free-text documentsare an important part of the electronic medicalrecord (EMR). Medical professionals often need tosearch the EMR for notes corresponding to specificmedical events for a particular patient. Recruitmentof subjects in research studies such as clinical tri-als involves searching through the EMR of multi-ple patients to find a cohort of relevant candidates.Most information retrieval approaches determine adocument to be relevant to a concept based on thepresence of that concept in the document. How-ever, these approaches fall short if these conceptsare negated, leading to a number of false positives.This is an important problem especially in the clini-cal domain. For example, the sentence: “The scan
showed no signs of malignancy” has the concept‘malignancy’ which was looked for in the patient,but was not observed to be present. The task of nega-tion detection is to identify whether a given conceptis negated or affirmed in a sentence. NegEx (Chap-man et al., 2001) is a rule-based system developed todetect negated concepts in the clinical domain andhas been extensively used in the literature.
In this paper, we show that a kernel-based ap-proach can map this rule-based system into a ma-chine learning system and extends its performance.We validate the generalization capabilities of ourapproach by evaluating it across datasets. Finally,we demonstrate that a semi-supervised approach canalso achieve an improvement over the baseline rule-based system, a valuable finding in the clinical do-main where annotated data is expensive to generate.
2 Related Work
Negation has been a popular research topic in themedical domain in recent years. NegEx (Chapmanet al., 2001) along with its extensions (South et al.,2006; Chapman et al., 2013) is one of the oldest andmost widely used negation detection system becauseof its simplicity and speed. An updated version -ConText (Harkema et al., 2009) was also released toincorporate features such as temporality and experi-encer identification, in addition to negation. Thesealgorithms are designed using simple rules that firebased on the presence of particular cues, before andafter the concept. However, as with all rule-basedsystems, they lack generalization. Shortage of train-ing data discouraged the use of machine learningtechniques in clinical natural language processing
41

(NLP) in the past. However, shared tasks (Uzuner etal., 2011) and other recent initiatives (Albright et al.,2013) are making more clinical data available. Thisshould be leveraged to harness the benefits offeredby machine learning solutions. Recently, Wu et al.(2014) argued that negation detection is not of prac-tical value without in-domain training and/or devel-opment, and described an SVM-based approach us-ing hand-crafted features.
3 Kernel Methods
Our approach uses kernel methods to extend theabilities of the NegEx system. A kernel is a sim-ilarity function K, that maps two inputs x and yfrom a given domain into a similarity score that isa real number (Hofmann et al., 2008). Formally, itis a function K(x, y) = 〈φ(x), φ(y)〉 → R, whereφ(x) is some feature function over instance x. Fora function K to be a valid kernel, it should be sym-metric and positive-semidefinite. In this section, wedescribe the different kernels we implemented forthe task of negation detection.
3.1 NegEx Features Kernel
The source code of NegEx1 reveals rules using threesets of negation cues. These are termed as pseudonegation phrases, negation phrases and post nega-tion phrases. Apart from these cues, the system alsolooks for a set of conjunctions in a sentence. Weused the source code of the rule-based system andconstructed a binary feature corresponding to eachcue and conjunction, and thus generated a featurevector for every sentence in the dataset. Using theLibSVM (Chang and Lin, 2011) implementation, weconstructed a linear kernel which we refer to as theNegEx Features Kernel (NF).
3.2 Augmented Bag of Words Kernel
We also designed a kernel that augmented with bagof words the decision by NegEx. For each dataset,we constructed a binary feature vector for every sen-tence. This vector is comprised of two parts, a vec-tor indicating presence or absence of every word inthat dataset and augment it with a single feature in-dicating the output of the NegEx rule-based system.We did not filter stop-words since many stop-words
1From https://code.google.com/p/NegEx/
serve as cues for negated assertions. The idea behindconstructing such a kernel was to allow the modelto learn relative weighting of the NegEx output andthe bag of words in the dataset. Again, a linear ker-nel using LibSVM was constructed: the AugmentedBag of Words Kernel (ABoW).
4 Datasets
A test set of de-identified sentences, extracted fromclinical notes at the University of Pittsburgh Medi-cal Center, is also available with the NegEx sourcecode. In each sentence, a concept of interest hasbeen annotated by physicians with respect to beingnegated or affirmed in the sentence. The conceptsare non numeric clinical conditions (such as symp-toms, findings and diseases) extracted from six typesof clinical notes (e.g., discharge summaries, opera-tive notes, echo-cardiograms).
The 2010 i2b2 challenge (Uzuner et al., 2011) onrelation extraction had assertion classification as asubtask. The corpus for this task along with the an-notations is freely available for download.2 Basedon a given target concept, participants had to clas-sify assertions as either present, absent, or possiblein the patient, conditionally present in the patient un-der certain circumstances, hypothetically present inthe patient at some future point, and mentioned inthe patient report but associated with someone otherthan the patient. Since we focus on negation detec-tion, we selected only assertions corresponding tothe positive and negative classes from the five as-sertion classes in the corpus, which simulates thetype of data found in the NegEx Corpus. The i2b2corpus has training data, partitioned into dischargesummaries from Partners Healthcare (PH) and theBeth Israel Deaconess (BID) Medical Center. Thisgave us datasets from two more medical institutions.The corpus also has a test set, but does not have asplit corresponding to these institutions.
Using the above corpora we constructed fivedatasets: 1) The dataset available with the NegExrule-based system, henceforth referred to as theNegCorp dataset; 2) We adapted the training setof the i2b2 assertion classification task for negationdetection, the i2b2Trainmod dataset; 3) The train-ing subset of i2b2Trainmod from Partners Health-
2From https://www.i2b2.org/NLP/DataSets/
42
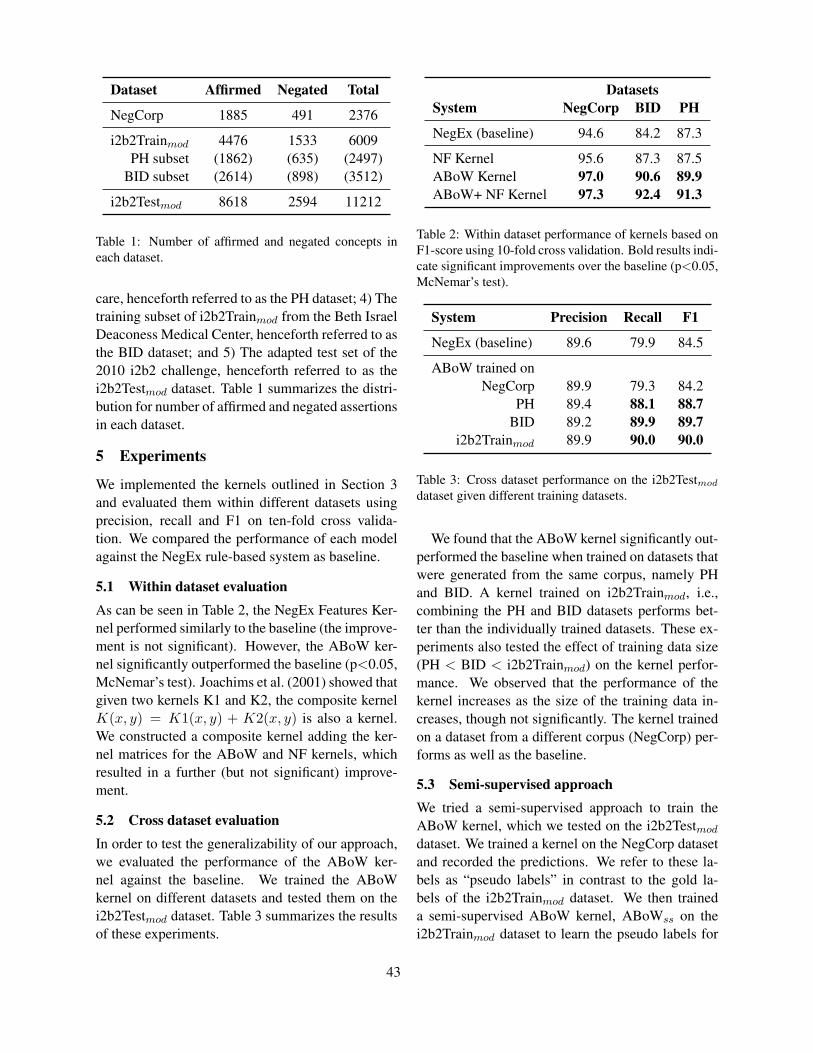
Dataset Affirmed Negated Total
NegCorp 1885 491 2376
i2b2Trainmod 4476 1533 6009PH subset (1862) (635) (2497)
BID subset (2614) (898) (3512)
i2b2Testmod 8618 2594 11212
Table 1: Number of affirmed and negated concepts ineach dataset.
care, henceforth referred to as the PH dataset; 4) Thetraining subset of i2b2Trainmod from the Beth IsraelDeaconess Medical Center, henceforth referred to asthe BID dataset; and 5) The adapted test set of the2010 i2b2 challenge, henceforth referred to as thei2b2Testmod dataset. Table 1 summarizes the distri-bution for number of affirmed and negated assertionsin each dataset.
5 Experiments
We implemented the kernels outlined in Section 3and evaluated them within different datasets usingprecision, recall and F1 on ten-fold cross valida-tion. We compared the performance of each modelagainst the NegEx rule-based system as baseline.
5.1 Within dataset evaluationAs can be seen in Table 2, the NegEx Features Ker-nel performed similarly to the baseline (the improve-ment is not significant). However, the ABoW ker-nel significantly outperformed the baseline (p<0.05,McNemar’s test). Joachims et al. (2001) showed thatgiven two kernels K1 and K2, the composite kernelK(x, y) = K1(x, y) + K2(x, y) is also a kernel.We constructed a composite kernel adding the ker-nel matrices for the ABoW and NF kernels, whichresulted in a further (but not significant) improve-ment.
5.2 Cross dataset evaluationIn order to test the generalizability of our approach,we evaluated the performance of the ABoW ker-nel against the baseline. We trained the ABoWkernel on different datasets and tested them on thei2b2Testmod dataset. Table 3 summarizes the resultsof these experiments.
DatasetsSystem NegCorp BID PH
NegEx (baseline) 94.6 84.2 87.3
NF Kernel 95.6 87.3 87.5ABoW Kernel 97.0 90.6 89.9ABoW+ NF Kernel 97.3 92.4 91.3
Table 2: Within dataset performance of kernels based onF1-score using 10-fold cross validation. Bold results indi-cate significant improvements over the baseline (p<0.05,McNemar’s test).
System Precision Recall F1
NegEx (baseline) 89.6 79.9 84.5
ABoW trained onNegCorp 89.9 79.3 84.2
PH 89.4 88.1 88.7BID 89.2 89.9 89.7
i2b2Trainmod 89.9 90.0 90.0
Table 3: Cross dataset performance on the i2b2Testmod
dataset given different training datasets.
We found that the ABoW kernel significantly out-performed the baseline when trained on datasets thatwere generated from the same corpus, namely PHand BID. A kernel trained on i2b2Trainmod, i.e.,combining the PH and BID datasets performs bet-ter than the individually trained datasets. These ex-periments also tested the effect of training data size(PH < BID < i2b2Trainmod) on the kernel perfor-mance. We observed that the performance of thekernel increases as the size of the training data in-creases, though not significantly. The kernel trainedon a dataset from a different corpus (NegCorp) per-forms as well as the baseline.
5.3 Semi-supervised approachWe tried a semi-supervised approach to train theABoW kernel, which we tested on the i2b2Testmod
dataset. We trained a kernel on the NegCorp datasetand recorded the predictions. We refer to these la-bels as “pseudo labels” in contrast to the gold la-bels of the i2b2Trainmod dataset. We then traineda semi-supervised ABoW kernel, ABoWss on thei2b2Trainmod dataset to learn the pseudo labels for
43

this predicted dataset. Finally, we tested ABoWss
on the i2b2Testmod dataset. Table 4 summarizesthe results of these experiments. For ease of com-parison, we restate the results of the ABoW ker-nel, ABoWgold trained on the gold labels of thei2b2Trainmod dataset.
System Precision Recall F1
NegEx 89.6 79.9 84.5ABoWss 89.7 82.1 85.7ABoWgold 89.9 90.0 90.0
Table 4: Semi-supervised models on the i2b2Testmod
dataset.
These results demonstrate that the kernel trainedusing a semi-supervised approach performs betterthan the baseline (p<0.05, McNemar’s test), but per-forms worse than a kernel trained using supervisedtraining. However, supervised training is dependenton gold annotations. Thus, the semi-supervised ap-proach achieves good results without the need forannotated data. This is an important result espe-cially in the clinical domain where available anno-tated data is sparse and extremely costly to generate.
6 Dependency Tree Kernels
Dependency tree kernels have been showed to beeffective for NLP tasks in the past. Culotta et al.(2004) showed that although tree kernels by them-selves may not be effective for relation extraction,combining a tree kernel with a bag of words ker-nel showed promising results. Dependency tree ker-nels have also been explored in the context of nega-tion extraction in the medical domain. Recently,Bowei et al. (2013) demonstrated the use of treekernel based approaches in detecting the scope ofnegations and speculative sentences using the Bio-Scope corpus (Szarvas et al., 2008). However, thetask of negation scope detection task is different thanthat of negation detection. Among other differences,an important one being the presence of annotationsfor negation cues in the Bioscope corpus. Sohn etal. (2012) developed hand crafted rules representingsubtrees of dependency parses of negated sentencesand showed that they were effective on a datasetfrom their institution.
Therefore, we implemented a dependency treekernel similar to the approach described in Culottaand Sorensen (2004) to automatically capture thestructural patterns in negated assertions. We usedthe Stanford dependencies parser (version 2.0.4) (deMarneffe et al., 2006) to get the dependency parsefor every assertion. As per their representation (deMarneffe and Manning, 2008) every dependency isa triple, consisting of a governor, a dependent anda dependency relation. In this triple, the gover-nor and dependent are words from the input sen-tence. Thus, the tree kernel comprised of nodescorresponding to every word and every dependencyrelation in the parse. Node similarity was com-puted based on features such as lemma, general-ized part-of-speech, WordNet (Fellbaum, 1998) syn-onymy and the UMLS (Bodenreider, 2004) semantictype obtained using MetaMap (Aronson, 2001) forword nodes.
Node similarity for dependency relation nodeswas computed based on name of the dependencyrelation. A tree kernel then computed the simi-larity between two trees by recursively computingnode similarity between two nodes as described in(Culotta and Sorensen, 2004). The only differencebeing, unlike our approach they have only wordnodes in the tree. The kernel is hence a functionK(T1, T2) which computes similarity between twodependency trees T1 and T2. See (Culotta andSorensen, 2004) for why K is a valid kernel func-tion. However, we got poor results. In experimentsinvolving within dataset evaluation, the tree kernelgave F1 scores of 77.0, 76.2 and 74.5 on NegCorp,BID and PH datasets respectively. We also tried con-structing composite kernels, by adding kernel ma-trices of the tree kernel and the ABoW kernel orNF kernel, hoping that they captured complimen-tary similarities between assertions. Although per-formance of the composite kernel was better than thetree kernel itself, there was no significant gain in theperformance as compared to those of the reportedkernels.
7 Discussion
We observe that while the precision of all the clas-sifiers is almost constant across all the set of experi-ments, it is the recall that changes the F1-score. This
44

implies that the kernel fetches more cases than thebaseline. The bag of words contributes towards theincrease in recall and thus raises performance.
It is instructive to look at sentences that were mis-classified by NegEx but correctly classified by theABoWgold system. The NegEx rule-based systemlooks for specific phrases, before or after the targetconcept, as negation cues. The scope of the nega-tion is determined using these cues and the presenceof conjunctions. False positives stem from instanceswhere the scope is incorrectly calculated. For exam-ple, in “No masses, neck revealed lymphadenopa-thy”, the concept ‘lymphadenopathy’ is taken to benegated. The issue of negation scope being a short-coming of NegEx has been acknowledged by its au-thors in Chapman et al. (2001). There were cer-tain instances where the NegEx negation cues andthe target concept overlapped. For example, in “ACT revealed a large amount of free air”, the targetconcept ‘free air’ was wrongly identified by NegExas negated. This is because ‘free’ is a post nega-tion cue, to cover cases such as “The patient is nowsymptom free”. Similarly, with ‘significant increasein tumor burden’ as the target concept, the sentence“A staging CT scan suggested no significant increasein tumor burden” was wrongly identified as an affir-mation. Since the closest negation cue was ‘no sig-nificant,’ NegEx would identify only concepts afterthe phrase ‘no significant’ as negated. We also foundinteresting cases such as, the “Ext: cool, 1 + predalpulses, - varicosities, - edema.” where the concept‘varicosities’ is negated using the minus sign.
We studied cases where NegEx made the right de-cision but which were incorrectly classified by oursystem. For example, in the assertion “extrm - traceedema at ankles, no cyanosis, warm/dry”, the ker-nel incorrectly classified “trace edema” as negated.In “a bone scan was also obtained to rule out an oc-cult hip fracture which was negative”, the concept“occult hip fracture” was incorrectly classified as af-firmed. We found no evident pattern in these exam-ples.
The tree kernel was constructed to automati-cally capture subtree patterns similar to those hand-crafted by Sohn et al. (2012). Although, it resultedin a poor performance, there are a number of possi-bilities to improve the current model of the kernel.Clinical data often consists of multi-word expres-
sions (e.g., “congestive heart failure”). However, theword nodes in our dependency tree kernel are uni-grams. Aggregating these unigrams (e.g., identifica-tion using MetaMap, followed by use of underscoresto replace whitespaces) to ensure they appear as asingle node in the tree could give dependency parsesthat are more accurate. Similarity for nodes involv-ing dependency tree relations; similarity in our ker-nel is a binary function examining identical namesfor dependency relations. This could be relaxed byclustering of dependency relations and computingsimilarity based on these clusters. We followed Cu-lotta and Sorensen (2004) and used WordNet syn-onymy for similarity of word nodes. However, open-domain terminologies such as WordNet are knownto be insufficient for tasks specific to the biomedicaldomain (Bodenreider and Burgun, 2001). This couldbe coupled with domain specific resources such asUMLS::Similarity (McInnes et al., 2009) for a betterestimate of similarity. Finally, since learning struc-tural patterns is a complex task achieved by the treekernel; training with a larger amount of data couldresult in improvements.
8 Conclusion
We demonstrate the use of kernel methods for thetask of negation detection in clinical text. Usinga simple bag of words kernel with the NegEx out-put as an additional feature yields significantly im-proved results as compared to the NegEx rule-basedsystem. This kernel generalizes well and showspromising results when trained and tested on differ-ent datasets. The kernel outperforms the rule-basedsystem primarily due to an increase in recall. Wealso find that for instances where we do not have ad-ditional labeled training data, we are able to leveragethe NegEx Corpus as a bootstrap to perform semi-supervised learning using kernel methods.
Acknowledgments
Research reported in this publication was supportedby the National Library of Medicine of the Na-tional Institutes of Health under award numberR01LM011116. The content is solely the respon-sibility of the authors and does not necessarily rep-resent the official views of the National Institutes ofHealth.
45

References
Daniel Albright, Arrick Lanfranchi, Anwen Fredrik-sen, William F Styler, Colin Warner, Jena D Hwang,Jinho D Choi, Dmitriy Dligach, Rodney D Nielsen,James Martin, et al. 2013. Towards comprehensivesyntactic and semantic annotations of the clinical nar-rative. Journal of the American Medical InformaticsAssociation, 20(5):922–930.
Alan R Aronson. 2001. Effective mapping of biomedicaltext to the UMLS Metathesaurus: the MetaMap pro-gram. In Proceedings of AMIA Annual Symposium.,pages 17–21.
Olivier Bodenreider and Anita Burgun. 2001. Compar-ing terms, concepts and semantic classes in WordNetand the Unified Medical Language System. In Pro-ceedings of the NAACL 2001 Workshop: WordNet andother lexical resources: Applications, extensions andcustomizations., pages 77–82.
Olivier Bodenreider. 2004. The Unified Medical Lan-guage System (UMLS): integrating biomedical ter-minology. Nucleic Acids Research, 32(Databaseissue):D267–70.
Zou Bowei, Zhou Guodong, and Zhu Qiaoming. 2013.Tree Kernel-based Negation and Speculation ScopeDetection with Structured Syntactic Parse Features.In Proceedings of the 2013 Conference on EmpiricalMethods in Natural Language Processing, pages 968–976.
Chih-Chung Chang and Chih-Jen Lin. 2011. LIBSVM:A library for support vector machines. ACM Transac-tions on Intelligent Systems and Technology, 2:27:1–27:27.
Wendy W Chapman, Will Bridewell, Paul Hanbury, Gre-gory F Cooper, and Bruce G Buchanan. 2001. A sim-ple algorithm for identifying negated findings and dis-eases in discharge summaries. Journal of BiomedicalInformatics, 34(5):301–10, October.
Wendy W Chapman, Dieter Hilert, Sumithra Velupillai,Maria Kvist, Maria Skeppstedt, Brian E Chapman,Michael Conway, Melissa Tharp, Danielle L Mowery,and Louise Deleger. 2013. Extending the NegEx lexi-con for multiple languages. Studies in health technol-ogy and informatics, 192:677.
Aron Culotta and Jeffrey Sorensen. 2004. DependencyTree Kernels for Relation Extraction. In Proceedingsof the 42Nd Annual Meeting on Association for Com-putational Linguistics, ACL ’04.
Marie-Catherine de Marneffe and Christopher D. Man-ning. 2008. The Stanford typed dependencies repre-sentation. In Coling 2008: Proceedings of the work-shop on Cross-Framework and Cross-Domain ParserEvaluation, pages 1–8.
Marie-Catherine de Marneffe, Bill MacCartney, andChristopher D Manning. 2006. Generating Typed De-pendency Parses from Phrase Structure Parses. In Pro-ceedings of LREC, pages 449–454.
Christiane Fellbaum. 1998. WordNet: An ElectronicLexical Database. Bradford Books.
Henk Harkema, John N Dowling, Tyler Thornblade, andWendy W Chapman. 2009. ConText: An algorithmfor determining negation, experiencer, and temporalstatus from clinical reports. Journal of Biomedical In-formatics, 42(5):839–851.
Thomas Hofmann, Bernhard Scholkopf, and Alexander J.Smola. 2008. Kernel methods in machine learning.The Annals of Statistics, 36(3):1171–1220, June.
Thorsten Joachims, Nello Cristianini, and John Shawe-Taylor. 2001. Composite Kernels for Hypertext Cate-gorisation. In Proceedings of the Eighteenth Interna-tional Conference on Machine Learning, pages 250–257. Morgan Kaufmann Publishers Inc.
Bridget T McInnes, Ted Pedersen, and Serguei V SPakhomov. 2009. UMLS-Interface and UMLS-Similarity : Open Source Software for MeasuringPaths and Semantic Similarity. In Proceedings of theAnnual AMIA Symposium., volume 2009, pages 431–5.
Sunghwan Sohn, Stephen Wu, and Christopher G Chute.2012. Dependency Parser-based Negation Detectionin Clinical Narratives. In Proceedings of AMIA Sum-mits on Translational Science.
Brett R South, Shobha Phansalkar, Ashwin D Swami-nathan, Sylvain Delisle, Trish Perl, and Matthew HSamore. 2006. Adaptation of the NegEx algorithmto Veterans Affairs electronic text notes for detectionof influenza-like illness (ILI). In Proceedings of theAMIA Annual Symposium, pages 1118–1118.
Gyorgy Szarvas, Veronika Vincze, Richard Farkas, andJanos Csirik. 2008. The BioScope Corpus: Anno-tation for Negation, Uncertainty and Their Scope inBiomedical Texts. In Proceedings of the Workshop onCurrent Trends in Biomedical Natural Language Pro-cessing, BioNLP ’08, pages 38–45.
Ozlem Uzuner, Brett R South, Shuying Shen, and Scott LDuVall. 2011. 2010 i2b2/VA challenge on concepts,assertions, and relations in clinical text. Journal of theAmerican Medical Informatics Association : JAMIA,18(5):552–6.
Stephen Wu, Timothy Miller, James Masanz, Matt Coarr,Scott Halgrim, David Carrell, and Cheryl Clark. 2014.Negations Not Solved: Generalizability Versus Opti-mizability in Clinical Natural Language Processing.PloS one, 9(11):e112774.
46

Author Index
Cairelli, Michael, 22
de Marneffe, Marie-Catherine, 41Diab, Mona, 32
Fancellu, Federico, 1Fosler-Lussier, Eric, 41
Kilicoglu, Halil, 22
Lai, Albert M., 41
Prabhakaran, Vinodkumar, 32
Rambow, Owen, 32Rehbein, Ines, 12Rindflesch, Thomas, 22Rosemblat, Graciela, 22
Shivade, Chaitanya, 41
Webber, Bonnie, 1Werner, Gregory, 32
47





























