Embed Size (px)
Citation preview

word2vec and friends
www.bgoncalves.com

www.bgoncalves.com@bgoncalves
• Computers are really good at crunching numbers but not so much when it comes to words.
• Perhaps can we represent words numerically?
• Can we do it in a way that preserves semantic information?
• Words that have similar meanings are used in similar contexts and the context in which a word is used helps us understand it’s meaning.
Teaching machines to read!
The red house is beautiful.The blue house is old. The red car is beautiful.The blue car is old.
“You shall know a word by the company it keeps”(J. R. Firth)
a 1about 2above 3after 4again 5against 6all 7am 8an 9and 10any 11are 12aren't 13as 14… …
vafter = (0, 0, 0, 1, 0, 0, · · · )T
vabove
= (0, 0, 1, 0, 0, 0, · · · )TOne-hot encoding

www.bgoncalves.com@bgoncalves
Teaching machines to read!
➡Words with similar meanings should have similar representations.
➡From a word we can get some idea about the context where it might appear
➡And from the context we have some idea about possible words
“You shall know a word by the company it keeps”(J. R. Firth)
max p (C|w)
max p (w|C)
The red _____ is beautiful.The blue _____ is old.
___ ___ house __ ____.___ ___ car __ _______.
www.bgoncalves.com@bgoncalves
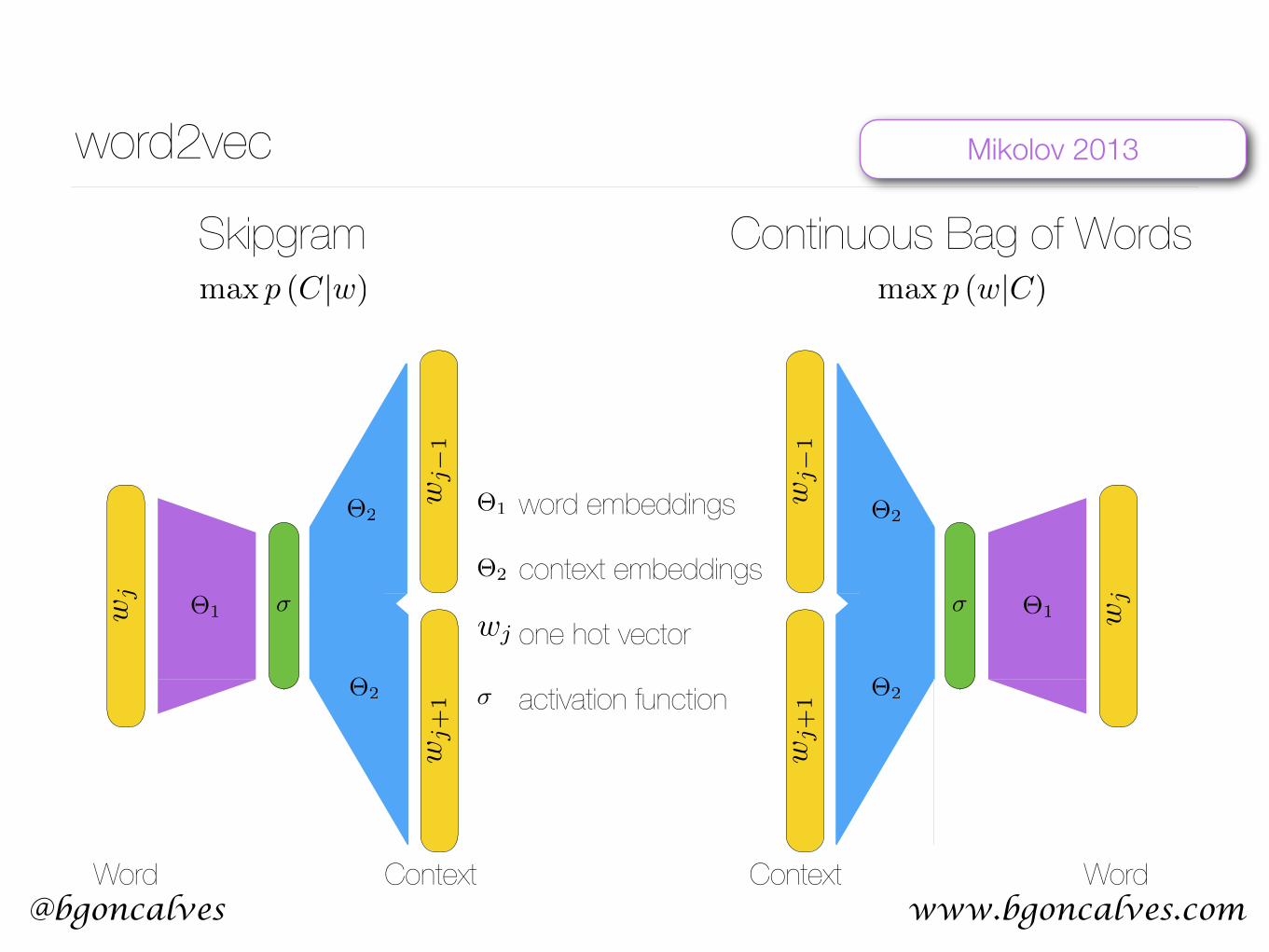
word2vec
max p (C|w) max p (w|C)
Skipgram Continuous Bag of Words
⇥1 �
wj�
1w
j+1
wj
⇥2
⇥2
wj+
1
⇥2
⇥2
⇥1� wj
wj�
1
Word Context Context Word
⇥1
⇥2
wj
word embeddings
context embeddings
one hot vector
activation function�
Mikolov 2013

www.bgoncalves.com@bgoncalves
• Let us take a better look at a simplified case with a single context word
• Words are one-hot encoded vectors of length V
• is an matrix so that when we take the product:
• We are effectively selecting the j’th column of :
• The linear activation function simply passes this value alongwhich is then multiplied by , a matrix.
• Each element k of the output layer its then given by:
• We convert these values to a normalized probability distribution by using the softmax
Skipgram
⇥1 �
softmax
wj ⇥2
wj+
1
wj = (0, 0, 1, 0, 0, 0, · · · )T
⇥1 (M ⇥ V )
⇥1 · wj
⇥1
vj = ⇥1 · wj
⇥2 (V ⇥M)
uTk · vj

www.bgoncalves.com@bgoncalves
• A standard way of converting a set of number to a normalized probability distribution:
• With this final ingredient we obtain:
• Our goal is then to learn:
• so that we can predict what the next word is likely to be using:
• But how can we quantify how far we are from the correct answer? Our error measure shouldn’t be just binary (right or wrong)…
Softmax
⇥1 �
softmax
wj ⇥2
wj+
1
softmax (x) =
exp (xj)Pl exp (xl)
p (wk|wj) ⌘ softmax
�u
Tk · vj
�=
exp
�u
Tk · vj
�P
l exp�u
Tl · vj
�
p (wj+1|wj)
⇥1 ⇥2

www.bgoncalves.com@bgoncalves
Cross-Entropy• First we have to recall that what we are, in effect, comparing two probability distributions:
• and the one-hot encoding of the context:
• The Cross Entropy measures the distance, in number of bits, between two probability distributions p and q:
• In our case, this becomes:
• So it’s clear that the only non zero term is the one that corresponds to the “hot” element of
• This is our Error function. But how can we use this to update the values of and ?
p (wk|wj)
H (p, q) = �X
k
pk log qk
H = � log p (wj+1|wj)
wj+1
wj+1 = (0, 0, 0, 1, 0, 0, · · · )T
H [wj+1, p (wk|wj)] = �X
k
wkj+1 log p (wk|wj)
⇥1 ⇥2
www.bgoncalves.com@bgoncalves
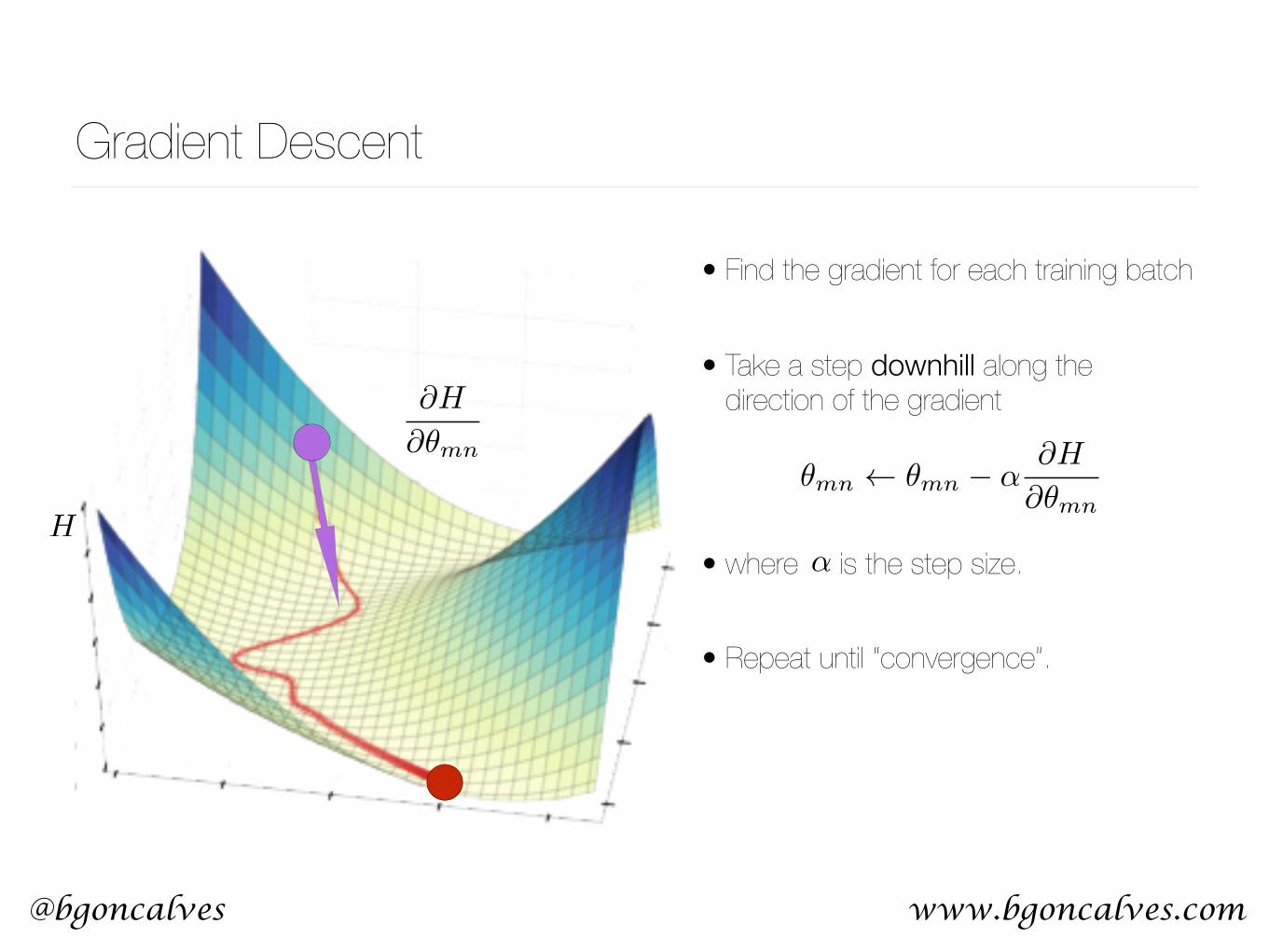
Gradient Descent
• Find the gradient for each training batch
• Take a step downhill along the direction of the gradient
• where is the step size.
• Repeat until “convergence”.
H
✓mn ✓mn � ↵@H
@✓mn
� @H
@✓mn
↵

www.bgoncalves.com@bgoncalves
Chain-rule• How can we calculate
• we rewrite:
• and expand:
• Then we can rewrite:
• and apply the chain rule:
@H
@✓mn=
@
@✓mnlog p (wj+1|wj)
@H
@✓mn=
@
@✓mnlog
exp
�uTk · vj
�P
l exp�uTl · vj
�
uTk · vj =
X
q
✓(2)kq ✓(1)qj
@f (g (x))
@x
=@f (g (x))
@g (x)
@g (x)
@x
@H
@✓mn=
@
@✓mn
"uTk · vj � log
X
l
exp
�uTl · vj
�#
✓mn =n
✓(1)mn, ✓(2)mn
o

www.bgoncalves.com@bgoncalves
SkipGram with Larger Contexts
• Use the same for all context words.
• Use the average of cross entropy.
• word order is not important (the average does not change).
⇥1 �softmax
wj ⇥2
wj+
1⇥1 �
wj�
1w
j+1
wj
⇥2
⇥2
H = � log p (wj+1|wj) H = � 1
T
X
t
log p (wj+t|wj)
⇥2
www.bgoncalves.com@bgoncalves
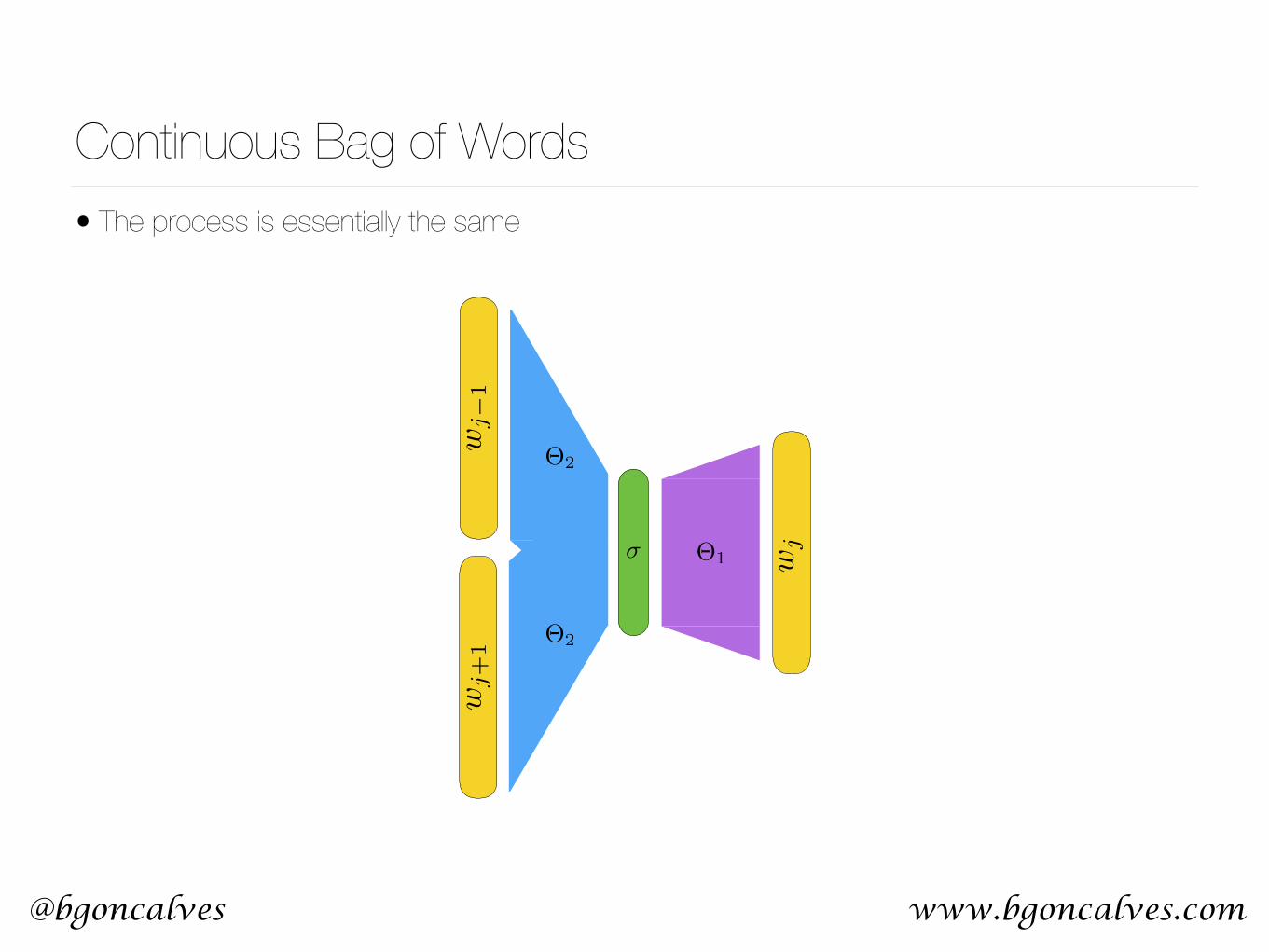
Continuous Bag of Words• The process is essentially the same
wj+
1
⇥2
⇥2
⇥1� wj
wj�
1
www.bgoncalves.com@bgoncalves
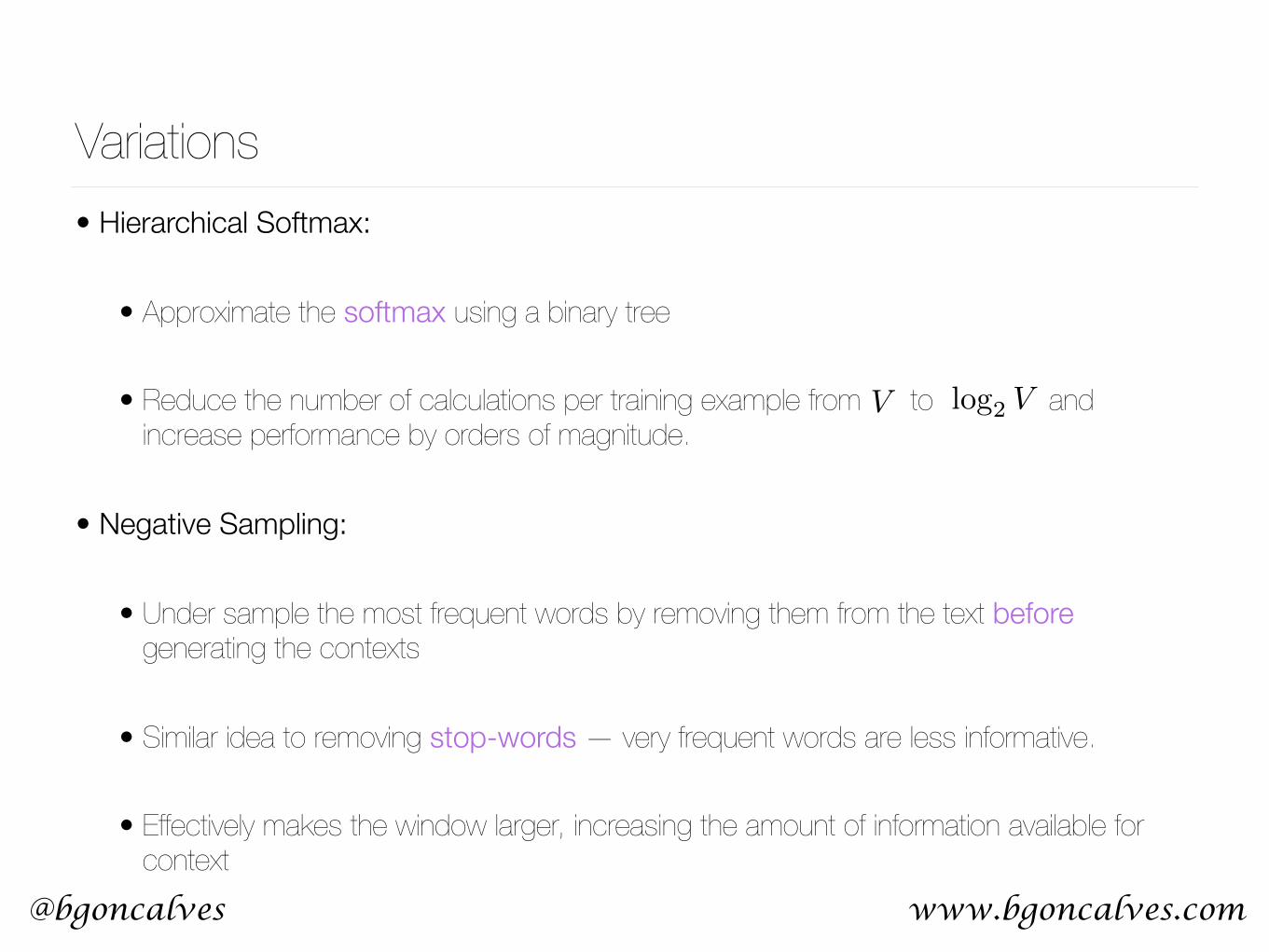
Variations• Hierarchical Softmax:
• Approximate the softmax using a binary tree
• Reduce the number of calculations per training example from to and increase performance by orders of magnitude.
• Negative Sampling:
• Under sample the most frequent words by removing them from the text before generating the contexts
• Similar idea to removing stop-words — very frequent words are less informative.
• Effectively makes the window larger, increasing the amount of information available for context
V log2 V

www.bgoncalves.com@bgoncalves
Comments• word2vec, even in its original formulation is actually a family
of algorithms using various combinations of:
• Skip-gram, CBOW
• Hierarchical Softmax, Negative Sampling
• The output of this neural network is deterministic:
• If two words appear in the same context (“blue” vs “red”, for e.g.), they will have similar internal representations in and
• and are vector embeddings of the input words and the context words respectively
• Words that are too rare are also removed.
• The original implementation had a dynamic window size:
• for each word in the corpus a window size k’ is sampled uniformly between 1 and k
⇥1 �
wj�
1w
j+1
wj
⇥2
⇥2
⇥1 ⇥2
⇥1 ⇥2

www.bgoncalves.com@bgoncalves
Online resources• C - https://code.google.com/archive/p/word2vec/ (the original one)
• Python/tensorflow - https://www.tensorflow.org/tutorials/word2vec
• Both a minimalist and an efficient versions are available in the tutorial
• Python/gensim - https://radimrehurek.com/gensim/models/word2vec.html
• Pretrained embeddings:
• 90 languages, trained using wikipedia: https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md

www.bgoncalves.com@bgoncalves
Analogies• The embedding of each word is a function of the context it appears in:
• words that appear in similar contexts will have similar embeddings:
• “Distributional hypotesis” in linguistics
� (red) = f (context (red))
context (red) ⇡ context (blue) =) � (red) ⇡ � (blue)
“You shall know a word by the company it keeps”(J. R. Firth)
Geometrical relations between contexts imply
semantic relations between words!
ParisRomeWashington DC
Lisbon
FrancePortugalItaly
USA
Capital context
Country context
� (France)� � (Paris) + � (Rome) = � (Italy)
www.bgoncalves.com@bgoncalves
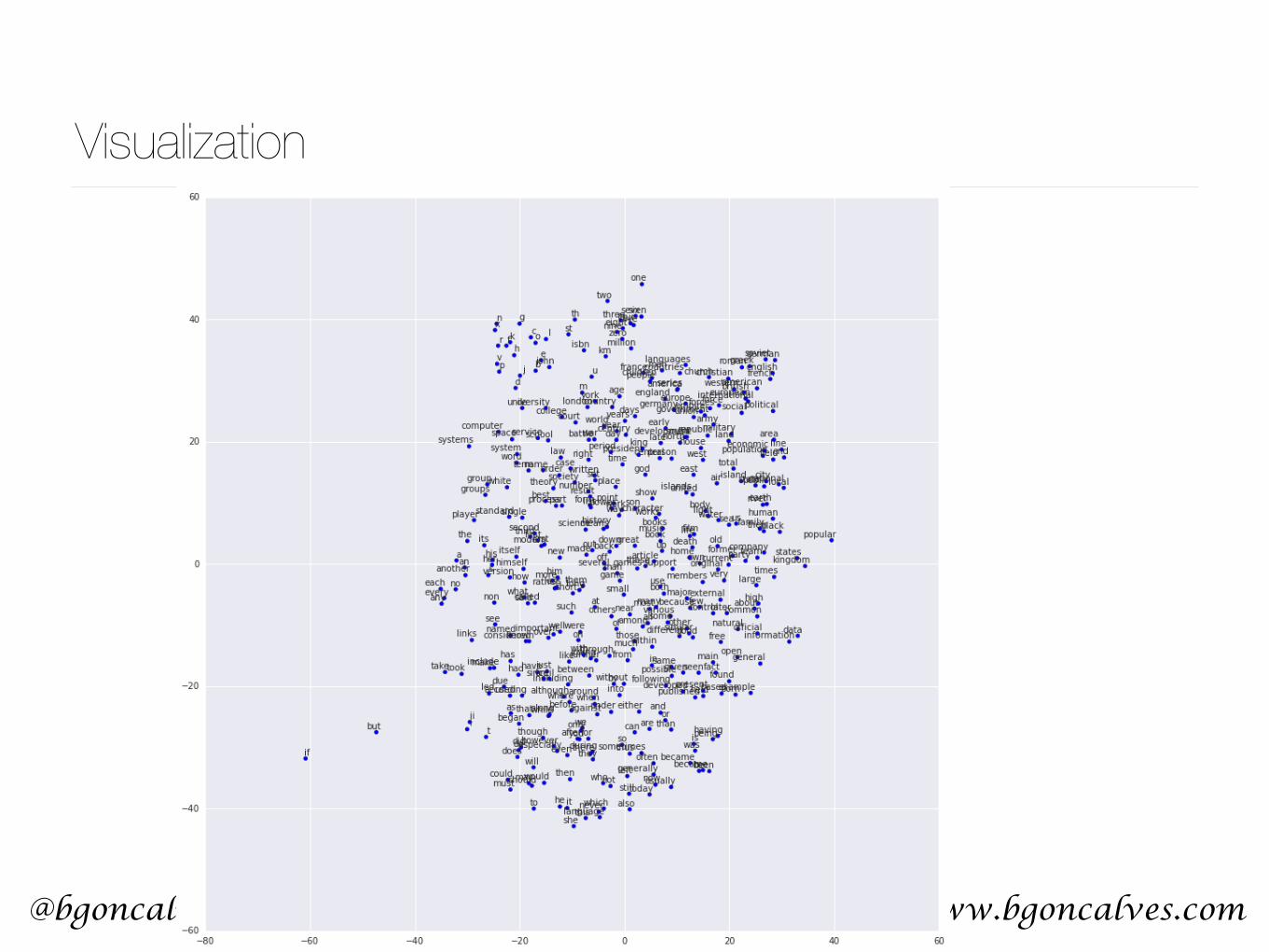
Visualization

www.bgoncalves.com@bgoncalves
Linguistic Change
• Train word embeddings for different years using Google Books
• Independently trained embeddings differ by an arbitrary rotation
• Align the different embeddings for different years
• Track the way in which the meaning of words shifted over time!
Statistically Significant Detection of Linguistic Change
Vivek Kulkarni
Stony Brook University, USA
Rami Al-Rfou
Stony Brook University, USA
Bryan Perozzi
Stony Brook University, USA
Steven Skiena
Stony Brook University, USA
ABSTRACTWe propose a new computational approach for tracking anddetecting statistically significant linguistic shifts in the mean-ing and usage of words. Such linguistic shifts are especiallyprevalent on the Internet, where the rapid exchange of ideascan quickly change a word’s meaning. Our meta-analysisapproach constructs property time series of word usage, andthen uses statistically sound change point detection algo-rithms to identify significant linguistic shifts.We consider and analyze three approaches of increasing
complexity to generate such linguistic property time series,the culmination of which uses distributional characteristicsinferred from word co-occurrences. Using recently proposeddeep neural language models, we first train vector represen-tations of words for each time period. Second, we warp thevector spaces into one unified coordinate system. Finally, weconstruct a distance-based distributional time series for eachword to track its linguistic displacement over time.
We demonstrate that our approach is scalable by track-ing linguistic change across years of micro-blogging usingTwitter, a decade of product reviews using a corpus of moviereviews from Amazon, and a century of written books usingthe Google Book Ngrams. Our analysis reveals interestingpatterns of language usage change commensurate with eachmedium.
Categories and Subject DescriptorsH.3.3 [Information Storage and Retrieval]: InformationSearch and Retrieval
KeywordsWeb Mining;Computational Linguistics
1. INTRODUCTIONNatural languages are inherently dynamic, evolving over
time to accommodate the needs of their speakers. Thise↵ect is especially prevalent on the Internet, where the rapidexchange of ideas can change a word’s meaning overnight.
Copyright is held by the International World Wide Web Conference Com-
mittee (IW3C2). IW3C2 reserves the right to provide a hyperlink to the
author’s site if the Material is used in electronic media.
WWW 2015, May 18–22, 2015, Florence, Italy.
ACM 978-1-4503-3469-3/15/05.
http://dx.doi.org/10.1145/2736277.2741627 .
Figure 1: A 2-dimensional projection of the latent seman-tic space captured by our algorithm. Notice the semantictrajectory of the word gay transitioning meaning in the space.
In this paper, we study the problem of detecting suchlinguistic shifts on a variety of media including micro-blogposts, product reviews, and books. Specifically, we seek todetect the broadening and narrowing of semantic senses ofwords, as they continually change throughout the lifetime ofa medium.We propose the first computational approach for track-
ing and detecting statistically significant linguistic shifts ofwords. To model the temporal evolution of natural language,we construct a time series per word. We investigate threemethods to build our word time series. First, we extractFrequency based statistics to capture sudden changes in wordusage. Second, we construct Syntactic time series by ana-lyzing each word’s part of speech (POS) tag distribution.Finally, we infer contextual cues from word co-occurrencestatistics to construct Distributional time series. In order todetect and establish statistical significance of word changesover time, we present a change point detection algorithm,which is compatible with all methods.
Figure 1 illustrates a 2-dimensional projection of the latentsemantic space captured by our Distributional method. Weclearly observe the sequence of semantic shifts that the wordgay has undergone over the last century (1900-2005). Ini-tially, gay was an adjective that meant cheerful or dapper.Observe for the first 50 years, that it stayed in the samegeneral region of the semantic space. However by 1975, ithad begun a transition over to its current meaning —a shiftwhich accelerated over the years to come.
The choice of the time series construction method deter-mines the type of information we capture regarding word
625
WWW’15, 625 (2015)Statistically Significant Detection of Linguistic Change
Vivek Kulkarni
Stony Brook University, USA
Rami Al-Rfou
Stony Brook University, USA
Bryan Perozzi
Stony Brook University, USA
Steven Skiena
Stony Brook University, USA
ABSTRACTWe propose a new computational approach for tracking anddetecting statistically significant linguistic shifts in the mean-ing and usage of words. Such linguistic shifts are especiallyprevalent on the Internet, where the rapid exchange of ideascan quickly change a word’s meaning. Our meta-analysisapproach constructs property time series of word usage, andthen uses statistically sound change point detection algo-rithms to identify significant linguistic shifts.We consider and analyze three approaches of increasing
complexity to generate such linguistic property time series,the culmination of which uses distributional characteristicsinferred from word co-occurrences. Using recently proposeddeep neural language models, we first train vector represen-tations of words for each time period. Second, we warp thevector spaces into one unified coordinate system. Finally, weconstruct a distance-based distributional time series for eachword to track its linguistic displacement over time.
We demonstrate that our approach is scalable by track-ing linguistic change across years of micro-blogging usingTwitter, a decade of product reviews using a corpus of moviereviews from Amazon, and a century of written books usingthe Google Book Ngrams. Our analysis reveals interestingpatterns of language usage change commensurate with eachmedium.
Categories and Subject DescriptorsH.3.3 [Information Storage and Retrieval]: InformationSearch and Retrieval
KeywordsWeb Mining;Computational Linguistics
1. INTRODUCTIONNatural languages are inherently dynamic, evolving over
time to accommodate the needs of their speakers. Thise↵ect is especially prevalent on the Internet, where the rapidexchange of ideas can change a word’s meaning overnight.
Copyright is held by the International World Wide Web Conference Com-
mittee (IW3C2). IW3C2 reserves the right to provide a hyperlink to the
author’s site if the Material is used in electronic media.
WWW 2015, May 18–22, 2015, Florence, Italy.
ACM 978-1-4503-3469-3/15/05.
http://dx.doi.org/10.1145/2736277.2741627 .
talkat ive
profligate
courageous
apparit ional
dappersublimely
unembarrassed
courteous
sorcerers
metonymy
religious
adolescentsphilanthropist
illiteratet ransgendered
art isans
healthy
gays
homosexual
t ransgender
lesbian
statesman
hispanic
uneducated
gay1900
gay1950 gay1975 gay1990
gay2005
cheerful
Figure 1: A 2-dimensional projection of the latent seman-tic space captured by our algorithm. Notice the semantictrajectory of the word gay transitioning meaning in the space.
In this paper, we study the problem of detecting suchlinguistic shifts on a variety of media including micro-blogposts, product reviews, and books. Specifically, we seek todetect the broadening and narrowing of semantic senses ofwords, as they continually change throughout the lifetime ofa medium.We propose the first computational approach for track-
ing and detecting statistically significant linguistic shifts ofwords. To model the temporal evolution of natural language,we construct a time series per word. We investigate threemethods to build our word time series. First, we extractFrequency based statistics to capture sudden changes in wordusage. Second, we construct Syntactic time series by ana-lyzing each word’s part of speech (POS) tag distribution.Finally, we infer contextual cues from word co-occurrencestatistics to construct Distributional time series. In order todetect and establish statistical significance of word changesover time, we present a change point detection algorithm,which is compatible with all methods.
Figure 1 illustrates a 2-dimensional projection of the latentsemantic space captured by our Distributional method. Weclearly observe the sequence of semantic shifts that the wordgay has undergone over the last century (1900-2005). Ini-tially, gay was an adjective that meant cheerful or dapper.Observe for the first 50 years, that it stayed in the samegeneral region of the semantic space. However by 1975, ithad begun a transition over to its current meaning —a shiftwhich accelerated over the years to come.
The choice of the time series construction method deter-mines the type of information we capture regarding word
625

www.bgoncalves.com@bgoncalves
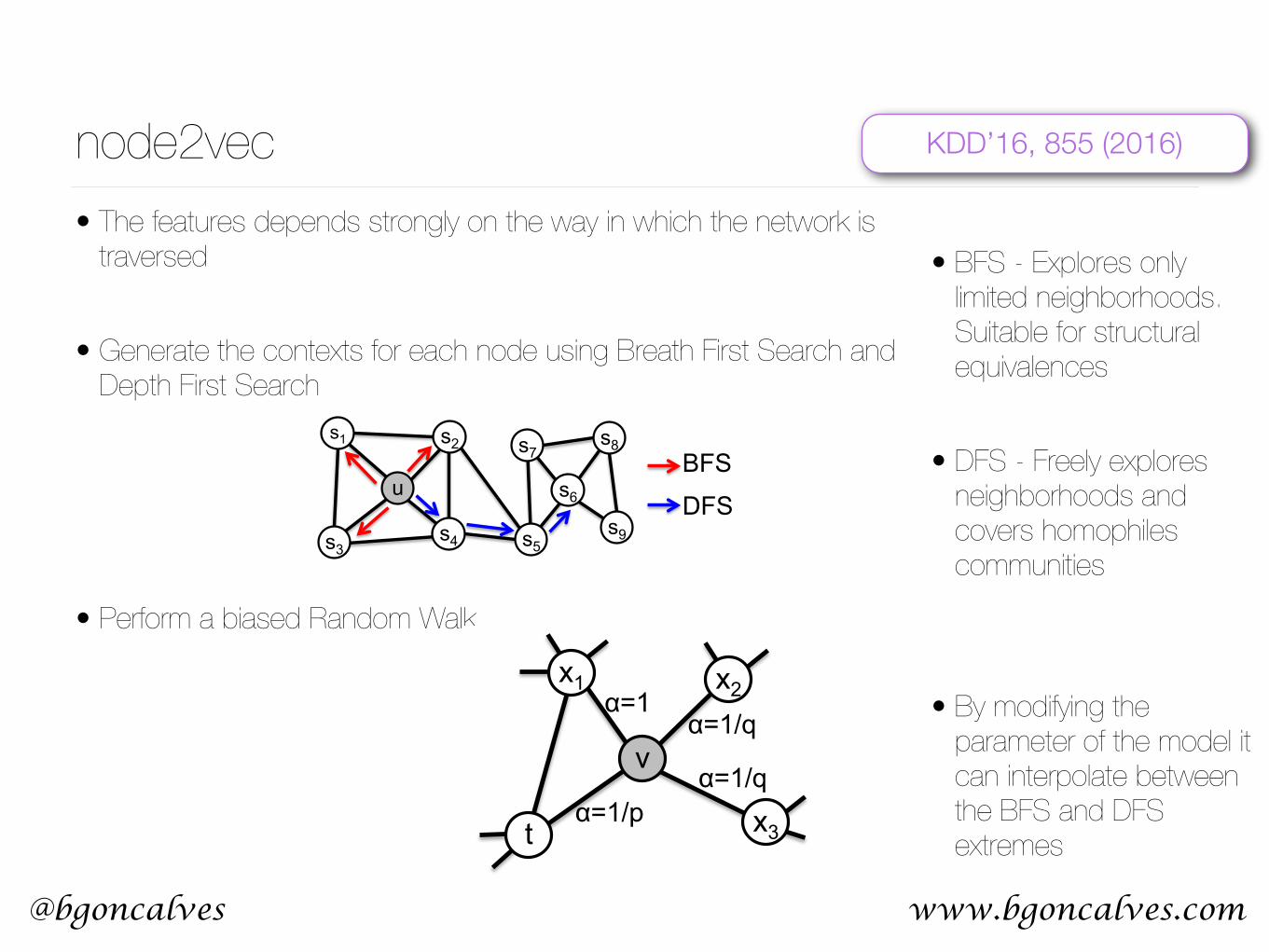
node2vec
• You can generate a graph out of a sequence of words by assigning a node to each word and connecting the words within their neighbors through edges.
• With this representation, a piece of text is a walk through the network. Then perhaps we can invert the process? Use walks through a network to generate a sequence of nodes that can be used to train node embeddings?
• node embeddings should capture features of the network structure and allow for detection of similarities between nodes.
node2vec: Scalable Feature Learning for Networks
Aditya GroverStanford University
Jure LeskovecStanford University
ABSTRACTPrediction tasks over nodes and edges in networks require carefuleffort in engineering features used by learning algorithms. Recentresearch in the broader field of representation learning has led tosignificant progress in automating prediction by learning the fea-tures themselves. However, present feature learning approachesare not expressive enough to capture the diversity of connectivitypatterns observed in networks.
Here we propose node2vec , an algorithmic framework for learn-ing continuous feature representations for nodes in networks. Innode2vec , we learn a mapping of nodes to a low-dimensional spaceof features that maximizes the likelihood of preserving networkneighborhoods of nodes. We define a flexible notion of a node’snetwork neighborhood and design a biased random walk procedure,which efficiently explores diverse neighborhoods. Our algorithmgeneralizes prior work which is based on rigid notions of networkneighborhoods, and we argue that the added flexibility in exploringneighborhoods is the key to learning richer representations.
We demonstrate the efficacy of node2vec over existing state-of-the-art techniques on multi-label classification and link predictionin several real-world networks from diverse domains. Taken to-gether, our work represents a new way for efficiently learning state-of-the-art task-independent representations in complex networks.Categories and Subject Descriptors: H.2.8 [Database Manage-ment]: Database applications—Data mining; I.2.6 [Artificial In-telligence]: LearningGeneral Terms: Algorithms; Experimentation.Keywords: Information networks, Feature learning, Node embed-dings, Graph representations.
1. INTRODUCTIONMany important tasks in network analysis involve predictions
over nodes and edges. In a typical node classification task, weare interested in predicting the most probable labels of nodes ina network [33]. For example, in a social network, we might beinterested in predicting interests of users, or in a protein-protein in-teraction network we might be interested in predicting functionallabels of proteins [25, 37]. Similarly, in link prediction, we wish to
Permission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full citationon the first page. Copyrights for components of this work owned by others than theauthor(s) must be honored. Abstracting with credit is permitted. To copy otherwise, orrepublish, to post on servers or to redistribute to lists, requires prior specific permissionand/or a fee. Request permissions from [email protected] ’16, August 13 - 17, 2016, San Francisco, CA, USA
c� 2016 Copyright held by the owner/author(s). Publication rights licensed to ACM.ISBN 978-1-4503-4232-2/16/08. . . $15.00DOI: http://dx.doi.org/10.1145/2939672.2939754
predict whether a pair of nodes in a network should have an edgeconnecting them [18]. Link prediction is useful in a wide varietyof domains; for instance, in genomics, it helps us discover novelinteractions between genes, and in social networks, it can identifyreal-world friends [2, 34].
Any supervised machine learning algorithm requires a set of in-formative, discriminating, and independent features. In predictionproblems on networks this means that one has to construct a featurevector representation for the nodes and edges. A typical solution in-volves hand-engineering domain-specific features based on expertknowledge. Even if one discounts the tedious effort required forfeature engineering, such features are usually designed for specifictasks and do not generalize across different prediction tasks.
An alternative approach is to learn feature representations bysolving an optimization problem [4]. The challenge in feature learn-ing is defining an objective function, which involves a trade-offin balancing computational efficiency and predictive accuracy. Onone side of the spectrum, one could directly aim to find a featurerepresentation that optimizes performance of a downstream predic-tion task. While this supervised procedure results in good accu-racy, it comes at the cost of high training time complexity due to ablowup in the number of parameters that need to be estimated. Atthe other extreme, the objective function can be defined to be inde-pendent of the downstream prediction task and the representationscan be learned in a purely unsupervised way. This makes the op-timization computationally efficient and with a carefully designedobjective, it results in task-independent features that closely matchtask-specific approaches in predictive accuracy [21, 23].
However, current techniques fail to satisfactorily define and opti-mize a reasonable objective required for scalable unsupervised fea-ture learning in networks. Classic approaches based on linear andnon-linear dimensionality reduction techniques such as PrincipalComponent Analysis, Multi-Dimensional Scaling and their exten-sions [3, 27, 30, 35] optimize an objective that transforms a repre-sentative data matrix of the network such that it maximizes the vari-ance of the data representation. Consequently, these approaches in-variably involve eigendecomposition of the appropriate data matrixwhich is expensive for large real-world networks. Moreover, theresulting latent representations give poor performance on variousprediction tasks over networks.
Alternatively, we can design an objective that seeks to preservelocal neighborhoods of nodes. The objective can be efficiently op-timized using stochastic gradient descent (SGD) akin to backpro-pogation on just single hidden-layer feedforward neural networks.Recent attempts in this direction [24, 28] propose efficient algo-rithms but rely on a rigid notion of a network neighborhood, whichresults in these approaches being largely insensitive to connectiv-ity patterns unique to networks. Specifically, nodes in networks
arX
iv:1
607.
0065
3v1
[cs.S
I] 3
Jul 2
016
KDD’16, 855 (2016)
www.bgoncalves.com@bgoncalves
node2vec• The features depends strongly on the way in which the network is
traversed
• Generate the contexts for each node using Breath First Search and Depth First Search
• Perform a biased Random Walk
KDD’16, 855 (2016)
could be organized based on communities they belong to (i.e., ho-
mophily); in other cases, the organization could be based on thestructural roles of nodes in the network (i.e., structural equiva-
lence) [7, 10, 36]. For instance, in Figure 1, we observe nodesu and s
1
belonging to the same tightly knit community of nodes,while the nodes u and s
6
in the two distinct communities share thesame structural role of a hub node. Real-world networks commonlyexhibit a mixture of such equivalences. Thus, it is essential to allowfor a flexible algorithm that can learn node representations obeyingboth principles: ability to learn representations that embed nodesfrom the same network community closely together, as well as tolearn representations where nodes that share similar roles have sim-ilar embeddings. This would allow feature learning algorithms togeneralize across a wide variety of domains and prediction tasks.
Present work. We propose node2vec , a semi-supervised algorithmfor scalable feature learning in networks. We optimize a customgraph-based objective function using SGD motivated by prior workon natural language processing [21]. Intuitively, our approach re-turns feature representations that maximize the likelihood of pre-serving network neighborhoods of nodes in a d-dimensional fea-ture space. We use a 2nd order random walk approach to generate(sample) network neighborhoods for nodes.
Our key contribution is in defining a flexible notion of a node’snetwork neighborhood. By choosing an appropriate notion of aneighborhood, node2vec can learn representations that organizenodes based on their network roles and/or communities they be-long to. We achieve this by developing a family of biased randomwalks, which efficiently explore diverse neighborhoods of a givennode. The resulting algorithm is flexible, giving us control over thesearch space through tunable parameters, in contrast to rigid searchprocedures in prior work [24, 28]. Consequently, our method gen-eralizes prior work and can model the full spectrum of equivalencesobserved in networks. The parameters governing our search strat-egy have an intuitive interpretation and bias the walk towards dif-ferent network exploration strategies. These parameters can alsobe learned directly using a tiny fraction of labeled data in a semi-supervised fashion.
We also show how feature representations of individual nodescan be extended to pairs of nodes (i.e., edges). In order to generatefeature representations of edges, we compose the learned featurerepresentations of the individual nodes using simple binary oper-ators. This compositionality lends node2vec to prediction tasksinvolving nodes as well as edges.
Our experiments focus on two common prediction tasks in net-works: a multi-label classification task, where every node is as-signed one or more class labels and a link prediction task, where wepredict the existence of an edge given a pair of nodes. We contrastthe performance of node2vec with state-of-the-art feature learningalgorithms [24, 28]. We experiment with several real-world net-works from diverse domains, such as social networks, informationnetworks, as well as networks from systems biology. Experimentsdemonstrate that node2vec outperforms state-of-the-art methods byup to 26.7% on multi-label classification and up to 12.6% on linkprediction. The algorithm shows competitive performance witheven 10% labeled data and is also robust to perturbations in theform of noisy or missing edges. Computationally, the major phasesof node2vec are trivially parallelizable, and it can scale to largenetworks with millions of nodes in a few hours.
Overall our paper makes the following contributions:1. We propose node2vec , an efficient scalable algorithm for
feature learning in networks that efficiently optimizes a novelnetwork-aware, neighborhood preserving objective using SGD.
2. We show how node2vec is in accordance with established
u
s3
s2 s1
s4
s8
s9
s6
s7
s5
BFS
DFS
Figure 1: BFS and DFS search strategies from node u (k = 3).
principles in network science, providing flexibility in discov-ering representations conforming to different equivalences.
3. We extend node2vec and other feature learning methods basedon neighborhood preserving objectives, from nodes to pairsof nodes for edge-based prediction tasks.
4. We empirically evaluate node2vec for multi-label classifica-tion and link prediction on several real-world datasets.
The rest of the paper is structured as follows. In Section 2, webriefly survey related work in feature learning for networks. Wepresent the technical details for feature learning using node2vec
in Section 3. In Section 4, we empirically evaluate node2vec onprediction tasks over nodes and edges on various real-world net-works and assess the parameter sensitivity, perturbation analysis,and scalability aspects of our algorithm. We conclude with a dis-cussion of the node2vec framework and highlight some promis-ing directions for future work in Section 5. Datasets and a refer-ence implementation of node2vec are available on the project page:http://snap.stanford.edu/node2vec.
2. RELATED WORKFeature engineering has been extensively studied by the machine
learning community under various headings. In networks, the con-ventional paradigm for generating features for nodes is based onfeature extraction techniques which typically involve some seedhand-crafted features based on network properties [8, 11]. In con-trast, our goal is to automate the whole process by casting featureextraction as a representation learning problem in which case wedo not require any hand-engineered features.
Unsupervised feature learning approaches typically exploit thespectral properties of various matrix representations of graphs, es-pecially the Laplacian and the adjacency matrices. Under this linearalgebra perspective, these methods can be viewed as dimensional-ity reduction techniques. Several linear (e.g., PCA) and non-linear(e.g., IsoMap) dimensionality reduction techniques have been pro-posed [3, 27, 30, 35]. These methods suffer from both computa-tional and statistical performance drawbacks. In terms of computa-tional efficiency, eigendecomposition of a data matrix is expensiveunless the solution quality is significantly compromised with ap-proximations, and hence, these methods are hard to scale to largenetworks. Secondly, these methods optimize for objectives that arenot robust to the diverse patterns observed in networks (such as ho-mophily and structural equivalence) and make assumptions aboutthe relationship between the underlying network structure and theprediction task. For instance, spectral clustering makes a stronghomophily assumption that graph cuts will be useful for classifica-tion [29]. Such assumptions are reasonable in many scenarios, butunsatisfactory in effectively generalizing across diverse networks.
Recent advancements in representational learning for natural lan-guage processing opened new ways for feature learning of discreteobjects such as words. In particular, the Skip-gram model [21] aimsto learn continuous feature representations for words by optimiz-ing a neighborhood preserving likelihood objective. The algorithm
we note that in order to ascertain structural equivalence, it is of-ten sufficient to characterize the local neighborhoods accurately.For example, structural equivalence based on network roles such asbridges and hubs can be inferred just by observing the immediateneighborhoods of each node. By restricting search to nearby nodes,BFS achieves this characterization and obtains a microscopic viewof the neighborhood of every node. Additionally, in BFS, nodes inthe sampled neighborhoods tend to repeat many times. This is alsoimportant as it reduces the variance in characterizing the distribu-tion of 1-hop nodes with respect the source node. However, a verysmall portion of the graph is explored for any given k.
The opposite is true for DFS which can explore larger parts ofthe network as it can move further away from the source node u(with sample size k being fixed). In DFS, the sampled nodes moreaccurately reflect a macro-view of the neighborhood which is es-sential in inferring communities based on homophily. However,the issue with DFS is that it is important to not only infer whichnode-to-node dependencies exist in a network, but also to charac-terize the exact nature of these dependencies. This is hard givenwe have a constrain on the sample size and a large neighborhoodto explore, resulting in high variance. Secondly, moving to muchgreater depths leads to complex dependencies since a sampled nodemay be far from the source and potentially less representative.
3.2 node2vecBuilding on the above observations, we design a flexible neigh-
borhood sampling strategy which allows us to smoothly interpolatebetween BFS and DFS. We achieve this by developing a flexiblebiased random walk procedure that can explore neighborhoods in aBFS as well as DFS fashion.
3.2.1 Random Walks
Formally, given a source node u, we simulate a random walk offixed length l. Let c
i
denote the ith node in the walk, starting withc0
= u. Nodes ci
are generated by the following distribution:
P (ci
= x | ci�1
= v) =
(⇡
vx
Z
if (v, x) 2 E
0 otherwise
where ⇡vx
is the unnormalized transition probability between nodesv and x, and Z is the normalizing constant.
3.2.2 Search bias ↵The simplest way to bias our random walks would be to sample
the next node based on the static edge weights wvx
i.e., ⇡vx
= wvx
.(In case of unweighted graphs w
vx
= 1.) However, this doesnot allow us to account for the network structure and guide oursearch procedure to explore different types of network neighbor-hoods. Additionally, unlike BFS and DFS which are extreme sam-pling paradigms suited for structural equivalence and homophilyrespectively, our random walks should accommodate for the factthat these notions of equivalence are not competing or exclusive,and real-world networks commonly exhibit a mixture of both.
We define a 2nd order random walk with two parameters p and qwhich guide the walk: Consider a random walk that just traversededge (t, v) and now resides at node v (Figure 2). The walk nowneeds to decide on the next step so it evaluates the transition prob-abilities ⇡
vx
on edges (v, x) leading from v. We set the unnormal-ized transition probability to ⇡
vx
= ↵pq
(t, x) · wvx
, where
↵pq
(t, x) =
8><
>:
1
p
if dtx
= 0
1 if dtx
= 1
1
q
if dtx
= 2
t
x2 x1
v
x3
α=1 α=1/q
α=1/q α=1/p
u
s3
s2 s1
s4
s7
s6
s5
BFS
DFS
v
α=1 α=1/q
α=1/q α=1/p
x2
x3 t
x1
Figure 2: Illustration of the random walk procedure in node2vec .The walk just transitioned from t to v and is now evaluating its nextstep out of node v. Edge labels indicate search biases ↵.
and dtx
denotes the shortest path distance between nodes t and x.Note that d
tx
must be one of {0, 1, 2}, and hence, the two parame-ters are necessary and sufficient to guide the walk.
Intuitively, parameters p and q control how fast the walk exploresand leaves the neighborhood of starting node u. In particular, theparameters allow our search procedure to (approximately) interpo-late between BFS and DFS and thereby reflect an affinity for dif-ferent notions of node equivalences.
Return parameter, p. Parameter p controls the likelihood of im-mediately revisiting a node in the walk. Setting it to a high value(> max(q, 1)) ensures that we are less likely to sample an already-visited node in the following two steps (unless the next node inthe walk had no other neighbor). This strategy encourages moder-ate exploration and avoids 2-hop redundancy in sampling. On theother hand, if p is low (< min(q, 1)), it would lead the walk tobacktrack a step (Figure 2) and this would keep the walk “local”close to the starting node u.
In-out parameter, q. Parameter q allows the search to differentiatebetween “inward” and “outward” nodes. Going back to Figure 2,if q > 1, the random walk is biased towards nodes close to node t.Such walks obtain a local view of the underlying graph with respectto the start node in the walk and approximate BFS behavior in thesense that our samples comprise of nodes within a small locality.
In contrast, if q < 1, the walk is more inclined to visit nodeswhich are further away from the node t. Such behavior is reflec-tive of DFS which encourages outward exploration. However, anessential difference here is that we achieve DFS-like explorationwithin the random walk framework. Hence, the sampled nodes arenot at strictly increasing distances from a given source node u, butin turn, we benefit from tractable preprocessing and superior sam-pling efficiency of random walks. Note that by setting ⇡
v,x
to bea function of the preceeding node in the walk t, the random walksare 2nd order Markovian.
Benefits of random walks. There are several benefits of randomwalks over pure BFS/DFS approaches. Random walks are compu-tationally efficient in terms of both space and time requirements.The space complexity to store the immediate neighbors of everynode in the graph is O(|E|). For 2nd order random walks, it ishelpful to store the interconnections between the neighbors of ev-ery node, which incurs a space complexity of O(a2|V |) where ais the average degree of the graph and is usually small for real-world networks. The other key advantage of random walks overclassic search-based sampling strategies is its time complexity. Inparticular, by imposing graph connectivity in the sample genera-tion process, random walks provide a convenient mechanism to in-crease the effective sampling rate by reusing samples across differ-ent source nodes. By simulating a random walk of length l > k wecan generate k samples for l � k nodes at once due to the Marko-
• BFS - Explores only limited neighborhoods. Suitable for structural equivalences
• DFS - Freely explores neighborhoods and covers homophiles communities
• By modifying the parameter of the model it can interpolate between the BFS and DFS extremes

www.bgoncalves.com@bgoncalves
dna2vec
• Separate the genome into long non-overlapping DNS fragments.
• Convert long DNA fragments into overlapping variable length k-mers
• Train embeddings of each k-mer using Gensim implementation of SkipGram.
• Summing embeddings is related to concatenating k-mers
• Cosign similarity of k-mer embeddings reproduces a biologically motivated similarity score (Needleman-Wunsch) that is used to align nucleoti
dna2vec: Consistent vector representations of
variable-length k-mers
Patrick [email protected]
AbstractOne of the ubiquitous representation of long DNA sequence is dividing it into shorter k-mer components.
Unfortunately, the straightforward vector encoding of k-mer as a one-hot vector is vulnerable to thecurse of dimensionality. Worse yet, the distance between any pair of one-hot vectors is equidistant. Thisis particularly problematic when applying the latest machine learning algorithms to solve problems inbiological sequence analysis. In this paper, we propose a novel method to train distributed representationsof variable-length k-mers. Our method is based on the popular word embedding model word2vec, whichis trained on a shallow two-layer neural network. Our experiments provide evidence that the summingof dna2vec vectors is akin to nucleotides concatenation. We also demonstrate that there is correlationbetween Needleman-Wunsch similarity score and cosine similarity of dna2vec vectors.
1 Introduction
The usage of k-mer representation has been a popular approach in analyzing long sequence of DNA fragments.The k-mer representation is simple to understand and compute. Unfortunately, its straightforward vectorencoding as a one-hot vector (i.e. bit vector that consists of all zeros except for a single dimension) isvulnerable to curse of dimensionality. Specifically, its one-hot vector has dimension exponential to the lengthof k. For example, an 8-mer needs a bit vector of dimension 48 = 65536. This is problematic when applyingthe latest machine learning algorithms to solve problems in biological sequence analysis, due to the fact thatmost of these tools prefer lower-dimensional continuous vectors as input (Suykens and Vandewalle, 1999;Angermueller et al., 2016; Turian et al., 2010). Worse yet, the distance between any arbitrary pair of one-hotvectors is equidistant, even though ATGGC should be closer to ATGGG than CACGA.
1.1 Word embeddings
The Natural Language Processing (NLP) research community has a long tradition of using bag-of-words withone-hot vector, where its dimension is equal to the vocabulary size. Recently, there has been an explosion ofusing word embeddings as inputs to machine learning algorithms, especially in the deep learning community(Mikolov et al., 2013b; LeCun et al., 2015; Bengio et al., 2013). Word embeddings are vectors of real numbersthat are distributed representations of words.
A popular training technique for word embeddings, word2vec (Mikolov et al., 2013a), consists of using a2-layer neural network that is trained on the current word and its surrounding context words (see Section2.3). This reconstruction of context of words is loosely inspired by the linguistic concept of distributionalhypothesis, which states that words that appear in the same context have similar meaning (Harris, 1954).Deep learning algorithms applied with word embeddings have had dramatic improvements in the areas ofmachine translation (Sutskever et al., 2014; Bahdanau et al., 2014; Cho et al., 2014), summarization (Chopraet al., 2016), sentiment analysis (Kim, 2014; Dos Santos and Gatti, 2014) and image captioning (Vinyalset al., 2015).
One of the most fascinating properties of word2vec is that its vector arithmetic can solve semantic and linguisticanalogies (Mikolov et al., 2013c,a). They showed that vec(king) ≠ vec(man) + vec(woman) ¥ vec(queen).In particular, the analogy task man:king :: woman:??? is interpreted as finding a word w such thatvec(king) ≠ vec(man) + vec(woman) is closest to vec(w) under cosine distance. Furthermore, (Levy et al.,2014) showed that analogy works for past-tense relation vec(capture) ≠ vec(captured) ¥ vec(go) ≠ vec(went),
1
arX
iv:1
701.
0627
9v1
[q-b
io.Q
M]
23 Ja
n 20
17
arXiv: 1701.06279 (2017)

www.bgoncalves.com@bgoncalveshttp://tinyletter.com/dataforscience








![Deep Learning Framework based on Word2Vec and CNN for ... · space [4]. Moreover, with Word2vec features can be obtained without human intervention. Word2Vec can also perform effectively](https://img.dokumen.tips/doc/110x75/5f0a677f7e708231d42b781f/deep-learning-framework-based-on-word2vec-and-cnn-for-space-4-moreover-with.jpg)




















