Embed Size (px)
Citation preview

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 1
Emergency-Relief Coordination on Social Media: Automatically Matching Resource
Requests and Offers
Hemant Purohit1, Carlos Castillo2, Fernando Diaz3, Amit Sheth1, Patrick Meier2
1Ohio Center of Excellence in Knowledge-enabled Computing (Kno.e.sis), Wright State
University, Dayton, USA. E-mail: {hemant,amit}@knoesis.org
2Qatar Computing Research Institute (QCRI), Doha, Qatar. E-mail:
{ccastillo,pmeier}@qf.org.qa
3Microsoft Research, NYC, USA. E-mail: {fdiaz}@microsoft.com
Direct comments to:
Hemant Purohit ([email protected]), Carlos Castillo ([email protected])
ABSTRACT
Disaster affected communities have increasingly taken up social media for communication and
coordination. This includes reports on needs (demands) and offers (supplies) of emergency
resources. Identifying and matching such requests with potential responders can substantially
accelerate emergency relief efforts. Current work of disaster management agencies is labor
intensive, and there is substantial interest in automated tools.
We present machine-learning methods to automatically identify and match social media needs
and offers encompassing shelter, money, clothing, volunteer work, etc. For instance, a message
such as “we are coordinating a clothing/food drive for families affected by Hurricane Sandy. If
you would like to donate, DM us” can be matched with a message such as “I got a bunch of
clothes I’d like to donate to hurricane sandy victims. Anyone know where/how I can do that?”
Compared to traditional search, our results can significantly improve the matchmaking efforts of
disaster response agencies.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 2
Table of Contents:
1. Introduction
2. Related work
3. Problems definition
4. Construction of corpora of resource-related messages
5. Matching requests and offers
6. Discussion
7. Conclusion
8. About the authors
9. Acknowledgement
10. References
1. INTRODUCTION
During emergencies, individuals and organizations use any communication medium available to
them for sharing experiences and the situation on the ground. Citizens as sensors (Sheth, 2009)
provide timely and valuable situational awareness information that is often not available through
other channels, especially during the first few hours of a disaster (Vieweg, 2012). For instance,
during the 2012 Hurricane Sandy (http://en.wikipedia.org/wiki/Hurricane_Sandy), the
microblogging service Twitter reported that more than 20 million messages (also known as
“tweets”) were posted on their platform (http://techcrunch.com/2012/11/02/twitter-releases-
numbers-related-to-hurricane-sandy-more-than-20m-tweets-sent-between-october-27th-and-
november-1st/). As in the most recent natural disasters, included in the voluminous tweets were
messages about resources related to emergency relief (Sarcevic et al., 2012). Use of social media
to support and improve coordination between affected persons, crisis response agencies and

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 3
other remotely situated helpers is increasing. Our research direction is to leverage social media
messages into actionable information that can aid in the decision making and improving response.
It includes mainly information abstraction and prioritization for needs by geography and time,
resource distribution, assessing severity of needs, information credibility and mapping with
involvement of crowdsourcing, finding users to engage with in the online communities,
visualization platform to coordinate, etc. as depicted in the general coverage of some of our prior
initiatives1. The focus of this article is one narrowly defined research study within a broader set
of computer-assisted emergency response activities-- that of matching supply (offer) and demand
(request) of resources or volunteer services via Twitter during disasters to improve coordination.
Figure 1 shows a schematic of the study covered in detail in this article.
Figure 1. Example from application of our analysis to match needs and offers1.
1 Prior work coverage: http://techpresident.com/news/wegov/24082/twitris-taking-crisis-mapping-next-level, http://www.forbes.com/sites/skollworldforum/2013/05/02/crisis-maps-harnessing-the-power-of-big-data-to-deliver-humanitarian-assistance/, http://www.thehindu.com/sci-tech/technology/gadgets/using-crisis-mapping-to-aid-uttarakhand/article4854027.ece. More at http://irevolution.net/media/

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 4
A typical request message involves an entity (person or organization) describing scarcity of a
certain resource or service (e.g., clothing, volunteering) and/or asking others to supply such a
resource. A typical offer involves an entity describing the availability and/or willingness to
supply a resource. We note that in both cases, the requests or offers may be done in the name of a
third-party, as observed in our dataset where many tweet messages repeated the Red Cross’
requests for money and blood donations. Regarding the types of resources, the primary types as
identified by the United Nations cluster system for coordination (http://www.unocha.org/what-
we-do/coordination-tools/cluster-coordination) that are also included in this study involve money,
volunteer work, shelter, clothing, blood and medical supplies. Table 1 shows some examples of
resource-related requests and offers during the Hurricane Sandy.
Across different emergencies, we can observe that the prevalence of different class of social
media messages varies. In a recent study (Imran et al., 2013) on the 2011 Joplin Tornado, the
number of resource-related messages (“donation-type” in their study) was found to be about 16%.
In another study (Kongthon et al., 2012) on the 2011 Thailand Floods, about 8% of all tweets
were “Requests for Assistance,” while 5% were “Requests for Information Categories.” In the
emergency we analyze in this paper (the 2012 Hurricane Sandy), this figure for resource-related
(donation) tweets is close to 5%.
Although messages related to requests and offers of resources are a small fraction of all
messages exchanged during a crisis, they are vital for improving response because even a single
message can be a lifesaver. An example is, ‘need for blood donors of type O negative’. Paid and
professional disaster responders cannot be everywhere at the same time, but the crowd is always
there. Moreover, disaster-affected communities have always been the real first responders as
observed in various studies (e.g., Palen et al., 2007).

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 5
Resource-related messages are a minority, which makes them hard to identify from a deluge of
millions of messages of general news, warning, sympathy, prayers, jokes, etc. Also, without a
robust coordination of actions between the response organizations and the public, there can be a
“second disaster” for response organizations to manage the unsolicited resource donations
including waste of stock capacity for unneeded resources
(http://www.npr.org/2013/01/12/169198037/the-second-disaster-making-good-intentions-useful).
Ideally, people's messages searching for and asking for resources should be matched with
relevant information quickly. In reality, waste occurs due to resources being under- or over-
supplied as well as misallocated. For instance, during recent emergency events, some
organizations were adamantly asking the public not to bring certain donations unless they knew
what was really needed and what was sufficiently available.
(http://www.npr.org/2013/01/09/168946170/thanks-but-no-thanks-when-post-disaster-donations-
overwhelm)
Currently, matchmaking coordination of resources is done manually. Response organizations like
FEMA and American Red Cross have recently started to explore methods for identifying needs
and offers by using general-purpose social media analysis tools, but there is a need for
automatically matching them as well. In this paper, we propose methods to automatically
identify resource requests in social media and automatically match these with the relevant offers
of help. Effectively matching these messages can help build resilience and enable communities
to bounce back more quickly following a disaster. To this end, automatically matching needs and
offers of resources at the local level during disasters can generate greater self-help and mutual-
aid actions, which accelerates disaster recovery and renders local communities to be more
resilient.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 6
This is, however, a challenging task. Like any other content generated online by users, Twitter
messages (tweets) are extremely varied in terms of relevance, usefulness, topicality, language,
etc. They tend to use informal language and often contain incomplete or ambiguous information,
sarcasm, opinions, jokes, and/or rumors. The 140-characters limit can be a blessing as it
encourages conciseness, as well as a curse as it reduces the context that can be exploited by
natural language processing (NLP) algorithms. Additionally, the volume of messages during a
crisis is often overwhelming.
Table 1. Example tweets in our dataset, including the original unstructured text of the
messages and its structured representation, generated automatically. Structured
representation is flexible to append other tweet metadata such as time, location and author.
Request
/ Offer
Resource
-type
Text (Unstructured) Structured representation
Request
Money
{ Text redcross to
90999 to donate $10 to
help those people that
were effected by
hurricane sandy
please donate
#SandyHelp }
{ RESOURCE-TYPE={class=money,
confidence=0.9},
IS-REQUEST={class=Yes, confidence=0.95},
IS-OFFER={class=No, confidence=0.9},
TEXT="Text ...#SandyHelp'' }
Request
Medical
{ Hurricane Sandy
Cancels 300 Blood
{ RESOURCE-TYPE={class=medical,
confidence=0.98},
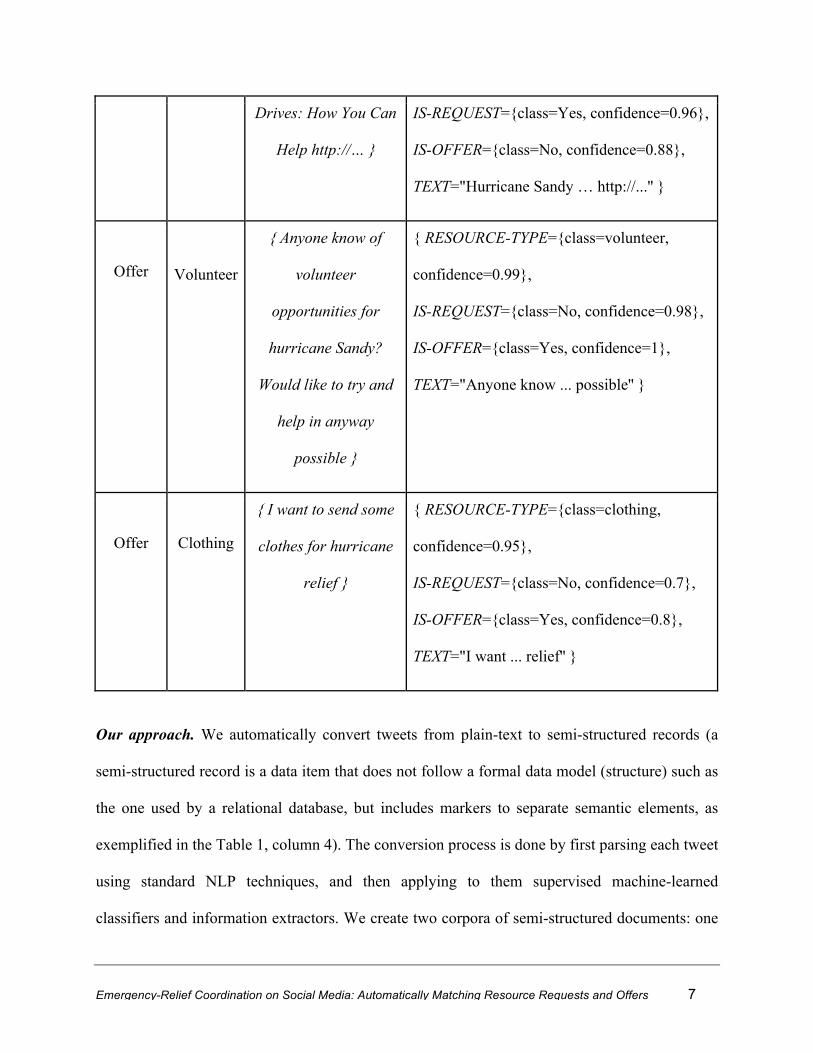
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 7
Drives: How You Can
Help http://… }
IS-REQUEST={class=Yes, confidence=0.96},
IS-OFFER={class=No, confidence=0.88},
TEXT="Hurricane Sandy … http://...'' }
Offer
Volunteer
{ Anyone know of
volunteer
opportunities for
hurricane Sandy?
Would like to try and
help in anyway
possible }
{ RESOURCE-TYPE={class=volunteer,
confidence=0.99},
IS-REQUEST={class=No, confidence=0.98},
IS-OFFER={class=Yes, confidence=1},
TEXT="Anyone know ... possible'' }
Offer
Clothing
{ I want to send some
clothes for hurricane
relief }
{ RESOURCE-TYPE={class=clothing,
confidence=0.95},
IS-REQUEST={class=No, confidence=0.7},
IS-OFFER={class=Yes, confidence=0.8},
TEXT="I want ... relief'' }
Our approach. We automatically convert tweets from plain-text to semi-structured records (a
semi-structured record is a data item that does not follow a formal data model (structure) such as
the one used by a relational database, but includes markers to separate semantic elements, as
exemplified in the Table 1, column 4). The conversion process is done by first parsing each tweet
using standard NLP techniques, and then applying to them supervised machine-learned
classifiers and information extractors. We create two corpora of semi-structured documents: one

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 8
containing the demand-side (resource requests), and one containing the supply-side (resource
offers). Illustrative examples of such requests and offers that we identified automatically are
shown in the Table 1. Next, to match requests and offers we apply methods developed in the
context of matchmaking in dating sites (Diaz et al., 2010). We interpret each request
(respectively, offer) as a semi-structured search query and run this query against the corpus of
offers (respectively, requests). This part of the system works similarly to the faceted search
process employed in online shopping catalogs, where users select some features of the product
from pre-defined values and additionally enter some keywords. For example, when searching for
a camera on Amazon.com, it shows various features to choose from- type of lens, brand, model,
price range, etc. to help match our intention. Figure 2 summarizes our approach and how it helps
the donation-coordination efforts in a real scenario.
Figure 2: Summary of our system for helping coordination of donation related messages
during crisis response. Shaded area shows our contribution, with references for respective
sections marked inside brackets.
Our contributions:
● We study and define the problem of automatically identifying and automatically
matching requests and offers during emergencies in social media (Section 3).

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 9
● We show how to convert unstructured tweets into semi-structured records with annotated
metadata as illustrated in the Table 1 (Section 4).
● We apply information retrieval (IR) methods to find the best match for a request to an
offer and vice-versa (Section 5).
● We achieve fair to excellent classification ability for identifying donation related,
requests, offers and resources-related messages. In addition, we achieve 72%
improvement over baseline for matching request-offer pairs.
Even with state-of-the-art automatic methods, we do not expect to have perfect annotations or a
perfect matching in each case of request and offer, due to complexity of the short and informal
text processing in the presence of multiple intentions (e.g., opinions) as noted earlier. We
systematically evaluate our annotation methods based on automatic classification using 10-fold
cross-validation technique and observe fair to excellent classification ability, given the Area
Under the Receiver Operating Characteristic curve (AUC) values for the classification fall in
0.75-0.98 range (details in Section 4). We also compare our matching method against a
traditional search method and observe a 72% relative improvement over baseline in the
performance measured by average precision of matching (details in Section 5).
The next section introduces related work, followed by the main technical sections. The last
section presents our conclusions.
2. RELATED WORK
Social media during crises. Social media mining for disaster response has been receiving an
increasing level of attention from the research community during the last five years (e.g. Imran et
al., 2013; Purohit et al., 2013; Blanchard et al., 2012; Cameron et al., 2012; Sarcevic et al., 2012;
Boulos et al., 2011; Vieweg et al., 2010; Starbird and Stamberger, 2010). Some of the current

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 10
approaches require a substantial amount of manual effort, and do not scale to the speed with
which messages arrive during a crisis situation.
Some methods described in the literature are automatic, and typically focus on situational
awareness with emphasis on event detection (e.g. Mathioudakis and Koudas, 2010), visualization
and mapping of information (e.g. ‘Ushahidi’ described in Banks and Hersman, 2009), and/or
understanding facets of information (e.g., Imran et al., 2013; Terpstra et al., 2012). In this work,
we try to move into the higher-level processes of decision-making and coordination. We advance
the state-of-the-art by creating a systematic approach for automatic identification and matching
of demand and supply of resources to help coordination.
Matching emergency relief resources. Emergency-response organizations such as the American
Red Cross use human volunteers to manually perform the task of matching resource requests or
offers. Others provide specialized portals for registration of volunteers and donations, such as
AIDMatrix
(http://www.aidmatrixnetwork.org/fema/PublicPortal/ListOfNeeds.aspx?PortalID=114) and
recovers.org. Instead, our approach leverages the information already shared on social media to
automatically find and match requests and offers.
Previous works have noted that the extraction of this information from social media would be
easier if users had a protocol to follow for formatting messages, for example, with need related
messages adding ‘#need #shelter’. Therefore, some attempts have been made to bring structure
on the information that will be processed, including the Tweak-the-Tweet project (Starbird and
Stamberger, 2010). However, the amount of messages that include this type of hashtags is
minimal. The lack of adoption may be in part due to the psychology of stressful times (Dietrich
and Meltzer, 2003). During an emergency situation, people are likely to be distracted and less

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 11
oriented to learn a new vocabulary and remember to use it. Hence, being able to exploit the
natural communication patterns that occur in emergency-relief messages in social media can be a
better alternative.
Recently, (Varga et al., 2013) studied the matching of problem related messages (e.g. "I do not
believe infant formula is sold on Sunday") with solution/aid messages (e.g. "At Justo
supermarket in Iwaki, you can still buy infant formula"). Their classification approach involves
the creation of annotated lists of "trouble expression" which serve to identify problem messages.
Their matching approach seeks to identify a "problem nucleus" and a "solution nucleus", which
are the key phrases in a potential pair of problem and solution messages that should be similar in
order for the matching to be considered satisfactory. By mapping "problem messages" to demand,
and "solution/aid messages" to supply, we have a setting that resembles ours but with key
differences. First, we focus on specific categories of resources, a fact that can be helpful, as
different response organizations may want to deal with specific categories of information.
Second, we use a completely different approach, which always preserves the entire message
(during the task of classification for identifying request-offer as well as matching) instead of
focusing on a segment.
Matchmaking in online media. Matching is a well-studied problem in computer science. It has
been studied in various scenarios, such as the stable roommate problem (Irving, 1985), automatic
matchmaking in dating sites (Diaz et al., 2010), assigning reviewers to papers (Karimzadehgan
and Zhai, 2009), etc. Matching has also been studied in the context of social question-answering
(QA) portals (Bian et al., 2008) and social media in general, including the problem of finding
question-like information needs in Twitter messages (Zhao and Mei, 2013). Additional coverage
of work in this area appears in a recent tutorial presented by the authors (ICWSM-2013 Tutorial:

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 12
http://www.slideshare.net/knoesis/icwsm-2013-tutorial-crisis-mapping-citizen-sensing-and-
social-media-analytics). The challenge addressed in this paper is beyond automatic QA systems,
because not all requests or offers are questions (as exemplified in the Table 1). Actually, many
requests and offers do not even describe information needs, but can benefit from being matched
against other messages that provide a natural complement to them (i.e. requests with offers).
3. PROBLEM DEFINITION
Resource-related messages. Based on manual data inspection, we observed that resource-
related tweets are of various, non-mutually-exclusive types:
1. Requests for resources needed, e.g. Me and @CeceVancePR are coordinating a
clothing/food drive for families affected by Hurricane Sandy. If you would like to donate,
DM us.
2. Offers for resources to be supplied, e.g. Anyone know where the nearest #RedCross is? I
wanna give blood today to help the victims of hurricane Sandy.
3. Reports of resources that have been exchanged, e.g. RT @CNBCSportsBiz: New York
Yankees to donate $500,000 to Hurricane #Sandy relief efforts in Tri- State area.
We limit the scope of the current study to cases of exclusive behavior of these types as a first
step, as this makes the assessment/evaluation less ambiguous than when messages can be e.g.
requests and offers at the same time.
Limitations. We ignore following dimensions of message-author types for resource-related
tweets, since they are not directly related to our focus on automatic matchmaking:
1. Whether the entity that demands or supplies the resource is an individual or an
organization, and

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 13
2. Whether the tweet is being posted by the entity that demands or supplies the resource, or
on behalf of a third-party.
We also limit our study to English language tweets, which includes more than one third of
worldwide tweets (Leetaru et al., 2013). Nevertheless, we believe this approach is easily
adaptable to other languages. For examples, capabilities corresponding to the tokenizers and
stemmers we used for processing English content are widely available for a large range of
languages.
Finally, we do not deal with issues of quantity/capacity, which would require to know more
information attributes such as how many rations of food or how many beds of shelter are
supplied or demanded. This is a relevant aspect of this problem that unfortunately is not
supported by our dataset: among the thousands of messages we manually labeled, almost none
quantified the number of items being requested or offered. Therefore, discussion on abstraction
for need assessment is beyond the scope of this work and we shall present it in a future study.
Problem statement. We specifically address the following two problems:
● Problem 1: Building resource-related corpora. The output of our pre-processing steps
described in Section 4 are two sets of records, Q and D, containing records extracted
from tweets requesting and offering resources, respectively. Our notation suggests that
requests can be seen as queries (Q) and the offers as documents (D) in an information
retrieval system (like a search engine) -- although these roles are interchangeable.
● Problem 2: Matching resource requests with offers. Let s : Q × D → [0, 1] be a function
that associates a likelihood between 0 to 1 to every (request, offer) pair, such that the
offer d satisfies the request q. The problem consists in finding all requests (�q � Q) and
the corresponding offers (d � D) such that offer d is most likely to satisfy the request in q.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 14
The converse problem, i.e. finding the best request to match an offer, is also of interest
but its treatment is analogous to the one we present here.
Given that the output of problem 1 is the input for problem 2, we expect that errors will
propagate, which is also what we observe empirically in some of the cases. Hence, building a
high-quality corpus of requests and offers is a critical step.
4. CONSTRUCTION OF CORPORA OF RESOURCE-RELATED MESSAGES
In this section we describe the method by which we created the corpus of requests and the corpus
of offers. This method starts with a dataset collected from Twitter, which is then filtered to find
donation-related tweets, and then further processed until each request- and offer-message found
has been converted into a semi-structured record as exemplified in the Table 1.
4.1 Data Collection and Preparation
We collect data using Twitter’s Streaming API (https://dev.twitter.com/docs/streaming-
apis/streams/public), which allows us to obtain a stream of tweets filtered according to a given
criteria. In our case, and as customary in other crisis-related collections, we start with a set of
keywords and hashtags (e.g. #sandy). This set was updated by periodically extracting the most
frequent hashtags and keywords from the downloaded tweets, and then manually selecting highly
unambiguous hashtags and keywords from this most frequent list, to provide a control for
contextual relevance of content to the event. We store the entire tweet data including their
metadata: time of posting, location (when available), and author information including author
location, profile description, number of followers and followees, etc.
Our collector ran for 11 days starting October 27th, 2012 with an exception of 5 hours on the
night of October 30th because of technical issues in the crawling machines. Due to limitations of
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 15
the Twitter API on providing a sample of the entire tweet stream, and the fact that our list of
keywords does not have perfect coverage, the set of 4.9 million tweets we obtained, while likely
not the entire set of tweets related to this crisis event, is a large sample of it. For more details on
the practical limitations of Twitter's API for capturing crisis data, see (Morstatter et al. 2013).
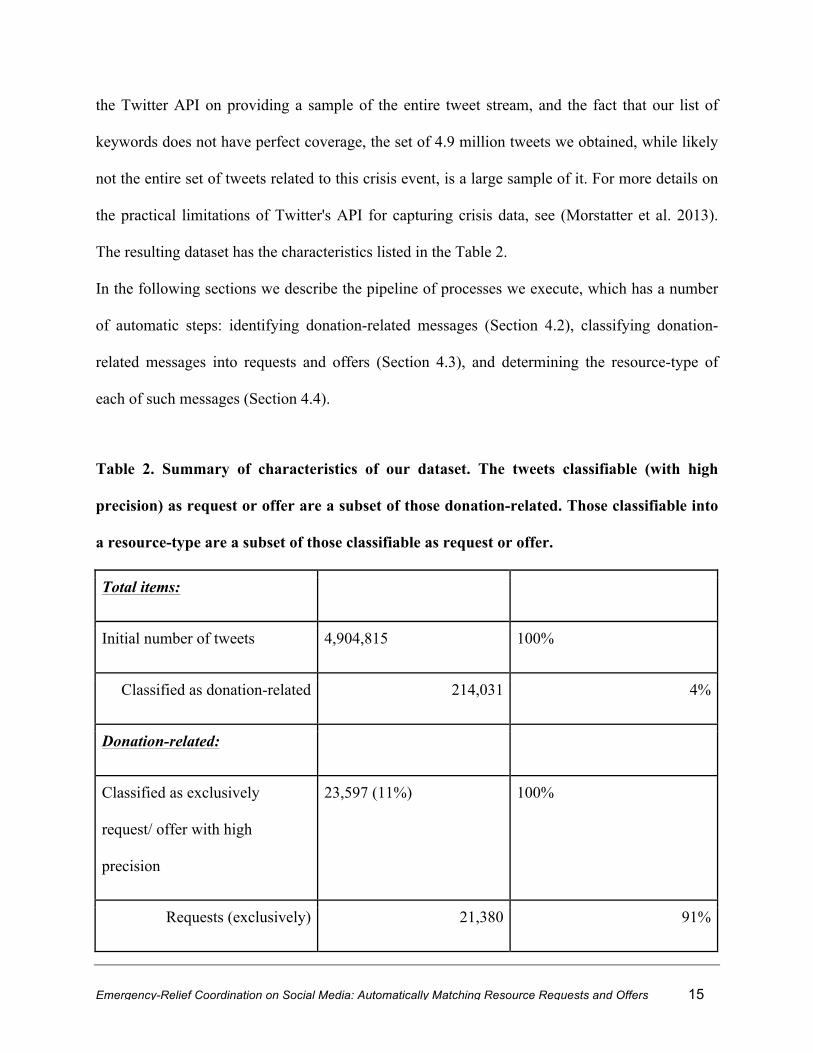
The resulting dataset has the characteristics listed in the Table 2.
In the following sections we describe the pipeline of processes we execute, which has a number
of automatic steps: identifying donation-related messages (Section 4.2), classifying donation-
related messages into requests and offers (Section 4.3), and determining the resource-type of
each of such messages (Section 4.4).
Table 2. Summary of characteristics of our dataset. The tweets classifiable (with high
precision) as request or offer are a subset of those donation-related. Those classifiable into
a resource-type are a subset of those classifiable as request or offer.
Total items:
Initial number of tweets 4,904,815 100%
Classified as donation-related 214,031 4%
Donation-related:
Classified as exclusively
request/ offer with high
precision
23,597 (11%) 100%
Requests (exclusively) 21,380 91%
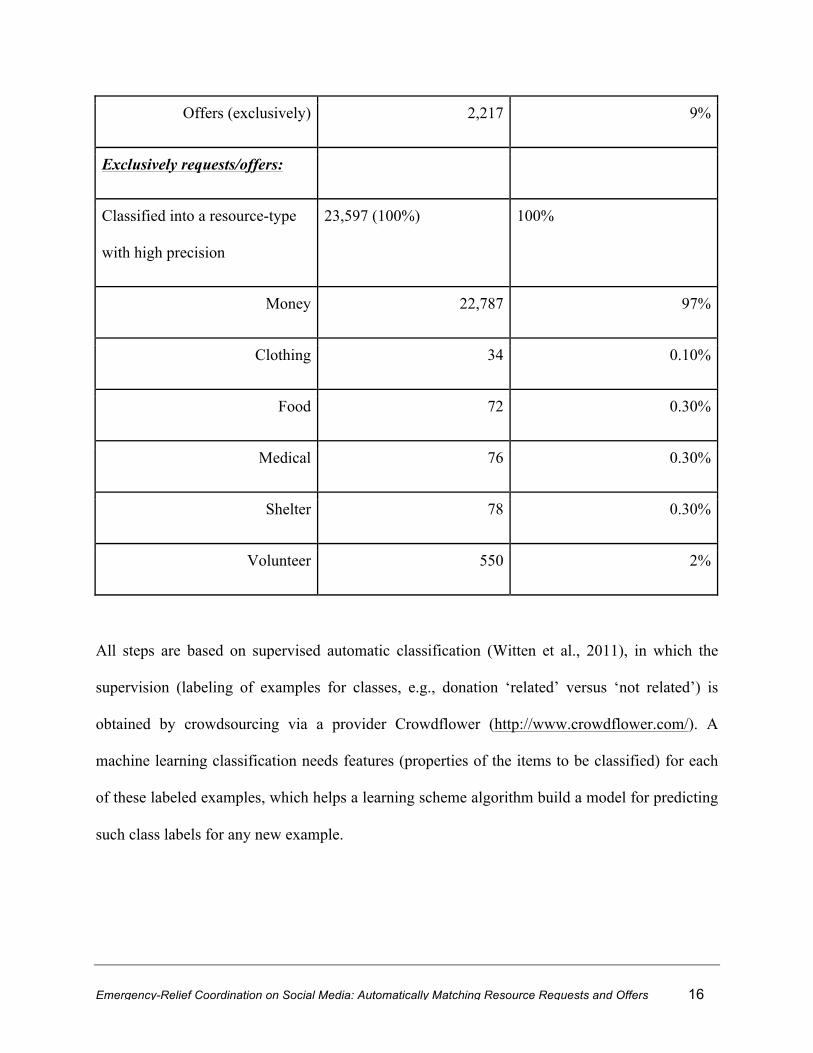
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 16
Offers (exclusively) 2,217 9%
Exclusively requests/offers:
Classified into a resource-type
with high precision
23,597 (100%) 100%
Money 22,787 97%
Clothing 34 0.10%
Food 72 0.30%
Medical 76 0.30%
Shelter 78 0.30%
Volunteer 550 2%
All steps are based on supervised automatic classification (Witten et al., 2011), in which the
supervision (labeling of examples for classes, e.g., donation ‘related’ versus ‘not related’) is
obtained by crowdsourcing via a provider Crowdflower (http://www.crowdflower.com/). A
machine learning classification needs features (properties of the items to be classified) for each
of these labeled examples, which helps a learning scheme algorithm build a model for predicting
such class labels for any new example.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 17
All automatic classification steps produce standard metrics for quality, precision and recall2
(Witten et al., 2011), where we emphasize precision over recall for the positive class (e.g.,
‘donation-related’, ‘is-exclusive-request’). Precision is a ratio of correctly predicted messages for
a class to the total predicted messages for that class, and recall is a ratio of correctly predicted
messages to the total actual number of messages for that class in the training examples. Given
true positive as tp, false positive as fp, and false negative as fn in a confusion matrix for the
original classes (actual observation) and predicted classes (expectation) by a classifier, then-
,
We tuned our classifiers to aim for 90% or higher precision (reducing the number of false
positives) at the expense of potentially having less recall (more false negatives).
Feature extraction. Each step is based on automatic supervised classification. Labels are
obtained through crowdsourcing. Tweets are represented as vectors of features, each feature
being a word N-gram (segment of N words), by performing standard text pre-processing
operations:
1. Removing non-ASCII characters.
2. Separating text into tokens (words), removing stopwords and performing stemming (reducing
to root words, such as ‘helping’ to ‘help’).
3. Generalizing some tokens by replacing numbers by the token _NUM_, hyperlinks by the token
_URL_, retweets (“RT @user_name”) by the token _RT_ and lastly, user mentions in the tweets
(@user_name) by the token _MENTION_.
2 Precision and Recall metrics for classification: http://en.wikipedia.org/wiki/Precision_and_recall

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 18
4. Generating uni-, bi-, and tri-grams of tokens, which correspond to sequences of one, two, or
three consecutive tokens after the pre-processing operations have been applied.
4.2 Donation-Related Classification
In a recent study by (Imran et al. 2013), authors manually coded a large sample of tweets from
the 2011 Joplin Tornado and found that about 16% of them were related to donations of goods
and services. We expect that the fraction of donation-related tweets will vary across disasters,
and we also expect that as we emphasize precision over recall, we will capture a high quality
fraction.
Labeling task preparation. A multiple-choice question was asked to crowdsourcing workers
(assessors), “Choose one of the following options to determine the type of a tweet”:
● Donation- a person/group/organization is asking or offering help with a resource such as
money, blood/medical supplies, volunteer work, or other goods or services.
● No donation- there is no offering or asking for any type of donations, goods or services.
● Cannot judge- the tweet is not in English or cannot be judged.
The options were worded to encourage assessors to understand “donation” in a broad sense,
otherwise (as we observed in an initial test) they tend to understand "donations" to mean
exclusively donations of money.
Sampling and labeling. Given our limited budget for the crowdsourcing task and the relatively
small prevalence of donation-related tweets in the data, we introduced some bias in the sample of
tweets to be labeled. We selected 1,500 unique tweets by uniform random sampling, and 1,500

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 19
unique tweets from the output of a conditional random field (CRF) based donation-related
information extractor borrowed from the work of (Imran et al., 2013). The two sets of tweets
were merged and randomly shuffled before showing them to the assessors.
We asked for 3 labels per tweet and obtained 2,673 instances labeled with a confidence value of
0.6 or more (range is 0 to 1). This confidence value is based on inter-assessor agreement and the
assessor agreement with a sub-set of 100 tweets for which we provided labels. Our labeled
dataset contained 29% tweets of ‘donation-related’ class.
Learning the Classification. We experimented with a number of standard Machine Learning
schemes (techniques). For this task, we obtained good performance by using attribute (feature)
selection using a Chi-squared Test, considering the top 600 features, and applying a Naïve Bayes
Classifier (Witten et al., 2011).
To reduce the number of false positives, we used asymmetric misclassification costs. In that, we
considered a non-donation classified tweet as donation as 15 times more costly than the case of a
donation classified as non-donation.
After 10-fold cross-validation, for the donation class we achieved a precision of 92.5% (meaning
that 92.5% of the items classified as ‘donation-related’ by the system are actually ‘donation-
related’) with 47.4% of recall (meaning that 47.4% of all the items in the data that are ‘actually
donation-related’ are identified by this system). The area under the ROC curve (AUC) is 0.85,
which implies good classification ability.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 20
4.3 Request-Offer Classification
Among the donation-related messages, we observe three information types: requests, offers, and
reports, as described in Section 3. Some messages belong to more than one type, as can be seen
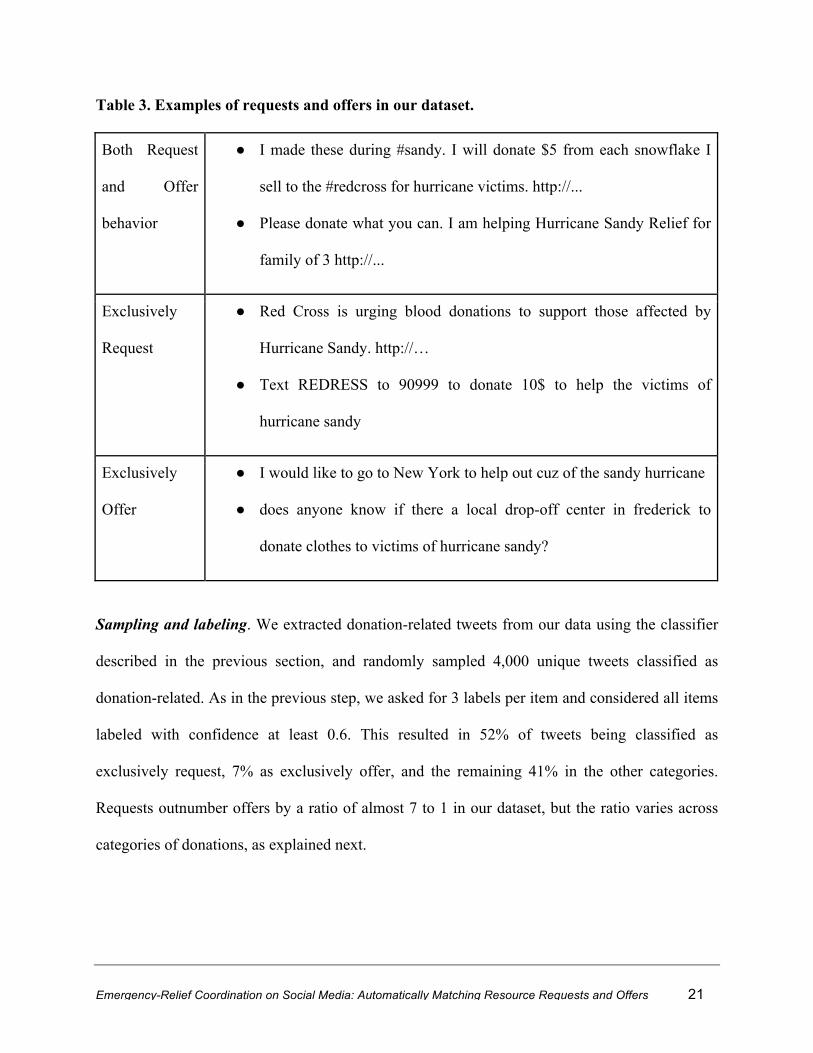
in the examples of Table 3.
We focus on messages that are either exclusively requests or exclusively offers because they can
be (a) classified without ambiguity by crowdsourcing workers, (b) classified more accurately by
automatic classifiers, and (c) better matched by the automatic matching system. Our follow up
work to this study shall address the challenge of messages in between the spectrum of the
exclusive behaviors of requests and offers.
Labeling task preparation. A multiple-choice question was asked to crowdsourcing workers,
asking to classify a tweet into one of the following categories:
● Request to get- when a person/group/organization needs to get some resource or service
such as money
● Offer to give- when a person/group/organization offers/wants to give/donate some
resource goods or provide a service
● Both request and offer
● Report of past donations of certain resources, not offering explicitly to give something
that can be utilized by someone
● None of the above
● Cannot judge
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 21
Table 3. Examples of requests and offers in our dataset.
Both Request
and Offer
behavior
● I made these during #sandy. I will donate $5 from each snowflake I
sell to the #redcross for hurricane victims. http://...
● Please donate what you can. I am helping Hurricane Sandy Relief for
family of 3 http://...
Exclusively
Request
● Red Cross is urging blood donations to support those affected by
Hurricane Sandy. http://…
● Text REDRESS to 90999 to donate 10$ to help the victims of
hurricane sandy
Exclusively
Offer
● I would like to go to New York to help out cuz of the sandy hurricane
● does anyone know if there a local drop-off center in frederick to
donate clothes to victims of hurricane sandy?
Sampling and labeling. We extracted donation-related tweets from our data using the classifier
described in the previous section, and randomly sampled 4,000 unique tweets classified as
donation-related. As in the previous step, we asked for 3 labels per item and considered all items
labeled with confidence at least 0.6. This resulted in 52% of tweets being classified as
exclusively request, 7% as exclusively offer, and the remaining 41% in the other categories.
Requests outnumber offers by a ratio of almost 7 to 1 in our dataset, but the ratio varies across
categories of donations, as explained next.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 22
Additional features. This classification task was more challenging than the donation-related
classification. In addition to the heavy class imbalance as noted by the ratio of requests to offers,
there are a number of constructs in the text that are common to requests and offers, e.g. “want to
donate for help, check here ...” (request) vs. “want to donate some money to help my friends who
lost everything in hurricane sandy disaster” (offer).
These subtle differences go beyond what we can capture with word n-gram tokens as features. In
order to capture them, we added an additional list of 18 regular-expressions, informed by
messages selected by experts at the Red Cross. Each regular-expression was translated to one
binary feature (the tweet matches the regular expression, implying 1; or does not match it,
implying 0). The following are two examples (the full list is available in our dataset release,
omitted here for brevity):
1. \b(like|want) \b.* \b(to)\b.*\b(bring|give|help|raise|donate) \b
2. \b(how)\b.* \b(can I|can we) \b.*\b(bring|give|help|raise|donate) \b
In these regular expressions, "\b" represents a word boundary, (word1|word2|...) indicates that
any of the words can occur, and ".*" stands for an arbitrary piece of text, even an empty space.
Learning the Classification. After extensive experimentation with different learning schemes
and configurations, in which we noticed that in general multi-class classification did not perform
well in our case, we decided to use two binary classifiers in a cascade configuration. The first
classifier has two classes: exclusively requests and other. The second classifier receives tweets in
the other class of the first classifier, and finds the exclusively offers in them. Each classifier was
based on Random Forest Tree algorithm with asymmetric costs (Witten et al., 2011), as detailed
in the Table 4. The overall performance of this classifier was a precision of 97.9% and recall of
29.7% with AUC value 0.82 for exclusively requests and a precision of 90.4% and recall of

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 23
29.2% with AUC value 0.75 for exclusively offers. The higher value of precision over the recall
is due to our design choice as pointed earlier, because we want to identify requests and offers
with high quality, instead of compromising on precision for sake of more coverage of all
partially possible items.
4.4 Resource-Type Classification
We use a supervised classifier to classify donation-related corpus according to resource-type,
where we limit ourselves for the current experiment to "hard" classes, in which each tweet is
related to a single resource-type. Our list of resource-types is the subset of those in the UN
Cluster System (UN OCHA, 2013) that were present in our dataset. To determine it, we
examined the top 200 most frequent terms in the donation-related tweets.
Labeling task preparation. As before, a multiple-choice question was asked to crowdsourcing
workers, “Choose one resource-type”, including example tweets of each class:
● Clothing
● Food
● Medical supplies including blood
● Money
● Shelter
● Volunteer work
● Not request or offer
● Request or offer for something else
● Cannot judge

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 24
Sampling and labeling. As in the donation-related classifier we introduced some bias in the
tweets to be labeled, in order to better use our crowdsourcing budget; otherwise we would not
have obtained a sufficient number of samples of the classes with smaller size. We selected 6,400
unique tweets in two parts. In the first part, 4,000 were selected by uniform random sampling
among the ones containing exclusively requests or exclusively offers in the output of the
previous automatic classifier. In the second part, remaining 2,400 were selected by searching for
keywords related to each of the 6 resource classes (e.g. “money”, “clothes”, “blood”, etc.) These
2,400 tweets were sampled from the entire input dataset (50% uniformly at random and 50%
from the output of the donation-related classifier).
Again, we asked for 3 labels per item and considered items with confidence at least 0.6; we also
discarded the tweets that were not considered to be in one of the categories (e.g. 10% were
labeled as request or offer for something else). The result was: money 71%, volunteer work 8%,
clothing 6%, medical supplies/blood 5%, food 5%, and shelter 5%.
Additional features. We reinforced our word n-gram features with regular-expression based
features, adding 15 patterns with the help of experts from the Red Cross. Each pattern produced
one binary feature based on the regex matcher result (true, false). Example patterns are listed
below (full list available in our dataset release):
1. \b(shelter|tent city|warm place|warming center|need a place|cots) \b
2. \b(food|meal|meals|lunch|dinner|breakfast|snack|snacks) \b
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 25
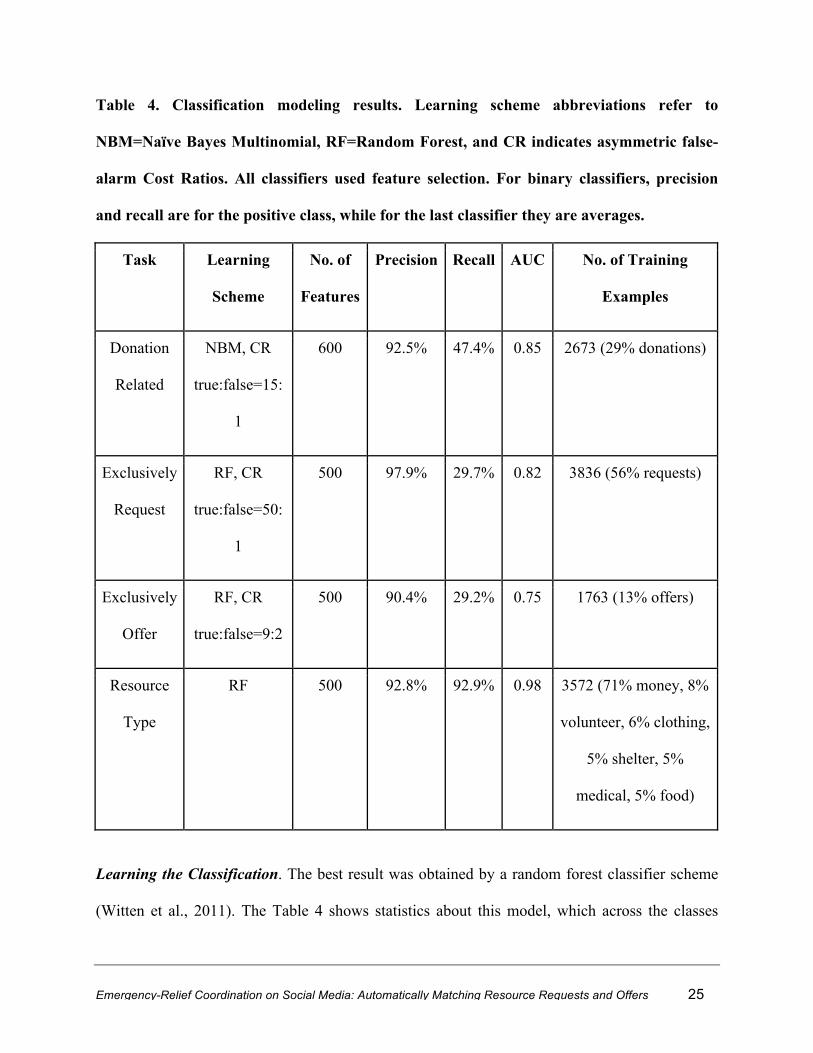
Table 4. Classification modeling results. Learning scheme abbreviations refer to
NBM=Naïve Bayes Multinomial, RF=Random Forest, and CR indicates asymmetric false-
alarm Cost Ratios. All classifiers used feature selection. For binary classifiers, precision
and recall are for the positive class, while for the last classifier they are averages.
Task Learning
Scheme
No. of
Features
Precision Recall AUC No. of Training
Examples
Donation
Related
NBM, CR
true:false=15:
1
600 92.5% 47.4% 0.85 2673 (29% donations)
Exclusively
Request
RF, CR
true:false=50:
1
500 97.9% 29.7% 0.82 3836 (56% requests)
Exclusively
Offer
RF, CR
true:false=9:2
500 90.4% 29.2% 0.75 1763 (13% offers)
Resource
Type
RF 500 92.8% 92.9% 0.98 3572 (71% money, 8%
volunteer, 6% clothing,
5% shelter, 5%
medical, 5% food)
Learning the Classification. The best result was obtained by a random forest classifier scheme
(Witten et al., 2011). The Table 4 shows statistics about this model, which across the classes
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 26
achieves average precision of 92.8% and recall of 92.9% with AUC of 0.98, suggesting excellent
classification ability.
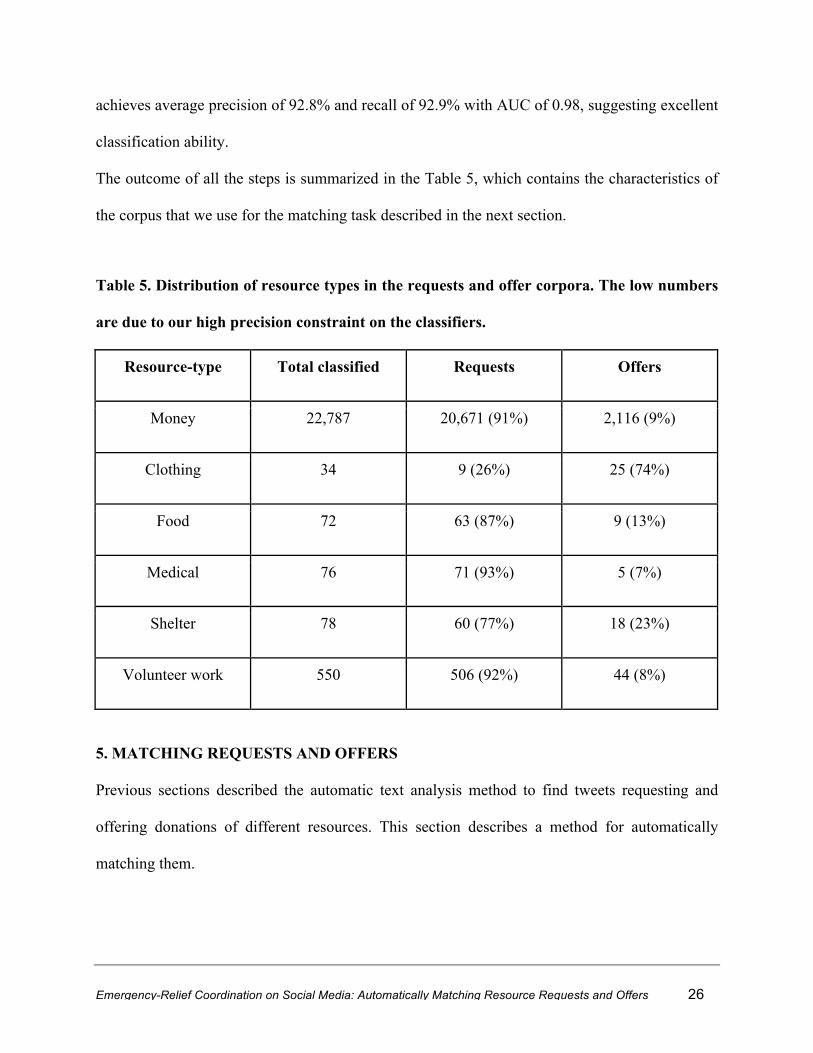
The outcome of all the steps is summarized in the Table 5, which contains the characteristics of
the corpus that we use for the matching task described in the next section.
Table 5. Distribution of resource types in the requests and offer corpora. The low numbers
are due to our high precision constraint on the classifiers.
Resource-type Total classified Requests Offers
Money 22,787 20,671 (91%) 2,116 (9%)
Clothing 34 9 (26%) 25 (74%)
Food 72 63 (87%) 9 (13%)
Medical 76 71 (93%) 5 (7%)
Shelter 78 60 (77%) 18 (23%)
Volunteer work 550 506 (92%) 44 (8%)
5. MATCHING REQUESTS AND OFFERS
Previous sections described the automatic text analysis method to find tweets requesting and
offering donations of different resources. This section describes a method for automatically
matching them.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 27
5.1 Algorithm
We consider the task of matching requests with offers as one of classifying whether an arbitrary
request and offer are relevant to each other. For example, consider the following request,
R1: “we are coordinating a clothing/food drive for families affected by Hurricane Sandy.
If you would like to donate, DM us”
and the following offer,
O1: “I got a bunch of clothes I’d like to donate to hurricane sandy victims. Anyone know
where/how I can do that?”
In this case, we would say that the offer-request pair <R1,O1> is relevant because R1 is relevant
to O1 and O1 is relevant to R1. Now consider the following offer,
O2: “Where can I donate food for Sandy victims?”
In this case, we would say that the offer-request pair <R1,O2> is not relevant because the offer
and request are not relevant to each other. The objective of our system is to correctly predict the
relevance of an arbitrary offer-request pair. A similar methodology was previously adopted in
the context of matchmaking in online dating sites (Diaz et al., 2010).
Feature selection. In the context of machine learning, features refer to properties of the item to
be classified; in this case, features refer to the properties of the offer-request pair we are trying to
classify as relevant or not relevant. There are obviously many properties of an offer-request pair.
We would like to only include features likely to be correlated with match relevance. These
include properties such as the text similarity between the offer and request. In general, we can
divide these features into two sets. Our first set of features consists of the classifier predictions
described in previous sections. For example, the confidence that a particular tweet is an offer
might be correlated with match relevance. Using the confidence instead of a binary prediction

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 28
(such as, ‘is_request’ or ‘is_not_request’) allows the model to better exploit information gathered
during the previous steps. In our second set as addition to the first set of derivative features, we
consider the text similarity between each candidate pair. Text similarity is likely to capture
relatedness of pairs of tweets not captured by our coarser upstream classifications. We compute
similarity by the cosine similarity of tf-idf term vectors (Baeza-Yates and Ribeiro-Neto 2011)
after stopword removal and stemming, similar to a traditional information retrieval method in the
search systems.
We evaluate the effectiveness of different feature sets by considering three experimental
conditions, using (i) only request-offer prediction probabilities and resource-type prediction
probabilities for each offer and request; (ii) only the text similarity; and (iii) all features.
Functional form. A machine-learning algorithm refers to an algorithm, which can learn the
relationship between features and the target classification, in this case, match relevance. In our
work, we use an algorithm known as Gradient-Boosted Decision Tree (GBDT) (Friedman, 2001).
Our small feature space makes the decision to use GBDT appropriate since the tree will use
complex conjunctions of features that is absent from linear classifiers. For example, this
algorithm might learn that “high text similarity and high request/offer confidence implies
relevance” but “high text similarity and very low request/offer confidence implies non-
relevance”.
5.2 Experiments and Results
Labeling task preparation. In order to train and evaluate our matching model, we collect labeled
training data for a random sample of 1,500 request-offer pairs from our resource-related corpora
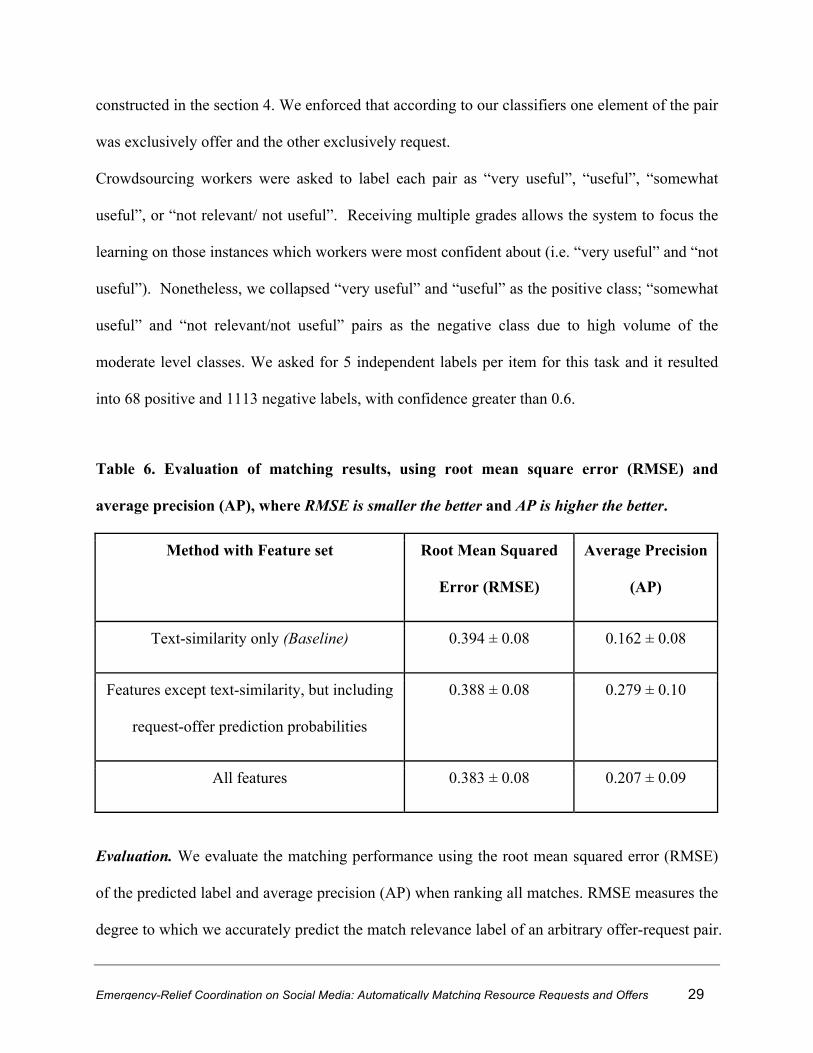
Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 29
constructed in the section 4. We enforced that according to our classifiers one element of the pair
was exclusively offer and the other exclusively request.
Crowdsourcing workers were asked to label each pair as “very useful”, “useful”, “somewhat
useful”, or “not relevant/ not useful”. Receiving multiple grades allows the system to focus the
learning on those instances which workers were most confident about (i.e. “very useful” and “not
useful”). Nonetheless, we collapsed “very useful” and “useful” as the positive class; “somewhat
useful” and “not relevant/not useful” pairs as the negative class due to high volume of the
moderate level classes. We asked for 5 independent labels per item for this task and it resulted
into 68 positive and 1113 negative labels, with confidence greater than 0.6.
Table 6. Evaluation of matching results, using root mean square error (RMSE) and
average precision (AP), where RMSE is smaller the better and AP is higher the better.
Method with Feature set Root Mean Squared
Error (RMSE)
Average Precision
(AP)
Text-similarity only (Baseline) 0.394 ± 0.08 0.162 ± 0.08
Features except text-similarity, but including
request-offer prediction probabilities
0.388 ± 0.08 0.279 ± 0.10
All features 0.383 ± 0.08 0.207 ± 0.09
Evaluation. We evaluate the matching performance using the root mean squared error (RMSE)
of the predicted label and average precision (AP) when ranking all matches. RMSE measures the
degree to which we accurately predict the match relevance label of an arbitrary offer-request pair.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 30
AP measures the ability to distinguish relevant and non-relevant pairs, regardless of predicting
the actual label. We conducted experiments using 10-fold cross-validation. Results are
summarized in Table 6.
We can make several observations from these results. First, a naïve system might attempt to
perform matching using text-similarity features alone, a form of traditional information retrieval
method. However, our results demonstrate that this baseline is the lowest performing across all
metrics. Second, although combining all features results in the lowest RMSE, using only the
features derived from the confidence scores of the classifier (request/offer) predictions achieve
the strongest AP. We observe 72% relative improvement in the AP against the lowest performing
metric, the baseline. This follows from the fact that GBDT minimizes squared error on the
training set. We suspect that incorporating a rank-based loss would lead to more consistent AP
between these other experimental settings. Nevertheless, these results provide support for
performing the classification preprocessing (request-offer predictions prior to the task of
classification for relevant pairs for matching).
6. DISCUSSION
6.1 Summary of findings
The proposed processing pipeline of (1) building a corpora with rich information about requests
and offers for donation coordination, and (2) matching resource requests with offers, has shown
to be effective for this task. This is a flexible framework where more components can be added
in the pipeline process. Even when errors may propagate through the different steps, setting high
thresholds to emphasize precision over recall helps to provide high quality inputs to the matching
task of coordination.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 31
Evaluation using 10- fold cross-validation for our classifiers (donation related, request, offer, and
resource-related) shows AUC range between fair (0.75) to excellent (0.98). It implies a good
classification ability for separating meaningful information inspite of a lot of noise in the dataset.
Also, our matching model achieves good performance when we combine the features of
prediction probabilities of the identified request or offer behavior for the messages with the text
similarity of the messages. In practice, users may interact with the system’s ranking of matches
and thus, help improve the performance.
6.2 Recommendations
As methods for managing social media messages improve, we should be attempting to move
from text mining and social media analytics, towards higher level activities (or actionable
information) such as supporting the coordination of actions. Effectively matching donation
messages is a good candidate for the kind of capability that more directly impact human actions
and decision, and in the case addressed in this work, can help build resilience and enable
communities to bounce back more quickly following a disaster.
The state-of-the-art approaches involve manually intensive effort as done by response
organizations such as the American Red Cross and others, which cannot scale. The usage of
commercially-available Twitter classification applications such as Crimson Hexagon and others
is a good first step, but it only solves the problem partially, as a matchmaking component for
requests and offers is still required.
6.3 Limitations
The main limitation of the proposed method is the recall of the various classifiers, which is
challenging due to various unstructured tweet characteristics. We believe that stronger classifiers

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 32
and better features can certainly be used at every step in the proposed system, while making sure
that high precision is preferred for any component. We note the following observations in the
steps of creating a resource-related corpora and matching requests and offers:
Imbalance in the requests and offers distribution. As we note in the Table 4, there are 10 times
more exclusively requests than exclusively offers in the training corpus as well as in the
predicted labels (Table 2). Therefore, it was challenging to classify requests and offers, despite
of taking help of domain experts driven features (the regular expression based patterns), there
were cases of ambiguous behavior (both request and offers) in the message content. In the future
work, we may want to capture all types of behavior- exclusive request, exclusive offer, as well as
mixed.
Imbalance in the resource-type distribution. The lower percentage of classified tweets into non-
Money classes (Table 5) such as Clothing, Food, etc. is partially due to our high precision
constraint on the classifiers. Also, the constraint of the exclusively requests and offers behavior
on the input reduces the potential set. But more fundamentally, it is likely due to imbalance
distribution existing in the dataset we analyzed, as noted in the training set (71% money related
messages).
The underlying cause for such distribution can be that donations of money are the most prevalent
way to help in this case. In our thousands of labeled examples, we noted that people were
propagating messages such as “Text redcross to 90999 to donate $10 to help those people that
were affected by hurricane sandy please donate” extensively. In any case, the imbalance does
not help the labeling process or the automatic classifiers. Furthermore, we observe the ratios of
requests and offers varying across different resource-type classes as we note from the Table 5,

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 33
for example, the "Clothing" class has higher number of offers than requests. The remaining
classes have higher proportions of requests than offers but the ratio varies. Again, the non-
uniformity may impact the performance of matching algorithm in the subsequent task.
Batch operation vs. continuous querying. A limitation unrelated to the classification
performance is that we have described this as a batch operation in which all requests and offers
are known at the same time. This may not always be the case in a real system. Systems where the
queries are given beforehand and as new elements arrive they should be answered, are known as
continuous querying systems (Chen et al. 2000, Terry et al. 1992). In practice, our system should
operate in the continuous manner, with the added complexity that both requests and offers may
constitute queries to the corresponding complementary set already collected at that point of time.
6.4 Future work
The framework we have described can be extended in many ways, including:
Tweet classification improvements. In some cases further information about a donation-related
message may be required. First, users may want to know whether the entity that demands or
supplies a resource is an individual or an organization, and/or other aspects that allow them to
evaluate the credibility of a message. Second, many messages are posted on behalf of a third-
party (e.g. individuals not associated with the Red Cross but that ask in Twitter for donations to
the Red Cross); we could try to detect messages that refer to a third party.
Additionally, we can envision a hybrid system in which manual and automatic classification
coexist. We could, for instance, make use of crowdsourcing to improve the quality of the

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 34
matching, by annotating a small subset of requests/offers in order to improve the overall
matching score of the messages that are matched, or the number of messages that are matchable.
Matching improvements. Geographical distance needs to be included in the objective function
for disasters covering large areas. Additional metadata about the tweets, such as author profiles
may help to prioritize messages.
Issues related to capacity (e.g. shelter for K people) or inventory sizes (e.g. K rations of food)
also need to be taken into account, when they are available in the data. As users' sophistication in
using social media tools rises, we could expect more detailed information in their messages.
In addition to the matching framework we have presented here, based on information retrieval
research studies, other methods could be tested. For instance, a machine translation approach
could yield good results, although it may require a larger amount of training data.
Application to other crisis information and aspects beyond donations. Ideally, automated
methods such as the one we have described should be tested across different crisis datasets of
different types, such as earthquakes, floods, hurricane, wildfires, etc. Also, developments for
non-English languages will be helpful, specially for the ones in which text processing tools are
available.
In addition to the problem of matching emergency-relief resources, there are other similar
matching problems, as the one described by (Varga et al. 2013). There are also applications
beyond the crisis domain. For instance, in the healthcare domain, people often share questions
and concerns about diseases, as well as their personal experience as a patient. Information
seekers could be matched with patients having experience with the same disease or treatment.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 35
7. CONCLUSION
We presented a systematic study to automatically identify requests and offers of donations for
various resource-types including shelter, money, volunteer work, clothing and medical supplies.
We also introduced a method for automatically matching them, helping in the donation
coordination during the emergency response phase.
While noting a number of limitations and avenues for future research, the methodology we have
described has shown to be useful in practice. For instance, during the Oklahoma Tornado, US in
May 2013 and floods in Uttarakhand, India in June 2013, we applied our processing framework
to quickly identify messages related to types of requests to help and offers of help and shared
with response organizations.
Reproducibility. Our dataset will be available upon request, for research purposes.
8. ABOUT THE AUTHORS
● Amit Sheth (PhD) is an educator, researcher and entrepreneur. He is currently the
LexisNexis Ohio Eminent Scholar at the Wright State University, Dayton OH and the
director of Kno.e.sis - the Ohio Center of Excellence in Knowledge-enabled Computing
which works on topics in Semantic, Social, Sensor, and Services computing over the Web,
with the goal of advancing from the information age to meaning age. He is also an IEEE
Fellow. Home page: http://knoesis.org/amit
● Patrick Meier (PhD) is an internationally recognized thought leader on the application of
new technologies for crisis early warning, humanitarian response and resilience. He
presently serves as Director of Social Innovation at the Qatar Foundation's Computing
Research Institute (QCRI). He is an accomplished writer and speaker, with talks at

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 36
several major venues including the White House, UN, the Skoll World Forum, Club de
Madrid, Mobile World Congress, PopTech, Where 2.0, TTI/Vanguard, SXSW and
several TEDx's. More about Patrick: http://irevolution.net/bio/
● Carlos Castillo (PhD) is a Senior Scientist in the Social Computing group of the Qatar
Foundation's Computing Research Institute (QCRI). Prior to QCRI, Carlos worked with
Yahoo Research. He has influenced research fields on several topics including
information retrieval, spam detection/demotion, usage analysis and social network
analysis. His current research interest is the mining of content, links, and usage data from
the Web to fuel applications in the news and crisis domains. More about Carlos:
http://www.chato.cl/research/
● Fernando Diaz (PhD) is a researcher at the Microsoft Research NYC lab. His primary
research interest is formal information retrieval models. His research experience includes
distributed information retrieval approaches to web search, temporal aspects of
information access, mouse-tracking, cross-lingual information retrieval, graph-based
retrieval methods, and synthesizing information from multiple corpora. Currently, he is
studying them in the context of unexpected crisis events. More about Fernando:
http://ciir.cs.umass.edu/~fdiaz/
● Hemant Purohit is an interdisciplinary (Computer and Social Sciences) researcher at the
Kno.e.sis - the Ohio Center of Excellence in Knowledge-enabled Computing at Wright
State University, USA, where he coordinates crisis informatics research under NSF SoCS
project. He is pursuing a unique approach of people-content-network analysis for
analyzing social signals with insights from psycholinguistic theories of coordination to
answer: whom to coordinate, why to coordinate and how to coordinate. His work also

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 37
involves problem spaces of community engagement and sustainability, expert detection
and presentation. More about Hemant: http://knoesis.org/hemant
9. ACKNOWLEDGEMENT
We thank NSF for sponsoring SoCS grant IIS-1111182 titled as `Social Media Enhanced
Organizational Sensemaking in Emergency Response', to partially enable this work. We want to
thank our colleagues at Kno.e.sis and QCRI for giving helpful feedback and assisting in
qualitative studies, especially Noora Al Emadi at QCRI.
10. REFERENCES
1. (Baeza-Yates and Ribeiro-Neto, 2011) Ricardo Baeza-Yates and Berthier Ribeiro-Neto,
2011. Modern Information Retrieval. 2nd Edition. Addison-Wesley Press.
2. (Banks and Hersman, 2009) K. Banks and E. Hersman, 2009. “FrontlineSMS and
Ushahidi- a demo,” Proceedings of International Conference on Information and
Communication Technologies and Development (ICTD’09). IEEE, pp. 484-484.
3. (Bian et al., 2008) J. Bian, Y. Liu, E. Agichtein, and H. Zha, 2008. “Finding the right
facts in the crowd: factoid question answering over social media,” Proceedings of the
17th international conference on World Wide Web (WWW’08). New York: ACM Press,
pp. 467–476.
4. (Blanchard et al., 2012) H. Blanchard, A. Carvin, M. E. Whitaker, and M. Fitzgerald,
2012. “The case for integrating crisis response with social media,” White Paper,
American Red Cross.
5. (Boulos et al., 2011) M. N. K. Boulos, B. Resch, D. N. Crowley, J. G. Breslin, G. Sohn,
R. Burtner, and K. Y. S. Chuang, 2011. “Crowdsourcing, citizen sensing and sensor web

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 38
technologies for public and environmental health surveillance and crisis management:
trends, OGC standards and application examples,” International journal of health
geographics, volume 10, number 1, pp. 67-96.
6. (Cameron et al., 2012) M. A. Cameron, R. Power, B. Robinson, and J. Yin, 2012.
“Emergency situation awareness from twitter for crisis management,” Proceedings of the
21st international conference companion on World Wide Web (WWW’12 Companion).
New York: ACM Press, pp. 695–698.
7. (Chen et al., 2000) J. Chen, D. J. DeWitt, F. Tian, and Y. Wang, 2000. “NiagaraCQ: A
scalable continuous query system for internet databases,” ACM SIGMOD Record, volume
29, number 2, pp. 379–390.
8. (Diaz et al., 2010) F. Diaz, D. Metzler, and S. Amer-Yahia, 2010. “Relevance and
ranking in online dating systems,” Proceedings of the 33rd international ACM SIGIR
conference on Research and development in information retrieval (SIGIR’10). New
York: ACM Press, pp 66–73.
9. (Dietrich and Meltzer, 2003) Rainer Dietrich and Tilman von Meltzer, 2003.
Communication in high risk environments. Volume 12. Hamburg: Buske Verlag Press.
10. (Friedman, 2001) Jerome H. Friedman, 2001. "Greedy function approximation: a gradient
boosting machine." Annals of Statistics, pp. 1189-1232.
11. (Imran et al., 2013) M. Imran, S. Elbassuoni, C. Castillo, F. Diaz, and P. Meier, 2013.
“Extracting information nuggets from disaster- related messages in social media,” In: T.
Comes, F. Fiedrich, S. Fortier, J. Geldermann and L. Yang (editors). Proceedings of the
10th International ISCRAM Conference (ISCRAM ’13), Baden-Baden, Germany.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 39
12. (Irving, 1985) Robert W. Irving, 1985. “An efficient algorithm for the ‘stable roommates’
problem,” Journal of Algorithms, volume 6, number 4, pp. 577–595.
13. (Karimzadehgan and Zhai, 2009) M. Karimzadehgan and C. Zhai, 2009. “Constrained
multi- aspect expertise matching for committee review assignment,” Proceedings of the
18th ACM conference on Information and knowledge management (CIKM’09), pp. 1697–
1700. New York: ACM Press.
14. (Kongthon et al., 2012) A. Kongthon, C. Haruechaiyasak, J. Pailai, and S. Kongyoung,
2012. “The role of twitter during a natural disaster: Case study of 2011 thai flood,”
Proceedings of International Conference on Technology Management for Emerging
Technologies (PICMET’12), IEEE. pp. 2227–2232.
15. (Leetaru et al., 2013) K. Leetaru, S. Wang, G. Cao, A. Padmanabhan, and E. Shook, 2013.
“Mapping the global Twitter heartbeat: The geography of Twitter,” First Monday,
volume 18, number 5 (6 May) at
http://firstmonday.org/ojs/index.php/fm/article/view/4366/3654 accessed 31 August 2013.
16. (Mathioudakis and Koudas, 2010) M. Mathioudakis and N. Koudas, 2010.
“Twittermonitor: trend detection over the twitter stream,” Proceedings of the 2010
International Conference on Management of data (SIGMOD’10). New York: ACM Press,
pp. 1155–1158.
17. (Mohan et al., 2011) A. Mohan, Z. Chen, and K. Q. Weinberger, 2011. “Web-search
ranking with initialized gradient boosted regression trees,” Journal of Machine Learning
Research (JMLR), Workshop and Conference Proceedings, volume 14, pp. 77–89.
18. (Morstatter et al., 2013) F. Morstatter, J. Pfeffer, H. Li and K. M. Carley, 2013. “Is the
Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 40
Firehose,” Proceedings of Seventh International AAAI Conference on Weblogs and
Social Media (ICWSM’13). AAAI Press, pp. 400-408.
19. (Palen et al., 2007) Leysia Palen, Starr Roxanne Hiltz, and Sophia B. Liu. 2007. Online
forums supporting grassroots participation in emergency preparedness and response.
Communications of the ACM - Emergency response information systems: emerging
trends and technologies, volume 50, number 3 (March 2007), pp. 54-58.
20. (Purohit et al., 2013) Hemant Purohit, Andrew Hampton, Valerie L. Shalin, Amit Sheth,
John Flach, and Shreyansh Bhatt, 2013. “What kind of #communication is twitter?
mining #psycholinguistic cues for emergency coordination,” Computers in Human
Behavior (CHB), volume 29, number 6, pp. 2438-2447.
21. (Sarcevic et al., 2012) A. Sarcevic, L. Palen, J. White, K. Starbird, M. Bagdouri, and K.
Anderson, 2012. “Beacons of hope in decentralized coordination: learning from on-the-
ground medical twitterers during the 2010 haiti earthquake,” Proceedings of the ACM
2012 conference on Computer Supported Cooperative Work (CSCW’12). New York:
ACM Press, pp. 47–56.
22. (Sheth, 2009) Amit Sheth, 2009. “Citizen sensing, social signals, and enriching human
experience,” IEEE Internet Computing, volume 13, number (4), pp. 87–92.
23. (Starbird and Stamberger, 2010) K. Starbird and J. Stamberger, 2010. “Tweak the tweet:
Leveraging microblogging proliferation with a prescriptive syntax to support citizen
reporting,” In: Simon French, Brian Tomaszewski, Cristopher Zobel, (editors).
Proceedings of the 7th International ISCRAM Conference (ISCRAM’10), Seattle, USA.
24. (Terpstra et al., 2012) T. Terpstra, A. de Vries, R. Stronkman, and G. Paradies, 2012.
“Towards a realtime twitter analysis during crises for operational crisis management,” In:

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 41
L. Rothkrantz, J. Ristvej, and Z. France (editors). Proceedings of the 9th International
ISCRAM Conference (ISCRAM’12), Vancouver, Canada.
25. (Terry et al., 1992) D. Terry, D. Goldberg, D. Nichols, and B. Oki, 1992. “Continuous
queries over append-only databases,” Proceedings of the 1992 ACM SIGMOD
International Conference on Management of Data (SIGMOD’92). New York: ACM
Press, pp. 321-330.
26. (UN OCHA, 2013) Cluster system for coordination from United Nations Office for
Coordination of Humanitarian Affairs (UNOCHA) at http://www.unocha.org/what-we-
do/coordination-tools/cluster-coordination, accessed 31 August, 2013.
27. (Varga et al., 2013) I. Varga, M. Sano, K. Torisawa, C. Hashimoto, K. Ohtake, T. Kawai,
J. H. Oh and S. D. Saeger, 2013. “Aid is Out There: Looking for Help from Tweets
during a Large Scale Disaster,” Proceedings of the 51th Annual Meeting of the
Association for Computational Linguistics (ACL’13). Association for Computational
Linguistics, pp. 1619-1629.
28. (Vieweg, 2012) Sarah Vieweg, 2012. “Situational Awareness in Mass Emergency: A
Behavioral and Linguistic Analysis of MicroBlogged Communications,” PhD thesis,
University of Colorado at Boulder.
29. (Vieweg et al., 2010) S. Vieweg, A. L. Hughes, K. Starbird, and L. Palen, 2010.
“Microblogging during two natural hazards events: what twitter may contribute to
situational awareness,” Proceedings of the SIGCHI Conference on Human Factors in
Computing Systems (CHI’10). New York: ACM Press, pp. 1079–1088.

Emergency-Relief Coordination on Social Media: Automatically Matching Resource Requests and Offers 42
30. (Witten et al., 2011) Ian H. Witten, Eibe Frank, and Mark A. Hall, 2011. Data Mining:
Practical Machine Learning Tools and Techniques. 3rd edition. Morgan Kaufmann,
Burlington, MA.
31. (Zhao and Mei, 2013) Z. Zhao and Q. Mei, 2013. “Questions about questions: An
empirical analysis of information needs on twitter,” Proceedings of the 22nd
international conference on World Wide Web (WWW’13). New York: ACM Press, pp.
1545-1556.





























