Embed Size (px)
Citation preview

COMPLETENESS AND CONSISTENCY CONDITIONS FORLEARNING FUZZY RULES �Antonio GONZALEZ, Raul PEREZDepartamento de Ciencias de la Computaci�on e Inteligencia Arti�cialE.T.S. de Ingenier��a Inform�aticaUniversidad de Granada18071-Granada (Spain)phone: +34.58.243199fax: +34.58.243317e-mail: [email protected] completeness and consistency conditions were introduced in order to achieve acceptable conceptrecognition rules. In real problems, we can handle noise-a�ected examples and it is not always possible tomaintain both conditions. Moreover, when we use fuzzy information there is a partial matching betweenexamples and rules, therefore the consistency condition becomes a matter of degree. In this paper, alearning algorithm based on soft consistency and completeness conditions is proposed. This learningalgorithm is tested on di�erent databases.Keywords: machine learning, fuzzy sets, fuzzy rules, genetic algorithms�This work has been supported by the CICYT under Project TIC92-06651

1 IntroductionInductive learning has been successfully applied to concept classi�cation problems. Usually, the knowledgeis represented through rules representing the relationships between the di�erent problem variables. In thispaper, we are interested in studying conditions that allow us to propose learning algorithms capable of learningconcept classi�cation rules. Moreover, we are interested in algorithms capable of handling fuzzy information[17] and capable of obtaining fuzzy rules. Several learning algorithms working in fuzzy environments havebeen proposed in the literature [3, 4, 9, 12, 14, 15, 16].Two conditions that must be satis�ed for a learning algorithm to obtain acceptable concept recognitionrules were introduced in [11]. These conditions are the completeness and the consistency conditions. Thecompleteness condition states that every example of some class must satisfy some rule from this class. Theconsistency condition states that if an example satis�es a description of some class, then it cannot be amember of a training set of any other class.Both conditions provide the logical foundation of algorithms for concept learning from examples, but inreal cases both conditions are di�cult to satisfy. In our case, we �nd two problems, �rst, on real problemswe can handle noise-a�ected examples and therefore it is not always possible to keep the completeness andconsistency conditions. Moreover, when we use fuzzy rules we have a second problem since the exampleshave a partial matching with the rules, and therefore the consistency condition becomes a matter of degree.Thus, we are interested in obtaining soft consistency and completeness conditions.The basic idea of the proposed learning algorithm consists in determining the best rules to represent a setof examples E. We know the consequent variable (representing the concept), and we want to know which arethe antecedent variables capable of identifying each value of the consequent variable. We shall choose amongthose rules that satisfy the soft consistency condition and we shall need a criterion to decide which are thebest rules. This criterion shall be applied in an ordered way. First, we �x a value of the consequent variableand next we select the rule that covers the maximum number of positive examples. Since it is possible thatthis value may be described for several di�erent rules, we eliminate the examples covered by the previousrule and we repeat the process until the soft completeness condition is veri�ed. These steps are carried out2

for each value of the consequent variable, and in the end, we have a set of rules that represent the originalset of examples, E. In each step, we shall use a genetic algorithm [6] as a search method for the best rule .The rule model that we use in this work consists in the left-hand side (the antecedent part) of a conjunc-tion of one or more variables whereas the right-hand side (the consequent part) indicates the value of theclassi�cation variable to be assigned to the examples that are matched by the left-hand side of the rule. Eachmember of the conjunction in the antecedent can have an internal disjunction, i.e., we accept that the valueassigned to an antecedent variable in the rules can be a subset of its domain. For example, a rule might takethe following expression: If (X1=Very-High) and(X2=Very-Low or Low or Medium) then (1)(Y=approximately equal to 0)where the domain of variables X1 and X2 has been represented in Figure 1.0 25 50 75 100
Very-Low Low Medium Hight Very-HightFigure 1: The fuzzy domain of X1 and X2.In order to learn the structure of a rule this model is fundamental in the proposed learning algorithm,since at the beginning it will start with all the possible antecedent variables and then it will decide which arethe relevant variables for the �xed consequent. In this process, the algorithm uses the aforementioned modelof rule to eliminate the non-relevant variables. When the best rule for a system has a value of a variablemade up by all possible values of the domain, then the algorithm has discovered that this variable is notrelevant to this consequent and it can be eliminated from the rule. This model of rule has been used inthe literature by several authors (see [2, 8, 11] for example). In the fuzzy learning literature, there are notmany previous papers suggesting solutions to this di�cult problem. The greater part of these papers achieve3

rules in which all the variables necessarily appear, and the algorithms are not able to eliminate non-relevantvariables. Therefore, these algorithms need a prior reduction in the possible variable set. In [10], this taskis carried out by an expert that proposes a pre-selection of "possible interesting" features. An exception is[14] in which an algorithm capable of determining the structure of the fuzzy rules is proposed.Moreover, the aforementioned model of rule is important since it allows us to change the granularity ofthe domain by combining di�erent elements. For example, the rule shown in (1) assigns the value fVery-Low, Low, Mediumg to the variable X2. This value may be interpreted as a new label "less than or equal tomedium". The proposed model of rule threfore allows us to include some structured descriptors [11] in aneasy way.This work deals with the problem of de�ning completeness and consistency conditions for learning fuzzyrules. The next Section invloves introducing a soft consistency condition. The completeness condition andthe learning algorithm are introduced in Section 3. We have implemented a system called SLAVE with theaforementioned features and in Section 4 we carry out di�erent experimental studies in order to study itspredictive performance. Finally, in the last section we propose a modi�cation of the algorithm that attemptsto simplify the practical choice of the parameters in SLAVE.2 The k-consistency conditionThe consistency condition states that if an example satis�es a description of some class, then it cannot be amember of a training set of any other class. We propose a weaker de�nition based on the non ful�lment ofthis condition in several cases.Let us suppose E is a set of examples containing every exampleX1 X2 X3 : : : Xn Ye1 e2 e3 : : : en c(e)n antecedent variables X1; X2; : : : ; Xn and a consequent variable Y .The referential set for each antecedent variableXi is Ui and the referential set for the consequent variableis V . The domains for the rules will be Di for the antecedent variables and F for the consequent variable.4

In this paper, we accept that the sets Di 8i 2 f1; : : : ; ng and F are �nite sets, and that some of them maybe fuzzy domains, i.e., set made up by fuzzy sets in the respective referential sets.Let e be a crisp example e = (e1; e2; : : : ; en; c(e))where ei 2 Ui are the values of the antecedent variables Xi and c(e) is the class associated to e. Let � bethe rule set � = P (D1) � P (D2)� : : :� P (Dn) � F:Let R be a crisp rule with an antecedent part ant(R) and a consequent part con(R). We are interestedin �nding the adaptation between the example and the rule. We can say that the example e adapts to therule R i�i) (e1; : : : ; en) � ant(R)ii) c(e) � con(R).For example, the example (10,red,1) adapts to the rule "If X is less than 20 and Y is any colour, then Zis an integer".By using the adaptation between example and rule, we can classify the examples as negative or positiveto a rule. An example is positive if it adapts to the rule, and an example is negative if i) is a true conditionthen ii) is a false condition.Let E be an example set. By using the concept stated, we can de�ne the following subsets of E:E+(R) = fe 2 E j e is a positive example to RgE�(R) = fe 2 E j e is a negative example to Rgand the cardinality of these subsets shall be denoted byn+E(R) = jE+(R)jn�E(R) = jE�(R)j:5

Let B 2 F be a �xed value of the consequent variable and H � � a set of rules, then the followingequivalence is obviously veri�edH satis�es the consistency condition , n�E(R) = 0 8R 2 H.Therefore, the consistency condition implies that the rules selected by the learning algorithm must nothave negative examples. In order to weaken this strong condition, the �rst idea consists in allowing it to havesome negative examples, but not many. How many examples can we admit? We can �x a hard threshold,i.e., H could satisfy a new consistency condition if and only if n�E(R) � " 8R 2 H. However, this de�nitiondoes not take into account the number of positive examples. Perhaps we might be interested in admittingtwo negative examples for a rule with 20 positive examples, but we don't admit it if the rule only has twopositive examples. Therefore we propose the following weak de�nition of consistency.De�nition 2.1 Let R 2 � be a rule and k 2 [0; 1] be a �xed parameter, we say that the rule R, such thatn+E(R) > 0, satis�es the k-consistency condition if and only if� k = 0 then n�E(R) = 0� k 2 (0; 1] then n�E(R) < kn+E(R)The classical consistency condition is included in this de�nition as a 0-consistency condition and, ingeneral, the parameter k allows us to weaken this condition. Parameter k may be interpreted as a noisethreshold since a rule satis�es the k-consistency condition when a noise level less than the 100*k percent ofthe positive examples, appears in the example set. Parameter k will be called the consistency parameter.This de�nition uses the same noise threshold for all rules. The k-consistency condition allows us to weakenthe hard consistency condition gradually through the growth of the parameter k, as the following propositionshows.Proposition 2.1 Let R 2 � be a rule and k1 � k2 thenR satis�es the k1-consistency condition ) R satis�es the k2-consistency condition6

By using this proposition, and if we denote by �k � �, the set of rules that satis�es the k-consistencycondition is then �k1 � �k28k1; k2 2 [0; 1] such that k1 � k2:Therefore if we increase the value of parameter k, we also increase the size of the search space for thebest rules (see Figure 2). This process might be necessary, since in some cases it is not possible to �nd goodrules in such a small space.∆
∆
0.1
0
0.2
∆
∆Figure 2: The k-consistency spacesOnce we have achieved a weak de�nition of consistency for crisp examples and rules, we extend thisde�nition to fuzzy examples and rules. In order to obtain this extension, we have to de�ne the set of negativeand positive examples of a rule. The basic concept in these de�nitions is the concept of compatibility betweentwo fuzzy sets.De�nition 2.2 Let a and b be two fuzzy sets in a common referential set U , and * a t-norm, we de�ne thecompatibility between a and b as the following function:�(a; b) = supx f�a(x) � �b(x)gIn this paper, we need to widen this de�nition to calculate the compatibility between two sets of fuzzysets, and we propose the following de�nition.De�nition 2.3 Let Dom1 and Dom2 be two domains made up by fuzzy sets in a common refential set U ,and C1 � Dom1 and C2 � Dom2 be two set of fuzzy sets, we de�ne the compatibility between both sets as:7

�(C1; C2) = supa2C1 supb2C2 �(a; b)From these concepts, we de�ne the adaptation between an example and the antecedent and consequent ofa rule respectively, through the extension to the cartesian product of a normalization of the said compatibility.Let e be an example e = (e1; e2; : : : ; en; c(e))where ei is now a fuzzy set in the referential set Ui, and c(e) is the class assigned to the example e. LetRB(A) be a rule with antecedent part A = (A1; : : : ; An) Ai � Di and consequent part B 2 F . For eachcomponent of the antecedent obviously the following quotient is a measure of possibilityPoss(Aijei) = �(ei; Ai)�(ei; Di)and its dual is a measure of necessity Nec(Aijei) = 1� �(ei; Ai)�(ei; Di) :Thus, we can de�ne the adaptation between an example and the antecedent of a rule combining a t-normusing the measure of possibility of each Ai given the evidence supported by the example. Since we have twopossible measures, we obtain two adaptation concepts:� Upper adaptation between example and antecedent of RB(A)U (e; A) = �i(Poss(Aijei))� Lower adaptation between example and antecedent of RB(A)L(e; A) = �i(Nec(Aijei))In the same way, we de�ne the adaptation between the example and the consequent of the rule as� Upper adaptation between example and consequent of RB(A)U (e; B) = �(c(e); B)�(c(e); F )8

� Lower adaptation between example and consequent of RB(A)L(e; B) = 1� �(c(e); B)�(c(e); F )Obviously the following inequalities are veri�edL(e; A) � U (e; A) 8e 2 Eand L(e; B) � U (e; B) 8e 2 E:These inequalities show that we have two possible adaptation concepts, the �rst one is a stricter de�nitionbased on a measure of necessity and the second one is a wider de�nition based on a measure of possibility.From these concepts we can de�ne the positive and negative example set in a rule.De�nition 2.4 The lower and upper set of positive examples for the rule RB(A) are the following fuzzysubsets of E E+L (RB(A)) = f(e; L(e; A) � L(e; B)) j e 2 EgE+U (RB(A)) = f(e; U (e; A) � U (e; B)) j e 2 Egwhere A = (A1; : : : ; An), and * is a t-norm.De�nition 2.5 The lower and upper set of negative examples for the rule RB(A) are the following fuzzysubsets of E E�L (RB(A)) = f(e; L(e; A) � L(e; B)) j e 2 EgE�U (RB(A)) = f(e; U (e; A) � U (e; B)) j e 2 Egwhere A = (A1; : : : ; An)), and * is a t-norm.Obviously E+L (RB(A)) � E+U (RB(A))E�L (RB(A)) � E�U (RB(A)):9

Usually, the domain of the consequent variable in concept classi�cation problems, consists in nominaldescriptors, i.e., the domain is formed by independent symbols or names, and therefore no structure isassumed to relate the values in the domain. In this case, the said de�nition may be simpli�ed, since L(e; B) =U (e; B) = 1 if c(e) = B and 0 otherwise, and, for example, the upper set of positive examples becomesE+U (RB(A)) = f(e; U (e; A)) j e 2 E and c(e) = Bg:Once we have de�nitions for positive and negative examples of a rule, we can use a counter to determinethe number of positive and negative examples for a rule, which are the concepts needed in the k-consistencycondition. Thus, let us denote jAj = Pu2U �A(u), as the cardinality of a fuzzy subset. By using this, weobtain the following de�nitions:� Number of positive examples on RB(A){ lower value n+L (RB(A)) = jE+L (RB(A))j{ upper value n+U (RB(A)) = jE+U (RB(A))jobviously n+L(RB(A)) � n+U (RB(A)):� Number of negative examples on RB(A){ lower value n�L (RB(A)) = jE�L (RB(A))j{ upper value n�U (RB(A)) = jE�U (RB(A))jobviously n�L (RB(A)) � n�U (RB(A)):Now, de�nition 2.1 can be also applied to fuzzy rules. However, since we have two concepts for positiveand negative examples of a rule, we also have two di�erent consistency de�nitions for fuzzy rules: a lowerconsistency condition (using n+L and n�L ) and an upper consistency condition (using n+U and n�U ). Wedenote by �kL and �kU , the set of rules that satis�es the lower and upper k-consistency conditions, respectively.These de�nitions are the basis for the learning algorithm that we propose in the next Section.10

3 Learning algorithm and completeness conditionLet E be an example set, as we said in the introduction we are interested in determining the best rulesto represent the set E. We know the consequent variable, and we want to know which are the antecedentvariables capable of identifying every value of the consequent variable. But now, we shall choose among thoserules that satisfy the k-consistency condition, with k 2 [0; 1] being a �xed parameter. The search space is�k � �. Thus, �rst we �x a value of the consequent variable and next we select the rule of �k that coversthe maximum number of positive examples. We eliminate the examples covered by the previous rule and werepeat the process until we have examples of this class. These steps are carried out for each value of theconsequent variable, and �nally, we obtain a set of rules that represents the original set of examples E.The basic step in the algorithm that we propose consists in obtaining rules covering the maximumnumberof examples in the training set E, i.e., for each value B 2 F , the main problem ismaxA2Dfn+(RB(A)) j RB(A) 2 �kg (2)where in the de�nition of n+ and n�, we can use the lower or upper de�nitions from the previous section,and D = P (D1) � P (D2)� : : :� P (Dn).In order to solve the problem of obtaining the rules covering the maximum number of examples, we needto clarify the concept of the set of examples covered by a fuzzy rule. We know that an example is coveredby a rule to a certain degree, therefore, in a sense, a rule covers all the examples, but we are interested inthe examples covered with the higher degree. Therefore we propose the following de�nition.De�nition 3.1 Let R be a rule and E a set of examples. The subset of E representing the examples �-coveredby R is the �-cut of E+(R). � will be called the covering parameter.We said earlier that the algorithm must repeat the process of searching for the best rule and eliminatingthe examples covered by it while there are examples of the present class. Really, this condition is equivalentto the completeness condition given in the previous section and it is very di�cult to satisfy when we workwith noisy or fuzzy examples. Thus, we propose a weaker condition that we call weak completeness conditionfor a class. The latter attempts to determine when the number of examples covered for a set of rules on a�xed class is su�cient to represent such a class. 11

De�nition 3.2 We suppose an algorithm which, when it �nds a rule for class C, eliminates the examples�-covered by the rule. Let E0 be the subset of examples that has not yet been eliminated. We say that a setof rules veri�es the weak completeness condition for the class C if and only ifjE+(Rlast)�j = 0where Rlast is the last rule obtained by the algorithm for class C , � is the covering parameter and the saidcardinal is calculated for E0.The last rule is really only used to conclude that the number of rules is enough to represent the class, butit is not included in the set of rules of this class.In order to give a detailed description of the learning algorithm, �rst we have to solve the associatedoptimizationproblem (2) by means of a procedure calledGENETIC, which basically uses a genetic algorithmto solve the best rule search problem.3.1 The genetic algorithmGenetic algorithms (GAs) are theoretically and empirically proven to provide robust search capabilities incomplex spaces, o�ering an interesting approach to problems requiring e�cient and e�ective search [6].In order to use a GA to solve the problem (2), we need to de�ne the main components of our problemin the common formulation of genetic algorithms. The �nal genetic algorithm adapted to solve (2) has beencalled GENETIC. First, we need a representation of the potential problem solution, i.e., the antecedent ofthe rules. In [7] we propose the following binary coding:If the database contains n possible antecedent variables and each one of them has a fuzzy domain Diassociated with mi components Xi ! Di = fAi1; : : : ; Aimigthen we use the following method of coding any elements of P (D1) � P (D2) � : : : � P (Dn) , a vector ofm1 +m2 + : : :+mn zero-one components, such that,component(m1+ : : :+mr�1+s) =8>><>>: 1 if the s-th element of the domain Dr is a value of the Xr variable0 otherwise 12

Example 1 Let us suppose we have three variables X1; X2 and X3, such that the fuzzy domain associatedwith each one is D1 = fA11; A12; A13gD2 = fA21; A22; A23; A24; A25gD3 = fA31; A32gIn this case, the vector 1010010111 represents the following antecedentX1 is fA11; A13g and X2 is fA23; A25g and X3 is fA31; A32g.Since X3 takes all the elements in the domain D3, the said antecedent is equivalent toX1 is fA11; A13g and X2 is fA23; A25g.Another important component of the genetic algorithm is the method for creating the initial solutionpopulation. In GENETIC we use a procedure for obtaining antecedents with a high possibility to guidethe search toward good solutions. The procedure consists in taking a subset of examples at ramdom amongthose with the current consequent. For each one of these examples, we select those antecedents to the highestadaptation with the example. For example, let us suppose three variables X1; X2 and X3 with the associatedfuzzy domain described in Figure 1, the same for all the variables. Thus, if we choose the example (26,54,100),the procedure will generate the antecedent corresponding to binary code 01100 00110 00001.The GENETIC procedure uses the following �tness function that measures the power of the rule (positiveexamples) whenever the rule satis�es the k-consistency condition.fitness(RB (A)) = 8>><>>: n+(RB(A)) if RB(A) 2 �k0 otherwisewhere the number of positive examples and the de�nition of �k have been achieved with the same adaptationfunction. Thus, in fact, we have two di�erent �tness functions, one based on the lower consistency conditionand the other one based on the upper consistency condition. From now on, we assume that the choice of theconsistency type is an additional parameter of the genetic algorithm and we do not indicate the speci�c typeselected. 13

The GENETIC procedure uses a standard set of genetic operators: the ranking linear selection, themutation operator and the two point crossover operator. Moreover, we have considered an elitist model.Finally, the genetic algorithm ends if at least one of the following sentences is true:� the number of iterations is greather than a �xed limit� the �tness function doesn't increase the value during at least a �xed number of iterations and ruleswith this consequent already being obtained� there are no rules with this value of the consequent but the �tness function doesn't increase the valueduring the �xed number of iterations and the current best rule �-covers at least one example, with �being the covering parameter.The input of the GENETIC procedure is a set of examples E and a value of the consequent variableB 2 F , and the output is a rule RB(A) 2 �k representing the rule with consequent B and the largest numberof positive examples in E.3.2 The learning algorithmNow, by using the consistency and completeness conditions, the GENETIC optimization procedure and theprevious general description, we can state the following learning algorithm:LEARNING ALGORITHM1. Let RULES be the set of rules, at the beginning RULES is empty, and let E be the training set ofexamples.2. Repeat for each B 2 F2.1 Assign the set E to EXAMPLES.2.2 Run the GENETIC procedure, with the input, EXAMPLES and B. Let R be the rule obtainedas the output of this procedure. 14

2.3 While the set of rules of class B doesn't satisfy the weak completeness condition, addR to RULES,eliminate the examples �-covered by R from EXAMPLES and go to step 2.2. Otherwise, takeanother value of the consequent variable and go on to step 2.3. Give the set RULES as the output of the algorithm.This learning algorithm has as input a set of examples, a set of parameters and a basic structure (theconsequent variable), and generates as output a set of rules that satis�es the k-consistency and the weakcompleteness condition.It would be worthwhile studying some properties of this algorithm, which would demonstrate its overallbehaviour.3.3 PropertiesFirstly, we attempt to discover whether the algorithm can generate contradictory rules, i.e., rules which havethe same antecedent but di�erent consequents. The answer is negative.Lemma 3.1 Let RULES be the set of rules generated by the learning algorithm and RB1(A); RB2(A) 2RULES, with B1 6= B2 then n�(RB1(A)) � n+(RB2(A)):ProofThe positive and negative example sets were de�ned using a lower or an upper measure, therefore thisresult must be proved for each measure.� By using the upper case:U (e; B1) = supb2B1�(c(e); b)�(c(e); F ) � �(c(e); B2)�(c(e); F ) = U (e; B2)therefore n�U (RB1(A)) =Xe2E U (e; A) � U (e; B1) �Xe2E U (e; A) � U (e; B2) = n+U (RB2(A))15

� By using the lower case: In a similar way it is very easy to show that U (e; B2) � U (e; B1), thereforeL(e; B1) = 1�U (e; B1) � 1�U (e; B2) = L(e; B2) and then n�L (RB1(A)) =Pe2E L(e; A) �L(e; B1) �Pe2E L(e; A) � L(e; B2) = n+L (RB1(A))Proposition 3.1 If RB1(A) 2 RULES then RB2(A) =2 RULES 8B2 2 F such that B1 6= B2ProofLet us suppose that both RB1(A); RB2(A) 2 RULES. In this case both rules must verify the k-consistencycondition, i.e., n�(RB1(A)) < kn+(RB1(A))n�(RB2(A)) < kn+(RB2(A))By using these expressions and the previous lemman+(RB2(A)) � n�(RB1(A)) < kn+(RB1(A))n+(RB1(A)) � n�(RB2(A)) < kn+(RB2(A))therefore n+(RB2(A)) < kn+(RB1(A)) < k2n+(RB2(A))and this expresion implies that k2 > 1since n+(RB2(A)) > 0, and this is a contradictory result with the range of the parameter k 2 [0; 1].This �rst result shows that the algorithm cannot produce contradictory rules, since both cannot verify thek-consistency condition simultaneously. The second result, which we are going to prove, shows the algorithm'sbehaviour.Proposition 3.2 Let RB(A1); RB(A2) 2 �k such that A1 � A2 thenfitness(RB (A1)) � fitness(RB (A2))Proof 16

Let A1 = (A11; : : : ; A1n) and A2 = (A21; : : : ; A2n). Since A1 � A2 then A1j � A2j 8j = 1; : : : ; n: Foreach example e we have Poss(A1j jej) � Poss(A2j jej)and Nec(A1j jej) � Nec(A2jjej):Therefore U (E;A1) � U (e; A2)and L(E;A1) � L(e; A2):Thus, the result is obvious.This result shows that if a rule RB(A2) is more general than another rule RB(A1), i.e., A1 � A2, thenthe �rst rule has more positive and negative examples. The algorithm always chooses the rule with morepositive examples, therefore if the more general rule continues verify the k-consistency condition then thealgorithm prefers this more general description. Finally, we can say that the learning algorithm chooses themost general description for a rule that satis�es the k-consistency condition.4 Experimental studiesWe have implemented SLAVE (Structural Learning Algorithms in Vague Environments) a graphical environ-ment for testing and experimenting with the proposed learning algorithm. SLAVE is a C written programmeworking in an OpenWindows environment. The algorithm uses several parameters in the learning process.Here we want to study the predictive performance of SLAVE for di�erent consistency type and parameters.One of the greatest di�culties associated with SLAVE will be the choice of these parameters. In this Section,we shall propose a modi�ed �tness function that make this selection easy.17

4.1 The domainsWe have tested the learning algorithm on four databases: three correspond to arti�cial domains and one toa natural domain. The arti�cial databases were designed to reveal the predictive performance of SLAVEwhen an uncertainty degree or noise increases in the di�erent database sets. For these databases, we use afour-feature world in which three have been considered as fuzzy ones and the associated domain correspondsto Figure 1, the fourth feature is binary. The target concept is de�ned through a �xed number of knownfuzzy rules. Each arti�cial database was created from the simulation of the same �xed fuzzy rule set, butadding in each case a noise percentage:� ART1: database without noise� ART2: database with a 10 % noise� ART3: database with a 25 % noiseWe take 500 examples from each database, and this contains positive and negative examples of the targetconcept.For the fourth database, we have selected a natural domain corresponding to a well known databasethe Iris Plants Database, IRIS, created by R.A. Fisher [5]. The domain of each continuous variable of thisdatabase has been produced without any speci�c information on the problem, and we used a simple methodthat generates a �xed number of uniformly distributed linguistic labels. The number of fuzzy labels wasusually �ve or seven.4.2 Learning algorithmsWe tried to investigate the predictive accuracy of SLAVE in the aforementioned databases. So, we carried outdi�erent trials considering di�erent consistency types (lower and upper) and di�erent consistency parameters.The common parameters used in all the trials were: 18

covering parameter � 0.85Size population 30maximum iteration number 2000t-norm minimumIn order to compare the behaviour of the learning algorithm we also used the well-known learning al-gorithms, CART [1] and backpropagation (BP) neural networks [13].4.3 Inference modelIn order to study SLAVE's predictive performance, we included an inference model on fuzzy rules in thissystem. Since all the examples considered here are crisp and they have a crisp consequent, we used theinference method which takes the consequent corresponding to the rule with maximum adaptation with theexample, i.e., let RULES be a set of rulesRules = fRi j i = 1; : : : ; nrgwith antecedent(Ri) = (Ai1; Ai2; : : : ; Ain)consequent(Ri) = Biand the example e = (e1; e2; : : : ; en)Let �(Rije) = minjmaxa2Aij�a(ej) an adaptation measure between each rule and the example. Then,the inference process involves selecting the consequent Bs such thatmaxi�(Rije) = �(Rsje):However, there is a decision problem in several cases. The controversial situation appears for examplewhen we have Bs1 and Bs2 such thatmaxi�(Rije) = �(Rs1je) = �(Rs2 je)19

and Bs1 6= Bs2 :We say that in this case we have a con ict in the rules set, and we need to decide what is the best consequentfor example e.Initially, rules are ordered according to their �tness function and this order is modi�ed when a con ictappears. The modi�cation is based on the concept of a more speci�c rule. By using binary coding of theantecedent of rules described earlier, we say that Rs1 is more speci�c than Rs2 i�antecedent(Rs1) � antecedent(Rs2):Therefore, in this case, the inference component of SLAVE prefers Bs1 as the correct class in the example.Thus, when the initial set of rules has been reordered by the speci�city criterion, SLAVE checks the adaptationbetween the example and each rule and gives the consequent corresponding to the �rst best value.4.4 ResultsThe examples were divided into a training and a test set. We have taken �ve di�erent partitions from eachtraining and test set in the di�erent database sets. The following tables show the accuracy rates for eachdatabase, on di�erent consistency parameters and the lower and upper consistency conditions, respectively.The accuracy of these tables corresponds to the average accuracy of the di�erent partitions for each test set.Lower casek ART1 ART2 ART3 IRIS0.005 0 0 0 00.006 100 100 98.59 87.670.01 100 100 99.27 90.360.1 100 100 93.84 89.620.2 86.75 88.13 92.05 86.49Upper casek ART1 ART2 ART3 IRIS0.01 95.36 96.62 60.51 79.570.1 100 100 83.18 87.250.2 100 93.77 92.86 93.110.3 89.93 92.40 96.73 93.110.4 80.73 85.40 91.46 92.3620

In order to compare the results obtained in the di�erent learning databases the next table shows theaverage accuracy for BP and CART in the di�erent partitions of each example set.Learning Algorithm ART1 ART2 ART3 IRISBP 97.39 99.04 95.00 92.68CART 100 99.04 98.14 93.62The evolution of SLAVE on di�erent consistency values and for the test sets rise up to a value(s) at whichthe accuracy is maximum, and as from this value the accuracy falls. This conclusion can be obtained bychecking the tables, where we show only one part (the most representative) of the complete trials that we havecarried out. This conclusion is made for the accuracy in the test sets and it is not easy to prove in general,we have made this a�rmation based only on the particular databases considered. In order to explain thisbehaviour of SLAVE, we can say that one of the possible reasons is that for very low k values the learningalgorithm doesn't obtain good rules since there is noise in the data, and for very high k values we are takingvery noisy rules that don't o�er good predictive performance. This a�rmation is true even for the noiselessdatabase, ART1, since very low k parameters prevent us from �nding any rules due to the fuzzyness of theoriginal rules. In any case, maximum accuracy is reached at di�erent values for each consistency type:� In the lower case, the maximum is obtained when k=0.01Lower case k=0.01ART1 ART2 ART3 IRIS100 100 99.27 90.36SLAVE improves the accuracy of the reference algorithms (BP and CART) only for the arti�cial data-bases.� In the upper case, the maximum is reached when k=0.1 for the low noisy databases ART1 and ART221

Upper case k=0.01ART1 ART2100 100and k=0.3 for the high noisy databases ART3 and IRISUpper case k=0.3ART3 IRIS96.73 93.11SLAVE improves the accuracy of the reference algorithms on ART1 and ART2, but it only improvesthe accuracy on ART3 and IRIS for the BP algorithm.Therefore, SLAVE is capable of learning with reasonable rates accuracy, but the �nal result is highlydependent on the consistency parameter chosen, and it is not easy to know a priori what this parameter is.The following Section suggests an alternative that makes selection of the consistency parameter easier andthat even improves the rates of accuracy.5 A modi�ed �tness function: the two parameter modelThe change between feasible and non-feasible solutions in the �tness function in the GENETIC procedureis radical. With the genetic algorithms this situation can be avoided so that the process evolves from a nearbut non-feasible solution to the best one. In order to solve this problem and to avoid the risky choice of onlyone consistency parameter we propose a new �tness function that smooths the change between k-consistencyand non k-consistency rules. This new �tness function uses two parameters, a maximum and a minimumconsistency parameter. In this case, the learning algorithm uses the following �tness function:fitness(RB (A)) = 8>>>>>>><>>>>>>>: n+(RB(A)) if RB(A) 2 �k1k2n+(RB(A))�n�(RB(A))k2�k1 if RB(A) 2 �k2 and RB(A) =2 �k10 otherwisewith k2 > k1: 22
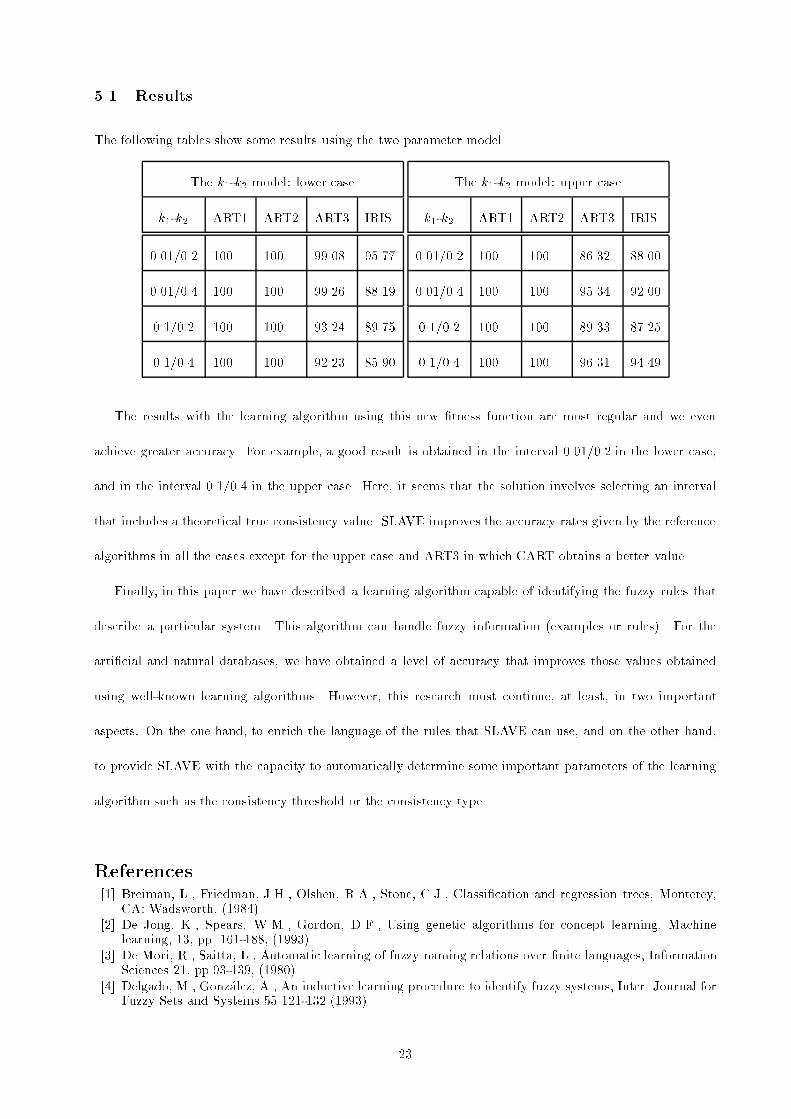
5.1 ResultsThe following tables show some results using the two parameter model.The k1-k2 model: lower casek1-k2 ART1 ART2 ART3 IRIS0.01/0.2 100 100 99.08 95.770.01/0.4 100 100 99.26 88.190.1/0.2 100 100 93.24 89.750.1/0.4 100 100 92.23 85.90The k1-k2 model: upper casek1-k2 ART1 ART2 ART3 IRIS0.01/0.2 100 100 86.32 88.000.01/0.4 100 100 95.34 92.000.1/0.2 100 100 89.33 87.250.1/0.4 100 100 96.31 94.49The results with the learning algorithm using this new �tness function are most regular and we evenachieve greater accuracy. For example, a good result is obtained in the interval 0.01/0.2 in the lower case,and in the interval 0.1/0.4 in the upper case. Here, it seems that the solution involves selecting an intervalthat includes a theoretical true consistency value. SLAVE improves the accuracy rates given by the referencealgorithms in all the cases except for the upper case and ART3 in which CART obtains a better value.Finally, in this paper we have described a learning algorithm capable of identifying the fuzzy rules thatdescribe a particular system. This algorithm can handle fuzzy information (examples or rules). For thearti�cial and natural databases, we have obtained a level of accuracy that improves those values obtainedusing well-known learning algorithms. However, this research must continue, at least, in two importantaspects: On the one hand, to enrich the language of the rules that SLAVE can use, and on the other hand,to provide SLAVE with the capacity to automatically determine some important parameters of the learningalgorithm such as the consistency threshold or the consistency type.References[1] Breiman, L., Friedman, J.H., Olshen, R.A., Stone, C.J., Classi�cation and regression trees, Monterey,CA: Wadsworth, (1984)[2] De Jong, K., Spears, W.M., Gordon, D.F., Using genetic algorithms for concept learning, Machinelearning, 13, pp. 161-188, (1993).[3] De Mori, R., Saitta, L., Automatic learning of fuzzy naming relations over �nite languages, InformationSciences 21, pp.93-139, (1980).[4] Delgado, M., Gonz�alez, A., An inductive learning procedure to identify fuzzy systems, Inter. Journal forFuzzy Sets and Systems 55 121-132 (1993). 23

[5] Fisher, R.A., The use of multiple measurements in taxonomic problems, Annual Eugenics, 7, Part II,179-188 (1936); also in Contributions to Mathematical Statistics, John Wiley, NY, (1950).[6] Goldberg, D.E., Genetic algorithms in search, optimization and machine learning, Addison-Wesley, NewYork, (1989).[7] Gonz�alez, A., P�erez, R., Verdegay, J.L., Learning thes structure of a fuzzy rule: a genetic approach,Proc. First European Congress on Fuzzy and Intelligent Technologies, Vol. 2, pp. 814-819, (1993).[8] Gonz�alez, A., A learning methodology in uncertain and imprecise environments, to appear in the Inter-national Journal of Intelligent Systems.[9] Ishibuchi, H., Nozaki, K., Yamamoto, N., Tanaka, H., Construction of fuzzy classi�cation systems withrectangular fuzzy rules using genetic algorithms, Fuzzy Sets and Systems 65, pp. 237-253, (1994).[10] Lesmo, L., Saitta, L. Torasso, Fuzzy production rules: a learning methodology, in Advances in FuzzySets Theory and Applications (ed. P.P. Wang), Plenum Press, pp. 181-198, (1983)[11] Michalski, R.S., A theory and methodology of inductive reasoning, in R.S. Michalski, J. Carbonell and T.Mitchel (Eds.), Machine Learning: An arti�cial intelligence approach (Vol. 1). San Mateo, CA: MorganKaufmann.[12] Peng, X.T., Wang, P., On generating liguistic rules for fuzzy rules, Lectures Notes in Computer Science313, Uncertainty and Intelligent Systems (b: Bouchon, L. Saitta, R.R. Yager (eds.)) pp. 185-192, (1988).[13] Rumelhart, D.E., Hinton, G.E., and Williams, R.J., Learning interior representation by error propaga-tion, Parallel Distributed Processing, vol.1, Ch. 8, D.E. Rumelhart and J.L. McClelland eds., MIT PressCambridge, Mass., 1986.[14] Sugeno, M., Tanaka, K., Successive identi�cation of a fuzzy model and its applications to prediction ofa complex system, Fuzzy Sets and Systems 42, pp. 315-334, (1991).[15] Tong, R.M., Synthesis of fuzzy models for industrial processes, Internat. J. Gen. Systems 4 pp. 143-162(1978)[16] Wang, L.X., Mendel, J.M., Generating fuzzy rules by learning from examples, IEEE Trans. on Systems,Man and Cybernetics, vol. 22, n. 6, pp. 1414-1427, (1992).[17] Zadeh, L.A., The concept of a linguistic variable and its applications to approximate reasoning, PartI Information Sciences vol. 8, pp. 199-249, Part II Information Sciences vol. 8, pp. 301-357, Part IIIInformation Sciences vol. 9, pp. 43-80, (1975).
24





























