Embed Size (px)
Citation preview

Resiliencein
Data Management
1

2015 Davide P. Carioni
Resiliency in data management
A case for Redundant Arrays of Inexpensive Disks
when: 1988
where: Chicago
who: D. A. Patterson, G. Gibson, and R. H. Katz
thesis: a top performing mainframe disk drive can be beaten on performance by an array
of inexpensive drives developed for personal computer market.
abstract:
2

2015 Davide P. Carioni
Resiliency in data management
RAID3

2015 Davide P. Carioni
Resiliency in data management
Redundant Arrays of Independent Disks
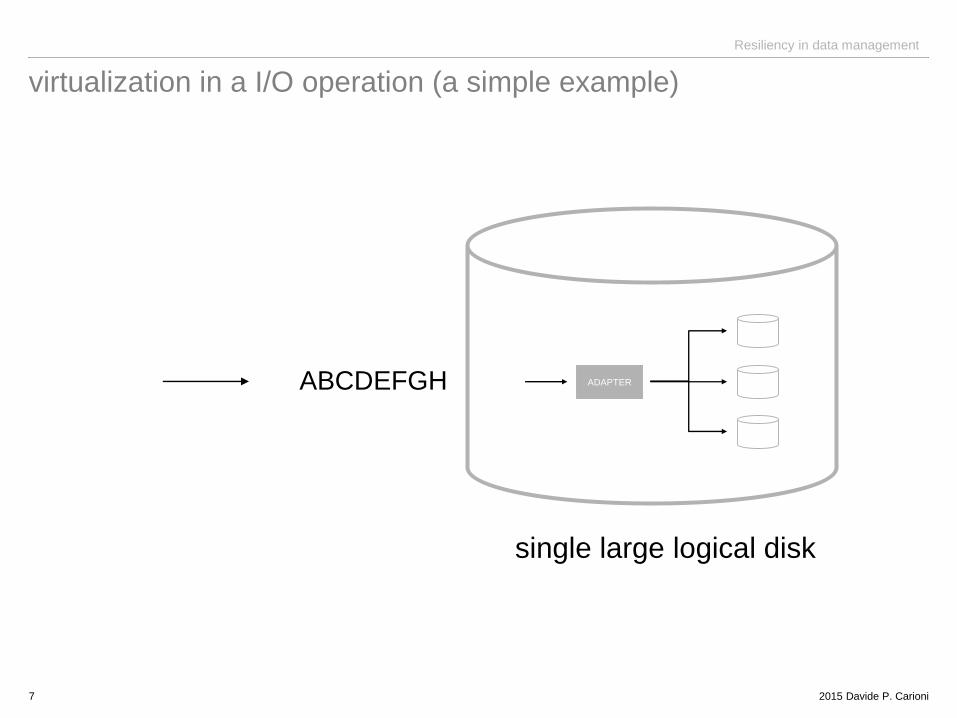
In disks array several independent disks are considered as a single, large, high-
performance logical disk.
The data are striped across several disks accessed in parallel:
• high data transfer rate: large data accesses (heavy I/O op.)
• high I/O rate: small but frequent data accesses (light I/O op.)
• load balancing across the disks
Two orthogonal techniques:
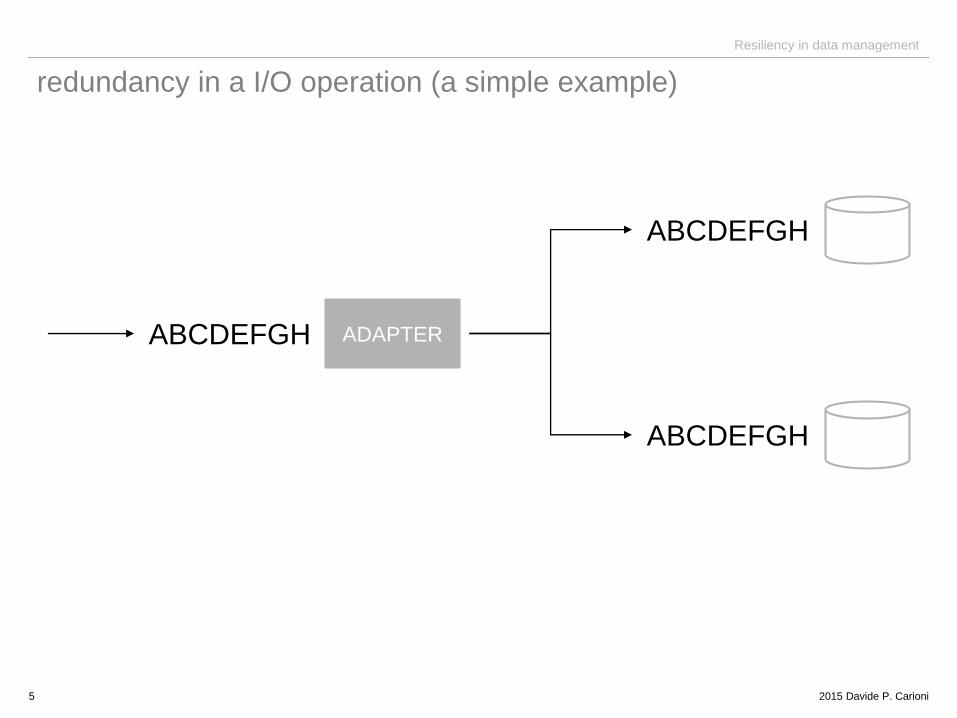
• redundancy: to improve reliability
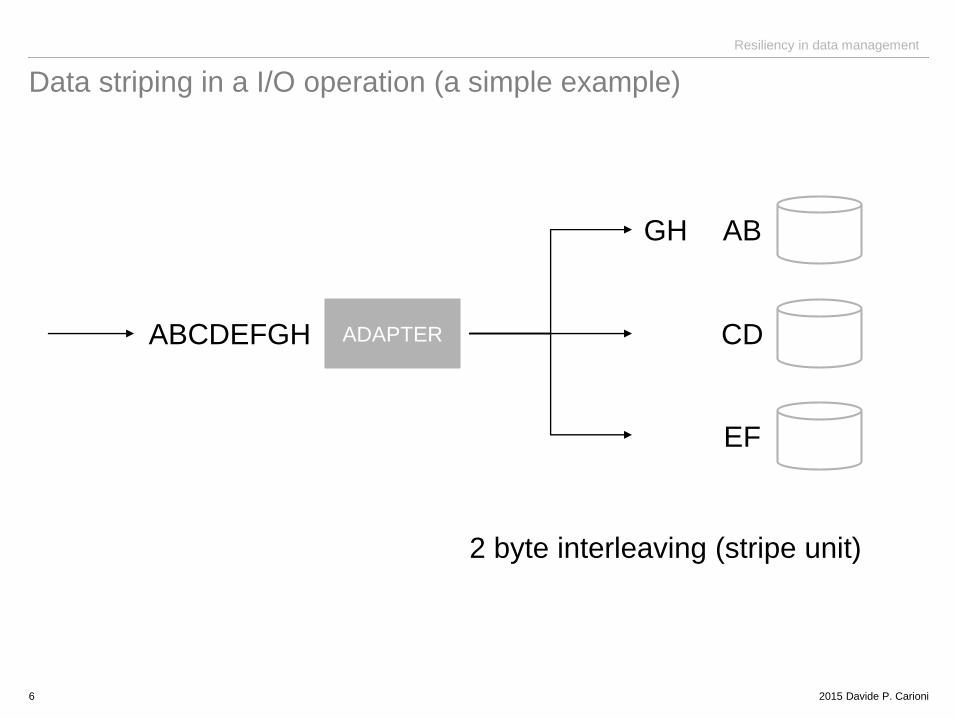
• data striping: to improve performance
4
2015 Davide P. Carioni
Resiliency in data management
redundancy in a I/O operation (a simple example)
5
ADAPTER
ABCDEFGH
ABCDEFGH
ABCDEFGH
2015 Davide P. Carioni
Resiliency in data management
Data striping in a I/O operation (a simple example)
6
AB
CD
EF
ADAPTER
GH
GH
GH
ABCDEFGH
2 byte interleaving (stripe unit)
2015 Davide P. Carioni
Resiliency in data management
virtualization in a I/O operation (a simple example)
7
ADAPTERABCDEFGH
single large logical disk

2015 Davide P. Carioni
Resiliency in data management
Data striping
striping: data are written sequentially in units on multiple disks according to a
cyclic algorithm (round robin)
stripe unit: dimension of the unit of data that are written on a single disk
stripe width: number of disks considered by the striping algorithm (does not
necessarily coincide with the number of physical disks in the array – there can
be “hot spares”)
Performance gains:
• multiple independent I/O requests will be executed in parallel by several
disks decreasing the queue length (and time) of the disks
• single multiple-block I/O requests will be executed by multiple disks in
parallel increasing of the transfer rate of a single request
8

2015 Davide P. Carioni
Resiliency in data management
Parallelism and reliability
the more physical disks in the array
the larger the size and performance gains
but …
the larger the probability of failure of a disk
⇓
this is the main motivation for the introduction of
redundancy
9

2015 Davide P. Carioni
Resiliency in data management
Parallelism and reliability
The probability of a failure (assuming independent failures) in an array of 100
disks is 100 higher the probability of a failure of a single disk
Redundancy: error correcting codes (stored on disks different from the ones
with the data) are computed to tolerate loss due to disk failures
Performance: since write operations must update also the redundant
information, their performance is worse than the one of the traditional writes
10
« if a disk has an Mean Time To Failure (MTTF) of 200,000 hours (~23 years)
an array of 100 disks will show a MTTF of 2000 hours (~ 3 months) »

2015 Davide P. Carioni
Resiliency in data management
Data reconstruction (a simple example)
11
12 8
data data checksum

2015 Davide P. Carioni
Resiliency in data management
Data reconstruction (a simple example)
12
12 8 20+ =data data checksum

2015 Davide P. Carioni
Resiliency in data management
Data reconstruction (a simple example)
13
12 8 20
12 20
+ =data data checksum
data data checksum

2015 Davide P. Carioni
Resiliency in data management
Data reconstruction (a simple example)
14
12 8 20
12 20
20 12 8
+ =
- =
data data checksum
data data checksum
checksum data data

2015 Davide P. Carioni
Resiliency in data management
RAID standard levels
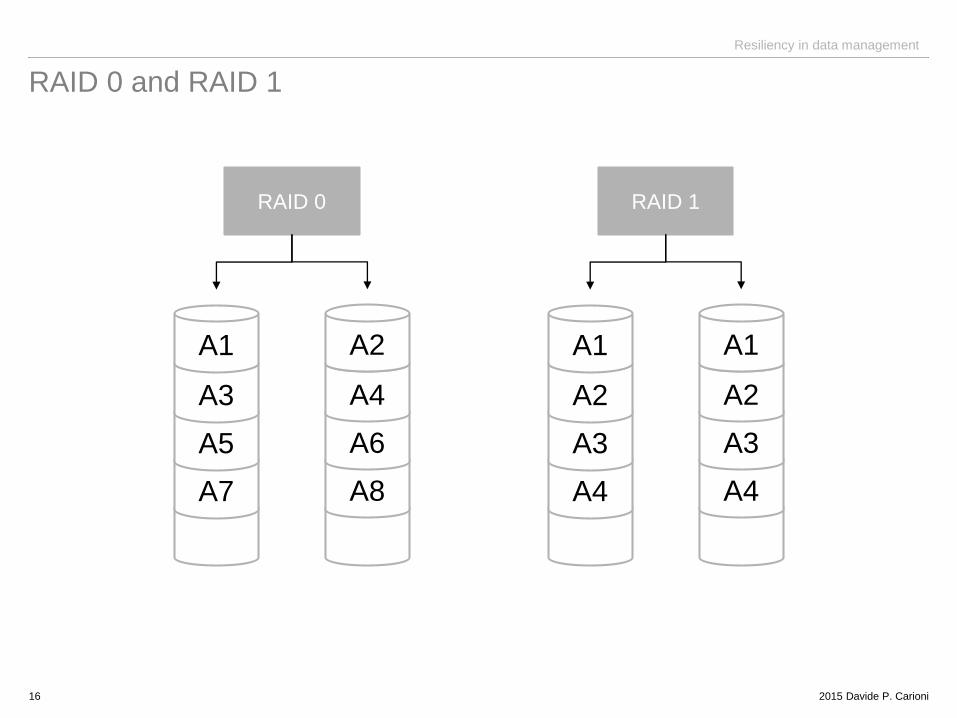
RAID 0 striping only
RAID 1 mirroring only
RAID 2 bit interleaving (not used)
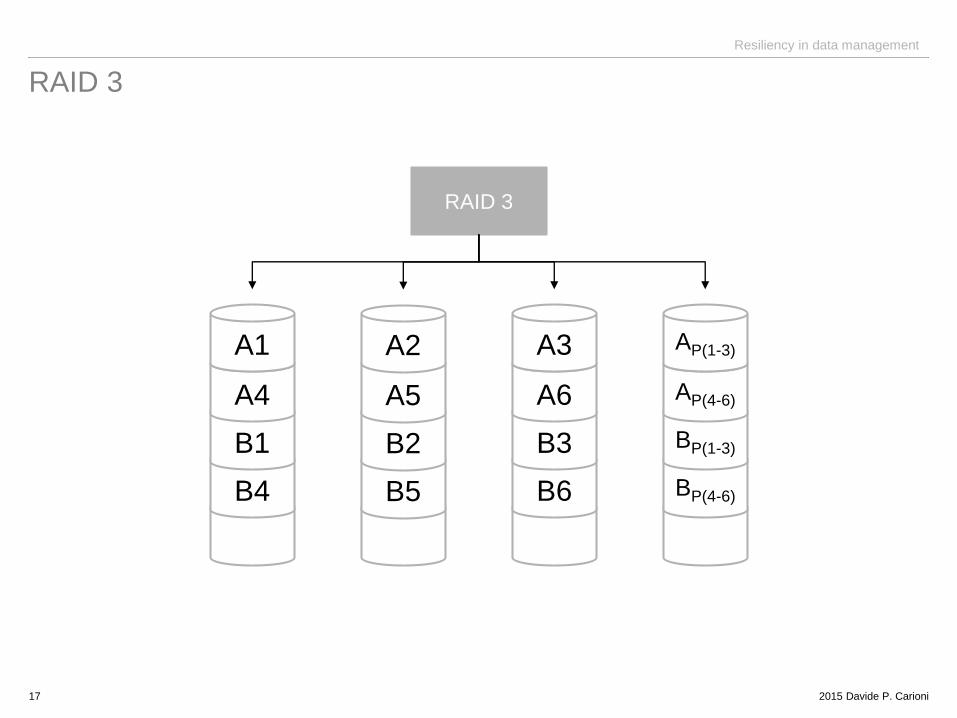
RAID 3 byte interleaving - redundancy (parity disk)
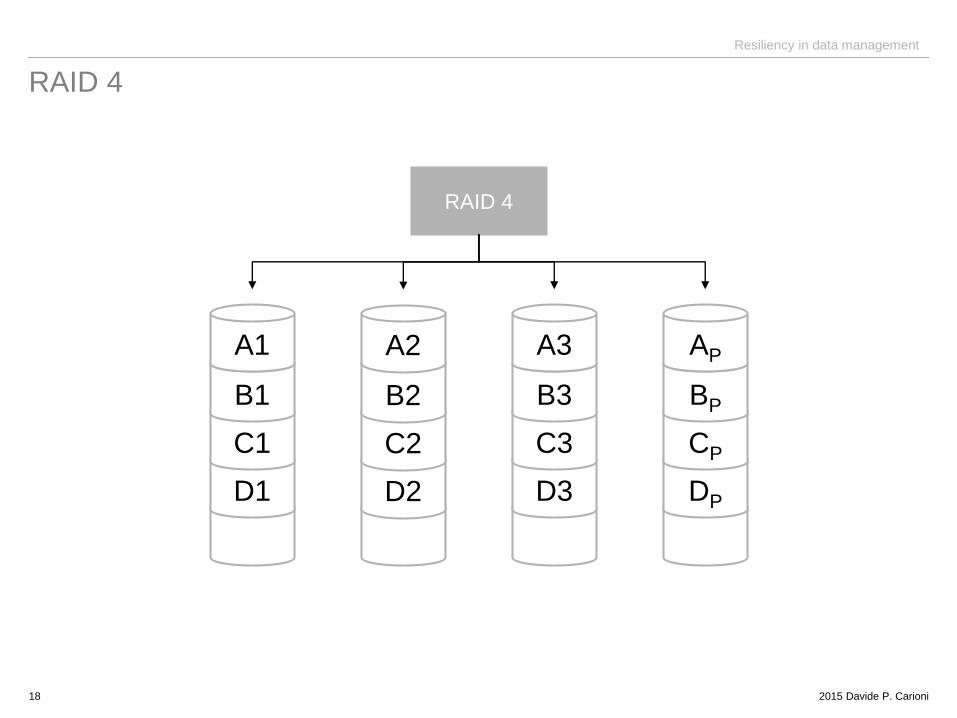
RAID 4 block interleaving - redundancy (parity disk)
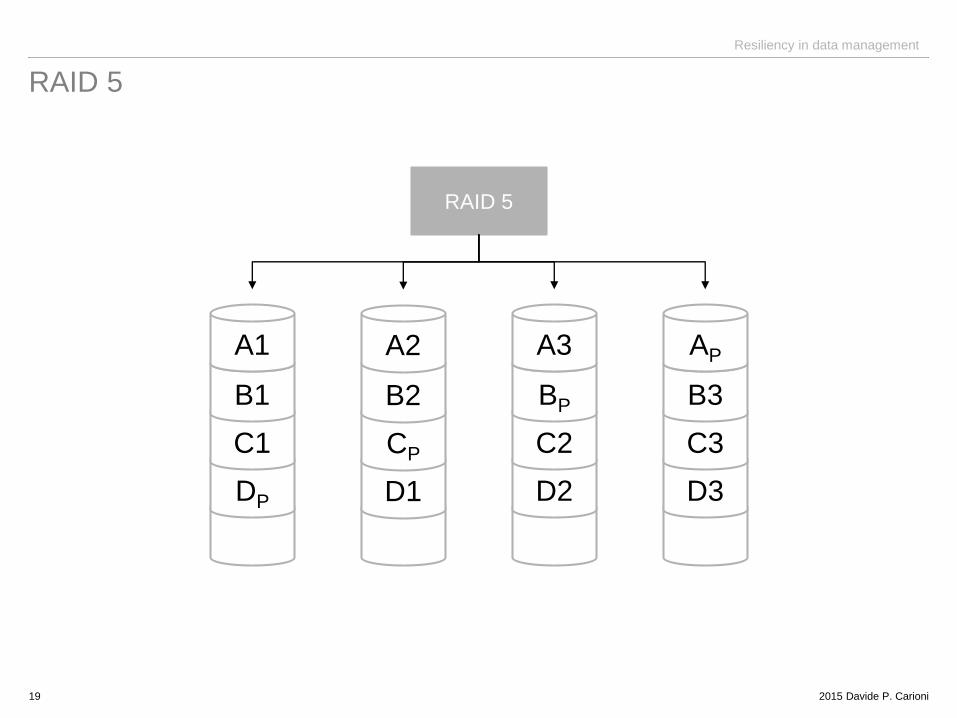
RAID 5 block interleaving - redundancy (parity block distributed) – highly utilized
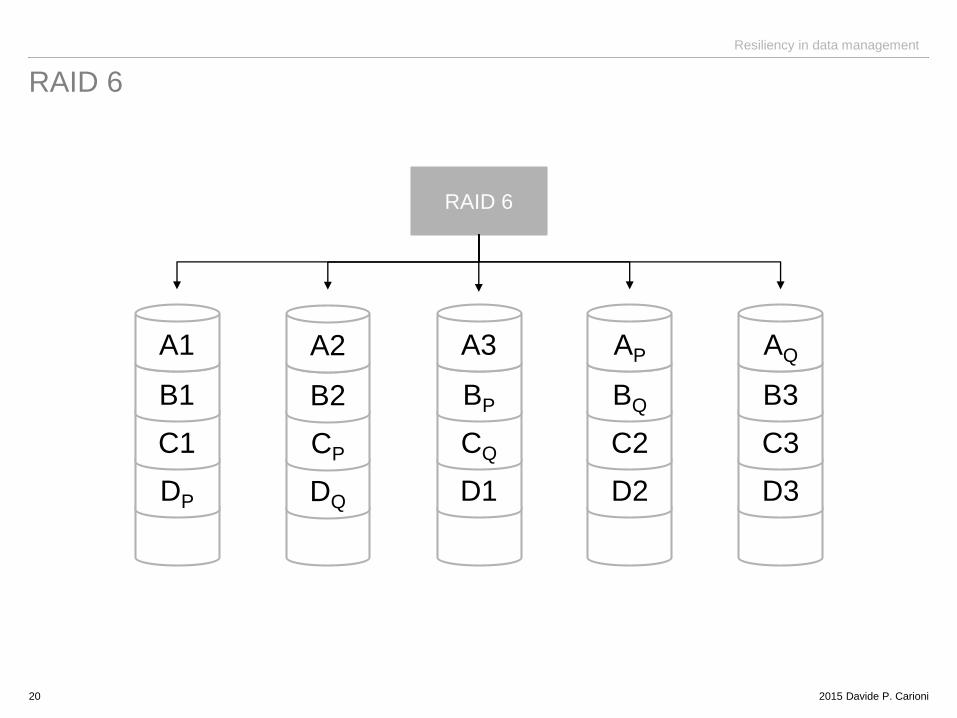
RAID 6 greater redundancy (tolerates up to two failed disks)
15
2015 Davide P. Carioni
Resiliency in data management
RAID 0 and RAID 1
16
RAID 0
A7
A5
A3
A1
A8
A6
A4
A2
RAID 1
A4
A3
A2
A1
A4
A3
A2
A1
2015 Davide P. Carioni
Resiliency in data management
RAID 3
17
RAID 3
B5
B2
A5
A2
B6
B3
A6
A3
B4
B1
A4
A1
BP(4-6)
BP(1-3)
AP(4-6)
AP(1-3)
2015 Davide P. Carioni
Resiliency in data management
RAID 4
18
RAID 4
D2
C2
B2
A2
D3
C3
B3
A3
D1
C1
B1
A1
DP
CP
BP
AP
2015 Davide P. Carioni
Resiliency in data management
RAID 5
19
RAID 5
D1
CP
B2
A2
D2
C2
BP
A3
DP
C1
B1
A1
D3
C3
B3
AP
2015 Davide P. Carioni
Resiliency in data management
RAID 6
20
RAID 6
DQ
CP
B2
A2
D1
CQ
BP
A3
DP
C1
B1
A1
D2
C2
BQ
AP
D3
C3
B3
AQ
2015 Davide P. Carioni
Resiliency in data management
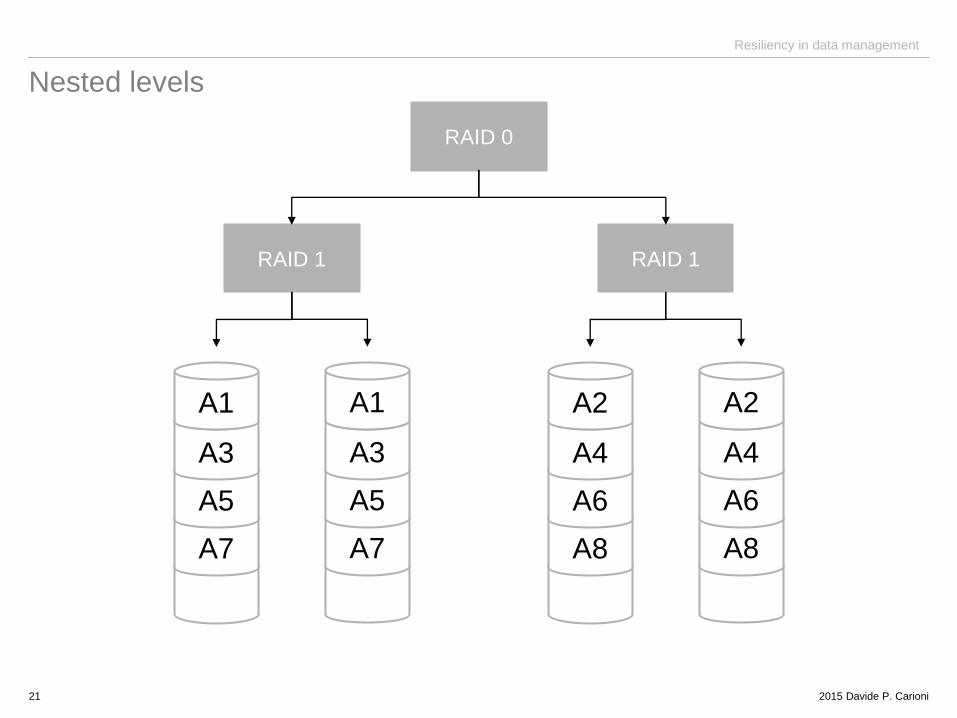
Nested levels
21
RAID 1
A7
A5
A3
A1
A7
A5
A3
A1
RAID 1
A8
A6
A4
A2
A8
A6
A4
A2
RAID 0

2015 Davide P. Carioni
Resiliency in data management
Overview
RAID level Utilization
ratio
Reliability R/W performance Rebuild
performance
0 1 N/A very good good
1 0.5 excellent very good/good good
3 (n-1)/n good good/fair fair
5 (n-1)/n good good/fair poor
6 (n-2)/n excellent very good/poor poor
1+0 0.5 excellent very good/good good
5+0 (n-1)/n excellent very good/good fair
22
Nota Bene: RAID technology should not be intended as a substitute for a suitable
backup procedure

2015 Davide P. Carioni
Resiliency in data management
Data Mirroring23

2015 Davide P. Carioni
Resiliency in data management
Synchronous VS Asynchronous mirroring
Synchronous mirroring: provides a consistent copy of a source disk on a
target disk. Data is synchronously written to the target disk after it is written to
the source virtual disk, so that the copy is continuously updated.
Asynchronous mirroring: provides a consistent copy of a source disk on a
target disk. Data is asynchronously written to the target virtual disk, so that the
copy is continuously updated, but the copy might not contain the last few
updates in the event that a disaster recovery operation is performed.
24

2015 Davide P. Carioni
Resiliency in data management
Synchronous VS Asynchronous mirroring
25
1. write 2. write
3. ack4. ack
primary secondary
1. write a. write
b. ack2. ack
primary secondary
Sinchronization clock

2015 Davide P. Carioni
Resiliency in data management
Multipath26
2015 Davide P. Carioni
Resiliency in data management
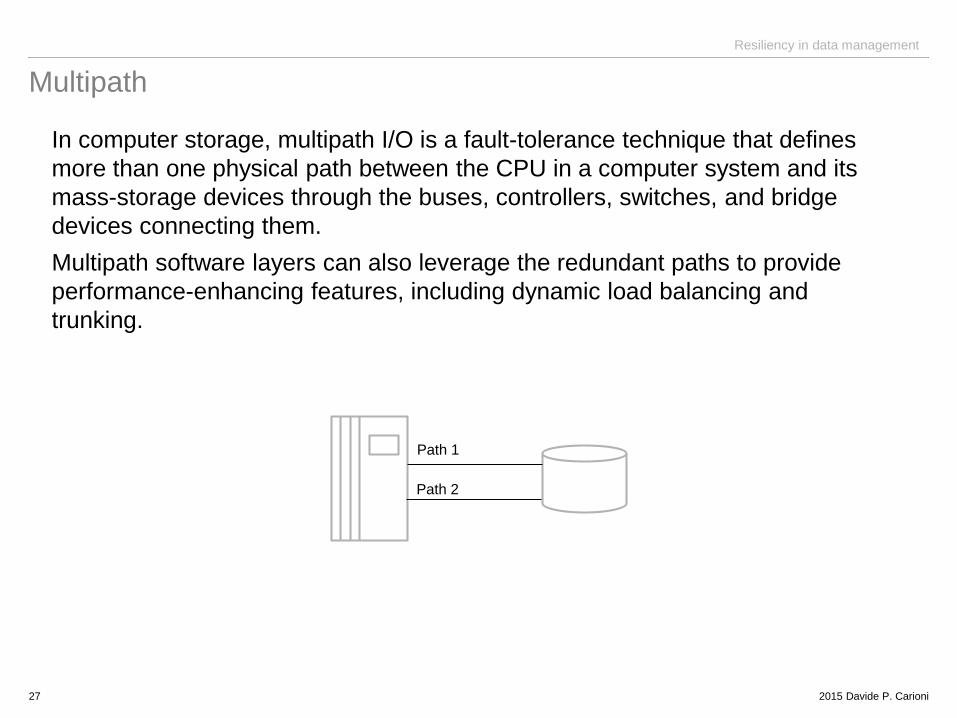
Multipath
In computer storage, multipath I/O is a fault-tolerance technique that defines
more than one physical path between the CPU in a computer system and its
mass-storage devices through the buses, controllers, switches, and bridge
devices connecting them.
Multipath software layers can also leverage the redundant paths to provide
performance-enhancing features, including dynamic load balancing and
trunking.
27
Path 1
Path 2

2015 Davide P. Carioni
Resiliency in data management
Backup28

2015 Davide P. Carioni
Resiliency in data management
Backup
Backup technologies provide effective recovery options for systems subject to
data loss from human error, hardware failure or major natural disasters. They
are ideally suited for quick restoration of large amounts of lost information and
can return complete systems to full operational capacity in a short period of time.
Two orthogonal techniques:
• Incremental backup: saves the data that has changed since the last backup.
• PROs: fast backup, small space occupancy
• CON: slow recovery
• Differential backup: saves the data that has changed since the last full
backup.
• PRO: fast recovery
• CONs: slow backup, big space occupancy
29
2015 Davide P. Carioni
Resiliency in data management
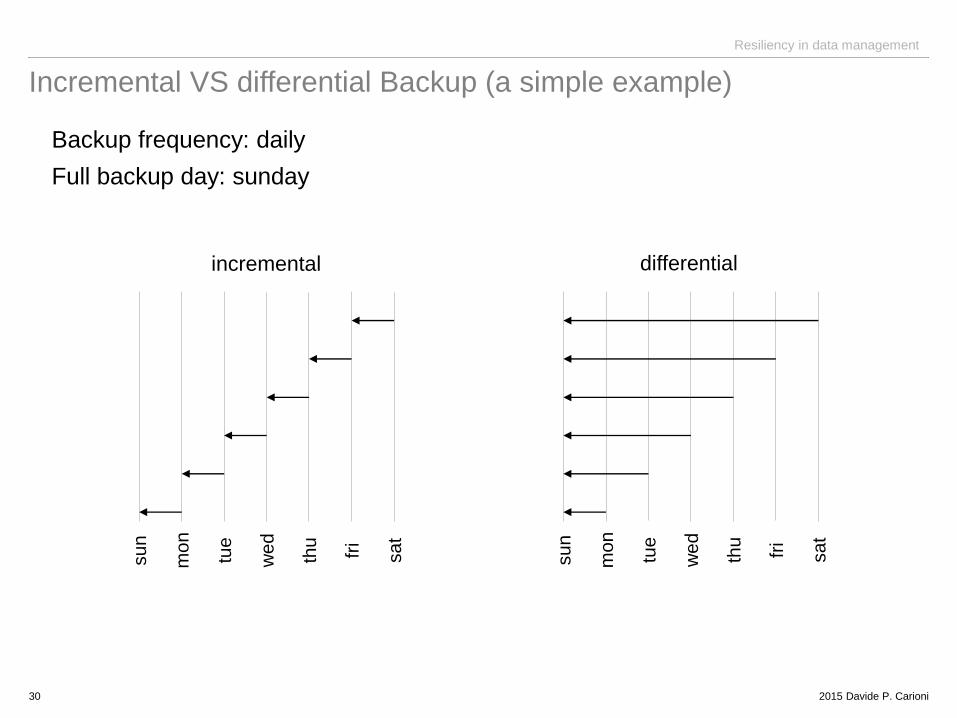
Incremental VS differential Backup (a simple example)
Backup frequency: daily
Full backup day: sunday
30
su
n
mon
tue
sa
t
fri
thu
we
d
su
n
mo
n
tue
sa
t
fri
thu
we
d
incremental differential

2015 Davide P. Carioni
Resiliency in data management
Point in time copy
A point in time copy is a logical image of the content of an associated base
volume created at a specific moment. A snapshot image can be thought of as a
restore point. Snapshot images are useful any time you need to be able to roll
back to a known good data set at a specific point in time.
For example, before performing a risky operation on a volume, you can create a
snapshot image to enable “undo” capability for the entire volume. A snapshot
image is created almost instantaneously, and initially uses no disk space,
because it stores only the incremental changes needed to roll the volume back
to the point-in-time when the snapshot image was created.
Two alternative approaches:
• copy on write
• redirect on write
31
2015 Davide P. Carioni
Resiliency in data management
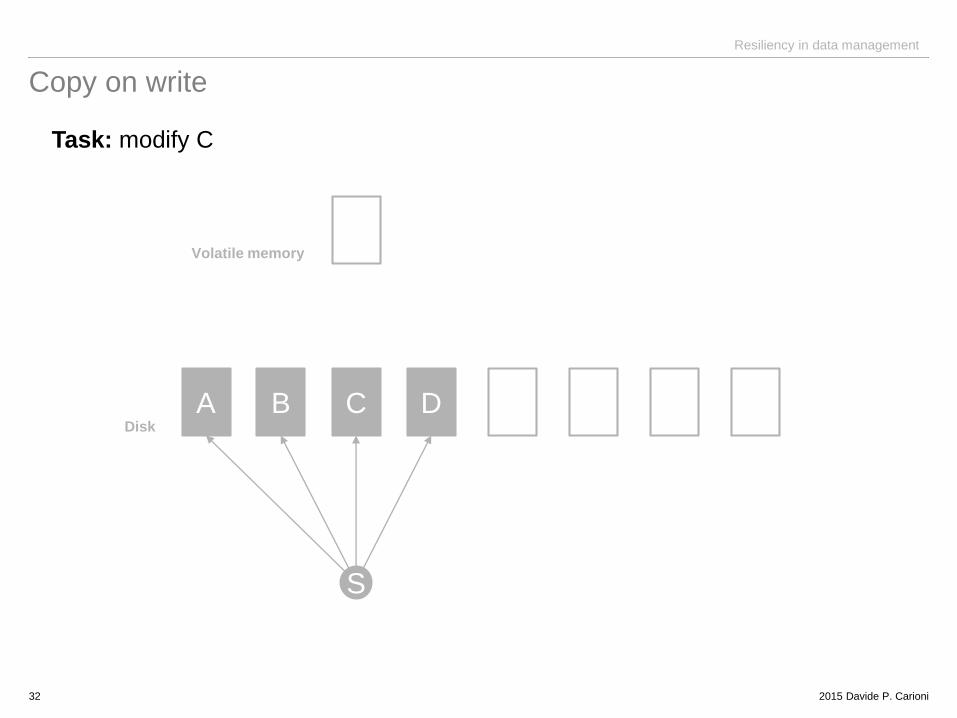
Copy on write
Task: modify C
32
A B C D
S
Disk
Volatile memory
2015 Davide P. Carioni
Resiliency in data management
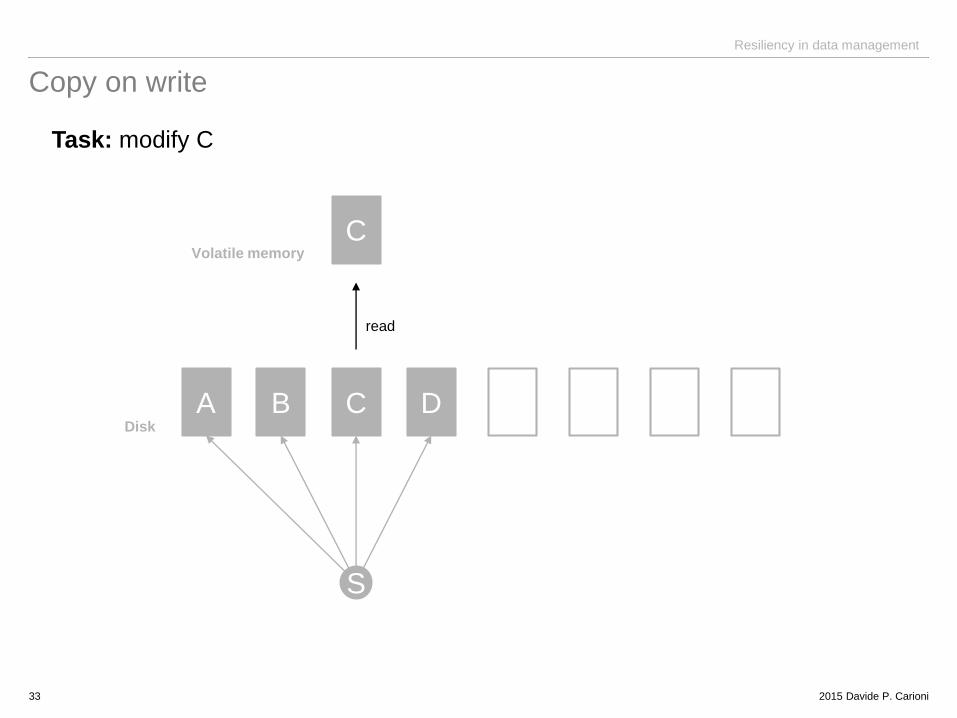
Copy on write
Task: modify C
33
A B C D
C
S
Disk
Volatile memory
read
2015 Davide P. Carioni
Resiliency in data management
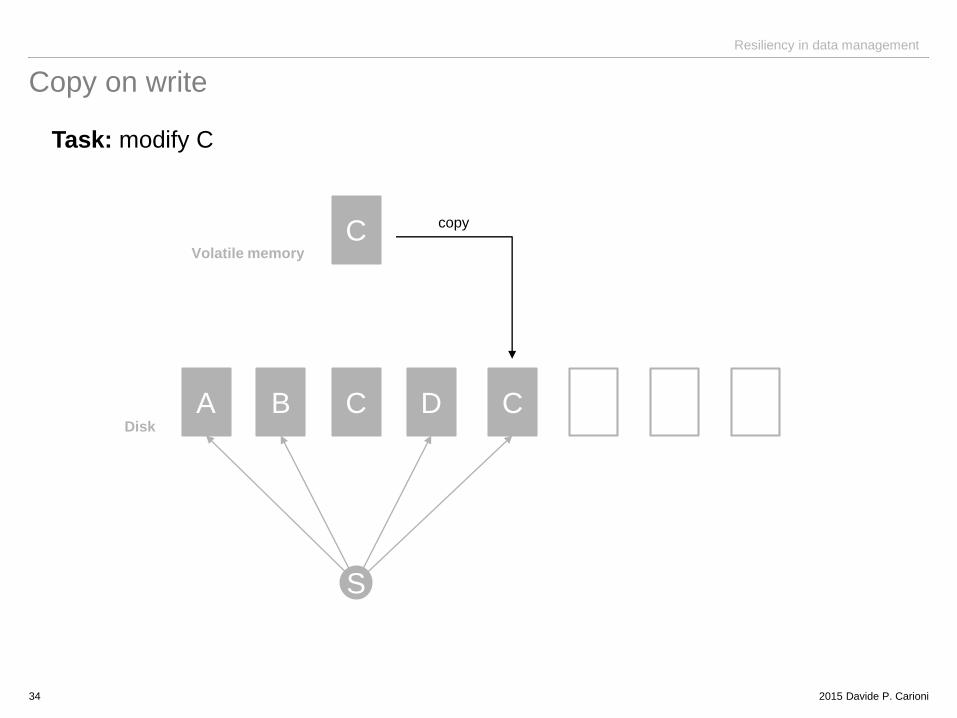
Copy on write
Task: modify C
34
A B C D C
C
S
Disk
Volatile memory
copy
2015 Davide P. Carioni
Resiliency in data management
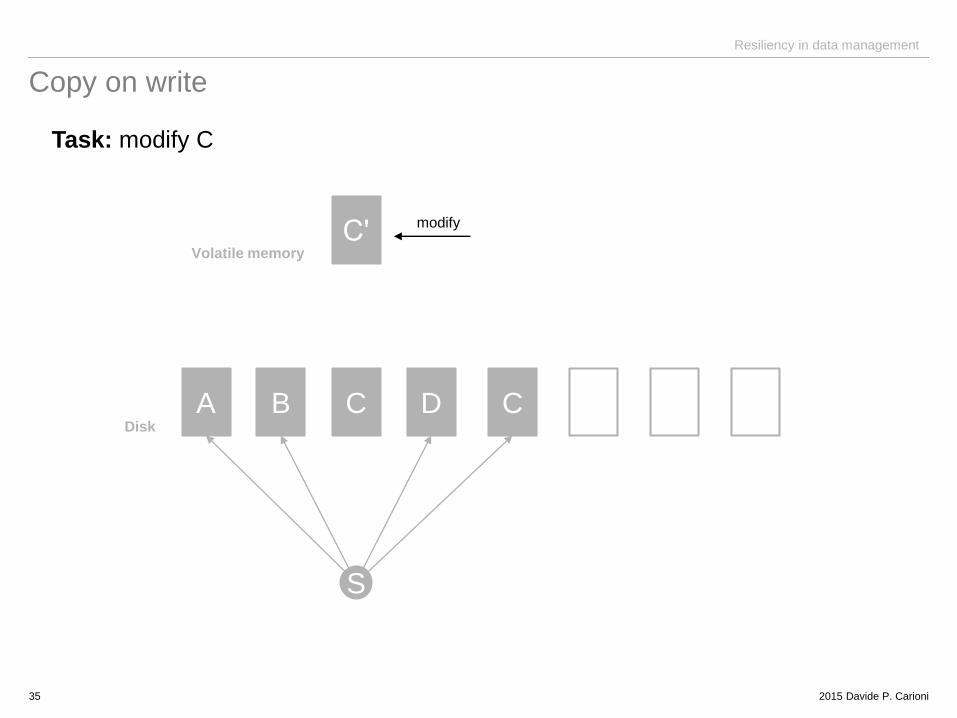
Copy on write
Task: modify C
35
A B C D C
Cʹ
S
Disk
Volatile memory
modify
2015 Davide P. Carioni
Resiliency in data management
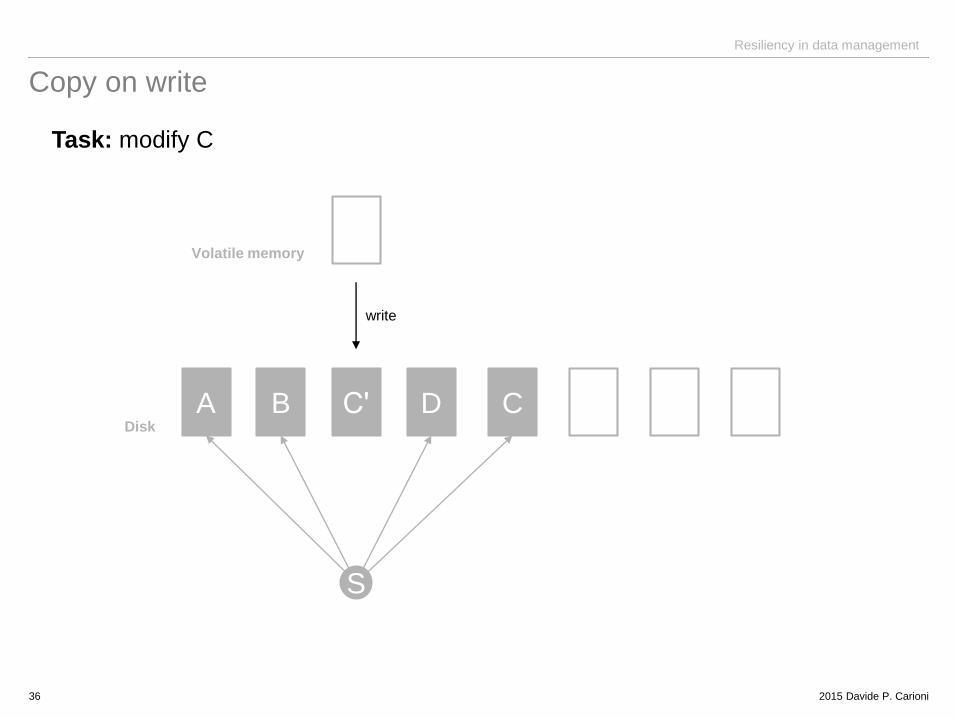
Copy on write
Task: modify C
36
A B Cʹ D C
S
Disk
Volatile memory
write
2015 Davide P. Carioni
Resiliency in data management
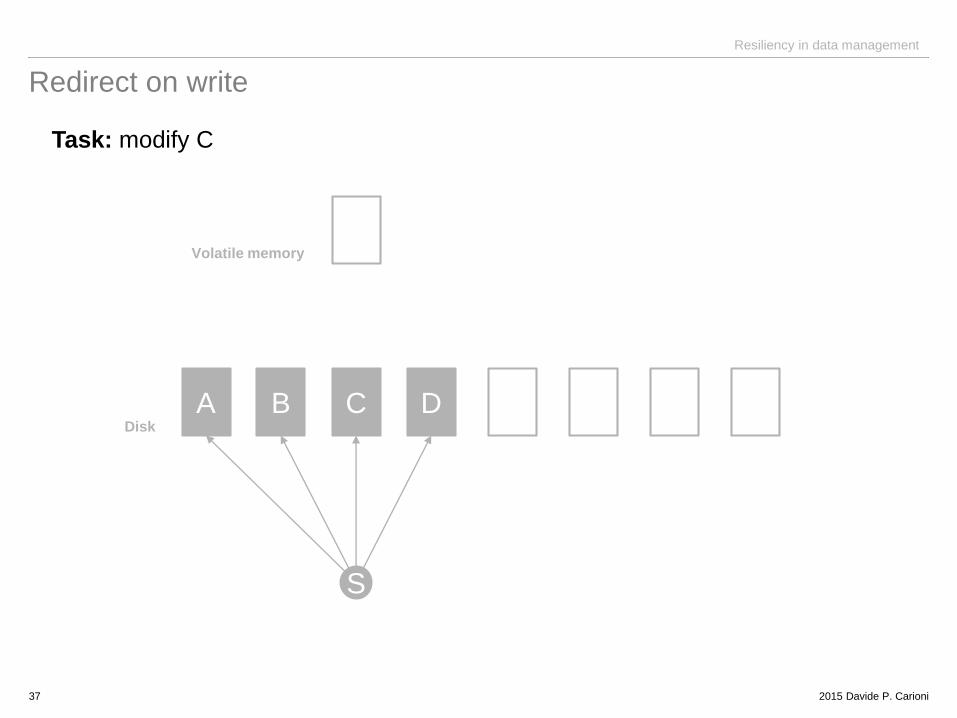
Redirect on write
Task: modify C
37
A B C D
S
Disk
Volatile memory
2015 Davide P. Carioni
Resiliency in data management
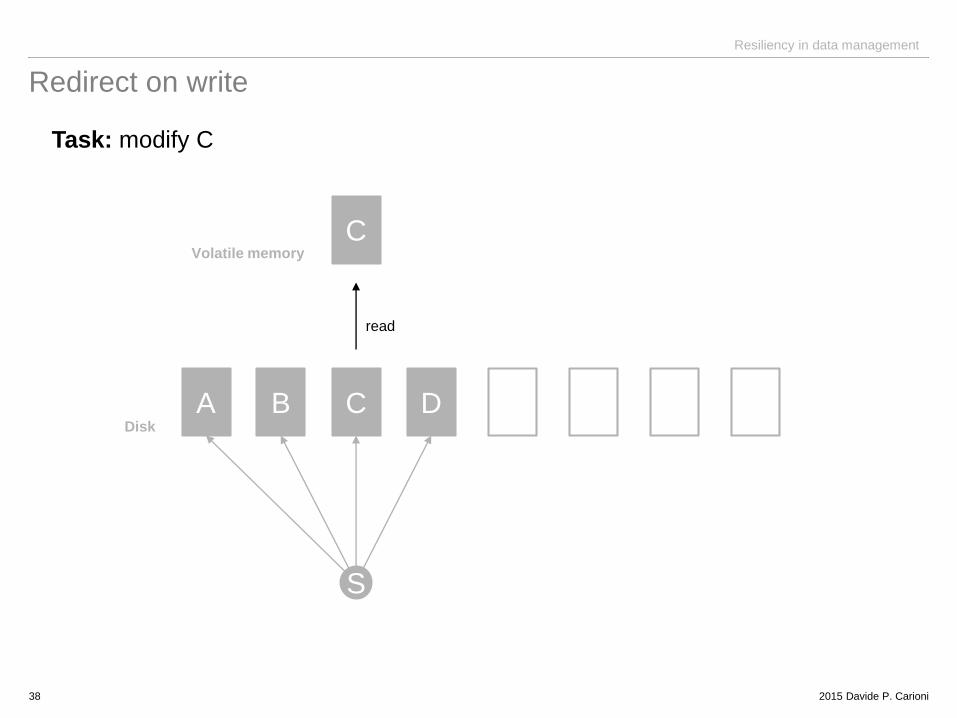
Redirect on write
Task: modify C
38
A B C D
C
S
Disk
Volatile memory
read
2015 Davide P. Carioni
Resiliency in data management
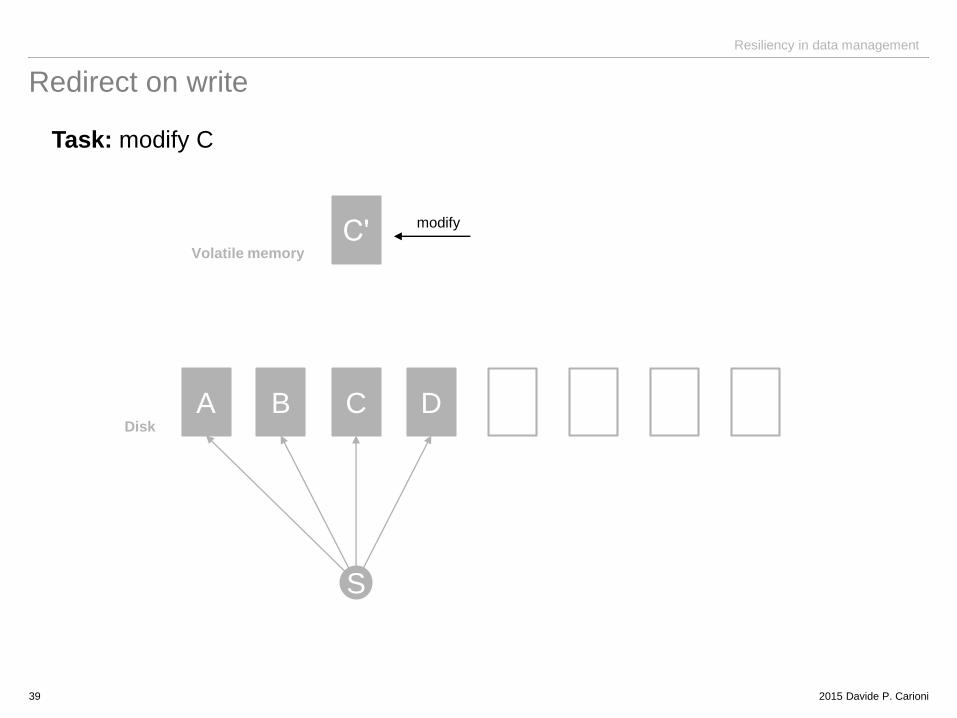
Redirect on write
Task: modify C
39
A B C D
Cʹ
S
Disk
Volatile memory
modify
2015 Davide P. Carioni
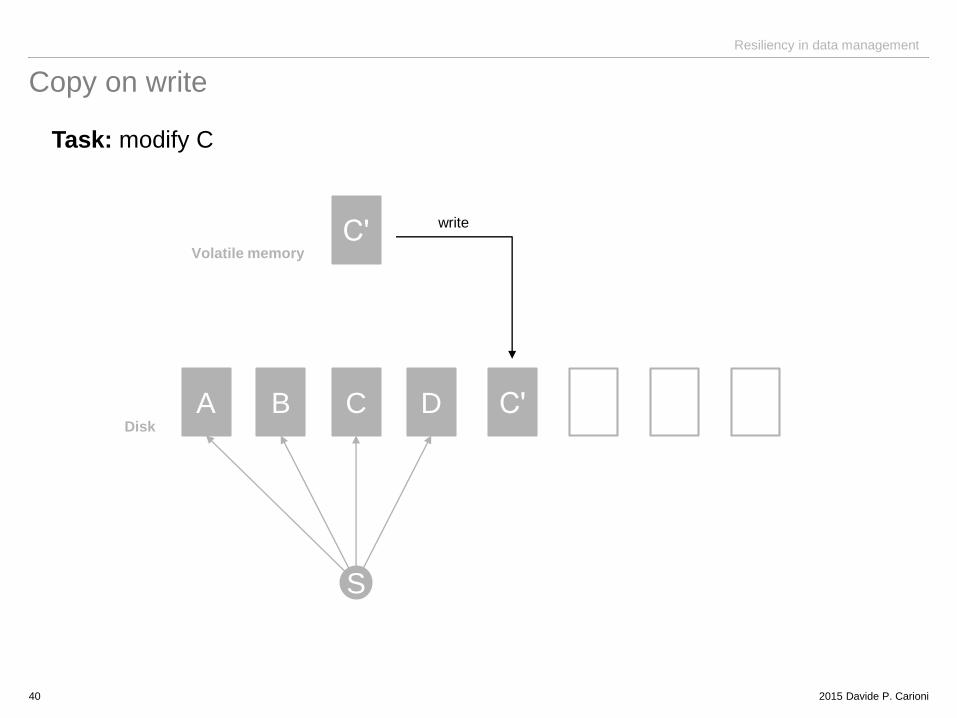
Resiliency in data management
Copy on write
Task: modify C
40
A B C D Cʹ
Cʹ
S
Disk
Volatile memory
write

2015 Davide P. Carioni
Resiliency in data management
Archive41

2015 Davide P. Carioni
Resiliency in data management
Archive
Archive technologies typically store a version of a file that's no longer changing,
or shouldn't be changing. Data archiving is intended as a repository for data that
needs to be stored for periods that may extend to decades.
Speed is less important in archives; even if the event is a legal action, you
typically only have a few days to respond. Searchabilty is more critical in
archives. In addition, importance is placed on the ability to scale data integrity
and data retention over a long period of time, possibly decades.
To effectively manage data, file archiving systems discover all files on a network
and provide an inventory of unstructured data. During the discovery process, the
systems collect file system metadata and extract file contents, building a
foundation for data classification and application of information governance
policies.
42
2015 Davide P. Carioni
Resiliency in data management
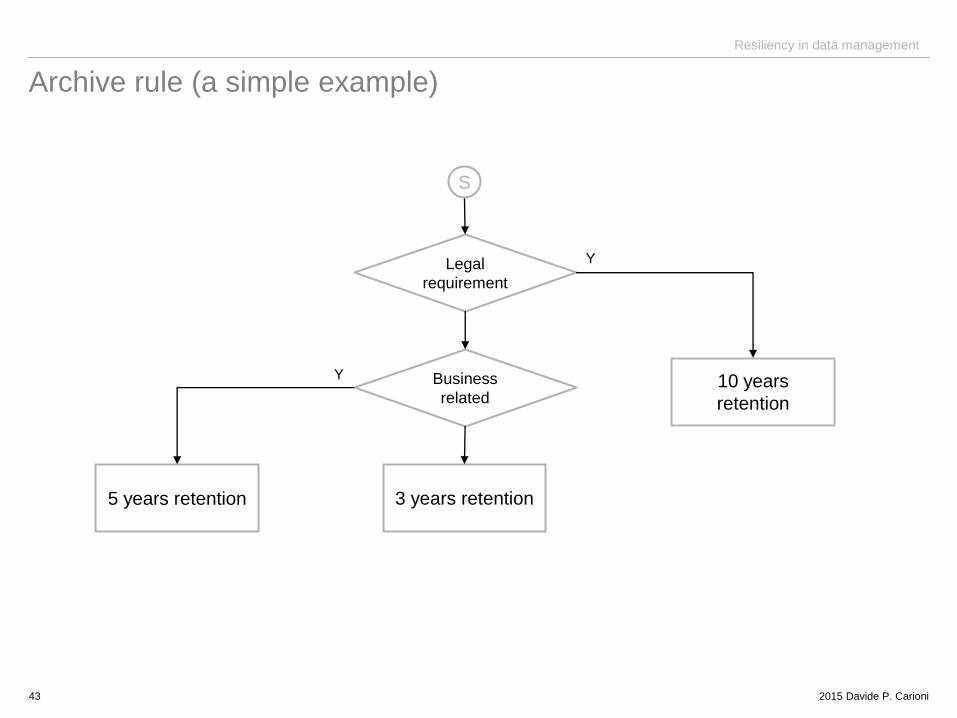
Archive rule (a simple example)
43
Legal
requirement
Business
related
5 years retention
10 years
retention
3 years retention
S
Y
Y
2015 Davide P. Carioni
Resiliency in data management
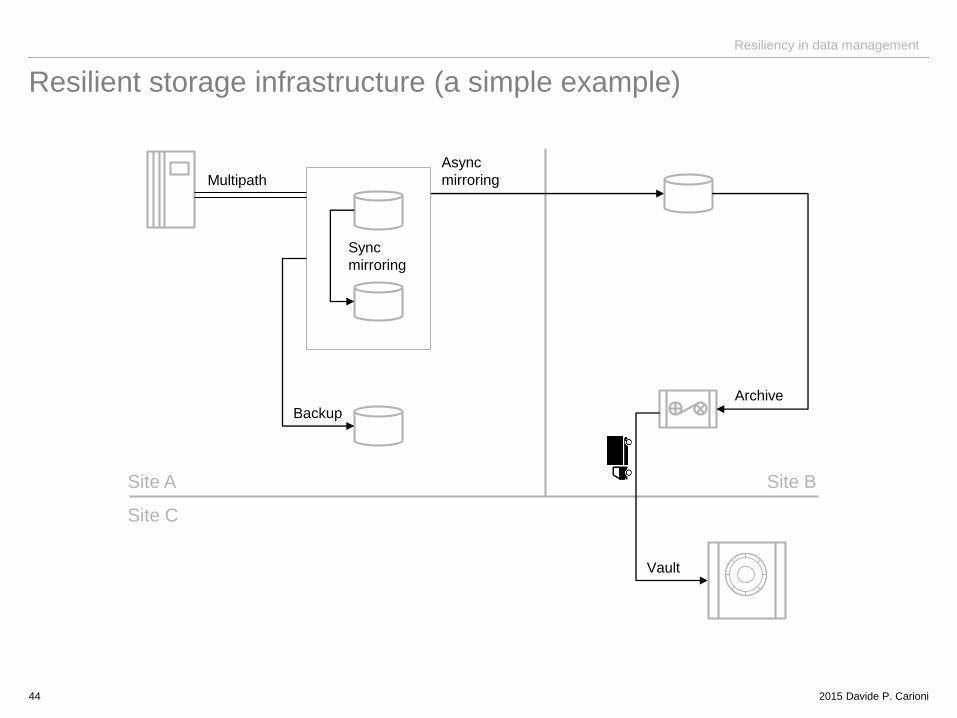
Resilient storage infrastructure (a simple example)
44
Site A Site B
Site C
Sync
mirroring
Multipath
Backup
Async
mirroring
Archive
Vault
2015 Davide P. Carioni
Resiliency in data management
Davide Carioni wrote this file.
As long as you retain this notice you can do whatever you want with
this stuff. If we meet some day, and you think this stuff is worth it,
you can buy me a beer in return.
45
Delivery truck image – by Freepik - Own work - Licensed under CC BY 3.0 via flaticon.com
BeerWare Logo - by Kita59 - Own work - Licensed under CC BY-SA 3.0 via Wikimedia Commons





























