Embed Size (px)
Citation preview

Beware… For It’S THE...
Vowpal platypusPeter HurforD(With a little help from some friends)

WE OFTEN WANT TO PREDICT STUFF...

WE OFTEN WANT TO PREDICT STUFF…...BUT WE RUN INTO LIMITATIONS.

WE OFTEN WANT TO PREDICT STUFF…...BUT WE RUN INTO LIMITATIONS.× ...Data set is too large, it doesn’t fit in RAM.

WE OFTEN WANT TO PREDICT STUFF…...BUT WE RUN INTO LIMITATIONS.× ...Data set is too large, it doesn’t fit in RAM.× ...Data set is so large, it doesn’t fit on disk!

WE OFTEN WANT TO PREDICT STUFF…...BUT WE RUN INTO LIMITATIONS.× ...Data set is too large, it doesn’t fit in RAM.× ...Data set is so large, it doesn’t fit on disk!× ...Model train time is so slow, you can’t iterate
and try things.

“I want to use parallel learning algorithms to create fantastic learning machines!”- John Langford, 1997

YOU FOOL! THE ONLY THING PARALLEL
MACHINES ARE USEFUL FOR ARE COMPUTATIONAL
WINDTUNNELS!

TEN YEARS LATER...

VOWPAL...Fast Online Learning
TEN YEARS LATER...

...WHAT’s WITH THE NAME?

...WHAT’s WITH THE NAME?

...WHAT’s WITH THE NAME?
+

...WHAT’s WITH THE NAME?
+

Traditional Approach
1. Load all training data into RAM at once.
2. Fit model to training dataset.
3. Load all predicting data into RAM at once.
4. Use trained model to make predictions.
WHAT DOES IT DO?

VW “Online” Approach
1. Train model on single datapoints, one at a time.
2. Do it again multiple times.
3. Use trained model to predict on new datapoints, one at a time.
Traditional Approach
1. Load all training data into RAM at once.
2. Fit model to training dataset.
3. Load all predicting data into RAM at once.
4. Use trained model to make predictions.
WHAT DOES IT DO?

× Online approach eventually converges to the same results as a traditional (batch) approach over enough iterations.
WHAT DOES IT DO?

WHAT DOES IT DO?× Online approach
eventually converges to the same results as a traditional (batch) approach over enough iterations.
× But you’re no longer dependent on RAM!

Kaggle: World Data Science Competitions
× 3rd, 14th, and 29th / 718 on $16K Criteo ad click challenge× 3rd / 472 on $2K KDD Cup Challenge× 8th / 128 on $25K Avito.ru illicit content filtering challenge
IS IT ANY GOOD?

× szilard/benchm-ml: widely cited (1127 star) independent ML speed benchmarks.
× Logistic Regression on 10M datapoints on a c3.8xlarge instance (32 cores, 60GB RAM).
DID I MENTION IT’S FAST?
Engine Speed
Python Sklearn Crashed
R 90sec
Vowpal Wabbit 15sec
Spark 35sec

× szilard/benchm-ml: widely cited (1127 star) independent ML speed benchmarks.
× Logistic Regression on 10M datapoints on a c3.8xlarge instance (32 cores, 60GB RAM).
DID I MENTION IT’S FAST?
Engine Speed
Python Sklearn Crashed
R 90sec
Vowpal Wabbit 15sec
Spark 35sec
Yes, this was Spark 2.0, but it was using MLLib. ML
performance is under testing now.

× szilard/benchm-ml: widely cited (1127 star) independent ML speed benchmarks.
× Logistic Regression on 10M datapoints on a c3.8xlarge instance (32 cores, 60GB RAM).
DID I MENTION IT’S FAST?
Engine Speed
Python Sklearn Crashed
R 90sec
Vowpal Wabbit 15sec
Spark 35sec
But this benchmark was only single core!

× szilard/benchm-ml: widely cited (1127 star) independent ML speed benchmarks.
× Logistic Regression on 10M datapoints on a c3.8xlarge instance (32 cores, 60GB RAM).
DID I MENTION IT’S FAST?
Engine Speed
Python Sklearn Crashed
R 90sec
Vowpal Wabbit 15sec
Spark 35sec
...and none of the benchmarks include
data load time! (VP has none.)

...But what’s THIS ABOUT A PLATYPUS?

WHAT IS VOWPAL PLATYPUS?× An open source vehicle for productionizing
Vowpal Wabbit in Python.

WHAT IS VOWPAL PLATYPUS?× An open source vehicle for productionizing
Vowpal Wabbit in Python.× Train and predict on Python dictionaries
instead of the obscure VW format.

WHAT IS VOWPAL PLATYPUS?× An open source vehicle for productionizing
Vowpal Wabbit in Python.× Train and predict on Python dictionaries
instead of the obscure VW format.× Easily use VW’s parallel features to go
multicore and multi-machine.

WHAT IS VOWPAL PLATYPUS?× An open source vehicle for productionizing
Vowpal Wabbit in Python.× Train and predict on Python dictionaries
instead of the obscure VW format.× Easily use VW’s parallel features to go
multicore and multi-machine.
VW has been used on “terascale datasets, with trillions of features, billions of training examples and millions of parameters in an hour using a cluster of 1000 machines.”

WHAT IS VOWPAL PLATYPUS?× An open source vehicle for productionizing
Vowpal Wabbit in Python.× Train and predict on Python dictionaries
instead of the obscure VW format.× Easily use VW’s parallel features to go
multicore and multi-machine.
...so far VP has only been used on a maximum of 3 machines (combined 108 core), but we’re getting there...

dEMo #1!



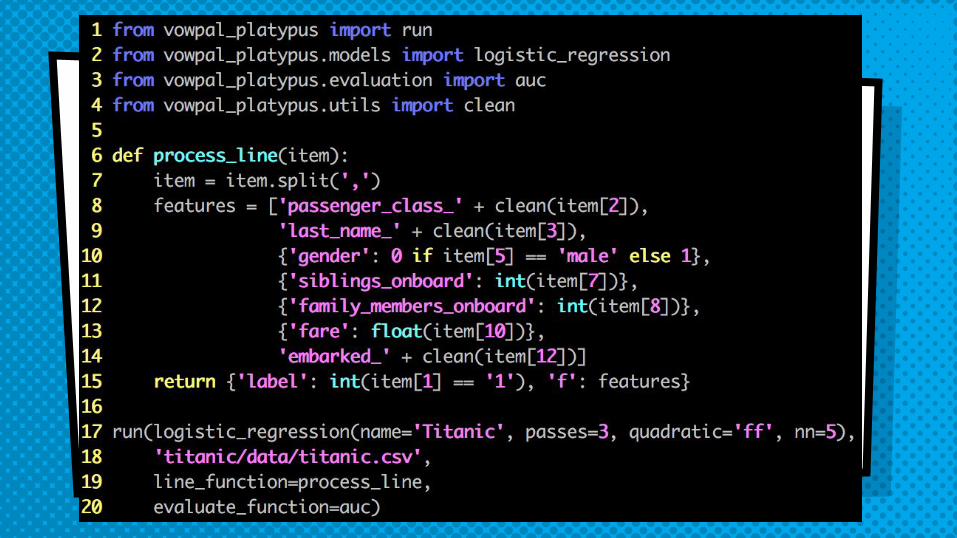

dEMo #2!

dEMo #2!

dEMo #2!27,279 MOVIES & 138,494 users

dEMo #2!27,279 MOVIES & 138,494 users
3,757,977,826 PReDICTIONS...need to be made.

dEMo #2!27,279 MOVIES & 138,494 users
21m47s
3,757,977,826 PReDICTIONS...need to be made.
Total runtime on3x c4.8xlarge(108 cores total)
342nanoseconds per prediction(wall clock time)

THE END! (...OR IS IT?)





























