Embed Size (px)
Citation preview

AUTOMATED ESSAY MARKING TOOL FOR ESL WRITING BASED ON HEURISTICS
Nazlia Omar
Universiti Kebangsaan Malaysia Malaysia
Nur Asma Mohd Razali Universiti Kebangsaan Malaysia
Malaysia [email protected]
Saadiyah Darus Universiti Kebangsaan Malaysia
Malaysia [email protected]
Abstract
Although computers and artificial intelligence have been proposed as tools to facilitate the evaluation of student essays, they are not specifically developed for Malaysian ESL (English as a second language) learners. A marking tool which is specifically developed to analyze errors in ESL writing is very much needed. Though there are numerous techniques adopted in automated essay marking, research on the formation and use of heuristics to aid the construction of computer-based essay marking system has been scarce. Thus, this paper aims to introduce new heuristics that can be used to mark essays automatically and detect grammatical errors in tenses. This approach, which uses natural language processing technique, can be applied as part of the software requirement for a CBEM (Computer Based Essay Marking) system for ESL learners. The preliminary result based on the training set shows that the heuristics are useful and can improve the effectiveness of automated essay marking tool for writing in ESL.
Keywords Computer based essay marking system, heuristics, errors and ESL writing, natural language processing
1. INTRODUCTION English has become a language for communication worldwide and it has been enrolled as part of courses in university. While writing is a good way to stimulate learning and critical thinking, writing skill is considered a very important skill, since it is a way to get the message across. Writing essays enables students to create avenues for their voices to be heard through communication particularly in writing. However, marking essays manually is an overwhelming task and time consuming for educators [1], especially when the size of the class increases. Larger classes reduce opportunities for learners’ feedback on written work and learners in turn may have little contact with their lecturers. A study carried out by Darus et al. [3, 4, 5] shows that students prefer to receive feedback on errors in essay and their type [2], coherence of the text and organization of ideas. In Malaysian educational context, English is used as a second language (ESL). ESL learners are those learners whose English is not their primary or first language (L1) but they are fairly able to write, read, speak or understand English. This paper aims to facilitate the task of essay marking especially to Malaysian ESL learners by automating the marking process. The task focuses on the identification of the grammatical errors in tenses made by the learners. Though there are numerous techniques adopted in automated essay marking, research on the formation and use of heuristics to aid the construction of computer-based

essay marking system has been scarce. Thus, this paper aims to introduce new heuristics that can be used to mark essays automatically and detect grammatical errors in tenses.
2. RELATED RESEARCH The use of computers and media for language learning and teaching has become two disciplines, known as computer-assisted language learning (CALL) and intelligent CALL (ICALL). Past research in the area of CALL and ICALL has shown that using technology can enhance the ability of student to communicate and learn. Artificial Intelligence and natural language processing techniques offer many possibilities to improve CALL systems. However, the application of these technologies is not adequate and still requires more research. In this paper, research prototypes that explore an automatic analysis of grammatical ESL writing and supplying meaningful feedback are reviewed.The research prototypes discussed here touch some of the new possibilities and directions for future investigations.
Two Distance Applications Support English Distance Learning [6] is a system that was developed through multimedia database and Internet Technologies called English multimedia corpus. English articles, dialogs, and videos are included in the system. To construct English multimedia corpus, semantic query and Link grammar are applied during implementation of the system. The system concentrated to teach English grammar and allowed teachers to understand the most frequent mistakes. The main function of this system is to query the English sentence pattern through keywords from the English multimedia corpus. The second function is to detect grammatical errors in written English.
A Rule-Based Style and Grammar Checker [7] is a project aimed to provide an Open Source style and grammar checker for the English language. This tool uses Rule-based checking technique. In this approach, the system generates a text and returns a list of possible error. For its purposes, each of the word in the text is assigned its part-of-speech tag and each sentence is split into chunks, e.g. noun phrase. The parsing results are processed further by matching all the checker’s pre-defined error rules. If a rule is matches, the text is supposed to contain error at the position of the match. Each rule includes an explanation of error and is shown to user.
A Sentence Analyzer and Viewer for Detecting Grammatical Errors [8] is a system that aims to identify grammatical errors in a sentence and has been implemented using Prolog language. In English, agreement is required for every sentence at the clause and noun-phrase levels. This system is able to detect agreement errors in sentence and display helpful messages to learners. The tool uses a few of stages in natural language processing which accesses tokenization, lexical analysis and syntactic analysis to analyze the learners’ input.
English Grammar Checking [9] is a system that applied Artificial Immune System (AIS) based technique as an approach for grammar checking. The motivation of the study comes from human immune system, which is able to identify external harmful entity from the self cells in human body. This grammar checker has been implemented using JAVA. It uses Reuters-21578, Distribution 1.0 text as a corpus and is tagged for part of speech by using MontyLingua parser. It can detect any grammatical construct outside the corpus and identify it as an error.
GRADES [10] is Grammar Diagnostic Expert System that can detect and explain grammatical errors of non-native speakers. It is designed to diagnose errors found by native Japanese adult who are learning ESL. It contains small lexicon of words and can be expanded easily. GRADES diagnosis through a classification process where an error category is considered and pattern matching rules are used. An explanation is generated to help the user learn why the sentence is ungrammatical.
3. LINGUISTIC ANALYSIS OF ESL WRITING
Ferris [11] has pointed out that written errors made by adult second language learners are often quite different from those made by NES (Native English Speakers). Common ESL writing errors are morphological errors, lexical errors, syntactic errors and mechanical errors. Truscott [12] noted that different types of errors may need varying treatment in terms of error correction. In addition, lecturers need to understand that different students may make distinct types of errors and they should understand to prioritize error feedback for individual students. Lim Ho Peng [13] produced a classification scheme of errors that were displayed by Malaysian high school students and the result of the error analysis is shown in Table 1.

Errors Examples
Tense One of them went in and steal a chain. Articles He ran to the Ahmad’s house right away. Agreement Azman do not know anything about it. Infinitive When it began moved I heard a sound. Pronouns He told she about his village. Word Order What work I must do? Negative Constructions She had not brother to take care of her. Lexical The noise was on our back. Mechanics It was quite far form my village. Use of Typical Malaysian Words I dapati that the cat was outside the house.
Table 1. Types of errors in ESL essays
3.1 Analysis of Errors 400 written essays by undergraduate students who enrolled in Written Communication course at the School of Language Studies and Linguistic, Faculty of Social Sciences and Humanities, Universiti Kebangsaan Malaysia were gathered. Markin 3.1 [14] was used to speed up the process of analyzing the essays of errors. The annotation buttons in the software are first customized accordingly based on
the error classification scheme. Markin 3.1 is a correction tool that allows instructors to mark written work submitted by students in the form of electronic documents. Markin 3.1 provides five marking facilities; annotation buttons, add feedback, add comment, add a grade, and compile error statistics. Figure 1 shows the marked essays using Markin 3.1.
Fig. 1. Original marked essays using Markin 3.1

3.2 Results on Error Analysis
The results on the error analysis using Markin 3.1 software is as shown in Table 2. The average is calculated by dividing the number of errors with the total numbers of essays. Six most common errors that are made by learners are as follows: tenses, prepositions, articles, word choice, mechanics, and verb to be. Based on the result of the analysis, it seems that the most errors that need to be analyzed by the error analysis marking tool are tenses.
Errors No. of errors Average
1. Tense 1595 3.99
2. Articles 1204 3.01
3. Subject verb agreement 631 1.58
4. Other agreement errors 520 1.30
5. Infinitive 145 0.36
6. Gerunds 292 0.73
7. Pronouns 696 1.74
8. Possessive and attributive 232 0.58
9. Word order 194 0.49
10. Incomplete structures 253 0.63
11. Negative construction 56 0.14
12. Prepositions 1468 3.67
13. Mechanics 1105 2.76
14. Miscellaneous unclassifiable 1117 2.79
15. Word choice 1123 2.81
16. Word form 629 1.57
17. Verb to be 820 2.05
Table 2. Result of error analysis
4. AUTOMATED ESSAY MARKING TOOL BASED ON HEURISTICS The next step in this study is the development of techniques and algorithm for detecting and analyzing tense error in learners’ essays. Based on these algorithms, the error-analysis marking tool will be developed. The approach used in the present study is similar to the study carried out by [15]. The heuristics are newly formed and developed based on the observation of essays written by ESL learners at Universiti Kebangsaan Malaysia. The rules of grammar are developed from [16] and details of the heuristics can be found in [17].
4.1 Overview of Heuristics Heuristics enable someone to learn and know something through their own experience [18]. Heuristics represent an indefinite assumption [19] often guided by common sense, to provide good but not necessarily optimal solutions to difficult problems, easily and quickly [20]. Research on the formation and use of heuristics to aid the construction of CBEM system has been scarce. The only existing work that proposes a large number of heuristics to be used in developing CBEM system is Argument Partitioning and Annotation Program (APA) [21]. APA selects the dictionary-based clue words, terms and non-lexical structures. APA uses partition, and annotate arguments specify syntactic structure and syntactic contexts. APA uses parsed essays to identify syntactic structure in essays.

Heuristic to identify error in simple present tense: If noun or pronoun is in the set of heuristic Simple Present 1, check all verbs after each noun. If verb is tagged as VB, the sentence has no grammatical error. You neglect your diet and take many unhealthy foods to release your tension.
You/PRP neglect/VB your/PRP$ diet/NN and/CC take/VB many/JJ unhealthy/JJ foods/NNS to/TO release/VB your/PRP$ tension/NN ./. Note that “You” is a pronoun and “neglect” is tagged as VB, so the sentence has no grammatical error. The example above illustrates this heuristic. Heuristic to identify error in present progressive: If noun or pronoun is in the set of heuristic Present Progressive 3 followed by ‘are’, check the verb. If verb is tagged as VBG, the sentence has no grammatical error. People are collecting the rubbish at Taman Negara. People/NNS are/VBP collecting/VBG the/DT rubbish/NN at/IN Taman/NNP /. / In this example, the noun ‘people’ is followed by ‘are’ and the verb ‘collecting’ is tagged VBG, so the sentence has no grammatical error. Heuristic to identify error in simple future: If noun or pronoun is in the set of heuristic Simple Future 1 followed by ‘will’, or “shall”, check the verb. If verb is tagged as VB, the sentence has no grammatical error. The staff will write the letters later. The/DT staff/NN will/MD write/VB the/DT letters/NNS later/RB /./ “Staff” is tagged as noun and followed by “will”, the immediate verb is tagged as VB, so this sentence has no grammatical error.
4.1. Results on training data set A manual test was carried out to test the new heuristics. Thirty writing samples were selected as the training dataset. Table 3 presents the results on the training dataset. Among the 30 writing samples, only Essay no. 10 and no. 13 have low percentage correctness. Most of these errors resulted from passive sentence and the use of modal like ‘can’, ‘can not’, ‘can not be’ and ‘will not be’ in the essays. The overall percentage of correctness of the training data set is 84%. This indicates that heuristics-rule based approach is viable and can be selected for the implementation.

Essays Detect error in tenses
Yes No Percentage correctness
1 5 0 100%
2 4 2 67%
3 6 0 100%
4 2 0 100%
5 5 0 100%
6 3 0 100%
7 4 0 100%
8 3 0 100%
9 4 2 67%
10 3 3 50%
11 6 0 100%
12 3 1 75%
13 2 2 50%
14 3 1 75%
15 4 0 100%
16 5 1 83%
17 2 0 100%
18 2 0 100%
19 3 0 100%
20 3 2 60%
21 5 1 83%
22 4 1 80%
23 4 0 100%
24 6 2 75%
25 4 1 80%
26 5 0 100%
27 3 1 75%
28 4 2 67%
29 3 2 60%
30 4 1 80%
Average 84%
Table 3. Result on training dataset
5. SYSTEM OVERVIEW The automated marking tool architecture mainly consists of two stages: the natural language stage and the logical stage. The natural language stage comprises of parsing the natural language input. Natural language processing is involved in the process of reading natural language input (in the form of essays) into the system. The process begins by reading a plain input text file containing sentences written in English. For this purpose, a parser is used to parse the English sentences to obtain their part-of-speech (POS) tags before processing further. POS assigns each word in an input sentence into its proper part of speech such as noun, verb and determiner to reflect the word’s syntactic category [22]. The parser used is Memory-based Shallow Parser (MBSP) [23, 24]. The parsed text is then being
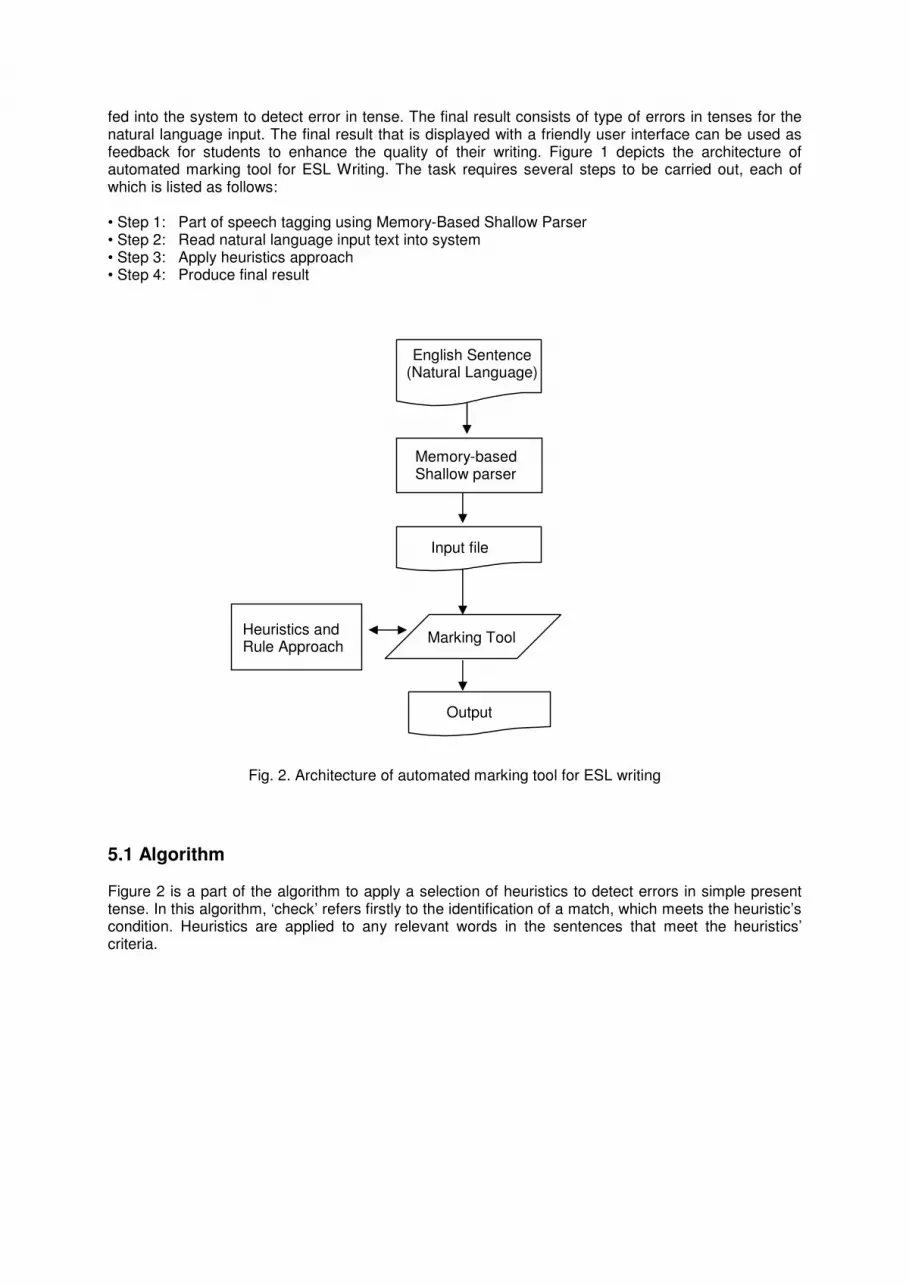
fed into the system to detect error in tense. The final result consists of type of errors in tenses for the natural language input. The final result that is displayed with a friendly user interface can be used as feedback for students to enhance the quality of their writing. Figure 1 depicts the architecture of automated marking tool for ESL Writing. The task requires several steps to be carried out, each of which is listed as follows: • Step 1: Part of speech tagging using Memory-Based Shallow Parser • Step 2: Read natural language input text into system • Step 3: Apply heuristics approach • Step 4: Produce final result
Fig. 2. Architecture of automated marking tool for ESL writing
5.1 Algorithm Figure 2 is a part of the algorithm to apply a selection of heuristics to detect errors in simple present tense. In this algorithm, ‘check’ refers firstly to the identification of a match, which meets the heuristic’s condition. Heuristics are applied to any relevant words in the sentences that meet the heuristics’ criteria.
English Sentence (Natural Language)
Memory-based Shallow parser
Output
Input file
Heuristics and Rule Approach
Marking Tool

Fig. 2. Extract from the algorithm for heuristics to detect error in Simple Present Tense
6. CONCLUSION AND FUTURE WORK
We have described an approach of developing an automated marking tool for tenses for ESL writing. Based on the observation of English sentence structure and grammar, the formation of heuristics can be further developed to improve the accuracy of the result. For future work, weights may need to be assigned to each of the heuristic in order to support the level of confidence of each of the heuristics. The next step is the development of algorithm based on the heuristics and rules-based approach for detecting errors in learners’ essays. Based on these algorithms, the automated marking tool will be developed. Acknowledgement: This study is funded by MOSTI (Ministry of Science, Technology and Innovation, Malaysia) with the following research code: e-ScienceFund 01-01-02-SF0092.
1. FOR each sentence in parsed and tagged text file, DO;
2. FOR each sentence, DO;
2.1 IF word is of type ‘noun’ DO; IF noun is in the set of heuristic Simple Present 1, IF noun is tagged as NNS, check the immediate verb after the noun. IF verb is tagged as VBP or VB, print the following sentence: The sentence has no grammatical error. IF noun is tagged as PRPplural, check the immediate verb after the noun. IF verb is tagged as VBP or VB, print the following sentence: The sentence has no grammatical error. IF noun is in the set of heuristic Simple Present 2, IF noun is tagged as NN, check the immediate verb after the noun. IF verb is tagged as VBZ, print the following sentence: The sentence has no grammatical error. IF noun is tagged as NNP, check the immediate verb after the noun. IF verb is tagged as VBZ, print the following sentence: The sentence has no grammatical error. IF noun is tagged as PRPsingular, check the immediate verb after the noun. IF verb is tagged as VBZ, print the following sentence: The sentence has no grammatical error. IF noun is in the set of heuristic Simple Present 3, IF noun is tagged as NNS followed by ‘do’ or ‘do not’, check the immediate verb after ‘do’ or ‘do not’. IF verb is tagged as VBP or VB, print the following sentence: The sentence has no grammatical error.

References
[1] Page, E.B. Computer grading of student prose - Using modern concept and software, Journal of Experimental Education, 62:127-142, 1994.
[2] James, C. Errors in Language Learning and Use -Exploring Error Analysis, Harlow, Essex: Addison Wesley Longman Limited, 1998.
[3] ] Darus, S., Hussin, S and Stapa, S.H. Students’ expectations of a computer-based essay marking system, In J. Mukundan (Ed.), Reflections, visions & dreams of practice: Selected papers from the IEC 2002 International Education Conference, Kuala Lumpur, Malaysia: ICT Learning Sdn Bhd, , pp. 197-204, 2001.
[4] Darus, S. A prospect of automatic essay marking, International Seminar on Language in the Global Context: Implications for the Language Classroom, RELC, Singapore, 1999.…….
[5] Darus, S., Stapa, S.H., Hussin, S and Koo, Y. L. A Survey of Computer-Based Essay Marking (CBEM) Systems. Proceedings of the International Conference on Education and ICT in the New Millennium, Universiti Putra Malaysia: Faculty of Educational Studies, ISBN: 983-2255-08-2,. pp. 519-529, 2000.
[6] Ying, H.W., Chih, H.L. Two Intelligent Applications Supports English Distance Learning, Proceedings of the 23 rd International Conference on Distributed Computing Systems Workshop, 2003.
[7] Naber, D. A Rule Based Style and Grammar Checker, Diplomarbeit Thesis, Universitat Bielefeld, 2003.
[8] Amoah, P, Lupiana, R, Ghemri, L. A Sentence Analyzer and Viewer for Detecting Grammatical Errors. Texas Southern University Research Week 2006. 2006.
[9] Kumar, A and Nair, S. An Artificial Immune System Based Approach for English Grammar Checking, ICARIS 2007, LNCS 4628, 2007, pp. 348-357.
[10] Fox, R. and Bowden, M. Automated Diagnosis of Non-Native English Speaker’s Natural Language, Proceeding of the 14
th IEEE International Conference on Tools with Artificial Intelligent
(ICTA’02), 2002, pp. 301-306. [11] Ferris, D. Treatment of error in second language student writing, Ann Arbor: The University
Michigan Press, 2002. [12] Truscott, J, The case against grammar correction in L2 writing classes, Language Learning, 1996,
pp. 327-369. [13] Lim Ho Peng. An error analysis of English compositions written by Malaysian - speaking high
school students, M.A. TESL thesis, University of California, 1974. [14] Holmes, M. Marking student work on the computer, The Internet TESL Journal, 1996.[24] Brill, E.
A Simple Rule-Based Part of Speech Tagger, In: Proceedings of the Third Conference on Applied Natural Language Processing, ACL, Trent, Italy, 1992, pp. 152-155.
[15] Omar, N. Heuristics-Based Entity Relationship Modelling Through Natural Language Processing. PhD Thesis. University of Ulster, UK. 2004.
[16] Noor, N. M and Mustaffa, R. Tatabahasa Inggeris. Utusan Publications & Distribution Sdn Bhd, 2002.
[17] Nur Asma Mohd Razali, Nazlia Omar, Saadiyah Darus, Tg Nor Rizan Tg Mohd Maasum, Mohd Juzaiddin Ab. Aziz. Pendekatan Heuristik dan Peraturan untuk Pemeriksaan Nahu secara Automatik bagi Penulisan Esei Bahasa Inggeris sebagai Bahasa Kedua. Prosiding Persidangan Kebangsaan Sains Pengaturcaraan Atur ’07, in Malay. Pan Pacific KLIA, pp.77-88. 2007.
[18] Kamus Dewan, Dewan Bahasa dan Pustaka, Kuala Lumpur, 2005. [19] Tjoa, A. M and Berger, L. Transformation of requirements Specifications Expressed in Natural
Language into an EER Model, Proceeding of the 12th International Conference on Approach,
Airlington, Texas, USA, 1993, pp. 206-217 [20] Zanakis, S.H. and Evans, J. R. Heuristics ‘Optimization’: Why, When and How to use it,
Interfaces, 1981, pp. 84-91. [21] Burstein, J.C., Braden-Harder, L., S. Chodorow, M., A. Kaplan, B., Kukich, K., Lu, C., A. Rock, D
and Wolff, S. System and method for computer based automatic essay scoring, United State Patent, 2002.
[22] Brill, E. A Simple Rule-Based Part of Speech Tagger, In: Proceedings of the Third Conference on Applied Natural Language Processing, ACL, Trent, Italy, 1992, pp. 152-155.
[23] Daelemans, W., Zavrel, J., Berck, P. and Gillies, S. MBT: A memory-based part of speech tagger generator, In: Ejerhed, E and Dagan, I. (eds.), Of Fourth Workshop on Very Large Corpora, Philadelphia, USA, 1996, pp. 14-27.

[24] Zavrel, J. and Daelemans, W. Recent Advances in Memory-Based Part-of-Speech-Tagging, In: Actas del VI Simposio International de Communication Social, Santiago de Cuba, 1999, pp. 590-597.





























