Embed Size (px)
Citation preview

COCA: More Accurate Multidimensional Histograms out of More Accurate Correlations Detection
CAO Wei1,2 QIN Xiongpai1,2 WANG Shan1,2 1 Key Laboratory of Data Engineering and Knowledge Engineering (Renmin University of
China), MOE, Beijing 100872, P. R. China 2 School of Information, Renmin University of China, Beijing, 100872, P.R. China
{caowei, xiongpai, swang}@ruc.edu.cn
Abstract
Detecting and exploiting correlations among columns in relational databases are of great value for query optimizers to generate better query execution plans (QEPs). We propose a more robust and informative metric, namely, entropy correlation coefficients, other than chi-square test to detect correlations among columns in large datasets. We introduce a novel yet simple kind of multi-dimensional synopses named COCA-Hist to cope with different correlations in databases. With the aid of the precise metric of entropy correlation coefficients, correlations of various degrees can be detected effectively; when correlation coefficients testify to mutual independence among columns, the AVI (attribute value independence) assumption can be adopted undoubtedly. COCA can also serve as a data-mining tool with superior qualities as CORDS does. We demonstrate the effectiveness and accuracy of our approach by several experiments. 1. Introduction
Estimating the result set size (or selectivity) of query predicates accurately is crucial for query optimization in that it helps the cost-based query optimizer to choose efficient query execution plans. So modern DBMS’s often take advantage of effective statistical information such as histograms instead of the plausible uniform assumption and attribute value independence assumption over data distributions to support accurate selectivity estimation.
In real-world data, correlations or dependencies among columns exist more than independences. The higher are dimensionalities, the more likely do dependencies occur. We propose COCA (COrrelation Coefficient based Auto-detection of association) to use
entropy correlation coefficients to depict the bidirectional dependencies between columns in a more accurate, more reasonable and simpler way.
Also in this paper we explore a new way to build more accurate multidimensional synopses than traditional ones for different degrees of correlations discovered by COCA, avoiding blindly constructing them. Experiments demonstrate the positive effect of correlation information on multidimensional synopses.
The rest of the paper is organized as follows. In Section 2 we present related works and show the position where COCA lies. In Section 3 we introduce COCA in detail, where we disclose its many merits. In Section 4 we bring out the multidimensional synopses for different correlations. Section 5 demonstrates the virtues of COCA through various experiments. Section 6 concludes this paper and discusses future work. 2. Related works
COCA is related to works from the two research categories: building more accurate histograms to approximate the joint data distributions, and automatically detecting correlations among columns.
Reference [7] introduces the first multidimensional histograms in literature. The whole multidimensional data space is partitioned along different dimensions recursively, resulting in buckets having nearly same number of tuples.
Based on a new taxonomy of histograms, reference [2] proposes a new kind of multidimensional histograms called MHIST which partitions the multi-dimensional data distribution matrix based on marginal distribution information with partition constraints such as MaxDiff, Compressed, V-optimal etc.
GENHIST [8] is a new histogram technique allowing overlapping of buckets in variable sizes over
The Ninth International Conference on Web-Age Information Management
978-0-7695-3185-4/08 $25.00 © 2008 IEEEDOI 10.1109/WAIM.2008.21
435
The Ninth International Conference on Web-Age Information Management
978-0-7695-3185-4/08 $25.00 © 2008 IEEEDOI 10.1109/WAIM.2008.21
429

highly correlated data distributions. The approximate data density is computed iteratively in a successively coarser grid structure. Approximation within each area is computed by combining all the overlapping buckets.
STHoles [3] are histograms utilizing query feedbacks to improve the histograms’ accuracy. They allow inclusion relationships among buckets. With the aid of query feedback information, more buckets can be created by drilling candidate holes, which contain exact information from query feedbacks.
There has been some work on automatic discovery of correlations in recent years.
BHUNT [9] is a sampling based technique that automatically discovers fuzzy functional dependencies between column pairs within probabilistic guarantees.
CORDS [1] is a sampling based automatic technique for discovery of correlations and soft functional dependencies between column pairs. Its discovery of soft functional dependencies relies simply on analysis and comparison of the number of distinct values in single columns and distinct combinatory values. Its discovery of correlations is based on chi-square test over the contingency table for the column pair. To overcome the limitations of chi-square test, namely, “chi-squared results cannot be trusted unless at least 80% of nij’s exceed 5”. CORDS categorizes large value domains into small number of disjoint partitions and bucketizes the data accordingly.
Both [11] and [10] address the problem of approximating high dimensional data sets by way of Markov graphical models to find the best interaction model.
There is also research on extending Bayesian network models to the relation setting to support accurate selectivity estimation [13].
The latter three methods mentioned above handle the two problems simultaneously for hi-dimensional data sets: discovering correlations among multiple attributes and approximating high dimensional data distributions.
But for medium and relatively lower dimensional data distributions, techniques from the two categories seldom meet. For example, traditional MHIST-2 histograms treat different multidimensional data distributions in the same way oblivious of different degree of correlations. CORDS only recommends candidate correlated column pairs for multi-dimensional synopses building but does not study the effect of correlations on conventional kinds of histograms.
To solve the problem, COCA joins the two concerns in a simple but effective way: it gives a unified metric of correlations for either the whole data sets or single column pairs; such metric also serves as an indicator of correlations resulting in different kinds of
histograms for different degrees of correlations. 3. Discovering correlations
CORDS [1] overcomes the limitations of chi-square test by several lossy methods to make it trustable. So the accuracy or the fairness is discounted. Second, implementing chi-square test is not a straightforward task: one needs to simulate chi-square distributions with different degrees of freedom under different confidence thresholds deriving proper quantiles. And third, chi-square test can only test whether or not there exist correlations between columns; it cannot tell furthermore which column determines the other and to what degree. Thus it is only a collective method where relative order of recommended columns pairs counts.
COCA addresses the same problem as CORDS but in a better way. It can be applied to either large data sets or to just a single pair of columns to accurately depict correlations between them. 3.1. Entropy correlation coefficients
In statistics, degrees of correlation between two random variables can be reflected by diminishing of uncertainty of one variable with the intervention of the other variable; the percentage of such decrease is called correlation coefficients [12], which are different from those approximating linear relationships such as Pearson correlation coefficients. Such correlation coefficients can be incarnated by several kinds of statistics one of which is entropy. The correlation coefficients derived from entropy for two random variables X and Y are from [12]:
i j i j i . . j1 1
Y X
i . i .1
[ / ( ) ]
-
X Y
X
D D
i jD
i
L n
L n
π π π πρ
π π
= =→
=
=∑ ∑
∑,
i j i j i . . j1 1
X Y
. j . j1
[ / ( ) ]
-
X Y
Y
D D
i jD
j
L n
L n
π π π πρ
π π
= =→
=
=∑ ∑
∑
They are both computed on contingency table of the
two variables. ijπ stands for the probability that (X,
Y) has the combinatorial value (Vi, Vj), where 1 ≤ i
≤ DX, and 1 ≤ j ≤ DY. i.π stands for the
marginal probability for X to be equal to Vi; .jπ
stands for the marginal probability for Y to be equal to Vj. Ln stands for natural logarithm.
As far as statistical correlations are concerned, data
436430

in relational databases can be seen as samples for different random variables. In COCA, we employ entropy correlation coefficients calculated from database samples to reflect the degree of correlations among real data. Based on contingency table (or the joint distribution matrix) of columns X and Y, we borrow the idea of the correlation coefficients derived from entropy for the data (samples) in [12] as follows:
∑
∑ ∑
=
= =→ −=
X
X Y
V
iii
V
i
V
jjiijij
XY
nnLnn
nnnnLnn
1..
1 1..
'
)/(
)/(ρ
∑
∑ ∑
=
= =→ −=
Y
X Y
V
jjj
V
i
V
jjiijij
YX
nnLnn
nnnnLnn
1..
1 1..
'
)/(
)/(ρ
where VX and VY means numbers of distinct values of column X and Y respectively. nij, ni., n.j are joint frequencies and marginal frequencies for values (xi, yj), (xi, *) and (*, yj) respectively.
Here Y X'ρ → and X Y'ρ → are approximations of
Y Xρ → and X Yρ → over the sample respectively. But that is sufficient to describe the correlations lurking in raw data. COCA just uses the sample
statistics Y X'ρ → and X Y'ρ → to characterize correlations columns in databases. 3.2. Merits of COCA 3.2.1. Simple and straightforward. Data samples’ entropy correlation coefficients pairs are simpler and more straightforward than chi-square tests. Their value intervals are [0, 1]. Intuitively, the closer to 0, the less correlated are the two columns. Coefficients of value 0 mean total independence between two columns, and coefficients of value 1 mean hard functional dependence. 3.2.2. Accurate and robust. COCA is not a lossy method to discern correlations between database columns. COCA is more accurate than CORDS in discovering soft functional dependencies. CORDS discovers soft functional dependencies only by the coarse ratio of number of distinct values in one column over the number of distinct combination values of the column pair. 3.2.3. Informative and unified. COCA’s entropy correlation coefficients can tell the degree of dependencies of both column X on column Y and Y
on X, so it is informative. In COCA, soft functional dependences and hard functional dependencies are special cases of correlations. “Unified” also means that COCA can be used either in a large dataset scenario or in a single column pair scenario as well.
Figure 1 and Figure 2 are the outlines of COCA algorithms for different application scenarios.
Algorithm: COCA in large datasets: Input: DB – large database, S – space constraint Output: a list of column pairs
1, Produce candidate column pairs; 2, If sampling mode is switched on, generate appropriate samples; 3, For each column pair (X, Y), compute correlation coefficients ρ’
Y→X, and ρ’X→Y over the sample or raw data;
4, Recommending a list of column pairs in descending order of max (ρ’
Y→X, ρ’X→Y) within the bounds of S.
Figure 1. COCA for large databases Algorithm: COCA in a single column pair
Input: a column pair X and Y Output: correlation coefficients for the pair
1, If sampling is switched on, generate joint distribution matrix
from the sample, otherwise from the raw data.;
2, If functional dependency is found thus far, return; 3, Compute correlation coefficients ρ’
Y→X, and ρ’X→Y, and return
them. Figure 2. COCA for a single column pair
4. Different histograms for different degrees of correlations
We differentiate the degrees of correlations into three categories: high correlations caused by value sparsity, mutual independence, and other situations, and propose improved multidimensional histograms according to degrees of correlations.
The following algorithm assumes that there are not uni-dimensional histograms on both columns:
ALGORITHM: COCA-Hist INPUT: A column pair (X, Y), S space constraint, OUTPUT: two-dimensional histograms COCA-Hist
optimized for different degrees of correlations 1, Compute the joint distribution for (X, Y), simultaneously compute the correlation coefficients: ρ’Y→X, ρ’X→Y; 2, If max(ρ’Y→X, ρ’X→Y) < Thresholdind, build uni-dimentional MaxDiff(V,A) histograms on each column; 3, Else if V(X, Y) / (VX * VY) ≦ ε, build Value Sparsity-histograms; 4, Else construct conventional MHist-2 histograms with MaxDiff(V, F) or MaxDiff(V, A) partition constraints. Figure 3. Building of COCA-Hist histograms
4.1. Histograms for value sparsity
Under sparse data value distribution, conventional MHIST [2] histograms tend to generate many sparse
437431

buckets which embrace many zero-cells (cells with frequency equals to 0) of the data distribution matrix. Such sparse buckets hurt the accuracy of the histograms greatly. We propose adding a squeezing step to the MHIST algorithm to condense the sparse buckets generated by the conventional algorithm.
The squeezing step is simple: when computing the marginal distribution for column X in a certain partition, check if the length of a run of continual zeros exceeds VX * Empty_factor. If so, we discard that empty area in our histogram building. Empty_factor is a parameter for squeezing step and a tuning knob for VS-histograms. Note that when space for histograms abounds, VS-histograms can achieve better accuracy under relatively lower Empty_factor. While when space falls short, VS-histograms can avoid additional number of buckets with squeezing by setting Empty_factor higher.
Another question is how to judge whether value sparsity exists. We find it out by using the sparsity metric: Value_density = V(X, Y) / (VX * VY) <= ε, where X is the column with more number of distinct values and ε is some threshold meeting ε ≥ 1 / VY. For now we empirically set ε to be 0.5, meaning if half of the distribution cells are 0’s then it is a sparse distribution matrix. 4.2. Histograms for mutual independence
Instead of blindly building two-dimensional histograms when given a column pair or checking the existence of correlation using unreliable chi-square tests as CORDS, we can employ AVI assumption with more guaranteed accuracy at less cost when the correlation coefficients precisely tell the mutual independence lurking among the raw data. 4.3. Histograms for other situations
For other situations of medium correlations and non-sparse data distribution, conventional MHist-MaxDiff histograms will work well with some minor improvements. 4.4. Other improvements
Aside from the improvements of differentiating data distribution by different correlations, we also apply general optimization to all the situations, for example, discarding empty buckets in any of the three kinds of distributions. 5. Experiments
We conduct experiments to verify the effectiveness of the correlation coefficients employed by COCA and effectiveness of COCA-Hist. The experimental setting is a PC Server with Intel Pentium 4 2.8GHz CPU, 1GB RAM, Windows 2000 Server and Microsoft Visual Studio 2005 compiler. 5.1. Effectiveness of COCA over CORDS
Table 1 summarizes the comparison between correlation coefficients and chi-square analysis over three data distributions. Column pairs 2 is synthetic; column pair 1 is from a course’s student scores table indicating the column Grade and Department of the student; column pair 3 is from a railway departure schedule with candidate columns for station sequence No. and mileage of the corresponding station. Both these real world column pairs are known to have deep correlations.
Table 1. Correlation coefficients vs. chi-square test
Column Pair #1 #2 #3 VX 9 20 30 VY 5 5 109 V (X, Y) 10 21 120 Tuple number 25 1882 137
χ2 freedom degree
(VX-1)*(VY-1)
32 76 3132
Φ2 in CORDS 0.998013 77.7 0.24
X Y'ρ → 0.96 0.96 0.67
Y X'ρ → 0.74 0.44 0.96
Table 1 shows the large freedom degree of chi-square distribution out of multiplication operation for relatively small-sized data distribution (Column pair 3), and the large value diversity of CORDS’s sample statistics (as low as 0.24 and as high as 77.7). And the distribution function of chi-square is also needed to judge the existence of correlation. All these shortcomings make it hard for CORDS to implement reliable chi-square analysis.
With the categorization and bucketing methods in CORDS, both real-world data, Column Pair 1 and 3, have their correlation coefficients pairs decreased to (0.39, 0.29) and (0.45, 0.58) respectively, indicating the lossy nature of such techniques. 5.2. Effectiveness of COCA-Hist histograms
We conduct experiments to test the accuracy of COCA-Histograms using synthetic data with different degrees of correlations from mutually independence to hard functional dependence and with different value sparsities. We tried some real world data, but they
438432
exhibited just the same high correlations as what we generated with the synthetic data. We plan to gather more persuasive real world data to test COCA’s effectiveness and efficiency in the future.
Given the input parameter VX and VY, we generate a two-dimensional VX * VY matrix M. Every cell of the matrix represents the frequency of the corresponding combinatorial value and is set randomly between a minimum frequency and maximum frequency. We manipulate the number of non-zero cells to generate different kinds of data distributions. If the number of non-zero cells equals max(VX,VY), then it is a functional dependency distribution.
For each data set with certain degree of correlation, we build MHist-MaxDiff(V, F), MHist-MaxDiff(V, A) and COCA-Hist histograms. We use as large as 1000 – 3000 queries’ workload and as small as 100 - 200 queries’ workload, with predicates of the form xl ≤ X ≤ xh and yl ≤ Y ≤ yh. xl ,xh , yl ,and yh are all created randomly in DX and DY. The metric for the accuracy of different histograms are the overall absolute error ratio:
∑∑
∈
∈
−=
Wq
Wqerrabs
qMact
qMactqHestRatio
),(
),(),(_ .
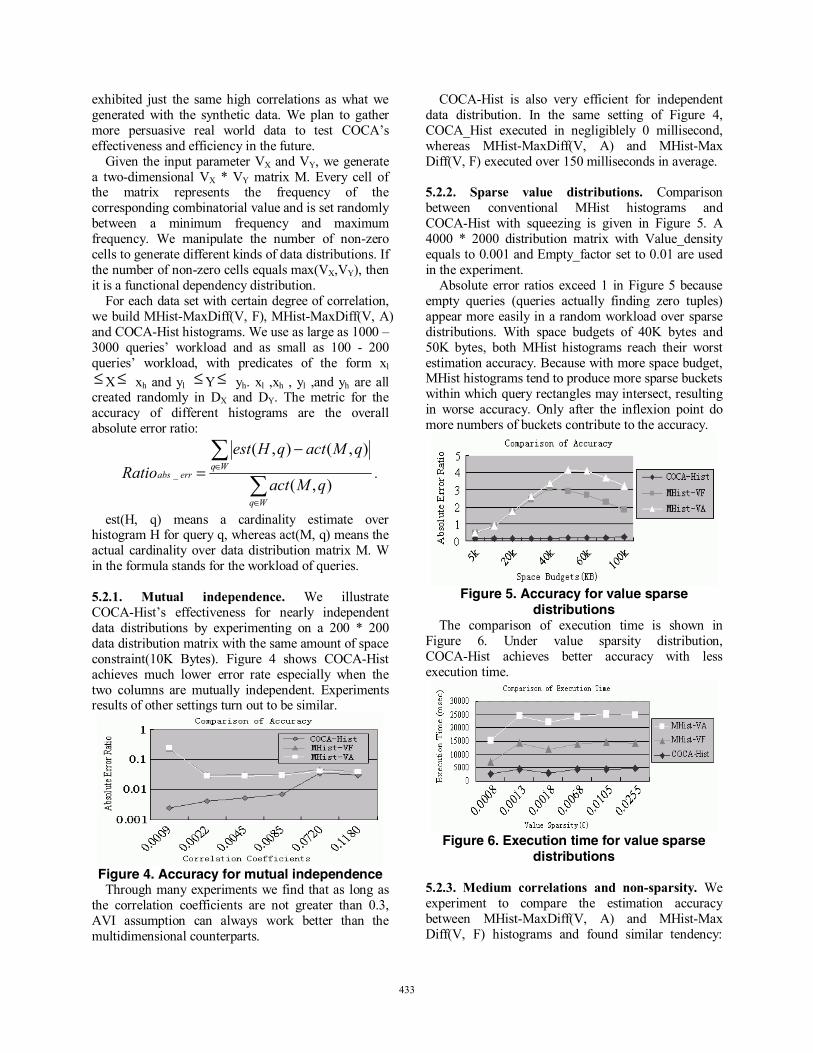
est(H, q) means a cardinality estimate over histogram H for query q, whereas act(M, q) means the actual cardinality over data distribution matrix M. W in the formula stands for the workload of queries. 5.2.1. Mutual independence. We illustrate COCA-Hist’s effectiveness for nearly independent data distributions by experimenting on a 200 * 200 data distribution matrix with the same amount of space constraint(10K Bytes). Figure 4 shows COCA-Hist achieves much lower error rate especially when the two columns are mutually independent. Experiments results of other settings turn out to be similar.
Figure 4. Accuracy for mutual independence
Through many experiments we find that as long as the correlation coefficients are not greater than 0.3, AVI assumption can always work better than the multidimensional counterparts.
COCA-Hist is also very efficient for independent data distribution. In the same setting of Figure 4, COCA_Hist executed in negligiblely 0 millisecond, whereas MHist-MaxDiff(V, A) and MHist-Max Diff(V, F) executed over 150 milliseconds in average. 5.2.2. Sparse value distributions. Comparison between conventional MHist histograms and COCA-Hist with squeezing is given in Figure 5. A 4000 * 2000 distribution matrix with Value_density equals to 0.001 and Empty_factor set to 0.01 are used in the experiment.
Absolute error ratios exceed 1 in Figure 5 because empty queries (queries actually finding zero tuples) appear more easily in a random workload over sparse distributions. With space budgets of 40K bytes and 50K bytes, both MHist histograms reach their worst estimation accuracy. Because with more space budget, MHist histograms tend to produce more sparse buckets within which query rectangles may intersect, resulting in worse accuracy. Only after the inflexion point do more numbers of buckets contribute to the accuracy.
Figure 5. Accuracy for value sparse
distributions The comparison of execution time is shown in
Figure 6. Under value sparsity distribution, COCA-Hist achieves better accuracy with less execution time.
Figure 6. Execution time for value sparse
distributions 5.2.3. Medium correlations and non-sparsity. We experiment to compare the estimation accuracy between MHist-MaxDiff(V, A) and MHist-Max Diff(V, F) histograms and found similar tendency:
439433

when space abounds, MHist-MaxDiff(V, A) histograms are more accurate; when space is limited, MHist-MaxDiff(V, F) histograms are more accurate as shown in Figure 7.
Figure 7. Medium correlations and
non-sparsity Figure 7 is from a 100 * 200 data distribution with
correlation coefficients being 0.47 and 0.53, value sparsity 0.68 (non-sparsity), and 10000 queries with conjunctive predicates intervals randomly generated. 6. Conclusions and future work
We propose a new scheme (COCA) to automatically discover correlations between two columns, which is more accurate and more robust than chi-squared tests. We find different ways in building highly accurate histograms (COCA-Hist) for different degrees of correlation.
COCA-Hist adopts several optimizing techniques such as squeezing to improve the accuracy for value sparse data distributions as well as cut down the histogram building cost. COCA-Hist can correctly identify weak correlations and take advantage of AVI assumption to achieve much better accuracy at much less cost. Our method is novel in that it is the first to differentiate different kind of data distributions to achieve better overall accuracy at lower expense.
The medium correlation and non-sparsity situation is what we will work on in the future. Also we need to find a way to cautiously set the right values for the important parameters in COCA-Hist algorithm, such as thresholdind, and ε. And we need to study the correlation existing in the data distribution in depth to find a better way to tackle the “correlation distribution” problem (different areas in the distribution matrix having different degrees of correlations). 7. References
[1] I. F. llyas, V. Markl, et al, “CORDS: Automatic Discovery of Correlations and Soft Functional Dependencies”, Proceedings of ACM SIGMOD 2004, ACM, New York, NY, USA, 2004, pp. 647 – 658. [2] V. Poosala, Y. Ioannidis, “Selectivity Estimation Without the Attribute Value Independence Assumption”, Proceedings of the 23th VLDB Conference, Morgan Kaufmann, San Francisco, CA, USA, 1997, pp. 486 - 495. [3] N. Bruno, S. Chaudhuri, L. Gravano, “STHoles: A Multidimensional Workload-Aware Histogram”, Proceedings of ACM SIGMOD 2001, ACM, New York, NY, USA, 2001, pp. 211 - 222. [4] Y. Matias, J. S. Vitter, M. Wang, “Wavelet-Based Histograms for Selectivity Estimation”, Proceedings of ACM SIGMOD 1998, ACM, New York, NY, USA, 1998, pp. 448 - 459. [5] M. Stillger, G. Lohman, V. Markl, M. Kandil, “LEO – DB2’s LEarning Optimizer”, Proceedings of the 27th VLDB Conference, Morgan Kaufmann, San Francisco, CA, USA, 2001, pp. 19 – 28. [6] S. Babu, P. Bizarro, D. DeWitt, “Proactive Re-Optimization”, Proceedings of ACM SIGMOD 2005, ACM, New York, NY, USA, 2005, pp. 107 - 118. [7] M. Muralikrishna, D. J. DeWitt, “Equi-Depth Histograms for Estimating Selectivity Factors for Multi-dimensional Queries”, Proceedings of ACM SIGMOD 1988, ACM, New York, NY, USA, 1988, pp. 28 - 36. [8]D. Gunopulos, G. Kollios, V.Tsotras, C. Domeniconi, “Approximating Multi-Dimensional Aggregate Range Queries Over Real Attributes”, Proceedings of ACM SIGMOD 2000, ACM, New York, NY, USA, 2000, pp.463-474. [9] P. G. Brown, P. J. Haas, “BHUNT: Automatic Discovery of Fuzzy Algebraic Constraints in Relational Data”, Proceedings of the 29th VLDB Conference, Morgan Kaufmann, San Francisco, CA, USA, 2003, pp. 668 - 679. [10] A. Deshpande, M. Garofalakis, “Independence is Good: Dependency-Based Histogram Synopses for High-Dimensional Data”, Proceedings of ACM SIGMOD 2001, ACM, New York, NY, USA, 2001, pp. 199 - 210. [11] L. Lim, M. Wang, J. S. Vitter, “SASH: A Self-Adaptive Histogram Set for Dynamically Changing Workloads”, Proceedings of the 29th VLDB Conference, Morgan Kaufmann, San Francisco, CA, USA, 2003, pp. 369 - 380. [12] L. Getoor, B. Taskar, D. Koller, “Selectivity Estimation Using Probabilistic Models”, Proceedings of ACM SIGMOD 2001, ACM, New York, NY, USA, 2001, pp. 461 - 472. [13] ZHANG R., et al, Statistical Analysis of Qualitative Data, Guangxi Normal University Press, Guangxi, P.R. China, 1991.
440434




























