Embed Size (px)
Citation preview

www.ietdl.org
IE
d
Published in IET Image ProcessingReceived on 6th February 2013Revised on 6th May 2013Accepted on 26th May 2013doi: 10.1049/iet-ipr.2013.0098
T Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724oi: 10.1049/iet-ipr.2013.0098
ISSN 1751-9659
Automated photo-consistency test for voxel colouringbased on fuzzy adaptive hysteresis thresholdingWalid Barhoumi, Mohamed Chafik Bakkay, Ezzeddine Zargouba
Research Team on Intelligent Systems in Imaging and Artificial Vision (SIIVA) – RIADI Laboratory, Manouba University, ISI,
2 Rue Abou Rayhane Bayrouni, 2080 Ariana, Tunisia
E-mail: [email protected]
Abstract: Voxel colouring is a popular method for reconstructing a three-dimensional surface model from a set of a few calibratedimages. However, the reconstruction quality is largely dependent on a thresholding procedure allowing the authors to decide, foreach voxel, whether it is photo-consistent or not. Nevertheless, in addition to the absence of any information on the neighbouringvoxels during the photo-consistency test, it is extremely difficult to define the appropriate thresholds, which should be precise andstable on all surface voxels. In this study, the authors propose an automated photo-consistency test based on fuzzy hysteresisthresholding. The proposed method allows the incorporation of the spatial coherence during volume reconstruction, whileavoiding ‘floating voxels’ and holes. Moreover, the ambiguity of choosing the thresholds is extremely minimised by defininga fuzzy degree of membership of each voxel into the class of consistent voxels. Also, there is no need for preset thresholdssince the hysteresis ones are defined automatically and adaptively depending on the number of images that the voxel isprojected onto. Preliminary results are very promising and demonstrate that the proposed method performs automaticallyprecise and smooth volumetric scene reconstruction.
1 Introduction
Volumetric scene reconstruction from a set oftwo-dimensional (2D) images is a very challenging openproblem in the computer vision field. It can have differentapplications in many areas from robotics to computergraphics and virtual reality [1]. For example, there is agrowing need for 3D model reconstruction in computergames and animation field which is having a significantdevelopment in the last decade. Thus, many differentapproaches have been proposed to solve this problem.These approaches can be classified into two main classes:passive methods and active ones. For the first class, onlyvideo cameras are used to infer 3D shape, under generalillumination and natural light. Indeed, in this class, theshape can be retrieved from a single camera (‘passivemono-ocular methods’) or from multiple cameras (‘passivemulti-ocular methods’). For ‘passive mono-ocular methods’,the shape can be inferred from cues like shading [2, 3],texture [4, 5] and focus [6]. These methods are oftenreferred to as shape from X, since the individual instancesare called shape from shading, shape from texture andshape from focus. For ‘passive multi-ocular methods’, wecan distinguish between binocular disparity methods, likethose based on stereovision [7], and the ones which did notuse disparity, such as shape-from-silhouette methods [8, 9]and shape-from-photo-consistency ones [10–12]. A 3Dshape can also be estimated using active illuminationtechniques comprised of the class of active methods. Thisclass contains ‘active mono-ocular methods’ which use only
active illumination sensors to retrieve depth from the scene[13, 14]. The most popular active illumination sensors arelaser, structured light and time of flight. This class alsoincludes ‘active multi-ocular methods’ that use bothmultiple cameras and active illumination to infer shape likestereovision with laser [13] and stereovision with structuredlight [14].Although the passive methods have lower precision than
the active ones, they are widely used in various fields.Indeed, they are handy methods using only general CCDcameras. Moreover, the methods based on active visionsuffer from lack of colour information and the precision ofthese methods depends on the type of the used sensors. Onthe other side, using more cameras can lead to even betterresults of obtaining depth information. Thus, ‘passivemulti-ocular methods’ can not only improve, comparativelyto mono-ocular ones, the quality of depth maps usingmultiple source images, but they can also create complete3D object models. Furthermore, the existence of multiplecameras enables more accurate reasoning about occlusions,since regions which are occluded in one image may bevisible in others [15, 16]. In particular, multi-ocular passivemethods based on stereovision produce reconstruction withhigh resolution and high accuracy, but they need complexalgorithms and thus high computational cost. For theshape-from-silhouette methods (also referred to asshape-from-contour methods), the 3D shape of an object ismainly recovered from its outline. These methods are veryrobust against lighting changes and photometric variationsbetween cameras. However, they are restricted only to
713& The Institution of Engineering and Technology 2013

www.ietdl.org
geometric information while ignoring colour information, andthen the resulting reconstruction of a shape-form-silhouettemethod is often incomplete [17, 18]. It reconstructsaccurately convex objects and cannot sufficiently describesurface concavities. In this study, we are interested in thevoxel colouring method which is one of theshape-from-photo-consistency approaches of volumetricscene reconstruction. This passive method, which wasoriginally introduced by Seitz and Dyer [10], is theimprovement of the space-sweep approach that provides asolution to the visibility and occlusion problems created bythe parallaxes between images. For instance, voxelcolouring has become a popular technique forreconstructing a 3D surface model from a set of calibrated2D photographs. The basic principle of this 3Dreconstruction method is to profit from nearly allinformation contained in the input images [19]. It classifieseach 3D element (voxel), within a discretised volume ofopaque voxels that encapsulates the scene to bereconstructed, to decide whether it belongs to the surface ofthe 3D object or not. This returns to test thephoto-consistency of each voxel, which is the oldest and thesimplest photometric property of a scene in the stereovisionliterature. It claims that, if a voxel belongs to the filmed 3Dvolume, the corresponding pixels are assumed to have thesame colour in the relative 2D projections. Otherwise,inconsistent voxels are iteratively carved out of the sceneuntil halting on the surface of the filmed 3D object. Indeed,a point on a surface should be seen with similar colourswhen it is not occluded. This property is based on a coupleof assumptions. On the one hand, objects in the sceneshould have Lambertian surfaces, such a surface is said tobe ‘Lambertian’ if its body reflection obeys Lambert’scosine law. This law asserts that the amount of light emittedfrom a surface in different directions is proportional to thecosine of the angle between the direction and the surfacenormal. Thus, the amount of light emitted from aLambertian surface is independent of the observer’sposition and the surface appears bright equally from alldirections. In fact, voxel colouring uses the Lambertianassumption in order to simplify the correlating pixels fromdifferent viewpoints. Although this assumption provides areasonable model for matte surfaces that scatter lightapproximately uniformly in all directions, it is notwell-suited for reconstructing highly specular surfaces [20].On the other hand, the second assumption, referred to asvisibility, supposes that the projection of any point in thescene on the images on which it appears can be efficientlycomputed [21].The voxel colouring method is able to perform aphotorealistic 3D reconstruction from a few images withoutcalculating image correspondences. It is widely usedbecause of its simplicity and its low-computational cost. Infact, since each voxel is visited only once, the space andtime complexities of the voxel colouring method are bothlinear in the number of images. This important advantageallows a huge number of images to be processed at once[22]. Furthermore, this method does not need a largenumber of images, and thus of cameras, to produce ahigh-quality reconstruction. However, the reconstructionquality of a voxel colouring method is strongly based onthe estimation of the photo-consistency of each voxel. Thisis achieved by projecting each voxel in 3D space onto theinput images in order to retrieve the colour values in thepatch where the voxel was projected. Under the assumptionof Lambertian reflectance, a voxel having almost the same
714& The Institution of Engineering and Technology 2013
colour in all images from which it is visible(photo-consistent voxel), should be given that colour.Otherwise, the voxel should be removed. This decision iswidely based on a thresholding step, which compares thephoto-consistency of each voxel with a pre-establishedsingle threshold. Nevertheless, in addition to the absence ofany information on the neighbouring voxels while accessingthe voxel space, it is extremely difficult to define theappropriate single threshold. Besides, even if the thresholdis defined optimally, the use of the same value on allsurface voxels generates a trade-off problem betweenprecision and stability [23]. For this reason, we suggest, inthis work, to integrate the geometric information by using ahysteresis thresholding which considers the connectivity ofcoloured voxels. This allows us particularly to handle‘floating voxels’ (voxels which may project intocolour-consistent pixels by chance) and holes, in thereconstructed model, during the photo-consistency test, in abetter manner. Moreover, the ambiguity of choosing thethresholds is extremely minimised while using a fuzzydegree of membership μCV of each voxel to the class ofconsistent voxels. Also, there is no need for presetthresholds since the hysteresis ones are definedautomatically and adaptively depending on the number N ofimages that the voxel is projected onto. In fact, the twohysteresis thresholds, Tl and Th (Tl < Th), are appropriatelymodelled with two alternating harmonic sequencesdepending on N. Since these sequences are adjacent, whenN increases then Tl increases and Th decreases, which makethe thresholding stricter. In fact, if the number N, of imagesthat the voxel is projected onto, is relatively high, then onlyhighly photo-consistent voxels (μCV ≥ Th) are automaticallyretained while allowing the maximum of their neighbouring(Tl < μCV < Th) ones to pass the photo-consistency. Thispermits us to incorporate the spatial coherence duringvolume reconstruction while avoiding ‘floating voxels’ andholes along the voxel colouring procedure.The remaining part of this paper is structured as follows.
Section 2 is devoted to a brief synthesis of the mostrelevant works on the photo-consistency test for voxelcolouring methods. In Section 3, we are going to presentthe proposed method for automated photo-consistency test,which is based on a fuzzy adaptive thresholding byhysteresis. Some experimental results and an objectivecomparative study are shown in Section 4 in order todemonstrate the effectiveness of the proposed work for 3Dmodel reconstruction. Section 5 concludes the paper andpresents some directions for future works.
2 Related works
The suggested solution for volumetric scene reconstructionbuilds upon the voxel colouring method, for which varioustechniques addressed the visibility [10, 11, 21, 24] and thephoto-consistency [25–29] problems. The visibility looks todefine the set of cameras which can view a voxel, whereasphoto-consistency is used to determine whether a givenvoxel is occupied or not. In general, the two tasks arecoupled. Indeed, the photo-consistency test is applied to thecorresponding pixels from cameras that can see the voxel,which in turn, depends on the visibility result. Similarly, inorder to solve visibility for a particular voxel, we need toknow whether any intervening voxel between it and thecamera is occupied, which itself relies on thephoto-consistency test results for such intervening voxels.
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098

www.ietdl.org
Since the selection of the photo-consistency test has a greatinfluence on the quality of the 3D reconstruction, we willfocus, in this paper, on the photo-consistency problemwhereas the visibility problem can be addressed in futureworks. In fact, the purpose of the photo-consistency test isthe decision of colouring or removing a voxel Vi. Thisdecision depends on the set of colours Πi, which isobtained by projecting the voxel Vi onto the images inwhich Vi is not occluded. To apply this, the patch Pijin each image Ij where the voxel Vi is visible is firstlocalised. Then, the non-empty set of colours Πi iscalculated as the union of all sets Pi
j in the input views.Once the set Πi is extracted, the photo-consistency of thevoxel Vi can be defined in various ways. Indeed, severalforms of photo-consistency tests have been proposed andthey are mentioned in what follows according to theirchronological order.Originally, photo-consistency was evaluated in [10] based
on the colour variance of the voxel. In fact, to determine if thevoxel Vi should be coloured consistently, the variance of thesetΠi is computed and thresholded. If the variance is less thana threshold then the voxel is labelled consistent. This methodis widely used [24, 30, 31], thanks to its computationalefficiency and to the often acceptable quality despite itsrestrictions such as perfectly Lambertian and well-texturedsurfaces under constant illumination conditions. Anextension to this photo-consistency test was proposed in[32]. It consists of incorporating information fromthroughout the volume in determining opacity. Thus,accurate reconstruction of opaque and transparent materialscan be performed. In this method, a model which representsthe transparency and the colour of a voxelisedrepresentation of 3D space is computed. This representationignores some of the more complex properties of imageformation. For example, the surface reflectance at eachsurface point and the scene illumination cannot beestimated. Nevertheless, such a representation containsinformation about the shapes and the locations of objectsand it also contains the basic information to computeconvincing synthetic views. Another interestingamelioration of the photo-consistency assessment wasproposed in [21]. Indeed, the mean colour of each block Pi
jis computed and then a likelihood ratio test of those meansis calculated and compared with a threshold that allowsadding robustness to the calibration errors. Also, a statisticalmethod for reliable outlier rejection is presented by Zýkaand Sára [33], while formulating the problem ofphoto-consistency as an outliers-rejection problem. In thesame context, Broadhurst et al. [25] proposed an extensionbased on a probabilistic framework to avoid image noiseduring the photo-consistency test. On the other side,photo-consistency can be also defined using Minkowskidistances (L1, L2 and L∞ norms) [34, 35]. First, the meancolour μj of each non-empty set Pi
j is determined. Then, forevery pair μj and μk (1≤ j, k ≤N ) of such means, the L1, L2or L∞ norm is computed. In [35], if the maximum norm ofall pairs is less than a threshold determined empirically,then the voxel is considered to be colour consistent,whereas in [34], all norms of all pairs must be less than athreshold to consider the voxel as colour consistent. Inother words, in [34], if the norm of a pair of colours isgreater or equals to the threshold, this voxel cannot bephoto-consistent. However, a common characteristic that allthe abovementioned photo-consistency measures have isthat they work appropriately only when the object’s surfacecolour is homogeneous. Otherwise, they would easily
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
diverge. In fact, textured regions or regions that containsharp edges have a higher colour variation than uniformregions, and they need thus very high thresholds. Thereforeno single threshold is ideal for an entire scene.In order to find an optimal trade-off between precision and
stability of the used thresholds, an adaptive photo-consistencytest has been proposed by Slabaugh et al. [36]. First, thestandard deviation si
j of each image Ij from which the voxelVi is visible is calculated. Then, given the average mean(si
j) of these standard deviations, if the relative standarddeviation σi of a voxel Vi is less than a threshold, which isdynamically defined according to the mean (si
j), then thevoxel is labelled consistent. Thus, the threshold value isdetermined according to the location of the voxel. If thevoxel is on the edge or on a textured surface, it has highstandard deviation in each image, and a greater thresholdcan then be used. This represents an important advantageover measures based on standard deviation. More recently,in order to get rid of thresholds, histogram-based colourconsistency tests were introduced by Stevens et al. [37],which presents a solution to abrupt colour changes. Indeed,photo-consistency assessment is performed in two steps. Acolour histogram is first constructed for every image fromwhich the voxel Vi is visible. Then, intersection tests areperformed between all pairs of histograms to see if they areconsistent. The advantage of this photo-consistencymeasure is that there is no need for preset thresholds.Furthermore, if the voxel is found to be inconsistent for apair of images, there is no need to test other pairs of views.Nevertheless, this photo-consistency test is not robustagainst noisy images [37]. Chhabra [38] proposed to usecolour caching, which brings a solution to the limitationscaused by the Lambertian assumption. In the first step,surface parts which show Lambertian reflectance propertiesare tested. In the second step, parts which fail Lambertianassumptions are tested with another measure whichconsiders the viewing orientation. Yang et al. [39]examined the problems of textureless regions and specularhighlights. In this method, photo-consistency is evaluatedbased on more sophisticated consistency measures. Indeed,sum-of-squared-differences and normalised cross-correlation(NCC) [40] of image patches Pi
j are proposed instead ofcolour variances. These measures reduce ambiguous colourconfigurations and account for changes in illuminationbecause of the involved normalisation step [41]. Inparticular, NCC-based consistency estimation methods [42,43] achieve very high-quality level of the reconstructedmodels. For instance, the technique in [42] is based ondeformable models, whereas global graph-cut optimisationis used by Vogiatzis et al. [43] in order to find an optimalsurface within a discretised volume that satisfies thephoto-consistency and smoothness constraints. However,NCC-based consistency estimation methods use projectivewarping which can generate considerable matching errorsfor medium-baseline and non-epipolar-aligned images [41].To conclude, most voxel colouring methods suffer from
several important limitations. First, they assume sufficienttexture and are usually very sensitive to noise andcalibration errors [21]. Furthermore, the voxel-basedrepresentation ignores the continuity of shape, which makesit very hard to enforce smoothness and spatial coherence.Another drawback of the earlier photo-consistency tests isthat the quality of the reconstruction is very sensitive to thevalue of the used thresholds. Strict thresholds can result inaccurate but generally incomplete reconstruction with a lotof object details missing. However, soft thresholds can
715& The Institution of Engineering and Technology 2013

www.ietdl.org
result in a more complete reconstruction to the detriment oferroneous voxels inclusion. Thus, to obtain accuratereconstruction, many threshold values must beexperimented with to get the best results. This can betime-consuming since the user must try by trial and error toget accurate thresholds. Besides, many voxels can beerroneously removed in a cascade effect and these voxelscannot be recovered later. This limitation is partiallymoderated by the probabilistic space carving (SC) method[25]. To alleviate the above-mentioned limitations, wepropose a new automated photo-consistency test thatminimises the influence of the thresholds by using fuzzylogic and that integrates geometric information by usingadaptive hysteresis thresholding in order to guaranteesmoothness and spatial coherence of the kept voxels.Besides, the proposed automated method is capable ofreconstructing accurately 3D scenes from a few views in asingle step and without need for preset thresholds. Indeed,the two hysteresis thresholds are appropriately modelledwith adjacent sequences according to the number of imagesthat the treated voxel is projected onto.3 Proposed method
After dividing the 3D scene space into a grid of voxels, theproposed voxel colouring method traverses each voxel inorder to test for photo-consistency, by which the voxel isdetermined to be coloured accordingly or removed. Tohandle occlusion properly, the voxel space is traversed in anadequate order under the ordinal visibility constraint.Indeed, the used cameras are placed on the same side of aplane, and the voxels closest to the camera are visited first.This near-to-far ordering ensures that a voxel cannot beoccluded by an unvisited voxel, which optimise theocclusions handling [44]. The resulting reconstruction iscalled the photo-hull [11], which is defined as themaximum volume, which is photo-consistent with the set ofinput views. To decide if it is photo-consistent or not, eachtreated voxel Vi is projected onto the input images {I1,…,IM}. Then, all pixels corresponding to these projectionswhich have not yet been marked are collected in set Πi. Ifset Πi is empty, then voxel Vi is carved. Otherwise, aftersorting all pixels intensities in order to eliminate outliers,the proposed automated method relies on a
Fig. 1 Outline of the proposed method for the automated voxel colouri
716& The Institution of Engineering and Technology 2013
photo-consistency metric and two dynamic thresholds toclassify voxels as interior or exterior to the reconstructed3D objects. Indeed, a fuzzy membership degree μCV(V
i) ofthe voxel Vi to the class of photo-consistent voxels isestimated using a homogeneity evaluation function. Then,two thresholds Ti
l and Tih are automatically defined
according to the number Ni of images in which the voxel Vi
is visible. Finally, given these two thresholds and the fuzzymembership degree μCV(V
i), a hysteresis thresholding isused in order to decide if the voxel Vi is consistent or not(Fig. 1). In fact, the type of the voxel Vi (type(Vi)∈{Consistent, ¬Consistent}) is determined according to itsappearance on all the images from where it is visible, andto the types of the already visited voxels V1,…, Vi−1. Thus,if the voxel Vi is photo-consistent, then it is marked astraversed, in order to handle accurately the occlusioneffects, while being coloured accordingly with the meancolour of pixels forming collection Πi. Otherwise, the voxelVi is carved and marked empty. The proposed methodpermits us to estimate reliably the photo-consistency of avoxel for precise 3D reconstruction based on volumetricscene representation, without any restrictions concerning thenumber of images on which the voxel is projected. Inaddition to the implicit integration of the spatial coherencethanks to hysteresis thresholding, the main contribution ofthe suggested method resides in the fact that it can searchthe optimal thresholds by itself.
3.1 Voxel projection
Once the input volume is discretised into small cubes(corresponding to the voxels), the first step of the proposedvoxel colouring method aims to project each voxel Vi intosignificant coloured patches in all images from which it isvisible. To do this, we used the idealised model of apinhole camera, which is a very good approximation tomost real-world cameras [45]. Indeed, since the usedcameras are properly calibrated, a sprite projection is usedin order to project a point from 3D space onto a 2D imageplane [45]. More precisely, given the eight vertices {P1,…,P8} of the cube corresponding to a voxel Vi and the set ofthe input calibrated images {I1,…, IM}, it is possible toconnect each vertex Pk = (Xk, Yk, Zk)
t, 1≤ k≤ 8, to its
projection pjk = xjk , yjk( )t
on the image plane Ij, while using
ng
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098

www.ietdl.org
homogeneous coordinates, according to (1)xjk , yjk , 1( )t= K j · Rj · T j · Xk , Yk , Zk , 1
( )t(1)
where, Rj (2) and Tj (3) denote the extrinsic parameters ofcamera Cj, which describe its placement and orientation inthe 3D world, and Kj denotes the matrix of the intrinsiccamera parameters (4), which depict the projection of thevoxel vertex Pk along the ray connecting it to the cameracentre. In fact, Tj is the translation matrix, which includesthe camera translation vector tj = (txj , tyj , tzj ) describing itsposition in world coordinates (2), and Rj is the rotationalpart which includes the 3 × 3 rotation matrixrj(= [r11j r12j r13j ; r21j r22j r23j ; r31j r32j r33j ]) specifying theorientation of camera Cj (3). The intrinsic parameters,(oxj , oyj ) and fj (4), are the coordinates of the principal pointof camera Cj and its focal length, respectively. Note that inour case we have simply assumed that η = 1 and t = 0,while neglecting the radial distortion effects of cameras,like most of the studied cases of typical CCD cameras [46].Indeed, if the camera uses non-square pixels, the intrinsicparameter matrix Kj should be extended by a parameter η,denoting a vertical scaling factor to make the camera moresuitable for real-world usage. Moreover, in the case of askewed sampling grid, which occurs when the used camerais not perpendicular to the optical axis, an additionalparameter t should also be integrated in the matrix Kj (4).
T j =1 1 11 1 11 1 1
txjtyjtzj
0 0 0 1
⎡⎢⎢⎢⎣
⎤⎥⎥⎥⎦ (2)
Rj =r11j r12j r13j 0
r21j r22j r23j 0
r31j r32j r33j 00 0 0 1
⎡⎢⎢⎢⎣
⎤⎥⎥⎥⎦ (3)
K j =fj t oxj 0
0 hfj oyj 0
0 0 1 0
⎡⎢⎣
⎤⎥⎦ (4)
After projecting the eight vertices {P1,…, P8} of the voxel Vi
on the image plane Ij, the bounding box Cij around their
projections { p1j , . . . , p8j } is used to approximate the actualvoxel shape. However, the photo-consistency test of thevoxel Vi is performed only on the set of images in whichthis voxel is visible. Indeed, a voxel Vi is defined to bevisible in an image Ij, only if the line of sight from thisvoxel to the set of corresponding pixels Ci
j in this image isnot occluded. This occlusion problem was solved by thespecified order in which the voxels were considered, whilerestricting the possible location of camera viewpoints (theordinal visibility constraint). Indeed, we proceed bysweeping the grid and the voxels closest to the set of allcameras are visited first, while marking the correspondentpixels to the visited voxels as ‘already affected’. Thisnear-to-far ordering ensures that the voxels which may beoccluded are evaluated for photo-consistency after thevoxels which may occlude it. Thus, among the pixelsbelonging to the bounding box Ci
j in Ij, only the set Pij of
pixels which are not already affected during the processing
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
of the previous voxels Vl(1 ≤ l < i) is considered (5).
∏ij
= Cij > Ij/
⋃i−1
l=1
∏lj
( )(5)
Hence, the colours of the retained pixels in the input imagesare collected in the same set Πi in order to evaluate thephoto-consistency of the voxel V i Pi = Pi
1<(
Pi2 < . . .Pi
M ).Besides, the number Ni of images in which Vi is visible (i.e.images Ij for which the set Pi
j is non-empty) is defined asfollows (6)
Ni = Ij [ I1, . . . , IM{ }
/Cij å
⋃i−1
l=1
Clj
{ }∣∣∣∣∣∣∣∣∣∣ (6)
where | | is the set cardinality operator. In other words, a voxelVi is considered as visible on an image Ij if and only if it existsfor at least one pixel in the bounding boxCi
j, which is outsidethe projections of the already traversed voxels Vl(1≤ l < i).
3.2 Photo-consistency assessment
After defining the images patches, Pi1, Pi
2, . . . , PiM ,
resulting from the projection of the current voxel Vi ontothe Ni images where it is visible, the next step of theproposed voxel colouring method consists of evaluating thephoto-consistency of the voxel Vi. This is done whileestimating the homogeneity of the set of colours Πi
enclosing the relative patches to Vi. The original voxelcolouring method estimates the homogeneity according tothe colour variance relatively to all pixels in Πi. Thisvariance-based photo-consistency estimate, which supportsefficient computation, is quite sensitive in practice tonon-Lambertian and weakly textured surfaces as well as tovarying illumination [41]. Hence, in order to evaluate thehomogeneity of the set Πi on which the decision ofremoving or colouring a voxel is strongly based, weintroduced a fuzzy technique allowing the definition of amembership degree μCV(V
i) (∈ [0, 1]) for each voxel Vi tothe class of consistent voxels (such that, μ¬CV(V
i) = 1− μCV(V
i)). The main idea behind the proposed fuzzyevaluation of the photo-consistency of a voxel is tominimise the dependence of the reconstruction results onthe used thresholds. Indeed, given the corresponding set ofcolours in Πi, the membership degree μCV(V
i) of a voxel Vi
to the class of consistent voxels is defined as follows (7).First, the non-empty set of pixels Πi is sorted according tothe colour intensity in order to exclude the outliers. Forthis, given the sorted version ζi of the set Πi, only pixelswhose colours are in the range di1, di9
[ ], where di1 and di9
are, respectively, the first and the ninth deciles, isconsidered for assessment of the correspondentphoto-consistency to the voxel Vi (7), such that the decilesare the values that divide the dataset into 10 parts. The goalof the outliers rejection is to handle the quantisation errors,varying illumination and the sensors noise in a bettermanner (cf. Section 4.). Besides, this permits us to considerthe fact that an image pixel may contain the mixed colourof multiple voxels [19]. In fact, these undesired effects areusually reflected by colours which are very far away fromall of the other colours inside set Πi enclosing the relativepatches to the same voxel Vi. Then, the membership degreeμCV(V
i) of the voxel Vi to the class of consistent voxels isdefined as the ratio between the lowest value and the
717& The Institution of Engineering and Technology 2013

www.ietdl.org
highest one among all the values in the retained set of colours(after the outliers rejection). This degree represents voxelswhich are strongly photo-consistent with a highmembership degree (i.e. mCV V i( ) ≃ 1). However, voxelsthat record low membership degrees (i.e. mCV V i( ) ≃ 0) areconsidered as non-photo-consistent and should be thenremoved from the resulting reconstruction. In particular, thefuzzy evaluation of the photo-consistency offers a bettermodelling of uncertainty and ambiguity, since it permitsus to postpone the decision of colouring or removing adubious voxel Vi (i.e. mCV V i( ) ≃ 0.5) until moreinformation can be available to make the final decision.This information is mainly deduced in our case from thetaken decisions for the connected voxels among theprevious ones Vl (1≤ l < i). In this way, we avoid the factthat some voxels can be erroneously removed in acascade effect, mainly that these removed voxels cannotbe recovered.mCV V i( )=min colour (x, y)/(x, y)[
∏i and colour (x, y)[ di1, di9
[ ]{ }max colour (x, y)/(x, y)[
∏i and colour (x, y)[ di1, di9
[ ]{ }(7)
3.3 Thresholds estimation for hysteresisthresholding
Given the membership degree μCV(Vi) of the current voxel Vi
to the class of consistent voxels and the number Ni of inputimages in which Vi is not occluded, the last step of thesuggested voxel colouring method aims to decide whetherthe considered voxel Vi is photo-consistent or not. Thisreturns to identify the type of the voxel Vi among twoclasses (type(Vi)∈ {Consistent, ¬Consistent}). For thispurpose, we introduced an automated hysteresisthresholding (8), in which two adaptive thresholds aredynamically defined. This thresholding by hysteresis aimsto incorporate spatial coherence in the resulting 3Dreconstruction while substantially discarding noise effects.The higher threshold Ti
h is used to select the mostphoto-consistent voxels, such that a voxel Vi is recognisedas photo-consistent if mCV V i( ) ≥ Ti
h, and should be thencoloured accordingly. Otherwise, if mCV V i( ) ≤ Ti
l , thevoxel Vi is identified as not photo-consistent and should bethen carved. All the other voxels Vi, for whichmCV V i( )
[ ]Til , Ti
h[, are considered as candidate voxels andshould be then treated recursively to decide on theirphoto-consistency. Indeed, if a candidate voxel Vi isconnected to an already visited photo-consistent voxel, thenthis candidate voxel should be coloured accordingly;otherwise, the voxel is carved (8). Making the assumptionof the connectivity of photo-consistent voxels allows us tocheck the neighbourhood of a given voxel and to discard afew noisy voxels that are not photo-consistent.
type V i( ) = Consistent ⇔ mCV V i( ) ≥ Tih
[ ]or mCV V i( )
[ ]Til , Ti
h[( )
and[
∃V l [ ℵ/type V l( )= Consistent( )]
(8)
where, ℵ is a homogeneous component, including the voxel Vi,of connecting voxels already recognised as photo-consistent.Furthermore, the explicit consideration of the connectivity
718& The Institution of Engineering and Technology 2013
information, the main contribution of the proposed automatedhysteresis thresholding resides in the fact that the two usedthresholds, Ti
l and Tih 0 , Ti
l , Tih , 1
( ), are adaptively
defined according to the number Ni of input images in whichthe treated voxel Vi is visible. This allows the hysteresisthresholds to be related to the visibility level of the concernedvoxel that can in turn be derived from its projection statistics.Indeed, as the first visited voxels are less occluded than thenext ones, they are projected on more pixels (Fig. 2a) thanthe other ones (i.e. ∀i, |Πi|≥ |Πi+1|), and consequently theirhomogeneities (Fig. 2b) are more strict (i.e. ∀i,μCV(V
i)≤ μCV(Vi+1)). Besides, the number Ni of views in
which the voxel Vi is visible changes in an opposite manner(Fig. 2c) relatively to the order by which the voxel space istraversed under the ordinal visibility constraint (i.e. ∀ i, Ni≤Ni+1). Thus, we assume that if the number Ni of images onwhich the input voxel Vi is not occluded is high (resp. low),the thresholding should be more strict, that is, Ti
l b and Tih
d, (resp. more soft, i.e. Til d and Ti
h b). In other words, ifthe number Ni of observations on the photo-consistency of avoxel Vi is relatively high, then only highly photo-consistentvoxels mCV V i( ) ≥ Ti
h
( )are automatically retained while
allowing the maximum of less-consistent neighbouring voxels(Ti
l , mCV V i( ), Ti
h) to be considered as candidates giventhe spatial coherence. For this, the two hysteresis thresholds,Til and Ti
h, are modelled with two adjacent sequencesaccording to Ni. Thus, when Ni increases then Ti
l increasesand Ti
h decreases, which guarantees a strict thresholding.Indeed, two adjacent sequences are such that one isincreasing and the other is decreasing and the terms of bothare coming closer as Ni tends to infinity. This means that theyare convergent and converge to the same limit. In our case,we supposed that Ti
l = UiN = S 2Ni( )
and Tih =
V iN = S 2Ni + 1
( ), such that S(n) is the alternating harmonic
sequence (9), which is the special case η(1) of the Dirichleteta function η(s). Hence, the two thresholds are modelledwith two adjacent sequences such that their values are in therange ]0, 1[ and they converge to the same limit l (i.e.∀Ni, 0 , Ui
N ≤ UiN+1 ≤ l ≤ V i
N+1 ≤ V iN ). We opted for
these two sequences since they are both going closer tolog(2) as Ni tends to infinity. In fact, our experiments haveshown that the best results of the 3D reconstruction, whileusing the introduced fuzzy photo-consistency assessmentmeasure (7) within the standard voxel colouring thresholdingwith a single threshold T (i.e. type(Vi) =consistent⇔ μCV(V
i)≥ T ), were obtained with thresholdvalues around log(2) (Fig. 3). Using this colour consistencychecking, the proposed technique does not require to begiven parameters as constant thresholds input and it canreconstruct more detail than using an original colourconsistency checking formula based on standardthresholding of the standard deviation of pixels intensities.In fact, the threshold values are appropriately definedaccording to the location of the voxel. In particular, if thevoxel is on the edge or on a textured surface, it has lowhomogeneity degree in each image, and a greater thresholdTih is then used. This permits us to incorporate the spatial
coherence during volume reconstruction while avoiding‘floating voxels’ and holes along the voxel colouringprocedure (cf. Section 4).
S(n) = 1
c
∑nk=1
(−1)k−1
k(9)
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
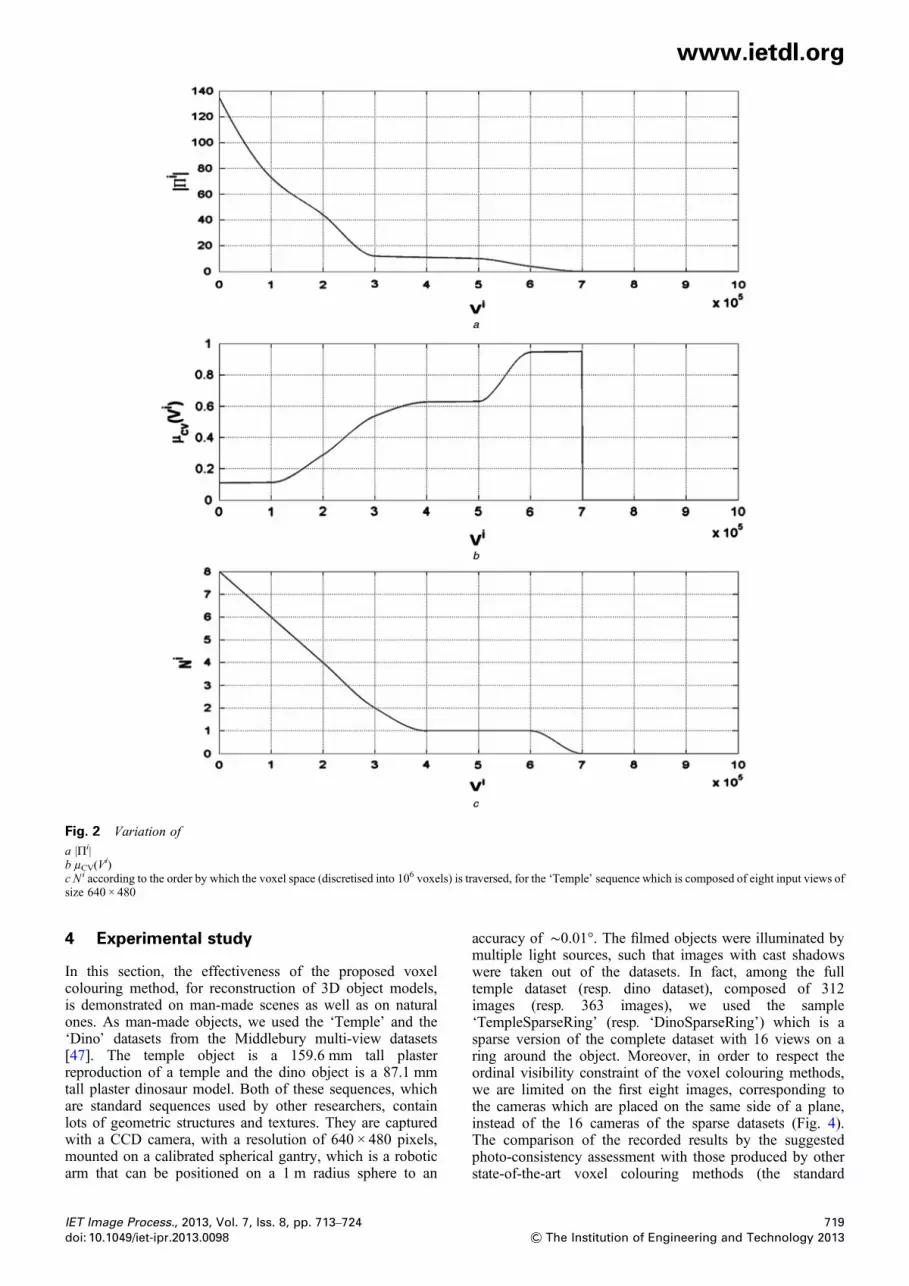
Fig. 2 Variation of
a |Πi|b μCV(V
i)c Ni according to the order by which the voxel space (discretised into 106 voxels) is traversed, for the ‘Temple’ sequence which is composed of eight input views ofsize 640 × 480
www.ietdl.org
4 Experimental study
In this section, the effectiveness of the proposed voxelcolouring method, for reconstruction of 3D object models,is demonstrated on man-made scenes as well as on naturalones. As man-made objects, we used the ‘Temple’ and the‘Dino’ datasets from the Middlebury multi-view datasets[47]. The temple object is a 159.6 mm tall plasterreproduction of a temple and the dino object is a 87.1 mmtall plaster dinosaur model. Both of these sequences, whichare standard sequences used by other researchers, containlots of geometric structures and textures. They are capturedwith a CCD camera, with a resolution of 640 × 480 pixels,mounted on a calibrated spherical gantry, which is a roboticarm that can be positioned on a 1 m radius sphere to an
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
accuracy of ∼0.01°. The filmed objects were illuminated bymultiple light sources, such that images with cast shadowswere taken out of the datasets. In fact, among the fulltemple dataset (resp. dino dataset), composed of 312images (resp. 363 images), we used the sample‘TempleSparseRing’ (resp. ‘DinoSparseRing’) which is asparse version of the complete dataset with 16 views on aring around the object. Moreover, in order to respect theordinal visibility constraint of the voxel colouring methods,we are limited on the first eight images, corresponding tothe cameras which are placed on the same side of a plane,instead of the 16 cameras of the sparse datasets (Fig. 4).The comparison of the recorded results by the suggestedphoto-consistency assessment with those produced by otherstate-of-the-art voxel colouring methods (the standard
719& The Institution of Engineering and Technology 2013

Fig. 3 Reconstruction results while using the fuzzy photo-consistency assessment with a single threshold T equals to
a 0.6b 0.5c 0.4d 0.3e 0.2
Fig. 4 Four out of eight input views into the proposed voxel colouring method
www.ietdl.org
deviation photo-consistency test [32], the adaptivephoto-consistency test [36] and the histogram-basedphoto-consistency test [38]), demonstrate that our methodoutperforms the compared methods for the used datasets(Fig. 5). Indeed, the multi-view stereo reconstructionresulting from the use of the proposed solution is muchmore precise and smooth, although our method is fullyautomated contrary to the compared methods (which requirethresholds setting). This is mainly because of the proposedfuzzy adaptive hysteresis thresholding, which enforcessmoothness and spatial coherence during volumereconstruction. In particular, ‘floating voxels’ and holes areclearly minimised by the proposed method along the voxelcolouring procedure, especially for the dino dataset despitethe lack of texture. In fact, the only texture in this sequencewas because of subtle shading variations on the surface.As natural objects, we used the standard dataset ‘Rose’ [48]
composed of 31 images of size 640 × 480, such that we arelimited on the first 15 images in order to respect the ordinalvisibility constraint of voxel colouring (Fig. 6a). In spite ofthe complex shape of the filmed object, the proposed
720& The Institution of Engineering and Technology 2013
method avoids clearly the holes in the reconstructed model(Fig. 6b). However, the proposed method misses precisionon this sequence. This is mainly because of the fact thatmany voxels (e.g. the rose back) are not visible in the inputviews since we use a reduced number of inputs, in order torespect the ordinal visibility constraint.Besides, the performance of the proposed method was
evaluated objectively on ‘Temple’ and ‘Dino’ datasets,through the ground truth of the Middlebury multi-viewdataset. To do it, we followed the methodology described in[47], which considers metrics on both accuracy andcompleteness of the 3D reconstruction. Indeed,reconstructions are evaluated by geometric comparison withthe ground truth model. The ground truth model is denotedas G and the reconstructed model, subject of the evaluation,is denoted as R. To measure the accuracy of areconstruction (how close R is to G), the distance betweenthe points in R and the nearest points on G is computed. Tomeasure the completeness (how much of G is modelled byR), the distances from G to R are computed (i.e. theopposite of what is done for measuring the accuracy).
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
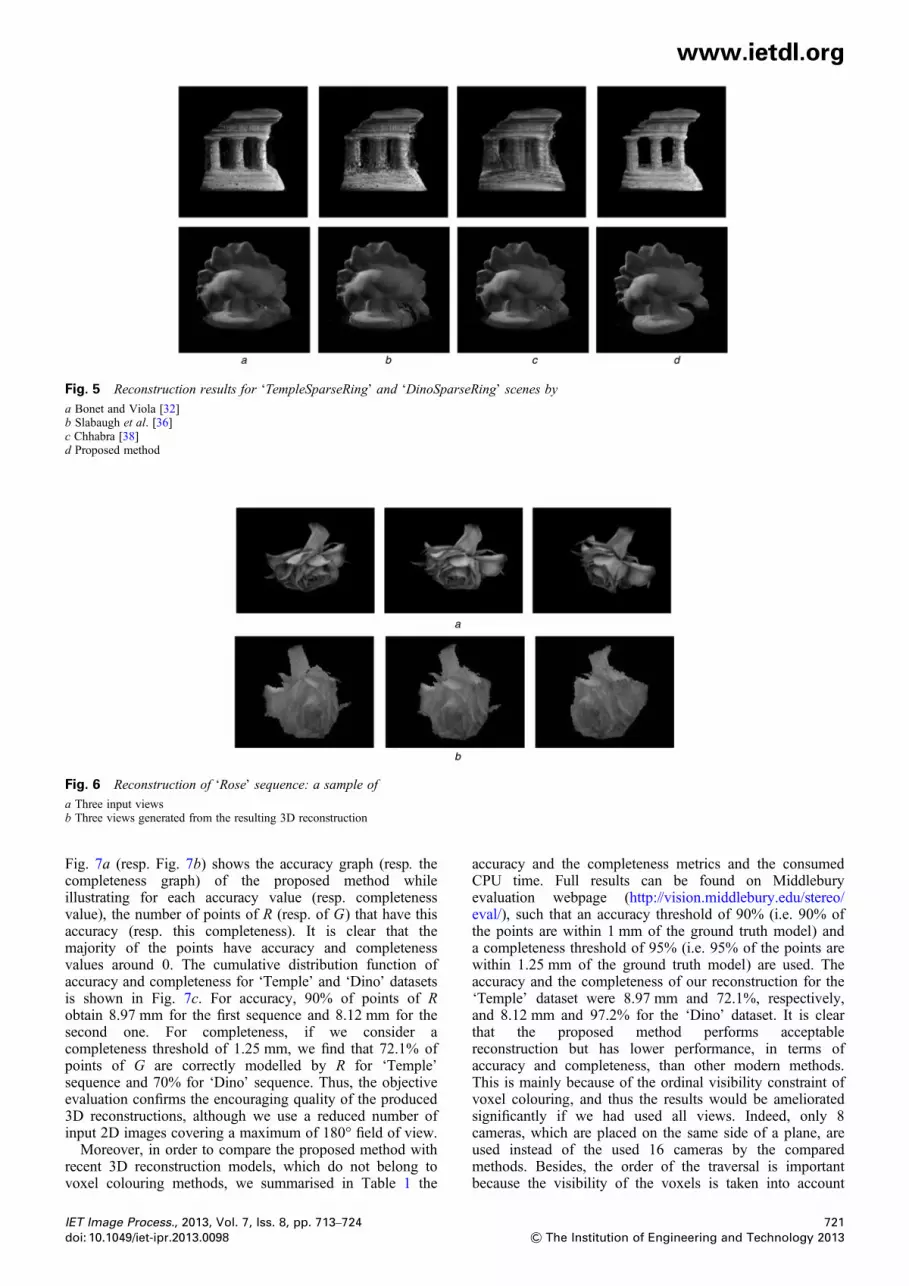
Fig. 6 Reconstruction of ‘Rose’ sequence: a sample of
a Three input viewsb Three views generated from the resulting 3D reconstruction
Fig. 5 Reconstruction results for ‘TempleSparseRing’ and ‘DinoSparseRing’ scenes bya Bonet and Viola [32]b Slabaugh et al. [36]c Chhabra [38]d Proposed method
www.ietdl.org
Fig. 7a (resp. Fig. 7b) shows the accuracy graph (resp. thecompleteness graph) of the proposed method whileillustrating for each accuracy value (resp. completenessvalue), the number of points of R (resp. of G) that have thisaccuracy (resp. this completeness). It is clear that themajority of the points have accuracy and completenessvalues around 0. The cumulative distribution function ofaccuracy and completeness for ‘Temple’ and ‘Dino’ datasetsis shown in Fig. 7c. For accuracy, 90% of points of Robtain 8.97 mm for the first sequence and 8.12 mm for thesecond one. For completeness, if we consider acompleteness threshold of 1.25 mm, we find that 72.1% ofpoints of G are correctly modelled by R for ‘Temple’sequence and 70% for ‘Dino’ sequence. Thus, the objectiveevaluation confirms the encouraging quality of the produced3D reconstructions, although we use a reduced number ofinput 2D images covering a maximum of 180° field of view.Moreover, in order to compare the proposed method with
recent 3D reconstruction models, which do not belong tovoxel colouring methods, we summarised in Table 1 the
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
accuracy and the completeness metrics and the consumedCPU time. Full results can be found on Middleburyevaluation webpage (http://vision.middlebury.edu/stereo/eval/), such that an accuracy threshold of 90% (i.e. 90% ofthe points are within 1 mm of the ground truth model) anda completeness threshold of 95% (i.e. 95% of the points arewithin 1.25 mm of the ground truth model) are used. Theaccuracy and the completeness of our reconstruction for the‘Temple’ dataset were 8.97 mm and 72.1%, respectively,and 8.12 mm and 97.2% for the ‘Dino’ dataset. It is clearthat the proposed method performs acceptablereconstruction but has lower performance, in terms ofaccuracy and completeness, than other modern methods.This is mainly because of the ordinal visibility constraint ofvoxel colouring, and thus the results would be amelioratedsignificantly if we had used all views. Indeed, only 8cameras, which are placed on the same side of a plane, areused instead of the used 16 cameras by the comparedmethods. Besides, the order of the traversal is importantbecause the visibility of the voxels is taken into account
721& The Institution of Engineering and Technology 2013
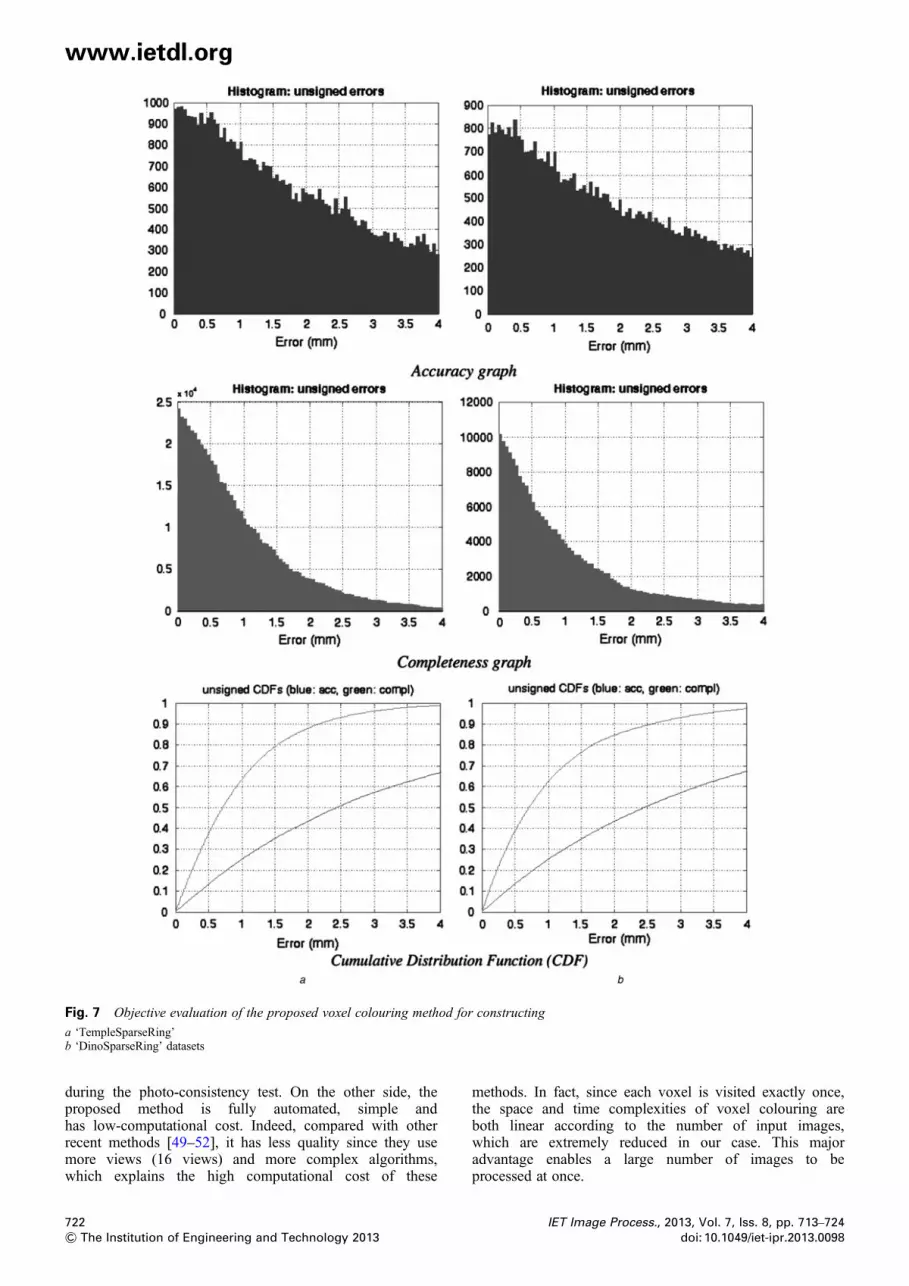
Fig. 7 Objective evaluation of the proposed voxel colouring method for constructing
a ‘TempleSparseRing’b ‘DinoSparseRing’ datasets
www.ietdl.org
during the photo-consistency test. On the other side, theproposed method is fully automated, simple andhas low-computational cost. Indeed, compared with otherrecent methods [49–52], it has less quality since they usemore views (16 views) and more complex algorithms,which explains the high computational cost of these
722& The Institution of Engineering and Technology 2013
methods. In fact, since each voxel is visited exactly once,the space and time complexities of voxel colouring areboth linear according to the number of input images,which are extremely reduced in our case. This majoradvantage enables a large number of images to beprocessed at once.
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098

Table 1 Objective comparison of the proposed methodagainst modern reconstruction models (which are not voxelcolouring methods)
TempleSparseRing DinoSparseRing
proposed method 8.97, 72.1%, 310 8.12, 70.0%, 375Vogiatzis et al. [43] 2.77, 79.4%, 2423 1.18, 90.8%, 2461Tran and Davis [29] 1.53, 85.4%, 8400 1.26, 89.3%, 10 079
First number x.xx measures accuracy: the distance d (in mm)such that 90% of the reconstruction is within d of the groundtruth mesh (GTM). The second number xx.x% specifiescompleteness: the percentage of points on the GTM that arewithin 1.25 mm of the reconstruction. The third number is thenormalised runtime (in s) at processor frequency of 3 GHz
www.ietdl.org
5 Conclusion
We have presented in this paper a new automatedphoto-consistency test for voxel colouring that recoverssurfaces at high resolution by using adaptive fuzzyhysteresis thresholding. This thresholding added geometricinformation by using hysteresis which considers theconnectedness of coloured voxels. Besides, the fuzzydefinition of homogeneity allows us to overcomeuser-defined thresholds. Indeed, we introduced an adaptivethresholding depending on the number of images the voxelis projected onto. Thus, in addition to the implicitintegration of the spatial coherence thanks to hysteresisthresholding, the main contribution of the suggested methodresides in the fact that it can search the optimal thresholdsby itself. Indeed, although we just use few input imagescovering a maximum of 180° field of view, thereconstructed models are precise and smooth and can matchwith the real objects and scenes to some extent. Inparticular, holes, noises and floating voxels are well treated.However, voxel colouring cannot produce completereconstruction because of the ordinal visibility constraint.One can solve this by adding input images that show these‘missing’ parts, but introducing these extra camera positionswill violate the ordinal visibility constraint of voxelcolouring. The only solution to this is to use algorithmssuch as generalised voxel colouring (GVC) [21] and spacecarving (SC) [31] that do not have this constraint. In fact,since GVC and SC handle arbitrary camera configurationsto have complete reconstruction, we will investigate, infuture works, whether the application of our technique onGVC and SC will enforce the completeness and theaccuracy of the reconstructed models.
6 Acknowledgments
The authors would like to acknowledge helpful discussionswith Daniel Scharstein and Koen Van de Sande. Prof.Scharstein, Middlebury College, performed numericalevaluation of our reconstructions and Dr. Van de Sande,University of Amsterdam, helped us in converting resultsfrom voxels to triangle meshes.
7 References
1 Adipranata, R., Soo, Y.T.: ‘3D object reconstruction using voxelcoloring with mean charts color consistency checking’. Proc. Int.Conf. Advances in Computer Science and Technology, Phuket,Thailand, April 2007, pp. 206–211
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098
2 Nehab, D., Rusinkiewicz, S., Davis, J., Ramamoorthi, R.: ‘Efficientlycombining positions and normals for precise 3D geometry’, ACMTrans. Graph., 2005, 24, (3), pp. 536–543
3 Harker, M., O’Leary, P.: ‘Least squares surface reconstruction frommeasured gradient fields’. Proc. Int. Conf. Computer Vision andPattern Recognition, Anchorage, USA, June 2008, pp. 1–7
4 Park, M., Brocklehurst, K., Collins, R.T., Liu, Y.: ‘Deformed latticedetection in real-world images using mean-shift belief propagation’,IEEE Trans. Pattern Anal. Mach. Intell., 2009, 31, (10), pp. 1804–1816
5 White, R., Crane, K., Forsyth, D.A.: ‘Capturing and animating occludedcloth’, ACM Trans. Graph., 2007, 26, (3), pp. 341–348
6 Favaro, P., Soatto, S.: ‘3-D shape estimation and image restoration:exploiting defocus and motion-blur’ (Springer, 2007)
7 Ivanchenko, V., Shen, H., Coughlan, J.: ‘Elevation-based stereoimplemented in real-time on a GPU’. Proc. IEEE Workshop onApplications ofComputerVision, Snowbird,USA,December 2009, pp. 1–8
8 Furukawa, Y., Ponce, J.: ‘Carved visual hulls for image-basedmodeling’, Int. J. Comput. Vis., 2009, 81, (1), pp. 53–67
9 Goesele, M., Curless, B., Seitz, S.: ‘Multi-view stereo revisited’. Proc.Int. Conf. Computer Vision and Pattern Recognition, New York,USA, June 2006, pp. 2402–2409
10 Seitz, S., Dyer, C.: ‘Photorealistic scene reconstruction by voxelcoloring’. Proc. Int. Conf. Computer Vision and Pattern Recognition,San Juan, Puerto Rico, June 1997, pp. 1067–1073
11 Kiriakos, N., Kutulakos, K., Seitz, S.: ‘A theory of shape by spacecarving’, Int. J. Comput. Vis., 2000, 38, (3), pp. 198–218
12 Pons, J.P., Keriven, R., Faugeras, O.: ‘Multi-view stereo reconstructionand scene flow estimation with a global image-based matching score’,Int. J. Comput. Vis., 2007, 72, (2), pp. 179–193
13 Banno, A., Masuda, T., Oishi, T., Ikeuchi, K.: ‘Flying laser range sensorfor large-scale site-modeling and its applications in Bayon digitalarchival project’, Int. J. Comput. Vis., 2008, 78, (2), pp. 207–222
14 Davis, J., Nahab, D., Ramamoorthi, R., Rusinkiewicz, S.: ‘Space-timestereo: a unifying framework for depth from triangulation’,IEEE Trans. Pattern Anal. Mach. Intell., 2005, 27, (2), pp. 296–302
15 Szeliski, R.: ‘A multi-view approach to motion and stereo’. Proc. Int.Conf. Computer Vision and Pattern Recognition, Ft. Collins, USA,June 1999, pp. 157–163
16 Kang, S.B., Szeliski, R.: ‘Extracting view-dependent depth maps from acollection of images’, Int. J. Comput. Vis., 2004, 58, (2), pp. 139–163
17 Martin, W.N., Aggarwal, J.K.: ‘Volumetric descriptions of objects frommultiple views’, IEEE Trans. Pattern Anal. Mach. Intell., 1983, 5, (2),pp. 150–158
18 Srinivasan, P., Liang, P., Hackwood, S.: ‘Computational geometricmethods in volumetric intersection for 3D reconstruction’, PatternRecognit., 1990, 23, (8), pp. 843–857
19 Liu, X., Yao, H., Chen, Y., Gao, W.: ‘An active volumetric model for 3Dreconstruction’. Proc. Int. Conf. Computer Image Processing, Genoa,Italy, September 2005, pp. 101–104
20 Seitz, S., Dyer, C.: ‘Photorealistic reconstruction by voxel coloring’,Int. J. Comput. Vis., 1999, 35, (2), pp. 1067–1073
21 Kutulakos, K.: ‘Approximate N-view stereo’. Proc. Euro. Conf.Computer Vision, Dublin, Ireland, June 2000, pp. 67–83
22 Leung, C., Lovell, B.C.: ‘3D reconstruction through segmentation ofmulti-view image sequences’. Proc. Int. Workshop on Digital ImageComputing, Brisbane, Australia, February 2003, pp. 87–92
23 Bakkay, M.C., Barhoumi, W., Zagrouba, E.: ‘Seuillage par hystérésispour le test de photo-consistance des voxels dans le cadre de lareconstruction 3D’. Proc. Magh. Conf. Extraction et de Gestion desConnaissances, Hammamet, Tunisia, November 2012, pp. 1–3
24 Culbertson, W.B., Malzbender, T., Slabaugh, G.G.: ‘Generalized voxelcoloring’. Proc. Int. Conf. Computer Vision, Corfu, Greece, September1999, pp. 100–115
25 Broadhurst, A., Drummond, T., Cipolla, R.: ‘A probabilistic frameworkfor space carving’. Proc. Int. Conf. Computer Vision, Vancouver,Canada, July 2001, pp. 388–393
26 Bhotika, R., Fleet, D., Kutulakos, K.: ‘A probabilistic theory ofoccupancy and emptiness’. Proc. Euro. Conf. Computer Vision,Copenhagen, Denmark, May 2002, pp. 112–130
27 Broadhurst, A., Cipolla, R.: ‘A statistical consistency check for the spacecarving algorithm’. Proc. Brit. Machine Vision Conf., Bristol, UK,September 2000, pp. 282–291
28 Agrawal, M., Davis, L.S.: ‘A probabilistic framework for surfacereconstruction from multiple images’. Proc. Int. Conf. Computer Visionand Pattern Recognition, Kauai, USA, December 2001, pp. 470–476
29 Tran, S., Davis, L.S.: ‘3D surface reconstruction using graph cuts withsurface constraints’. Proc. Euro. Conf. Computer Vision, Graz,Austria, May 2006, pp. 219–231
30 Sinha, S., Pollefeys, M.: ‘Multi-view reconstruction usingphoto-consistency and exact silhouette constraints: a maximum-flow
723& The Institution of Engineering and Technology 2013

www.ietdl.org
formulation’. Proc. Int. Conf. Computer Vision, Beijing, China, October2005, pp. 349–35631 Slabaugh, G.G., Schafer, R.W., Hans, M.C.: ‘Image-based photo hullsfor fast and photo-realistic new view synthesis’, Real-Time Imaging,2003, 9, (5), pp. 347–360
32 Bonet, J.S.D., Viola, P.A.: ‘Roxels: responsibility weighted 3D volumereconstruction’. Proc. Int. Conf. Computer Vision, Corfu, Greece,September 1999, pp. 418–425
33 Zýka, V., Sára, R.: ‘Polynocular image set consistency for local modelverification’. Proc. Workshop of the Austrian Association for PatternRecognition, Villach, Austria, May 2000, pp. 81–88
34 Slabaugh, G.G., Schafer, R.W., Malzbender, T., Culbertson, W.B.: ‘Asurvey of methods for volumetric scene reconstruction methods fromphotographs’. Proc. Int. Conf. Volume Graphics, New York, USA,June 2001, pp. 81–101
35 Steinbach, E., Eisert, P., Girod, B., Betz, A.: ‘3-D object reconstructionusing spatially extended voxels and multi-hypothesis voxel coloring’.Proc. Int. Conf. Pattern Recognition, Barcelona, Spain, September2000, pp. 774–777
36 Slabaugh, G.G., Culbertson, W.B., Malzbender, T., Stevens, M.R.,Schafer, R.W.: ‘Methods for volumetric reconstruction of visualscenes’, Int. J. Comput. Vis., 2004, 57, (3), pp. 179–199
37 Stevens, M., Culbertson, B., Malzbender, T.: ‘A histogram-based colorconsistency test for voxel coloring’. Proc. Int. Conf. PatternRecognition, Quebec, Canada, August 2002, pp. 118–121
38 Chhabra, V.: ‘Reconstructing specular objects with image basedrendering using color caching’. PhD thesis, Worcester PolytechnicInstitute, 2001
39 Yang, R., Pollefeys, M., Welch, G.: ‘Dealing with textureless regionsand specular highlight: a progressive space carving scheme using anovel photo-consistency measure’. Proc. Int. Conf. Computer Vision,Nice, France, October 2003, pp. 576–584
40 Shen, Y.: ‘Efficient normalized cross correlation calculation method forstereo vision based robot navigation’, Front. Comput. Sci. China, 2011,5, (2), pp. 227–235
724& The Institution of Engineering and Technology 2013
41 Hornung, A., Kobbelt, L.: ‘Robust and efficient photo-consistencyestimation for volumetric 3D reconstruction’. Proc. Euro. Conf.Computer Vision, Graz, Austria, May 2006, pp. 179–190
42 Esteban, C.H.: ‘Stereo and silhouette fusion for 3D object modelingfrom uncalibrated images under circular motion’. PhD thesis, EcoleNationale Supérieure des Télécommunications, 2004
43 Vogiatzis, G., Torr, P., Cipolla, R.: ‘Multi-view stereo via volumetricgraph-cuts’. Proc. Int. Conf. Computer Vision and PatternRecognition, San Diego, USA, June 2005, pp. 391–398
44 Leung, C., Appleton, B., Buckley, M., Sun, C.: ‘Embedded voxelcolouring with adaptive threshold selection using globally minimalsurfaces’, Int. J. Comput. Vis., 2012, 99, (2), pp. 215–231
45 Barhoumi, W., Bakkay, M.C., Zagrouba, E.: ‘An online approach formulti-sprite generation based on camera parameters estimation’, SignalImage Video Process., 2011, 7, (4), pp. 1–11
46 Farin, D., De With, P.H.N.: ‘Automatic video-object segmentationemploying multi-sprites with constrained delay’. Proc. Int. Conf.Consumer Electronics, Berlin, Germany, January 2006, pp. 479–480
47 Seitz, S., Curless, B., Diebel, J., Scharstein, D., Szeliski, R.: ‘Acomparison and evaluation of multi-view stereo reconstructionalgorithms’. Proc. Int. Conf. Computer Vision and PatternRecognition, New York, USA, June 2006, pp. 519–528
48 Van de Sande, K.: ‘A practical setup for voxel coloring usingoff-the-shelf components’. PhD thesis, University of Amsterdam, 2004
49 Chang, J., Park, H., Park, I., Lee, K., Lee, S.: ‘GPU-friendly multi-viewstereo reconstruction using surfel representation and graph cuts’,Computer Vis. Image Underst., 2011, 115, (5), pp. 620–634
50 Deng, Y., Liu, Y., Dai, Q., Zhang, Z., Wang, Y.: ‘Noisy depth mapsfusion for multi-view stereo via matrix completion’, Sel. Top. SignalProcess., 2012, 6, (5), pp. 566–582
51 Guillemaut, J.Y., Hilton, A.: ‘Joint multi-layer segmentation andreconstruction for free-viewpoint video applications’, Int. J. Comput.Vis., 2011, 93, (1), pp. 73–100
52 Liu, Y., Cao, X., Dai, Q., Xu, W.: ‘Continuous depth estimation forMulti-view stereo’. Proc. Int. Conf. Computer Vision and PatternRecognition, Miami, USA, June 2009, pp. 2121–2128
IET Image Process., 2013, Vol. 7, Iss. 8, pp. 713–724doi: 10.1049/iet-ipr.2013.0098




























